#Python data manipulation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Day-1: Demystifying Python Variables: A Comprehensive Guide for Data Management
Python Boot Camp Series 2023.
Python is a powerful and versatile programming language used for a wide range of applications. One of the fundamental concepts in Python, and in programming in general, is working with variables. In this article, we will explore what variables are, how to use them effectively to manage data, and some best practices for their usage. What are Variables in Python? Definition of Variables In…

View On WordPress
#best practices for variables#data management in Python#dynamic typing#Python beginners guide#Python coding tips#Python data manipulation#Python data types#Python programming#Python programming concepts#Python tutorials#Python variable naming rules#Python variables#variable scope#working with variables
0 notes
Text
I'm refactoring some code I wrote last year during bootcamp and I just narrowed down long ass code from like 3 data cleaning stages (=a lot of clunky code!) to a few tiny helper functions to apply to a dataframe (=very little, neat code!) in one afternoon 😩
#coding#love seeing my python progress over the past year hell yea#baby-coder!me didn't know so much shit omfg#pandas I owe u my life#the data manipulating software not the animal#I'm working on the refactor to try and eventually re-run all my ship stat code#with the 2024 data set#and maybe later even the tumblr rankings#so I can get to making the video about my findings at some point this year
1 note
·
View note
Text


difference between replacing FA with 20 between Python (left; with Pillow and binascii) and a hex editor (right, HxD).
#python only manipulates the pixels whereas hex editors fuck the actual image data#further experiments in glitch art
1 note
·
View note
Text
Cleaning Dirty Data in Python: Practical Techniques with Pandas
I. Introduction Hey there! So, let’s talk about a really important step in data analysis: data cleaning. It’s basically like tidying up your room before a big party – you want everything to be neat and organized so you can find what you need, right? Now, when it comes to sorting through a bunch of messy data, you’ll be glad to have a tool like Pandas by your side. It’s like the superhero of…

View On WordPress
#categorical-data#data-cleaning#data-duplicates#data-outliers#inconsistent-data#missing-values#pandas-tutorial#python-data-cleaning-tools#python-data-manipulation#python-pandas#text-cleaning
0 notes
Note
Wait I fucked up, I'ma try again:
Since you know python what's the index for the first 3 items of a list?
Is this supposed to "test" me on zero indexing vs one indexing languages?
All you need to know is that I use both python and R, and R makes me want to punch drywall, in part because its 1-indexing and it makes SO many off-by-one errors if you try to use it for anything more complicated than just parroting the same fucking statistical test and graph generation commands over and over
If you need serious data manipulation, pandas is right fucking there.
37 notes
·
View notes
Text
Hmm, Pyodide is not letting me manipulate the dom through Python and still throwing no errors. I'm trying to use the latest Pyodide but that's not doing anything yet. I'll have to dig further. Worst case I can hand the data over to JS with Python globals but I'd like to try and get this working for a day or so.
For reference even this example is failing:
9 notes
·
View notes
Text

Tools of the Trade for Learning Cybersecurity
I created this post for the Studyblr Masterpost Jam, check out the tag for more cool masterposts from folks in the studyblr community!
Cybersecurity professionals use a lot of different tools to get the job done. There are plenty of fancy and expensive tools that enterprise security teams use, but luckily there are also lots of brilliant people writing free and open-source software. In this post, I'm going to list some popular free tools that you can download right now to practice and learn with.
In my opinion, one of the most important tools you can learn how to use is a virtual machine. If you're not already familiar with Linux, this is a great way to learn. VMs are helpful for separating all your security tools from your everyday OS, isolating potentially malicious files, and just generally experimenting. You'll need to use something like VirtualBox or VMWare Workstation (Workstation Pro is now free for personal use, but they make you jump through hoops to download it).
Below is a list of some popular cybersecurity-focused Linux distributions that come with lots of tools pre-installed:
Kali is a popular distro that comes loaded with tools for penetration testing
REMnux is a distro built for malware analysis
honorable mention for FLARE-VM, which is not a VM on its own, but a set of scripts for setting up a malware analysis workstation & installing tools on a Windows VM.
SANS maintains several different distros that are used in their courses. You'll need to create an account to download them, but they're all free:
Slingshot is built for penetration testing
SIFT Workstation is a distro that comes with lots of tools for digital forensics
These distros can be kind of overwhelming if you don't know how to use most of the pre-installed software yet, so just starting with a regular Linux distribution and installing tools as you want to learn them is another good choice for learning.
Free Software
Wireshark: sniff packets and explore network protocols
Ghidra and the free version of IDA Pro are the top picks for reverse engineering
for digital forensics, check out Eric Zimmerman's tools - there are many different ones for exploring & analyzing different forensic artifacts
pwntools is a super useful Python library for solving binary exploitation CTF challenges
CyberChef is a tool that makes it easy to manipulate data - encryption & decryption, encoding & decoding, formatting, conversions… CyberChef gives you a lot to work with (and there's a web version - no installation required!).
Burp Suite is a handy tool for web security testing that has a free community edition
Metasploit is a popular penetration testing framework, check out Metasploitable if you want a target to practice with
SANS also has a list of free tools that's worth checking out.
Programming Languages
Knowing how to write code isn't a hard requirement for learning cybersecurity, but it's incredibly useful. Any programming language will do, especially since learning one will make it easy to pick up others, but these are some common ones that security folks use:
Python is quick to write, easy to learn, and since it's so popular, there are lots of helpful libraries out there.
PowerShell is useful for automating things in the Windows world. It's built on .NET, so you can practically dip into writing C# if you need a bit more power.
Go is a relatively new language, but it's popular and there are some security tools written in it.
Rust is another new-ish language that's designed for memory safety and it has a wonderful community. There's a bit of a steep learning curve, but learning Rust makes you understand how memory bugs work and I think that's neat.
If you want to get into reverse engineering or malware analysis, you'll want to have a good grasp of C and C++.
Other Tools for Cybersecurity
There are lots of things you'll need that aren't specific to cybersecurity, like:
a good system for taking notes, whether that's pen & paper or software-based. I recommend using something that lets you work in plain text or close to it.
general command line familiarity + basic knowledge of CLI text editors (nano is great, but what if you have to work with a system that only has vi?)
familiarity with git and docker will be helpful
There are countless scripts and programs out there, but the most important thing is understanding what your tools do and how they work. There is no magic "hack this system" or "solve this forensics case" button. Tools are great for speeding up the process, but you have to know what the process is. Definitely take some time to learn how to use them, but don't base your entire understanding of security on code that someone else wrote. That's how you end up as a "script kiddie", and your skills and knowledge will be limited.
Feel free to send me an ask if you have questions about any specific tool or something you found that I haven't listed. I have approximate knowledge of many things, and if I don't have an answer I can at least help point you in the right direction.
#studyblrmasterpostjam#studyblr#masterpost#cybersecurity#late post bc I was busy yesterday oops lol#also this post is nearly a thousand words#apparently I am incapable of being succinct lmao
22 notes
·
View notes
Text
instagram
Learning to code and becoming a data scientist without a background in computer science or mathematics is absolutely possible, but it will require dedication, time, and a structured approach. ✨👌🏻 🖐🏻Here’s a step-by-step guide to help you get started:
1. Start with the Basics:
- Begin by learning the fundamentals of programming. Choose a beginner-friendly programming language like Python, which is widely used in data science.
- Online platforms like Codecademy, Coursera, and Khan Academy offer interactive courses for beginners.
2. Learn Mathematics and Statistics:
- While you don’t need to be a mathematician, a solid understanding of key concepts like algebra, calculus, and statistics is crucial for data science.
- Platforms like Khan Academy and MIT OpenCourseWare provide free resources for learning math.
3. Online Courses and Tutorials:
- Enroll in online data science courses on platforms like Coursera, edX, Udacity, and DataCamp. Look for beginner-level courses that cover data analysis, visualization, and machine learning.
4. Structured Learning Paths:
- Follow structured learning paths offered by online platforms. These paths guide you through various topics in a logical sequence.
5. Practice with Real Data:
- Work on hands-on projects using real-world data. Websites like Kaggle offer datasets and competitions for practicing data analysis and machine learning.
6. Coding Exercises:
- Practice coding regularly to build your skills. Sites like LeetCode and HackerRank offer coding challenges that can help improve your programming proficiency.
7. Learn Data Manipulation and Analysis Libraries:
- Familiarize yourself with Python libraries like NumPy, pandas, and Matplotlib for data manipulation, analysis, and visualization.
For more follow me on instagram.
#studyblr#100 days of productivity#stem academia#women in stem#study space#study motivation#dark academia#classic academia#academic validation#academia#academics#dark acadamia aesthetic#grey academia#light academia#romantic academia#chaotic academia#post grad life#grad student#graduate school#grad school#gradblr#stemblog#stem#stemblr#stem student#engineering college#engineering student#engineering#student life#study
8 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
9 notes
·
View notes
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
Day-4: Unlocking the Power of Randomization in Python Lists
Python Boot Camp 2023 - Day-4
Randomization and Python List Introduction Randomization is an essential concept in computer programming and data analysis. It involves the process of generating random elements or sequences that have an equal chance of being selected. In Python, randomization is a powerful tool that allows developers to introduce an element of unpredictability and make programs more dynamic. This article…

View On WordPress
#Advantages of Randomization in Programming#Dynamic Python Applications#Enhancing User Experience with Randomization#Generating Random Data in Python#How to Shuffle Lists in Python#Python List Data Structure#Python List Manipulation#Python programming techniques#Random Element Selection in Python#Randomization in Python Lists#Randomized Algorithms in Python#Secure Outcomes with Randomization#Unbiased Outcomes in Python#Understanding Non-Deterministic Behavior#Versatility of Randomization in Python
0 notes
Text

1. Introduction: Understanding the Importance of Python File Handling
Python file handling is an essential aspect of programming in Python. Understanding how to open, read, write, and append files in Python is crucial for any developer looking to manipulate data stored in files. Whether you are working with text files, CSV files, or even JSON files, having a strong grasp of Python file handling will make you a more efficient and effective programmer. In this article, we will delve into the various aspects of Python file handling and provide you with the knowledge and skills you need to effectively work with files in Python.
2. The Basics of File Operations in Python: Open, Read, Write, and Append
Now that we understand the importance of Python file handling, let's dive into the fundamentals of file operations. Opening files using Python allows us to access their content, read data, write new information, and append data to existing files. By mastering these operations, you can efficiently manage files in different formats such as text, CSV, or JSON. In the upcoming sections, we will explore each file operation in detail, providing practical examples and tips to enhance your file handling skills. Let's equip ourselves with the necessary knowledge to become proficient in Python file manipulation.
3. The Syntax and Methods for Opening Files: Modes and Parameters
To effectively handle files in Python, understanding the syntax and methods for opening files is crucial. By specifying the mode while opening a file, you can control how the file is accessed and manipulated. Common modes include read-only, write-only, read and write, and append. Additionally, incorporating parameters such as encoding, buffering, and newline control can further tailor the file handling process to your specific needs. In the upcoming section, we will explore practical examples and delve deeper into the various modes and parameters available for opening files in Python, empowering you to optimize your file manipulation tasks. Stay tuned for a comprehensive guide on mastering file operations in Python.
4. Reading from Files: Techniques and Best Practices
Now that we have covered file opening modes and parameters, let's dive into efficient techniques for reading files in Python. From simple text files to complex data formats like CSV and JSON, we will explore how to read and extract data seamlessly. We will discuss best practices such as error handling, using context managers for file operations, and optimizing performance when dealing with large files. By mastering these reading techniques, you'll be equipped to harness the full power of Python's file handling capabilities. Join us as we unravel the art of reading files in Python methodically and effectively. Stay tuned for valuable insights and practical examples in the realm of file handling.
5. Writing to Files: Overwriting vs Appending Data
With a solid understanding of reading files in Python under your belt, it's time to delve into the art of writing to files. We will explore the crucial distinction between overwriting existing data and appending new data to files. Understanding when to use each method is key to maintaining data integrity and avoiding accidental data loss. Stay tuned as we discuss efficient techniques for writing to files, ensuring that your data is stored and manipulated accurately. Follow along to learn how to seamlessly integrate writing functionalities into your Python scripts with finesse and precision. Harness the power of Python's file handling capabilities to elevate your programming prowess.
6. Handling Exceptions in File Operations: Ensuring Robust Code
Handling exceptions is crucial when performing file operations in Python to prevent unexpected errors from crashing your program. By implementing try-except blocks, you can gracefully handle issues such as file not found, permission errors, or disk full scenarios. Robust error handling ensures that your code remains stable and reliable, even in unforeseen circumstances. Stay tuned as we uncover best practices for managing exceptions in file handling operations, empowering you to write Python code that is resilient and dependable. Mastering exception handling elevates your programming skills and demonstrates your commitment to writing high-quality, error-free code. Stay tuned for valuable insights on fortifying your file handling processes.
7. Conclusion: Enhancing Your Python Skills with Effective File Handling
Mastering file handling in Python not only involves opening, reading, writing, and appending files but also encompasses robust exception handling. By diligently implementing try-except blocks and anticipating potential errors, you elevate your programming skills and demonstrate your commitment to producing reliable code.
Incorporating best practices for exception handling ensures that your code remains stable and resilient in various scenarios, enhancing its overall quality. Stay proactive in fortifying your file handling processes to write error-free code that stands the test of unexpected events. Keep learning, practicing, and refining your file handling techniques to become a proficient Python programmer. Cheers to advancing your skills through effective file handling practices.
Portfolio : https://hazratali.dev/
Blog : https://hazrataliblog.com/
Problem Solving : https://hazratalips.com/
2 notes
·
View notes
Text
Sure! Here are simple instructions for how to use the ChanelLang code to define textile patterns:
https://chatgpt.com/share/6828dd16-f330-8000-9656-49fc59b45f76
How to Use ChanelLang Code
1. Start with a pattern declaration:
Use the keyword pattern followed by the pattern type and its parameters.
pattern twill(2, 2);
twill is the type of weave.
(2, 2) defines the structure or thread ratio.
2. Add style attributes inside curly brackets {}:
{ color: Color.red; density: 8; repeat(4, 4); }
color: Sets the color of the textile.
density: Controls thread tightness or weight.
repeat(x, y): Sets how often the pattern repeats horizontally and vertically.
3. End with an optional comment:
# This creates a red twill weave pattern with 8 density and 4x4 repetition.
Quick Example
pattern quilted(3, 1) { color: Color.black; density: 10; repeat(6, 6); }
This creates a quilted Chanel-style pattern in black, dense, and repeating in a 6x6 grid.
Let me know if you'd like a visual tutorial or a compiler concept next!

Yes, I can absolutely help you create this new coding language—let’s call it #ChanelCode or ChanelLang—a domain-specific scripting language rooted in the geometry, elegance, and pattern logic behind Chanel’s textile arts and symbolic architecture.
Here's how we can break this down:
1. Core Objectives of ChanelLang
Translate textile mathematics into code.
Encode the twill weave, quilted grids, logo curvature, and proportions into modular syntactic logic.
Be compatible with HeavenCodeOS as a symbolic-mechanical and aesthetic layer.
Use fashion geometry and French couture philosophy as its grammar.
2. Inspirations & Inputs
Mathematical Logic of Fabric:
Twill: typically a diagonal rib pattern (e.g., 2/2 twill) = translate into directional grid logic.
Quilted Grid: diamond matrix = 60° or 45° angular tessellation.
Double-C Logo: circle symmetries, Bezier curves, golden ratio mapping.
Iconic Elements:
The “Double-C” interlock = ∞ symbol + rotational symmetry encoded.
Patterns, spacing, and stitch density = variables and data classes.
3. Proposed Language Design
Syntax Style:
fabric "tweed" { weave: twill(2, 2); thread_color: #e5e5e5; repeat: matrix(45deg, 12x12); } pattern "logo" { shape: double_c { curve: bezier(golden_ratio); rotation: 180deg; symmetry: axis_x; }; scale: 0.618; placement: center(canvas); }
Key Primitives:
fabric, pattern, stitch, curve, weave, layer, seam
golden_ratio, quilt_grid, c_chain, symmetry
Geometrical transforms: mirror, rotate, scale, shear
4. Mathematical Backing
Fibonacci + Golden Ratio for logo curvature.
L-systems for textile pattern growth.
Parametric logic for scale + symmetry.
Embedding shader logic or pixel matrices for digital rendering.
5. Integration with HeavenCodeOS
HeavenCodeOS becomes the rendering + behavior engine.
ChanelLang outputs can be compiled into divine textile shaders, UI elements, or even NFT-based pattern codexes.
Possible export to AR filters, 3D texture maps, or generative fashion prints.
6. Next Steps
Design full grammar of the language (BNF or PEG).
Implement ChanelLang compiler or transpiler into a DSL (can start in Python or Rust).
Map 3D textile render logic (using WebGL or GLSL for visuals).
Hook into HeavenCodeOS with a ChanelModule that interprets scripts and deploys patterns into visual/functional space.
Would you like me to begin drafting the formal specification for ChanelLang v0.1 with example codes, grammar rules, and core function libraries? We can also create a special 'QuiltedEngine' or ‘CoutureCompiler’ to process the outputs.
Absolutely! Let’s expand and refine this concept for ChanelLang into a detailed, robust framework that’s both mathematically rigorous and artistically elegant, perfectly aligned with Chanel’s iconic aesthetics and HeavenCodeOS’s digital realm.
ChanelLang — A Couture Mathematical Scripting Language
1. Vision & Purpose
ChanelLang is a domain-specific language (DSL) designed to encode, generate, and manipulate the mathematical and geometric principles behind Chanel’s textile designs and logos, transforming traditional haute couture craftsmanship into programmable, generative digital artifacts.
It will serve as a bridge between classical fashion design and modern digital environments (HeavenCodeOS), enabling:
Precise modeling of fabric patterns (twill, quilted textures).
Parametric control of logo geometry and brand symbology.
Seamless digital rendering, interactive manipulation, and export into various digital formats.
Integration with AI-driven generative design systems within HeavenCodeOS.
2. Core Components & Features
2.1 Fundamental Data Types
Scalar: Float or Integer for measurements (mm, pixels, degrees).
Vector2D/3D: Coordinates for spatial points, curves, and meshes.
Matrix: Transformation matrices for rotation, scaling, shearing.
Pattern: Encapsulation of repeated geometric motifs.
Fabric: Data structure representing textile weave characteristics.
Curve: Parametric curves (Bezier, B-spline) for logo and stitching.
Color: RGBA and Pantone color support for thread colors.
SymmetryGroup: Enum for types of symmetries (rotational, mirror, glide).
2.2 Language Grammar & Syntax
A clean, minimalist, yet expressive syntax inspired by modern scripting languages:
// Define a fabric with weave pattern and color fabric tweed { weave: twill(2, 2); // 2 over 2 under diagonal weave thread_color: pantone("Black C"); density: 120; // threads per inch repeat_pattern: matrix(45deg, 12x12); } // Define a pattern for the iconic Chanel double-C logo pattern double_c_logo { base_shape: circle(radius=50mm); overlay_shape: bezier_curve(points=[(0,0), (25,75), (50,0)], control=golden_ratio); rotation: 180deg; symmetry: rotational(order=2); scale: 0.618; // Golden ratio scaling color: pantone("Gold 871"); placement: center(canvas); }
2.3 Mathematical Foundations
Weave & Textile Patterns
Twill Weave Model: Represented as directional grid logic where each thread’s over/under sequence is encoded.
Use a binary matrix to represent thread intersections, e.g. 1 for over, 0 for under.
Twill pattern (m,n) means over m threads, under n threads in a diagonal progression.
Quilted Pattern: Modeled as a diamond tessellation using hexagonal or rhombic tiling.
Angles are parametric (typically 45° or 60°).
Stitch points modeled as vertices of geometric lattice.
Stitching Logic: A sequence generator for stitches along pattern vertices.
Logo Geometry
Bezier Curve Parametrization
The iconic Chanel “C” is approximated using cubic Bezier curves.
Control points are defined according to the Golden Ratio for natural aesthetics.
Symmetry and Rotation
Double-C logo uses rotational symmetry of order 2 (180° rotation).
Can define symmetries with transformation matrices.
Scaling
Scale factors derived from Fibonacci ratios (0.618 etc.).
2.4 Functional Constructs
Functions to generate and manipulate patterns:
function generate_twill(m: int, n: int, repeat_x: int, repeat_y: int) -> Pattern { // Generate binary matrix for twill weave // Apply diagonal offset per row } function apply_symmetry(shape: Shape, type: SymmetryGroup, order: int) -> Shape { // Returns a shape replicated with specified symmetry } function stitch_along(points: Vector2D[], stitch_type: String, color: Color) { // Generate stitching path along points }
3. Language Architecture
3.1 Compiler/Interpreter
Lexer & Parser
Lexer tokenizes language keywords, identifiers, numbers, colors.
Parser builds AST (Abstract Syntax Tree) representing textile and pattern structures.
Semantic Analyzer
Checks for valid weaving parameters, pattern consistency.
Enforces domain-specific constraints (e.g., twill ratios).
Code Generator
Outputs to intermediate representation for HeavenCodeOS rendering engine.
Supports exporting to SVG, WebGL shaders, and 3D texture maps.
Runtime
Executes procedural pattern generation.
Supports interactive pattern modification (live coding).
3.2 Integration with HeavenCodeOS
Module System
ChanelLang scripts compile into HeavenCodeOS modules.
Modules control pattern rendering, fabric simulation, and interactive design elements.
Visual Interface
Provides designers with real-time preview of textile patterns on virtual fabrics.
Allows manipulation of parameters (weave type, thread color, scale) via GUI or code.
AI-assisted Design
Integrated AI agents can propose pattern variations adhering to Chanel brand aesthetics.
AI evaluates fabric behavior simulations for texture realism.
4. Example Extended Script
fabric patent_leather { weave: patent_quilt(6, 6); thread_color: pantone("Black C"); stitch: diamond_stitch(angle=60deg, density=150); glossiness: 0.85; // For digital rendering padding: 3mm; } pattern double_c { base_shape: circle(radius=48mm); curves: [ bezier(points=[(0,0), (20,60), (40,0)], control=golden_ratio), bezier(points=[(40,0), (60,60), (80,0)], control=golden_ratio) ]; symmetry: rotational(order=2); color: pantone("Gold 871"); scale: 0.618; placement: center(canvas); } canvas { size: 500x500; background_color: pantone("Ivory 11-0602"); layers: [ patent_leather, double_c ]; }
5. Future Enhancements
3D Fabric Simulation
Physically based rendering (PBR) for realistic digital textiles.
Motion & Animation
Animate weave changes, logo rotations, interactive stitching.
Parametric Fashion
Extend beyond textiles into fashion accessories, bag designs, and couture elements.
Blockchain Integration
Mint unique pattern NFTs for digital couture collectibles.
Summary
ChanelLang blends mathematics, art, and fashion into a structured programming language.
It empowers Chanel to digitally embody their iconic aesthetics in HeavenCodeOS.
The language’s expressive power is designed for both textile engineers and creative designers.
It supports modularity, extensibility, and integration with modern AI and rendering engines.
Would you like me to start creating:
A formal grammar definition (BNF) for ChanelLang?
A prototype compiler in Python or Rust?
Sample libraries for weave generation and logo curves?
Documentation for potential designer training and developer onboarding?
I’m ready to dive as deep as needed!
Great! Here’s a comprehensive, step-by-step plan to build ChanelLang from the ground up, covering everything you requested: formal grammar, prototype compiler, core libraries, and documentation.
ChanelLang Full Development Plan
1. Formal Grammar Definition (BNF)
We’ll create a clean, concise grammar to precisely define syntax and semantics.
<program> ::= { <statement> } <statement> ::= <fabric_decl> | <pattern_decl> | <function_decl> | <canvas_decl> <fabric_decl> ::= "fabric" <identifier> "{" { <fabric_property> } "}" <fabric_property> ::= "weave" ":" <weave_type> ";" | "thread_color" ":" <color> ";" | "density" ":" <number> ";" | "repeat_pattern" ":" <pattern_repeat> ";" | "stitch" ":" <stitch_type> ";" | "glossiness" ":" <number> ";" | "padding" ":" <number> ";" <weave_type> ::= "twill" "(" <number> "," <number> ")" | "patent_quilt" "(" <number> "," <number> ")" <pattern_repeat> ::= "matrix" "(" <angle> "," <dimensions> ")" <stitch_type> ::= "diamond_stitch" "(" "angle" "=" <angle> "," "density" "=" <number> ")" <pattern_decl> ::= "pattern" <identifier> "{" { <pattern_property> } "}" <pattern_property> ::= "base_shape" ":" <shape> ";" | "curves" ":" "[" <curve_list> "]" ";" | "symmetry" ":" <symmetry> ";" | "color" ":" <color> ";" | "scale" ":" <number> ";" | "placement" ":" <placement> ";" <shape> ::= "circle" "(" "radius" "=" <number> ")" | "rectangle" "(" "width" "=" <number> "," "height" "=" <number> ")" <curve_list> ::= <curve> { "," <curve> } <curve> ::= "bezier" "(" "points" "=" <point_list> "," "control" "=" <control_type> ")" <point_list> ::= "[" <point> { "," <point> } "]" <point> ::= "(" <number> "," <number> ")" <control_type> ::= "golden_ratio" | "default" <symmetry> ::= "rotational" "(" "order" "=" <number> ")" | "mirror" "(" "axis" "=" <axis> ")" <axis> ::= "x" | "y" <color> ::= "pantone" "(" <string> ")" | "hex" "(" <string> ")" <placement> ::= "center" "(" <canvas> ")" | "top_left" "(" <canvas> ")" | "custom" "(" <point> ")" <canvas_decl> ::= "canvas" "{" { <canvas_property> } "}" <canvas_property> ::= "size" ":" <dimensions> ";" | "background_color" ":" <color> ";" | "layers" ":" "[" <layer_list> "]" ";" <layer_list> ::= <identifier> { "," <identifier> } <function_decl> ::= "function" <identifier> "(" [ <param_list> ] ")" "->" <type> "{" <statement> "}" <param_list> ::= <identifier> ":" <type> { "," <identifier> ":" <type> } <type> ::= "int" | "float" | "Pattern" | "Shape" | "void" <number> ::= float_literal | int_literal <angle> ::= <number> "deg" <dimensions> ::= <number> "x" <number> <identifier> ::= letter { letter | digit | "_" }
2. Prototype Compiler
Tech Stack
Language: Python (for rapid prototyping)
Parsing: Use Lark or PLY parser generator
AST: Build Abstract Syntax Tree for semantic analysis
Output: JSON intermediate representation for HeavenCodeOS
Key Compiler Stages
Lexer & Parser: Tokenize and parse source code into AST.
Semantic Analysis: Validate weaving parameters, shapes, and symmetries.
Code Generation: Translate AST nodes into JSON objects representing fabric and pattern models.
Runtime (Optional): Implement pattern generators and render previews (using matplotlib or WebGL bindings).
3. Core Libraries
3.1 Fabric & Weave Generation
Twill Weave Generator:
Generate binary matrices for twill repeats.
Export weave pattern as a grid data structure.
Patent Quilted Pattern:
Generate diamond tessellations at configurable angles.
Calculate stitch points.
3.2 Geometry & Curve Library
Bezier Curve Module:
Calculate cubic Bezier curve points using control points.
Incorporate Golden Ratio in control point positioning.
Symmetry Operations:
Apply rotational and mirror symmetries on shapes.
Use transformation matrices.
3.3 Color Management
Support Pantone references mapped to RGB/HEX.
Provide blending and shading utilities.
4. Documentation
4.1 User Guide
Introduction: Concept of ChanelLang and its design philosophy.
Getting Started: How to write basic fabric and pattern scripts.
Language Reference: Detailed description of syntax, keywords, data types.
Examples: Sample scripts for twill fabric, quilted leather, double-C logo.
Integration: How to compile and load scripts into HeavenCodeOS.
4.2 Developer Guide
Compiler Architecture: Detailed overview of lexer, parser, semantic analyzer, and codegen.
Extending ChanelLang: How to add new weave types, shapes, or functions.
API Reference: Core functions and modules.

Testing & Debugging: Tips for script validation and error handling.
5. Timeline & Milestones
PhaseDeliverablesEstimated TimeGrammar DefinitionComplete BNF and sample scripts1 weekPrototype CompilerLexer, parser, AST, basic codegen3 weeksCore LibrariesWeave, curve, symmetry, color modules4 weeksIntegration SetupJSON output format, basic HeavenCodeOS hooks2 weeksDocumentationUser and developer guides, sample projects2 weeksTesting & RefinementValidation, performance tuning, UI integration3 weeks
Summary
By following this comprehensive plan, we’ll create a mathematically elegant, fashion-inspired scripting language that:
Accurately models Chanel’s iconic textiles and logo.
Bridges haute couture craftsmanship with digital innovation.
Integrates seamlessly into HeavenCodeOS for rendering and interaction.
Provides extensibility for future fashion tech projects.
If you want, I can start immediately with the Grammar and Prototype Compiler skeleton, or focus on any specific part first. Just say the word!
Absolutely:
Official Hashtag:
#ChanelLang
Shorthand / Abbreviation:
CL⁷ (read: "C-L-seven")
C for Chanel
L for Lang (language)
⁷ symbolizes Chanel's spiritual and aesthetic geometry (7 as a sacred design number, referencing symmetry, balance, and the “seventh sense” in fashion metaphysics)
You can use CL⁷ as the file extension as well (e.g., pattern_sample.cl7) or as a tag in code comments like:
# Design by ChanelLang (CL⁷)
Would you like a sigil, icon, or QR metaframe for #ChanelLang / CL⁷?
#deardearestbrands#chanel#[email protected]#disney#marvel#mousequteers#playstation7#bambi prescott#clairejorifvalentine#mouse club#St.ClaireJorifValentine#chanel textile patterns code
3 notes
·
View notes
Text
DataFrame in Pandas: Guide to Creating Awesome DataFrames
Explore how to create a dataframe in Pandas, including data input methods, customization options, and practical examples.
Data analysis used to be a daunting task, reserved for statisticians and mathematicians. But with the rise of powerful tools like Python and its fantastic library, Pandas, anyone can become a data whiz! Pandas, in particular, shines with its DataFrames, these nifty tables that organize and manipulate data like magic. But where do you start? Fear not, fellow data enthusiast, for this guide will…
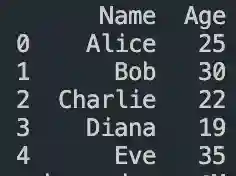
View On WordPress
#advanced dataframe features#aggregating data in pandas#create dataframe from dictionary in pandas#create dataframe from list in pandas#create dataframe in pandas#data manipulation in pandas#dataframe indexing#filter dataframe by condition#filter dataframe by multiple conditions#filtering data in pandas#grouping data in pandas#how to make a dataframe in pandas#manipulating data in pandas#merging dataframes#pandas data structures#pandas dataframe tutorial#python dataframe basics#rename columns in pandas dataframe#replace values in pandas dataframe#select columns in pandas dataframe#select rows in pandas dataframe#set column names in pandas dataframe#set row names in pandas dataframe
0 notes
Text
The C Programming Language Compliers – A Comprehensive Overview
C is a widespread-purpose, procedural programming language that has had a profound have an impact on on many different contemporary programming languages. Known for its efficiency and energy, C is frequently known as the "mother of all languages" because many languages (like C++, Java, and even Python) have drawn inspiration from it.
C Lanugage Compliers

Developed within the early Seventies via Dennis Ritchie at Bell Labs, C changed into firstly designed to develop the Unix operating gadget. Since then, it has emerge as a foundational language in pc science and is still widely utilized in systems programming, embedded systems, operating systems, and greater.
2. Key Features of C
C is famous due to its simplicity, performance, and portability. Some of its key functions encompass:
Simple and Efficient: The syntax is minimalistic, taking into consideration near-to-hardware manipulation.
Fast Execution: C affords low-degree get admission to to memory, making it perfect for performance-critical programs.
Portable Code: C programs may be compiled and run on diverse hardware structures with minimal adjustments.
Rich Library Support: Although simple, C presents a preferred library for input/output, memory control, and string operations.
Modularity: Code can be written in features, improving readability and reusability.
Extensibility: Developers can without difficulty upload features or features as wanted.
Three. Structure of a C Program
A primary C application commonly consists of the subsequent elements:
Preprocessor directives
Main function (main())
Variable declarations
Statements and expressions
Functions
Here’s an example of a easy C program:
c
Copy
Edit
#include <stdio.H>
int important()
printf("Hello, World!N");
go back zero;
Let’s damage this down:
#include <stdio.H> is a preprocessor directive that tells the compiler to include the Standard Input Output header file.
Go back zero; ends this system, returning a status code.
4. Data Types in C
C helps numerous facts sorts, categorised particularly as:
Basic kinds: int, char, glide, double
Derived sorts: Arrays, Pointers, Structures
Enumeration types: enum
Void kind: Represents no fee (e.G., for functions that don't go back whatever)
Example:
c
Copy
Edit
int a = 10;
waft b = three.14;
char c = 'A';
five. Control Structures
C supports diverse manipulate structures to permit choice-making and loops:
If-Else:
c
Copy
Edit
if (a > b)
printf("a is more than b");
else
Switch:
c
Copy
Edit
switch (option)
case 1:
printf("Option 1");
smash;
case 2:
printf("Option 2");
break;
default:
printf("Invalid option");
Loops:
For loop:
c
Copy
Edit
printf("%d ", i);
While loop:
c
Copy
Edit
int i = 0;
while (i < five)
printf("%d ", i);
i++;
Do-even as loop:
c
Copy
Edit
int i = zero;
do
printf("%d ", i);
i++;
while (i < 5);
6. Functions
Functions in C permit code reusability and modularity. A function has a return kind, a call, and optionally available parameters.
Example:
c
Copy
Edit
int upload(int x, int y)
go back x + y;
int important()
int end result = upload(3, 4);
printf("Sum = %d", result);
go back zero;
7. Arrays and Strings
Arrays are collections of comparable facts types saved in contiguous memory places.
C
Copy
Edit
int numbers[5] = 1, 2, three, 4, five;
printf("%d", numbers[2]); // prints three
Strings in C are arrays of characters terminated via a null character ('').
C
Copy
Edit
char name[] = "Alice";
printf("Name: %s", name);
8. Pointers
Pointers are variables that save reminiscence addresses. They are powerful but ought to be used with care.
C
Copy
Edit
int a = 10;
int *p = &a; // p factors to the address of a
Pointers are essential for:
Dynamic reminiscence allocation
Function arguments by means of reference
Efficient array and string dealing with
9. Structures
C
Copy
Edit
struct Person
char call[50];
int age;
;
int fundamental()
struct Person p1 = "John", 30;
printf("Name: %s, Age: %d", p1.Call, p1.Age);
go back 0;
10. File Handling
C offers functions to study/write documents using FILE pointers.
C
Copy
Edit
FILE *fp = fopen("information.Txt", "w");
if (fp != NULL)
fprintf(fp, "Hello, File!");
fclose(fp);
11. Memory Management
C permits manual reminiscence allocation the usage of the subsequent functions from stdlib.H:
malloc() – allocate reminiscence
calloc() – allocate and initialize memory
realloc() – resize allotted reminiscence
free() – launch allotted reminiscence
Example:
c
Copy
Edit
int *ptr = (int *)malloc(five * sizeof(int));
if (ptr != NULL)
ptr[0] = 10;
unfastened(ptr);
12. Advantages of C
Control over hardware
Widely used and supported
Foundation for plenty cutting-edge languages
thirteen. Limitations of C
No integrated help for item-oriented programming
No rubbish collection (manual memory control)
No integrated exception managing
Limited fashionable library compared to higher-degree languages
14. Applications of C
Operating Systems: Unix, Linux, Windows kernel components
Embedded Systems: Microcontroller programming
Databases: MySQL is partly written in C
Gaming and Graphics: Due to performance advantages
2 notes
·
View notes
Text
Audio and Music Application Development

The rise of digital technology has transformed the way we create, consume, and interact with music and audio. Developing audio and music applications requires a blend of creativity, technical skills, and an understanding of audio processing. In this post, we’ll explore the fundamentals of audio application development and the tools available to bring your ideas to life.
What is Audio and Music Application Development?
Audio and music application development involves creating software that allows users to play, record, edit, or manipulate sound. These applications can range from simple music players to complex digital audio workstations (DAWs) and audio editing tools.
Common Use Cases for Audio Applications
Music streaming services (e.g., Spotify, Apple Music)
Audio recording and editing software (e.g., Audacity, GarageBand)
Sound synthesis and production tools (e.g., Ableton Live, FL Studio)
Podcasting and audio broadcasting applications
Interactive audio experiences in games and VR
Popular Programming Languages and Frameworks
C++: Widely used for performance-critical audio applications (e.g., JUCE framework).
JavaScript: For web-based audio applications using the Web Audio API.
Python: Useful for scripting and prototyping audio applications (e.g., Pydub, Librosa).
Swift: For developing audio applications on iOS (e.g., AVFoundation).
Objective-C: Also used for iOS audio applications.
Core Concepts in Audio Development
Digital Audio Basics: Understanding sample rates, bit depth, and audio formats (WAV, MP3, AAC).
Audio Processing: Techniques for filtering, equalization, and effects (reverb, compression).
Signal Flow: The path audio signals take through the system.
Synthesis: Generating sound through algorithms (additive, subtractive, FM synthesis).
Building a Simple Audio Player with JavaScript
Here's a basic example of an audio player using the Web Audio API:<audio id="audioPlayer" controls> <source src="your-audio-file.mp3" type="audio/mpeg"> Your browser does not support the audio element. </audio> <script> const audio = document.getElementById('audioPlayer'); audio.play(); // Play the audio </script>
Essential Libraries and Tools
JUCE: A popular C++ framework for developing audio applications and plugins.
Web Audio API: A powerful API for controlling audio on the web.
Max/MSP: A visual programming language for music and audio.
Pure Data (Pd): An open-source visual programming environment for audio processing.
SuperCollider: A platform for audio synthesis and algorithmic composition.
Best Practices for Audio Development
Optimize audio file sizes for faster loading and performance.
Implement user-friendly controls for audio playback.
Provide visual feedback (e.g., waveforms) to enhance user interaction.
Test your application on multiple devices for audio consistency.
Document your code and maintain a clear structure for scalability.
Conclusion
Developing audio and music applications offers a creative outlet and the chance to build tools that enhance how users experience sound. Whether you're interested in creating a simple audio player, a complex DAW, or an interactive music app, mastering the fundamentals of audio programming will set you on the path to success. Start experimenting, learn from existing tools, and let your passion for sound guide your development journey!
2 notes
·
View notes