#Python Pandas Tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text

Learn data analysis easily with this Python Pandas Tutorial. It covers all the basics of Pandas, including DataFrames and Series, perfect for beginners who want to work with data.
0 notes
Text
Python Pandas Tutorial: The Ultimate Guide to DataFrames and Series

If you want to work with data in Python, then this Python Pandas Tutorial is the perfect starting point for you. Pandas is one of the most popular libraries in Python used for data analysis and data handling. It helps users organize, clean, and understand data with simple tools and functions.
Pandas makes it easy to work with structured data like tables and spreadsheets. The two most important tools in Pandas are Series and DataFrames. A Series is a one-dimensional list of data, while a DataFrame is a two-dimensional table made up of rows and columns, just like an Excel sheet.
This Python Pandas Tutorial is designed for beginners who are new to Python or data science. You don’t need to be an expert programmer. With Pandas, you can do many tasks such as reading data from files (like CSV or Excel), filtering information, sorting, removing duplicates, and even calculating values like average or total.
Pandas is widely used in jobs like data analysis, machine learning, and business intelligence. It helps save time by making complex tasks easy and quick. Learning Pandas is a big step toward becoming a skilled data analyst or data scientist.
If you're looking to learn more in a simple and structured way, visit Python Pandas Tutorial for a complete beginner-friendly guide. It’s a great resource to start your data journey with confidence!
0 notes
Text
Unlock the Power of Pandas: Easy-to-Follow Python Tutorial for Newbies

Python Pandas is a powerful tool for working with data, making it a must-learn library for anyone starting in data analysis. With Pandas, you can effortlessly clean, organize, and analyze data to extract meaningful insights. This tutorial is perfect for beginners looking to get started with Pandas.
Pandas is a Python library designed specifically for data manipulation and analysis. It offers two main data structures: Series and DataFrame. A Series is like a single column of data, while a DataFrame is a table-like structure that holds rows and columns, similar to a spreadsheet.
Why use Pandas? First, it simplifies handling large datasets by providing easy-to-use functions for filtering, sorting, and grouping data. Second, it works seamlessly with other popular Python libraries, such as NumPy and Matplotlib, making it a versatile tool for data projects.
Getting started with Pandas is simple. After installing the library, you can load datasets from various sources like CSV files, Excel sheets, or even databases. Once loaded, Pandas lets you perform tasks like renaming columns, replacing missing values, or summarizing data in just a few lines of code.
If you're looking to dive deeper into how Pandas can make your data analysis journey smoother, explore this beginner-friendly guide: Python Pandas Tutorial. Start your journey today, and unlock the potential of data analysis with Python Pandas!
Whether you're a student or a professional, mastering Pandas will open doors to numerous opportunities in the world of data science.
0 notes
Text
Python Pandas Tutorial in Hindi | Learn in 6 hours | Pandas for Data Science & Analysis |Amit Thinks
Pandas is a powerful and easy-to-use open-source tool built on top of the Python programming language. It is useful for data … source
0 notes
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
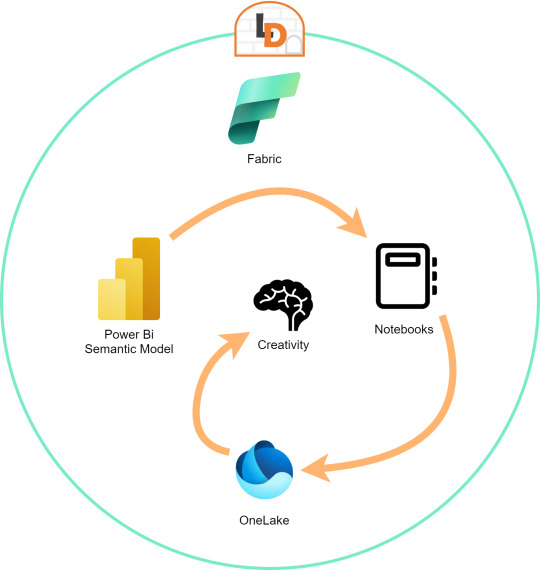
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
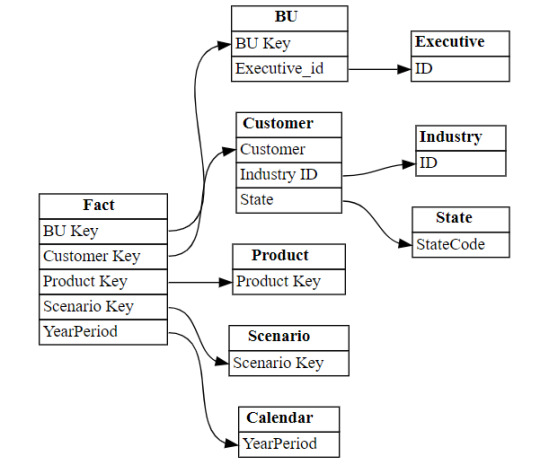
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
Learn the art of web scraping with Python! This beginner-friendly guide covers the basics, ethics, legal considerations, and a step-by-step tutorial with code examples. Uncover valuable data and become a digital explorer.
#API#BeautifulSoup#Beginner’s Guide#Data Extraction#Data Science#Ethical Hacking#Pandas#Python#Python Programming#Requests#Tutorial#Web Crawler#web scraping
1 note
·
View note
Text
Cleaning Dirty Data in Python: Practical Techniques with Pandas
I. Introduction Hey there! So, let’s talk about a really important step in data analysis: data cleaning. It’s basically like tidying up your room before a big party – you want everything to be neat and organized so you can find what you need, right? Now, when it comes to sorting through a bunch of messy data, you’ll be glad to have a tool like Pandas by your side. It’s like the superhero of…

View On WordPress
#categorical-data#data-cleaning#data-duplicates#data-outliers#inconsistent-data#missing-values#pandas-tutorial#python-data-cleaning-tools#python-data-manipulation#python-pandas#text-cleaning
0 notes
Text
instagram
Learning to code and becoming a data scientist without a background in computer science or mathematics is absolutely possible, but it will require dedication, time, and a structured approach. ✨👌🏻 🖐🏻Here’s a step-by-step guide to help you get started:
1. Start with the Basics:
- Begin by learning the fundamentals of programming. Choose a beginner-friendly programming language like Python, which is widely used in data science.
- Online platforms like Codecademy, Coursera, and Khan Academy offer interactive courses for beginners.
2. Learn Mathematics and Statistics:
- While you don’t need to be a mathematician, a solid understanding of key concepts like algebra, calculus, and statistics is crucial for data science.
- Platforms like Khan Academy and MIT OpenCourseWare provide free resources for learning math.
3. Online Courses and Tutorials:
- Enroll in online data science courses on platforms like Coursera, edX, Udacity, and DataCamp. Look for beginner-level courses that cover data analysis, visualization, and machine learning.
4. Structured Learning Paths:
- Follow structured learning paths offered by online platforms. These paths guide you through various topics in a logical sequence.
5. Practice with Real Data:
- Work on hands-on projects using real-world data. Websites like Kaggle offer datasets and competitions for practicing data analysis and machine learning.
6. Coding Exercises:
- Practice coding regularly to build your skills. Sites like LeetCode and HackerRank offer coding challenges that can help improve your programming proficiency.
7. Learn Data Manipulation and Analysis Libraries:
- Familiarize yourself with Python libraries like NumPy, pandas, and Matplotlib for data manipulation, analysis, and visualization.
For more follow me on instagram.
#studyblr#100 days of productivity#stem academia#women in stem#study space#study motivation#dark academia#classic academia#academic validation#academia#academics#dark acadamia aesthetic#grey academia#light academia#romantic academia#chaotic academia#post grad life#grad student#graduate school#grad school#gradblr#stemblog#stem#stemblr#stem student#engineering college#engineering student#engineering#student life#study
8 notes
·
View notes
Text
What’s the Big Deal About Python?
If you’ve been around the tech world even for a minute, you’ve probably heard people raving about Python. No, not the snake, we’re talking about the programming language. But what’s so special about it? Why is everyone from beginner coders to AI researchers using Python like it’s their best friend? Let’s break it down in simple words.

Easy to Learn, Easy to Use
First things first, Python is super easy to learn. The code looks almost like regular English, which means you don’t have to memorize weird symbols or endless rules. If you’re just starting your programming journey, Python won’t scare you away.
For example, printing a sentence in Python is as simple as:

That’s it. No extra setup, no confusing syntax. It just works.
Used Everywhere
Python isn’t just for small scripts or learning projects. It’s everywhere, web development, data science, automation, artificial intelligence, game development, even robotics.
Big companies like Google, Netflix, and Instagram use Python behind the scenes to make their products work better.
Huge Library Support
One of the best things about Python is its rich library ecosystem. Libraries are like pre-written tools that help you do complex stuff without writing all the code yourself. Want to analyze data? Use Pandas. Want to build a web app? Try Django or Flask. Want to build a chatbot or train a machine learning model? There’s TensorFlow and PyTorch for that.
Great Community
Python has a massive community. That means if you ever get stuck, there’s a good chance someone has already solved your problem and posted about it online. You’ll find tons of tutorials, forums, and helpful folks willing to guide you.
Not the Fastest, But Fast Enough
Python isn’t the fastest language out there — it’s not meant for super high-speed system-level programming. But for most tasks, it’s more than fast enough. And if you really need to speed things up, there are ways to connect Python with faster languages like C or C++.
So, Should You Learn Python?
Absolutely. Whether you’re a student, a hobbyist, or someone switching careers, Python is a great place to start. It’s beginner friendly, powerful, and widely used. You’ll be surprised how much you can build with just a few lines of Python code.
2 notes
·
View notes
Text

Discover the Python Pandas Tutorial for Beginners and learn how to easily manage and analyze data. This beginner-friendly guide covers all the basics. For a detailed tutorial, visit TAE.
0 notes
Text
How do I learn Python in depth?
Improving Your Python Skills
Writing Python Programs Basics: Practice the basics solidly.
Syntax and Semantics: Make sure you are very strong in variables, data types, control flow, functions, and object-oriented programming.
Data Structures: Be able to work with lists, tuples, dictionaries, and sets, and know when to use which.
Modules and Packages: Study how to import and use built-in and third-party modules.
Advanced Concepts
Generators and Iterators: Know how to develop efficient iterators and generators for memory-efficient code.
Decorators: Learn how to dynamically alter functions using decorators.
Metaclasses: Understand how classes are created and can be customized.
Context Managers: Understand how contexts work with statements.
Project Practice
Personal Projects: You will work on projects that you want to, whether building a web application, data analysis tool, or a game.
Contributing to Open Source: Contribute to open-source projects in order to learn from senior developers. Get exposed to real-life code.
Online Challenges: Take part in coding challenges on HackerRank, LeetCode, or Project Euler.
Learn Various Libraries and Frameworks
Scientific Computing: NumPy, SciPy, Pandas
Data Visualization: Matplotlib, Seaborn
Machine Learning: Scikit-learn, TensorFlow, PyTorch
Web Development: Django, Flask
Data Analysis: Dask, Airflow
Read Pythonic Code
Open Source Projects: Study the source code of a few popular Python projects. Go through their best practices and idiomatic Python.
Books and Tutorials: Read all the code examples in books and tutorials on Python.
Conferences and Workshops
Attend conferences and workshops that will help you further your skills in Python. PyCon is an annual Python conference that includes talks, workshops, and even networking opportunities. Local meetups will let you connect with other Python developers in your area.
Learn Continuously
Follow Blogs and Podcasts: Keep reading blogs and listening to podcasts that will keep you updated with the latest trends and developments taking place within the Python community.
Online Courses: Advanced understanding in Python can be acquired by taking online courses on the subject.
Try It Yourself: Trying new techniques and libraries expands one's knowledge.
Other Recommendations
Readable-Clean Code: For code writing, it's essential to follow the style guide in Python, PEP
Naming your variables and functions as close to their utilization as possible is also recommended.
Test Your Code: Unit tests will help in establishing the correctness of your code.
Coding with Others: Doing pair programming and code reviews would provide you with experience from other coders.
You are not Afraid to Ask for Help: Never hesitate to ask for help when things are beyond your hand-on areas, be it online communities or mentors.
These steps, along with consistent practice, will help you become proficient in Python development and open a wide range of possibilities in your career.
2 notes
·
View notes
Text
Pandas Data Visualization Using Matplotlib. Seaborn. Plotly and Mplfinance - Python Tutorial
Welcome to our comprehensive tutorial on Data Visualization using Pandas in Python! In this video, we’ll get into the exciting … source
0 notes
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
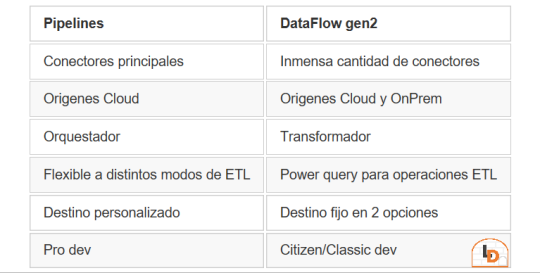
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
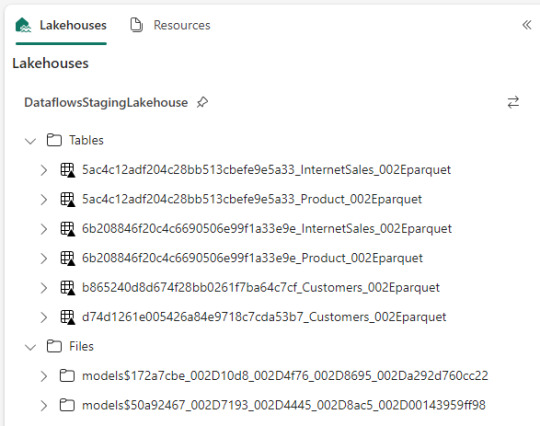
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
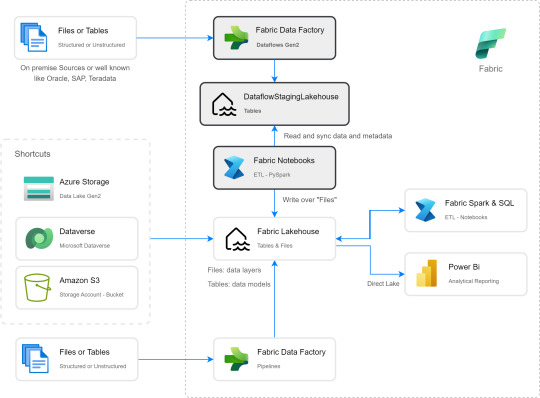
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes
Text
DataFrame in Pandas: Guide to Creating Awesome DataFrames
Explore how to create a dataframe in Pandas, including data input methods, customization options, and practical examples.
Data analysis used to be a daunting task, reserved for statisticians and mathematicians. But with the rise of powerful tools like Python and its fantastic library, Pandas, anyone can become a data whiz! Pandas, in particular, shines with its DataFrames, these nifty tables that organize and manipulate data like magic. But where do you start? Fear not, fellow data enthusiast, for this guide will…
View On WordPress
#advanced dataframe features#aggregating data in pandas#create dataframe from dictionary in pandas#create dataframe from list in pandas#create dataframe in pandas#data manipulation in pandas#dataframe indexing#filter dataframe by condition#filter dataframe by multiple conditions#filtering data in pandas#grouping data in pandas#how to make a dataframe in pandas#manipulating data in pandas#merging dataframes#pandas data structures#pandas dataframe tutorial#python dataframe basics#rename columns in pandas dataframe#replace values in pandas dataframe#select columns in pandas dataframe#select rows in pandas dataframe#set column names in pandas dataframe#set row names in pandas dataframe
0 notes
Text
youtube
📊 Welcome to Mind Benderx! In this video, we're on a mission to transform you into a complete data analyst. 🚀 Join us as we explore five phenomenal YouTube channels that will guide you through the intricate world of data analysis.
🔍 Channels Featured: ====================
Alex the Analyst: Dive into practical data analysis with Alex's comprehensive tutorials.
Codebasics: Master the coding side of data analysis with in-depth Python tutorials.
Chandoo: Elevate your Excel skills and learn data visualization techniques.
Corey Schafer: Unravel the secrets of Pandas and data manipulation using Python.
🎓 Whether you're a beginner or looking to enhance your skills, these channels offer a treasure trove of knowledge to propel you on your data analyst journey.
2 notes
·
View notes