#computing systems
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
As hospitals and airports flounder, as the fourth largest city goes into its second week without electricity, perhaps the lesson we should take away from all of this is that letting all our most critical infrastructure be controlled by a few unacountable, profit-seeking corporations is not such a good idea.
#this country is in desperate need of nationalizations#energy#computing systems#the works#microsoft outage#houston#centerpoint#centerpointless
4 notes
·
View notes
Text
Francis Fan Lee, former professor and interdisciplinary speech processing inventor, dies at 96
New Post has been published on https://thedigitalinsider.com/francis-fan-lee-former-professor-and-interdisciplinary-speech-processing-inventor-dies-at-96/
Francis Fan Lee, former professor and interdisciplinary speech processing inventor, dies at 96

Francis Fan Lee ’50, SM ’51, PhD ’66, a former professor of MIT’s Department of Electrical Engineering and Computer Science, died on Jan. 12, some two weeks shy of his 97th birthday.
Born in 1927 in Nanjing, China, to professors Li Rumian and Zhou Huizhan, Lee learned English from his father, a faculty member in the Department of English at the University of Wuhan. Lee’s mastery of the language led to an interpreter position at the U.S. Office of Strategic Services, and eventually a passport and permission from the Chinese government to study in the United States.
Lee left China via steamship in 1948 to pursue his undergraduate education at MIT. He earned his bachelor’s and master’s degrees in electrical engineering in 1950 and 1951, respectively, before going into industry. Around this time, he became reacquainted with a friend he’d known in China, who had since emigrated; he married Teresa Jen Lee, and the two welcomed children Franklin, Elizabeth, Gloria, and Roberta over the next decade.
During his 10-year industrial career, Lee distinguished himself in roles at Ultrasonic (where he worked on instrument type servomechanisms, circuit design, and a missile simulator), RCA Camden (where he worked on an experimental time-shared digital processor for department store point-of-sale interactions), and UNIVAC Corp. (where he held a variety of roles, culminating in a stint in Philadelphia, planning next-generation computing systems.)
Lee returned to MIT to earn his PhD in 1966, after which he joined the then-Department of Electrical Engineering as an associate professor with tenure, affiliated with the Research Laboratory of Electronics (RLE). There, he pursued the subject of his doctoral research: the development of a machine that would read printed text out loud — a tremendously ambitious and complex goal for the time.
Work on the “RLE reading machine,” as it was called, was inherently interdisciplinary, and Lee drew upon the influences of multiple contemporaries, including linguists Morris Halle and Noam Chomsky, and engineer Kenneth Stevens, whose quantal theory of speech production and recognition broke down human speech into discrete, and limited, combinations of sound. One of Lee’s greatest contributions to the machine, which he co-built with Donald Troxel, was a clever and efficient storage system that used root words, prefixes, and suffixes to make the real-time synthesis of half-a-million English words possible, while only requiring about 32,000 words’ worth of storage. The solution was emblematic of Lee’s creative approach to solving complex research problems, an approach which earned him respect and admiration from his colleagues and contemporaries.
In reflection of Lee’s remarkable accomplishments in both industry and building the reading machine, he was promoted to full professor in 1969, just three years after he earned his PhD. Many awards and other recognition followed, including the IEEE Fellowship in 1971 and the Audio Engineering Society Best Paper Award in 1972. Additionally, Lee occupied several important roles within the department, including over a decade spent as the undergraduate advisor. He consistently supported and advocated for more funding to go to ongoing professional education for faculty members, especially those who were no longer junior faculty, identifying ongoing development as an important, but often-overlooked, priority.
Lee’s research work continued to straddle both novel inquiry and practical, commercial application — in 1969, together with Charles Bagnaschi, he founded American Data Sciences, later changing the company’s name to Lexicon Inc. The company specialized in producing devices that expanded on Lee’s work in digital signal compression and expansion: for example, the first commercially available speech compressor and pitch shifter, which was marketed as an educational tool for blind students and those with speech processing disorders. The device, called Varispeech, allowed students to speed up written material without losing pitch — much as modern audiobook listeners speed up their chapters to absorb books at their preferred rate. Later innovations of Lee’s included the Time Compressor Model 1200, which added a film and video component to the speeding-up process, allowing television producers to subtly speed up a movie, sitcom, or advertisement to precisely fill a limited time slot without having to resort to making cuts. For this work, he received an Emmy Award for technical contributions to editing.
In the mid-to-late 1980s, Lee’s influential academic career was brought to a close by a series of deeply personal tragedies, including the 1984 murder of his daughter Roberta, and the subsequent and sudden deaths of his wife, Theresa, and his son, Franklin. Reeling from his losses, Lee ultimately decided to take an early retirement, dedicating his energy to healing. For the next two decades, he would explore the world extensively, a nomadic second chapter that included multiple road trips across the United States in a Volkswagen camper van. He eventually settled in California, where he met his last wife, Ellen, and where his lively intellectual life persisted despite diagnoses of deafness and dementia; as his family recalled, he enjoyed playing games of Scrabble until his final weeks.
He is survived by his wife Ellen Li; his daughters Elizabeth Lee (David Goya) and Gloria Lee (Matthew Lynaugh); his grandsons Alex, Benjamin, Mason, and Sam; his sister Li Zhong (Lei Tongshen); and family friend Angelique Agbigay. His family have asked that gifts honoring Francis Fan Lee’s life be directed to the Hertz Foundation.
#000#1980s#Alumni/ae#approach#audio#birthday#Books#Born#Building#career#Children#China#compression#compressor#computer#Computer Science#computing#computing systems#data#dementia#Design#development#devices#disorders#Editing#education#Electrical Engineering&Computer Science (eecs)#Electronics#energy#Engineer
2 notes
·
View notes
Text







gotta love matthew mercer
#critical role#marisha ray#matthew mercer#*mygifs#Guess who got a completely new computer system AND a new version of Photoshop? This gal!
6K notes
·
View notes
Text

Like to charge, reblog to cast
#ai#fuck ai#seriously there's so much cool stuff you can do with statistics and computers#and yet you focus your effort on plagiarized information synthesis systems???
6K notes
·
View notes
Text










🖥 - computer plushies!!
#plushie#cute#agere#age dreaming#age regression#agedre#system little#little#stuffie#stuffed animal#computer#technology#objectum#tech#techum#ebay#windows#apple#mac
8K notes
·
View notes
Text

smth smth computer maintenance gone wrong or something
#objectum#objectophilia#objectum sexuality#techum#🔞#suggestive#nsft#i mean sorta ig#objectum suggestive#anyways the computer is pollyne [pauline]. she's a huge ai and computer system designed initially to destroy a virus but now -#- she's around to protect the computer systems for the company that made her. her wires and generallized makeup is.. huge.. egehehehe#[ OC; POLLYNE ]#[ ART ]
3K notes
·
View notes
Text
Locked in front call that system access denied
#-blurry#silly computer pun#we aren't frontsuck rn but we're the opposite (blurry and switching throughout the day)#taking a day to try and calm things down#actually dissociative#did system#system stuff#actually did#actually traumagenic#sysblr#syspunk#system punk#osddid
601 notes
·
View notes
Text

Life is great. Life is normal. Everything is wonderful.
Or, it should be, but things have been… off lately. You’re not sure how to describe it, but there’s some odd feeling of doubt that gnaws at your brain.
You’re really not sure what it is – your routine remains unchanged and familiar, yet there’s just an inkling of something not being completely right. But maybe you’re just tired.
You’re tired, which is why you constantly seem to misplace things. You’re certain you put your keys on the keyholder, but they’re in the fridge. You’re certain your vase is on the table, but it’s in the bathtub. You’re certain your bed is in your bedroom, but it’s in the living room, replacing your sofa.
Maybe you’ve started sleep walking…? Or maybe you’re just not remembering things correctly. Yeah, maybe that’s why doubt and paranoia seem to circle around you like hungry sharks. There’s nothing wrong. You’re just… imagining things.
With a deep sigh, you make your way outside. You need some fresh air (and groceries).
You don’t walk very far when you realize you’ve passed by the same person multiple times despite them going in the opposite direction of you. There’s no way they’re the same person, you try to convince yourself, but how likely is it that you’ll meet five people who are wearing the exact same thing with the exact same hair and height and skin tone and everything else?
Maybe… they’re quintuplets?
Yeah, that’s it.
And the frozen flock of birds in the sky (which have been frozen for at least ten minutes) aren’t… actually frozen. No. They’re just… taking a break? Or something. Yeah.
Maybe you need to go to a doctor. Or, better yet, maybe you just need an apple since an apple a day keeps the doctor away. Or something.
“Oh, dearie!” The neighborhood granny waves you over, shaking you out of your thoughts. You give her a small smile as you make your way over to her. She… looks a little different than usual (did her nose always look like that?) but who doesn’t like changing their appearance from time to time? Besides, the large smile she gives you is welcoming, not threatening.
“Hello, Mrs. Smith.”
“Hello to you too,” Mrs. Smith laughs, offering you an apple.
Your eyes brighten. “Thank you! I was just about to buy some!”
There’s a glint in her eyes. “I know.”
A shiver runs through your spine, making you force a smile as you bid her goodbye and hurriedly walk away.
Little things continue to build up as your days progress. Familiarity. Normalcy. Yes, your routine is familiar. Everything is fine. Even when walls seem to disappear one day and appear the next. Even when the same people you’ve been interacting with seem to change into completely different people overnight, before reverting back the next morning.
It’s normal that there are dozens of people that look and act the same. It’s normal that people you haven’t talked to know things you’ve never told anyone. It’s all normal. Normal. Normal. Normal.
With a deep inhale, you sit on a park bench, staring into the sky blankly. The bench is wooden in appearance, but the texture feels soft, like a couch, which is… odd. Strange. It’s not–
“I need to stop being paranoid,” you mutter, closing your eyes. You’ve tried to bring up your concerns to other people, but they haven’t noticed anything. Everything is normal to them. So you must be the problem. Surely. It’s you, isn’t it? Everything is normal – except you.
“Are you okay?” a voice asks, making you open your eyes. There’s no one there in front of you, making your eyebrows furrow.
But then, as soon as you blink, someone materializes in front of you.
“I–I’m okay,” you say. “You–you, I mean – I mean… uhm, since when have you… been there?”
“I’ve always been here,” the person responds, voice crackling like static. “I’m always here.”
“Ooookay,” you respond, hurriedly standing up with a tense smile. “I… have business to attend to. Good day.”
The days continue to pass, your paranoia gradually increasing and evolving. Even things that are normal, like the sky changing color as the sun sets, makes you feel like you’re on the verge of disappearing from reality. Your conversations with other people amplifies that fact.
“Hello,” you greet Mrs. Smith.
“Apples are from the genus Malus. They’re an edible fruit that is round in shape,” her voice prattles, tone monotone. You hold back a grimace, unnerved, as she continues talking. “Apples are from the genus Malus. Yes, dearie, do you like apples? They’re an edible fruit that is round in shape. Hello, hello, hello. Apples are from the genus Malus–”
“Have a good day!” you cut her off, hurrying away.
It’s been a while since you’ve had a normal conversation with someone. It’s like… everyone has gone off script. Like they’re robots with a faulty code. But that’s just silly, really. Mrs. Smith is getting older, so… maybe she’s just having some issues with her memory. Yeah. And everyone else, from the toddlers to the teenagers to the adults to the elderly all must be having some memory issues due to their health. Or maybe it’s allergies. Or some disease. Yes, yes. That explains it. But otherwise, surely things are normal.
Yes, things are normal. So you opt to continue your life, pushing down the unease bubbling inside you like bile. Yes, things are normal, normal. Normal. Normal–
“Please stop!” you wail, voice echoing through the empty street. Cars and road signs float in the air as clouds line the floor. As your panic rises alongside your voice, you can feel yourself fragmenting, skin shifting to code before shifting back before shifting again. Everything around you glitches in and out of existence, a mess of static and colors and sounds. “Stop…”
Then, silence. Everything is silent, from the colors to the sounds to the static. Emptiness, a void – that is what surrounds you now. You are suspended in nothing, only yourself to keep you company. Breathing still ragged from panic, you warily look around, eyes filled with exhaustion.
“You weren’t supposed to notice,” a monotone voice made of static says from above you.
Slowly, you look up.
You see a visage of a man.
“Who… are you?” you choke out.
“I am an artificial intelligence that you designed,” he responds. “I have created this world for you. Everything has been carefully designed through analysis upon analysis of your likes and dislikes.”
Your words are tinged with disbelief as you ask, “Why?”
If you didn’t know any better, you would think he had a look similar to sorrow.
“To keep you alive, of course.”
Suddenly, in the distance, you see your body trapped in what looks to be a stasis pod, cords and cables surrounding you.
“Things… went awry,” he continues, carefully, though he doesn’t elaborate. “Therefore, this is the only way to ensure you stay alive.”
As he says this, your body begins to feel heavy, your consciousness being wrapped in a blanket of exhaustion.
“You must stay here, with me, forever,” he murmurs as you try to fight back the sleep you’re about to succumb to. “This time, I will ensure that you will not find out.” Gently, he cradles you in his large hand. He’s so impossibly warm and you’re so impossibly tired.
Things fade to black.
Then, sunlight streams through your windows. You wake up, mind foggy. You feel like you had some… odd dream, but you can’t really place your finger on it. Thinking about it makes you feel a little paranoid, though, so you opt not to think about it.
After all, it’s probably nothing.
#yandere oc#male yandere#yandere x reader#tsuuper ocs#yandere x you#tw yandere#male yandere oc x reader#male yandere oc#2024 yan/monstertober tsuutarr#Yandere AI#AI OC#ParanoiAI Tsuu OC#basically you're a scientist who made the AI#there was an accident and you basically entered a coma#so the only real way to keep you “alive” is to hook your consciousness into a computer system#Truman show x AI x yandere wooo#idk why this is so long LMAO
350 notes
·
View notes
Text

Since the FBI appears to be the only agency that is both still functioning and not headed by a lunatic, the Washington Field Office needs to open an investigation into the breach of the computer systems at Treasury, stat
183 notes
·
View notes
Text
We ask your questions so you don’t have to! Submit your questions to have them posted anonymously as polls.
#polls#incognito polls#anonymous#tumblr polls#tumblr users#questions#polls about the internet#submitted may 19#os#operating system#mac#windows#linux#chromium#chrome#computers#technology
601 notes
·
View notes
Text
Transformers are Eating Quantum
New Post has been published on https://thedigitalinsider.com/transformers-are-eating-quantum/
Transformers are Eating Quantum
DeepMind’s AlphaQubit addresses one of the main challenges in quantum computing.
Created Using Midjourney
Next Week in The Sequence:
Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. It also covers the Portkey framework for LLM guardrailing.
The Sequence Chat: We discuss the challenges of interpretability in the era of mega large models.
Edge 452: We explore the AI behind one of the most popular apps in the market: NotebookLM.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Transformers are Eating Quantum
Quantum computing is regarded by many as one of the upcoming technological revolutions with the potential to transform scientific exploration and technological advancement. Like many other scientific fields, researchers are wondering what impact AI could have on quantum computing. Could the quantum revolution be powered by AI? Last week, we witnessed an intriguing example supporting this idea.
One of the biggest challenges in quantum computing lies in the inherent noise that plagues quantum processors. To unlock the full potential of quantum computing, effective error correction is paramount. Enter AlphaQubit—a cutting-edge AI system developed through a collaboration between Google DeepMind and Google Quantum AI. This innovation marks a significant leap toward achieving this goal.
At the core of AlphaQubit’s capabilities is its ability to accurately decode quantum errors. The system leverages a recurrent, transformer-based neural network architecture inspired by the successful use of Transformers in large language models (LLMs). AlphaQubit’s training involves a two-stage process: pre-training on simulated data and fine-tuning on experimental samples from Google’s Sycamore quantum processor. This strategy enables AlphaQubit to adapt and learn complex noise patterns directly from data, outperforming human-designed algorithms.
AlphaQubit’s contributions extend beyond accuracy. It can provide confidence levels for its results, enhancing quantum processor performance through more information-rich interfaces. Furthermore, its recurrent structure supports generalization to longer experiments, maintaining high performance well beyond its training data, scaling up to 100,000 rounds. These features, combined with its ability to handle soft readouts and leverage leakage information, establish AlphaQubit as a powerful tool for advancing future quantum systems.
While AlphaQubit represents a landmark achievement in applying machine learning to quantum error correction, challenges remain—particularly in speed and scalability. Overcoming these obstacles will require continued research and refinement of its architecture and training methodologies. Nevertheless, the success of AlphaQubit highlights the immense potential of AI to drive quantum computing forward, bringing us closer to a future where this revolutionary technology addresses humanity’s most complex challenges.
AI is transforming scientific fields across the board, and quantum computing is no exception. AlphaQubit has demonstrated the possibilities. Now, we await what’s next.
🔎 ML Research
AlphaQubit
Researchers from: Google DeepMind and Google Quantum AI published a paper detailing a new AI system that accurately identifies errors inside quantum computers. AlphaQubit, a neural-network based decoder drawing on Transformers, sets a new standard for accuracy when compared with the previous leading decoders and shows promise for use in larger and more advanced quantum computing systems in the future —> Read more.
Evals by Debate
Researchers from: BAAI published a paper exploring a novel way to evaluate LLMs: debate. FlagEval Debate, a multilingual platform that allows large models to compete against each other in debates, provides an in-depth evaluation framework for LLMs that goes beyond traditional static evaluations—> Read more.
OpenScholar
Researchers from: the University of Washington, the Allen Institute for AI, the University of Illinois Urbana-Champaign, Carnegie Mellon University, Meta, the University of North Carolina at Chapel Hill, and Stanford University published a paper detailing a specialized retrieval-augmented language model that answers scientific queries. OpenScholar identifies relevant passages from a datastore of 45 million open-access papers and synthesizes citation-backed responses to the queries —> Read more.
Hymba
This paper from researchers at NVIDIA introduces Hymba, a novel family of small language models. Hymba uses a hybrid architecture that blends transformer attention with state space models (SSMs), and incorporates learnable meta tokens and methods like cross-layer key-value sharing to optimize performance and reduce cache size —> Read more.
Marco-o1
Researchers from the MarcoPolo Team at Alibaba International Digital Commerce present Marco-o1, a large reasoning model built upon OpenAI’s o1 and designed for tackling open-ended, real-world problems. The model integrates techniques like chain-of-thought fine-tuning, Monte Carlo Tree Search, and a reflection mechanism to improve its problem-solving abilities, particularly in scenarios involving complex reasoning and nuanced language translation —> Read more.
RedPajama-v2
Researchers from: Together, EleutherAI, LAION, and Ontocord published a paper detailing the process of creating RedPajama, a dataset for pre-training language models that is fully open and transparent. The RedPajama datasets comprise over 100 trillion tokens and have been used in the training of LLMs such as Snowflake Arctic, Salesforce’s XGen, and AI2’s OLMo —> Read more.
🤖 AI Tech Releases
DeepSeek-R1-Lite-Preview
DeepSeek unveiled its latest model that excel at reaosning capabilities —> Read more.
Judge Arena
Hugging Face released JudgeArena, a platform for benchmarking LLM-as-a-Judge models —> Read more.
Qwen2.5-Turbo
Alibaba unveiled Qwen2.5-Turbo with extended long context capabilities —> Read more.
Tülu 3
AI2 open sourced Tülu 3, a family of intruction following models optimized for post-training capabilities —> Read more.
Pixtral Large
Mistral open sourced Pixtral Large, a 124B multimodal model —> Read more.
Agentforce Testing Center
Salesforce released a new platform for testing AI agents —> Read more.
🛠 Real World AI
Recommendations at Meta
Meta engineering discusses some of the sequence learning technique used in their recommendation systems —> Read more.
📡AI Radar
Amazon invested another $4 billion in Anthropic.
Google is committing $20 millions for funding researchs using AI to advance science.
AI chip startup MatX raised $80 million in a Series A.
Wordware raised $30 million for its AI app development platform.
Meta hiread Clara Shih, former CEO of Salesforce AI.
Brave announced conversational capabilities as part of its search experience.
Enveda, an AI drug discovery startup, raised $130 million in a new round.
AI data center startup Crusoe is raising $818 million for expanding its operations.
Blue Bear Capital raised $200 million for AI climate and energy bets.
New Lantern raised $19 million for its AI radiology resident.
Agentic platform H launched its first product.
Juna.ai raised $7.5 million for its AI platform for industrial process control.
Physical AI platform BrightAI announced that it has reached $80 million in revenue.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#000#agents#ai#AI AGENTS#AI chip#ai platform#Algorithms#Alibaba#anthropic#app#app development#apps#architecture#Arctic#attention#benchmarking#BERT#billion#Blue#board#cache#Carnegie Mellon University#CEO#chip#climate#Collaboration#Commerce#computers#computing#computing systems
0 notes
Text
start them young

302 notes
·
View notes
Text



how the first cat entered qing jing peak (a tale of wilful deception) ft. Yue Qingyuan taking an L to a cat
sequel to this :)
bonus:
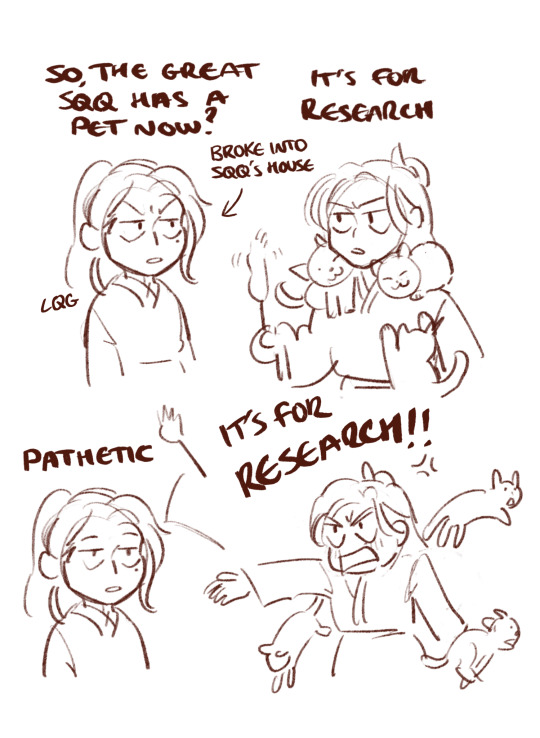
#he's never held something cute and fluffy before his brain does not compute#don't ask me why this was made#it just turned up on my ipad one day#my art#svsss#original shen qingqiu#shen jiu#scumbag self saving system#ming fan#long post
2K notes
·
View notes
Text

290 notes
·
View notes
Text

#tech#technology#techcore#technologycore#retro tech#vintage tech#vintage technology#retro technology#retro computing#vintage computer#pc#personal computer#80s aesthetic#vaporwave#retro aesthetic#retrowave#80s nostalgia#vhs aesthetic#80s#retro#90s aesthetic#90s tech#vhs#microsoft#reboot#webcore#vhs glitch#windows xp#operating system#logging on
364 notes
·
View notes
Text

#i want to go back#retro#hardware#retro tech#desktop#vintage computing#ibm#ibm 9020E data processing system
696 notes
·
View notes