#data bias
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
“Several studies conducted over the past decade or so show that letters of recommendation are another seemingly gender-neutral part of a hiring process that is in fact anything but. One U.S. study found that female candidates are described with more communal (warm; kind; nurturing) and less active (ambitious; self-confident) language than men. And having communal characteristics included in your letter of recommendation makes it less likely that you will get the job, particularly if you're a woman: while 'team-player' is taken as a leadership quality in men, for women the term ‘can make a woman seem like a follower’”. - Caroline Criado Perez (Invisible Women: Data Bias in a World Designed for Men)
#Caroline Criado Perez#womanhood#feminism#sex based discrimination#Invisible Women: Data Bias in a World Designed for Men#letter of recommendation#data bias#work culture#sexism
162 notes
·
View notes
Text
You ever randomly remember excerpts from Invisible Women: Exposing Data Bias in a World Designed for Men by Caroline Criado-Perez and get mad all over again? Like there's no place on Earth where a woman won't be overlooked, ignored, taken for granted, expected to be in pain, or expected to suffer and die.
2 notes
·
View notes
Text
I love good Audiobooks on new tech.
#Accessibility#AI#AI 2041#AI and Global Power#AI Ethics#AI hidden costs#AI history#AI risk#AI successes and setbacks#AI systems#Ajay Agrawal#Alexa#Algorithms of Oppression#Artificial Intelligence: A Guide for Thinking Humans#Atlas of AI#Audible#Audiobooks#Brian Christian#Caroline Criado Perez#Data bias#Ethical Machines#Future of artificial intelligence#Google's AI#Inclusivity#Invisible Women#Kai-Fu Lee#Kate Crawford#Literature consumption#Mark Coeckelbergh#Melanie Mitchell
2 notes
·
View notes
Text

"Invisible Women" by Caroline Criado-Perez
Thank you @womensbookclub_paris for the rec! ❤️
#Invisible women#Data Bias#Bias#Sexism#Patriarchy#Feminism#How the world works#Women stories#women experiences#lived experiences#science#caroline criado perez#statistics#good statistics#why
0 notes
Text
TRYING AGAIN WITH CLEARER WORDING. PLS READ BEFORE VOTING
*Meaning: When did you stop wearing a mask to a majority of your public activities? Wearing a mask when you feel sick or very rarely for specific events/reasons counts as “stopping”
[More Questions Here]
#poll#covid#covid 19#reblog for sample size#I could tag this post ‘environmental storytelling’ cause goddamn#if you reblogged the original please reblog this one#I just want my DATA#hey#excellent deminstration of the scientific process here#needing to correct for confusion on your participants end to get the results you want#can’t fix the tumblr sampling bias but apparently there’s anti-maskers here too#peoples life circumstance can vary so no judgement from me OP on when you stopped#unless you never masked. then I am judging you#like you didn’t even TRY?
624 notes
·
View notes
Text
YOU, the person who watches Once Upon A Witchlight, are autistic
#bias data pool of 1. me#well ok#2. me and my friend#once upon a witchlight#ouaw#legends of avantris#text#this is a true fact
216 notes
·
View notes
Text
One of my favourite things about Ford is that he's like WAIT SAFETY about somethings when he disagrees (the Fiddleford becoming president thing, him being like it's too stressful for Fiddleford) BUT when it's something he's interested in he's like endangering my life is fine and normal (ie, him jumping into the abyss of the alien space ship with a magnetic gun; which is also a ship that has a security system).
The irony of it is amusing to me, but it's also I think it's a very good example that as much as Ford likes to say he's a Scientist™ and governed by Logic™... He's actually first and foremost driven by his emotions, and the logic is something that comes secondhand when he needs an explanation. Case in point with him drawing his relationship and contact with Bill in a way of him making new discoveries for mankind... When in TBOB it becomes very plainly obvious the main reason why he called on Bill was because he was desperately lonely (driven by emotion), less so about his scientific discovery (driven by logic). And I think there's a very human, relatable aspect to it because we all do this. That's why arguing with climate deniers and citing study after study about climate change, or even dealing with racist people and talking about equality and abstract morals doesn't work; there's an emotional aspect that drives people, always beyond our tower of cards of logic...
#hugin rambles#hugin rambles gf#ford pines#stanford pines#gravity falls#gravity falls stanford#bill cipher#billford#the book of bill#as a biologist and a scientist... its all a big sham about emotions. nothing is ever not biased#we like to lie about that. so its always amusing to me to see characters that are like Im a Scientist™ and mean being very logical when in#fact they are by and large driven by emotion. yes you should consciously not bias your data and outputs but you can NEVER remove your bias#in entirety#but yeah. fictional scientists driven by emotion my beloved#stanford pines meta#if tiny
194 notes
·
View notes
Text
“A UK Department for Transport study highlighted the stark difference between male and female perceptions of danger, finding that 62% of women are scared walking in multi-story car parks, 60% are scared waiting on train platforms, 49% are scared waiting at the bus stop, and 59% are scared walking home from a bus stop or station.
The figures for men are 31%, 25%, 20% and 25%, respectively. Fear of crime is particularly high among low-income women, partly because they tend to live in areas with higher crime rates, but also because they are likely to be working odd hours and often come home from work in the dark.' Ethnic-minority women tend to experience more fear for the same reasons, as well as having the added danger of (often gendered) racialised violence to contend with.” - Caroline Criado Perez (Invisible Women: Data Bias in a World Designed for Men)
#Invisible Women: Data Bias in a World Designed for Men#Caroline Criado Perez#crime#violence against women#so based violence#dibs#data bias#womanhood#feminism#patriarchy#women’s safety#this is why we need feminism#statistic#poor women
2 notes
·
View notes
Text
#Adversarial testing#AI#Artificial Intelligence#Auditing#Bias detection#Bias mitigation#Black box algorithms#Collaboration#Contextual biases#Data bias#Data collection#Discriminatory outcomes#Diverse and representative data#Diversity in development teams#Education#Equity#Ethical guidelines#Explainability#Fair AI systems#Fairness-aware learning#Feedback loops#Gender bias#Inclusivity#Justice#Legal implications#Machine Learning#Monitoring#Privacy and security#Public awareness#Racial bias
0 notes
Text
Tackling Misinformation: How AI Chatbots Are Helping Debunk Conspiracy Theories
New Post has been published on https://thedigitalinsider.com/tackling-misinformation-how-ai-chatbots-are-helping-debunk-conspiracy-theories/
Tackling Misinformation: How AI Chatbots Are Helping Debunk Conspiracy Theories
Misinformation and conspiracy theories are major challenges in the digital age. While the Internet is a powerful tool for information exchange, it has also become a hotbed for false information. Conspiracy theories, once limited to small groups, now have the power to influence global events and threaten public safety. These theories, often spread through social media, contribute to political polarization, public health risks, and mistrust in established institutions.
The COVID-19 pandemic highlighted the severe consequences of misinformation. The World Health Organization (WHO) called this an “infodemic,” where false information about the virus, treatments, vaccines, and origins spread faster than the virus itself. Traditional fact-checking methods, like human fact-checkers and media literacy programs, needed to catch up with the volume and speed of misinformation. This urgent need for a scalable solution led to the rise of Artificial Intelligence (AI) chatbots as essential tools in combating misinformation.
AI chatbots are not just a technological novelty. They represent a new approach to fact-checking and information dissemination. These bots engage users in real-time conversations, identify and respond to false information, provide evidence-based corrections, and help create a more informed public.
The Rise of Conspiracy Theories
Conspiracy theories have been around for centuries. They often emerge during uncertainty and change, offering simple, sensationalist explanations for complex events. These narratives have always fascinated people, from rumors about secret societies to government cover-ups. In the past, their spread was limited by slower information channels like printed pamphlets, word-of-mouth, and small community gatherings.
The digital age has changed this dramatically. The Internet and social media platforms like Facebook, Twitter, YouTube, and TikTok have become echo chambers where misinformation booms. Algorithms designed to keep users engaged often prioritize sensational content, allowing false claims to spread quickly. For example, a report by the Center for Countering Digital Hate (CCDH) found that just twelve individuals and organizations, known as the “disinformation dozen,” were responsible for nearly 65% of anti-vaccine misinformation on social media in 2023. This shows how a small group can have a huge impact online.
The consequences of this unchecked spread of misinformation are serious. Conspiracy theories weaken trust in science, media, and democratic institutions. They can lead to public health crises, as seen during the COVID-19 pandemic, where false information about vaccines and treatments hindered efforts to control the virus. In politics, misinformation fuels division and makes it harder to have rational, fact-based discussions. A 2023 study by the Harvard Kennedy School’s Misinformation Review found that many Americans reported encountering false political information online, highlighting the widespread nature of the problem. As these trends continue, the need for effective tools to combat misinformation is more urgent than ever.
How AI Chatbots Are Equipped to Combat Misinformation
AI chatbots are emerging as powerful tools to fight misinformation. They use AI and Natural Language Processing (NLP) to interact with users in a human-like way. Unlike traditional fact-checking websites or apps, AI chatbots can have dynamic conversations. They provide personalized responses to users’ questions and concerns, making them particularly effective in dealing with conspiracy theories’ complex and emotional nature.
These chatbots use advanced NLP algorithms to understand and interpret human language. They analyze the intent and context behind a user’s query. When a user submits a statement or question, the chatbot looks for keywords and patterns that match known misinformation or conspiracy theories. For example, suppose a user mentions a claim about vaccine safety. In that case, the chatbot cross-references this claim with a database of verified information from reputable sources like the WHO and CDC or independent fact-checkers like Snopes.
One of AI chatbots’ biggest strengths is real-time fact-checking. They can instantly access vast databases of verified information, allowing them to present users with evidence-based responses tailored to the specific misinformation in question. They offer direct corrections and provide explanations, sources, and follow-up information to help users understand the broader context. These bots operate 24/7 and can handle thousands of interactions simultaneously, offering scalability far beyond what human fact-checkers can provide.
Several case studies show the effectiveness of AI chatbots in combating misinformation. During the COVID-19 pandemic, organizations like the WHO used AI chatbots to address widespread myths about the virus and vaccines. These chatbots provided accurate information, corrected misconceptions, and guided users to additional resources.
AI Chatbots Case Studies from MIT and UNICEF
Research has shown that AI chatbots can significantly reduce belief in conspiracy theories and misinformation. For example, MIT Sloan Research shows that AI chatbots, like GPT-4 Turbo, can dramatically reduce belief in conspiracy theories. The study engaged over 2,000 participants in personalized, evidence-based dialogues with the AI, leading to an average 20% reduction in belief in various conspiracy theories. Remarkably, about one-quarter of participants who initially believed in a conspiracy shifted to uncertainty after their interaction. These effects were durable, lasting for at least two months post-conversation.
Likewise, UNICEF’s U-Report chatbot was important in combating misinformation during the COVID-19 pandemic, particularly in regions with limited access to reliable information. The chatbot provided real-time health information to millions of young people across Africa and other areas, directly addressing COVID-19 and vaccine safety
concerns.
The chatbot played a vital role in enhancing trust in verified health sources by allowing users to ask questions and receive credible answers. It was especially effective in communities where misinformation was extensive, and literacy levels were low, helping to reduce the spread of false claims. This engagement with young users proved vital in promoting accurate information and debunking myths during the health crisis.
Challenges, Limitations, and Future Prospects of AI Chatbots in Tackling Misinformation
Despite their effectiveness, AI chatbots face several challenges. They are only as effective as the data they are trained on, and incomplete or biased datasets can limit their ability to address all forms of misinformation. Additionally, conspiracy theories are constantly evolving, requiring regular updates to the chatbots.
Bias and fairness are also among the concerns. Chatbots may reflect the biases in their training data, potentially skewing responses. For example, a chatbot trained in Western media might not fully understand non-Western misinformation. Diversifying training data and ongoing monitoring can help ensure balanced responses.
User engagement is another hurdle. It cannot be easy to convince individuals deeply ingrained in their beliefs to interact with AI chatbots. Transparency about data sources and offering verification options can build trust. Using a non-confrontational, empathetic tone can also make interactions more constructive.
The future of AI chatbots in combating misinformation looks promising. Advancements in AI technology, such as deep learning and AI-driven moderation systems, will enhance chatbots’ capabilities. Moreover, collaboration between AI chatbots and human fact-checkers can provide a robust approach to misinformation.
Beyond health and political misinformation, AI chatbots can promote media literacy and critical thinking in educational settings and serve as automated advisors in workplaces. Policymakers can support the effective and responsible use of AI through regulations encouraging transparency, data privacy, and ethical use.
The Bottom Line
In conclusion, AI chatbots have emerged as powerful tools in fighting misinformation and conspiracy theories. They offer scalable, real-time solutions that surpass the capacity of human fact-checkers. Delivering personalized, evidence-based responses helps build trust in credible information and promotes informed decision-making.
While data bias and user engagement persist, advancements in AI and collaboration with human fact-checkers hold promise for an even stronger impact. With responsible deployment, AI chatbots can play a vital role in developing a more informed and truthful society.
#000#2023#Africa#ai#AI chatbots#Algorithms#approach#apps#artificial#Artificial Intelligence#Bias#bots#cdc#change#chatbot#chatbots#Collaboration#Community#conspiracy theory#content#covid#data#data bias#data privacy#Database#databases#datasets#Deep Learning#democratic#deployment
0 notes
Note
Are you familiar with this frog?


Yeah pretty sure that's Larry from down the pub. 'Ullo, Larry!
But in all seriousness, I'm afraid I cannot help without location information. Orientation within Bufonidae without location is a nightmare. If this is Africa, we're talking genus Sclerophrys. If it's the USA, it's probably Anaxyrus. If it's Europe, it's probably Bufo. If it's South America we're in Rhinella territory. And so on, and so forth.
#toad#Bufonidae#probably Anaxyrus based on user bias of the hellsite#but even then getting further to ID is really hard without moderately precise location data#please do not dox yourself for frog ID though#but do share on iNaturalist if you want more reliable and also faster identifications#answers by Mark#broomfrog
171 notes
·
View notes
Text
**I’m aware some of these are vastly different genres and are not necessarily comparable (eg some people value drama more than comedy and vice versa) and they all also have very different stakes in terms of the overall story they’re trying to tell so let that sway you if you want! These are legit just the seasons of shows that have made me go 10/10 no notes 👏 both from a storytelling pov and in terms of my own personal enjoyment
#basically I was going through my skam tag and I started thinking about this#bc skam s3 was for sure the first time I was like ‘ok this is a perfect season’#I don’t know what my fave would be currently#probably the bear or iwtv but that may be recency bias lmao#mine#is throwing 911 in here going to skew the data??#probably asgdjsk
66 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
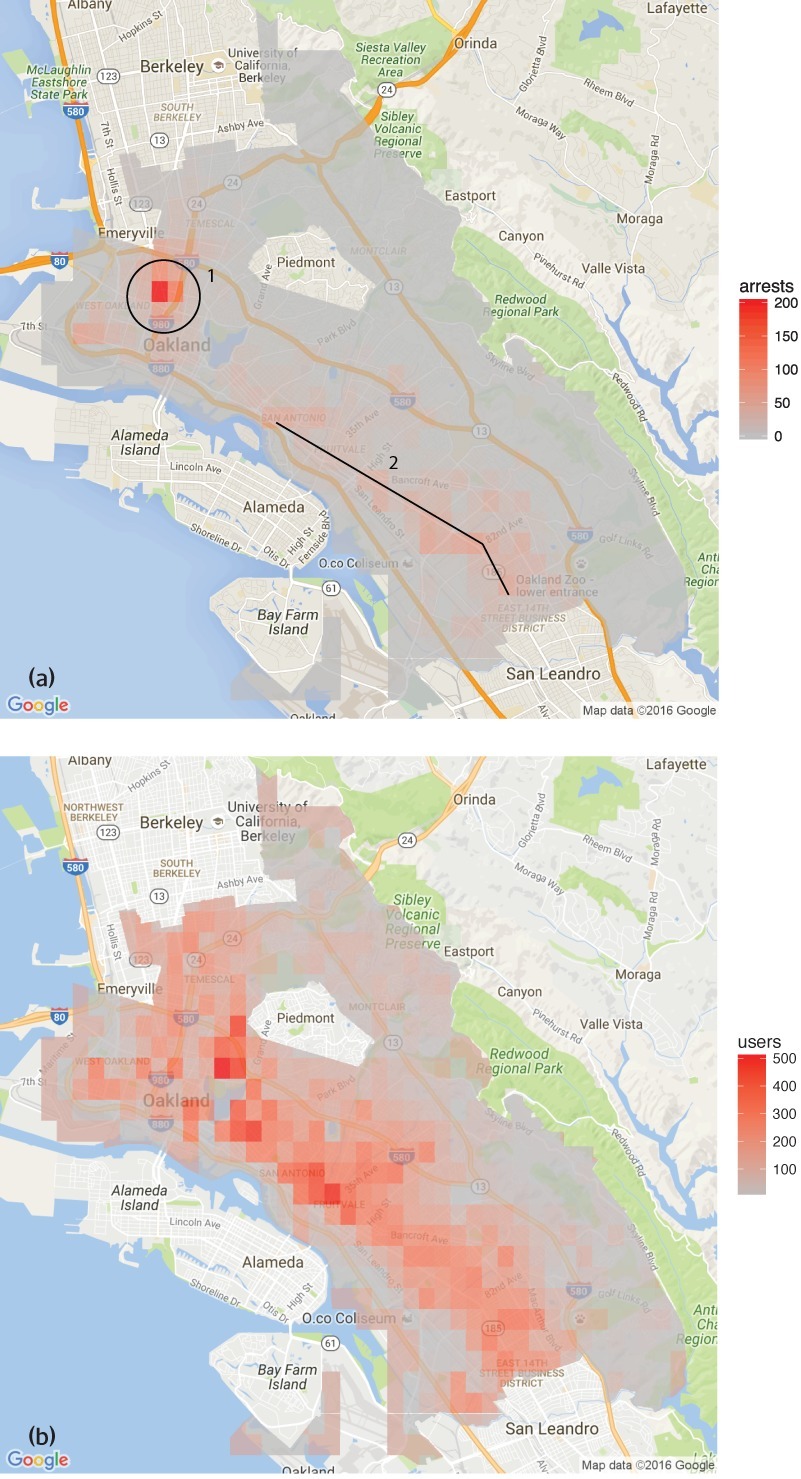
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
831 notes
·
View notes
Text
My bisexual girlfriend has observed that there are more frog enthusiasts among bi people than in the general population.
"A lot" could mean: you often seek out pictures and videos of frogs or information about them, you go looking for frogs in the wild, you have pet frogs, or you buy frog-related items.
If you're not bisexual but are some closely-related identity, you can decide if it makes the most sense for the purposes of this poll to align yourself with bi people or everyone else.
#I know this is a very tumblr poll but please help me get data for N#frogs#polls#bisexual#I realize these tags could skew the results but it is going to have sampling bias anyway because this is tumblr#frogblr#bisexuality#bi
44 notes
·
View notes
Text
just had google give me a pop up for their new AI in my drive so maybe time to stop using google docs people
#I don't trust 'you have to opt in' and claims it won't use your data actually#find a new word processor#maybe bias because I already use scrivener and dropbox for that#but damn that fucking gemini pop up filled me with dread
14 notes
·
View notes
Text

Fun fact! 'Funny cross stitch' is the 16ᵗʰ most common tag given to cross-stitch listings on Etsy (right after 'pdf cross stitch' and before 'cute cross stitch'). But how many of those patterns are actually funny? What's the average humor level? And which among them is the funniest? I think it's time we found out!
Click Here* [2024 UPDATE: now here!] to cast your vote on any of 997 different 'funny' cross-stitch patterns, all randomly scraped from Etsy throughout the year, and check back later this month for the results!
Patterns pictured here: [dark sense] [keith haring] [love] [pew pew] [gnomes]
*the site is uhhhh a little hacked-together, so if it crashes lemme know and I'll fix it. website design is my passion
#cross stitch#embroidery#survey#data collection#cross stitch stats#made by me#id in alt text#let's goooo it's number crunching time!#this here is one part of a larger (🤞🤞🤞) data project#anyway here's the hypothesis (rot13 if you don't want to bias your votes):#yrff guna 20 creprag jvyy or shaal#data time
117 notes
·
View notes