#Hadoop
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
5 Ways Big Data is Transforming Industries and Decision-Making:
Big Data has transitioned from a simple, trendy phrase to a fundamental catalyst for transformation across various industries in today's information-driven landscape. Organizations can carefully inspect it to draw out priceless insights and update their decision-making processes because it provides an enormous layup of organized and unstructured data. Choose the best Big Data online training that helps organizations adapts, build up, and achieve something in a complicated and increasingly competitive global economy.
Here are top 5 ways Big Data is transforming industries and decision-making are listed below:
Data-driven Decision Making:
The ability of big data to affect decision-making is one of its most evident benefits. Decision-making in the past has been largely influenced by instinct and previous experiences. Due to the development of big data analytics, businesses can now support their choices with factual data.
By examining large datasets, businesses can learn more about consumer performance, market trends, and operational efficiency. Organizations become more agile and approachable due to data-driven decision-making, increasing accuracy and speed.
Improved Operational Efficiency:
Big Data is an effective tool for improving interior procedures and raising operational effectiveness within businesses. Companies can establish bottlenecks, find inefficiencies, and spot areas that can be enhanced by carefully monitoring and analyzing data collected from many aspects of their operations.
For instance, data analytics can be used in manufacturing to optimize production processes, avoiding waste and downtime. Businesses may streamline their supply chains using data-driven insights to ensure customers get products at the ideal time and location.
In addition to lowering operational costs, this enlarged efficiency enables businesses to offer goods and services faster, improving them competitively in their particular marketplaces.
Enhanced Customer Insights:
Big Data is crucial for a thorough insight into the consumer behavior required for any business to flourish. Companies can gather and analyze data from a variety of sources, such as social media, online transactions, and customer feedback, to create a comprehensive and nuanced picture of their client.
With these priceless insights, companies can modify their offers to correspond with client preferences, proactively anticipate their needs, and produce a more unique and enjoyable experience. This higher level of client results in enhanced customer satisfaction and loyalty and drives more profits since customers feel acknowledged, valued, and consistently given offerings that connect with them.

Competitive Advantage:
Securing a competitive advantage is crucial for success in today's highly competitive corporate world. Through the discovery of complex insights online, big data proves to be a powerful instrument for gaining this edge. Businesses are skilled at utilizing big data analytics can identify developing industry trends, identify altering consumer preferences, and predict possible disruptors before their rivals.
Due to their early insight, their ability to adapt and improve their methods places them at the forefront of the industry. In addition, the organization may maintain its competitive edge over time by continuously analyzing and optimizing its operations with Big Data, assuring long-term success in a constantly changing environment.
Predictive Analytics:
Big data has enabled businesses to benefit from the potent capabilities of predictive analytics.For this, sophisticated machine learning algorithms are used to examine past data in order to produce accurate predictions of present and potential future trends and events. Predictive analytics is crucial in the financial sector for determining credit risk and quickly spotting fraudulent transactions in real time, protecting assets, and preserving financial stability.
Healthcare providers use predictive analytics to anticipate patient outcomes and disease outbreaks, enabling proactive and timely interventions. Predictive analytics has a strategic foresight that enables businesses to take proactive measures, reducing risks and seizing new possibilities, eventually improving operational effectiveness and competitiveness.
Summing it up:
Big Data is a technological improvement that alters entire sectors and ways of making decisions. Organizations can improve operational efficiency, forecast future trends, maintain a competitive edge, and make better decisions using Big Data analytics. Big Data online course helps to know the top strategies that help reshape industries and decision-making as technology develops and data volumes rise. Businesses that use big data today will be well-positioned to prosper in the data-driven society of the future.
Tags: Big Data Hadoop Online Trainings, Big Data Hadoop at H2k infosys, Big Data Hadoop, big data analysis courses, online big data courses, Big Data Hadoop Online Training and 100% job guarantee courses, H2K Infosys, Big Data Fundamentals, Hadoop Architecture, HDFS Setup and Configuration, Programming,Management,HBase Database, Hive Data Warehousing, Pig Scripting, Apache Spark, Kafka Streaming, Data Ingestion and Processing, Data Transformation
#BigDataHadoop #BigDataHadoopCourseOnline #BigDataHadoopTraining #BigDataHadoopCourse, #H2KInfosys, #ClusterComputing, #RealTimeProcessing, #MachineLearning, #AI, #DataScience, #CloudComputing#BigDataAnalytics, #DataEngineering
Contact: +1-770-777-1269 Mail: training@h2kinfosys.com
Location: Atlanta, GA - USA, 5450 McGinnis Village Place, # 103 Alpharetta, GA 30005, USA.
Facebook: https://www.facebook.com/H2KInfosysLLC
Instagram: https://www.instagram.com/h2kinfosysllc/
Youtube: https://www.youtube.com/watch?v=BxIG2VoC70c
Visit: https://www.h2kinfosys.com/courses/hadoop-bigdata-online-training-course-details
BigData Hadoop Course: bit.ly/3KJClRy
#online learning#learning#courses#onlinetraining#marketing#education#online course#bigdata#hadoop#h2kinfosys
2 notes
·
View notes
Text


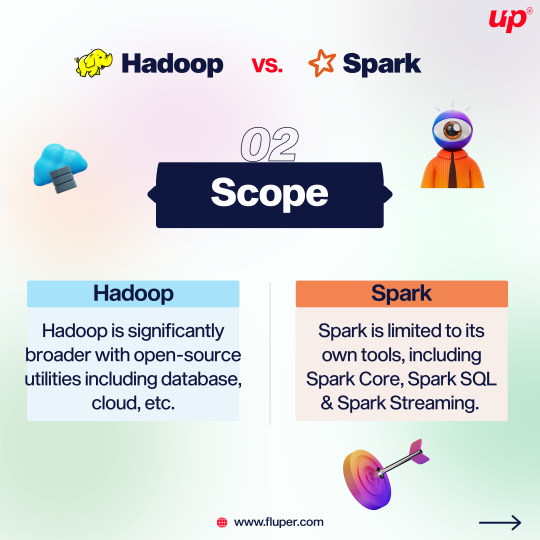




Apache Spark and Apache Hadoop are both popular, open-source data science tools offered by the Apache Software Foundation. . . . . Join the development and support of the community with Fluper, and continue to grow in popularity and features.
2 notes
·
View notes
Text
instagram
#hadoop#alarm#Apache spark#coding#code#machinelearning#programming#datascience#python#programmer#artificialintelligence#deeplearning#ai#Instagram
6 notes
·
View notes
Text
What Are the Hadoop Skills to Be Learned?
With the constantly changing nature of big data, Hadoop is among the most essential technologies for processing and storing big datasets. With companies in all sectors gathering more structured and unstructured data, those who have skills in Hadoop are highly sought after. So what exactly does it take to master Hadoop? Though Hadoop is an impressive open-source tool, to master it one needs a combination of technical and analytical capabilities. Whether you are a student looking to pursue a career in big data, a data professional looking to upskill, or someone career transitioning, here's a complete guide to the key skills that you need to learn Hadoop. 1. Familiarity with Big Data Concepts Before we jump into Hadoop, it's helpful to understand the basics of big data. Hadoop was designed specifically to address big data issues, so knowing these issues makes you realize why Hadoop operates the way it does. • Volume, Variety, and Velocity (The 3Vs): Know how data nowadays is huge (volume), is from various sources (variety), and is coming at high speed (velocity). • Structured vs Unstructured Data: Understand the distinction and why Hadoop is particularly suited to handle both. • Limitations of Traditional Systems: Know why traditional relational databases are not equipped to handle big data and how Hadoop addresses that need. This ground level knowledge guarantees that you're not simply picking up tools, but realizing their context and significance.
2. Fundamental Programming Skills Hadoop is not plug-and-play. Though there are tools higher up the stack that layer over some of the complexity, a solid understanding of programming is necessary in order to take advantage of Hadoop. • Java: Hadoop was implemented in Java, and much of its fundamental ecosystem (such as MapReduce) is built on Java APIs. Familiarity with Java is a major plus. • Python: Growing among data scientists, Python can be applied to Hadoop with tools such as Pydoop and MRJob. It's particularly useful when paired with Spark, another big data application commonly used in conjunction with Hadoop. • Shell Scripting: Because Hadoop tends to be used on Linux systems, Bash and shell scripting knowledge is useful for automating jobs, transferring data, and watching processes. Being comfortable with at least one of these languages will go a long way in making Hadoop easier to learn. 3. Familiarity with Linux and Command Line Interface (CLI) Most Hadoop deployments run on Linux servers. If you’re not familiar with Linux, you’ll hit roadblocks early on. • Basic Linux Commands: Navigating the file system, editing files with vi or nano, and managing file permissions are crucial. • Hadoop CLI: Hadoop has a collection of command-line utilities of its own. Commands will need to be used in order to copy files from the local filesystem and HDFS (Hadoop Distributed File System), to start and stop processes, and to observe job execution. A solid comfort level with Linux is not negotiable—it's a foundational skill for any Hadoop student.
4. HDFS Knowledge HDFS is short for Hadoop Distributed File System, and it's the heart of Hadoop. It's designed to hold a great deal of information in a reliable manner across a large number of machines. You need: • Familiarity with the HDFS architecture: NameNode, DataNode, and block allocation. • Understanding of how writing and reading data occur in HDFS. • Understanding of data replication, fault tolerance, and scalability. Understanding how HDFS works makes you confident while performing data work in distributed systems.
5. MapReduce Programming Knowledge MapReduce is Hadoop's original data processing engine. Although newer options such as Apache Spark are currently popular for processing, MapReduce remains a topic worth understanding. • How Map and Reduce Work: Learn about the divide-and-conquer technique where data is processed in two phases—map and reduce. • MapReduce Job Writing: Get experience writing MapReduce programs, preferably in Java or Python. • Performance Tuning: Study job chaining, partitioners, combiners, and optimization techniques. Even if you eventually favor Spark or Hive, studying MapReduce provides you with a strong foundation in distributed data processing.
6. Working with Hadoop Ecosystem Tools Hadoop is not one tool—its an ecosystem. Knowing how all the components interact makes your skills that much better. Some of the big tools to become acquainted with: • Apache Pig: A data flow language that simplifies the development of MapReduce jobs. • Apache Sqoop: Imports relational database data to Hadoop and vice versa. • Apache Flume: Collects and transfers big logs of data into HDFS. • Apache Oozie: A workflow scheduler to orchestrate Hadoop jobs. • Apache Zookeeper: Distributes systems. Each of these provides useful functionality and makes Hadoop more useful. 7. Basic Data Analysis and Problem-Solving Skills Learning Hadoop isn't merely technical expertise—it's also problem-solving. • Analytical Thinking: Identify the issue, determine how data can be harnessed to address it, and then determine which Hadoop tools to apply. • Data Cleaning: Understand how to preprocess and clean large datasets before analysis. • Result Interpretation: Understand the output that Hadoop jobs produce. These soft skills are typically what separate a decent Hadoop user from a great one.
8. Learning Cluster Management and Cloud Platforms Although most learn Hadoop locally using pseudo-distributed mode or sandbox VMs, production Hadoop runs on clusters—either on-premises or in the cloud. • Cluster Management Tools: Familiarize yourself with tools such as Apache Ambari and Cloudera Manager. • Cloud Platforms: Learn how Hadoop runs on AWS (through EMR), Google Cloud, or Azure HDInsight. It is crucial to know how to set up, monitor, and debug clusters for production-level deployments. 9. Willingness to Learn and Curiosity Last but not least, you will require curiosity. The Hadoop ecosystem is large and dynamic. New tools, enhancements, and applications are developed regularly. • Monitor big data communities and forums. • Participate in open-source projects or contributions. • Keep abreast of tutorials and documentation. Your attitude and willingness to play around will largely be the distinguishing factor in terms of how well and quickly you learn Hadoop. Conclusion Hadoop opens the door to the world of big data. Learning it, although intimidating initially, can be made easy when you break it down into sets of skills—such as programming, Linux, HDFS, SQL, and problem-solving. While acquiring these skills, not only will you learn Hadoop, but also the confidence in creating scalable and intelligent data solutions. Whether you're creating data pipelines, log analysis, or designing large-scale systems, learning Hadoop gives you access to a whole universe of possibilities in the current data-driven age. Arm yourself with these key skills and begin your Hadoop journey today.
Website: https://www.icertglobal.com/course/bigdata-and-hadoop-certification-training/Classroom/60/3044
0 notes
Text

Explore IGMPI’s Big Data Analytics program, designed for professionals seeking expertise in data-driven decision-making. Learn advanced analytics techniques, data mining, machine learning, and business intelligence tools to excel in the fast-evolving world of big data.
#Big Data Analytics#Data Science#Machine Learning#Predictive Analytics#Business Intelligence#Data Visualization#Data Mining#AI in Analytics#Big Data Tools#Data Engineering#IGMPI#Online Analytics Course#Data Management#Hadoop#Python for Data Science
0 notes
Text
IT Classes Online: Master Data Science at Code With TLS
In today’s data-driven world, mastering data science is a valuable skill for aspiring IT professionals. Code With TLS offers comprehensive IT classes online that focus on Data Science, helping students gain expertise in analytics, machine learning, and big data technologies.
Why Choose Code With TLS for Data Science?
Code With TLS provides industry-relevant courses with hands-on training, making learning both practical and engaging. Their IT classes online are designed to suit both beginners and professionals looking to upskill. Some key features include:
Expert-Led Training: Learn from industry professionals with real-world experience.
Practical Hands-on Projects: Work on live projects and case studies to apply concepts in real scenarios.
Flexible Learning: Online classes allow you to learn at your own pace from anywhere.
Placement Assistance: Get job-ready with resume-building sessions and interview preparation.
What Will You Learn?
The IT classes online at Code With TLS cover a wide range of data science topics, including:
Python for Data Science – Learn the basics of Python programming, data manipulation, and visualization.
Statistics & Probability – Understand the fundamentals of data analysis and statistical modeling.
Machine Learning Algorithms – Get hands-on experience with supervised and unsupervised learning techniques.
Deep Learning & AI – Explore neural networks, NLP, and computer vision applications.
Big Data & Cloud Computing – Work with Hadoop, Spark, and cloud-based data storage solutions.
Data Visualization & BI Tools – Master tools like Tableau, Power BI, and Matplotlib.
Who Can Join?
This IT class online is perfect for:
Beginners with no prior coding experience.
IT professionals looking to switch to data science.
Business analysts who want to enhance their data analytics skills.
Entrepreneurs who need data-driven decision-making skills.
How to Enroll?
Joining the IT classes online for Data Science at Code With TLS is simple. Visit Code With TLS, explore the course details, and sign up for a demo class.
Unlock new career opportunities by mastering data science with Code With TLS today! 🚀
#ITClassesOnline#DataScienceTraining#LearnDataScience#OnlineLearning#CodeWithTLS#MachineLearning#PythonForDataScience#BigData#AIandML#CareerInTech#TechSkills#OnlineITCourses#DigitalLearning#UpskillNow#JobReady#DataAnalytics#CloudComputing#DeepLearning#TableauTraining#ITCertification#ProgrammingForBeginners#DataScienceCareer#PythonProgramming#BusinessIntelligence#Hadoop#AITraining#ITCoursesOnline
0 notes
Text
What Are The Advantages Of Learning Big Data?

Introduction
In today's digital age, data is being generated at an unprecedented rate. From interactions on social media to transactions online, the sheer volume of information produced every second is staggering. This explosion of data has given rise to the field of Big Data – the science of collecting, processing, and analyzing massive datasets to extract valuable insights. But why should you consider learning Big Data? What are the advantages? Let's explore the key benefits that make Big Data a powerful skill in 2024.
High Demand And Lucrative Career Opportunities
One of the most compelling reasons to learn Big Data is the high demand for skilled professionals. Organizations across industries, including healthcare, finance, retail, and technology, leverage Big Data to drive decision-making and enhance operational efficiency. As a result, there is a growing need for data analysts, data scientists, Big Data engineers, and architects. Welcome to Infycle Technologies, your gateway to mastering Big Data! Our comprehensive Big Data Training in Chennai is meticulously designed to align with industry standards, offering a blend of theoretical knowledge and practical, hands-on training.
According to industry reports, the demand for Big Data professionals will continue rising in the coming years. Companies are interested in offering competitive salaries to attract top talent, and learning big data enhances one's employability and opens doors to lucrative career opportunities.
Enhanced Decision-Making Capabilities
Big Data empowers organizations to make data-driven results with greater accuracy and confidence. By finding vast amounts of structured and unstructured data, companies can uncover hidden patterns, trends, and correlations that were previously impossible to detect.
For example, retailers can use Big Data analytics to know customer preferences, optimize inventory management, and create personalized marketing campaigns. Similarly, financial institutions can leverage Big Data to assess risks, detect fraudulent activities, and improve investment strategies. By mastering Big Data, you can contribute to strategic decision-making processes, making you a valuable asset to any organization.
Competitive Advantage For Businesses
In today's highly competitive market, businesses that effectively utilize Big Data have a distinct advantage over their competitors. By gaining insights into customer behaviour, market trends, and operational inefficiencies, companies can make proactive decisions to stay ahead of the competition.
For instance, streaming platforms like Netflix and Spotify use Big Data to analyze user preferences and provide personalized content recommendations. E-commerce giants like Amazon leverage Big Data to optimize pricing strategies and enhance customer experiences. By learning Big Data, you can help organizations tackle the power of data to gain a competitive edge and drive business growth.
Innovation And Product Development
Big Data is a driving force behind innovation and product development. Companies can identify unmet needs by analyzing customer feedback, social media interactions, and usage patterns and create products to expand their target audience.
For example, smartphone manufacturers use Big Data analytics to understand user preferences and design features that enhance user experience. Similarly, the automotive industry leverages Big Data to develop connected vehicles and autonomous driving technologies. Learning Big Data equips you with the skills to contribute to innovative product development and shape the future of technology.
Improved Operational Efficiency
Organizations continuously seek ways to optimize operations and reduce costs. Big Data analytics helps businesses identify inefficiencies, streamline processes, and improve productivity.
For instance, supply chain management can be enhanced by analyzing inventory levels, demand forecasts, and logistics data. This allows companies to optimize inventory management, reduce stockouts, and minimize operational costs. By mastering Big Data, you can help organizations enhance operational efficiency and achieve cost savings.
Enhanced Customer Experience
In the age of digital transformation, customer experience has become a key differentiator for businesses. Big Data enables companies to understand customer behaviour, preferences, and pain points, allowing them to deliver personalized experiences.
For example, e-commerce platforms use Big Data to provide products based on user browsing history and purchase behaviour. Streaming services analyze viewing patterns to offer personalized content suggestions. Learning Big Data enables you to play an important role in enhancing customer experiences and building brand loyalty.
Versatility And Applicability Across Industries
One of the unique advantages of learning Big Data is its versatility and applicability across various industries. Whether healthcare, finance, retail, manufacturing, or entertainment, every sector is leveraging Big Data to gain valuable insights and drive decision-making.
For example, in healthcare, Big Data is used to predict disease outbreaks, improve patient outcomes, and optimize hospital operations. In finance, it is utilized for fraud detection, risk management, and algorithmic trading. By acquiring Big Data skills, you can explore diverse career opportunities across multiple industries and make a meaningful impact.
Future-Proof Your Career
As technology continues to evolve, data will continue to grow exponentially. The importance of Big Data is only expected to increase in the future. By learning Big Data now, you are future-proofing your career and staying applicable in the ever-changing job market. Unlock your destiny and build a rewarding career in software development with Infycle Technologies, the Best Software Training Institute in Chennai.
With advancements in AI, Machine Learning (ML), & the Internet of Things (IoT), the demand for Big Data professionals will continue to rise. Gaining expertise in Big Data ensures that you remain in demand and adaptable to future technological changes.
Entrepreneurial Opportunities
Big Data is not just for large enterprises; it also offers immense potential for entrepreneurs and startups. By leveraging data analytics, startups can identify market gaps, understand customer needs, and develop innovative solutions.
For instance, ride-sharing platforms like Uber and Lyft use Big Data to optimize routes, reduce wait times, and improve customer satisfaction. Health tech startups use Big Data to offer personalized healthcare solutions and wellness recommendations. Mastering Big Data allows you to explore entrepreneurial opportunities and build data-driven startups that solve real-world problems.
Conclusion
In conclusion, learning Big Data offers many advantages, from lucrative career opportunities to enhanced decision-making and innovation. It empowers you to contribute to business growth, improve operational efficiency and provide tailored customer experiences. With its applicability across industries and growing demand for skilled professionals, Big Data is a valuable skill that future-proofs your career. Whether you're a student, a professional looking to upskill, or an aspiring entrepreneur, investing in Big Data learning is a strategic decision that opens doors to endless possibilities.
If you're interested in entering the world of Big Data, consider enrolling in a comprehensive training program. Infycle Technologies offers specialized Big Data Training in Chennai, designed to provide you with the knowledge & skills required to excel in this dynamic field. Start your Big Data journey today and unlock a world of opportunities!
0 notes
Text
Hadoop, an open-source framework, enables distributed storage and processing of massive datasets, making it essential for big data analytics and cloud computing.
1 note
·
View note
Text
tecnologías, proyectos y beneficios potenciales empresas Ibex35
Propuesta de Valor: Propuesta que busca integrar de manera más profunda los conceptos y ofrecer una visión más práctica y estratégica de cómo las empresas del IBEX 35 podrían estar aprovechando estas tecnologías: Matriz de Relación: Tecnologías, Proyectos y Beneficios Potenciales TecnologíaProyectoBeneficios PotencialesEmpresas IBEX 35 Ejemplos (Hipotéticos)Business Intelligence (Power BI,…
#alation#analisisdeclientes#analiticadedatos#apachekafka#aws#BBVA#BigData#businessintelligence#cienciadedatos#collibra#corporaciones#costes#d3js#dataanalysis#dataengineering#datagovernance#datascience#datavisualization#datos#desarrollodenuevosproductos#detecciondefraud#eficiencia#empresa#googlebigquery#hadoop#iberdrola#IBEX35#INDITEX#industria40#informacion
0 notes
Text

Big Data Tools in Action! 🚀 Curious about the tools driving modern data analytics? Hadoop for storage and Spark for real-time processing are game changers! These technologies power everything from analyzing massive datasets to delivering real-time insights. Are you ready to dive into the world of Big Data?
Contact Us :- +91 9948801222

#BigData#DataAnalytics#Hadoop#ApacheSpark#RealTimeProcessing#DataScience#TechMemes#ITHumor#MachineLearning#DataVisualization#DigitalTransformation
0 notes
Text

Hadoop Interview Question . . . . for more questions like this https://bit.ly/4bxvgjd
check the above link
0 notes
Text
Apache Hadoop: El Pilar de la Gestión de Grandes Datos en la Ciberseguridad
El volumen de datos generado cada segundo es asombroso. Las empresas, gobiernos y organizaciones acumulan cantidades masivas de información que necesitan ser procesadas, analizadas y protegidas. Aquí es donde entra en juego Apache Hadoop, un marco de software de código abierto que ha revolucionado la forma en que manejamos grandes volúmenes de datos. Este artículo explora qué es Apache Hadoop, su…
0 notes
Text
Hadoop Consulting and Development Services | Driving Big Data Success

In today’s data-driven world, harnessing the power of big data is crucial for businesses striving to stay competitive. Hadoop, an open-source framework, has emerged as a game-changer in processing and managing vast amounts of data. Companies across industries are leveraging Hadoop to gain insights, optimize operations, and drive innovation. However, implementing Hadoop effectively requires specialized expertise. This is where Hadoop consulting and development services come into play, offering tailored solutions to unlock the full potential of big data.
Understanding Hadoop's Role in Big Data
Hadoop is a robust framework designed to handle large-scale data processing across distributed computing environments. It allows organizations to store and analyze massive datasets efficiently, enabling them to make informed decisions based on real-time insights. The framework’s scalability and flexibility make it ideal for businesses that need to manage complex data workflows, perform detailed analytics, and derive actionable intelligence from diverse data sources.
The Importance of Hadoop Consulting Services
While Hadoop offers significant advantages, its successful implementation requires a deep understanding of both the technology and the specific needs of the business. Hadoop consulting services provide businesses with the expertise needed to design, deploy, and manage Hadoop environments effectively. Consultants work closely with organizations to assess their current infrastructure, identify areas for improvement, and develop a strategy that aligns with their business goals.
Key benefits of Hadoop consulting services include:
Customized Solutions: Consultants tailor Hadoop deployments to meet the unique requirements of the business, ensuring optimal performance and scalability.
Expert Guidance: Experienced consultants bring a wealth of knowledge in big data technologies, helping businesses avoid common pitfalls and maximize ROI.
Efficient Implementation: With expert guidance, businesses can accelerate the deployment process, reducing time-to-market and enabling faster access to valuable insights.
Hadoop Development Services: Building Robust Big Data Solutions
In addition to consulting, Hadoop development services play a critical role in creating customized applications and solutions that leverage the power of Hadoop. These services involve designing and developing data pipelines, integrating Hadoop with existing systems, and creating user-friendly interfaces for data visualization and analysis. By working with skilled Hadoop developers, businesses can build scalable and reliable solutions that meet their specific data processing needs.
Hadoop development services typically include:
Data Ingestion and Processing: Developing efficient data pipelines that can handle large volumes of data from multiple sources.
System Integration: Integrating Hadoop with other enterprise systems to ensure seamless data flow and processing.
Custom Application Development: Creating applications that enable users to interact with and analyze data in meaningful ways.
Performance Optimization: Fine-tuning Hadoop environments to ensure high performance, even as data volumes grow.
Why Choose Feathersoft Company for Hadoop Consulting and Development?
When it comes to Hadoop consulting and development services, choosing the right partner is crucial. Feathersoft Company offers a proven track record of delivering successful Hadoop implementations across various industries. With a team of experienced consultants and developers, Feathersoft company provides end-to-end services that ensure your Hadoop deployment is optimized for your business needs. Whether you’re looking to enhance your data processing capabilities or develop custom big data solutions, Feathersoft company has the expertise to help you achieve your goals.
Conclusion
Hadoop consulting and development services are essential for businesses looking to harness the full potential of big data. By working with experts, organizations can implement Hadoop effectively, drive better business outcomes, and stay ahead of the competition. As you embark on your big data journey, consider partnering with a trusted provider like Feathersoft Inc Solution to ensure your Hadoop initiatives are successful.
#Hadoop#BigData#DataAnalytics#DataScience#DataEngineering#TechConsulting#DataConsulting#HadoopConsulting#BigDataSolutions#HadoopDevelopment#DataManagement#CloudComputing#EnterpriseData#DataProcessing#DataTechnology#TechInnovation#BusinessIntelligence#DataIntegration#DataStrategy#DataTransformation#TechTrends#DataDriven#ScalableSolutions#TechServices#ITConsulting
0 notes
Text
What is Data Science? A Comprehensive Guide for Beginners

In today’s data-driven world, the term “Data Science” has become a buzzword across industries. Whether it’s in technology, healthcare, finance, or retail, data science is transforming how businesses operate, make decisions, and understand their customers. But what exactly is data science? And why is it so crucial in the modern world? This comprehensive guide is designed to help beginners understand the fundamentals of data science, its processes, tools, and its significance in various fields.
#Data Science#Data Collection#Data Cleaning#Data Exploration#Data Visualization#Data Modeling#Model Evaluation#Deployment#Monitoring#Data Science Tools#Data Science Technologies#Python#R#SQL#PyTorch#TensorFlow#Tableau#Power BI#Hadoop#Spark#Business#Healthcare#Finance#Marketing
0 notes
Text
Understanding Big Data: Characteristics, Importance, and Applications
Big Data refers to the huge amount of data that is generated really quickly from lots of different sources. This data is often so big, complicated, and fast that regular data processing methods and tools can’t handle it. Big Data is usually linked to the following characteristics, also known as the “3 Vs”: Volume: The sheer amount of data generated and collected today is massive, from social…
0 notes