
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by alcoholismoporansiedad and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
6 days ago
Number of Posts By Type
Text
5
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Making Data Management Decisions
Starting with import the libraries to use
import pandas as pd import numpy as np
data=pd.read_csv("nesarc_pds.csv", low_memory=False)
Now we create a new data with the variables that we want
sub_data=data[[ 'AGE', 'S2AQ8A' , 'S2AQ8B' , 'S4AQ20C' , 'S9Q19C']]
I made a copy to wort with it
sub_data2=sub_data.copy()
We can obtain info of our dataframe to see what are the types of the variables
sub_data2.info()
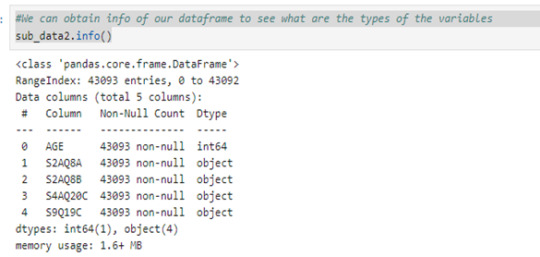
#We see that foru variables are objects, so we can convert it in type float by using pd.to_numeric
sub_data2 =sub_data2.apply(pd.to_numeric, errors='coerce') sub_data2.info()

At this point of the code we may to observe that some variables has values with answers that don´t give us any information



We can see that this four variables includes the values 99 and 9 as unknown answers so we can replace it by Nan with the next line code:
sub_data2 =sub_data2.replace(99,np.nan) sub_data2=sub_data2.replace(9, np.nan)
And drop this values with
sub_data2=sub_data2.dropna() print(len(sub_data2)) 1058
I want to create a secondary variable that tells me how many drinks did the individual consume last year so I recode the values of S2AQ8A as how many times the individual consume alcohol last year.
For example, the value 1 in S2AQ8A is the answer that the individual consume alcohol everyday, so he consumed alcohol 365 times last year. For the value 2, I codify as the individual consume 29 days per motnh so this give 348 times in the last year.
I made it with the next statement:
recode={1:365, 2:348, 3:192, 4:96, 5:48, 6:36, 7:12, 8:11, 9:6, 10:2} sub_data2['S2AQ8A']=sub_data2['S2AQ8A'].map(recode)
Adicionally I grupo the individual by they ages, dividing by 18 to 30, 31 to 50 and 50 to 99.
sub_data2['AGEGROUP'] = pd.cut(sub_data2.AGE, [17, 30, 50, 99])
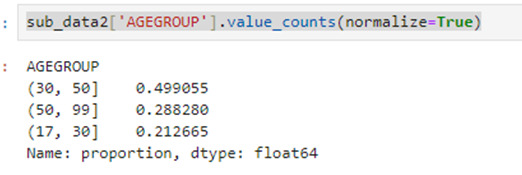
And I can see the percentages of each interval
sub_data2['AGEGROUP'].value_counts(normalize=True)
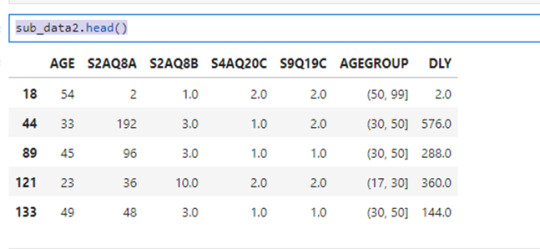
Now I create the variable 'DLY' for the drinks consumed last year by the next statemen:
sub_data2['DLY']=sub_data2['S2AQ8A']*sub_data2['S2AQ8B'] sub_data2.head()
The variables S4AQ20C and S9Q19C correspond to the questions:
DRANK ALCOHOL TO IMPROVE MOOD PRIOR TO LAST 12 MONTHS
DRANK ALCOHOL TO AVOID GENERALIZED ANXIETY PRIOR TO LAST 12 MONTHS
respectively.
The values for this question are:
1 = yes
2 = no
I want to know if people who decide to consume alcohol to avoid anxiety or improve mood tends to consume more alcohol that peoplo who don´t do it.
So I made this:
sub_data3=sub_data2.groupby(['S4AQ20C','S9Q19C','AGEGROUP'], observed=True)
And I use value_counts to analyze the frecuency
sub_data3['S4AQ20C'].value_counts()

From this we can see the next things:
158 individuals consume alcohol to improve mood or avoid anxiety which represents the 14.93%
151 individuals consume alcohol to improve mood but no to avoid anxiety which represents the 14.27%
57 individuals consume alcohol to avoid anxiety but no to improve mood which represents the 05.40%
692 individuals don´t consume alcohol to avoid anxiety or improve mood which represents the 65.40%
We can obtain more informacion by using
sub_data3[['S2AQ8A','S2AQ8B','DLY']].agg(['count','mean', 'std'])
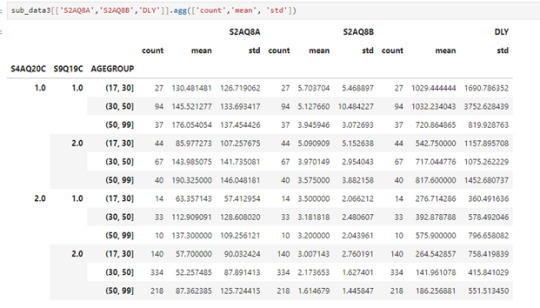
From this we can see for example:
Mots people are betwen 31 to 50 year old and they don´t consume alcohol to improve mood or avoid anxiety and they have a average of 141 drinks in the laste year which is the lowest average.
The highest average of drinks consumed last year its 1032 and correspond to individuals betwen 31 to 50 years old and the consume alcohol to improve mood or avoid anxiety and the second place its for indivuals that are betwen 18 to 30 year old and also consume alcohol to improve mood or avoid anxiety
This suggests that the age its not a determining factor to 'DYL' but 'S2AQ8A' and 'S2AQ8B' si lo son
0 notes
Text
Making my first program assigment
This is my code in python:
#-- coding: utf-8 --
""" Spyder Editor
This is a temporary script file. """ import pandas as pd import numpy as np
data = pd.read_csv('nesarc_pds.csv', low_memory=False) print(len(data))
print("counts for S2AQ1 usual quantity for drank at least 1 alcoholic drink in life by:" "1=yes and 2=no") c1=data['S2AQ1'].value_counts(sort=False, dropna=False) print(c1)
print("percentages for S2AQ1 usual quantity for drank at least 1 alcoholic drink in life by:" "1=yes and 2=no") p1=data['S2AQ1'].value_counts(sort=False,dropna=False, normalize=True) print(p1)
print("counts for S2AQ2 usual quantity for drank at least 12 alcoholic drink in last 12 months by:" "1=yes, 2=no and 9=unknown") c2=data['S2AQ2'].value_counts(sort=False, dropna=False) print(c2)
print("percentage for S2AQ2 usual quantity for drank at least 12 alcoholic drink in last 12 months by:" "1=yes, 2=no and 9=unknown") p2=data['S2AQ2'].value_counts(sort=False, dropna=False, normalize=True) print(p2)
print("counts for CONSUMER usual quatity the drinkins status categorizaded by:" "1=Current drinker, 2=Ex-drinker and 3=Lifetime Abstainer") c3=data['CONSUMER'].value_counts(sort=False, dropna=False) print(c3)
print("percentages for CONSUMER usual quatity the drinkins status categorizaded by:" "1=Current drinker, 2=Ex-drinker and 3=Lifetime Abstainer") p3=data['CONSUMER'].value_counts(sort=False,normalize=True, dropna=False) print(p3)
#As a subcollection I choose to work with people who are between 18 and 28 years old and they are currently drinkers
sub1=data[(data["AGE"]>=18) & (data["AGE"]<28) & (data["CONSUMER"]==1)] sub2=sub1.copy()
#Now we can see if my sample its correctly
print("Counts for Age") c4=sub2["AGE"].value_counts(sort=False) print(c4)
print("Percentages for Age") c5=sub2["AGE"].value_counts(sort=False, normalize=True) print(c5)
print("Counts for CONSUMER") c6=sub2["CONSUMER"].value_counts(sort=False) print(c6)
print("Percentages for CONSUMER") c7=sub2["CONSUMER"].value_counts(sort=False, normalize=True)
print("So we can see that just 5047 of the 43093 individuals are currently consumers and they are between 18 and 28 years old")
And his output is:
43093 counts for S2AQ1 usual quantity for drank at least 1 alcoholic drink in life by:1=yes and 2=no S2AQ1 2 8266 1 34827 Name: count, dtype: int64 percentages for S2AQ1 usual quantity for drank at least 1 alcoholic drink in life by:1=yes and 2=no S2AQ1 2 0.191818 1 0.808182 Name: proportion, dtype: float64 counts for S2AQ2 usual quantity for drank at least 12 alcoholic drink in last 12 months by:1=yes, 2=no and 9=unknown S2AQ2 2 22225 1 20836 9 32 Name: count, dtype: int64 percentage for S2AQ2 usual quantity for drank at least 12 alcoholic drink in last 12 months by:1=yes, 2=no and 9=unknown S2AQ2 2 0.515745 1 0.483512 9 0.000743 Name: proportion, dtype: float64 counts for CONSUMER usual quatity the drinkins status categorizaded by:1=Current drinker, 2=Ex-drinker and 3=Lifetime Abstainer CONSUMER 3 8266 1 26946 2 7881 Name: count, dtype: int64 percentages for CONSUMER usual quatity the drinkins status categorizaded by:1=Current drinker, 2=Ex-drinker and 3=Lifetime Abstainer CONSUMER 3 0.191818 1 0.625299 2 0.182884 Name: proportion, dtype: float64 Counts for Age AGE 19 465 18 401 21 560 25 488 22 531 20 476 24 582 26 476 23 536 27 532 Name: count, dtype: int64 Percentages for Age AGE 19 0.092134 18 0.079453 21 0.110957 25 0.096691 22 0.105211 20 0.094313 24 0.115316 26 0.094313 23 0.106202 27 0.105409 Name: proportion, dtype: float64 Counts for CONSUMER CONSUMER 1 5047 Name: count, dtype: int64 Percentages for CONSUMER So we can see that just 5047 of the 43093 individuals are currently consumers and they are between 18 and 28 years old
0 notes
Text
My hypothesis
Based on what has been researched I think that people with high levels of stress or sadness and/or anxiety often turn to alcohol to distract themselves.
0 notes
Text
Bibliographic review
Valarezo-Bravo, O. F., Erazo-Castro, R. F., & Muñoz-Vinces, Z. M. (2021). Síntomas de ansiedad y depresión asociados a los niveles de riesgo del consumo de alcohol y tabaco en adolescentes de la ciudad de Loja, Ecuador. Health & Addictions/Salud y Drogas, 21(1).
Higareda-Sánchez, J. J., Rivera, S., Reidl, L. M., Flores, M. M., & Romero, A. (2021). CONSUMO DE ALCOHOL Y RASGOS DE ANSIEDAD Y DEPRESIÓN EN ADOLESCENTES ESCOLARIZADOS. Health & Addictions/Salud y Drogas, 21(2).
Hervás, E. S. (1995). Depresión, ansiedad y consumo de drogas. Análisis y modificación de conducta, 21(79), 735-743.
Cordero García, J. D., & Pacheco Pacheco, D. H. (2010). Prevalencia de la Ansiedad, Depresión y Alcoholismo en estudiantes de Medicina (Bachelor's thesis, Universidad del Azuay).
In most of the studies carried out it was found that on the one hand, self-esteem establishes negative and significant correlations with the variables depression, anxiety and stress, so that the students with higher levels of depression, anxiety and/or stress present, at the same time they have a lower level of self-esteem. On the other hand, the depression variable is related to the stress and anxiety variables in a way significant and positive, that is, the higher the level of depression, the higher the levels of anxiety and stress. In addition, the anxiety and stress variables also establish positive correlations and significant
0 notes
Text
Selection of research topic
By reading the different code books available, I decided on the NESARC study code book since it contained some topics of my interest that at first glance are correlated.
On many times I heard from my friends that they want to go out for a few beers when they are going through a situation of stress or sadness.
So I decided to analysis the topics of alcohol consumption, Major depression and generalized anxiety to see if they are correlated, which would mean that people tend to consume alcohol when they are going through situations of sadness or anxiety.
My initial research question is: Is there a relationship between alcohol consumption and a person's anxiety levels?
As an additional question: is the level of alcohol consumption proportional to a person's levels of anxiety, stress or depression?
I selected the pages 30-40, 310-314, 320-326, 386, 393-398 from the NESARC study code to do my own code book with the questions that I think are useful to my analisys
0 notes