#speeching software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
⚠️Vote for whomever YOU DO NOT KNOW⚠️‼️


#ultimate obscure blorbo#polls#Round I#Sofia Wernher#The eccentric duchess#Software Automatic Mouth#Text-to-speech software
29 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
252 notes
·
View notes
Text

#art#traditional art#watercolour#fanart#virvox project#aoyama ryuusei#voicevox#he also has an aivoice bank but thats like. the worst seo name possible for a text to speech software so tagging it probably wont help orz#still so fucked up that hes 6'4. who is allowed to do that. i assumed he would be 6'2 at most#WHERE does he get his oversized jacket. I NEED to know. what big and tall retailer is he going to.#i do love him but im 5'4 so legally i have to bully anyone a foot taller than me. sorry ryuusei
20 notes
·
View notes
Text
My only real gripe with Dropout is their subtitling. It is horrendous, I think especially on D20. Constant mistakes and seems like every other line won't make sense if you're deaf or hard-of-hearing.
I just have auditory processing issues so most of the time I can tell that the captions are wrong, but I can't imagine how misleading the captions are to folks with less of an ability to decipher the audio.
Like I'm sorry to sound harsh but hire someone new for that department, because the quality control is abysmal.
#dimension 20#dropout#sometimes it seems like they fed the audio through a text-to-speech ai software or something when its so egregiously inaccurate#closed captions#subtitles#accessibility
44 notes
·
View notes
Text
I screwed around with some tts last night and came up with this masterpiece
#cw swearing#tts#text to speech#microsoft sam#software automatic mouth#s.a.m.#dectalk#i thought it was funny
23 notes
·
View notes
Note
can I ask what text in the RESTRICT act you are reading as criminalizing the use of VPNs? I am seeing this repeatedly and on reading the bill, I don't understand the logic of how VPNs would be effected, or any software not developed in a country outside of the list mentioned in the bill, or how these penalties would apply to most civilians. for example, proton is Swiss-based. wouldn't the US need to name Switzerland as a hostile foreign power to outlaw their VPN? how would an individual user utilizing a VPN to access software developed in say, Venezuela, be in violation of the act, based on its wording and likely legal interpretation? I only see information relevant to financial transactions, and any fine would be based on the value of said transaction?
obviously broad expansions of national security legislation with the intent to choke out foreign competitors are bad! and also, I just do not understand where this claim is coming from. this interpretation seems to state that "transaction" means viewing a site, and using a VPN is "abetting a transaction" and this seems... unlikely.
You're right about the foreign country part, where it wouldn't be considered if it were from a country not listed as hostile. I'll admit that I missed that one in my readings until someone else pointed it out.
I do want to be clear and say that I'm not a professional at this, this was all from my readings of the bill as well as some more research and seeing viewpoints of others, many of which ARE professionals, so I'm actually glad you're doing your own research on it. And I want to encourage you to continue doing so.
But as for the VPN issue, it comes down to section 11, subsection 2-F.
No person may engage in any transaction or take any other action with intent to evade the provisions of this Act, or any regulation, order, direction, mitigation measure, prohibition, or other authorization or directive issued thereunder.
Keywords "any other action". Basically VPNs would fall under that as it could be used to circumvent any bans of foreign services of companies based in the mentioned hostile countries. From my understanding, it would be less likely - to use your example - if you used it to access an online service based in Venezuela that wasn't available in the US as Venezuela isn't listed as hostile.
But then that's where the whole accessing your personal data comes into play. If the Secretary of Commerce and their team were to conduct an audit, you could be chosen at random. And if you use a VPN, they may decide to look closer at you to ensure you're not using it to access a banned service.
The reason VPNs are being discussed is because most people that bring it up are speaking in terms of using it to access tiktok if it were banned, or to access anything else that could be banned under this bill. THAT is where the problem with VPNs lie and why many people are warning others not to use them for this reason, due to the hefty penalties attached. VPNs themselves aren't targeted to be banned, just their use to access services that are.
A big part of it also comes down to discretion as well. If they so wished, if this bill were to pass, they could even push further to create another bill or expand this one to find a way to ban VPNs themselves, though that is less likely.
As of writing all this, the bill has only been introduced. It hasn't even passed the senate, so it's only in it's first stages. It could easily change as time goes on, or it could even fail to pass with or without American's intervention. It's all still very early, which is why we're all pushing so hard to stop it while we still can so that it doesn't escalate even further beyond what this bill proposes.
50 notes
·
View notes
Text
We Return! Quick News Catch-Up!
Hey everyone! Thank you for your patience! I’m now officially back from my Holiday and am ready to start reporting on Vocal Synth Release news again! First things first though, there’s been a lot of news since I’ve been on break so I’ll go over the big pieces very briefly as to catch up! There’s been a lot so please bear with me as the summaries will be extremely short! A.I. VOICE We’ve had a…

View On WordPress
#AH-Soft#AH-Software#AHS#AI VOICE#AI VOICE 2#Candy Cream Algorithm#CeVIO#CeVIO AI#Chorical#Kakyo Yosari#Kanato Mell#Koharu Rikka#Kotonoha Akane & Aoi#Natsuki Karin#Shikoku Metan#Soyogi Fractal#Soyogi Soyogi#SSS LTD#Tange Kotoe Project#Techno-speech#Tohoku Itako#Tohoku Kiritan#Tohoku Project#Tohoku Zunko#Tokyo6#Tsukuyomi-chan#Tsurumaki Maki#TYC Project#VOCALOID#VOCALOID6
2 notes
·
View notes
Text
I’m obsessed with the Praat logo makes me giggle every time I open it up
#I promise I am serious linguist with serious software#^ something about cat speech and omission of articles
3 notes
·
View notes
Text
I hope the amount of research I have to do for c:u! shows because it’s the most frustrating aspect of this project LOL
#jontalks#sorry for deleting prev post and ask I do that then get extremely paranoid I shared too much and nuke everything LOL#I can def talk about second update because that is when the cast expands that’s not spoilers you’ve read the presentation walkthrough page#I hope#anyway I have a very like big problem where I get extremely irrationally angry when someone tries to do something with older tech and it#very obviously wouldn’t do that. can’t do that. or just doesn’t make sense for the time#like every god damn analog horror series just putting boring ass text on a blank background or using ballroom music#that doesn’t make sense and you fucking suck#you can take some liberties SURE but you better show me some accuracy with all the other shit#this reminds me when mag protocol was like haha isn’t weird for this old software to have text to speech and I screemed in pain so loud#my throat hurt from how mad I was#do you know how painful it was to do any trope in c:u for the first update like the glitching I started crying bc I was like it wouldn’t#do this…..noooo..nooooo but I’ll remember I’m basing this more off creepypastas then stupid ass analog horror series and calm down#I don’t like analog horror I hope this is apparent#walten files gets a pass bc the fourth tape actually knocked me on my ass
3 notes
·
View notes
Text
Elevate Your Marketing Videos: The Power of AI Text-to-Speech with Different Voices

In today's fast-paced digital world, capturing audience attention is more crucial than ever. Marketing videos have become a cornerstone of successful marketing campaigns, offering a dynamic and engaging way to connect with your target audience. However, creating high-quality video content can be a time-consuming and expensive endeavor, especially when it comes to professional voiceovers.
This is where the magic of AI text-to-speech (TTS) technology comes in. Imagine a world where you can transform your marketing scripts into captivating voiceovers with just a few clicks. AI text-to-speech allows you to do just that, offering a powerful and versatile tool for businesses of all sizes. By leveraging the power of AI, you can create professional-sounding voiceovers in a variety of styles and languages, all at a fraction of the traditional cost.
Beyond the Human Voice: Unveiling the Versatility of AI Text-to-Speech (AI text to speech different voices)
Gone are the days of being limited to a single voice narrator. AI text-to-speech technology boasts a vast library of AI voices, each offering unique characteristics and personalities. This opens up a world of possibilities for your marketing videos. Imagine tailoring the voiceover to perfectly match the tone and style of your brand. Need a friendly and approachable voice for a product explainer video? AI has you covered. Creating a high-energy commercial? No problem! The variety of AI voices allows you to select the perfect narrator to resonate with your target audience and enhance the overall message of your video.
But the versatility of AI text-to-speech goes beyond just voice selection. Many platforms allow you to fine-tune the speaking style, adjusting the pace, pitch, and even adding emphasis for dramatic effect. This level of control empowers you to craft the ideal voiceover that seamlessly integrates with the visuals of your video, creating a truly immersive experience for viewers.
Crafting the Perfect Tone: How AI Creates Emotionally-Charged Voiceovers (convert text to speech with emotions AI)
The human voice is a powerful tool for conveying emotions. A skilled voiceover artist can inject the right amount of enthusiasm, authority, or warmth to captivate the audience. But what if you could achieve the same level of emotional resonance with AI? Believe it or not, AI text-to-speech technology is rapidly evolving to incorporate emotional intelligence.
Some advanced platforms allow you to choose from a range of pre-programmed emotional styles, such as joyful, persuasive, or urgent. This allows you to tailor the emotional delivery of your voiceover to perfectly compliment the message you're trying to convey. Imagine a heartwarming ad for a charity using a gentle and compassionate voice, or a product demonstration packed with excitement and energy. AI text-to-speech empowers you to evoke the desired emotions in your audience, fostering a deeper connection and ultimately driving results.
Elevate Your Reach: Expanding Your Audience with Multilingual AI Voices (AI text to speech for marketing videos)
The global marketplace offers a vast pool of potential customers. However, language barriers can often present a significant hurdle for marketing campaigns. AI text-to-speech technology breaks down these barriers by offering a multilingual solution. Many platforms support a wide range of languages, allowing you to create voiceovers in the native tongue of your target audience. This not only enhances the overall understanding and engagement of your videos but also demonstrates a commitment to catering to a global audience.
Imagine reaching new markets and expanding your brand awareness without the need for expensive voiceover translations. AI text-to-speech provides a cost-effective and efficient way to localize your marketing videos, ensuring your message resonates across borders.
From Budget-Friendly Options to Premium Solutions: Choosing the Best AI Text-to-Speech Software (best AI text to speech software)
The beauty of AI text-to-speech technology lies in its accessibility. A variety of options are available, catering to different needs and budgets. For those just starting out, several free AI text-to-speech converters (free AI text to speech converter) offer basic functionality. These platforms can be a great way to experiment with AI voiceovers and see if they align with your marketing strategy. However, keep in mind that free options may have limitations in terms of voice selection, audio quality, and customization features.
For businesses seeking a more professional and feature-rich solution, several premium AI text-to-speech software providers exist. These platforms offer a wider range of voices, advanced control over audio parameters, and even integration with text to speech API with AI for seamless workflow integration with your video editing software. While premium options come with a cost, the investment can pay off handsomely, allowing you to create high-quality marketing videos that truly stand out from the crowd.
#best AI text to speech software#free AI text to speech converter#AI text to speech for eLearning#create realistic voice with AI#text to speech for audiobooks AI#AI text to speech different voices#use AI for voiceover#text to speech API with AI#AI text to speech for accessibility#AI text to speech for marketing videos#convert text to speech with emotions AI#AI text to speech for podcasts#future of AI text to speech#ethical considerations of AI text to speech
2 notes
·
View notes
Text
Quick update on the State of the Nation & Very Important Technological Advancement:
The speech-to-text tool on my Android phone recognizes the word "destiel".
It's a little janky and apparently 50% likely to spontaneously delete all the other words in the sentence and just leave "destiel" for some reason.
But isn't that what Supernatural is really about? Aren't we really all just here in this fandom to forget all the words except for Destiel??
.... Now if I could JUST get speech-to-text to REMEMBER LITERALLY ANY ETHNIC NAME, THAT'D BE GREAT.
I know for a fact that it is possible and even relatively easy to teach speech recognition software to register new words because I used to work testing and calibrating Alexa apps. I KNOW HUMANITY HAS THE TECHNOLOGY, DAMMIT! - But I haven't been able to find a speech-to-text app that allows me to do this. Anyone else have more success than me?
#original#spn#destiel#speech-to-text#speech recognition#speech recognition software#speech to text#carpal tunnel#one of the main characters in my graphic novel is named Kuruk which is a rare Plains Indian Pawnee name and lemme tell ya#speech to text will not accept this name no matter what i do#some notable guesses it's made: cool rock. iraq. curl Rick. korok. correct. Clorox. cur lock. kurok - oh that one is actually so close!!!#typing accessibility#accessibility#accessibility software#disabled writer
4 notes
·
View notes
Text
Are you guys excited about Tumblr potentially joining the Fediverse? 👀 I know I am!👇
https://www.howtogeek.com/850954/tumblr-and-flickr-might-join-mastodons-fediverse-network/
And if you have absolutely no sweet clue what the Fediverse even is, now is the time to learn about it because it’s the new Internet 2.0!

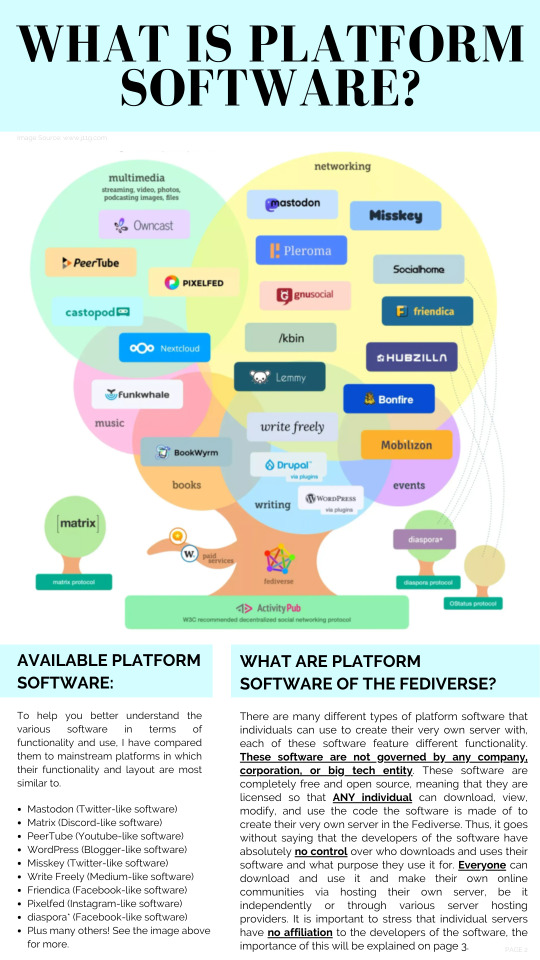


So what does it mean if Tumblr joins the Fediverse?
It means that we will be part of a very interconnected space with thousands and thousands of independently run platforms that are completely outside of the Tumblr platform. Potentially, we will be able to follow, interact with other users, and support our favorite content creators across various platforms in the Fediverse without having to be part of those platforms if we don’t want to be. And Vice Versa, they will be able to follow and interact with those of us on Tumblr without having to be on the Tumblr platform themselves. How cool is that?!
#fediverse#mastodon#twitter#tumblr#internet 2.0#decentralized#open source#foss#free and open-source software licenses#free and open source#big tech#corruption#power to the people#freedom#freedom of speech#The Death Of Big Tech#No More Censorship#Social Media Empowerment#Your server your rules#We the people rule the internet now#elon#elon musk#tech#technology#technology news#news#world news
16 notes
·
View notes
Text
Challenge 2
My dissertation aims to create a digital game in European Portuguese as a means of supporting language therapy for preschool children, both in session and at home. Note that the purpose of this work has been narrowed, from speech and language therapy to language therapy, as a result of further discussions with my advisors, including the therapist.
Speech and language therapy are two separate fields of study, and each subdivides itself into many different areas of intervention, meaning it would not be feasible to aim for a solution that would encompass all areas. According to the American Speech-Language-Hearing Association [1], people with a spoken language disorder (SLD) face challenges in acquiring and using language due to difficulties in comprehension and/or production in any, or multiple, of the 5 domains of language: phonology, morphology, syntax, semantics and pragmatics.
Having little to no prior knowledge about these topics, especially scientifically supported information and data, it is of the utmost importance that preliminary research is conducted about subjects such as:
Spoken language disorders in preschool children;
Different methods used during therapy intervention sessions for preschool children;
Mechanics used in digital games to assist language/speech therapy for preschool children;
Methods used in digital games to best engage preschool children, in order to retain their attention, and enhance the potential for better results;
Methods used in digital games to include the parents of preschool children.
This information will be sourced from scientific literature, such as peer-reviewed studies, and conference papers, but also from conversations with specialists in the field of speech and language therapy for children.
The exploration and understanding of the most relevant studies and theories on these topics, as well as the current context of the problem is, indeed, invaluable. It will be a continuous component of this dissertation, with a heightened focus during the initial stages of the project. This will establish a strong, robust foundation of knowledge, allowing for a deeper understanding of the issues at hand, and, in turn, fuel me with information that can directly be applied to the conceptualization, development, testing and deployment of a possible solution.
The purpose of the game will be to immerse children in a new universe, making therapy not feel like therapy. This will be achieved by delivering intervention exercises as a means of achieving progress in the overall game, for example having to answer correctly to the identification of images to unlock a door and move on to new challenges. There are age-appropriate considerations that need to be taken into account when designing the game, such as the developmental stage of the target audience and how to appeal to them, as explored in Chapter 9 of Digital Storytelling, Tackling Projects for Children [2]. It is, however, yet to be determined if these exercises will encompass all five domains of SLD, or focus on the selection of a few. The Programa de Intervenção em Competências Linguísticas [3] is the only Portuguese-validated program for intervention in the domains of semantics, morphology and syntax, and is currently and habitually used by therapists in sessions. It provides great insight into what types of games and play are employed with preschool children, which will later serve as an inspiration, and moulded to fit a digital game format, used amongst other game mechanics directed towards this age group.
Therefore, this represents an instance of action research, more specifically interactive research, using an interpretive approach. The primary goal is to address a practical issue, specifically the absence of digital game-based resources within the context of Portuguese language therapy for preschool children. This involves taking proactive steps and developing a solution, therefore action research, commencing with a comprehensive and thorough literature review on pertinent subjects to best inform future decision-making for the product. These decisions will be shared with all stakeholders, and their experiences with the product will be assessed, to register, and subsequently analyze, all their input and feedback. If deemed necessary and feasible, adjustments will be made to the product, in order for it to best fit the requirements, perspectives, motivations and expectations of the professional practitioners and the target audience, hence an interpretive approach. This forms a cyclical process, as the product will continually undergo development and improvement phases, thus too, an interactive approach to the development of a solution.
Moreover, considering that the primary objective of this dissertation is not to validate the solution through a case study, but rather to introduce a solution validated by the stakeholders actively engaged in the process, it paves the way for potential future research with an explanatory focus, as other researchers may be interested in assessing the potential impact of my work.
References
[1] Spoken Language Disorders, Publisher: American Speech-Language-Hearing Association. [Online]. Available: https://www.asha.org/practice-portal/clinical-topics/spoken-language-disorders/ (visited on 10/20/2023). [2] C. H. Miller, Digital Storytelling: A Creator’s Guide to Interactive Entertainment. USA: Taylor & Francis, 2004, ISBN: 0-240-80510-0. [3] M. Lousada, M. Ramalho, and C. Marques, Programa de Intervenção em Competências Linguísticas. Universidade de Aveiro, 2015.
4 notes
·
View notes
Text

aiv2 ryuusei 👍
#art#traditional art#watercolour#fanart#vocal synth#aoyama ryuusei#a.i.voice2#i keep saying this but this is the most tragically seo destroyed talk synth software name on earth#theyve been using the name for years..... years.......... before they even started using dl tech....#voicevox#<- for good measure#virvox project#anyway. ryuuseis big stupid huge boobs. 👍.#I AM also very curious for someone who owns him to see how he sounds with a2sync. he's like less expressive than his voicevox it sounds#since he doesnt have any emotion modes but he does sound pretty clean. id like to see how it sounds in a song LOL#dont mess with vocal synth fans. they will see a text-to-speech software and immediately want to hear it sing
4 notes
·
View notes
Text
Mom: How do I avoid viruses and hackers?
Me: Try to seek out FOSS when you need to download a new program, use Firefox and/or Brave when browsing, use a VPN, disable pop-ups…
Mom: I know! Pathological avoidance of the EXE extension!
#cybersecurity#computer viruses#FOSS#free software#free as in speech not beer#open-source#open source#open source software#open-source software#Firefox#brave browser#VPN#virtual private network#pop-up#pop-up ads#EXE files#Windows Executables#The lady also has well over 20 tabs open in Chrome on her so-so Dell Laptop whenever I visit her#And wonders why she needs to replace her computer every so often
11 notes
·
View notes
Text
honestly I'm surprised that nintendo's old servers have stayed up as long as they have considering the incredibly bare-bones moderation (ie.NOT AT ALL) . however I'm sad that I just now am getting around to modding a DS :pensive: Here's hoping there are fanservers
#vwoop.noises#Now. The question is will these fanservers bring back moderation. press x to doubt. I can't wait for the PSS to be even more genuinely vile#Idk. Maybe it will deter some people. Or maybe fanservers will not tolerate hate speech#Idek if they'd have the tools 2 moderate that on the server if clearly there is just none in the software#But. maybe all the hate speech is just one guy who put it there years ago and it stayed < coping#Genuinely it could be this bc even taking one for the team and trading for them just soft resets your game iirc and the pokemon can't be#removed from the GTS#< i don't reccomend this because I am so frightened
2 notes
·
View notes