#Kubernetes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
64 vCPU/256 GB ram/2 TB SSD EC2 instance with #FreeBSD or Debian Linux as OS 🔥

38 notes
·
View notes
Text
CHECK FOR THINGS THAT PHYSICALLY EXIST BUT HAVE NOT BEEN PERCEIVED YET
INCORPORATE MORE ACCURATE PHYSICAL REALITY INTO GAME
#CHECK FOR THINGS THAT PHYSICALLY EXIST BUT HAVE NOT BEEN PERCEIVED YET#taylor swift#INCORPORATE MORE ACCURATE PHYSICAL REALITY INTO GAME#VIRTUAL MACHINES#VIRTUAL MACHINE#vmware#container#kubernetes#zero trust#microsoft#cisa.gov#pluralsight#pluralsight.com#Wikipedia#wikipedia#wikimedia commons#wii sports wiki#wikipedia.org
17 notes
·
View notes
Text
so at work theres a kubernetes command called kgpo that is used to list pods and i just mentally call it the "kagepro" command :p
4 notes
·
View notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Load Balancing Web Sockets with K8s/Istio
When load balancing WebSockets in a Kubernetes (K8s) environment with Istio, there are several considerations to ensure persistent, low-latency connections. WebSockets require special handling because they are long-lived, bidirectional connections, which are different from standard HTTP request-response communication. Here’s a guide to implementing load balancing for WebSockets using Istio.
1. Enable WebSocket Support in Istio
By default, Istio supports WebSocket connections, but certain configurations may need tweaking. You should ensure that:
Destination rules and VirtualServices are configured appropriately to allow WebSocket traffic.
Example VirtualService Configuration.
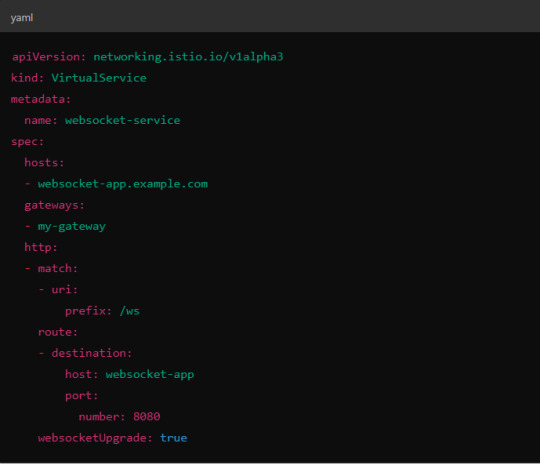
Here, websocketUpgrade: true explicitly allows WebSocket traffic and ensures that Istio won’t downgrade the WebSocket connection to HTTP.
2. Session Affinity (Sticky Sessions)
In WebSocket applications, sticky sessions or session affinity is often necessary to keep long-running WebSocket connections tied to the same backend pod. Without session affinity, WebSocket connections can be terminated if the load balancer routes the traffic to a different pod.
Implementing Session Affinity in Istio.
Session affinity is typically achieved by setting the sessionAffinity field to ClientIP at the Kubernetes service level.
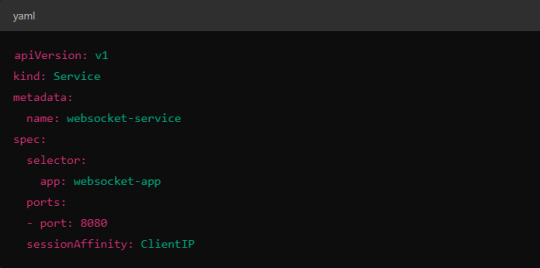
In Istio, you might also control affinity using headers. For example, Istio can route traffic based on headers by configuring a VirtualService to ensure connections stay on the same backend.
3. Load Balancing Strategy
Since WebSocket connections are long-lived, round-robin or random load balancing strategies can lead to unbalanced workloads across pods. To address this, you may consider using least connection or consistent hashing algorithms to ensure that existing connections are efficiently distributed.
Load Balancer Configuration in Istio.
Istio allows you to specify different load balancing strategies in the DestinationRule for your services. For WebSockets, the LEAST_CONN strategy may be more appropriate.
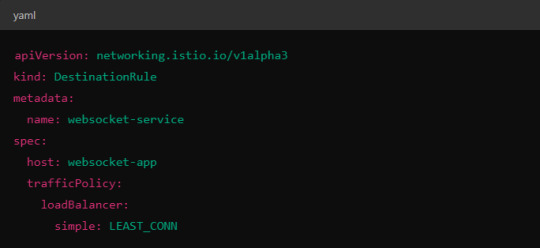
Alternatively, you could use consistent hashing for a more sticky routing based on connection properties like the user session ID.
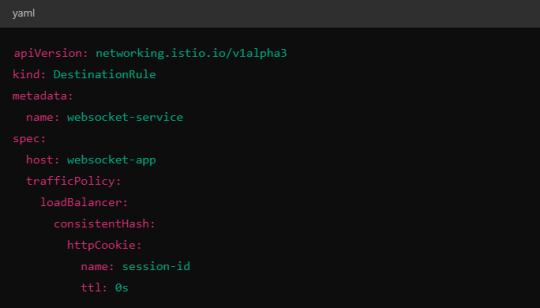
This configuration ensures that connections with the same session ID go to the same pod.
4. Scaling Considerations
WebSocket applications can handle a large number of concurrent connections, so you’ll need to ensure that your Kubernetes cluster can scale appropriately.
Horizontal Pod Autoscaler (HPA): Use an HPA to automatically scale your pods based on metrics like CPU, memory, or custom metrics such as open WebSocket connections.
Istio Autoscaler: You may also scale Istio itself to handle the increased load on the control plane as WebSocket connections increase.
5. Connection Timeouts and Keep-Alive
Ensure that both your WebSocket clients and the Istio proxy (Envoy) are configured for long-lived connections. Some settings that need attention:
Timeouts: In VirtualService, make sure there are no aggressive timeout settings that would prematurely close WebSocket connections.

Keep-Alive Settings: You can also adjust the keep-alive settings at the Envoy level if necessary. Envoy, the proxy used by Istio, supports long-lived WebSocket connections out-of-the-box, but custom keep-alive policies can be configured.
6. Ingress Gateway Configuration
If you're using an Istio Ingress Gateway, ensure that it is configured to handle WebSocket traffic. The gateway should allow for WebSocket connections on the relevant port.
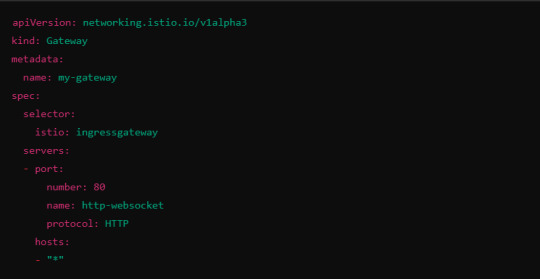
This configuration ensures that the Ingress Gateway can handle WebSocket upgrades and correctly route them to the backend service.
Summary of Key Steps
Enable WebSocket support in Istio’s VirtualService.
Use session affinity to tie WebSocket connections to the same backend pod.
Choose an appropriate load balancing strategy, such as least connection or consistent hashing.
Set timeouts and keep-alive policies to ensure long-lived WebSocket connections.
Configure the Ingress Gateway to handle WebSocket traffic.
By properly configuring Istio, Kubernetes, and your WebSocket service, you can efficiently load balance WebSocket connections in a microservices architecture.
#kubernetes#websockets#Load Balancing#devops#linux#coding#programming#Istio#virtualservices#Load Balancer#Kubernetes cluster#gateway#python#devlog#github#ansible
5 notes
·
View notes
Text

YEEEEEEhawwwwww
(this actually represents several days of hard work and a great accomplishment toward understanding kubernetes)
4 notes
·
View notes
Text
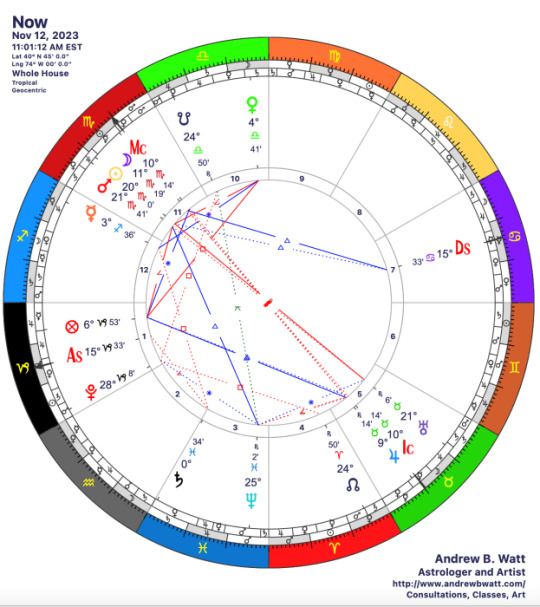
Sun in Scorpio III (12-22 November 2023)
The Kouroi/Curetes/Korybantes, the 'male' spirits of the more dangerous aspects of the Land, rule the next ten days. How do you relate to the risks of living life on Earth? Do you take the risks, accept them, or avoid them?
The Sun enters Scorpio III on November 12, 2023 at 11:01 am EST. We’ve passed the gate of Daylight Saving Time (falling back one hour), and we’re now in the season of darkness pretty definitively. Austin Coppock called this decan The Crow, relating it both to the constellation Corvus and a myth of how Crow stole the feasting-goblet of the sun-god Apollo and was burned black for his trouble.…
View On WordPress
11 notes
·
View notes
Text
Kubernetes is simple, they say ;-)

80 notes
·
View notes
Text
Ansible Collections: Extending Ansible’s Capabilities
Ansible is a powerful automation tool used for configuration management, application deployment, and task automation. One of the key features that enhances its flexibility and extensibility is the concept of Ansible Collections. In this blog post, we'll explore what Ansible Collections are, how to create and use them, and look at some popular collections and their use cases.
Introduction to Ansible Collections
Ansible Collections are a way to package and distribute Ansible content. This content can include playbooks, roles, modules, plugins, and more. Collections allow users to organize their Ansible content and share it more easily, making it simpler to maintain and reuse.
Key Features of Ansible Collections:
Modularity: Collections break down Ansible content into modular components that can be independently developed, tested, and maintained.
Distribution: Collections can be distributed via Ansible Galaxy or private repositories, enabling easy sharing within teams or the wider Ansible community.
Versioning: Collections support versioning, allowing users to specify and depend on specific versions of a collection. How to Create and Use Collections in Your Projects
Creating and using Ansible Collections involves a few key steps. Here’s a guide to get you started:
1. Setting Up Your Collection
To create a new collection, you can use the ansible-galaxy command-line tool:
ansible-galaxy collection init my_namespace.my_collection
This command sets up a basic directory structure for your collection:
my_namespace/
└── my_collection/
├── docs/
├── plugins/
│ ├── modules/
│ ├── inventory/
│ └── ...
├── roles/
├── playbooks/
├── README.md
└── galaxy.yml
2. Adding Content to Your Collection
Populate your collection with the necessary content. For example, you can add roles, modules, and plugins under the respective directories. Update the galaxy.yml file with metadata about your collection.
3. Building and Publishing Your Collection
Once your collection is ready, you can build it using the following command:
ansible-galaxy collection build
This command creates a tarball of your collection, which you can then publish to Ansible Galaxy or a private repository:
ansible-galaxy collection publish my_namespace-my_collection-1.0.0.tar.gz
4. Using Collections in Your Projects
To use a collection in your Ansible project, specify it in your requirements.yml file:
collections:
- name: my_namespace.my_collection
version: 1.0.0
Then, install the collection using:
ansible-galaxy collection install -r requirements.yml
You can now use the content from the collection in your playbooks:--- - name: Example Playbook hosts: localhost tasks: - name: Use a module from the collection my_namespace.my_collection.my_module: param: value
Popular Collections and Their Use Cases
Here are some popular Ansible Collections and how they can be used:
1. community.general
Description: A collection of modules, plugins, and roles that are not tied to any specific provider or technology.
Use Cases: General-purpose tasks like file manipulation, network configuration, and user management.
2. amazon.aws
Description: Provides modules and plugins for managing AWS resources.
Use Cases: Automating AWS infrastructure, such as EC2 instances, S3 buckets, and RDS databases.
3. ansible.posix
Description: A collection of modules for managing POSIX systems.
Use Cases: Tasks specific to Unix-like systems, such as managing users, groups, and file systems.
4. cisco.ios
Description: Contains modules and plugins for automating Cisco IOS devices.
Use Cases: Network automation for Cisco routers and switches, including configuration management and backup.
5. kubernetes.core
Description: Provides modules for managing Kubernetes resources.
Use Cases: Deploying and managing Kubernetes applications, services, and configurations.
Conclusion
Ansible Collections significantly enhance the modularity, distribution, and reusability of Ansible content. By understanding how to create and use collections, you can streamline your automation workflows and share your work with others more effectively. Explore popular collections to leverage existing solutions and extend Ansible’s capabilities in your projects.
For more details click www.qcsdclabs.com
#redhatcourses#information technology#linux#containerorchestration#container#kubernetes#containersecurity#docker#dockerswarm#aws
2 notes
·
View notes
Text
#DevOps lifecycle#components of devops lifecycle#different phases in devops lifecycle#best devops consulting in toronto#best devops consulting in canada#DevOps#kubernetes#docker#agile
2 notes
·
View notes
Text
youtube
The Best DevOps Development Team in India | Boost Your Business with Connect Infosoft
Please Like, Share, Subscribe, and Comment to us.
Our experts are pros at making DevOps work seamlessly for businesses big and small. From making things run smoother to saving time with automation, we've got the skills you need. Ready to level up your business?
#connectinfosofttechnologies#connectinfosoft#DevOps#DevOpsDevelopment#DevOpsService#DevOpsTeam#DevOpsSolutions#DevOpsCompany#DevOpsDeveloper#CloudComputing#CloudService#AgileDevOps#ContinuousIntegration#ContinuousDelivery#InfrastructureAsCode#Automation#Containerization#Microservices#CICD#DevSecOps#CloudNative#Kubernetes#Docker#AWS#Azure#GoogleCloud#Serverless#ITOps#TechOps#SoftwareDevelopment
2 notes
·
View notes
Text
I need someone to make Kubernetes their special interest so I can have them help me figure out what the fuck I’m doing.
I can give you praise if you’re into that.
2 notes
·
View notes
Text
What is Docker and its use case?
Docker is a powerful tool that has revolutionized the way applications are deployed and managed. It is an open-source platform that allows developers to build, package, and deploy applications in a consistent and efficient manner. In this blog post, we will explore Docker and its uses Docker uses a lightweight virtualization approach to package applications and their dependencies into a…

View On WordPress
5 notes
·
View notes
Text
3 notes
·
View notes