#quadratic scaling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
X spells in magic the gathering are where the fact it was designed by a maths guy really pops. Majority of the maths in magic is "can I pay cost" or "is damage dealt enough to kill a creature/player", so playing around with that number being variable rather than fixed makes some sense, and maths has X as a default variable, so you get fireball

right there in the first set - variable cost for variable damage, 1:1. This spell is great for ending games, which makes up for it's poor rate for the time (see lightning bolt, where you pay 1 mana for 3 damage)

So now you can use X for the cost to give a linear scaling effect, such as additional counters on creatures


Where we get really mathsy next is the relatively few examples of effectively "do something X times, X times" for example:


These two cards are roughly equivalent in what they do to the previous two - but appear to scale at a much worse rate, having to pay two or three times the cost for each time you do "X" but the trick here is these aren't actually scaling linearly, they're scaling quadratically, making them much more effective than they seem.
Anyway all this to say that sometimes evaluating how good a magic card can require understanding quadratic scaling!*
*but almost never will because these effects are almost certainly intentionally costed too highly and attached to traditionally uncompetitive effects, likely so that players don't actually have to think about quadratic scaling. This is probably for the best. Also there's one card that scales exponentially (2 to the power of X) rather than quadratically (X to the power of 2). It's literally called exponential growth.

#mtg#magic the gathering#quadratic scaling#richard Garfield phd was a maths professor but maths guy gets the point across#exponential growth#maths#just throwing tags on here. hashtag whatever#i hope this auto does read more. sorry if this has taken forever to scroll past.
51 notes
·
View notes
Text
thinking about the walls of benin and how the british destroyed them, and thinking about all of the literature of south america that the spanish destroyed just like that and then thinking about the library of alexandria
because how many more libraries were ravaged by colonialization yk? how much knowledge and architecture was destroyed for conquest?
feeling feelings
#rant in the tags#would it be brash to say that despite how tragic the destruction of the library was despite the fact that it was an isolated incident#and of a *far* smaller scale compared to colonial destruction#but its still the first to be brought up when we talk about the destruction of knowledge#but why not south america? why not asia? why not africa? why not the rest of the mediterranian world? why not egypt in its colonial era?#by the 15 and 1600s asia and africa were probably far more sophisticated than in 48 BC#bc logically over time cultures gain more knowledge#and thats when they set us back so many years#to the point that many countries are still fucking suffering from a lack of education#its so damned sickening#colonialism#history#and the way they colonize things that were discovered in the east too#the pythagorean theorem was discovered first in the east#the quadratic formula is al-khwarizmi's formula#pascals triangle was known for centuries#oh not to mention the social stuff because so many countries had a queer culture regardless of the social perception of it#and then the fucking west came in enforcing their regressive laws#and then when they progress and the east is still harping on with THEIR POLICIES#some people have the gall to call africa and asia morally depraved#section 377 in india was a british law by the fucking way#fuck colonizers bro#and the fact that its still happening in the form of neo-colonialism but no one talks about it nearly enough#anti colonialism#that is also a tag that exists
2 notes
·
View notes
Text

Balance the Scales
Summary: Aventurine attempts to help his child with their tricky algebra homework, but his usual high-stakes, risk-taking mindset doesn’t translate well into structured math lessons. Frustration mounts until his partner steps in, guiding both their child and Aventurine through the problem with patience and clarity. What starts as a struggle turns into a heartwarming family moment, proving that some things—like love and learning—are best tackled together.
Tags: Aventurine x Reader, Fluff, Domestic Bliss, Humor, Found Family, Wholesome Moments, Lighthearted.
A/N: Nah, cuz me too- I MEAN WHO SAID THAT?! 🤨📸
Tagslist: @vasharoulette

[Header credits: @sundaysconsort]
The evening air in your shared penthouse hummed with quiet luxury—dim, golden light reflecting off polished mahogany, the faint shuffle of playing cards from Aventurine’s idle hands, and the occasional frustrated sigh from your child, slouched over a sleek holo-tablet.
You leaned against the doorway, watching the scene unfold. Aventurine, draped in his signature attire, lounged with casual elegance at the dining table, one arm propped lazily on the back of his chair. Across from him, your child frowned at a particularly complex set of algebraic equations, tapping at the screen in mounting frustration.
"Alright, little gem," Aventurine said, his usual smooth, charismatic drawl carrying a hint of amusement. "What’s the problem?"
"They’re all the problem," your child grumbled, running a hand through their hair. "Why do I even need to learn this? It's just numbers!"
Aventurine chuckled, flipping a poker chip between his fingers. "Numbers, my dear, rule everything. Money, markets, even the odds of you getting that fancy gadget you wanted for your birthday. You wouldn't want to miscalculate and lose, would you?"
Your child shot him a skeptical glare. "But I don’t gamble for a living."
"Yet," he quipped with a wink, earning an exasperated groan.
You stifled a laugh before finally stepping in. "Aventurine, sweetheart, I don’t think comparing algebra to high-stakes investing is helping."
He pressed a hand to his chest in mock offense. "I’ll have you know, I am explaining it. I’m just giving them a real-world application."
Your child slumped forward. "It’s not working."
Sighing, you pulled up a chair and glanced at the problem on their tablet. Quadratic equations. Not the hardest thing in the world, but given Aventurine’s approach to numbers—where ‘X’ was just another factor in an ever-changing gamble—it made sense that teaching a structured, step-by-step solution wasn’t his forte.
You reached for the stylus. "Here, let me break it down."
Aventurine watched as you patiently rewrote the equation, explaining each step in clear, concise terms. You could feel his gaze flick between you and your child, his usual smirk softening into something more thoughtful.
"Wait, so you just... move the number over?" your child asked, eyebrows furrowed.
"Exactly," you said, smiling. "Think of it like balancing a scale. Whatever you do to one side, you have to do to the other."
There was a moment of silence before Aventurine tapped the table, a glint of realization in his eyes. "Ah. That’s the trick. A calculated move, not a gamble."
You rolled your eyes playfully. "Yes, darling. That’s how math works."
He leaned back, fingers laced behind his head. "Well, I suppose this is why I keep you around. You make the impossible possible."
You raised an eyebrow. "Impossible? Says the man who once convinced an entire board of executives that investing in artificial asteroid casinos was a low-risk endeavor?"
Your child giggled. Aventurine feigned deep contemplation. "You know, when you put it that way, perhaps I am the one who needs lessons."
You shook your head, reaching out to ruffle your child's hair. "Alright, let’s try another one. Together, this time."
And so, with Aventurine occasionally chiming in with unnecessary but admittedly entertaining commentary, the three of you tackled the next problem—turning what had once been a frustrating homework session into something warm, familiar, and, surprisingly, fun.
Because, as Aventurine always said, life was a gamble. But some bets—like the love shared around this table—were always worth making.

#x reader#honkai star rail#hsr#honkai star rail x reader#hsr x reader#hsr aventurine#aventurine x reader#hsr aventurine x reader#aventurine x you#fluff#domestic bliss#humor#lighthearted#found family#wholesome moments#hsr x you#hsr x y/n#honkai star rail x you#honkai star rail x gender neutral reader#honkai x reader#honkai x you#honkai sr x reader#x you#x y/n#x you fluff#x y/n fluff#aventurine honkai star rail#aventurine hsr#aventurine x y/n#character x reader
59 notes
·
View notes
Note
having albedo and scaramouche as both your roommates—ohh…damn. double whammy…
like yeah, if you think scaramouche’s picture taking habits are bad, take a look at this guy *thumb pointing at albedo* this guy is NUTS!!! i know he’s probably broken a camera or two because of that. and on a freak-off scale between the two, i’d wager money on albedo breaking that scale in full. sure, both are weird and creepy, but it’s always the calm and stoic ones that got the craziest unimaginable tricks up their sleeves. and tbf scaramouche isn’t completely overt about his interests and motives, but he’s a little more pathetic about it bc he’s prone to accidentally exposing himself if he ever fucks up. not albedo though. he’s too perfect. too pristine. and he has that same cleanliness and smile as to idk hannibal. albedo is perfect premeditated. scaramouche is just a hot mess with a wetter dick.
also kabukimono scaramouche 💆♀️💆♀️ i like to imagine that it’s some kind of childhood friends/crushes (possibility one sided), who got separated because one or the other moves somewhere, then reunited only to figure out that little boy you used to hang out with is now all grown up and completely different than what you remember. but he still likes you. but he reallllyyy likes you this time around. and might have been following you around all these years oh well
or kabukimono > scaramouche pipeline might have had happened after an intense breakup and he crashed out and did an entire personality 180. scaramouche has phoenixed into a bitter ex-boyfriend. his mom thinks it’s a phase like most kids this days, but oh boy this little guy truly means it this time
running laps around this ask because you get me so bad,,, you get me !!
yandere albedo is so delicious because it's impossible for him to get outed as a freak !! his countermeasures against being found out are too high; too elaborate. and also... it's speculated by the traveler in the paralogism quest that albedo would never be put on trial for murder because if he did commit the crime, he'd never be found out because he's just too good, thus never being suspected in the first place LMFAOOOO. his reputation and personality in general causes people to think of him being a freak to be like,,,, an impossible concept. fanfiction levels of OOC for them, if you will. but if they had mind-reading powers, then they'd see the degeneracy that plagues albedo's thoughts 24/7 :(((
random npc: wow, mister albedo looks so serious! :0 i wonder what he's thinking about! albedo, thinking about (y/n): no lube, no protection, all night, all day, from the kitchen floor to the toilet seat, from the dining table to the bedroom, from the bathroom sink to the shower, from the front porch to the balcony, vertically, horizontally, quadratic, exponent al, logarithmic, while i gasp for air, scream and see the light, missionary, cowgirl, reverse cow girl, doggy, backwards, forwards, sideways, upside down, on the floor, in the bed, on the couch, on a chair, being carried against the wall, outsid-
whereas scara, specifically modern au roomie, is the ultimate boyfailure who's just too unhinged and much of a gooner to keep all his freakyness to himself. it's quite impossible for him to function as a normal human being whenever your in the vicinity, in fact, just a simple whiff of your scent is enough to have his pants tightening :(( what more if you willingly speak to him, or accidentally... touch him !? he's so obvious to the point where even you get the hint a month or two in him being your roommate. though you mistake his infatuation as a simple crush instead of what it actually is: a maddening obsession.
and childhood friend scara is such a cute concept,,, he's literally been in love with you since the age where you could only waddle around, and he's never stopped being in love with you even after all this time... despite the distance and unfamiliarity. and while his version of love is a tad bit too intense for normal human comprehension, it's very much real and genuine :((((
#also... bitter ex bf scara ikefneikgnegne dw guys being inside you will fix him i swear#outro's asks <3#outro's interlude <3
58 notes
·
View notes
Note
What are common keywords any game design resume should include?
It depends on the kind of designer position you're aiming for. We want to see key words for common tasks that those kind of designers have done. Here are some examples:

Common
Experience, craft, create, live, season, update, content, schedule, create, design, team, player, UX.
Level Design
Layout, place, trigger, volume, spawn, point, reward, treasure, quest, lighting, light, dark, texture, object, obstacle, blocking, whitebox, direct, draw, through, inviting, space, place, multiplayer, competitive, cooperative, co-op, deathmatch, capture the flag, ctf, domination, asymmetric, symmetric.
Quest Design
Text, reward, spawn, balance, level, pace, pacing, word, budget, localization, loc, narrative, item, itemization, dialogue, branch, spawn, difficulty, player, multiplayer, encounter, placement, place, trigger, chain, pre req, pre-requisite, condition, scripting, faction, seasonal, event.
Cinematic Design
Narrative, camera, character, blocking, screen, position, ease-in, ease-out, pan, cut, smash, storyboard, frame, framing, beat, cue, pacing, feel, shot, zoom, sfx, vfx, mark, contextual, conditional, quick time, event, timing.
System Design
Balance, numbers, formula, spreadsheet, excel, curve, quadratic, linear, logarithmic, growth, plot, level, power, over, under, even, normal, distribution, player, total, analysis, scale, scaling, script, scripting, math.

If you're at all familiar with the regular kind of duties and tasks that any of these kind of designers do on a regular basis, you'll immediately start to see how these words fit into describing what we do day in and day out. These are going to be the kind of words we see used to describe the sort of experience we expect to see on a resume/CV from someone who has done this kind of work before. We won't expect all of them in every resume, but we expect a good many of these words on the resume/CV of a reasonable candidate.
[Join us on Discord] and/or [Support us on Patreon]
Got a burning question you want answered?
Short questions: Ask a Game Dev on Twitter
Short questions: Ask a Game Dev on BlueSky
Long questions: Ask a Game Dev on Tumblr
Frequent Questions: The FAQ
28 notes
·
View notes
Text
Ukugyps orcesi Lo Coco et al., 2024 (new genus and species)
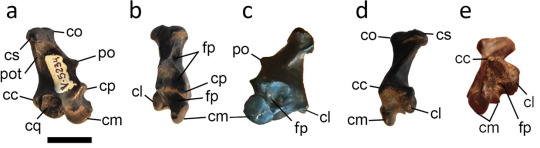
(Type quadrate [bone in the back of the skull] of Ukugyps orcesi [scale bar = 10 mm], from Lo Coco et al., 2024)
Meaning of name: Ukugyps = reign of death [in Quechua] vulture [in Latin]; orcesi = for Gustavo Orcés Villagómez [Ecuadorian biologist]
Age: Pleistocene (Late Pleistocene), between 17,800–19,000 years ago
Where found: Tablazo Formation (La Carolina tar deposits), Santa Elena Province, Ecuador
How much is known: A partial right quadrate (bone in the back of the skull).
Notes: Ukugyps was an American vulture, around the size of the extant king vulture (Sarcoramphus papa). Although it is based on very little fossil material, it can be distinguished from all other Pleistocene American vultures for which the quadrate is known.
Reference: Lo Coco, G.E., F.L. Agnolín, and J.L.R. Carrión. 2024. New records of Pleistocene birds of prey from Ecuador. Journal of Ornithology advance online publication. doi: 10.1007/s10336-024-02229-1
42 notes
·
View notes
Text
I really wish there was an "any standard" format in magic. It feels like it would very neatly address the issues of non-rotating formats having to deal with a quadratically-scaling number of interactions that make these formats have absurd power levels, while still allowing new cards and strategies to enter the meta. I think it would prevent older decks from being permanently power-scaled out of the meta, because old cards aren't directly competing against new cards -- cards can only be directly replaced by cards from the same standard, so many weaker older cards can be carried by stronger cards from the same standard, hopefully leading to greater deck diversity.
13 notes
·
View notes
Text
CUPID 💌🏹
IN WHICH our cast plays cupid for their loser (endearingly) friends who can’t seem to take their own relationship advice.
CHAPTER 002. sneaky little tax evader (smau + written) 🎧

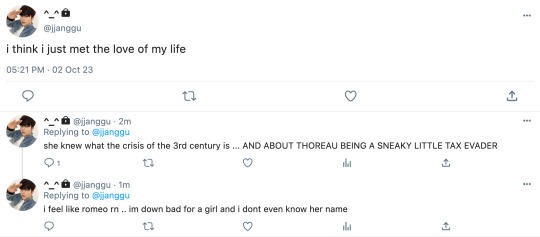
“HI!” you greet the boy that you’ve been not-so-secretly eyeing for the past hour and a half.
“Hi!” he smiles. you internally melt and almost don’t notice the hands belonging to the boy in front of you that are giving you a book to check out. He doesn’t break eye contact once. Usually, that would be a little odd and would kind of sketch you out but there’s just something about his big brown eyes that makes you feel safe.
“Will that be all for you today?” you ask. You’re the one to finally break eye contact, but only to quickly look down so you can locate the barcode and scan it. Your eyes graze over the cover, “The Crisis of the 3rd Century? Interesting choice…” You must have a quizzical look on your face because he laughs and it’s the most beautiful sound you think you’ve ever heard.
“I know. It's one of my favorite things to whip out at trivia night. No one ever sees it coming! First, it’s the Quadratic Formula … easy peasy … and then Boom! It’s the near collapse of Ancient Rome! Well, that and the fact that Henry David Thoreau committed tax evasion. Multiple times.”
“Oh my gosh, no way… no one ever knows about that! Every time I reference it, my friends think I'm some sort of nerd. Not that you’re a nerd or anything.” you could’ve rambled on and on but a thought pops up and stops you in your tracks. “I'm sorry, I just have to ask. Exactly how often do you think about the Roman Empire, and I’m not talking about The Gladiator (2000) with Russell Crowe all oiled up Roman Empire. I’m talking like actual Roman Empire?”
“Trust me … you don’t want to know. “ the pretty, brown haired boy replies while trying his best to look serious. It doesn’t work though because a few seconds later, he bursts into the same laughter as before and you swear your world stops for a second. All you can do is pray that he doesn’t hear your heart about to beat right out of your chest. In an attempt to hide your rosy cheeks, you look away from him and towards the register which now displays his total.
“Your total is going to be $15.89 today, cash or card?”
He pulls out a $20 from what seems to be an off-brand Lightning McQueen wallet and hands it to you. You take it, put it in the register, and give him back his change. He takes it from you with a smile that you’re convinced could bring world peace and drops all $4.11 into the tip jar sitting on the counter in front of you. He says “Have a good evening.” to which you reply “you too.” and watch him walk out the door, bag and cup in hand.
“Woah, your cheeks are redder than a tomato. Be honest, on a scale of 1 to 10, how down bad are you?” Taerae, your best friend, questions as he walks over from his post at Bluebird, the in-store cafe that sits right by the checkout and also happens to give him the perfect view of what just went down.
You sigh and dramatically place a hand to your forehead as if you’re swooning. “I fear I’m in love and I don’t even know his name.”
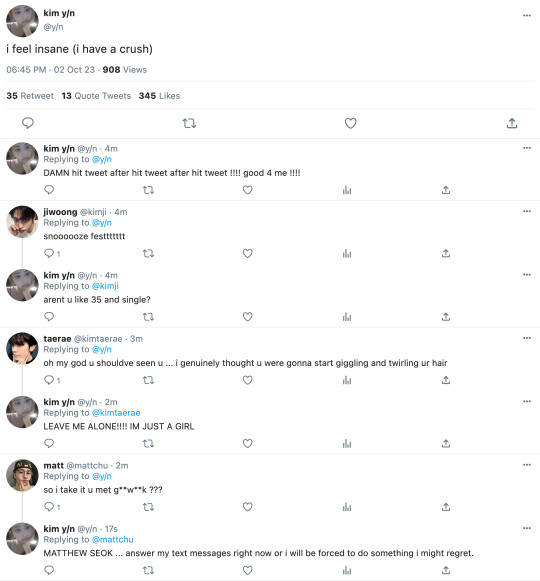
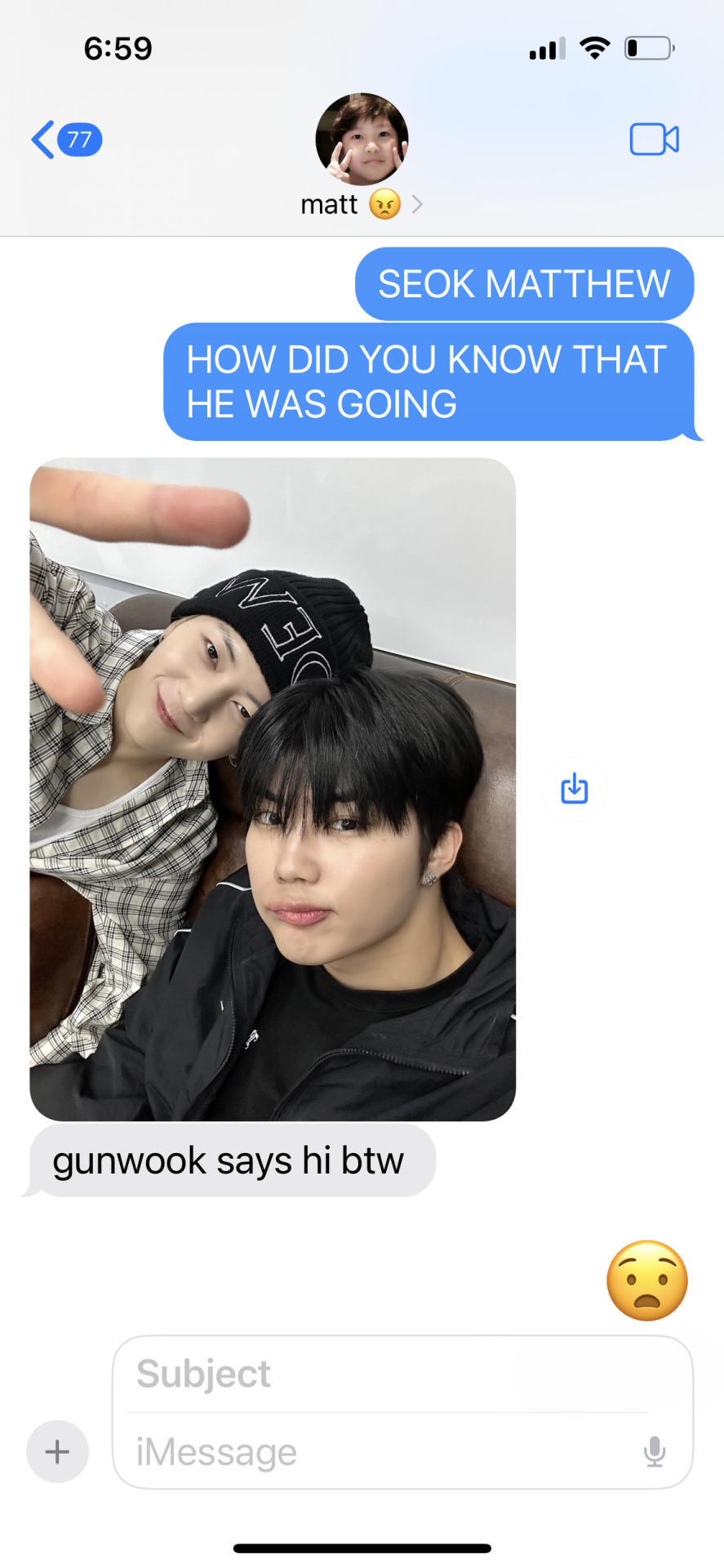
🔭 ★ mlist. previous. next.
☆★ TAGLIST: @annoyingbitch83 @vernonburger @doiedecimal @taekwondoes @imthisclosetokms @kaynunu (bold can't be tagged ; pls check your settings + make sure u can be tagged ... ty ^_^)
want to join? -> taglist form . 🫀
#prkwook#002. cupid 💌 🏹#zerobaseone#park gunwook#zb1 gunwook#gunwook x reader#park gunwook imagines#park gunwook x reader#zb1 fluff#zerobaseone imagines#zb1 x reader#zerobaseone fluff#zerobaseone x reader#gunwook fluff#park gunwook smau#gunwook imagine#gunwook smau#zb1 imagines#zb1 scenarios#zb1 smau#zb1#zerobaseone smau#cupid 💌 🏹
46 notes
·
View notes
Text
I hope I fixed the “displays at full length” issue from earlier postings. Anyways. This one is something different from my usual work. It’s the most updated draft for Part 1 of 10 for my planned science-fantasy work: the Song of Tarn. It follows a gene-enhanced lizardman as he attempts to navigate his Calling, a journey thrust upon him so he may become one of his people’s legendary heroes: a warrior of the Fang Guard. It will attempt to balance spirituality, psionics, high technology, and genetic manipulation, within the context of a barbaric society in the galaxy’s backwaters. I appreciate any attempts to read and offer critiques, as I’m not the greatest with prose. Length should be about 20 pages for this part, so be warned if you wanna look it over: it’s a long read. I’d like to hit that length roughly for every part of the story. Without further ado, the Song of Tarn - Part One
— — —
The Song of Tarn
Grand was the day about the streets of Tall Karik. The Clades of the Ssirith Brood had filled the walkways with revelers and merrymakers, with their frills and fringes and scales of many hues baking in sun, the rhythmic beating of drums and the aroma of sizzling meats breathing fresh life into its air. The teeming cityscape stretched out across the flat table of the Plateau of Second Rising, lording over the surrounding scrubland with pleasant countenance. Worn, angular walls encapsulated the entirety of the polis, set into the lip of the plateau long ago. Squat quadrate buildings crowded the face of the city, for the only structures permitted to reach unto the heavens were the city’s five grand megaliths: the Temples of the Aspects. Five high places for five city corners, highest of which, the Temple of the Heart, overlooked the city’s southernmost reach. This stark edifice served as the center of governance for both the world upon which it sat, Skeniq, and the empire the Ssirith had forged amongst the stars. Today, this high seat captured special attention from the masses, for there was to be an Exaltation.
A lone warrior climbed the final stairway up from the Warrens, the scabbards hung at his hips scraping along rocky cavern walls as he followed the stream of jubilants out of the Middle Mouth. Many were the hours since he had seen the sun, for the Warrens of Tall Karik stretched deep into the belly of the plateau and out to the surrounding dusts. His eyes adjusted. The bare, monotonous sandstone of which most of the city was built had been newly painted over in striking shades of blue and green and red. These vibrant daubings of color formed patterns along the footpaths with their stripes and dots and zigzags. Images of holy significance were laid out upon the walls. As he scanned the scenery, the warfighter found himself surrounded by depictions of the Great Serpent, His scale-clad soldiery, His blade-dancing Swordpriests, the legendary heroes of His construction, all arrayed in their splendor. Tarn paused to behold the exquisite detailing, noting the silvery spears held in the hands of painted Clade Warband fighters and the tiny jewels brushed upon their helms. Tarn strolled slowly along the path, giving each icon its due. The warrior seldom enjoyed such a chance to appreciate his people’s art. Displayed upon the wall of the Coinchanger’s Den, between two great flat arches veiled by beaded curtains of silver and jade and coral, was depicted the Once-High Himself, Srikanakatess, the Serpent of the Stars, in his full form. The black snake was shown curling around the homeworld of the Ssirith Brood, a place once called Ssi. Minute filigree in every color bordered the scales of the Serpent. His massive curled fangs pierced the ice of world’s northern pole. His tail pointed to the Place of Unbecoming. A spawnling bumped hard into Tarn’s leg, interrupting the warrior’s musings. A look of horrified realization broke about the child’s face as she scraped herself from the flagstones and retreated hastily into the safety of the vibrantly-hued crowd. Further still, Tarn strode.
He could see the Pillar of Aspect as he approached Temple Muster. Stood tall in the center of the square, beset on all sides by foliage and stone braziers, was a pentagonal pillar topped with a large cube. It loomed over the low buildings surrounding the Muster, a height of at least four Tarns, or six of the lesser Cladekin of the Brood. It, too, had received decoration. The thick trunk of orange stone had its ancient carvings enlivened with color, each face displaying one of the five Aspects of Srikanakatess. Tarn approached the work so that his spirit may be replenished. He gazed first upon the Heart, his eyes alight with reverence as the crimson of its sinew and the royal blue of its vessels imparted visions of the Serpent’s lifeblood coursing through the veins of each creature fashioned in His image. The grandest of the gifts of the Serpent, the Heart was given unto the Ssirith so that all those kin of Srikanakatess might live and breathe and stride the heavens with His power nestled within them. The Heart given to sew life into the divine likeness from which He had carved the Brood. The Heart which rose the Ssirith from their bellies. The Heart which birthed the First Heroes from the dusts of Ssi. The Heart which imparted to the First Priest his high station of lordship. The Heart was the center of all things. He tensed the muscles in his arms and breast, so that he might feel the essence of The Heart within him.
Tarn, cutting through the crowd, walked around the pillar to its next face, so that he may contemplate the Tongue. The indigo, masterfully smeared about the stone rendition of the Tongue of Srikanakatess, accented by jet black striations down the Tongue’s central groove, impressed upon the warrior the gravity of its blessings. Just as the Serpent had given His Heart and its blood to the Ssirith Brood, so too had He given His Tongue, with it whispering into them thought and reason and law and fate. The Tongue gave the glint to the mind of the Brood, the capacity for the understanding of worlds and the heavens, the wit for the forging of weapons and wheels and vessels, the script with which to draft the writs of justice, the ability to hear and comprehend the Song of the Aspects, and the voice with which the Ssirith would knit together their domains. His hand grazed over the pommel of one of the paired swords hung at his hips, for every blade fashioned by his people served a visage of the Tongue. He was roused from his musings by a faint tap upon his tricep.
“Pardon, warrior.”
He turned his head. Stood aside him was a Cladekin, a female. Thin, waifish, trembling, the yellow striping on her auburn scales betrayed her as belonging to the Clade Ufthishi, a lineage famed for their numerosity and brilliant holdings. Detached, he summoned an obligatory reply.
“Yes?”
“I would ask of you, why is it you’ve come to Skeniq this day? Is there to be bloodshed?”
He sighed. Tarn had grown accustomed to such questions, for the Cladekin are cut from a softer cloth. Yet, he still felt their othering. He replied curtly.
“No, there is no warring to be made today.”
He watched her a bit closer now, as she exhaled out the nerves which wracked her, placing a hand over her breastbone, dropping her shoulders. It seemed exaggerated. Rehearsed. She grinned.
“Then why is it you’ve come? For the Exaltation?”
Internally, the warrior groaned. He’d hoped to avoid such attention. The lesser forms that make up the Clades dreaded him enough already, Tarn would have preferred not to have adoration mixed in.
“No.”
Her grin widened as she leaned slightly towards him. “You lie, Bright Clutch.”
The reiver turned about fully now, to gaze upon the Cladekin. Great bangles and frill caps of gold decorated her red-brown hide, which she’d clothed in a fine silken stola of a brilliant white and accented with fronds stitched of auric thread. All trappings of high birth. Her eyes, black in sclera and white in iris, narrowed, conveying her smugness. She’d gotten the better of him.
“You are a bold accuser.” Tarn twitched. Angered. Found out.
She did him a small mercy by closing in further, whispering her next words. Tarn was taken aback at how quickly she’d dispensed with the pretenses of fear.
“I know you are to receive Exaltation this day. The Song told me as I took in the sight of you. Do not be so quick to anger, dear slayer. All I would ask of you is your name.”
The warrior was taken by strange emotion. His flash of temper lingered still, yet, there was something else. Something small and sweet and stirring held within her whispered tones, the flowery scent of the balm upon her, the way the robe flowed about her figure in the gentle breeze. Something filling, something warm. Something that could not be allowed. His purpose was war. His life was death. She gripped the upper portion of arm with both hands. She was bold.
“Please,” she pleaded softly, “just your name.”
He stood frozen, as still as the stone of the Pillar before them. Every nerve within the confines of his skull burned, locked in battle, a heated stalemate which seemed to last an eternity. Her eyes bore into him, their tender stare rending his spirit asunder. His savage nature would eventually prove the victor, as he snatched his arm from her embrace and stormed past her. He called back as he left her company, his voice stern.
“I am Tarn, warrior of the Bright Clutches. Now mind yourself.”
In the far reaches of his mind, there was loss.
Tarn strode through the crowd again, his footfall heavy. They parted for him. They always parted for him. He was a being apart. The war garb which draped his body belayed its purpose in its ruggedness. His hideweave mantle, thick and dark, comprised of compressed layerings of leather and studded with golden rectangular devices called hirisis, three per side, for dispersing the impact of solid projectiles. Its edges were lined with the bristling honey-colored furs of the Surik Bear he’d hunted to craft it, as is required of a warrior of the Bright Clutches. Beneath this rested his Raiment of Pearls, a black silk garment laiden with the genesculpted and augmented pearls of the Kreshi-Si. He could feel the pearls, always. They linked to his nerves, delivering sense signals and shocking pulses in the heat of combat, hyperstimulating his musculature to assist his body in bladework and evasion. Resting atop his skull, a simple helm of dense alloy wracked with gouges and craters, a long and wide noseplate extending half the length of his snout, the sides and rear of the helm terminating about his lower jaw. Hung about the waist were two swords he had named Ithi and Srev, broad-bladed implements of whirling death, banded leather wrapping their grips, stout cylindrical caps for their pommels, and minute vermillion gems decorating either side of their pronged guards. Each blade had the fury of the Song forged within it, channeled forth via arcane circuitry sung into them by the Bladepriests. Upon either forearm rested bracers of hideweave and weathered metal, battered by years of fighting. Strung along his waist, a skirt with three leather pteruges dangling from the belt, a garment serving primarily to display the colors of his Warrior Cadre, assigned by his genesmith sires. In three zigzagging lines, over the black field of the skirt, were a deep maroon, above a burnt ochre, above a pale yellow. The Cadre of Rent Sky.
Tarn’s talons clacked against the wide blocks of the square as he walked on, the lesser Clades of the Brood shrinking from him as he does. The third face of the Pillar of Aspect met his gaze in kind, for he now stood before the Eyes of Srikanakatess. Two orbs, displaced from their host, colored now with the orange-yellow of a raging sun and striped throughout with all the shades of the Song, mystic hues of light blues and bright greens and fuschia and lavender. In the beginning, the Tongue may have given words to the Song of the Vaulted Sky, yet it is the Eyes with which the Ssirith Sing. The Eyes that command. The Eyes that impart the will of the gods onto the realms. Tarn spots an Eyepriest enraptured in prayer before them, knelt low at the front of the crowd in his black robes and golden bead chains, and wonders how well he wields the Song. The warrior had seen it devastate the enemies of the Brood time and time again. He brushed his hands over his swords as the memories threatened to pour in. He steeled himself instead, for there was more he wished to reflect upon before he ascended the temple stairs.
Tarn continued to work his way around the Pillar. He noticed the crowd swelling in size, glancing briefly towards the road he’d taken to arrive here. The time is nearly upon me, he thought, a unique blend of foreboding and pride swelling within his chest. He spotted the highborn female from before, melting into the number arrayed about the temple’s rise. A small sting. He then turned his eyes upward. Upon the Pillar’s face was a rectangular shield of scales, entirely black, save for the borders of each scale, which had been vividly painted in every shade available to his vision, a sight equal parts solemn and spectacular. The Scales of Srikanakatess, given unto those of the Brood by the Once-High so that they might embody His constitution, display His likeness, and become the recipients of His protection. It is the Scales that mark a being as a child of Srikanakatess. It is the Scales that steal the Serpent’s scions away from the perils of the Void. It is the Scales that wrap the tired, the downtrodden, and the meek in their tender embrace. The warrior, stood proud, recalled whimpered prayers of the Clade Warband soldiery he’d led through the antechambers of the hives on H’resket, when he was a newblood. He tried, this time in vain, to shake the memories loose from his mind.
“Bandchief! The ordnance!”
Tarn whipped around wildly. Through the frenzied melee he spotted a Clade fighter stood pinned to the wall of the antechamber, affixed to it by the three spears run through his gut, his humors pooling upon the floor. He pointed weakly across the length of the room to a large bronze-hued canister.
“Damnable wretches!” cursed Tarn.
It had been the seventh time the Bright Clutch had sewn death in service to the Ssirith Brood. Still a newblood, still sloppy. The direct attack upon the entrance to the hive of the Ifthashek had been a disaster: all around Tarn, the gore of hundreds of Clade fighters smeared the high walls and decorated the carapace of the advancing insectoid monstrosities, which flooded forth from dozens of openings lining the edge of the domed structure. The antechamber had become an abattoir.
“The lines are broken!” cried a Cladekin. Tarn shot a glance to his left, glimpsing a formation of Ssirith spearminders as they became encircled by their verminous foes. They were not long to live.
The enemy presented as a nightmare. Sickening in their visage, with gnashing pincers and mandibles about their faces and thoraxes, a slick umber sheen coloring the armored chitin of the bipedal formidians, which faded into burgundy at the terminus of their thin extremities. Though Tarn dwarfed these drones in stature, his foe displayed no fear of him, as their morale matched the vastness of their number. A throng of their drones rushed headlong towards the warfighter. Tarn would respond in kind, his failures at command fueling his bloodlust.
The berserker crashed into the Ifthashek drones, shattering their obsidian-ripped spears with blade and fist. Early in his career as a Bright Clutch, he wielded a single sword by the name of Breaker, long and thick and rough and cheap. Its heft would serve well this day; the copper-colored brand easily cleaved apart the Ifthashek. In a flurry of wide swings and sharp thrusts and powerful chops, he would expose the pale meat and simple minds of the hive’s drones to the open air. The warrior spoke death to sevenscore and four of their ceaseless tide in mere minutes. It had made no difference.
“Rifles!” Tarn cried over the cacophony, “Send up the rifles! I must have a path!”
Dozens of shouts rose out from amidst the spearminders and their Underchiefs, carrying their erstwhile Bandchief’s demands to the entrance of the hive. Moments later, his wish would be granted. A mob of Cladekin numbered in their hundreds poured in through the breach brandishing swing-rifles affixed with glaive bayonets, a war cry upon their lips:
“Death to the Heartless! Victory to the Scales!”
Tarn continued his slaying, pivoting upon his left foot and snatching a head from its shoulders with Breaker in a single motion. He was dotted in shallow wounds, blood staining his many-colored lamella. All about his flesh and war garb were flects of shattered insect carapace and white chunks of their innards, trophies gathered from slain thousands over the course of the morning. There was no time to clean off, no time to stop. Just then, a sound as heavenly as the Singing of the Aspects Themselves filled the air about the antechamber. Shot. Thunderous shot. Tarn snapped his head to the right to see an explosion of viscera and umber fragments appear amongst the ranks of the Ifthashek. The wide barrels of the swing-rifles poured their penetrating hate into the surging flood of insects, exploding their abdomens and ripping limbs from their housings. In the mess of the firing, Tarn spotted the ordnance. He sent up his voice once more.
“Rage, my warriors, rage! The hour of victory is at hand!”
The forces of the Scale had been on the back foot from the moment they’d taken the entrance to the hive’s antechamber. Now, looking on as their leader charged through the gap created by the rifleminders, his sword risen to the heavens, they felt the Song well within them. The Cladekin, seeking to avenge their scores of fallen brethren with spear and wheelpistol and swing-rifle, set upon the Ifthashek. The carnage of the day had reached its crescendo. Tarn ended his sprint with a slide across the floor of the killing grounds, scooping the large bronze canister under his left arm. It was deceptively heavy, a reflection of the destructive magnitude held within. He looked to the tapered column at the center of the chamber, the midpoint of the support structure hiding his ultimate goal. His musculature ached and his wounds seared, yet he soldiered on, slaying one then two then ten then more of the chitinous bipeds as Breaker fell again and again and again. Forward, his mind sang, forward. He soldiered up the lower mound of the support column, hacking through the pitiful resistance levied against him. As reached its narrow center, he plunged Breaker in, splaying apart the hard spit-worked mud and paperlike inner supports of the insects’ design. Peering downwards inside of the hive’s main support spire, he saw only darkness, a hollow shaft seemingly without end. Unfortunately for them, Tarn had learned of these creatures, and of how they construct their lairs. He allowed Breaker to fall to his side as he mustered all of his vigor and with a primal roar hefted the canister into the gap he had made. The explosive disappeared into the lightless depths within the crust of H’resket, falling down the support structure to the throneroom of the vermin’s Queen.
A spear point pierced his lower calf. With a roll over and a kick, he crushed the face plates of his assailant inwards, wobbling on its barbed feet before falling still upon the ground. Tarn took in a deep breath.
“Glory! I say glory! The day is won! Fall back my warmakers, to the fields, let these beasts consume themselves!”
The Cladekin retreated with whooping and hollering as an explosion from the hellish chambers below shook the hive to its foundations. Tarn retrieved Breaker, felling a few more Ifthashek as he exited the battlefield, though he hardly needed to: without their Queen to guide them, the insects were given to blind fury and madness, setting upon their own number with pincer and spear. He passed over the corpses of his soldiers. He would learn later that the honored dead numbered over twelve-hundred, given back to the Song over their five hours of mayhem. His glory would turn to ash in his mouth.
Tarn shook his head, turning away from the painted depiction upon the monument. He strolled once more through the onlookers and came to rest before the last Aspect etched into the Pillar: the Tail of Srikanakatess. He mustered a snort, remembering how he’d hated the Lashpriests of the Tail as a whelp. The Serpent of the Stars imparted to the Brood the knowledge and discernment to create law and foster brilliance of the mind by the giving of the Tongue, and He gave His Tail to ensure those made in His image have the discipline to carry out these tasks. The Tail of Srikanakatess is the whip by which a people are corrected. It is the whip by which one scores themself across the back for the weight of their transgressions. It is the whip by which a sire guides their whelps. Perhaps most importantly, it is the whip one cracks in the seat of the mind to press on, to spite the struggles of living with tenacity and force of will. Tarn finally allowed himself to glance skyward, above the Tail, above the body of the Pillar, to the last of the painted stone to view: the Stone of the Unbecoming. The cube of rock decorated the top of the Pillar of Aspects, its sides extending for roughly three spans over the outer surfaces of the edifice below. The equally portioned stone slab was truly ancient, predating the Brood’s capitol city of Tall Karik by thousands of years and said to have been carved directly after the Unbecoming. Upon each face was displayed the same graven image: Srikanakatess’s complete form, sundered. The Serpent depicted slain, His innards spilled forth in ribbons, His Heart ripped out, His Eyes plucked, His Tail sectioned, His Tongue severed, His fangs smashed, and His Scales shredded. This is the Unbecoming, the moment that one god became five. Each Aspect a deity, rent from the corpse of the Once-High by the Beyonder, an unknowable hate given form. The sacrifice made so that the Brood may walk the heavens in Srikanakatess’s stead, with His blessings to guide the way.
I am prepared, thought Tarn. He departed the Muster, the bright sun of noon having dwindled to a softer, mid-afternoon temperament. The sea of bodies around him had swollen to its zenith, the Brood having donned their fine robes and golden trinkets and scented balms to witness the occasion of the day. His hide, a yellow-white mottled with rivers of viridian and tendrils of dandelion and peppered with dark gray splotches, separated him from those Cladesmen he’d been wading through to a similar degree that his immense stature did. A warrior of the Bright Clutches, sired by none, sired by many, a streaked and speckled goliath crafted from the gene-slurry of a million Clades and superconcentrated growth fluids by an army of clutchminders and genesmiths. In this moment, he saw no true peer. He was a creature. The result of hundreds of years of effort to rectify the Brood’s Clutchdeath Curse, weaponized. Their bodies not only taller, not only stronger, but vastly altered from the base Ssirith; their arms much longer, their bones much thicker, their spines hunched about the shoulders, their tails armored down their length and beset with tufts of thin hairlike frills about the tip, their snouts and jaws wider and longer and caked with thickened layers of scale appearing as leather yet hard as stone, their skin and scales tinged by the interweaving of genesource samplings into patchworks of color unseen in any naturally sired Ssirith. Their minds were given special attention as well. Each Bright Clutch warrior is gifted with a cunning only bested by high-minded scholars and the Priestly Clades, honed by instruction in tactics and combat sense from the time they are old enough to speak. Heroes. Clad in the finest of armor, wielding the finest of blades, brandishing the most excellent of rifles and pistols and cannons, decorated in the most intricate of personal heraldries, and possessed of the skill-at-arms to humble all but the greatest of beasts or most terrible of demons in single combat. Tarn looked like no other. He spoke like no other. His only peers, also crafted to resemble no other.
He ascended the steps at the Temple of the Heart of Srikanakatess, a skyward-reaching building cut from the same orange, chalky stone present in the rest of the city’s architecture, its edges softened by wind and time but hinting at a once sharp, angular, blocky construction. Yet still it appeared simple, a massive rectangle with a stone awning several stories above its grand threshold, supported by five pillars, the central pillar having been painted entirely with crimson. Its entrance obscured by a curtain comprised of long strands of beads, fashioned from silver, gold, and onyx. He could see smoke rising from the temple’s threshold. At his back, at his sides, all around him, there were eyes. Eyes for him, upon him. For today was his. He ascended, the climb steep and lengthy, yet for the finest of the Bright Clutches, it was effortless. The hour is upon me, he thought, the just reward for my mettle. The warrior allowed his mind to wander to the past, to the caves deep below the Palace of the Eyes at Fthek, the place where he’d won his greatest of honors. He remembered his Cadre, the Cadre of Rent Sky, at his back, numbered at nine with Tarn making the tenth. Each of them defiant, each more mighty than the last, spitting fury in the faces of the Hidrii. He threatened a grin. How their blades fell! How their war cries echoed in the chambers of the monsters! How they piled the severed heads and cleaved tendrils of the wretched beasts! How valiant they had been! Their broken bodies lie still now, behind Tarn’s furrowed brow. How dire things had been. How potent were the words shared. The thought falters him, strands of memory weaving together a painful tapestry in his mind’s eye.
“Tarn,” a low familiar voice had called out, echoing slightly in the tightness of the cave chamber, “I must ask you something.”
The Cadre of Rent Sky had ceased their descent to the realm below the Palace only momentarily, stopping within a defensible dome large enough to fit the entirety of the group. The soft sounds of the oiling of blades and the undoing of pack straps filled the still air. They numbered seven now. Sheshra had been granted the reprieve to limp back to the surface the day prior, his left leg and tail splayed open to the bone by the barbed tendrils of their fell adversaries, too grave a condition to carry on his warmaking. He was blessed, though, for Siruth and Hish had been splayed out in heaps of crushed gore by a motherbeast within the opening hours of the bloodshed. Tarn glanced over his shoulder to his kin, to address his caller.
“What do you ask, Thruvi?”
The warrior stood before Tarn, a strained look plastered upon his scaled cerulean face. In his hands he held a half-eaten strip of dried flesh, the sustenance required to continue their slaying.
“Do you ever puzzle the questions of living?”
“Yes,” replied Tarn, furrowing his brow, “though not often.”
“In a place such as this, I am snared by them.” Thruvi lowered his gaze sheepishly, shamed by his distraction, “The nature of our foe captures me.”
Tarn turned fully about, crossing his arms over his hideweave and silently awaiting his kinsman’s explanation.
“Are they not creatures of the Scale?” The words barely escaped Thruvi’s tightened maw, his teeth nearly brought to quivering at the thought of chancing sacrilege. He continued, beginning to pace. “Their hides have them. Their faces, armored just as ours. Their wretched spawn birthed into clutches of eggs, just as ours. Their shrieks…they sound like a spawnling, only one of great size.”
Tarn chuckled, to consider the Hidrii as fellows was a thought so strange to him that it impressed comedy upon him.
“These beasts are not of our ilk, Thruvi. They are monsters. Their thoughts are base.” Tarn retorted his underling with surety. “Aside from this, why would a being of the Scale attack its brethren the way these abominations do?”
“I am unsure,” said Thruvi, “but they are blessed of the Aspect of the Scale, are they not?”
“I am not certain if it is wisdom to say they are blessed, but yes, the beasts have scales.”
“And, they way they fight. You say they are base and yet they move in unison. They divide their prey. They hold numbers in reserve. They retreat. They redouble. The motherbeasts writhe their bodies before their young, raging on no matter how many scores of their tendrils we cut.” Thruvi’s hands moved to grip the handles of his twinned blades, allowing the meat he’d been holding to fall to the slate floor. “When these strike the chitin of one head, another of their four lunges to bite the blade.”
“Perhaps your words ring true, but I do not see what you’re playing at.”
“I see within them the Blessings of the Tongue and the Tail.”
“I see.” Tarn sighed. “You strain me, Thruvi. Tell me then, what is the grand meaning of your puzzlings?”
The rest of the warriors of the Cadre of Rent Sky had been pretending not to listen, yet it was here their facade dropped, for to cast aside the wisdom of a slayer is a terrible sin. Thruvi’s mottled hide of blue and black and amaranth tightened over his musculature, summoning forth the Heart and Tongue so he might convey himself justly. Slowly, the words escaped from him.
“The Hidrii appear as beasts. Yet, they possess the Blessings, save for the Eyes. In hushed whispers at our backs, those of the Clades speak of the Bright Clutches as beasts, too. We also possess the Blessings, save for the Eyes. This is the puzzling that snares me. We pass into history as legends and heroes, but I fear our smaller kin would score our hides with blade and shot if only we were not so needed.”
The following silence threatened to drown the warriors in that chamber, for they knew Thruvi spoke truth. Images of the strife that would occur should the genecrafted marauders of the Ssirith become enemies of the Clades washed over them. Sivhar eventually broke the silence, his mangled snout offering an unwitting gesture of mercy.
“I thinkths the Warleader haths the Eyeths. I heardth our Thordprietht thpeak of it. He couldth be-“
Poor Sivhar did not get to finish his thought. He had always been a touch oafish compared to his kin, a plight which his newfound wounds only served to worsen. The oppression of the moment evaporated in an instant, as Tarn doubled over himself in laughter. It was not long before his compatriots joined him, first Thruvi, then Ftax, then Hethis, and so on. They laughed long and hard and loud and allowed their levity to resound all throughout their immediacy and beyond, yet they cared not if they were heard. They knew they would be the ruin of any who dared to strike.
Tarn slammed his eyelids shut, and opened them again. He continued his climb up the steps to the Temple of the Heart, the falter in his stride imperceptible to the mystified onlookers.
Tarn’s talons came to rest at the top of the stairs, the scent of incense caressing his nostrils, the jangling sound of the Seeing Bones striking against their cauldron echoed out from the temple ahead. He glanced back, only once. Behind him, as far as the eye could see, he saw Ssirith lining the streets of Tall Karik. To either side, he could see the orange walls of the city meeting the dry plateau upon which the settlement was founded, and beyond this, the scrublands stretching outwards to the horizon. Ahead, he saw destiny. The wind brushed at his back, as though to carry him forth. Forth, he went.
The beads rattled and tinked against one another as he entered the Temple of the Heart. The sight which awaited him was one he could never have foreseen. Smoke lingered about the hall of the temple, shrouding the orange sandstone walls behind a thick haze, originating from grand censers hung from the high vault, arrayed in groupings of four all along the ceiling of the hall as they poured down their scented wisps. The aroma was that of Zhisdi nuts, an overpowering odor of hardwood carrying a stinging spice with it as it flooded Tarn’s nostrils. The warrior attempted to gaze to the rear wall of the temple, finding it obscured from view entirely save for the upper length where the wall meets the ceiling. Scanning his vicinity, the place appeared barren, lacking any furnishing within view, the only features of note perceptible through the fog of the censers being two great archways piercing either wall of the structure with wide lonely passageways. He did not recall hearing chanting from the exterior of the temple, yet mystic droning now accosted his senses, sharp exclamations in tongues he could not comprehend. As he wandered deeper into this place, the Temple of the Heart, Tarn found within him a blend of reverence and dread that increased in potency with every passing second. He located the source of the chanting. As he peered through the archway on his left he was faced with a dark chamber, and a pile of writhing forms: Ssirith females, beautiful in feature with their short snouts and plump tails and wide eyes of black, crawling over and upon each other at the feet of a decrepit-looking Eyepriest and his two underlings, each of the menagerie in various states of undress. The warrior’s mind was lit ablaze. What sort of Singing is this, thought Tarn, what madness drives this rancid display? The words burned his eardrums, each syllable producing a unique pain, constantly shifting from sting pounding, burning sensation Never once did any of the figures turn to look at him.
The clang of Seeing Bones broke him free from his shock. He pressed on. Further into the hall, to his right, he glimpsed the floor of the chambers of the Ssirith Moot, the meeting place of the Clade Chiefs, as Eyepriests cast burning bones out from their cauldrons into the sandy pit at the center of the room, producing intense flames of violet. Seated around them in the cavea, upon three ascending rows of stone benches, and numbering thirty-something strong he spied the Chiefs, those chosen of their people to impose will upon the realms of the Brood. Each one had been more strikingly adorned than the last: High-crested helms and battle-worn war garb draped the person of some, robes and jewels and finery upon the form of others, interspersed with those given to a more savage disposition, decorated in thick furs and leathers and bony remains of fallen foes. Save for the clanging of the cauldrons and the sizzling of the Seeing Bones, the scene were silent as death, the Chiefs transfixed by the work of the priests. I shall not invite menace upon myself here, he thought, and cast his eyes downward, soldiering on through the thickness of the smoke.
The Temple of the Heart had not been what he’d envisioned. In his musings he’d come to expect high minds of order and law seated around grand tables of fine wood, bickering, endlessly exchanging blows of the tongue and mind, tempered only by the fierce Heartpriests who would enforce the sanctity of the place with their vigor. He’d hoped for life abounding within the walls, dreaming of vegetation and vibrant banners accenting the exalted decor of hearths and statues and trophy plinths displaying the spoils of Ssirith victory. He’d imagined the Song breathing levity and vitality into the air of the temple, bringing with it the surety of constitution that only the Aspect of the Heart can provide. Yet now, as he tread the cool stone floor of the hall, the place felt more like the parlor of a vast tomb; both structures beset similarly by mystique and ill omens, and greeting the inhabitants of either seemingly equal in foreboding. He’d not seen a single Heartpriest.
It was then he heard a voice.
“Come, Tarn, Warrior of the Cadre of Rent Sky, He-Who-Is-Called-High. Your gawking only serves to delay the awarding of your valors.”
It was an elder’s voice, stern yet softly chiding, the weight of years carried in its resonance. The warrior watched as through a thick cloud of grey emerged a Heartpriest, short and hunched and clothed in the red and white robes of a Heartpriest, yet, not simply a Heartpriest. No, Tarn realized, that is no mere Heartpriest at all. It dawned upon him the High Priest of the Heart of Srikanakatess, Silu-sha the Wisened Will, the chiefest of all creatures in the holdings of the Ssirith Brood, the First of the Audience of the Aspects, the most beloved and feared Ssirith to have lived since the Unbecoming, now stood before him. Tarn fell upon his knees, sure that his heart would erupt.
“Rise, whelp, rise!” the elder said with a chuckle “Did you not behold my gift?”
Tarn’s head rose to scan the room. He was certain that he had not seen it earlier, nor could he have possibly overlooked such a thing, yet now he could see a table of black stone, veined with golden streaks, behind the Heartpriest. Tarn stood. Upon the table lay a sword, great in width and as long from pommel to tip as Tarn was tall. A gilded serpent trapping a globe of onyx amidst its jaws formed the guard of the weapon. The handle, sized for a two-handed grip, wrapped in leather, black as midnight. The pommel, carved into a gilded heart. In its length and its heft and its grandeur the sword embodied all the trappings of a Great Fang, the famed armament of the Fang Guard, a weapon to rend bastions and pierce leviathans.
“I have named this blade for you, Tarn, Savior of Fthek, Chiefest of His Cadre, He-Who-Is-Called-High. I have named it Eqa’vrii’thei’qaal, named in the Beyonder’s Tongue, as are all legend brands of the Fang Guard. It means ‘biter in the dark.’ Gazing upon the spirit wrestling within your bosom, I deem it a worthy name. A powerful name.”
Tarn stood in bewilderment. The Beyonder’s Tongue sent a burning sensation about his eardrums as it was spoken. However unreal the utterance had been, it was the station being bestowed upon him which truly confounded the warrior. The Fang Guard? He recalled the imaginings he’d allowed himself upon being commanded by the Chief Eye of Fthek to present to the Temple of the Heart at Tall Karik, on the world of Skeniq, for an Exaltation and just reward. His journey to the world had invited fanciful visions, dreams of leading a Slayer’s Band to reive the border planets of Mankind or striking deep into the heart of the Voidshadow’s demonic realms. This, however? Too grand. Too much. Too high a station. His mind barely grasped the words of the High Priest as they rattled about his skull. Each member of the Fang Guard existed as a hero of legend in their own right, mighty paragons of martial prowess. I, Tarn told himself, am undeserving.
The warrior’s quiet turmoil amused the High Priest. The ancient Ssirith grinned wryly, his head cocking to the side.
“Fray not your mind, whelp. Take the blade, and leave this place at once. The Forces of the Song and the Sung Voices of the Aspects will rip those of low spirit in twain. You will not survive my presence” the High Priest commanded him, softly, as a sire would command a dawdling spawnling to grasp their hand, lest they fall and scrape a knee. The withered visage of the High Priest and warm tone of his voice contrasted sharply with the gravity of his words, for he told the truth: it is a grave tempting of fate to stand long in a place and in company so touched by the Song. “A star vessel and a Tablet of Calling await you in the Valley of the Rains. You will show strength. Your Calling’s completion will mark your ascension to the Fang Guard. The Song of the Aspects reveals the way.”
The High Priest pointed to the beaded shroud obscuring the entryway. Tarn knew he could stay no longer. He grasped the blade. The power held within, self-evident. He felt the Song flowing out from his being into this instrument of devastation, flooding forth with the resonance and intensity of a swirling typhoon. The channels within the weapon which had summoned this torrent of power shon golden rays of light, a glowing band down the center of the Great Fang. Tarn slid the radiant greatblade into the black scabbard laid beside it and hastily affixed it to his belt. The Great Fang sat uncomfortably atop one of the paired swords he’d brought with him, however, he had no time for comfort. He offered the High Priest a deep bow and an immediate retreat, for he knew better than to return a Heartpriest’s command with any pitiable utterances he could muster, and could feel the Song begin to churn within the temple’s walls. The chanting had fallen silent now, no cauldrons sang, no crackling of burning bones, there existed no life within the place at all, save for a lone warrior, and perhaps the High Priest still, though Tarn dare not glance back.
Tarn stood atop the stairs. The onlookers, thousands of scaled figures huddled together in silence, save for hushed whispers and the jostling of robes, a sea of baited breath. Then, Tarn drew his Great Fang, and hoisted the sword to the heavens. The crowd erupted.
The Calling had begun.
#science fantasy#sci fi#scifi#sci fi and fantasy#the song of tarn#writers and poets#writeblr#writers on tumblr
2 notes
·
View notes
Text
Love trying to deduce facts about strangers having conversations near me.
Just walked past some guys and they were laughing about something "scaling quadratically" and one of them made a Terminator reference, to critical acclaim from his peers.
Ah, computer scientists
2 notes
·
View notes
Quote
Life is not an orderly progression, self-contained like a musical scale or a quadratic equation... If one is to record one's life truthfully, one must aim at getting into the record of it something of the disorderly discontinuity which makes it so absurd, unpredictable, bearable.
Leonard Woolf
#Leonard Woolf#quotelr#quotes#literature#lit#biography#bloomsbury#bloomsbury-group#leonard-woolf#life#writing
5 notes
·
View notes
Text
Stanotte ho fatto un sogno abbastanza particolare Era sera e mi trovavo a casa mia, a primo piano, c'erano tanti amici e parenti vari Ad un certo punto vedo che è già orario di cena e mi ricordo che i miei cugini avevano prenotato in un locale Mi affaccio al balcone e vedo che i miei suddetti cugini sono giù per strada, già in auto Quindi, invece di scendere dalle scale di casa e uscire, per fare prima scavalco la ringhiera del balcone e mi butto giù Il fatto è che nel sogno, non era una cosa nuova per me ma qualcosa che avevo già fatto in passato e a cui ero abituato, inoltre i miei genitori che mi guardavano farlo erano piuttosto tranquilli Così mi lancio dal balcone, atterro in piedi facilmente e senza dolore, tutto a posto Cerco di entrare in auto che c'è mio fratello ma fa il classico scherzetto di accelerare un po' ogni volta che sto per entrare, nel mentre che lo sportello resta aperto, anche se per lui era per sbrigarsi, cioè per non tenere l'auto ferma Ad una certa infatti mi rompo e faccio un tratto a piedi Finalmente si arriva in questo locale, entriamo ed è terribile... È una stanza sola molto grande con un lungo tavolo tutto per noi, però sembra tutto molto vecchio e molto trascurato, il pavimento fatto interamente con mattonelle quadrate, è molto irregolare, pieno di buche e con diverse mattonelle mancanti In tutto ciò oltre a noi cugini c'erano altri conoscenti che dovevano mangiare con noi, due delle quali stavano litigando abbastanza intensamente ed erano una bambina e una ragazza adulta che era amica della madre della bambina Però in realtà al di fuori del sogno non so chi siano, non so nemmeno se esistano davvero Io mi sposto dalla stanza del locale verso fuori, per non sentire la litigata più che altro, anche il locale ha un balcone e anche il locale è a primo piano proprio come casa mia Così mi affaccio e guardo per strada e vedo che i miei cugini sono rimasti a piano terra che stavano aiutando qualcuno a spostare cose, forse i gestori del locale Allora penso, piuttosto che stare qui ad aspettare e sentire quelle che litigano, scendo giù e li aiuto e anche in questo caso mi verrebbe da buttarmi giù dal balcone, ma alla fine non faccio nulla e il sogno finisce lì
2 notes
·
View notes
Text
genshin spiderbit
Cellbit - dendro catalyst, 3 attack string, 2 modes, 'pen' mode and 'knife' mode, gets stacks when attacking with pen mode that are used up to buff when the skill is used. burst has the same 2 modes, pen mode gives buffs to the team and knife mode augments his own damage and does lots of damage. damage mainly comes from autos. when has 3 stacks of pen, if the character is changed and is a meele weapon, their attacks will be imbued with dendro. if 'knife' autos come in contact with pyro they will deal extra dendro damage depending on the number of stacks. his autos also have a slightly smaller icd (1 sec instead of 2.5, every other attack instead of every third)
Roier - pyro sword, 4 attack string, each button press is 2 damage instances, skill is a dash like yelan that marks and connects the enemies in a web-like thing. the web periodically pulses, dealing pyro damage and pulling the enemies towards the center of the web. without anything, the web pulses 3 time (7.5 secs), but if a burning or pyro swirl reaction is triggered the duration of the web is extended, up to 25 secs. burst is coordinated attacks like xingqiu or yelan for around 7 seconds. if the attacks hit an enemy marked by the web, the web will pulse, and when the burst ends, the web timer is reset. has a lot about quadratic scaling in his kit
#qsmp#qsmp cellbit#qsmp roier#just posting for the sake of posting#i need to think about the passives scaling the ascension stats...#ill prolly do it other day#genshin impact#genshin#shiros genshin fankit
8 notes
·
View notes
Note
🌻
(Oh man, the mortifying ordeal of actually having to pick something to talk about when I have so many ideas...)
Uh, OK, I'm talking about galactic algorithms, I've decided! Also, there are some links peppered throughout this post with some extra reading, if any of my simplifications are confusing or you want to learn more. Finally, all logarithms in this post are base-2.
So, just to start from the basics, an algorithm is simply a set of instructions to follow in order to perform a larger task. For example, if you wanted to sort an array of numbers, one potential way of doing this would be to run through the entire list in order to find the largest element, swap it with the last element, and then run though again searching for the second-largest element, and swapping that with the second-to-last element, and so on until you eventually search for and find the smallest element. This is a pretty simplified explanation of the selection sort algorithm, as an example.
A common metric for measuring how well an algorithm performs is to measure how the time it takes to run changes with respect to the size of the input. This is called runtime. Runtime is reported using asymptotic notation; basically, a program's runtime is reported as the "simplest" function which is asymptotically equivalent. This usually involves taking the highest-ordered term and dropping its coefficient, and then reporting that. Again, as a basic example, suppose we have an algorithm which, for an input of size n, performs 7n³ + 9n² operations. Its runtime would be reported as Θ(n³). (Don't worry too much about the theta, anyone who's never seen this before. It has a specific meaning, but it's not important here.)
One notable flaw with asymptotic notation is that two different functions which have the same asymptotic runtime can (and do) have two different actual runtimes. For an example of this, let's look at merge sort and quick sort. Merge sort sorts an array of numbers by splitting the array into two, recursively sorting each half, and then merging the two sub-halves together. Merge sort has a runtime of Θ(nlogn). Quick sort picks a random pivot and then partitions the array such that items to the left of the pivot are smaller than it, and items to the right are greater than or equal to it. It then recursively does this same set of operations on each of the two "halves" (the sub-arrays are seldom of equal size). Quick sort has an average runtime of O(nlogn). (It also has a quadratic worst-case runtime, but don't worry about that.) On average, the two are asymptotically equivalent, but in practice, quick sort tends to sort faster than merge sort because merge sort has a higher hidden coefficient.
Lastly (before finally talking about galactic algorithms), it's also possible to have an algorithm with an asymptotically larger runtime than a second algorithm which still has a quicker actual runtime that the asymptotically faster one. Again, this comes down to the hidden coefficients. In practice, this usually means that the asymptotically greater algorithms perform better on smaller input sizes, and vice versa.
Now, ready to see this at its most extreme?
A galactic algorithm is an algorithm with a better asymptotic runtime than the commonly used algorithm, but is in practice never used because it doesn't achieve a faster actual runtime until the input size is so galactic in scale that humans have no such use for them. Here are a few examples:
Matrix multiplication. A matrix multiplication algorithm simply multiplies two matrices together and returns the result. The naive algorithm, which just follows the standard matrix multiplication formula you'd encounter in a linear algebra class, has a runtime of O(n³). In the 1960s, German mathematician Volker Strassen did some algebra (that I don't entirely understand) and found an algorithm with a runtime of O(n^(log7)), or roughly O(n^2.7). Strassen's algorithm is now the standard matrix multiplication algorithm which is used nowadays. Since then, the best discovered runtime (access to paper requires university subscription) of matrix multiplication is now down to about O(n^2.3) (which is a larger improvement than it looks! -- note that the absolute lowest possible bound is O(n²), which is theorized in the current literature to be possible), but such algorithms have such large coefficients that they're not practical.
Integer multiplication. For processors without a built-in multiplication algorithm, integer multiplication has a quadratic runtime. The best runtime which has been achieved by an algorithm for integer multiplication is O(nlogn) (I think access to this article is free for anyone, regardless of academic affiliation or lack thereof?). However, as noted in the linked paper, this algorithm is slower than the classical multiplication algorithm for input sizes less than n^(1729^12). Yeah.
Despite their impracticality, galactic algorithms are still useful within theoretical computer science, and could potentially one day have some pretty massive implications. P=NP is perhaps the largest unsolved problem in computer science, and it's one of the seven millennium problems. For reasons I won't get into right now (because it's getting late and I'm getting tired), a polynomial-time algorithm to solve the satisfiability problem, even if its power is absurdly large, would still solve P=NP by proving that the sets P and NP are equivalent.
Alright, I think that's enough for now. It has probably taken me over an hour to write this post lol.
5 notes
·
View notes
Text
Quantum Computing and Data Science: Shaping the Future of Analysis
In the ever-evolving landscape of technology and data-driven decision-making, I find two cutting-edge fields that stand out as potential game-changers: Quantum Computing and Data Science. Each on its own has already transformed industries and research, but when combined, they hold the power to reshape the very fabric of analysis as we know it.
In this blog post, I invite you to join me on an exploration of the convergence of Quantum Computing and Data Science, and together, we'll unravel how this synergy is poised to revolutionize the future of analysis. Buckle up; we're about to embark on a thrilling journey through the quantum realm and the data-driven universe.
Understanding Quantum Computing and Data Science
Before we dive into their convergence, let's first lay the groundwork by understanding each of these fields individually.

A Journey Into the Emerging Field of Quantum Computing
Quantum computing is a field born from the principles of quantum mechanics. At its core lies the qubit, a fundamental unit that can exist in multiple states simultaneously, thanks to the phenomenon known as superposition. This property enables quantum computers to process vast amounts of information in parallel, making them exceptionally well-suited for certain types of calculations.
Data Science: The Art of Extracting Insights
On the other hand, Data Science is all about extracting knowledge and insights from data. It encompasses a wide range of techniques, including data collection, cleaning, analysis, and interpretation. Machine learning and statistical methods are often used to uncover meaningful patterns and predictions.
The Intersection: Where Quantum Meets Data
The fascinating intersection of quantum computing and data science occurs when quantum algorithms are applied to data analysis tasks. This synergy allows us to tackle problems that were once deemed insurmountable due to their complexity or computational demands.
The Promise of Quantum Computing in Data Analysis
Limitations of Classical Computing
Classical computers, with their binary bits, have their limitations when it comes to handling complex data analysis. Many real-world problems require extensive computational power and time, making them unfeasible for classical machines.

Quantum Computing's Revolution
Quantum computing has the potential to rewrite the rules of data analysis. It promises to solve problems previously considered intractable by classical computers. Optimization tasks, cryptography, drug discovery, and simulating quantum systems are just a few examples where quantum computing could have a monumental impact.
Quantum Algorithms in Action
To illustrate the potential of quantum computing in data analysis, consider Grover's search algorithm. While classical search algorithms have a complexity of O(n), Grover's algorithm achieves a quadratic speedup, reducing the time to find a solution significantly. Shor's factoring algorithm, another quantum marvel, threatens to break current encryption methods, raising questions about the future of cybersecurity.
Challenges and Real-World Applications
Current Challenges in Quantum Computing
While quantum computing shows great promise, it faces numerous challenges. Quantum bits (qubits) are extremely fragile and susceptible to environmental factors. Error correction and scalability are ongoing research areas, and practical, large-scale quantum computers are not yet a reality.

Real-World Applications Today
Despite these challenges, quantum computing is already making an impact in various fields. It's being used for simulating quantum systems, optimizing supply chains, and enhancing cybersecurity. Companies and research institutions worldwide are racing to harness its potential.
Ongoing Research and Developments
The field of quantum computing is advancing rapidly. Researchers are continuously working on developing more stable and powerful quantum hardware, paving the way for a future where quantum computing becomes an integral part of our analytical toolbox.
The Ethical and Security Considerations
Ethical Implications
The power of quantum computing comes with ethical responsibilities. The potential to break encryption methods and disrupt secure communications raises important ethical questions. Responsible research and development are crucial to ensure that quantum technology is used for the benefit of humanity.
Security Concerns
Quantum computing also brings about security concerns. Current encryption methods, which rely on the difficulty of factoring large numbers, may become obsolete with the advent of powerful quantum computers. This necessitates the development of quantum-safe cryptography to protect sensitive data.
Responsible Use of Quantum Technology
The responsible use of quantum technology is of paramount importance. A global dialogue on ethical guidelines, standards, and regulations is essential to navigate the ethical and security challenges posed by quantum computing.
My Personal Perspective
Personal Interest and Experiences
Now, let's shift the focus to a more personal dimension. I've always been deeply intrigued by both quantum computing and data science. Their potential to reshape the way we analyze data and solve complex problems has been a driving force behind my passion for these fields.
Reflections on the Future
From my perspective, the fusion of quantum computing and data science holds the promise of unlocking previously unattainable insights. It's not just about making predictions; it's about truly understanding the underlying causality of complex systems, something that could change the way we make decisions in a myriad of fields.
Influential Projects and Insights
Throughout my journey, I've encountered inspiring projects and breakthroughs that have fueled my optimism for the future of analysis. The intersection of these fields has led to astonishing discoveries, and I believe we're only scratching the surface.
Future Possibilities and Closing Thoughts
What Lies Ahead
As we wrap up this exploration, it's crucial to contemplate what lies ahead. Quantum computing and data science are on a collision course with destiny, and the possibilities are endless. Achieving quantum supremacy, broader adoption across industries, and the birth of entirely new applications are all within reach.
In summary, the convergence of Quantum Computing and Data Science is an exciting frontier that has the potential to reshape the way we analyze data and solve problems. It brings both immense promise and significant challenges. The key lies in responsible exploration, ethical considerations, and a collective effort to harness these technologies for the betterment of society.
#data visualization#data science#big data#quantum computing#quantum algorithms#education#learning#technology
4 notes
·
View notes
Text
how to construct the geometry where this is a rhombus:
consider points in terms of polar coordinates (theta, r)
define distance analogously to taxicab geometry, as the sum of the radial distance between two points and the arc distance (taken along the circle of smaller radius)
further constrain that arc distance may only be measured clockwise - i.e., for points of equal r, AB + BA = 2pi r. this is necessary in order to allow major arcs and minor arcs to both properly serve as line segments (i.e., be uniquely determined by their endpoints), but it breaks the usual commutativity of the endpoints of a line segment
then we have our four points (0, r1), (0, r2), (theta, r2), (theta, r1). the lengths of our segments are then
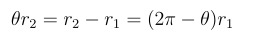
which allows us to solve for theta (given that r2 is nonzero):

The quadratic formula gives two possible values of theta,
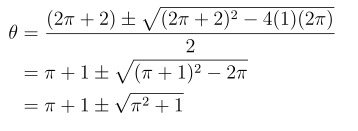
We can discard the root with the positive sign as theta must be between 0 and 2pi, so the allowed angle must be

While the image can be scaled arbitrarily, the ratio of the radii is fixed; returning to our expression for r1 gives
From here, it is straightforward to set r2 to 1, which will show that the lengths of the arcs and the radius segments are all equal.
I love seeing a meme and being like oh, tumblrs going to love this one
#i got nerd sniped#anyway here is the One angle that this is possible with (on a plane)#ccw also works and is more 'formal' but the figure has arrows going clockwise so i said clockwise#you can of course set r2 to anything except 0. it just scales the figure.#1 is the easiest though
65K notes
·
View notes