#Hadoop and Spark
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
The Impact of Big Data Analytics on Business Decisions
Introduction
Big data analytics has transformed the way of doing business, deciding, and strategizing for future actions. One can harness vast reams of data to extract insights that were otherwise unimaginable for increasing the efficiency, customer satisfaction, and overall profitability of a venture. We steer into an in-depth view of how big data analytics is equipping business decisions, its benefits, and some future trends shaping up in this dynamic field in this article. Read to continue
#Innovation Insights#TagsAI in Big Data Analytics#big data analytics#Big Data in Finance#big data in healthcare#Big Data in Retail#Big Data Integration Challenges#Big Data Technologies#Business Decision Making with Big Data#Competitive Advantage with Big Data#Customer Insights through Big Data#Data Mining for Businesses#Data Privacy Challenges#Data-Driven Business Strategies#Future of Big Data Analytics#Hadoop and Spark#Impact of Big Data on Business#Machine Learning in Business#Operational Efficiency with Big Data#Predictive Analytics in Business#Real-Time Data Analysis#trends#tech news#science updates#analysis#adobe cloud#business tech#science#technology#tech trends
0 notes
Text


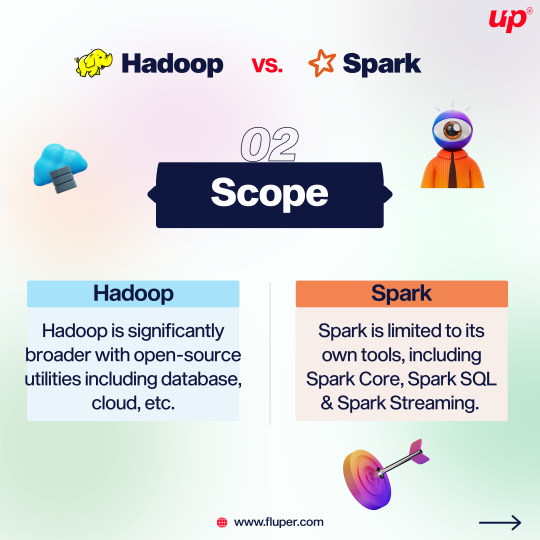




Apache Spark and Apache Hadoop are both popular, open-source data science tools offered by the Apache Software Foundation. . . . . Join the development and support of the community with Fluper, and continue to grow in popularity and features.
2 notes
·
View notes
Text
instagram
#hadoop#alarm#Apache spark#coding#code#machinelearning#programming#datascience#python#programmer#artificialintelligence#deeplearning#ai#Instagram
6 notes
·
View notes
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Text
Are you looking to build a career in Big Data Analytics? Gain in-depth knowledge of Hadoop and its ecosystem with expert-led training at Sunbeam Institute, Pune – a trusted name in IT education.
Why Choose Our Big Data Hadoop Classes?
🔹 Comprehensive Curriculum: Covering Hadoop, HDFS, MapReduce, Apache Spark, Hive, Pig, HBase, Sqoop, Flume, and more. 🔹 Hands-on Training: Work on real-world projects and industry use cases to gain practical experience. 🔹 Expert Faculty: Learn from experienced professionals with real-time industry exposure. 🔹 Placement Assistance: Get career guidance, resume building support, and interview preparation. 🔹 Flexible Learning Modes: Classroom and online training options available. 🔹 Industry-Recognized Certification: Boost your resume with a professional certification.
Who Should Join?
✔️ Freshers and IT professionals looking to enter the field of Big Data & Analytics ✔️ Software developers, system administrators, and data engineers ✔️ Business intelligence professionals and database administrators ✔️ Anyone passionate about Big Data and Machine Learning

#Big Data Hadoop training in Pune#Hadoop classes Pune#Big Data course Pune#Hadoop certification Pune#learn Hadoop in Pune#Apache Spark training Pune#best Big Data course Pune#Hadoop coaching in Pune#Big Data Analytics training Pune#Hadoop and Spark training Pune
0 notes
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text

Big Data Battle Alert! Apache Spark vs. Hadoop: Which giant rules your data universe? Spark = Lightning speed (100x faster in-memory processing!) Hadoop = Batch processing king (scalable & cost-effective).Want to dominate your data game? Read more: https://bit.ly/3F2aaNM
0 notes
Text
What is Data Science? A Comprehensive Guide for Beginners

In today’s data-driven world, the term “Data Science” has become a buzzword across industries. Whether it’s in technology, healthcare, finance, or retail, data science is transforming how businesses operate, make decisions, and understand their customers. But what exactly is data science? And why is it so crucial in the modern world? This comprehensive guide is designed to help beginners understand the fundamentals of data science, its processes, tools, and its significance in various fields.
#Data Science#Data Collection#Data Cleaning#Data Exploration#Data Visualization#Data Modeling#Model Evaluation#Deployment#Monitoring#Data Science Tools#Data Science Technologies#Python#R#SQL#PyTorch#TensorFlow#Tableau#Power BI#Hadoop#Spark#Business#Healthcare#Finance#Marketing
0 notes
Text
Understanding Big Data: Characteristics, Importance, and Applications
Big Data refers to the huge amount of data that is generated really quickly from lots of different sources. This data is often so big, complicated, and fast that regular data processing methods and tools can’t handle it. Big Data is usually linked to the following characteristics, also known as the “3 Vs”: Volume: The sheer amount of data generated and collected today is massive, from social…
0 notes
Link
0 notes
Text

Join Now : https://meet.goto.com/844038797
Attend Online Free Demo On AWS Data Engineering with Data Analytics by Mr. Srikanth
Demo on: 09th December (Saturday) @ 9:30 AM (IST).
Contact us: +91-9989971070.
Join us on Telegram: https://t.me/+bEu9LVFFlh5iOTA9
Join us on WhatsApp: https://www.whatsapp.com/catalog/919989971070Visit: https://www.visualpath.in/aws-data-engineering-with-data-analytics-training.html
#aws#AWSRedshift#redshift#athena#S3#Hadoop#MSSQL#Sqoop#EMR#Scala#BigData#MySQL#java#database#spark#git#ETL#Dataengineer#MongoDB#oracle#visualpathedu#FreeDemo#onlinetraining#newcourses#latesttechnology#dataanalysis#dataanalytics#awsdataengineer#dataengineering#awsdataengineering
0 notes
Text
Greetings from Ashra Technologies
we are hiring
#ashra#ashratechnologies#jobs#hiring#recruiting#recruitingpost#Data#dataengineer#bigdataengineer#spark#scala#python#hadoop#hive#etl#linkedincommunity#linkedinjobs#linkedinjobsearch#linkedinconnections#linkedinnetwork#linkedinnews#linkedingrowth#linkedinlive#linkedincreators#linkedinarticle
0 notes
Text
Apache Spark vs. Hadoop: Is Spark Set to Replace Hadoop?
In today's data-driven world, the demand for efficient data processing frameworks has never been higher. Apache Spark is a versatile data processing framework that works seamlessly with Hadoop. It offers significant advantages, including lightning-fast data processing and support for various programming languages like Java, Scala, and Python. Spark's in-memory computations dramatically boost processing speeds, reducing the need for disk I/O. Unlike Hadoop, Spark utilizes Resilient Distributed Datasets (RDDs) for fault tolerance, eliminating the necessity for data replication.

While Spark can operate within the Hadoop ecosystem, it isn't a Hadoop replacement. It serves as a complementary tool, excelling in areas where Hadoop MapReduce falls short. For instance, Spark's in-memory storage allows it to handle iterative algorithms, interactive data mining, and stream processing with remarkable efficiency. It runs on multiple platforms, including Hadoop, Mesos, standalone setups, and the cloud, and can access diverse data sources like HDFS, Cassandra, HBase, and S3.
Major Use Cases for Spark Over Hadoop:
Iterative Algorithms in Machine Learning
Interactive Data Mining and Data Processing
High-speed data warehousing that outperforms Hive
Stream processing for live data streams, enabling real-time analytics
Sensor data processing facilitates the rapid consolidation and analysis of data from multiple sources.
In conclusion, Apache Spark, with its exceptional speed, versatility, and compatibility, stands as a formidable contender in the world of big data processing. While it doesn't necessarily replace Hadoop, it offers a compelling alternative for real-time data processing and interactive analytics, making it an invaluable addition to the data engineer's toolkit.
0 notes
Text

Are you looking to build a career in Big Data Analytics? Gain in-depth knowledge of Hadoop and its ecosystem with expert-led training at Sunbeam Institute, Pune – a trusted name in IT education.
Why Choose Our Big Data Hadoop Classes?
🔹 Comprehensive Curriculum: Covering Hadoop, HDFS, MapReduce, Apache Spark, Hive, Pig, HBase, Sqoop, Flume, and more. 🔹 Hands-on Training: Work on real-world projects and industry use cases to gain practical experience. 🔹 Expert Faculty: Learn from experienced professionals with real-time industry exposure. 🔹 Placement Assistance: Get career guidance, resume building support, and interview preparation. 🔹 Flexible Learning Modes: Classroom and online training options available. 🔹 Industry-Recognized Certification: Boost your resume with a professional certification.
Who Should Join?
✔️ Freshers and IT professionals looking to enter the field of Big Data & Analytics ✔️ Software developers, system administrators, and data engineers ✔️ Business intelligence professionals and database administrators ✔️ Anyone passionate about Big Data and Machine Learning
Course Highlights:
✅ Introduction to Big Data & Hadoop Framework ✅ HDFS (Hadoop Distributed File System) – Storage & Processing ✅ MapReduce Programming – Core of Hadoop Processing ✅ Apache Spark – Fast and Unified Analytics Engine ✅ Hive, Pig, HBase – Data Querying & Management ✅ Data Ingestion Tools – Sqoop & Flume ✅ Real-time Project Implementation
#Big Data Hadoop training in Pune#Hadoop classes Pune#Big Data course Pune#Hadoop certification Pune#learn Hadoop in Pune#Apache Spark training Pune#best Big Data course Pune#Hadoop coaching in Pune#Big Data Analytics training Pune#Hadoop and Spark training Pune
0 notes
Text
Apache Hadoop is a Java-based framework that uses clusters to store and process large amounts of data in parallel. Being a framework, Hadoop is formed from multiple modules which are supported by a vast ecosystem of technologies. Let’s take a closer look at the Apache Hadoop ecosystem and the components that make it up.
1 note
·
View note