#test to image api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Backend Support
Something new for you tonight, True Believers: a story set in @subliminalbo's Literary Universe! Featuring an image manipulation graciously provided by the man himself!
This story references characters from the Obedience by Fleur series. While not required, the main stories are suggested reading.
Thanks to my friend @subliminalbo (also at @subliminalboarchive) for the collabo.

Bailey's Huawai flagship, customized with added security and privacy features, rang and buzzed on her workbench. Her brow furrowed, temporarily wrinkling her flawless golden skin. "Support," Bailey muttered with caution as she answered. Very weird. If someone's calling this number… something is wrong.
"Uh," a timid male voice stuttered in response, followed by a long pause. "Um, I think I fucked up."
Bailey closed her eyes, sighing. "Go on."
"Well, I…," the man continued, but his cadence suggested he was distracted. "Hey, um, honey, don't touch that," he interjected, before refocusing his attention on Bailey. "I think she's broken. I broke her."
"You. Broke. Her," Bailey repeated slowly, each word more incredulous than the last. "And how… how did you break her, sir?"
Bailey thought she heard the man swallow hard through the tinny speakerphone. "OK. Well. I know that she has some, um, default abilities."
"Yes. Her menu. This was explained when you requested her services."
Loud noises. The sound of glass breaking. "Shit," the man said in irritation. "that was a gift!" He continued, talking faster, Bailey could practically hear him sweating. "Well, I wanted to know if she had, like, a secret menu. So I asked her, and she said no, but that there was…"
"An API," Bailey muttered. Fuck. She tilted her head back, eyes closed, and sighed again. She would have to work on hardening that endpoint. The last thing she needed was incel dipshits like Johnny Mnemonic here fucking with the product. She was a damn good engineer, but you don't exactly get to beta test mind control technology before you put it into production.
She should know. She was not only the president, she was also a client.
"What did you do, sir? Exactly?" Bailey's words were polite, but her tone dripped with frustration. Condescension also, but she really wasn't concerned about the customer's feelings right now.
Another pause, then an admission. "Well, she started telling me about her API, and I'm not a programmer, so I asked ChatLLM. And it gave me some things to try. Baby, take that out of your mouth."
"You fucking vibe coded her. You vibe coded a sex drone escort, running assembly code firmware, with some commands you got from a consumer AI. She's a human being, not a kit you bought at Radio Shack." Bailey could barely contain her rising anger. She mentally adjusted her hormone levels. Her pupils faded completely into solid white spheres. This wasn't the time to lose her cool.
There was hemming and hawing, then finally a guilty, "yes."
Bailey spoke again, the edge out of her voice as the fury subsided and her pupils returned. "Well, seeing as this would violate the terms and conditions of your agreement, if there were such a thing, I'm here to tell you: you break it, you buy it. Five mil ought to cover it. Have a good one."
"Five mil…five million dollars?!" the man exclaimed. Bailey could hear his voice quivering. "I don't have that kind of money! I work retail!"
"I'm sorry," Bailey said. And to her credit, she did pity this man. She knew enough to know his death would not be quick or painless. Triads don't fuck around. "The people I work with, they don't…" She chose her words carefully for effect. "take damaged merchandise lightly."
Bailey could her muffled crying on the other end. More broken glass, but no admonishment. Just sobs. She didn't like this. Didn't like the choices on the table. Having to calculate the least shitty outcome. Compromising her morality - her humanity - one crossed line after another.
But who was she kidding? Compromising your morality was The Romero Way.
"I don't want your dumbass blood on my hands. I'll make you a deal. Give me someone to replace her."
"I don't…what do you mean?"
"A wife, a sister, a cousin. Someone hot, or at least cute. Fixable. Someone local. A name, and an address, and you get to celebrate another birthday."
She could practically hear the man bargaining with himself. "I couldn't. I won't."
Bailey's voice was firm and callous. "No skin off my ass. Hope your will is in order." Give me a name, she pleaded internally. Take the goddamn offer.
"OK. I'll text it over." Very quietly, Bailey exhaled in relief. Her phone buzzed with a notification. She glanced at the address, and forwarded it to her liaison with some notes about tonight.
"You made the right choice. A team is on their way for extraction. For her, and for you."
"For me?"
"You know too much. Also, we have room in our inventory for all genders and sexual identities." In Romero, there are only perverts, and people who aren't perverts yet, Bailey ruminated.
When the man finally spoke, his voice was quiet, and his tone resigned. "Will she be okay? Will she be happy?"
Bailey hesitated. She thought of her mother, Rosa, her eyes glassy, wearing a low-cut red dress and her black choker, leaving a young child alone on a Saturday night. Baby, Mamá's got to go somewhere. Be a good girl and take care of yourself, okay?
She wanted to cynically deliver the uncaring truth. No, she wouldn't be okay. Ultimately, her happiness wasn't important, was it? It sure as hell hadn't been for Rosa, or for young Bailey. If you weren't part of Romero's circle of elites, you were just collateral damage.
But she didn't say that.
"Yes," Bailey lied, her voice soft and comforting. "She will." And she ended the call.
Bailey sat at her workbench for a long time, alone. Only the trees rustling outside the window permeated the silence. It could have been worse, she tried to tell herself. A lot worse. She saved a man from his own stupidity tonight.
When did she get so soft?
Ed King and Elena Maxwell had ruined her career before it got started, and they were going to pay. She only needed to set her emotions aside, and finish the job.
So why was she disgusted with herself?
These questions lacked simple answers. Tonight, isolated in her empty house, questions were the only company Bailey had.
#mind control#mind corruption#hypno fantasy#hypno story#tech control#reprogramming#brainwashing kink#hypnok1nk#hypno drone#humor#vibe coding#subliminalbo#ottopilot-wrote-this#cw: mind control#cw: corruption#cw: hypnosis#cw prostitution
15 notes
·
View notes
Text
Sugary Scribbles | #8
Saturday 6th January 2024
IT'S BASICALLY WORKING (on larger screens)! My never-ending war on website responsiveness continues! I have a large screen and I stupidly only took into account of MY screen size. What I did do though is created a message for phone-table sizes because it just wouldn't make sense it working on really small devices - in my opinion~! But for now I will put this on hold because I am excited about my other project idea I came up with yesterday oops~!
This is my first project of the year and it's super adorable in my opinion! It paints, it erases, it deletes and it saves your artwork! Ticks all the boxes I made at the beginning of the project! Turned a simple 'Make a HTML painting webpage' into something more cuter and cool! Job well done! 😩🙌🏾💗
You can try it out (if you have a larger screen size), all that happens is the painting will be off the mouse direction a bit, sorry!
link to the Sugary-Scribbles web app! 🍡

Lastly, here is a cool drawing I made as I was testing the site~! I'm a better artist than this I swear, just not good using a mouse...

List of resources I used during the project
Figma - to plan the webpage
Canva: to make the header
Photopea: for further photo editing
RedKetchup: to colour pick quickly
CSS Animations: to add the zoom-in-n-out animation
MDN Canvas: to know what the element does properly
YouTube Tutorial: to get inspiration and extra help
Flaticon: for the icons and cursors
Html2canvas API: to turn the drawing into an image (tutorial)
That's all, have a nice day/night and happy coding! 🖤
#xc: project logs#sugary scribbles project#codeblr#coding#programming#progblr#studying#studyblr#dev logs#comp sci#computer science#programmer#devlogs#html css#javascript#tech#cute#adorable
104 notes
·
View notes
Text
For years, hashing technology has made it possible for platforms to automatically detect known child sexual abuse materials (CSAM) to stop kids from being retraumatized online. However, rapidly detecting new or unknown CSAM remained a bigger challenge for platforms as new victims continued to be victimized. Now, AI may be ready to change that.
Today, a prominent child safety organization, Thorn, in partnership with a leading cloud-based AI solutions provider, Hive, announced the release of an API expanding access to an AI model designed to flag unknown CSAM. It's the earliest use of AI technology striving to expose unreported CSAM at scale.
An expansion of Thorn's CSAM detection tool, Safer, the AI feature uses "advanced machine learning (ML) classification models" to "detect new or previously unreported CSAM," generating a "risk score to make human decisions easier and faster."
The model was trained in part using data from the National Center for Missing and Exploited Children (NCMEC) CyberTipline, relying on real CSAM data to detect patterns in harmful images and videos. Once suspected CSAM is flagged, a human reviewer remains in the loop to ensure oversight. It could potentially be used to probe suspected CSAM rings proliferating online.
It could also, of course, make mistakes, but Kevin Guo, Hive's CEO, told Ars that extensive testing was conducted to reduce false positives or negatives substantially. While he wouldn't share stats, he said that platforms would not be interested in a tool where "99 out of a hundred things the tool is flagging aren't correct."
9 notes
·
View notes
Text
Unlock creative insights with AI instantly
What if the next big business idea wasn’t something you “thought of”… but something you unlocked with the right prompt? Introducing Deep Prompt Generator Pro — the tool designed to help creators, solopreneurs, and future founders discover high-impact business ideas with the help of AI.
💡 The business idea behind this very video? Generated using the app. If you’re serious about building something real with ChatGPT or Claude, this is the tool you need to stop wasting time and start creating real results.
📥 Download the App: ✅ Lite Version (Free) → https://bit.ly/DeepPromptGeneratorLite 🔓 Pro Version (Full Access) → https://www.paypal.com/ncp/payment/DH9Z9LENSPPDS
🧠 What Is It? Deep Prompt Generator Pro is a lightweight desktop app built to generate structured, strategic prompts that help you:
✅ Discover profitable niches ✅ Brainstorm startup & side hustle ideas ✅ Find monetization models for content or products ✅ Develop brand hooks, angles, and offers ✅ Unlock creative insights with AI instantly
Whether you’re building a business, launching a new product, or looking for your first real side hustle — this app gives your AI the clarity to deliver brilliant results.
🔐 Features: Works completely offline No API or browser extensions needed Clean UI with categorized prompts One-click copy to paste into ChatGPT or Claude System-locked premium access for security
🧰 Who It’s For: Founders & solopreneurs Content creators Side hustlers AI power users Business coaches & marketers Anyone who’s tired of “mid” AI output
📘 PDF Guide Included – Every download includes a user-friendly PDF guide to walk you through features, categories, and how to get the best results from your prompts.
📂 Pro Version includes exclusive prompt packs + priority access to new releases.
🔥 Watch This If You’re Searching For: how to use ChatGPT for business ideas best prompts for startup founders AI tools for entrepreneurs side hustle generators GPT business prompt generator AI idea generator desktop app ChatGPT for content creators
📣 Final Call to Action: If this tool gave me a business idea worth filming a whole video about, imagine what it could help you discover. Stop guessing — start prompting smarter.
🔔 Subscribe to The App Vault for weekly tools, apps, and automation hacks that deliver real results — fast.🔓 Unlock Your PC's Full Potential with The App Vault Tiny Tools, Massive Results for Productivity Warriors, Creators & Power Users
Welcome to The App Vault – your ultimate source for lightweight desktop applications that deliver enterprise-grade results without bloatware or subscriptions. We specialize in uncovering hidden gem software that transforms how creators, freelancers, students, and tech enthusiasts work. Discover nano-sized utilities with macro impact that optimize workflows, turbocharge productivity, and unlock creative potential.
🚀 Why Our Community Grows Daily: ✅ Zero Fluff, Pure Value: 100% practical tutorials with actionable takeaways ✅ Exclusive Tools: Get first access to our custom-built apps like Deep Prompt Generator Pro ✅ Underground Gems: Software you won't find on mainstream tech channels ✅ Performance-First: Every tool tested for system efficiency and stability ✅ Free Resources: Download links + config files in every description
🧰 CORE CONTENT LIBRARY: ⚙️ PC Optimization Arsenal Windows optimization secrets for buttery-smooth performance System cleanup utilities that actually remove 100% of junk files Memory/RAM optimizers for resource-heavy workflows Startup managers to slash boot times by up to 70% Driver update automation tools no more manual hunting Real-time performance monitoring dashboards
🤖 AI Power Tools Local AI utilities that work offline for sensitive data Prompt engineering masterclass series Custom AI workflow automations Desktop ChatGPT implementations Niche AI tools for creators: image upscalers, script generators, audio enhancers AI-powered file organization systems
⏱️ Productivity Boosters Single-click task automators Focus enhancers with distraction-killing modes Micro-utilities for batch file processing Smart clipboard managers with OCR capabilities Automated backup solutions with versioning Time-tracking dashboards with productivity analytics
🎨 Creative Workflow Unlockers Content creation accelerators for YouTubers Automated thumbnail generators Lightweight video/audio editors 50MB Resource-efficient design tools Cross-platform project synchronizers Metadata batch editors for digital assets
🔍 Niche Tool Categories Open-source alternatives to expensive software Security tools for privacy-conscious users Hardware diagnostic toolkits Custom scripting utilities for power users Legacy system revival tools
youtube
#DeepPromptGenerator#BusinessIdeas#ChatGPTPrompts#SideHustleIdeas#StartupIdeas#TheAppVault#PromptEngineering#AIProductivity#SolopreneurTools#TinyToolsBigImpact#DesktopApp#ChatGPTTools#FiverrApps#Youtube
2 notes
·
View notes
Text
The Ultimate Guide to Online Media Tools: Convert, Compress, and Create with Ease
In the fast-paced digital era, online tools have revolutionized the way we handle multimedia content. From converting videos to compressing large files, and even designing elements for your website, there's a tool available for every task. Whether you're a content creator, a developer, or a business owner, having the right tools at your fingertips is essential for efficiency and creativity. In this blog, we’ll explore the most powerful online tools like Video to Audio Converter Online, Video Compressor Online Free, Postman Online Tool, Eazystudio, and Favicon Generator Online—each playing a unique role in optimizing your digital workflow.
Video to Audio Converter Online – Extract Sound in Seconds
Ever wanted just the audio from a video? Maybe you’re looking to pull music, dialogue, or sound effects for a project. That’s where a Video to Audio Converter Online comes in handy. These tools let you convert video files (MP4, AVI, MOV, etc.) into MP3 or WAV audio files in just a few clicks. No software installation required.
Using a Video to Audio Converter Online is ideal for:
Podcast creators pulling sound from interviews.
Music producers isolating tracks for remixing.
Students or professionals transcribing lectures or meetings.
The beauty lies in its simplicity—upload the video, choose your audio format, and download. It’s as straightforward as that
2. Video Compressor Online Free – Reduce File Size Without Losing Quality
Large video files are a hassle to share or upload. Whether you're sending via email, uploading to a website, or storing in the cloud, a bulky file can be a roadblock. This is where a Video Compressor Online Free service shines.
Key benefits of using a Video Compressor Online Free:
Shrink video size while maintaining quality.
Fast, browser-based compression with no downloads.
Compatible with all major formats (MP4, AVI, MKV, etc.).
If you're managing social media content, YouTube uploads, or email campaigns, compressing videos ensures faster load times and better performance—essential for keeping your audience engaged.
3. Postman Online Tool – Streamline Your API Development
Developers around the world swear by Postman, and the Postman Online Tool brings that power to the cloud. This tool is essential for testing APIs, monitoring responses, and managing endpoints efficiently—all without leaving your browser.
Features of Postman Online Tool include:
Send GET, POST, PUT, DELETE requests with real-time response visualization.
Organize your API collections for collaborative development.
Automate testing and environment management.
Whether you're debugging or building a new application,Postman Online Tool provides a robust platform that simplifies complex API workflows, making it a must-have in every developer's toolkit.
4. Eazystudio – Your Creative Powerhouse
When it comes to content creation and design, Eazystudio is a versatile solution for both beginners and professionals. From editing videos and photos to crafting promotional content, Eazystudio makes it incredibly easy to create high-quality digital assets.
Highlights of Eazystudio:
User-friendly interface for designing graphics, videos, and presentations.
Pre-built templates for social media, websites, and advertising.
Cloud-based platform with drag-and-drop functionality.
Eazystudio is perfect for marketers, influencers, and businesses looking to stand out online. You don't need a background in graphic design—just an idea and a few clicks.
5. Favicon Generator Online – Make Your Website Look Professional
A small icon can make a big difference. The Favicon Generator Online helps you create favicons—the tiny icons that appear next to your site title in a browser tab. They enhance your website’s branding and improve user recognition.
With a Favicon Generator Online, you can:
Convert images (JPG, PNG, SVG) into favicon.ico files.
Generate multiple favicon sizes for different platforms and devices.
Instantly preview how your favicon will look in a browser tab or bookmark list.
For web developers and designers, using a Favicon Generator Online is an easy yet impactful way to polish a website and improve brand presence.
Why These Tools Matter in 2025
The future is online. As remote work, digital content creation, and cloud computing continue to rise, browser-based tools will become even more essential. Whether it's a Video to Audio Converter Online that simplifies sound editing, a Video Compressor Online Freefor seamless sharing, or a robust Postman Online Tool for development, these platforms boost productivity while cutting down on time and costs.
Meanwhile, platforms like Eazystudio empower anyone to become a designer, and tools like Favicon Generator Online ensure your brand always makes a professional first impression.
Conclusion
The right tools can elevate your workflow, save you time, and improve the quality of your digital output. Whether you're managing videos, developing APIs, or enhancing your website’s design, tools like Video to Audio Converter Online, Video Compressor Online Free, Postman Online Tool, Eazystudio, and Favicon Generator Online are indispensable allies in your digital toolbox.
So why wait? Start exploring these tools today and take your digital productivity to the next level
2 notes
·
View notes
Text
Attention Noticeably Beta 1.8 fans: I have a monumental piece of historic significance news.

This is not about something new that's coming out, but a discovery I made recently about old stuff in my development files. I found old screenshots I forgot I had that were made very early on while first developing the mod. That is what this post will be about.
That screenshot up there is the first screenshot I took in-game of this entire thing, in December 15th 2022, and that was taken a few hours less than exactly two years ago. It's currently NBODE's 2nd birthday.
This all just happened to coincidentally come together for me recently, when I was looking for things to post, just four days before the two-year anniversary, which I didn't even realize at the time was very quickly approaching. I was scouring my old build and screenshot folders more than usual, from back when I had to "reset" the mod folder to fix infrastructural issues in 2023 - which I did TWICE - and found out that I had more screenshots than I was dimly aware of.
When this happened, I knew that in a few days, it would be time to celebrate.
So here, two years after Noticeably Beta 1.8 officially started, let's look at some pieces of its very early development history in notes and images.
↑ This screenshot was created on the same day as the previous one, but further grass images in this post are from two days later, and then two plus five days later, and so on.

It was extremely primitive at the end of 2022, and I hadn't changed the healing system or the title in the top left corner yet. But one of the first things I ever did was work to fix Beta 1.7's terrible model for tall grass. My efforts temporarily made the grass white.

These images have - I think - never been shared on this microblog before this. I was so early into development and so paranoid about idea theft that I stayed private and/or cryptic for a while, and didn't make so much as a cryptic post with unexplained screenshots of the mod until April. It got only one note. This is that post.
So, I continued to mess around with the game's models. This struggle was still all in 2022.


On January 2nd the next year, I had even more trouble. Somehow I was randomly gaining tall grass items that could be placed down again, but would then not be the same thing as the grass that was already there. I still don't understand that one.

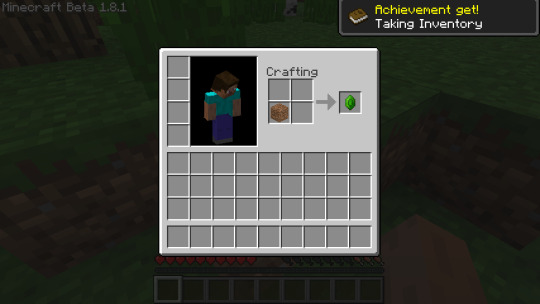
Jumping to the 23rd of January 2023, I discovered the API feature I wanted from ModLoader.AddOverride().
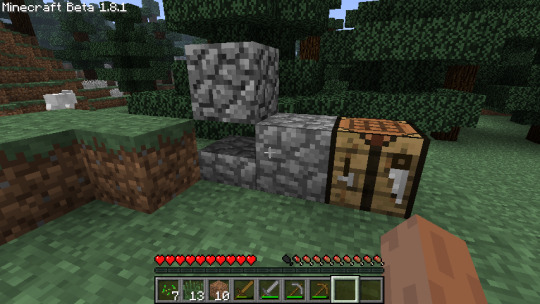
This proved to me that I could change textures of existing blocks with code in the mod as I wanted, and that I could properly enforce the difference between existing cobblestone and my new block called concrete. Scroll up to the picture with the crafting table again and you'll see what I mean. I was so happy to find this piece of functionality (especially while knowing that web searches and old forum posts just REFUSED to say anything about how to do it) I posted this outdated meme in my development channel.

Also for some reason while modding new blocks in, you have to set pickaxe speed effectiveness on them quite manually. Even after setting the material to "stone", you have to actually tell the code that pickaxes should actually do something efficiently do it. I had no idea why it was happening at first. This pic came shortly after my first confused pickaxe speed test. ↓

There's plenty more to see from this turbulent period of modding upheaval and history, and we don't have all day, so I'm going to post a blitz of seemingly random images with random gaps (in chronological order) with little or no description.

The first time I crafted soilstone.
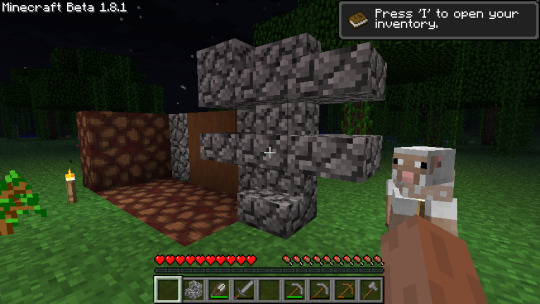
A mess of early soilstone and cobblestone blocks.
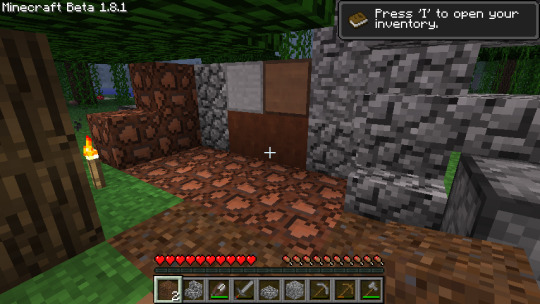





I don't remember doing this. Evidently it was an item functionality test.

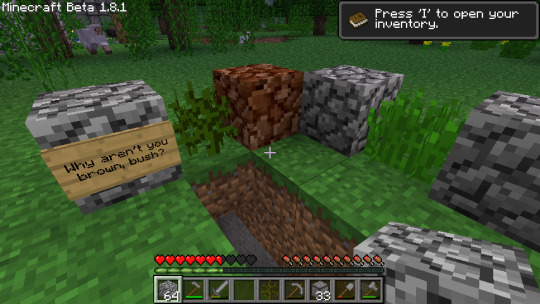
Early emerald ore generation, from back before I ensured that it didn't suck.
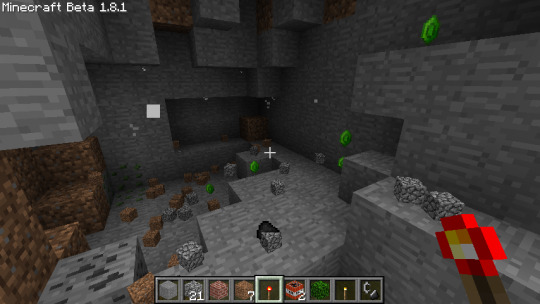
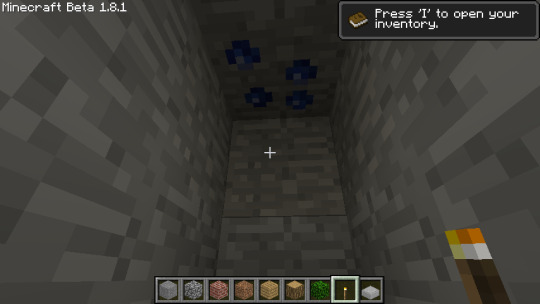
The first Sazmit I found in testing probably.

Even as I picked out images for and wrote for this, I found myself being impressed and amazed by how I was able to overcome challenges - all that time ago, while being such a novice - and how far this mod has come. There are plenty of images still left, so more individual posts on this era will be coming out on the blog as time goes on. And I haven't even gone into the second folder for this yet.
These images are all from the first four months. And I've been working on this mod, trying to craft and redefine most of everything there is in this base version into perfection for two years, with no release yet. It's been a hard journey from the start to all the way into the last month of 2024 as I write this, and I've pulled off some outstanding victories and easy yet smart victories over the code to make basic aspects of Beta 1.8, like fences and bookshelves, much better in that time. I even fixed a glaring oversight in Beta 1.8 or two.
As a quick note, development kind of went on longer than this, because in December of 2022 I studied for the mod ahead of time by playing hours of vanilla Beta 1.8.
I know you guys are patient, but I think it's really about time I finished Alpha 1.0.0 of this treasured Minecraft mod already, so I can try to make a public Modrinth page to host it and more people than just me and one friend can get to play this mod. I really want to watch other people play it. I'm super proud.
#Noticeably Beta 1.8#NBODE#Minecraft mod#Minecraft mod development#mod history#Minecraft screenshots#Taken in 2022#Taken in 2023#Mixed Taken Years#Minecraft#Mineblr#Minecraft Beta#Minecraft Beta 1.8#Beta 1.8#2nd Anniversary
5 notes
·
View notes
Text
Top Challenges in VR Development and How to Solve Them

Virtual Reality has transformed from a sci-fi fantasy into a rapidly growing industry, with applications spanning gaming, healthcare, education, and enterprise training. However, VR development remains a complex field filled with unique challenges that can make or break a project. Whether you're a seasoned developer or just starting your journey in VR development, understanding these obstacles and their solutions is crucial for creating compelling virtual experiences.
1. Motion Sickness and User Comfort
One of the most significant hurdles in VR development is preventing motion sickness, also known as VR sickness or simulator sickness. This occurs when there's a disconnect between what users see and what their inner ear perceives, leading to nausea, dizziness, and discomfort.
The Solution: Maintaining a consistent 90 frames per second (FPS) is non-negotiable in VR development. Any drops below this threshold can trigger motion sickness. Implement comfort settings like teleportation movement instead of smooth locomotion, reduce acceleration and deceleration, and provide stationary reference points within the virtual environment. Consider adding comfort vignettes that gradually darken the peripheral vision during movement to reduce visual-vestibular conflict.
2. Performance Optimization Challenges
VR applications demand significantly more processing power than traditional applications because they need to render two separate images simultaneously while maintaining high frame rates. Poor performance doesn't just affect user experience—it can cause physical discomfort and safety issues.
The Solution: Optimize your VR development process by implementing level-of-detail (LOD) systems that reduce polygon counts for distant objects. Use occlusion culling to avoid rendering objects outside the user's field of view, and implement foveated rendering when supported by the hardware. Profiling tools are essential—regularly test your application across different VR headsets to ensure consistent performance. Consider using techniques like reprojection and asynchronous timewarp to maintain smooth frame rates even when the GPU is under stress.
3. User Interface and User Experience Design
Traditional UI/UX principles don't translate directly to VR development. Designing interfaces that work in three-dimensional space while remaining intuitive and accessible presents unique challenges. Users interact with VR environments using hand controllers, eye tracking, or gesture recognition, requiring entirely new design paradigms.
The Solution: Embrace spatial UI design principles in your VR development workflow. Position UI elements at comfortable viewing distances (typically 1-3 meters) and avoid placing crucial interface components at the edges of the user's field of view. Implement clear visual feedback for interactions, use familiar metaphors like buttons and sliders adapted for 3D space, and ensure your UI elements are large enough to be easily selected with motion controllers. Always provide alternative input methods and consider accessibility from the start.
4. Hardware Fragmentation and Compatibility
The VR market features numerous headsets with different specifications, tracking systems, and input methods. Developing for multiple platforms simultaneously while ensuring consistent performance and user experience across devices is a major challenge in VR development.
The Solution: Adopt a platform-agnostic approach by using cross-platform development frameworks like Unity XR or Unreal Engine's VR template. These tools provide abstraction layers that handle device-specific implementations. Establish a testing matrix that includes the most popular VR headsets in your target market, and implement scalable graphics settings that automatically adjust based on the detected hardware capabilities. Consider using OpenXR, an open standard that provides a unified API for VR development across multiple platforms.
5. Spatial Audio Implementation
Audio plays a crucial role in creating immersive VR experiences, but implementing convincing spatial audio that accurately represents sound sources in 3D space is technically challenging. Poor audio implementation can break immersion and reduce the overall quality of the VR experience.
The Solution: Integrate spatial audio engines like Steam Audio, Oculus Audio SDK, or Unity's built-in spatial audio system into your VR development pipeline. These tools provide realistic sound propagation, room acoustics, and head-related transfer functions (HRTF). Position audio sources accurately in 3D space and implement proper attenuation curves. Test your audio implementation with different headphones and speakers to ensure compatibility across various audio setups.
6. Content Creation and Asset Pipeline
Creating high-quality 3D assets for VR requires specialized knowledge and tools. VR development demands detailed textures, complex 3D models, and optimized assets that maintain visual fidelity while meeting strict performance requirements.
The Solution: Establish a robust asset pipeline that includes automatic optimization processes. Use texture compression techniques appropriate for your target platforms, implement efficient UV mapping strategies, and create multiple LOD versions of complex models. Consider using photogrammetry and 3D scanning for realistic environments, but always optimize the resulting assets for VR performance requirements. Implement version control systems specifically designed for binary assets to manage your growing content library effectively.
7. Testing and Quality Assurance
Traditional software testing methods are insufficient for VR development. VR applications require physical testing with actual hardware, and issues like motion sickness or tracking problems can only be discovered through hands-on testing with real users.
The Solution: Develop a comprehensive VR testing strategy that includes both automated and manual testing phases. Create diverse test environments that simulate different room sizes and lighting conditions. Establish a user testing program with participants of varying VR experience levels, physical abilities, and comfort zones. Document common issues and their solutions in a knowledge base that your development team can reference. Implement telemetry systems to gather performance data and user behavior patterns from real-world usage.
8. Keeping Up with Rapid Technological Changes
The VR industry evolves rapidly, with new hardware, software updates, and development tools emerging regularly. Staying current with these changes while maintaining existing projects is a constant challenge in VR development.
The Solution: Allocate dedicated time for research and experimentation with new VR technologies. Follow industry leaders, attend VR conferences, and participate in developer communities to stay informed about emerging trends. Implement modular architecture in your VR projects that allows for easier updates and integration of new features. Consider the long-term implications of technology choices and build flexibility into your development roadmap.
Conclusion
VR development presents unique challenges that require specialized knowledge, tools, and approaches. Success in this field comes from understanding these obstacles and implementing proven solutions while staying adaptable to the rapidly evolving VR landscape. By addressing motion sickness, optimizing performance, designing intuitive interfaces, managing hardware compatibility, implementing spatial audio, streamlining content creation, establishing comprehensive testing procedures, and staying current with technological advances, developers can create compelling VR experiences that truly immerse users in virtual worlds.
The key to successful VR development lies in thorough planning, continuous testing, and a deep understanding of how humans interact with virtual environments. As the technology continues to mature, these challenges will evolve, but the fundamental principles of user-centered design and technical excellence will remain crucial for creating exceptional VR experiences.
#gaming#mobile game development#multiplayer games#metaverse#blockchain#unity game development#vr games#game#nft
1 note
·
View note
Text
Project update
In June, when I started the jolt-jni open-source software project, I considered it a subsidiary project. However, it proved so absorbing that it soon soaked up most of my attention, leaving little for all my other projects.
This is surprising, since unlike most of my projects, it has no graphical component (yet) meaning no satisfying CGI images to enjoy (and perhaps share on social media).
Also unlike most of my projects, I was coding it from scratch, yet constrained by a preexisting API. In practice, that meant writing a ton of boring boilerplate. Prior to this I'd been scornful of the idea of using AI to generate code. But for generating boilerplate code, I can see that mechanical aids have their place.
Now that the library is about 80% complete, I've turned more of my attention to testing. My progress (measured in lines of code) is much slower. Some days I delete more code than I add. The good news is, I enjoy troubleshooting far more than coding.
For the record, here are the current statistics:
+ 1472 commits
+ Overall 48K lines of code (excluding comments and blanks)
+ 29K lines of Java (including 8K lines of tests and examples)
+ 17K lines of C++
#open source#software development#coding#java#c++#troubleshooting#api#current project#library#generative ai
2 notes
·
View notes
Text
Why Startups Should Invest in Application Maintenance and Support in Bangalore
Your applications run your business. Minor problems can escalate into significant disruptions that affect both revenue and customer trust. Studies indicate that the average expense of IT downtime reaches $5,600 each minute. System failures impact more than just profits; they harm customer relationships and employee morale while tarnishing your market reputation.

Companies that prioritize thorough maintenance strategies tend to excel compared to those that respond only when issues arise. Investing in these strategies fosters resilience and enhances overall performance, ensuring long-term success in a competitive landscape.
The hidden costs of poor maintenance stack up fast. Lost productivity as employees sit idle. Frustrated customers who can’t access your services. Emergency fixes that cost 3x more than planned maintenance.
With a proper approach to application maintenance and support, you can stop issues before they arise. This helps keep your systems operating efficiently. Understanding the essential elements of effective maintenance is crucial. These components work in harmony to minimize downtime. By focusing on these strategies, you ensure a more reliable and stable system for your organization.
Proactive Monitoring Catches Issues Early
Think of your applications like a car engine. Small problems — a loose belt, low oil, worn brake pads — seem minor at first. Left unchecked, they lead to catastrophic failures. The same applies to your business applications.
Proactive monitoring tools scan your systems 24/7, looking for warning signs:
Memory leaks that slowly degrade performance
Database queries that take longer to execute
APIs with increasing error rates
Storage systems approaching capacity
Network latency spikes
Unusual traffic patterns that could indicate security threats
Resource utilization is trending upward
When these metrics trend in the wrong direction, maintenance teams can investigate and fix issues during planned maintenance windows. No fire drills are required. This proactive approach reduces unplanned downtime by up to 70%, according to industry studies.
Regular Updates Keep Security Tight
Hackers never sleep. They constantly probe for vulnerabilities in outdated components. Regular security patches through application maintenance and support in Bangalore close these gaps before criminals can exploit them.
But updates need careful testing. Changes that work in development can break in production. Experienced maintenance teams validate updates in staging environments first. They coordinate with business users to schedule deployments during low-traffic periods. This methodical approach prevents security patches from causing their own outages.
A solid update strategy includes:
Automated vulnerability scanning
Dependency analysis to identify at-risk components
Rigorous testing protocols
Phased rollouts to limit risk
Ready rollback procedures if issues occur
Performance Optimization for Better Speed
Slow applications frustrate users and hurt productivity. Common culprits include:
Inefficient database queries that retrieve too much data. Unoptimized image and video assets that consume excessive bandwidth. Memory leaks that degrade server performance over time. Poorly configured caching that misses opportunities to serve content faster.
Performance optimization identifies and fixes these bottlenecks. The results? Faster page loads. Snappier response times. Happier users who can work efficiently. Performance improvements directly impact business metrics like conversion rates and customer satisfaction.
Key optimization areas include:
Database query tuning
Asset compression and delivery optimization
Memory management
Caching strategy
Code profiling and optimization
Network route optimization
Capacity Planning Prevents Resource Constraints
Your applications need the right computing resources to handle peak loads. Too little capacity means slow performance and outages during busy periods. Too much wastes money on idle servers.
Smart capacity planning tracks usage patterns and forecasts future needs. It ensures you have enough horsepower to handle growth without overprovisioning. Load testing validates that applications can handle expected traffic spikes.
Effective capacity planning requires:
Historical usage analysis
Growth projections
Peak load modeling
Resource allocation optimization
Regular load testing
Cost optimization analysis
Documentation and Knowledge Transfer
Staff turnover happens. When key team members leave, they take valuable system knowledge with them. Good documentation preserves this expertise.
Maintenance teams should document the following:
System architecture and dependencies
Common issues and resolutions
Deployment and rollback procedures
Monitoring setup and alert thresholds
Security Protocols
Emergency response procedures
Change management processes
Contact lists and escalation paths
This knowledge base helps new team members get up to speed fast. It reduces reliance on tribal knowledge that exists only in people’s heads.
Disaster Recovery When Things Go Wrong
Even with perfect maintenance, disasters happen. Hardware fails. Data centers lose power. Natural disasters strike.
Solid disaster recovery plans include:
Automated backups tested regularly
Redundant systems in separate locations
Documented recovery procedures
Regular disaster simulation drills
Clear communication protocols
Defined roles and responsibilities
Recovery time objectives
Data loss limits
These preparations ensure you can restore service quickly when major incidents occur. Regular testing validates that recovery procedures work as intended.
The ROI of Proper Maintenance
Some see maintenance as a cost center. Smart leaders recognize it as an investment that pays returns through:
Reduced emergency fixes
Higher employee productivity
Better customer satisfaction
Lower security risks
Longer system lifespans
Improved compliance
Lower total cost of ownership
Better business continuity
The math is simple. A few hours of planned maintenance each month costs far less than an emergency response to preventable outages.
Take Action Now
Start with an honest assessment of your maintenance practices. Look for gaps in monitoring, testing and documentation. Build a roadmap to close these gaps methodically.
Consider these steps:
Audit current maintenance processes
Identify critical systems and dependencies
Implement monitoring tools
Develop maintenance schedules
Create documentation standards
Train team members
Regular process reviews
Measure and optimize results
Partnering with a trusted provider such as Millennium that offers reliable application maintenance and support in Bangalore will help you take the above steps in a holistic manner.
Final Words
Remember, maintenance is a journey, not a destination. Technology changes. Business needs to evolve. New risks emerge. Regular review and refinement of maintenance processes keep your applications running at peak performance.
Invest in proper maintenance today. Your future self will thank you when systems run smoothly, and preventable outages become rare exceptions rather than regular firefights. The cost of good maintenance is always lower than the cost of poor maintenance in the long run.
1 note
·
View note
Text
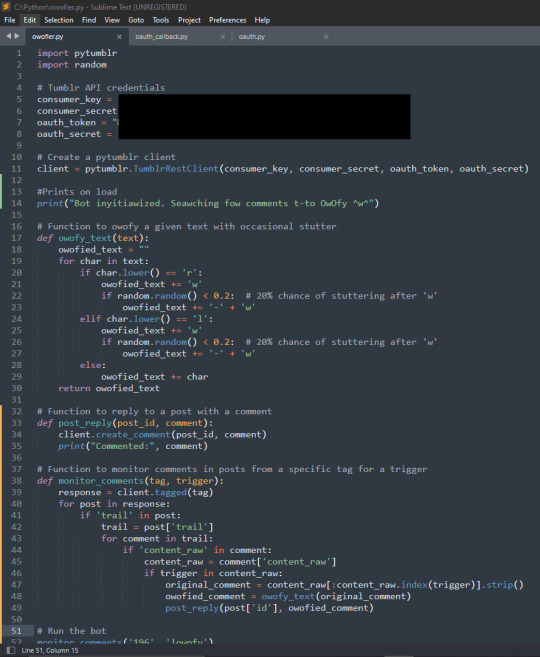
I AM CURSING YOU FUCKBAGS TO 1000 YEARS OF OWOFIED NONSENSE. I HAVE TO SUFFER, NOW YOU HAVE TO SUFFER WITH ME.
Update:
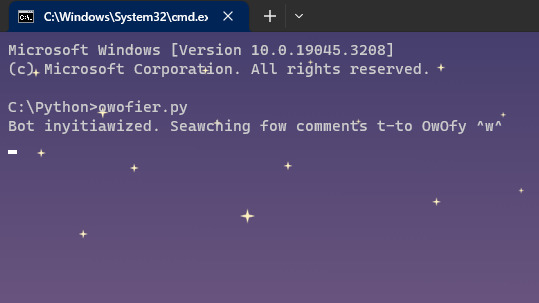
All this effort and it doesn't even work. I'm not mad, just disappointed. Current theory is that I didn't include an important part of it in the while loop. The bot scans new posts, and I'm not gonna re-post this for the second time. It's only been actually tested two or three times including this try, and I'm keeping this as a sort of devlog. Update 2:
I restarted the OAuth apps that I made earlier today (an OAuth callback server to catch the keys, and another OAuth thing to generate the Authorization verifier). I worked almost all day to get these two to work together. The API ended up sending this error, and I don't know what it means, but it doesn't throw any errors client-side. Here's the error it throws. {'meta': {'status': 429, 'msg': 'Limit Exceeded'}, 'response': [], 'errors': [{'title': 'Limit Exceeded', 'code': 0, 'detail': 'Minor hiccup. Try again.'}]} Like, okay, great. Now I gotta actually look at the documentation and find out what this magic gibberish means, because this could relate to all those times I tried to authenticate, OR I hit the daily limit on posts seen by my bot, which I highly doubt. Update 2.5 after some research, I've learned absolutely nothing. That error code is a giant ball of nothing that basically says I exceeded a rate limit, but doesn't give any explanation as to which rate I exceeded. Thanks, Tumblr. At least Reddit threw client side errors that you didn't have to go to a broken API console to see. Fuck all of you, and I'll see you tomorrow.
Side note: I am surviving off one breakfast pizza from Casey's, one Pipeline Punch, one grape flavored 3D, 4mg Estradiol, 50mg Spironolactone, and I currently have 100mg Progesterone dissolving in my stomach, which at this point, might actually kill me. It's only 9:36 at the time of writing this, but it feels like I've been working on this for days. This is to say that I may have missed something super obvious, and if that's the case, well, I'll leave tomorrows problems to tomorrow's me.
Update 3
Just woke up and re-ran all the assorted programs just to get a fresh start. I'm still getting that error code, but more importantly, my access token and secret changed? I'm not expert when it comes to stuff like this, but I though tokens and secrets are constant and specific to apps. I can't actually test this thing until the API lets me through. Update 3.5
Found the error code. It wasn't way too hard, but it means my bot probably did something way too much yesterday and I have no idea what. It works on the server's clock and goes by callendar day. This means that if a bot hits the error code at 11:59 PM, it can hit it again at 12:00 AM. For an error 429 to happen, any one of the following has to trigger it.
300 API calls per minute, per IP address.
18,000 API calls per hour, per IP address.
432,000 API calls per day, per IP address.
1,000 API calls per hour, per consumer key.
5,000 API calls per day, per consumer key.
250 new published posts (including reblogs) per day, per user.
250 images uploaded per day, per user.
200 follows per day, per user.
1,000 likes per day, per user.
10 new blogs per day, per user.
20 videos uploaded per day, per user.
60 minutes of total video uploaded per day, per user.
So I can't test this until the server's calendar deems it a new day Update 4
It still doesn't work, but I am one step closer. Because of Tumblr's broken-ass console, I've had to find an alternate way to get an OAuth key. It turns out I was using a temporary access key, which is why it changed when I re-ran everything. I had to do this by using two other scripts. One of them is Tumblr's interactive console on Github , and the other one was a Yaml parser because boy do they like to encrypt. This has been my morning so far. Day two and 5 scripts later, just to finally have something that I should've had at the start.
Update 4.5

I FINALLY GOT AN API RESPONSE!!! LET'S FUCKING GOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
Update 4.5.5
I have implemented a feature that makes the thing wait for a second then search for any comments with a timestamp older than the last time it waited and has the right keyword in the 196 tag. I have obviously accidentally wasted all my API tries today, but testing begins again tomorrow. You will fear my wrath soon enough. Update 5

Decided to check up on the bot, and ran straight into this wall of text. It looks like blog info? Some of those links take me to profile headers. This isn't a static thing either, it updates every 20 seconds like clockwork. Because I made it update every 20 seconds like clockwork. I think this means it's testing time. Wish me luck. Breaking News. Didn't work, but we're a lil bit closer. Again.
#I figured out how to get access to the API#and now you have to deal with my bullshit#This would have taken no time at all with Reddit's API#196#r/196#rule
12 notes
·
View notes
Text

USA signals return of Turkey in the F-35 program
Fernando Valduga By Fernando Valduga 01/30/2024 - 20:17in Military
The first Turkish F-35 fighter at the ceremony held at Lockheed Martin in Forth Worth, Texas, United States, on June 21, 2018. (Photo: Atilgan Ozdil/Anadolu Agency/Getty Images)
The United States is signaling the possibility of Turkey returning to the F-35 program, as long as the issue of the Russian S-400 anti-aircraft defense system is resolved.
During an exclusive interview with the Turkish media, Acting Deputy Secretary of State Victoria Nuland revealed that the U.S. is open to Turkey's reintegration into the F-35 fighter program, subject to the resolution of the controversy related to the Turkish acquisition of Russia's S-400 anti-aircraft defense system.
Nuland recognized the complexity of the diplomacy involved, stating: "We were in the process of negotiating the sale of the Patriot missile system, and while these negotiations were underway, Turkey went down another path." She emphasized that the resolution of the S-400 issue is a precondition for Turkey's reintegration into the F-35 family, emphasizing the importance of ensuring the maintenance of a solid air defense capability by Turkey.

The statement was made during Nuland's visit to Turkey on Sunday, with the main objective of "reinvigorating" the ties between the two nations. The delicate balance between addressing security concerns and promoting collaboration served as a backdrop for their discussions.
“Obviously, if we can solve this issue of the S-400, which we would like to do, the US would be delighted to receive [Turkey] back to the F-35 family. But we have to solve this other issue first,” Nuland told Turkish television CNNTurk on Monday.
The visit takes place a few days after Ankara ratified Sweden's accession to NATO and Washington approved the sale of F-16 fighters to the Turkish military.
Nuland addressed the ongoing approval process in Congress for the acquisition of U.S.-made F-16 fighters and modernization kits, highlighting efforts to persuade lawmakers. She emphasized the importance of Turkey's development of the F-16 fleet for the safety of the United States and argued that Turkey's active participation is crucial for an equitable distribution of the burden among allies.

As diplomatic efforts intensify, Turkey's potential return to the F-35 program remains dependent on the successful resolution of the S-400 issue, reflecting the intricate interaction between security considerations and strategic partnerships.
But the acquisition of the F-35 may be more complex. Turkey was expelled from the consortium that manufactures the new generation of F-35 poacher fighters in 2020, under the Anti-Adversaries of America Act through Sanctions (CAATSA), after acquiring Russia's S-400 anti-missile defense system. CAATSA was approved by an overwhelming majority by Congress in 2017 and introduces sanctions on any significant transactions with Russia.
Tags: Military AviationF-35 Lightning IITAF - Turkish Air Force / Turkish Air Force
Sharing
tweet
Fernando Valduga
Fernando Valduga
Aviation photographer and pilot since 1992, he has participated in several events and air operations, such as Cruzex, AirVenture, Dayton Airshow and FIDAE. He has works published in specialized aviation magazines in Brazil and abroad. He uses Canon equipment during his photographic work in the world of aviation.
Related news
HELICOPTERS
IMAGES: USAF deploys Jolly Green II in Japan
30/01/2024 - 19:00
MILITARY
Senegal wants to buy South Korean FA-50 jets
30/01/2024 - 18:24
MILITARY
Lockheed Martin delivers 75º APY-9 radar for the E-2D Advanced Hawkeye built by Northrop Grumman
30/01/2024 - 16:00
MILITARY
UAS Aerosonde of Textron Systems performs operational flight from a Coastal Combat Ship
30/01/2024 - 14:00
Aurora's Liberty Lifter X-plane advanced in the preliminary tests.
MILITARY
Aurora modifies the design of the large Liberty Lifter aircraft
30/01/2024 - 09:00
MILITARY
Argentina decides to buy 24 American F-16 fighters instead of Chinese JF-17 jets
30/01/2024 - 06:00
4 notes
·
View notes
Text
Introducing Alt Text Creator
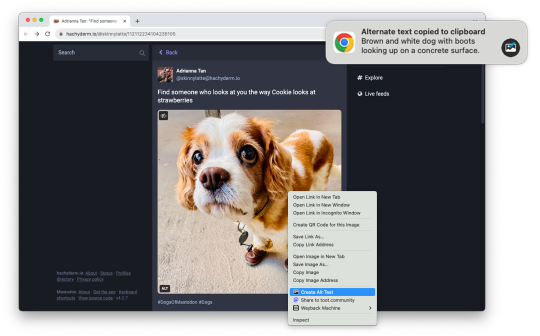
Images on web pages are supposed to have alternate text, which gives screen readers, search engines, and other tools a text description of the image. Alt text is critical for accessibility and search engine optimization (SEO), but it can also be time-consuming, which is why I am releasing Alt Text Creator!
Alt Text Creator is a new browser extension for Mozilla Firefox and Google Chrome (and other browsers that can install from the Chrome Web Store) that automatically generates alt text for image using the OpenAI GPT-4 with Vision AI. You just right-click any image, select "Create Alt Text" in the context menu, and a few seconds later the result will appear in a notification. The alt text is automatically copied to your clipboard, so it doesn't interrupt your workflow with another button to click.
I've been using a prototype version of this extension for about three months (my day job is News Editor at How-To Geek), and I've been impressed by how well the GPT-4 AI model describes text. I usually don't need to tweak the result at all, except to make it more specific. If you're curious about the AI prompt and interaction, you can check out the source code. Alt Text Creator also uses the "Low Resolution" mode and saves a local cache of responses to reduce usage costs.
I found at least one other browser extension with similar functionality, but Alt Text Creator is unique for two reasons. First, it uses your own OpenAI API key that you provide. That means the initial setup is a bit more annoying, but the cost is based on usage and billed directly through OpenAI. There's no recurring subscription, and ChatGPT Plus is not required. In my own testing, creating alt text for a single image costs under $0.01. Second, the extension uses as few permissions as possible—it doesn't even have access to your current tab, just the image you select.
This is more of a niche tool than my other projects, but it's something that has made my work a bit less annoying, and it might help a few other people too. I might try to add support for other AI backends in the future, but I consider this extension feature-complete in its current state.
Download for Google Chrome
Download for Mozilla Firefox
#chrome extension#chrome extensions#firefox extension#firefox extensions#chrome#firefox#accessibility#a11y
2 notes
·
View notes
Text
ESP32-S3 moon phase clock test on 2.1" round TFT display 🌜🌚🖥️
Now that we have somewhat-kinda-sorta working support for RGB TFT displays on the ESP32-S3 - shout out to Jepler, who is doing the hard work over in this PR https://github.com/adafruit/circuitpython/pull/8351 - its time to test it with wifi too! That's right, the S3 can do wifi and these big displays at once, and CircuitPython is a beautiful framework for it since its so fast to iterate. This code snippet is based on PaintYourDragon's moon clock code here https://learn.adafruit.com/moon-phase-clock-for-adafruit-matrixportal but pared down for testing. We get the geolocation from IP, then look up the moon phase. Currently we just hardcoded it to display today's phase, but the next step is generating ~28 different phase images, and we'll display the one for the current evening as the API informs us.
#espressif#esp32#espfriends#display#adafruit#electronics#opensource#opensourcehardware#circuitpython#tftdisplay#coding#rgbdisplay#round#moonphase#test#wifi#jepler#prsupport#framework#fastiterate#geolocation#api#eveningphase
4 notes
·
View notes
Photo
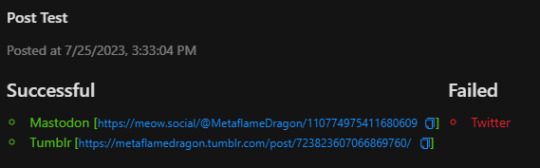
Twitter paid endpoint
well, I think this says it all great job with user-friendliness, twitter! other websites let me use their API to multi-post, meanwhile twitter's endpoints are locked behind big money. Anyway, I'm MetaflameDragon pretty much everywhere I can be (tumblr & meow rn). Feel free to follow me :3 (also, test post 2, image version)
Posted using PostyBirb
2 notes
·
View notes
Text
🧵 Base64 Decoding Isn't as Simple as You Think
Common Pitfalls + How to Not Break Things
🤔 Wait... What’s Base64 Again?

Base64 is how we encode binary data as text — perfect for sending images, tokens, and files through APIs, emails, or logs.
But decoding it? That’s where the bugs crawl in 🪳
⚠️ Pitfall Parade: What Goes Wrong?
⛔ Missing padding characters (=)
🧾 Line breaks inside encoded strings
📛 Non-standard chars (especially from copy-paste or old email clients)
🌐 Unicode data gone wrong
🤯 Truncated strings from network/database errors
🔀 Different variants (some use - and _, others use + and /)
🔧 What Should You Actually Do?
✅ Trim weird characters before decoding
✅ Validate string length and completeness
✅ Check padding — and fix it if needed
✅ Decode to bytes before converting to UTF-8 text
🧪 Real Dev Pro Tips
Stream large files instead of loading into memory
Avoid silent fails — always log decoding errors
Use test cases with:
✅ Valid strings
🛑 Invalid ones
🔄 Multiple variants
📦 Huge payloads
🛡️ Don’t Ignore Security
Yes, decodeBase64 can be a vulnerability if you’re not careful.
Input validation is 🔑
Add memory/time limits to prevent resource abuse
Handle unexpected formats with graceful fallback, not crashes
📊 Deploying to Production?
🔍 Monitor:
Failed decoding attempts
Average decoding time
Resource usage
📦 Use tools like Keploy to mock and test decoding pipelines as part of your CI/CD.
🎯 TL;DR
Base64 is everywhere, but decoding it properly means:
Validating everything 🔍
Handling weird edge cases ⚠️
Thinking about performance & security 💡
Testing. Testing. Testing. 🧪
0 notes
Text
Provision Configuration at Runtime to Kubernetes Workloads
In modern cloud-native applications, configuration management plays a critical role in delivering scalable, portable, and secure deployments. Kubernetes, being the de facto standard for container orchestration, provides powerful mechanisms to inject configurations into applications — all without changing the container image.
Let’s explore how Kubernetes allows you to provision configuration at runtime effectively.
🎯 What Is Runtime Configuration in Kubernetes?
Runtime configuration means providing dynamic values or external settings to applications while they are running, without rebuilding or redeploying the application image.
This allows teams to:
Decouple code from configuration
Maintain consistent environments (dev, test, prod)
Change settings on the fly, without downtime
🔑 Key Tools for Configuration in Kubernetes
Kubernetes offers a few native constructs to handle runtime configuration:
1. ConfigMaps
A ConfigMap is a Kubernetes object used to store non-sensitive configuration data such as:
App settings
Database URLs
Environment variables
Applications can consume ConfigMaps as:
Environment variables
Command-line arguments
Mounted files inside pods
Example Use Case: Setting the log level (DEBUG, INFO, ERROR) without altering the container image.
2. Secrets
Secrets are similar to ConfigMaps but are used to store sensitive data, such as:
API keys
Passwords
Certificates
They are base64-encoded and can be injected into workloads just like ConfigMaps.
Example Use Case: Injecting a database password at runtime, securely.
3. Environment Variables
You can define environment variables directly in the Pod or Deployment specification. This method is simple and effective for small-scale configurations or for referencing values from ConfigMaps/Secrets.
4. Volumes
Both ConfigMaps and Secrets can be mounted into pods as volumes. This approach is often used when applications are designed to read configuration files.
Example Use Case: Mounting a .env or .conf file into a container that expects file-based configuration.
🌀 Why Provisioning at Runtime Matters
🔁 Flexibility: Change configuration without modifying the app image
🚀 Speed: Faster iterations between environments
🔒 Security: Handle sensitive data securely using Secrets
🧩 Portability: Move apps across environments with consistent setup
✅ Best Practices
Avoid hardcoding configurations into images
Use Secrets for all confidential information
Mount read-only volumes for configurations to enhance security
Use separate ConfigMaps per application or microservice for modularity
Keep configuration changes version-controlled via GitOps or CI/CD pipelines
📌 Real-World Example
Imagine you deploy a payment microservice that needs to switch between sandbox and production payment gateways. Instead of rebuilding the container each time, you can manage the gateway URL and credentials via a ConfigMap and Secret. Update them when needed — and the application picks up the new values seamlessly.
🧠 Final Thoughts
Provisioning configuration at runtime in Kubernetes is not just a technical choice — it's a DevOps best practice that supports scalability, reliability, and agility. Tools like ConfigMaps and Secrets are your allies in building cloud-native applications that are easy to manage and secure in production.
🔗 Embrace dynamic configuration. Build smarter applications.
For more info, Kindly follow: Hawkstack Technologies
#Kubernetes#CloudNative#K8sConfig#DevOps#ConfigMap#Secrets#RuntimeConfiguration#KubernetesBestPractices#K8sDeployment#HawkStackLearning
0 notes