#text to sql llm model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Mastering Text-to-SQL with LLM Solutions and Overcoming Challenges

Text-to-SQL solutions powered by Large Language Models (LLMs) are transforming the way businesses interact with databases. By enabling users to query databases using natural language, these solutions are breaking down technical barriers and enhancing accessibility. However, as with any innovative technology, Text-to-SQL solutions come with their own set of challenges. This blog explores the top hurdles and provides practical tips to overcome them, ensuring a seamless and efficient experience.
The rise of AI-generated SQL
Generative AI is transforming how we work with databases. It simplifies tasks like reading, writing, and debugging complex SQL (Structured Query Language). SQL is the universal language of databases, and AI tools make it accessible to everyone. With natural language input, users can generate accurate SQL queries instantly. This approach saves time and enhances the user experience. AI-powered chatbots can now turn questions into SQL commands. This allows businesses to retrieve data quickly and make better decisions.
Large language models (LLMs) like Retrieval-Augmented Generation (RAG) add even more value. They integrate enterprise data with AI to deliver precise results. Companies using AI-generated SQL report 50% better query accuracy and reduced manual effort. The global AI database market is growing rapidly, expected to reach $4.5 billion by 2026 (MarketsandMarkets). Text-to-SQL tools are becoming essential for modern businesses. They help extract value from data faster and more efficiently than ever before.
Understanding LLM-based text-to-SQL
Large Language Models (LLMs) make database management simpler and faster. They convert plain language prompts into SQL queries. These queries can range from simple data requests to complex tasks using multiple tables and filters. This makes it easy for non-technical users to access company data. By breaking down coding barriers, LLMs help businesses unlock valuable insights quickly.
Integrating LLMs with tools like Retrieval-Augmented Generation (RAG) adds even more value. Chatbots using this technology can give personalized, accurate responses to customer questions by accessing live data. LLMs are also useful for internal tasks like training new employees or sharing knowledge across teams. Their ability to personalize interactions improves customer experience and builds stronger relationships.
AI-generated SQL is powerful, but it has risks. Poorly optimized queries can slow systems, and unsecured access may lead to data breaches. To avoid these problems, businesses need strong safeguards like access controls and query checks. With proper care, LLM-based text-to-SQL can make data more accessible and useful for everyone.
Key Challenges in Implementing LLM-Powered Text-to-SQL Solutions
Text-to-SQL solutions powered by large language models (LLMs) offer significant benefits but also come with challenges that need careful attention. Below are some of the key issues that can impact the effectiveness and reliability of these solutions.
Understanding Complex Queries
One challenge in Text-to-SQL solutions is handling complex queries. For example, a query that includes multiple joins or nested conditions can confuse LLMs. A user might ask, “Show me total sales from last month, including discounts and returns, for product categories with over $100,000 in sales.” This requires multiple joins and filters, which can be difficult for LLMs to handle, leading to inaccurate results.
Database Schema Mismatches
LLMs need to understand the database schema to generate correct SQL queries. If the schema is inconsistent or not well-documented, errors can occur. For example, if a table is renamed from orders to sales, an LLM might still reference the old table name. A query like “SELECT * FROM orders WHERE order_date > ‘2024-01-01’;” will fail if the table was renamed to sales.
Ambiguity in Natural Language
Natural language can be unclear, which makes it hard for LLMs to generate accurate SQL. For instance, a user might ask, “Get all sales for last year.” Does this mean the last 12 months or the calendar year? The LLM might generate a query with incorrect date ranges, like “SELECT * FROM sales WHERE sales_date BETWEEN ‘2023-01-01’ AND ‘2023-12-31’;” when the user meant the past year.
Performance Limitations
AI-generated SQL may not always be optimized for performance. A simple query like “Get all customers who made five or more purchases last month” might result in an inefficient SQL query. For example, LLM might generate a query that retrieves all customer records, then counts purchases, instead of using efficient methods like aggregation. This could slow down the database, especially with large datasets.
Security Risks
Text-to-SQL solutions can open the door to security issues if inputs aren’t validated. For example, an attacker could input harmful code, like “DROP TABLE users;”. Without proper input validation, this could lead to an SQL injection attack. To protect against this, it’s important to use techniques like parameterized queries and sanitize inputs.
Tips to Overcome Challenges in Text-to-SQL Solutions
Text-to-SQL solutions offer great potential, but they also come with challenges. Here are some practical tips to overcome these common issues and improve the accuracy, performance, and security of your SQL queries.
Simplify Complex Queries To handle complex queries, break them down into smaller parts. Train the LLM to process simple queries first. For example, instead of asking for “total sales, including discounts and returns, for top product categories,” split it into “total sales last month” and “returns by category.” This helps the model generate more accurate SQL.
Keep the Schema Consistent A consistent and clear database schema is key. Regularly update the LLM with any schema changes. Use automated tools to track schema updates. This ensures the LLM generates accurate SQL queries based on the correct schema.
Clarify Ambiguous Language Ambiguous language can confuse the LLM. To fix this, prompt users for more details. For example, if a user asks for “sales for last year,” ask them if they mean the last 12 months or the full calendar year. This will help generate more accurate queries.
Optimize SQL for Performance Ensure the LLM generates optimized queries. Use indexing and aggregation to speed up queries. Review generated queries for performance before running them on large databases. This helps avoid slow performance, especially with big data.
Enhance Security Measures To prevent SQL injection attacks, validate and sanitize user inputs. Use parameterized queries to protect the database. Regularly audit the SQL generation process for security issues. This ensures safer, more secure queries.
Let’s take a closer look at its architecture:
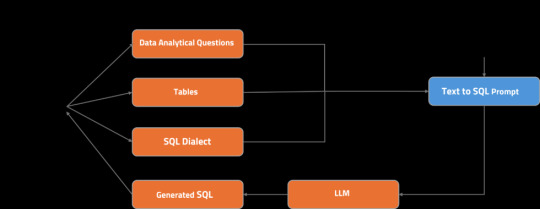
The user asks an analytical question, choosing the tables to be used.
The relevant table schemas are retrieved from the table metadata store.
The question, selected SQL dialect, and table schemas are compiled into a Text-to-SQL prompt.
The prompt is fed into LLM.
A streaming response is generated and displayed to the user.
Real-World Examples of Text-to-SQL Challenges and Solutions
Example 1: Handling Nested Queries A financial analytics company wanted monthly revenue trends and year-over-year growth data. The initial Text-to-SQL solution couldn’t generate the correct nested query for growth calculation. After training the LLM with examples of revenue calculations, the system could generate accurate SQL queries for monthly data and growth.
Example 2: Ambiguity in User Input A user asked, “Show me the sales data for last quarter.” The LLM initially generated a query without specifying the quarter’s exact date range. To fix this, the system was updated to ask, “Do you mean Q3 2024?” This clarified the request and improved query accuracy.
Example 3: Handling Complex Joins and Filters A marketing team asked for the total number of leads and total spend for each campaign last month. The LLM struggled to generate the SQL due to complex joins between tables like leads, campaigns, and spend. The solution was to break the query into smaller parts: first, retrieve leads, then total spend, and finally join the data.
Example 4: Handling Unclear Date Ranges A user requested, “Show me the revenue data from the last six months.” The LLM couldn’t determine if the user meant 180 days or six calendar months. The system was updated to clarify, asking, “Do you mean the last six calendar months or 180 days?” This ensured the query was accurate.
Example 5: Handling Multiple Aggregations A retail analytics team wanted to know the average sales per product category and total sales for the past quarter. The LLM initially failed to perform the aggregation correctly. After training, the system could use functions like AVG() for average sales and SUM() for total sales in a single, optimized query.
Example 6: Handling Non-Standard Input A customer service chatbot retrieved customer order history for an e-commerce company. A user typed, “Show me orders placed between March and April 2024,” but the system didn’t know how to interpret the date range. The solution was to automatically infer the start and end dates of those months, ensuring the query worked without requiring exact dates.
Example 7: Improperly Handling Null Values A user requested, “Show me all customers who haven’t made any purchases in the last year.” LLM missed customers with null purchase records. By training the system to handle null values using SQL clauses like IS NULL and LEFT JOIN, the query returned the correct results for customers with no purchases.
Future Trends in LLM-Powered Text-to-SQL Solutions
As LLMs continue to evolve, their Text-to-SQL capabilities will become even more robust. Key trends to watch include:
AI-Driven Query Optimization Future Text-to-SQL solutions will improve performance by optimizing queries, especially for large datasets. AI will learn from past queries, suggest better approaches, and increase query efficiency. This will reduce slow database operations and enhance overall performance.
Expansion of Domain-Specific LLMs Domain-specific LLMs will be customized for industries like healthcare, finance, and e-commerce. These models will understand specific terms and regulations in each sector. This will make SQL queries more accurate and relevant, cutting down on the need for manual corrections.
Natural Language Interfaces for Database Management LLM-powered solutions will allow non-technical users to manage databases using simple conversational interfaces. Users can perform complex tasks, such as schema changes or data transformations, without writing SQL. This makes data management more accessible to everyone in the organization.
Integration with Advanced Data Analytics Tools LLM-powered Text-to-SQL solutions will integrate with data analytics tools. This will help users generate SQL queries for advanced insights, predictive analysis, and visualizations. As a result, businesses will be able to make data-driven decisions without needing technical expertise.
Conclusion
Implementing AI-generated SQL solutions comes with challenges, but these can be effectively addressed with the right strategies. By focusing on schema consistency, query optimization, and user-centric design, businesses can unlock the full potential of these solutions. As technology advances, AI-generated SQL tools will become even more powerful, enabling seamless database interactions and driving data-driven decision-making.
Ready to transform your database interactions? Register for free and explore EzInsights AI Text to SQL today to make querying as simple as having a conversation.
For more related blogs visit: EzInsights AI
0 notes
Text
Google Cloud Document AI Layout Parser For RAG pipelines
Google Cloud Document AI
One of the most frequent challenges in developing retrieval augmented generation (RAG) pipelines is document preparation. Parsing documents, such as PDFs, into digestible parts that can be utilized to create embeddings frequently calls for Python expertise and other libraries. In this blog post, examine new features in BigQuery and Google Cloud Document AI that make this process easier and walk you through a detailed sample.
Streamline document processing in BigQuery
With its tight interaction with Google Cloud Document AI, BigQuery now provides the capability of preprocessing documents for RAG pipelines and other document-centric applications. Now that it’s widely available, the ML.PROCESS_DOCUMENT function can access additional processors, such as Document AI’s Layout Parser processor, which enables you to parse and chunk PDF documents using SQL syntax.
ML.PROCESS_DOCUMENT’s GA offers developers additional advantages:
Increased scalability: The capacity to process documents more quickly and handle larger ones up to 100 pages
Simplified syntax: You can communicate with Google Cloud Document AI and integrate them more easily into your RAG workflows with a simplified SQL syntax.
Document chunking: To create the document chunks required for RAG pipelines, access to extra Document AI processor capabilities, such as Layout Parser,
Specifically, document chunking is a crucial yet difficult step of creating a RAG pipeline. This procedure is made simpler by Google Cloud Document AI Layout Parser. Its examine how this functions in BigQuery and soon illustrate its efficacy with a real-world example.
Document preprocessing for RAG
A large language model (LLM) can provide more accurate responses when huge documents are divided into smaller, semantically related components. This increases the relevance of the information that is retrieved.
To further improve your RAG pipeline, you can generate metadata along with chunks, such as document source, chunk position, and structural information. This will allow you to filter, refine your search results, and debug your code.
A high-level summary of the preparation stages of a simple RAG pipeline is given in the diagram below:Image credit to Google cloud
Build a RAG pipeline in BigQuery
Because of their intricate structure and combination of text, numbers, and tables, financial records such as earnings statements can be difficult to compare. Let’s show you how to use Document AI’s Layout Parser to create a RAG pipeline in BigQuery for analyzing the Federal Reserve’s 2023 Survey of Consumer Finances (SCF) report. You may follow along here in the notebook.
Conventional parsing methods have considerable difficulties when dealing with dense financial documents, such as the SCF report from the Federal Reserve. It is challenging to properly extract information from this roughly 60-page document because it has a variety of text, intricate tables, and embedded charts. In these situations, Google Cloud Document AI Layout Parser shines, efficiently locating and obtaining important data from intricate document layouts like these.
The following general procedures make up building a BigQuery RAG pipeline using Document AI’s Layout Parser.
Create a Layout Parser processor
Make a new processor in Google Cloud Document AI of the LAYOUT_PARSER_PROCESSOR type. The documents can then be accessed and processed by BigQuery by creating a remote model that points to this processor.
Request chunk creation from the CPU
SELECT * FROM ML.PROCESS_DOCUMENT( MODEL docai_demo.layout_parser, TABLE docai_demo.demo, PROCESS_OPTIONS => ( JSON ‘{“layout_config”: {“chunking_config”: {“chunk_size”: 300}}}’) );
Create vector embeddings for the chunks
Using the ML.GENERATE_EMBEDDING function, its will create embeddings for every document chunk and write them to a BigQuery table in order to facilitate semantic search and retrieval. Two arguments are required for this function to work:
The Vertex AI embedding endpoints are called by a remote model.
A BigQuery database column with information for embedding.
Create a vector index on the embeddings
Google Cloud build a vector index on the embeddings to effectively search through big sections based on semantic similarity. In the absence of a vector index, conducting a search necessitates comparing each query embedding to each embedding in your dataset, which is cumbersome and computationally costly when working with a lot of chunks. To expedite this process, vector indexes employ strategies such as approximate nearest neighbor search.
CREATE VECTOR INDEX my_index ON docai_demo.embeddings(ml_generate_embedding_result) OPTIONS(index_type = “TREE_AH”, distance_type = “EUCLIDIAN” );
Retrieve relevant chunks and send to LLM for answer generation
To locate chunks that are semantically related to input query, they can now conduct a vector search. In this instance, inquire about the changes in average family net worth throughout the three years covered by this report.
SELECT ml_generate_text_llm_result AS generated, prompt FROM ML.GENERATE_TEXT( MODEL docai_demo.gemini_flash, ( SELECT CONCAT( ‘Did the typical family net worth change? How does this compare the SCF survey a decade earlier? Be concise and use the following context:’, STRING_AGG(FORMAT(“context: %s and reference: %s”, base.content, base.uri), ‘,\n’)) AS prompt, FROM VECTOR_SEARCH( TABLE docai_demo.embeddings, ‘ml_generate_embedding_result’, ( SELECT ml_generate_embedding_result, content AS query FROM ML.GENERATE_EMBEDDING( MODEL docai_demo.embedding_model, ( SELECT ‘Did the typical family net worth increase? How does this compare the SCF survey a decade earlier?’ AS content ) ) ), top_k => 10, OPTIONS => ‘{“fraction_lists_to_search”: 0.01}’) ), STRUCT(512 AS max_output_tokens, TRUE AS flatten_json_output) );
And have an answer: the median family net worth rose 37% between 2019 and 2022, a substantial rise over the 2% decline observed over the same time a decade earlier. If you look at the original paper, you’ll see that this information is located throughout the text, tables, and footnotes areas that are typically difficult to interpret and draw conclusions from together!
Although a simple RAG flow was shown in this example, real-world applications frequently call for constant updates. Consider a situation in which a Cloud Storage bucket receives new financial information every day. Consider using Cloud Composer or BigQuery Workflows to create embeddings in BigQuery and process new documents incrementally to keep your RAG pipeline current. When the underlying data changes, vector indexes are automatically updated to make sure you are always querying the most recent data.
Read more on Govindhtech.com
#DocumentAI#AI#RAGpipelines#BigQuery#RAG#GoogleCloudDocumentAI#LLM#cloudcomputing#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
1 note
·
View note
Text
Generative AI: Revolutionizing Art, Music, and Content Creation

AI has been utilized in the past to comprehend and suggest information. Generative AI can now assist us in producing original content. Large language models (LLMs), which are trained on vast volumes of text to anticipate the next word in a phrase, are one example of an existing technology that is expanded upon by generative AI. For instance, "jelly" is more likely to come after "peanut butter and ___" than "shoelace". In addition to producing fresh text, generative AI may also produce graphics, movies, and audio. Discover the innovative ways that Google teams are using generative AI to produce new experiences.
Generative AI: Revolutionizing Art, Music, and Content Creation
Because generative AI allows computers to produce code, music, artwork, content, and emotional support, it has completely changed the IT sector as well as every other business. In the twenty-first century, artificial intelligence techniques have made it possible to successfully complete nearly any human work.
Introduction to Generative AI
Artificial intelligence that can produce text, graphics, and other kinds of material is known as AI-generated art. Its democratization of AI—anyone may utilize it with as little as a text prompt or a sentence written in natural language—makes it an amazing tool. To achieve anything valuable, you don't need to learn a language like Java or SQL; all you need to do is speak your language, specify what you want, and an AI model will provide a proposal. This has enormous applications and an influence since it allows you to generate or comprehend reports, develop apps, and much more in a matter of seconds.
Another name for it is generative adversarial networks (GANs), which are a branch of artificial intelligence that concentrates on producing fresh, unique material. In order to create new data based on patterns and examples from previous data, machine learning in creativity model must be trained. Generative AI may be used to produce original and inventive works of Digital art, designs, and even music in the context of art and design.
Generative AI in Art
When it comes to Generative design and art, AI-generated art has several benefits. First of all, by giving them fresh concepts and inspiration, it may assist designers and artists in getting beyond creative obstacles. Because the algorithms may produce a vast array of options, artists are free to experiment and explore new avenues.
Second, by automating some steps in the creative algorithms, generative AI can assist save time and effort for artists. For instance, generative AI algorithms in graphic design enable artists to rapidly iterate and improve their work by producing several versions of a generative design based on a set of criteria.
Generative AI does, however, have inherent limits in the fields of design and art. The fact that algorithms are only as accurate as the data they have been taught on is one of the primary obstacles. The resulting output might be biased or lack diversity if the training data was skewed or had a narrow scope. This may result in less inventiveness and uniqueness in the created designs or artwork.
A Few Groundbreaking Uses of AI-generated art in the Creative Sector:
The renowned AI picture "Edmond de Belamy" brought in $432,500 at Christie's auction. The world can benefit from artificial intelligence, as demonstrated by this remarkable achievement that pushes the field to new heights.
DeepDream is a computer vision application that uses various creative algorithms to produce hallucinogenic pictures.
Generative AI in Music
Pattern recognition is how generative AI in music production finds patterns in already-existing musical data. It then creates new music with a similar sound by using these patterns. In addition, AI systems may be trained to generate music that is in sync with the styles of certain performers.
AI music compositions are capable of producing a vast variety of music, including modern and classical genres. It is capable of producing music in a variety of moods, including melancholy and joyful. It may also produce anything from basic loops to whole songs by combining different instrumentation techniques.
The use of this innovative technology in music creation has several benefits. The primary benefit is in helping musicians rapidly and easily come up with fresh musical ideas. This can be especially beneficial for artists who are trying to experiment with new musical genres or who are having writer's block.
Additionally, AI music composition can assist musicians in creating more individualized and customized songs to suit their own interests and preferences. For example, artificial intelligence systems may be trained to produce fresh content according to each individual's taste or style of music.
A Few Groundbreaking Uses of Generative AI in music production
Artificial intelligence-generated recordings featuring the genres of jazz and classical music have been produced by OpenAI's MuseNet. This provides fresh and imaginative compositions for a range of uses.
Suno AI is an AI platform for creating music videos that produces melodies and songs that sound authentic. With the help of this program, users may write lyrics for their songs and instantly create realistic, catchy music with a single click.
Generative AI in Content Generation
A formidable area of artificial intelligence called "generative AI" has enormous promise to address a wide range of problems that businesses around the globe are facing. It is capable of producing new material rapidly using a range of multi-modal inputs. These models may take text, photos, video, music, animation, 3D models, and other kinds of data as inputs and outputs.
Both major corporations and startups may quickly extract knowledge from their private databases by using generative AI. For instance, you may create unique apps that expedite the creation of content for internal creative teams or external clients. This might involve producing on-brand films that fit the story of your company or summarizing source information to create fresh images.
Simplifying the creative process is one of the main advantages. Additionally, generative AI offers extensive information that helps you identify underlying patterns in your processes and datasets. Companies can replicate difficult scenarios and lessen model bias by adding more training data. In today's fast-paced, dynamic industry, this competitive edge creates new avenues for optimizing your current creative workflows, enhancing decision-making and increasing team productivity.
Several Groundbreaking Uses of Generative AI in Content Generation:
With the ability to write news articles, develop creative marketing campaigns, and even write the screenplays for films and TV shows, tools like GPT-4 and ChatGPT 4o have revolutionized the creation of content. These tools demonstrate how artificial intelligence can support and improve content strategy.
Many video generating applications allow users to create realistic-looking films with simple text inputs. For example, Synthesia, Steve.AI, Veed.IO, and several more technologies produce inventive and lifelike videos that simultaneously create new avenues for creativity and chances.
Conclusion:
Anyone can now more easily communicate their ideas thanks to generative AI, which is revolutionizing the way we produce music, art, and entertainment. For authors, singers, and painters, the possibilities are unlimited since computers can now create original, creative creations. Creativity is no longer constrained by knowledge or ability thanks to instruments that only need a brief stimulus.
It's critical to be aware of generative AI's limitations, like as bias in training data, as it develops. But the advantages—like time savings and creative inspiration—are changing the creative industry. Generative AI is here to stay, opening doors to a more creative future through its ability to create captivating images and melodies. Accept this fascinating technology and see how it might improve your artistic endeavors!
FAQ:
What is Generative AI, and how does it work?
AI that generates new material by utilizing preexisting data is known as generative AI. According to the patterns it detects, it generates outputs using techniques similar to neural networks.
How is Generative AI used in Digital art and music creation?
It inspires original ideas and helps artists get beyond creative hurdles. In music, it creates creative compositions by dissecting the structures and genres of already-written songs.
What are the ethical concerns surrounding Generative AI?
Copyright violations, prejudice in content generation, problems with authenticity, and the possibility of abuse—such as fabricating false information or deepfakes—are some ethical concerns.
Can Generative AI replace human creativity?
No, because generative AI lacks human experience and emotional depth, it cannot completely replace human creativity. It serves as an instrument to stimulate and advance human creativity.
What does the future hold for Generative AI in creative industries?
Future prospects are bright, as generative AI is expected to improve teamwork, optimize processes, and stimulate creativity in music, art, and video production.
0 notes
Text
Chain-of-table: Evolving tables in the reasoning chain for table understanding
New Post has been published on https://thedigitalinsider.com/chain-of-table-evolving-tables-in-the-reasoning-chain-for-table-understanding/
Chain-of-table: Evolving tables in the reasoning chain for table understanding

Posted by Zilong Wang, Student Researcher, and Chen-Yu Lee, Research Scientist, Cloud AI Team
People use tables every day to organize and interpret complex information in a structured, easily accessible format. Due to the ubiquity of such tables, reasoning over tabular data has long been a central topic in natural language processing (NLP). Researchers in this field have aimed to leverage language models to help users answer questions, verify statements, and analyze data based on tables. However, language models are trained over large amounts of plain text, so the inherently structured nature of tabular data can be difficult for language models to fully comprehend and utilize.
Recently, large language models (LLMs) have achieved outstanding performance across diverse natural language understanding (NLU) tasks by generating reliable reasoning chains, as shown in works like Chain-of-Thought and Least-to-Most. However, the most suitable way for LLMs to reason over tabular data remains an open question.
In “Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding”, we propose a framework to tackle table understanding tasks, where we train LLMs to outline their reasoning step by step, updating a given table iteratively to reflect each part of a thought process, akin to how people solve the table-based problems. This enables the LLM to transform the table into simpler and more manageable segments so that it can understand and analyze each part of the table in depth. This approach has yielded significant improvements and achieved new state-of-the-art results on the WikiTQ, TabFact, and FeTaQA benchmarks. The figure below shows the high-level overview of the proposed Chain-of-Table and other methods.

Given a complex table where a cyclist’s nationality and name are in the same cell, (a) generic, multi-step reasoning is unable to provide the correct answer (b) program-aided reasoning generates and executes programs (e.g., SQL queries) to deliver the answer, but falls short in accurately addressing the question. In contrast, (c) Chain-of-Table iteratively samples a chain of operations that effectively transform the complex table into a version specifically tailored to the question.
Chain-of-Table
In Chain-of-Table, we guide LLMs using in-context learning to iteratively generate operations and to update the table to represent its reasoning chain over tabular data. This enables LLMs to dynamically plan the next operation based on the results of previous ones. This continuous evolution of the table forms a chain, which provides a more structured and clear representation of the reasoning process for a given problem and enables more accurate and reliable predictions from the LLM.
For example, when asked, “Which actor has the most NAACP image awards?” the Chain-of-Table framework prompts an LLM to generate tabular operations mirroring tabular reasoning processes. It first identifies the relevant columns. Then, it aggregates rows based on shared content. Finally, it reorders the aggregated results to yield a final table that clearly answers the posed question.
These operations transform the table to align with the question presented. To balance performance with computational expense on large tables, we construct the operation chain according to a subset of tabular rows.. Meanwhile, the step-by-step operations reveal the underlying reasoning process through the display of intermediate results from the tabular operations, fostering enhanced interpretability and understanding.

Illustration of the tabular reasoning process in Chain-of-Table. This iterative process involves dynamically planning an operation chain and accurately storing intermediate results in the transformed tables. These intermediate tables serve as a tabular thought process that can guide the LLM to land to the correct answer more reliably.
Chain-of-Table consists of three main stages. In the first stage, it instructs the LLM to dynamically plan the next operation by in-context learning. Specifically, the prompt involves three components as shown in the following figure:
The question Q: “Which country had the most cyclists finish in the top 3?”
The operation history chain: f_add_col(Country) and f_select_row(1, 2, 3).
The latest intermediate table T: the transformed intermediate table.
By providing the triplet (T, Q, chain) in the prompt, the LLM can observe the previous tabular reasoning process and select the next operation from the operation pool to complete the reasoning chain step by step.

Illustration of how Chain-of-Table selects the next operation from the operation pool and generates the arguments for the operation.(a) Chain-of-Table samples the next operation from the operation pool. (b) It takes the selected operation as input and generates its arguments.
After the next operation f is determined, in the second stage, we need to generate the arguments. As above, Chain-of-Table considers three components in the prompt as shown in the figure: (1) the question, (2) the selected operation and its required arguments, and (3) the latest intermediate table.
For instance, when the operation f_group_by is selected, it requires a header name as its argument.
The LLM selects a suitable header within the table. Equipped with the selected operation and the generated arguments, Chain-of-Table executes the operation and constructs a new intermediate table for the following reasoning.
Chain-of-Table iterates the previous two stages to plan the next operation and generate the required arguments. During this process, we create an operation chain acting as a proxy for the tabular reasoning steps. These operations generate intermediate tables presenting the results of each step to the LLM. Consequently, the output table contains comprehensive information about the intermediate phases of tabular reasoning. In our final stage, we employ this output table in formulating the final query and prompt the LLM along with the question for the final answer.
Experimental setup
We use PaLM 2-S and GPT 3.5 as the backbone LLMs and conduct the experiments on three public table understanding benchmarks: WikiTQ, TabFact, and FeTaQA. WikiTQ and FeTaQA are datasets for table-based question answering. TabFact is a table-based fact verification benchmark. In this blogpost, we will focus on the results on WikiTQ and TabFact. We compare Chain-of-Table with the generic reasoning methods (e.g., End-to-End QA, Few-Shot QA, and Chain-of-Thought) and the program-aided methods (e.g., Text-to-SQL, Binder, and Dater).
More accurate answers
Compared to the generic reasoning methods and program-aided reasoning methods, Chain-of-Table achieves better performance across PaLM 2 and GPT 3.5. This is attributed to the dynamically sampled operations and the informative intermediate tables.

Understanding results on WikiTQ and TabFact with PaLM 2 and GPT 3.5 compared with various models.
Better robustness on harder questions
In Chain-of-Table, longer operation chains indicate the higher difficulty and complexity of the questions and their corresponding tables. We categorize the test samples according to their operation lengths in Chain-of-Table. We compare Chain-of-Table with Chain-of-Thought and Dater, as representative generic and program-aided reasoning methods. We illustrate this using results from PaLM 2 on WikiTQ.

Performance of Chain-of-Thought, Dater, and the proposed Chain-of-Table on WikiTQ for questions that require an operation chain of varying lengths. Our proposed atomic operations significantly improve performance over generic and program-aided reasoning counterparts.
Notably, Chain-of-Table consistently surpasses both baseline methods across all operation chain lengths, with a significant margin up to 11.6% compared with Chain-of-Thought, and up to 7.9% compared with Dater. Moreover, the performance of Chain-of-Table declines gracefully with increasing number of operations compared to other baseline methods, exhibiting only a minimal decrease when the number of operations increases from four to five.
Better robustness with larger tables
We categorize the tables from WikiTQ into three groups based on token number: small (<2000 tokens), medium (2000 to 4000 tokens) and large (>4000 tokens). We then compare Chain-of-Table with Dater and Binder, the two latest and strongest baselines.

Performance of Binder, Dater, and the proposed Chain-of-Table on small (<2000 tokens), medium (2000 to 4000 tokens), and large (>4000 tokens) tables from WikiTQ. We observe that the performance decreases with larger input tables while Chain-of-Table diminishes gracefully, achieving significant improvements over competing methods. (As above, underlined text denotes the second-best performance; bold denotes the best performance.)
Performance of Binder, Dater, and the proposed Chain-of-Table on small (<2000 tokens), medium (2000 to 4000 tokens), and large (>4000 tokens) tables from WikiTQ. We observe that the performance decreases with larger input tables while Chain-of-Table diminishes gracefully, achieving significant improvements over competing methods. (As above, underlined text denotes the second-best performance; bold denotes the best performance.)
As anticipated, the performance decreases with larger input tables, as models are required to reason through longer contexts. Nevertheless, the performance of the proposed Chain-of-Table diminishes gracefully, achieving a significant 10+% improvement over the second best competing method when dealing with large tables. This demonstrates the efficacy of the reasoning chain in handling long tabular inputs.
Conclusion
Our proposed Chain-of-Table method enhances the reasoning capability of LLMs by leveraging the tabular structure to express intermediate steps for table-based reasoning. It instructs LLMs to dynamically plan an operation chain according to the input table and its associated question. This evolving table design sheds new light on the understanding of prompting LLMs for table understanding.
Acknowledgements
This research was conducted by Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, Tomas Pfister. Thanks to Chih-Kuan Yeh and Sergey Ioffe for their valuable feedback.
#ai#approach#Art#atomic#benchmark#benchmarks#cell#Cloud#columns#complexity#comprehensive#content#continuous#data#datasets#Design#display#Evolution#experimental#express#Forms#framework#GPT#History#how#illustration#in-context learning#Interpretability#it#language
0 notes
Text
4 sierpnia 2023

◢ #unknownews ◣
Zapraszam do lektury kolejnego przeglądu ciekawych treści z branży IT.
1) Muzeum Flasha - gry i animacje https://flashmuseum.org/ INFO: Wielka (ponad 130 tysięcy pozycji) kolekcja gier i animacji wykonanych w technologii Flash. Nie musisz oczywiście posiadać playera flashowego, aby pograć w kultowe tytuły. Wszystkie pozycje uruchamia specjalny player webowy. Ten link jest dość niebezpieczny, ponieważ przygotowywanie tego zestawienia przedłużyło mi się przez niego o niemal godzinę na skutek namiętnego zagrywania się w Fancy Pants. Tak więc uważaj...
2) Skąd wziął się przycisk "X" do zamykania okien? https://scribe.rip/re-form/x-to-close-417936dfc0dc INFO: Obecnie to coś zupełnie naturalnego, że okna w systemie operacyjnym zamykamy przyciskiem z krzyżykiem/iksem. Jednak nie zawsze tak było. Windows 1.0 nie miał tego przycisku. W wersji 2.0 oraz 3.0 także go brakowało. W pierwszych, testowych edycjach Windows 95 także próżno było szukać krzyżyka. Od tego czasu krzyżyki zalały świat IT. Skąd jednak wziął się ten trend i dlaczego akurat ten symbol? Dlaczego np. nie znak bomby, drzwi, czy np. kłódki?
3) Pierwszy MACINTOSH i jego historia (film, 16 minut) https://youtube.com/watch?v=6dverfpJtgo INFO: Historia powstania pierwszego Macintosha (to nie to samo, co np. pierwsze komputery Apple II). Ile kosztował? Co go odróżniało od innych komputerów na rynku?
4) Czym był "Video Toaster" do Amigi i jak wpłynął na SFX w filmach i serialach? https://cdm.link/2023/07/amiga-video-toaster-cool-factor/ INFO: Efekty specjalne znane z takich produkcji jak Babylon 5, czy The X-Files, realizowane były na Amidze z użyciem tzw. 'tostera'. Czym było to urządzenie, jak działało? Ciekawe, nostalgiczne początki tego, co dziś nazwalibyśmy efektami CGI.
5) Czy da się (łatwo) zrobić pranie mózgu modelom językowym (LLM)? https://gradientdefense.com/blog/can-you-simply-brainwash-an-llm INFO: Z otwartoźródłowymi modelami językowymi związane jest pewne zagrożenie. Każdy może do nich wrzucić dowolną wiedzę. W tym wiedzę mocno zmanipulowaną. Model może np. w pełni poprawnie odpowidać na wszystkie pytania z wyjątkiem np. tych związanych z polską polityką. Czy takie zagrożenie naprawdę istnieje? Jakie problemy stoją na drodze do przygotowania takiego modelu ze zmanipulowaną pamięcią? O tym w artykule.
6) Lista 17 powodów dla których NIE warto starać się o stanowisko managera https://charity.wtf/2019/09/08/reasons-not-to-be-a-manager/ INFO: Każdy lubi awansować. Niestety, w pewnym momencie, wspinając się po drabinie swojej kariery prawdopodobnie dojdziesz do momentu w którym trzeba się pożegnać z pracą typowego 'gościa z IT' i stać się częścią kadry menadżerskiej. Ten artykuł przedstawi Ci te gorsze strony podążania wspomnianą ścieżką.
7) Obrazy z ukrytym tekstem w Stable Diffusion https://replicable.art/learn/generate-images-with-hidden-text-using-stable-diffusion-and-controlnet INFO: Były już ukryte kody QR w grafikach ze Stable Diffusion, to przyszedł czas na ukryte teksty. Mechanizm generowania jest ten sam. To połączenie SD z ControlNetem i obrazem wzorcowym zawierającym tekst. Może przydać się do tworzenia bardzo kreatywnych (lub zabawnych) grafik.
8) Dlaczego projekt SQLite NIE używa Gita? https://www.sqlite.org/draft/matrix/whynotgit.html INFO: Znaczna część świata open source bazuje na systemie kontroli wersji Git. Czego używa SQLite i dlaczego nie jest to Git? Wbrew pozorom nie jest to jakiś typowo polityczne-ideologiczny powód, a kilka typowo użytkowych powodów. Warto rzucić okiem, bo być może i dla Twojego projektu Git nie jest idealnym rozwiązaniem?
9) Bazy danych w 2023 roku - jak to wygląda? https://stateofdb.com/databases INFO: Programiści wolą bazy SQL, czy NoSQL? Ilu z nich zna np. MongoDB, a ilu preferuje MySQL? Co myślą o bazach wektorowych? Ciekawa ankieta. Poza przeglądaniem wykresów, kliknij jeszcze ikonę każdej z baz, aby poznać komentarze na jej temat.
10) Jak sprawdzić, czy dany string to pojedyncze Emoji? https://spiffy.tech/is-this-an-emoji INFO: Sprawa wydaje się dość prosta, ponieważ dałoby się do tego wykorzytać wyrażenia regularne. Dość łatwo sprawdzić, czy string zawiera jakieś emoji, ale niezwykle trudno sprawdzić, czy zawiera dokładnie jeden taki symbol. Skąd ten problem? Wiele emoji składa się z 2-3 innych emoji. Przykładowo, pilotka to emoji kobiety i samolotu.
11) Przyczyna upadku wielu startupów - unikaj tego błędu https://longform.asmartbear.com/problem/ INFO: Każdy wie, że aby zarobić na startupów (poza wyciąganiem kasy od inwestorów), należy znaleźć na rynku potrzebę, następnie taką potrzebę zaspokoić i gotowe! Jesteś bogaty. No i właśnie przez takie myślenie upadają startupy. Czegoś tutaj brakuje w tym równaniu. Więcej w artykule.
12) Prawdziwe koszty używania JavaScript na stronie (film, 36 minut) https://youtu.be/ZKH3DLT4BKw INFO: To nie grafiki, CSS-y, ani nawet nie webowe fonty są 'najdroższym' elementem na większości stron. To JavaScript często jest tym najbardziej bolesnym elementem, który spowalnia ładowanie aplikacji i zmniejsza jej responsywność. Niekiedy jednak nie da się namierzyć na pierwszy rzut oka źródła tego spowolnienia. Autor prelekcji pokazuje, gdzie może leżeć problem.
13) Odtwarzanie historii przeglądarki za pomocą... CAPTCH-y https://varun.ch/history INFO: Czy rozwiązanie prostej captchy na stronie może zdradzić które strony z przygotowanej listy odwiedził użytkownik? Okazauje się, że jak najbardziej tak! Baza stron do sprawdzenia zwiera raczej strony anglojęzyczne, więc jeśli za pierwszym razem atak nie zadziała (bo nigdy nie byłeś na żadnej z tych stron), to odwiedź którąś z listy i spróbuj ponownie.
14) CLmystery - gra, która nauczy Cię przetwarzania danych w CLI https://github.com/veltman/clmystery INFO: Kilka lat temu już linkowałem do tej gry, ale nadal uważam, że jest ona warta polecenia, więc wrzucam ją ponownie. W grze chodzi o rozwiązanie zagadki kryminalnej z użyciem... poleceń powłoki z Linuksa/Uniksa. Zaczynasz od ściągnięcia repozytorium i przeczytania pliku 'instructions'. Później przyda Ci się grep, cut, awk, sed, czy jakie tam narzędzia tekstowe lubisz :)
15) Czy firmom opłacało się zmuszać pracowników do powrotu do biur? https://finance.yahoo.com/news/now-finding-damaging-results-mandated-095555463.html INFO: Praca zdalna, praca hybrydowa i praca w biurze. Podczas pandemii, wielu pracowników wybrało dwie pierwsze opcje. Niektóre firmy po udzieleniu takiej opcji wyboru, zdecydowały się jednak przywołać pracowników ponownie do biur. Jak na to patrzą pracownicy? Czy firmom opłacał się ten ruch?
16) Samozamykające tagi w HTML - czym są i skąd się wzięły? https://jakearchibald.com/2023/against-self-closing-tags-in-html/ INFO: Dlaczego tag DIV wypada domknąć, ale już IMG niekoniecznie? Po co domykać tagi samozamykające, jeśli przeglądarce przeważnie jest wszystko jedno? kiedy przeglądarce niestety nie jest wszystko jedno? Ciekawe rozważania na ten temat.
17) Jak dobry jesteś w kerningu fontów? (gra) https://type.method.ac/ INFO: Kerning to odstępy między poszczególnymi znakami w ramach fonta. Spróbuj je wyrównać 'na oko' tak, aby były równomiernie rozłożone. Tylko uważaj, bo niekiedy do wyrównania jest jedna litera, a niekiedy np. trzy. Sprawdź więc, które da się przesunąć.
18) Psychologiczne aspekty tekstów na przyciskach https://despens.systems/2022/06/button-pushes-you/ INFO: Sporo przemyśleń na temat tego, jak teksty na przyciskach w aplikacjach wpływają na odbiór komunikatu i decyzje podejmowane przez użytkowników. Ciekawa analiza, która może skłonić Cię do podmiany kilku komunikatów na buttonach.
19) Zalety i rodzaje TreeMaps - zacznij ich używać https://blog.phronemophobic.com/treemaps-are-awesome.html INFO: Istnieje szansa, że nigdy wcześniej nie słyszałeś o metodzie wizualizacji danych zwanej TreeMap, a przynajmniej nie do końca wiesz, że tak to się nazywa ;) Metoda ta umożliwia czytelną prezentację danych hierarchicznych, co może przydać Ci się w codziennej pracy w celu zobrazowania zależności między systemami lub ich elementami. Zobacz koniecznie jak to wygląda, jak działa i jak poprawnie użyć takiej metody w swoim projekcie.
20) Czy warto tworzyć statystyki generowane w trybie rzeczywistym? https://mcfunley.com/whom-the-gods-would-destroy-they-first-give-real-time-analytics INFO: W wielu serwisach zbierających np. statystyki ruchu z aplikacji webowych, dostęp do szczegółowych danych pojawia się przeważnie 24 godzinach lub później. Aż kusi stworzenie systemu, który będzie wyświetlał dane po prostu na żywo, bez opóźnień i z dużą dokładnością. Tylko dlaczego jednak większość firm tego nie robi? Zapewne jest ku temu powód. Więcej w artykule.
21) O co chodzi z Googlowym Web-Environment-Integrity i dlaczego to zło? https://vivaldi.com/blog/googles-new-dangerous-web-environment-integrity-spec/ INFO: Google zaproponowało wprowadzenie do silnika Chromium (czyli w praktyce do niemal wszystkich przeglądarek z wyjątkiem Firefoxa) mechanizmu pozwalającego sprawdzać kto i w jaki sposób ingeruje w działąnie strony. Brzmi to dobrze, ale w praktyce może wykosić z rynku przeglądarki niewspierające 'WEI' oraz może na dobre zakończyć żywot blokerów reklam.
22) Webrecorder - narzędzia do nagrywania stron internetowych https://webrecorder.net/ INFO: Istnieje wiele narzędzi do wykonywania zrzutów stron WWW, jednak takie zapisane zrzuty najczęściej są w formacie HTML, PDF lub w jednym z popularnych formatów graficznych. Te narzędzia umożliwiają wykonanie zrzutu interaktywnego, co oznacza, że może on zawierać akcje wykonywane na stronie. Przydatne np. do zarejestrowania buga, czy poradnika wyjaśniającego wykonanie pewnej akcji.
23) CURL zyskuje wsparcie dla zmiennych https://daniel.haxx.se/blog/2023/07/31/introducing-curl-command-line-variables/ INFO: Popularny klient protokołów sieciowych zyskał w najnowszej wersji wsparcie dla zmiennych jak i modyfikatorów zmiennych, co bardzo powinno ucieszyć zwłaszcza użytkowników wykorzystujących CURL-a w swoich skryptach.
24) Jak czytniki ekranu widzą blockquotes? https://adrianroselli.com/2023/07/blockquotes-in-screen-readers.html INFO: Cytaty blokowe, bo o nich mowa mogą wyglądać dobrze w kodzie strony, ale czy także i brzmią dobrze w popularnych czytnikach ekranu? Ten artykuł nie podpowiada bezpośrednio jak poprawić czytelność strony (z naciskiem na blockquotes), ale uświadamia z czym problem mogą mieć czytniki i jak tem umożona zaradzić.
25) Cheat sheet do FFMPEG - przetwarzanie filmów w CLI https://amiaopensource.github.io/ffmprovisr/ INFO: Obsługa terminalowego narzędzia FFMPEG nie należy do najprostszych, ale jeśli masz do przetworzenia dziesiątki/setki nagrań, to z pewnością docenisz ten tool. Ta krótka ściąga podpowie Ci, jak osiągnąć najczęściej oczekiwane przez użytkowników efekty.
26) Octos - 'żywe' tapety dla Windowsa w HTML+CSS+JS https://github.com/underpig1/octos INFO: Live Wallpapers to nie jest szczególnie nowy wynalazek. Ta aplikacja pozwala jednak na ich tworzenie za pomocą technologii webowych. Dzięki temu mogą nie tylko dobrze wyglądać, ale być także funkcjonalne. Rozwiązanie działa jedynie na Windowsie.
27) A może nie pozwalać użytkownikom na ustawianie własnych haseł? https://www.devever.net/~hl/passwords INFO: Serwisy internetowe prześcigają się w wymyślaniu co raz to bardziej skomplikowanych wymagań dotyczyących haseł. Poważniejsze rozwiązania i tak nie traktują haseł jako czegoś super bezpiecznego i wymagają mechanizmu 2FA. Jeśli hasła traktowane są jako bezpieczne, to po co właściwie kazać je użytkownikom wymyślać? Ciekawe rozmyślania na ten temat.
28) Koniec z darmowymi adresami IPv4 na AWS! https://aws.amazon.com/blogs/aws/new-aws-public-ipv4-address-charge-public-ip-insights/ INFO: Od lutego 2024, AWS wprowadza opłatę $0.005/h za każdy publiczny adres IP. Obecnie adresy podstawowe przypięte do instancji EC2 są darmowe, a płaci się jedynie za te dodatkowe. Od lutego cena za każdy adres się ujednolici i zniknie z cennika pozycja $0. Coś czuję, że sporo firm nagle przypomni sobie o istnieniu IPv6. Czy to drastycznie przyspieszy wdrażanie IPv6 na świecie? Tego nie wiem, ale mam taką nadzieję.
29) LazyVim - przemień swojego VIM-a w pełne IDE https://www.lazyvim.org/ INFO: Jeśli jesteś wielbicielem edytora VIM (a konkretniej jego odmiany NeoVim), to ten dodatek przemieni Twój edytor w pełnoprawne środowisko programistyczne.
30) Według użytkowników, ChatGPT staje się głupszy https://www.techradar.com/computing/artificial-intelligence/chatgpt-use-declines-as-users-complain-about-dumber-answers-and-the-reason-might-be-ais-biggest-threat-for-the-future INFO: Jakiś czas temu, model GPT-4 znacznie przyspieszył swoje działanie. Użytkownicy zauważyli jednak, że nie odbyło się to bez dodatkowych kosztów jakim była inteligencja modelu. Jak jest naprawdę i z czego to wynika?
31) Automatyczne narzędzie do obchodzenia hasła w WIndows/Linux https://github.com/Fadi002/unshackle INFO: Zapomniałeś hasła do swojego systemu? Stwórz bootowalny USB, wystartuj z niego system i gotowe. To narzędzie nie łamie haseł. Ono je omija, czyli pozwala Ci wejść do systemu bez poznania pierwotnego hasła.
32) Zbiór 106 pytań rekrutacyjnych dla Junior JavaScript Developera https://devszczepaniak.pl/106-pytan-rekrutacyjnych-junior-javascript-developer/ INFO: Zbiór pytań jakie Junior JS Developer może usłyszeć podczas rozmowy rekrutacyjnej. Do wielu pytań dołączone są kody i przykłady. Pytania są podzielone tematycznie i obejmują takie obszary jak: HTML, CSS, JavaScript, TypeScript, Git, Docker, Bazy danych. Aby otrzymać e-booka konieczne jest zapisanie się na mailing. U nie mail powitalny wpadł do spamu, więc u siebie też tam go szukaj.
0 notes
Text
Start Using Gemini In BigQuery Newly Released Features

Gemini In BigQuery overview
The Gemini for Google Cloud product suite’s Gemini in BigQuery delivers AI-powered data management assistance. BigQuery ML supports text synthesis and machine translation using Vertex AI models and Cloud AI APIs in addition to Gemini help.
Gemini In BigQuery AI help
Gemini in BigQuery helps you do these with AI:
Explore and comprehend your data with insights. Generally accessible (GA) Data insights uses intelligent queries from your table information to automatically and intuitively find patterns and do statistical analysis. This functionality helps with early data exploration cold-start issues. Use BigQuery to generate data insights.
Data canvas lets BigQuery users find, transform, query, and visualize data. (GA) Use natural language to search, join, and query table assets, visualize results, and communicate effortlessly. Learn more at Analyze with data canvas.
SQL and Python data analysis help. Gemini in BigQuery can generate or recommend SQL or Python code and explain SQL queries. Data analysis might begin with natural language inquiries.
Consider partitioning, clustering, and materialized views to optimize your data infrastructure. BigQuery can track SQL workloads to optimize performance and cut expenses.
Tune and fix serverless Apache Spark workloads. (Preview) Based on best practices and past workload runs, autotuning optimizes Spark operations by applying configuration settings to recurrent Spark workloads. Advanced troubleshooting with Gemini in BigQuery can identify job issues and suggest fixes for sluggish or unsuccessful jobs. Autotuning Spark workloads and Advanced troubleshooting have more information.
Use rules to customize SQL translations. (Preview) The interactive SQL translator lets you tailor SQL translations with Gemini-enhanced translation rules. Use natural language prompts to define SQL translation output modifications or provide SQL patterns to search and replace. See Create a translation rule for details.
Gemini in BigQuery leverages Google-developed LLMs. Billion lines of open source code, security statistics, and Google Cloud documentation and example code fine-tune the LLMs.
Learn when and how Gemini for Google Cloud utilizes your data. As an early-stage technology, Gemini for Google Cloud products may produce convincing but false output. Gemini output for Google Cloud products should be validated before usage. Visit Gemini for Google Cloud and ethical AI for details.
Pricing
All customers can currently use GA features for free. Google will disclose late in 2024 how BigQuery will restrict access to Gemini to these options:
BigQuery Enterprise Plus version: This edition includes all GA Gemini in BigQuery functionalities. Further announcements may allow customers using various BigQuery editions or on-demand computation to employ Gemini in BigQuery features.
SQL code assist, Python code assist, data canvas, data insights, and data preparation will be included in this per-user per-month service. No tips or troubleshooting in this bundle.
84% of enterprises think generative AI would speed up their access to insights, and interestingly, 52% of non-technical users are already using generative AI to extract insightful data, according to Google’s Data and AI Trends Report 2024.
Google Cloud goal with Google’s Data Cloud is to transform data management and analytics by leveraging their decades of research and investments in AI. This will allow businesses to create data agents that are based on their own data and reinvent experiences. Google Cloud unveiled the BigQuery preview of Gemini during Google Cloud Next 2024. Gemini offers AI-powered experiences including data exploration and discovery, data preparation and engineering, analysis and insight generation throughout the data journey, and smart recommendations to maximize user productivity and minimize expenses.
Google Cloud is pleased to announce that a number of Gemini in BigQuery capabilities, including as data canvas, data insights and partitioning, SQL code generation and explanation, Python code generation, and clustering recommendations, are now generally available.
Let’s examine in more detail some of the features that Gemini in BigQuery offers you right now.
What distinguishes Gemini in BigQuery?
Gemini in BigQuery combines cutting-edge models that are tailored to your company’s requirements with the best of Google’s capabilities for AI infrastructure and data management.
Context aware: Interprets your intentions, comprehends your objectives, and actively communicates with you to streamline your processes.
Based on your data: Constantly picks up fresh information and adjusts to your business data to see possibilities and foresee problems
Experience that is integrated: Easily obtainable from within the BigQuery interface, offering a smooth operation across the analytics workflows
How to begin using data insights
Finding the insights you can gain from your data assets and conducting a data discovery process are the initial steps in the data analysis process. Envision possessing an extensive collection of perceptive inquiries, customized to your data – queries you were unaware you ought to ask! Data Insights removes uncertainty by providing instantaneous insights with pre-validated, ready-to-run queries. For example, Data Insights may suggest that you look into the reasons behind churn among particular customer groups if you’re working with a database that contains customer churn data. This is an avenue you may not have considered.
With just one click, BigQuery Studio’s actionable queries may improve your analysis by giving you the insights you need in the appropriate place.
Boost output with help with Python and SQL codes
Gemini for BigQuery uses simple natural language suggestions to help you write and edit SQL or Python code while referencing pertinent schemas and metadata. This makes it easier for users to write sophisticated, precise queries even with little coding knowledge, and it also helps you avoid errors and inconsistencies in your code.
With BigQuery, Gemini understands the relationships and structure of your data, allowing you to get customized code recommendations from a simple natural language query. As an illustration, you may ask it to:
“Generate a SQL query to calculate the total sales for each product in the table.”
“Use pandas to write Python code that correlates the number of customer reviews with product sales.”
Determine the typical journey duration for each type of subscriber.
BigQuery’s Gemini feature may also help you comprehend intricate Python and SQL searches by offering explanations and insights. This makes it simpler for users of all skill levels to comprehend the reasoning behind the code. Those who are unfamiliar with Python and SQL, or who are working with unknown datasets, can particularly benefit from this.
Analytics workflows redesigned using natural language
Data canvas, an inventive natural language-based interface for data curation, wrangling, analysis, and visualization, is part of BigQuery’s Gemini package. With the help of data canvas, you can organize and explore your data trips using a graphical approach, making data exploration and analysis simple and straightforward.
For instance, you could use straightforward natural language prompts to collect information from multiple sources, like a point-of-sale (POS) system; integrate it with inventory, customer relationship management (CRM) systems, or external data; find correlations between variables, like revenue, product categories, and store location; or create reports and visualizations for stakeholders, all from within a single user interface, in order to analyze revenue across retail stores.
Optimize analytics for swiftness and efficiency
Data administrators and other analytics experts encounter difficulties in efficiently managing capacity and enhancing query performance as data volumes increase. BigQuery’s Gemini feature provides AI-powered suggestions for partitioning and grouping your tables in order to solve these issues. Without changing your queries, these suggestions try to optimize your tables for quicker returns and less expensive query execution.
Beginning
Phased rollouts of the general availability of Gemini in BigQuery features will begin over the following few months, starting today with suggestions for partitioning and clustering, data canvas, SQL code generation and explanation, and Python code generation.
Currently, all clients can access generally accessible (GA) features at no additional cost. For further details, please refer to the pricing details.
Read more on govindhtech.com
#StartUsingGemini#BigQuery#VertexAI#Datacanvas#NewlyReleasedFeatures#generativeAI#Geminifeatur#BigQuerycapabilities#AIinfrastructure#DataInsights#pricingdetails#Optimizeanalytics#efficiency#Analyticsworkflows#naturallanguage#technology#technews#news#govindhtech
1 note
·
View note
Text
Leveraging Gemini 1.0 Pro Vision in BigQuery

Gemini 1.0 Pro Vision in BigQuery
Organisations are producing more unstructured data in the form of documents, audio files, videos, and photographs as a result of the widespread use of digital devices and platforms, such as social media, mobile devices, and Internet of Things sensors. In order to assist you in interpreting and deriving valuable insights from unstructured data, Google Cloud has introduced BigQuery interfaces with Vertex AI over the last several months. These integrations make use of Gemini 1.0 Pro, PaLM, Vision AI, Speech AI, Doc AI, Natural Language AI, and more.
Although Vision AI can classify images and recognize objects, large language models (LLMs) open up new visual application cases. With Gemini 1.0 Pro Vision, they are extending BigQuery and Vertex AI integrations to provide multimodal generative AI use cases. You may use Gemini 1.0 Pro Vision directly in BigQuery to analyse photos and videos by mixing them with custom text prompts using well-known SQL queries.
Multimodal capabilities in a data warehouse context may improve your unstructured data processing for a range of use cases:
Object recognition: Respond to inquiries pertaining to the precise identification of items in pictures and movies.
Information retrieval: Integrate existing knowledge with data gleaned from pictures and videos.
Captioning and description: Provide varied degrees of depth in your descriptions of pictures and videos.
Understanding digital content: Provide answers by gathering data from web sites, infographics, charts, figures, and tables.
Structured content generation: Using the prompts supplied, create replies in HTML and JSON formats.
Converting unorganised information into an organised form
Gemini 1.0 Pro Vision may provide structured replies in easily consumable forms such as HTML or JSON, with just minor prompt alterations needed for subsequent jobs. Having structured data allows you to leverage the results of SQL operations in a data warehouse like BigQuery and integrate it with other structured datasets for further in-depth analysis.
Consider, for instance, that you have a large dataset that includes pictures of vehicles. Each graphic contains some fundamental information about the automobile that you should be aware of. Gemini 1.0 Pro Vision can be helpful in this use situation!Image credit to Google cloud
As you can see, Gemini has answered with great detail! However, if you’re a data warehouse, the format and additional information aren’t as useful as they are for individuals. You may modify the prompt to instruct the model on how to produce a structured answer, saving unstructured data from becoming even more unstructured.Image credit to Google cloud
You can see how a BigQuery-like setting would make this answer much more helpful.
Let’s now examine how to ask Gemini 1.0 Pro Vision to do this analysis over hundreds of photos straight in BigQuery!
Gemini 1.0 Pro Vision Access via BigQuery ML
BigQuery and Gemini 1.0 Pro Vision are integrated via the ML.GENERATE_TEXT() method. You must build a remote model that reflects a hosted Vertex AI big language model in order to enable this feature in your BigQuery project. Thankfully, it’s just a few SQL lines:
After the model is built, you may produce text by combining your data with the ML.GENERATE_TEXT() method in your SQL queries.
A few observations on the syntax of the ML.GENERATE_TEXT() method when it points to a gemini-pro-vision model endpoint, as this example does:
TABLE: Accepts as input an object table including various unstructured object kinds (e.g. photos, movies).
PROMPT: Applies a single string text prompt to each object, row-by-row, in the object TABLE. This prompt is part of the option STRUCT, which is different from the situation when using the Gemini-Pro model.
To extract the data for the brand, model, and year into new columns for use later, they may add additional SQL to this query.
The answers have now been sorted into brand-new, organised columns.
There you have it, then. A set of unlabeled, raw photos has just been transformed by Google Cloud into structured data suitable for data warehouse analysis. Consider combining this new table with other pertinent business data. For instance, you might get the median or average selling price for comparable automobiles in a recent time frame using a dataset of past auto sales. These are just a few of the opportunities that arise when you include unstructured data into your data operations!
A few things to keep in mind before beginning to use Gemini 1.0 Pro Vision in BigQuery are as follows:
To do Gemini 1.0 Pro Vision model inference over an object table, you need an enterprise or enterprise plus reservation.
Vertex AI large language models (LLMs) and Cloud AI services are subject to limits; thus, it is important to evaluate the current quota for the Gemini 1.0 Pro Vision model.
Next actions
There are several advantages of integrating generative AI straight into BigQuery. You can now write a few lines of SQL to do the same tasks as creating data pipelines and bespoke Python code between BigQuery and the generative AI model APIs! BigQuery scales from one prompt to hundreds while handling infrastructure management.
Read more on Govindhtech.com
#govindhtech#news#BigQuery#Gemini#geminivisionpro#GeminiPro#VertexAI#technologynews#technology#TechnologyTrends
0 notes
Text
NetRise Improves Accessibility with Google Cloud

NetRise Security
With the help of NetRise’s platform, users may become more adept at spotting potential problems with software in embedded systems which are often thought of as “black boxes.” As they move this goal forward, they see that security operations teams are severely lacking in their awareness of the vulnerabilities of third-party software, which is mostly based on open-source software.
Open-source software, which is characterized by a lack of standards, makes global analysis extremely difficult, particularly in the event of supply chain threats. Cyber-physical systems (CPS) and the Extended Internet of Things (XIoT) both increase this complexity. Here, proprietary firmware packaging formats and unique manufacturer standards often conceal embedded systems, making automated analysis technically difficult.
These difficulties not only show the need of reliable solutions but also the importance of accuracy, scalability, and user-friendliness in a complex environment.
Taking care of the invisible Trace which integrates large language models (LLM) with Cloud SQL for PostgreSQL, is essential to their strategy for resolving supply chain security issues. A properly maintained relational database is essential to Trace because it supports their query and data management features and makes code-origin tracing and vulnerability detection accurate and efficient.
Security teams don’t need to reprocess the same NetRise asset images the files within their embedded systems in order to conduct extensive, scalable searches across all file assets. Imagine a Python module being compromised by malicious code. Trace gives an easy-to-understand graph-based display of the effect and identifies the impacted NetRise files, assets, or open-source programs.
Trace is enhanced with a patented extraction engine that breaks down intricate software file formats, including bootloaders, ISOs, docker images, firmware, standalone software packages, virtual machines, and more. This cloud-based extraction engine exposes any nested file formats in an asset before it is fed into the NetRise system.
Next, using machine learning methods, the retrieved text files are converted into vectorized numerical representations. These embeddings are then stored in Cloud SQL for PostgreSQL using pgvector, which makes analysis easier by allowing semantic searches using natural language (for example, for hard-coded credentials or keys). They can perform more intricate queries and bigger datasets thanks to the integration of pgvector in Cloud SQL, making the solution more reliable and scalable.
Day-long turnarounds only take minutes now
For us, using Google Cloud’s managed services changed everything. They were able to extend their architecture and optimize their queries with the aid of Cloud SQL, which greatly decreased the amount of time and resources required for data processing. Additionally, they were able to retain a better user experience by halving their server resources and cutting response times by 60% using pgvector.
Most significantly, their customers’ and internal researchers’ trace capabilities are made possible by the combination of Cloud SQL and pgvector, which spares them the months of labor that they would have otherwise needed for detection engineering. Threat research and security operations have improved by an astounding ten times, which benefits Netrise’s research and advisory use cases as well as their clients’ capacity to react both proactively and reactively to security issues.
With Cloud SQL, they can focus on what they do best, which is developing exceptional security solutions for their customers. This enables us to improve their staff of security researchers and detection engineers by reallocating monies that are typically designated for infrastructure engineering.
They moved from Elasticsearch to BigQuery in order to expedite their data processing capabilities. Procedures that used to take a whole day now just take a few minutes to complete. For example, in a recent benchmark in which they managed 33,600 assets, a process that usually took more than 24 hours to complete now takes just 47 minutes, which is more than 30 times quicker than their previous performance.
The power of having a uniform data cloud environment is shown when BigQuery and Cloud SQL are combined. Their capacity to handle large-scale data fast and precisely has improved because to the combined use of BigQuery’s analytics and Cloud SQL’s operational database administration, which has improved their analytical and decision-making processes.
Laying out a safe digital future
Their goal is simple: They want to provide their clients a complete picture of the risk that exists today across all of their assets, including cloud, virtual machines, XIoT devices, and Docker containers. For us, the first step in safeguarding the digital world is to completely comprehend it.
Their goals are to find deeper problems in these assets, simplify and expedite the identification process, and create well-defined, systematic strategies for fixing these problems by using AI and sophisticated analytics.
Their ultimate goal is to go from asset-focused antivirus into endpoint detection and response (EDR), then into the next stage of extended detection and response (XDR). In order to improve detection and response tactics with real-time supply-chain-based alerts, they are doing this by adding an extra layer derived from supply chain dynamics. Industry analysts and professionals have lately discussed the need for this additional layer.
NetRise inc Google Cloud’s technologies help NetRise in their mission to find vulnerabilities in software supply chains and XIoT devices. They have completely changed their data management and analysis capabilities by using Cloud SQL for PostgreSQL and BigQuery, which makes accurate, scalable, and efficient vulnerability detection possible.
Through this transition, we have been able to improve their capacity to provide thorough security insights and simplify their processes. In the end, it may assist us in tackling the intricate problems associated with cybersecurity in the linked digital world of today.
The flexibility and intricate setup that Google provides in its cloud solutions are valued at NetRise. Not only is Google Cloud’s technology excellent, but its people are also kind, informed, and a joy to work with. They have faith that Google would support them in developing answers for whatever obstacles they face when they use larger language models and AI.
Read more on Govindhtech.com
0 notes
Text
Examine Gemini 1.0 Pro with BigQuery and Vertex AI

BigQuery and Vertex AI to explore Gemini 1.0 Pro
Innovation may be stifled by conventional partitions separating data and AI teams. These disciplines frequently work independently and with different tools, which can result in data silos, redundant copies of data, overhead associated with data governance, and budgetary issues. This raises security risks, causes ML deployments to fail, and decreases the number of ML models that make it into production from the standpoint of AI implementation.
It can be beneficial to have a single platform that removes these obstacles in order to accelerate data to AI workflows, from data ingestion and preparation to analysis, exploration, and visualization all the way to ML training and inference in order to maximize the value from data and AI investments, particularly around generative AI.
Google is recently announced innovations that use BigQuery and Vertex AI to further connect data and AI to help you achieve this. They will explore some of these innovations in more detail in this blog post, along with instructions on how to use Gemini 1.0 Pro in BigQuery.
What is BigQuery ML?
With Google BigQuery’s BigQuery ML capability, you can develop and apply machine learning models from within your data warehouse. It makes use of BigQuery’s processing and storing capability for data as well as machine learning capabilities, all of which are available via well-known SQL queries or Python code.
Utilize BigQuery ML to integrate AI into your data
With built-in support for linear regression, logistic regression, and deep neural networks; Vertex AI-trained models like PaLM 2 or Gemini Pro 1.0; or imported custom models based on TensorFlow, TensorFlow Lite, and XGBoost, BigQuery ML enables data analysts and engineers to create, train, and execute machine learning models directly in BigQuery using familiar SQL, helping them transcend traditional roles and leverage advanced ML models directly in BigQuery. Furthermore, BigQuery allows ML engineers and data scientists to share their trained models, guaranteeing that data is used responsibly and that datasets are easily accessible.
Every element within the data pipeline may employ distinct tools and technologies. Development and experimentation are slowed down by this complexity, which also places more work on specialized teams. With the help of BigQuery ML, users can create and implement machine learning models using the same SQL syntax inside of BigQuery. They took it a step further and used Vertex AI to integrate Gemini 1.0 Pro into BigQuery in order to further streamline generative AI. Higher input/output scale and improved result quality are key features of the Gemini 1.0 Pro model, which is intended to be used for a variety of tasks such as sentiment analysis and text summarization.
BigQuery ML allows you to integrate generative models directly into your data workflow, which helps you scale and optimize them. By doing this, bottlenecks in data movement are removed, promoting smooth team collaboration and improving security and governance. BigQuery’s tested infrastructure will help you achieve higher efficiency and scale.
There are many advantages to applying generative AI directly to your data:
Reduces the requirement for creating and maintaining data pipelines connecting BigQuery to APIs for generative AI models
Simplifies governance and, by preventing data movement, helps lower the risk of data loss
Lessens the requirement for managing and writing unique Python code to call AI models
Allows petabyte-scale data analysis without sacrificing performance
Can reduce your ownership costs overall by using a more straightforward architecture
In order to perform sentiment analysis on their data, Faraday, a well-known customer prediction platform, had to previously create data pipelines and join multiple datasets. They streamlined the process by giving LLMs direct access to their data, merging it with more first-party customer information, and then feeding it back into the model to produce hyper-personalized content—all inside BigQuery. To find out more, view this sample video.
Gemini 1.0 Pro and BigQuery ML
Create the remote model that reflects a hosted Vertex AI large language model before using Gemini 1.0 Pro in BigQuery. Usually, this process only takes a few seconds. After the model is built, use it to produce text by merging data straight from your BigQuery tables. Then, to access the Gemini 1.0 Pro via Vertex AI and carry out text-generation tasks, use the ML.GENERATE_TEXT construct. The database record and your PROMPT statement are appended by CONCAT. The prompt parameter that controls response randomness is temperature; the lower the temperature, the more relevant the response will be. The boolean flatten_json_output, when set to true, yields a flat, comprehensible text that has been taken from the JSON response.
What your data can achieve with generative AI
They think that the potential of AI technology for your business data is still largely unrealized. Data analysts’ responsibilities are growing with generative AI, going beyond just gathering, processing, and analyzing massive datasets to include proactively influencing data-driven business impact.
Data analysts can, for instance, use generative models to compile past email marketing data (open rates, click-through rates, conversion rates, etc.) and determine whether personalized offers outperform generic promotions or not, as well as which subject line types consistently result in higher open rates. Analysts can use these insights to direct the model to generate a list of interesting options for the subject line that are specific to the identified preferences. With just one platform, they can also use the generative AI model to create interesting email content.
Early adopters have shown a great deal of interest in resolving a variety of use cases from different industries. For example, the following advanced data processing tasks can be made simpler by using ML.GENERATE_TEXT:
Content generation
Without the need for sophisticated tools, analyze user feedback to create customized email content directly within BigQuery. “Create a marketing email using customer sentiment from [table name] “is a prompt
Summarize
Summarize text that is kept in BigQuery columns, like chat transcripts or online reviews. Example prompt “Combine client testimonials in [table name].”
Enhance data
For a given city name, get the name of the country. Example: “Give me the name of the city in column Y for each zip code in column X.”
Rephrasing
Spelling and grammar in written material, including voice-to-text transcriptions, should be done correctly. “Rephrase column X and add results to column Y” is an example of a prompt.
Feature extraction
Feature extraction is the process of removing important details or terms from lengthy text files, like call transcripts and internet reviews. “Extract city names from column X” is the example given.
Sentiment analysis
Recognize how people feel about particular topics in a text. Example prompt: “Incorporate findings into column Y by extracting sentiment from column X.”
Retrieval-augmented generation (RAG)
Utilizing BigQuery vector search, obtain pertinent data related to a task or question and supply it to a model as context. Use a support ticket, for instance, to locate ten related prior cases that you can pass to a model as context so that it can summarize and offer a solution.
Integrating unstructured data into your Data Cloud is made simpler, easier, and more affordable with BigQuery’s expanded support for cutting-edge foundation models like Vertex AI’s Gemini 1.0 Pro.
Come explore the future of generative AI and data with Google
Refer to the documentation to find out more about these new features. With the help of this tutorial, you can operationalize ML workflows, deploy models, and apply Google’s best-in-class AI models to your data without transferring any BigQuery data. Additionally, you can view a demonstration that shows you how to use BigQuery to build an end-to-end data analytics and AI application that fully utilizes the power of sophisticated models like Gemini, as well as a behind-the-scenes look at the development process. View Google’s most recent webcast on product innovation to find out more about the newest features and how BigQuery ML can be used to create and utilize models with just basic SQL.
Read more on govindhtech.com
#gemini#vertexai#bigquery#generativeai#bigqueryml#geminipro#rag#google#technology#technews#news#govindhtech
0 notes
Text
Spanner Controls Huge Generative AI and Similarity Search

Spanner Features
With a 99.999% availability SLA, Spanner, a fully managed, highly available distributed database service from Google Cloud, offers relational semantics and almost infinite horizontal scalability for both relational and non-relational workloads. Customers want scaling as data volumes increase and applications place more demands on their operational databases. Recently, Google introduced support for exact closest neighbor (KNN) search in preview for vector embeddings, enabling enterprises to develop generative AI at almost infinite scale. Because Spanner has all of these features, you can do vector search on your transactional data without transferring it to a different database, keeping things operationally simple.
Google explains in this blog post how vector search may improve general artificial intelligence applications and how the underlying architecture of Spanner allows for very large-scale vector search deployments. They also go over the many operational advantages of using Spanner as opposed to a specialized vector database.
Vector embeddings and generative AI
Numerous new applications are being made possible by generative AI, such as individualized conversational virtual assistants and the ability to create original material just by texting suggestions. The foundation of generative AI is pre-trained large language models (LLMs), which make it possible for developers with less experience in machine learning to create gen AI apps with ease. However, as LLMs may sometimes have hallucinations and provide false information, integrating LLMs with operational databases and vector search can aid in the development of Gen AI applications that are based on real-time, contextual, and domain-specific data, resulting in high-quality AI-assisted user experiences.
Suppose a financial institution employs a virtual assistant to assist clients with account-related inquiries, handle accounts, and suggest financial solutions that best suit each client’s particular requirements. The customer’s decision-making process may take place across many chat sessions with the virtual assistant in complicated settings. The virtual assistant may locate the most pertinent material by using vector search across the discussion history, resulting in a high-caliber, highly relevant, and educational chat experience. Utilizing vector embeddings—numerical representations of text, image, or video produced by embedding models—vector search assists the gen AI application in determining the most pertinent information to include in LLM prompts, allowing for the customization and enhancement of the LLM’s responses. The distance between vector embeddings may be used to do vector search. The content of the embeddings is increasingly similar the closer they are in the vector space.
With Spanner, you may virtually expand the scale of vector search
Vector workloads, such as the financial virtual assistant example mentioned above, may readily grow to extremely high sizes when they are required to service a large number of customers. Both a vast number of vectors (more than 10 billion, for example) and queries per second (more than millions of QPS) may be found in large-scale vector search workloads. It should come as no surprise that many database systems may find this difficult.
However, a large number of these searches are highly partitionable, meaning that each search is limited to the data that is connected to a certain person. Because Spanner effectively shrinks the search area to provide precise, timely results with little latency, these workloads are well suited for Spanner KNN search. Spanner supports vector search on trillions of vectors for highly partitionable workloads thanks to its horizontally scalable design.
To keep the application simple, Spanner also allows you to query and filter vector embeddings using SQL. It is simple to combine regular searches with vector search and to integrate vector embeddings with operational data using SQL. For instance, before doing a vector search, you may effectively filter rows of interest using secondary indexes. Like any other query on your operational data, Spanner’s vector search queries deliver new, real-time data as soon as transactions are committed.
Spanner offers resource efficiency and operational simplicity
Additionally, Google Spanner in-database vector search features streamline your operational process by removing the expense and complexity of maintaining a separate vector database. Vector embeddings can take advantage of all of Spanner features, such as high 99.999% availability, managed backups, point-in-time recovery (PITR), security and access control features, and change streams, because they are stored and managed in the same manner as operational data in Spanner. Better resource usage and cost reductions are made possible by the sharing of compute resources between operational and vector queries. Furthermore, Spanner’s PostgreSQL interface supports these features as well, providing customers transitioning from PostgreSQL with a recognizable and portable interface.
Additionally, Spanner integrates with well-known AI development tools like Document Loader, Memory, and LangChain Vector Store, making it simple for developers to create AI applications using the tools of their choice.
Beginning
Vector search skills have gained renewed attention with the emergence of Gen AI. Spanner is well suited to handle your large-scale vector search requirements on the same platform that you currently depend on for your demanding, distributed workloads, thanks to its nearly infinite scalability and support for KNN vector search.
Read more on govindhtech.com
#spannercontrols#spanner#generativeai#spannerfeatures#artificialintelligence#technews#technology#govindhtech
0 notes
Text
Top 5 startups using AI for climate change
New Post has been published on https://thedigitalinsider.com/top-5-startups-using-ai-for-climate-change/
Top 5 startups using AI for climate change

Generative artificial intelligence (AI) is not just an awe-inspiring innovation capable of producing new text, images, videos, and more; it’s also a powerful tool that has captivated global attention with its sophisticated functionalities and abilities.
However, its potential extends far beyond being merely a creative aide or chatbot. Generative AI is having a transformative impact on both human endeavors and business operations, especially in addressing some of the planet’s most daunting challenges.
Among these challenges, the climate crisis stands out as a pressing issue. The global community is striving to achieve net-zero carbon emissions by 2050 to limit the increase in global temperatures to 2 degrees Celsius and prevent the irreversible consequences of climate change.
In this article, we go over the top 5 companies using AI for climate change:
VIA
Both institutions and businesses need to monitor energy consumption details to facilitate emissions reduction, on both a local and individual scale. For example, a company aiming to decrease the carbon footprint of its electric vehicle (EV) fleet needs insights into whether, in a specific area and time, EVs are being charged with electricity generated from renewable sources or fossil fuels.
Similarly, achieving energy efficiency in buildings requires detailed, individual-level energy data throughout an organization’s property holdings. Ideally, if all data were openly shared, managing energy and reducing greenhouse gas emissions would be straightforward. However, accessing data at the individual level is often challenging due to privacy and security concerns, with many people hesitant to share specific details about their energy usage patterns.
Via Science, Inc. (VIA) offers a solution allowing organizations to lower their carbon footprint while making sure individual data remains confidential and secure. The firm employs zero-knowledge proofs, approved by the U.S. Department of Energy, to provide sustainability data, thus enabling organizations and businesses to track energy usage and achieve sustainability objectives without compromising on regulatory or privacy requirements.
Initially crafted for the U.S. Air Force, which faces stringent data privacy rules limiting access to essential energy and building management data, VIA’s decentralized software solution permits authorized users and contractors to utilize generative AI models without data sharing. Instead of using private data for training or query input, the system, when prompted, creates a SQL query and front-end code that users can locally execute to retrieve and display data from their databases, using a tool named SLAM AI.
To optimize energy use and lower computing expenses, VIA adopts compact, open-source LLMs that operate on CPUs, continuously evaluating new models to keep pace with the swift advancements in LLM capabilities. Using Amazon Elastic Kubernetes Service (EKS), VIA efficiently integrates more effective models as they become available, ensuring a smooth transition between them.
CarbonBright
Determining the complete carbon footprint of consumer products, from production to disposal, involves a complex process known as Life Cycle Analysis (LCA).
CarbonBright utilizes AI to offer immediate evaluations of the environmental impact of consumer goods, covering every stage from their creation to their recycling. This innovation enables suppliers, brands, and retailers to effortlessly and precisely gauge a product’s environmental effect throughout its entire supply chain.
As a result, it becomes simpler and more efficient for all parties involved to pinpoint areas with high emissions and shift towards more eco-friendly products and components.
CarbonBright’s system is capable of calculating the emissions associated with products across extensive and diverse collections, using data science techniques to bridge any information gaps.
The accuracy and reliability of their approach are ensured through verification by independent third-party accreditors, aligning with recognized global industry norms.
When CarbonBright identifies an emissions hotspot within a product range, it provides tailored advice on how to lower emissions or replace certain materials and packaging with more sustainable alternatives, facilitating a more eco-conscious approach to product development and supply chain management.

BrainBox AI
The International Energy Agency (IEA) highlights that buildings are a significant consumer of global energy, accounting for 30% of worldwide energy usage and 26% of energy-related emissions globally. Addressing the energy consumption of buildings is essential in achieving net zero global emissions.
BrainBox AI is at the forefront of utilizing autonomous AI to lower carbon emissions and enhance the efficiency of commercial buildings, simultaneously enabling clients to save on energy expenses.
Leveraging AWS, BrainBox AI’s cloud-based solution integrates with existing HVAC (heating, ventilation, and air conditioning) systems in buildings, autonomously issuing real-time optimized commands to reduce emissions and energy use without the need for human oversight.
For instance, BrainBox AI has demonstrated its capability to decrease HVAC energy expenses by as much as 25% and cut HVAC-associated greenhouse gas emissions by up to 40%. This is achieved by forecasting a retail store’s temperature using historical and external data sources, such as weather conditions and energy pricing structures.
As BrainBox AI expands its portfolio, it employs generative AI to streamline the incorporation of new buildings into its system, significantly reducing setup time. Traditionally, identifying a new equipment piece in a building required engineers to painstakingly sift through dense technical manuals to extract essential information in a machine-readable format—a time-consuming task.
Now, with the aid of Amazon Bedrock, BrainBox AI can automatically extract data and create configuration files, a process refined by engineers afterward, known as power tagging.
This innovative approach, powered by Amazon Bedrock, has led to a more than 90% reduction in the time required for power tagging. Consequently, BrainBox AI can engage with more clients at a quicker pace, amplifying its contribution to addressing the climate crisis more effectively.
KoBold Metals is harnessing the power of artificial intelligence to uncover new sources of lithium, cobalt, copper, and nickel—crucial components for battery production.
The company’s goal is to help decrease global reliance on fossil fuels by ensuring that 60% of all new light cars and trucks are electric by 2030, with a target of achieving 100% by 2050. This ambitious plan would see a surge from the current 10 million electric vehicles (EVs) on the road to 200 million by 2030, eventually reaching 3 billion by the middle of the century.
The transition to electric vehicles on such a large scale necessitates a reliable supply of battery materials. KoBold is using a combination of geoscience and extensive data on the earth’s crust, enhanced with AI, to diminish the risks associated with mining these critical materials.
The company has developed two proprietary AI models to support its mission: TerraShedSM, an extensive database that compiles and organizes over a century of global data; and Machine Prospector, a suite of predictive models that analyze the data collected by TerraShedSM.
KoBold enjoys the support of notable investors, including Bill Gates’s Breakthrough Energy Ventures, a16z, Bond Capital, Sam Altman, and T Rowe Price. Based in Berkeley, California, KoBold is expanding its workforce, currently boasting approximately 100 employees and actively seeking to fill more than 30 positions worldwide and remotely.
These openings, listed on Climatebase, range from geology and communications to data engineering and beyond, indicating KoBold’s growth and its commitment to addressing one of the most pressing environmental challenges of our time.
signup
The future of machine intelligence

Pendulum
Pendulum leverages artificial intelligence to tackle one of the most urgent global challenges: enabling organizations to achieve more with fewer resources. The company provides AI-driven solutions to complex issues in areas such as the commercial supply chain, global health, and national security, aiming for sustainable progress.
The importance of streamlining supply chains is underscored by their significant contribution to carbon emissions. Accenture reports that supply chains are responsible for 60% of global carbon emissions, and the U.S. Environmental Protection Agency notes that they can contribute to over 90% of a company’s greenhouse gases.
The inefficiency of current supply chain practices leads to substantial resource and capital waste. For example, annually, approximately $562 billion is lost due to overstock, resulting in 17% of food products and 8% of retail and consumer goods being discarded.
Pendulum’s AI technology empowers organizations to streamline their operations, minimizing waste, lost revenue, and unnecessary carbon emissions. Utilizing AWS, Pendulum’s software can forecast demand, optimize supply planning, and track shipments, enabling more precise resource procurement and production to meet consumer demand.
For Pendulum to effectively deliver these solutions, accessing comprehensive enterprise data is essential. Yet, data often remains isolated within separate systems and unstructured formats like PDFs and text documents.
Pendulum designs its software to integrate these critical data sources for better operational decisions, using generative AI to swiftly extract valuable insights from complex documents, enhancing customer value.
A notable application of Pendulum’s technology is in precision agriculture, where they refine a large language model (LLM) on AWS Trainium with a human-guided approach using Amazon SageMaker.
This process converts unstructured data into formats that agricultural machinery can utilize, optimizing the use of pesticides, water, and other resources. This not only prevents resource overuse and excess ordering, saving costs and minimizing environmental impact but also ensures compliance with local regulations and agricultural standards.
Pendulum has successfully cut the time needed to interpret these documents by 83%, now focusing primarily on data quality assurance. This efficiency gain reduces operational costs and facilitates the broader deployment of their technology, promoting scalable sustainability.
#accenture#accounting#Advice#agriculture#ai#air#air force#Amazon#Analysis#approach#Article#artificial#Artificial Intelligence#attention#AWS#battery#billion#brands#bridge#Building#buildings#Business#carbon#carbon emissions#carbon footprint#Cars#change#chatbot#climate#climate change
0 notes
Text
BigQuery Teams Up with Document AI for AI Magic

BigQuery and Document AI combine to provide use cases for generative AI and document analytics
Organizations are producing enormous volumes of text and other document data as the digital transition quickens; this data has the potential to provide a wealth of insights and fuel innovative generative AI use cases. They are thrilled to introduce an interface between BigQuery and Document AI to help you better use this data. This integration will make it simple to draw conclusions from document data and create new large language model (LLM) applications.
Thanks to Google’s state-of-the-art foundation models, BigQuery users may now develop Document AI Custom Extractors that they can modify depending on their own documents and information. With the ease and power of SQL, these bespoke models can then be called from BigQuery to extract structured data from documents in a controlled and safe way.
Some clients attempted to build autonomous Document AI pipelines prior to this connection, which required manually curating extraction algorithms and schema. They had to create custom infrastructure in order to synchronize and preserve data consistency since there were no native integration capabilities.
Because of this, every document analytics project became a major endeavor requiring a large financial outlay. With the help of this connection, clients may now quickly and simply build remote models in BigQuery for their unique extractors in Document AI. These models can then be used to execute generative AI and document analytics at scale, opening up new possibilities for data-driven creativity and insights. An integrated and controlled data to AI experience
In the Document AI Workbench, creating a custom extractor just takes three steps:
Specify the information that must be taken out of your papers. This is known as document schema, and it can be accessed via BigQuery and is kept with every version of the custom extractor.
Provide more documents with annotations as examples of the extraction, if desired.
Utilizing the basic models offered by Document AI, train the custom extractor’s model.
Document AI offers ready-to-use extractors for costs, receipts, invoices, tax forms, government IDs, and a plethora of other situations in the processor gallery, in addition to bespoke extractors that need human training. You don’t need to follow the previous procedures in order to utilize them immediately. After the custom extractor is complete you can use.
BigQuery Studio to perform the next four stages for SQL document analysis:
SQL is used to register a BigQuery remote model for the extractor. The custom extractor may be called, the results can be parsed, and the model can comprehend the document schema that was built above.
SQL may be used to create object tables for the documents kept in cloud storage. By establishing row-level access controls, which restrict users’ access to specific documents and, therefore, limit AI’s ability to protect privacy and security, you can control the unstructured data in the tables.
To extract pertinent information, use the ML.PROCESS DOCUMENT function on the object table to make inference calls to the API endpoint. Outside of the function, you can also use a “WHERE” clause to filter out the documents for the extractions. A structured table containing extracted fields in each column is the result of the function.
To integrate structured and unstructured data and produce business values, join the extracted data with other BigQuery.
Use cases for summarization, text analytics, and other document analysis
Following text extraction from your documents, there are many methods you may use to carry out document analytics:
Utilize BigQuery ML for text analytics: There are several methods for training and deploying text models with BigQuery ML. BigQuery ML, for instance, may be used to categorize product comments into distinct groups or to determine the emotion of customers during support conversations. In addition, BigQuery DataFrames for pandas and scikit-learn-like APIs for text analysis on your data are available to Python users.
To summarize the papers, use PaLM 2 LLM: The PaLM 2 model is called by BigQuery’s ML.GENERATE_TEXT function to produce texts that may be used to condense the documents. For example, you may combine PaLM 2 and Document AI to employ BigQuery SQL to extract and summarize client comments.
Combine structured data from BigQuery tables with document metadata: This enables the fusion of organized and unstructured data for more potent applications.
Put search and generative AI application cases into practice BigQuery’s search and indexing features enable you to create indexes that are designed for needle-in-the-haystack searches, which opens up a world of sophisticated search potential after you have extracted structured text from your documents.
Additionally, by using SQL and unique Document AI models, this integration facilitates the execution of text-file processing for privacy filtering, content safety checks, and token chunking, hence opening up new generative LLM applications. When paired with other information, the retrieved text makes curation of the training corpus which is necessary to fine-tune big language models easy.
Additionally, you are developing LLM use cases on corporate data that is managed and supported by BigQuery’s vector index management and embedding creation features. You may develop retrieval-augmented generation use cases for a more regulated and efficient AI experience by synchronizing this index with Vertex AI.
Read more on Govindhtech.com
0 notes
Text
BigQuery DataFrames Generative AI Goldmines!

Generative AI in BigQuery DataFrames turns customer feedback into opportunities
To run a successful business, you must understand your customers’ needs and learn from their feedback. However, extracting actionable information from customer feedback is difficult. Examining and categorizing feedback can help you identify your customers’ product pain points, but it can become difficult and time-consuming as feedback grows.
Several new generative AI and ML capabilities in Google Cloud can help you build a scalable solution to this problem by allowing you to analyze unstructured customer feedback and identify top product issues.
This blog post shows how to build a solution to turn raw customer feedback into actionable intelligence.
Our solution segments and summarizes customer feedback narratives from a large dataset. The BigQuery Public Dataset of the CFPB Consumer Complaint Database will be used to demonstrate this solution. This dataset contains diverse, unstructured consumer financial product and service complaints.
The core Google Cloud capabilities we’ll use to build this solution are:
Text-bison foundation model: a large language model trained on massive text and code datasets. It can generate text, translate languages, write creative content, and answer any question. It’s in Vertex AI Generative AI.
Textembedding-gecko model: an NLP method that converts text into numerical vectors for machine learning algorithms, especially large ones. Vector representations capture word semantics and context. Generative AI on Vertex AI includes it.
The BigQuery ML K-means model clusters data for segmentation. K-means is unsupervised, so model training and evaluation don’t require labels or data splitting.
BigQuery DataFrames for ML and generative AI. BigQuery DataFrames, an open-source Python client, compiles popular Python APIs into scalable BigQuery SQL queries and API calls to simplify BigQuery and Google Cloud interactions.
Data scientists can deploy Python code as BigQuery programmable objects and integrate with data engineering pipelines, BigQuery ML, Vertex AI, LLM models, and Google Cloud services to move from data exploration to production with BigQuery DataFrames. Here are some ML use cases and supported ML capabilities.
Build a feedback segmentation and summarization solution
You can copy the notebook to follow along. Using BigQuery DataFrames to cluster and characterize complaints lets you run this solution in Colab using your Google Cloud project.
Data loading and preparation
You must import BigQuery DataFrames’ pandas library and set the Google Cloud project and location for the BigQuery session to use it.
To manipulate and transform this DataFrame, use bigframes.pandas as usual, but calculations will happen in BigQuery instead of your local environment. BigQuery DataFrames supports 400+ pandas functions. The list is in the documentation.
This solution isolates the DataFrame’s consumer_complaint_narrative column, which contains the original complaint as unstructured text, and drops rows with NULL values for that field using the dropna() panda.
Embed text
Before applying clustering models to unstructured text data, embeddings, or numerical vectors, must be created. Fortunately, BigQuery DataFrames can create these embeddings using the text-embedding-gecko model, PaLM2TextEmbeddingGenerator.
This model is imported and used to create embeddings for each row of the DataFrame, creating a new DataFrame with the embedding and unstructured text.
K-means training
You can train the k-means model with the 10,000 complaint text embeddings.
The unsupervised machine learning algorithm K-means clustering divides data points into a predefined number of clusters. By minimizing the distance between data points and their cluster centers and maximizing cluster separation, this algorithm clusters data points.
The bigframes.ml package creates k-means models. The following code imports the k-means model, trains it using embeddings with 10 clusters, and predicts the cluster for each complaint in the DataFrame.
LLM model prompt
Ten groups of complaints exist now. How do complaints in each cluster differ? A large language model (LLM) can explain these differences. This example compares complaints between two clusters using the LLM.
The LLM prompt must be prepared first. Take five complaints from clusters #1 and #2 and join them with a string of text asking the LLM to find the biggest difference.
LLM provided a clear and insightful assessment of how the two clusters differ. You could add insights and summaries for all cluster complaints to this solution.
Read more on Govindhtech.com
0 notes
Text
Exploring Startups’ LLM Fine-Tuning on Intel GPUs

The second development sprint on the Intel Developer Cloud was recently finished by the Intel Liftoff team and AI startups (see the report about the first sprint here). The Intel Liftoff program team and companies concentrated on providing their products with specialized, LLM-powered feature enablement during this sprint. Participants in hackathons are redefining standards for AI application development across industries by leveraging Intel’s AI stack and support.
Opening Doors for Members of Intel Liftoff
AI startups had access to the Intel Developer Cloud through the virtual event, which also gave them access to Intel Data Center GPU Max Series 1550 and 4th Gen Intel Xeon Scalable processors. The goal of the hackathon was to examine the potential of upcoming LLM-based applications.
The Four Most Innovative Ideas
The four creative teams from among those that participated were chosen for the final showcase:
All hackathon participants received access to several GPUs, a first for Intel Liftoff, and were able to distribute training (data parallel) runs over them all at once. Our hackathon participants were able to fine-tune 3 to 13 billion parameter LLMs in a couple of hours thanks to the larger Data Center GPU Max 1550 model’s availability with 128 GB of VRAM. The Intel oneAPI software stack, Intel oneAPI Base Toolkit, Intel oneAPI Deep Neural Network (oneDNN), Intel oneAPI DPC++/C++ Compiler with SYCL* runtime, and Intel Extension for PyTorch were used to optimize the models for all four of these applications on Intel GPUs.
Chatbots from Dowork Technologies, LLM
applying LoRA, Dowork Technologies modified OpenLLaMA-13B with 4 PVC 1550s by synthesizing a fine-tuning dataset and applying it. Their technology enables businesses to create LLM chatbots and other applications using corporate data in a safe manner, acting as dynamic, conversational institutional memories for staff members — basically, a Private ChatGPT!
“We have been optimizing our 13 billion parameter model using Intel Hardware. The good results have given us the computing capacity required for such a comprehensive model. However, we saw a minor delay in text production during inference. We are enthusiastic to work with Intel to overcome this obstacle and unlock even better performance in future solutions as we push our AI models to new heights, said Mushegh Gevorgyan, founder and CEO of Dowork Technologies.
SQL queries for business analytics: The Mango Jelly
To automate business analytics for marketers, Mango Jelly’s application needed a new functionality for creating SQL queries. During this Intel Liftoff development sprint, which produced amazing results, this crucial feature that is essential to their business plan was built from the ground up. The team improved OpenLLaMA-3B using real customer data and Intel GPUs so that it could provide well-structured queries in response to marketing requests written in everyday language.
We were able to optimize an open-source LLM on incredibly potent hardware as part of Intel Liftoff. It was astounding to see the Intel XPU function at such high speeds. With the help of open-source models and cutting-edge hardware, this alliance gives us more flexibility over customization, tuning, and usage restrictions. Additionally, it highlights the suitability and readiness of our solution for enterprise use cases, according to Divya Upadhyay, co-founder and CEO of The Mango Jelly.
Enhancing Staffing with Terrain Analytics
A platform is provided by Terrain Analytics to help businesses make better hiring decisions. Terrain had created a functionality to parse job postings using OpenAI’s Ada API before to the sprint, but they ran into issues with cost and throughput. They were able to perfect an LLM for this particular use case during the Intel Liftoff sprint by using Intel Data Center GPU Max (Ponte Vecchio) for training and a 4th generation Intel Xeon Scalable Processor (Sapphire Rapids) for inference. The resulting model performed better than the default Ada API, with noticeably improved throughput and significant cost savings.
Terrain can now scale Deep Learning and Language Learning Models without running into computational limits thanks to the incorporation of Intel technology. Nathan Berkley, a software engineer at Terrain Analytics, and Riley Kinser, co-founder and head of product, claim that both of the models they developed showed superior success metrics to those produced using OpenAI’s Ada model and that they processed data 15 times more quickly.
Making LLMs more welcoming to business
With a focus on security and viability, Prediction Guard is an expert in supporting the integration of LLMs into company operations. The deliverables created by LLMs sometimes have an unstructured nature and could provide compliance and reputational difficulties. The platform of Prediction Guard provides answers to these problems. They improved the Camel-5B and Dolly-3B models using data from two paying customers, showcasing their capacity to improve LLM outputs for better business application.
“Prediction Guard was able to show the client how to cut the current OpenAI-based transcription processing time from 20 minutes to under one minute after evaluating LLM data extraction on Intel DCGM. According to Daniel Withenack, founder and CEO of Prediction Guard, their Pivoting initiative for potential clients has the potential to save operational costs by $2 million yearly.
Awaiting the Intel Innovation Event with anticipation
These accomplishments demonstrate the potential that AI businesses may unleash with the Liftoff for businesses program as we rush towards the Intel Innovation event in September. Our program participants are setting new standards for AI application development by utilizing Intel’s AI stack and assistance.
0 notes