#Vehicle Comparison
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text



various tugs ocs :-)
capo/captain/miss claymore is a figure from captain zero’s past that he desperately tries to forget. as mentioned in the picture, she is quite the imposing figure, and with her line of work, it’s a given that she’s as ruthless and cunning as one may expect. claymore and her men handle jobs that involve racketeering and smuggling, from weapons to booze, and back when she was younger (and still had a leash around captain zero’s neck which made her a source of extreme paranoia for him) she’s extremely adamant on how things should be done in her turf. after captain zero ditched his relations with her and left her to handle the smuggling business he haphazardly left behind, she has her sights on him and promised to give him the welcome back party he deserves, even going so far as wanting to invite his employees as well! how courteous of her.
zayin (in TUGS canon) is the newest addition to the z-stacks. although he’s a generally pleasant fellow and wants to be on at least good terms with everyone, zayin is protective of his self image – he makes sure he’s perceived as someone respectable and has a tendency of viewing others as beneath them (not that he’ll ever admit it, but the way he sometimes talk… shows). being a switcher, zayin takes up various jobs around bigg city port, and boy is he competent at them! they're one of the few z-stacks that zorran somewhat likes because they always get the job done and right and quick. nonetheless, he's often exasperated at how zayin quickly skedaddles to chat up the star tugs and continue his amicable relationship with them, especially top hat (whom he has a strange fixation on). zip and zug likes zayin for his friendliness, though, and he views them as charming yet pitiable beings.
#this is tugs#tugs oc#claymore (oc)#zayin (oc)#fortezza bigg city#senjart#dont be fooled by claymore's calm demeanor. she makes the z-stacks look like mickey mouse's clubhouse in comparison to her crew#still getting the hang of drawing vehicles with faces! I think I nailed it this time though#another pr*jmoon reference has hit the bruhstation towers#also fitting that zayin is the seventh letter in the hebrew alphabet and he can be seen as the seventh member of the z-stacks#(if we include captain zero)#also also because it sounds cool. And starts with Z.#the reason why I made him no. x is because I kept thinking of other z stacks ocs (that share the number 6)#so zayin's number being a common variable in maths makes it so people can see him as having whatever number there is#if they wanna keep other z-stacks ocs in mind too. if you get my drift#also also ALSO zayin may or may not be related to claymore.... tee hee
176 notes
·
View notes
Text



randomly was possessed with desire to make topsters. 25 albums, 25 games, 25 tv/movies. all ordered based on whatever vibes are evident to me at this exact fleeting moment. i will disagree with it upon posting and that's ok
edit: versions w all the titles beneath the cut



#m#music#let's also like not think that hard abt my tv/movie one it's called uh I Didn't Really Watch Movies until like last year and mostly i've#just been watching comfort media bc i am tortured by spirits and movies are like my escapism vehicle#i wanna watch more stuff in the future tho... hopefully more diverse picks#also like by comparison i could easily fill out at least a 12x12 of music i like. my focus was there
10 notes
·
View notes
Note
Hi quick question, do you have maybe a rough reference for Sunrazor's height?? Like in comparison to Sides and Sunny maybe. So I could whittle out the difference between her and Comet? If you don't mind I know your busy..
Or maybe even how you decided on their height difference??? I know your making something involving the two of them :D
Funny enough, I was actually about to ask you about that lol
Here’s a height reference thing I started but never finished with some of my other OCs

Please ignore how messy everything is haha
I’d say the average height for bots are somewhere between Leoblast (the second guy to the last) and Valkyrie. She’s like in the middle though.
If I had to guess I’d put Sunstreaker around this tall compared to her. Once again. Using the same logic that says Soundwave can turn into a cassette player and Megatron into a gun, she can be big.
I also just really love myself some big bulky characters that can just throw people around.

I swear she’s freakishly big for a reason. It’s important for the story. Trust.
I hope this kinda helps. I also haven’t completely locked down the sizes. This is just kinda like… a general idea? Basically, it could change but it probably wouldn’t be too dramatic or anything.
#transformer oc#height comparison#you get to see more of my children#she also does transform into a really big truck so#I mean it’s not without reason to put her there#gonna nerd out for a moment here haha#I got the inspiration for Sunrazor after I noticed our lack of truck alt modes in transformers#and as a very proud truck owner myself. I decided I’d help fix that#my truck is a Ram 1500. on the vehicle and truck classification that’s a class 2#that class includes things like cargo vans and minivans#Sunrazor is based of of a truck that would fall into class 3#basically any vehicle that ranges from 10000lbs-14000lbs#the average weight of most cars is like 4000lbs#Lamborghini’s weigh in at like 3700lbs generally speaking… so yeah#she’s big#sorry for the rant#I just really like trucks#also sorry I took so long to reply lol#asks
6 notes
·
View notes
Text
love when you see a content creator you hate come on your feed and then they say something that is immediately so stupid that you close the app.
anyway I just saw that linguistics tiktok guy say “a lot of people are comparing the ban of tiktok to the burning of the library of alexandria”
#like I get sort of where that’s coming from. but don’t do that.#tiktok isn’t an information source it’s a public forum. compare it to other vehicles of free speech.#not a fucking. archive of factual information like a library#tiktok#tiktok ban#idk the nyt did comparisons of the tiktok ban to historical events better than this shit
5 notes
·
View notes
Text
I have been spending and objectively disturbing amount of time on the war thunder forums...
#Like fucking hell man this is embarrassing#need to get some stats and comparisons for vehicle performance somewhere I guess#They're all a bit... enthusiastic about this though
5 notes
·
View notes
Text
Sometimes I think about if the CH reboot took the late 2010s cartoon route of doing episodic shit for the first few seasons and then slowly introducing serialized elements instead of pretending it was still a parody when they clearly took their characters and storylines seriously too much for it to actually be one.
#clone high#clone high reboot#text post#like it starts OFF still being the same parody but slowly introduces plotpoints and characters that come back later#even though in the moment they pretend they aren’t important/are one-offs#so you’re blindsided by the reveals but you can also clearly go back and pinpoint when they were set up#I genuinely think they COULD pull it off if they had a good enough writing staff#uuh but they wanted to write their / everyone fic into the show instead#but I get it would be weird for a cartoon that was primarily a parody of a#genre of show or one specific show to introduce serialization even if slowly while also fleshing out the characters meant to be#used as vehicles for jokes…#…#(this is where the Venture Bros comparison goes)#if the show that started off as what if Scooby Doo but they can swear and the kids are inept#can do it I know you can too Clone High#I KNOW you have capable writers because a bunch of them wrote the old season one which was AMAZING
3 notes
·
View notes
Text
車跟馬誰大?
在台灣的街頭巷尾,經常有人會好奇地問:「車跟馬誰大?」這個問題看似簡單,但卻蘊藏著深刻的思考。當我們站在現代交通工具與傳統動物之間,不禁反思:究竟是速度與科技讓車變得更”偉大”,還是自然與歷史讓馬依然具有不可取代的價值?事實上,「大小」並非唯一衡量標準。一輛汽車代表著人類智慧和進步,而馬則象徵著傳統、耐力與文化底蘊。在台灣,無論是在都市繁華或鄉村田野,兩者都扮演著不同但同樣重要的角色。理解這個問題,不僅能幫助我們認識交通發展,也提醒我們珍惜那些陪伴我們成長的元素。真正的大,是能夠融合過去與未來,用心打造出符合時代需求的生活方式。因此,下次當你再遇到「車跟馬誰大?」這個問題時,不妨換個角度想:也許答案不在於比較大小,而是在於彼此共存,共創更美好的明天。 文章目錄 車輛與馬匹:歷史演進與交通工具的比較 駕馭之道:車輛與馬匹的操控技巧與安全考量 常見問答 因此 車輛與馬匹:歷史演進與交通工…
0 notes
Text
Electric Cars vs Gasoline Cars: Which One Is Better in 2025?
As the auto industry rapidly evolves, the debate between electric cars (EVs) and gasoline-powered vehicles continues to intensify. With rising fuel costs, stricter emissions regulations, and growing environmental concerns, many drivers are reevaluating their options. So, how do electric cars compare to traditional gas-powered cars in 2025? In this article, we’ll explore the pros and cons of…
#are electric cars better#electric cars 2025#electric cars vs gasoline cars#EV maintenance vs gas#EV vs gas car comparison#pros and cons of electric vehicles
0 notes
Text
Aftermarket vs OEM Windshields: Which One Should You Choose?
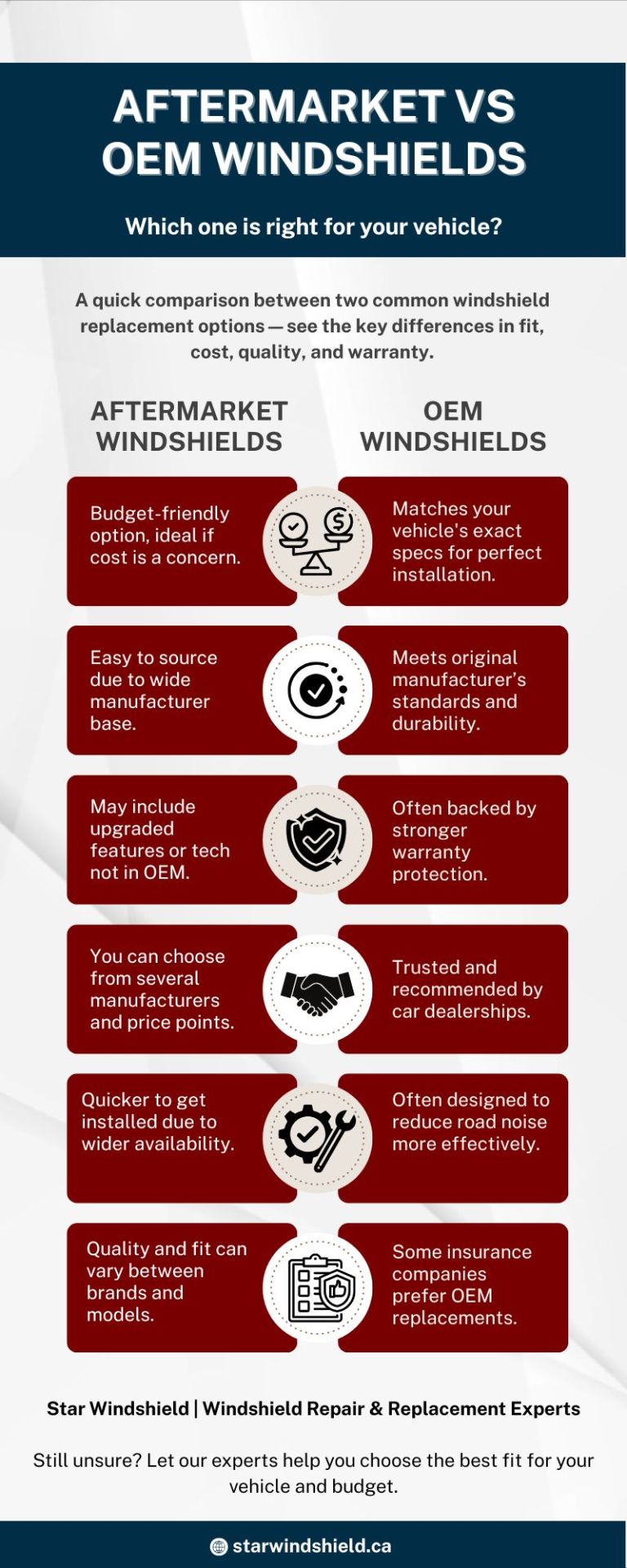
Not sure whether to go with an OEM or aftermarket windshield? This quick infographic breaks down the differences in cost, fit, warranty, and performance — so you can make the right choice for your vehicle and budget. Visit https://starwindshield.ca/ for more details.
#aftermarket windshields#OEM windshields#windshield replacement#auto glass comparison#windshield repair tips#OEM vs aftermarket#car windshield options#auto glass warranty#vehicle safety#Star Windshield
0 notes
Text
In a world increasingly focused on sustainability and reducing carbon footprints, the debate of electric cars vs hybrid cars continues to gain momentum. As both types of fuel-efficient vehicles gain popularity in India and around the world, potential car buyers are often left wondering which option is better suited to their needs. In this blog, we will dive deep into the differences, advantages, and disadvantages of electric vehicles (EVs) and hybrid vehicles, helping you make an informed choice.
Understanding Electric Vehicles (EVs)
Electric vehicles are powered entirely by electricity. These cars run on a rechargeable battery pack that supplies power to an electric motor. Since they don’t use petrol or diesel, EVs produce zero tailpipe emissions, making them ideal for environmentally-conscious consumers. Brands like Tata, MG, Hyundai, and Tesla are now offering impressive EV models in India with longer ranges and enhanced performance. READ MORE
#Car reviews#Car comparisons#Automotive news and updates#Vehicle buying guides#Electric vehicles (EVs)
0 notes
Text
Mahindra XEV 9e Review: A Premier Electric SUV Unveiled
The Indian automotive market is evolving rapidly, and Mahindra has long been known for crafting vehicles that blend ruggedness with a distinctly Indian sensibility. With the XEV 9e, Mahindra signals a bold, calculated push into the premium electric SUV space, not merely aiming to compete—but to define. Let’s dive deeply into what makes the Mahindra XEV 9e tick, what it gets right, and where it…
#500km range EV#Alexa in car#Connected Car#Electric Car Features#Electric Vehicle Review#EV Comparison India#EV SUV India#EV under 25 lakhs#EV with ChatGPT#EV with V2L#family EV car#Futuristic SUV#Indian electric car#Long Range EV#Mahindra 2025 launch#Mahindra electric lineup#Mahindra Electric SUV#Mahindra EV 2025#Mahindra XEV 9e#Mahindra XUV.e platform#new electric SUV India#no ADAS EV#Performance Electric SUV#rear wheel drive EV#tech loaded EV#triple screen dashboard#XUV.e9
0 notes
Text
AI and the Future of Autonomous Vehicles: Transforming the Automotive Market with Robotaxis and Freight Logistics
New Post has been published on https://thedigitalinsider.com/ai-and-the-future-of-autonomous-vehicles-transforming-the-automotive-market-with-robotaxis-and-freight-logistics/
AI and the Future of Autonomous Vehicles: Transforming the Automotive Market with Robotaxis and Freight Logistics

The automotive industry is primed for rapid innovation because of its background of widely available data on roads, vehicles, and the environment in general. Two key areas stand out: freight transportation and robotaxis. Both sectors offer unique opportunities for innovation and efficiency because decades of accumulated solutions are finally reaching the market.
Let’s discuss each direction’s features, business support, and the regions where further development will happen.
Who Leads the Market
The global autonomous vehicle market is primarily shaped by three key regions: the United States, Europe, and China.
Europe is known for having some of the most comprehensive regulatory frameworks in this area. Detailed standards such as the GDPR, privacy-related requirements, and the recently adopted EU AI Act can present challenges to innovation. In such a tightly controlled environment, technology development may proceed more cautiously.
In contrast, China takes a different approach and actively sponsors AI initiatives. Even when autonomous vehicles are involved in incidents, they are usually not pursued in the same way; they do not have the same negative impact on the parties involved. The main priority is technological advancement, which is viewed as a benefit for the future.
As for the United States, before Donald Trump’s presidency, the country was largely leaving AI initiatives to individual states. However, with the new administration came a strategic shift: the authorities realized that maintaining the old approach could cause the country to fall into the tech race. As a result, the U.S. began moving toward a more liberal regulatory model — aimed at fostering technological growth and ensuring the country remains competitive on the global stage, particularly in comparison to fast-moving developments in China.
Robotaxis
The robotaxi industry experienced substantial growth in 2024. In China, Baidu’s Apollo Go operated over 400 autonomous taxis in Wuhan. Waymo expanded services to Los Angeles in the United States, offering rides to the general public and managing over 150,000 weekly trips. Analysts project that the global robotaxi market will reach $174 billion by 2045, reflecting a 37% compound annual growth rate from 2025.
Why are robotaxis becoming increasingly popular? There are at least two key reasons for this.
The first reason is consumer-driven
Users are interested in robotaxis because it eliminates many risks and discomforts associated with human drivers. There’s no concern about the driver being tired, aggressive, unstable, or unskilled. People want a car that arrives on its own, takes them safely to their destination, and does so reliably.
The second reason is business-oriented
Robotaxis create new business opportunities for individuals and small entrepreneurs. Much like how Airbnb allows apartment owners to earn income by renting out their properties, robotaxis allow anyone to purchase one or more autonomous vehicles, put them on the road, and generate income by managing their fleet. This opens the door to a new segment of small-scale business and entrepreneurship.
Freight Transportation
The autonomous freight transportation sector has seen significant growth and transformation in recent years. In 2024 the global autonomous truck market was valued at approximately $356.9 billion. These figures are from research companies, although the reality is much bigger because logistics is among the largest industries on the planet primed for disruption.
Every day, hundreds of thousands of trucks travel the roads of Europe and America, delivering goods, Amazon packages, food products, and more — countless vast supply chains worth trillions of dollars.
This sector’s potential for autonomous trucks is even greater than passenger transport. Trucks mostly operate on long, straight highways, where conditions are more predictable than in urban environments. This makes the task easier for autonomous systems.
At the same time, logistics efficiency increases significantly:
Human drivers need to take breaks for rest and sleep to avoid accidents.
An autonomous truck can operate almost non-stop, stopping only for refueling or recharging.
With sufficient range, even these stops can be minimized.
Delivery speed increases, costs decrease, and supply chains become more efficient.
At Keymakr, we support several major players in the autonomous freight industry, so we can see innovations that aren’t on the market yet. Our team works extensively on large-scale annotation projects tailored for highway driving scenarios — including object detection, lane segmentation, and sensor fusion data for LiDAR and camera systems.
The demand for these projects highlights the real maturity of the sector.
Business Perspective
Generally, everything related to the business environment—corporate transport, B2B solutions, and so on — tends to provide higher profit margins than B2C sectors. Specialized logistics operators tend to have higher revenue than taxi service providers, with some exceptions, such as Uber. This is due to different pricing levels, operations scales, and the tasks’ specific nature.
Another key difference is that B2B operates in a more closed environment and experiences less public attention and information noise, while B2C is more dependent on the news cycle.
This reduces risks and simplifies the launch of new technologies. With less focus on generating attention, companies can develop and implement innovative solutions more quickly, even if they are not fully mature. For these reasons, the B2B segment will see the most active development of autonomous transportation systems, especially logistics.
The Question of Liability
Autonomous vehicles face a difficult situation with liability — namely, when an accident occurs, who has to take responsibility for its consequences? There are many more parties involved with autonomous cars than traditional vehicles — everyone from the owner to the software developer to the OEMs plays a part in their safety.
This question is often raised, and, in essence, it has already been addressed. The main responsibility will lie with the companies that manage fleets (fleet managers). These could be large corporations like Uber or Lyft. Such companies create algorithms and processes for fleet management, including routing, maintenance, and legal aspects. This model is similar to Airbnb: when you manage a resource, you are responsible for it, and the platform provides a framework to resolve disputes.
Therefore, the managing company will also be liable for any incidents. The market will arrange a system of insurance for this that can help determine the exact proportion of liability for software developers, hardware manufacturers, and other parties involved.
To summarize, the future belongs to those who can combine technological solutions, business intuition, and adaptability — these companies will lead the new era of mobility.
#000#2024#2025#accidents#Administration#ai#ai act#Algorithms#Amazon#America#approach#attention#automotive#automotive industry#autonomous#autonomous cars#autonomous systems#autonomous vehicle#autonomous vehicles#B2B#background#baidu#billion#Business#business environment#Cars#China#Companies#comparison#comprehensive
0 notes
Text

Luxury vs. Budget Vehicle Rentals: Which One to Choose?
Confused about luxury vs budget cars? This car rental comparison guide provides you with a simple way of making the right choice. Whether your priority is comfort or price, discover intelligent rental car solutions through Droom's quality vehicle rental services.
0 notes
Text
Road Test Riot: 2025 Toyota Tundra, 2025 Lincoln Nautilus, 2025 Mazda CX-50, 2025 Hyundai Elantra N Line
Just as 7-Eleven offers too much good stuff, that’s what we have in this week’s episode of America on the Road. We’ve been driving a lot of interesting vehicles lately, and so today we thought we’d bring you not two road tests but four — 2025 Toyota Tundra, 2025 Lincoln Nautilus, 2025 Mazda CX-50, 2025 Hyundai Elantra N Line. It’s a fascinating quartet of vehicles each with something special to…
#2025 Hyundai Elantra N Line#2025 Lincoln Nautilus#2025 Mazda CX-50 Hybrid#2025 Toyota Tundra TRD Rally#auto industry#Auto Tariffs#automotive technology#car reviews#hybrid vehicles#insurance#Lincoln Nautilus#motorists#NACTOY#New Cars#Nissan#North American Car of the Year#Tariffs#Toyota Tundra#Uninsured#Used Cars#vehicle comparisons#vehicle pricing
0 notes
Text
My Favorite Form of Transportation in Fiction. Oh, how I wish they were real. I would pay the price in installments.









0 notes
Text
youtube
#classic wheels tv#autos and vehicles#automobile#fast charging#fastcharging#byd fast charging#charging#evcharging#charging technology#reduced charging time#ev charging efficiency#byd seal charging speed#charging speed comparison#byd seal interior changes#electric car range#changan#buying an electric car#chinesecar#BYD Takes The LEAD With 5 Minute EV Charging#STOP Wasting Time With Slow EV Charging#BYD Is Revolutionizing EV Charging With FAST 5 Minute Technology#Youtube
0 notes