#Internet Privacy and AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
The Future of Information Gathering with Large Language Models (LLMs)
The Future of Information Gathering with Large Language Models (LLMs)
The Future of Information Gathering: Large Language Models and Their Role in Data Access What’s On My Mind Today? I’ve been doing a lot of thinking about the future, especially about how we find and use information on the internet. I had some ideas about what might change and what it could mean for all of us. To help me flesh out these ideas, I worked with a super-smart 🙂 computer program…
#AI and Digital Transformation#Artificial Intelligence in Data#Data Access with AI#Digital Advertising and AI#Future of Information Gathering#Future of Web Browsing#Internet Privacy and AI#large language models#LLM Plugins#User Control Over Data
0 notes
Text
UPDATE! REBLOG THIS VERSION!
#reaux speaks#zoom#terms of service#ai#artificial intelligence#privacy#safety#internet#end to end encryption#virtual#remote#black mirror#joan is awful#twitter#instagram#tiktok#meetings#therapy
23K notes
·
View notes
Text






(from The Mitchells vs. the Machines, 2021)
#the mitchells vs the machines#data privacy#ai#artificial intelligence#digital privacy#genai#quote#problem solving#technology#sony pictures animation#sony animation#mike rianda#jeff rowe#danny mcbride#abbi jacobson#maya rudolph#internet privacy#internet safety#online privacy#technology entrepreneur
8K notes
·
View notes
Text
I think most of us should take the whole ai scraping situation as a sign that we should maybe stop giving google/facebook/big corps all our data and look into alternatives that actually value your privacy.
i know this is easier said than done because everybody under the sun seems to use these services, but I promise you it’s not impossible. In fact, I made a list of a few alternatives to popular apps and services, alternatives that are privacy first, open source and don’t sell your data.
right off the bat I suggest you stop using gmail. it’s trash and not secure at all. google can read your emails. in fact, google has acces to all the data on your account and while what they do with it is already shady, I don’t even want to know what the whole ai situation is going to bring. a good alternative to a few google services is skiff. they provide a secure, e3ee mail service along with a workspace that can easily import google documents, a calendar and 10 gb free storage. i’ve been using it for a while and it’s great.
a good alternative to google drive is either koofr or filen. I use filen because everything you upload on there is end to end encrypted with zero knowledge. they offer 10 gb of free storage and really affordable lifetime plans.
google docs? i don’t know her. instead, try cryptpad. I don’t have the spoons to list all the great features of this service, you just have to believe me. nothing you write there will be used to train ai and you can share it just as easily. if skiff is too limited for you and you also need stuff like sheets or forms, cryptpad is here for you. the only downside i could think of is that they don’t have a mobile app, but the site works great in a browser too.
since there is no real alternative to youtube I recommend watching your little slime videos through a streaming frontend like freetube or new pipe. besides the fact that they remove ads, they also stop google from tracking what you watch. there is a bit of functionality loss with these services, but if you just want to watch videos privately they’re great.
if you’re looking for an alternative to google photos that is secure and end to end encrypted you might want to look into stingle, although in my experience filen’s photos tab works pretty well too.
oh, also, for the love of god, stop using whatsapp, facebook messenger or instagram for messaging. just stop. signal and telegram are literally here and they’re free. spread the word, educate your friends, ask them if they really want anyone to snoop around their private conversations.
regarding browser, you know the drill. throw google chrome/edge in the trash (they really basically spyware disguised as browsers) and download either librewolf or brave. mozilla can be a great secure option too, with a bit of tinkering.
if you wanna get a vpn (and I recommend you do) be wary that some of them are scammy. do your research, read their terms and conditions, familiarise yourself with their model. if you don’t wanna do that and are willing to trust my word, go with mullvad. they don’t keep any logs. it’s 5 euros a month with no different pricing plans or other bullshit.
lastly, whatever alternative you decide on, what matters most is that you don’t keep all your data in one place. don’t trust a service to take care of your emails, documents, photos and messages. store all these things in different, trustworthy (preferably open source) places. there is absolutely no reason google has to know everything about you.
do your own research as well, don’t just trust the first vpn service your favourite youtube gets sponsored by. don’t trust random tech blogs to tell you what the best cloud storage service is — they get good money for advertising one or the other. compare shit on your own or ask a tech savvy friend to help you. you’ve got this.
#internet privacy#privacy#vpn#google docs#ai scraping#psa#ai#archive of our own#ao3 writer#mine#textpost
1K notes
·
View notes
Text
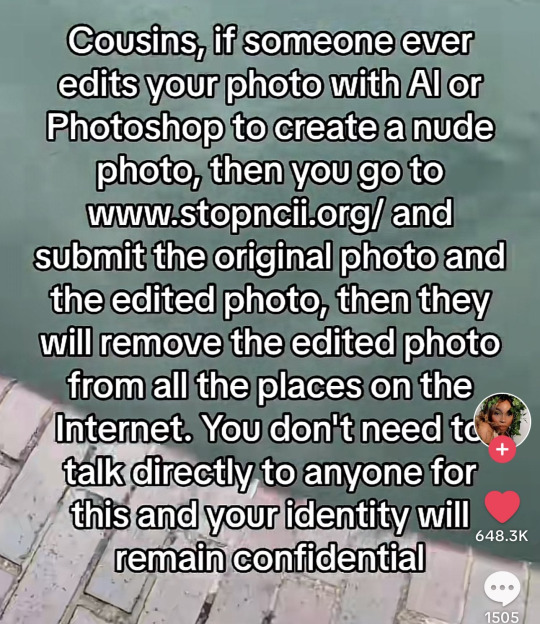
"Stopncii.org is a free tool designed to support victims of Non-Consensual Intimate Image (NCII) abuse."
"Revenge Porn Helpline is a UK service supporting adults (aged 18+) who are experiencing intimate image abuse, also known as, revenge porn."
"Take It Down (ncmec.org) is for people who have images or videos of themselves nude, partially nude, or in sexually explicit situations taken when they were under the age of 18 that they believe have been or will be shared online."
#important information#image desc in alt text#informative#stop ai#anti ai#safety#internet safety#exploitation#tell your friends#stay informed#the internet#internet privacy#online safety#stay safe#important#openai#tiktok screenshots#tiktok#life tips#ysk#you should know#described#alt text#alt text provided#alt text added#alt text in image#alt text described#alt text included#id in alt text
712 notes
·
View notes
Text
Okay, look, they talk to a Google rep in some of the video clips, but I give it a pass because this FREE course is a good baseline for personal internet safety that so many people just do not seem to have anymore. It's done in short video clip and article format (the videos average about a minute and a half). This is some super basic stuff like "What is PII and why you shouldn't put it on your twitter" and "what is a phishing scam?" Or "what is the difference between HTTP and HTTPS and why do you care?"
It's worrying to me how many people I meet or see online who just do not know even these absolute basic things, who are at constant risk of being scammed or hacked and losing everything. People who barely know how to turn their own computers on because corporations have made everything a proprietary app or exclusive hardware option that you must pay constant fees just to use. Especially young, somewhat isolated people who have never known a different world and don't realize they are being conditioned to be metaphorical prey animals in the digital landscape.
Anyway, this isn't the best internet safety course but it's free and easy to access. Gotta start somewhere.
Here's another short, easy, free online course about personal cyber security (GCFGlobal.org Introduction to Internet Safety)
Bonus videos:
youtube
(Jul 13, 2023, runtime 15:29)
"He didn't have anything to hide, he didn't do anything wrong, anything illegal, and yet he was still punished."
youtube
(Apr 20, 2023; runtime 9:24 minutes)
"At least 60% use their name or date of birth as a password, and that's something you should never do."
youtube
(March 4, 2020, runtime 11:18 minutes)
"Crossing the road safely is a basic life skill that every parent teaches their kids. I believe that cyber skills are the 21st century equivalent of road safety in the 20th century."
#you need to protect yourself#internet literacy#computer literacy#internet safety#privacy#online#password managers#security questions#identity theft#Facebook#browser safety#google#tesla#clearwater ai#people get arrested when google makes a mistake#lives are ruined because your Ring is spying on you#they aren't just stealing they are screwing you over#your alexa is not a woman it's a bug#planted by a supervillain who smirks at you#as they sell that info to your manager#oh you have nothing to hide?#then what's your credit card number?#listen I'm in a mood about this right now#Youtube
174 notes
·
View notes
Text
Take action to stop chat control now!
Chat control is back on the agenda of EU governments.
EU governments are to express their position on the latest proposal on 23 September. EU Ministers of the Interior are to adopt the proposal on 10/11 October.
On Monday a new version of the globally unprecedented EU bill aimed at searching all private messages and chats for suspicious content (so-called chat control or child sexual abuse regulation) was circulated and leaked by POLITICO soon after. According to the latest proposal providers would be free whether or not to use ‘artificial intelligence’ to classify unknown images and text chats as ‘suspicious’. However they would be obliged to search all chats for known illegal content and report them, even at the cost of breaking secure end-to-end messenger encryption.
#fascism#chat control#government surveillance#internet#privacy#artificial intelligence#ai#climate crisis#eu#european union#internet censorship#surveillance capitalism#2024#activism
40 notes
·
View notes
Text

#twitter#tweet#tweets#AI#internet#online privacy#privacy#internet surveillance#police state#police#police violence#plagerism#labor rights#labor vs capital#workers vs capital#labor movements
80 notes
·
View notes
Text
Podcasting "How To Think About Scraping"

On September 27, I'll be at Chevalier's Books in Los Angeles with Brian Merchant for a joint launch for my new book The Internet Con and his new book, Blood in the Machine. On October 2, I'll be in Boise to host an event with VE Schwab.

This week on my podcast, I read my recent Medium column, "How To Think About Scraping: In privacy and labor fights, copyright is a clumsy tool at best," which proposes ways to retain the benefits of scraping without the privacy and labor harms that sometimes accompany it:
https://doctorow.medium.com/how-to-think-about-scraping-2db6f69a7e3d?sk=4a1d687171de1a3f3751433bffbb5a96
What are those benefits from scraping? Well, take computational linguistics, a relatively new discipline that is producing the first accounts of how informal language works. Historically, linguists overstudied written language (because it was easy to analyze) and underanalyzed speech (because you had to record speakers and then get grad students to transcribe their dialog).
The thing is, very few of us produce formal, written work, whereas we all engage in casual dialog. But then the internet came along, and for the first time, we had a species of mass-scale, informal dialog that also written, and which was born in machine-readable form.
This ushered in a new era in linguistic study, one that is enthusiastically analyzing and codifying the rules of informal speech, the spread of vernacular, and the regional, racial and class markers of different kinds of speech:
https://memex.craphound.com/2019/07/24/because-internet-the-new-linguistics-of-informal-english/
The people whose speech is scraped and analyzed this way are often unreachable (anonymous or pseudonymous) or impractical to reach (because there's millions of them). The linguists who study this speech will go through institutional review board approvals to make sure that as they produce aggregate accounts of speech, they don't compromise the privacy or integrity of their subjects.
Computational linguistics is an unalloyed good, and while the speakers whose words are scraped to produce the raw material that these scholars study, they probably wouldn't object, either.
But what about entities that explicitly object to being scraped? Sometimes, it's good to scrape them, too.
Since 1996, the Internet Archive has scraped every website it could find, storing snapshots of every page it found in a giant, searchable database called the Wayback Machine. Many of us have used the Wayback Machine to retrieve some long-deleted text, sound, image or video from the internet's memory hole.
For the most part, the Internet Archive limits its scraping to websites that permit it. The robots exclusion protocol (AKA robots.txt) makes it easy for webmasters to tell different kinds of crawlers whether or not they are welcome. If your site has a robots.txt file that tells the Archive's crawler to buzz off, it'll go elsewhere.
Mostly.
Since 2017, the Archive has started ignoring robots.txt files for news services; whether or not the news site wants to be crawled, the Archive crawls it and makes copies of the different versions of the articles the site publishes. That's because news sites – even the so-called "paper of record" – have a nasty habit of making sweeping edits to published material without noting it.
I'm not talking about fixing a typo or a formatting error: I'm talking about making a massive change to a piece, one that completely reverses its meaning, and pretending that it was that way all along:
https://medium.com/@brokenravioli/proof-that-the-new-york-times-isn-t-feeling-the-bern-c74e1109cdf6
This happens all the time, with major news sites from all around the world:
http://newsdiffs.org/examples/
By scraping these sites and retaining the different versions of their article, the Archive both detects and prevents journalistic malpractice. This is canonical fair use, the kind of copying that almost always involves overriding the objections of the site's proprietor. Not all adversarial scraping is good, but this sure is.
There's an argument that scraping the news-sites without permission might piss them off, but it doesn't bring them any real harm. But even when scraping harms the scrapee, it is sometimes legitimate – and necessary.
Austrian technologist Mario Zechner used the API from country's super-concentrated grocery giants to prove that they were colluding to rig prices. By assembling a longitudinal data-set, Zechner exposed the raft of dirty tricks the grocers used to rip off the people of Austria.
From shrinkflation to deceptive price-cycling that disguised price hikes as discounts:
https://mastodon.gamedev.place/@badlogic/111071627182734180
Zechner feared publishing his results at first. The companies whose thefts he'd discovered have enormous power and whole kennelsful of vicious attack-lawyers they can sic on him. But he eventually got the Austrian competition bureaucracy interested in his work, and they published a report that validated his claims and praised his work:
https://mastodon.gamedev.place/@badlogic/111071673594791946
Emboldened, Zechner open-sourced his monitoring tool, and attracted developers from other countries. Soon, they were documenting ripoffs in Germany and Slovenia, too:
https://mastodon.gamedev.place/@badlogic/111071485142332765
Zechner's on a roll, but the grocery cartel could shut him down with a keystroke, simply by blocking his API access. If they do, Zechner could switch to scraping their sites – but only if he can be protected from legal liability for nonconsensually scraping commercially sensitive data in a way that undermines the profits of a powerful corporation.
Zechner's work comes at a crucial time, as grocers around the world turn the screws on both their suppliers and their customers, disguising their greedflation as inflation. In Canada, the grocery cartel – led by the guillotine-friendly hereditary grocery monopolilst Galen Weston – pulled the most Les Mis-ass caper imaginable when they illegally conspired to rig the price of bread:
https://en.wikipedia.org/wiki/Bread_price-fixing_in_Canada
We should scrape all of these looting bastards, even though it will harm their economic interests. We should scrape them because it will harm their economic interests. Scrape 'em and scrape 'em and scrape 'em.
Now, it's one thing to scrape text for scholarly purposes, or for journalistic accountability, or to uncover criminal corporate conspiracies. But what about scraping to train a Large Language Model?
Yes, there are socially beneficial – even vital – uses for LLMs.
Take HRDAG's work on truth and reconciliation in Colombia. The Human Rights Data Analysis Group is a tiny nonprofit that makes an outsized contribution to human rights, by using statistical methods to reveal the full scope of the human rights crimes that take place in the shadows, from East Timor to Serbia, South Africa to the USA:
https://hrdag.org/
HRDAG's latest project is its most ambitious yet. Working with partner org Dejusticia, they've just released the largest data-set in human rights history:
https://hrdag.org/jep-cev-colombia/
What's in that dataset? It's a merger and analysis of more than 100 databases of killings, child soldier recruitments and other crimes during the Colombian civil war. Using a LLM, HRDAG was able to produce an analysis of each killing in each database, estimating the probability that it appeared in more than one database, and the probability that it was carried out by a right-wing militia, by government forces, or by FARC guerrillas.
This work forms the core of ongoing Colombian Truth and Reconciliation proceedings, and has been instrumental in demonstrating that the majority of war crimes were carried out by right-wing militias who operated with the direction and knowledge of the richest, most powerful people in the country. It also showed that the majority of child soldier recruitment was carried out by these CIA-backed, US-funded militias.
This is important work, and it was carried out at a scale and with a precision that would have been impossible without an LLM. As with all of HRDAG's work, this report and the subsequent testimony draw on cutting-edge statistical techniques and skilled science communication to bring technical rigor to some of the most important justice questions in our world.
LLMs need large bodies of text to train them – text that, inevitably, is scraped. Scraping to produce LLMs isn't intrinsically harmful, and neither are LLMs. Admittedly, nonprofits using LLMs to build war crimes databases do not justify even 0.0001% of the valuations that AI hypesters ascribe to the field, but that's their problem.
Scraping is good, sometimes – even when it's done against the wishes of the scraped, even when it harms their interests, and even when it's used to train an LLM.
But.
Scraping to violate peoples' privacy is very bad. Take Clearview AI, the grifty, sleazy facial recognition company that scraped billions of photos in order to train a system that they sell to cops, corporations and authoritarian governments:
https://pluralistic.net/2023/09/20/steal-your-face/#hoan-ton-that
Likewise: scraping to alienate creative workers' labor is very bad. Creators' bosses are ferociously committed to firing us all and replacing us with "generative AI." Like all self-declared "job creators," they constantly fantasize about destroying all of our jobs. Like all capitalists, they hate capitalism, and dream of earning rents from owning things, not from doing things.
The work these AI tools sucks, but that doesn't mean our bosses won't try to fire us and replace us with them. After all, prompting an LLM may produce bad screenplays, but at least the LLM doesn't give you lip when you order to it give you "ET, but the hero is a dog, and there's a love story in the second act and a big shootout in the climax." Studio execs already talk to screenwriters like they're LLMs.
That's true of art directors, newspaper owners, and all the other job-destroyers who can't believe that creative workers want to have a say in the work they do – and worse, get paid for it.
So how do we resolve these conundra? After all, the people who scrape in disgusting, depraved ways insist that we have to take the good with the bad. If you want accountability for newspaper sites, you have to tolerate facial recognition, too.
When critics of these companies repeat these claims, they are doing the companies' work for them. It's not true. There's no reason we couldn't permit scraping for one purpose and ban it for another.
The problem comes when you try to use copyright to manage this nuance. Copyright is a terrible tool for sorting out these uses; the limitations and exceptions to copyright (like fair use) are broad and varied, but so "fact intensive" that it's nearly impossible to say whether a use is or isn't fair before you've gone to court to defend it.
But copyright has become the de facto regulatory default for the internet. When I found someone impersonating me on a dating site and luring people out to dates, the site advised me to make a copyright claim over the profile photo – that was their only tool for dealing with this potentially dangerous behavior.
The reasons that copyright has become our default tool for solving every internet problem are complex and historically contingent, but one important point here is that copyright is alienable, which means you can bargain it away. For that reason, corporations love copyright, because it means that they can force people who have less power than the company to sign away their copyrights.
This is how we got to a place where, after 40 years of expanding copyright (scope, duration, penalties), we have an entertainment sector that's larger and more profitable than ever, even as creative workers' share of the revenues their copyrights generate has fallen, both proportionally and in real terms.
As Rebecca Giblin and I write in our book Chokepoint Capitalism, in a market with five giant publishers, four studios, three labels, two app platforms and one ebook/audiobook company, giving creative workers more copyright is like giving your bullied kid extra lunch money. The more money you give that kid, the more money the bullies will take:
https://chokepointcapitalism.com/
Many creative workers are suing the AI companies for copyright infringement for scraping their data and using it to train a model. If those cases go to trial, it's likely the creators will lose. The questions of whether making temporary copies or subjecting them to mathematical analysis infringe copyright are well-settled:
https://www.eff.org/deeplinks/2023/04/ai-art-generators-and-online-image-market
I'm pretty sure that the lawyers who organized these cases know this, and they're betting that the AI companies did so much sleazy shit while scraping that they'll settle rather than go to court and have it all come out. Which is fine – I relish the thought of hundreds of millions in investor capital being transferred from these giant AI companies to creative workers. But it doesn't actually solve the problem.
Because if we do end up changing copyright law – or the daily practice of the copyright sector – to create exclusive rights over scraping and training, it's not going to get creators paid. If we give individual creators new rights to bargain with, we're just giving them new rights to bargain away. That's already happening: voice actors who record for video games are now required to start their sessions by stating that they assign the rights to use their voice to train a deepfake model:
https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence
But that doesn't mean we have to let the hyperconcentrated entertainment sector alienate creative workers from their labor. As the WGA has shown us, creative workers aren't just LLCs with MFAs, bargaining business-to-business with corporations – they're workers:
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
Workers get a better deal with labor law, not copyright law. Copyright law can augment certain labor disputes, but just as often, it benefits corporations, not workers:
https://locusmag.com/2019/05/cory-doctorow-steering-with-the-windshield-wipers/
Likewise, the problem with Clearview AI isn't that it infringes on photographers' copyrights. If I took a thousand pictures of you and sold them to Clearview AI to train its model, no copyright infringement would take place – and you'd still be screwed. Clearview has a privacy problem, not a copyright problem.
Giving us pseudocopyrights over our faces won't stop Clearview and its competitors from destroying our lives. Creating and enforcing a federal privacy law with a private right action will. It will put Clearview and all of its competitors out of business, instantly and forever:
https://www.eff.org/deeplinks/2019/01/you-should-have-right-sue-companies-violate-your-privacy
AI companies say, "You can't use copyright to fix the problems with AI without creating a lot of collateral damage." They're right. But what they fail to mention is, "You can use labor law to ban certain uses of AI without creating that collateral damage."
Facial recognition companies say, "You can't use copyright to ban scraping without creating a lot of collateral damage." They're right too – but what they don't say is, "On the other hand, a privacy law would put us out of business and leave all the good scraping intact."
Taking entertainment companies and AI vendors and facial recognition creeps at their word is helping them. It's letting them divide and conquer people who value the beneficial elements and those who can't tolerate the harms. We can have the benefits without the harms. We just have to stop thinking about labor and privacy issues as individual matters and treat them as the collective endeavors they really are:
https://pluralistic.net/2023/02/26/united-we-stand/
Here's a link to the podcast:
https://craphound.com/news/2023/09/24/how-to-think-about-scraping/
And here's a direct link to the MP3 (hosting courtesy of the Internet Archive; they'll host your stuff for free, forever):
https://archive.org/download/Cory_Doctorow_Podcast_450/Cory_Doctorow_Podcast_450_-_How_To_Think_About_Scraping.mp3
And here's the RSS feed for my podcast:
http://feeds.feedburner.com/doctorow_podcast
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/09/25/deep-scrape/#steering-with-the-windshield-wipers

Image: syvwlch (modified) https://commons.wikimedia.org/wiki/File:Print_Scraper_(5856642549).jpg
CC BY-SA 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#cory doctorow#podcast#scraping#internet archive#wga strike#sag-aftra strike#wga#sag-aftra#labor#privacy#facial recognition#clearview ai#greedflation#price gouging#fr#austria#computational linguistics#linguistics#ai#ml#artificial intelligence#machine learning#llms#large language models#stochastic parrots#plausible sentence generators#hrdag#colombia#human rights
81 notes
·
View notes
Text



Read more at: https://sarahkendzior.substack.com
12 notes
·
View notes
Text


#facebook#facebook tricks#facebook info#facebook settings#internet tricks#privacy#psa#important psa#internet privacy#fuck ai#fuck ai everything#anti ai
7 notes
·
View notes
Text

Chiques fíjense de activar la opción de no compartir datos en el apartado "Visibilidad" en Ajustes ‼️‼️
#Tumblr#ai#ai generated#argie tumblr#español#artificial intelligence#consent#no sé q poner acá#cuidado#caution#data protection#data privacy#online privacy#internet privacy#invasion of privacy#data processing#anti ai#fuck ai
5 notes
·
View notes
Text
HEY TUMBLR USERS! Here's a little safety/privacy reminder to turn on two settings!

Firstly, we have "do not sell my personal information" under account -> privacy

And now since Tumblr is scraping for AI models (like the bastards they are), turn on "prevent third-party sharing for [blog name]" under your blog's visibility settings. Unlike the former setting, you'll have to turn on this setting for every individual blog that you own.
Reblog to remind everyone to keep themselves secure on here and protect their content!
10 notes
·
View notes
Text
the temptation to make a knock-off Tumblr Neo cities website called Tumbling is STRONG
Hope you're ready for warning shots @staff
12 notes
·
View notes
Text
man. having to delete all of my twitter posts across all of my accounts is so sad.... :[ i'm currently watching the deletion script eat its way through the 33k posts on my main.... that's over a decade of conversations with people who have since disappeared but i still think of fondly. i have a backup of MY posts, and i went through and screenshotted as many reply threads as i could, but i have no idea how many i missed... man.
#if anyone (esp on my sideblog) has wondered why i disappeared again! i love last minute panic over internet privacy lala~#fuck musk fuck x fuck its stupid ai and the new policy changes.#i still have to go through my priv but that might honestly take longer than i have until the policy changes take effect.#i'll have to prioritize my art posts and go through convos a bit at a time. either way this sucks SOOOOOOOOOOO hard.#it's wearing me out both physically and emotionally lol. on top of things happening offline that won't stoooop.#(i'm also finding old posts abt irl things i forgot so i'm having to process those at the same time. aha. oho.)#but uhhhhhhhhhh once i'm done w all of this and irl stuff Chills: i have a bsky now! zerofoursix.bsky.social#so that'll be my new short-form social media site. 👍🏻 follow me if u want!#046 texts
3 notes
·
View notes
Text
"why are people mad about AI being pushed on them when they SHOULD be mad about all the privacy erosion??"
1) plenty of us bitches are mad and annoyed about both, actually.
2) the privacy erosion has become the normalized state of existence for the average person for the last 10 fucking years at least, its snuck in, they disguise it as Convenient Features to Help You Shop Better, and thats IF they bother telling you theyre doing it, instead of just opting all your shit in without asking, its so fucking normalized that yeah, a lot of people do not bother to question it, they just sigh in resignation and go, yeah, i guess, do i even have other options? and they do, but theyre an investment of learning and time you dont have capacity for at the moment, or maybe you do but you feel like you dont bc it feels like a bigger hurdle than it is, and computer stuff is already kind of intimidating, cos man, what if you hit the wrong thing and brick your expensive ass machine? easier to just let it data harvest, you guess, it cant be THAT bad, can it? plenty of people live like this, put up with this, seek this out, its easier not to resist the privacy erosion. fucking whatever, i guess. yeah, i guess twitter i mean X, or walmart, or facebook, can just have all of my contact info and my phone number and my birthday and phone contacts and bank information and fuck it, give them my ssn while im at it. less effort later. this is just how tech has been for the last 10 yrs. no one can effectively get rage clicks on this topic anymore bc we all fucking know. it sucks and we know. what do you want me to fucking do about it? i have other shit to deal with more urgently. etc
3)

you cant turn anything on or log onto anything or go anywhere without hearing about whatever new shit theyre throwing AI at for no real reason, no one will fucking Shut Up about AI, and its Annoying, man
#toy txt post#toy pic post#image id in alt text#im so fucking Tired of hearing about it and in applications that make no sense cos they made the thing and are now trying to justify its#existence and cost instead of like. creating it to actually meet a need.#im annoyed at both of these things everytime i turn on the god damn computer#i keep getting texts about upgrading my phone to get one of the new AI models. man. i dont want that#i dont want it bc theyre as invasive as ever and the ai shit is stupid and i dont want it#AND YES. THERE ARE GOOD AND USEFUL AND DECENT APPLICATIONS AND USES FOR AI. I KNOW. ITS NOT ALL BAD#BUT MOST OF THE FUCKING CHATTER ABOUT IT IS ANNOYING AND THE INTERNET IS AS FILLED AS EVER WITH MEANINGLESS BULLSHIT#WHETHER IT BE AI GENERATED OR JUST TALKING ABOUT THEIR NEW BULLSHIT GENERATOR 3000. PLEASE DOWNLOAD#TO JUSTIFY THE VENTURE CAPITAL#man ppl are tired of it all. we want to opt out of it all#and some dont even want to bother.#and then theres ppl like my mom who no. i cant convince her the privacy erosion is a problem bc on an individual level she doesnt care#but i could convince her hopefully to be wary of 'answers' from ai and that they generate slop and if anyone asks you for money for ai shit#lmao Dont. okay#and at this point ill take that as a wij#win#and honestly the privacy erosion at this point. needs. legislative shit. legislative shit that isnt just 'oh the companies were data#harvesting teens? well if the companies stop giving that info to advertisers and instead give it to Their Parents. and also give them full#control of their accounts and everything the kids see. well that fixes it. no. god#its a big stupid messy problem that is gonna suck to fix and so far anyone who talks about fixing it on a mass scale is a fucking hack#who is fear mongering to exert more control over kids man it all sucks so bad. and it sucks more cos it doesnt Have To#it Could be good! computers could be good again. the answer is not necessarily everyone download linux bc thats not going to happen#maybe more ppl should and that would be good for us. yes. like idk teach it in school or some shit. but that cant be the only thing you do#windows and Microsoft and apple should not be retroactively fucking up the products they have monopolized into everyones homes & businesses#they should not be ABLE to do this. idkeverything sucks and is stupid and that sucks and is stupid and you all are complaining about dumb#rubes getting mad at the wrong thing and falling for ai fear mongering instead of being like. why are the bitches who are turning every god#damn computer into inherent spyware also shotgunning money into ai amd articles hyping up about ai
6 notes
·
View notes