#replace values in pandas dataframe
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
DataFrame in Pandas: Guide to Creating Awesome DataFrames
Explore how to create a dataframe in Pandas, including data input methods, customization options, and practical examples.
Data analysis used to be a daunting task, reserved for statisticians and mathematicians. But with the rise of powerful tools like Python and its fantastic library, Pandas, anyone can become a data whiz! Pandas, in particular, shines with its DataFrames, these nifty tables that organize and manipulate data like magic. But where do you start? Fear not, fellow data enthusiast, for this guide will…
View On WordPress
#advanced dataframe features#aggregating data in pandas#create dataframe from dictionary in pandas#create dataframe from list in pandas#create dataframe in pandas#data manipulation in pandas#dataframe indexing#filter dataframe by condition#filter dataframe by multiple conditions#filtering data in pandas#grouping data in pandas#how to make a dataframe in pandas#manipulating data in pandas#merging dataframes#pandas data structures#pandas dataframe tutorial#python dataframe basics#rename columns in pandas dataframe#replace values in pandas dataframe#select columns in pandas dataframe#select rows in pandas dataframe#set column names in pandas dataframe#set row names in pandas dataframe
0 notes
Text
0 notes
Text
Unlock the Power of Pandas: Easy-to-Follow Python Tutorial for Newbies

Python Pandas is a powerful tool for working with data, making it a must-learn library for anyone starting in data analysis. With Pandas, you can effortlessly clean, organize, and analyze data to extract meaningful insights. This tutorial is perfect for beginners looking to get started with Pandas.
Pandas is a Python library designed specifically for data manipulation and analysis. It offers two main data structures: Series and DataFrame. A Series is like a single column of data, while a DataFrame is a table-like structure that holds rows and columns, similar to a spreadsheet.
Why use Pandas? First, it simplifies handling large datasets by providing easy-to-use functions for filtering, sorting, and grouping data. Second, it works seamlessly with other popular Python libraries, such as NumPy and Matplotlib, making it a versatile tool for data projects.
Getting started with Pandas is simple. After installing the library, you can load datasets from various sources like CSV files, Excel sheets, or even databases. Once loaded, Pandas lets you perform tasks like renaming columns, replacing missing values, or summarizing data in just a few lines of code.
If you're looking to dive deeper into how Pandas can make your data analysis journey smoother, explore this beginner-friendly guide: Python Pandas Tutorial. Start your journey today, and unlock the potential of data analysis with Python Pandas!
Whether you're a student or a professional, mastering Pandas will open doors to numerous opportunities in the world of data science.
0 notes
Text
Generating a Correlation Coefficient
This assignment aims to statistically assess the evidence, provided by NESARC codebook, in favor of or against the association between cannabis use and mental illnesses, such as major depression and general anxiety, in U.S. adults. More specifically, since my research question includes only categorical variables, I selected three new quantitative variables from the NESARC codebook. Therefore, I redefined my hypothesis and examined the correlation between the age when the individuals began using cannabis the most (quantitative explanatory, variable “S3BD5Q2F”) and the age when they experienced the first episode of major depression and general anxiety (quantitative response, variables “S4AQ6A” and ”S9Q6A”). As a result, in the first place, in order to visualize the association between cannabis use and both depression and anxiety episodes, I used seaborn library to produce a scatterplot for each disorder separately and interpreted the overall patterns, by describing the direction, as well as the form and the strength of the relationships. In addition, I ran Pearson correlation test (Q->Q) twice (once for each disorder) and measured the strength of the relationships between each pair of quantitative variables, by numerically generating both the correlation coefficients r and the associated p-values. For the code and the output I used Spyder (IDE).
The three quantitative variables that I used for my Pearson correlation tests are:


FOLLWING IS A PYTHON PROGRAM TO CALCULATE CORRELATION
import pandas import numpy import seaborn import scipy import matplotlib.pyplot as plt
nesarc = pandas.read_csv ('nesarc_pds.csv' , low_memory=False)
Set PANDAS to show all columns in DataFrame
pandas.set_option('display.max_columns', None)
Set PANDAS to show all rows in DataFrame
pandas.set_option('display.max_rows', None)
nesarc.columns = map(str.upper , nesarc.columns)
pandas.set_option('display.float_format' , lambda x:'%f'%x)
Change my variables to numeric
nesarc['AGE'] = pandas.to_numeric(nesarc['AGE'], errors='coerce') nesarc['S3BQ4'] = pandas.to_numeric(nesarc['S3BQ4'], errors='coerce') nesarc['S4AQ6A'] = pandas.to_numeric(nesarc['S4AQ6A'], errors='coerce') nesarc['S3BD5Q2F'] = pandas.to_numeric(nesarc['S3BD5Q2F'], errors='coerce') nesarc['S9Q6A'] = pandas.to_numeric(nesarc['S9Q6A'], errors='coerce') nesarc['S4AQ7'] = pandas.to_numeric(nesarc['S4AQ7'], errors='coerce') nesarc['S3BQ1A5'] = pandas.to_numeric(nesarc['S3BQ1A5'], errors='coerce')
Subset my sample
subset1 = nesarc[(nesarc['S3BQ1A5']==1)] # Cannabis users subsetc1 = subset1.copy()
Setting missing data
subsetc1['S3BQ1A5']=subsetc1['S3BQ1A5'].replace(9, numpy.nan) subsetc1['S3BD5Q2F']=subsetc1['S3BD5Q2F'].replace('BL', numpy.nan) subsetc1['S3BD5Q2F']=subsetc1['S3BD5Q2F'].replace(99, numpy.nan) subsetc1['S4AQ6A']=subsetc1['S4AQ6A'].replace('BL', numpy.nan) subsetc1['S4AQ6A']=subsetc1['S4AQ6A'].replace(99, numpy.nan) subsetc1['S9Q6A']=subsetc1['S9Q6A'].replace('BL', numpy.nan) subsetc1['S9Q6A']=subsetc1['S9Q6A'].replace(99, numpy.nan)
Scatterplot for the age when began using cannabis the most and the age of first episode of major depression
plt.figure(figsize=(12,4)) # Change plot size scat1 = seaborn.regplot(x="S3BD5Q2F", y="S4AQ6A", fit_reg=True, data=subset1) plt.xlabel('Age when began using cannabis the most') plt.ylabel('Age when expirenced the first episode of major depression') plt.title('Scatterplot for the age when began using cannabis the most and the age of first the episode of major depression') plt.show()
data_clean=subset1.dropna()
Pearson correlation coefficient for the age when began using cannabis the most and the age of first the episode of major depression
print ('Association between the age when began using cannabis the most and the age of the first episode of major depression') print (scipy.stats.pearsonr(data_clean['S3BD5Q2F'], data_clean['S4AQ6A']))
Scatterplot for the age when began using cannabis the most and the age of the first episode of general anxiety
plt.figure(figsize=(12,4)) # Change plot size scat2 = seaborn.regplot(x="S3BD5Q2F", y="S9Q6A", fit_reg=True, data=subset1) plt.xlabel('Age when began using cannabis the most') plt.ylabel('Age when expirenced the first episode of general anxiety') plt.title('Scatterplot for the age when began using cannabis the most and the age of the first episode of general anxiety') plt.show()
Pearson correlation coefficient for the age when began using cannabis the most and the age of the first episode of general anxiety
print ('Association between the age when began using cannabis the most and the age of first the episode of general anxiety') print (scipy.stats.pearsonr(data_clean['S3BD5Q2F'], data_clean['S9Q6A']))
OUTPUT:

The scatterplot presented above, illustrates the correlation between the age when individuals began using cannabis the most (quantitative explanatory variable) and the age when they experienced the first episode of depression (quantitative response variable). The direction of the relationship is positive (increasing), which means that an increase in the age of cannabis use is associated with an increase in the age of the first depression episode. In addition, since the points are scattered about a line, the relationship is linear. Regarding the strength of the relationship, from the pearson correlation test we can see that the correlation coefficient is equal to 0.23, which indicates a weak linear relationship between the two quantitative variables. The associated p-value is equal to 2.27e-09 (p-value is written in scientific notation) and the fact that its is very small means that the relationship is statistically significant. As a result, the association between the age when began using cannabis the most and the age of the first depression episode is moderately weak, but it is highly unlikely that a relationship of this magnitude would be due to chance alone. Finally, by squaring the r, we can find the fraction of the variability of one variable that can be predicted by the other, which is fairly low at 0.05.
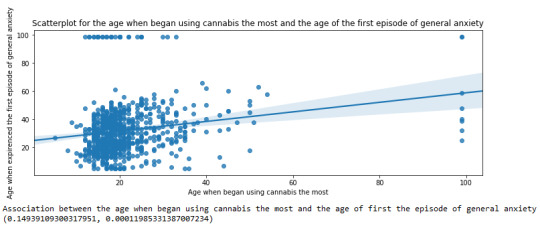
For the association between the age when individuals began using cannabis the most (quantitative explanatory variable) and the age when they experienced the first episode of anxiety (quantitative response variable), the scatterplot psented above shows a positive linear relationship. Regarding the strength of the relationship, the pearson correlation test indicates that the correlation coefficient is equal to 0.14, which is interpreted to a fairly weak linear relationship between the two quantitative variables. The associated p-value is equal to 0.0001, which means that the relationship is statistically significant. Therefore, the association between the age when began using cannabis the most and the age of the first anxiety episode is weak, but it is highly unlikely that a relationship of this magnitude would be due to chance alone. Finally, by squaring the r, we can find the fraction of the variability of one variable that can be predicted by the other, which is very low at 0.01.
0 notes
Text
Module 3 : Making Data Management Decisions Analyzing the Impact of Work Modes on Employee Productivity and Stress Levels: A Data-Driven Approach
Introduction
In the evolving landscape of work environments, understanding how different work modes—Remote, Hybrid, and Office—affect employee productivity and stress levels is crucial for organizations aiming to optimize performance and employee well-being. This analysis leverages a dataset of 20 employees, capturing various metrics such as Task Completion Rate, Meeting Frequency, and Stress Level. By examining these variables, we aim to uncover patterns and insights that can inform better management practices and work culture improvements.
Data Management and Analysis
To ensure the data is clean and meaningful, we performed several data management steps:
Handling Missing Data: We used the fillna() function to replace any missing values with a defined value, ensuring no gaps in our analysis.
Creating Secondary Variables: We introduced a Productivity Score, calculated as the average of Task Completion Rate and Meeting Frequency, to provide a composite measure of productivity.
Binning Variables: We categorized the Productivity Score into three groups—Low, Medium, and High—to facilitate easier interpretation and analysis.
We then ran frequency distributions for key variables, including Work Mode, Task Completion Rate, Stress Level, and the newly created Productivity Category. Let’s start by implementing the data management decisions and then proceed to run the frequency distributions for the chosen variables.
Step 1: Data Management
Handling Missing Data:
We’ll use the fillna() function to replace any NaN values with a defined value. For this example, we’ll assume there are no NaN values in the provided dataset, but we’ll include the code for completeness.
Creating Secondary Variables:
We’ll calculate a new variable, Productivity Score, based on Task Completion Rate (%) and Meeting Frequency (per week). This score will be a simple average of these two metrics.
Binning or Grouping Variables:
We’ll group the Productivity Score into three categories: Low, Medium, and High for salary revision purposes.
Step 2: Frequency Distributions
We’ll run frequency distributions for the following variables:
Work Mode
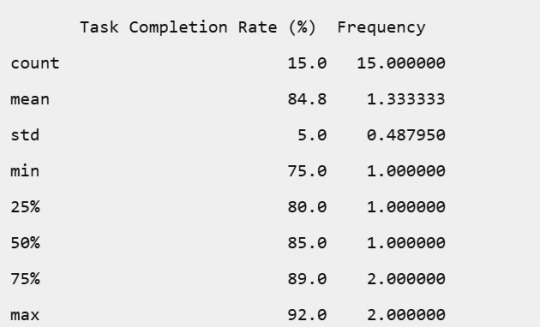
Task Completion Rate (%)
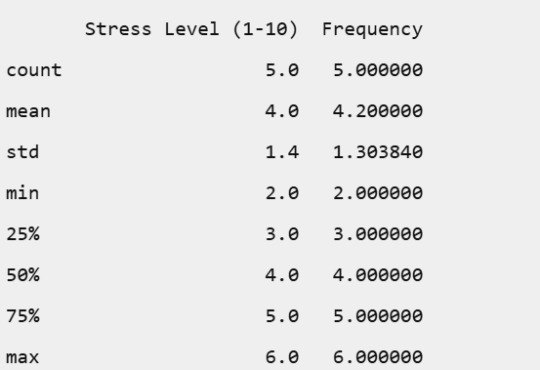
Stress Level (1-10)
Productivity Score (grouped)
Here’s the complete implementation:
import pandas as pd
import numpy as np
# Creating the DataFrame
data = {
'Employee ID': range(1, 21),
'Work Mode': ['Remote', 'Hybrid', 'Office', 'Remote', 'Hybrid', 'Office', 'Remote', 'Hybrid', 'Office', 'Remote',
'Hybrid', 'Office', 'Remote', 'Hybrid', 'Office', 'Remote', 'Hybrid', 'Office', 'Remote', 'Hybrid'],
'Productive Hours': ['9:00 AM - 12:00 PM', '10:00 AM - 1:00 PM', '11:00 AM - 2:00 PM', '8:00 AM - 11:00 AM',
'1:00 PM - 4:00 PM', '9:00 AM - 12:00 PM', '2:00 PM - 5:00 PM', '11:00 AM - 2:00 PM',
'10:00 AM - 1:00 PM', '7:00 AM - 10:00 AM', '9:00 AM - 12:00 PM', '1:00 PM - 4:00 PM',
'10:00 AM - 1:00 PM', '8:00 AM - 11:00 AM', '2:00 PM - 5:00 PM', '9:00 AM - 12:00 PM',
'10:00 AM - 1:00 PM', '11:00 AM - 2:00 PM', '8:00 AM - 11:00 AM', '1:00 PM - 4:00 PM'],
'Task Completion Rate (%)': [85, 90, 80, 88, 92, 75, 89, 87, 78, 91, 84, 82, 86, 89, 77, 90, 85, 79, 87, 91],
'Meeting Frequency (per week)': [5, 3, 4, 2, 6, 4, 3, 5, 4, 2, 3, 5, 4, 2, 6, 3, 5, 4, 2, 6],
'Meeting Duration (minutes)': [30, 45, 60, 20, 40, 50, 25, 35, 55, 20, 30, 45, 35, 25, 50, 40, 30, 60, 20, 25],
'Breaks (minutes)': [60, 45, 30, 50, 40, 35, 55, 45, 30, 60, 50, 40, 55, 60, 30, 45, 50, 35, 55, 60],
'Stress Level (1-10)': [4, 3, 5, 2, 3, 6, 4, 3, 5, 2, 4, 5, 3, 2, 6, 4, 3, 5, 2, 3]
}
df = pd.DataFrame(data)
# Handling missing data (if any)
df.fillna(0, inplace=True)
# Creating a secondary variable: Productivity Score
df['Productivity Score'] = (df['Task Completion Rate (%)'] + df['Meeting Frequency (per week)']) / 2
# Binning Productivity Score into categories
bins = [0, 50, 75, 100]
labels = ['Low', 'Medium', 'High']
df['Productivity Category'] = pd.cut(df['Productivity Score'], bins=bins, labels=labels, include_lowest=True)
# Displaying frequency tables
work_mode_freq = df['Work Mode'].value_counts().reset_index()
work_mode_freq.columns = ['Work Mode', 'Frequency']
task_completion_freq = df['Task Completion Rate (%)'].value_counts().reset_index()
task_completion_freq.columns = ['Task Completion Rate (%)', 'Frequency']
stress_level_freq = df['Stress Level (1-10)'].value_counts().reset_index()
stress_level_freq.columns = ['Stress Level (1-10)', 'Frequency']
productivity_category_freq = df['Productivity Category'].value_counts().reset_index()
productivity_category_freq.columns = ['Productivity Category', 'Frequency']
# Displaying the tables
print("Frequency Table for Work Mode:")
print(work_mode_freq.to_string(index=False))
print("\nFrequency Table for Task Completion Rate (%):")
print(task_completion_freq.to_string(index=False))
print("\nFrequency Table for Stress Level (1-10):")
print(stress_level_freq.to_string(index=False))
print("\nFrequency Table for Productivity Category:")
print(productivity_category_freq.to_string(index=False))
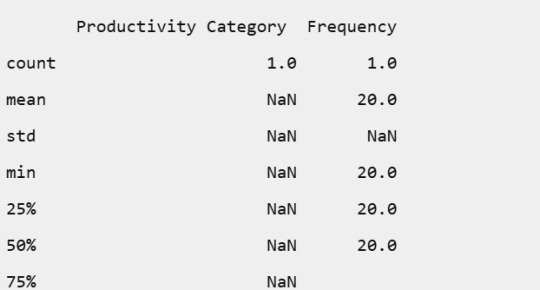
# Summary of frequency distributions
summary = {
'Work Mode': work_mode_freq.describe(),
'Task Completion Rate (%)': task_completion_freq.describe(),
'Stress Level (1-10)': stress_level_freq.describe(),
'Productivity Category': productivity_category_freq.describe()
}
print("\nSummary of Frequency Distributions:")
for key, value in summary.items():
print(f"\n{key}:")
print(value.to_string())
------------------------------------------------------------------------------
Output Interpretation:
Frequency Table for Work Mode:

Frequency Table for Task Completion Rate (%):

Frequency Table for Stress Level (1-10):

Frequency Table for Productivity Category:

Summary of Frequency Distributions
Work Mode:

Task Completion Rate (%):
Stress Level (1-10):
Productivity Category:
Conclusion
The frequency distributions revealed insightful patterns:
Work Mode: Remote work was the most common, followed by Hybrid and Office modes.
Task Completion Rate: The rates varied, with most employees achieving high completion rates, indicating overall good productivity.
Stress Level: Stress levels were generally moderate, with a few instances of higher stress.
Productivity Category: All employees fell into the Medium productivity category, suggesting a balanced workload and performance across the board.
These findings highlight the importance of flexible work arrangements in maintaining high productivity and manageable stress levels. By understanding these dynamics, organizations can better support their employees, leading to a more efficient and healthier work environment.
0 notes
Text
AI_MLCourse_Day04
Topic: Managing Data (Week 2 Summary)
Building a Data Matrix
When first making a matrix it is important that the features (which are the columns when looking at a Pandas Dataframe) are clearly defined. One of these features will be called a 'label' and that is what the model will try to predict.
Understand the sample. Clearly define it. They can overlap one another so long as the model only looks at what it needs to.
Data types include numeric (continuous and integer), and categorical (ordinal and nominative). Continuous and integer are generally ready for ML without much prep but, can lead to outliers (continuous especially). Ordinal can be represented as an integer value but the range is so small it might as well be categorical. Note that numerical ordinal values will be treated as a number by the model, so special care must be made. Use regression and classification on these values.
Feature Engineering
When starting to feature engineer focus on either mapping concepts to data representations or manipulating the data so it is appropriate for common ML API's.
Often times, you will need to adjust the features present so that the better fit a model. There are many different ways to accomplish this but, one important one is called One-hot encoding. It is a manner of transforming categorical values into binary features.
Exploring Data
When looking at data frames the questions of how is it distributed, is it redundant, and how do features correlate with the chosen label should be on the forefront of the mind. The whole point of data analysis is to check for data quality issues.
Good python libraries to do this through include Matplot and Seaborn. Matplot is good on its own, but Seaborn builds off of Matplot to be even better at tabular data.
Avoid correlation between features by looking at the bivariate distribution. Review old statistics notes. They are helpful.
Cleaning Data
Look for any outliers in the data. They could show that you have fucked something up in getting the data or that you just have something weird happening. Methods of detection? Z-Score and Interquartile Range (ha you thought you were done with this shit you are never done with anything in CS there is always a call back)
Handle said outliers through execution. Or winsorizatio (where you replace the outliers with a reasonable high value).
__________
That's it for this week. I am tired but carrying on. I leave you with a quote, "It's not enough to win, everyone else must lose," or something along those lines.
0 notes
Text
weight of smokers
import pandas as pd import numpy as np
Read the dataset
data = pd.read_csv('nesarc_pds.csv', low_memory=False)
Bug fix for display formats to avoid runtime errors
pd.set_option('display.float_format', lambda x: '%f' % x)
Setting variables to numeric
numeric_columns = ['TAB12MDX', 'CHECK321', 'S3AQ3B1', 'S3AQ3C1', 'WEIGHT'] data[numeric_columns] = data[numeric_columns].apply(pd.to_numeric)
Subset data to adults 100 to 600 lbs who have smoked in the past 12 months
sub1 = data[(data['WEIGHT'] >= 100) & (data['WEIGHT'] <= 600) & (data['CHECK321'] == 1)]
Make a copy of the subsetted data
sub2 = sub1.copy()
def print_value_counts(df, column, description): """Print value counts for a specific column in the dataframe.""" print(f'{description}') counts = df[column].value_counts(sort=False, dropna=False) print(counts) return counts
Initial counts for S3AQ3B1
print_value_counts(sub2, 'S3AQ3B1', 'Counts for original S3AQ3B1')
Recode missing values to NaN
sub2['S3AQ3B1'].replace(9, np.nan, inplace=True) sub2['S3AQ3C1'].replace(99, np.nan, inplace=True)
Counts after recoding missing values
print_value_counts(sub2, 'S3AQ3B1', 'Counts for S3AQ3B1 with 9 set to NaN and number of missing requested')
Recode missing values for S2AQ8A
sub2['S2AQ8A'].fillna(11, inplace=True) sub2['S2AQ8A'].replace(99, np.nan, inplace=True)
Check coding for S2AQ8A
print_value_counts(sub2, 'S2AQ8A', 'S2AQ8A with Blanks recoded as 11 and 99 set to NaN') print(sub2['S2AQ8A'].describe())
Recode values for S3AQ3B1 into new variables
recode1 = {1: 6, 2: 5, 3: 4, 4: 3, 5: 2, 6: 1} recode2 = {1: 30, 2: 22, 3: 14, 4: 5, 5: 2.5, 6: 1}
sub2['USFREQ'] = sub2['S3AQ3B1'].map(recode1) sub2['USFREQMO'] = sub2['S3AQ3B1'].map(recode2)
Create secondary variable
sub2['NUMCIGMO_EST'] = sub2['USFREQMO'] * sub2['S3AQ3C1']
Examine frequency distributions for WEIGHT
print_value_counts(sub2, 'WEIGHT', 'Counts for WEIGHT') print('Percentages for WEIGHT') print(sub2['WEIGHT'].value_counts(sort=False, normalize=True))
Quartile split for WEIGHT
sub2['WEIGHTGROUP4'] = pd.qcut(sub2['WEIGHT'], 4, labels=["1=0%tile", "2=25%tile", "3=50%tile", "4=75%tile"]) print_value_counts(sub2, 'WEIGHTGROUP4', 'WEIGHT - 4 categories - quartiles')
Categorize WEIGHT into 3 groups (100-200 lbs, 200-300 lbs, 300-600 lbs)
sub2['WEIGHTGROUP3'] = pd.cut(sub2['WEIGHT'], [100, 200, 300, 600], labels=["100-200 lbs", "201-300 lbs", "301-600 lbs"]) print_value_counts(sub2, 'WEIGHTGROUP3', 'Counts for WEIGHTGROUP3')
Crosstab of WEIGHTGROUP3 and WEIGHT
print(pd.crosstab(sub2['WEIGHTGROUP3'], sub2['WEIGHT']))
Frequency distribution for WEIGHTGROUP3
print_value_counts(sub2, 'WEIGHTGROUP3', 'Counts for WEIGHTGROUP3') print('Percentages for WEIGHTGROUP3') print(sub2['WEIGHTGROUP3'].value_counts(sort=False, normalize=True))
Counts for original S3AQ3B1 S3AQ3B1 1.000000 81 2.000000 6 5.000000 2 4.000000 6 3.000000 3 6.000000 4 Name: count, dtype: int64 Counts for S3AQ3B1 with 9 set to NaN and number of missing requested S3AQ3B1 1.000000 81 2.000000 6 5.000000 2 4.000000 6 3.000000 3 6.000000 4 Name: count, dtype: int64 S2AQ8A with Blanks recoded as 11 and 99 set to NaN S2AQ8A 6 12 4 2 7 14 5 16 28 1 6 2 2 10 9 3 5 9 5 8 3 Name: count, dtype: int64 count 102 unique 11 top freq 28 Name: S2AQ8A, dtype: object Counts for WEIGHT WEIGHT 534.703087 1 476.841101 5 534.923423 1 568.208544 1 398.855701 1 .. 584.984241 1 577.814060 1 502.267758 1 591.875275 1 483.885024 1 Name: count, Length: 86, dtype: int64 Percentages for WEIGHT WEIGHT 534.703087 0.009804 476.841101 0.049020 534.923423 0.009804 568.208544 0.009804 398.855701 0.009804
584.984241 0.009804 577.814060 0.009804 502.267758 0.009804 591.875275 0.009804 483.885024 0.009804 Name: proportion, Length: 86, dtype: float64 WEIGHT - 4 categories - quartiles WEIGHTGROUP4 1=0%tile 26 2=25%tile 25 3=50%tile 25 4=75%tile 26 Name: count, dtype: int64 Counts for WEIGHTGROUP3 WEIGHTGROUP3 100-200 lbs 0 201-300 lbs 0 301-600 lbs 102 Name: count, dtype: int64 WEIGHT 398.855701 437.144557 … 599.285226 599.720557 WEIGHTGROUP3 … 301-600 lbs 1 1 … 1 1
[1 rows x 86 columns] Counts for WEIGHTGROUP3 WEIGHTGROUP3 100-200 lbs 0 201-300 lbs 0 301-600 lbs 102 Name: count, dtype: int64 Percentages for WEIGHTGROUP3 WEIGHTGROUP3 100-200 lbs 0.000000 201-300 lbs 0.000000 301-600 lbs 1.000000 Name: proportion, dtype: float64
I changed the code to see the weight of smokers who have smoked in the past year. For weight group 3, 102 people over 102lbs have smoked in the last year
0 notes
Text
Making Data Management Decisions
Starting with import the libraries to use
import pandas as pd import numpy as np
data=pd.read_csv("nesarc_pds.csv", low_memory=False)
Now we create a new data with the variables that we want
sub_data=data[[ 'AGE', 'S2AQ8A' , 'S2AQ8B' , 'S4AQ20C' , 'S9Q19C']]
I made a copy to wort with it
sub_data2=sub_data.copy()
We can obtain info of our dataframe to see what are the types of the variables
sub_data2.info()
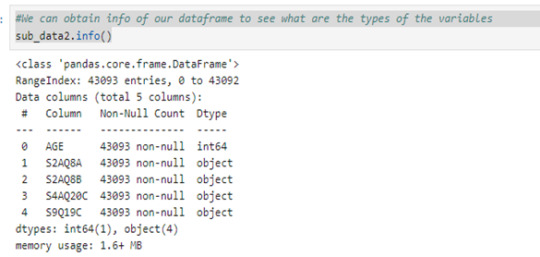
#We see that foru variables are objects, so we can convert it in type float by using pd.to_numeric
sub_data2 =sub_data2.apply(pd.to_numeric, errors='coerce') sub_data2.info()

At this point of the code we may to observe that some variables has values with answers that don´t give us any information



We can see that this four variables includes the values 99 and 9 as unknown answers so we can replace it by Nan with the next line code:
sub_data2 =sub_data2.replace(99,np.nan) sub_data2=sub_data2.replace(9, np.nan)
And drop this values with
sub_data2=sub_data2.dropna() print(len(sub_data2)) 1058
I want to create a secondary variable that tells me how many drinks did the individual consume last year so I recode the values of S2AQ8A as how many times the individual consume alcohol last year.
For example, the value 1 in S2AQ8A is the answer that the individual consume alcohol everyday, so he consumed alcohol 365 times last year. For the value 2, I codify as the individual consume 29 days per motnh so this give 348 times in the last year.
I made it with the next statement:
recode={1:365, 2:348, 3:192, 4:96, 5:48, 6:36, 7:12, 8:11, 9:6, 10:2} sub_data2['S2AQ8A']=sub_data2['S2AQ8A'].map(recode)
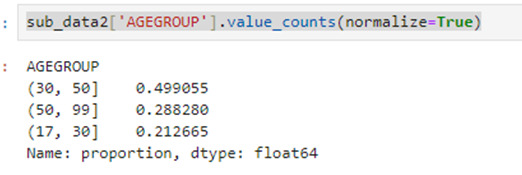
Adicionally I grupo the individual by they ages, dividing by 18 to 30, 31 to 50 and 50 to 99.
sub_data2['AGEGROUP'] = pd.cut(sub_data2.AGE, [17, 30, 50, 99])
And I can see the percentages of each interval
sub_data2['AGEGROUP'].value_counts(normalize=True)
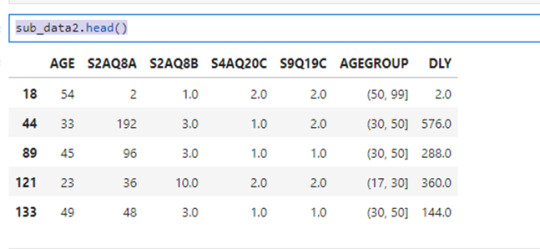
Now I create the variable 'DLY' for the drinks consumed last year by the next statemen:
sub_data2['DLY']=sub_data2['S2AQ8A']*sub_data2['S2AQ8B'] sub_data2.head()
The variables S4AQ20C and S9Q19C correspond to the questions:
DRANK ALCOHOL TO IMPROVE MOOD PRIOR TO LAST 12 MONTHS
DRANK ALCOHOL TO AVOID GENERALIZED ANXIETY PRIOR TO LAST 12 MONTHS
respectively.
The values for this question are:
1 = yes
2 = no
I want to know if people who decide to consume alcohol to avoid anxiety or improve mood tends to consume more alcohol that peoplo who don´t do it.
So I made this:
sub_data3=sub_data2.groupby(['S4AQ20C','S9Q19C','AGEGROUP'], observed=True)
And I use value_counts to analyze the frecuency
sub_data3['S4AQ20C'].value_counts()

From this we can see the next things:
158 individuals consume alcohol to improve mood or avoid anxiety which represents the 14.93%
151 individuals consume alcohol to improve mood but no to avoid anxiety which represents the 14.27%
57 individuals consume alcohol to avoid anxiety but no to improve mood which represents the 05.40%
692 individuals don´t consume alcohol to avoid anxiety or improve mood which represents the 65.40%
We can obtain more informacion by using
sub_data3[['S2AQ8A','S2AQ8B','DLY']].agg(['count','mean', 'std'])
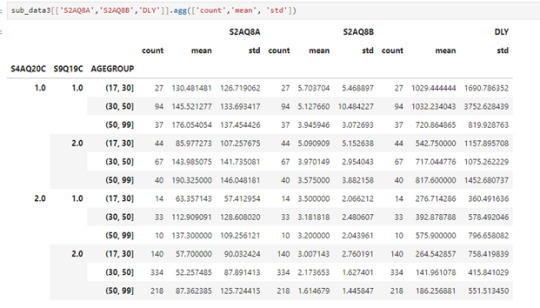
From this we can see for example:
Mots people are betwen 31 to 50 year old and they don´t consume alcohol to improve mood or avoid anxiety and they have a average of 141 drinks in the laste year which is the lowest average.
The highest average of drinks consumed last year its 1032 and correspond to individuals betwen 31 to 50 years old and the consume alcohol to improve mood or avoid anxiety and the second place its for indivuals that are betwen 18 to 30 year old and also consume alcohol to improve mood or avoid anxiety
This suggests that the age its not a determining factor to 'DYL' but 'S2AQ8A' and 'S2AQ8B' si lo son
0 notes
Text
Demystifying Data Science: Essential Concepts for Beginners
In today's data-driven world, the field of data science stands out as a beacon of opportunity. With Python programming as its cornerstone, data science opens doors to insights, predictions, and solutions across countless industries. If you're a beginner looking to dive into this exciting realm, fear not! This article will serve as your guide, breaking down essential concepts in a straightforward manner.
1. Introduction to Data Science
Data science is the art of extracting meaningful insights and knowledge from data. It combines aspects of statistics, computer science, and domain expertise to analyze complex data sets.
2. Why Python?
Python has emerged as the go-to language for data science, and for good reasons. It boasts simplicity, readability, and a vast array of libraries tailored for data manipulation, analysis, and visualization.
3. Setting Up Your Python Environment
Before we dive into coding, let's ensure your Python environment is set up. You'll need to install Python and a few key libraries such as Pandas, NumPy, and Matplotlib. These libraries will be your companions throughout your data science journey.
4. Understanding Data Types
In Python, everything is an object with a type. Common data types include integers, floats (decimal numbers), strings (text), booleans (True/False), and more. Understanding these types is crucial for data manipulation.
5. Data Structures in Python
Python offers versatile data structures like lists, dictionaries, tuples, and sets. These structures allow you to organize and work with data efficiently. For instance, lists are sequences of elements, while dictionaries are key-value pairs.
6. Introduction to Pandas
Pandas is a powerhouse library for data manipulation. It introduces two main data structures: Series (1-dimensional labeled array) and DataFrame (2-dimensional labeled data structure). These structures make it easy to clean, transform, and analyze data.
7. Data Cleaning and Preprocessing
Before diving into analysis, you'll often need to clean messy data. This involves handling missing values, removing duplicates, and standardizing formats. Pandas provides functions like dropna(), fillna(), and replace() for these tasks.
8. Basic Data Analysis with Pandas
Now that your data is clean, let's analyze it! Pandas offers a plethora of functions for descriptive statistics, such as mean(), median(), min(), and max(). You can also group data using groupby() and create pivot tables for deeper insights.
9. Data Visualization with Matplotlib
They say a picture is worth a thousand words, and in data science, visualization is key. Matplotlib, a popular plotting library, allows you to create various charts, histograms, scatter plots, and more. Visualizing data helps in understanding trends and patterns.
Conclusion
Congratulations! You've embarked on your data science journey with Python as your trusty companion. This article has laid the groundwork, introducing you to essential concepts and tools. Remember, practice makes perfect. As you explore further, you'll uncover the vast possibilities data science offers—from predicting trends to making informed decisions. So, grab your Python interpreter and start exploring the world of data!
In the realm of data science, Python programming serves as the key to unlocking insights from vast amounts of information. This article aims to demystify the field, providing beginners with a solid foundation to begin their journey into the exciting world of data science.
0 notes
Text
Linear regression alcohol consumption vs number of alcoholic parents
Code
import pandas import numpy import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score import statsmodels.api as sm import seaborn import statsmodels.formula.api as smf
print("start import") data = pandas.read_csv('nesarc_pds.csv', low_memory=False) print("import done")
upper-case all Dataframe column names --> unification
data.colums = map(str.upper, data.columns)
bug fix for display formats to avoid run time errors
pandas.set_option('display.float_format', lambda x:'%f'%x)
print (len(data)) #number of observations (rows) print (len(data.columns)) # number of variables (columns)
checking the format of your variables
setting variables you will be working with to numeric
data['S2DQ1'] = pandas.to_numeric(data['S2DQ1']) #Blood/Natural Father data['S2DQ2'] = pandas.to_numeric(data['S2DQ2']) #Blood/Natural Mother data['S2BQ3A'] = pandas.to_numeric(data['S2BQ3A'], errors='coerce') #Age at first Alcohol abuse data['S3CQ14A3'] = pandas.to_numeric(data['S3CQ14A3'], errors='coerce')
Blood/Natural Father was alcoholic
print("number blood/natural father was alcoholic")
0 = no; 1= yes; unknown = nan
data['S2DQ1'] = data['S2DQ1'].replace({2: 0, 9: numpy.nan}) c1 = data['S2DQ1'].value_counts(sort=False).sort_index() print (c1)
print("percentage blood/natural father was alcoholic") p1 = data['S2DQ1'].value_counts(sort=False, normalize=True).sort_index() print (p1)
Blood/Natural Mother was alcoholic
print("number blood/natural mother was alcoholic")
0 = no; 1= yes; unknown = nan
data['S2DQ2'] = data['S2DQ2'].replace({2: 0, 9: numpy.nan}) c2 = data['S2DQ2'].value_counts(sort=False).sort_index() print(c2)
print("percentage blood/natural mother was alcoholic") p2 = data['S2DQ2'].value_counts(sort=False, normalize=True).sort_index() print (p2)
Data Management: Number of parents with background of alcoholism is calculated
0 = no parents; 1 = at least 1 parent (maybe one answer missing); 2 = 2 parents; nan = 1 unknown and 1 zero or both unknown
print("number blood/natural parents was alcoholic") data['Num_alcoholic_parents'] = numpy.where((data['S2DQ1'] == 1) & (data['S2DQ2'] == 1), 2, numpy.where((data['S2DQ1'] == 1) & (data['S2DQ2'] == 0), 1, numpy.where((data['S2DQ1'] == 0) & (data['S2DQ2'].isna()), numpy.nan, numpy.where((data['S2DQ1'] == 0) & (data['S2DQ2'].isna()), numpy.nan, numpy.where((data['S2DQ1'] == 0) & (data['S2DQ2'] == 0), 0, numpy.nan)))))
c5 = data['Num_alcoholic_parents'].value_counts(sort=False).sort_index() print(c5)
print("percentage blood/natural parents was alcoholic") p5 = data['Num_alcoholic_parents'].value_counts(sort=False, normalize=True).sort_index() print (p5)
___________________________________________________________________Graphs_________________________________________________________________________
Diagramm für c5 erstellen
plt.figure(figsize=(8, 5)) plt.bar(c5.index, c5.values) plt.xlabel('Num_alcoholic_parents') plt.ylabel('Häufigkeit') plt.title('Häufigkeitsverteilung von Num_alcoholic_parents') plt.xticks(c5.index) plt.show()
Diagramm für p5 erstellen
plt.figure(figsize=(8, 5)) plt.bar(p5.index, p5.values*100) plt.xlabel('Num_alcoholic_parents') plt.ylabel('Häufigkeit (%)') plt.title('Häufigkeitsverteilung von Num_alcoholic_parents') plt.xticks(c5.index) plt.show()
print("lineare Regression")
Entfernen Sie Zeilen mit NaN-Werten in den relevanten Spalten.
data_cleaned = data.dropna(subset=['Num_alcoholic_parents', 'S2BQ3A'])
Definieren Sie Ihre unabhängige Variable (X) und Ihre abhängige Variable (y).
X = data_cleaned['Num_alcoholic_parents'] y = data_cleaned['S2BQ3A']
Fügen Sie eine Konstante hinzu, um den Intercept zu berechnen.
X = sm.add_constant(X)
Erstellen Sie das lineare Regressionsmodell.
model = sm.OLS(y, X).fit()
Drucken Sie die Zusammenfassung des Modells.
print(model.summary()) Result
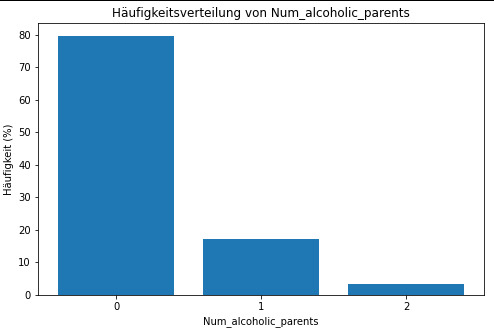
frequency distribution shows how many of the people from the study have alcoholic parents and if its only 1 oder both parents.
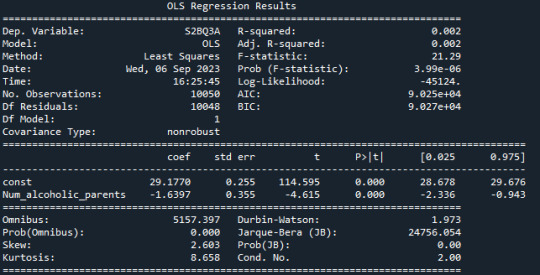
R-squared: The R-squared value is 0.002, indicating that only about 0.2% of the variation in "S2BQ3A" (quantity of alcoholic drinks consumed) is explained by the variable "Num_alcoholic_parents" (number of alcoholic parents). This suggests that there is likely no strong linear relationship between these two variables.
F-statistic: The F-statistic has a value of 21.29, and the associated probability (Prob (F-statistic)) is very small (3.99e-06). The F-statistic is used to assess the overall effectiveness of the model. In this case, the low probability suggests that at least one of the independent variables has a significant impact on the dependent variable.
Coefficients: The coefficients of the model show the estimated effects of the independent variables on the dependent variable. In this case, the constant (const) has a value of 29.1770, representing the estimated average value of "S2BQ3A" when "Num_alcoholic_parents" is zero. The coefficient for "Num_alcoholic_parents" is -1.6397, meaning that an additional alcoholic parent is associated with an average decrease of 1.6397 units in "S2BQ3A" (quantity of alcoholic drinks consumed).
P-Values (P>|t|): The p-values next to the coefficients indicate the significance of each coefficient. In this case, both the constant and the coefficient for "Num_alcoholic_parents" are highly significant (p-values close to zero). This suggests that "Num_alcoholic_parents" has a statistically significant impact on "S2BQ3A."
AIC and BIC: AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) are model evaluation measures. Lower values indicate a better model fit. In this case, both AIC and BIC are relatively low, which could indicate the adequacy of the model.
In summary, there is a statistically significant but very weak negative relationship between the number of alcoholic parents and the quantity of alcoholic drinks consumed. This means that an increase in the number of alcoholic parents is associated with a slight decrease in the quantity of alcohol consumed, but it explains only a very limited amount of the variation in the quantity of alcohol consumed.
0 notes
Text
Data analysis Tools: Module 3. Pearson correlation coefficient (r / r2)
According my last studies ( ANOVA and Chi square test of independence), there is a relationship between the variables under observation:
Quantitative variable: Femaeemployrate (Percentage of female population, age above 15, that has been employed during the given year)
Quantitative variable: Incomeperperson (Gross Domestic Product per capita in constant 2000 US$).
I have calculated the Pearson Correlation coefficient and I have created the graphic:
“association between Income per person and Female employ rate
PearsonRResult(statistic=0.3212540576761761, pvalue=0.015769942076727345)”
r=0.3212540576761761à It means that the correlation between female employ rate and income per person rate is positive and it is stark (near to 0)
p-value=0,015 < 0.05 it means that the is a relationship
The graphic shows the positive correlation.
In the graphic in the low range of the x axis is obserbed a different correlation, perhaps this correlation should be also analysis.
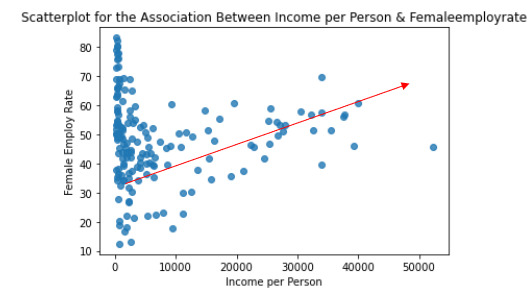
And the r2=0,32125*0,32125= 0,10
It can be predicted 10% of the variability in the rate of female employ rate according the income per person. (The fraction of the variability of one variable that can be predicted by the other).
Program:
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 31 13:59:25 2023
@author: ANA4MD
"""
import pandas
import numpy
import seaborn
import scipy
import matplotlib.pyplot as plt
data = pandas.read_csv('gapminder.csv', low_memory=False)
# lower-case all DataFrame column names - place after code for loading data above
data.columns = list(map(str.lower, data.columns))
# bug fix for display formats to avoid run time errors - put after code for loading data above
pandas.set_option('display.float_format', lambda x: '%f' % x)
# to fix empty data to avoid errors
data = data.replace(r'^\s*$', numpy.NaN, regex=True)
# checking the format of my variables and set to numeric
data['femaleemployrate'].dtype
data['polityscore'].dtype
data['incomeperperson'].dtype
data['urbanrate'].dtype
data['femaleemployrate'] = pandas.to_numeric(data['femaleemployrate'], errors='coerce', downcast=None)
data['polityscore'] = pandas.to_numeric(data['polityscore'], errors='coerce', downcast=None)
data['incomeperperson'] = pandas.to_numeric(data['incomeperperson'], errors='coerce', downcast=None)
data['urbanrate'] = pandas.to_numeric(data['urbanrate'], errors='coerce', downcast=None)
data['incomeperperson']=data['incomeperperson'].replace(' ', numpy.nan)
# to create bivariate graph for the selected variables
print('relationship femaleemployrate & income per person')
# bivariate bar graph Q->Q
scat2 = seaborn.regplot(
x="incomeperperson", y="femaleemployrate", fit_reg=False, data=data)
plt.xlabel('Income per Person')
plt.ylabel('Female Employ Rate')
plt.title('Scatterplot for the Association Between Income per Person & Femaleemployrate')
data_clean=data.dropna()
print ('association between Income per person and Female employ rate')
print (scipy.stats.pearsonr(data_clean['incomeperperson'], data_clean['femaleemployrate']))
Results:
relationship femaleemployrate & income per person
association between Income per person and Female employ rate
PearsonRResult(statistic=0.3212540576761761, pvalue=0.015769942076727345)
Data analysis Tools: Module 3. Pearson correlation coefficient (r / r2)
According my last studies ( ANOVA and Chi square test of independence), there is a relationship between the variables under observation:
Quantitative variable: Femaeemployrate (Percentage of female population, age above 15, that has been employed during the given year)
Quantitative variable: Incomeperperson (Gross Domestic Product per capita in constant 2000 US$).
I have calculated the Pearson Correlation coefficient and I have created the graphic:
“association between Income per person and Female employ rate
PearsonRResult(statistic=0.3212540576761761, pvalue=0.015769942076727345)”
r=0.3212540576761761à It means that the correlation is positive and it is stark (near to 0)
p-value=0,015 < 0.05 à it means that the is a relationship
The graphic shows the positive correlation.
And the r2=0,32125*0,32125= 0,10àwe can predict 10% of the variability in the rate of female employ rate according the income per person. (The fraction of the variability of one variable that can be predicted by the other).
Program:
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 31 13:59:25 2023
@author: ANA4MD
"""
import pandas
import numpy
import seaborn
import scipy
import matplotlib.pyplot as plt
data = pandas.read_csv('gapminder.csv', low_memory=False)
# lower-case all DataFrame column names - place after code for loading data above
data.columns = list(map(str.lower, data.columns))
# bug fix for display formats to avoid run time errors - put after code for loading data above
pandas.set_option('display.float_format', lambda x: '%f' % x)
# to fix empty data to avoid errors
data = data.replace(r'^\s*$', numpy.NaN, regex=True)
# checking the format of my variables and set to numeric
data['femaleemployrate'].dtype
data['polityscore'].dtype
data['incomeperperson'].dtype
data['urbanrate'].dtype
data['femaleemployrate'] = pandas.to_numeric(data['femaleemployrate'], errors='coerce', downcast=None)
data['polityscore'] = pandas.to_numeric(data['polityscore'], errors='coerce', downcast=None)
data['incomeperperson'] = pandas.to_numeric(data['incomeperperson'], errors='coerce', downcast=None)
data['urbanrate'] = pandas.to_numeric(data['urbanrate'], errors='coerce', downcast=None)
data['incomeperperson']=data['incomeperperson'].replace(' ', numpy.nan)
# to create bivariate graph for the selected variables
print('relationship femaleemployrate & income per person')
# bivariate bar graph Q->Q
scat2 = seaborn.regplot(
x="incomeperperson", y="femaleemployrate", fit_reg=False, data=data)
plt.xlabel('Income per Person')
plt.ylabel('Female Employ Rate')
plt.title('Scatterplot for the Association Between Income per Person & Femaleemployrate')
data_clean=data.dropna()
print ('association between Income per person and Female employ rate')
print (scipy.stats.pearsonr(data_clean['incomeperperson'], data_clean['femaleemployrate']))
Results:
relationship femaleemployrate & income per person
association between Income per person and Female employ rate
PearsonRResult(statistic=0.3212540576761761, pvalue=0.015769942076727345)
0 notes
Text
0 notes
Text
Course: Data Analysis Tools | Assignment Week 4
For assessment of a moderating effect by a third variable, I studied the association between the life expectancy and the breast cancer rate of the Gapminder dataset.
The scatterplot clearly indicates that breast cancer rate increases with life expectancy. This is not surprising, as the chance to develop breast cancer increases with longer life time. At the same time, low breast cancer rates are distributed over a wide range of life expectancy. Thus, the hypothesis was that the development of a country (i.e. the urban rate) poses a moderating effect on the correlation between breast cancer rate and life expectancy.

Results:
The correlation is statistically significant for all three urban rate groups (Low, Mid, High)
The correlation gets more positive for higher urban rate
So I'd infer that there is no major moderation effect, but potentially a minor one that leads to a more positive correlation with increasing urban rate
association between life expectancy and breast cancer rate for countries with LOW urban rate (0.40957438891713366, 0.0031404508682154326)
association between life expectancy and breast cancer rate for countries with MIDDLE urban rate (0.5405502238971076, 1.1386264359630638e-06)
association between life expectancy and breast cancer rate for countries with HIGH urban rate (0.6334067851215266, 6.086281365524001e-07)
Code:
Import Libraries
import pandas import numpy import seaborn import matplotlib.pyplot as plt
smf provides ANOVA F-test
import statsmodels.formula.api as smf
multi includes the package to do Post Hoc multi comparison test
import statsmodels.stats.multicomp as multi
scipy includes the Chi Squared Test of Independence
import scipy.stats
bug fix for display formats to avoid run time errors
pandas.set_option('display.float_format', lambda x:'%f'%x)
Set Pandas to show all colums and rows in Dataframes
pandas.set_option('display.max_columns', None) pandas.set_option('display.max_rows', None)
Import gapminder.csv
data = pandas.read_csv('gapminder.csv', low_memory=False)
Replace all empty entries with 0
data = data.replace(r'^\s*$', numpy.NaN, regex=True)
Extract relevant variables from original dataset and save it in subdata set
print('List of extracted variables in subset') subdata = data[['breastcancerper100th', 'lifeexpectancy', 'urbanrate']]
Safe backup file of reduced dataset
subdata2 = subdata.copy()
Convert all entries to numeric format
subdata2['breastcancerper100th'] = pandas.to_numeric(subdata2['breastcancerper100th']) subdata2['lifeexpectancy'] = pandas.to_numeric(subdata2['lifeexpectancy']) subdata2['urbanrate'] = pandas.to_numeric(subdata2['urbanrate'])
All rows containing value 0 / previously had no entry are deleted from the subdata set
subdata2 = subdata2.dropna() print(subdata2)
Describe statistical distribution of variable values
print('Statistics on "Breastcancerper100th"') desc_income = subdata2['breastcancerper100th'].describe() print(desc_income) print('Statistics on "Life Expectancy"') desc_lifeexp = subdata2['lifeexpectancy'].describe() print(desc_lifeexp) print('Statistics on "urban rate"') desc_suicide = subdata2['urbanrate'].describe() print(desc_suicide)
Identify min & max values within each column
print('Minimum & Maximum Breastcancerper100th') min_bcr = min(subdata2['breastcancerper100th']) print(min_bcr) max_bcr = max(subdata2['breastcancerper100th']) print(max_bcr) print('')
print('Minimum & Maximum Life Expectancy') min_lifeexp = min(subdata2['lifeexpectancy']) print(min_lifeexp) max_lifeexp = max(subdata2['lifeexpectancy']) print(max_lifeexp) print('')
print('Minimum & Maximum Urban Rate') min_srate = min(subdata2['urbanrate']) print(min_srate) max_srate = max(subdata2['urbanrate']) print(max_srate) print('')
scat1 = seaborn.regplot(x="breastcancerper100th", y="lifeexpectancy", fit_reg=True, data=subdata2) plt.xlabel('Breast cancer rate per 100') plt.ylabel('Life expectancy, years') plt.title('Scatterplot for the Association Between Life Expectancy and Breast Cancer rate per 100')
scat2 = seaborn.regplot(x="urbanrate", y="breastcancerper100th", fit_reg=True, data=subdata2) plt.xlabel('Breast cancer rate per 100') plt.ylabel('urban rate') plt.title('Scatterplot for the Association Between Breast Cancer rate and urban rate')
print (scipy.stats.pearsonr(subdata2['breastcancerper100th'], subdata2['urbanrate']))
def urbanrategrp (row): if row['urbanrate'] <= 40: return 1 elif row['urbanrate'] <= 70: return 2 elif row['urbanrate'] <= 100: return 3
subdata2['urbanrategrp'] = subdata2.apply (lambda row: urbanrategrp (row),axis=1)
chk1 = subdata2['urbanrategrp'].value_counts(sort=False, dropna=False) print(chk1)
sub1=subdata2[(subdata2['urbanrategrp']== 1)] sub2=subdata2[(subdata2['urbanrategrp']== 2)] sub3=subdata2[(subdata2['urbanrategrp']== 3)]
print ('association between life expectancy and breast cancer rate for countries with LOW urban rate') print (scipy.stats.pearsonr(sub1['lifeexpectancy'], sub1['breastcancerper100th'])) print (' ') print ('association between life expectancy and breast cancer rate for countries with MIDDLE urban rate') print (scipy.stats.pearsonr(sub2['lifeexpectancy'], sub2['breastcancerper100th'])) print (' ') print ('association between life expectancy and breast cancer rate for countries with HIGH urban rate') print (scipy.stats.pearsonr(sub3['lifeexpectancy'], sub3['breastcancerper100th']))
0 notes
Text
Hypothesis Testing and Chi Square Test of Independence
This assignment aims to directly test my hypothesis by evaluating, based on a sample of 2412 U.S. cannabis users aged between 18 and 30 years old (subsetc2), my research question with the goal of generalizing the results to the larger population of NESARC survey, from where the sample has been drawn. Therefore, I statistically assessed the evidence, provided by NESARC codebook, in favor of or against the association between cannabis use and mental illnesses, such as major depression and general anxiety, in U.S. adults. As a result, in the first place I used crosstab function, in order to produce a contingency table of observed counts and percentages for each disorder separately. Next, I wanted to examine if the cannabis use status (1=Yes or 2=No) variable ‘S3BQ1A5’, which is a 2-level categorical explanatory variable, is correlated with depression (‘MAJORDEP12’) and anxiety (‘GENAXDX12’) disorders, which are both categorical response variables. Thus, I ran Chi-square Test of Independence (C->C) twice and calculated the χ-squared values and the associated p-values for each disorder, so that null and alternate hypothesis are specified. In addition, in order visualize the association between frequency of cannabis use and depression diagnosis, I used factorplot function to produce a bivariate graph. Furthermore, I used crosstab function once again and tested the association between the frequency of cannabis use (‘S3BD5Q2E’), which is a 10-level categorical explanatory variable, and major depression diagnosis, which is a categorical response variable. In this case, for my third Chi-square Test of Independence (C->C), after measuring the χ-square value and the p-value, in order to determine which frequency groups are different from the others, I performed a post hoc test, using Bonferroni Adjustment approach, since my explanatory variable has more than 2 levels. In the case of ten groups, I actually need to conduct 45 pair wise comparisons, but in fact I examined indicatively two and compared their p-values with the Bonferroni adjusted p-value, which is calculated by dividing p=0.05 by 45. By this way it is possible to identify the situations where null hypothesis can be safely rejected without making an excessive type 1 error. For the code and the output I used Spyder (IDE).
FOLLOWING IS A CODE WHICH IS USE TO CONDUCT
Chi Square Test
import pandas import numpy import scipy.stats import seaborn import matplotlib.pyplot as plt
nesarc = pandas.read_csv ('nesarc_pds.csv' , low_memory=False)
Set PANDAS to show all columns in DataFrame
pandas.set_option('display.max_columns', None)
Set PANDAS to show all rows in DataFrame
pandas.set_option('display.max_rows', None)
nesarc.columns = map(str.upper , nesarc.columns)
pandas.set_option('display.float_format' , lambda x:'%f'%x)
Change my variables to numeric
nesarc['AGE'] = pandas.to_numeric(nesarc['AGE'], errors='coerce') nesarc['S3BQ4'] = pandas.to_numeric(nesarc['S3BQ4'], errors='coerce') nesarc['S3BQ1A5'] = pandas.to_numeric(nesarc['S3BQ1A5'], errors='coerce') nesarc['S3BD5Q2B'] = pandas.to_numeric(nesarc['S3BD5Q2B'], errors='coerce') nesarc['S3BD5Q2E'] = pandas.to_numeric(nesarc['S3BD5Q2E'], errors='coerce') nesarc['MAJORDEP12'] = pandas.to_numeric(nesarc['MAJORDEP12'], errors='coerce') nesarc['GENAXDX12'] = pandas.to_numeric(nesarc['GENAXDX12'], errors='coerce')
Subset my sample
subset1 = nesarc[(nesarc['AGE']>=18) & (nesarc['AGE']<=30)] # Ages 18-30 subsetc1 = subset1.copy()
subset2 = nesarc[(nesarc['AGE']>=18) & (nesarc['AGE']<=30) & (nesarc['S3BQ1A5']==1)] # Cannabis users, ages 18-30 subsetc2 = subset2.copy()
Setting missing data for frequency and cannabis use, variables S3BD5Q2E, S3BQ1A5
subsetc1['S3BQ1A5']=subsetc1['S3BQ1A5'].replace(9, numpy.nan) subsetc2['S3BD5Q2E']=subsetc2['S3BD5Q2E'].replace('BL', numpy.nan) subsetc2['S3BD5Q2E']=subsetc2['S3BD5Q2E'].replace(99, numpy.nan)
Contingency table of observed counts of major depression diagnosis (response variable) within cannabis use (explanatory variable), in ages 18-30
contab1=pandas.crosstab(subsetc1['MAJORDEP12'], subsetc1['S3BQ1A5']) print (contab1)
Column percentages
colsum=contab1.sum(axis=0) colpcontab=contab1/colsum print(colpcontab)
Chi-square calculations for major depression within cannabis use status
print ('Chi-square value, p value, expected counts, for major depression within cannabis use status') chsq1= scipy.stats.chi2_contingency(contab1) print (chsq1)
Contingency table of observed counts of geberal anxiety diagnosis (response variable) within cannabis use (explanatory variable), in ages 18-30
contab2=pandas.crosstab(subsetc1['GENAXDX12'], subsetc1['S3BQ1A5']) print (contab2)
Column percentages
colsum2=contab2.sum(axis=0) colpcontab2=contab2/colsum2 print(colpcontab2)
Chi-square calculations for general anxiety within cannabis use status
print ('Chi-square value, p value, expected counts, for general anxiety within cannabis use status') chsq2= scipy.stats.chi2_contingency(contab2) print (chsq2)
#
Contingency table of observed counts of major depression diagnosis (response variable) within frequency of cannabis use (10 level explanatory variable), in ages 18-30
contab3=pandas.crosstab(subset2['MAJORDEP12'], subset2['S3BD5Q2E']) print (contab3)
Column percentages
colsum3=contab3.sum(axis=0) colpcontab3=contab3/colsum3 print(colpcontab3)
Chi-square calculations for mahor depression within frequency of cannabis use groups
print ('Chi-square value, p value, expected counts for major depression associated frequency of cannabis use') chsq3= scipy.stats.chi2_contingency(contab3) print (chsq3)
recode1 = {1: 9, 2: 8, 3: 7, 4: 6, 5: 5, 6: 4, 7: 3, 8: 2, 9: 1} # Dictionary with details of frequency variable reverse-recode subsetc2['CUFREQ'] = subsetc2['S3BD5Q2E'].map(recode1) # Change variable name from S3BD5Q2E to CUFREQ
subsetc2["CUFREQ"] = subsetc2["CUFREQ"].astype('category')
Rename graph labels for better interpretation
subsetc2['CUFREQ'] = subsetc2['CUFREQ'].cat.rename_categories(["2 times/year","3-6 times/year","7-11 times/years","Once a month","2-3 times/month","1-2 times/week","3-4 times/week","Nearly every day","Every day"])
Graph percentages of major depression within each cannabis smoking frequency group
plt.figure(figsize=(12,4)) # Change plot size ax1 = seaborn.factorplot(x="CUFREQ", y="MAJORDEP12", data=subsetc2, kind="bar", ci=None) ax1.set_xticklabels(rotation=40, ha="right") # X-axis labels rotation plt.xlabel('Frequency of cannabis use') plt.ylabel('Proportion of Major Depression') plt.show()
Post hoc test, pair comparison of frequency groups 1 and 9, 'Every day' and '2 times a year'
recode2 = {1: 1, 9: 9} subsetc2['COMP1v9']= subsetc2['S3BD5Q2E'].map(recode2)
Contingency table of observed counts
ct4=pandas.crosstab(subsetc2['MAJORDEP12'], subsetc2['COMP1v9']) print (ct4)
Column percentages
colsum4=ct4.sum(axis=0) colpcontab4=ct4/colsum4 print(colpcontab4)
Chi-square calculations for pair comparison of frequency groups 1 and 9, 'Every day' and '2 times a year'
print ('Chi-square value, p value, expected counts, for pair comparison of frequency groups -Every day- and -2 times a year-') cs4= scipy.stats.chi2_contingency(ct4) print (cs4)
Post hoc test, pair comparison of frequency groups 2 and 6, 'Nearly every day' and 'Once a month'
recode3 = {2: 2, 6: 6} subsetc2['COMP2v6']= subsetc2['S3BD5Q2E'].map(recode3)
Contingency table of observed counts
ct5=pandas.crosstab(subsetc2['MAJORDEP12'], subsetc2['COMP2v6']) print (ct5)
Column percentages
colsum5=ct5.sum(axis=0) colpcontab5=ct5/colsum5 print(colpcontab5)
Chi-square calculations for pair comparison of frequency groups 2 and 6, 'Nearly every day' and 'Once a month'
print ('Chi-square value, p value, expected counts for pair comparison of frequency groups -Nearly every day- and -Once a month-') cs5= scipy.stats.chi2_contingency(ct5) print (cs5)
OUTPUT:

When examining the patterns of association between major depression (categorical response variable) and cannabis use status (categorical explanatory variable), a chi-square test of independence revealed that among young adults aged between 18 and 30 years old (subsetc1), those who were cannabis users, were more likely to have been diagnosed with major depression in the last 12 months (18%), compared to the non-users (8.4%), X2 =171.6, 1 df, p=3.16e-39 (p-value is written in scientific notation). As a result, since our p-value is extremely small, the data provides significant evidence against the null hypothesis. Thus, we reject the null hypothesis and accept the alternate hypothesis, which indicates that there is a positive correlation between cannabis use and depression diagnosis.

When testing the correlation between general anxiety (categorical response variable) and cannabis use status (categorical explanatory variable), a chi-square test of independence revealed that among young adults aged between 18 and 30 years old (subsetc1), those who were cannabis users, were more likely to have been diagnosed with general anxiety in the last 12 months (3.8%), compared to the non-users (1.6%), X2 =40.22, 1 df, p=2.26e-10 (p-value is written in scientific notation). As a result, since our p-value is again extremely small, the data provides significant evidence against the null hypothesis. Thus, we reject the null hypothesis and accept the alternate hypothesis, which indicates that there is a positive correlation between cannabis use and anxiety diagnosis.

A Chi Square test of independence revealed that among cannabis users aged between 18 and 30 years old (subsetc2), the frequency of cannabis use (explanatory variable collapsed into 10 ordered categories) and past year depression diagnosis (response binary categorical variable) were significantly associated, X2 =35.18, 10 df, p=0.00011.

In the bivariate graph (C->C) presented above, we can see the correlation between frequency of cannabis use (explanatory variable) and major depression diagnosis in the past year (response variable). Obviously, we have a left-skewed distribution, which indicates that the more an individual (18-30) smoked cannabis, the better were the chances to have experienced depression in the last 12 months.

The post hoc comparison (Bonferroni Adjustment) of rates of major depression by the pair of “Every day” and “2 times a year” frequency categories, revealed that the p-value is 0.00019 and the percentages of major depression diagnosis for each frequency group are 23.7% and 11.6% respectively. As a result, since the p-value is smaller than the Bonferroni adjusted p-value (adj p-value = 0.05 / 45 = 0.0011>0.00019), we can assume that these two rates are significantly different from one another. Therefore, we reject the null hypothesis and accept the alternate.

Similarly, the post hoc comparison (Bonferroni Adjustment) of rates of major depression by the pair of "Nearly every day” and “once a month” frequency categories, indicated that the p-value is 0.046 and the proportions of major depression diagnosis for each frequency group are 23.3% and 13.7% respectively. As a result, since the p-value is larger than the Bonferroni adjusted p-value (adj p-value = 0.05 / 45 = 0.0011<0.046), we can assume that these two rates are not significantly different from one another. Therefore, we accept the null hypothesis.
0 notes
Text
Hypothesis Testing with Pearson Correlation
Introduction:
This assignment examines a 2412 sample of Marijuana / Cannabis users from the NESRAC dataset between the ages of 18 and 30. My Research question is as follows:
Is the number of Cannabis joints smoked per day amongst young adults in USA between the Ages of 18 and 30 the leading cause of mental health disorders such as depression and anxiety?
My Hypothesis Test statements are as follows:
H0: The number of Cannabis joints smoked per day amongst young adults in USA between the Ages of 18 and 30 is not the leading cause of mental health disorders such as depression and anxiety.
Ha: The number of Cannabis joints smoked per day amongst young adults in USA between the Ages of 18 and 30 is the leading cause of mental health disorders such as depression and anxiety.
Explanation of the Code:
My research question only categorical variables but for this Pearson Correlation test I have selected three different quantitative variables from the NESARC dataset. Thus, I have refined the hypothesis and examined the correlation between age with the people that have been using cannabis the most, which is the quantitative explanatory variable (‘S3BD5Q2F’) and the age when they experienced their first episode of general anxiety and major depression, which are the quantitative response variables (‘S9Q6A’) and (‘S4AQ6A’).
For visualizing the relationship and association between cannabis use and general anxiety and major depression episodes, I used the seaborn library to produce scatterplots for each of the mental health disorders separately and the interpretation thereof, by describing the direction as well as the strength and form of the relationships. Additionally I ran a Pearson correlation test twice, one for each mental health disorder, and measured the strength of the relationships between each of the quantitative variables by generating the correlation coefficients “r” and their associated p-values.
Code / Syntax:
-- coding: utf-8 --
""" Created on Mon Apr 2 15:00:39 2023
@author: Oteng """
import pandas import numpy import seaborn import scipy import matplotlib.pyplot as plt
nesarc = pandas.read_csv ('nesarc_pds.csv' , low_memory=False)
Set PANDAS to show all columns in DataFrame
pandas.set_option('display.max_columns', None)
Set PANDAS to show all rows in DataFrame
pandas.set_option('display.max_rows', None)
nesarc.columns = map(str.upper , nesarc.columns)
pandas.set_option('display.float_format' , lambda x:'%f'%x)
Change my variables variables of interest to numeric
nesarc['AGE'] = pandas.to_numeric(nesarc['AGE'], errors='coerce') nesarc['S3BQ4'] = pandas.to_numeric(nesarc['S3BQ4'], errors='coerce') nesarc['S4AQ6A'] = pandas.to_numeric(nesarc['S4AQ6A'], errors='coerce') nesarc['S3BD5Q2F'] = pandas.to_numeric(nesarc['S3BD5Q2F'], errors='coerce') nesarc['S9Q6A'] = pandas.to_numeric(nesarc['S9Q6A'], errors='coerce') nesarc['S4AQ7'] = pandas.to_numeric(nesarc['S4AQ7'], errors='coerce') nesarc['S3BQ1A5'] = pandas.to_numeric(nesarc['S3BQ1A5'], errors='coerce')
Subset my sample
subset1 = nesarc[(nesarc['S3BQ1A5']==1)] #Cannabis users subsetc1 = subset1.copy()
Setting missing data
subsetc1['S3BQ1A5']=subsetc1['S3BQ1A5'].replace(9, numpy.nan) subsetc1['S3BD5Q2F']=subsetc1['S3BD5Q2F'].replace('BL', numpy.nan) subsetc1['S3BD5Q2F']=subsetc1['S3BD5Q2F'].replace(99, numpy.nan) subsetc1['S4AQ6A']=subsetc1['S4AQ6A'].replace('BL', numpy.nan) subsetc1['S4AQ6A']=subsetc1['S4AQ6A'].replace(99, numpy.nan) subsetc1['S9Q6A']=subsetc1['S9Q6A'].replace('BL', numpy.nan) subsetc1['S9Q6A']=subsetc1['S9Q6A'].replace(99, numpy.nan)
Scatterplot for the age when began using cannabis the most and the age of first episode of major depression
plt.figure(figsize=(12,4)) # Change plot size scat1 = seaborn.regplot(x="S3BD5Q2F", y="S4AQ6A", fit_reg=True, data=subset1) plt.xlabel('Age when began using cannabis the most') plt.ylabel('Age when expirenced the first episode of major depression') plt.title('Scatterplot for the age when began using cannabis the most and the age of first the episode of major depression') plt.show()
data_clean=subset1.dropna()
Pearson correlation coefficient for the age when began using cannabis the most and the age of first the episode of major depression
print ('Association between the age when began using cannabis the most and the age of the first episode of major depression') print (scipy.stats.pearsonr(data_clean['S3BD5Q2F'], data_clean['S4AQ6A']))
Scatterplot for the age when began using cannabis the most and the age of the first episode of general anxiety
plt.figure(figsize=(12,4)) # Change plot size scat2 = seaborn.regplot(x="S3BD5Q2F", y="S9Q6A", fit_reg=True, data=subset1) plt.xlabel('Age when began using cannabis the most') plt.ylabel('Age when expirenced the first episode of general anxiety') plt.title('Scatterplot for the age when began using cannabis the most and the age of the first episode of general anxiety') plt.show()
Pearson correlation coefficient for the age when began using cannabis the most and the age of the first episode of general anxiety
print ('Association between the age when began using cannabis the most and the age of first the episode of general anxiety') print (scipy.stats.pearsonr(data_clean['S3BD5Q2F'], data_clean['S9Q6A']))
Output 1
Pearson Correlation test results are as follows:



Output 2:

The scatterplot illustrates the relationship and correlation between the age individuals started using cannabis the most, a quantitative explanatory variable, and the age when they started experiencing their first major depression episode, a quantitative response variable. The direction is a positively increasing relationship; as the age when individual began using cannabis the most increases, the age when they experience their first major depression episode increases. From the Pearson Correlation test, which resulted in a correlation of coefficient of 0.23, indicates a weak positive linear relationship between the two quantitative variables of interest. The associated p-value is 2.27e-09 which is significantly small. This means that the relationship is statistically significant and indicates that the association between the two quantitative variables of interest is weak.
Output 3:

From the scatterplot above the association between the age of when individuals began using cannabis the most, quantitative explanatory variable, and the age when they experience their first general anxiety episode, a quantitative response variable. The direction is a positive linear relationship. The Pearson Correlation test, which resulted in a correlation coefficient of 0.1494, which indicates a weak positive linear relationship between the two quantitative variables. The associated p-value is 0.00012 which indicates a statistically significant relationship. Thus the relationship between the age of when individuals began using cannabis the most and the age when they experience their first general anxiety episode is weak. The r^2 , which is 0.01, is very low for us to find the fraction of the variable that can be predicted from one variable to another.
0 notes
Photo
Machine Learning Week 3: Lasso
Question for this part
Is Having Relatives with Drinking Problems associated with current drinking status?
Parameters
I kept the parameters for this question the same as all the other question. I limited this study to participants who started drinking more than sips or tastes of alcohol between the ages of 5 and 83.
Explanation of Variables
Target Variable -- Response Variable: If the participant is currently drinking (Binary – Yes/No) –DRINKSTAT
· Currently Drinking – YES - 1
· Not Currently Drinking – No- 0 - I consolidated Ex-drinker and Lifetime Abstainer into a No category for the purposes of this experiment.
Explanatory Variables (Categorical):
· TOTALRELATIVES: If the participant has relatives with drinking problems or alcohol dependence (1=Yes, 0=No)
· SEX (1=male, 0=female)
· HISPLAT: Hispanic or Latino (1=Yes, 0=No)
· WHITE (1=Yes, 0=No)
· BLACK (1=Yes, 0=No)
· ASIAN (1=Yes, 0=No)
· PACISL: Pacific Islander or Native Hawaiian (1=Yes, 0=No)
· AMERIND: American Indian or Native Alaskan (1=Yes, 0=No)
Explanatory Variables (Quantitative):
· AGE
Lasso
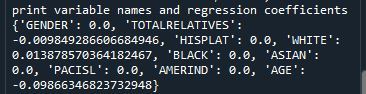
Predictor variables and the Regression Coefficients
Predictor variables with regression coefficients equal to zero means that the coefficients for those variables had shrunk to zero after applying the LASSO regression penalty, and were subsequently removed from the model. So the results show that of the 9 variables, 3 were chosen in the final model. All the variables were standardized on the same scale so we can also use the size of the regression coefficients to tell us which predictors are the strongest predictors of drinking status. For example, White ethnicity had the largest regression coefficient and was most strongly associated with drinking status. Age and total number of relatives with drinking problems were negatively associated with drinking status.
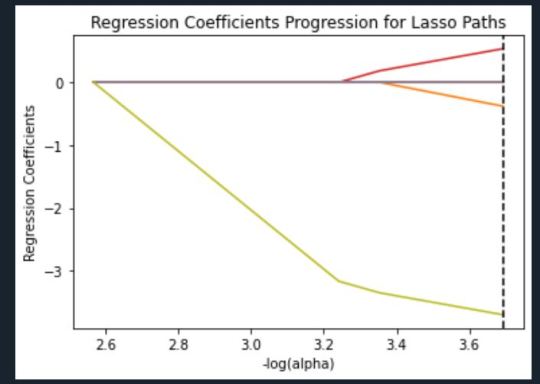
Regression Coefficients Progression Plot
This plot shows the relative importance of the predictor variable selected at any step of the selection process, how the regression coefficients changed with the addition of a new predictor at each step, and the steps at which each variable entered the new model. Age was entered first, it is the largest negative coefficient, then White ethnicity (the largest positive coefficient), and then Total Relatives (a negative coefficient).
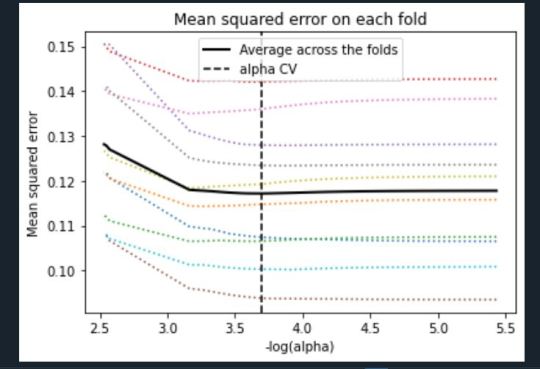
Mean Square Error Plot
The Mean Square Error plot shows the change in mean square error for the change in the penalty parameter alpha at each step in the selection process. The plot shows that there is variability across the individual cross-validation folds in the training data set, but the change in the mean square error as variables are added to the model follows the same pattern for each fold. Initially it decreases, and then levels off to a point a which adding more predictors doesn’t lead to much reduction in the mean square error.
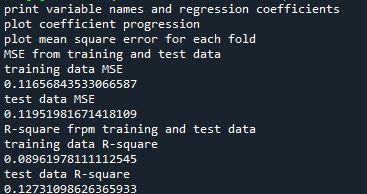
Mean Square Error for Training and Test Data
Training: 0.11656843533066587
Test: 0.11951981671418109
The test mean square error was very close to the training mean square error, suggesting that prediction accuracy was pretty stable across the two data sets.
R-Square from Training and Test Data
Training: 0.08961978111112545
Test: 0.12731098626365933
The R-Square values were 0.09 and 0.13, indicating that the selected model explained 9% and 13% of the variance in drinking status for the training and the test sets, respectively. This suggests that I should think about adding more explanatory variables but I must be careful and watch for an increase in variance and bias.
Python Code
from pandas import Series, DataFrame import pandas import numpy import os import matplotlib.pylab as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LassoLarsCV
os.environ['PATH'] = os.environ['PATH']+';'+os.environ['CONDA_PREFIX']+r"\Library\bin\graphviz"
data = pandas.read_csv('nesarc_pds.csv', low_memory=False)
## Machine learning week 3 addition## #upper-case all DataFrame column names data.columns = map(str.upper, data.columns) ## Machine learning week 3 addition##
#setting variables you will be working with to numeric data['IDNUM'] =pandas.to_numeric(data['IDNUM'], errors='coerce') data['AGE'] =pandas.to_numeric(data['AGE'], errors='coerce') data['SEX'] = pandas.to_numeric(data['SEX'], errors='coerce') data['S2AQ16A'] =pandas.to_numeric(data['S2AQ16A'], errors='coerce') data['S2BQ2D'] =pandas.to_numeric(data['S2BQ2D'], errors='coerce') data['S2DQ1'] =pandas.to_numeric(data['S2DQ1'], errors='coerce') data['S2DQ2'] =pandas.to_numeric(data['S2DQ2'], errors='coerce') data['S2DQ11'] =pandas.to_numeric(data['S2DQ11'], errors='coerce') data['S2DQ12'] =pandas.to_numeric(data['S2DQ12'], errors='coerce') data['S2DQ13A'] =pandas.to_numeric(data['S2DQ13A'], errors='coerce') data['S2DQ13B'] =pandas.to_numeric(data['S2DQ13B'], errors='coerce') data['S2DQ7C1'] =pandas.to_numeric(data['S2DQ7C1'], errors='coerce') data['S2DQ7C2'] =pandas.to_numeric(data['S2DQ7C2'], errors='coerce') data['S2DQ8C1'] =pandas.to_numeric(data['S2DQ8C1'], errors='coerce') data['S2DQ8C2'] =pandas.to_numeric(data['S2DQ8C2'], errors='coerce') data['S2DQ9C1'] =pandas.to_numeric(data['S2DQ9C1'], errors='coerce') data['S2DQ9C2'] =pandas.to_numeric(data['S2DQ9C2'], errors='coerce') data['S2DQ10C1'] =pandas.to_numeric(data['S2DQ10C1'], errors='coerce') data['S2DQ10C2'] =pandas.to_numeric(data['S2DQ10C2'], errors='coerce') data['S2BQ3A'] =pandas.to_numeric(data['S2BQ3A'], errors='coerce')
###### WEEK 4 ADDITIONS #####
#hispanic or latino data['S1Q1C'] =pandas.to_numeric(data['S1Q1C'], errors='coerce')
#american indian or alaskan native data['S1Q1D1'] =pandas.to_numeric(data['S1Q1D1'], errors='coerce')
#black or african american data['S1Q1D3'] =pandas.to_numeric(data['S1Q1D3'], errors='coerce')
#asian data['S1Q1D2'] =pandas.to_numeric(data['S1Q1D2'], errors='coerce')
#native hawaiian or pacific islander data['S1Q1D4'] =pandas.to_numeric(data['S1Q1D4'], errors='coerce')
#white data['S1Q1D5'] =pandas.to_numeric(data['S1Q1D5'], errors='coerce')
#consumer data['CONSUMER'] =pandas.to_numeric(data['CONSUMER'], errors='coerce')
data_clean = data.dropna()
data_clean.dtypes data_clean.describe()
sub1=data_clean[['IDNUM', 'AGE', 'SEX', 'S2AQ16A', 'S2BQ2D', 'S2BQ3A', 'S2DQ1', 'S2DQ2', 'S2DQ11', 'S2DQ12', 'S2DQ13A', 'S2DQ13B', 'S2DQ7C1', 'S2DQ7C2', 'S2DQ8C1', 'S2DQ8C2', 'S2DQ9C1', 'S2DQ9C2', 'S2DQ10C1', 'S2DQ10C2', 'S1Q1C', 'S1Q1D1', 'S1Q1D2', 'S1Q1D3', 'S1Q1D4', 'S1Q1D5', 'CONSUMER']]
sub2=sub1.copy()
#setting variables you will be working with to numeric cols = sub2.columns sub2[cols] = sub2[cols].apply(pandas.to_numeric, errors='coerce')
#subset data to people age 6 to 80 who have become alcohol dependent sub3=sub2[(sub2['S2AQ16A']>=5) & (sub2['S2AQ16A']<=83)]
#make a copy of my new subsetted data sub4 = sub3.copy()
#Explanatory Variables for Relatives #recode - nos set to zero recode1 = {1: 1, 2: 0, 3: 0}
sub4['DAD']=sub4['S2DQ1'].map(recode1) sub4['MOM']=sub4['S2DQ2'].map(recode1) sub4['PATGRANDDAD']=sub4['S2DQ11'].map(recode1) sub4['PATGRANDMOM']=sub4['S2DQ12'].map(recode1) sub4['MATGRANDDAD']=sub4['S2DQ13A'].map(recode1) sub4['MATGRANDMOM']=sub4['S2DQ13B'].map(recode1) sub4['PATBROTHER']=sub4['S2DQ7C2'].map(recode1) sub4['PATSISTER']=sub4['S2DQ8C2'].map(recode1) sub4['MATBROTHER']=sub4['S2DQ9C2'].map(recode1) sub4['MATSISTER']=sub4['S2DQ10C2'].map(recode1)
#### WEEK 4 ADDITIONS #### sub4['HISPLAT']=sub4['S1Q1C'].map(recode1) sub4['AMERIND']=sub4['S1Q1D1'].map(recode1) sub4['ASIAN']=sub4['S1Q1D2'].map(recode1) sub4['BLACK']=sub4['S1Q1D3'].map(recode1) sub4['PACISL']=sub4['S1Q1D4'].map(recode1) sub4['WHITE']=sub4['S1Q1D5'].map(recode1) sub4['DRINKSTAT']=sub4['CONSUMER'].map(recode1) sub4['GENDER']=sub4['SEX'].map(recode1) #### END WEEK 4 ADDITIONS ####
#Replacing unknowns with NAN sub4['DAD']=sub4['DAD'].replace(9, numpy.nan) sub4['MOM']=sub4['MOM'].replace(9, numpy.nan) sub4['PATGRANDDAD']=sub4['PATGRANDDAD'].replace(9, numpy.nan) sub4['PATGRANDMOM']=sub4['PATGRANDMOM'].replace(9, numpy.nan) sub4['MATGRANDDAD']=sub4['MATGRANDDAD'].replace(9, numpy.nan) sub4['MATGRANDMOM']=sub4['MATGRANDMOM'].replace(9, numpy.nan) sub4['PATBROTHER']=sub4['PATBROTHER'].replace(9, numpy.nan) sub4['PATSISTER']=sub4['PATSISTER'].replace(9, numpy.nan) sub4['MATBROTHER']=sub4['MATBROTHER'].replace(9, numpy.nan) sub4['MATSISTER']=sub4['MATSISTER'].replace(9, numpy.nan) sub4['S2DQ7C1']=sub4['S2DQ7C1'].replace(99, numpy.nan) sub4['S2DQ8C1']=sub4['S2DQ8C1'].replace(99, numpy.nan) sub4['S2DQ9C1']=sub4['S2DQ9C1'].replace(99, numpy.nan) sub4['S2DQ10C1']=sub4['S2DQ10C1'].replace(99, numpy.nan) sub4['S2AQ16A']=sub4['S2AQ16A'].replace(99, numpy.nan) sub4['S2BQ2D']=sub4['S2BQ2D'].replace(99, numpy.nan) sub4['S2BQ3A']=sub4['S2BQ3A'].replace(99, numpy.nan)
#add parents togetheR sub4['IFPARENTS'] = sub4['DAD'] + sub4['MOM']
#add grandparents together sub4['IFGRANDPARENTS'] = sub4['PATGRANDDAD'] + sub4['PATGRANDMOM'] + sub4['MATGRANDDAD'] + sub4['MATGRANDMOM']
#add IF aunts and uncles together sub4['IFUNCLEAUNT'] = sub4['PATBROTHER'] + sub4['PATSISTER'] + sub4['MATBROTHER'] + sub4['MATSISTER']
#add SUM uncle and aunts together sub4['SUMUNCLEAUNT'] = sub4['S2DQ7C1'] + sub4['S2DQ8C1'] + sub4['S2DQ9C1'] + sub4['S2DQ10C1']
#add relatives together sub4['SUMRELATIVES'] = sub4['IFPARENTS'] + sub4['IFGRANDPARENTS'] + sub4['SUMUNCLEAUNT']
def TOTALRELATIVES (row): if row['SUMRELATIVES'] == 0 : return 0 elif row['SUMRELATIVES'] >= 1 : return 1
sub4['TOTALRELATIVES'] = sub4.apply (lambda row: TOTALRELATIVES (row), axis=1)
sub4_clean = sub4.dropna()
sub4_clean.dtypes sub4_clean.describe()
###Machine Learning week 3 additions##
#select predictor variables and target variable as separate data sets
predvar = sub4_clean[['GENDER','TOTALRELATIVES', 'HISPLAT', 'WHITE', 'BLACK', 'ASIAN', 'PACISL', 'AMERIND', 'AGE']]
target = sub4_clean.DRINKSTAT
# standardize predictors to have mean=0 and sd=1 predictors=predvar.copy() from sklearn import preprocessing
predictors['GENDER']=preprocessing.scale(predictors['GENDER'].astype('float64')) predictors['TOTALRELATIVES']=preprocessing.scale(predictors['TOTALRELATIVES'].astype('float64')) predictors['HISPLAT']=preprocessing.scale(predictors['HISPLAT'].astype('float64')) predictors['WHITE']=preprocessing.scale(predictors['WHITE'].astype('float64')) predictors['BLACK']=preprocessing.scale(predictors['BLACK'].astype('float64')) predictors['ASIAN']=preprocessing.scale(predictors['ASIAN'].astype('float64')) predictors['PACISL']=preprocessing.scale(predictors['PACISL'].astype('float64')) predictors['AMERIND']=preprocessing.scale(predictors['AMERIND'].astype('float64')) predictors['AGE']=preprocessing.scale(predictors['AGE'].astype('float64'))
# split data into train and test sets pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, target, test_size=.3, random_state=123)
# specify the lasso regression model model=LassoLarsCV(cv=10, precompute=False).fit(pred_train,tar_train)
# print variable names and regression coefficients print("print variable names and regression coefficients") coef_dict = dict(zip(predictors.columns, model.coef_)) print(coef_dict)
# plot coefficient progression print("plot coefficient progression") m_log_alphas = -numpy.log10(model.alphas_) ax = plt.gca() plt.plot(m_log_alphas, model.coef_path_.T) plt.axvline(-numpy.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.ylabel('Regression Coefficients') plt.xlabel('-log(alpha)') plt.title('Regression Coefficients Progression for Lasso Paths')
# plot mean square error for each fold print("plot mean square error for each fold") m_log_alphascv = -numpy.log10(model.cv_alphas_) plt.figure() plt.plot(m_log_alphascv, model.cv_mse_path_, ':') plt.plot(m_log_alphascv, model.cv_mse_path_.mean(axis=-1), 'k', label='Average across the folds', linewidth=2) plt.axvline(-numpy.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.legend() plt.xlabel('-log(alpha)') plt.ylabel('Mean squared error') plt.title('Mean squared error on each fold')
# MSE from training and test data print("MSE from training and test data") from sklearn.metrics import mean_squared_error train_error = mean_squared_error(tar_train, model.predict(pred_train)) test_error = mean_squared_error(tar_test, model.predict(pred_test)) print ('training data MSE') print(train_error) print ('test data MSE') print(test_error)
# R-square from training and test data print("R-square frpm training and test data") rsquared_train=model.score(pred_train,tar_train) rsquared_test=model.score(pred_test,tar_test) print ('training data R-square') print(rsquared_train) print ('test data R-square') print(rsquared_test)
1 note
·
View note