
Blog comunitario de la suite de analítica de Microsoft de la mano de Power Platform y Azure Data Platform. @ignacho_07
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by ibarrau and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
3
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
15 days ago
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
[PowerBi] ¿Qué es TMDL?
Hace un tiempo que Microsoft ha anunciado TMDL. Puede que muchos se preguntaran qué es y porque aún no vemos cambios. La respuesta pasa porque es un concepto que estaba más de fondo, más en el código.
Hace tiempo que la comunidad de Power Bi traia algunos dolores no resueltos con desarrollos complejos. Pasando por el versionado y repositorio de código hasta la replicación de lógicas o formatos complejos. Este nuevo concepto puede ayudarnos.
Dado que a partir del último release de PowerBi Desktop vamos a poder visualizarlo en una vista propia, hemos decidido escribir este artículo para comprender de que se trata y porque es importante.
Vamos a comenzar como gusta hacer aqui en LaDataWeb con su definición de libro directa de Microsoft.
El lenguaje de definición de modelos tabulares (TMDL) es una sintaxis de definición del modelo de objetos para los modelos de datos tabulares en el nivel de compatibilidad 1200 o superior.
En palabras más simples es código. Un lenguaje que podemos disponibilizar para los modelos tabulares modernos. Ahora, ¿por que querriamos disponibilizarlo? por las razones antes mencionadas. Si tenemos activado el uso de este código, entonces podríamos resguardar mucho mejor un historial de versiones, resolver conflictos entre trabajos en paralelo en un repositorio; replicar conceptos, lógicas o formatos, etc.
¿Cómo se relaciona con PowerBi Desktop?
¿Recuerdan que hace un tiempo hablabamos de "Guardar como proyecto" a un archivo de Power Bi en este artículo? Bueno, ahi estabamos dando los primeros pasos para desagregar un pbix en archivos de código. En ese momento el formato por defecto no era muy amigable y tenía ciertos conflictos para interpretarlo o combinarlo en desarrollos concurrentes. Por esta razón se crea TMDL para facilitarnos la lectura, comprensión y uso.
Veamos su estructura que busca ayudarnos:

Lo primero es que podremos leer a un desarrollo de PowerBi en archivos de código. Antes de asustarnos sepamos que puede abrirse desde Power Bi Desktop como siempre o con VScode y una extensión TMDL.
A la izquierda en la imagen podemos apreciar la estructura de nuestro archivo de PowerBi desagregada. Dividida en reporte y modelo semántico. Así mismo detecta conceptos como cultura, perspectiva, roles o tablas. Todo materia de cosas que ya hemos visto en el mismo programa. Estos archivos de código estan por conceptos. Por ejemplo la imagen muestra un archivo de tabla. La estrcutura del archivo esta siempre bajo definiciones de la tabla como nombres, medidas o columnas a la izquierda y en un color y sus características o propiesdades con una sangría que ayuda a dividir a quien pertenece. Si quieren ver el detalle de las sentencias en fino pueden pasar por aqui: https://learn.microsoft.com/es-es/analysis-services/tmdl/tmdl-overview?view=asallproducts-allversions
¿De que nos sirve este código? ¿Puedo seguir desarrollando igual que siempre?
Lo cierto es que quien desarrolla puede seguir igual que siempre. La diferencia pasa por nuevas opciones. Un desarrollador interiorizado con esto, podrá copiar y replicar este código. Código que tiene propiedades, formatos, lógicas, visualizaciones configuradas, etc. Antes tal vez era imposible pensar en copiar valores de una visualización entre dos archivos de power bi, o pensar en copiar medidas, inclusive roles. Nos la pasabamos recreando en lugar de copiar. Imaginen si la comunidad comienza a compartir patrones de este código como por ejemplo convertir un gráfico de lineas en uno de puntos o de barras redondeadas como ya se ha visto en videos al alcance de un copiar y pegar.
Conflictos en equipo
Este concepto no solo pasa por la replicación y desarrollo basado en código. También añade una más simple solución al momento de tratar conflictos de código entre dos desarrollos. Ya habíamos mencionado en posts anteriores que guardar como proyecto ayudaba a que dos desarrolladores pudieran usar un repositorio, hacer pull del contenido, modificarlo y devolverlo al ambiente apropiado. Sin embargo, cuando dos de ellos manipulan conceptos similares aparece un conflicto. Por ejemplo, los dos modifican la misma medida o agregan medidas en la misma tabla. Con TMDL, podemos identiciar fácilmente la diferencia y hasta combinar los códigos para que convivan a diferencia de la modalidad antigua TMSL (basada en json). Con todo esto queremos aclarar el beneficio pero no queremos entrar en tanto detalle técnico de merges porque podríamos escribir varios artículos del tratamiento.
Primeros pasos
Para dar inicio y comenzar a estudiar este código, recomiendo leerlo sobre archivos de PowerBi con los que estén familiarizados. Lo primero será guardar nuestro PowerBi como proyecto. Luego tenemos dos métodos para ver el código.
1- Visual studio code extensión TMDL
Para quienes les gusten más las pantallas negras y vivir del código seguramente encontrar este espacio más familiar. Basta con instalar la extensió: https://marketplace.visualstudio.com/items?itemName=analysis-services.TMDL

2- Power Bi Desktop TMDL view
De momento está en preview, lo que significa que tenemos que activiarla en las opciones de Desktop. Una vez activada veríamos un nuevo icono a la izquierda. Solo con abrirlo y arrastrar un objeto a su canva podremos comenzar a ver el código:

Conclusión
Este tema va a revolucionar los desarrollos de la reportería. Tanto si nos sumamos a la ola como si no lo hacemos, indiscutiblemente es un concepto que va a dirrumpir el mercado con sus posibilidades de generar scripts para la comunidad de reutilización y trabajar en equipo comodamente. Como un beneficio adicional les comparto que si usamos código, podemos usar Github Copilot que ayudaría bastante en los desarrollos.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#power bi TMDL#TMDL
0 notes
Text
[Fabric] Protegé la experiencia de usuarios en una capacidad
Cada día más y más personas se suman a la ola de Fabric. Gracias a su amplia variedad de planes permite a pequeñas y grandes empresas nutrirse de sus características desde tempranas etapas. Algo primordial al momento de construir servicios o contenido en un recurso dedicado es monitorear esa capacidad.
¿Por que lo hacemos? porque necesitamos asegurarnos que sus recursos sean viables y no se sobrecargue. Si hay una sobrecarga todo se vuelve lento, la experiencia de usuario cae dado que no logramos dar respuesta a sus peticiones por fallas o demoras.
En este artículo mostraremos como mantener la experiencia de usuario sana aunque los procesos operativos colapsaran.
Hace unos días escribimos sobre la importancia de mantener una capacidad sana y hemos mencionado formas de montiorearla/administrarla. Ambos artículos son una gran fuente de aprendizaje para velar por un espacio dedicado que respondas a las necesidades de los usuarios con los recursos disponibles.
En estos artículos hacemos mención sobre dos categorías de operaciones que utiliza la capacidad. Hablamos de operaciones background e interactive. Tal como su nombre lo indica una refiere a todos los procesos bach, código, calendarizados, flujos, etc. Mientras que interactivo vela por la respuesta de los modelos dentro de los informes para usuarios finales. En enero 2025 microsoft fabric incorporó una excelente característica que nos ayude a poner límites porcentuales a operaciones background.
La característica se llama Surge Protection, y la definición en palabras microsoft:
"La protección contra sobrecargas ayuda a limitar el uso excesivo de su capacidad al limitar la cantidad de cómputo consumido por los trabajos en segundo plano. Puede configurar la protección contra sobrecargas para cada capacidad. La protección contra sobrecargas ayuda a prevenir el estrangulamiento y los rechazos, pero no es un sustituto de la optimización de la capacidad, el escalado vertical y el escalado horizontal. Cuando la capacidad alcanza su límite de cómputo, experimenta retrasos interactivos, rechazos interactivos o todos los rechazos incluso cuando la protección contra sobrecargas está habilitada."
Muy bien define que esta es una característica que se suma a ayudarnos. No va a reemplazar las prácticas anteriores.
¿Cómo funciona?
Ahora disponemos de dos parámetros nuevos para definirle a las capacidades. Por un lado el porcentaje máximo de la capacidad que pueden alcanzar las operaciones de segundo plano (Background Rejection threshold) y por otro el porcentaje al cual debe bajar el procesamiento para retomar las operaciones de segundo plano. Tomemos un ejemplo para explicarlo mejor (Background Recovery threshold)
LaDataWeb ha configurado estos parametros delimitando 70% para el rechazo de operaciones y 40% para la recuperación. Elegimos 70% porque conocemos la actividad de interactividad de los usuarios y casi siempre ronda entre 17% y 20% según nuestra Fabric Capacity Metrics app. Entonces sabemos que resguardando 30% estaremos seguro y limitamos 70% a las de segundo plano. Podríamos pensarlo como que hemos partido el 100% de la capacidad limitando al back a usar hasta cierto punto.
El día comienza a las 8 am cuando la gente inicia la jornada tradicional de trabajo y corre más operaciones de lo debido manualmente logrando que el background llegue a 70%. Surge Protection al llegar al 70%, continuará las operaciones que este "En ejecución", pero comenzará a rechazar todas las operaciones nuevas que intenten correr. ¿Como sabremos que rechazó? podran saberlo al ejecutar porque verán así:

O en la Fabric capacity metrics app en el nuevo apartado de "System events":

Esto significa que por 24 horas Fabric intentará reducir la capacidad de background rechazando nuevas peticiones. Los usuarios que dan uso con operaciones de interactividad dispondran de 30% de la capacidad. Si su uso es el promedio especulado, no se verían afectados en performance en sus operaciones. Lo cual permite a la empresa seguir operando.
¿Hasta cuando estará bloqueado el back? seguirá rechazando peticiones hasta que la capacidad baje hasta un 40% como lo fue especificado en el parametro de recuperación de capacidad.
¿Cómo configurarlo?
Abrimos el menú de configuración -> Admin portal -> opciones de capacidad. Seleccionamos la capacidad deseada para configurarlo y prendemos la opción de Surge Protection. Luego delimitamos los valores como el ejemplo de la imagen:

Así llegamos al final del artículo donde revisamos una excelente característica que nos ayuda a mantener la experiencia de los usuarios aún cuando los procesos estan en situaciones críticas.
Espero que esta nueva feature los ayude.
#microsoftfabric#fabric#fabric tutorial#fabric tips#fabric training#fabric jujuy#fabric argentina#fabric cordoba#ladataweb#fabric capacity
0 notes
Text
[PowerQuery] Múltiples reemplazos estilo switch o case
Hace tiempo no escribíamos un tip en M. Recientemente, me comentaron que querían hacer varios reemplazos de texto por nro para generar una columna de ID y mejorar la relación para que sea más liviana. Un buen ejercicio para alivianar el modelo.
Recorde que había escrito un post al inicio del blog con múltiples reemplazos, pero quise probar una técnica que aprendí hace unos años y hoy voy a compartir aqui.
Este artículo mostrará lo más parecido que tenemos en power query para generar algo estilo case o switch.
Para poder generar un case en Power Query vamos a realizar algo similar a un archivo de formato json. Veamos el caso simplificado.
Contamos con una tabla de hechos que traía el estado de una operación en texto y tenemos una dimension de estados. Sin embargo para reducir el tamaño de la relación y buena práctica, sería mejor que la relación este dada por un entero y no texto.

Vamos a asumir que la operación no puede desarrollarse en base de datos, porque recordemos que "mientras más temprano o atrás podamos resolver data modeling mejor será". Este escenario esta a modo de ejemplo.
Conociendo los estados y sus ID podríamos crear una función que reemplace el texto por el número esperado bajo una condición.
El primer paso será generar una variable que tenga las opciones de reemplazo

El primer valor será el que queremos encontrar y el segundo el que reemplazaremos. Podríamos definir que es una lista de listas, puesto que los {} en Power Query representan listas.
Para pode ejecutar el reemplazo sobre un texto seguiremos con la siguiente indicación:

De ese modo selecciona una lista devolviendo el primer resultado {0} quiere el segundo item {1}. Para filtrar ese item haremos un contains de texto de "rawText" validando contra cada fila (haciendo un each validamos fila por fila) donde _ representa una lista de las recorridas y {0} el primer item de la fila al cual lo compara.
Para mejor desarrollo esto podemos englobarlo en una función que recibe el texto por parametro y llamaremos "ChageStatus"

Para ejecutarlo en nuestra tabla de operación podemos llamarlo de dos maneras. Por un lado con "Agregar columna personalizada". La nueva columna simplemente haría ChangeStatus([Estado]).
Si queremos reemplazar la columna existente con sus múltiples reemplazos, entonces agregaremos un paso personalizado con el botón fx.
Nos nutriremos de TransformColumns y generaremos un código de este estilo:
= Table.TransformColumns( #"Paso anterior", { { "Estado", each ChangeStatus(_) } } )
El método permite ejecutar varias funciones recorriendo fila a fila sobre una columna. De nuevo una lista de listas. En nuestro caso es una sola operación de lista en la listas. Para ello, definimos la columna Estado como la involucrada al reemplazo y llamamos la función con each. Each nos permite ir fila a fila capturando el record de la columna con "_". Por esta razón, lo colocamos como parámetro.
De esa forma reemplazaremos nuestros textos por números de texto. Solo restará cambiar el tipo de la columna a entero para reducir el tamaño de la relación cuando esta generado el modelo.
Espero que este pequeño tip les haya servido y despligue nuevas ideas sobre Power Query y su manejo de listas.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power query#power query tips#power query training#power query tutorial#ladataweb#power query switch#power query case
0 notes
Text
[PowerBI] Usando Iconos y código SVG
Una parte fundamental en nuestros tableros de datos es la estética para la experiencia de usuario. Las interpretaciones pueden mejorar de gran manera si nos fortalecemos con imagenes que aporten al mensaje objetivo que tiene el tablero.
Esta demostrado que la experiencia de usuarios es más enriquecedora si nuestras tarjetas tienen un icono al lado o si nuestras tablas tienen formato condicional.
Este artículo nos muestra alternativas para enriquecer de esa forma nuestros reportes desarrollados.
La flexibilidad de Power Bi ha crecido de gran manera. Lo que nos ha permitido jugar con muchas alternativas útiles o divertidas para contar historias con datos. Hoy podemos nutrir de imagenes informes con visualizaciones a través de url, imagenes cargadas por sistema, botones, unichars, formatos condicionales y hasta svgs.
Básicos
Lo primero que se nos presentó y deberíamos conocer es cargar imagenes y controlar formatos condicionales. Las imagenes pueden ser cargadas de dos formas. Por un lado por el botón de la interfaz:
Y por otro como parte de un componente, por ejemplo un botón en blanco. Tanto en propiedades de estilo "Icons" o "Fill" podremos encontrar opciones para cargarlas:

En caso de trabajo de iconos en tablas, el estándar es el formato condicional por iconos que trae unos por defecto.
Usandolos podemos incorporar a nuestras tarjetas, tablas o enfoques de tablero una mejor experiencia.
Otras formas
Esta puede ser útil pero carece de flexibilidad. Cargar un .png por cada guia que queremos mostrar o si nuestra usuario quiere iconos especiales para el formato condicional, estos y otros requerimientos pueden verse limitados. Por ésta razón, vamos a ver tres métodos adicionales para enriquecer nuestras historias.
Emoticones o smiles: tradicionales que encontramos en cualquier chat
Unichars: valores estandarizados de íconos que PowerBi lee por DAX
SVG: es un formato vectorial muy útil para su uso online por su flexibilidad. Permite crear una imagen en una gran URL
Estas tres opciones podemos aplicarlas en visualizaciones individuales como tarjetas, en formas, en visualizaciones que lean imagenes como simple image y también en tablas o matrices.
Emoticones
Tal vez la forma más simple de tarjeta que no conocíamos que se renderiza en todo lugar de windows. Con un simple "Windwos + ." en el teclado se nos desplega un menú para incorporar el ícono como texto. Así podríamos facilmente utilizarlo en reglas de dax para determinar un formato. Por ejemplo:

Unichar
No son realmente iconos o imágenes sino que son caracteres especiales llamados unicode. Unicode es un estándar de codificación de caracteres diseñado para facilitar el tratamiento informático. Para usarlo nos nutrimos de la función DAX UNICHAR. La misma, devuelve el carácter Unicode al que hace referencia el valor numérico. ¿Cómo sabremos que número escribir?, podemos asesorarnos de algún sitio web, por ejemplo "https://unichar.app/web/"
En este ejemplo en lugar de seleccionar un solo ícono, pense en puntuar los valores de venta en cinco estrellas. Según las reglas colocara estrellas vacías o llenas
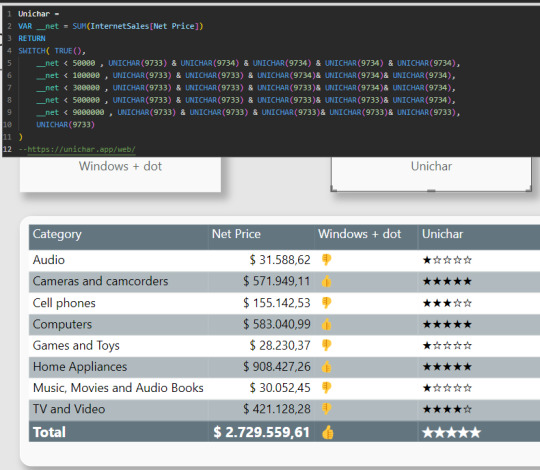
Con tanta libertad de unicodes para usar con unichars, la creatividad será nuestro límte. Asi con estrellas podemos simular puntajes, rankings, etc. Podríamos haber usado algo similar a pulgares también.
Una gran característica de los unichar es que son considerados "texto" en la medida. Lo que significa que podemos pintarlos de cualquier color al igual que el texto.
SVGs
Tal vez el modo que más asusta es el SVG. Pero así también es el más versátil puesto que no se queda en la forma de un objeto sino que da pie a animación. Podemos pensar en el svg como algo similar al código html, puesto que tiene tags y configuraciones de estilo. El modo en el que power bi puede renderizarlo es considerandolo como una "Image URL". Si utilizamos una medida o columna, debemos categorizarla como tal:
Un SVG se compone de la siguiente manera:
data:image/svg+xml;utf8, <svg width='200' height='50' xmlns='http://www.w3.org/2000/svg'>[Código]</svg>
La carcaza siempre es la misma y se modifica normalmente sobre código. Se puede jugar con width y height como tamaños horizontales y verticales límites para el dibujo. Consideren que algunas visualizaciones, como las tablas, tiene configuraciones de formato para esto también:
Dichas propiedades pueden afectar al tamaño del renderizado en la visualización.
Veamos dos ejemplos. Por un lado podríamos poner tags similares a los editores modernos de tablas. Con un código que construya un tag para buenos resultados (success) y malos (failure) junto con una medida que sea un simple IF como windows + dot para elegir podríamos hacer grandes cosas. Veamos ejemplo de success:

Como pueden ver, dentro del tag svg construimos dos tags más. Por un lado el fondo rect que refiere a rectángulo con bordes redondeados y el text que tiene texto por encima.
SVG también nos permite jugar con animaciones. Entonces podríamos usar formas tradicionales como cuadrados o círculos y jugar con animaciones que llamen la atención. En este ejemplo también construimos dos SVG, un cuadrado rojo y un círculo verde. Ambos con movimientos y separados por el mismo IF que hablamos antes para separar valores a modo de ejemplo objetivo. Veamos como:

Por supuesto que el gif da el ejemplo, pero no reproduce tan fluido como el resultado final que es mucho más agradable a la vista. En este caso, incorporamos el tag animate que nos da la flexibilidad de jugar con movimientos.
¿Cómo crear SVG?
Tal vez piensen que no tienen tiempo para aprender esto de código svg. Hay varios caminos, no debemos cancelarlo por ello. Puede que algunas personas más académicas les interese conocer las sentencias de código posible y saber suficiente para controlarlo y entenderlo todo. Quienes no quieran esto hay dos alternativas. Por un lado, buscar otros SVG y posteos de comunidad al respecto. Por otro lado, podemos utilizar IA. Así es, una IA puede ayudarnos con esto. El círculo verde con su movimiento fue construido 100% por IA. Le pedi eso a un chat bastante famoso y me devolvió el código con la animación.
En definitiva podemos validar ideas y pedir códigos escritos. Ya no hay excusa para usar Iconos y SVGs para adornar nuestra UI de informes y brindar aspectos más agradables a los usuarios finales. Recuerden que pueden descargar el archivo de Power Bi Desktop desde mi GitHub.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#data viz#data visualization
0 notes
Text
[Fabric] Fast Copy con Dataflows gen2
Cuando pensamos en integración de datos con Fabric está claro que se nos vienen dos herramientas a la mente al instante. Por un lado pipelines y por otro dataflows. Mientras existía Azure Data Factory y PowerBi Dataflows la diferencia era muy clara en audiencia y licencias para elegir una u otra. Ahora que tenemos ambas en Fabric la delimitación de una u otra pasaba por otra parte.
Por buen tiempo, el mercado separó las herramientas como dataflows la simple para transformaciones y pipelines la veloz para mover datos. Este artículo nos cuenta de una nueva característica en Dataflows que podría cambiar esta tendencia.
La distinción principal que separa estas herramientas estaba basado en la experiencia del usuario. Por un lado, expertos en ingeniería de datos preferían utilizar pipelines con actividades de transformaciones robustas d datos puesto que, para movimiento de datos y ejecución de código personalizado, es más veloz. Por otro lado, usuarios varios pueden sentir mucha mayor comodidad con Dataflows puesto que la experiencia de conectarse a datos y transformarlos es muy sencilla y cómoda. Así mismo, Power Query, lenguaje detrás de dataflows, ha probado tener la mayor variedad de conexiones a datos que el mercado ha visto.
Cierto es que cuando el proyecto de datos es complejo o hay cierto volumen de datos involucrado. La tendencia es usar data pipelines. La velocidad es crucial con los datos y los dataflows con sus transformaciones podían ser simples de usar, pero mucho más lentos. Esto hacía simple la decisión de evitarlos. ¿Y si esto cambiara? Si dataflows fuera veloz... ¿la elección sería la misma?
Veamos el contexto de definición de Microsoft:
Con la Fast Copy, puede ingerir terabytes de datos con la experiencia sencilla de flujos de datos (dataflows), pero con el back-end escalable de un copy activity que utiliza pipelines.
Como leemos de su documentación la nueva característica de dataflow podría fortalecer el movimiento de datos que antes frenaba la decisión de utilizarlos. Todo parece muy hermoso aun que siempre hay frenos o limitaciones. Veamos algunas consideraciones.
Origenes de datos permitidos
Fast Copy soporta los siguientes conectores
ADLS Gen2
Blob storage
Azure SQL DB
On-Premises SQL Server
Oracle
Fabric Lakehouse
Fabric Warehouse
PostgreSQL
Snowflake
Requisitos previos
Comencemos con lo que debemos tener para poder utilizar la característica
Debe tener una capacidad de Fabric.
En el caso de los datos de archivos, los archivos están en formato .csv o parquet de al menos 100 MB y se almacenan en una cuenta de Azure Data Lake Storage (ADLS) Gen2 o de Blob Storage.
En el caso de las bases de datos, incluida la de Azure SQL y PostgreSQL, 5 millones de filas de datos o más en el origen de datos.
En configuración de destino, actualmente, solo se admite lakehouse. Si desea usar otro destino de salida, podemos almacenar provisionalmente la consulta (staging) y hacer referencia a ella más adelante. Más info.
Prueba
Bajo estas consideraciones construimos la siguiente prueba. Para cumplir con las condiciones antes mencionadas, disponemos de un Azure Data Lake Storage Gen2 con una tabla con información de vuelos que pesa 1,8Gb y esta constituida por 10 archivos parquet. Creamos una capacidad de Fabric F2 y la asignaciones a un área de trabajo. Creamos un Lakehouse. Para corroborar el funcionamiento creamos dos Dataflows Gen2.
Un dataflow convencional sin FastCopy se vería así:

Podemos reconocer en dos modos la falta de fast copy. Primero porque en el menú de tabla no tenemos la posibilidad de requerir fast copy (debajo de Entable staging) y segundo porque vemos en rojo los "Applied steps" como cuando no tenemos query folding andando. Allí nos avisaría si estamos en presencia de fast copy o intenta hacer query folding:
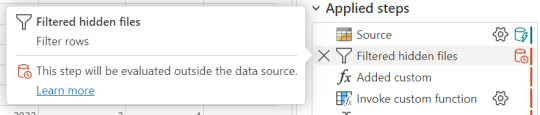
Cuando hace query folding menciona "... evaluated by the datasource."
Activar fast copy
Para activarlo, podemos presenciar el apartado de opciones dentro de la pestaña "Home".
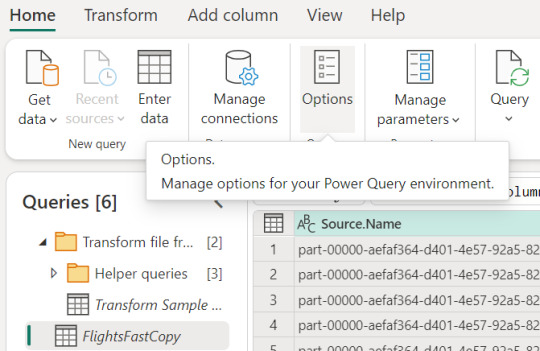
Allí podemos encontrarlo en la opción de escalar o scale:
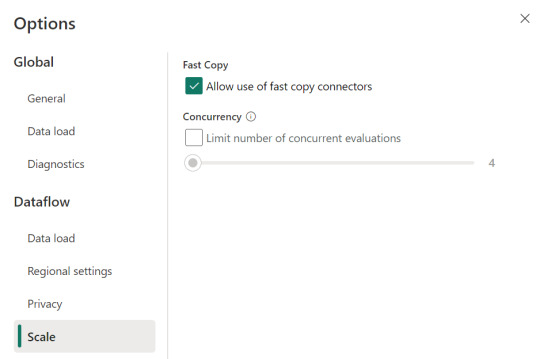
Mientras esa opción esté encendida. El motor intentará utilizar fast copy siempre y cuando la tabla cumpla con las condiciones antes mencionadas. En caso que no las cumpla, por ejemplo la tabla pese menos de 100mb, el fast copy no será efectivo y funcionaría igual que un dataflow convencional.
Aquí tenemos un problema, puesto que la diferencia de tiempos entre una tabla que usa fast copy y una que no puede ser muy grande. Por esta razón, algunos preferiríamos que el dataflow falle si no puede utilizar fast copy en lugar que cambie automaticamente a no usarlo y demorar muchos minutos más. Para exigirle a la tabla que debe usarlo, veremos una opción en click derecho:

Si forzamos requerir fast copy, entonces la tabla devolverá un error en caso que no pueda utilizarlo porque rompa con las condiciones antes mencionadas a temprana etapa de la actualización.
En el apartado derecho de la imagen tambien podemos comprobar que ya no está rojo. Si arceramos el mouse nos aclarará que esta aceptado el fast copy. "Si bien tengo otro detalle que resolver ahi, nos concentremos en el mensaje aclarando que esta correcto. Normalmente reflejaría algo como "...step supports fast copy."
Resultados
Hemos seleccionado exactamente los mismos archivos y ejecutado las mismas exactas transformaciones con dataflows. Veamos resultados.
Ejecución de dataflow sin fast copy:

Ejecución de dataflow con fast copy:

Para validar que tablas de nuestra ejecución usan fast copy. Podemos ingresar a la corrida

En el primer menú podremos ver que en lugar de "Tablas" aparece "Actividades". Ahi el primer síntoma. El segundo es al seleccionar una actividad buscamos en motor y encontramos "CopyActivity". Así validamos que funcionó la característica sobre la tabla.
Como pueden apreciar en este ejemplo, la respuesta de fast copy fue 4 veces más rápida. El incremento de velocidad es notable y la forma de comprobar que se ejecute la característica nos revela que utiliza una actividad de pipeline como el servicio propiamente dicho.
Conclusión
Seguramente esta característica tiene mucho para dar e ir mejorando. No solamente con respecto a los orígenes sino tambien a sus modos. No podemos descargar que también lo probamos contra pipelines y aqui esta la respuesta:
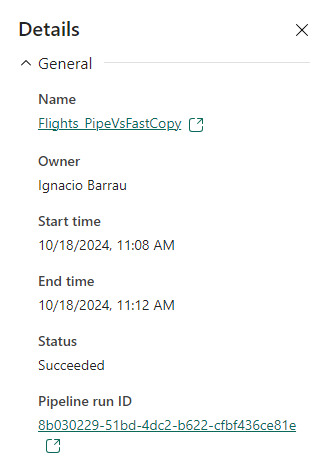
En este ejemplo los Data Pipelines siguen siendo superiores en velocidad puesto que demoró 4 minutos en correr la primera vez y menos la segunda. Aún tiene mucho para darnos y podemos decir que ya está lista para ser productiva con los origenes de datos antes mencionados en las condiciones apropiadas. Antes de terminar existen unas limitaciones a tener en cuenta:
Limitaciones
Se necesita una versión 3000.214.2 o más reciente de un gateway de datos local para soportar Fast Copy.
El gateway VNet no está soportado.
No se admite escribir datos en una tabla existente en Lakehouse.
No se admite un fixed schema.
#fabric#microsoft fabric#fabric training#fabric tips#fabric tutorial#data engineering#dataflows#fabric dataflows#fabric data factory#ladataweb
0 notes
Text
Fabric Rest API ahora en SimplePBI
La Data Web trae un regalo para esta navidad. Luego de un gran tiempo de trabajo, hemos incorporado una gran cantidad de requests provenientes de la API de Fabric a la librería SimplePBI de python . Los llamados globales ya están en preview y hemos intentado abarcar los más destacados.
Este es el comienzo de un largo camino de desarrollo que poco a poco intentar abarcar cada vez más categorías para facilitar el uso como venimos haciendo con Power Bi hace años.
Este artículo nos da un panorama de que hay especificamente y como comenzar a utilizarla pronto.
Para ponernos en contexto comenzamos con la teoría. SimplePBI es una librería de Python open source que vuelve mucho más simple interactuar con la PowerBi Rest API. Ahora incorpora también Fabric Rest API. Esto significa que no tenemos que instalar una nueva librería sino que basta con actualizarla. Esto podemos hacerlo desde una consola de comandos ejecutando pip siempre y cuando tengamos python instalado y PIP en las variables de entorno. Hay dos formas:
pip install --upgrade SimplePBI pip install -U SimplePBI
Necesitamos una versión 1.0.1 o superior para disponer de la nueva funcionalidad.
Pre requisitos
Tal como lo hacíamos con la PowerBi Rest API, lo primero es registrar una app en azure y dar sus correspondientes permisos. De momento, todos los permisos de Fabric se encuentran bajo la aplicación delegada "Power Bi Service". Podes ver este artículo para ejecutar el proceso: https://blog.ladataweb.com.ar/post/740398550344728576/seteo-powerbi-rest-api-por-primera-vez
Características
La nueva incorporación intentará cubrir principalmente dos categorías indispensables de la Rest API. Veamos la documentación para guiarnos mejor: https://learn.microsoft.com/en-us/rest/api/fabric/articles/api-structure
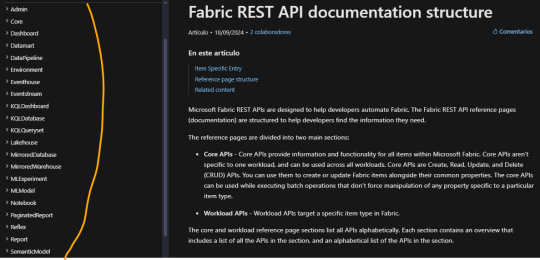
A la izquierda podemos ver todas las categorías bajo las cuales consultar u operar siempre y cuando tengamos permisos. Fabric ha optado por denominar "Items" a cada tipo de contenido creable en su entorno. Por ejemplo un item podría ser un notebook, un modelo semántico o un reporte. En este primer release, hemos decidido enfocarnos en las categorías más amplias. Estamos hablando de Admin y Core. Cada una contiene una gran cantidad métodos. Una enfocada en visión del tenant y otro en operativo de la organización. Admin contiene subcategorías como domains, items, labels, tenant, users, workspaces. En core encontraremos otra como capacities, connections, deployment pipelines, gateways, items, job scheduler, long running operations, workspaces.
La forma de uso es muy similar a lo que simplepbi siempre ha presentado con una ligera diferencia en su inicialización de objeto, puesto que ahora tenemos varias clases en un objeto como admin o core.
Para importar llamaremos a fabric desde simplepbi aclarando la categoría deseada
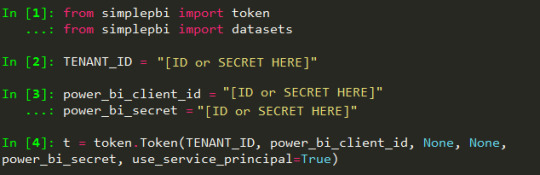
from simplepbi.fabric import core
Para autenticar vamos a necesitar valores de la app registrada. Podemos hacerlo por service principal con un secreto o nuestras credenciales. Un ejemplo para obtener un token que nos permita utilizar los objetos de la api con service principal es:
t = token.Token(tenant_id, app_client_id, None, None, app_secret_key, use_service_principal=True)
Vamos intentar que las categorías de la documentación coincidan con el nombre a colocar luego de importar. Sin embargo, puede que algunas no coincidan como "Admin" de fabric no puede usarse porque ya existe en simplepbi. Por lo tanto usariamos "adminfab". Luego inicializamos el objeto con la clase deseada de la categoría de core.
it = core.Items(t.token)
De este modo tenemos accesibilidad a cada método en items de core. Por ejemplo listarlos:
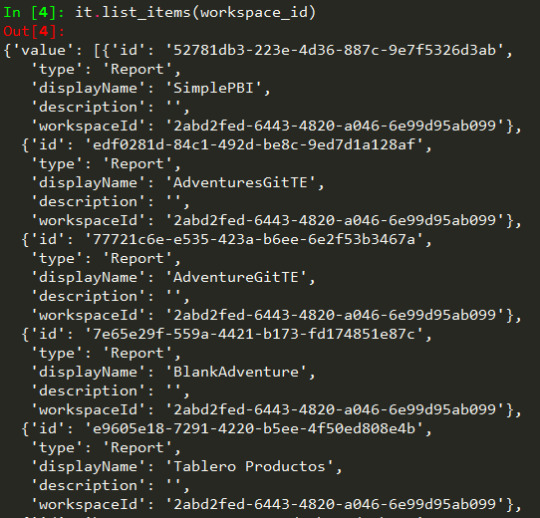
Consideraciones
No todos los requests funcionan con Service Principal. La documentación especifica si podremos usar dicha autenticación o no. Leamos con cuidado en caso de fallas porque podría no soportar ese método.
Nuevos lanzamientos en core y admin. Nos queda un largo año en que buscaremos tener esas categorías actualizadas y poco a poco ir planificando bajo prioridad cuales son las más atractivas para continuar.
Para conocer más, seguirnos o aportar podes encontrarnos en pypi o github.
Recordemos que no solo la librería esta incorporando estos requests como preview sino también que la Fabric API esta cambiando cada día con nuevos lanzamientos y modificaciones que podrían impactar en su uso. Por esto les pedimos feedback y paciencia para ir construyendo en comunidad una librería más robusta.
#fabric#microsoftfabric#fabric tutorial#fabric training#fabric tips#fabric rest api#power bi rest api#fabric python#ladataweb#simplepbi#fabric argentina#fabric cordoba#fabric jujuy
0 notes
Text
[Fabric] Herramientas para administrar o monitorear la organización
Con el lanzamiento de fabric en 2023 aparecieron herramientas que nos ayudan a comprender mejor el uso de la plataforma. Una deuda pendiente que transcurría en Power Bi. Desde ese entonces, la plataforma no deja de sorprender. Incluso ahora en ignite 2024 volvemos a incorporar más herramientas útiles que nos asistan a entender nuestro entorno.
Este artículo listara las herramientas disponibles que hay para entender el uso de la plataforma, que hay creado por todas partes, monitorear sus corridas, monitorear la capacidad, etc. Cada una de ellas con distintos filtros de gran introspección
Vamos a comenzar separando el artículo en herramientas de monitoreo y herramientas de administración. Cada una de ellas con objetivos diferentes. Casi todas vienen visibles por defecto para poder utilizarlas. Algunas son accesibles por todo usuario y otras solo por administradores.
Administrativas
A mi parecer lo que conlleva a la administración pasa por comprender que está desplegado en la organización. La administración puede ser del Tenant o inclusive de un usuario convencional que es responsable de X cantidad de áreas de trabajo. Lo importante es poder explorar cuantos reportes (u otro contenido) hay, donde se encuentran, quienes lo crearon, etc. Esa información la tenemos disponible en dos formas.
Área de trabajo de administración
En esta área de trabajo, exclusiva de administradores, podremos ver la totalidad de la organización. Cada workspace, modelo semantico, notebook, etc. Aquí existe un informe llamado "Purview Hub". Este informe refleja todos los items creados en el ecosistema Fabric, sus dominios, etiquetas de sensibilidad de datos, endorsements (si fueron certificados o promovidos), etc. Una vista rápida para que se den una idea de como podríamos comprender todos los items es:

En caso de tener confusión en su uso, tiene una excelente guia de bookmarks en el primer botón de arriba a la izquierda llamado "Take a tour".

OneLake Catalag
Un lanzamiento reciente que tiene un foco similar es el Catálogo de Onelake. La principal diferencia se basa en que el catálogo está visible para todo usuario de Fabric y muestra sobre lo que el usuario tiene permisos en lugar de mostrar toda la organización. Se encuentra accesible en el menú izquierdo de navegación.
Tiene una muy simple y sencilla interfaz que nos permite buscar por área de trabajo o items (lakehouse, semantic model, report, pipeline, etc)

Me parece ideal para quienes sea administradores responsables de ciertos desarrollos en varias áreas de trabajo.
Monitoreo
Tenemos tres herramientas de monitoreo en distintos ejes, una de administradores, una app que podemos disponibilizar permisos y una para cada usuario.
Métricas/Logs de uso de plataforma.
Al igual que Purview hub, en el admin workspace encontraremos un segundo informe llamado "Feature usage and Adoption". Este informe se enfoca en revelarnos la actividad de cada usuario que ingresó a la plataforma los últimos 30 días. Registra el uso que dan los usuarios a la plataforma. La lista de operaciones que guardará al momento de ejecutarse podemos leerla en este enlace: https://learn.microsoft.com/en-us/fabric/admin/operation-list?wt.mc_id=DP-MVP-5004778
El informe nos permite explorar por area de trabajo y capacidad las actividades registradas. Podemos ver que usuario ejecuto que operación en que día. Siempre se registran últimos 30 días y no más.

Pronto podemos visualizar las operaciones más realizadas. En este caso get data source details, puesto que es un tenant que hay más investigaciones que reportes para visualizar. Para más detalles de su uso podemos revisar su doc aqui: https://learn.microsoft.com/en-us/fabric/admin/feature-usage-adoption?wt.mc_id=DP-MVP-5004778
Fabric Capacity metrics app
No tenemos una manera de monitorear una capacidad dedicada por defecto. Por eso, esta app es muy importante de leer e instalar. Cuando compramos una capacidad es crítico monitorear sus recursos. Comprender que contenidos, flujos de datos, etc están siendo más pesados que otros. Podemos comprender si la capacidad tiene mucho flujo de background o mucha interactividad de usuarios. Estos detalles y muchos más pueden verse con la Fabric Capacity Metrics App. La herramienta es clave para poder gestionar una sana capacidad como lo expresamos en este artículo.
Esta herramienta no viene por defecto en la organización. Debe instalarse desde el menú de Apps "Get Apps". Allí aparecen muchas de distintas emrpesas. Buscamos el nombre y la instalamos.
La app funciona igual que una PowerBi App de workspace. Crea una nueva área y permite dar permiso a quien querramos. Para configurarla debemos ser owners de la capacidad y completar los parámetros del dataset.

Para conocer en mayor detalle su funcionalidad, podemos ver el siguiente enlace: https://learn.microsoft.com/en-us/fabric/enterprise/metrics-app-compute-page?wt.mc_id=DP-MVP-5004778
Sección Monitoreo
¿Qué nos falta? comprender si nuestras operaciones de background estan corriendo satisfactoriamente. Si hoy usamos fabric, seguramente tenemos muchos contenidos de integración de datos poblando lakehouse o transformando, limpiando y preparando datos para leer. Este espacio nos permite ver el estado de esas operaciones con versátiles filtros de estado, tipo de item, fecha de corrida relativa, quien lo hizo o en que área de trabajo se encuentra. Así mismo brinda una variedad de columnas para ver en mayor detalle.

Esta sección la pueden ver todos los usuarios y les muestra aquellos elementos que tenga permisos de ver o controlar. Nuevamente, muy útil para ingenieros de datos con muchos flujos, administradores de áreas de trabajo o dominios, etc.
¿Eso es todo?
No claro que no. Todo el tiempo surjen actualizaciones e ideas de personas que traen más y más visibilidad. Por ejemplo, hay artículos revelando como leer información de los audit logs para llegar a una medida más profunda de una capacidad de Fabric. Podemos usar la API para generar un histórico de las operaciones para no quedarnos en últimos 30 días. Incluso armar nuestro propio purview hub basado en datos profundos que consigamos con API. Hay muchos miembros activo de la comunidad con nuevas ideas para afinar detalles o dar alternativas. Recientemente, en el ignite 2024, las áreas de trabajo incorporaron un monitoreo en tiempo real que podemos setear con recursos realtime:

Nosotros expresamos las que vienen por defecto y una indispensable. Ustedes pueden adaptar muchas otras nuevas en distintos ejes o utilizar lo que mostramos.
#fabric#microsoft fabric#microsoftfabric#fabric tutorial#fabric tips#fabric training#fabric monitor#administrate fabric#fabric capacity#ladataweb#fabric ladataweb#fabric cordoba#fabric argentina#fabric jujuy
0 notes
Text
[DataModeling] Tip DAX para autoreferencia o recurrencia de tabla
Hace tiempo que no nos sentrabamos en acompañar un escenario de modelado. En esta oportunidad, nos vamos a enfocar en como resolver una situación de auto referencia o recurrencia de tabla. Suele ocurrir que una tabla puede tener ids o claves de referencia para si misma y las formas de resolverlo pueden variar.
En este artículo, vamos a mostrar como valernos de DAX para resolver un esquema jerárquico corporativo que ayude a develar un organigrama organizacional basado en niveles o posiciones/cargos superiores.
Contexto
Entre las formas de modelar bases de datos transaccionales, buscamos normalizar los datos para evitar la redundancia lo más posible. Así es como pueden aparecer escenarios donde hay tablas que van a referenciarse a si mismas. Esto quiere decir que podemos tener una clave foránea apuntando a una clave primaria. Para no abordar tanta teoría veamos un ejemplo que ayude a enfocar el caso.
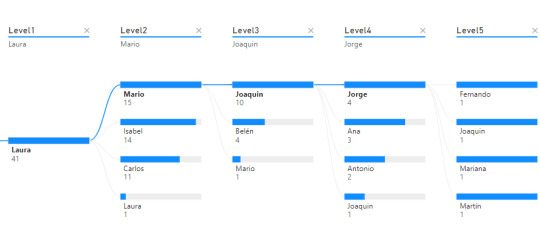
Nos enviaron un requerimiento que pide detallar un organigrama o estructura jerárquica en la organización que permita explorar la cantidad de empleados según distintos focos de mando. Piden que la información sea explorable, puede ser una matriz o árbol del siguiente estilo:
Árbol de decomposición
Matriz

Supongamos que tenemos una tabla de Empleados en nuestra base de datos. La organización tiene un gran volumen de personal, lo que hace que naturalmente haya una estructura jerárquica con cargos de mando o de management. Todas las personas institucionales forman parte de la tabla empleados fila por fila. Sin embargo, necesitamos guardar información sobre la persona a la cual responden. Aquí aparece la auto referencia. Para resolver esta operación en vistas de base de datos transaccional, será más performante y menos costoso delimitar una nueva columna que autoreferencie a otra fila en lugar de otras tablas para los cargos pertinentes. Veamos como quedaría una tabla con la nueva columna:

Fíjense que la columna id_superior pertenece a un id_empleado de otra fila. Cuando esto ocurre, estamos frente a un caso de auto referencia.
Dependiendo el proceso y escenario a delimtiar en nuestro modelo semántico, puede ser resuelto de distintas formas. Podríamos generar fact factless que orienten un mapeo de quienes responden a quienes o podemos tomar esta tabla como dimensión y generar columnas que representen el mando jerárquico como columnas categóricas de la dimension.
Este artículo se enfocará en la segunda solución. Vamos a generar columnas categoricas que nos ayuden a construir algo semejante a lo siguiente:
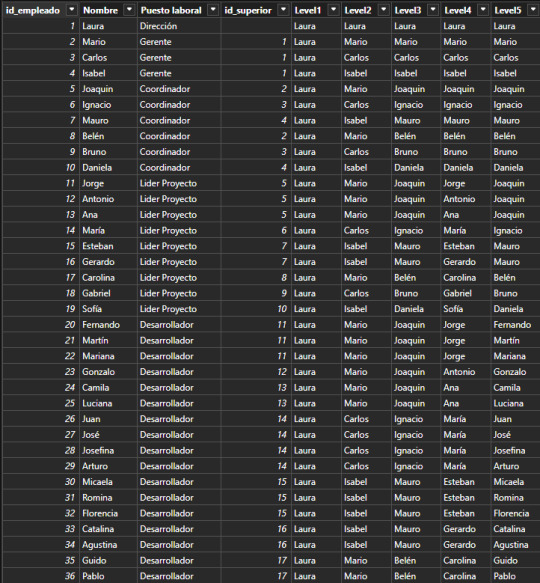
La idea es generar columns por cantidad de niveles jerárquicos que se presenten. Si bien la mejor solución es implementarlo lo más temprano posible, es decir en un warehouse, lakehouse o procesamiento intermedio; aquí vamos a mostrar como crear las columnas con DAX.
Vamos a crear una columna calculada de la siguiente manera:
Level1 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 1 , INTEGER ) )
Vamos a nutrirnos de tres funciones para generar un recorrido dentro de la misma tabla.
LOOKUPVALUE: Esta función busca un valor en una columna específica de una tabla, basándose en criterios de búsqueda. En este caso, está buscando el nombre de un empleado con criterio de igualdad entre id_empleado que mapee al id_superior de la fila actual.
PATH: Esta función crea una cadena que representa la jerarquía de empleados, utilizando los id_empleado y id_superior. Busca los ID y los separa por Pipes. Entonces por ejemplo en la fila de ID = 5 de Joaquín. El resultado de Path será "1|2|5" representando que los ID de sus superiores son primero el empleado 2 y luego el empleado 1.
PATHITEM(..., 1, INTEGER): Esta función toma la cadena generada por PATH y extrae un elemento de ella. En este caso, está extrayendo el primer elemento (el id del empleado que está en la posición 1). Aquí, el 1 se refiere a la posición que queremos extraer (el primer ítem en la jerarquía). Si Joaquín tenía 3 valores, vamos a buscar el de la primera posición, en este caso "1".
Resultado: lookupvalue buscara el nombre del empleado con ID 1 para la columna.
Esta función podríamos replicarla para cada nivel. La función antes vista traería el primero de la cadena, es decir la dirección de la empresa. Para llegar al siguiente nivel cambiamos el parametro de pathitem de manera que traiga el segundo resultado de Path en sus pipes.
Level2 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 2 , INTEGER ) )
En primera instancia esto parecería resolverlo. Este sería nuestro resultado:
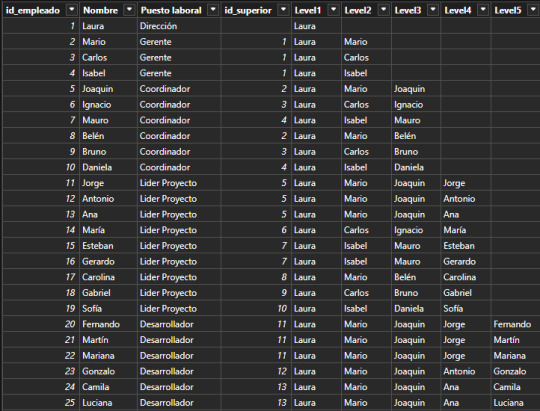
Esta puede ser una solución directa si solo queremos navegar por nombres de personas en cadena (filtramos Level5 <> Blank). Sin embargo, si también quisieramos conocer la cantidad de personas que tienen a cargo, es necesario contar a la persona al mando como parte del equipo, sino generaríamos una cadena de "Blanks" como pueden ver en niveles del 2 al 5. Esto lo podemos corregir copiando el nivel anterior cuando ocurre un blanco.
Level2 = VAR __lvl2 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 2 , INTEGER ) ) RETURN IF ( ISBLANK(__lvl2) , Empleados_Jerarquia[Level1], __lvl2 )
De esa forma el equipo de Laura (primera) cuenta con tres gerentes y si misma al conteo total de empleados.
Las visualizaciones pueden ser construidas por cada nivel como columnas categóricas de las dimensiones:
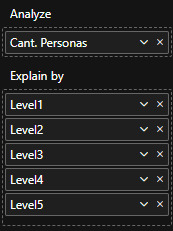
Así mismo podría usarse el nombre del cargo como nombre de columna para ver la pirámide institucional de una manera más sencilla.
De esta forma llegaríamos al resultado esperado y mostrado en la primera imagen de requerimiento.
Ojala esta solución les sirva para resolver situaciones de modelado recursivo. Recuerden que si podemos ejecutar esto en SQL en nuestra capa de transformación, sería lo mejor para construir la dimensión. Como siempre pueden descargar el archivo de ejemplo de mi GitHub.
#dax#dax tip#dax tutorial#dax training#data modeling#powerbi#power bi#power bi desktop#power bi cordoba#power bi argentina#power bi jujuy#ladataweb
0 notes
Text
[Fabric] Como administrar una sana capacidad
Estamos atravesando una etapa donde la madurez analítica de las compañías crece y ya cuenta con un buen volumen de reportes para la toma de decisiones.
El desafío que antes consistía en construir informes ahora atraviesa una nueva etapa que consiste en un balance de nuestro entorno productivo. Puede que todavía algunas instituciones no lo sientan porque aún trabajan con capacidades compartidas de licencias pro.
Sin embargo, cuando disponemos de una capacidad dedicada, ya sea porque contamos con un Power Bi Premium o estamos analizando comenzar con Fabric, es necesario establecer estándares o prácticas que nos ayuden a dar el mejor uso de la capacidad.
En este artículo veremos prácticas que nos ayuden a velar la sanidad de una capacidad dedicada en PowerBi Service o Fabric.
Iniciamos este recorrido con una práctica que no puede faltar cuando somos administradores de un recursos de procesamiento, monitoreo. Se vuelve indispensable conocer el estado de nuestra capacidad si queremos entenderla para acompañar su estabilidad. Fabric nos da cierto apoyo automático en un área de trabajo administrativa. Estos dos informes, que un Fabric Administrator puede ver, apuntan a conocer la actividad que los usuarios hacen de la capacidad y el contenido desplegado. Son muy útiles y yo diría que secundarias. La principal fortaleza para monitorear es una aplicación que debemos buscar en el store de PowerBi Apps llamada Fabric Metrics Capacity App.
No me voy a detener a explicar cada visualización de la aplicación, para esto la documentación de Microsoft lo detalla de muy buena manera en este enlace:
https://learn.microsoft.com/es-es/fabric/enterprise/metrics-app?wt.mc_id=DP-MVP-5004778

Partiendo de esa base es que podemos pensar en prácticas que fortalezcan nuestra capacidad puesto que comprenderíamos que el procesamiento y memoria de nuestra capacidad se divide en dos operaciones, background (Azul) e interactive (rojo)

Adicionalmente, está el proceso o metodología de desarrollo que implementemos en la organización. Se vuelve muy importante delimitar si utilizaremos ambientes de desarrollo, control de versiones, etc. Más que nada porque los ambientes pueden ayudarnos a distribuir nuestra capacidad, por ejemplo, podríamos disponer de dos capacidades, una fuerte para lo productivo y una más simple para el desarrollo que sabemos tendría menos interactividad. También podríamos pensar en un ambiente de desarrollo de capacidad compartida (licencias pro) siempre y cuando los modelos nos lo permitan (limitaciones de características). Este y cualquier otro estándar previo a que comience a convivir un modelo semántico con la capacidad puede fortalecer indirectamente la administración. Otro ejemplo es una validación, test o paso por buenas prácticas de archivos de Power Bi a modo de auditoria antes de ser publicados. Si buscamos una automatización puede darse con las buenas prácticas de Tabular Editor, optimización modelo o buenas prácticas de Power Query. Éstas últimas tres puedes dar introspección en los artículos:
[TabularEditor] Analizador de buenas prácticas de modelado
[DataModeling] 5 tips de reducción de tamaño de modelo
[PowerQuery] Buenas prácticas en el editor de consulta
Reducción operación Background
Éstas se refieren a procesos previos a la construcción de un modelo. Directamente relacionadas a lo que comúnmente pensamos como ETL. Los contenidos y operaciones que nos impactan son dataflows, notebooks, pipelines, dataset refreshes, etc. ¿Cómo podríamos disminuir su impacto? En su mayoría definiendo reglas o estándares. Veamos ejemplos.
Los modelos medianos o grandes si o si deben ser trabajados en capa de Warehouse/Lakehouse entregando tablas que sean consumidas sin interacción posterior con prácticas de data modeling que eviten operaciones power query.
Definir proceso de extracción y transformación apropiado. Ajustarse a un estándar y no permitir que se cree lo que cada usuario le sea más simple. Usualmente, ocurre con dataflows puesto que, si no son usados apropiadamente, son operaciones costosas.
Cuando deban realizarse transformaciones en Power Query, seguir las buenas prácticas antes mencionadas. Pueden hacer encuentros de control de su procesamiento o informar diagnósticos de sus resultados (con la herramienta de diagnósticos del editor de consultas)
Limitar actualizaciones programadas: delimitar un estándar de actualizaciones para modelos importados por día. Para eventualidades analizar caso puntual y quien lidere el requerimiento justificar la excepción.
Distribuir las actualizaciones programadas de modelos importados a lo largo del día o en rangos de horas por unidad de negocio o tableros. Las actualizaciones masivas en mismo horario pueden generar overloads.
Delimitar estándares para refresh on demand, pedir permiso al realizarlo o delimitar un horario permitido para correrlos.
Activar Large storage en workspace de medianos y grandes modelos. La opción permite trabajar con el almacenamiento columnar permitiendo una optimización de memoria cargando únicamente las columnas que fueron usadas recientemente bajo condiciones de temperatura como priorización.
Usar capacidad compartida PRO para escenarios que no lo requieran. Si tenemos desarrollos que solo verán usuarios pro y los informes no son muy pesados, entonces podría ser un área de trabajo de capacidad compartida. No todo debe estar en la capacidad. Si trabajamos con más de un ambiente, considerar que el de desarrollo podría ser pro para que su carga no impacte en la capacidad productiva.
Dividir la capacidad en ambientes de desarrollo. Si tenemos un F128, podríamos utilizar dos F64 para separar ambientes de desarrollo y productivos para evitar que quienes desarrollan y necesitan actualizaciones con validaciones no consuman la memoria de tableros definitivos que están dando producción a la organización o dirección.
Auditorias de modelos semánticos: Control de calidad de desarrollo antes de publicar en la capacidad dedicada garantizando que las teorías de data modeling fueron aplicadas.
En caso de no poder realizar auditorías constantes para todo, monitorear contenido de workspaces que más usan la capacidad. Agendarles control de prácticas de desarrollo para dichos contenidos puntuales.
Construir una herramienta de monitoreo de refreshes a partir de Power Bi Rest API.
Construir herramienta de monitoreo a partir de azure logs que den más detalle que la Fabric Capacity Metrics App.
Reducción operación Interactive
Éstas se ejecutan cuando un usuario interactúa con un informe o con el modelo semántico directamente. Algunas prácticas para reducirla son:
Estándares de data visualization. Si definimos reglas visuales como límite en cantidad de visualizaciones, no construir páginas gigantes con scroll, reducción custom visuals, no sobrecargar de campos las tablas, etc. Ayudaremos a que los tableros sean más livianos.
Indirectamente realizar un correcto modelado de datos se reflejará en medidas DAX más simples y livianas que eviten sobrecargar la memoria de las visuales.
Política respecto a “Analizar en Excel”. Conectar un Excel al modelo semántico puede resultar muy costoso puesto que usuarios expertos podrían construir tablas pivot demasiado sobrecargadas de datos.
Mejorar entendimiento de DAX. Si conocemos con más detalles sus motores, formula engine y storage engine, será el primer paso para optimizar medidas que no colapsen visualizaciones.
Activar Large storage también repercute sobre la interactividad puesto que la cantidad de memoria con la que el usuario interactúa es menor. Carga en memoria por columnas a demanda con referencia de temperatura (data caliente o fría).
Encender scaleout de modelos muy concurridos. Ayuda a ofrecer un rendimiento rápido mientras una gran audiencia consume los informes y paneles. Hospeda una o varias réplicas de solo lectura del modelo semántico principal. Al aumentar el rendimiento, las réplicas de solo lectura aseguran que el rendimiento no se ralentice cuando varios usuarios envían consultas al mismo tiempo.
Al igual que con background no todo debe ir a la capacidad dedicada. Si tenemos tableros o unidades que solo tienen usuarios pro, podríamos usar capacidades compartidas que reduzcan también la interactividad.
Política de uso y límites para copilot. Si contamos con las características del copiloto, sería prudente establecer límites de uso u horarios permitidos para que usuarios no se excedan en pruebas o curiosidades que afecten la capacidad.
Estas y seguramente otras prácticas serán necesarias para cada escenario puntual puesto que cada capacidad tiene desployado soluciones diferentes. Ojala los ayude a ver prácticas y modos que velen por la sanidad de su capacidad.
#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#fabric capacity#fabric jujuy#fabric cordoba#fabric argentina#ladataweb#power bi premium#power bi service#power bi#powerbi
1 note
·
View note
Text
[SimplePBI] Documentar modelo semantico automáticamente
A medida que más modelos y reportes se construyen se vuelve más crítica la necesidad de tener documentos que ayuden a la interpretación de los mismos. La popularidad de la herramienta ya lleva muchos años de desarrollo y todos los días nuevos desarrolladores deben modificar o dar soporte a modelos que no construyeron.
Tanto por soporte, interpretación, mantenimiento y mucho más, se vuelve indispensable documentar lo que sucedió en el modelo semántico para que otros puedan seguir el hilo de nuestro trabajo. En este artículo veremos como podemos ejecutar una sentencia en python usando SimplePBI para exportar un documento html de un informe publicado en Power Bi Service.
Documentar es una de las tareas más odiadas por desarrolladores de múltiples industrias. Aunque a la mayoría no le guste es innegable que tiene beneficios. Uno de mis favoritos es mejorar la colaboración entre equipos. Imaginen que bueno sería dar soporte a una medida que tenga una buena Descripción o sus varias líneas de código con comentarios. Seguramente, la experiencia de modificar una así a 20 lineas sin especificar reduciría el tiempo de respuesta para resolverlo.
Pre-requisitos
Para poder utilizar esta herramienta es necesario contar con acceso a la Power Bi Rest API. Podes leer como dar tus primeros pasos aqui.
Limitaciones
Este método está basado en ejecuciones de consultas contra el modelo semántico. Si utilizamos un Service Principal para realizar este documento, no es posible ejecutar consultas contra un modelo semántico que tenga configurado RLS o de conexión direct lake o direct query.
Creación del documento
Veamos que simple que es exportar un documento html que lea un informe de un modelo semantico en el servicio de power bi. Para mejor experiencia de usuario, hemos desarrollado dos tipos de documento. Uno por contenido y otro por tablas.
La ejecución es bastante simple. Buscamos en nuestra interfaz el modelo semántico que queremos analizar y lo abrimos. Esto lo hacemos para poder extraer el id del área de trabajo y del modelo semántico de la URL

Doc por contenido
Como ya aclaramos muchas veces para iniciar la librería importamos los módulos que nos interesan y autenticamos un token para ejecutar los requests.
from simplepbi import token from simplepbi import datasets # Variables de autenticación TENANT_ID = "xxxx-xxxx-xxxx-xxxx" power_bi_client_id = 'xxxx-xxxx-xxxx-xxxx' power_bi_secret = 'xxxx-xxxx-xxxx-xxxx' workspace_id = 'xxxx-xxxx-xxxx-xxxx' dataset_id = 'xxxx-xxxx-xxxx-xxxx' # Creación de objetos con requests y token t = token.Token(TENANT_ID, power_bi_client_id, None, None, power_bi_secret, use_service_principal=True) d = datasets.Datasets(t.token)
Como podemos apreciar en la siguiente imagen, el nuevo método los datos que nos piden son del workspace y dataset id.

Fíjense que podemos elegir si queremos exportar el documento a un path local o pedir la respuesta en una cadena de texto "string" que podríamos copiar y pegar en un archivo vacío y crear el html nosotros. Esto porque dependerá de donde estemos ejecutando el código. Por ejemplo:
d.create_doc_by_content_dataset_in_group(workspace_id, dataset_id, "file", r"C:\Users\IBARRAU\Documents\css templates\doc_by_content.html")

El documento está dividido por contenido. Entonces tiene tres partes. Primero las tablas con su diagrama, luego las columnas de todas las tablas y finalmente las medidas de todas las tablas. Algo así:

Doc por Tabla
De la misma manera la exportación funciona exactamente igual. La diferencia esta en el tipo de contenido. Veamos el código

También aqui podemos delimitar si queremos "Text" o "File". La sentencía sería:
d.create_doc_by_table_dataset_in_group(workspace_id, dataset_id, "file", r"C:\Users\IBARRAU\Documents\css templates\doc_by_table.html")

Este documento es un poco más completo puesto que añade las definiciones de consultas de Power Query escondidas en un elemento html que colapsa el código para que no sea tan largo. Esta construido mostrando el diagrama de tablas seguido tabla por tabla. Cada tabla muestra la definición de su consulta, las columnas y sus medidas (en caso de tenerlas).

Ambos documentos podemos encontrarlos en mi repositorio de GitHub en caso que quieran leerlos con detalle. Si queres conocer más de SimplePBI, su repositorio y documentación esta en GitHub.
Así concluimos las exportaciones automáticas que pueden ayudarnos con los detalles de un modelo para tenerlos cerca si necesitamos conocer detalles de un modelo desplegado en el servicio de Power Bi.
#simplepbi#fabric#powerbi#power bi#power bi documentation#microsoft fabric#power bi argentina#power bi jujuy#power bi cordoba#ladataweb#power bi python
0 notes
Text
[Fabric] Integrar repo GitHub con área de trabajo
Una característica que no para de causar revuelo y preguntas al momento de persistir los desarrollos de Fabric es la integración de áreas de trabajo con Github. Desde el lanzamiento de Fabric podíamos integrarnos a un repositorio, pero era exclusivamente con Azure DevOps. La historia continuó con el lanzamiento de Power Bi Projects que nos permitía desagregar el desarrollo de un pbix en código para poder persistirlo y mergearlo. La cuenta pendiente más grande de desarrollos de Power Bi estaba saldada. El desarrollo ya podía ser versionado en su totalidad.
En este artículo vamos a ver como configurar un repo de Github para estar integrado con un Area de trabajo en Fabric/PowerBi.
Lo primero que recomiendo si están iniciando este artículo sin conocer que es una integración de Git en un área de trabajo es pasar por este artículo anterior que explica el funcionamiento y la desagregación de archivos que consolidan un Proyecto de Power Bi.
Prerrequisitos
Cuenta de Github
Repositorio creado (se recomienda privado para desarrollos y manejo de datos corporativos sensibles)
Una Personal Access Token (PAT)
Un área de trabajo con capacidad dedicada
Asumiendo que conocemos como crear una cuenta de Github y un repositorio, comencemos con la creación de la PAT. Para ellos vamos a nuestro perfil, menú settings > Developer settings. Los tokens de acceso pueden ser classic o fine-grained. Recomiendo crear fine-grained que son la próxima generación de tokens y es bueno estar actualizados.
https://github.com/settings/tokens?type=beta

Delimitamos un nombre para nuestro token de acceso y en el apartado de permisos seleccionamos Read and Write para Contents.
Tras crear el token es necesario guardar el valor generado porque no podremos volver a verlo. Copienlo bien y resguárdenlo.
Ahora si podemos volver a PowerBi para abrir las configuraciones del área de trabajo en la parte de integraciones de Git. Hay dos configuraciones. Iniciamos logueando el proveedor con la dirección del repo y el token:

Una vez configurado se ve así. Continuamos sincronizando el pertinente Branch que nos permite seleccionar inclusive una carpeta o subcarpeta especifica. Tengamos presente que símbolos y espacios en las carpetas podrían generar dificultades para reconocerlas.

Así conseguimos nuestra integración para comenzar a trabajar en equipo sobre los reportes y modelos semánticos desarrollados como Power Bi Projects o elementos de Fabric.
Esta sencilla configuración nos permite comenzar a versionar nuestros desarrollos de PowerBi con simplemente una capacidad dedicada puesto que Github cuenta con servicio gratuito que fortalece no incorporar una licencia adicional.
Otros repositorios
Las áreas de trabajo permiten integración con dos repositorios Git hasta el momento (19-09-2024), Azure DevOps y GitHub. veamos algunas comparaciones entre las plataformas:

Si queres saber más sobre la integración con Azure DevOps podes ver este post.
Así completamos nuestro artículo para conectar un repositorio GitHub con un Área de trabajo. ¿Cual usar? depende de cada organización respecto de que tecnología se adaptaría mejor o cual están usando actualmente.
#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#power bi service#power bi versioning#power bi git#github#fabric tips#fabric tutorial#fabric training#ladataweb
0 notes
Text
[DAX] INFO functions
Hace varios meses ya que microsoft nos ha sorprendido agregando nuevas funciones en DAX que responden a información del modelo. Conocer detalles del modelo se vuelve indispensable para documentar o trabajar por primera vez con un modelo ya creado.
Ya son más de 50 nuevas funciones que permiten preguntarle al modelo detalles particulares como por ejemplo indagar en las expresiones de las medidas de nuestro modelo o los roles de seguridad por filas creados.
Lo cierto es que ya existía una forma de llegar a esta información. Desde el inicio de modelos tabulares tuvimos exposición a DMV (Dynamic Management Views). Como nos gusta hacer aqui en LaDataWeb, primero veamos el contexto teórico:
Las vistas de administración dinámica (DMV) de Analysis Services son consultas que devuelven información sobre los objetos del modelo, las operaciones del servidor y el estado del servidor. La consulta, basada en SQL, es una interfaz para esquemas de conjuntos de filas.
Si quieren traer un poco más a la memoria o un ejemplo de ello, pueden revisar este viejo artículo. El nuevo esquema INFO en DAX nos brinda más de 50 funciones para obtener información del esquema TMSCHEMA de DMV.
Si ya existía... ¿Por qué tanto revuelo?
Las INFO de DAX vienen a evolucionar algunos aspectos que no podíamos resolver antes y darnos creatividad para explotarlos en otros que tal vez no habíamos pensado.
No es necesario utilizar una sintaxis de consulta diferente a DAX para ver información sobre tu modelo semántico (antes SQL). Son funciones DAX nativas y aparecen en IntelliSense cuando escribes INFO.
Puedes combinarlas usando otras funciones DAX. La sintaxis de consulta DMV existente no te permite combinarlas. Como función DAX, la salida es de tipo de datos Tabla y se pueden usar funciones DAX existentes que unen tablas o las resumen.
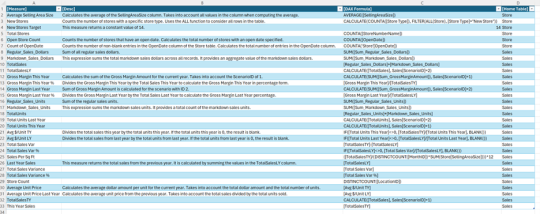
Estas son el eslabón inicial bajo el cual se llamó la atención. Ahora podemos pensar solo en DAX y si buscamos INFO de Tablas, relaciones, columnas o medidas, podemos combinarlas para mejorar el resultado de nuestra consulta. Si quisieramos conocer las medidas de una tabla puntual con su nombre, podríamos ejecutar algo así:
EVALUATE VAR _measures = SELECTCOLUMNS( INFO.MEASURES(), "Measure", [Name], "Desc", [Description], "DAX formula", [Expression], "TableID", [TableID] ) VAR _tables = SELECTCOLUMNS( INFO.TABLES(), "TableID", [ID], "Table", [Name] ) VAR _combined = NATURALLEFTOUTERJOIN(_measures, _tables) RETURN SELECTCOLUMNS( _combined, "Measure", [Measure], "Desc", [Desc], "DAX Formula", [DAX formula], "Home Table", [Table] )
Así obtendríamos una tabla con su nombre, sus medidas, sus descripciones de medidas y las expresiones de las medidas. El resultado puede ser documentación de modelo exportado a excel:
¿Donde o cómo puede ejecutarlo?
Las funciones de información puede ayudarnos para explorar un modelo en edición actual. Si estamos conociendo un modelo por primera vez o culminando un trabajo para documentar, podríamos abrir la vista de consultas DAX de un Power Bi Desktop para ejecutar el código. También siempre dispondríamos de DAX Studio que no solo permite ejecutar con un PowerBi Desktop, sino también contra un modelo en una capacidad dedicada en Fabric o PowerBi Service.
En mi opinión lo más interesante es que esto es DAX nativo. Como gran amante de la PowerBi Rest API, eso me entusiasma, dado que el método que permite ejecutar código DAX contra un modelo semántico en el portal de PowerBi, no permite DMV. Restringe a DAX nativo. Esto abre las puertas a ejecutar por código una consulta de información al modelo. Podríamos estudiar y comprender que es lo que a nuestra organización más nos ayuda entender de un modelo o nos gustaría documentar. A partir de ello construir un código que obtenga esa información de un modelo semántico que necesitemos comprender. Veamos la siguiente imagen que aclare más

Espero que las funciones los ayuden a construir flujos que les brinden la información que desean obtener de sus modelos.
#powerbi#power bi#power bi desktop#DAX#power bi tips#power bi tutorial#power bi training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb#simplepbi
1 note
·
View note
Text
[SimplePBI] Get tablas, medidas, columnas o roles de un modelo con código Python
Al día de hoy PowerBi esta instaurado masivamente. Ya lo usan muchísimas empresas y la cantidad de modelos e informes deployados es enorme. Esto hace que los desafíos de hoy, ya no sean los de antes.
Antes había más concentración en la comunidad por aprender PowerBi tips, buscar como armar una característica puntual de experiencia de usuario. Esto se daba porque eran los primeros informes de muchas empresas. Hoy nos toca entender informes ya implementados por otras personas o empresas. ¿Cómo entender que hay detrás de un modelo semántico publicado? El nuevo update/release de la librería de Python, SimplePBI, para leer la PowerBi Rest API puede ayudarnos a obtener información de tablas, medidas, columnas y hasta roles que existen en el modelo.
Cuando necesitamos editar, dar soporte y comprender algún modelo semántico en producción. Puede ser un gran desafío si no contamos con las prácticas adecuadas de versionado. Si necesitamos entender rápidamente sobre un linaje fino (tabla) del origen y no tenemos un catálogo de gobernanza apropiado hay un inconveniente.
Para estas situaciones y muchísimas más, SimplePBI incorporó la posibilidad de preguntar fácilmente con código python por información de un modelo semántico. ¿Qué podemos consultar?
Tablas: datos de las tablas del modelo.
Medidas: todas las medidas del modelo, sus expresiones y a que tabla pertencen.
Columns datos de las columnas del modelo y a que tabla pertenecen.
Roles: datos de roles de RLS creados en el modelo.
Veamos que simple que es consultar el modelo.
Pre requisitos
Lo primero que necesitamos es conocer como se utiliza la PowerBi Rest API, para ello podes dar tus primeros pasos con este artículo. Lo segundo es asegurarnos que tenemos una versión 0.1.10 o superior de la librería:

Si ya tenian la librería pueden correr en consola:
pip install SimplePBI --upgrade
Obtener información del modelo
A partir de ese momento podremos consultar un modelo semántico o conjunto de datos de un área de trabajo puntual.
Autenticamos y generamos un token:
Creamos el objeto de la categoría que nos gustaría ejecutar. En este caso datasets hace referencia a modelos semánticos:
d = datasets.Dataset(t.token)
Aún siendo desarrollo propio de la librería, los métodos a ejecutar tienen nombre amigables muy similares a los que ya existían en la documentación de la API:
get_tables_from_dataset_in_group
get_measures_from_dataset_in_group
get_columns_from_dataset_in_group
get_tables_from_dataset_in_group
Podemos obtener el id de área de trabajo y del modelo semántico desde la URL del navegador cuando abrimos el modelo. Se ve así:
https://app.powerbi.com/groups/[Workspace ID]/datasets/[Dataset ID]/details?experience=power-bi
Así ejecutaríamos las medidas:

Como podemos apreciar, es una simple linea que trae toda la información. Cada item de la lista de rows en el diccionario de respuesta tiene una medida. En este caso podemos ver tres medidas de la tabla "MEDIDAS". Entre los datos de mayor interes vemos su nombre, tipo de datos y expresión.
Espero que esto los ayude a investigar más sobre modelos deployados para aprender en caso de dar soporte, mejorar nuestras estructuras de catálogos o revisar rápidamente expresiones de medidas. El uso en definitiva tiene como límite su creatividad.
#powerbi#power bi#power bi tips#power bi tutorial#power bi training#power bi service#power bi rest api#python#simplepbi#ladataweb#power bi argentina#power bi jujuy#power bi cordoba
1 note
·
View note
Text
Fabric Mirroring
Estamos atravesando tiempos que avanzan muy rápido en materia de desarrollos de tecnología, software y datos. Especificamente, en el universo de datos podemos apreciarlo en el cambio constante que ocurre a las necesidades de cada empresa en construcciones analíticas.
Entre los más ocurrentes tenemos problemas que hablan de encontrar escalabilidad con menor costo, accesibilidad a todo tipo de usuario y reducir los data silos. Si están pensando en usar Fabric o ya lo usan. Mirroring puede ayudarnos en parte con estos problemas.
Contexto
Me gustaría comenzar recordando que las replicas o mirror no son algo nueva en industria tecnología. Veamos un concepto genérico en mirror de bases de datos que era algo bastante común.
"Mirroring en base de datos es una copia de seguridad completa de la base de datos que se puede usar si la base de datos principal falla. Las transacciones y cambios en la base de datos principal se transfieren directamente al espejo y se procesan de inmediato, por lo que el espejo siempre está actualizado y disponible como un 'standby' activo."
En tradicional desarrollo de software nacía como dar certeza que una falla no prevenga el acceso. Sin embargo, en materia de análisis de datos se consideraba crucial para evitar que el computo de grandes consultas analíticas no impactara directamente en la base de datos transaccional.
A mi modo de pensar ambos apuntan a un mismo foco indispensable. Disponibilidad. Que los accesos a datos siempre tengan certeza de consulta.
Fabric Mirror
Fabric Mirroring es una solución de bajo costo y baja latencia para unir datos de varios sistemas en una sola plataforma de análisis. Puedes replicar continuamente tu conjunto de datos existente directamente en OneLake de Fabric. Actualmente cuenta con tres posibles orígenes:
Azure SQL Database
Azure Cosmos DB
Snowflake.
Entre las características que me gustaría destacar estan:
Permite replicar bases de datos en Fabric sin necesidad de ETL
Los datos se replican en OneLake en formato Delta y se mantienen actualizados en tiempo casi real. (Mi favorita)
Todos los servicios de almacenamiento de Fabric funcionan instantáneamente con la réplica de OneLake, incluidas las experiencias de warehouse y lakehouse.
El almacenamiento y la replicación para el mirror están incluidos en tu capacidad de Fabric sin costo adicional.
Construido sobre CDC (Change data capture) para solo mover en el instante los cambios de datos.
Soporte para DDL (Data definition language): permitiendo que nuevas tablas sean instántaneamente agregadas (en caso que hagamos replica de todas las tablas)
Mi favorito y la principal diferencia con un caso convencional de mirror es que la replica se reguarda en formato abierto delta. Perfecto y listo para ser consultado en Fabric. Al igual que con Lakehouse y Warehouse, cuando creamos un mirror se generan la misma cantidad de contenidos. Un SQL endpoint para consultar datos y un modelo semántico por defecto para analizar datos con direct lake.

Para crear uno simplemente ponemos "Nuevo" y buscamos el contenido de mirror al origen deseado. Delimitamos la base de datos y nos aparecerá una guia para conectarnos tal como si estuvieramos agregando un conjunto de datos en gateway o dataflow gen2.

Luego podremos elegir si replicar toda la base de datos o simplemente una delimitada selección de tablas con objetivo de análisis de datos. Por defecto el recurso principal nos deja monitorear cada tabla:

Si nos dirigimos al SQL Analytics endpoint podremos tener vista previa de los datos e incluso encontrar su lugar puntual en el OneLake en su modo delta parquet.

De ese modo tenemos un excelente y simple proceso para tener al instante los datos que buscamos para construir proyectos de datos sin complejos ETL, disponible para consultar con computo de spark usando notebooks, sql o powerbi.
Pre requisitos
Necesitas tener una capacidad existente de Fabric. Si no la tienes, inicia una prueba de Fabric.
Habilita Fabric mirroring en tu configuración para inquilino de Microsoft Fabric (admin portal).
Si vas a trabajar con service principals, habilita la configuración de inquilinos de Fabric 'Permitir a los principales de servicio utilizar las API de Power BI'.
Requisitos de red para que Fabric acceda a la fuente de datos. Cada origen tiene configuración adicional en el origen. Puede verse en un tutorial de la doc de microsoft.
Espero que esta feature les resulte útil. Tiene un potencial inmenso que seguramente crecerá más y más a medida que pueda disponibilizar más orígenes. Hoy permitir snowflake es un bombazo y seguramente tendrá más.
#fabric#microsoft fabric#fabric jujuy#fabric cordoba#fabric argentina#ladataweb#fabric tips#fabric tutorial#fabric training#fabric mirroring#fabric snowflake
0 notes
Text
[SimplePBI] Como armar un histórico de Fabric Capacity Metrics App
Cada día me llegan más solicitudes de instalar una herramienta de monitoreo para administrar una capacidad dedicada. Allí es cuando aparece la App de Microsoft. Sin embargo, la herramienta, o debería decir el modelo semántico, cuenta con una limitada historia para monitorear. Resulta que el informe resguarda pocos días hacia atrás y algunas instituciones prefieren contar con valores históricos para poder analizar tendencias o dar explicaciones a sucesos pasados y no solamente a lo que ocurre ahora.
En este artículo veremos como podemos extraer datos del modelo semántico de Fabric Capacity Metrics App para construir un histórico utilizando la librería SimplePBI de Python en un jupyter notebook.
Si tenemos nuestros desarrollos desplegados en una capacidad, seguramente estamos utilizando Fabric Capacity Metrics App. Digo "seguro" porque la aplicación del store de Microsoft provee un informe para monitorear el uso de nuestra capacidad (Unidades de procesamiento/capacity CUs). A diferencia del Admin Monitoring que provee un detalle de lo que esta desplegado en la organización y las operaciones o actividades que se ejecutan, la Capacity metrics nos ayuda a entender cuantos recursos de la capacidad esta utilizando un contenido como un modelo semantico, un dataflow gen2, un Fabric notebook o un pipeline de Fabric Data Factory.
Cuando disponemos de una capacidad la administración cambia completamente. Las acciones diarias y los hitos por proyectos o deploys nuevos deben tenerse en cuenta. Si queremos comparar o analizar cambios en deploys mensuales de proyectos complejos, necesitamos almacenar un histórico. Si necesitamos analizar si una tendencia actual que esta relentizando o consumiendo todos los recursos estaba sucediendo en el pasado y no es excepcional, necesitamos histórico. Por esta y muchas otras razones que me comentaron algunos clientes se me ocurrió escribir este artículo.
Prerequisitos
Lo primero que necesitamos será definir nuestro almacenamiento. Si ya utilizamos Fabric es posible usar lakehouse o warehouse con Fabric notebooks, sin embargo tal vez querramos aislar este desarrollo para que no tenga la más mínima influencia en la capacidad. Una vez definido el almacenamiento debemos asegurarnos que podemos usar la Power Bi Rest API. Este artículo puede ayudarlos. Por último, instalar en el entorno donde correremos código Python la librería SimplePBI.
¿Qué vamos a extraer?
El modelo semántico de la Capacity Metrics esta lleno de tablas y contiene parámetros dinámicos. Sin embargo, hoy nos vamos a concentrar en lo más usados.
Timepoints: puntos temporales donde ocurre un movimiento de la capacidad.
Items: contenido que ha utilizado la capacidad al menos una vez.
Background Operations: operaciones de código que incluyen procesamientos o transformaciones.
Interactive Operations: refiere a las interacciones de los usuarios explorando y utilizando los informes.
Vamos a iniciar importando librería, recolectando valores de nuestra Aplicacion Registrada en Azure para usar la API. También podemos buscar el id de la capacidad en el portal de administración de Fabric, administrando capacidades.
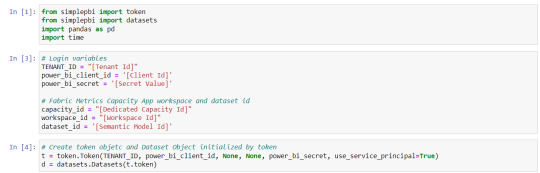
Para obtener los datos vamos a ejecutar una consulta/query contra el modelo de datos. Veamos por ejemplo una función para traer los Timepoints de un día específico.
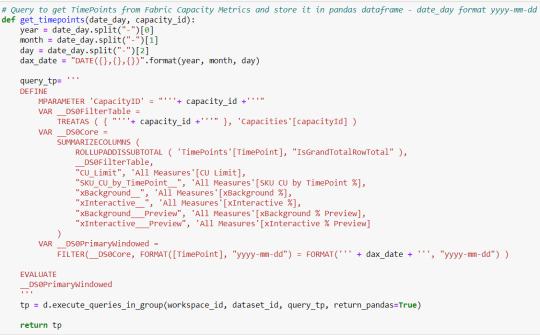
Para comenzar debemos mandar un parámetro dinámico de M PowerQuery. Mandamos el id de capacidad y ejecutamos un SUMMARIZECOLUMNS buscando el listado de timepoints y algunas columnas más de operaciones.
A partir de los timepoints podremos buscar las operaciones puesto que se desencadenan para cada timepoint. Entonces hay muchas operaciones por cada timepoint. El primer desafío es que la API nos limita a 1.000.000 de celdas o registros. Calculando cuantas filas podemos traer para la cantidad de columnas que conllevan ese volumen, hablamos de 66.666 filas aproximadamente. Esta información es clave para iterar operaciones de nuestra capacidad.
NOTA: Esto solo será necesario si tenemos mucha cantidad de contenido o usuarios operando.
Comenzaremos ejecutando un COUNT de filas de las operaciones para partir la cantidad de iteraciones cada 66.666 filas.
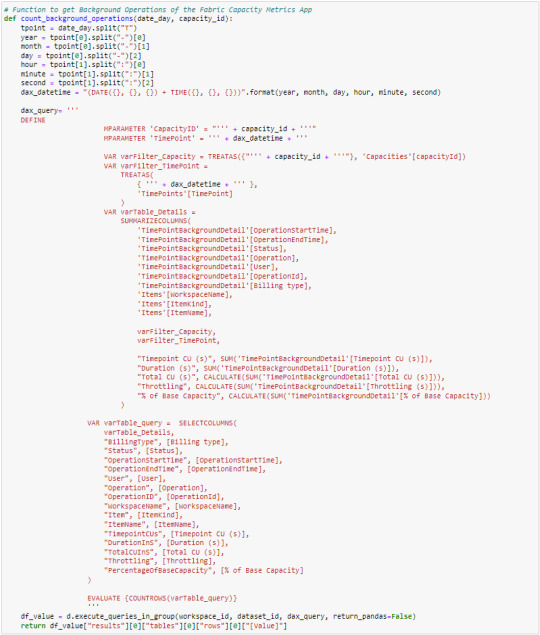
La consulta para saber las filas y traer los resultados es similar. Ambas pasarán los parámetros dinámicos de M (id de capacidad y timepoint) y buscaran las columnas esperadas, las renombraremos y al final cambiará si buscamos contar las filas o traer los resultados en "ventanas" de 66.666 filas.

Con las funciones que nos den las filas y la ejecución de cada timepoint, vamos a construir la iteración.
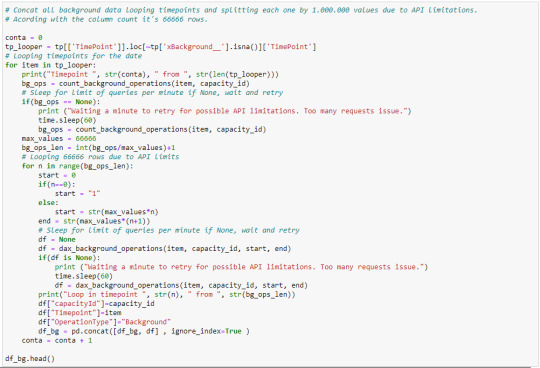
En caso que las operaciones lleguen en "None", lo más probable es que sea porque la librería SimplePBI no hay podido traer los resultados por limitación de cantidad de requests ejecutados con la API. Entonces desencaderá una espera de 1 minuto para reanudar. Pueden observar cada paso con sus comentarios para ir comprendiendo el código o construir uno propio. Aqui iteramos dos veces, por un lado una lista timepoints "tp_looper" y por cada una de ella la limitación de filas de la API. Agregamos tres columnas que nos ayuden a reconocer el resultado, el id de capacidad (por si tenemos más de una capacidad), el timepoint (para conocer la fecha con exactitud) y tipo de operación (si es de back o interactiva). Vamos agregando los resultados en un solo pandas dataframe.
Así formamos un frame de operaciones background. Para las operaciones interactive es realmente muy similar, cambian un par de nombre de columnas y tablas.
Finalmente, traemos los items involucrados para constituir una dimensión de ellos. Sería bueno que al integrarlos comparemos el destino para ver de agregar únicamente las filas nuevas.

Así constituimos las 4 tablas que podrán ejecutarse cada día para ir construyendo un histórico.
Pueden repasar el Notebook completo en mi GitHub.
Espero que les sea de utilidad y puedan almacenar las operaciones historicas ordenadas en este modelo estrella sencillo de dimensiones de timepoints e items con hechos de operaciones background e interactivas.
#fabric metrics#fabric#microsoft fabric#power bi premium#power bi#powerbi#power bi cordoba#power bi jujuy#power bi argentina#ladataweb#simplepbi#fabric capacity
0 notes
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
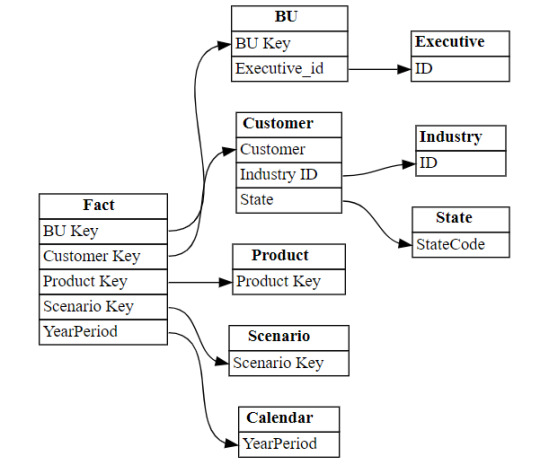
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
[PowerBi] Efectos en botones mouse over
Si bien hay mucho escrito sobre botones en PowerBi y en este blog se ha escrito bastate sobre el tema, no he visto en mucho tiempo el uso de estos efectos para mejorar la experiencia de usuario.
Este artículo nos mostrará una forma de acondicionar los botones para dar una grata experiencia similar a la que podemos apreciar en distintos sitios y sistemas de información. Se trate de jugar con cambios al posicionar el mouse por encima. Si, muchos dirán, "obvio que cambio el background al pasar el mouse para que se vea lindo". Bueno pues aqui mostraremos otras dos ideas diferentes a pintar el background.
Antes de comenzar me gustaría aclarar una regla de oro para lograr una grata experiencia de usuarios con botones. Con esto me refiero a dar evidencia al usuario respecto a cual es el botón actualmente seleccionado frente a otros. Puede sonar sencillo y muchos dirán que el navigator que existe hoy lo resuelve, pero cuando queremos llegar más lejos con los efectos, necesitaremos un poco de creatividad retro con nuestros amigos bookmarks.
NOTA: Si no conoces como delimitar sencillamente un botón seleccionado pintando su fondo, podes revisar este artículo.
A continuación vamos a ver dos efectos por separado que tranquilamente podrían aplicarse juntos.
Subrayado por sobre fondo
Lo más natural al generar botones es concentrase en el fondo que presentan, tanto para la selección como para el paso del mouse. Sin embargo, si prestamos atención a la web, podremos apreciar que un efecto mucho más liviano a la visa aparece con titulos subrayados.

Con un simple subrayado puedo apreciar rapidamente cual es el botón seleccionado en este momento. También puedo jugar con el mismo efecto para cuando el cursor se posiciona por encima de las otras medidas.
Para construirlo vamos a necesitar de dos botones (el activo y el inactivo como en el artículo anterior) y una linea horizontal común. El botón inactivo en su estado común presenta un fondo sólido (transparencia 0%) con exacto decimal que el fondo que posee con letra gris. Mientras que su estado al pasar el mouse por encima presenta letra blanca y fondo transparente 100% para hacer visible la línea que hay por detrás.

Cuando clickeamos el botón activo, es decir el que lleva el estado actual de lo que vemos, permance oculto hasta clickear el botón. Luego de clickearlo con bookmarks lo haremos visible. Este botón esta posicionado exactamente encima del inactivo. Mientras el botón activo este visible vamos a ocultar el inactivo. El botón activo tendrá como "Default" las mismas propiedades que "On Hover" del inactivo, de manera que haga visible la línea horizontal y letra blanca. Veamos como queda todo armado:

Si nos fijamos este efecto podría ser transferido tranquilamente al menú de la izquierda también con una línea vertical.
Espaciado de movimiento
Aún que Power Bi no tenga visualizaciones que nos permitan jugar mucho con efectos de movimiento, algunas veces podemos simularlo. En este caso vamos a simular un ligero movimiento del texto hacia la derecha cuando posicionamos el cursor por encima del botón. Para lograrlo nuevamente vamos a utilizar 3 elementros, dos botones y una línea vertical. La diferencia en esta oportunidad es que no vamos a cubrir la línea de forma simple como antes sino que vamos a ocultarla y mostrarla. ¿Por qué la complicaríamos de ese modo? simplemente porque el fondo tiene un grandiente. En esos casos no podemos hacer que el botón en estado por defecto la oculte porque sería muy complejo lograr el mismo efecto en el fondo del botón. Por ello vamos a tener las líneas ocultas hasta que el botón sea presionado y la refleje en definitiva.
Para lograr este efecto veamos pondremos el botón inactivo con texto gris sin fondo y el truco estará en su estado "On Hover". En ese estado vamos a colocar carateres invisibles.
¿Qué es un caracter invisible? El texto invisible o caracteres invisibles se refiere a caracteres especiales que no pueden ser vistos en la pantalla pero son tratados como letras normales.
Nuestro texto al pasar el mouse comenzará con caracteres invisibles de manera que genere el efecto de que el texto se mueve levemente a la derecha al pasar por encima. Algo así:

Fijense que parece que hubiera espacios al inicio, pero no son espacios.
Aquí dejo los caracteres por si quieren copiarlos: <- atrás de la fecha. Si quieren comprobar que no es broma ni nada, pueden pegar el texto en Notepadd++ (que es capas de reconocerlos) y verán algo así:

La magia del movimiento ya está. Ahora ¿Cómo sigue la experiencia de usuario? con la regla de oro. Al hacer click vamos a ocultar el botón inactivo para hacer visible la línea vertical y el botón activo que en este caso tiene el texto pintado del mismo color que la línea.
Veamos como queda:

Esto fue todo, espero que les traiga nuevas ideas para ir reflejando nuevas experiencias amigables y similares a aplicaciones web que vemos diariamente. Recuerden que pueden combinar ambos efectos. Podríamos tener la lista vertical mostrando la línea vertical ademas de moverse.
#uxui#powerbi#power bi#power bi tips#power bi tutorial#power bi training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb
0 notes