#text to sql ai
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Mastering Text-to-SQL with LLM Solutions and Overcoming Challenges

Text-to-SQL solutions powered by Large Language Models (LLMs) are transforming the way businesses interact with databases. By enabling users to query databases using natural language, these solutions are breaking down technical barriers and enhancing accessibility. However, as with any innovative technology, Text-to-SQL solutions come with their own set of challenges. This blog explores the top hurdles and provides practical tips to overcome them, ensuring a seamless and efficient experience.
The rise of AI-generated SQL
Generative AI is transforming how we work with databases. It simplifies tasks like reading, writing, and debugging complex SQL (Structured Query Language). SQL is the universal language of databases, and AI tools make it accessible to everyone. With natural language input, users can generate accurate SQL queries instantly. This approach saves time and enhances the user experience. AI-powered chatbots can now turn questions into SQL commands. This allows businesses to retrieve data quickly and make better decisions.
Large language models (LLMs) like Retrieval-Augmented Generation (RAG) add even more value. They integrate enterprise data with AI to deliver precise results. Companies using AI-generated SQL report 50% better query accuracy and reduced manual effort. The global AI database market is growing rapidly, expected to reach $4.5 billion by 2026 (MarketsandMarkets). Text-to-SQL tools are becoming essential for modern businesses. They help extract value from data faster and more efficiently than ever before.
Understanding LLM-based text-to-SQL
Large Language Models (LLMs) make database management simpler and faster. They convert plain language prompts into SQL queries. These queries can range from simple data requests to complex tasks using multiple tables and filters. This makes it easy for non-technical users to access company data. By breaking down coding barriers, LLMs help businesses unlock valuable insights quickly.
Integrating LLMs with tools like Retrieval-Augmented Generation (RAG) adds even more value. Chatbots using this technology can give personalized, accurate responses to customer questions by accessing live data. LLMs are also useful for internal tasks like training new employees or sharing knowledge across teams. Their ability to personalize interactions improves customer experience and builds stronger relationships.
AI-generated SQL is powerful, but it has risks. Poorly optimized queries can slow systems, and unsecured access may lead to data breaches. To avoid these problems, businesses need strong safeguards like access controls and query checks. With proper care, LLM-based text-to-SQL can make data more accessible and useful for everyone.
Key Challenges in Implementing LLM-Powered Text-to-SQL Solutions
Text-to-SQL solutions powered by large language models (LLMs) offer significant benefits but also come with challenges that need careful attention. Below are some of the key issues that can impact the effectiveness and reliability of these solutions.
Understanding Complex Queries
One challenge in Text-to-SQL solutions is handling complex queries. For example, a query that includes multiple joins or nested conditions can confuse LLMs. A user might ask, “Show me total sales from last month, including discounts and returns, for product categories with over $100,000 in sales.” This requires multiple joins and filters, which can be difficult for LLMs to handle, leading to inaccurate results.
Database Schema Mismatches
LLMs need to understand the database schema to generate correct SQL queries. If the schema is inconsistent or not well-documented, errors can occur. For example, if a table is renamed from orders to sales, an LLM might still reference the old table name. A query like “SELECT * FROM orders WHERE order_date > ‘2024-01-01’;” will fail if the table was renamed to sales.
Ambiguity in Natural Language
Natural language can be unclear, which makes it hard for LLMs to generate accurate SQL. For instance, a user might ask, “Get all sales for last year.” Does this mean the last 12 months or the calendar year? The LLM might generate a query with incorrect date ranges, like “SELECT * FROM sales WHERE sales_date BETWEEN ‘2023-01-01’ AND ‘2023-12-31’;” when the user meant the past year.
Performance Limitations
AI-generated SQL may not always be optimized for performance. A simple query like “Get all customers who made five or more purchases last month” might result in an inefficient SQL query. For example, LLM might generate a query that retrieves all customer records, then counts purchases, instead of using efficient methods like aggregation. This could slow down the database, especially with large datasets.
Security Risks
Text-to-SQL solutions can open the door to security issues if inputs aren’t validated. For example, an attacker could input harmful code, like “DROP TABLE users;”. Without proper input validation, this could lead to an SQL injection attack. To protect against this, it’s important to use techniques like parameterized queries and sanitize inputs.
Tips to Overcome Challenges in Text-to-SQL Solutions
Text-to-SQL solutions offer great potential, but they also come with challenges. Here are some practical tips to overcome these common issues and improve the accuracy, performance, and security of your SQL queries.
Simplify Complex Queries To handle complex queries, break them down into smaller parts. Train the LLM to process simple queries first. For example, instead of asking for “total sales, including discounts and returns, for top product categories,” split it into “total sales last month” and “returns by category.” This helps the model generate more accurate SQL.
Keep the Schema Consistent A consistent and clear database schema is key. Regularly update the LLM with any schema changes. Use automated tools to track schema updates. This ensures the LLM generates accurate SQL queries based on the correct schema.
Clarify Ambiguous Language Ambiguous language can confuse the LLM. To fix this, prompt users for more details. For example, if a user asks for “sales for last year,” ask them if they mean the last 12 months or the full calendar year. This will help generate more accurate queries.
Optimize SQL for Performance Ensure the LLM generates optimized queries. Use indexing and aggregation to speed up queries. Review generated queries for performance before running them on large databases. This helps avoid slow performance, especially with big data.
Enhance Security Measures To prevent SQL injection attacks, validate and sanitize user inputs. Use parameterized queries to protect the database. Regularly audit the SQL generation process for security issues. This ensures safer, more secure queries.
Let’s take a closer look at its architecture:
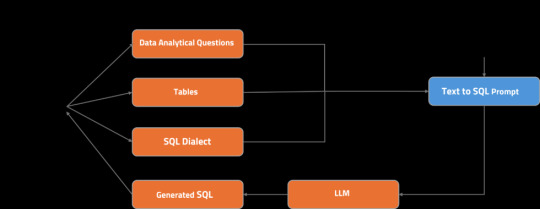
The user asks an analytical question, choosing the tables to be used.
The relevant table schemas are retrieved from the table metadata store.
The question, selected SQL dialect, and table schemas are compiled into a Text-to-SQL prompt.
The prompt is fed into LLM.
A streaming response is generated and displayed to the user.
Real-World Examples of Text-to-SQL Challenges and Solutions
Example 1: Handling Nested Queries A financial analytics company wanted monthly revenue trends and year-over-year growth data. The initial Text-to-SQL solution couldn’t generate the correct nested query for growth calculation. After training the LLM with examples of revenue calculations, the system could generate accurate SQL queries for monthly data and growth.
Example 2: Ambiguity in User Input A user asked, “Show me the sales data for last quarter.” The LLM initially generated a query without specifying the quarter’s exact date range. To fix this, the system was updated to ask, “Do you mean Q3 2024?” This clarified the request and improved query accuracy.
Example 3: Handling Complex Joins and Filters A marketing team asked for the total number of leads and total spend for each campaign last month. The LLM struggled to generate the SQL due to complex joins between tables like leads, campaigns, and spend. The solution was to break the query into smaller parts: first, retrieve leads, then total spend, and finally join the data.
Example 4: Handling Unclear Date Ranges A user requested, “Show me the revenue data from the last six months.” The LLM couldn’t determine if the user meant 180 days or six calendar months. The system was updated to clarify, asking, “Do you mean the last six calendar months or 180 days?” This ensured the query was accurate.
Example 5: Handling Multiple Aggregations A retail analytics team wanted to know the average sales per product category and total sales for the past quarter. The LLM initially failed to perform the aggregation correctly. After training, the system could use functions like AVG() for average sales and SUM() for total sales in a single, optimized query.
Example 6: Handling Non-Standard Input A customer service chatbot retrieved customer order history for an e-commerce company. A user typed, “Show me orders placed between March and April 2024,” but the system didn’t know how to interpret the date range. The solution was to automatically infer the start and end dates of those months, ensuring the query worked without requiring exact dates.
Example 7: Improperly Handling Null Values A user requested, “Show me all customers who haven’t made any purchases in the last year.” LLM missed customers with null purchase records. By training the system to handle null values using SQL clauses like IS NULL and LEFT JOIN, the query returned the correct results for customers with no purchases.
Future Trends in LLM-Powered Text-to-SQL Solutions
As LLMs continue to evolve, their Text-to-SQL capabilities will become even more robust. Key trends to watch include:
AI-Driven Query Optimization Future Text-to-SQL solutions will improve performance by optimizing queries, especially for large datasets. AI will learn from past queries, suggest better approaches, and increase query efficiency. This will reduce slow database operations and enhance overall performance.
Expansion of Domain-Specific LLMs Domain-specific LLMs will be customized for industries like healthcare, finance, and e-commerce. These models will understand specific terms and regulations in each sector. This will make SQL queries more accurate and relevant, cutting down on the need for manual corrections.
Natural Language Interfaces for Database Management LLM-powered solutions will allow non-technical users to manage databases using simple conversational interfaces. Users can perform complex tasks, such as schema changes or data transformations, without writing SQL. This makes data management more accessible to everyone in the organization.
Integration with Advanced Data Analytics Tools LLM-powered Text-to-SQL solutions will integrate with data analytics tools. This will help users generate SQL queries for advanced insights, predictive analysis, and visualizations. As a result, businesses will be able to make data-driven decisions without needing technical expertise.
Conclusion
Implementing AI-generated SQL solutions comes with challenges, but these can be effectively addressed with the right strategies. By focusing on schema consistency, query optimization, and user-centric design, businesses can unlock the full potential of these solutions. As technology advances, AI-generated SQL tools will become even more powerful, enabling seamless database interactions and driving data-driven decision-making.
Ready to transform your database interactions? Register for free and explore EzInsights AI Text to SQL today to make querying as simple as having a conversation.
For more related blogs visit: EzInsights AI
0 notes
Text
Idea Frontier #4: Enterprise Agentics, DaaS, Self-Improving LLMs
TL;DR — Edition #4 zeroes-in on three tectonic shifts for AI founders: Enterprise Agentics – agent frameworks such as Google’s new ADK, CrewAI and AutoGen are finally hardened for production, and AWS just shipped a reference pattern for an enterprise-grade text-to-SQL agent; add DB-Explore + Dynamic-Tool-Selection and you get a realistic playbook for querying 100-table warehouses with…
#ai#AI Agents#CaseMark#chatGPT#DaaS#DeepSeek#Enterprise AI#Everstream#generative AI#Idea Frontier#llm#LoRA#post-training LLMs#Predibase#Reinforcement learning#RLHF#text-to-SQL
0 notes
Text
Is cPanel on Its Deathbed? A Tale of Technology, Profits, and a Slow-Moving Train Wreck
Ah, cPanel. The go-to control panel for many web hosting services since the dawn of, well, web hosting. Once the epitome of innovation, it’s now akin to a grizzled war veteran, limping along with a cane and wearing an “I Survived Y2K” t-shirt. So what went wrong? Let’s dive into this slow-moving technological telenovela, rife with corporate greed, security loopholes, and a legacy that may be hanging by a thread.
Chapter 1: A Brief, Glorious History (Or How cPanel Shot to Stardom)
Once upon a time, cPanel was the bee’s knees. Launched in 1996, this software was, for a while, the pinnacle of web management systems. It promised simplicity, reliability, and functionality. Oh, the golden years!
Chapter 2: The Tech Stack Tortoise
In the fast-paced world of technology, being stagnant is synonymous with being extinct. While newer tech stacks are integrating AI, machine learning, and all sorts of jazzy things, cPanel seems to be stuck in a time warp. Why? Because the tech stack is more outdated than a pair of bell-bottom trousers. No Docker, no Kubernetes, and don’t even get me started on the lack of robust API support.
Chapter 3: “The Corpulent Corporate”
In 2018, Oakley Capital, a private equity firm, acquired cPanel. For many, this was the beginning of the end. Pricing structures were jumbled, turning into a monetisation extravaganza. It’s like turning your grandma’s humble pie shop into a mass production line for rubbery, soulless pies. They’ve squeezed every ounce of profit from it, often at the expense of the end-users and smaller hosting companies.
Chapter 4: Security—or the Lack Thereof
Ah, the elephant in the room. cPanel has had its fair share of vulnerabilities. Whether it’s SQL injection flaws, privilege escalation, or simple, plain-text passwords (yes, you heard right), cPanel often appears in the headlines for all the wrong reasons. It’s like that dodgy uncle at family reunions who always manages to spill wine on the carpet; you know he’s going to mess up, yet somehow he’s always invited.
Chapter 5: The (Dis)loyal Subjects—The Hosting Companies
Remember those hosting companies that once swore by cPanel? Well, let’s just say some of them have been seen flirting with competitors at the bar. Newer, shinier control panels are coming to market, offering modern tech stacks and, gasp, lower prices! It’s like watching cPanel’s loyal subjects slowly turn their backs, one by one.
Chapter 6: The Alternatives—Not Just a Rebellion, but a Revolution
Plesk, Webmin, DirectAdmin, oh my! New players are rising, offering updated tech stacks, more customizable APIs, and—wait for it—better security protocols. They’re the Han Solos to cPanel’s Jabba the Hutt: faster, sleeker, and without the constant drooling.
Conclusion: The Twilight Years or a Second Wind?
The debate rages on. Is cPanel merely an ageing actor waiting for its swan song, or can it adapt and evolve, perhaps surprising us all? Either way, the story of cPanel serves as a cautionary tale: adapt or die. And for heaven’s sake, update your tech stack before it becomes a relic in a technology museum, right between floppy disks and dial-up modems.
This outline only scratches the surface, but it’s a start. If cPanel wants to avoid becoming the Betamax of web management systems, it better start evolving—stat. Cheers!
#hosting#wordpress#cpanel#webdesign#servers#websites#webdeveloper#technology#tech#website#developer#digitalagency#uk#ukdeals#ukbusiness#smallbussinessowner
14 notes
·
View notes
Text
Optimizing Business Operations with Advanced Machine Learning Services
Machine learning has gained popularity in recent years thanks to the adoption of the technology. On the other hand, traditional machine learning necessitates managing data pipelines, robust server maintenance, and the creation of a model for machine learning from scratch, among other technical infrastructure management tasks. Many of these processes are automated by machine learning service which enables businesses to use a platform much more quickly.
What do you understand of Machine learning?
Deep learning and neural networks applied to data are examples of machine learning, a branch of artificial intelligence focused on data-driven learning. It begins with a dataset and gains the ability to extract relevant data from it.
Machine learning technologies facilitate computer vision, speech recognition, face identification, predictive analytics, and more. They also make regression more accurate.
For what purpose is it used?
Many use cases, such as churn avoidance and support ticket categorization make use of MLaaS. The vital thing about MLaaS is it makes it possible to delegate machine learning's laborious tasks. This implies that you won't need to install software, configure servers, maintain infrastructure, and other related tasks. All you have to do is choose the column to be predicted, connect the pertinent training data, and let the software do its magic.
Natural Language Interpretation
By examining social media postings and the tone of consumer reviews, natural language processing aids businesses in better understanding their clientele. the ml services enable them to make more informed choices about selling their goods and services, including providing automated help or highlighting superior substitutes. Machine learning can categorize incoming customer inquiries into distinct groups, enabling businesses to allocate their resources and time.
Predicting
Another use of machine learning is forecasting, which allows businesses to project future occurrences based on existing data. For example, businesses that need to estimate the costs of their goods, services, or clients might utilize MLaaS for cost modelling.
Data Investigation
Investigating variables, examining correlations between variables, and displaying associations are all part of data exploration. Businesses may generate informed suggestions and contextualize vital data using machine learning.
Data Inconsistency
Another crucial component of machine learning is anomaly detection, which finds anomalous occurrences like fraud. This technology is especially helpful for businesses that lack the means or know-how to create their own systems for identifying anomalies.
Examining And Comprehending Datasets
Machine learning provides an alternative to manual dataset searching and comprehension by converting text searches into SQL queries using algorithms trained on millions of samples. Regression analysis use to determine the correlations between variables, such as those affecting sales and customer satisfaction from various product attributes or advertising channels.
Recognition Of Images
One area of machine learning that is very useful for mobile apps, security, and healthcare is image recognition. Businesses utilize recommendation engines to promote music or goods to consumers. While some companies have used picture recognition to create lucrative mobile applications.
Your understanding of AI will drastically shift. They used to believe that AI was only beyond the financial reach of large corporations. However, thanks to services anyone may now use this technology.
2 notes
·
View notes
Text
I don't really think they're like, as useful as people say, but there are genuine usecases I feel -- just not for the massive, public facing, plagiarism machine garbage fire ones. I don't work in enterprise, I work in game dev, so this goes off of what I have been told, but -- take a company like Oracle, for instance. Massive databases, massive codebases. People I know who work there have told me that their internally trained LLM is really good at parsing plain language questions about, say, where a function is, where a bit oif data is, etc., and outputing a legible answer. Yes, search machines can do this too, but if you've worked on massive datasets -- well, conventional search methods tend to perform rather poorly.
From people I know at Microsoft, there's an internal-use version of co-pilot weighted to favor internal MS answers that still will hallucinate, but it is also really good at explaining and parsing out code that has even the slightest of documentation, and can be good at reimplementing functions, or knowing where to call them, etc. I don't necessarily think this use of LLMs is great, but it *allegedly* works and I'm inclined to trust programmers on this subject (who are largely AI critical, at least wrt chatGPT and Midjourney etc), over "tech bros" who haven't programmed in years and are just execs.
I will say one thing that is consistent, and that I have actually witnessed myself; most working on enterprise code seem to indicate that LLMs are really good at writing boilerplate code (which isn't hard per se, bu t extremely tedious), and also really good at writing SQL queries. Which, that last one is fair. No one wants to write SQL queries.
To be clear, this isn't a defense of the "genAI" fad by any means. chatGPT is unreliable at best, and straight up making shit up at worst. Midjourney is stealing art and producing nonsense. Voice labs are undermining the rights of voice actors. But, as a programmer at least, I find the idea of how LLMs work to be quite interesting. They really are very advanced versions of old text parsers like you'd see in old games like ZORK, but instead of being tied to a prewritten lexicon, they can actually "understand" concepts.
I use "understand" in heavy quotes, but rather than being hardcoded to relate words to commands, they can connect input written in plain english (or other languages, but I'm sure it might struggle with some sufficiently different from english given that CompSci, even tech produced out of the west, is very english-centric) to concepts within a dataset and then tell you about the concepts it found in a way that's easy to parse and understand. The reason LLMs got hijacked by like, chatbots and such, is because the answers are so human-readable that, if you squint and turn your head, it almost looks like a human is talking to you.
I think that is conceptually rather interesting tech! Ofc, non LLM Machine Learning algos are also super useful and interesting - which is why I fight back against the use of the term AI. genAI is a little bit more accurate, but I like calling things what they are. AI is such an umbrella that includes things like machine learning algos that have existed for decades, and while I don't think MOST people are against those, I see people who see like, a machine learning tool from before the LLM craze (or someone using a different machine learning tool) and getting pushback as if they are doing genAI. To be clear, thats the fault of the marketing around LLMs and the tech bros pushing them, not the general public -- they were poorly educated, but on purpose by said PR lies.
Now, LLMs I think are way more limited in scope than tech CEOs want you to believe. They aren't the future of public internet searches (just look at google), or art creation, or serious research by any means. But, they're pretty good at searching large datasets (as long as there's no contradictory info), writing boilerplate functions, and SQL queries.
Honestly, if all they did was SQL queries, that'd be enough for me to be interested fuck that shit. (a little hyperbolic/sarcastic on that last part to be clear).
ur future nurse is using chapgpt to glide thru school u better take care of urself
154K notes
·
View notes
Text
An Introduction to Multi-Hop Orchestration AI Agents

The journey of Artificial Intelligence has been a fascinating one. From simple chatbots providing canned responses to powerful Large Language Models (LLMs) that can generate human-quality text, AI's capabilities have soared. More recently, we've seen the emergence of AI Agents – systems that can not only understand but also act upon user requests by leveraging external tools (like search engines or APIs).
Yet, many real-world problems aren't simple, one-step affairs. They are complex, multi-faceted challenges that require strategic planning, dynamic adaptation, and the chaining of multiple actions. This is where the concept of Multi-Hop Orchestration AI Agents comes into play, representing the next frontier in building truly intelligent and autonomous AI systems.
Beyond Single Steps: The Need for Orchestration
Consider the evolution:
Traditional AI/LLMs: Think of a powerful calculator or a knowledgeable oracle. You give it an input, and it gives you an output. It’s reactive and often single-turn.
Basic AI Agents (e.g., simple RAG): These agents can perform an action based on your request, like searching a database (Retrieval Augmented Generation) and generating an answer. They are good at integrating external information but often follow a pre-defined, linear process.
The gap lies in tackling complex, dynamic workflows. How does an AI plan a multi-stage project? How does it decide which tools to use in what order? What happens if a step fails, and it needs to adapt its plan? These scenarios demand an orchestrating intelligence.
What is Multi-Hop Orchestration AI?
At its heart, a Multi-Hop Orchestration AI Agent is an AI system designed to break down a high-level, complex goal into a series of smaller, interconnected sub-goals or "hops." It then dynamically plans, executes, monitors, and manages these individual steps to achieve the overarching objective.
Imagine the AI as a highly intelligent project manager or a symphony conductor. You give the conductor the score (your complex goal), and instead of playing one note, they:
Decompose the score into individual movements and sections.
Assign each section to the right instrument or group of musicians (tools or sub-agents).
Conduct the performance, ensuring each part is played at the right time and in harmony.
Listen for any errors and guide the orchestra to self-correct.
Integrate all the parts into a seamless, final masterpiece.
That's Multi-Hop Orchestration in action.
How Multi-Hop Orchestration AI Agents Work: The Conductor's Workflow
The process within a Multi-Hop Orchestration Agent typically involves an iterative loop, often driven by an advanced LLM serving as the "orchestrator" or "reasoning engine":
Goal Interpretation & Decomposition:
The agent receives a complex, open-ended user request (e.g., "Research sustainable supply chain options for our new product line, draft a proposal outlining costs and benefits, and prepare a presentation for the board.").
The orchestrator interprets this high-level goal and dynamically breaks it down into logical, manageable sub-tasks or "hops" (e.g., "Identify key sustainability metrics," "Research eco-friendly suppliers," "Analyze cost implications," "Draft proposal sections," "Create presentation slides").
Dynamic Planning & Tool/Sub-Agent Selection:
For each sub-task, the orchestrator doesn't just retrieve information; it reasons about the best way to achieve that step.
It selects the most appropriate tools from its available arsenal (e.g., a web search tool for market trends, a SQL query tool for internal inventory data, an API for external logistics providers, a code interpreter for complex calculations).
In advanced setups, it might even delegate entire sub-tasks to specialized sub-agents (e.g., a "finance agent" to handle cost analysis, a "design agent" for slide creation).
Execution & Monitoring:
The orchestrator executes the chosen tools or activates the delegated sub-agents.
It actively monitors their progress, ensuring they are running as expected and generating valid outputs.
Information Integration & Iteration:
As outputs from different steps or agents come in, the orchestrator integrates this information, looking for connections, contradictions, or gaps in its knowledge.
It then enters a self-reflection phase: "Is this sub-goal complete?" "Do I have enough information for the next step?" "Did this step fail, or did it produce unexpected results?"
Based on this evaluation, it can decide to:
Proceed to the next planned hop.
Re-plan a current hop if it failed or yielded unsatisfactory results.
Create new hops to address unforeseen issues or gain missing information.
Seek clarification from the human user if truly stuck.
Final Outcome Delivery:
Once all hops are completed and the overall goal is achieved, the orchestrator synthesizes the results and presents the comprehensive final outcome to the user.
Why Multi-Hop Orchestration Matters: Game-Changing Use Cases
Multi-Hop Orchestration AI Agents are particularly transformative for scenarios demanding deep understanding, complex coordination, and dynamic adaptation:
Complex Enterprise Automation: Automating multi-stage business processes like comprehensive customer onboarding (spanning CRM, billing, support, and sales systems), procurement workflows, or large-scale project management.
Deep Research & Data Synthesis: Imagine an AI autonomously researching a market, querying internal sales databases, fetching real-time news via APIs, and then synthesizing all information into a polished, insightful report ready for presentation.
Intelligent Customer Journeys: Guiding customers through complex service requests that involve diagnostic questions, looking up extensive order histories, interacting with different backend systems (e.g., supply chain, billing), and even initiating multi-step resolutions like refunds or complex technical support.
Autonomous Software Development & DevOps: Agents that can not only generate code but also test it, identify bugs, suggest fixes, integrate with version control, and orchestrate deployment to various environments.
Personalized Learning & Mentoring: Creating dynamic educational paths that adapt to a student's progress, strengths, and weaknesses across different subjects, retrieving varied learning materials and generating customized exercises on the fly.
The Road Ahead: Challenges and the Promise
Building Multi-Hop Orchestration Agents is incredibly complex. Challenges include:
Robust Orchestration Logic: Designing the AI's internal reasoning and planning capabilities to be consistently reliable across diverse and unpredictable scenarios.
Error Handling & Recovery: Ensuring agents can gracefully handle unexpected failures from tools or sub-agents and recover effectively.
Latency & Cost: Multi-step processes involve numerous LLM calls and tool executions, which can introduce latency and increase computational costs.
Transparency & Debugging: The "black box" nature of LLMs makes it challenging to trace and debug long, multi-hop execution paths when things go wrong.
Safety & Alignment: Ensuring that autonomous, multi-step agents always remain aligned with human intent and ethical guidelines, especially as they undertake complex sequences of actions.
Despite these challenges, frameworks like LangChain, LlamaIndex, Microsoft's AutoGen, and CrewAI are rapidly maturing, providing the architectural foundations for developers to build these sophisticated systems.
Multi-Hop Orchestration AI Agents represent a significant leap beyond reactive AI. They are the conductors of the AI orchestra, transforming LLMs from clever responders into proactive problem-solvers capable of navigating the intricacies of the real world. This is a crucial step towards truly autonomous and intelligent systems, poised to unlock new frontiers for AI's impact across every sector.
1 note
·
View note
Text
Unlock Your Future with the Best Data Scientist Course in Pune

In today’s digital-first era, data is the new oil. From tech giants to startups, businesses rely heavily on data-driven decisions. This has skyrocketed the demand for skilled professionals who can make sense of large volumes of data. If you’re in Pune and aspiring to become a data scientist, the good news is – your opportunity starts here. GoDigi Infotech offers a top-notch Data Scientist Course in Pune tailored to shape your future in one of the most lucrative tech domains.
Why Data Science is the Career of the Future
Data Science combines the power of statistics, programming, and domain knowledge to extract insights from structured and unstructured data. The emergence of machine learning, artificial intelligence, and big data has amplified its importance.
Companies across sectors like finance, healthcare, retail, e-commerce, and manufacturing are hiring data scientists to boost efficiency and predict future trends. Choosing a comprehensive Data Scientist Course in Pune from a reputed institute like GoDigi Infotech can be your launchpad to a successful career.
Why Choose Pune for a Data Science Course?
Pune has emerged as a major IT and educational hub in India. With leading tech companies, research institutions, and a thriving startup ecosystem, Pune provides the perfect environment to study and practice data science. Enrolling in a Data Scientist Course in Pune not only gives you access to expert faculty but also opens doors to internships, projects, and job placements in renowned organizations.
Key Highlights of the Data Scientist Course in Pune by GoDigi Infotech
Here’s what makes GoDigi Infotech stand out from the rest:
1. Industry-Centric Curriculum
The course is curated by experienced data scientists and industry experts. It includes in-demand tools and topics such as Python, R, SQL, Machine Learning, Deep Learning, Power BI, Tableau, Natural Language Processing (NLP), and more.
2. Hands-on Projects
Practical knowledge is key in data science. You’ll work on real-world projects including sales forecasting, customer segmentation, fraud detection, and more – enhancing your portfolio.
3. Experienced Trainers
The course is delivered by certified professionals with years of experience in data science, AI, and analytics. They guide students from basics to advanced topics with a hands-on approach.
4. Placement Support
With strong corporate ties and an in-house career cell, GoDigi Infotech provides resume building, mock interviews, and placement assistance. Their Data Scientist Course in Pune ensures you're not just trained, but job-ready.
5. Flexible Learning Options
Whether you're a working professional, a fresher, or someone switching careers, GoDigi Infotech offers flexible batches – including weekends and online options.
Who Should Enroll in the Data Scientist Course in Pune?
This course is suitable for:
Fresh graduates (BE, BSc, BCA, MCA, etc.)
Working professionals from IT, finance, marketing, or engineering domains
Entrepreneurs and business analysts looking to upgrade their data knowledge
Anyone with a passion for data, numbers, and problem-solving
What Will You Learn in the Data Scientist Course?
1. Programming Skills
Python for data analysis
R for statistical computing
SQL for data manipulation
2. Statistical and Mathematical Foundations
Probability
Linear algebra
Hypothesis testing
3. Data Handling and Visualization
Pandas, Numpy
Data cleaning and wrangling
Data visualization using Matplotlib, Seaborn, and Tableau
4. Machine Learning Algorithms
Supervised and unsupervised learning
Regression, classification, clustering
Decision trees, SVM, k-means
5. Advanced Topics
Deep Learning (Neural Networks, CNN, RNN)
Natural Language Processing (Text analytics)
Big Data tools (Hadoop, Spark – optional)
Benefits of a Data Scientist Course in Pune from GoDigi Infotech
Get trained under mentors who have worked with Fortune 500 companies.
Join a growing community of data science enthusiasts and alumni.
Build a strong project portfolio that can impress employers.
Opportunity to work on live industry projects during the course.
Certification recognized by top employers.
How the Course Boosts Your Career
���️ High-Paying Job Roles You Can Target:
Data Scientist
Machine Learning Engineer
Data Analyst
Business Intelligence Developer
AI Specialist
✔️ Industries Hiring Data Scientists:
IT & Software
Healthcare
E-commerce
Banking & Finance
Logistics and Supply Chain
Telecommunications
Completing the Data Scientist Course in Pune puts you on a fast-track career path in the tech industry, with salaries ranging between ₹6 LPA to ₹25 LPA depending on experience and skills.
Student Testimonials
"GoDigi Infotech’s Data Science course changed my life. From a fresher to a full-time Data Analyst at a fintech company in just 6 months – the mentorship was incredible!" – Rohit J., Pune
"The best part is the practical exposure. The projects we did were based on real datasets and actual business problems. I landed my first job thanks to this course." – Sneha M., Pune
Frequently Asked Questions (FAQs)
Q. Is prior coding experience required for this course? No, basic programming will be taught from scratch. Prior experience is helpful but not mandatory.
Q. Do you provide certification? Yes, upon course completion, you’ll receive an industry-recognized certificate from GoDigi Infotech.
Q. What is the duration of the course? Typically 3 to 6 months, depending on the batch type (fast-track/regular).
Q. Are there any EMI options available? Yes, EMI and easy payment plans are available for all learners.
Conclusion
A career in data science promises growth, innovation, and financial rewards. Choosing the right learning partner is the first step toward success. GoDigi Infotech’s Data Scientist Course in Pune equips you with the knowledge, skills, and hands-on experience to thrive in this data-driven world. Whether you're a beginner or looking to switch careers, this course can be your stepping stone toward becoming a successful data scientist.
0 notes
Text
How TigerEye is redefining AI-powered business intelligence
New Post has been published on https://thedigitalinsider.com/how-tigereye-is-redefining-ai-powered-business-intelligence/
How TigerEye is redefining AI-powered business intelligence

At the Generative AI Summit in Silicon Valley, Ralph Gootee, Co-founder of TigerEye, joined Tim Mitchell, Business Line Lead, Technology at the AI Accelerator Institute, to discuss how AI is transforming business intelligence for go-to-market teams.
In this interview, Ralph shares lessons learned from building two companies and explores how TigerEye is rethinking business intelligence from the ground up with AI, helping organizations unlock reliable, actionable insights without wasting resources on bespoke analytics.
Tim Mitchell: Ralph, it’s a pleasure to have you here. We’re on day two of the Generative AI Summit, part of AI Silicon Valley. You’re a huge part of the industry in Silicon Valley, so it’s amazing to have you join us. TigerEye is here as part of the event. Maybe for folks that aren’t familiar with the brand, you can just give a quick rundown of who you are and what you’re doing.
Ralph: I’m the co-founder of TigerEye – my second company. It’s exciting to be solving some of the problems we had with our first company, PlanGrid, in this one. We sold PlanGrid to Autodesk. I had a really good time building it. But when you’re building a company, you end up having many internal metrics to track, and a lot of things that happen with sales. So, we built a data team.
With TigerEye, we’re using AI to help build that data team for other companies, so they can learn from our past mistakes. We’re helping them build business intelligence that’s meant for go-to-market, so sales, marketing, and finance all together in one package.
Lessons learned from PlanGrid
Tim: What were some of those mistakes that you’re now helping others avoid?
Ralph: The biggest one was using highly skilled resources to build internal analytics, time that could’ve gone into building customer-facing features. We had talented data engineers figuring out sales metrics instead of enhancing our product. That’s a key learning we bring to TigerEye.
What makes TigerEye unique
Tim: If I can describe TigerEye in short as an AI analyst for business intelligence, what’s unique about TigerEye in that space?
Ralph: One of the things that’s unique is we were built from the ground up for AI. Where a lot of other companies are trying to tack on or figure out how they’re going to work with AI, TigerEye was built in generative AI as a world. Rather than relying on text or trying to gather up metrics that could cause hallucination, we actually write SQL from the bottom up. Our platform is built on SQL, so we can give answers that show your math. You can see why the win rate is that, and it will decrease over time.
Why Generative AI Summit matters
Tim: And what’s interesting about this conference for you?
Ralph: The conference brings together both big companies and startups. It’s really nice to have conversations with companies that have more mature data issues, versus startups that are just figuring out how their sales motions work.
The challenges of roadmapping in AI
Tim: You’re the co-founder, but as CTO, in what kind of capacity does the roadmapping cause you headaches? What does that process look like for a solution like this?
Ralph: In the AI world, roadmapping is challenging because it keeps getting so much better so quickly. The only thing you know for sure is you’re going to have a new model drop that really moves things forward. Thankfully for us, we solve what we see as the hardest part of AI, giving 100% accurate answers. We still haven’t seen foundational models do that on their own, but they get much better at writing code.
So the way we’ve taught to write SQL, and how we work with foundational models, both go into the roadmap. Another part is what foundational models we support. Right now, we work with OpenAI, Gemini, and Anthropic. Every time there’s a new model drop, we evaluate it and think about whether we want to bring that in.
Evaluating and choosing models
Tim: How do you choose which model to use?
Ralph: There are two major things. One, we have a full evaluation framework. Since we specialize in sales questions, we’ve seen thousands of sales questions, and we know what the answer should be and how to write the code for them. We run new models through that and see how they look.
The other is speed. Latency really matters; people want instant responses. Sometimes, even within the same vendor, the speed will vary model by model, but that latency is important.
The future of AI-powered business intelligence
Tim: What’s next for you guys? Any AI-powered revelations we can expect?
Ralph: We think AI is going to be solved first in business intelligence in deep vertical sections. It’s hard to imagine AI solving a Shopify company’s challenge and also a supply chain challenge for an enterprise. We’re going deep into verticals to see what new features AI has to understand.
For example, in sales, territory management is a big challenge: splitting up accounts, segmenting business. We’re teaching AI how to optimize territory distribution and have those conversations with our customers. That’s where a lot of our roadmap is right now.
Who’s adopting AI business intelligence?
Tim: With these new products, who are you seeing the biggest wins with?
Ralph: Startups and mid-market have a good risk tolerance for AI products. Enterprises, we can have deep conversations, but it’s a slower process. They’re forming their strategic AI teams but not getting deep into it yet. Startups and mid-market, especially AI companies themselves, are going full-bore.
Tim: And what are the risks or doubts that enterprises might have?
Ralph: Most enterprises have multiple AI teams, and they don’t even know it. It happened out of nowhere. Then they realize they need an AI visionary to lead those teams. The AI visionary is figuring out their job, and the enterprise is going through that process.
The best enterprises focus on delivering more value to their customers with fewer resources. We’re seeing that trend – how do I get my margins up and lower my costs?
Final thoughts
As AI continues to reshape business intelligence, it’s clear that success will come to those who focus on practical, reliable solutions that serve real go-to-market needs.
TigerEye’s approach, combining AI’s power with transparent, verifiable analytics, offers a glimpse into the future of business intelligence: one where teams spend less time wrestling with data and more time acting on insights.
As the technology evolves, the companies that go deep into vertical challenges and stay laser-focused on customer value will be the ones leading the charge.
#Accounts#ai#ai summit#AI-powered#AI-powered business#amazing#Analytics#anthropic#approach#Articles#Artificial Intelligence#Building#Business#Business Intelligence#challenge#code#Companies#conference#CTO#data#engineers#enterprise#Enterprises#evaluation#event#Features#finance#focus#framework#Full
0 notes
Text
The Future of Database Management with Text to SQL AI

Database management transforms from Text to SQL AI, allowing businesses to interact with data through simple language rather than complex code. Studies reveal that 65% of business users need data insights without SQL expertise, and text-to-SQL AI fulfills this need by translating everyday language into accurate database queries. For example, users can type “Show last month’s revenue,” and instantly retrieve the relevant data.
As the demand for accessible data grows, text-to-SQL converter AI and generative AI are becoming essential, with the AI-driven database market expected to reach $6.8 billion by 2025. These tools reduce data retrieval times by up to 40%, making data access faster and more efficient for businesses, and driving faster, smarter decision-making.
Understanding Text to SQL AI
Text to SQL AI is an innovative approach that bridges the gap between human language and database querying. It enables users to pose questions or commands in plain English, which the AI then translates into Structured Query Language (SQL) queries. This technology significantly reduces the barriers to accessing data, allowing those without technical backgrounds to interact seamlessly with databases. For example, a user can input a simple request like, “List all customers who purchased in the last month,” and the AI will generate the appropriate SQL code to extract that information.
The Need for Text-to-SQL
As data grows, companies need easier ways to access insights without everyone having to know SQL. Text-to-SQL solves this problem by letting people ask questions in plain language and get accurate data results. This technology makes it simpler for anyone in a company to find the information they need, helping teams make decisions faster.
Text-to-SQL is also about giving more power to all team members. It reduces the need for data experts to handle basic queries, allowing them to focus on bigger projects. This easy data access encourages everyone to use data in their work, helping the company make smarter, quicker decisions.
Impact of Text to SQL Converter AI
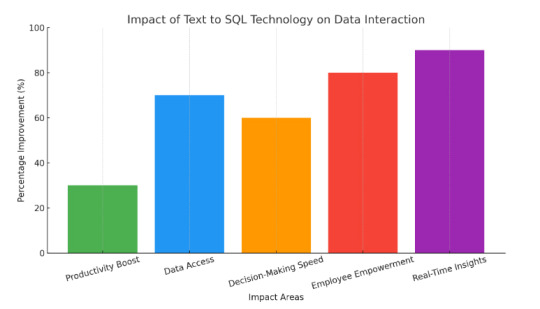
The impact of Text-to-SQL converter AI is significant across various sectors, enhancing how users interact with databases and making data access more intuitive. Here are some key impacts:
Simplified Data Access: By allowing users to query databases using natural language, Text-to-SQL AI bridges the gap between non-technical users and complex SQL commands, democratizing data access.
Increased Efficiency: It reduces the time and effort required to write SQL queries, enabling users to retrieve information quickly and focus on analysis rather than syntax.
Error Reduction: Automated translation of text to SQL helps minimize human errors in query formulation, leading to more accurate data retrieval.
Enhanced Decision-Making: With easier access to data insights, organizations can make informed decisions faster, improving overall agility and responsiveness to market changes.
Broader Adoption of Data Analytics: Non-technical users, such as business analysts and marketers, can leverage data analytics tools without needing deep SQL knowledge, fostering a data-driven culture.
The Future of Data Interaction with Text to SQL
The future of data interaction is bright with Text to SQL technology, enabling users to ask questions in plain language and receive instant insights. For example, Walmart utilizes this technology to allow employees at all levels to access inventory data quickly, improving decision-making efficiency. Research shows that organizations adopting such solutions can boost productivity by up to 30%. By simplifying complex data queries, Text to SQL empowers non-technical users, fostering a data-driven culture. As businesses generate more data, this technology will be vital for real-time access and analysis, enabling companies to stay competitive and agile in a fast-paced market.
Benefits of Generative AI
Here are some benefits of generative AI that can significantly impact efficiency and innovation across various industries.
Automated Code Generation In software development, generative AI can assist programmers by generating code snippets based on natural language descriptions. This accelerates the coding process, reduces errors, and enhances overall development efficiency.
Improved Decision-Making Generative AI can analyze vast amounts of data and generate insights, helping businesses make informed decisions quickly. This capability enhances strategic planning and supports better outcomes in various operational areas.
Enhanced User Experience By providing instant responses and generating relevant content, generative AI improves user experience on platforms. This leads to higher customer satisfaction and fosters loyalty to brands and services.
Data Augmentation Generative AI can create synthetic data to enhance training datasets for machine learning models. This capability improves model performance and accuracy, especially when real data is limited or difficult to obtain.
Cost Reduction By automating content creation and data analysis, generative AI reduces operational costs for businesses. This cost-effectiveness makes it an attractive solution for organizations looking to maximize their resources.
Rapid Prototyping Organizations can quickly create prototypes and simulations using generative AI, streamlining product development. This speed allows for efficient testing of ideas, ensuring better outcomes before launching to the market.
Challenges in Database Management
Before Text-to-SQL, data analysts faced numerous challenges in database management, from complex SQL querying to dependency on technical teams for data access.
SQL Expertise Requirement Analysts must know SQL to retrieve data accurately. For those without deep SQL knowledge, this limits efficiency and can lead to errors in query writing.
Time-Consuming Querying Writing and testing complex SQL queries can be time intensive. This slows down data retrieval, impacting the speed of analysis and decision-making.
Dependency on Database Teams Analysts often rely on IT or database teams to access complex data sets, causing bottlenecks and delays, especially when teams are stretched thin.
Higher Risk of Errors Manual SQL query writing can lead to errors, such as incorrect joins or filters. These errors affect data accuracy and lead to misleading insights.
Limited Data Access for Non-Experts Without SQL knowledge, non-technical users can’t access data on their own, restricting valuable insights to those with specialized skills.
Difficulty Handling Large Datasets Complex SQL queries on large datasets require significant resources, slowing down systems and making analysis challenging for real-time insights.
Learning Curve for New Users For new analysts or team members, learning SQL adds a steep learning curve, slowing down onboarding and data access.
Challenges with Ad-Hoc Queries Creating ad-hoc queries for specific data questions can be tedious, especially when quick answers are needed, which makes real-time analysis difficult.
Real-World Applications of Text to SQL AI
Let’s explore the real-world applications of AI-driven natural language processing in transforming how businesses interact with their data.
Customer Support Optimization Companies use Text to SQL AI to analyze customer queries quickly. Organizations report a 30% reduction in response times, enhancing customer satisfaction and loyalty.
Sales Analytics Sales teams utilize Text to SQL AI for real-time data retrieval, leading to a 25% increase in revenue through faster decision-making and improved sales strategies based on accurate data insights.
Supply Chain Optimization Companies use AI to analyze supply chain data in real-time, improving logistics decision-making. This leads to a 25% reduction in delays and costs, enhancing overall operational efficiency.
Retail Customer Behaviour Analysis Retailers use automated data retrieval to study customer purchasing patterns, gaining insights that drive personalized marketing. This strategy boosts customer engagement by 25% and increases sales conversions.
Real Estate Market Evaluation Real estate professionals access property data and market trends with ease, allowing for informed pricing strategies. This capability enhances property sales efficiency by 35%, leading to quicker transactions.
Conclusion
In summary, generative AI brings many benefits, from boosting creativity to making everyday tasks easier. With tools like Text to SQL AI, businesses can work smarter, save time, and make better decisions. Ready to see the difference it can make for you? Sign up for a free trial with EzInsights AI and experience powerful, easy-to-use data tools!
For more related blogs visit: EzInsights AI
0 notes
Text
How Artificial Intelligence Courses in London Are Preparing Students for AI-Powered Careers?
Artificial Intelligence (AI) has become a cornerstone of technological innovation, revolutionizing industries from healthcare and finance to transportation and marketing. With AI-driven automation, analytics, and decision-making reshaping the global job market, there is a growing need for professionals who are not only tech-savvy but also trained in cutting-edge AI technologies. London, as a global tech and education hub, is rising to meet this demand by offering world-class education in AI. If you're considering an Artificial Intelligence course in London, you’ll be stepping into a well-rounded program that blends theoretical foundations with real-world applications, preparing you for AI-powered careers.
Why Choose London for an Artificial Intelligence Course?
London is home to some of the top universities, research institutions, and tech startups in the world. The city offers access to:
Globally renowned faculty and researchers
A diverse pool of tech companies and AI startups
Regular AI meetups, hackathons, and industry events
Proximity to innovation hubs like Cambridge and Oxford
Strong networking and career opportunities across the UK and Europe
An Artificial Intelligence course in London not only provides robust academic training but also places you in the center of the AI job ecosystem.
Core Components of an AI Course in London
Artificial Intelligence programs in London are designed to produce industry-ready professionals. Whether you're enrolling in a university-led master's program or a short-term professional certificate, here are some core components covered in most AI courses:
1. Foundational Knowledge
Courses start with fundamental concepts such as:
Algorithms and Data Structures
Linear Algebra, Probability, and Statistics
Introduction to Machine Learning
Basics of Python Programming
These are essential for understanding how AI models are built, optimized, and deployed.
2. Machine Learning and Deep Learning
Students dive deep into supervised and unsupervised learning techniques, along with:
Neural Networks
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs)
Transfer Learning
Generative Adversarial Networks (GANs)
These modules are crucial for domains like image recognition, natural language processing, and robotics.
3. Natural Language Processing (NLP)
With the rise of chatbots, language models, and voice assistants, NLP has become a vital skill. London-based AI courses teach:
Tokenization and Word Embeddings
Named Entity Recognition (NER)
Text Classification
Sentiment Analysis
Transformer Models (BERT, GPT)
4. Data Handling and Big Data Tools
Students learn to preprocess, clean, and manage large datasets using:
Pandas and NumPy
SQL and NoSQL databases
Apache Spark and Hadoop
Data visualization libraries like Matplotlib and Seaborn
These tools are indispensable in any AI role.
5. Real-World Projects
Perhaps the most defining element of an Artificial Intelligence course in London is hands-on project work. Examples include:
AI-powered financial fraud detection
Predictive analytics in healthcare
Facial recognition for surveillance systems
Customer behavior prediction using recommendation systems
These projects simulate real-world scenarios, providing students with a portfolio to showcase to employers.
Tools & Technologies Students Master
London AI programs focus on practical skills using tools such as:
Programming Languages: Python, R
Libraries & Frameworks: TensorFlow, Keras, PyTorch, Scikit-learn
Cloud Platforms: AWS AI/ML, Google Cloud AI, Microsoft Azure
Deployment Tools: Docker, Flask, FastAPI, Kubernetes
Version Control: Git and GitHub
Familiarity with these tools enables students to contribute immediately in professional AI environments.
Industry Integration and Career Readiness
What sets an Artificial Intelligence course in London apart is its strong integration with the industry. Many institutes have partnerships with companies for:
1. Internships and Work Placements
Students gain hands-on experience through internships with companies in finance, healthcare, logistics, and more. This direct exposure bridges the gap between education and employment.
2. Industry Mentorship
Many programs invite AI experts from companies like Google, DeepMind, Meta, and fintech startups to mentor students, evaluate projects, or deliver guest lectures.
3. Career Services and Networking
Institutes offer:
Resume workshops
Mock interviews
Career fairs and employer meetups
Job placement assistance
These services help students transition smoothly into the workforce after graduation.
Solving Real-World AI Challenges
Students in AI courses in London aren’t just learning — they’re solving actual challenges. Some examples include:
1. AI in Climate Change
Projects focus on analyzing weather patterns and environmental data to support sustainability efforts.
2. AI in Healthcare
Students build models to assist with medical image analysis, drug discovery, or early disease diagnosis.
3. Ethics and Fairness in AI
With growing concern about algorithmic bias, students are trained to design fair, explainable, and responsible AI systems.
4. Autonomous Systems
Courses often include modules on reinforcement learning and robotics, exploring how AI can control autonomous drones or vehicles.
Popular Specializations Offered
Many AI courses in London offer the flexibility to specialize in areas such as:
Computer Vision
Speech and Language Technologies
AI in Business and Finance
AI for Cybersecurity
AI in Healthcare and Biotech
These concentrations help students align their training with career goals and industry demand.
AI Career Paths After Completing a Course in London
Graduates from AI programs in London are in high demand across sectors. Typical roles include:
AI Engineer
Machine Learning Developer
Data Scientist
NLP Engineer
Computer Vision Specialist
MLOps Engineer
AI Product Manager
With London being a European startup capital and home to major tech firms, job opportunities are plentiful across industries like fintech, healthcare, logistics, retail, and media.
Final Thoughts
In a world increasingly shaped by intelligent systems, pursuing an Artificial Intelligence course in London is a smart investment in your future. With a mix of academic rigor, hands-on practice, and industry integration, these courses are designed to equip you with the knowledge and skills needed to thrive in AI-powered careers.
Whether your ambition is to become a machine learning expert, data scientist, or AI entrepreneur, London offers the ecosystem, exposure, and education to turn your vision into reality. From mastering neural networks to tackling ethical dilemmas in AI, you’ll graduate ready to lead innovation and make a meaningful impact.
#Best Data Science Courses in London#Artificial Intelligence Course in London#Data Scientist Course in London#Machine Learning Course in London
0 notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Link
This post evaluates the key options for querying data using generative AI, discusses their strengths and limitations, and demonstrates why Text-to-SQL is the best choice for deterministic, schema-specific tasks. We show how to effectively use Text-t #AI #ML #Automation
0 notes
Text
Is ChatGPT Easy to Use? Here’s What You Need to Know
Introduction: A Curious Beginning I still remember the first time I stumbled upon ChatGPT my heart raced at the thought of talking to an AI. I was a fresh-faced IT enthusiast, eager to explore how a “gpt chat” interface could transform my workflow. Yet, as excited as I was, I also felt a tinge of apprehension: Would I need to learn a new programming language? Would I have to navigate countless settings? Spoiler alert: Not at all. In this article, I’m going to walk you through my journey and show you why ChatGPT is as straightforward as chatting with a friend. By the end, you’ll know exactly “how to use ChatGPT” in your day-to-day IT endeavors whether you’re exploring the “chatgpt app” on your phone or logging into “ChatGPT online” from your laptop.
What Is ChatGPT, Anyway?
If you’ve heard of “chat openai,” “chat gbt ai,” or “chatgpt openai,” you already know that OpenAI built this tool to mimic human-like conversation. ChatGPT sometimes written as “Chat gpt”—is an AI-powered chatbot that understands natural language and responds with surprisingly coherent answers. With each new release remember buzz around “chatgpt 4”? OpenAI has refined its approach, making the bot smarter at understanding context, coding queries, creative brainstorming, and more.
GPT Chat: A shorthand term some people use, but it really means the same as ChatGPT just another way to search or tag the service.
ChatGPT Online vs. App: Although many refer to “chatgpt online,” you can also download the “chatgpt app” on iOS or Android for on-the-go access.
Free vs. Paid: There’s even a “chatgpt gratis” option for users who want to try without commitment, while premium plans unlock advanced features.
Getting Started: Signing Up for ChatGPT Online
1. Creating Your Account
First things first head over to the ChatGPT website. You’ll see a prompt to sign up or log in. If you’re wondering about “chat gpt free,” you’re in luck: OpenAI offers a free tier that anyone can access (though it has usage limits). Here’s how I did it:
Enter your email (or use Google/Microsoft single sign-on).
Verify your email with the link they send usually within seconds.
Log in, and voila, you’re in!
No complex setup, no plugin installations just a quick email verification and you’re ready to talk to your new AI buddy. Once you’re “ChatGPT online,” you’ll land on a simple chat window: type a question, press Enter, and watch GPT 4 respond.
Navigating the ChatGPT App
While “ChatGPT online” is perfect for desktop browsing, I quickly discovered the “chatgpt app” on my phone. Here’s what stood out:
Intuitive Interface: A text box at the bottom, a menu for adjusting settings, and conversation history links on the side.
Voice Input: On some versions, you can tap the microphone icon—no need to type every query.
Seamless Sync: Whatever you do on mobile shows up in your chat history on desktop.
For example, one night I was troubleshooting a server config while waiting for a train. Instead of squinting at the station’s Wi-Fi, I opened the “chat gpt free” app on my phone, asked how to tweak a Dockerfile, and got a working snippet in seconds. That moment convinced me: whether you’re using “chatgpt online” or the “chatgpt app,” the learning curve is minimal.
Key Features of ChatGPT 4
You might have seen “chatgpt 4” trending this iteration boasts numerous improvements over earlier versions. Here’s why it feels so effortless to use:
Better Context Understanding: Unlike older “gpt chat” bots, ChatGPT 4 remembers what you asked earlier in the same session. If you say, “Explain SQL joins,” and then ask, “How does that apply to Postgres?”, it knows you’re still talking about joins.
Multi-Turn Conversations: Complex troubleshooting often requires back-and-forth questions. I once spent 20 minutes configuring a Kubernetes cluster entirely through a multi-turn conversation.
Code Snippet Generation: Want Ruby on Rails boilerplate or a Python function? ChatGPT 4 can generate working code that requires only minor tweaks. Even if you make a mistake, simply pasting your error output back into the chat usually gets you an explanation.
These features mean that even non-developers say, a project manager looking to automate simple Excel tasks can learn “how to use ChatGPT” with just a few chats. And if you’re curious about “chat gbt ai” in data analytics, hop on and ask ChatGPT can translate your plain-English requests into practical scripts.
Tips for First-Time Users
I’ve coached colleagues on “how to use ChatGPT” in the last year, and these small tips always come in handy:
Be Specific: Instead of “Write a Python script,” try “Write a Python 3.9 script that reads a CSV file and prints row sums.” The more detail, the more precise the answer.
Ask Follow-Up Questions: Stuck on part of the response? Simply type, “Can you explain line 3 in more detail?” This keeps the flow natural—just like talking to a friend.
Use System Prompts: At the very start, you can say, “You are an IT mentor. Explain in beginner terms.” That “meta” instruction shapes the tone of every response.
Save Your Favorite Replies: If you stumble on a gem—say, a shell command sequence—star it or copy it to a personal notes file so you can reference it later.
When a coworker asked me how to connect a React frontend to a Flask API, I typed exactly that into the chat. Within seconds, I had boilerplate code, NPM install commands, and even a short security note: “Don’t forget to add CORS headers.” That level of assistance took just three minutes, demonstrating why “gpt chat” can feel like having a personal assistant.
Common Challenges and How to Overcome Them
No tool is perfect, and ChatGPT is no exception. Here are a few hiccups you might face and how to fix them:
Occasional Inaccuracies: Sometimes, ChatGPT can confidently state something that’s outdated or just plain wrong. My trick? Cross-check any critical output. If it’s a code snippet, run it; if it’s a conceptual explanation, ask follow-up questions like, “Is this still true for Python 3.11?”
Token Limits: On the “chatgpt gratis” tier, you might hit usage caps or get slower response times. If you encounter this, try simplifying your prompt or wait a few minutes for your quota to reset. If you need more, consider upgrading to a paid plan.
Overly Verbose Answers: ChatGPT sometimes loves to explain every little detail. If that happens, just say, “Can you give me a concise version?” and it will trim down its response.
Over time, you learn how to phrase questions so that ChatGPT delivers exactly what you need quickly—no fluff, just the essentials. Think of it as learning the “secret handshake” to get premium insights from your digital buddy.
Comparing Free and Premium Options
If you search “chat gpt free” or “chatgpt gratis,” you’ll see that OpenAI’s free plan offers basic access to ChatGPT 3.5. It’s great for light users students looking for homework help, writers brainstorming ideas, or aspiring IT pros tinkering with small scripts. Here’s a quick breakdown: FeatureFree Tier (ChatGPT 3.5)Paid Tier (ChatGPT 4)Response SpeedStandardFaster (priority access)Daily Usage LimitsLowerHigherAccess to Latest ModelChatGPT 3.5ChatGPT 4 (and beyond)Advanced Features (e.g., Code)LimitedFull accessChat History StorageShorter retentionLonger session memory
For someone just dipping toes into “chat openai,” the free tier is perfect. But if you’re an IT professional juggling multiple tasks and you want the speed and accuracy of “chatgpt 4” the upgrade is usually worth it. I switched to a paid plan within two weeks of experimenting because my productivity jumped tenfold.
Real-World Use Cases for IT Careers
As an IT blogger, I’ve seen ChatGPT bridge gaps in various IT roles. Here are some examples that might resonate with you:
Software Development: Generating boilerplate code, debugging error messages, or even explaining complex algorithms in simple terms. When I first learned Docker, ChatGPT walked me through building an image, step by step.
System Administration: Writing shell scripts, explaining how to configure servers, or outlining best security practices. One colleague used ChatGPT to set up an Nginx reverse proxy without fumbling through documentation.
Data Analysis: Crafting SQL queries, parsing data using Python pandas, or suggesting visualization libraries. I once asked, “How to use chatgpt for data cleaning?” and got a concise pandas script that saved hours of work.
Project Management: Drafting Jira tickets, summarizing technical requirements, or even generating risk-assessment templates. If you ever struggled to translate technical jargon into plain English for stakeholders, ChatGPT can be your translator.
In every scenario, I’ve found that the real magic isn’t just the AI’s knowledge, but how quickly it can prototype solutions. Instead of spending hours googling or sifting through Stack Overflow, you can ask a direct question and get an actionable answer in seconds.
Security and Privacy Considerations
Of course, when dealing with AI, it’s wise to think about security. Here’s what you need to know:
Data Retention: OpenAI may retain conversation data to improve their models. Don’t paste sensitive tokens, passwords, or proprietary code you can’t risk sharing.
Internal Policies: If you work for a company with strict data guidelines, check whether sending internal data to a third-party service complies with your policy.
Public Availability: Remember that anyone else could ask ChatGPT similar questions. If you need unique, private solutions, consult official documentation or consider an on-premises AI solution.
I routinely use ChatGPT for brainstorming and general code snippets, but for production credentials or internal proprietary logic, I keep those aspects offline. That balance lets me benefit from “chatgpt openai” guidance without compromising security.
Is ChatGPT Right for You?
At this point, you might be wondering, “Okay, but is it really easy enough for me?” Here’s my honest take:
Beginners who have never written a line of code can still ask ChatGPT to explain basic IT concepts no jargon needed.
Intermediate users can leverage the “chatgpt app” on mobile to troubleshoot on the go, turning commute time into learning time.
Advanced professionals will appreciate how ChatGPT 4 handles multi-step instructions and complex code logic.
If you’re seriously exploring a career in IT, learning “how to use ChatGPT” is almost like learning to use Google in 2005: essential. Sure, there’s a short learning curve to phrasing your prompts for maximum efficiency, but once you get the hang of it, it becomes second nature just like typing “ls -la” into a terminal.
Conclusion: Your Next Steps
So, is ChatGPT easy to use? Absolutely. Between the intuitive “chatgpt app,” the streamlined “chatgpt online” interface, and the powerful capabilities of “chatgpt 4,” most users find themselves up and running within minutes. If you haven’t already, head over to the ChatGPT website and create your free account. Experiment with a few prompts maybe ask it to explain “how to use chatgpt” and see how it fits into your daily routine.
Remember:
Start simple. Ask basic questions, then gradually dive deeper.
Don’t be afraid to iterate. If an answer isn’t quite right, refine your prompt.
Keep security in mind. Never share passwords or sensitive data.
Whether you’re writing your first “gpt chat” script, drafting project documentation, or just curious how “chat gbt ai” can spice up your presentations, ChatGPT is here to help. Give it a try, and in no time, you’ll wonder how you ever managed without your AI sidekick.
1 note
·
View note
Text
Agentic RAG: How It Works, Use Cases, Comparison With RAG

Large Language Models (LLMs) have revolutionized how we interact with information, offering unprecedented capabilities in understanding and generating human-like text. Yet, even the most powerful LLMs have inherent limitations: their knowledge is static (limited to their last training cut-off), and they are prone to "hallucinations" – confidently presenting incorrect information.
Enter Retrieval-Augmented Generation (RAG). RAG addresses these issues by grounding LLMs in external, up-to-date knowledge bases. But what happens when you need your AI to do more than just search and summarize? What if you need it to reason, plan, use multiple tools, and even self-correct to answer truly complex questions? This is where Agentic RAG steps in, representing the next evolution in intelligent AI systems.
A Quick Recap: The Power of Traditional RAG
Before we dive into the "agentic" twist, let's briefly recall how traditional RAG works:
User Query: You ask a question.
Retrieval: The RAG system searches a vast knowledge base (often a vector database of documents) to find relevant chunks of information.
Augmentation: These retrieved documents are then fed as context to the LLM alongside your original query.
Generation: The LLM uses this real-time context to generate a more accurate, grounded, and up-to-date answer, minimizing hallucinations.
Benefits of Traditional RAG: Reduced hallucinations, access to current information, and answers grounded in verifiable sources. It's excellent for FAQs, summarizing documents, or answering direct questions from a defined knowledge base.
Limitations: Traditional RAG is a relatively linear process. It's reactive, simply retrieving based on the initial query. It struggles with multi-step reasoning, complex questions requiring data from multiple types of sources (not just documents), or situations where it needs to dynamically adapt its search strategy. It can't actively use other tools beyond its core retrieval mechanism.
Introducing Agentic RAG: Your AI's Intelligent Research Assistant
Imagine, instead of just a librarian who fetches books, you had a highly skilled research assistant. This assistant not only knows where to find information but also understands your project's nuances, can formulate complex search strategies, cross-reference multiple sources, use various databases, perform calculations, and even refine their approach based on interim findings. This is the essence of Agentic RAG.
Agentic RAG combines the strengths of RAG with the capabilities of autonomous AI agents. The "agentic" part means the AI system can reason, plan, select and use external tools, and iterate to achieve a complex goal. It's not just retrieving information; it's strategizing its information retrieval and processing.
How Agentic RAG Works: The "Agentic Loop" in Action
The core of Agentic RAG lies in an intelligent AI agent (often powered by another LLM or specialized AI components) that orchestrates the entire process:
Goal Understanding & Planning:
The agent receives a complex user query (e.g., "Analyze Q2 sales data for product X across all regions, compare it to last year, and suggest potential reasons for any significant deviations based on customer feedback and market news.").
It breaks this down into smaller, actionable sub-goals (e.g., "Retrieve Q2 sales data for product X (current year)", "Retrieve Q2 sales data for product X (previous year)", "Analyze deviations", "Retrieve customer feedback on product X", "Search market news for product X").
Tool Selection & Execution:
For each sub-goal, the agent intelligently decides which "tools" from its arsenal to use. This is where Agentic RAG truly shines over traditional RAG. Tools can include:
Vector Database Search: For unstructured documents (e.g., customer feedback transcripts, internal reports).
SQL/NoSQL Database Query Engine: To retrieve structured sales data from a database.
API Calls: To fetch real-time market data, news articles from specific sources, or even interact with an internal CRM/ERP system.
Code Interpreter: To perform complex calculations, statistical analysis, or data transformations on retrieved data.
Web Scraper: To extract specific information from public websites if needed.
Other Agents: In multi-agent setups (like CrewAI or AutoGen), one agent might delegate a sub-task to another specialized agent.
Information Synthesis & Refinement:
As the agent executes tools, it processes the incoming results. It synthesizes information from disparate sources, looking for connections, discrepancies, and new insights.
This step often involves self-reflection: the agent might realize the initial data isn't sufficient, or that its understanding of a sub-goal needs refinement.
Iteration & Self-Correction:
Based on its synthesis and reflection, the agent can loop back to step 1 or 2. It might reformulate a query, select a different tool, dig deeper into a specific data point, or even re-plan its entire approach until it believes the main goal is adequately addressed. This iterative problem-solving is key to handling complexity.
Final Response Generation:
Once satisfied with the gathered and processed information, the agent compiles everything into a comprehensive, accurate, and well-grounded response for the user, often citing its sources and explaining its reasoning process.
Where Agentic RAG Shines: Transformative Use Cases
Agentic RAG is particularly powerful for enterprise applications where queries are complex, data resides in multiple systems, and dynamic decision-making is required:
Intelligent Enterprise Search & Knowledge Management: Go beyond simple document search. Ask an Agentic RAG system, "What's the best practice for deploying a new microservice in our Azure environment, considering our recent security audits and the latest architectural guidelines?" The agent could query internal wikis, code repositories, security reports, and even external best practices to provide a holistic answer.
Automated Research & Report Generation: Instead of manually compiling data for a market analysis report, an Agentic RAG agent can autonomously pull data from news feeds, financial databases, social media, and internal sales figures, then synthesize it into a coherent, cited report, saving hundreds of hours.
Proactive Customer Support & Service: Imagine a customer service bot that can not only access FAQs but also check a customer's order history, troubleshoot device logs, initiate a return process via an API, and even escalate complex issues to the right human department with all relevant context pre-populated.
Personalized Business Intelligence & Analytics: Business leaders can ask natural language questions like, "Show me product sales performance for the last quarter broken down by customer segment, identify any regions with declining growth, and propose marketing adjustments based on competitor activity in those areas." The agent could query databases, run statistical models, and pull market intelligence.
Automated Compliance & Risk Management: In regulated industries, Agentic RAG can continuously monitor evolving regulations (from external sources), compare them against internal policies and transactions (from internal databases), and flag potential compliance risks in real-time.
Agentic RAG vs. Traditional RAG: A Comparative View

The Future is Intelligent and Active
Agentic RAG is a crucial step towards truly intelligent and autonomous AI systems. It transforms LLMs from passive information providers into active problem-solvers that can navigate the complexities of real-world data and tasks. Frameworks like LangChain, LlamaIndex, Microsoft's AutoGen, and CrewAI are rapidly maturing, making it easier for developers to build these sophisticated agentic systems.
While challenges remain – including increased operational complexity, latency in multi-step processes, and ensuring reliable tool execution – the benefits of enhanced accuracy, deeper insights, and significant automation for complex enterprise workflows are undeniable. Agentic RAG is not just an incremental improvement; it's a fundamental shift in how we leverage AI to interact with, understand, and act upon the vast oceans of information. The era of the AI research assistant is truly here.
0 notes
Text
Identify elements of a search solution
A search index contains your searchable content. In an Azure AI Search solution, you create a search index by moving data through the following indexing pipeline:
Start with a data source: the storage location of your original data artifacts, such as PDFs, video files, and images. For Azure AI Search, your data source could be files in Azure Storage, or text in a database such as Azure SQL Database or Azure Cosmos DB.
Indexer: automates the movement data from the data source through document cracking and enrichment to indexing. An indexer automates a portion of data ingestion and exports the original file type to JSON (in an action called JSON serialization).
Document cracking: the indexer opens files and extracts content.
Enrichment: the indexer moves data through AI enrichment, which implements Azure AI on your original data to extract more information. AI enrichment is achieved by adding and combining skills in a skillset. A skillset defines the operations that extract and enrich data to make it searchable. These AI skills can be either built-in skills, such as text translation or Optical Character Recognition (OCR), or custom skills that you provide. Examples of AI enrichment include adding captions to a photo and evaluating text sentiment. AI enriched content can be sent to a knowledge store, which persists output from an AI enrichment pipeline in tables and blobs in Azure Storage for independent analysis or downstream processing.
Push to index: the serialized JSON data populates the search index.
The result is a populated search index which can be explored through queries. When users make a search query such as "coffee", the search engine looks for that information in the search index. A search index has a structure similar to a table, known as the index schema. A typical search index schema contains fields, the field's data type (such as string), and field attributes. The fields store searchable text, and the field attributes allow for actions such as filtering and sorting.
0 notes
Text
Mistral OCR 25.05, Mistral AI Le Chat Enterprise on Google

Google Cloud offers Mistral AI’s Le Chat Enterprise and OCR 25.05 models.
Google Cloud provides consumers with an open and adaptable AI environment to generate customised solutions. As part of this commitment, Google Cloud has upgraded AI solutions with Mistral AI.
Google Cloud has two Mistral AI products:
Google Cloud Marketplace’s Le Chat Enterprise
Vertex AI Mistral OCR 25.05
Google Cloud Marketplace Mistral AI Le Chat Enterprise
Le Chat Enterprise is a feature-rich generative AI work assistant. Available on Google Cloud Marketplace. Its main purpose is to boost productivity by integrating technologies and data.
Le Chat Enterprise offers many functions on one platform, including:
Custom data and tool integrations (Google Drive, Sharepoint, OneDrive, Google Calendar, and Gmail initially, with more to follow, including templates)
Enterprise search
Agents build
Users can create private document libraries to reference, extract, and analyse common documents from Drive, Sharepoint, and uploads.
Personalised models
Implementations hybrid
Further MCP support for corporate system connectivity; Auto Summary for fast file viewing and consumption; secure data, tool connections, and libraries
Mistral AI’s Medium 3 model powers Le Chat Enterprise. AI productivity on a single, flexible, and private platform is its goal. Flexible deployment choices like self-hosted, in your public or private cloud, or as a Mistral cloud service let you choose the optimal infrastructure without being locked in. Data is protected by privacy-first data connections and strict ACL adherence.
The stack is fully configurable, from models and platforms to interfaces. Customisation includes bespoke connectors with company data, platform/model features like user feedback loops for model self-improvement, and assistants with stored memories. Along with thorough audit logging and storage, it provides full security control. Mistral’s AI scientists and engineers help deliver value and improve solutioning.
Example Le Chat Enterprise use cases:
Agent creation: Users can develop and implement context-aware, no-code agents.
Accelerating research and analysis: Summarises large reports, extracts key information from documents, and conducts brief web searches.
Producing actionable insights: It can automate financial report production, produce text-to-SQL queries for financial research, and turn complex data into actionable insights for finance.
Accelerates software development: Code generation, review, technical documentation, debugging, and optimisation.
Canvas improves content production by letting marketers interact on visuals, campaign analysis, and writing.
For scalability and security, organisations can use Le Chat Enterprise on the Google Cloud Marketplace. It integrates to Google Cloud services like BigQuery and Cloud SQL and facilitates procurement.
Contact Mistral AI sales and visit the Le Chat Enterprise Google Cloud Marketplace page to use Mistral’s Le Chat Enterprise. The Mistral AI announcement has further details. Le Chat (chat.mistral.ai) and their mobile apps allow free trial use.
OCR 25.05 model llm Mistral
One new OCR API is Mistral OCR 25.05. Vertex AI Model Garden has it. This model excels at document comprehension. It raises the bar in this discipline and can cognitively interpret text, media, charts, tables, graphs, and equations in content-rich papers. From PDFs and photos, it retrieves organised interleaved text and visuals.
Cost of Mistral OCR?
With a Retrieval Augmented Generation (RAG) system that takes multimodal documents, Mistral OCR is considered the ideal model. Additionally, millions of Le Chat users use Mistral OCR as their default document interpretation model. Mistral’s Platform developer suite offers the Mistral-ocr-latest API, which will soon be offered on-premises and to cloud and inference partners. The API costs 1000 pages/$ (double with batch inference).
Highlights of Mistral OCR include:
Cutting-edge comprehension of complex papers, including mathematical formulas, tables, interleaved images, and LaTeX formatting, helps readers understand rich content like scientific articles.
This system is multilingual and multimodal, parsing, understanding, and transcribing thousands of scripts, fonts, and languages. This is crucial for global and hyperlocal businesses.
Excellent benchmarks: This model consistently outperforms top OCR models in rigorous benchmark tests. Compared to Google Document AI, Azure OCR, Gemini models, and GPT-4o, Mistral OCR 2503 scores highest in Overall, Math, Multilingual, Scanned, and Tables accuracy. It also has the highest Fuzzy Match in Generation and multilingual scores compared to Azure OCR, Google Doc AI, and Gemini-2.0-Flash-001. It extracts embedded images and text, unlike other LLMs in the benchmark.
The lightest and fastest in its class, processing 2000 pages per minute on a single node.
Structured output called “doc-as-prompt” uses documents as prompts for powerful, clear instructions. This allows data to be extracted and formatted into structured outputs like JSON, which may be linked into function calls to develop agents.
Organisations with high data protection needs for classified or sensitive information might self-host within their own infrastructure.
Example of Mistral OCR 25.05
Use cases for Mistral OCR 25.05 include:
Digitising scientific research: Making articles and journals AI-ready for downstream intelligence engines streamlines scientific procedures.
Preservation and accessibility can be achieved by digitising historical records and artefacts.
Simplifying customer support: indexing manuals and documentation to improve satisfaction and response times.
AI literature preparation in various fields: We help businesses convert technical literature, engineering drawings, lecture notes, presentations, regulatory filings, and more into indexed, answer-ready formats to gain insights and enhance productivity across vast document volumes.
Integrating Mistral OCR 25.05 as a MaaS on Vertex AI creates a full AI platform. It provides enterprise-grade security and compliance for confident growth and fully controlled infrastructure. The Vertex AI Model Garden includes over 200 foundation models, including Mistral OCR 25.05, so customers can choose the best one for their needs. Vertex AI now offers Mistral OCR 25.05, along with Anthropic models Claude Opus 4 and Claude Sonnet 4.
To develop using Mistral OCR 25.05 on Vertex AI, users must go to the model card in the Model Garden, click “Enable,” and follow the instructions. Platform users can access the API, and Le Chat users can try Mistral OCR for free.
#MistralOCR#LeChatEnterprise#MistralOCR2505#MistralAILeChatEnterprise#MistralOCRmodel#Mistralocr2505modelllm#technology#technews#news#technologynews#govindhtech
1 note
·
View note