#API Call Optimization
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Shopify Webhooks Best Practices
Webhooks are a powerful tool in Shopify that allow developers to automate workflows, integrate third-party services, and keep external applications in sync with store data. By using Shopify webhooks, businesses can receive real-time updates on orders, customers, inventory, and more. However, improper implementation can lead to security risks, data inconsistencies, and performance issues. In this…
#API Call Optimization#E-commerce Automation#E-commerce Scalability#Real-Time Data Sync#Secure Webhook Implementation#Shopify API Integration#Shopify App Development#Shopify Development#Shopify Store Management#Shopify Webhooks#Shopify Workflow Automation#Webhook Performance Optimization#Webhook Security#Webhooks Best Practices
0 notes
Text
Kentucky court system needs to fire its web developers.
#are they trying to run ocr/optimization on uploads and then rejecting the filing if the process takes too long or output looks weird#and if not. what are they fucking doing#that requires calls to a paid remote pdf processing api on every fucking upload#this is clearly not a security/virus screening. they don't believe in those. they are the kentucky court system.#the law
8 notes
·
View notes
Text
youtube
People Think It’s Fake" | DeepSeek vs ChatGPT: The Ultimate 2024 Comparison (SEO-Optimized Guide)
The AI wars are heating up, and two giants—DeepSeek and ChatGPT—are battling for dominance. But why do so many users call DeepSeek "fake" while praising ChatGPT? Is it a myth, or is there truth to the claims? In this deep dive, we’ll uncover the facts, debunk myths, and reveal which AI truly reigns supreme. Plus, learn pro SEO tips to help this article outrank competitors on Google!
Chapters
00:00 Introduction - DeepSeek: China’s New AI Innovation
00:15 What is DeepSeek?
00:30 DeepSeek’s Impressive Statistics
00:50 Comparison: DeepSeek vs GPT-4
01:10 Technology Behind DeepSeek
01:30 Impact on AI, Finance, and Trading
01:50 DeepSeek’s Effect on Bitcoin & Trading
02:10 Future of AI with DeepSeek
02:25 Conclusion - The Future is Here!
Why Do People Call DeepSeek "Fake"? (The Truth Revealed)
The Language Barrier Myth
DeepSeek is trained primarily on Chinese-language data, leading to awkward English responses.
Example: A user asked, "Write a poem about New York," and DeepSeek referenced skyscrapers as "giant bamboo shoots."
SEO Keyword: "DeepSeek English accuracy."
Cultural Misunderstandings
DeepSeek’s humor, idioms, and examples cater to Chinese audiences. Global users find this confusing.
ChatGPT, trained on Western data, feels more "relatable" to English speakers.
Lack of Transparency
Unlike OpenAI’s detailed GPT-4 technical report, DeepSeek’s training data and ethics are shrouded in secrecy.
LSI Keyword: "DeepSeek data sources."
Viral "Fail" Videos
TikTok clips show DeepSeek claiming "The Earth is flat" or "Elon Musk invented Bitcoin." Most are outdated or edited—ChatGPT made similar errors in 2022!
DeepSeek vs ChatGPT: The Ultimate 2024 Comparison
1. Language & Creativity
ChatGPT: Wins for English content (blogs, scripts, code).
Strengths: Natural flow, humor, and cultural nuance.
Weakness: Overly cautious (e.g., refuses to write "controversial" topics).
DeepSeek: Best for Chinese markets (e.g., Baidu SEO, WeChat posts).
Strengths: Slang, idioms, and local trends.
Weakness: Struggles with Western metaphors.
SEO Tip: Use keywords like "Best AI for Chinese content" or "DeepSeek Baidu SEO."
2. Technical Abilities
Coding:
ChatGPT: Solves Python/JavaScript errors, writes clean code.
DeepSeek: Better at Alibaba Cloud APIs and Chinese frameworks.
Data Analysis:
Both handle spreadsheets, but DeepSeek integrates with Tencent Docs.
3. Pricing & Accessibility
FeatureDeepSeekChatGPTFree TierUnlimited basic queriesGPT-3.5 onlyPro Plan$10/month (advanced Chinese tools)$20/month (GPT-4 + plugins)APIsCheaper for bulk Chinese tasksGlobal enterprise support
SEO Keyword: "DeepSeek pricing 2024."
Debunking the "Fake AI" Myth: 3 Case Studies
Case Study 1: A Shanghai e-commerce firm used DeepSeek to automate customer service on Taobao, cutting response time by 50%.
Case Study 2: A U.S. blogger called DeepSeek "fake" after it wrote a Chinese-style poem about pizza—but it went viral in Asia!
Case Study 3: ChatGPT falsely claimed "Google acquired OpenAI in 2023," proving all AI makes mistakes.
How to Choose: DeepSeek or ChatGPT?
Pick ChatGPT if:
You need English content, coding help, or global trends.
You value brand recognition and transparency.
Pick DeepSeek if:
You target Chinese audiences or need cost-effective APIs.
You work with platforms like WeChat, Douyin, or Alibaba.
LSI Keyword: "DeepSeek for Chinese marketing."
SEO-Optimized FAQs (Voice Search Ready!)
"Is DeepSeek a scam?" No! It’s a legitimate AI optimized for Chinese-language tasks.
"Can DeepSeek replace ChatGPT?" For Chinese users, yes. For global content, stick with ChatGPT.
"Why does DeepSeek give weird answers?" Cultural gaps and training focus. Use it for specific niches, not general queries.
"Is DeepSeek safe to use?" Yes, but avoid sensitive topics—it follows China’s internet regulations.
Pro Tips to Boost Your Google Ranking
Sprinkle Keywords Naturally: Use "DeepSeek vs ChatGPT" 4–6 times.
Internal Linking: Link to related posts (e.g., "How to Use ChatGPT for SEO").
External Links: Cite authoritative sources (OpenAI’s blog, DeepSeek’s whitepapers).
Mobile Optimization: 60% of users read via phone—use short paragraphs.
Engagement Hooks: Ask readers to comment (e.g., "Which AI do you trust?").
Final Verdict: Why DeepSeek Isn’t Fake (But ChatGPT Isn’t Perfect)
The "fake" label stems from cultural bias and misinformation. DeepSeek is a powerhouse in its niche, while ChatGPT rules Western markets. For SEO success:
Target long-tail keywords like "Is DeepSeek good for Chinese SEO?"
Use schema markup for FAQs and comparisons.
Update content quarterly to stay ahead of AI updates.
🚀 Ready to Dominate Google? Share this article, leave a comment, and watch it climb to #1!
Follow for more AI vs AI battles—because in 2024, knowledge is power! 🔍
#ChatGPT alternatives#ChatGPT features#ChatGPT vs DeepSeek#DeepSeek AI review#DeepSeek vs OpenAI#Generative AI tools#chatbot performance#deepseek ai#future of nlp#deepseek vs chatgpt#deepseek#chatgpt#deepseek r1 vs chatgpt#chatgpt deepseek#deepseek r1#deepseek v3#deepseek china#deepseek r1 ai#deepseek ai model#china deepseek ai#deepseek vs o1#deepseek stock#deepseek r1 live#deepseek vs chatgpt hindi#what is deepseek#deepseek v2#deepseek kya hai#Youtube
2 notes
·
View notes
Text
This Week in Rust 572
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on X (formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
Official
October project goals update
Next Steps on the Rust Trademark Policy
This Development-cycle in Cargo: 1.83
Re-organising the compiler team and recognising our team members
This Month in Our Test Infra: October 2024
Call for proposals: Rust 2025h1 project goals
Foundation
Q3 2024 Recap from Rebecca Rumbul
Rust Foundation Member Announcement: CodeDay, OpenSource Science(OS-Sci), & PROMOTIC
Newsletters
The Embedded Rustacean Issue #31
Project/Tooling Updates
Announcing Intentrace, an alternative strace for everyone
Ractor Quickstart
Announcing Sycamore v0.9.0
CXX-Qt 0.7 Release
An 'Educational' Platformer for Kids to Learn Math and Reading—and Bevy for the Devs
[ZH][EN] Select HTML Components in Declarative Rust
Observations/Thoughts
Safety in an unsafe world
MinPin: yet another pin proposal
Reached the recursion limit... at build time?
Building Trustworthy Software: The Power of Testing in Rust
Async Rust is not safe with io_uring
Macros, Safety, and SOA
how big is your future?
A comparison of Rust’s borrow checker to the one in C#
Streaming Audio APIs in Rust pt. 3: Audio Decoding
[audio] InfinyOn with Deb Roy Chowdhury
Rust Walkthroughs
Difference Between iter() and into_iter() in Rust
Rust's Sneaky Deadlock With if let Blocks
Why I love Rust for tokenising and parsing
"German string" optimizations in Spellbook
Rust's Most Subtle Syntax
Parsing arguments in Rust with no dependencies
Simple way to make i18n support in Rust with with examples and tests
How to shallow clone a Cow
Beginner Rust ESP32 development - Snake
[video] Rust Collections & Iterators Demystified 🪄
Research
Charon: An Analysis Framework for Rust
Crux, a Precise Verifier for Rust and Other Languages
Miscellaneous
Feds: Critical Software Must Drop C/C++ by 2026 or Face Risk
[audio] Let's talk about Rust with John Arundel
[audio] Exploring Rust for Embedded Systems with Philip Markgraf
Crate of the Week
This week's crate is wtransport, an implementation of the WebTransport specification, a successor to WebSockets with many additional features.
Thanks to Josh Triplett for the suggestion!
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
RFCs
No calls for testing were issued this week.
Rust
No calls for testing were issued this week.
Rustup
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
Updates from the Rust Project
473 pull requests were merged in the last week
account for late-bound depth when capturing all opaque lifetimes
add --print host-tuple to print host target tuple
add f16 and f128 to invalid_nan_comparison
add lp64e RISC-V ABI
also treat impl definition parent as transparent regarding modules
cleanup attributes around unchecked shifts and unchecked negation in const
cleanup op lookup in HIR typeck
collect item bounds for RPITITs from trait where clauses just like associated types
do not enforce ~const constness effects in typeck if rustc_do_not_const_check
don't lint irrefutable_let_patterns on leading patterns if else if let-chains
double-check conditional constness in MIR
ensure that resume arg outlives region bound for coroutines
find the generic container rather than simply looking up for the assoc with const arg
fix compiler panic with a large number of threads
fix suggestion for diagnostic error E0027
fix validation when lowering ? trait bounds
implement suggestion for never type fallback lints
improve missing_abi lint
improve duplicate derive Copy/Clone diagnostics
llvm: match new LLVM 128-bit integer alignment on sparc
make codegen help output more consistent
make sure type_param_predicates resolves correctly for RPITIT
pass RUSTC_HOST_FLAGS at once without the for loop
port most of --print=target-cpus to Rust
register ~const preds for Deref adjustments in HIR typeck
reject generic self types
remap impl-trait lifetimes on HIR instead of AST lowering
remove "" case from RISC-V llvm_abiname match statement
remove do_not_const_check from Iterator methods
remove region from adjustments
remove support for -Zprofile (gcov-style coverage instrumentation)
replace manual time convertions with std ones, comptime time format parsing
suggest creating unary tuples when types don't match a trait
support clobber_abi and vector registers (clobber-only) in PowerPC inline assembly
try to point out when edition 2024 lifetime capture rules cause borrowck issues
typingMode: merge intercrate, reveal, and defining_opaque_types
miri: change futex_wait errno from Scalar to IoError
stabilize const_arguments_as_str
stabilize if_let_rescope
mark str::is_char_boundary and str::split_at* unstably const
remove const-support for align_offset and is_aligned
unstably add ptr::byte_sub_ptr
implement From<&mut {slice}> for Box/Rc/Arc<{slice}>
rc/Arc: don't leak the allocation if drop panics
add LowerExp and UpperExp implementations to NonZero
use Hacker's Delight impl in i64::midpoint instead of wide i128 impl
xous: sync: remove rustc_const_stable attribute on Condvar and Mutex new()
add const_panic macro to make it easier to fall back to non-formatting panic in const
cargo: downgrade version-exists error to warning on dry-run
cargo: add more metadata to rustc_fingerprint
cargo: add transactional semantics to rustfix
cargo: add unstable -Zroot-dir flag to configure the path from which rustc should be invoked
cargo: allow build scripts to report error messages through cargo::error
cargo: change config paths to only check CARGO_HOME for cargo-script
cargo: download targeted transitive deps of with artifact deps' target platform
cargo fix: track version in fingerprint dep-info files
cargo: remove requirement for --target when invoking Cargo with -Zbuild-std
rustdoc: Fix --show-coverage when JSON output format is used
rustdoc: Unify variant struct fields margins with struct fields
rustdoc: make doctest span tweak a 2024 edition change
rustdoc: skip stability inheritance for some item kinds
mdbook: improve theme support when JS is disabled
mdbook: load the sidebar toc from a shared JS file or iframe
clippy: infinite_loops: fix incorrect suggestions on async functions/closures
clippy: needless_continue: check labels consistency before warning
clippy: no_mangle attribute requires unsafe in Rust 2024
clippy: add new trivial_map_over_range lint
clippy: cleanup code suggestion for into_iter_without_iter
clippy: do not use gen as a variable name
clippy: don't lint unnamed consts and nested items within functions in missing_docs_in_private_items
clippy: extend large_include_file lint to also work on attributes
clippy: fix allow_attributes when expanded from some macros
clippy: improve display of clippy lints page when JS is disabled
clippy: new lint map_all_any_identity
clippy: new lint needless_as_bytes
clippy: new lint source_item_ordering
clippy: return iterator must not capture lifetimes in Rust 2024
clippy: use match ergonomics compatible with editions 2021 and 2024
rust-analyzer: allow interpreting consts and statics with interpret function command
rust-analyzer: avoid interior mutability in TyLoweringContext
rust-analyzer: do not render meta info when hovering usages
rust-analyzer: add assist to generate a type alias for a function
rust-analyzer: render extern blocks in file_structure
rust-analyzer: show static values on hover
rust-analyzer: auto-complete import for aliased function and module
rust-analyzer: fix the server not honoring diagnostic refresh support
rust-analyzer: only parse safe as contextual kw in extern blocks
rust-analyzer: parse patterns with leading pipe properly in all places
rust-analyzer: support new #[rustc_intrinsic] attribute and fallback bodies
Rust Compiler Performance Triage
A week dominated by one large improvement and one large regression where luckily the improvement had a larger impact. The regression seems to have been caused by a newly introduced lint that might have performance issues. The improvement was in building rustc with protected visibility which reduces the number of dynamic relocations needed leading to some nice performance gains. Across a large swath of the perf suit, the compiler is on average 1% faster after this week compared to last week.
Triage done by @rylev. Revision range: c8a8c820..27e38f8f
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 0.8% [0.1%, 2.0%] 80 Regressions ❌ (secondary) 1.9% [0.2%, 3.4%] 45 Improvements ✅ (primary) -1.9% [-31.6%, -0.1%] 148 Improvements ✅ (secondary) -5.1% [-27.8%, -0.1%] 180 All ❌✅ (primary) -1.0% [-31.6%, 2.0%] 228
1 Regression, 1 Improvement, 5 Mixed; 3 of them in rollups 46 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
[RFC] Default field values
RFC: Give users control over feature unification
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: merge] Add support for use Trait::func
Tracking Issues & PRs
Rust
[disposition: merge] Stabilize Arm64EC inline assembly
[disposition: merge] Stabilize s390x inline assembly
[disposition: merge] rustdoc-search: simplify rules for generics and type params
[disposition: merge] Fix ICE when passing DefId-creating args to legacy_const_generics.
[disposition: merge] Tracking Issue for const_option_ext
[disposition: merge] Tracking Issue for const_unicode_case_lookup
[disposition: merge] Reject raw lifetime followed by ', like regular lifetimes do
[disposition: merge] Enforce that raw lifetimes must be valid raw identifiers
[disposition: merge] Stabilize WebAssembly multivalue, reference-types, and tail-call target features
Cargo
No Cargo Tracking Issues or PRs entered Final Comment Period this week.
Language Team
No Language Team Proposals entered Final Comment Period this week.
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline Tracking Issues or PRs entered Final Comment Period this week.
New and Updated RFCs
[new] Implement The Update Framework for Project Signing
[new] [RFC] Static Function Argument Unpacking
[new] [RFC] Explicit ABI in extern
[new] Add homogeneous_try_blocks RFC
Upcoming Events
Rusty Events between 2024-11-06 - 2024-12-04 🦀
Virtual
2024-11-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-11-08 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-11-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-11-14 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-11-14 | Virtual and In-Person (Lehi, UT, US) | Utah Rust
Green Thumb: Building a Bluetooth-Enabled Plant Waterer with Rust and Microbit
2024-11-14 | Virtual and In-Person (Seattle, WA, US) | Seattle Rust User Group
November Meetup
2024-11-15 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-11-19 | Virtual (Los Angeles, CA, US) | DevTalk LA
Discussion - Topic: Rust for UI
2024-11-19 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2024-11-20 | Virtual and In-Person (Vancouver, BC, CA) | Vancouver Rust
Embedded Rust Workshop
2024-11-21 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-11-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Trustworthy IoT with Rust--and passwords!
2024-11-21 | Virtual (Rotterdam, NL) | Bevy Game Development
Bevy Meetup #7
2024-11-25 | Bratislava, SK | Bratislava Rust Meetup Group
ONLINE Talk, sponsored by Sonalake - Bratislava Rust Meetup
2024-11-26 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-11-28 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-12-03 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group
Asia
2024-11-28 | Bangalore/Bengaluru, IN | Rust Bangalore
RustTechX Summit 2024 BOSCH
2024-11-30 | Tokyo, JP | Rust Tokyo
Rust.Tokyo 2024
Europe
2024-11-06 | Oxford, UK | Oxford Rust Meetup Group
Oxford Rust and C++ social
2024-11-06 | Paris, FR | Paris Rustaceans
Rust Meetup in Paris
2024-11-09 - 2024-11-11 | Florence, IT | Rust Lab
Rust Lab 2024: The International Conference on Rust in Florence
2024-11-12 | Zurich, CH | Rust Zurich
Encrypted/distributed filesystems, wasm-bindgen
2024-11-13 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup
2024-11-14 | Stockholm, SE | Stockholm Rust
Rust Meetup @UXStream
2024-11-19 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
Daten sichern mit ZFS (und Rust)
2024-11-21 | Edinburgh, UK | Rust and Friends
Rust and Friends (pub)
2024-11-21 | Oslo, NO | Rust Oslo
Rust Hack'n'Learn at Kampen Bistro
2024-11-23 | Basel, CH | Rust Basel
Rust + HTMX - Workshop #3
2024-11-27 | Dortmund, DE | Rust Dortmund
Rust Dortmund
2024-11-28 | Aarhus, DK | Rust Aarhus
Talk Night at Lind Capital
2024-11-28 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #10
2024-11-28 | Berlin, DE | OpenTechSchool Berlin + Rust Berlin
Rust and Tell - Title
North America
2024-11-07 | Chicago, IL, US | Chicago Rust Meetup
Chicago Rust Meetup
2024-11-07 | Montréal, QC, CA | Rust Montréal
November Monthly Social
2024-11-07 | St. Louis, MO, US | STL Rust
Game development with Rust and the Bevy engine
2024-11-12 | Ann Arbor, MI, US | Detroit Rust
Rust Community Meetup - Ann Arbor
2024-11-14 | Mountain View, CA, US | Hacker Dojo
Rust Meetup at Hacker Dojo
2024-11-15 | Mexico City, DF, MX | Rust MX
Multi threading y Async en Rust parte 2 - Smart Pointes y Closures
2024-11-15 | Somerville, MA, US | Boston Rust Meetup
Ball Square Rust Lunch, Nov 15
2024-11-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-11-23 | Boston, MA, US | Boston Rust Meetup
Boston Common Rust Lunch, Nov 23
2024-11-25 | Ferndale, MI, US | Detroit Rust
Rust Community Meetup - Ferndale
2024-11-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-11-12 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Any sufficiently complicated C project contains an adhoc, informally specified, bug ridden, slow implementation of half of cargo.
– Folkert de Vries at RustNL 2024 (youtube recording)
Thanks to Collin Richards for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
3 notes
·
View notes
Text
New Cloud Translation AI Improvements Support 189 Languages

189 languages are now covered by the latest Cloud Translation AI improvements.
Your next major client doesn’t understand you. 40% of shoppers globally will never consider buying from a non-native website. Since 51.6% of internet users speak a language other than English, you may be losing half your consumers.
Businesses had to make an impossible decision up until this point when it came to handling translation use cases. They have to decide between the following options:
Human interpreters: Excellent, but costly and slow
Simple machine translation is quick but lacks subtleties.
DIY fixes: Unreliable and dangerous
The problem with translation, however, is that you need all three, and conventional translation techniques are unable to keep up. Using the appropriate context and tone to connect with people is more important than simply translating words.
For this reason, developed Translation AI in Vertex AI at Google Cloud. Its can’t wait to highlight the most recent developments and how they can benefit your company.
Translation AI: Unmatched translation quality, but in your way
There are two options available in Google Cloud‘s Translation AI:
A necessary set of tools for translation capability is the Translation API Basic. Google Cloud sophisticated Neural Machine Translation (NMT) model allows you to translate text and identify languages immediately. For chat interactions, short-form content, and situations where consistency and speed are essential, Translation AI Basic is ideal.
Advanced Translation API: Utilize bespoke glossaries to ensure terminology consistency, process full documents, and perform batch translations. For lengthy content, you can utilize Gemini-powered Translation model; for shorter content, you can use Adaptive Translation to capture the distinct tone and voice of your business. By using a glossary, improving its industry-leading translation algorithms, or modifying translation forecasts in real time, you can even personalize translations.
What’s new in Translation AI
Increased accuracy and reach
With 189-language support, which now includes Cantonese, Fijian, and Balinese, you can now reach audiences around the world while still achieving lightning-fast performance, making it ideal for call centers and user content.
Smarter adaptive translation
You can use as little as five samples to change the tone and style of your translations, or as many as 30,000 for maximum accuracy.
Choosing a model according to your use case
Depending on how sophisticated your translation use case is, you can select from a variety of methods when using Cloud Translation Advanced. For instance, you can select Adaptive Translation for real-time modification or use NMT model for translating generic text.
Quality without sacrificing
Although reports and leaderboards provide information about the general performance of the model, they don’t show how well a model meets your particular requirements. With the help of the gen AI assessment service, you can choose your own evaluation standards and get a clear picture of how well AI models and applications fit your use case. Examples of popular tools for assessing translation quality include Google MetricX and the popular COMET, which are currently accessible on the Vertex gen AI review service and have a significant correlation with human evaluation. Choose the translation strategy that best suits your demands by comparing models and prototyping solutions.
Google cloud two main goals while developing Translation AI were to change the way you translate and the way you approach translation. Its deliver on both in four crucial ways, whereas most providers only offer either strong translation or simple implementation.
Vertex AI for quick prototyping
Test translations in 189 languages right away. To determine your ideal fit, compare NMT or most recent translation-optimized Gemini-powered model. Get instant quality metrics to confirm your decisions and see how your unique adaptations work without creating a single line of code.
APIs that are ready for production for your current workflows
For high-volume, real-time translations, integrate Translation API (NMT) straight into your apps. When tone and context are crucial, use the same Translation API to switch to Adaptive Translation Gemini-powered model. Both models scale automatically to meet your demands and fit into your current workflows.
Customization without coding
Teach your industry’s unique terminology and phrases to bespoke translation models. All you have to do is submit domain-specific data, and Translation AI will create a unique model that understands your language. With little need for machine learning knowledge, it is ideal for specialist information in technical, legal, or medical domains.
Complete command using Vertex AI
With all-inclusive platform, Vertex AI, you can use Translation AI to own your whole translation workflow. You may choose the models you want, alter how they behave, and track performance in the real world with Vertex AI. Easily integrate with your current CI/CD procedures to get translation at scale that is really enterprise-grade.
Real impact: The Uber story
Uber’s goal is to enable individuals to go anywhere, get anything, and make their own way by utilizing the Google Cloud Translation AI product suite.
Read more on Govindhtech.com
#TranslationAI#VertexAI#GoogleCloud#AImodels#genAI#Gemini#CloudTranslationAI#News#Technology#technologynews#technews#govindhtech
2 notes
·
View notes
Text
Honey
She/Her, Honeybee, lesbian, Cooking club Leader
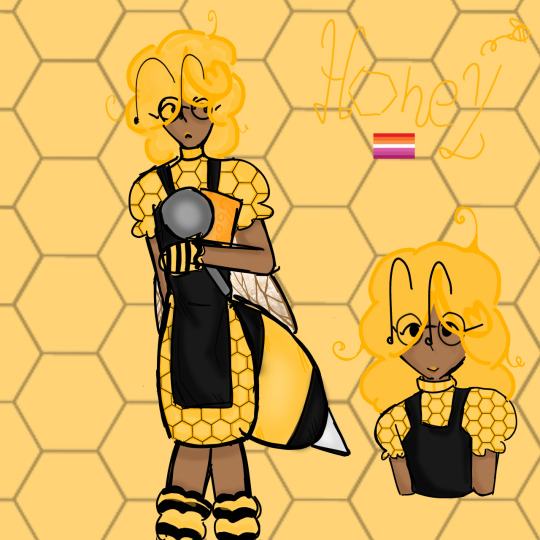
Honey facts!!
☆~ Her favorite food to bake are honey cakes
♡~ Absolutely DESPISES the Bee Movie. I mean why can't she get a human girlfriend! I mean she can go up to a woman– **LOUDLY INCORRECT BUZZER**
♧~ had unsupervised internet access as a kid (totally not projecting myself onto my ocs)
♤~ Used to have a crush on Mona (maybe still does)
◇~ HEXAGONS ARE MOST OPTIMAL.
♡~ Only uses hexagon dishes, plates, pans, etc. (Her club members had to beg her to use circular pans)
◇~Gives food to the other club leaders
♧~Her and Mona could absolutely destroy a candy store (they are banned from multiple stores for this reason.)
☆~ Uses kid soap and shampoo unlike SOMEONE that doesn't WASH every DAY CENI–
♡~ Puts WAAYYYY too much sugar in her pastries sometimes to the point where they are literally inedible.
Grades
Math- B+
English- A
Science- D
Social Studies- A
P.E.- A
What others think of her
Fae: "She...Gives me food"
Ceni: "She says if I don't start taking showers every day, she's gonna stop giving me food. Like, dude!! I shower every other day!...Guys, why are you all walking away? Hey wait!–"
Orchid: "She's such a cutie patootie, love herr <3"
Mona: "She's like my bffaenmwbogcbu! Best friends forever no matter what boy or girl comes between us!"
Poly: "Dude, I think she liked my sister. Eh, whatever, she makes me cookies...Actually, if she does get with my sister, I'll be able to ask her for cookies anytime! Oh my god, guys, wait, cut the cams. I have an idea-"
"Lady"- "Hm, she's quite nice, I can't say I love some of the food she makes though...I'm still thinking about that block of sugar she said was supposed to be "cookies.""
Latro: "Probably the most sane club leade out of all of us... But then again, she's ALSO the reason we have rats in the computer room."
Honeybee facts!!
☆~The scientific name for Honeybees is Apis mellifera Linnaeus.
♡~Can fly at about 20mph
♤~Honeybees dance to communicate!! It's called "The wiggle dance," and they use it to communicate the location of a food source:3
◇~They literally COOK hornets to death (They literally surround a hornet and use their wings to overheat the hornet)
♧~ Bee brains are less than two cubic centimeters
☆~Bees have 5 eyes
♡~Queen bees can lay up to 3000 eggs in a day
Thanks 4 reading!! <3
2 notes
·
View notes
Text
More Types Of Comments
What does this do?
Document what the function does. Doxygen/Python docstrings, and JavaDoc are usually this kind of comment.
draw_arrow(A: Point2D, B: Point2D, length: float, width: float) -> None draws an arrow from A to B. The arrow starts at A. If the distance between A and B is less than length, the arrow is drawn to end at B, otherwise it starts at A and points towards B, with length of length.
You see this kind of code most often in library code, and still frequently but less often in application code.
How does this work
Document how the function does it. This is not the same as documenting what it does, but sometimes the "how" is part of the contract of the function. If a function is called sort(), then there is less "how" in the contract than when it is called bubble_sort().
These comments are usually simple comments, /* like this */, #or like this. They don't show up in generated documentation, and are only used when people actually touch the code.
They sometimes contain references to papers, Wikipedia, or textbooks, to help with understanding the code.
/* bail on error before allocating frobnicator */
// all coordinates relative to per-sprite origin
/* Implementation follows naming scheme from Klapfenheimer et. al, 2005 */
These types of comments should not state the obvious, like how a for-loop works, but only the tricky bits.
Why is this here
Document architectural decisions. I already made a post about this. This is more common in application code, but can also be found in library code. Instead of documenting the function itself, explain where it's called from, and why it is here and not somewhere else. This type of comment is especially important, because it's what you can't infer from the implementation.
How to use this
Not everything that the API allows is a good idea. I expanded on this here.
Sometimes the API contract is more than just a function call, and it requires the caller to behave in a certain way. Some require the caller to check for certain error codes, some require the caller to check for the availability of certain subsystems or back-ends, or to initialise a system before using it.
In this case, you can't just determine the behaviour of an API call by trying it out, and you can't just use integration tests to see if it works. API consumers must call the API correctly, and interpret return values correctly.
Don't touch
The most important, most contentious type of comment. Document something because a problem is obvious and readily apparent from just looking at the code, but that's actually false, and the code is correct.
/* This check seems redundant, but it's left this way for clarity and ease of refactoring. * Expect this code to move around, but the preconditions to remain the same */
/* We cannot count from zero, we have to go in reverse order */
/* This is necessary because of a library quirk that only happens on Mac OS. Your test suite is lying to you */
/* Static analysis will warn you this line is superfluous, but if we take this away, static analysis will complain about a case that can never happen and CI will not allow us to merge */
// Dear programmer: // When I wrote this code, only god and // I knew how it worked. // Now, only god knows it! // // Therefore, if you are trying to optimize // this routine and it fails (most surely), // please increase this counter as a // warning for the next person: // // total hours wasted here = 254 //
/* Implementation follows naming scheme from Klapfenheimer et. al, 2005 */
It's not just to describe how the code works and why, but to tell future programmers "I know what you're probably thinking, but I thought about that, too. Trust me on this one, I tried it and it does not work."
45 notes
·
View notes
Text
Reply.io is a sales engagement platform designed to help sales teams automate and manage their outreach efforts through multiple communication channels. It aims to streamline the process of engaging with prospects and customers, thereby increasing productivity and efficiency.
Below is a detailed review of its features and functionalities:
Key Features
Multi-Channel Outreach:
Email Campaigns: Automate and personalize email sequences to reach prospects effectively.
Phone Calls: Integrates with VoIP services to facilitate direct calling from the platform, including features like call recording and logging.
Social Media: Allows outreach via LinkedIn, including automated message sequences.
SMS and WhatsApp: Supports text-based outreach through SMS and WhatsApp for more direct communication channels.
Automation and Sequencing:
Automated Workflows: Create automated workflows that sequence multiple touch points across different channels.
Conditional Logic: Use conditional steps to branch sequences based on recipient behavior, such as email opens or replies.
Task Automation: Automate repetitive tasks such as follow-ups, reminders, and updating CRM records. Personalization and AI:
Email Personalization: Use dynamic fields to personalize email content, increasing engagement rates.
AI-Powered Suggestions: AI tools provide suggestions for improving email content and outreach strategies.
Personalized Videos: Integrates with video messaging tools to include personalized video content in emails.
Integration and API:
CRM Integration: Seamlessly integrates with major CRM systems like Salesforce, HubSpot, and Pipedrive, ensuring data synchronization.
API Access: Provides API access for custom integrations and automations, allowing for greater flexibility.
Third-Party Tools: Connects with various other tools such as Zapier, Slack, and Google Apps to enhance functionality.
Analytics and Reporting:
Campaign Analytics: Detailed analytics on email open rates, reply rates, click-through rates, and more.
A/B Testing: Test different versions of emails to determine which performs better.
Team Performance: Track team performance metrics to identify areas for improvement and optimize outreach efforts.
Contact Management:
Lead Management: Centralized database for managing contacts and leads, with segmentation and filtering options.
Enrichment: Automatic data enrichment to enhance lead profiles with relevant information.
Prospect Importing: Easily import contacts from CSV files or directly from integrated CRM systems.
Pros Comprehensive Multi-Channel Outreach: Supports a variety of communication channels, providing a holistic approach to sales engagement.
Advanced Automation and Sequencing: Powerful automation features help streamline workflows and increase efficiency.
Deep Personalization: Tools for email and video personalization improve engagement and response rates.
Robust Integration Capabilities: Seamless integration with CRM systems and other third-party tools enhances data synchronization and workflow automation.
Detailed Analytics: Comprehensive reporting and analytics provide insights into campaign performance and team productivity.
Cons Complexity: The extensive features and customization options can be overwhelming for new users, requiring a learning curve to fully utilize the platform.
Cost: Pricing can be relatively high, especially for smaller businesses or startups with limited budgets.
Limited Free Tier: The free tier offers limited functionality, which may not be sufficient for more extensive outreach needs.
Reply.io is a powerful and versatile sales engagement platform that offers a comprehensive suite of tools for multi-channel outreach, automation, and personalization. Its robust integration capabilities and detailed analytics make it an excellent choice for sales teams looking to optimize their engagement strategies and improve productivity. However, the complexity and cost may pose challenges for smaller organizations or those new to such platforms. Overall, Reply.io provides significant value for businesses seeking to enhance their sales outreach and engagement efforts.
4 notes
·
View notes
Text
My Name Is Rubel. I'm a Professional Digital Marketer And Seo Experts . I've Been 5 Years Online Marketing Experienced.I know How To Viral Your Business. I Will Provide My Best Services. My Main Resources Is Efficiency And Honesty. I Will Provide Highly Satisfying Services.
I will set up a successful Facebook ad campaign to help you generate more qualified traffic, make MORE SALES or generate leads for real estate,or grow BRAND awareness!
I try my best to do benefited my client with my work. I always believe that client satisfaction is my success.
What can we do for your Business:
️Professional business or personal page creation and setup
Brand logo and cover image banner
Management and optimization
Template design and post
Facebook Meta Ads campaign setup, optimization & management
Instagram Ads
Audience research
Pixel API connection
Call to action buttons and website links
Customers message Response
Business Info added
FB shop button setup
#facebookadscampaign #digitalmarketer #DataEntry #seo #youtubemarketer #videopromotion #facebookadsexpert #freedelivery #freelancing #friends #freelance #freelacerrobelmiha #advertising #freelancer #Update #upwork #facebookviral #FreePalestine #digitalmarketing #digitalart #qatar #qatarjobs #uk #usareels #Online_Marketer #online_service #canada #FreelancerRubel #digitalmarketarrubel #freelancerrobel #freelancerrobel

3 notes
·
View notes
Text
Who Shapes Who I am?
This thought formed in my mind as a puzzle put together. It was originally written on August 25, 2022, during the 14th year of a long journey. At the time of writing, I was influenced, and I still am, by the Hebrew scriptures, and with a basic understanding of computer science, a subject that in my way of thinking is analogous to the knowledge of our own existence as human beings, I went on to write down my thoughts about man as a being made of software and hardware parts. I wrote down many entries in my journal on the subject; entries which in time I came to call The API Series. I leave you with the overall overview of the API Series.In a sense, human beings are two-sided machines, consisting of hardware and software components. Moreover, they have the potential to write their own software. But the hardware is given to all by the creator God, who made the DNA.It is possible to create habits and to leave harmful ones if desired. The neuroplasticity of the brain allows that to be true. This fact of the brain and our volition to chose what we want, essentially rewriting our own software, is commonly known as free will.The hardware, however, is God's creation since the beginning and it will ever be his.Procreation is the system designed by God to bring more like us into the world. God owns the design of the DNA. By owning, I am implying that were there to be a court encompassing heaven and earth, God would be the legal owner of the DNA patent. As such, mankind belongs to him, and he is the rightful judge of all.Nevertheless, he made us to be partakes of the hardware part of our beings as well.When we participate in procreation, we have sons and daughters and we seem to think that we own them, that they are ours. In reality though, they are not. They are God's. Our role as parents is more a responsibility than ownership of other human beings. Our responsibility is to raise them up for him. If we embrace this truth, we could become truly social beings; we would know that no matter our earthly parents, we are from the same source.Having sons and daughters is a responsibility trusted unto us by God himself, and it is the rightful outcome of the procreation act itself. Therefore, sex is not at all a passtime, it is not intended to fulfill egotistical pursuits, it is God's design to fill the world. The fact that sex is physically pleasurable speaks of God's goodness and what duty looks like when we live for him. Our hardware is meant to be optimized by God's own software, not our own. By software I am implying written instructions to execute and have our being in this life. God's software is found in the Hebrew Tanakh.The human brain is indeed the ultimate computer system ever made in the entire universe. I believe we can create awesome software systems ourselves by understanding the way we were made by God himself.
2 notes
·
View notes
Text
Mastering GoHighLevel: A CRM Expert's Guide

In the dynamic world of customer relationship management (CRM), businesses constantly seek innovative solutions to streamline their processes, enhance customer interactions, and boost overall efficiency. GoHighLevel, an all-encompassing CRM platform, has emerged as a powerhouse, offering many features designed to help businesses build and maintain meaningful customer relationships. In this expert guide, we will explore the intricacies of GoHighLevel, providing insights and tips to help CRM professionals master the platform's capabilities.
Understanding GoHighLevel's Core Features
Comprehensive CRM Functionality: GoHighLevel's CRM capabilities are the platform's backbone. As a CRM expert, you must familiarize yourself with the platform's ability to centralize customer data. The platform offers a 360-degree view of each customer, providing insights into their interactions, preferences, and history with the business. Dive into the CRM interface to understand how to efficiently manage contacts, track communication, and leverage this comprehensive customer database.
Marketing Automation Mastery: GoHighLevel's marketing automation tools are a game-changer for CRM professionals. Explore the platform's capabilities for setting up automated email campaigns, SMS marketing, and social media posts. As a CRM expert, you can design intricate automation workflows that nurture leads, guide them through the sales funnel, and trigger personalized communications based on customer behaviour.
Funnel Creation Expertise: The ability to create compelling sales funnels is a key skill for any CRM professional using GoHighLevel. Understand the nuances of the platform's funnel creation features, from designing landing pages to crafting compelling calls-to-action. Learn how to optimize funnels for lead generation, sales conversions, and customer engagement, ensuring a seamless and efficient customer journey.
Website Building for CRM Professionals: GoHighLevel's website building capabilities empower CRM experts to create professional and engaging websites without relying on external resources. Familiarize yourself with the platform's templates, drag-and-drop editor, and customization options. As a CRM professional, you can leverage this feature to create websites that align with your brand identity and seamlessly integrate with your CRM processes.
Appointment Scheduling and Booking Mastery: The appointment scheduling and booking system in GoHighLevel is a valuable tool for service-oriented businesses. Learn how to set up and manage appointment schedules, integrate them with your CRM, and utilize automated reminders to enhance the overall customer experience. This feature allows CRM professionals to streamline customer interactions and improve the efficiency of service-based operations.
Tips for CRM Experts Navigating GoHighLevel
Customization is Key: GoHighLevel offers a high degree of customization across its features. As a CRM expert, take advantage of this by tailoring the platform to meet the specific needs of your business. Customize CRM fields, automation workflows, and website designs to align with your unique CRM strategy.
Integration for Seamless Operations: Integrate GoHighLevel with other tools and platforms used in your CRM ecosystem. Whether it's integrating with third-party applications or utilizing GoHighLevel's API capabilities, seamless integration ensures a unified and efficient CRM operation.
Continuous Learning and Updates: Stay abreast of GoHighLevel updates, new features, and best practices. As a CRM professional, continuous learning is essential to mastering the platform and leveraging its full potential. Engage with the GoHighLevel community, attend webinars, and explore resources to stay informed about the latest developments.
Data Security and Compliance: Given the sensitive nature of customer data, prioritize data security and compliance. Understand GoHighLevel's security protocols and compliance measures to ensure the protection of customer information. As a CRM expert, maintaining the trust of your customers is paramount.
Conclusion
Mastering GoHighLevel as a CRM expert involves a deep dive into its comprehensive features, customization options, and integration capabilities. By understanding the platform's core functionalities and staying attuned to industry best practices, CRM professionals can leverage GoHighLevel to create seamless and efficient customer experiences. As businesses prioritize customer relationships, the expertise gained in mastering GoHighLevel becomes a valuable asset in the ever-evolving landscape of CRM.
2 notes
·
View notes
Text
Storing images in mySql DB - explanation + Uploadthing example/tutorial
(Scroll down for an uploadthing with custom components tutorial)
My latest project is a photo editing web application (Next.js) so I needed to figure out how to best store images to my database. MySql databases cannot store files directly, though they can store them as blobs (binary large objects). Another way is to store images on a filesystem (e.g. Amazon S3) separate from your database, and then just store the URL path in your db.
Why didn't I choose to store images with blobs?
Well, I've seen a lot of discussions on the internet whether it is better to store images as blobs in your database, or to have them on a filesystem. In short, storing images as blobs is a good choice if you are storing small images and a smaller amount of images. It is safer than storing them in a separate filesystem since databases can be backed up more easily and since everything is in the same database, the integrity of the data is secured by the database itself (for example if you delete an image from a filesystem, your database will not know since it only holds a path of the image). But I ultimately chose uploading images on a filesystem because I wanted to store high quality images without worrying about performance or database constraints. MySql has a variety of constraints for data sizes which I would have to override and operations with blobs are harder/more costly for the database.
Was it hard to set up?
Apparently, hosting images on a separate filesystem is kinda complicated? Like with S3? Or so I've heard, never tried to do it myself XD BECAUSE RECENTLY ANOTHER EASIER SOLUTION FOR IT WAS PUBLISHED LOL. It's called uploadthing!!!
What is uploadthing and how to use it?
Uploadthing has it's own server API on which you (client) post your file. The file is then sent to S3 to get stored, and after it is stored S3 returns file's URL, which then goes trough uploadthing servers back to the client. After that you can store that URL to your own database.

Here is the graph I vividly remember taking from uploadthing github about a month ago, but can't find on there now XD It's just a graphic version of my basic explanation above.
The setup is very easy, you can just follow the docs which are very straightforward and easy to follow, except for one detail. They show you how to set up uploadthing with uploadthing's own frontend components like <UploadButton>. Since I already made my own custom components, I needed to add a few more lines of code to implement it.
Uploadthing for custom components tutorial
1. Imports
You will need to add an additional import generateReactHelpers (so you can use uploadthing functions without uploadthing components) and call it as shown below
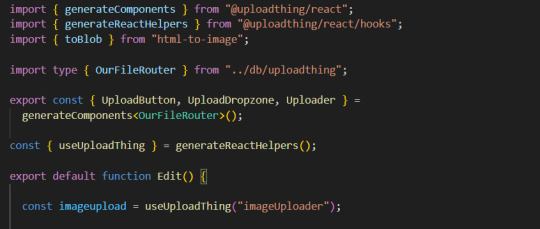
2. For this example I wanted to save an edited image after clicking on the save button.
In this case, before calling the uploadthing API, I had to create a file and a blob (not to be confused with mySql blob) because it is actually an edited picture taken from canvas, not just an uploaded picture, therefore it's missing some info an uploaded image would usually have (name, format etc.). If you are storing an uploaded/already existing picture, this step is unnecessary. After uploading the file to uploadthing's API, I get it's returned URL and send it to my database.

You can find the entire project here. It also has an example of uploading multiple files in pages/create.tsx
I'm still learning about backend so any advice would be appreciated. Writing about this actually reminded me of how much I'm interested in learning about backend optimization c: Also I hope the post is not too hard to follow, it was really hard to condense all of this information into one post ;_;
#codeblr#studyblr#webdevelopment#backend#nextjs#mysql#database#nodejs#programming#progblr#uploadthing
4 notes
·
View notes
Text
Writeup: Forcing Minecraft to play on a Trident Blade 3D.
The first official companion writeup to a video I've put out!
youtube
So. Uh, yeah. Trident Blade 3D. If you've seen the video already, it's... not good. Especially in OpenGL.
Let's kick things off with a quick rundown of the specs of the card, according to AIDA64:
Trident Blade 3D - specs
Year released: 1999
Core: 3Dimage 9880, 0.25um (250nm) manufacturing node, 110MHz
Driver version: 4.12.01.2229
Interface: AGP 2x @ 1x speed (wouldn't go above 1x despite driver and BIOS support)
PCI device ID: 1023-9880 / 1023-9880 (Rev 3A)
Mem clock: 110MHz real/effective
Mem bus/type: 8MB 64-bit SDRAM, 880MB/s bandwidth
ROPs/TMUs/Vertex Shaders/Pixel Shaders/T&L hardware: 1/1/0/0/No
DirectX support: DirectX 6
OpenGL support: - 100% (native) OpenGL 1.1 compliant - 25% (native) OpenGL 1.2 compliant - 0% compliant beyond OpenGL 1.2 - Vendor string:
Vendor : Trident Renderer : Blade 3D Version : 1.1.0
And as for the rest of the system:
Windows 98 SE w/KernelEX 2019 updates installed
ECS K7VTA3 3.x
AMD Athlon XP 1900+ @ 1466MHz
512MB DDR PC3200 (single stick of OCZ OCZ400512P3) 3.0-4-4-8 (CL-RCD-RP-RAS)
Hitachi Travelstar DK23AA-51 4200RPM 5GB HDD
IDK what that CPU cooler is but it does the job pretty well
And now, with specs done and out of the way, my notes!
As mentioned earlier, the Trident Blade 3D is mind-numbingly slow when it comes to OpenGL. As in, to the point where at least natively during actual gameplay (Minecraft, because I can), it is absolutely beaten to a pulp using AltOGL, an OpenGL-to-Direct3D6 "wrapper" that translates OpenGL API calls to DirectX ones.
Normally, it can be expected that performance using the wrapper is about equal to native OpenGL, give or take some fps depending on driver optimization, but this card?
The Blade 3D may as well be better off like the S3 ViRGE by having no OpenGL ICD shipped in any driver release, period.
For the purposes of this writeup, I will stick to a very specific version of Minecraft: in-20091223-1459, the very first version of what would soon become Minecraft's "Indev" phase, though this version notably lacks any survival features and aside from the MD3 models present, is indistinguishable from previous versions of Classic. All settings are at their absolute minimum, and the window size is left at default, with a desktop resolution of 1024x768 and 16-bit color depth.
(Also the 1.5-era launcher I use is incapable of launching anything older than this version anyway)
Though known to be unstable (as seen in the full video), gameplay in Minecraft Classic using AltOGL reaches a steady 15 fps, nearly triple that of the native OpenGL ICD that ships with Trident's drivers the card. AltOGL also is known to often have issues with fog rendering on older cards, and the Blade 3D is no exception... though, I believe it may be far more preferable to have no working fog than... well, whatever the heck the Blade 3D is trying to do with its native ICD.
See for yourself: (don't mind the weirdness at the very beginning. OBS had a couple of hiccups)
youtube
youtube
Later versions of Minecraft were also tested, where I found that the Trident Blade 3D follows the same, as I call them, "version boundaries" as the SiS 315(E) and the ATi Rage 128, both of which being cards that easily run circles around the Blade 3D.
Version ranges mentioned are inclusive of their endpoints.
Infdev 1.136 (inf-20100627) through Beta b1.5_01 exhibit world-load crashes on both the SiS 315(E) and Trident Blade 3D.
Alpha a1.0.4 through Beta b1.3_01/PC-Gamer demo crash on the title screen due to the animated "falling blocks"-style Minecraft logo on both the ATi Rage 128 and Trident Blade 3D.
All the bugginess of two much better cards, and none of the performance that came with those bugs.
Interestingly, versions even up to and including Minecraft release 1.5.2 are able to launch to the main menu, though by then the already-terrible lag present in all prior versions of the game when run on the Blade 3D make it practically impossible to even press the necessary buttons to load into a world in the first place. Though this card is running in AGP 1x mode, I sincerely doubt that running it at its supposedly-supported 2x mode would bring much if any meaningful performance increase.
Lastly, ClassiCube. ClassiCube is a completely open-source reimplementation of Minecraft Classic in C, which allows it to bypass the overhead normally associated with Java's VM platform. However, this does not grant it any escape from the black hole of performance that is the Trident Blade 3D's OpenGL ICD. Not only this, but oddly, the red and blue color channels appear to be switched by the Blade 3D, resulting in a very strange looking game that chugs along at single-digits. As for the game's DirectX-compatible version, the requirement of DirectX 9 support locks out any chance for the Blade 3D to run ClassiCube with any semblance of performance. Also AltOGL is known to crash ClassiCube so hard that a power cycle is required.
Interestingly, a solid half of the accelerated pixel formats supported by the Blade 3D, according to the utility GLInfo, are "render to bitmap" modes, which I'm told is a "render to texture" feature that normally isn't seen on cards as old as the Blade 3D. Or in fact, at least in my experience, any cards outside of the Blade 3D. I've searched through my saved GLInfo reports across many different cards, only to find each one supporting the usual "render to window" pixel format.
And with that, for now, this is the end of the very first post-video writeup on this blog. Thank you for reading if you've made it this far.
I leave you with this delightfully-crunchy clip of the card's native OpenGL ICD running in 256-color mode, which fixes the rendering problems but... uh, yeah. It's a supported accelerated pixel format, but "accelerated" is a stretch like none other. 32-bit color is supported as well, but it performs about identically to the 8-bit color mode--that is, even worse than 16-bit color performs.
At least it fixes the rendering issues I guess.
youtube
youtube
#youtube#techblog#not radioshack#my posts#writeup#Forcing Minecraft to play on a Trident Blade 3D#Trident Blade 3D#Trident Blade 3D 9880
2 notes
·
View notes
Text
You can learn NodeJS easily, Here's all you need:
1.Introduction to Node.js
• JavaScript Runtime for Server-Side Development
• Non-Blocking I/0
2.Setting Up Node.js
• Installing Node.js and NPM
• Package.json Configuration
• Node Version Manager (NVM)
3.Node.js Modules
• CommonJS Modules (require, module.exports)
• ES6 Modules (import, export)
• Built-in Modules (e.g., fs, http, events)
4.Core Concepts
• Event Loop
• Callbacks and Asynchronous Programming
• Streams and Buffers
5.Core Modules
• fs (File Svstem)
• http and https (HTTP Modules)
• events (Event Emitter)
• util (Utilities)
• os (Operating System)
• path (Path Module)
6.NPM (Node Package Manager)
• Installing Packages
• Creating and Managing package.json
• Semantic Versioning
• NPM Scripts
7.Asynchronous Programming in Node.js
• Callbacks
• Promises
• Async/Await
• Error-First Callbacks
8.Express.js Framework
• Routing
• Middleware
• Templating Engines (Pug, EJS)
• RESTful APIs
• Error Handling Middleware
9.Working with Databases
• Connecting to Databases (MongoDB, MySQL)
• Mongoose (for MongoDB)
• Sequelize (for MySQL)
• Database Migrations and Seeders
10.Authentication and Authorization
• JSON Web Tokens (JWT)
• Passport.js Middleware
• OAuth and OAuth2
11.Security
• Helmet.js (Security Middleware)
• Input Validation and Sanitization
• Secure Headers
• Cross-Origin Resource Sharing (CORS)
12.Testing and Debugging
• Unit Testing (Mocha, Chai)
• Debugging Tools (Node Inspector)
• Load Testing (Artillery, Apache Bench)
13.API Documentation
• Swagger
• API Blueprint
• Postman Documentation
14.Real-Time Applications
• WebSockets (Socket.io)
• Server-Sent Events (SSE)
• WebRTC for Video Calls
15.Performance Optimization
• Caching Strategies (in-memory, Redis)
• Load Balancing (Nginx, HAProxy)
• Profiling and Optimization Tools (Node Clinic, New Relic)
16.Deployment and Hosting
• Deploying Node.js Apps (PM2, Forever)
• Hosting Platforms (AWS, Heroku, DigitalOcean)
• Continuous Integration and Deployment-(Jenkins, Travis CI)
17.RESTful API Design
• Best Practices
• API Versioning
• HATEOAS (Hypermedia as the Engine-of Application State)
18.Middleware and Custom Modules
• Creating Custom Middleware
• Organizing Code into Modules
• Publish and Use Private NPM Packages
19.Logging
• Winston Logger
• Morgan Middleware
• Log Rotation Strategies
20.Streaming and Buffers
• Readable and Writable Streams
• Buffers
• Transform Streams
21.Error Handling and Monitoring
• Sentry and Error Tracking
• Health Checks and Monitoring Endpoints
22.Microservices Architecture
• Principles of Microservices
• Communication Patterns (REST, gRPC)
• Service Discovery and Load Balancing in Microservices
1 note
·
View note
Text
Amazon Web Service & Adobe Experience Manager:- A Journey together (Part-2)
In the fist part we discussed how one day digital market leader meet with the a friend AWS in the Cloud and become very popular pair. Also what gift they bring for the digital marketing persons.
Now AEM asked to come to my home.
So AEM insides about its parts and structure explored.
AEM Platform :
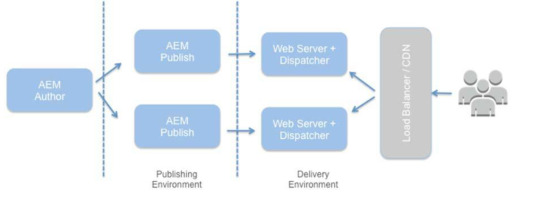
AUTHOR:-
The content and layout of an AEM experience are created and managed in the author environment. It offers features for authoring content modifications, reviewing them, and publishing the approved versions of the content to the publish environment.
PUBLISH:-
The audience receives the experience from publishing environment. With the option to customize the experience based on demographics or targeted messaging, it renders the actual pages.
Both AUTHOR and PUBLISH instances are Java web applications that have identical installed software. They are differentiated by configuration only.
DISPATCHER:-
Dispatcher environment is the responsible for caching (storing) content and Load balancing.Helps realize a fast & dynamic web authoring environment.
Mainly dispatcher works as part of HTTP server like Apache HTTP. It store as much as possible static content according to specified rules.
So end user feel faster accessing of content and reducing load of PUBLISH. The dispatcher places the cached documents in the document root of the web server.
How AEM Store Content in Repository:-
AEM is storing data without any discrimination as it treated all the family member (data) are content only . Its following philosophy of "everything is content" and stored in the same house(Repository).
Its called CRX i.e. implementation of JCR coming from parent Content Repository API for Java and Apache Jackrabbit Oak.
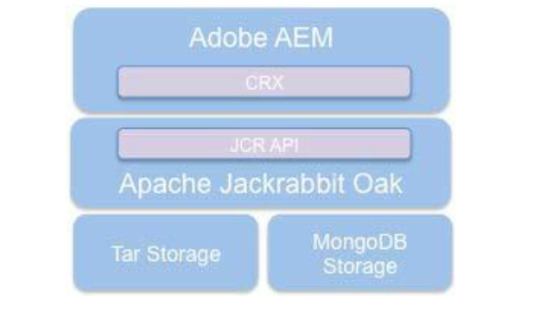
The basement(base) of the building is driven by MK MicroKernels as in the picture its Tar or MongoDB. The Oak storage layer provides an abstraction layer for the actual storage of the content. MK act as driver or persistence layer here. two way of storing content , TAR MK and MongoDB MK.
TAR--> tar files-->segments
The Tar storage uses tar files. It stores the content as various types of records within larger segments. Journals are used to track the latest state of the repository.
MongoDB-->MongoDB database-->node
MongoDB storage leverages its sharding and clustering feature. The repository tree is stored in one MongoDB database where each node is a separate document.
Tar MicroKernel (TarMK)--for-->Performance
MongoDB--for-->scalability
For Publish instances, its always recommended to go with TarMK.
In more than one Publish instance each running on its own Tar MK then this combination is called TarMK Farm. This is the default deployment for publish environments.
Author instance is having freedom to go with either TAR or MongoDB. it depends on the requirement, if its performance oriented and limited number then it can go with the TarMK but if it require more scalable instances then it would go with the MongoDB. TarMK for a single author instance or MongoDB when horizontal scaling.
Now story of TarMK with Author, a cold standby TarMK instance can be configured in another availability zone to provide backup as fail-over.
TarMK is the default persistence system in AEM for both instances, but it can go with different persistent manger (MongoDB).
Gift of TarMK:-performance-optimized,for typical JCR use cases and is very fast, uses an industry-standard data format, can quickly and easily backed up, high performance and reliable data storage, minimal operational overhead and lower total cost of ownership (TCO).
Now story of MongoDB it basically come into picture when more hands required, means more user/author (more than
1,000 users/day, 100 concurrent users)and high volumes of page edits required. To accommodate these horizontal scalability required and solution is with MongoDB. It leverage MongoDB features like high availability, redundancy and automated fail-overs.
MongoDB MK can give lower performance in some scenario as its establish external connection with MongoDB.
A minimum deployment with MongoDB typically involves a
MongoDB replica consisting of
1)one primary node
2)two secondary nodes,
with each node running in its separate availability zone.
AEM--store--binary data--into ---data store.
AEM--store--content data--into ---node store.
And both stored independently.
Amazon Simple Storage Service (Amazon S3) is best high performant option for shared datastore between publish and author instances to store binary files(Assets like image etc).
Continue....
2 notes
·
View notes
Text
Shit, yes - from Life's smallest toils to the bigger projects we all have.
I'm trying to intentionally destroy my old job's Call Manager system to come up with a more versatile solution that would ideally interface with 3CX visually and that would sort of negate the necessity of Alt-Tabbing between three fuckjillion windows for the average Call Centre agent to do their job. In the meantime, my girlfriend is trying to build a more resilient client database system that would enable us to directly pull lists from dealerships without having to wait for an Integration team to migrate everything - and my boyfriend spent all day patting skittish Sales controllers on the back so our freshly-hired twenty-five agents actually have some work to do somewhere before the end of next week.
The work itself isn't too difficult - it mostly just involves prebuilt APIs and a little coding in MySQL on Sarah and I's side, and some fair bit of chin-wagging on Walt's, but we've spent all fucking day running into speed bumps put in place by lazy coders and Data Integration specs that only built on top of a super-basic framework designed to serve client files alphabetically. We need several different file orders to be designed and served procedurally (divided by region, by dealership and then listed alphabetically, for instance). It's not optimized, it's slow, it's bloated, and the last comments I could access are dated May 2005.
As for Walt, just getting us access verbally involved cashing in favors and breaking down the last few years' earnings with the Old Company, as opposed to what we could project within five years at our most optimistic. That's eight hours of chin-wagging, glad-handing and self-debasing. Sarah and I are tired, the big guy just waved us off and slumped into bed.
If only my former employers had been smarter and less stingy, we wouldn't be poring over code printouts in the evening.
There's a light at the end of the tunnel, though - tomorrow's mostly completely off at the cabin. Our plan is to lounge around, cuddle, bitch and moan together and then get back down to brass tacks once we'll have evacuated all our frustrations.
Oh, and I'm also reserving time to demo Linux-based VoIP solutions that we could control locally. I am not putting my livelihood in the hands of flimsy middleware.
On the plus side, we'll have our own server room, with our own office space. Seeing as most of the agents are going to be working remotely, we'll only need a small footprint - and we'll have our own closed offices.
You could say I'm tired, anxious and a little worried - but also cautiously pumped. The Fucking Difficulty is right - but we're pushing through.
shoutout to everyone dealing with. thhe fucking difficulty
242K notes
·
View notes