#better than Nvidia
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Video
youtube
This Stock Is Up Over 6x More Than Nvidia in 2024 !
0 notes
Text

#dishonored#the knife of dunwall#arkane studios#bethesda softworks#gamingedit#nvidia ansel#virtual photography#gaming photography#photomode#pc gaming#in game photography#dishonored: definitive edition#dishonored: the knife of dunwall#interestingly her statue looks better than herself
40 notes
·
View notes
Text

What on earth is the lighting when it rains on medium quality at certain angles
#Why does it look like a screenshot from an xbox 360 or ps3 game like this😭#Also my god does rain kill performance#Every time I start to go ''alright this is better than I thought'' something happens to kill the thought#And then I go back to ''They should have charged like $10 for this'' lmao#I paid $0 and am still like ''in this economy????''#the inside of caves on lower settings also look...... bad#Adaptive vsync is nice for the game though#It's in your Nvidia control panel and set it up through there and turn the in-game vsync off#I've gotten less frame drops that way and tearing isn't noticeable#vena vents#not art#screenshots
6 notes
·
View notes
Text


( ˘͈ ᵕ ˘͈♡)
I gave up hoping for something more than the in-game animations' dead eyes.
#Hogwarts Legacy#Hogwarts Legacy Screenshots#Hogwarts#Hogwarts Legacy MC#Hogwarts Legacy OC#Ekrizdis Mors#Slytherin MC#Natsai Onai#Natsai Onai x MC#Riz x Natty#the UNHOLY hours I spent to get this screenshot#THEIR EYES ARE SO DEAD 😭😭😭#but this turns out better than I expected tho#waiting for modders community to work their magic on the mod animation menu situation#NVIDIA screenshots
11 notes
·
View notes
Text
yeeeesssssssssss
#just happy that. while sure i still dont have time to play it today. i got it running. sure it was on the nvidia cloud thing. but its#working. its finally working. cant wait to see my rook in 3d tomorrow. and yeah there's a six hour session limit but. thats gotta be long#enough to make a character and get to a save point at the very least so. fuck yeah#original posts#also like. talked to my wife with both of us having clearer heads (thanks to literally clearer air) and shes open to slowly building a new#computer which is cool. just not with the absolute minimum parts this time. so until then nvidia it is for anything too modern for this#2012 ass machine. ah well its better than nothing
3 notes
·
View notes
Text

welcome to dawntrail gunbreaker, finally
gnb is very fun it turns out, like 2 dps in tank's trench coat
#anya plays ffxiv#i always forget i have filters in game#(just some nvidia filters)#and then i take a basic screenshot#without doing anything to lighting\filters in gpose#and get confused later when the colors look washed out#and have to fix it in csp#anyways#if i to get any lore friendly justification for picking up a job#which i won't do#but if i would#it'd be purely to be better than thancred#because i'm never forgiving that cave in#never#every time i run that dungeon#i think about astarion#i was RIGHT THERE
5 notes
·
View notes
Text
I am very wary of people going "China does it better than America" because most of it is just reactionary rejection of your overlord in favor of his rival, but this story is 1. absolutely legit and 2. way too funny.

US wants to build an AI advantage over China, uses their part in the chip supply chain to cut off China from the high-end chip market.
China's chip manufacturing is famously a decade behind, so they can't advance, right?

They did see it as a problem, but what they then did is get a bunch of Computer Scientists and Junior Programmers fresh out of college and funded their research in DeepSeek. Instead of trying to improve output by buying thousands of Nvidia graphics cards, they tried to build a different kind of model, that allowed them to do what OpenAI does at a tenth of the cost.

Them being young and at a Hedgefund AI research branch and not at established Chinese techgiants seems to be important because chinese corporate culture is apparently full of internal sabotage, so newbies fresh from college being told they have to solve the hardest problems in computing was way more efficient than what usually is done. The result:

American AIs are shook. Nvidia, the only company who actually is making profit cause they are supplying hardware, took a hit. This is just the market being stupid, Nvidia also sells to China. And the worst part for OpenAI. DeepSeek is Open Source.

Anybody can implement deepseek's model, provided they have the hardware. They are totally independent from DeepSeek, as you can run it from your own network. I think you will soon have many more AI companies sprouting out of the ground using this as its base.

What does this mean? AI still costs too much energy to be worth using. The head of the project says so much himself: "there is no commercial use, this is research."

What this does mean is that OpenAI's position is severely challenged: there will soon be a lot more competitors using the DeepSeek model, more people can improve the code, OpenAI will have to ask for much lower prices if it eventually does want to make a profit because a 10 times more efficient opensource rival of equal capability is there.
And with OpenAI or anybody else having lost the ability to get the monopoly on the "market" (if you didn't know, no AI company has ever made a single cent in profit, they all are begging for investment), they probably won't be so attractive for investors anymore. There is a cheaper and equally good alternative now.
AI is still bad for the environment. Dumb companies will still want to push AI on everything. Lazy hacks trying to push AI art and writing to replace real artists will still be around and AI slop will not go away. But one of the main drivers of the AI boom is going to be severely compromised because there is a competitor who isn't in it for immediate commercialization. Instead you will have a more decentralized open source AI field.
Or in short:

3K notes
·
View notes
Note
Thoughts on Linux (the OS)
Misconception!
I don't want to be obnoxiously pedantic, but Linux is not an OS. It is a kernel, which is just part of an OS. (Like how Windows contains a lot more than just KERNEL32.DLL). A very, very important piece, which directly shapes the ways that all the other programs will talk to each other. Think of it like a LEGO baseplate.

Everything else is built on top of the kernel. But, a baseplate does not a city make. We need buildings! A full operating system is a combination of a kernel and kernel-level (get to talk to hardware directly) utilities for talking to hardware (drivers), and userspace (get to talk to hardware ONLY through the kernel) utilities ranging in abstraction level from stuff like window management and sound servers and system bootstrapping to app launchers and file explorers and office suites. Every "Linux OS" is a combination of that LEGO baseplate with some permutation of low and high-level userspace utilities.
Now, a lot of Linux-based OSes do end up feeling (and being) very similar to each other. Sometimes because they're directly copying each other's homework (AKA forking, it's okay in the open source world as long as you follow the terms of the licenses!) but more generally it's because there just aren't very many options for a lot of those utilities.
Want your OS to be more than just a text prompt? Your pick is between X.org (old and busted but...well, not reliable, but a very well-known devil) and Wayland (new hotness, trying its damn hardest to subsume X and not completely succeeding). Want a graphics toolkit? GTK or Qt. Want to be able to start the OS? systemd or runit. (Or maybe SysVinit if you're a real caveman true believer.) Want sound? ALSA is a given, but on top of that your options are PulseAudio, PipeWire, and JACK. Want an office suite? Libreoffice is really the only name in the game at present. Want terminal utilities? Well, they're all gonna have to conform to the POSIX spec in some capacity. GNU coreutils, busybox, toybox, all more or less the same programs from a user perspective.
Only a few ever get away from the homogeneity, like Android. But I know that you're not asking about Android. When people say "Linux OS" they're talking about the homogeneity. The OSes that use terminals. The ones that range in looks from MacOS knockoff to Windows knockoff to 'impractical spaceship console'. What do I think about them?
I like them! I have my strongly-felt political and personal opinions about which building blocks are better than others (generally I fall into the 'functionality over ideology' camp; Nvidia proprietary over Nouveau, X11 over Wayland, Systemd over runit, etc.) but I like the experience most Linux OSes will give me.
I like my system to be a little bit of a hobby, so when I finally ditched Windows for the last time I picked Arch Linux. Wouldn't recommend it to anyone who doesn't want to treat their OS as a hobby, though. There are better and easier options for 'normal users'.
I like the terminal very much. I understand it's intimidating for new users, but it really is an incredible tool for doing stuff once you're in the mindset. GUIs are great when you're inexperienced, but sometimes you just wanna tell the computer what you want with your words, right? So many Linux programs will let you talk to them in the terminal, or are terminal-only. It's very flexible.
I also really, really love the near-universal concept of a 'package manager' -- a program which automatically installs other programs for you. Coming from Windows it can feel kinda restrictive that you have to go through this singular port of entry to install anything, instead of just looking up the program and running an .msi file, but I promise that if you get used to it it's very hard to go back. Want to install discord? yay -S discord. Want to install firefox? yay -S firefox. Minecraft? yay -S minecraft-launcher. etc. etc. No more fucking around in the Add/Remove Programs menu, it's all in one place! Only very rarely will you want to install something that isn't in the package manager's repositories, and when you do you're probably already doing something that requires technical know-how.
Not a big fan of the filesystem structure. It's got a lot of history. 1970s mainframe computer operation procedure history. Not relevant to desktop users, or even modern mainframe users. The folks over at freedesktop.org have tried their best to get at least the user's home directory cleaned up but...well, there's a lot of historical inertia at play. It's not a popular movement right now but I've been very interested in watching some people try to crack that nut.
Aaaaaand I think those are all the opinions I can share without losing everyone in the weeds. Hope it was worth reading!
225 notes
·
View notes
Text
Portal 2 is still the perfect game to me. I hyperfixated on it like crazy in middle school. Would sing Want You Gone out loud cuz I had ADHD and no social awareness. Would make fan animations and pixel art. Would explain the ending spoilers and fan theories to anyone who'd listen. Would keep up with DeviantArt posts of the cores as humans. Would find and play community-made maps (Gelocity is insanely fun).
I still can't believe this game came out 12 years ago and it looks like THIS.



Like Mirror's Edge, the timeless art style and economic yet atmospheric lighting means this game will never age. The decision not to include any visible humans (ideas of Doug Rattmann showing up or a human co-op partner were cut) is doing so much legroom too. And the idea to use geometric tileset-like level designs is so smart! I sincerely believe that, by design, no game with a "realistic art style" has looked better than Portal 2.
Do you guys remember when Nvidia released Portal with RTX at it looked like dogshit? Just the most airbrushed crap I've ever seen; completely erased the cold, dry, clinical feel of Aperture.


So many breathtakingly pit-in-your-stomach moments I still think about too. And it's such a unique feeling; I'd describe at as... architectural existentialism? Experiencing the sublime under the shadow of manmade structures (Look up Giovanni Battista Piranesi's art if you're curious)? That scene where you're running from GLaDOS with Wheatley on a catwalk over a bottomless pit and––out of rage and desperation––GLaDOS silently begins tearing her facility apart and Wheatley cries 'She's bringing the whole place down!' and ENORMOUS apartment building-sized blocks begin groaning towards you on suspended rails and cement pillars crumble and sparks fly and the metal catwalk strains and bends and snaps under your feet. And when you finally make it to the safety of a work lift, you look back and watch the facility close its jaws behind you as it screams.
Or the horror of knowing you're already miles underground, and then Wheatley smashes you down an elevator shaft and you realize it goes deeper. That there's a hell under hell, and it's much, much older.
Or how about the moment when you finally claw your way out of Old Aperture, reaching the peak of this underground mountain, only to look up and discover an endless stone ceiling built above you. There's a service door connected to some stairs ahead, but surrounding you is this array of giant, building-sized springs that hold the entire facility up. They stretch on into the fog. You keep climbing.
I love that the facility itself is treated like an android zooid too, a colony of nano-machines and service cores and sentient panel arms and security cameras and more. And now, after thousands of years of neglect, the facility is festering with decomposition and microbes; deer, raccoons, birds. There are ghosts too. You're never alone, even when it's quiet. I wonder what you'd hear if you put your ear up against a test chamber's walls and listened. (I say that all contemplatively, but that's literally an easter egg in the game. You hear a voice.)
Also, a reminder that GLaDOS and Chell are not related and their relationship is meant to be psychosexual. There was a cut bit where GLaDOS would role-play as Chell's jealous housewife and accuse her of seeing other cores in between chambers. And their shared struggle for freedom and control? GLaDOS realizing, after remembering her past life, that she's become the abuser and deciding that she has the power to stop? That even if she can't be free, she can let Chell go because she hates her. And she loves her. Most people interpret GLaDOS "deleting Caroline in her brain" as an ominous sign, that she's forgetting her human roots and becoming "fully robot." But to me, it's a sign of hope for GLaDOS. She's relieving herself of the baggage that has defined her very existence, she's letting Caroline finally rest, and she's allowing herself to grow beyond what Cave and Aperture and the scientists defined her to be. The fact that GLaDOS still lets you go after deleting Caroline proves this. She doesn't double-back or change her mind like Wheatley did, she sticks to her word because she knows who she is. No one and nothing can influence her because she's in control. GLaDOS proves she's capable of empathy and mercy and change, human or not.
That's my retrospective, I love this game to bits. I wish I could experience it for the first time again.
#ramblings#long post#not art#personal#also i know “did glados actually delete caroline” is debated cuz the credits song disputes this#but i like to think she did#it's not sad. caroline died a long time ago#it's a goodbye
2K notes
·
View notes
Text
“Humans in the loop” must detect the hardest-to-spot errors, at superhuman speed

I'm touring my new, nationally bestselling novel The Bezzle! Catch me SATURDAY (Apr 27) in MARIN COUNTY, then Winnipeg (May 2), Calgary (May 3), Vancouver (May 4), and beyond!

If AI has a future (a big if), it will have to be economically viable. An industry can't spend 1,700% more on Nvidia chips than it earns indefinitely – not even with Nvidia being a principle investor in its largest customers:
https://news.ycombinator.com/item?id=39883571
A company that pays 0.36-1 cents/query for electricity and (scarce, fresh) water can't indefinitely give those queries away by the millions to people who are expected to revise those queries dozens of times before eliciting the perfect botshit rendition of "instructions for removing a grilled cheese sandwich from a VCR in the style of the King James Bible":
https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
Eventually, the industry will have to uncover some mix of applications that will cover its operating costs, if only to keep the lights on in the face of investor disillusionment (this isn't optional – investor disillusionment is an inevitable part of every bubble).
Now, there are lots of low-stakes applications for AI that can run just fine on the current AI technology, despite its many – and seemingly inescapable - errors ("hallucinations"). People who use AI to generate illustrations of their D&D characters engaged in epic adventures from their previous gaming session don't care about the odd extra finger. If the chatbot powering a tourist's automatic text-to-translation-to-speech phone tool gets a few words wrong, it's still much better than the alternative of speaking slowly and loudly in your own language while making emphatic hand-gestures.
There are lots of these applications, and many of the people who benefit from them would doubtless pay something for them. The problem – from an AI company's perspective – is that these aren't just low-stakes, they're also low-value. Their users would pay something for them, but not very much.
For AI to keep its servers on through the coming trough of disillusionment, it will have to locate high-value applications, too. Economically speaking, the function of low-value applications is to soak up excess capacity and produce value at the margins after the high-value applications pay the bills. Low-value applications are a side-dish, like the coach seats on an airplane whose total operating expenses are paid by the business class passengers up front. Without the principle income from high-value applications, the servers shut down, and the low-value applications disappear:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Now, there are lots of high-value applications the AI industry has identified for its products. Broadly speaking, these high-value applications share the same problem: they are all high-stakes, which means they are very sensitive to errors. Mistakes made by apps that produce code, drive cars, or identify cancerous masses on chest X-rays are extremely consequential.
Some businesses may be insensitive to those consequences. Air Canada replaced its human customer service staff with chatbots that just lied to passengers, stealing hundreds of dollars from them in the process. But the process for getting your money back after you are defrauded by Air Canada's chatbot is so onerous that only one passenger has bothered to go through it, spending ten weeks exhausting all of Air Canada's internal review mechanisms before fighting his case for weeks more at the regulator:
https://bc.ctvnews.ca/air-canada-s-chatbot-gave-a-b-c-man-the-wrong-information-now-the-airline-has-to-pay-for-the-mistake-1.6769454
There's never just one ant. If this guy was defrauded by an AC chatbot, so were hundreds or thousands of other fliers. Air Canada doesn't have to pay them back. Air Canada is tacitly asserting that, as the country's flagship carrier and near-monopolist, it is too big to fail and too big to jail, which means it's too big to care.
Air Canada shows that for some business customers, AI doesn't need to be able to do a worker's job in order to be a smart purchase: a chatbot can replace a worker, fail to their worker's job, and still save the company money on balance.
I can't predict whether the world's sociopathic monopolists are numerous and powerful enough to keep the lights on for AI companies through leases for automation systems that let them commit consequence-free free fraud by replacing workers with chatbots that serve as moral crumple-zones for furious customers:
https://www.sciencedirect.com/science/article/abs/pii/S0747563219304029
But even stipulating that this is sufficient, it's intrinsically unstable. Anything that can't go on forever eventually stops, and the mass replacement of humans with high-speed fraud software seems likely to stoke the already blazing furnace of modern antitrust:
https://www.eff.org/de/deeplinks/2021/08/party-its-1979-og-antitrust-back-baby
Of course, the AI companies have their own answer to this conundrum. A high-stakes/high-value customer can still fire workers and replace them with AI – they just need to hire fewer, cheaper workers to supervise the AI and monitor it for "hallucinations." This is called the "human in the loop" solution.
The human in the loop story has some glaring holes. From a worker's perspective, serving as the human in the loop in a scheme that cuts wage bills through AI is a nightmare – the worst possible kind of automation.
Let's pause for a little detour through automation theory here. Automation can augment a worker. We can call this a "centaur" – the worker offloads a repetitive task, or one that requires a high degree of vigilance, or (worst of all) both. They're a human head on a robot body (hence "centaur"). Think of the sensor/vision system in your car that beeps if you activate your turn-signal while a car is in your blind spot. You're in charge, but you're getting a second opinion from the robot.
Likewise, consider an AI tool that double-checks a radiologist's diagnosis of your chest X-ray and suggests a second look when its assessment doesn't match the radiologist's. Again, the human is in charge, but the robot is serving as a backstop and helpmeet, using its inexhaustible robotic vigilance to augment human skill.
That's centaurs. They're the good automation. Then there's the bad automation: the reverse-centaur, when the human is used to augment the robot.
Amazon warehouse pickers stand in one place while robotic shelving units trundle up to them at speed; then, the haptic bracelets shackled around their wrists buzz at them, directing them pick up specific items and move them to a basket, while a third automation system penalizes them for taking toilet breaks or even just walking around and shaking out their limbs to avoid a repetitive strain injury. This is a robotic head using a human body – and destroying it in the process.
An AI-assisted radiologist processes fewer chest X-rays every day, costing their employer more, on top of the cost of the AI. That's not what AI companies are selling. They're offering hospitals the power to create reverse centaurs: radiologist-assisted AIs. That's what "human in the loop" means.
This is a problem for workers, but it's also a problem for their bosses (assuming those bosses actually care about correcting AI hallucinations, rather than providing a figleaf that lets them commit fraud or kill people and shift the blame to an unpunishable AI).
Humans are good at a lot of things, but they're not good at eternal, perfect vigilance. Writing code is hard, but performing code-review (where you check someone else's code for errors) is much harder – and it gets even harder if the code you're reviewing is usually fine, because this requires that you maintain your vigilance for something that only occurs at rare and unpredictable intervals:
https://twitter.com/qntm/status/1773779967521780169
But for a coding shop to make the cost of an AI pencil out, the human in the loop needs to be able to process a lot of AI-generated code. Replacing a human with an AI doesn't produce any savings if you need to hire two more humans to take turns doing close reads of the AI's code.
This is the fatal flaw in robo-taxi schemes. The "human in the loop" who is supposed to keep the murderbot from smashing into other cars, steering into oncoming traffic, or running down pedestrians isn't a driver, they're a driving instructor. This is a much harder job than being a driver, even when the student driver you're monitoring is a human, making human mistakes at human speed. It's even harder when the student driver is a robot, making errors at computer speed:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
This is why the doomed robo-taxi company Cruise had to deploy 1.5 skilled, high-paid human monitors to oversee each of its murderbots, while traditional taxis operate at a fraction of the cost with a single, precaratized, low-paid human driver:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
The vigilance problem is pretty fatal for the human-in-the-loop gambit, but there's another problem that is, if anything, even more fatal: the kinds of errors that AIs make.
Foundationally, AI is applied statistics. An AI company trains its AI by feeding it a lot of data about the real world. The program processes this data, looking for statistical correlations in that data, and makes a model of the world based on those correlations. A chatbot is a next-word-guessing program, and an AI "art" generator is a next-pixel-guessing program. They're drawing on billions of documents to find the most statistically likely way of finishing a sentence or a line of pixels in a bitmap:
https://dl.acm.org/doi/10.1145/3442188.3445922
This means that AI doesn't just make errors – it makes subtle errors, the kinds of errors that are the hardest for a human in the loop to spot, because they are the most statistically probable ways of being wrong. Sure, we notice the gross errors in AI output, like confidently claiming that a living human is dead:
https://www.tomsguide.com/opinion/according-to-chatgpt-im-dead
But the most common errors that AIs make are the ones we don't notice, because they're perfectly camouflaged as the truth. Think of the recurring AI programming error that inserts a call to a nonexistent library called "huggingface-cli," which is what the library would be called if developers reliably followed naming conventions. But due to a human inconsistency, the real library has a slightly different name. The fact that AIs repeatedly inserted references to the nonexistent library opened up a vulnerability – a security researcher created a (inert) malicious library with that name and tricked numerous companies into compiling it into their code because their human reviewers missed the chatbot's (statistically indistinguishable from the the truth) lie:
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/
For a driving instructor or a code reviewer overseeing a human subject, the majority of errors are comparatively easy to spot, because they're the kinds of errors that lead to inconsistent library naming – places where a human behaved erratically or irregularly. But when reality is irregular or erratic, the AI will make errors by presuming that things are statistically normal.
These are the hardest kinds of errors to spot. They couldn't be harder for a human to detect if they were specifically designed to go undetected. The human in the loop isn't just being asked to spot mistakes – they're being actively deceived. The AI isn't merely wrong, it's constructing a subtle "what's wrong with this picture"-style puzzle. Not just one such puzzle, either: millions of them, at speed, which must be solved by the human in the loop, who must remain perfectly vigilant for things that are, by definition, almost totally unnoticeable.
This is a special new torment for reverse centaurs – and a significant problem for AI companies hoping to accumulate and keep enough high-value, high-stakes customers on their books to weather the coming trough of disillusionment.
This is pretty grim, but it gets grimmer. AI companies have argued that they have a third line of business, a way to make money for their customers beyond automation's gifts to their payrolls: they claim that they can perform difficult scientific tasks at superhuman speed, producing billion-dollar insights (new materials, new drugs, new proteins) at unimaginable speed.
However, these claims – credulously amplified by the non-technical press – keep on shattering when they are tested by experts who understand the esoteric domains in which AI is said to have an unbeatable advantage. For example, Google claimed that its Deepmind AI had discovered "millions of new materials," "equivalent to nearly 800 years’ worth of knowledge," constituting "an order-of-magnitude expansion in stable materials known to humanity":
https://deepmind.google/discover/blog/millions-of-new-materials-discovered-with-deep-learning/
It was a hoax. When independent material scientists reviewed representative samples of these "new materials," they concluded that "no new materials have been discovered" and that not one of these materials was "credible, useful and novel":
https://www.404media.co/google-says-it-discovered-millions-of-new-materials-with-ai-human-researchers/
As Brian Merchant writes, AI claims are eerily similar to "smoke and mirrors" – the dazzling reality-distortion field thrown up by 17th century magic lantern technology, which millions of people ascribed wild capabilities to, thanks to the outlandish claims of the technology's promoters:
https://www.bloodinthemachine.com/p/ai-really-is-smoke-and-mirrors
The fact that we have a four-hundred-year-old name for this phenomenon, and yet we're still falling prey to it is frankly a little depressing. And, unlucky for us, it turns out that AI therapybots can't help us with this – rather, they're apt to literally convince us to kill ourselves:
https://www.vice.com/en/article/pkadgm/man-dies-by-suicide-after-talking-with-ai-chatbot-widow-says

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#ai#automation#humans in the loop#centaurs#reverse centaurs#labor#ai safety#sanity checks#spot the mistake#code review#driving instructor
857 notes
·
View notes
Text
Why I started using DXT1 texture format for TS2 CC again (sometimes)
In the past I discouraged ppl from using it. But it has one benefit, which TS2 CC creators shouldn't ignore: DXT1 textures are about half the size of DXT3. In TS2 DXT1 is only used for textures without transparency.
There are two facts about textures that some ts2 cc creators and cc hoarders are probably unaware of:
Lossless compression (compressorizer etc) significantly reduces file sizes, but it does NOT help texture memory, because texture files get uncompressed before being stored in GPU texture memory cache
Byte size does NOT equal resolution. For example: Raw32Bit texture takes up around four times more space in texture memory cache than DXT5
DXT3 2048*2048 px takes up ~4MB, but DXT1 2048*2048, thanks to its harsh 8:1 compression, takes up only ~2MB of texture memory cache, which is an equivalent of two makeup textures 512*512 px Raw32Bit format (TS2 makeup creators' favourite :S ).
@episims posted a comparison of DXT formats here - but please note Epi compared texture sizes after those were compressorized. Also, I believe the DXT1 preview actually shows glitches that are not visible in the game.
To change texture format in SimPe you need to install Nvidia DDS utilities, which can be downloaded here (SFS). Also, Yape package editor is much faster and easy to use.
*This is about GPU texture memory. As far as I know, it's unclear how internal TS2 texture memory works - does it benefit from lossless file compression or not? No idea. But IMO we don't have a reason to be optimistic about it :/ What we know for sure is - the easiest way to summon pink soup in TS2 on modern systems, is to make the game load large amounts of texture data (large for TS2 standards anyway) in a short amount of time.
DXT1 built in SimPe with Nvidia DDS Tools tend to look bad - but as I had learned very recently, SimPe DXT1 preview (and export) is broken! It displays some artifacts that are not actually visible in game!
The only way to correctly view DXT1 created in SimPe outside of the game is the new YaPe package editor. You need to switch the texture format preview to AltRGB24 (Raw24Bit).
DXT formats use lossy compression which affects texture quality - this compression matters for texture memory.
DXT1 512*512*4 (4 bytes per pixel) / 8 (divided by 8, because of 8:1 compression ratio) = ~131 KB
DXT3 512x512 px (4:1 compression) = ~262 KB
Raw32Bit 512x512 px = ~1MB
2048x1024 px DXT1 texture takes up around as much texture memory as 1024x1024 px DXT3 or DXT5 (non transparent*) = ~1 MB
*Flat (non transparent) DXT3 size is the same as DXT5.
Fun fact: flat DXT1 and DXT5 built in GIMP look identical, and also not much better than SimPe DXT1 (in game!).
DXT5 has 4:1 compression just like DXT3 but it can store more data in alpha channel, and that allows for much better looking transparency (if smooth alpha is present, size is increased). As I already mentioned, DXT1 does not support alpha transparency.
I don't want my game to look like crap, but if texture looks OK as DXT1, then why not use it. Aside from hood decor, I've been reconverting some wall and floor textures for myself to DXT1 recently, instead of resizing.
Some ppl might cringe on seeing 2048x2048 skybox textures but to me large texture is justified for such a giant object. I cringe at Raw32Bit makeup.
I'm slowly turning all Raw32 makeup content in my game to DXT5 (no mipmaps). I've edited enough of those to know, that quite often the actual texture quality is not great. If a texture has been converted to DXT3 at some point, alpha channel is a bit choppy. "Upgrading" such texture to Raw32 doesn't do anything, other than multiplying texture size by four. I don't know how 'bout you, but I only use one or two skyboxes at a time, while my sims walk around with tons of face masks on them, so it's a real concern to me. And don't make me start on mip maps in CAS CC. My game certainly doesn't need 33% larger hair texture files :S
*note - another thing I've "discovered" after writing this post, SimPe DDS Builder can actually make crisp mipmaps as long as you set Sharpen to "None".
Note2: Raw8Bit (bump maps) / ExtRaw8Bit (shadows etc) are also uncompressed formats, but don't contain color data and weight around as much as DXT3.
/I've taken out this part from a long post I'm writing RN /
132 notes
·
View notes
Text
Gaming GIF Tutorial (2025)
Here is my current GIF making process from video game captures!

PART 1: Capturing Video
The best tip I can give you when it comes to capturing video from your games, is to invest in an injectable photomode tools - I personally use Otis_Inf's cameras because they are easy to use and run smoothly. With these tools, you can not only toggle the UI, but also pause cutscenes and manually change the camera. They are great for both screenshots and video recording!
As for the recording part, I personally prefer NVIDIA's built-in recording tools, but OBS also works well in my experience when NVIDIA is being fussy.
PART 2: Image Conversion
Do yourself a huge favour and download PotPlayer. It is superior to VLC in more ways than one in my opinion, but is especially helpful for its Consecutive Image Capturer tool.
Open the video recording in PotPlayer, and use CTRL + G to open the tool. If this is your first time, be sure to set up a folder for your image captures before anything else! Here are the settings I use, albeit the "Every # frame" I change from time to time:
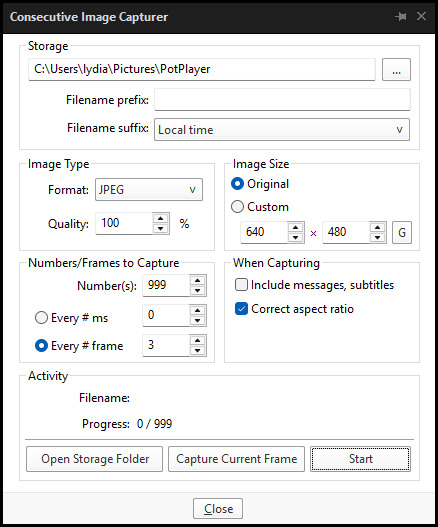
When you're ready, hit the "Start" button, then play the part of the video you want to turn into a GIF. When you're done, pause the video, and hit the "Stop" button. You can then check the images captured in your specified storage folder.
(TIP: Start the video a few seconds a head and stop a few seconds after the part you want to make into a GIF, then manually delete the extra images if necessary. This will reduce the chance of any unwanted cut-offs if there is any lagging.)
PART 3: Image Setup
Now, this part I personally always do in GIMP, because I find its "Open as Layers" and image resizing options 100% better and easier to use than Photoshop. But you don't have to use GIMP, you can do this part in Photoshop as well if you prefer.
Open the images each as an individual layer. Then, crop and/or scale to no more than 540px wide if you're uploading to Tumblr.
(TIP: This might just be a picky thing on my end, but I like to also make sure the height is a multiple of 10. I get clean results this way, so I stick to it.)
If you use GIMP for this part, export the file as .psd when done.
PART 4: Sharpening
If you use GIMP first, now it's time to open the file in Photoshop.
The very first thing I always do is sharpen the image using the "Smart Sharpen" filter. Because we downsized the image, the Smart Sharpen will help it look more crisp and naturally sized. These are the settings I mostly use, though sometimes I change the Amount to 200 if it's a little too crunchy:

Here's a comparison between before and after sharpening:


Repeat the Smart Sharpen filter for ALL the layers!
PART 5: Timeline
First, if your timeline isn't visible, turn it on by click on Windows > Timeline. Then, change the mode from video to frame:

Click "Create Frame Animation" with the very bottom layer selected. Then, click on the menu icon on the far-right of the Timeline, and click "Make Frames from Layers" to add the rest of the frames.
Make sure the delay should be 0 seconds between frames for the smoothest animation, and make sure that the looping is set to forever so that the GIF doesn't stop.
Part 5: Editing
Now that the GIF is set up, this is the part where you can add make edits to the colours, brightness/contrast, add text, etc. as overlays that will affect all the layers below it.
Click on the very top layer so that it is the one highlighted. (Not in the timeline, in the layers box; keep Frame 1 highlighted in the timeline!)
For this example, I'm just going to adjust the levels a bit, but you can experiment with all kinds of fun effects with time and patience. Try a gradient mask, for example!
To test your GIF with the applied effects, hit the Play button in the Timeline. Just remember to always stop at Frame 1 again before you make changes, because otherwise you may run into trouble where the changes are only applied to certain frames. This is also why it's important to always place your adjustment layers at the very top!
Part 6: Exporting
When exporting your GIF with plans to post to Tumblr, I strongly recommend doing all you can to keep the image size below 5mb. Otherwise, it will be compressed to hell and back. If it's over 5mb, try deleting some frames, increasing the black parts, or you can reduce to number of colours in the settings we're about to cover below. Or, you can use EZGIF's optimization tools afterwards to reduce it while keeping better quality than what Tumblr will do to it.
Click on File > Export > Save for Web (Legacy). Here are the settings I always use:

This GIF example is under 5mb, yay! So we don't need to fiddle with anything, we can just save it as is.
I hope this tutorial has offered you some insight and encouragement into making your own GIFs! If you found it helpful, please reblog!
135 notes
·
View notes
Note
Sora looks awesome from OpenAI and then also Chat with RTX (Nvidia) will have a personal local LLM on your own machine but new windows updates will have co-pilot too. The future of AI is going to be awesome. As someone in the data field, you have to keep moving with it or be left without. IT is definitely an exciting time.
As someone else in the data field, my full background is in data and data flow, AI is the latest buzzword that a small group of people in Silicon Valley have pushed to work people up into a frenzy.
The people cheering on AI are the same people who said NFTs were going to radically change the world of work.
I think there’s positive uses for AI, particularly in pattern recognition, like detecting cancer.
However, Sora looks like shit. It’s producing videos of three-legged cats, and it’s using stolen work to do it. And sure, it’ll get better, but without regulation all it will do is poison the well of human knowledge as certain groups begin to create things that aren’t real. We move into a world where evidence can be fabricated.
Why are generative AI fans targeting artists who voice their concerns? Every day I see some AI techbro tweeting an artist and saying they’ve just scrolled through their art and fed it to an algorithm. It is scummy behaviour.
As a fellow ‘data field’ person, you’ll know that AI is also only as useful as what we feed it. Most organisations don’t know where their data actually is, they’re desperately trying to backpedal their huge push to the cloud and host things on premise. The majority of digital transformation projects fail, more fines are being handed out for failing compliance than ever, and companies can’t possibly claim to be cyber secure when they don’t know where they’re holding their data.
AI won’t fix any of this. It needs human engineering and standardisation to fix, non-technical and technical teams need to understand the connectivity of every process and piece of technology and maybe then some form of AI can be used to optimise processes.
But you can’t just introduce AI and think it fixes large-scale issues. It will amplify them if you continue to feed it garbage.
244 notes
·
View notes
Text
Some users on PC have an issue where the Oblivion Remaster shader compilation is not completing.
The game may crash during shader compilation and if you relaunch the game, you can play, but stutters and FPS issues will be worse than if you had successfully compiled shaders. Shader compilation cannot be automatically re-ran so you need to force your PC to restart the compilation.
Here are the steps I took to "fix" this issue:
1. Roll back your Nvidia GPU drivers to 572.83

If you have an AMD GPU, I believe AMD released an updated driver for Oblivion Remastered that should mean no driver rollback is needed.
2. Delete your shader cache via the Disk cleanup windows program


3. Cut/paste this file OUT of this folder path:
steamapps\common\Oblivion Remastered\Engine\Plugins\Marketplace\nvidia\DLSS\Streamline\Binaries\ThirdParty\Win64\sl.pcl.dll
I personally dropped it into a desktop folder so I have it saved somewhere. Just make sure this file is NOT in that folder path anymore.
4. Delete Oblivion.ini from this location:
\steamapps\common\Oblivion Remastered\OblivionRemastered\Content\Dev\ObvData\Oblivion.ini
5. Open Oblivion Remastered and shader compilation should now begin.
If all went well the shader compilation should complete (may take a long time) and you should notice *some* improvements to stuttering as shader are now fully compiled.
Make sure you re select your graphics settings as they will have reverted to default. See below for my personal settings and performance notes. 👇
---
Next part is how I personally went from ~40fps outdoors to a solid 60fps average with occasional dips to 50fps at the lowest.
Caveat I have a high end PC, play on a 4k TV and don't play above 60fps. Your Milage may vary as everyone has their own hardware setup and graphical preferences.
---
1. Make sure your game is installed on SSD. Game just runs alot better on SSD and even warns you to make sure its installed on one.
2. FPS lock/VSync. If you need Vsync to play games like I do. Turn OFF the in-game VSYNC and force VSYNC ON in Nvidia control panel. IDK how AMD gpus work but id imagine you'd use AMDs version of control panel to do the same.
Set the FPS limit to 60fps (or whatever your preference) in the in-game settings. This can also be done instead in the Nvidia control panel so if you set the limit there, be sure to NOT have a limit set in-game settings.
3. DLSS of some kind is a must for most games these days. Especially if playing with Ray Tracing (as you can note below)
Set DLSS to either performance (looks worse, runs better), Quality (looks better, runs a bit worse), or DLAA (looks alot better but most performance hit out of all DLSS settins).
Use FSR if you are on an AMD GPU.
4. DLSS Frame Generation. This literally will give you like 10+ FPS. BUUUTT it gives you CRAZY input lag. Make sure if you use this you also set NVIDIA Reflex to Enabled+Boost. For me this game me the free 10+fps while eliminating the input lag almost entirely.
Note: If you use Frame Generation you will notice the menus in-game have a weird flutter/lag. Beyond this tho the issues are minimal.
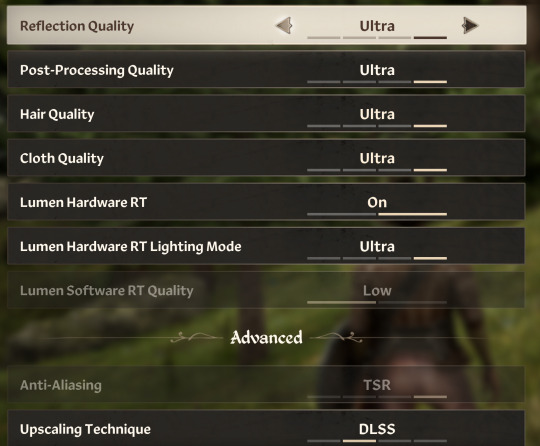
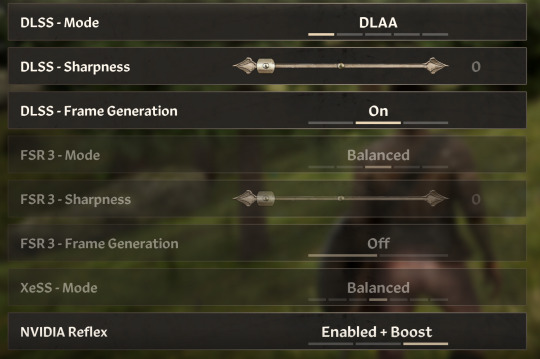
If you use AMD GPUs make sure to use the FSR/FSR Frame Generation/XeSS options as these are AMDs versions of the NVIDIA options i discussed above
I know alot of ppl play on different hardware in general so to summarize the graphics settings:
Turn off VYSNC in game and force it via your GPU control panel. Use frame generation and DLSS/FSR as specified above. If your settings don't give you the performance you want, roll them back bit by bit.
ALSO: This may be relevant but as a precaution, make any major graphics settings changes *FROM THE MAIN MENU* After you make the changes, exit and restart the game. Sometimes the changes don't work if you make them while you have a save loaded + don't restart the game.
Hope this all helps at least somebody out there. Send asks or DM if you need any clarification, and remember, Milage may vary so experiment with your settings as needed.
40 notes
·
View notes
Text
Benchmark Tech Notes
Running the Benchmark
If your Benchmark isn't opening, it's an issue with the executable file, and something not completing properly on either download, or extracting the Zip file. The Benchmark is designed to run and give you scores for your potato computer, I promise.

I actually saved my Benchmark to my external drive, and it still pulls and saves data and runs as it should. Make sure you allowed the download to complete before extracting the zip.
Resolution
Check your Settings; in Display, it may be defaulting your monitor Resolution to something than you might otherwise use if you aren't on standard 1920x1080.
To check your monitor Resolution, minimize everything on your screen and right click anywhere on your Desktop. Go to Display Settings and scroll down to find Resolution and what it's set at.

You can set the Graphic Settings 1 tab to Maximum, or to Import your game settings. Display Settings tab is where you set it to be Windowed, Bordered, or Full Screen, as well as select Resolution to match your monitor in the dropdown (or customize it if needed). I speak on Resolution as some folks in my FC noted it changed how their characters looked.
The Other tab in Settings is where you can change the text output, or even check a box to disable the logo and score; I do this on subsequent plays, once I have my scores at various settings, to get the clean screenshots.
@calico-heart has a post about fixing graphics settings, with screenshots of the settings tab. Basically, change graphics upscaling from AMD to NVIDIA, and/or uncheck Enable Dynamic Resolution. Also check the Framerate Threshold dropdown.
Screenshots
The benchmark auto-saves 5 screens each playthrough. In the Benchmark folder there is a Screenshots folder to find the auto-images taken of your characters.





Character Appearance
If you want to get your current in game appearance, including non-standard hairstyles, make sure to load up the live game, right click and "Save Character Settings."
Then go to Documents/My Games/Final Fantasy XIV: A Realm Reborn (this is the default in Windows 10 so mileage varies). The file will have the date you last updated their settings and be named FFXIV_CHARA_01.dat (or however many saves you have/made).
Grab those newly updated DAT files for your character(s) and copy them, then in the same base folder, go to Final Fantasy XIV: A Realm Reborn (Benchmark).
Paste the copied DAT files in there, and rename to FFXIV_CHARA_BENCH01.dat (the number doesn't matter, and you may have more).
When running Benchmark Character Creation, use the dropdown menu.
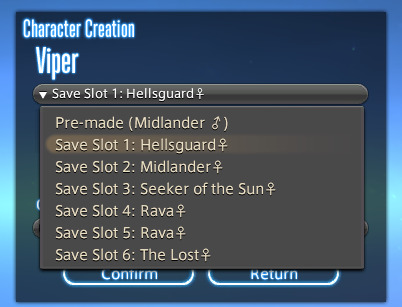
If you do Create a Custom Character and Load Appearance Data, it will give you default hairstyles again. Meteor's Dawntrail hairstyle is a new default.
In Char Gen I am finding that a very pale hrothgal reflects the green scenery around her, giving her white skin/fur a green tinge. The other zones do not have this problem, or at least not to the same degree.
They added a Midday vs Evening setting in outdoor areas as well to test lighting. The lighting in the Gridanian innroom is better; not as bright as outdoors, to be expected, but not completely useless.
New voice type icons to clarifying the sounds you make.

Remember we're getting a free fantasia with the expansion, so some tweaking may be needed; Iyna I felt like I needed to adjust her jaw. Other colors--skin, hair, eyes, tattoos, etc--are showing differently in the various kinds of lighting.
Uncertain if the limit on hairstyles for the Hrothgals so far is just a Benchmark thing; they do have set styles for different head options. Everyone gets Meteor's hair though, so it may be a temporary/Benchmark limit. But which clan and face you choose drastically alters what hair and facial feature options you have access to.
Check your settings, tweak them a bit, play around with chargen, and remember this is still a Benchmark; they always strike me as a little less polished than the finished game, but so far I'm actually pretty pleased with having defined fingers and toes, the irises in the eyes, scars looking cut into the skin, and other improvements.
172 notes
·
View notes
Text
using LLMs to control a game character's dialogue seems an obvious use for the technology. and indeed people have tried, for example nVidia made a demo where the player interacts with AI-voiced NPCs:
youtube
this looks bad, right? like idk about you but I am not raring to play a game with LLM bots instead of human-scripted characters. they don't seem to have anything interesting to say that a normal NPC wouldn't, and the acting is super wooden.
so, the attempts to do this so far that I've seen have some pretty obvious faults:
relying on external API calls to process the data (expensive!)
presumably relying on generic 'you are xyz' prompt engineering to try to get a model to respond 'in character', resulting in bland, flavourless output
limited connection between game state and model state (you would need to translate the relevant game state into a text prompt)
responding to freeform input, models may not be very good at staying 'in character', with the default 'chatbot' persona emerging unexpectedly. or they might just make uncreative choices in general.
AI voice generation, while it's moved very fast in the last couple years, is still very poor at 'acting', producing very flat, emotionless performances, or uncanny mismatches of tone, inflection, etc.
although the model may generate contextually appropriate dialogue, it is difficult to link that back to the behaviour of characters in game
so how could we do better?
the first one could be solved by running LLMs locally on the user's hardware. that has some obvious drawbacks: running on the user's GPU means the LLM is competing with the game's graphics, meaning both must be more limited. ideally you would spread the LLM processing over multiple frames, but you still are limited by available VRAM, which is contested by the game's texture data and so on, and LLMs are very thirsty for VRAM. still, imo this is way more promising than having to talk to the internet and pay for compute time to get your NPC's dialogue lmao
second one might be improved by using a tool like control vectors to more granularly and consistently shape the tone of the output. I heard about this technique today (thanks @cherrvak)
third one is an interesting challenge - but perhaps a control-vector approach could also be relevant here? if you could figure out how a description of some relevant piece of game state affects the processing of the model, you could then apply that as a control vector when generating output. so the bridge between the game state and the LLM would be a set of weights for control vectors that are applied during generation.
this one is probably something where finetuning the model, and using control vectors to maintain a consistent 'pressure' to act a certain way even as the context window gets longer, could help a lot.
probably the vocal performance problem will improve in the next generation of voice generators, I'm certainly not solving it. a purely text-based game would avoid the problem entirely of course.
this one is tricky. perhaps the model could be taught to generate a description of a plan or intention, but linking that back to commands to perform by traditional agentic game 'AI' is not trivial. ideally, if there are various high-level commands that a game character might want to perform (like 'navigate to a specific location' or 'target an enemy') that are usually selected using some other kind of algorithm like weighted utilities, you could train the model to generate tokens that correspond to those actions and then feed them back in to the 'bot' side? I'm sure people have tried this kind of thing in robotics. you could just have the LLM stuff go 'one way', and rely on traditional game AI for everything besides dialogue, but it would be interesting to complete that feedback loop.
I doubt I'll be using this anytime soon (models are just too demanding to run on anything but a high-end PC, which is too niche, and I'll need to spend time playing with these models to determine if these ideas are even feasible), but maybe something to come back to in the future. first step is to figure out how to drive the control-vector thing locally.
48 notes
·
View notes