#benchmarks
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
THANK YOU SM OMFG!!!! Although I don’t share my follower count anymore, I love being able to keep track of benchmarks and stuff for myself and being able to express how grateful I am.
Thank you for reading my work, interacting, and support me and my blog!!! I remember thanking for 6k and then stuff after only a couple months ago and being like “there can’t be anyone else in this fandom” but holy fuck you guys are insanely sweet, kind, and generous!!!
I’m so happy to have a community and friends on here. I still have a note that has all my ideas to write and it is endless and long. I already have stuff drafted to release and I can’t wait to share more with you guys!!!! I love you and my dog likes you too (if ur not a man. Sorry she hates men….)


59 notes
·
View notes
Text






You guys I love her so much. I was so excited for the graphics update and when I spawned into character creator and saw her (her eyes!!!!! So pretty!!!) I literally cried, from joy! Then I continued to cry as I watched the benchmark and saw her with all the new environments and details and… Just *WOW.* She’s missing her hat (Matoya’s Hat) that she never takes off. But that can be a surprise for launch I suppose!!
I feel for the people who aren’t happy with their characters, I do, but these changes really brought Loran to life and I am *so* excited to see her in her proper attire, come 7.0!
It’s full speed ahead on *this* hype train! I am gonna be trying to make it through a full NG+ playthrough and enjoying the events as they come and go until June 28th!! (And probably popping back into the Benchmark to see my future girl on occasion!)
See you all in Dawntrail everyone!!! 💜✨
#ffxiv#final fantasy 14#ff14#ffxiv dawntrail#dawntrail#benchmarks#FFXIV benchmark#dawntrail benchmark
8 notes
·
View notes
Text

Greetings, everyone! I'd like to introduce the updated Athena! For a while, Athena's author has been treating her as half Miqo'te, half Hrothgar. They have done a lot of work to get the character to be a bit more in line with their mental image of Athena.
Now, that image is crystal clear.
Say hello again to Athena Natlho, daughter of a Hrothgar and Miqo'te, this time taking much more after her father.


Of note, we will not be changing any of the past screenshots, stories, or posts, but we will use this version of the character moving forward.
Stay tuned in Dawntrail for more cool screenshots of all the girls together again, and thanks for staying tuned this far.
<3
#ffxiv#ffxiv roleplay#ffxiv oc#ff14#final fantasy 14#ffxiv rp#gpose#gposers#ff14 gpose#ffxiv gpose#Athena Natlho#original character#final fantasy gpose#final fantasy xiv#final#dawntrail#ffxiv benchmark#benchmarks#hrothgar#hrothgal#hrothgirl#female hrothgar#fem hrothgar
15 notes
·
View notes
Text

Hellsguard women are one of the biggest losers of the graphical update. The nose spot was a charm point, and it looks like they tried to wipe it off with a washcloth
#ffxiv#ffxiv roegadyn#roegadame#roegadyn#final fantasy xiv#final fantasy 14#benchmarks#benchmark#ffxiv benchmark#dawntrail#ffxiv dawntrail
6 notes
·
View notes
Text
So uh
I think SE's min requirements for Dawntrail might have been a tiny bit overzealous
2 notes
·
View notes
Photo
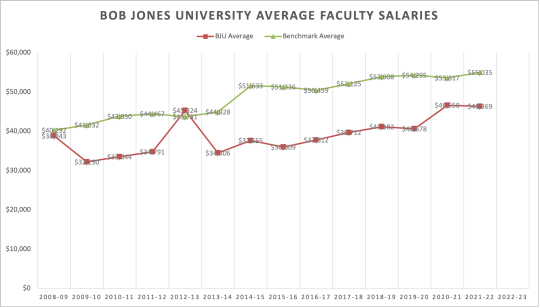
So taking the BJU faculty salary average and comparing it to their benchmarks, you can see that there was a bump for 2020-21, but then things leveled out.
#Bob Jones University#Financial Crisis#Charts and Graphs#Revenue#Expenses#990s#501c3#IPEDS#Salary#Benchmarks#Faculty
1 note
·
View note
Text
Leaker: Xiaomi 16 Ultra Tipped to Use SmartSens Camera Sensor Instead of Sony LYT-900 to be a one of a kind in 2026
Over the weekend, it was reported that the Xiaomi 16 Ultra could feature the same 1-inch sensor that Huawei is using in its Pura 80 Ultra. Now a leaker has shared more details about the Leica camera of the Xiaomi 16 Ultra and the sensors of the other Xiaomi 16 variants. This time it seems that more variants will be launched in the market than the previous one. It seems that Xiaomi is still in…
#1-inch sensor#200 megapixel telephoto#benchmarks#graphics card#Keywords Xiaomi 16 Ultra#laptop#Leica camera#Mobile#netbook#notebook#Omnivision#processor#reports#review#reviews#sensor#SmartSens#specs#tech news#technical data#test#tests#Today Wold#Xiaomi 16 Pro#Xiaomi 16 Pro Max
0 notes
Text
Tex Garment Zone: Setting New Benchmarks in Quality and Design
#Benchmarks#Design#Garment#how Tex Garment Zone leading the clothing industry#Quality#Setting#Tex#Zone
0 notes
Text

【実機を試す!】世界を変えるPC Copilot+PCガチでレビューするぞ!Microsoft Surface Laptop【忖度一切無し!】
#AIモデル解説#ainews#xelite#xplus#評価#copilotai#snapdragonx#解説動画#microsoftnews#windows11#性能#aipc#benchmarks#PC#コパイロット#win11#パソコン#コパイロットpc#cpu#生成AI#GPU#コパイロット使い方#ガジェット紹介#AI#copilotpc#リコール#パソコン初心者#chatgpt#Recall#ImageCreator
0 notes
Text
Early RTX 5060 Ti benchmarks reveal why Nvidia withheld the 8GB version from reviewers
Serving tech enthusiasts for over 25 years. TechSpot means tech analysis and advice you can trust. In brief: Nvidia’s marketing for the RTX 5060 Ti has so far focused exclusively on the 16GB model, raising eyebrows as the company has refused to provide reviewers with access to the 8GB version. This decision suggests an effort to downplay the cheaper variant’s underwhelming performance, and an…
0 notes
Text

lady of sorrows
#bg3#bg3 fanart#shadowheart#baldur's gate 3#i actually started this at the end of the year but got so busy i couldnt finish until now#first art of the year and predictably...shart#this is the official chas benchmark lets see how far i can go this year!!!!!!!!!!!!!
14K notes
·
View notes
Text
Portefeuilles : situation au 01.02.2025
Le Portefeuille déterminant conclut ce mois de janvier avec un joli gain de 2.05% (en CHF). Le PP 2.x fait encore mieux, avec 3.83%. Malgré ces belles performances, ils se font clairement dépasser par le MSCI Switzerland, qui casse la baraque avec 8.25% ! Il faut dire que ce dernier revient de très loin, après une année 2024 assez misérable. Performance du mois écoulé (portefeuilles et…

View On WordPress
0 notes
Text


Doubt I'll post many of these, but here's a side-by-side of current settings in current patch, vs current settings in the benchmark.
#ffxiv#ff14#final fantasy 14#gpose#carmen weaver#dawntrail#benchmarks#final fantasy xiv#FFXIV benchmark
7 notes
·
View notes
Text
Phi 4 is just 14B But Better than llama 3.1 70b for several tasks.

0 notes
Audio
Listen to: Next Year by Benchmarks
every morning when I wake up it's the same old thing I'm always waiting for the summer, I'm waiting for spring I can't stay awake in daylight and God knows I can't sleep at night I'm tired of this room, it's always just like the last one always less of a home and more like a place to crash so can I stay the night at your place till the weekend or the winter ends I know next year things will be better
1 note
·
View note
Text
OnePlus 13T Price | launched with 12GB RAM | know full Specifications & Features | Mobile Phone
OnePlus 13T Price under $X99 | ₹ XX,990 launched with 512GB Storage | Know full Specifications & Features. See here what are the prices of OnePlus 13T in different stores. OnePlus 13T Price | Specs | Specifications GeneralDetailsBrandOnePlusModelOnePlus 13TPrice$X99.99 | ₹XX,990 (Note:- See below to know the exact price)Launch DateMay 202XForm factorTouchscreenWeight (g)210gBattery capacity…
#Android#benchmarks#cellphone#compact smartphone#Dimensity 9300 Plus#Dimensity 9400 Plus#Find X8 Mini#Find X8S Plus#graphics card#info#laptop#martphone#Mobile#netbook#notebook#OnePlus 13T#opinion#Oppo#Oppo Find X8S#phone#reports#review#reviews#Snapdragon 8 Elite#specification#specs#tech news#test#tests#Today Wold
0 notes