#cnns
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
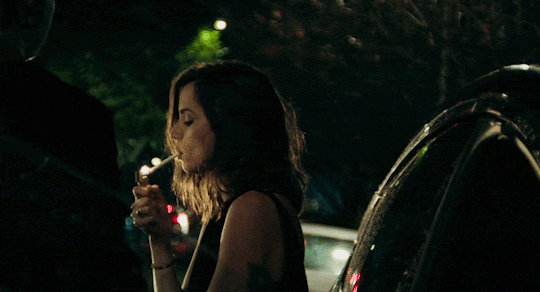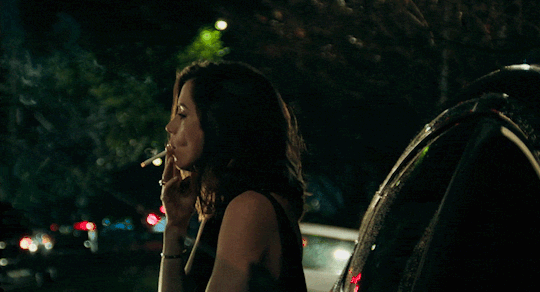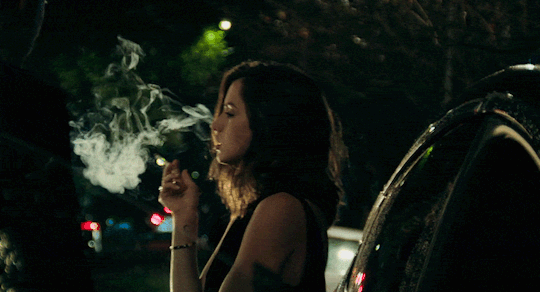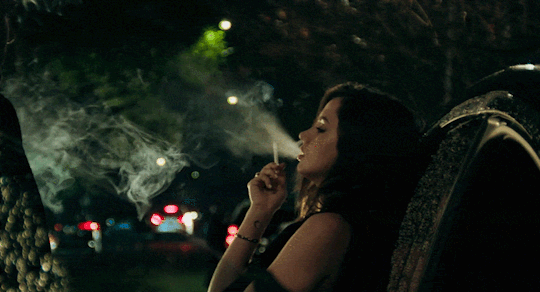
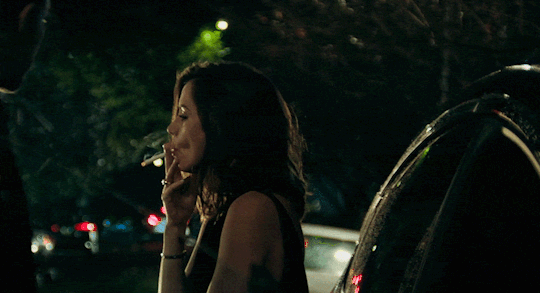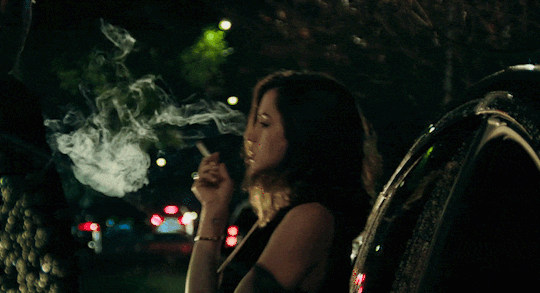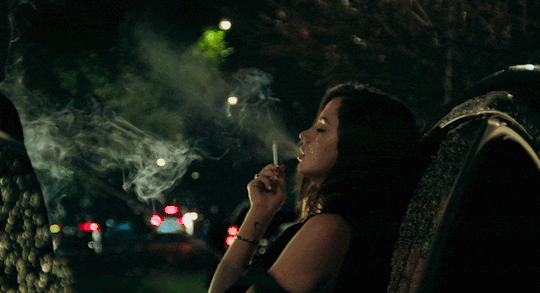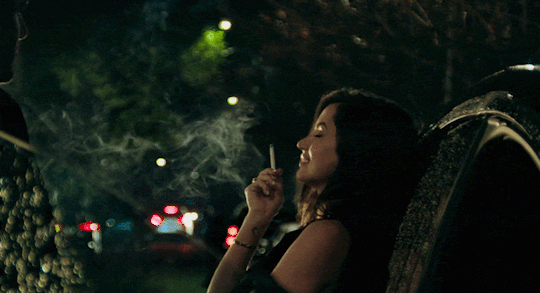
[Ana de Armas] alto, quem vem lá? oh, só podia ser [Danielle Aldana Leblanc], a [psicóloga] de [32] anos que veio de [d’aubelac]. você quase se atrasou hoje, hein? eu sei que você é normalmente [compreensiva & bondosa], mas também sei bem que é [misteriosa & sonsa], então nem tente me enganar. ande, estão te esperando; entre pela porta de trás.
about her ,
Danielle é filha de um imigrante cubano, que decidiu tentar a sorte na França. Seu plano inicial era mudar de vida, fazer algum dinheiro vivendo daquilo que sempre soube fazer: plantar e colher. O que ele não esperava, era acabar se apaixonando pela camponesa francesa que morava ao seu lado. Um típico romance entre vizinhos que começam amigos e logo viram algo mais. Apaixonados, não demoraram a ter sua primeira e logo única filha: Danielle.
Os primeiros anos se passaram sem muita dificuldade. A mulher havia se dedicado completamente a maternidade, enquanto o marido pegava trabalho atrás de trabalho, apenas para não deixar que nada faltasse à pequena Dani. Não existiam muitas regalias em sua casa, e ela aprendeu a crescer com o pouco, considerando-o muito. Com o passar dos meses seu vocabulário fora ficando mais forte do que o de qualquer outra criança em sua idade. Ela era literalmente a criança prodígio, e assistir a luta de seus pais intensificava isso. Danielle sonhava com um futuro melhor para si, onde ela pudesse ter uma vida confortável, e dar para aqueles que tanto amava, uma vida confortável.
Empenhada e focada em seus objetivos, Danielle sempre enfiou a cara nos estudos em paralelo, ajudava nos afazeres da casa e na plantação do pai, sempre fazendo o possível para ajudar a família. Os pais reconhecendo a garra da garota, juntaram o pouco dinheiro que tinham e a mandaram para concluir os estudos fora. Como eles não tinham muito, o que Dani conseguiu foi bancar a passagem e ao chegar nos Estados Unidos, ela arrumou um trabalho de meio período e deu seu jeito de se manter até que terminasse os estudos.
Danielle vivia um sonho, na medida do possível. Sempre preocupada com o lar e seu regresso, quase não tinha tempo para outras interações sociais até que tudo mudou. Ela conheceu o amor e ele tinha cabelos loiros, um sorriso irresistível e um olhar meio morto, mas ainda assim adorável. Sempre sonhou em viver um amor como o dos pais e acreditou fielmente que o tinha encontrado. Casaram dentro de poucos meses, e o que começou como um furacão, também terminou como um. Não tardou para que as brigas começassem, ciúmes de ambos os lados, conflitos, abajures arremessados... Estava terminado.
Decidida a nunca mais passar por uma relação que considerou como tóxica e abusiva (dos dois lados), Dani regressou para o seu lar, só estava mudada. A mulher focada e meticulosa, havia dado espaço para uma que era jogada, queria viver até o limite, sentir tudo que não tinha sentido e simplesmente se jogar de cabeça. Obviamente, escondeu esse modo impulsivo ao fazer entrevista para a vaga de psicóloga no castelo. Um emprego que traria renome e uma boa condição financeira para que vivesse a vida confortável que tanto almejada. E claro, de quebra ela saberia algumas fofocas reais, quem não gostava disso?
A mulher está no cargo há seis anos. Tempo suficiente para saber como seguir aquela dança com a monarquia, em largos sorrisos, acenos gentis e modos recatados.
CONEXÕES BÁSICAS:
muse a: desenvolveram uma boa amizade dentro do castelo. Como uma pessoa leal, Elle sempre estará disposta a ajudar o/a amigo/a em qualquer empreitada;
muse b: Elle vê a pessoa como alguém completamente infantil, e não consegue passar muito tempo perto dessa pessoa sem perder a cabeça, tudo vira um jogo de provocações e ironias;
emilia inarssdóttir: como filha única, Danielle nunca experienciou um laço fraternal antes de conhecer muse, com quem nutre um carinho de irmã;
muse d: tem alguma coisa nessa pessoa que instiga Elle. Ela não sabe dizer ao certo o que é, mas sempre que se encontram ela se sente tomada e envolvida, suas paredes internas chegam a estremecer na presença desta pessoa
8 notes
·
View notes
Text

7 notes
·
View notes
Text
@ghcstlly




MARRY MY HUSBAND (2024)
957 notes
·
View notes
Text


https://x.com/trtworld/status/1785959608168731091
#how sick do you have to be#hind rajab#free palestine#palestine#cnn#current events#tel avic#israel#free gaza#all eyes on rafah#all eyes on palestine#gaza
23K notes
·
View notes
Text
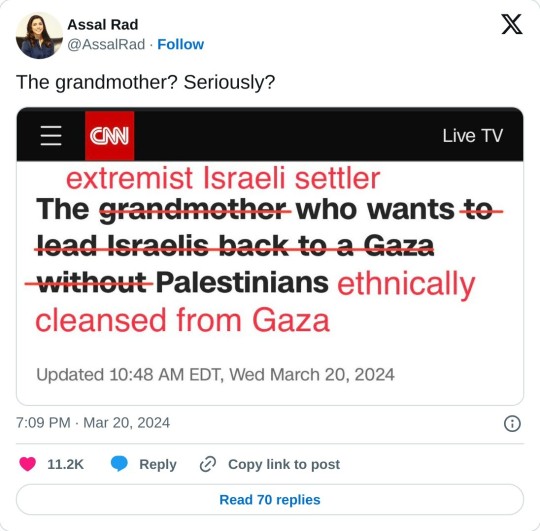
They're already trying to create support for new settlements in Gaza. Unreal.
#yemen#jerusalem#tel aviv#current events#palestine#free palestine#gaza#free gaza#news on gaza#palestine news#news update#war news#war on gaza#cnn#settler colonialism#manufactured consent#media bias
32K notes
·
View notes
Text
In contemporary times, road accidents stand out as significant contributors to human fatalities. Among these, motorcycle accidents are prevalent and often result in severe injuries. Helmets serve as crucial protective gear for motorcyclists, yet adherence to helmet laws remains lacking.
0 notes
Text
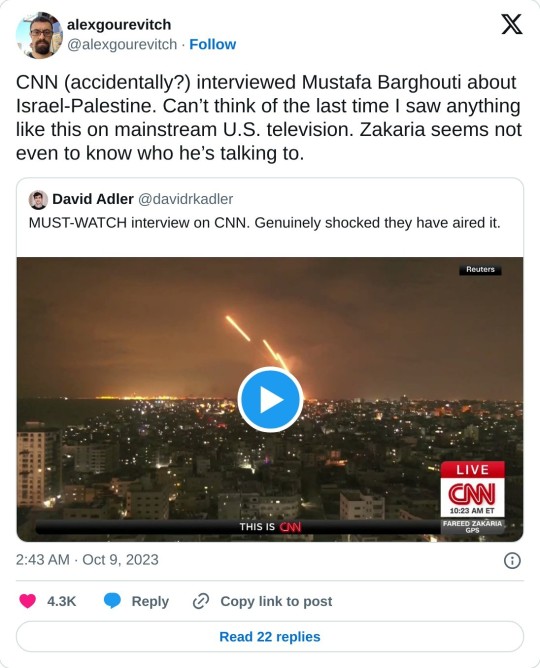
39K notes
·
View notes
Text
🔥 CRYPTO TRADERS, LISTEN UP! 🔥

Tired of losing to the market due to your sluggish human emotions and reactions? Ready to take your trading game to the next level with the power of artificial intelligence?
I just stumbled upon an INSANELY awesome article on AI-Based Trading Bot Optimization Strategies for Cryptocurrencies! 🤖💰
It covers cutting-edge machine learning algorithms like neural networks, convolutional networks, genetic algorithms, and reinforcement learning. This is a real trading revolution!
Imagine having a trading bot that can: ✅ Predict prices and trends with mind-blowing accuracy ✅ Analyze time-series data and spot intricate patterns ✅ Optimize trading strategies based on historical data ✅ Adapt to changing market conditions on the fly!
Plus, it breaks down real-world case studies of successful AI-based trading strategies. This unlocks entirely new realms of profitability and risk management potential! 🔝
Of course, there are risks like model overfitting and security concerns. But when done right, the potential of AI in crypto trading is limitless.
So hit that link, dive into this topic, and join the vanguard of future traders! Artificial intelligence is game-changing, and we need to be ready. 💥🔜
#AITradingBots#CryptocurrencyTrading#MachineLearning#NeuralNetworks#CNNs#GeneticAlgorithms#ReinforcementLearning#TradingStrategyOptimization
0 notes
Text

#News#cnn#idf#israel#democrats#republicans#politics#gaza#gaza strip#woc#poc#women of color#muslims#jerusalem#genocide#journalism#usa
16K notes
·
View notes
Text

Israel mistook three hostages for Palestinian civilians and killed them.
Israel killed 20,000 civilians and counting. I wonder how many Palestinians of these 20,000 killed will make it on the front page of CNN, or any news outlet for that matter.
#palestine#gaza#israel#important#current events#free palestine#ethnic cleansing#free gaza#gaza strip#gaza under attack#gaza under genocide#israel is terrorist#israel is an apartheid state#israel is a terrorist state#israel apartheid#cnn
14K notes
·
View notes
Text
What is a convolutional neural Network (CNN)?
Rakesh Jatav January 05, 2024
What is a convolutional neural network?

Introduction
Deep learning, a subset of artificial intelligence (AI), has permeated various domains, revolutionizing tasks through its ability to learn from data. At the forefront of deep learning's impact is image classification, a pivotal process in computer vision and object recognition. This necessitates the utilization of specialized models, with Convolutional Neural Networks (CNNs) standing out as indispensable tools.
What to Expect
In this article, we will delve into the intricate workings of CNNs, understanding their components and exploring their applications in image-related domains.
Readers will gain insights into:
The fundamental components of CNNs, including convolutional layers, pooling layers, and fully-connected layers
The training processes and advancements that have propelled CNNs to the forefront of deep learning
The diverse applications of CNNs in computer vision and image recognition
The profound impact of CNNs on the evolution of image recognition models
Through an in-depth exploration of CNNs, readers will uncover the underlying mechanisms that power modern image classification systems, comprehending the significance of these networks in shaping the digital landscape.
Understanding the Components of a Convolutional Neural Network

Convolutional neural networks (CNNs) are composed of various components that work together to extract features from images and perform image classification tasks. In this section, we will delve into the three main components of CNNs: convolutional layers, pooling layers, and fully-connected layers.
1. Convolutional Layers
Convolutional layers are the building blocks of CNNs and play a crucial role in feature extraction. They apply filters or kernels to input images in order to detect specific patterns or features. Here's a detailed exploration of the key concepts related to convolutional layers:
Feature Maps
A feature map is the output of a single filter applied to an input image. Each filter is responsible for detecting a specific feature, such as edges, textures, or corners. By convolving the filters over the input image, multiple feature maps are generated, each capturing different aspects of the image.
Receptive Fields
The receptive field refers to the region in the input image that affects the value of a neuron in a particular layer. Each neuron in a convolutional layer is connected to a small region of the previous layer known as its receptive field. By sliding these receptive fields across the entire input image, CNNs can capture both local and global information.
Weight Sharing
Weight sharing is a fundamental concept in convolutional layers that allows them to learn translation-invariant features. Instead of learning separate parameters for each location in an image, convolutional layers share weights across different spatial locations. This greatly reduces the number of parameters and enables CNNs to generalize well to new images.
To illustrate these concepts, let's consider an example where we want to train a CNN for object recognition. In the first convolutional layer, filters might be designed to detect low-level features like edges or textures. As we move deeper into subsequent convolutional layers, filters become more complex and start detecting higher-level features, such as shapes or object parts. The combination of these features in deeper layers leads to the classification of specific objects.
Convolutional layers are the backbone of CNNs and play a crucial role in capturing hierarchical representations of images. They enable the network to learn meaningful and discriminative features directly from the raw pixel values.
2. Pooling Layers and Dimensionality Reduction
Pooling layers are responsible for reducing the spatial dimensions of feature maps while preserving important features. They help reduce the computational complexity of CNNs and provide a form of translation invariance. Let's explore some key aspects related to pooling layers:
Spatial Dimensions Reduction
Pooling layers divide each feature map into non-overlapping regions or windows and aggregate the values within each region. The most common pooling technique is max pooling, which takes the maximum value within each window. Average pooling is another popular method, where the average value within each window is computed. These operations downsample the feature maps, reducing their spatial size.
Preserving Important Features
Also read :A Comprehensive Guide on How to Become a Machine Learning Engineer in 2024
Although pooling layers reduce the spatial dimensions, they retain important features by retaining the strongest activations within each window. This helps maintain robustness to variations in translation, scale, and rotation.
Pooling layers effectively summarize local information and provide an abstract representation of important features, allowing subsequent layers to focus on higher-level representations.
3. Fully-Connected Layers for Classification Tasks
Fully-connected layers are responsible for classifying images based on the extracted features from convolutional and pooling layers. These layers connect every neuron from one layer to every neuron in the next layer, similar to traditional neural networks. Here's an in-depth look at fully-connected layers:
Class Predictions
The output of fully-connected layers represents class probabilities for different categories or labels. By applying activation functions like softmax, CNNs can assign a probability score to each possible class based on the extracted features.
Backpropagation and Training
Fully-connected layers are trained using the backpropagation algorithm, which involves iteratively adjusting the weights based on the computed gradients. This process allows the network to learn discriminative features and optimize its performance for specific classification tasks.
Fully-connected layers at the end of CNNs leverage the extracted features to make accurate predictions and classify images into different classes or categories.
By understanding the components of CNNs, we gain insights into how these neural networks process images and extract meaningful representations. The convolutional layers capture local patterns and features, pooling layers reduce spatial dimensions while preserving important information, and fully-connected layers classify images based on the extracted features. These components work together harmoniously to perform image classification tasks effectively.
2. Pooling Layers and Dimensionality Reduction

Pooling layers are an essential component of convolutional neural networks (CNNs) that play a crucial role in reducing spatial dimensions while preserving important features. They work in conjunction with convolutional layers and fully-connected layers to create a powerful architecture for image classification tasks.
Comprehensive Guide to Pooling Layers in CNNs
Pooling layers are responsible for downsampling the output of convolutional layers, which helps reduce the computational complexity of the network and makes it more robust to variations in input images. Here's a breakdown of the key aspects of pooling layers:
1. Spatial Dimension Reduction
One of the main purposes of pooling layers is to reduce the spatial dimensions of the feature maps generated by the previous convolutional layer. By downsampling the feature maps, pooling layers effectively decrease the number of parameters in subsequent layers, making the network more efficient.
2. Preserving Important Features
Despite reducing the spatial dimensions, pooling layers aim to preserve important features learned by convolutional layers. This is achieved by considering local neighborhoods of pixels and summarizing them into a single value or feature. By doing so, pooling layers retain relevant information while discarding less significant details.
Overview of Popular Pooling Techniques
There are several commonly used pooling techniques in CNNs, each with its own characteristics and advantages:
Max Pooling: Max pooling is perhaps the most widely used pooling technique in CNNs. It operates by partitioning the input feature map into non-overlapping rectangles or regions and selecting the maximum value within each region as the representative value for that region. Max pooling is effective at capturing dominant features and providing translation invariance.
Average Pooling: Unlike max pooling, average pooling calculates the average value within each region instead of selecting the maximum value. This technique can be useful when preserving detailed information across different regions is desired, as it provides a smoother representation of the input.
Global Pooling: Global pooling is a pooling technique that aggregates information from the entire feature map into a single value or feature vector. This is achieved by applying a pooling operation (e.g., max pooling or average pooling) over the entire spatial dimensions of the feature map. Global pooling helps capture high-level semantic information and is commonly used in the final layers of a CNN for classification tasks.
Example: Pooling Layers in Action
To illustrate the functionality of pooling layers, let's consider an example with a simple CNN architecture for image classification:
Convolutional layers extract local features and generate feature maps.
Pooling layers then downsample the feature maps, reducing their spatial dimensions while retaining essential information.
Fully-connected layers process the pooled features and make class predictions based on learned representations.
By incorporating pooling layers in between convolutional layers, CNNs are able to hierarchically learn features at different levels of abstraction. The combination of convolutional layers, pooling layers, and fully-connected layers enables CNNs to effectively classify images and perform complex computer vision tasks.
Also read :Comparing Google Gemini and ChatGPT: Performance, Generalization Abilities, and Ethical Considerations
In summary, pooling layers are an integral part of CNNs that contribute to dimensionality reduction while preserving important features. Techniques like max pooling, average pooling, and global pooling allow CNNs to downsample feature maps and capture relevant information for subsequent processing. Understanding how these building blocks work together provides insights into the functionality of convolutional neural networks and their effectiveness in image classification tasks.
3. Fully-Connected Layers for Classification Tasks

In a convolutional neural network (CNN), fully-connected layers play a crucial role in making class predictions based on the extracted features from previous layers. These layers are responsible for learning and mapping high-level features to specific classes or categories.
The Role of Fully-Connected Layers
After the convolutional and pooling layers extract important spatial features from the input image, fully-connected layers are introduced to perform classification tasks. These layers are similar to the traditional neural networks where all neurons in one layer are connected to every neuron in the subsequent layer. The output of the last pooling layer, which is a flattened feature map, serves as the input to the fully-connected layers.
The purpose of these fully-connected layers is to learn complex relationships between extracted features and their corresponding classes. By connecting every neuron in one layer to every neuron in the next layer, fully-connected layers can capture intricate patterns and dependencies within the data.
Training Fully-Connected Layers with Backpropagation
To train fully-connected layers, CNNs utilize backpropagation, an algorithm that adjusts the weights of each connection based on the error calculated during training. The process involves iteratively propagating the error gradient backward through the network and updating the weights accordingly.
During training, an input image is fed forward through the network, resulting in class predictions at the output layer. The predicted class probabilities are then compared to the true labels using a loss function such as cross-entropy. The error is calculated by measuring the difference between predicted and true probabilities.
Backpropagation starts by computing how much each weight contributes to the overall error. This is done by propagating error gradients backward from the output layer to the input layer, updating weights along the way using gradient descent optimization. By iteratively adjusting weights based on their contribution to error reduction, fully-connected layers gradually learn to make accurate class predictions.
Limitations and Challenges
Fully-connected layers have been effective in many image classification tasks. However, they have a few limitations:
Computational Cost: Fully-connected layers require a large number of parameters due to the connections between every neuron, making them computationally expensive, especially for high-resolution images.
Loss of Spatial Information: As fully-connected layers flatten the extracted feature maps into a one-dimensional vector, they discard the spatial information present in the original image. This loss of spatial information can be detrimental in tasks where fine-grained details are important.
Limited Translation Invariance: Unlike convolutional layers that use shared weights to detect features across different regions of an image, fully-connected layers treat each neuron independently. This lack of translation invariance can make CNNs sensitive to small changes in input position.
Example Architecture: LeNet-5
One of the early successful CNN architectures that utilized fully-connected layers is LeNet-5, developed by Yann LeCun in 1998 for handwritten digit recognition. The LeNet-5 architecture consisted of three sets of convolutional and pooling layers followed by two fully-connected layers.
The first fully-connected layer in LeNet-5 had 120 neurons, while the second fully-connected layer had 84 neurons before reaching the output layer with 10 neurons representing the digits 0 to 9. The output layer used softmax activation to produce class probabilities.
LeNet-5 showcased the effectiveness of fully-connected layers in learning complex relationships and achieving high accuracy on digit recognition tasks. Since then, numerous advancements and variations of CNN architectures have emerged, emphasizing more intricate network designs and deeper hierarchies.
Summary
Fully-connected layers serve as the final stages of a CNN, responsible for learning and mapping high-level features to specific classes or categories. By utilizing backpropagation during training, these layers gradually learn to make accurate class predictions based on extracted features from earlier layers. However, they come with limitations such as computational cost, loss of spatial information, and limited translation invariance. Despite these challenges, fully-connected layers have played a crucial role in achieving state-of-the-art performance in various image classification tasks.
Training and Advancements in Convolutional Neural Networks

Neural network training involves optimizing model parameters to minimize the difference between predicted outputs and actual targets. In the case of CNNs, this training process is crucial for learning and extracting features from input images. Here are some key points to consider when discussing the training of CNNs and advancements in the field:
Training Process
Also read :Explore the Latest in Gadgets: Gadgets 360, Officer-Approved Tech, Lottery Winners' Gadgets, NDTV Reviews, SK Premium Selection, and Self-Defense & Electronic Marvels!
The training of a CNN typically involves:
Feeding annotated data through the network
Performing a forward pass to generate predictions
Calculating the loss (difference between predictions and actual targets)
Updating the network's weights through backpropagation to minimize this loss
This iterative process helps the CNN learn to recognize patterns and features within the input images.
Advanced Architectures
Several advanced CNN architectures have significantly contributed to pushing the boundaries of performance in image recognition tasks:
LeNet-5
AlexNet
VGGNet
GoogLeNet
ResNet
ZFNet
Each of these models introduced novel concepts and architectural designs that improved the accuracy and efficiency of CNNs for various tasks.
LeNet-5
LeNet-5 was one of the pioneering CNN architectures developed by Yann LeCun for handwritten digit recognition. It consisted of several convolutional and subsampling layers followed by fully connected layers. LeNet-5 demonstrated the potential of CNNs in practical applications.
AlexNet
AlexNet gained widespread attention after winning the ImageNet Large Scale Visual Recognition Challenge in 2012. This architecture featured a deeper network design with multiple convolutional layers and introduced the concept of using ReLU (Rectified Linear Unit) activation functions for faster convergence during training.
VGGNet
VGGNet is known for its simple yet effective architecture with small 3x3 convolutional filters stacked together to form deeper networks. This approach led to improved feature learning capabilities and better generalization on various datasets.
GoogLeNet
GoogLeNet introduced the concept of inception modules, which allowed for more efficient use of computational resources by incorporating parallel convolutional operations within the network.
ResNet
ResNet (Residual Network) addressed the challenge of training very deep neural networks by introducing skip connections that enabled better gradient flow during backpropagation. This architectural innovation facilitated training of networks with hundreds of layers while mitigating issues related to vanishing gradients.
ZFNet
ZFNet (Zeiler & Fergus Network) made significant contributions to understanding visual patterns by incorporating deconvolutional layers for visualization of learned features within the network.
These advancements in CNN architectures have not only improved performance but also paved the way for exploring more complex tasks in computer vision and image recognition.
Applications of CNNs in Computer Vision

Highlighting the Wide Range of Computer Vision Tasks
Object Detection: CNNs have proven to be highly effective in detecting and localizing objects within images. They can accurately identify and outline various objects, even in complex scenes with multiple overlapping elements.
Semantic Segmentation: By employing CNNs, computer vision systems can understand the context of different parts of an image. This allows for precise identification and differentiation of individual objects or elements within the image.
Style Transfer: CNNs have been utilized to transfer artistic styles from one image to another, offering a creative application of computer vision. This technology enables the transformation of photographs into artworks reflecting the styles of famous painters or artistic movements.
By excelling in these computer vision tasks, CNNs have significantly advanced the capabilities of machine vision systems, leading to breakthroughs in fields such as autonomous vehicles, medical imaging, and augmented reality.

Examine how the introduction of CNNs revolutionized the field of image recognition and paved the way for state-of-the-art models. Discuss recent advancements in image recognition achieved through CNN-based approaches like transfer learning and attention mechanisms.
CNNs have significantly impacted the realm of image recognition models, bringing about a paradigm shift and enabling the development of cutting-edge approaches. Here's a closer look at their profound influence:
Revolutionizing Image Recognition
Also read :What is a convolutional neural Network (CNN)?
The introduction of CNNs has transformed the landscape of image recognition, pushing the boundaries of what was previously achievable. By leveraging convolutional layers for feature extraction and hierarchical learning, CNNs have enabled the creation of sophisticated models capable of accurately classifying and identifying visual content.
Recent Advancements in Image Recognition
In recent years, significant advancements in image recognition have been realized through the application of CNN-based methodologies. Two notable approaches that have garnered attention are:
Transfer Learning: This approach involves utilizing pre-trained CNN models as a starting point for new image recognition tasks. By leveraging knowledge gained from large-scale labeled datasets, transfer learning enables the adaptation and fine-tuning of existing CNN architectures to suit specific recognition objectives. This method has proven particularly valuable in scenarios where labeled training data is limited, as it allows for the efficient reutilization of learned features.
Attention Mechanisms: The integration of attention mechanisms within CNN architectures has emerged as a powerful technique for enhancing image recognition capabilities. By dynamically focusing on relevant regions within an image, these mechanisms enable CNNs to selectively attend to crucial visual elements, thereby improving their capacity to discern intricate details and patterns. This targeted approach contributes to heightened accuracy and robustness in image recognition tasks.
The utilization of transfer learning and attention mechanisms underscores the ongoing evolution and refinement of image recognition models, demonstrating the adaptability and versatility inherent in CNN-based strategies.
As we continue to witness strides in image recognition propelled by CNN innovations, it becomes evident that these developments are instrumental in shaping the future trajectory of visual analysis and classification.
FAQ (Frequently Asked Questions):
1. How does transfer learning facilitate the reutilization of learned features in CNN architectures?
Transfer learning allows for the transfer of knowledge gained from pre-training on a large dataset to a target task with limited labeled data. By freezing and utilizing the lower layers of a pre-trained CNN, important low-level features can be leveraged for the new task, while only fine-tuning higher layers to adapt to the specific recognition objectives.
2. How do attention mechanisms enhance image recognition capabilities?
Attention mechanisms enable CNNs to focus on relevant regions within an image, improving their ability to discern intricate details and patterns. This selective attention helps CNNs prioritize crucial visual elements, contributing to heightened accuracy and robustness in image recognition tasks.
3. What role do these advancements play in the future of visual analysis and classification?
The integration of transfer learning and attention mechanisms highlights the adaptability and versatility of CNN-based strategies. These advancements continue to shape the trajectory of image recognition, offering promising avenues for improving accuracy, efficiency, and interpretability in complex visual analysis tasks.
Conclusion
In conclusion, convolutional neural networks (CNNs) have revolutionized the field of image recognition and opened up new possibilities for state-of-the-art models. Through their introduction, image-related tasks have seen significant advancements and improved performance.
As readers, it is highly encouraged to explore and experiment with CNNs in your own deep learning projects or research endeavors. The potential for innovation in image-related domains is vast, and CNNs provide a powerful tool to tackle complex problems.
To get started with CNNs, consider the following steps:
Learn the fundamentals: Familiarize yourself with the key components of CNNs, including convolutional layers, pooling layers, and fully-connected layers. Understand their roles in feature extraction, dimensionality reduction, and classification.
Gain practical experience: Implement CNN architectures using popular deep learning frameworks such as TensorFlow or PyTorch. Work on image classification tasks and experiment with different network architectures to understand their strengths and weaknesses.
Stay updated: Keep up with the latest advancements in CNN research and explore new approaches like transfer learning and attention mechanisms. These techniques have shown promising results in improving image recognition accuracy.
Remember, CNNs are not limited to image recognition alone. They can be applied to various other domains such as object detection, semantic segmentation, style transfer, and more.
By harnessing the power of convolutional neural networks, you can contribute to the ongoing progress in computer vision and make significant strides in solving real-world challenges related to image analysis.
So go ahead and dive into the world of CNNs - unlock the potential of deep learning for image-related tasks and drive innovation forward!
#artificial intelligence#convolutional neural network#machine learning#Deep Learning#CNNs#Neural Networks
0 notes
Text
Unveiling the Depths of Intelligence: A Journey into the World of Deep Learning

Embark on a captivating exploration into the cutting-edge realm of Deep Learning, a revolutionary paradigm within the broader landscape of artificial intelligence. Read More. https://www.sify.com/ai-analytics/unveiling-the-depths-of-intelligence-a-journey-into-the-world-of-deep-learning/
#DeepLearning#ArtificialIntelligence#AI#ConvolutionalNeuralNetworks#CNNs#GenerativeAdversarialNetworks#GANs#Autoencoders
0 notes
Text

5K notes
·
View notes
Text

wtf kind of debate is this
#cnn#debate#debate night#donald trump#trump#biden#joe biden#usa#us politics#political art#politics#memes#smiling friends#mr frog#mr frog for president#adult swim#digital painting#fanart#fan drawing#drawing#art#artwork#illustration#digital art#digital artwork#digital illustration#artists on tumblr#ibispaintx
5K notes
·
View notes
Text
Ten journalists who have covered the war on Gaza for two of the world’s leading news networks, CNN and the BBC, have revealed the inner workings of those outlets’ newsrooms from October 7 onward, alleging pro-Israel bias in coverage, systematic double standards and frequent violations of journalistic principles. In several cases, they accused senior newsroom figures of failing to hold Israeli officials to account and of interfering in reporting to downplay Israeli atrocities. In one instance at CNN, false Israeli propaganda was put on air despite advance warnings from staff members.
5 October 2024
2K notes
·
View notes
Text
I mean this genuinely, and also as a massive hypocrite: watching the election results come in this early in the night will not make you happy, and it will not tell you who is going to win the election.
Reporting comes in inconsistently. There is a mild panic about Virginia every four years before the extremely blue counties report all of their numbers.
It will feel bad. It will look bad. Until states have reported enough to get an actual clear view of the results, we have no way of knowing if it will be bad.
Give yourself a break. If you must watch, watch on mute. This will be a long day or multiple days. Pace yourself.
#us politics#i say this as someone with cnn playing (currently on mute)#plus nyt 538 and twitter open#we simply do not know what the result will be at this point in time
2K notes
·
View notes