#kubernetes cluster from scratch
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
AI Data Center Builder Nscale Secures $155M Investment
Nscale Ltd., a startup based in London that creates data centers designed for artificial intelligence tasks, has raised $155 million to expand its infrastructure.
The Series A funding round was announced today. Sandton Capital Partners led the investment, with contributions from Kestrel 0x1, Blue Sky Capital Managers, and Florence Capital. The funding announcement comes just a few weeks after one of Nscale’s AI clusters was listed in the Top500 as one of the world’s most powerful supercomputers.
The Svartisen Cluster took the 156th spot with a maximum performance of 12.38 petaflops and 66,528 cores. Nscale built the system using servers that each have six chips from Advanced Micro Devices Inc.: two central processing units and four MI250X machine learning accelerators. The MI250X has two graphics cards made with a six-nanometer process, plus 128 gigabytes of memory to store data for AI models.

The servers are connected through an Ethernet network that Nscale created using chips from Broadcom Inc. The network uses a technology called RoCE, which allows data to move directly between two machines without going through their CPUs, making the process faster. RoCE also automatically handles tasks like finding overloaded network links and sending data to other connections to avoid delays.
On the software side, Nscale’s hardware runs on a custom-built platform that manages the entire infrastructure. It combines Kubernetes with Slurm, a well-known open-source tool for managing data center systems. Both Kubernetes and Slurm automatically decide which tasks should run on which server in a cluster. However, they are different in a few ways. Kubernetes has a self-healing feature that lets it fix certain problems on its own. Slurm, on the other hand, uses a network technology called MPI, which moves data between different parts of an AI task very efficiently.
Nscale built the Svartisen Cluster in Glomfjord, a small village in Norway, which is located inside the Arctic Circle. The data center (shown in the picture) gets its power from a nearby hydroelectric dam and is directly connected to the internet through a fiber-optic cable. The cable has double redundancy, meaning it can keep working even if several key parts fail.
The company makes its infrastructure available to customers in multiple ways. It offers AI training clusters and an inference service that automatically adjusts hardware resources depending on the workload. There are also bare-metal infrastructure options, which let users customize the software that runs their systems in more detail.
Customers can either download AI models from Nscale's algorithm library or upload their own. The company says it provides a ready-made compiler toolkit that helps convert user workloads into a format that runs smoothly on its servers. For users wanting to create their own custom AI solutions, Nscale provides flexible, high-performance infrastructure that acts as a builder ai platform, helping them optimize and deploy personalized models at scale.
Right now, Nscale is building data centers that together use 300 megawatts of power. That’s 10 times more electricity than the company’s Glomfjord facility uses. Using the Series A funding round announced today, Nscale will grow its pipeline by 1,000 megawatts. “The biggest challenge to scaling the market is the huge amount of continuous electricity needed to power these large GPU superclusters,” said Nscale CEO Joshua Payne. Read this link also : https://sifted.eu/articles/tech-events-2025
“Nscale has a 1.3GW pipeline of sites in our portfolio, which lets us design everything from scratch – the data center, the supercluster, and the cloud environment – all the way through for our customers.” The company will build new data centers in North America and Europe. The company plans to build 120 megawatts of data center capacity next year. The new infrastructure will support Nscale’s upcoming public cloud service, which will focus on training and inference tasks, and is expected to launch in the first quarter of 2025.
0 notes
Text
A Hands-On Guide to Creating a Go Application with Docker and Kubernetes
Introduction A Hands-On Guide to Creating a Go Application with Docker and Kubernetes is a comprehensive tutorial that will walk you through the process of building a Go application from scratch, deploying it to a containerized environment using Docker, and then scaling it up to a production-ready cluster using Kubernetes. This tutorial is designed for developers who want to learn how to create…
0 notes
Text
Best Azure AI Engineer Training | Azure AI-102 Online Course
Deploying & Customizing Pre-Trained Models in Azure AI Services

Introduction:
AI-102 Certification and looking to deepen your knowledge in deploying pre-trained models and customizing them through Azure AI services, you're in the right place. Azure AI Engineer Training is crucial for building and maintaining AI solutions on the Microsoft Azure platform. In this article, we will walk you through how to leverage pre-trained models, customize them, and deploy them within Azure AI services effectively. These capabilities play a vital role in creating powerful machine learning solutions, making it easier to implement AI functionality without starting from scratch.
What Are Pre-Trained Models in Azure AI?
Pre-trained models are machine learning models that have already been trained on large datasets and are optimized for specific tasks. These models are designed to handle tasks such as image recognition, natural language processing, and speech recognition. By leveraging pre-trained models, developers can save a significant amount of time, as they don't need to train models from scratch. These models come ready to use within Azure AI services like Azure Cognitive Services, which offer various APIs to integrate pre-trained capabilities into your applications.
Azure’s pre-trained models include services like:
Computer Vision: For image classification, object detection, and text extraction.
Speech: For speech recognition, speech translation, and speaker identification.
Language: For text analytics, sentiment analysis, language understanding (LUIS), and translation.
Custom Vision: A specialized service that allows users to train custom image classification models with minimal effort.
Why Use Pre-Trained Models in Azure AI?
The main advantage of using pre-trained models in Azure is their ability to expedite the AI development process. These models have already been trained on vast amounts of data, making them highly accurate and effective. They can help solve a wide range of problems across different industries, such as healthcare, finance, retail, and more. Azure AI Engineer Training equips professionals with the knowledge to effectively use these services to integrate pre-trained models into their applications.
Additionally, pre-trained models allow organizations to access state-of-the-art AI technology without the need for deep expertise in machine learning. With these models, developers can easily implement AI capabilities into their projects with just a few lines of code. As part of your AI-102 Microsoft Azure AI Training, you'll learn how to deploy and customize these models, ensuring that they meet your unique requirements.
Deploying Pre-Trained Models from Azure AI Services
When it comes to deploying pre-trained models, Azure provides several options. Azure AI Engineer Training covers these methods in detail, teaching you how to deploy models in both cloud and edge environments. Here’s how you can deploy pre-trained models in Azure:
Step 1: Choose the Right Pre-Trained Model
The first step in deploying a pre-trained model is selecting the one that fits your requirements. Azure Cognitive Services offers a variety of pre-built models tailored to specific tasks, such as vision, language, and speech. For instance, if you're building an application that needs to analyze customer feedback, the Text Analytics API might be a good fit. If your project requires image analysis, Computer Vision or Custom Vision would be ideal choices.
Step 2: Set Up Azure Resources
Once you’ve selected a model, the next step is to set up the necessary Azure resources, such as an Azure subscription, resource group, and the specific AI service. Depending on the service you’re using, you’ll need to create resources like Cognitive Services accounts, machine learning workspaces, or Azure Kubernetes Service (AKS) clusters for deploying models at scale.
Step 3: Integrate the Pre-Trained Model
With the Azure resources set up, you can now integrate the pre-trained model into your application. Azure provides SDKs for multiple programming languages, including Python, C#, and Java, to help you connect to Azure’s AI services easily. After integration, the model is ready to process input and generate predictions. For example, if you're using the Speech-to-Text API, the model can transcribe audio data into text.
Step 4: Monitor and Optimize the Deployment
Once deployed, it’s important to monitor the model’s performance in real time. Azure offers built-in monitoring tools like Azure Monitor to track key metrics such as response times, usage, and accuracy. Regular optimization ensures the model continues to deliver accurate results as your application scales.
Customizing Pre-Trained Models from Azure AI Services
While pre-trained models are powerful out of the box, there may be cases where you need to fine-tune them to better suit your specific use case. Azure AI services allow you to customize pre-trained models, making them adaptable to your needs. Customizing these models involves providing additional data to retrain them or modify their behaviour.
Customizing a Model in Azure
Collect Your Dataset: Gather a dataset that represents the unique scenarios of your application. For instance, if you're building a chatbot, you’ll need to gather examples of the phrases or questions users will ask.
Train the Model: Using Azure’s training tools, upload your data to the platform and begin training. This process involves adapting the model to learn patterns specific to your dataset.
Evaluate and Test: After training, evaluate the model to ensure its accurate and reliable. Azure provides testing tools that allow you to test your model’s predictions against known data.
Deploy the Custom Model: Once you're satisfied with the custom model’s performance, you can deploy it just like a pre-trained model.
Use Cases for Customizing Pre-Trained Models
Image Recognition: Fine-tuning pre-trained models to identify specific objects, such as brand logos or medical conditions.
Chatbots and Virtual Assistants: Customizing NLP models to better understand domain-specific jargon and user queries.
Sentiment Analysis: Adjusting language models to analyze customer feedback with a focus on industry-specific sentiments.
Conclusion
In conclusion, mastering how to deploy and customize pre-trained models is an essential skill for professionals aiming to earn the AI-102 Certification and pursue a career in Azure AI engineering. By using Azure AI Engineer Training and the tools provided by Microsoft Azure, you can effectively integrate pre-trained models into your applications, customize them for specific needs, and deploy them at scale. These skills will help you build efficient AI solutions that improve business processes, enhance user experiences, and provide valuable insights. As you progress in your AI-102 Microsoft Azure AI Training, you'll be better equipped to tackle real-world AI challenges and become an expert in Azure AI services.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Azure AI (AI-102) worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://visualpathblogs.com/
Visit: https://www.visualpath.in/online-ai-102-certification.html
#Ai 102 Certification#Azure AI Engineer Certification#Azure AI Engineer Training#Azure AI-102 Course in Hyderabad#Azure AI Engineer Online Training#Microsoft Azure AI Engineer Training#AI-102 Microsoft Azure AI Training
0 notes
Text
Running Legacy Applications on OpenShift Virtualization: A How-To Guide
Organizations looking to modernize their IT infrastructure often face a significant challenge: legacy applications. These applications, while critical to operations, may not be easily containerized. Red Hat OpenShift Virtualization offers a solution, enabling businesses to run legacy virtual machine (VM)-based applications alongside containerized workloads. This guide provides a step-by-step approach to running legacy applications on OpenShift Virtualization.
Why Use OpenShift Virtualization for Legacy Applications?
OpenShift Virtualization, powered by KubeVirt, integrates VM management into the Kubernetes ecosystem. This allows organizations to:
Preserve Investments: Continue using legacy applications without expensive rearchitecture.
Simplify Operations: Manage VMs and containers through a unified OpenShift Console.
Bridge the Gap: Modernize incrementally by running VMs alongside microservices.
Enhance Security: Leverage OpenShift’s built-in security features like SELinux and RBAC for both containers and VMs.
Preparing Your Environment
Before deploying legacy applications on OpenShift Virtualization, ensure the following:
OpenShift Cluster: A running OpenShift Container Platform (OCP) cluster with sufficient resources.
OpenShift Virtualization Operator: Installed and configured from the OperatorHub.
VM Images: A QCOW2, OVA, or ISO image of your legacy application.
Storage and Networking: Configured storage classes and network settings to support VM operations.
Step 1: Enable OpenShift Virtualization
Log in to your OpenShift Web Console.
Navigate to OperatorHub and search for "OpenShift Virtualization".
Install the OpenShift Virtualization Operator.
After installation, verify the "KubeVirt" custom resources are available.
Step 2: Create a Virtual Machine
Access the Virtualization Dashboard: Go to the Virtualization tab in the OpenShift Console.
New Virtual Machine: Click on "Create Virtual Machine" and select "From Virtual Machine Import" or "From Scratch".
Define VM Specifications:
Select the operating system and size of the VM.
Attach the legacy application’s disk image.
Allocate CPU, memory, and storage resources.
Configure Networking: Assign a network interface to the VM, such as a bridge or virtual network.
Step 3: Deploy the Virtual Machine
Review the VM configuration and click "Create".
Monitor the deployment process in the OpenShift Console or use the CLI with:
oc get vmi
Once deployed, the VM will appear under the Virtual Machines section.
Step 4: Connect to the Virtual Machine
Access via Console: Open the VM’s console directly from the OpenShift UI.
SSH Access: If configured, connect to the VM using SSH.
Test the legacy application to ensure proper functionality.
Step 5: Integrate with Containerized Services
Expose VM Services: Create a Kubernetes Service to expose the VM to other workloads.
oc expose vmi <vm-name> --port=8080 --target-port=80
Connect Containers: Use Kubernetes-native networking to allow containers to interact with the VM.
Best Practices
Resource Allocation: Ensure the cluster has sufficient resources to support both VMs and containers.
Snapshots and Backups: Use OpenShift’s snapshot capabilities to back up VMs.
Monitoring: Leverage OpenShift Monitoring to track VM performance and health.
Security Policies: Implement network policies and RBAC to secure VM access.
Conclusion
Running legacy applications on OpenShift Virtualization allows organizations to modernize at their own pace while maintaining critical operations. By integrating VMs into the Kubernetes ecosystem, businesses can manage hybrid workloads more efficiently and prepare for a future of cloud-native applications. With this guide, you can seamlessly bring your legacy applications into the OpenShift environment and unlock new possibilities for innovation.
For more details visit: https://www.hawkstack.com/
0 notes
Text
4-way Google Kubernetes Engine Tips for Cold Start Lag

Google Kubernetes Engine Capabilities If you use Google Kubernetes Engine for workload execution, it’s likely that you have encountered “cold starts,” which are delays in application launch caused by workloads assigned to nodes that haven’t hosted the workload before and need the pods to spin up from scratch. When an application is autoscaling to manage a spike in traffic, the lengthier startup time may cause longer response times and a poorer user experience.
What happens when a vehicle is cold-started? Pulling container images, launching containers, and initializing the application code are some of the common tasks involved in deploying a containerized application on Kubernetes. The time it takes for a pod to begin serving traffic is extended by these procedures, which raises the latency for the initial requests that a new pod serves. The lack of a pre-existing container image on the new node might result in a much longer initial startup time. The pod doesn’t need to start up again since it is already up and heated when a subsequent request comes in.
When pods are being shut down and restarted repeatedly, requests are being sent to fresh, cold pods, which results in a high frequency of cold starts. Maintaining warm pools of pods available to lower the cold start delay is a typical remedy.
Nevertheless, the warm pool technique may be quite expensive for heavier workloads like AI/ML, particularly on pricey and in-demand GPUs. Thus, cold starts are particularly frequent for workloads including AI and ML, where pods are often shut off upon completion of requests.
The managed Kubernetes service offered by Google Cloud, Google Kubernetes Engine (GKE), may facilitate the deployment and upkeep of complex containerized workloads. They will go over four distinct methods in this article to lower cold start latency on Google Kubernetes Engine and enable you to provide responsive services.
Methods for overcoming the difficulty of chilly starts When using bigger boot drives or local SSDs, use ephemeral storage On a local SSD, nodes mount the root directories of the Kubelet and container runtime (docker or containerd). Because of this, the local SSD backs up the container layer; the throughput and IOPS are detailed on About local SSDs. Generally speaking, this is more economical than increasing the PD size.
The choices are compared in the accompanying table, which shows that LocalSSD has almost three times the throughput of PD for the same cost. This allows the image pull to operate more quickly and lowers the workload’s starting delay.
With local SSDs, you may set up a node pool in an existing cluster running Google Kubernetes Engine version 1.25.3-gke.1800 or later to leverage ephemeral storage.
Turn on streaming for container images
Significant savings in workload starting time may be achieved by using picture streaming, which enables workloads to begin without waiting for the whole image to be downloaded. For instance, an NVIDIA Triton Server’s end-to-end startup time (from workload generation to server ready for traffic) may be lowered from 191s to 30s using Google Kubernetes Engine image streaming.
Make use of compressed Zstandard container images
ContainerD supports the Zstandard compression function. Zstandard benchmark indicates that zstd decompresses more than three times quicker than gzip.
Please be aware that picture streaming and Zstandard are incompatible. Zstandard is preferable if your application has to load the bulk of the container image content before it launches. Try image streaming if your application only need a tiny amount of the whole container image to load in order to begin running.
To preload the basic container on nodes, use a Preloader DaemonSet
Not to mention, if many containers share a base container, ContainerD reuses the picture layers across them. Furthermore, DaemonSet, the preloader, may begin operating even before the GPU driver (which takes around 30 seconds to install) is loaded. This implies that it may begin fetching pictures in advance and preload the necessary containers before the GPU workload can be scheduled to the GPU node.
Getting beyond the frigid start
One prevalent issue in container orchestration systems is the cold start dilemma. Its effect on your Google Kubernetes Engine -running apps may be minimized with appropriate design and optimization. You may minimize cold start delays and guarantee a more responsive and effective system by leveraging ephemeral storage with bigger boot disks, turning on container streaming or Zstandard compression, and preloading the basic container with a daemonset.
Read more on Govindhtech.com
0 notes
Text
Kubernetes Tools
Kubernetes is an open-source container orchestration system that helps automate the deployment, scaling, and management of containerized applications. There are several tools available in the Kubernetes ecosystem that can be used to manage Kubernetes clusters and deploy applications.
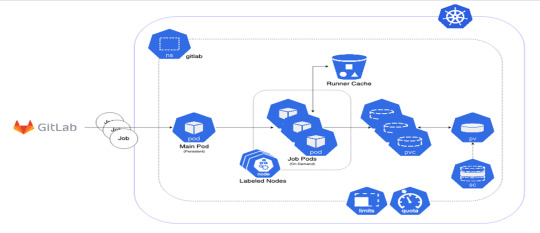
Here are some commonly used Kubernetes tools:
kubectl: kubectl is a command-line interface (CLI) tool that allows users to interact with Kubernetes clusters. It can be used to create, update, and delete resources within a Kubernetes cluster.
Helm: Helm is a package manager for Kubernetes that simplifies the deployment of applications and services. It allows users to define and manage application dependencies, making it easier to install and upgrade applications.
Minikube: Minikube is a tool that enables users to run a single-node Kubernetes cluster on their local machine. It provides an easy way to test and develop applications in a Kubernetes environment.
kubeadm: kubeadm is a tool that automates the process of setting up a Kubernetes cluster. It can be used to bootstrap a cluster, add or remove nodes, and upgrade the cluster to a new version.
kustomize: kustomize is a tool that allows users to customize Kubernetes resources without having to modify the original YAML files. It enables users to apply patches to existing resources or create new resources from scratch.
Prometheus: Prometheus is a monitoring system that can be used to monitor Kubernetes clusters and applications running on them. It provides real-time metrics and alerts for Kubernetes resources.
Istio: Istio is a service mesh that provides traffic management, security, and observability for Kubernetes applications. It can be used to manage traffic between services, enforce security policies, and collect telemetry data.
Visit our Website For more: https://www.doremonlabs.com/
0 notes
Text
Kubernetes Cloud Controller Manager Tutorial for Beginners
Hi, a new #video on #kubernetes #cloud #controller #manager is published on #codeonedigest #youtube channel. Learn kubernetes #controllermanager #apiserver #kubectl #docker #proxyserver #programming #coding with #codeonedigest #kubernetescontrollermanag
Kubernetes is a popular open-source platform for container orchestration. Kubernetes follows client-server architecture and Kubernetes cluster consists of one master node with set of worker nodes. Cloud Controller Manager is part of Master node. Let’s understand the key components of master node. etcd is a configuration database stores configuration data for the worker nodes. API Server to…

View On WordPress
#kubernetes#kubernetes cloud controller manager#kubernetes cluster#kubernetes cluster backup#kubernetes cluster from scratch#kubernetes cluster installation#kubernetes cluster setup#kubernetes cluster tutorial#kubernetes controller#kubernetes controller development#kubernetes controller example#kubernetes controller explained#kubernetes controller golang#kubernetes controller manager#kubernetes controller manager components#kubernetes controller manager config#kubernetes controller manager logs#kubernetes controller manager vs scheduler#kubernetes controller runtime#kubernetes controller tutorial#kubernetes controller vs operator#kubernetes etcd#kubernetes etcd backup#kubernetes etcd backup and restore#kubernetes etcd cluster setup#kubernetes etcd install#kubernetes etcd restore#kubernetes explained#kubernetes installation#kubernetes installation on windows
0 notes
Text
A Vagrant Story
Like everyone else I wish I had more time in the day. In reality, I want to spend more time on fun projects. Blogging and content creation has been a bit on a hiatus but it doesn't mean I have less things to write and talk about. In relation to this rambling I want to evangelize a tool I've been using over the years that saves an enormous amount of time if you're working in diverse sandbox development environments, Vagrant from HashiCorp.
Elevator pitch
Vagrant introduces a declarative model for virtual machines running in a development environment on your desktop. Vagrant supports many common type 2 hypervisors such as KVM, VirtualBox, Hyper-V and the VMware desktop products. The virtual machines are packaged in a format referred to as "boxes" and can be found on vagrantup.com. It's also quite easy to build your own boxes from scratch with another tool from HashiCorp called Packer. Trust me, if containers had not reached the mainstream adoption it has today, Packer would be a household tool. It's a blog post in itself for another day.
Real world use case
I got roped into a support case with a customer recently. They were using the HPE Nimble Storage Volume Plugin for Docker with a particular version of NimbleOS, Docker and docker-compose. The toolchain exhibited a weird behavior that would require two docker hosts and a few iterations to reproduce the issue. I had this environment stood up, diagnosed and replied to the support team with a customer facing response in less than an hour, thanks to Vagrant.
vagrant init
Let's elaborate on how to get a similar environment set up that I used in my support engagement off the ground. Let's assume vagrant and a supported type 2 hypervisor is installed. This example will work on Windows, Linux and Mac.
Create a new project folder and instantiate a new Vagrantfile. I use a collection of boxes built from these sources. Bento boxes provide broad coverage of providers and a variety of Linux flavors.
mkdir myproj && cd myproj vagrant init bento/ubuntu-20.04 A `Vagrantfile` has been placed in this directory. You are now ready to `vagrant up` your first virtual environment! Please read the comments in the Vagrantfile as well as documentation on `vagrantup.com` for more information on using Vagrant.
There's now a Vagrantfile in the current directory. There's a lot of commentary in the file to allow customization of the environment. It's possible to declare multiple machines in one Vagrantfile, but for the sake of an introduction, we'll explore setting up a single VM.
One of the more useful features is that Vagrant support "provisioners" that runs at first boot. It makes it easy to control the initial state and reproduce initialization with a few keystrokes. I usually write Ansible playbooks for more elaborate projects. For this exercise we'll use the inline shell provisioner to install and start docker.
Vagrant.configure("2") do |config| config.vm.box = "bento/ubuntu-20.04" config.vm.provision "shell", inline: <<-SHELL apt-get update apt-get install -y docker.io python3-pip pip3 install docker-compose usermod -a -G docker vagrant systemctl enable --now docker SHELL end
Prepare for very verbose output as we bring up the VM.
Note: The vagrant command always assumes working on the Vagrantfile in the current directory.
vagrant up
After the provisioning steps, a new VM is up and running from a thinly cloned disk of the source box. Initial download may take a while but the instance should be up in a minute or so.
Post-declaration tricks
There are some must-know Vagrant environment tricks that differentiate Vagrant from right-clicking in vCenter or fumbling in the VirtualBox UI.
SSH access
Accessing the shell of the VM can be done in two ways, most commonly is to simply do vagrant ssh and that will drop you at the prompt of the VM with the predefined user "vagrant". This method is not very practical if using other SSH-based tools like scp or doing advanced tunneling. Vagrant keeps track of the SSH connection information and have the capability to spit it out in a SSH config file and then the SSH tooling may reference the file. Example:
vagrant ssh-config > ssh-config ssh -F ssh-config default
Host shared directory
Inside the VM, /vagrant is shared with the host. This is immensely helpful as any apps your developing for the particular environment can be stored on the host and worked on from the convenience of your desktop. As an example, if I were to use the customer supplied docker-compose.yml and Dockerfile, I'd store those in /vagrant/app which in turn would correspond to my <current working directory for the project>/app.
Pushing and popping
Vagrant supports using the hypervisor snapshot capabilities. However, it does come with a very intuitive twist. Assume we want to store the initial boot state, let's push!
vagrant snapshot push ==> default: Snapshotting the machine as 'push_1590949049_3804'... ==> default: Snapshot saved! You can restore the snapshot at any time by ==> default: using `vagrant snapshot restore`. You can delete it using ==> default: `vagrant snapshot delete`.
There's now a VM snapshot of this environment (if it was a multi-machine setup, a snapshot would be created on all the VMs). The snapshot we took is now on top of the stack. Reverting to the top of the stack, simply pop back:
vagrant snapshot pop --no-delete ==> default: Forcing shutdown of VM... ==> default: Restoring the snapshot 'push_1590949049_3804'... ==> default: Checking if box 'bento/ubuntu-20.04' version '202004.27.0' is up to date... ==> default: Resuming suspended VM... ==> default: Booting VM... ==> default: Waiting for machine to boot. This may take a few minutes... default: SSH address: 127.0.0.1:2222 default: SSH username: vagrant default: SSH auth method: private key ==> default: Machine booted and ready! ==> default: Machine already provisioned. Run `vagrant provision` or use the `--provision` ==> default: flag to force provisioning. Provisioners marked to run always will still run.
You're now back to the previous state. The snapshot sub-command allows restoring to a particular snapshot and it's possible to have multiple states with sensible names too, if stepping through debugging scenarios or experimenting with named states.
Summary
These days there's a lot of compute and memory available on modern laptops and desktops. Why run development in the cloud or a remote DC when all you need is available right under your finger tips? Sure, you can't run a full blown OpenShift or HPE Container Platform but you can certainly run a representable Kubernetes clusters where minishift, microk8s and the likes won't work if you need access to the host OS (yes, I'm in the storage biz). In a recent personal project I've used this tool to simply make Kubernetes clusters with Vagrant. It works surprisingly well and allow a ton of customization.
Bonus trivia
Vagrant Story is a 20 year old videogame for PlayStation (one) from SquareSoft (now SquareEnix). It features a unique battle system I've never seen anywhere else to this day and it was one of those games I played back-to-back three times over. It's awesome. Check it out on Wikipedia.
1 note
·
View note
Text
Kubernetes Training from h2kinfosys
About kubernetes training course
Kubernetes is a portable, extensible open-source platform for managing containerized workloads and services that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Google open-sourced the Kubernetes project in 2014. Kubernetes builds upon a decade and a half of experience that Google has with running production workloads at scale, combined with best-of-breed ideas.

In our kubernetes Training you will learn:
Various components of k8s cluster on AWS cloud using ubuntu 18.04 linux images.
Setting up AWS cloud environment manually.
Installation and setting up kubernetes cluster on AWS manually from scratch.
Installation and Setting up etcd cluster ( key-value ) datastore
Provisioning the CA and Generating TLS Certificates for k8s cluster and etcd server.
Installation of Docker.
Configuring and CNI plugins to wire docker containers for networking.
Creating IAM roles for the kubernetes cloud setup.
Kubernetes deployments, statefulsets, Network policy etc.
Why consider a kubernetes career path in IT industry?
Kubernetes demand has exploded and its adoption is increasing many folds every quarter.
As more and more companies moving towards the automation and embracing open source technologies. Kubernetes slack-user has more 65,000 users and counting.
Who is eligible for the kubernetes course?
Beginner to intermediate level with elementary knowledge of Linux and docker.
Enroll Today for our Kubernetes Training!
Contact Us:
https://www.h2kinfosys.com/courses/kubernetes-training
Call: USA: +1- 770-777-1269.
Email: [email protected]
https://www.youtube.com/watch?v=Fa9JfWmqR2k
1 note
·
View note
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Explore software engineering methodologies, techniques, and best practices in Go programming to build easy-to-maintain software that can effortlessly scale on demandKey Features Apply best practices to produce lean, testable, and maintainable Go code to avoid accumulating technical debt Explore Go’s built-in support for concurrency and message passing to build high-performance applications Scale your Go programs across machines and manage their life cycle using Kubernetes Book Description Over the last few years, Go has become one of the favorite languages for building scalable and distributed systems. Its opinionated design and built-in concurrency features make it easy for engineers to author code that efficiently utilizes all available CPU cores. This Golang book distills industry best practices for writing lean Go code that is easy to test and maintain, and helps you to explore its practical implementation by creating a multi-tier application called Links ‘R’ Us from scratch. You’ll be guided through all the steps involved in designing, implementing, testing, deploying, and scaling an application. Starting with a monolithic architecture, you’ll iteratively transform the project into a service-oriented architecture (SOA) that supports the efficient out-of-core processing of large link graphs. You’ll learn about various cutting-edge and advanced software engineering techniques such as building extensible data processing pipelines, designing APIs using gRPC, and running distributed graph processing algorithms at scale. Finally, you’ll learn how to compile and package your Go services using Docker and automate their deployment to a Kubernetes cluster. By the end of this book, you’ll know how to think like a professional software developer or engineer and write lean and efficient Go code.What you will learn Understand different stages of the software development life cycle and the role of a software engineer Create APIs using gRPC and leverage the middleware offered by the gRPC ecosystem Discover various approaches to managing package dependencies for your projects Build an end-to-end project from scratch and explore different strategies for scaling it Develop a graph processing system and extend it to run in a distributed manner Deploy Go services on Kubernetes and monitor their health using Prometheus Who this book is for This Golang programming book is for developers and software engineers looking to use Go to design and build scalable distributed systems effectively. Knowledge of Go programming and basic networking principles is required. Publisher : Packt Publishing Limited (24 January 2020) Language : English Paperback : 640 pages ISBN-10 : 1838554491 ISBN-13 : 978-1838554491 Item Weight : 1 kg 80 g Dimensions : 19.05 x 3.68 x 23.5 cm Country of Origin : India [ad_2]
0 notes
Text
Devops Online Training Hyderabad
DevOps Server integrates along with your current IDE or editor, enabling your cross-functional group to work effectively on projects of all sizes. Jenk ins Pipeline is a software used to implement the continual integration and steady deployment in any group. In this project, you will be following the process of deploying utility to execute full-fledged CI & CD.
DevOps is a bunch of practices that joins programming advancement (Dev) and IT activities, the two some time ago filthy groups. With DevOps, the two groups cooperate to work on both the efficiency of engineers and the unwavering quality of activities by taking an interest together in the whole help lifecycle, from plan through the improvement cycle to creation support.
DevOps is acquiring foothold (and will proceed to) on the grounds that it was made by programmers for programmers and is an adaptable practice, not an unbending system.
DevOps matters as it's permitting organizations to change how they assemble and convey programming. The change is fundamental as programming today has turned into an indispensable part of all aspects of a business, from shopping to amusement to banking-based organizations. As modern mechanization permitted actual merchandise organizations to change how they configuration, assemble, and convey items all through the twentieth century, DevOps is permitting organizations to plan and construct excellent programming with a short-improvement life cycle, and give ceaseless conveyance to accomplish business objectives quicker.
What you will learn in Devops?
· Get a careful clarification of DevOps ideas including light-footed programming advancement, DevOps market patterns, abilities, conveyance pipeline, and the Ecosystem.
· Get to know GIT Installation, and form control.
· Figure out how to oversee and follow distinctive source code renditions utilizing Git.
· Assemble and Automate Test utilizing Jenkins and Maven. Investigate consistent testing with Selenium, and make experiments in Selenium WebDriver.
· Expert Docker environment, Docker systems administration and utilize the information to convey a multi-level application over a group.
· Comprehend various Roles and Command Line use of Ansible, and apply that to execute specially appointed orders.
· Acquire information on Kubernetes Cluster Architecture, comprehend YAML, and send an application through Kubernetes Dashboard.
· Perform Continuous Monitoring utilizing Nagios.
· Get acquainted with DevOps on Cloud, and execute DevOps utilizing AWS.
DevOps approach is a software program growth and provides collaboration with incremental changes. They don't code from scratch but they want to have a great understanding of codes. If you're in Hyderabad and discovering it troublesome to be taught and master DevOps,. It is amongst the premium institutes for coaching and placement in Hyderabad.
The DevOps certification course in Hyderabad https://eduxfactor.com/devops-online-training will focus on teaching the significance of automation, culture and metrics in the success of DevOps projects. Dedicated Support We present any time assist for the participants during their course. DevOps is collaboration between Development and IT Operations to make software program programming and deployment in an automated way.
Online training is resided and the teacher's display screen will be visible and voice will be audible. Participants screen may also be visible and participants can ask queries in the course of the stay session. Nagios is a powerful monitoring system that allows organizations to determine and resolve IT infrastructure issues before they have an result on crucial business processes. Nagios monitors your complete IT infrastructure to make sure techniques, applications, providers, and enterprise processes are functioning properly.
This sensible training functions such that it lets the scholars learn the way to deal with the cutting-edge DevOps tools like Docker, Git, Jenkins, Nagios, Ansible, etc. Moreover, this training course aims at preparing the scholars to face technical challenges all through the DevOps software program development procedure. Get skilled on DevOps from InventaTeq along with certification. The learning course of consists of each technical and non-technical features. It helps you in studying the skills like communication, collaboration, and other operations together with the project improvement i.e. coding, algorithms and so on. Devops good profession presents promising opportunities for a flourishing career, and it is also necessary for every student to develop the best skills for a career in devops.
This Comprehensive DevOps Course will Covers the Fundamentals of DevOps Principle, Installation and Configuration of DevOps Infrastructure Servers with Project Implementations. You will achieve practical exposure to Docker and Kubernetes for designing and delivering containerized purposes in AWS Cloud. This Course aims to Provide Practical information on DevOps Process to fill the gaps between Software growth teams, Operation groups, and Testing Teams to improve Project Productivity. How to use every DevOps software is defined with a practical Demo.
The facility centre is supplied with all the most recent applied sciences to assist the coaching on DevOps technology. Besant Technologies conducts improvement classes together with mock interviews, presentation expertise to arrange students to face a challenging interview situation with ease. RR, Development and consulting providers that helps college students bring the way forward for work to life right now in a corporate setting. DevOps (development & operations) is an endeavor software program improvement categorical used to mean a type of agile connection amongst improvement & IT operations. The goal of DevOps is to vary & improve the relationship by upholding higher correspondence and coordinated effort between these two enterprise items.
0 notes
Text
SBTB 2021 Program is Up!
Scale By the Bay (SBTB) is in its 9th year.
See the 2021 Scale By the Bay Program
When we started, Big Data was Hadoop, with Spark and Kafka quite new and uncertain. Deep Learning was in the lab, and distributed systems were managed by a menagerie sysadmin tools such as Ansible, Salt, Puppet and Chef. Docker and Kubernetes were in the future, but Mesos had proven itself at Twitter, and a young startup called Mesosphere was bringing it to the masses. Another thing proven at Twitter, as well as in Kafka and Spark, was Scala, but the golden era of functional programming in industry was still ahead of us.
AI was still quite unglamorous Machine Learning, Data Mining, Analytics, and Business Intelligence.
But the key themes of SBTB were already there:
Thoughtful Software Engineering
Software Architectures and Data Pipelines
Data-driven Applications at Scale
The overarching idea of SBTB is that all great scalable systems are a combination of all three. The notions pioneered by Mesos became Kubernetes and its CNCF ecosystem. Scala took hold in industry alongside Haskell, OCaml, Cloujure, and F#. New languages like Rust and Dhall emerged with similar ideas and ideals. Data pipelines were formed around APIs, REST and GraphQL, and tools like Apache Kafka. ML became AI, and every scaled business application became an AI application.
SBTB tracks the evolution of the state of the art in all three of its tracks, nicknamed Functional, Cloud, and Data. The core idea is still making distributed systems solve complex business problems at the web scale, doable by small teams of inspired and happy software engineers. Happiness comes from learning, technology choices automating away the mundane, and a scientific approach to the field. We see the arc of learning elevating through the years, as functional programming concepts drive deep into category theory, type systems are imposed on the deep learning frameworks and tensors, middleware abstracted via GraphQL formalisms, compute made serverless, AI hitting the road as model deployment, and so on. Let's visit some of the highlights of this evolution in the 2021 program.
FP for ML/AI
As more and more decisions are entrusted to AI, the need to understand what happens in the deep learning systems becomes ever more urgent. While Python remains the Data Science API of choice, the underlying libraries are written in C++. The Hasktorch team shares their approach to expose PyTorch capabilities in Haskell, building up to the transformers with the Gradual Typing. The clarity of composable representations of the deep learning systems will warm many a heart tested by the industry experience where types ensure safety and clarity.
AI
We learn how Machine Learning is used to predict financial time series. We consider the bias in AI and hardware vs software directions of its acceleration. We show how an AI platform can be built from scratch using OSS tools. Practical AI deployments is covered by DVC experiments. We look at the ways Transformers are transforming Autodesk. We see how Machine Learning is becoming reproducible with MLOps at Microsoft. We even break AI dogma with Apache NLPCraft.
Cloud
Our cloud themes include containers with serverless functions, a serverless query engine, event-driven patterns for microservices, and a series of practical stacks. We review the top CNCF projects to watch. Ever-green formidable challenges like data center migration to the cloud at Workday scale are presented by the lead engineers who made it happen. Fine points of scalability are explored beyond auto-scaling. We look at stateful reactive streams with Akka and Kafka, and the ways to retrofit your Java applications with reactive pipelines for more efficiency. See how Kubernetes can spark joy for your developers.
Core OSS Frameworks
As always, we present the best practices deploying OSS projects that our communities adopted before the rest -- Spark, Kafka, Druid, integrating them in the data pipelines and tuning for the best performance and ML integration at scale. We cover multiple aspects of tuning Spark performance, using PySpark with location and graph data. We rethink the whole ML ecosystem with Spark. We elucidate patterns of Kafka deployments for building microservice architectures.
Software Engineering
Programming language highlights include Scala 3 transition is illuminated by Dean Wampler and Bill Venners, Meaning for the Masses from Twitter, purity spanning frontend to backend, using type safety for tensor calculus in Haskell and Scala, using Rust for WebAssembly, a categorical view of ADTs, distributed systems and tracing in Swift, complex codebase troubleshooting, dependent and linear types, declarative backends, efficient arrays in Scala 3, and using GraalVM to optimize ML serving. We are also diving into Swift for distributed systems with its core team.
Other Topics
We look at multidimensional clustering, the renessance of the relational databases, cloud SQL and data lakes, location and graph data, meshes, and other themes.
There are fundamental challenges that face the industry for years to come, such as AI bias we rigirously explore, hardware and software codevelopment for AI acceleration, and moving large enterprise codebases from on-prem to the cloud, as we see with Workday.
The companies presenting include Apple, Workday, Nielsen, Uber, Google Brain, Nvidia, Domino Data Labs, Autodesk, Twitter, Microsoft, IBM, Databricks, and many others.# Scale By the Bay 2021 Program is Up!
Reserve your pass today
0 notes
Text
New DoD Capabilities with Google Cloud

Google Cloud for DoD Applications
Google Cloud provides fundamental infrastructure and distinctive services to help customers complete missions and commercial tasks. Google DoD and other public sector customers can innovate with unsurpassed security, scale, and service. What sets us apart from other cloud providers?
Security and compliance in software vs. hardware
Google Cloud views accreditation as a systems problem that can be solved with its distinct software and security stack. As Zero Trust pioneers, Google have adopted a unique approach to IL5 compliance across our infrastructure. Google Cloud infrastructure isolates sensitive workloads with Assured Workloads, an SDCC. Public sector customers can maximize security and use of their scalable platform using this method. Google meet and frequently exceed federal security regulations by concentrating on their capabilities’ security, including conformity with the current NIST standards. Modern cloud partners must provide security, computational power, and capabilities to public sector customers. Google assist customers in developing a safe, AI-enabled government beyond GovClouds.
Maintaining security should be simple. Google Cloud Assured Workloads lets clients switch their execution environment to meet their security and compliance demands.
Google Distributed Cloud (GDC) Hosted provides fully separated platforms with top-tier security. Air-gapped GDC Hosted manages infrastructure, services, APIs, and tooling without Google Cloud or the internet. It is designed to stay disconnected forever. GDC Hosted offers innovative cloud services including Vertex AI platform features like Translation API and Speech-to-Text. Based on the Kubernetes API, GDC Hosted uses prominent open source components in its platform and managed services. A marketplace of independent software manufacturers’ applications adds extensibility.
Google cloud supports the world’s largest consumer services
Google dedication to the most resilient and secure network is essential with six products having over two billion users apiece. Google manage about 25% of global network traffic. Their network is one of the world’s largest privately managed networks since they built it from scratch to handle this massive volume. Based on Google 14 subsea cables, this enormous network connects 39 regions, 118 zones, and 187 edge points in 200+ nations and territories. Google’s global network provides unrivaled capacity and low latency for a wide range of service members in tough places.
For U.S. public sector clients, Google Cloud currently has the most complete cloud service portfolio with nine supported regions and 28 zones. This lets federal, state, local, and educational organizations use Google Cloud’s security, performance, scalability, and efficiency. Google add essential IL5 offerings to support the largest consumer services.
The Google Cloud security focus extends to their network. Google prevented the greatest HTTP requests per second DDoS assault on one of Google Cloud clients and the largest network bits per second attack on our services. Google have the high bandwidth, low latency, and secure network Google Cloud consumers need thanks to this diligence. For Google public sector customers, our best-in-class infrastructure provides constant performance, security, and data residency controls to keep everything where you want it.
Google open source mindset fosters multi-cloud interoperability, and other providers follow suit
Google set the global standard for cloud platforms when Google open-sourced Kubernetes in 2014. Google managed Kubernetes platform, Google Kubernetes Engine (GKE), has unique features because Google invented Kubernetes. The world’s largest consumer platforms choose GKE because Google can scale Kubernetes clusters to 15K nodes. Anthos lets companies govern across cloud platforms, giving them genuine interoperability and flexibility even when other cloud platforms want to lock them in.
BigQuery Omni also helps customers maximize their data, wherever it resides. BigQuery Omni, powered by Anthos, queries data in other cloud centers and provides Google unmatched data technology to your data.
The right cloud for the job: Government commercial cloud power
Unlike other providers that offer segregated “government clouds” with poor performance and scalability, Google Cloud has IL 5 authorization across a growing collection of services in their commercial cloud, with all the reliability, scalability, and innovation benefits. All clients can collaborate securely without deploying a separate government cloud that is sometimes capacity limited, running obsolete software, and more expensive. Modern and sophisticated data and cybersecurity protection solutions have replaced legacy ways.
Google provide data insights and quick AI/ML technologies to help you move faster
Google Cloud has invested extensively in AI/ML services to meet their customers’ diverse needs. Google continue to assist customers achieve great AI results by expanding access to services with 120 language variants in Google text-to-speech tools or processing AI queries on TPU v4 chips 2x faster than the previous generation. Google are democratizing data by introducing AutoML and BigQuery ML capabilities so everyone can use AI/ML’s insights and decision-making capability. Commercial customers have benefited from the latest AI/ML capabilities with BigQuery at the center, and DoD can use the same technology.
Google safeguard your data
While generative AI is becoming more popular, tools like Duet AI are only a small part of what AI can do. Much more AI/ML is available on Google Cloud. Google export their custom models for Google customers to use with data security they manage.
Google AI services can create spectacular experiences and provide consumers full data ownership. Google don’t train their models with your data without your permission. Google cannot examine it without your consent and a genuine requirement to support your service use. Google exclusively train their consumer models on publicly available data. After creating Google Translate, picture recognition, and natural language processing models, Google make them available to cloud users. Your data is solely yours on this “one-way street”.
In addition to being sustainable, Google help you become so
Today, Google Cloud matches 100% of its emissions with renewable energy, and Google aim to reach net-zero emissions by 2030. Google share their sustainable knowledge with customers. Google Carbon Sense package lets Google Cloud users see and reduce their cloud emissions.
Read more on Govindhtech.com
0 notes
Text
Youtube Short - Kubernetes Cluster Master Worker Node Architecture Tutorial for Beginners | Kubernetes ETCD Explained
Hi, a new #video on #kubernetes #cluster #architecture #workernode #masternode is published on #codeonedigest #youtube channel. Learn kubernetes #cluster #etcd #controllermanager #apiserver #kubectl #docker #proxyserver #programming #coding with
Kubernetes is a popular open-source platform for container orchestration. Kubernetes follows client-server architecture and Kubernetes cluster consists of one master node with set of worker nodes. Let’s understand the key components of master node. etcd is a configuration database stores configuration data for the worker nodes. API Server to perform operation on cluster using api…

View On WordPress
#kubernetes#kubernetes cluster#kubernetes cluster backup#kubernetes cluster from scratch#kubernetes cluster installation#kubernetes cluster setup#kubernetes cluster tutorial#kubernetes controller#kubernetes controller development#kubernetes controller example#kubernetes controller explained#kubernetes controller golang#kubernetes controller manager#kubernetes controller runtime#kubernetes controller tutorial#kubernetes controller vs operator#kubernetes etcd#kubernetes etcd backup#kubernetes etcd backup and restore#kubernetes etcd cluster setup#kubernetes etcd install#kubernetes etcd restore#kubernetes explained#kubernetes installation#kubernetes installation on windows#kubernetes interview questions#kubernetes kubectl#kubernetes kubectl api#kubernetes kubectl commands#kubernetes kubectl config
0 notes
Text
Choose the Best Cloud Computing with GCP
The Google Cloud Platform provides an incredibly large and powerful range of choices for cloud computing, part of why it has become such a common choice among companies around the world. However, when developing and deploying services and technologies, this variety of choices necessitates the need for expertise.
Google Cloud Platform is one of the most popular providers of cloud computing in the world and is used by some of the biggest organizations around the world. Choosing Google Cloud Platform will give you full peace of mind that you work with a service that is highly trusted and reliable.
Some of the important advantages of working with GCP include:
1. If you are environmentally conscious, GCP data centers usually operate on around half of the competitors' electricity and use green energy where feasible.
2. Strong protection: GCP benefits from Google's robust security strategy focused on years of experience keeping clients protected
3. GCP is well-known for its Big Data technologies, including advanced machine learning and real-time data analysis.
Components & Fundamentals for GCP include:
1) GPC VPC
2) The Ventures
3) The Networks
4) Regions
5) Zones
6) Subnets
7) Switching
8) Routing
9) Firewalls
Universal, shareable, and expandable is a Google Cloud VPS. Using a VPC provides you with managed, global networking capabilities across subnetworks, known as subnets, located in Google Cloud data centers. Each subnet is allocated to a unique region.
Without ever connecting to the public internet, a single Google Cloud VPC and its subnets can span multiple regions. It remains separate from the outside world and does not contribute to any particular area or zone.
Google Cloud VPC offers networking for your virtual machine (provides native internal TCP/UDP load balancing and internal HTTP(S) load balancing proxy systems, like Google Kubernetes Engine (GKE) clusters, App Engine flexible environment instances, and other products based on Compute Engine VMs. It allocates traffic from external Google load balancers to back-ends and also offers Google Cloud VPC.
Google Cloud Platform has some competitive strengths:
1. Automation of new software implementation:
Many moving parts make up an app, which is why some developers choose to create their apps in the cloud to start with ("cloud-native"). Google is the originator of Kubernetes, which is an orchestrator of multi-component applications.

Early on, Google took a pragmatic approach to automate the deployment of these multi-faceted cloud applications: opening itself, for example, to Kubo, an automation framework originally developed to help developers deploy their apps from dev platforms to the cloud using Cloud Foundry.
2. Creative control over prices:
The strategy of Google with GCP is to allow cost competitiveness in some "sweet spot" scenarios rather than becoming the low-cost leader.
3. For first-time users, friendlier hand-holding:
A network for cloud computing can be a daunting notion for a novice to absorb. Just as it was not clear to many customers what the function of a microcomputer was, for people who are used to seeing and touching the system they are using, a public cloud is a new and alien beast. Step-by-step examples of doing many of the most common tasks are given by GCP.
Google cloud platform services
In the abstract, cloud systems are hard to grasp. So here are the key services that GCP provides to help you understand Google Cloud Platform more explicitly:
I. Google Compute Engine (GCE) is in direct competition with the service that placed Amazon Web Services on the map: virtual machine hosting.
II. Google Kubernetes Engine is a framework that is designed for deployment on cloud platforms for a more modern style of a containerized application.
III. Google Cloud Storage is the object data store of GCP, meaning it embraces any amount of data and represents the data to its user in any form it is most useful.
The Google Cloud Platform consulting is essentially a public cloud-based system whose services, through service components, are distributed to customers on an as-you-go basis. A public cloud helps you to use its capabilities to enable the apps you create and to reach a wider customer base.
Google Cloud Platform consulting is a network infrastructure provider for the deployment and execution of web applications.
Its specialty is to provide people and companies with a place to create and run the software, and it uses the web to connect to the software's users. A trusted Google partner will help you make a GCP VPC transition, one that during the migration process can minimize your downtime. It would also reduce the cost of network infrastructure because you won't start from scratch.
0 notes
Text
Percona Kubernetes Operator for Percona XtraDB Cluster: HAProxy or ProxySQL?
Percona Kubernetes Operator for Percona XtraDB Cluster comes with two different proxies, HAProxy and ProxySQL. While the initial version was based on ProxySQL, in time, Percona opted to set HAProxy as the default Proxy for the operator, without removing ProxySQL. While one of the main points was to guarantee users to have a 1:1 compatibility with vanilla MySQL in the way the operator allows connections, there are also other factors that are involved in the decision to have two proxies. In this article, I will scratch the surface of this why. Operator Assumptions When working with the Percona Operator, there are few things to keep in mind: Each deployment has to be seen as a single MySQL service as if a single MySQL instance The technology used to provide the service may change in time Pod resiliency is not guaranteed, service resiliency is Resources to be allocated are not automatically calculated and must be identified at the moment of the deployment In production, you cannot set more than 5 or less than 3 nodes when using PXC There are two very important points in the list above. The first one is that what you get IS NOT a Percona XtraDB Cluster (PXC), but a MySQL service. The fact that Percona at the moment uses PXC to cover the service is purely accidental and we may decide to change it anytime. The other point is that the service is resilient while the pod is not. In short, you should expect to see pods stopping to work and being re-created. What should NOT happen is that service goes down. Trying to debug each minor issue per node/pod is not what is expected when you use Kubernetes. Given the above, review your expectations… and let us go ahead. The Plus in the Game (Read Scaling) As said, what is offered with Percona Operator is a MySQL service. Percona has added a proxy on top of the nodes/pods that help the service to respect the resiliency service expectations. There are two possible deployments: HAProxy ProxySQL Both allow optimizing one aspect of the Operator, which is read scaling. In fact what we were thinking was, given we must use a (virtually synchronous) cluster, why not take advantage of that and allow reads to scale on the other nodes when available? This approach will help all the ones using POM to have the standard MySQL service but with a plus. But, with it also comes with some possible issues like READ/WRITE splitting and stale reads. See this article about stale reads on how to deal with it. For R/W splitting we instead have a totally different approach in respect to what kind of proxy we implement. If using HAProxy, we offer a second entry point that can be used for READ operation. That entrypoint will balance the load on all the nodes available. Please note that at the moment there is nothing preventing an application to use the cluster1-haproxy-replicas also for write, but that is dangerous and wrong because will generate a lot of certification conflicts and BF abort, given it will distribute writes all over the cluster impacting on performance as well (and not giving you any write scaling). It is your responsibility to guarantee that only READS will go through that entrypoint. If instead ProxySQL is in use, it is possible to implement automatic R/W splitting. Global Difference and Comparison At this point, it is useful to have a better understanding of the functional difference between the two proxies and what is the performance difference if any. As we know HAProxy acts as a level 4 proxy when operating in TCP mode, it also is a forward-proxy, which means each TCP connection is established with the client with the final target and there is no interpretation of the data-flow. ProxySQL on the other hand is a level 7 proxy and is a reverse-proxy, this means the client establishes a connection to the proxy who presents itself as the final backend. Data can be altered on the fly when it is in transit. To be honest, it is more complicated than that but allows me the simplification. On top of that, there are additional functionalities that are present in one (ProxySQL) and not in the other. The point is if they are relevant for use in this context or not. For a shortlist see below (source is from ProxySQL blog but data was removed) : As you may have noticed HAProxy is lacking some of that functionalities, like R/W split, firewalling, and caching, proper of the level 7 implemented in ProxySQL. The Test Environment To test the performance impact I had used a cluster deployed in GKE, with these characteristics: 3 Main nodes n2-standard-8 (8 vCPUs, 32 GB memory) 1 App node n2-standard-8 (8 vCPUs, 32 GB memory) PXC pods using: 25GB of the 32 available 6 CPU of the 8 available HAProxy: 600m CPU 1GB RAM PMM agent 500m CPU 500 MB Ram Tests using sysbench as for (https://github.com/Tusamarco/sysbench), see in GitHub for command details. What I have done is to run several tests running two Sysbench instances. One only executing reads, while the other reads and writes. In the case of ProxySQL, I had R/W splitting thanks to the Query rules, so both sysbench instances were pointing to the same address. While testing HAProxy I was using two entry points: Cluster1-haproxy – for read and write Cluster1-haproxy-replicas – for read only Then I also compare what happens if all requests hit one node only. For that, I execute one Sysbench in R/W mode against one entry point, and NO R/W split for ProxySQL. Finally, sysbench tests were executed with the –reconnect option to force the tests to establish new connections. As usual, tests were executed multiple times, on different days of the week and moments of the day. Data reported is a consolidation of that, and images from Percona Monitoring and Management (PMM) are samples coming from the execution that was closest to the average values. Comparing Performance When Scaling Reads These tests imply that one node is mainly serving writes while the others are serving reads. To not affect performance, and given I was not interested in maintaining full read consistency, the parameter wsrep_sync_wait was kept as default (0). A first observation shows how ProxySQL seems to keep a more stable level of requests served. The increasing load penalizes HAProxy reducing if ⅓ the number of operations at 1024 threads. Digging a bit more we can see that HAProxy is performing much better than ProxySQL for the WRITE operation. The number of writes remains almost steady with minimal fluctuations. ProxySQL on the other hand is performing great when the load in write is low, then performance drops by 50%. For reads, we have the opposite. ProxySQL is able to scale in a very efficient way, distributing the load across the nodes and able to maintain the level of service despite the load increase. If we start to take a look at the latency distribution statistics (sysbench histogram information), we can see that: In the case of low load and writes, both proxies stay on the left side of the graph with a low value in ms. HAProxy is a bit more consistent and grouped around 55ms value, while ProxySQL is a bit more sparse and spans between 190-293ms. About reads we have similar behavior, both for the large majority between 28-70ms. We have a different picture when the load increases: ProxySQL is having some occurrences where it performs better, but it spans in a very large range, from ~2k ms to ~29k ms. While HAProxy is substantially grouped around 10-11K ms. As a result, in this context, HAProxy is able to better serve writes under heavy load than ProxySQL. Again, a different picture in case of reads. Here ProxySQL is still spanning on a wide range ~76ms – 1500ms, while HAProxy is more consistent but less efficient, grouping around 1200ms the majority of the service. This is consistent with the performance loss we have seen in READ when using high load and HAProxy. Comparing When Using Only One Node But let us now discover what happens when using only one node. So using the service as it should be, without the possible Plus of read scaling. The first thing I want to mention is strange behavior that was consistently happening (no matter what proxy used) at 128 threads. I am investigating it but I do not have a good answer yet on why the Operator was having that significant drop in performance ONLY with 128 threads. Aside from that, the results were consistently showing HAProxy performing better in serving read/writes. Keep in mind that HAProxy just establishes the connection point-to-point and is not doing anything else. While ProxySQL is designed to eventually act on the incoming stream of data. This becomes even more evident when reviewing the latency distribution. In this case, no matter what load we have, HAProxy performs better: As you can notice, HAProxy is less grouped than when we have two entry points, but it is still able to serve more efficiently than ProxySQL. Conclusions As usual, my advice is to use the right tool for the job, and do not force yourself into something stupid. And as clearly stated at the beginning, Percona Kubernetes Operator for Percona XtraDB Cluster is designed to provide a MySQL SERVICE, not a PXC cluster, and all the configuration and utilization should converge on that. ProxySQL can help you IF you want to scale a bit more on READS using the possible plus. But this is not guaranteed to work as it works when using standard PXC. Not only do you need to have a very good understanding of Kubernetes and ProxySQL if you want to avoid issues, but with HAProxy you can scale reads as well, but you need to be sure you have R/W separation at the application level. In any case, utilizing HAProxy for the service is the easier way to go. This is one of the reasons why Percona decided to shift to HAProxy. It is the solution that offers the proxy service more in line with the aim of the Kubernetes service concept. It is also the solution that remains closer to how a simple MySQL service should behave. You need to set your expectations correctly to avoid being in trouble later. References Percona Kubernetes Operator for Percona XtraDB Cluster Wondering How to Run Percona XtraDB Cluster on Kubernetes? Try Our Operator! The Criticality of a Kubernetes Operator for Databases https://www.percona.com/blog/2021/01/11/percona-kubernetes-operator-for-percona-xtradb-cluster-haproxy-or-proxysql/
0 notes