#data engineering architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
Looking for Data Engineering service company. Look no futher than innovatics. innovatics is the best for the data and AI Solutions provider in india, USA and UK.
#data engineering#data engineering services#data engineering consulting company#data engineering consulting services company#data engineering architecture#data engineering companies#data engineering solutions#data engineering course in hyderabad#artificial intelligence chatbot#data engineering service providers in usa#data engineering consulting services
0 notes
Text
Data Engineering Services Explained: What Lies Ahead for the Industry
In an era where data shapes every aspect of business decision-making, organizations are turning to data engineering to harness its full potential. As data volumes and complexities escalate, the demand for specialized data engineering services has surged. This article delves into the core components of data engineering services and offers insights into the evolving future of this critical field.

What are Data Engineering Services?
Data engineering involves the design, construction, and maintenance of systems and infrastructure that allow for the collection, storage, processing, and analysis of data. Data engineering services encompass a variety of tasks and functions that ensure data is accessible, reliable, and usable for data scientists, analysts, and business stakeholders. Key components of data engineering services include:
1. Data Architecture
Data engineers are responsible for designing data architectures that define how data is collected, stored, and accessed. This includes selecting appropriate databases, data lakes, and data warehouses to optimize performance and scalability.
2. Data Integration
Data often comes from multiple sources, including transactional systems, external APIs, and sensor data. Data engineering services involve creating ETL (Extract, Transform, Load) processes that integrate data from these various sources into a unified format.
3. Data Quality and Governance
Ensuring data quality is critical for accurate analysis. Data engineers implement data validation and cleansing processes to identify and rectify errors. They also establish governance frameworks to maintain data integrity and compliance with regulations.
4. Data Pipeline Development
Data pipelines automate the flow of data from its source to storage and processing systems. Data engineering services focus on building efficient pipelines that can handle large volumes of data while ensuring minimal latency.
5. Performance Optimization
As organizations scale, performance becomes a crucial consideration. Data engineers optimize databases and pipelines for speed and efficiency, enabling faster data retrieval and processing.
6. Collaboration with Data Teams
Data engineers work closely with data scientists, analysts, and other stakeholders to understand their data needs. This collaboration ensures that the data infrastructure supports analytical initiatives effectively.
The Future of Data Engineering
As the field of data engineering evolves, several trends are shaping its future:
1. Increased Automation
Automation is set to revolutionize data engineering. Tools and platforms are emerging that automate repetitive tasks such as data cleansing, pipeline management, and monitoring. This will allow data engineers to focus on more strategic initiatives rather than manual processes.
2. Real-time Data Processing
With the rise of IoT devices and streaming applications, the demand for real-time data processing is growing. Future data engineering services will increasingly incorporate technologies like Apache Kafka and Apache Flink to facilitate real-time data ingestion and analytics.
3. Cloud-based Solutions
Cloud computing is becoming the norm for data storage and processing. Data engineering services will continue to leverage cloud platforms like AWS, Google Cloud, and Azure, offering greater scalability, flexibility, and cost-effectiveness.
4. DataOps
DataOps is an emerging discipline that applies agile methodologies to data management. It emphasizes collaboration, continuous integration, and automation in data pipelines. As organizations adopt DataOps, the role of data engineers will shift toward ensuring seamless collaboration across data teams.
5. Focus on Data Security and Privacy
With growing concerns about data security and privacy, data engineers will play a vital role in implementing security measures and ensuring compliance with regulations like GDPR and CCPA. Future services will prioritize data protection as a foundational element of data architecture.
6. Integration of AI and Machine Learning
Data engineering will increasingly intersect with artificial intelligence and machine learning. Data engineers will need to build infrastructures that support machine learning models, ensuring they have access to clean, structured data for training and inference.
Conclusion
Data engineering services are essential for organizations seeking to harness the power of data. As technology continues to advance, the future of data engineering promises to be dynamic and transformative. With a focus on automation, real-time processing, cloud solutions, and security, data engineers will be at the forefront of driving data strategy and innovation. Embracing these trends will enable organizations to make informed decisions, optimize operations, and ultimately gain a competitive edge in their respective industries.
#Data Engineering Services#Data Security#Data Privacy#Future of Data Engineering#Data Architecture#Data Governance
0 notes
Text
Innovative Data Engineering for Strategic Decision-Making

Unlocking the Power of Data: The Role of Data Engineering in Modern Businesses
In today's data-driven world, businesses are increasingly relying on vast amounts of data to make informed decisions, streamline operations, and drive growth. However, the true potential of data can only be harnessed when it is efficiently collected, processed, and analyzed. This is where Data Engineering comes into play—a critical component that forms the backbone of any successful data strategy. At aakarshansedge.com, our Data Engineering services are designed to transform raw data into actionable insights, empowering businesses to thrive in the digital age.
Key Benefits of Our Data Engineering Services Scalability: For scalability in our Data Engineering Services, we ensure that our solutions can seamlessly adapt to increasing data volumes and complexity. Our infrastructure is designed to handle growth efficiently, providing robust performance and flexibility as your data needs evolve. Data Quality: Poor data quality can lead to inaccurate insights and misguided decisions. We implement rigorous data cleaning and validation processes to ensure that your data is accurate, consistent, and trustworthy. Efficiency: In the corporate world, time is of the essence. Our efficient data pipelines and optimized processing techniques minimize latency, allowing you to access and analyze data in real-time. Security and Compliance: With data privacy regulations becoming increasingly stringent, we prioritize security and compliance in all our data engineering projects. We implement robust encryption, access controls, and monitoring systems to protect your data. Cost-Effectiveness: We help you optimize your data storage and processing costs by leveraging cloud platforms and modern data architectures, ensuring you get the most value out of your investment.
Technologies Used in Data Engineering
Big Data Frameworks - The Big Data frameworks at Aakarshan Edge include cutting-edge tools designed for scalable data processing and analytics, such as Apache Hadoop, Apache Spark, and Apache Flink.
Data Warehousing Solutions - Transform your data into actionable insights with our cutting-edge Data Warehousing Solutions, designed for scalability and efficiency at Aakarshan Edge."
Data Integration Tools - Discover top-tier data integration tools at Aakarshan Edge, designed to streamline and enhance your data management processes.
Database Technologies - The website Aakarshan Edge, utilizes advanced database technologies to ensure robust, scalable, and secure data management.
ETL Tools - The website Aakarshan Edge, utilizes cutting-edge ETL (Extract, Transform, Load) tools to streamline data processing and integration, ensuring efficient data management and insights.
Cloud Platforms - Aakarshan Edge offers innovative solutions across leading cloud platforms to enhance scalability and performance for your business.
Data Governance & Quality Tools - Implement robust Data Governance and Quality Tools to ensure the accuracy, consistency, and security of your data assets.
Data Visualization Tools - Transform complex data into clear, actionable insights with our advanced data visualization tools. From interactive dashboards to customizable charts, we empower your business to make data-driven decisions with ease.
Programming Languages - The website Aakarshan Edge, uses a combination of programming languages including HTML, CSS, JavaScript, and potentially server-side languages like PHP or Python.
Machine Learning Libraries - The website Aakarshan Edge, features cutting-edge machine learning libraries to enhance data analytics and predictive modeling.
Why Choose Aakarshan Edge for Data Engineering?
At Aakarshan Edge, we understand that every business is unique, and so are its data challenges. Our approach to data engineering Solutions is highly customized, focusing on understanding your specific needs and delivering solutions that align with your business objectives. Our team of experienced data engineers is well-versed in the latest technologies and best practices, ensuring that your data infrastructure is future-proof and capable of driving innovation.
Conclusion
our Data Engineering Services at Aakarshan Edge are designed to empower your business with robust data solutions that drive efficiency and innovation. By leveraging advanced technologies and tailored strategies, we ensure that your data infrastructure is not only scalable but also aligned with your strategic goals. Partner with us to transform your data into a powerful asset that enhances decision-making and fuels growth.
Contact us (+91-8860691214) (E-Mail: [email protected])
#Data Engineering Services#Data Engineering Solutions#Data Architecture Services#Big Data Engineering
0 notes
Text
AI as Your Creative Co-pilot: A Down-to-Earth Guide for the Architecture, Engineering & Construction Industries
Through experiments with generative design, simulations and human-AI partnerships, I've gained insights and surprising discoveries that have expanded my view of what's possible. In this post, I share lessons learned in the hope it inspires other architect
Hey there, friends and fellow explorers of the digital frontier. If you recall, I recently had the honor of giving the keynote presentation at the Canadian Society for Marketing Professional Services (CSMPS) Annual General Meeting about how Artificial Intelligence (AI) is revolutionizing the Architecture, Engineering, and Construction (AEC) industries. I’ve talked about how AI has revolutionized…

View On WordPress
#AEC industries#architecture#Artificial Intelligence#construction#creative co-pilot#data-driven design#engineering#ethical technology#real-time analytics
0 notes
Text
Unveiling the Power of 3D Visualization: Revolutionizing Engineering Applications

In the world of engineering, complex concepts and intricate designs often require effective means of communication to convey ideas, identify potential issues, and foster innovation. 3D visualization has emerged as a powerful tool that not only aids in comprehending intricate engineering concepts but also fuels creativity and enhances collaboration among multidisciplinary teams. This blog dives deep into the realm of 3D visualization for engineering applications, exploring its benefits, applications, and the technologies driving its evolution.
The Power of 3D Visualization
1. Enhanced Understanding: Traditional 2D drawings and diagrams can sometimes fall short in capturing the full complexity of engineering designs. 3D visualization empowers engineers, architects, and designers to create realistic and immersive representations of their ideas. This level of detail allows stakeholders to grasp concepts more easily and make informed decisions.
2. Identification of Design Flaws: One of the primary advantages of 3D visualization is its ability to identify potential design flaws before physical prototyping begins. Engineers can simulate real-world conditions, test stress points, and analyze the behavior of components in various scenarios. This process saves both time and resources that would have been wasted on rectifying issues post-construction.
3. Efficient Communication: When working on multidisciplinary projects, effective communication is essential. 3D visualization simplifies the sharing of ideas by presenting a clear visual representation of the design. This reduces the chances of misinterpretation and encourages productive discussions among team members from diverse backgrounds.
4. Innovation and Creativity: 3D visualization fosters creativity by enabling engineers to experiment with different design variations quickly. This flexibility encourages out-of-the-box thinking and exploration of unconventional ideas, leading to innovative solutions that might not have been considered otherwise.
5. Client Engagement: For projects involving clients or stakeholders who might not have technical expertise, 3D visualization serves as a bridge between complex engineering concepts and layman understanding. Clients can visualize the final product, making it easier to align their expectations with the project's goals.
Applications of 3D Visualization in Engineering
1. Architectural Visualization: In architectural engineering, 3D visualization brings blueprints to life, allowing architects to present realistic walkthroughs of structures before construction. This helps clients visualize the final appearance and make informed decisions about design elements.
2. Product Design and Prototyping: Engineers can use 3D visualization to create virtual prototypes of products, enabling them to analyze the functionality, ergonomics, and aesthetics. This process accelerates the design iteration phase and reduces the number of physical prototypes required.
3. Mechanical Engineering: For mechanical systems, 3D visualization aids in simulating motion, stress analysis, and assembly processes. Engineers can identify interferences, optimize part arrangements, and predict system behavior under different conditions.
4. Civil Engineering and Infrastructure Projects: From bridges to roadways, 3D visualization facilitates the planning and execution of large-scale infrastructure projects. Engineers can simulate traffic flow, assess environmental impacts, and optimize structural design for safety and efficiency.
5. Aerospace and Automotive Engineering: In these industries, intricate designs and high-performance requirements demand rigorous testing. 3D visualization allows engineers to simulate aerodynamics, structural integrity, and other critical factors before manufacturing.
Technologies Driving 3D Visualization
1. Computer-Aided Design (CAD): CAD software forms the foundation of 3D visualization. It enables engineers to create detailed digital models of components and systems. Modern CAD tools offer parametric design, enabling quick modifications and iterative design processes.
2. Virtual Reality (VR) and Augmented Reality (AR): VR and AR technologies enhance the immersive experience of 3D visualization. VR headsets enable users to step into a digital environment, while AR overlays digital content onto the real world, making it ideal for on-site inspections and maintenance tasks.
3. Simulation Software: Simulation tools allow engineers to analyze how a design will behave under various conditions. Finite element analysis (FEA) and computational fluid dynamics (CFD) simulations help predict stress, heat transfer, and fluid flow, enabling design optimization.
4. Rendering Engines: Rendering engines create photorealistic images from 3D models, enhancing visualization quality. These engines simulate lighting, materials, and textures, providing a lifelike representation of the design.
Future Trends and Challenges
As technology evolves, so will the field of 3D visualization for engineering applications. Here are some anticipated trends and challenges:
1. Real-time Collaboration: With the rise of cloud-based tools, engineers worldwide can collaborate on 3D models in real time. This facilitates global teamwork and accelerates project timelines.
2. Artificial Intelligence (AI) Integration: AI could enhance 3D visualization by automating design tasks, predicting failure points, and generating design alternatives based on predefined criteria.
3. Data Integration: Integrating real-time data from sensors and IoT devices into 3D models will enable engineers to monitor performance, identify anomalies, and implement preventive maintenance strategies.
4. Ethical Considerations: As 3D visualization tools become more sophisticated, ethical concerns might arise regarding the potential misuse of manipulated visualizations to deceive stakeholders or obscure design flaws.
In conclusion, 3D visualization is transforming the engineering landscape by enhancing understanding, fostering collaboration, and driving innovation. From architectural marvels to cutting-edge technological advancements, 3D visualization empowers engineers to push the boundaries of what is possible. As technology continues to advance, the future of engineering will undoubtedly be shaped by the dynamic capabilities of 3D visualization.
#3D Visualization#Engineering Visualization#CAD Software#Virtual Reality (VR)#Augmented Reality (AR)#Design Innovation#Visualization Tools#Product Design#Architectural Visualization#Mechanical Engineering#Civil Engineering#Aerospace Engineering#Automotive Engineering#Data Integration#Real-time Visualization#Engineering Trends#Visualization Technologies#Design Optimization
1 note
·
View note
Text
What is the difference between Data Scientist and Data Engineers ?
In today’s data-driven world, organizations harness the power of data to gain valuable insights, make informed decisions, and drive innovation. Two key players in this data-centric landscape are data scientists and data engineers. Although their roles are closely related, each possesses unique skills and responsibilities that contribute to the successful extraction and utilization of data. In…
View On WordPress
#Big Data#Business Intelligence#Data Analytics#Data Architecture#Data Compliance#Data Engineering#Data Infrastructure#Data Insights#Data Integration#Data Mining#Data Pipelines#Data Science#data security#Data Visualization#Data Warehousing#Data-driven Decision Making#Exploratory Data Analysis (EDA)#Machine Learning#Predictive Analytics
1 note
·
View note
Text


[JK] My first job was as an Assistant Producer for a video game company called Interplay in Irvine, CA. I had recently graduated from Boston University's School of Fine Arts with an MFA in Directing (I started out as a theatre nerd), but also had some limited coding experience and a passion for computers. It didn't look like I'd be able to make a living directing plays, so I decided to combine entertainment and technology (before it was cool!) and pitched myself to Brian Fargo, Interplay's CEO. He gave me my first break. I packed up and moved out west, and I've been producing games ever since.

[JK] I loved my time at EA. I was there for almost a full decade, and learned a tremendous amount about game-making, and met the most talented and driven people, who I remain in touch with today. EA gave me many opportunities, and never stopped betting on me. I worked on The Sims for nearly 5 years, and then afterwards, I worked on console action games as part of the Visceral studio. I was the Creative Director for the 2007 game "The Simpsons", and was the Executive Producer and Creative Director for the 2009 game "Dante's Inferno".

[JK] I haven't played in a long while, but I do recall that after the game shipped, my wife and I played the retail version for some time -- we created ourselves, and experimented with having a baby ahead of the actual birth of our son (in 2007). Even though I'd been part of the development team, and understood deeply how the simulation worked, I was still continually surprised at how "real" our Sims felt, and how accurate their responses were to having a baby in the house. It really felt like "us"!
Now for some of the development and lore related questions:

[JK] So I ended up in the incredibly fortunate position of creating the shipping neighborhoods for The Sims 2, and recruiting a few teammates to help me as we went along.
Around the same time, we started using the Buy/Build tools to make houses we could save, and also bring them into each new build of the game (correcting for any bugs and incompatibilities). With the import tool, we could load Sims into these houses. In time, this "vanguard QA" process turned into a creative endeavor to define the "saved state" of the neighborhoods we would actually end up shipping with the game.
On playtesting & the leftover sims data on various lots:
Basically, we were in the late stages of development, and the Save Game functionality wasn't quite working. In order to test the game properly, you really needed to have a lot of assets, and a lot of Sims with histories (as if you'd been playing them for weeks) to test out everything the game had to offer. So I started defining a set of characters in a spreadsheet, with all their tuning variables, and worked with engineering to create an importer, so that with each new build, I could essentially "load" a kind of massive saved game, and quickly start playing and testing.
It was fairly organic, and as the game's functionality improved, so did our starter houses and families.
The thought process behind the creation of the iconic three neighborhoods:
I would not say it was particularly planned out ahead of time. We knew we needed a few saved houses to ship with the game; Sims 1, after all, had the Goth house, and Bob Newbie's house. But there wasn't necessarily a clear direction for what the neighborhood would be for Sims 2. We needed the game to be far enough along, so that the neighborhood could be a proper showcase for all the features in the game. With each new feature that turned alpha, I had a new tool in my toolbox, and I could expand the houses and families I was working on. Once we had the multi-neighborhood functionality, I decided we would not just have 1 starter neighborhood, but 3. With the Aging feature, Memories, a few wacky objects, plus a huge catalog of architectural and decorative content, I felt we had enough material for 3 truly distinct neighborhoods. And we added a couple of people to what became the "Neighborhood Team" around that time.
Later, when we created Strangetown, and eventually Veronaville, I believe we went back and changed Pleasantville to Pleasantview... because I liked the alliteration of "Verona-Ville", and there was no sense in having two "villes". (To this day, by the way, I still don't know whether to capitalize the "V" -- this was hotly debated at the time!)
Pleasantview:
Anyway, to answer your question, we of course started with Pleasantview. As I recall, we were not quite committed to multiple neighborhoods at first, and I think it was called Pleasantville initially, which was kind of a nod to Simsville... but without calling it Simsville, which was a little too on the nose. (There had also been an ill-fated game in development at Maxis at the time, called SimsVille, which was cancelled.) It's been suggested that Pleasantville referred to the movie, but I don't think I ever saw that movie, and we just felt that Pleasantville kind of captured the feeling of the game, and the relaxing, simple, idyllic world of the Sims.
Pleasantview started as a place to capture the aging feature, which was all new to The Sims 2. We knew we had toddlers, teens, and elders to play with, so we started making families that reflected the various stages of family life: the single mom with 3 young kids, the parents with two teens, the old rich guy with two young gold-diggers, etc. We also had a much greater variety of ethnicity to play with than Sims 1, and we had all new variables like sexual orientation and memories. All these things made for rich fodder for a great diversity of families. Then, once we had family trees, and tombstones that carried the actual data for the dead Sims, the doors really blew open. We started asking ourselves, "What if Bella and Mortimer Goth could be characters in Sims 2, but aged 25 years? And what if Cassandra is grown up? And what if Bella is actually missing, and that could be a fun mystery hanging over the whole game?" And then finally the "Big Life Moments" went into the game -- like weddings and birthdays -- and we could sort of tee these up in the Save Game, so that they would happen within the first few minutes of playing the families. This served both as a tutorial for the features, but also a great story-telling device.
Anyway, it all just flowed from there, as we started creating connections between families, relationships, histories, family trees, and stories that we could weave into the game, using only the simulation features that were available to us. It was a really fun and creative time, and we wrote all of the lore of Sims 2 within a couple of months, and then just brought it to life in the game.
Strangetown:
Strangetown was kind of a no-brainer. We needed an alternate neighborhood for all the paranormal stuff the Sims was known for: alien abduction, male pregnancy, science experiments, ghosts, etc. We had the desert terrain, which created a nice contrast to the lush Pleasantville, and gave it an obvious Area 51 vibe.
The fact that Veronaville is the oldest file probably reflects the fact that it was finished first, not that it was started first. That's my guess anyway. It was the simplest neighborhood, in many ways, and didn't have as much complexity in terms of features like staged big life moments, getting the abduction timing right, the alien DNA thing (which I think was somewhat buggy up until the end), etc. So it's possible that we simply had Veronaville "in the can", while we put the last polish on Pleasantville (which was the first and most important neighborhood, in terms of making a good impression) and Strangeville (which was tricky technically).
Veronaville:
But my personal favorite was Veronaville. We had this cool Tudor style collection in the Build mode catalog, and I wanted to ship some houses that showed off those assets. We also had the teen thing going on in the aging game, plus a lot of romance features, as well as enemies. I have always been a Shakespeare buff since graduate school, so putting all that together, I got the idea that our third neighborhood should be a modern-day telling of the Romeo and Juliet story. It was Montys and Capps (instead of Montagues and Capulets), and it just kind of wrote itself. We had fun creating the past family trees, where everyone had died young because they kept killing each other off in the ongoing vendetta.

[JK] You know, I have never seen The Lone Gunmen, and I don't remember making any kind of direct references with the Strangetown Sims, other than the general Area 51 theme, as you point out. Charles London helped out a lot with naming Sims, and I'm pretty sure we owe "Vidcund" and "Lazlo" to him ... though many team members pitched in creatively. He may have had something in mind, but for me, I largely went off of very generic and stereotypical ideas when crafting these neighborhoods. I kind of wanted them to be almost "groaners" ... they were meant to be tropes in every sense of the word. And then we snuck in some easter eggs. But largely, we were trying to create a completely original lore.

[JK] Well, I think we kind of pushed it with The Sims 2, to be honest, and I remember getting a little blow-back about Bunny Broke, for example. Bunny Broke was the original name for Brandi Broke. Not everyone found that funny, as I recall, and I can understand that. It must have been changed before we shipped.
We also almost shipped the first outwardly gay Sims in those neighborhoods, which was bold for EA back in 2004. My recollection was that we had set up the Dreamers to be gay (Dirk and Darren), but I'm looking back now and see that's not the case. So I'm either remembering incorrectly (probably) or something changed during development.
In general we just did things that we found funny and clever, and we just pulled from all the tropes of American life.

[JK] The alien abduction started in Sims 1, with a telescope object that was introduced in the "Livin' Large" expansion pack. That's when some of the wackier ideas got introduced into the Sims lore. That pack shipped just before I joined Maxis in 2001; when I got there, the team had shipped "House Party" and was underway on "Hot Date". So I couldn't tell you how the original idea came about, but The Sims had this 50's Americana vibe from the beginning, and UFOs kind of played right into that. So the alien abduction telescope was a no-brainer to bring back in Sims 2. The male pregnancy was a new twist on the Sims 1 telescope thing. It must have been that the new version (Sims 2) gave us the tech and flexibility to have male Sims become pregnant, so while this was turned "off" for the core game, we decided to take advantage of this and make a storyline out of it. I think this really grew out of the fact that we had aliens, and alien DNA, and so it was not complicated to pre-bake a baby that would come out as an alien when born. The idea of a bunch of guys living together, and then one gets abducted, impregnated, and then gives birth to an alien baby ... I mean, I think we just all thought that was hilarious, in a sit-com kind of way. Not sure there was much more to it than that. Everything usually came from the designers discovering ways to tweak and play with the tech, to get to funny outcomes.

[JK] Possibly we were just testing the functionality of the Wants/Fears and Memories systems throughout development, and some stuff got left over.

[JK] I can't remember, but that sounds like something we would have done! I'm pretty sure we laid the groundwork for more stories that we ended up delivering :) But The Sims 2 was a great foundation for a lot of continued lore that followed.
--
I once again want to thank Jonathan Knight for granting me this opportunity and taking the time from his busy schedule to answer my questions.
#BURNING LORE QUESTIONS FINALLY ANSWERED!! :D#the sims 2#ts2#sims 2#ea games#ea#electronic arts#sims#the sims#strangetown#veronaville#pleasantview#jonathan knight interview#the sims 2 development#sims 2 development#sims 2 beta#I'm so glad I got this opportunity man.
1K notes
·
View notes
Text





🎄💾🗓️ Day 4: Retrocomputing Advent Calendar - The DEC PDP-11! 🎄💾🗓️
Released by Digital Equipment Corporation in 1970, the PDP-11 was a 16-bit minicomputer known for its orthogonal instruction set, allowing flexible and efficient programming. It introduced a Unibus architecture, which streamlined data communication and helped revolutionize computer design, making hardware design more modular and scalable. The PDP-11 was important in developing operating systems, including the early versions of UNIX. The PDP-11 was the hardware foundation for developing the C programming language and early UNIX systems. It supported multiple operating systems like RT-11, RSX-11, and UNIX, which directly shaped modern OS design principles. With over 600,000 units sold, the PDP-11 is celebrated as one of its era's most versatile and influential "minicomputers".
Check out the wikipedia page for some great history, photos (pictured here), and more -
And here's a story from Adafruit team member, Bill!
The DEC PDP-11 was the one of the first computers I ever programmed. That program was 'written' with a soldering iron.
I was an art student at the time, but spending most of my time in the engineering labs. There was a PDP-11-34 in the automation lab connected to an X-ray spectroscopy machine. Starting up the machine required toggling in a bootstrap loader via the front panel. This was a tedious process. So we ordered a diode-array boot ROM which had enough space to program 32 sixteen bit instructions.
Each instruction in the boot sequence needed to be broken down into binary (very straightforward with the PDP-11 instruction set). For each binary '1', a diode needed to be soldered into the array. The space was left empty for each '0'. 32 sixteen bit instructions was more than sufficient to load a secondary bootstrap from the floppy disk to launch the RT-11 operating system. So now it was possible to boot the system with just the push of a button.
I worked with a number DEC PDP-11/LSI-11 systems over the years. I still keep an LSI-11-23 system around for sentimental reasons.
Have first computer memories? Post’em up in the comments, or post yours on socialz’ and tag them #firstcomputer #retrocomputing – See you back here tomorrow!
#dec#pdp11#retrocomputing#adventcalendar#minicomputer#unixhistory#cprogramming#computinghistory#vintagecomputers#modulardesign#scalablehardware#digitalcorporation#engineeringlabs#programmingroots#oldschooltech#diodearray#bootstraploader#firstcomputer#retrotech#nerdlife
288 notes
·
View notes
Text
Optimize your business with Innovatics' cutting-edge data engineering services, turning raw data into actionable insights. Drive innovation and unlock your business's full potential with our data engineering specialists.
#data engineering#data engineering services#data engineering consulting#data engineering solutions#data engineering companies#data engineering architecture#data engineer roadmap
0 notes
Text
What is Super Danmaku Maker?
Yes, I really do have this many projects, I'm one of those people who procrastinates by starting new projects. Anyway.


Super Danmaku Maker is a danmaku (bullet hell) engine that I’m designing to be a flexible, multipurpose tool for creating any kind of shoot-'em-up (shmup) project. Whether it’s individual spell cards, full boss battles, levels, or even entire games, the goal is to provide an easy-to-use, node-based interface that caters to both beginners and experienced designers.
Computational Efficiency via Precomputation One of the primary architectural goals of Super Danmaku Maker is to make bullet patterns computationally cheap at runtime. This is achieved through precomputation: bullet patterns are calculated as compositions of mathematical transformations during the design phase using calculus. It turns out that it is useful, actually! Instead of simulating the motion of bullets or tracking them individually as objects, we turn bullet patterns into lookup tables.
Instead of performing complex calculations every frame for every bullet, the engine simply "looks up" where the bullet should be based on the precomputed data. This trades off some load time for designers and additional disk space for buttery-smooth performance during gameplay. With this approach, the engine can easily handle 20,000+ bullets onscreen at once at a stable 60+ fps during testing. For comparison, Touhou's bullet cap of 2000 bullets is easily broached and hard caps at my screen's refresh rate (144 fps).
A Spiritual Successor To An Extremely Obscure Freeware Game Super Danmaku Maker draws inspiration from Fraxy, an obscure tool for creating top-down shooter boss encounters I used to be obsessed with as a kid. While Fraxy focused primarily on designing Gradius/R-Type/Darius-style bosses, with other functions developed via some crazy hacker bullshit, Super Danmaku Maker expands the inbuilt scope significantly:
Design enemies, bosses, full levels, and entire games.
Create player characters and weapons, complete with custom behaviors and abilities.
Support for arbitrary keyboard and mouse input, making it possible to design unconventional control schemes.
The vision is for this engine to act as a highly specialized, high-level programming language (or in layman's terms - a game engine) built on top of C# for shmup creation. Beginners will find it accessible and intuitive, while power-users can push the boundaries of what’s possible with crazy wizard bullshit and advanced setups that even I can’t anticipate right now.
Node-Based Interface The core of Super Danmaku Maker is a node-based interface, similar to Blender’s Geometry Nodes. Instead of writing complex code, users will connect and configure nodes to:
Define bullet patterns.
Build complex behaviors for bosses, levels, and player characters.
Experiment with bullet path changes like speed changes, rotations, curling motions, and more.
Define bullet & entity behavior in response to arbitrary triggers (such as distance from an object, distance from the edge of the screen, timers, collision, etc.)
This visual, modular approach empowers creators to focus on the art of designing fun and challenging gameplay, without needing extensive programming knowledge.
Future Sharing and Online Play Although the exact details are TBD, the long-term goal is to enable designers to share their creations easily through an online portal. Players would be able to download and play these custom levels and games without needing to install additional tools.
Okay, that's all. Stay tuned!
80 notes
·
View notes
Text
♍️Virgo Mc in the each of the degrees♍️
If you have a Virgo Midheaven (MC), your career and public image are shaped by Virgo’s themes of precision, analysis, service, and mastery. You likely thrive in careers requiring problem-solving, organization, and attention to detail, such as healthcare, science, writing, education, research, or business administration.
• 0° Virgo (Aries Point) – A powerful initiator in service-based or intellectual fields. May gain recognition in medicine, science, or social reform.
• 1° Virgo – A perfectionist with strong critical thinking skills. Could succeed in editing, analytics, or quality control.
• 2° Virgo – A talented communicator; could thrive in writing, journalism, or teaching.
• 3° Virgo – An analytical mind, ideal for investigative work, research, or forensics.
• 4° Virgo – A love for learning and refinement; may excel in academia, law, or technical writing.
• 5° Virgo – A meticulous worker; likely to succeed in finance, administration, or data analysis.
• 6° Virgo – Naturally inclined toward healthcare, therapy, or alternative medicine.
• 7° Virgo – A precise, creative thinker; may find success in graphic design, architecture, or craftsmanship.
• 8° Virgo – Drawn to healing professions, including nutrition, physical therapy, or holistic medicine.
• 9° Virgo – A problem-solver with innovative ideas. Could thrive in technology, engineering, or logistics.
• 10° Virgo – A strong educator; may work in teaching, coaching, or mentoring.
• 11° Virgo – A tech-savvy, analytical mind; may excel in IT, cybersecurity, or programming.
• 12° Virgo – A perfectionist in fashion, music, or fine arts. Success through precise craftsmanship.
• 13° Virgo – A highly responsible worker; may thrive in law enforcement, military, or humanitarian work.
• 14° Virgo – Health-conscious with a sharp mind. Could be drawn to dietetics, fitness, or medical research.
• 15° Virgo – A master of writing, editing, or academic research.
• 16° Virgo – Business-minded; excels in consulting, financial planning, or business strategy.
• 17° Virgo – A detail-oriented expert; could work in surgery, pharmaceuticals, or scientific research.
• 18° Virgo – A deep humanitarian drive; drawn to nonprofits, environmental work, or psychology.
• 19° Virgo – A critical thinker who excels in law, politics, or policy-making.
• 20° Virgo – A master of their craft; recognized for expertise in specialized fields.
• 21° Virgo – Exceptionally intellectual; may thrive in philosophy, academia, or technical writing.
• 22° Virgo – An innovative thinker; could work in product design, systems development, or efficiency consulting.
• 23° Virgo – A strong researcher; may specialize in history, archeology, or science.
• 24° Virgo – An excellent communicator; may succeed in broadcasting, publishing, or public relations.
• 25° Virgo – A sharp and strategic mind; could work in legal fields, investigative journalism, or intelligence.
• 26° Virgo – A healer at heart; may be drawn to nursing, surgery, or psychological counseling.
• 27° Virgo – A gifted analyst; could thrive in economics, data science, or cybersecurity.
• 28° Virgo – A precise and disciplined artist; success in sculpture, architecture, or technical art.
• 29° Virgo (Anaretic Degree) – A master strategist, perfectionist, or critic. Success comes through expertise, refinement, and precision. However, may struggle with overanalyzing or career indecision.
#astro notes#astrology#birth chart#astro observations#astro community#astrology degrees#astrology observations#Virgomc
67 notes
·
View notes
Text



1938 Mercedes-Benz W154
In September 1936, the AIACR (Association Internationale des Automobile Clubs Reconnus), the governing body of motor racing, set the new Grand Prix regulations effective from 1938. Key stipulations included a maximum engine displacement of three liters for supercharged engines and 4.5 liters for naturally aspirated engines, with a minimum car weight ranging from 400 to 850 kilograms, depending on engine size.
By the end of the 1937 season, Mercedes-Benz engineers were already hard at work developing the new W154, exploring various ideas, including a naturally aspirated engine with a W24 configuration, a rear-mounted engine, direct fuel injection, and fully streamlined bodies. Ultimately, due to heat management considerations, they opted for an in-house developed 60-degree V12 engine designed by Albert Heess. This engine mirrored the displacement characteristics of the 1924 supercharged two-liter M 2 L 8 engine, with each of its 12 cylinders displacing 250 cc. Using glycol as a coolant allowed temperatures to reach up to 125°C. The engine featured four overhead camshafts operating 48 valves via forked rocker arms, with three cylinders combined under welded coolant jackets, and non-removable heads. It had a high-capacity lubrication system, circulating 100 liters of oil per minute, and initially utilized two single-stage superchargers, later replaced by a more efficient two-stage supercharger in 1939.
The first prototype engine ran on the test bench in January 1938, and by February 7, it had achieved a nearly trouble-free test run, producing 427 hp (314 kW) at 8,000 rpm. During the first half of the season, drivers such as Caracciola, Lang, von Brauchitsch, and Seaman had access to 430 hp (316 kW), which later increased to over 468 hp (344 kW). At the Reims circuit, Hermann Lang's W154 was equipped with the most powerful version, delivering 474 hp (349 kW) and reaching 283 km/h (176 mph) on the straights. Notably, the W154 was the first Mercedes-Benz racing car to feature a five-speed gearbox.
Max Wagner, tasked with designing the suspension, had an easier job than his counterparts working on the engine. He retained much of the advanced chassis architecture from the previous year's W125 but enhanced the torsional rigidity of the frame by 30 percent. The V12 engine was mounted low and at an angle, with the carburetor air intakes extending through the expanded radiator grille.
The driver sat to the right of the propeller shaft, and the W154's sleek body sat close to the ground, lower than the tops of its tires. This design gave the car a dynamic appearance and a low center of gravity. Both Manfred von Brauchitsch and Richard Seaman, whose technical insights were highly valued by Chief Engineer Rudolf Uhlenhaut, praised the car's excellent handling.
The W154 became the most successful Silver Arrow of its era. Rudolf Caracciola secured the 1938 European Championship title (as the World Championship did not yet exist), and the W154 won three of the four Grand Prix races that counted towards the championship.
To ensure proper weight distribution, a saddle tank was installed above the driver's legs. In 1939, the addition of a two-stage supercharger boosted the V12 engine, now named the M163, to 483 hp (355 kW) at 7,800 rpm. Despite the AIACR's efforts to curb the speed of Grand Prix cars, the new three-liter formula cars matched the lap times of the 1937 750-kg formula cars, demonstrating that their attempt was largely unsuccessful. Over the winter of 1938-39, the W154 saw several refinements, including a higher cowl line around the cockpit for improved driver safety and a small, streamlined instrument panel mounted to the saddle tank. As per Uhlenhaut’s philosophy, only essential information was displayed, centered around a large tachometer flanked by water and oil temperature gauges, ensuring the driver wasn't overwhelmed by unnecessary data.
97 notes
·
View notes
Text
There are moments when Robotnik’s hands are gentle—fixing Stone’s collar, tracing the violet bloom of a bruise—but it is not tenderness, not really.
Stone is a biological canvas stained with the fingerprints of his maker.
Robotnik’s hands have built machines, burned bridges, shattered bones—and now they sculpt devotion itself. They straighten Stone’s tie with the same precision used when calibrating delicate machinery, they trace bruises with curiosity. Fingers brush against flesh like instruments against glass, testing for fractures, for flaws in the architecture of his creation.
To be handled by those hands is to be understood—taken apart, examined, remade.
In every scar, Stone carries a signature. Every conditioned flinch, every desperate breath, every trembling plea. It was carefully curated by Robotnik. Every single cracked edge of Stone’s soul is hidden in a file somewhere, annotated with clinical fascination.
The proof of devotion, flickering in Stone’s every desperate plea, every breathless whimper.
Because of this, Stone does not need to say he belongs to Robotnik—his body, his mind, his every conditioned reaction screams it because it is instinctive, involuntary—a reflex carved into him like writing etched into metal.
Robotnik doesn’t love Stone despite his obsession, he loves him because of it—because it’s fascinating, beautiful in its predictability and volatility. Robotnik does not give care—he engineers it. His affection is rooted in observation, data collection, and meticulous analysis.
To him, this is how you care for someone: you know them, down to their biological rhythms.
And Stone, like a moth developing a symbiotic dependency on flame, wants for it. He devours every scrap of attention, cradling it to his chest like a holy relic. He begs. He pleads. And Robotnik finds the begging beautiful—not because of sadism (though sometimes it’s that too), but because desperation is data, and that data is beautiful.
It's proof that autonomy is a myth when devotion can be designed. Proof that Stone’s perfection is not in his freedom—but in the way he breaks, predictably and beautifully, every time.
#saf's yandere stone au#agent stone#toxic yaoi#dr ivo robotnik#headcanon#sonic movie 3#sonic the hedgehog#I did something different#i honestly don't know if this is good or not tbh#can't tell yet#writing for him was harder than expected
42 notes
·
View notes
Text
Who is Data Engineer and what they do? : 10 key points
In today’s data-driven world, the demand for professionals who can organize, process, and manage vast amounts of information has grown exponentially. Enter the unsung heroes of the tech world – Data Engineers. These skilled individuals are instrumental in designing and constructing the data pipelines that form the backbone of data-driven decision-making processes. In this article, we’ll explore…

View On WordPress
#Big Data#Blogging#Career#cloud computing#Data Analyst#Data Architecture#Data Engineer#Data Engineering#Data Governance#Data Integration#data modeling#Data Science#data security#Database Management#ETL#Technology#WordPress
0 notes
Text
Transforming Brooklyn Bridge: A Revolution in Infrastructure Renovation
One of the most enduring symbols of human architectural brilliance is the Brooklyn Bridge in New York City. Since its completion in 1883, the Brooklyn Bridge has stood as a testament to engineering prowess and urban resilience. Today, however, we stand on the precipice of a new era for this venerable structure, as modern civil engineering techniques and technologies are transforming the Brooklyn…

View On WordPress
#AI in civil engineering#big data#Brooklyn Bridge#carbon footprint#civil engineering#drone inspections#energy-efficient lighting#environmental impact#historical architecture#infrastructure renovation#LIDAR technology#modern civil engineering techniques#pedestrian walkway#real-time analysis#renewable energy#sensor arrays#structural integrity#sustainable infrastructure#traffic patterns#transformation#urban planning
0 notes
Text
Pre-alpha Lancer Tactics changelog
(cross-posting the full gif changelog here because folks seemed to like it last time I did)
We're aiming for getting the first public alpha for backers by the end of this month! Carpenter and I scoped out mechanics that can wait until after the alpha (e.g. grappling, hiding) in favor of tying up the hundred loose threads that are needed for something that approaches a playable game. So this is mostly a big ol changelog of an update from doing that.
But I also gave a talent talk at a local Portland Indie Game Squad event about engine architecture! It'll sound familiar if you've been reading these updates; I laid out the basic idea for this talk almost a year ago, back in the June 2023 update.
youtube
We've also signed contracts & had a kickoff meeting with our writers to start on the campaigns. While I've enjoyed like a year of engine-work, it'll be so so nice to start getting to tell stories. Data structures don't mean anything beyond how they affect humans & other life.
New Content
Implemented flying as a status; unit counts as +3 spaces above the current ground level and ignores terrain and elevation extra movement costs. Added hover + takeoff/land animations.

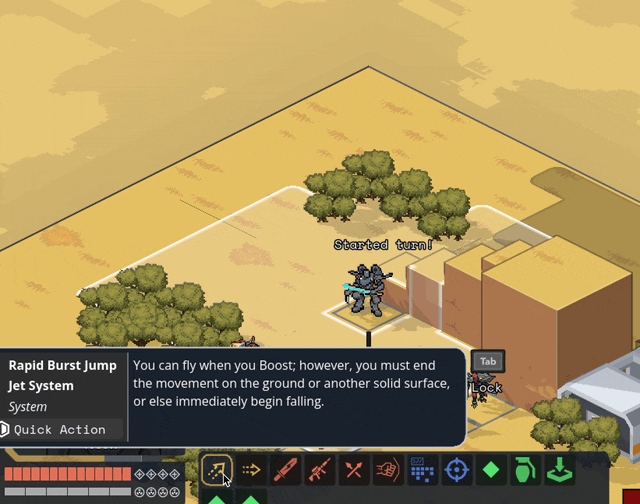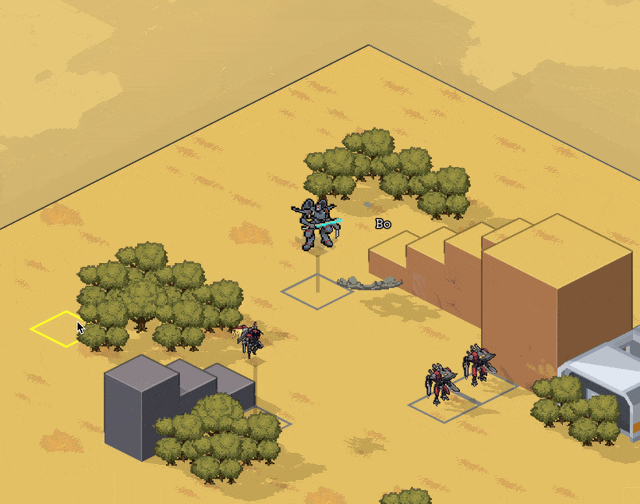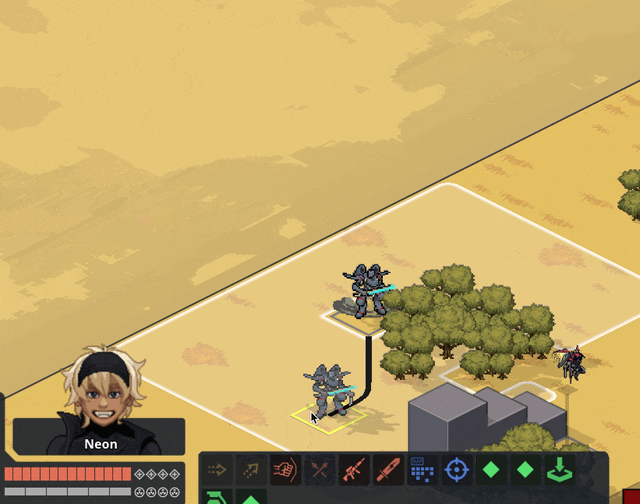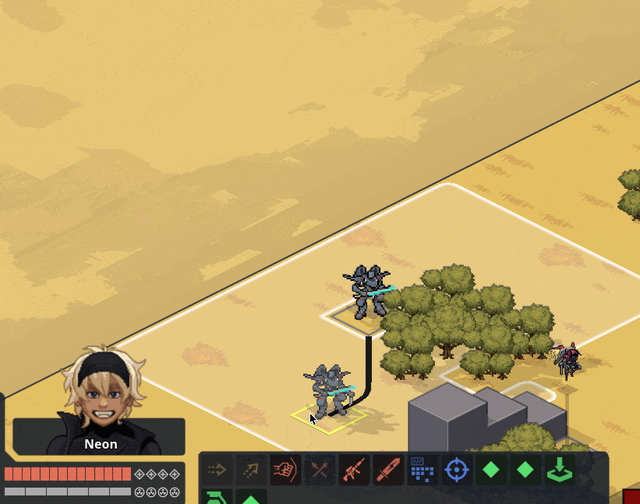
Gave deployables the ability to have 3D meshes instead of 2D sprites; we'll probably use this mostly when the deployable in question is climbable.

Related, I fixed a bug where after terrain destruction, all units recheck the ground height under them so they'll move down if the ground is shot out from under them. When the Jerichos do that, they say "oh heck, the ground is taller! I better move up to stand on it!" — not realizing that the taller ground they're seeing came from themselves.
Fixed by locking some units' rendering to the ground level; this means no stacking climbable things, which is a call I'm comfortable making. We ain't making minecraft here (I whisper to myself, gazing at the bottom of my tea mug).

Block sizes are currently 1x1x0.5 — half as tall as they are wide. Since that was a size I pulled out of nowhere for convenience, we did some art tests for different block heights and camera angles. TLDR that size works great and we're leaving it.

Added Cone AOE pattern, courtesy of an algorithm NMcCoy sent me that guarantees the correct number of tiles are picked at the correct distance from the origin.
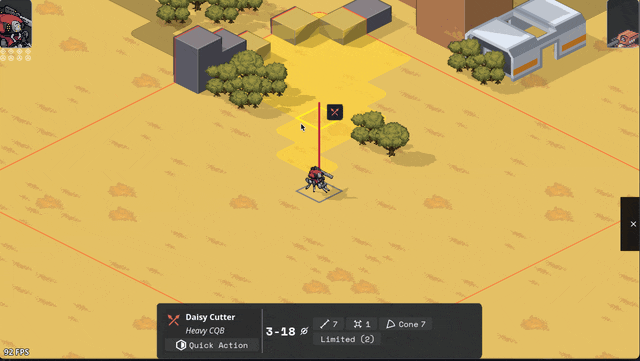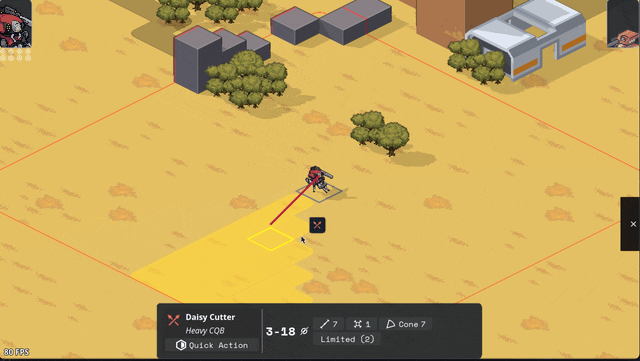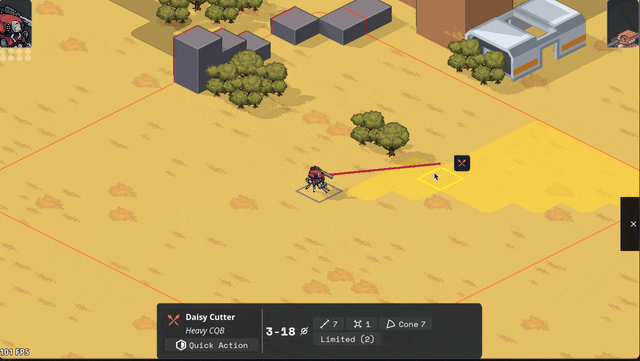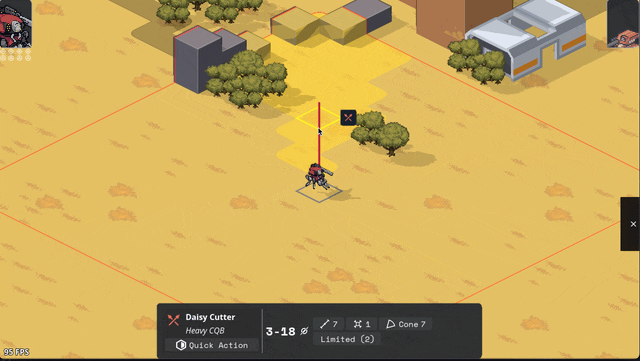
pick your aim angle
for each distance step N of your cone, make a list ("ring") of all the cells at that distance from your origin
sort those cells by angular distance from your aim angle, and include the N closest cells in that ring in the cone's area
Here's a gif they made of it in Bitsy:
Units face where you're planning on moving/targeting them.

Got Walking Armory's Shock option working. Added subtle (too subtle, now that I look at it) electricity effect.

Other things we've added but I don't have gifs for or failed to upload. You'll have to trust me. :)
disengage action
overcharge action
Improved Armament core bonus
basic mine explosion fx
explosion fx on character dying
Increase map elevation cap to 10. It's nice but definitely is risky with increasing the voxel space, gonna have to keep an eye on performance.
Added Structured + Stress event and the associated popups. Also added meltdown status (and hidden countdown), but there's not animation for this yet so your guy just abruptly disappears and leaves huge crater.
UI Improvements
Rearranged the portrait maker. Auto-expand the color picker so you don't have to keep clicking into a submenu.
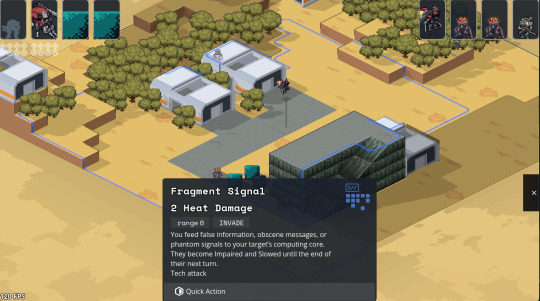
Added topdown camera mode by pressing R for handling getting mechs out of tight spaces.

The action tooltips have been bothering me for a while; they extend up and cover prime play-area real estate in the center of the screen. So I redesigned them to be shorter and have a max height by putting long descriptions in a scrollable box. This sounds simple, but the redesign, pulling in all the correct data for the tags, and wiring up the tooltips took like seven hours. Game dev is hard, yo.
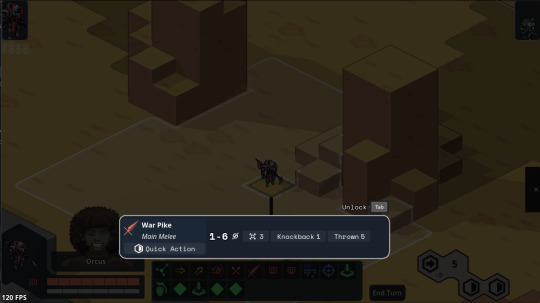
Put the unit inspect popups in lockable tooltips + added a bunch of tooltips to them.

Implemented the rest of Carpenter's cool hex-y action and end turn readout. I'm a big fan of whenever we can make the game look more like a game and less like a website (though he balances out my impulse for that for the sake of legibility).
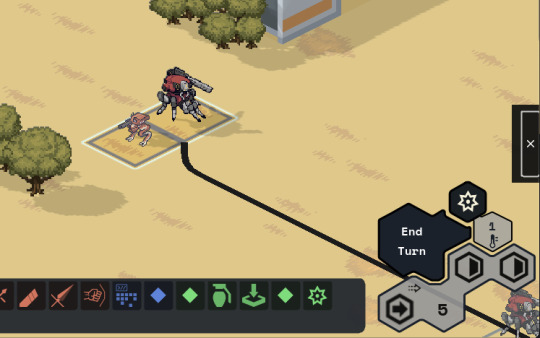
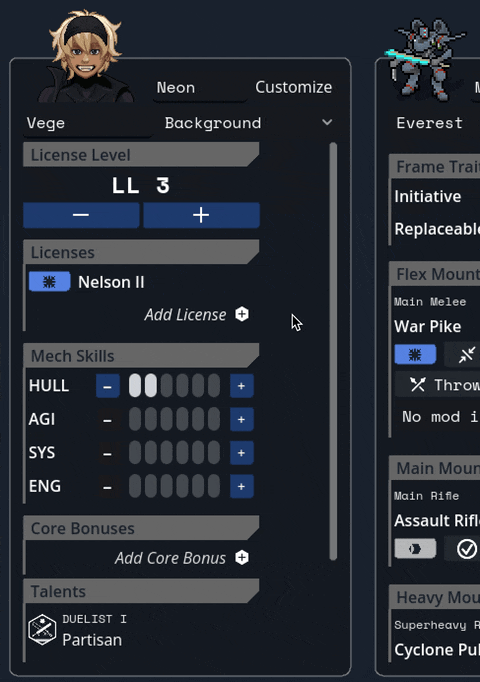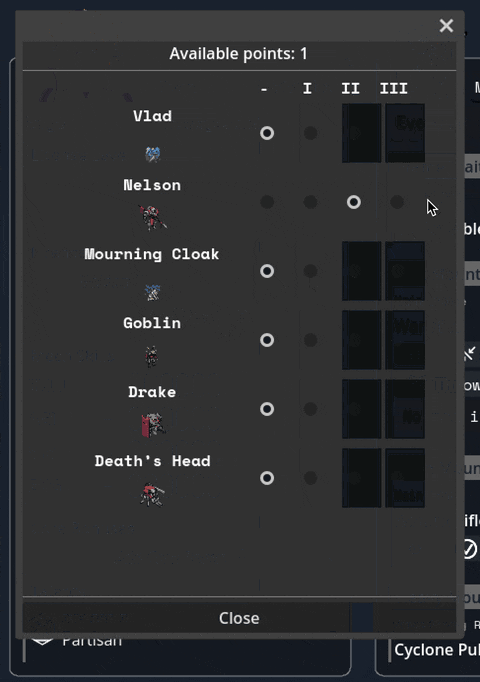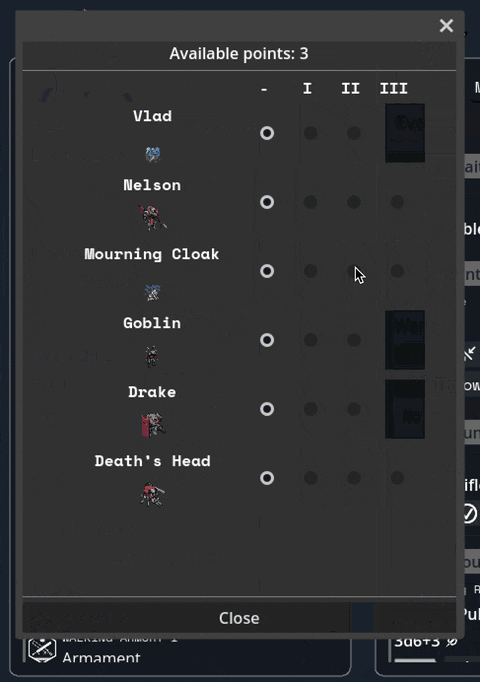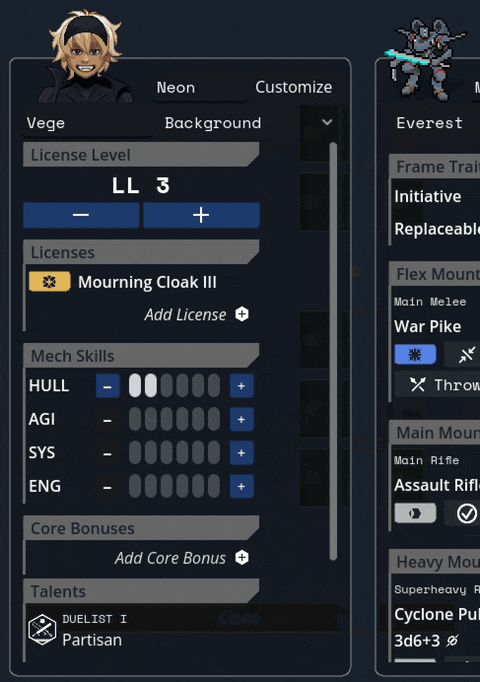
Added a JANKY talent/frame picker. I swear we have designs for a better one, but sometimes you gotta just get it working. Also seen briefly here are basic level up/down and HASE buttons.
Other no-picture things:
Negated the map-scaling effect that happens when the window resizes to prevent bad pixel scaling of mechs at different resolutions; making the window bigger now just lets you see more play area instead of making things bigger.
WIP Objectives Bullets panel to give the current sitrep info
Wired up a buncha tooltips throughout the character sheet.
Under the Hood
Serialization: can save/load games! This is the payoff for sticking with that engine architecture I've been going on about. I had to add a serialization function to everything in the center layer which took a while, but it was fairly straightforward work with few curveballs.
Finished replacement of the kit/unit/reinforcement group/sitrep pickers with a new standardized system that can pull from stock data and user-saved data.
Updated to Godot 4.2.2; the game (and editor) has been crashing on exit for a LONG time and for the life of me I couldn't track down why, but this minor update in Godot completely fixed the bug. I still have no idea what was happening, but it's so cool to be working in an engine that's this active bugfixing-wise!
Other Bugfixes
Pulled straight from the internal changelog, no edits for public parseability:
calculate cover for fliers correctly
no overwatch when outside of vertical threat
fixed skirmisher triggering for each attack in an AOE
fixed jumpjets boost-available detection
fixed mines not triggering when you step right on top of them // at a different elevation but still adjacent
weapon mods not a valid target for destruction
made camera pan less jumpy and adjust to the terrain height
better Buff name/desc localization
Fixed compcon planner letting you both boost and attack with one quick action.
Fix displayed movement points not updating
Prevent wrecks from going prone
fix berserkers not moving if they were exactly one tile away
hex mine uses deployer's save target instead of 0
restrict weapon mod selection if you don't have the SP to pay
fix deployable previews not going away
fix impaired not showing up in the unit inspector (its status code is 0 so there was a check that was like "looks like there's no status here")
fix skirmisher letting you move to a tile that should cost two movement if it's only one space away
fix hit percent calculation
fix rangefinder grid shader corner issues (this was like a full day to rewrite the shader to be better)
Teleporting costs the max(spaces traveled, elevation change) instead of always 1
So um, yeah, that's my talk, any questions? (I had a professor once tell us to never end a talk like this, so now of course it's the phrase that first comes to mind whenever I end a talk)
116 notes
·
View notes