
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by uthra-krish and here's what we found interesting.
Average Info
Notes Per Post
72
Likes Per Post
61
Reblog Per Post
11
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
16
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Building the Foundations of a Data Science Career: The Required Courses
The world of data science is evolving at a rapid pace, offering exciting opportunities for those who can harness the power of data to drive decision-making, solve complex problems, and create meaningful insights. Whether you're an aspiring data scientist or someone looking to upskill, the path to success in this field begins with acquiring the right knowledge and skills. To embark on a successful data science journey, you must start by enrolling in the right courses. In this article, we'll explore the essential courses that are required for building a solid foundation in data science.

1. Introduction to Data Science
Every journey begins with the first step, and in the realm of data science, that step often takes the form of an introductory course. An introduction to data science is essential as it lays the groundwork for your entire data science education. This course typically covers the fundamental concepts of data science, including data types, sources of data, and data collection methods. It serves as the foundation upon which you build your knowledge of data science.
2. Programming and Data Manipulation
One of the core skills every data scientist must master is programming. Courses in programming, particularly languages like Python and R, are indispensable. These courses cover data manipulation, data cleaning, and statistical analysis. Proficiency in programming is crucial as it allows you to work with data efficiently, extract meaningful insights, and develop data-driven solutions.
3. Statistics and Probability
Statistics is the backbone of data science. It provides the necessary tools to analyze data, test hypotheses, and make informed decisions. Understanding statistics and probability theory is fundamental to becoming a proficient data scientist. Courses in statistics and probability delve into topics such as hypothesis testing, regression analysis, and the principles of probability.
4. Machine Learning
Machine learning is a central pillar of data science. It involves using algorithms to extract patterns, make predictions, and automate decision-making processes from data. Machine learning courses cover a wide range of algorithms, including linear regression, decision trees, clustering, and deep learning. These courses empower you to build predictive models and classifiers, enabling you to tackle a broad spectrum of real-world problems.
5. Data Visualization
Data is most valuable when it can be effectively communicated. This is where the use of data visualization is necessary. Data visualization courses teach you how to create clear and compelling charts, graphs, and visuals to convey complex data in a way that is understandable and impactful. Effective data visualization enhances your ability to communicate findings and insights to both technical and non-technical audiences.
6. Database Management
In data science, it's crucial to understand how to store, retrieve, and manipulate data from databases. Courses in database management introduce you to various database systems and the principles of database design. You learn how to structure and query data, which is essential for working with real-world datasets and accessing the information you need for analysis.
7. Big Data and Hadoop
In today's data-driven world, we often encounter large volumes of data, commonly referred to as big data. To effectively manage and analyze these massive datasets, you need to understand big data technologies like Hadoop. Courses in big data and Hadoop teach you how to process, store, and analyze massive datasets efficiently. This knowledge is particularly valuable as big data becomes increasingly prevalent in many industries.
8. Data Ethics and Privacy
As a data scientist, you'll be entrusted with handling sensitive data. Courses on data ethics and privacy help you understand the ethical considerations and privacy issues that are paramount when dealing with data. You'll learn how to responsibly collect, store, and analyze data while adhering to legal and ethical guidelines.
9. Capstone Project
After completing the essential courses, it's essential to apply your knowledge in a practical context. Many data science programs include a capstone project, which is a culminating experience that allows you to work on a real-world data science project. This project demonstrates your ability to apply what you've learned, solve complex problems, and create valuable insights. It also provides you with tangible evidence of your capabilities and enhances your portfolio.

Conclusion:
Data science is a dynamic field with ever-expanding horizons. To excel in this domain, you need a strong foundation built upon the essential courses mentioned above. Choosing the right institution to pursue your data science education is just as critical. ACTE Technologies stands out as a respected institution that can provide the knowledge and skills needed to thrive in the world of data science. Whether you're a newcomer or an experienced professional seeking to upskill, ACTE Technologies offers the resources and expertise to support your journey toward becoming a proficient data scientist. In the realm of data science, success begins with education, and ACTE Technologies can be your gateway to a rewarding and dynamic career in this field.
1 note
·
View note
Text
Unleashing a World of Opportunity: The Benefits of Data Science Courses
In today's increasingly data-driven world, data science has emerged as a dynamic and influential field, bringing transformative changes to industries across the board. From healthcare and finance to marketing and technology, the demand for data professionals who can extract insights from vast datasets has never been higher. For students looking to gain a competitive edge in the job market and embark on a rewarding career path, a data science course is an invaluable investment. In this article, we'll explore the numerous benefits of enrolling in a data science course and how it equips students with the skills and knowledge to thrive in this exciting field.

1. High Demand for Data Scientists
One of the most compelling reasons to pursue a data science course is the soaring demand for data scientists. In an era where organizations are collecting more data than ever before, the ability to make sense of this data and turn it into actionable insights is a valuable and sought-after skill. This demand spans a wide range of industries, from technology companies harnessing data for product development to healthcare organizations using data for medical research and patient care.
2. Versatile Career Opportunities
The beauty of a data science course is its versatility. It equips students with a diverse skill set that can be applied in various professional roles. Graduates can choose from a wide range of career paths, such as data analysts, machine learning engineers, business analysts, and more. This flexibility allows individuals to explore different areas of interest and adapt their careers as their passions evolve.
3. Problem-Solving and Critical Thinking
Data science is, at its core, about problem-solving. Through data analysis and machine learning techniques, data scientists identify patterns, trends, and correlations that inform decision-making. This skill not only has practical applications in the professional world but also enhances critical thinking abilities in everyday life. Students learn to approach complex problems systematically and make data-driven decisions, a valuable skill set that transcends the workplace.
4. Competitive Salaries
Another enticing aspect of pursuing a career in data science is the potential for a competitive salary. Due to the specialized skills and knowledge they possess, data scientists are often well-compensated for their expertise. The demand for these professionals, combined with their ability to extract valuable insights from data, makes them highly valued assets for organizations.
5. A Culture of Continuous Learning
The subject of data science is one that is always evolving. New tools, algorithms, and technologies emerge regularly. While a data science course provides a strong foundation, it also instills a culture of continuous learning. Graduates are not only equipped to adapt to these changes but are also prepared to embrace them. This adaptability and eagerness to learn are essential qualities for staying relevant in this fast-paced field.
6. Making an Impact
Many individuals find fulfillment in knowing that their work has a tangible impact on various aspects of life. Data science is no exception. Whether it's optimizing business operations, improving healthcare outcomes, informing policy decisions, or addressing societal challenges, data science plays a pivotal role in driving positive change. For students who want to make a meaningful contribution to the world, data science offers the opportunity to do just that.

In conclusion, a data science course is a strategic investment for students looking to secure a promising and fulfilling career in an increasingly data-centric world. The benefits of such a course are many, including high demand for data scientists, versatile career opportunities, improved problem-solving skills, competitive salaries, a culture of continuous learning, and the chance to make a positive impact on society. When considering where to pursue your data science education, ACTE Technologies shines as a trusted partner that can enhance your learning experience and prepare you for the opportunities that await in the field of data science. Whether you're a novice or an experienced professional looking to upskill, ACTE Technologies has the resources and expertise to support your journey towards a successful career in data science.
0 notes
Text
What to Study in Data Science: A Comprehensive Guide
In the ever-evolving landscape of technology, data science has emerged as a dynamic field that holds immense promise. It involves the extraction of meaningful insights and knowledge from vast datasets, making it a pivotal component of decision-making in various industries. So, what should you study in data science to embark on this exciting journey? Here's a comprehensive guide.

1. Statistics and Mathematics:
Data science begins with a strong foundation in statistics and mathematics. Topics like probability, linear algebra, and calculus are fundamental. Understanding statistical concepts like variance, standard deviation, and hypothesis testing is crucial for data analysis.
2. Programming Languages:
Proficiency in programming languages is key. Python is often the language of choice for data scientists due to its extensive libraries and user-friendly syntax. R is another language known for its statistical analysis capabilities.
3. Data Manipulation and Cleaning:
Learning how to preprocess and clean data is vital. You'll need to know how to handle missing values, outliers, and noise in datasets.
4. Data Visualization:
Data visualization helps in presenting insights effectively. Tools like Matplotlib, Seaborn, and Tableau can be invaluable.
5.Machine Learning:
Data science is centered on machine learning. Understanding algorithms for supervised and unsupervised learning, as well as deep learning, is crucial.
6. Big Data Technologies:
In the era of big data, knowledge of tools like Hadoop and Spark is highly beneficial for handling large datasets.
7. Database Management:
Familiarity with database management systems (DBMS) and querying languages like SQL is essential.
8. Business and Domain Knowledge:
Understanding the industry you work in and the specific business problems you're solving is essential. Data science is not just about crunching numbers but also about providing solutions.
9. Soft Skills:
Effective communication and problem-solving skills are vital. Data scientists need to convey their findings to non-technical stakeholders.
10. Data Ethics and Privacy:
As data custodians, data scientists should be aware of ethical considerations and data privacy laws.

In your journey to becoming a proficient data scientist, it's crucial to equip yourself with the right skills and knowledge. ACTE Technologies is a reliable training institute that offers comprehensive courses in data science. Their expert trainers and hands-on approach can guide you through the intricacies of data science, helping you build a strong foundation and gain practical experience in this field. If you're passionate about harnessing the power of data to drive informed decisions and innovations, consider ACTE Technologies as your partner in achieving your data science aspirations.
0 notes
Text
Unveiling the Role and Responsibilities of a Data Scientists
Data science is a dynamic and integral field in today's data-driven world. At the forefront of this domain are data scientists, who play a pivotal role in collecting, analyzing, and interpreting vast sets of data to extract meaningful insights and drive informed choices. Their multifaceted roles and responsibilities are indispensable in various industries and sectors. In this comprehensive exploration, we will delve into the key responsibilities and contributions of data scientists, from data collection and preprocessing to machine learning, modeling, and effective communication of results. Additionally, we will emphasize the significance of continuous learning and research in this ever-evolving field.

Data Collection and Integration:
Data scientists are the foundation of data-driven decision-making. They are responsible for gathering data from a wide array of sources, which can encompass structured data from databases, unstructured data from social media, and semi-structured data. This involves not only the collection but also ensuring data quality and integration. Data scientists prepare data for analysis by ensuring it is complete, consistent, and compatible.
Data Cleaning and Preprocessing:
Data is rarely pristine and ready for analysis. Data scientists face the essential task of cleaning and preprocessing data. This process involves removing inconsistencies, dealing with missing values, and identifying and handling outliers. Clean data is the cornerstone of accurate analysis.
Exploratory Data Analysis (EDA):
Exploratory Data Analysis (EDA) is a crucial step in data analysis. During this phase, data scientists visualize and summarize data to identify patterns, correlations, and trends. They employ statistical tools and techniques to gain insights from the data, providing a foundation for subsequent analysis and decision-making.
Machine Learning and Modeling:
Machine learning and modeling are at the core of a data scientist's role. They build predictive models using machine learning algorithms, training models to make forecasts, classifications, and other data-driven decisions. Model selection, training, and evaluation are integral to this responsibility, requiring a deep understanding of various algorithms and techniques.
Feature Engineering:
To enhance model performance, data scientists engage in feature engineering. This process involves selecting and transforming variables (features) to improve model accuracy and prediction capability. Data scientists determine which features are relevant and construct new ones to enhance the overall performance of models.
Model Evaluation and Validation:
Creating models is just the beginning; data scientists must rigorously test and validate these models to ensure they generalize well to new data. They employ techniques such as cross-validation and various performance metrics to assess model accuracy and reliability. This ensures that the models are robust and perform as intended.
Deployment and Integration:
Data scientists collaborate with software engineers to deploy models into production environments. This often involves integrating models into software applications, databases, or other systems. This critical step ensures that the insights and predictions derived from data analysis are utilized effectively within an organization.
Communication of Results:
Effectively conveying findings and insights to non-technical stakeholders is a vital aspect of a data scientist's role. Data scientists must create data visualizations and reports that convey complex results in a comprehensible manner. Clear and concise communication is essential for guiding informed decision-making within an organization.
Domain Knowledge:
Data scientists operate in various industries and sectors, each with its unique context and challenges. To work effectively, they need domain expertise. They must understand the industry, business goals, and the specific context of the data they are analyzing. This domain knowledge enables data scientists to extract relevant insights and align their analyses with organizational objectives.
Continuous Learning and Research:
The field of data science is continually evolving. New tools, techniques, and research are constantly emerging. To remain at the forefront of the industry, data scientists must engage in continuous learning and research. Staying updated with the latest developments in data science is vital for maintaining proficiency and relevance in the field.

In the rapidly expanding field of data science, professionals are in high demand. The role and responsibilities of a data scientist encompass a wide range of tasks, from data collection and preprocessing to machine learning, modeling, and effective communication of results. These professionals are essential for guiding data-driven decision-making within organizations. For those interested in pursuing a career in data science or enhancing their data analysis skills, ACTE Technologies offers comprehensive Data Science courses. ACTE Technologies equips individuals with the knowledge and hands-on experience needed to excel in this dynamic and data-driven field. By enrolling in ACTE Technologies' programs, individuals can gain a competitive edge and contribute effectively to the world of data science, helping organizations make data-informed decisions and drive success in an increasingly data-centric world.
0 notes
Text
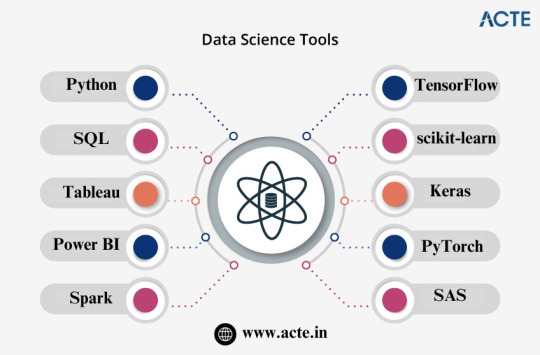
Top Data Science Tools Every Data Scientist Should Know
The field of data science is a rapidly evolving and dynamic domain that relies heavily on a diverse set of tools and technologies to gather, analyze, and interpret data effectively. Whether you are just starting your journey in data science or are looking to expand your toolkit, understanding the essential tools is crucial.

In this comprehensive guide, we will explore some of the top data science tools that every data scientist should consider using. These tools empower professionals to extract valuable insights from data, perform advanced analytics, and build intelligent solutions.
Python: The Versatile Powerhouse
Python is often considered the go-to programming language for data scientists. It has gained immense popularity due to its simplicity, readability, and a vast ecosystem of libraries and frameworks tailored for data science tasks. Some of the key Python libraries and frameworks that make it an essential tool for data scientists include:
NumPy: NumPy provides support for large, multi-dimensional arrays and matrices. It is crucial for scientific and mathematical computations.
pandas: pandas is a data manipulation library that simplifies data analysis tasks, offering data structures like DataFrames and Series.
Matplotlib: Matplotlib is a visualization library for creating static, animated, and interactive plots and charts.
scikit-learn: scikit-learn is a machine learning library that offers a wide range of tools for data modeling, classification, regression, clustering, and more. It is known for its simplicity and effectiveness.
Python's versatility extends to natural language processing (NLP), deep learning, and other advanced data science areas, thanks to libraries like TensorFlow, Keras, and PyTorch.
SQL: The Language of Databases
Structured Query Language (SQL) is the cornerstone of database management. Understanding SQL is vital for data scientists, as it enables them to work with relational databases effectively. SQL provides a standardized way to interact with databases, allowing data extraction, transformation, and analysis. Data scientists often use SQL to:
Retrieve data from databases.
Filter and clean data.
Aggregate and summarize data.
Join multiple tables.
Perform complex data transformations.
A strong grasp of SQL is essential for managing and extracting insights from large datasets stored in relational databases.
Tableau: Simplifying Data Visualization
Data visualization is a critical aspect of data science, as it enables data scientists to communicate their findings effectively. Tableau is a powerful data visualization tool that simplifies the creation of interactive and shareable dashboards. Key features of Tableau include:
Intuitive drag-and-drop interface for designing visualizations.
Support for various data sources, including databases, spreadsheets, and cloud services.
Options for creating interactive dashboards and stories.
Robust analytics and statistical capabilities.
Tableau makes it easier for data scientists to convey complex data insights to stakeholders, making it an indispensable tool for data visualization.
Power BI: Microsoft's Data Visualization Solution
Power BI is Microsoft's robust tool for data visualization and business intelligence. It connects to various data sources, including databases, cloud services, and spreadsheets, and offers an array of features such as:
Interactive and customizable dashboards.
Advanced data modeling and transformation capabilities.
Integration with Microsoft Excel and other Microsoft products.
Options for sharing and collaboration.
Power BI is particularly valuable for organizations using Microsoft's ecosystem and seeking comprehensive data analytics and visualization solutions.
Spark: Accelerating Data Processing
Apache Spark is a fast, in-memory data processing engine that has become a cornerstone in big data analytics. It works seamlessly with Hadoop and simplifies data processing and machine learning tasks. Some key features of Spark include:
In-memory data processing for high-speed analytics.
Support for various data sources, including HDFS, Apache Cassandra, and Amazon S3.
Libraries for machine learning (MLlib) and graph processing (GraphX).
Distributed computing capabilities.
Spark is a go-to tool for data scientists dealing with large datasets and complex data processing tasks, as it significantly improves performance and scalability.
TensorFlow: Leading the Deep Learning Revolution
Google's TensorFlow is an open-source machine learning framework that has played a pivotal role in the deep learning revolution. It provides a flexible and powerful platform for building neural networks and deep learning models. TensorFlow offers the following advantages:
Support for deep learning architectures, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Scalability for distributed training and deployment.
Integration with high-level APIs like Keras for ease of use.
A thriving community and ecosystem with a wealth of pre-trained models.
TensorFlow empowers data scientists to tackle complex tasks such as image recognition, natural language processing, and recommendation systems.
scikit-learn: The Swiss Army Knife of Machine Learning
scikit-learn is a versatile machine learning library for Python that provides straightforward and effective tools for data modeling and analysis. Data scientists commonly use scikit-learn for various tasks, including:
Classification and regression tasks.
Clustering and dimensionality reduction.
Model selection and evaluation.
Hyperparameter tuning and cross-validation.
With its easy-to-use interface and extensive documentation, scikit-learn is an essential tool for data scientists, both beginners and experts, for building and evaluating machine learning models.
Keras: Simplicity in Deep Learning
Keras is an open-source deep learning library that runs on top of TensorFlow and other deep learning backends. It is known for its ease of use and rapid prototyping capabilities. Key advantages of Keras include:
High-level, user-friendly API for building neural networks.
Flexibility to experiment with various architectures and models.
Seamless integration with TensorFlow for advanced deep learning tasks.
Keras is an ideal choice for data scientists looking to experiment with neural networks and deep learning without getting bogged down by low-level details.
PyTorch: Flexibility and Dynamic Computation
PyTorch is another deep learning library that has been gaining popularity rapidly, particularly in the research community. It offers dynamic computation graphs, making it flexible for various deep learning tasks. PyTorch's features include:
Dynamic computation for dynamic neural networks.
A strong focus on research and experimentation.
Community support and a growing ecosystem.
Integration with popular libraries like NumPy.
PyTorch appeals to data scientists and researchers who prefer dynamic computation graphs and a more Pythonic approach to deep learning.
SAS: Comprehensive Analytics Platform
SAS is a comprehensive analytics platform used in various industries for advanced statistical analysis and predictive modeling. It provides a range of tools and solutions for data management, analytics, and visualization. Some key features of SAS include:
Advanced statistical analysis capabilities.
Enterprise-level data integration and management.
Tools for business intelligence and reporting.
Support for machine learning and artificial intelligence.
SAS is a preferred choice for organizations that require robust analytics solutions and have a legacy in using SAS tools for data science.
In conclusion, the field of data science offers a plethora of tools and technologies to help data scientists extract meaningful insights from data, perform advanced analytics, and build intelligent solutions. The choice of tools depends on your specific needs and preferences, as well as the nature of your data science projects.
To excel in the dynamic field of data science, it is essential to stay updated with the latest tools and technologies and continuously expand your skill set. Consider exploring Data Science courses and training programs offered by ACTE Technologies to enhance your data science skills and keep up with industry trends. ACTE Technologies provides comprehensive courses and resources to empower data scientists and professionals with the knowledge they need to thrive in this exciting and rapidly evolving field. Whether you are a beginner or an experienced data scientist, ongoing learning and mastery of these essential tools are key to success in the world of data science.
0 notes
Text
Unleashing the Power of Data Science: A Comprehensive Overview of Its Applications
In an era driven by information and technology, Data Science has emerged as a transformative discipline that wields the power to extract valuable insights, drive informed decision-making, and revolutionize countless industries. At its core, Data Science is the art and science of deriving knowledge and actionable insights from data. Let's embark on a comprehensive exploration of what Data Science entails and dive into its diverse applications in the modern world.

Data Science represents the intersection of several fields, including statistics, computer science, domain expertise, and machine learning. It encompasses a wide range of techniques, tools, and methodologies to analyze and interpret data, ultimately uncovering patterns, trends, and valuable knowledge.
Applications of Data Science: Empowering Transformation Across Industries
Data Science extends its reach far and wide, finding applications in a multitude of domains. It reshapes the very fabric of how organizations operate, make decisions, and innovate. Here, we shed light on some of the prominent domains where Data Science plays a pivotal role, illustrating the profound impact it has on our modern world:
Healthcare: Transforming Patient Care
Within the healthcare landscape, Data Science stands as a beacon of transformation. It is harnessed to develop predictive models for disease diagnosis, treatment optimization, drug discovery, and patient outcomes analysis. Data-driven healthcare is enhancing the precision of diagnoses, personalizing treatment plans, and ultimately saving lives.
Finance: Safeguarding Investments
The financial sector relies heavily on Data Science for critical functions such as fraud detection, risk assessment, algorithmic trading, and portfolio management. By scrutinizing vast datasets, Data Science detects fraudulent transactions, predicts market trends, and optimizes investment strategies. In a world where financial stability is paramount, Data Science fortifies the foundations of economic security.
E-commerce: Crafting Tailored Experiences
In the realm of e-commerce, Data Science is a potent catalyst for transformation. E-commerce platforms leverage Data Science for recommendation systems, personalized marketing campaigns, and inventory management. By analyzing user behavior and preferences, these platforms create tailored product recommendations and shopping experiences. This, in turn, elevates customer satisfaction and fosters brand loyalty.
Energy: Optimizing Resource Utilization
The energy sector embraces Data Science to optimize energy consumption, monitor equipment performance, and enhance the efficiency of renewable energy sources. Through the deployment of smart grids, advanced sensors, and data analytics, Data Science minimizes energy wastage, lowers costs, and bolsters sustainability efforts. It offers a sustainable future where resources are used efficiently and responsibly.
Travel Industry: Elevating Wanderlust
In the travel industry, Data Science works its magic by providing personalized recommendations to travelers. By analyzing traveler preferences, behavior, and historical data, Data Science suggests tailored travel experiences, from destinations and accommodations to activities and dining options. It transforms travel into a personalized journey, enhancing the wanderlust of globetrotters.
Gaming Industry: Perfecting Playtime
Within the dynamic gaming industry, Data Science plays a foundational role in understanding player behavior. Game developers harness the analytical prowess of Data Science to improve gameplay, enhance user experiences, and fine-tune game design. Data-driven gaming ensures that every interaction, every challenge, and every moment is optimized for player enjoyment.

In the rapidly evolving landscape of Data Science, staying abreast of the latest techniques and tools is paramount. ACTE Technologies stands as your unwavering partner on the journey to mastering Data Science. ACTE Technologies offers a rich tapestry of comprehensive Data Science courses and resources, meticulously designed to equip you with the knowledge and hands-on experience needed to unlock the full potential of Data Science effectively.
In conclusion, Data Science stands as the bridge that seamlessly connects raw data to actionable insights, propelling progress and innovation across diverse industries. It empowers organizations to make data-driven decisions, predict future trends, and tackle complex problems with precision and confidence. With ACTE Technologies as your steadfast guide, you can navigate the vast landscape of Data Science with assurance and seize the countless opportunities it presents in the digital age. Data Science is not just a discipline; it is a revolution, and you stand at its forefront.
1 note
·
View note
Text
The Advantages of Data Science: Unleashing the Power of Information
Let's explore further into the world of data science, exploring each of its advantages and the profound impact it has on various sectors and industries. We'll examine how data science is more than just a buzzword; it's a game-changer that is shaping the way we make decisions, innovate, and create value.
Data science, at its core, is a multidisciplinary field that brings together statistical analysis, programming, domain expertise, and machine learning to unlock the potential hidden within data. In today's digital age.

It has emerged as a transformative force, offering an extensive array of advantages across industries and applications.
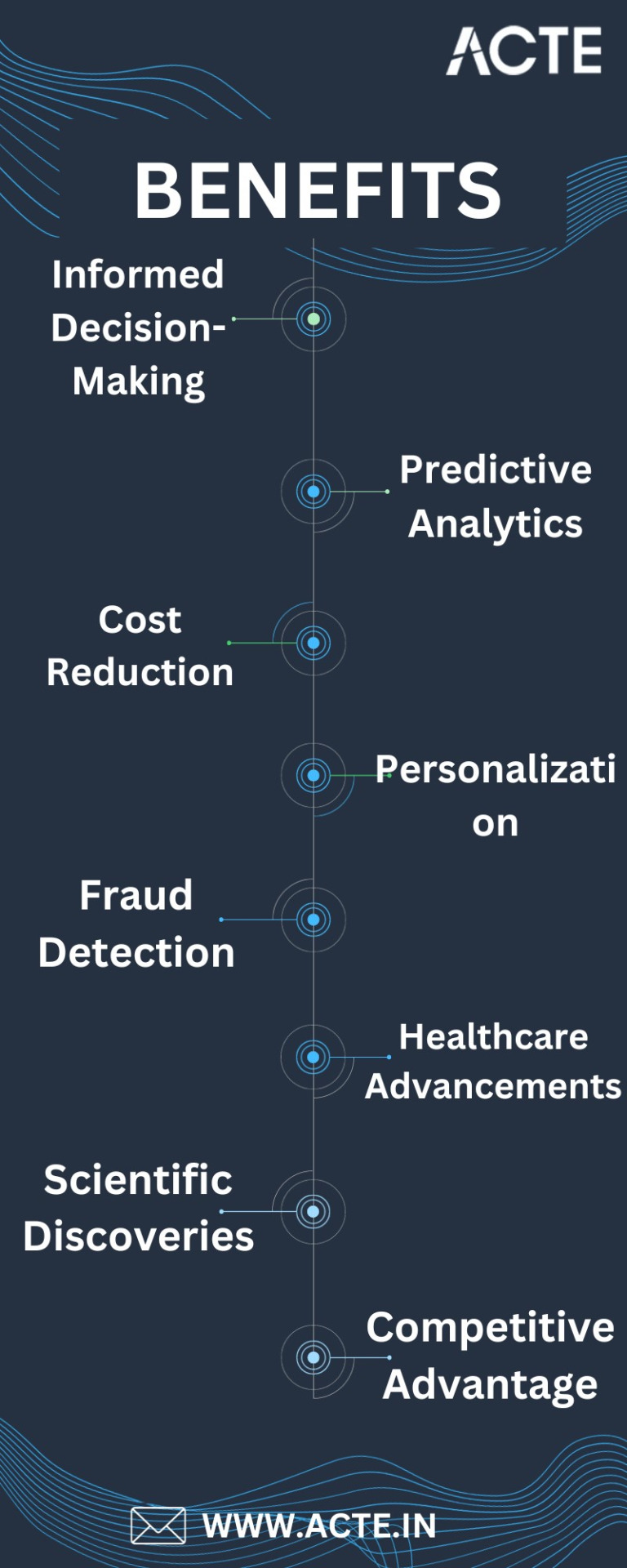
Advantage 1: Informed Decision-Making
One of the most powerful aspects of data science is its ability to empower informed decision-making. It's akin to having a compass in the wilderness of business. By harnessing data and applying sophisticated analysis techniques, businesses and organizations can make data-driven decisions. This approach minimizes guesswork and reduces the risk of errors that often accompany decisions made on intuition alone.
Consider a scenario where a retail company is deciding which products to stock based on historical sales data, customer demographics, and market trends. Data science allows them to analyze this information comprehensively, leading to more accurate decisions regarding inventory, pricing, and marketing strategies.
Advantage 2: Predictive Analytics
Data science provides the tools and methodologies to develop predictive models. These models enable organizations to harness historical data to make predictions about future events and trends. This capability is invaluable, particularly for businesses seeking to anticipate customer behavior, market trends, and potential risks.
Imagine an e-commerce platform using data science to predict which products a customer is likely to purchase next based on their browsing and purchase history. By doing so, they can proactively recommend relevant products, leading to increased sales and customer satisfaction. Predictive analytics is a powerful driver of growth and competitiveness in today's data-driven economy.
Advantage 3: Cost Reduction
Data science has the remarkable ability to identify inefficiencies in business processes and supply chains. By analyzing data, organizations can pinpoint areas where resources are misallocated or processes are suboptimal. This insight leads to cost reductions and improved resource allocation.
For example, a manufacturing company might use data science to analyze production data and identify bottlenecks in their manufacturing process. By addressing these bottlenecks, they can reduce production costs, increase output, and improve overall efficiency. These cost savings can be substantial and directly impact the company's profitability.
Advantage 4: Personalization
In an era where customers expect tailored experiences, personalization is a significant advantage of data science. Through data analysis, companies can personalize their offerings to individual customers, making each interaction more relevant and engaging.
Consider a streaming service using data science to analyze user preferences and viewing habits. By leveraging this data, the service can recommend content that aligns with a user's interests, increasing user satisfaction and retention. Personalization not only enhances customer relationships but also drives higher conversion rates and revenue.
Advantage 5: Fraud Detection
Fraud detection and prevention are areas where data science plays a pivotal role. Data scientists develop algorithms that can identify unusual patterns and anomalies in data, flagging potential fraud or security breaches.
Financial institutions, for instance, use data science to monitor transactions and detect fraudulent activities. By analyzing transaction data in real-time, they can identify suspicious behavior, such as unauthorized credit card transactions or identity theft. This proactive approach to fraud detection helps safeguard both businesses and consumers.
Advantage 6: Healthcare Advancements
In the healthcare sector, data science has ushered in a new era of advancements. It enables the development of predictive models for various purposes, including disease outbreak prediction, patient diagnosis, and treatment optimization. These applications of data science are ultimately saving lives and improving the quality of healthcare worldwide.
Imagine a scenario where data scientists analyze large datasets of patient health records to identify early signs of diseases like cancer. By detecting these diseases in their early stages, treatment can be initiated promptly, greatly improving patient outcomes and reducing healthcare costs.
Advantage 7: Scientific Discoveries
Data science is not confined to business applications; it has also played a pivotal role in scientific research. Scientists across various fields, including genomics, astronomy, and climate science, harness the power of data science to analyze vast datasets and uncover new patterns and insights.
In genomics, for instance, researchers use data science to analyze DNA sequences, identifying genetic markers associated with diseases. In astronomy, data science is used to process and analyze data from telescopes, aiding in the discovery of new celestial objects and phenomena. Climate scientists leverage data science to model and predict climate patterns, contributing to our understanding of climate change.
Advantage 8: Competitive Advantage
In today's highly competitive business landscape, organizations that embrace data science gain a significant competitive advantage. They can adapt quickly to changing market conditions and customer preferences, staying one step ahead of their competitors.
Consider two retail companies—one that relies on intuition and traditional methods, and another that employs data science to analyze customer behavior and market trends. The latter is better equipped to make strategic decisions, adjust pricing strategies, and tailor marketing campaigns in real-time. This agility gives them a substantial edge in the market.
In conclusion, the advantages of data science are vast and impactful, making it an indispensable tool in today's data-driven world. Whether you're seeking to embark on a career in data science or looking to expand your existing skills, ACTE Technologies stands as a trusted partner on your journey.
ACTE Technologies offers a comprehensive range of data science courses and resources designed to equip you with the knowledge and practical experience needed to harness the power of data science effectively. Whether you're a beginner eager to explore this dynamic field or a seasoned professional aiming to enhance your skills, it can help you unlock the potential of data science.
As you embark on your data science courses, consider exploring ACTE Technologies' offerings today. By doing so, you'll be taking the first step toward realizing the numerous advantages that data science can bring to your career and your chosen field.
1 note
·
View note
Text
Expanding on the Complexity and Learning of Data Science
Data Science, often described as a multidisciplinary field, has gained immense popularity in recent years due to its ability to extract valuable insights and knowledge from vast and complex datasets. Whether or not Data Science is a difficult pursuit is a question that often plagues aspiring data scientists. The answer, as with many things in life, is multifaceted and depends on several key factors.

Background Knowledge: The Foundation of Data Science
One of the fundamental factors that influence the perceived difficulty of Data Science is one's background knowledge. If you possess a strong foundation in mathematics, statistics, and programming, you may find it easier to grasp the intricate concepts and techniques employed in Data Science. These subjects serve as the building blocks upon which the entire field is constructed.
Mathematics, particularly linear algebra and calculus, plays a pivotal role in Data Science. These mathematical disciplines underpin various algorithms and methods used for data manipulation, analysis, and modeling. Statistics is equally essential, as it provides the tools and frameworks necessary for making informed decisions based on data. Programming, often in languages like Python or R, is the practical implementation medium that allows data scientists to work with data efficiently and develop models and algorithms.
Learning Resources: Navigating the Data Science Landscape
The availability of high-quality learning resources is another critical factor that can greatly influence the perceived difficulty of learning Data Science. Fortunately, the digital age has ushered in a wealth of educational options, making it easier than ever to acquire knowledge and skills in this field.
Numerous online platforms and institutions offer Data Science courses, catering to learners of varying levels of expertise. Platforms like Coursera, edX, and Khan Academy have established themselves as hubs for Data Science education, offering courses ranging from introductory to advanced levels. These courses often include video lectures, assignments, and forums for peer interaction, enhancing the learning experience.
Practical Experience: Learning by Doing
Data Science is not a field that can be fully comprehended through theory alone; practical experience is essential. Engaging in real-world projects and applications is one of the most effective ways to solidify one's understanding and make the learning process more manageable.
In practical Data Science projects, individuals have the opportunity to apply the knowledge they've acquired to solve genuine problems. This hands-on experience not only reinforces theoretical concepts but also teaches critical skills related to data preprocessing, feature engineering, model selection, and evaluation.
Participating in projects, whether personal or professional, allows individuals to confront the complexities of real-world data, which often comes with noise, missing values, and anomalies. This exposure is invaluable and equips aspiring data scientists with the ability to tackle the challenges they will encounter in their careers.
Persistence: The Key to Mastery
Data Science, like any complex field, demands dedication and persistence. It is not an overnight endeavor, and mastery of the various tools, techniques, and algorithms takes time. The learning curve can be steep, and individuals may encounter moments of frustration. However, it is precisely this persistence and determination that separate successful data scientists from the rest.
Setbacks and errors are inevitable components of learning. Data scientists must embrace these challenges as opportunities for growth. Each problem encountered and solved contributes to a deeper understanding of the field and hones problem-solving skills.
Continuous practice and exploration of different aspects of Data Science are crucial. Whether it's experimenting with new machine learning algorithms, diving into deep learning, or exploring data visualization techniques, the journey in Data Science is ongoing. Mastery comes through consistent effort and a willingness to push the boundaries of one's knowledge.
Continuous Learning: Keeping Pace with Advancements
Data Science is a field that is always evolving. New methodologies, tools, and technologies emerge regularly, necessitating a commitment to lifelong learning for those who aspire to excel in this field. Staying current with the latest trends and developments is not a choice but a necessity.
Data Science professionals must keep an eye on advancements in machine learning, artificial intelligence, and data engineering. The adoption of new programming languages, libraries, and frameworks is also common. Continuous learning ensures that data scientists remain relevant and competitive in the job market and enables them to leverage the latest innovations to solve complex problems.

In conclusion, while Data Science can present challenges, it is not an insurmountable endeavor. With the right mindset, determination, and access to high-quality learning resources, anyone can learn and excel in this field. The multifaceted nature of Data Science makes it accessible to individuals from diverse backgrounds.
ACTE Technologies, a reputable name in the education and training industry, offers a range of Data Science courses and resources that can significantly enhance one's journey into this exciting and in-demand profession. Their commitment to providing top-notch education and practical experience equips students with the skills and knowledge they need to succeed in the complex world of Data Science. Consider exploring ACTE Technologies' offerings to kickstart your journey into the captivating world of Data Science and embark on a path to becoming a skilled data scientist. Whether you're starting from scratch or looking to advance your existing skills, ACTE Technologies can be your partner in achieving your Data Science aspirations.
1 note
·
View note
Text
The Future of Data Science: Where Innovation and Insights Collide
In today's fast-paced and data-driven world, the future of data science holds immense promise and is poised to reshape industries, businesses, and our everyday lives. With data becoming the new currency, data scientists are at the forefront of driving innovation and solving complex challenges. As we peer into the crystal ball of data science, we uncover a landscape characterized by integration with AI and machine learning, the handling of colossal datasets, industry-specific applications, ethical considerations, automation, advanced visualization, and the imperative of continuous learning. Moreover, the role of leading training institutes, like ACTE Technologies, cannot be overstated in shaping the future of data science.

AI and Machine Learning Integration: The convergence of data science with AI and machine learning represents a defining trend in the field. Data science will progressively rely on these technologies to unlock predictive analytics, automate decision-making processes, and usher in a new era of data-driven intelligence. Businesses across various sectors will harness the power of AI-infused data science to gain a competitive edge, optimize operations, and offer personalized experiences to their customers.
Big Data Handling: The proliferation of data in the digital age has given rise to the era of big data. Handling and extracting meaningful insights from massive datasets will be a cornerstone of data science in the future. Data scientists will need to master sophisticated tools and techniques for data wrangling, cleansing, storage, and analysis. This expertise will empower organizations to extract valuable nuggets of information from the data deluge, driving data-informed decision-making.
Industry-Specific Applications: Data science will evolve to become increasingly industry-specific, tailoring its approaches and solutions to the unique needs of various sectors. From healthcare and finance to marketing and agriculture, data science will play a pivotal role in optimizing processes, improving outcomes, and solving domain-specific challenges. Customized data science applications will revolutionize industries, delivering precision and efficiency like never before.
Data Privacy and Ethics: As data collection and analysis continue to gain prominence, the ethical considerations surrounding data usage and privacy will become paramount. Data scientists will be entrusted with the responsibility of navigating the complex terrain of data ethics. They will need to strike a delicate balance between harnessing data's potential for good while safeguarding individual privacy and complying with evolving regulations.
Increased Automation: The future of data science will witness the automation of routine data analysis tasks. Machine learning algorithms and AI-driven tools will handle data preprocessing, pattern recognition, and even predictive modeling, allowing data scientists to focus their expertise on more intricate and strategic aspects of their work. Automation will lead to increased efficiency and faster insights.
Advanced Visualization: Data visualization tools will undergo a significant transformation, offering more advanced and interactive ways to represent complex data. Visualization will no longer be confined to static charts and graphs; instead, it will embrace immersive experiences, allowing users to explore data in three dimensions and gain deeper insights. Enhanced visualization will bridge the gap between data scientists and non-technical stakeholders, facilitating better communication and decision-making.
Continuous Learning: Data science is a dynamic and rapidly evolving field. Staying at the forefront of this domain will require a commitment to continuous learning and upskilling. Professionals will need to adapt to emerging tools, technologies, and methodologies. Training institutes and educational platforms will play a pivotal role in facilitating lifelong learning for data scientists, ensuring they remain relevant and effective in their roles.

In the era of data science's transformation, institutions like ACTE Technologies are pivotal in shaping the future workforce. It stands as a beacon for aspiring data scientists, providing comprehensive courses that cover a wide spectrum of data science topics. These courses encompass machine learning, big data analytics, data visualization, and more. Graduates of ACTE emerge not only with theoretical knowledge but also with practical, hands-on experience that prepares them to contribute meaningfully to the evolving landscape of data science.
In conclusion, the future of data science is a landscape of unprecedented possibilities. AI and machine learning integration, big data handling, industry-specific applications, data ethics, automation, advanced visualization, and the commitment to continuous learning are the guiding stars in this data-driven journey. As we navigate this landscape, institutions like ACTE Technologies serve as invaluable guides, equipping data scientists with the knowledge and skills needed to harness the full potential of data science. The future belongs to those who embrace the transformative power of data, and with the right training and expertise, individuals can become key players in this data-driven revolution.
1 note
·
View note
Text
The Skills I Acquired on My Path to Becoming a Data Scientist
Data science has emerged as one of the most sought-after fields in recent years, and my journey into this exciting discipline has been nothing short of transformative. As someone with a deep curiosity for extracting insights from data, I was naturally drawn to the world of data science. In this blog post, I will share the skills I acquired on my path to becoming a data scientist, highlighting the importance of a diverse skill set in this field.
The Foundation — Mathematics and Statistics
At the core of data science lies a strong foundation in mathematics and statistics. Concepts such as probability, linear algebra, and statistical inference form the building blocks of data analysis and modeling. Understanding these principles is crucial for making informed decisions and drawing meaningful conclusions from data. Throughout my learning journey, I immersed myself in these mathematical concepts, applying them to real-world problems and honing my analytical skills.
Programming Proficiency
Proficiency in programming languages like Python or R is indispensable for a data scientist. These languages provide the tools and frameworks necessary for data manipulation, analysis, and modeling. I embarked on a journey to learn these languages, starting with the basics and gradually advancing to more complex concepts. Writing efficient and elegant code became second nature to me, enabling me to tackle large datasets and build sophisticated models.
Data Handling and Preprocessing
Working with real-world data is often messy and requires careful handling and preprocessing. This involves techniques such as data cleaning, transformation, and feature engineering. I gained valuable experience in navigating the intricacies of data preprocessing, learning how to deal with missing values, outliers, and inconsistent data formats. These skills allowed me to extract valuable insights from raw data and lay the groundwork for subsequent analysis.
Data Visualization and Communication
Data visualization plays a pivotal role in conveying insights to stakeholders and decision-makers. I realized the power of effective visualizations in telling compelling stories and making complex information accessible. I explored various tools and libraries, such as Matplotlib and Tableau, to create visually appealing and informative visualizations. Sharing these visualizations with others enhanced my ability to communicate data-driven insights effectively.

Machine Learning and Predictive Modeling
Machine learning is a cornerstone of data science, enabling us to build predictive models and make data-driven predictions. I delved into the realm of supervised and unsupervised learning, exploring algorithms such as linear regression, decision trees, and clustering techniques. Through hands-on projects, I gained practical experience in building models, fine-tuning their parameters, and evaluating their performance.
Database Management and SQL
Data science often involves working with large datasets stored in databases. Understanding database management and SQL (Structured Query Language) is essential for extracting valuable information from these repositories. I embarked on a journey to learn SQL, mastering the art of querying databases, joining tables, and aggregating data. These skills allowed me to harness the power of databases and efficiently retrieve the data required for analysis.

Domain Knowledge and Specialization
While technical skills are crucial, domain knowledge adds a unique dimension to data science projects. By specializing in specific industries or domains, data scientists can better understand the context and nuances of the problems they are solving. I explored various domains and acquired specialized knowledge, whether it be healthcare, finance, or marketing. This expertise complemented my technical skills, enabling me to provide insights that were not only data-driven but also tailored to the specific industry.
Soft Skills — Communication and Problem-Solving
In addition to technical skills, soft skills play a vital role in the success of a data scientist. Effective communication allows us to articulate complex ideas and findings to non-technical stakeholders, bridging the gap between data science and business. Problem-solving skills help us navigate challenges and find innovative solutions in a rapidly evolving field. Throughout my journey, I honed these skills, collaborating with teams, presenting findings, and adapting my approach to different audiences.
Continuous Learning and Adaptation
Data science is a field that is constantly evolving, with new tools, technologies, and trends emerging regularly. To stay at the forefront of this ever-changing landscape, continuous learning is essential. I dedicated myself to staying updated by following industry blogs, attending conferences, and participating in courses. This commitment to lifelong learning allowed me to adapt to new challenges, acquire new skills, and remain competitive in the field.
In conclusion, the journey to becoming a data scientist is an exciting and dynamic one, requiring a diverse set of skills. From mathematics and programming to data handling and communication, each skill plays a crucial role in unlocking the potential of data. Aspiring data scientists should embrace this multidimensional nature of the field and embark on their own learning journey. If you want to learn more about Data science, I highly recommend that you contact ACTE Technologies because they offer Data Science courses and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested. By acquiring these skills and continuously adapting to new developments, they can make a meaningful impact in the world of data science.
#data science#data visualization#education#information#technology#machine learning#database#sql#predictive analytics#r programming#python#big data#statistics
15 notes
·
View notes
Text
Bayesian Statistics: A Powerful Tool for Uncertainty Modeling
Bayesian statistics is a framework for handling uncertainty that has become increasingly popular in various fields. It provides a flexible and systematic approach to modeling and quantifying uncertainty, allowing us to make better-informed decisions. In this article, we will delve into the foundations of Bayesian statistics, understand its significance in uncertainty modeling, and explore its applications in real-world scenarios.
Defining Bayesian Statistics
Bayesian statistics can be defined as a framework for reasoning about uncertainty.
It is based on Bayes’ theorem, which provides a mathematical formula for updating our beliefs in the presence of new evidence.
Bayesian statistics allows us to incorporate prior knowledge and update it with data to obtain posterior probabilities.
Historical Context of Bayesian Statistics
In the 18th century, the Reverend Thomas Bayes introduced the theorem that forms the backbone of Bayesian statistics. However, it was not until the 20th century that Bayesian methods started gaining prominence in academic research and practical applications. With the advent of computational tools and increased recognition of uncertainty, Bayesian statistics has evolved into a powerful tool for modeling and decision-making.
Significance of Uncertainty Modeling
Uncertainty is intrinsic to many real-world phenomena, from complex biological systems to financial markets. Accurately modeling and quantifying uncertainty is crucial for making informed decisions and predictions. Bayesian statistics plays a vital role in addressing uncertainty by providing a probabilistic framework that allows us to account for inherent variability and incorporate prior knowledge into our analysis.
Foundations of Bayesian Statistics
A. Bayes’ Theorem
Bayes’ theorem is at the core of Bayesian statistics and provides a formula for updating our beliefs based on new evidence. It enables us to revise our prior probabilities in light of observed data. Mathematically, Bayes’ theorem can be expressed as:
P(A|B) = (P(B|A) * P(A)) / P(B)
Bayes’ theorem allows us to explicitly quantify and update our beliefs as we gather more data, resulting in more accurate and precise estimates.
B. Prior and Posterior Probability
In Bayesian inference, we begin with an initial belief about a parameter of interest, expressed through the prior probability distribution. The prior distribution represents what we believe about the parameter before observing any data. As new data becomes available, we update our beliefs using Bayes’ theorem, resulting in the posterior distribution. The posterior probability distribution reflects our updated beliefs after considering the data.
The prior probability distribution acts as a regularization term, influencing the final estimates. It allows us to incorporate prior knowledge, domain expertise, or informed assumptions into the analysis. On the other hand, the posterior distribution represents our refined knowledge about the parameter, considering both the prior beliefs and the observed data.
Bayesian Inference Process
A. Likelihood Function
The likelihood function plays a pivotal role in Bayesian statistics as it captures the relationship between the observed data and the unknown parameters. It quantifies the probability of obtaining the observed data under different parameter values. By maximizing the likelihood function, we can estimate the most probable values for the parameters of interest.
The likelihood function is a key component in Bayesian inference, as it combines the data with the prior information to update our beliefs. By calculating the likelihood for different parameter values, we can explore the range of potential parameter values that are consistent with the observed data.
B. Posterior Distribution
The posterior distribution is the ultimate goal of Bayesian inference. It represents the updated distribution of the parameters of interest after incorporating the prior beliefs and the observed data. The posterior distribution provides a comprehensive summary of our uncertainty and captures the trade-off between prior knowledge and new evidence.
Bayesian updating involves multiplying the prior distribution by the likelihood function and normalizing it to obtain the posterior distribution. This process allows us to continually refine our estimates as more data becomes available. The posterior distribution represents the most up-to-date knowledge about the parameters and encompasses both uncertainty and variability.

Bayesian Models and Applications
A. Bayesian Parameter Estimation
Bayesian statistics offers a robust framework for parameter estimation. It allows us to estimate unknown parameters and quantify the associated uncertainty in a principled manner. By incorporating prior knowledge in the form of prior distributions, Bayesian parameter estimation can make efficient use of limited data.
In fields such as finance, Bayesian parameter estimation has found applications in option pricing, risk management, and portfolio optimization. In healthcare, Bayesian models have been utilized for personalized medicine, clinical trials, and disease prognosis. The ability to incorporate prior information and continuously update estimates makes Bayesian parameter estimation a powerful tool in various domains.
B. Bayesian Hypothesis Testing
Bayesian hypothesis testing provides an alternative to frequentist methods by offering a way to quantify the evidence in favor of different hypotheses. Unlike frequentist methods that rely on p-values, Bayesian hypothesis testing uses posterior probabilities to assess the likelihood of different hypotheses given the data.
By incorporating prior information into the analysis, Bayesian hypothesis testing allows for more informative decision-making. It avoids some of the pitfalls of frequentist methods, such as the reliance on arbitrary significance levels. Bayesian hypothesis testing has found applications in research, industry, and policy-making, providing a more intuitive and flexible approach to drawing conclusions.
Uncertainty Propagation
A. Uncertainty Quantification
Uncertainty quantification is a fundamental aspect of Bayesian modeling, enabling us to understand and communicate the uncertainty associated with model outputs. It provides a means to quantify the inherent variability and lack of perfect information in our predictions.
Methods for uncertainty quantification in Bayesian modeling include calculating credible intervals or using Bayesian hierarchical models to capture uncertainty at different levels of the modeling process. Uncertainty quantification allows decision-makers to account for ambiguity and risk when interpreting and utilizing model outputs.
B. Monte Carlo Methods
Monte Carlo methods are widely used for uncertainty propagation in Bayesian analysis. These techniques, including Markov Chain Monte Carlo (MCMC), allow for efficient sampling from complex posterior distributions, which often have no closed-form analytic solution.
MCMC algorithms iteratively draw samples from the posterior distribution, exploring the parameter space to approximate the true distribution. These samples can then be used to estimate summary statistics, compute credible intervals, or perform model comparison. Monte Carlo methods, especially MCMC, have revolutionized Bayesian analysis and made it feasible to handle complex and high-dimensional models.
Bayesian Machine Learning
A. Bayesian Neural Networks
Bayesian statistics can be integrated into neural networks, resulting in Bayesian neural networks (BNNs). BNNs provide a principled way to incorporate uncertainty estimation within the neural network framework.
By placing priors on the network weights, BNNs enable us to capture uncertainty in the network’s predictions. Bayesian neural networks are particularly useful when data is limited, as they provide more realistic estimates of uncertainty compared to traditional neural networks.
The benefits of Bayesian neural networks extend to a wide range of applications, including anomaly detection, reinforcement learning, and generative modeling.
B. Bayesian Model Selection
Model selection is a critical step in statistical modeling and Bayesian techniques offer reliable approaches to tackle this challenge. Bayesian model selection allows for direct comparison of different models and quantifying the evidence in favor of each model based on the observed data.
Bayesian Information Criterion (BIC) is one of the widely used metrics in Bayesian model selection. It balances the goodness-of-fit of the model with model complexity to avoid overfitting. By accounting for the uncertainty in model selection, Bayesian methods provide a principled approach for choosing the most appropriate model.
Challenges and Considerations
A. Computational Complexity
Bayesian analysis often involves complex models with a high dimensional parameter space, which presents computational challenges. Sampling from and exploring the posterior distribution can be computationally expensive, especially when dealing with large datasets or intricate models.
To overcome these challenges, researchers have developed advanced sampling algorithms such as Hamiltonian Monte Carlo and variational inference techniques. Additionally, the availability of high-performance computing resources has made it easier to tackle computationally demanding Bayesian analyses.
B. Data Requirements
Bayesian modeling relies on the availability of sufficient data to reliably estimate parameters and quantify uncertainty. In cases where data is limited, such as in rare diseases or in emerging fields, Bayesian approaches need to be supplemented with expert knowledge and informative priors.
However, even with limited data, Bayesian techniques can be valuable. By incorporating external information through prior distributions, Bayesian models can leverage existing knowledge and provide reasonable estimates even in data-scarce settings.
Real-World Examples
A. Bayesian Statistics in Finance
Bayesian methods have demonstrated their utility in various financial applications. In risk assessment, Bayesian statistics allows for the incorporation of historical data, expert knowledge, and subjective opinions to estimate the probabilities of market events. Bayesian portfolio optimization considers both expected returns and uncertainty to construct portfolios that balance risk and return.
Credit scoring also benefits from Bayesian statistics, enabling lenders to make accurate predictions by incorporating information from credit bureaus, loan applications, and other relevant sources. Bayesian statistics in finance provides a flexible and rigorous framework for decision-making in uncertain financial markets.
B. Bayesian Statistics in Healthcare
Bayesian statistics has made significant contributions to healthcare decision-making. In medical diagnosis, Bayesian models can combine patient symptoms, test results, and prior information to estimate the probability of disease. Bayesian approaches to drug development utilize prior knowledge, clinical trial data, and animal studies to optimize drug dosage and minimize risks.
In epidemiology, Bayesian statistics is employed to estimate disease prevalence, evaluate the effectiveness of interventions, and forecast future disease trends. Bayesian statistics enhances healthcare decision-making by integrating various sources of information and addressing uncertainty in medical research and practice.
Advancements and Tools
A. Bayesian Software and Packages
Several software packages and libraries have been developed to facilitate Bayesian analysis. Popular tools include:
Stan: A probabilistic programming language that allows for flexible modeling and efficient computation of Bayesian models.
PyMC3: A Python library that provides a simple and intuitive interface for probabilistic programming with Bayesian inference.
JAGS: Just Another Gibbs Sampler, a program for Bayesian analysis using Markov chain Monte Carlo (MCMC) algorithms.

These tools provide user-friendly interfaces, efficient sampling algorithms, and a wide range of pre-built models, making Bayesian analysis accessible to researchers and practitioners across different domains.
B. Recent Developments
Bayesian statistics that continues to evolve with ongoing research and technological advancements. Recent developments include advancements in scalable Bayesian computation, hierarchical modeling, and deep learning with Bayesian approaches. Emerging applications in fields such as autonomous driving, natural language processing, and Bayesian optimization highlight the versatility and expanding reach of Bayesian statistics.
As researchers continue to innovate, Bayesian statistics will remain a powerful tool for uncertainty modeling, providing decision-makers with more accurate estimates, better predictions, and improved risk assessment.
In conclusion, Bayesian statistics offers a compelling framework for uncertainty modeling that has wide-ranging applications across various disciplines. Through the use of prior knowledge, data updating, and careful estimation of posterior distributions, Bayesian statistics enables us to make informed decisions in the face of uncertainty. By acknowledging and quantifying uncertainty, Bayesian statistics empowers decision-makers to account for risk and make better-informed choices. Its flexibility, ability to handle complex models, and emphasis on incorporating prior knowledge make Bayesian statistics an invaluable tool for uncertainty modeling in today’s data-driven world. Embracing the Bayesian approach can unlock new insights, provide more accurate predictions, and enable proactive decision-making. With the advancement of computational tools and the availability of user-friendly software, exploring Bayesian statistics has become more accessible and practical for researchers and practitioners alike. To assist people in their pursuit of a Data Science education, ACTE Institute offers a variety of Data Science courses, boot camps, and degree programs. Let us embrace Bayesian statistics and harness its power for robust uncertainty modeling in our respective fields.
0 notes
Text
Time Series Prediction Techniques for Advanced Analytics
In today’s fast-paced and data-driven world, the importance of time series prediction in advanced analytics cannot be overstated. Time series data, which represents a sequence of observations taken at different points in time, is widely used across industries for forecasting future values and making informed decisions. As organizations strive to gain a competitive edge, the analysis and prediction of time series data have become increasingly crucial.

Understanding Time Series Data
Time series data refers to a collection of observations made over successive periods. Unlike cross-sectional data, which captures a snapshot of different variables at a particular point in time, time series data provides a historical perspective and enables the identification of patterns and trends. This type of data is characterized by its temporal order and can be represented graphically, showcasing how variables change over time. Real-world examples of time series data include stock market prices, weather readings, and medical sensor data.
Importance of Time Series Prediction
Predicting future values in a time series is immensely valuable for a variety of reasons. Firstly, it allows organizations to anticipate trends and patterns, enabling better decision-making and planning. For instance, in finance, accurate predictions of stock prices can inform investment strategies. In healthcare, time series prediction can aid in forecasting disease outbreaks or patient readmissions. Weather forecasting heavily relies on time series prediction to provide accurate forecasts for planning purposes.
Common Time Series Prediction Techniques
A. Moving Averages
Moving averages are simple yet effective techniques for time series prediction. They involve calculating the average of a subset of data points within a specified window. Simple moving averages treat all data points equally, while weighted moving averages assign weights to different data points based on their significance. While moving averages smooth out short-term fluctuations, they may not capture complex patterns and can be sensitive to outliers.
B. Exponential Smoothing
Exponential smoothing methods, such as single, double, and triple exponential smoothing, provide a flexible approach for time series prediction. By assigning exponentially decreasing weights to past observations, these methods give more importance to recent data. Exponential smoothing is particularly useful when there is a trend or seasonality in the data. Using different smoothing factors, practitioners can strike a balance between capturing short-term fluctuations and long-term trends.
C. Autoregressive Integrated Moving Average (ARIMA)
ARIMA models are widely used for time series prediction due to their ability to capture complex dynamics. This model comprises three main components: autoregressive (AR), integrated (I), and moving average (MA). The AR component considers the relationship between present and past observations, the MA component models the dependency among residuals, and the I component accounts for differences between consecutive observations. By selecting the appropriate order for each component, ARIMA models can provide accurate predictions.
D. Prophet Forecasting
Prophet, developed by Facebook, is a powerful tool for time series prediction. It combines the flexibility of additive regression models with the ability to capture seasonality and long-term trends. Prophet enables analysts to model time series data with ease, making it accessible to a wide range of users. With its intuitive interface and customizable features, Prophet has gained popularity in various domains, including finance, retail, and supply chain management.

Advanced Time Series Prediction Techniques
A. Long Short-Term Memory (LSTM) Networks
Deep learning techniques, such as Long Short-Term Memory (LSTM) networks, have revolutionized time series prediction. Unlike traditional methods, LSTM networks can capture long-term dependencies and context in sequential data. By incorporating memory cells and gates, LSTM networks can learn from past observations and make accurate predictions. Their ability to handle non-linear relationships and perform automatic feature extraction makes them highly advantageous for complex time series analysis.
B. Gradient Boosting with XGBoost and LightGBM
Ensemble methods, such as XGBoost and LightGBM, have emerged as powerful techniques for time series forecasting. These methods combine multiple weak models to create a strong predictive model. By using a gradient boosting framework, XGBoost and LightGBM iteratively improve the model’s accuracy by minimizing prediction errors. These methods excel in capturing non-linear relationships and complex interactions, leading to enhanced prediction performance.
C. Hybrid Models
Combining traditional methods, such as ARIMA, with machine learning techniques can yield improved predictions. Hybrid models leverage the strengths of both approaches to handle various complexities in time series data. For example, an ARIMA model can capture the underlying trends and seasonality, while a machine learning model can capture non-linear relationships and interactions. Hybrid models have been successfully applied in areas such as electricity demand forecasting and sales predictions.
Evaluation and Metrics
To assess the performance of time series prediction models, various metrics are commonly used. Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE) are frequently employed to measure the accuracy of predictions. Cross-validation, which involves partitioning the data into training and validation sets, is essential to evaluate the model’s generalizability.
Challenges and Considerations
Time series prediction comes with its fair share of challenges. Seasonality, which refers to regular patterns that occur at fixed intervals, can be difficult to handle. Additionally, missing data poses a significant hurdle in accurately predicting future values. Strategies such as seasonal decomposition and imputation techniques can help address these challenges effectively.
Practical Tips and Best Practices
Selecting the right technique and model for a specific dataset requires careful consideration. Prior to modeling, robust data preprocessing and feature engineering are crucial steps to ensure accurate predictions. Properly handling outliers and scaling the data can significantly impact the model’s performance. Furthermore, regular model monitoring and updating are essential to adapt to changing patterns and maintain optimal prediction accuracy.
Case Studies
Real-world case studies exemplify the practical applications of time series prediction techniques. Industries such as retail, energy, and healthcare have successfully utilized these techniques to optimize inventory management, predict electricity demand, and forecast patient readmissions, respectively. These case studies showcase the potential of time series prediction in various domains and demonstrate the tangible benefits of implementing these techniques.
In conclusion, time series prediction techniques have become indispensable in advanced analytics. By leveraging the power of these techniques, organizations can anticipate future trends and make informed decisions. From simple moving averages to sophisticated deep learning models, the range of methods available ensures flexibility and adaptability across different industries. It is essential for professionals to explore and apply these techniques in their own projects, unlocking the vast potential of time series prediction in driving business success. The ACTE Institute offers various Data Science courses, boot camps, and degree programs to support individuals in their Data Science education journey.
#data science#data science course#education#information#big data#data visualization#data analytics#technology
0 notes
Text
Quantum Computing and Data Science: Shaping the Future of Analysis
In the ever-evolving landscape of technology and data-driven decision-making, I find two cutting-edge fields that stand out as potential game-changers: Quantum Computing and Data Science. Each on its own has already transformed industries and research, but when combined, they hold the power to reshape the very fabric of analysis as we know it.
In this blog post, I invite you to join me on an exploration of the convergence of Quantum Computing and Data Science, and together, we'll unravel how this synergy is poised to revolutionize the future of analysis. Buckle up; we're about to embark on a thrilling journey through the quantum realm and the data-driven universe.
Understanding Quantum Computing and Data Science
Before we dive into their convergence, let's first lay the groundwork by understanding each of these fields individually.

A Journey Into the Emerging Field of Quantum Computing
Quantum computing is a field born from the principles of quantum mechanics. At its core lies the qubit, a fundamental unit that can exist in multiple states simultaneously, thanks to the phenomenon known as superposition. This property enables quantum computers to process vast amounts of information in parallel, making them exceptionally well-suited for certain types of calculations.
Data Science: The Art of Extracting Insights
On the other hand, Data Science is all about extracting knowledge and insights from data. It encompasses a wide range of techniques, including data collection, cleaning, analysis, and interpretation. Machine learning and statistical methods are often used to uncover meaningful patterns and predictions.
The Intersection: Where Quantum Meets Data
The fascinating intersection of quantum computing and data science occurs when quantum algorithms are applied to data analysis tasks. This synergy allows us to tackle problems that were once deemed insurmountable due to their complexity or computational demands.
The Promise of Quantum Computing in Data Analysis
Limitations of Classical Computing
Classical computers, with their binary bits, have their limitations when it comes to handling complex data analysis. Many real-world problems require extensive computational power and time, making them unfeasible for classical machines.

Quantum Computing's Revolution
Quantum computing has the potential to rewrite the rules of data analysis. It promises to solve problems previously considered intractable by classical computers. Optimization tasks, cryptography, drug discovery, and simulating quantum systems are just a few examples where quantum computing could have a monumental impact.
Quantum Algorithms in Action
To illustrate the potential of quantum computing in data analysis, consider Grover's search algorithm. While classical search algorithms have a complexity of O(n), Grover's algorithm achieves a quadratic speedup, reducing the time to find a solution significantly. Shor's factoring algorithm, another quantum marvel, threatens to break current encryption methods, raising questions about the future of cybersecurity.
Challenges and Real-World Applications
Current Challenges in Quantum Computing
While quantum computing shows great promise, it faces numerous challenges. Quantum bits (qubits) are extremely fragile and susceptible to environmental factors. Error correction and scalability are ongoing research areas, and practical, large-scale quantum computers are not yet a reality.

Real-World Applications Today
Despite these challenges, quantum computing is already making an impact in various fields. It's being used for simulating quantum systems, optimizing supply chains, and enhancing cybersecurity. Companies and research institutions worldwide are racing to harness its potential.
Ongoing Research and Developments
The field of quantum computing is advancing rapidly. Researchers are continuously working on developing more stable and powerful quantum hardware, paving the way for a future where quantum computing becomes an integral part of our analytical toolbox.
The Ethical and Security Considerations
Ethical Implications
The power of quantum computing comes with ethical responsibilities. The potential to break encryption methods and disrupt secure communications raises important ethical questions. Responsible research and development are crucial to ensure that quantum technology is used for the benefit of humanity.
Security Concerns
Quantum computing also brings about security concerns. Current encryption methods, which rely on the difficulty of factoring large numbers, may become obsolete with the advent of powerful quantum computers. This necessitates the development of quantum-safe cryptography to protect sensitive data.
Responsible Use of Quantum Technology
The responsible use of quantum technology is of paramount importance. A global dialogue on ethical guidelines, standards, and regulations is essential to navigate the ethical and security challenges posed by quantum computing.
My Personal Perspective
Personal Interest and Experiences
Now, let's shift the focus to a more personal dimension. I've always been deeply intrigued by both quantum computing and data science. Their potential to reshape the way we analyze data and solve complex problems has been a driving force behind my passion for these fields.
Reflections on the Future
From my perspective, the fusion of quantum computing and data science holds the promise of unlocking previously unattainable insights. It's not just about making predictions; it's about truly understanding the underlying causality of complex systems, something that could change the way we make decisions in a myriad of fields.
Influential Projects and Insights
Throughout my journey, I've encountered inspiring projects and breakthroughs that have fueled my optimism for the future of analysis. The intersection of these fields has led to astonishing discoveries, and I believe we're only scratching the surface.
Future Possibilities and Closing Thoughts
What Lies Ahead
As we wrap up this exploration, it's crucial to contemplate what lies ahead. Quantum computing and data science are on a collision course with destiny, and the possibilities are endless. Achieving quantum supremacy, broader adoption across industries, and the birth of entirely new applications are all within reach.
In summary, the convergence of Quantum Computing and Data Science is an exciting frontier that has the potential to reshape the way we analyze data and solve problems. It brings both immense promise and significant challenges. The key lies in responsible exploration, ethical considerations, and a collective effort to harness these technologies for the betterment of society.
#data visualization#data science#big data#quantum computing#quantum algorithms#education#learning#technology
4 notes
·
View notes
Text
Exploring Data Science Tools: My Adventures with Python, R, and More
Welcome to my data science journey! In this blog post, I'm excited to take you on a captivating adventure through the world of data science tools. We'll explore the significance of choosing the right tools and how they've shaped my path in this thrilling field.
Choosing the right tools in data science is akin to a chef selecting the finest ingredients for a culinary masterpiece. Each tool has its unique flavor and purpose, and understanding their nuances is key to becoming a proficient data scientist.
I. The Quest for the Right Tool
My journey began with confusion and curiosity. The world of data science tools was vast and intimidating. I questioned which programming language would be my trusted companion on this expedition. The importance of selecting the right tool soon became evident.
I embarked on a research quest, delving deep into the features and capabilities of various tools. Python and R emerged as the frontrunners, each with its strengths and applications. These two contenders became the focus of my data science adventures.
II. Python: The Swiss Army Knife of Data Science
Python, often hailed as the Swiss Army Knife of data science, stood out for its versatility and widespread popularity. Its extensive library ecosystem, including NumPy for numerical computing, pandas for data manipulation, and Matplotlib for data visualization, made it a compelling choice.
My first experiences with Python were both thrilling and challenging. I dove into coding, faced syntax errors, and wrestled with data structures. But with each obstacle, I discovered new capabilities and expanded my skill set.

III. R: The Statistical Powerhouse
In the world of statistics, R shines as a powerhouse. Its statistical packages like dplyr for data manipulation and ggplot2 for data visualization are renowned for their efficacy. As I ventured into R, I found myself immersed in a world of statistical analysis and data exploration.
My journey with R included memorable encounters with data sets, where I unearthed hidden insights and crafted beautiful visualizations. The statistical prowess of R truly left an indelible mark on my data science adventure.
IV. Beyond Python and R: Exploring Specialized Tools
While Python and R were my primary companions, I couldn't resist exploring specialized tools and programming languages that catered to specific niches in data science. These tools offered unique features and advantages that added depth to my skill set.

For instance, tools like SQL allowed me to delve into database management and querying, while Scala opened doors to big data analytics. Each tool found its place in my toolkit, serving as a valuable asset in different scenarios.
V. The Learning Curve: Challenges and Rewards
The path I took wasn't without its share of difficulties. Learning Python, R, and specialized tools presented a steep learning curve. Debugging code, grasping complex algorithms, and troubleshooting errors were all part of the process.
However, these challenges brought about incredible rewards. With persistence and dedication, I overcame obstacles, gained a profound understanding of data science, and felt a growing sense of achievement and empowerment.
VI. Leveraging Python and R Together
One of the most exciting revelations in my journey was discovering the synergy between Python and R. These two languages, once considered competitors, complemented each other beautifully.

I began integrating Python and R seamlessly into my data science workflow. Python's data manipulation capabilities combined with R's statistical prowess proved to be a winning combination. Together, they enabled me to tackle diverse data science tasks effectively.
VII. Tips for Beginners
For fellow data science enthusiasts beginning their own journeys, I offer some valuable tips:
Embrace curiosity and stay open to learning.
Work on practical projects while engaging in frequent coding practice.
Explore data science courses and resources to enhance your skills.
Seek guidance from mentors and engage with the data science community.
Remember that the journey is continuous—there's always more to learn and discover.
My adventures with Python, R, and various data science tools have been transformative. I've learned that choosing the right tool for the job is crucial, but versatility and adaptability are equally important traits for a data scientist.
As I summarize my expedition, I emphasize the significance of selecting tools that align with your project requirements and objectives. Each tool has a unique role to play, and mastering them unlocks endless possibilities in the world of data science.
I encourage you to embark on your own tool exploration journey in data science. Embrace the challenges, relish the rewards, and remember that the adventure is ongoing. May your path in data science be as exhilarating and fulfilling as mine has been.
Happy data exploring!
23 notes
·
View notes
Text
Exploring the Depths of Data Science: My Journey into Advanced Topics
In my journey through the ever-evolving landscape of data science, I've come to realize that the possibilities are as vast as the data itself. As I venture deeper into this realm, I find myself irresistibly drawn to the uncharted territories of advanced data science topics. The data universe is a treasure trove of intricate patterns, concealed insights, and complex challenges just waiting to be unraveled. This exploration isn't merely about expanding my knowledge; it's about discovering the profound impact that data can have on our world.

A. Setting the Stage for Advanced Data Science Exploration
Data science has transcended its initial boundaries of basic analyses and simple visualizations. It has evolved into a field that delves into the intricacies of machine learning, deep learning, big data, and more. Advanced data science is where we unlock the true potential of data, making predictions, uncovering hidden trends, and driving innovation.
B. The Evolving Landscape of Data Science
The field of data science is in a perpetual state of flux, with new techniques, tools, and methodologies emerging constantly. The boundaries of what we can achieve with data are continually expanding, offering exciting opportunities to explore data-driven solutions for increasingly complex problems.
C.My Motivation for Diving into Advanced Topics
Fueled by an insatiable curiosity and a desire to make a meaningful impact, I've embarked on a journey to explore advanced data science topics. The prospect of unearthing insights that could reshape industries, enhance decision-making, and contribute to societal progress propels me forward on this thrilling path.
II. Going Beyond the Basics: A Recap of Foundational Knowledge
Before diving headfirst into advanced topics, it's paramount to revisit the fundamentals that serve as the bedrock of data science. This refresher not only reinforces our understanding but also equips us to confront the more intricate challenges that lie ahead.

A. Revisiting the Core Concepts of Data Science
From the nitty-gritty of data collection and cleaning to the art of exploratory analysis and visualization, the core concepts of data science remain indomitable. These foundational skills provide us with a sturdy platform upon which we construct our advanced data science journey.
B. The Importance of a Strong Foundation for Advanced Exploration
Just as a towering skyscraper relies on a solid foundation to reach great heights, advanced data science hinges on a strong understanding of the basics. Without this firm grounding, the complexities of advanced techniques can quickly become overwhelming.
C. Reflecting on My Own Data Science Journey
When I look back on my personal data science journey, it's evident that each step I took paved the way for the next. As I progressed from being a novice to an intermediate practitioner, my hunger for knowledge and my drive to tackle more intricate challenges naturally led me toward the realm of advanced topics.
III. The Path to Mastery: Advanced Statistical Analysis
Advanced statistical analysis takes us far beyond the realm of simple descriptive statistics. It empowers us to draw nuanced insights from data and make informed decisions with a heightened level of confidence.
A. An Overview of Advanced Statistical Techniques
Advanced statistical techniques encompass the realm of multivariate analysis, time series forecasting, and more. These methods enable us to capture intricate relationships within data, providing us with a richer and more profound perspective.
B. Bayesian Statistics and Its Applications
Bayesian statistics offers a unique perspective on probability, allowing us to update our beliefs as new data becomes available. This powerful framework finds applications in diverse fields such as medical research, finance, and even machine learning.
C. The Role of Hypothesis Testing in Advanced Data Analysis
Hypothesis testing takes on a more intricate form in advanced data analysis. It involves designing robust experiments, grasping the nuances of p-values, and addressing the challenges posed by multiple comparisons.
IV. Predictive Modeling: Beyond Regression
While regression remains an enduring cornerstone of predictive modeling, the world of advanced data science introduces us to a spectrum of modeling techniques that can elegantly capture the complex relationships concealed within data.
A. A Deeper Dive into Predictive Modeling
Predictive modeling transcends the simplicity of linear regression, offering us tools like decision trees, random forests, and gradient boosting. These techniques furnish us with the means to make more precise predictions for intricate data scenarios.
B. Advanced Regression Techniques and When to Use Them
In the realm of advanced regression, we encounter techniques such as Ridge, Lasso, and Elastic Net regression. These methods effectively address issues of multicollinearity and overfitting, ensuring that our models remain robust and reliable.
C. Embracing Ensemble Methods for Enhanced Predictive Accuracy
Ensemble methods, a category of techniques, ingeniously combine multiple models to achieve higher predictive accuracy. Approaches like bagging, boosting, and stacking harness the strengths of individual models, resulting in a formidable ensemble.
V. The Power of Unstructured Data: Natural Language Processing (NLP)
Unstructured text data, abundant on the internet, conceals a trove of valuable information. NLP equips us with the tools to extract meaning, sentiment, and insights from text.
A. Understanding the Complexities of Unstructured Text Data
Text data is inherently messy and nuanced, making its analysis a formidable challenge. NLP techniques, including tokenization, stemming, and lemmatization, empower us to process and decipher text data effectively.
B. Advanced NLP Techniques, Including Sentiment Analysis and Named Entity Recognition
Sentiment analysis gauges the emotions expressed in text, while named entity recognition identifies entities like names, dates, and locations. These advanced NLP techniques find applications in diverse fields such as marketing, social media analysis, and more.
C. Real-World Applications of NLP in Data Science
NLP's applications span from dissecting sentiment in customer reviews to generating human-like text with deep learning models. These applications not only drive decision-making but also enhance user experiences.
VI. Deep Learning and Neural Networks
At the heart of deep learning lies the neural network architecture, enabling us to tackle intricate tasks like image recognition, language translation, and even autonomous driving.
A. Exploring the Neural Network Architecture
Grasping the components of a neural network—layers, nodes, and weights—forms the foundation for comprehending the intricacies of deep learning models.
B. Advanced Deep Learning Concepts like CNNs and RNNs
Convolutional Neural Networks (CNNs) excel at image-related tasks, while Recurrent Neural Networks (RNNs) proficiently handle sequences like text and time series data. These advanced architectures amplify model performance, expanding the horizons of what data-driven technology can accomplish.
C. Leveraging Deep Learning for Complex Tasks like Image Recognition and Language Generation
Deep learning powers image recognition in self-driving cars, generates human-like text, and translates languages in real time. These applications redefine what's possible with data-driven technology, propelling us into an era of boundless potential.
VII. Big Data and Distributed Computing
As data scales to unprecedented sizes, the challenges of storage, processing, and analysis necessitate advanced solutions like distributed computing frameworks.
A. Navigating the Challenges of Big Data in Data Science
The era of big data demands a paradigm shift in how we handle, process, and analyze information. Traditional methods quickly become inadequate, making way for innovative solutions to emerge.
B. Introduction to Distributed Computing Frameworks like Apache Hadoop and Spark
Distributed computing frameworks such as Apache Hadoop and Spark empower us to process massive datasets across clusters of computers. These tools enable efficient handling of big data challenges that were previously insurmountable.
C. Practical Applications of Big Data Technologies
Big data technologies find applications in diverse fields such as healthcare, finance, and e-commerce. They enable us to extract valuable insights from data that was once deemed too vast and unwieldy for analysis.
VIII. Ethical Considerations in Advanced Data Science
As data science advances, ethical considerations become even more pivotal. We must navigate issues of bias, privacy, and transparency with heightened sensitivity and responsibility.
A. Addressing Ethical Challenges in Advanced Data Analysis
Advanced data analysis may inadvertently perpetuate biases or raise new ethical dilemmas. Acknowledging and confronting these challenges is the initial step toward conducting ethical data science.
B. Ensuring Fairness and Transparency in Complex Models
Complex models can be opaque, making it challenging to comprehend their decision-making processes. Ensuring fairness and transparency in these models is a pressing concern that underscores the ethical responsibilities of data scientists.
C. The Responsibility of Data Scientists in Handling Sensitive Data
Data scientists shoulder a profound responsibility when handling sensitive data. Employing advanced encryption techniques and data anonymization methods is imperative to safeguard individual privacy and uphold ethical standards.
IX. The Journey Continues: Lifelong Learning and Staying Updated
In the realm of advanced data science, learning is an unending odyssey. Staying abreast of the latest advancements is not just valuable; it's imperative to remain at the vanguard of the field.
A. Embracing the Mindset of Continuous Learning in Advanced Data Science
Continuous learning isn't a choice; it's a necessity. As data science continually evolves, so must our skills and knowledge. To stand still is to regress.
B. Resources and Communities for Staying Updated with the Latest Advancements
The ACTE Institute provides an array of resources, from books and Data science courses to research papers and data science communities, offers a wealth of opportunities to remain informed about the latest trends and technologies.
C. Personal Anecdotes of Growth and Adaptation in the Field
My expedition into advanced data science has been replete with moments of growth, adaptation, and occasionally, setbacks. These experiences have profoundly influenced my approach to confronting complex data challenges and serve as a testament to the continuous nature of learning.
In conclusion, the journey into advanced data science is an exhilarating odyssey. It's a voyage that plunges us into the deepest recesses of data, where we unearth insights that possess the potential to transform industries and society at large. As we reflect on the indispensable role of essential data science tools, we comprehend that the equilibrium between tools and creativity propels us forward. The data universe is boundless, and with the right tools and an insatiable curiosity, we are poised to explore its ever-expanding horizons.
So, my fellow data enthusiasts, let us persist in our exploration of the data universe. There are discoveries yet to be unearthed, solutions yet to be uncovered, and a world yet to be reshaped through the power of data.
8 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
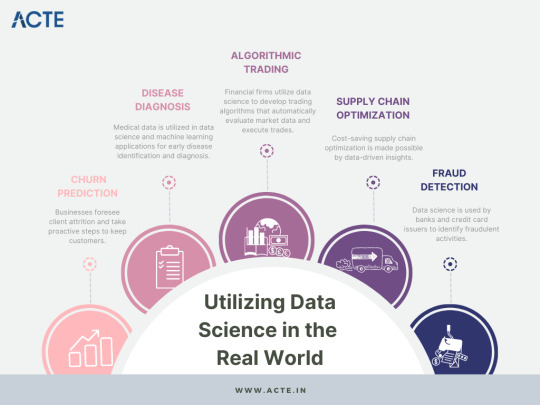
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes