#python data science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Complete Excel, AI and Data Science mega bundle.
Unlock Your Full Potential with Our 100-Hour Masterclass: The Ultimate Guide to Excel, Python, and AI.
Why Choose This Course? In today’s competitive job market, mastering a range of technical skills is more important than ever. Our 100-hour comprehensive course is designed to equip you with in-demand capabilities in Excel, Python, and Artificial Intelligence (AI), providing you with the toolkit you need to excel in the digital age.
To read more click here <<
Become an Excel Pro Delve deep into the intricacies of Excel functions, formulae, and data visualization techniques. Whether you’re dealing with basic tasks or complex financial models, this course will make you an Excel wizard capable of tackling any challenge.
Automate Your Workflow with Python Scripting in Python doesn’t just mean writing code; it means reclaiming your time. Automate everyday tasks, interact with software applications, and boost your productivity exponentially.
If you want to get full course click here <<

Turn Ideas into Apps Discover the potential of Amazon Honeycode to create custom apps tailored to your needs. Whether it’s for data management, content tracking, or inventory — transform your creative concepts into practical solutions.
Be Your Own Financial Analyst Unlock the financial functionalities of Excel to manage and analyze business data. Create Profit and Loss statements, balance sheets, and conduct forecasting with ease, equipping you to make data-driven decisions.
Embark on an AI Journey Step into the future with AI and machine learning. Learn to build advanced models, understand neural networks, and employ TensorFlow. Turn big data into actionable insights and predictive models.
Master Stock Prediction Gain an edge in the market by leveraging machine learning for stock prediction. Learn to spot trends, uncover hidden patterns, and make smarter investment decisions.
Who Is This Course For? Whether you’re a complete beginner or a seasoned professional looking to upskill, this course offers a broad and deep understanding of Excel, Python, and AI, preparing you for an ever-changing work environment.
Invest in Your Future This isn’t just a course; it’s a game-changer for your career. Enroll now and set yourself on a path to technological mastery and unparalleled career growth.
Don’t Wait, Transform Your Career Today! Click here to get full course <<

#data science#complete excel course#excel#data science and machine learning#microsoft excel#difference between ai and data science#learn excel#complete microsoft excel tutorial#difference between data science and data engineering#365 data science#aegis school of data science#advanced excel#excel tips and tricks#advanced excel full course#computer science#ms in data science#pgp in data science#python data science#python data science tutorial#Tumblr
1 note
·
View note
Text


13/100 days of productivity
i am slowly getting my head above water, not only by getting things done but by realizing people don't secretly hate me (i know but be patient i only realized this yesterday)
academically speaking: python python python different types of regressions different models python python data tables APIs python python pyt*loses her mind*
#studyblr#university#uni#coffee#college#uni student#university student#bookblr#dark academia#information management#information science#library science#study inspiration#study studyspo#study motivation#100 days of productivity#uni inspiration#uni life#food#books#barista#uni motivation#international student#python#coding#data science#student#uni student aesthetic#studyblr aesthetic#uni aesthetic
19 notes
·
View notes
Text
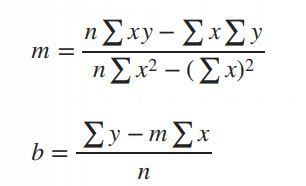
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
plotting
plot random mundane stuff its fun
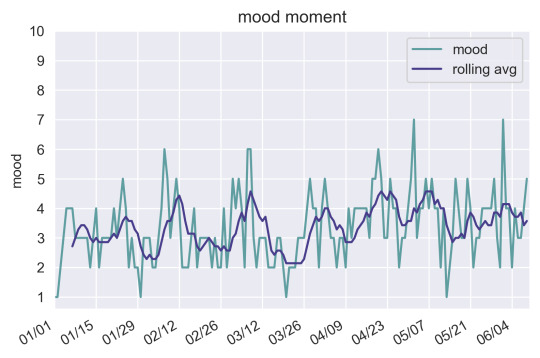
heres a plot of my mood rated 1-10 over time for the past half a year (rolling average with a window of 7 days)
always good to practice processing data and visualizing it
105 notes
·
View notes
Text
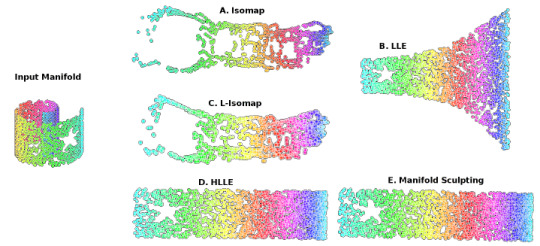
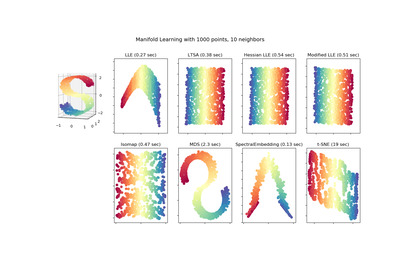
Locally Linear Embedding (LLE) approaches
#gradschool#light academia#data visualization#science#math#mathblr#studybrl#machine learning#ai#python#topology
46 notes
·
View notes
Text
Mars Crater Study-1
This article was written as a practice exercise with reference to the information provided in the COURSERA course, specifically the Mars Crater Study.
=========================================
My program,
import pandas as pd
import statsmodels.formula.api as smf
# Set display format
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# Read dataset
data = pd.read_csv('marscrater_pds.csv')
# Convert necessary variables to numeric format
data['DIAM_CIRCLE_IMAGE'] = pd.to_numeric(data['DIAM_CIRCLE_IMAGE'], errors='coerce')
data['DEPTH_RIMFLOOR_TOPOG'] = pd.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'], errors='coerce')
# Perform basic linear regression analysis
print("OLS regression model for the association between crater diameter and depth")
reg1 = smf.ols('DEPTH_RIMFLOOR_TOPOG ~ DIAM_CIRCLE_IMAGE', data=data).fit()
print(reg1.summary())
=========================================
Output results,
Dep. Variable: DEPTH_RIMFLOOR_TOPOG
R-squared:0.344
Model: OLS
Adj. R-squared:0.344
Method:Least Squares
F-statistic:2.018e+05
Date:Thu, 27 Mar 2025
Prob (F-statistic):0.00
Time:14:58:20
Log-Likelihood:1.1503e+05
No. Observations:384343
AIC:-2.301e+05
Df Residuals:384341
BIC:-2.300e+05
Df Model: 1
Covariance Type:nonrobust
coef std err t P>|t| [0.025 0.975]
Intercept 0.0220 0.000 70.370 0.000 0.021 0.023
DIAM_CIRCLE_IMAGE
0.0151 3.37e-05 449.169 0.000 0.015 0.015
Omnibus:390327.615
Durbin-Watson:1.276
Prob(Omnibus):0.000
Jarque-Bera (JB):4086668077.223
Skew:��-3.506
Prob(JB):0.00
Kurtosis:508.113
Cond. No.10.1
=========================================
Results Summary:
Regression Model Results:
R-squared: 0.344, indicating that the model explains approximately 34.4% of the variability in crater depth.
Regression Coefficient (DIAMCIRCLEIMAGE): 0.0151, meaning that for each unit increase in crater diameter, the depth increases by an average of 0.0151 units.
p-value: 0.000, indicating that the effect of diameter on depth is statistically significant.
Intercept: 0.0220, which is the predicted crater depth when the diameter is zero.
Conclusion:
The analysis shows a significant positive association between crater diameter and depth. While the model provides some explanatory power, other factors likely influence crater depth, and further exploration is recommended.
2 notes
·
View notes
Text
https://www.bipamerica.org/data-scientists-toolkit-top-python-libraries
A Data Scientist's toolkit heavily relies on Python libraries to handle data processing, analysis, and modeling. NumPy is essential for numerical computations and array operations, while Pandas provides powerful tools for data manipulation and analysis. Matplotlib and Seaborn are key for data visualization, enabling the creation of insightful charts and graphs.
5 notes
·
View notes
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
8 notes
·
View notes
Text
What is Data Structure in Python?
Summary: Explore what data structure in Python is, including built-in types like lists, tuples, dictionaries, and sets, as well as advanced structures such as queues and trees. Understanding these can optimize performance and data handling.

Introduction
Data structures are fundamental in programming, organizing and managing data efficiently for optimal performance. Understanding "What is data structure in Python" is crucial for developers to write effective and efficient code. Python, a versatile language, offers a range of built-in and advanced data structures that cater to various needs.
This blog aims to explore the different data structures available in Python, their uses, and how to choose the right one for your tasks. By delving into Python’s data structures, you'll enhance your ability to handle data and solve complex problems effectively.
What are Data Structures?
Data structures are organizational frameworks that enable programmers to store, manage, and retrieve data efficiently. They define the way data is arranged in memory and dictate the operations that can be performed on that data. In essence, data structures are the building blocks of programming that allow you to handle data systematically.
Importance and Role in Organizing Data
Data structures play a critical role in organizing and managing data. By selecting the appropriate data structure, you can optimize performance and efficiency in your applications. For example, using lists allows for dynamic sizing and easy element access, while dictionaries offer quick lookups with key-value pairs.
Data structures also influence the complexity of algorithms, affecting the speed and resource consumption of data processing tasks.
In programming, choosing the right data structure is crucial for solving problems effectively. It directly impacts the efficiency of algorithms, the speed of data retrieval, and the overall performance of your code. Understanding various data structures and their applications helps in writing optimized and scalable programs, making data handling more efficient and effective.
Read: Importance of Python Programming: Real-Time Applications.
Types of Data Structures in Python
Python offers a range of built-in data structures that provide powerful tools for managing and organizing data. These structures are integral to Python programming, each serving unique purposes and offering various functionalities.
Lists
Lists in Python are versatile, ordered collections that can hold items of any data type. Defined using square brackets [], lists support various operations. You can easily add items using the append() method, remove items with remove(), and extract slices with slicing syntax (e.g., list[1:3]). Lists are mutable, allowing changes to their contents after creation.
Tuples
Tuples are similar to lists but immutable. Defined using parentheses (), tuples cannot be altered once created. This immutability makes tuples ideal for storing fixed collections of items, such as coordinates or function arguments. Tuples are often used when data integrity is crucial, and their immutability helps in maintaining consistent data throughout a program.
Dictionaries
Dictionaries store data in key-value pairs, where each key is unique. Defined with curly braces {}, dictionaries provide quick access to values based on their keys. Common operations include retrieving values with the get() method and updating entries using the update() method. Dictionaries are ideal for scenarios requiring fast lookups and efficient data retrieval.
Sets
Sets are unordered collections of unique elements, defined using curly braces {} or the set() function. Sets automatically handle duplicate entries by removing them, which ensures that each element is unique. Key operations include union (combining sets) and intersection (finding common elements). Sets are particularly useful for membership testing and eliminating duplicates from collections.
Each of these data structures has distinct characteristics and use cases, enabling Python developers to select the most appropriate structure based on their needs.
Explore: Pattern Programming in Python: A Beginner’s Guide.
Advanced Data Structures
In advanced programming, choosing the right data structure can significantly impact the performance and efficiency of an application. This section explores some essential advanced data structures in Python, their definitions, use cases, and implementations.
Queues
A queue is a linear data structure that follows the First In, First Out (FIFO) principle. Elements are added at one end (the rear) and removed from the other end (the front).
This makes queues ideal for scenarios where you need to manage tasks in the order they arrive, such as task scheduling or handling requests in a server. In Python, you can implement a queue using collections.deque, which provides an efficient way to append and pop elements from both ends.
Stacks
Stacks operate on the Last In, First Out (LIFO) principle. This means the last element added is the first one to be removed. Stacks are useful for managing function calls, undo mechanisms in applications, and parsing expressions.
In Python, you can implement a stack using a list, with append() and pop() methods to handle elements. Alternatively, collections.deque can also be used for stack operations, offering efficient append and pop operations.
Linked Lists
A linked list is a data structure consisting of nodes, where each node contains a value and a reference (or link) to the next node in the sequence. Linked lists allow for efficient insertions and deletions compared to arrays.
A singly linked list has nodes with a single reference to the next node. Basic operations include traversing the list, inserting new nodes, and deleting existing ones. While Python does not have a built-in linked list implementation, you can create one using custom classes.
Trees
Trees are hierarchical data structures with a root node and child nodes forming a parent-child relationship. They are useful for representing hierarchical data, such as file systems or organizational structures.
Common types include binary trees, where each node has up to two children, and binary search trees, where nodes are arranged in a way that facilitates fast lookups, insertions, and deletions.
Graphs
Graphs consist of nodes (or vertices) connected by edges. They are used to represent relationships between entities, such as social networks or transportation systems. Graphs can be represented using an adjacency matrix or an adjacency list.
The adjacency matrix is a 2D array where each cell indicates the presence or absence of an edge, while the adjacency list maintains a list of edges for each node.
See: Types of Programming Paradigms in Python You Should Know.
Choosing the Right Data Structure
Selecting the appropriate data structure is crucial for optimizing performance and ensuring efficient data management. Each data structure has its strengths and is suited to different scenarios. Here’s how to make the right choice:
Factors to Consider
When choosing a data structure, consider performance, complexity, and specific use cases. Performance involves understanding time and space complexity, which impacts how quickly data can be accessed or modified. For example, lists and tuples offer quick access but differ in mutability.
Tuples are immutable and thus faster for read-only operations, while lists allow for dynamic changes.
Use Cases for Data Structures:
Lists are versatile and ideal for ordered collections of items where frequent updates are needed.
Tuples are perfect for fixed collections of items, providing an immutable structure for data that doesn’t change.
Dictionaries excel in scenarios requiring quick lookups and key-value pairs, making them ideal for managing and retrieving data efficiently.
Sets are used when you need to ensure uniqueness and perform operations like intersections and unions efficiently.
Queues and stacks are used for scenarios needing FIFO (First In, First Out) and LIFO (Last In, First Out) operations, respectively.
Choosing the right data structure based on these factors helps streamline operations and enhance program efficiency.
Check: R Programming vs. Python: A Comparison for Data Science.
Frequently Asked Questions
What is a data structure in Python?
A data structure in Python is an organizational framework that defines how data is stored, managed, and accessed. Python offers built-in structures like lists, tuples, dictionaries, and sets, each serving different purposes and optimizing performance for various tasks.
Why are data structures important in Python?
Data structures are crucial in Python as they impact how efficiently data is managed and accessed. Choosing the right structure, such as lists for dynamic data or dictionaries for fast lookups, directly affects the performance and efficiency of your code.
What are advanced data structures in Python?
Advanced data structures in Python include queues, stacks, linked lists, trees, and graphs. These structures handle complex data management tasks and improve performance for specific operations, such as managing tasks or representing hierarchical relationships.
Conclusion
Understanding "What is data structure in Python" is essential for effective programming. By mastering Python's data structures, from basic lists and dictionaries to advanced queues and trees, developers can optimize data management, enhance performance, and solve complex problems efficiently.
Selecting the appropriate data structure based on your needs will lead to more efficient and scalable code.
#What is Data Structure in Python?#Data Structure in Python#data structures#data structure in python#python#python frameworks#python programming#data science
5 notes
·
View notes
Text
What Is a Dynamically Typed Language?
When learning Python, you might hear the term “dynamically typed language” frequently. But what does it mean? Let’s break it down.
Typing refers to type-checking—the process of verifying whether the data types in your code are compatible with the operations being performed.
1️⃣ Strongly vs. Weakly Typed Languages
Strongly-Typed Languages (e.g., Python): These languages don’t allow type-coercion (implicit type conversion). For example:
pythonCopy code"1" + 2 # TypeError: cannot concatenate 'str' and 'int'
Weakly-Typed Languages (e.g., JavaScript): These languages allow type-coercion:
javascriptCopy code"1" + 2 // Outputs: "12"
2️⃣ Static vs. Dynamic Typing
Type-checking can occur at two stages:
Static Typing (e.g., Java, C++): Data types are checked before the program runs. You must declare the type of variables explicitly:
javaCopy codeintx=10;
Dynamic Typing (e.g., Python): Data types are checked during program execution. Variable types are inferred automatically:
pythonCopy codex = 10 # No need to declare 'x' as an integer.
Python: A Dynamically Typed Language
Since Python is an interpreted language, it executes code line by line. Type-checking happens on the fly, allowing you to write flexible and concise code.
Example: pythonCopy codex = "Hello"x = 10 # No error—Python allows 'x' to change types.
This flexibility makes Python beginner-friendly but also increases the risk of runtime errors if types are misused.
Key Takeaway
Dynamic typing simplifies coding by removing the need for explicit type declarations. However, it also requires careful testing to ensure type-related bugs don’t creep in.
Python learners, embrace dynamic typing—it’s one of the reasons Python is so versatile and fun to use!
2 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text

Beginner’s Guide to Ridge Regression in Machine Learning
Introduction
Regression analysis is a fundamental technique in machine learning, used to predict a dependent variable based on one or more independent variables. However, traditional regression methods, such as simple linear regression, can struggle to deal with multicollinearity (high correlation between predictors). This is where ridge regression comes in handy.
Ridge regression is an advanced form of linear regression that reduces overfitting by adding a penalty term to the model. In this article, we will cover what ridge regression is, why it is important, how it works, its assumptions, and how to implement it using Python.
What is Ridge Regression?
Ridge regression is a type of regularization technique that modifies the linear
click here to read more
https://datacienceatoz.blogspot.com/2025/02/a-beginners-guide-to-ridge-regression.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data
4 notes
·
View notes
Text
I need Study Blogs to follow!! pls give this a like if you are one , I need to stay motivated !! :)
#codeblr#studyblr#comp sci#data analytics#python#coding#study motivation#study blog#technology#PC#sql#studying#computer science#excel#information technology#university#student life#student
7 notes
·
View notes
Text
Hey all, so the crowdfund is up for ReachAI. If anyone wants to go check it out it would mean a lot to me! Also you can watch the video there on IndieGOGO or here:
youtube
It should give you a bit of an idea on what ReachAI is and what the nonprofit will be doing as well as the benefits of becoming a donor (which there are even more than I talked about in the video including Webinars, 1-on-1 sessions with me, a newsletter update on research the organization is working on or right now that I am). I am excited to be bringing ReachAI closer to launch day, I am really hoping I can raise the money to get it started! I know it could do so much good in the world :3
#programming#programmer#artificial intelligence#machine learning#technology#python programming#coding#ai#python#programmers#data science#medical research#medical technology#aicommunity#aiinnovation#Youtube
24 notes
·
View notes
Text
Exploring Data Science Tools: My Adventures with Python, R, and More
Welcome to my data science journey! In this blog post, I'm excited to take you on a captivating adventure through the world of data science tools. We'll explore the significance of choosing the right tools and how they've shaped my path in this thrilling field.
Choosing the right tools in data science is akin to a chef selecting the finest ingredients for a culinary masterpiece. Each tool has its unique flavor and purpose, and understanding their nuances is key to becoming a proficient data scientist.
I. The Quest for the Right Tool
My journey began with confusion and curiosity. The world of data science tools was vast and intimidating. I questioned which programming language would be my trusted companion on this expedition. The importance of selecting the right tool soon became evident.
I embarked on a research quest, delving deep into the features and capabilities of various tools. Python and R emerged as the frontrunners, each with its strengths and applications. These two contenders became the focus of my data science adventures.
II. Python: The Swiss Army Knife of Data Science
Python, often hailed as the Swiss Army Knife of data science, stood out for its versatility and widespread popularity. Its extensive library ecosystem, including NumPy for numerical computing, pandas for data manipulation, and Matplotlib for data visualization, made it a compelling choice.
My first experiences with Python were both thrilling and challenging. I dove into coding, faced syntax errors, and wrestled with data structures. But with each obstacle, I discovered new capabilities and expanded my skill set.

III. R: The Statistical Powerhouse
In the world of statistics, R shines as a powerhouse. Its statistical packages like dplyr for data manipulation and ggplot2 for data visualization are renowned for their efficacy. As I ventured into R, I found myself immersed in a world of statistical analysis and data exploration.
My journey with R included memorable encounters with data sets, where I unearthed hidden insights and crafted beautiful visualizations. The statistical prowess of R truly left an indelible mark on my data science adventure.
IV. Beyond Python and R: Exploring Specialized Tools
While Python and R were my primary companions, I couldn't resist exploring specialized tools and programming languages that catered to specific niches in data science. These tools offered unique features and advantages that added depth to my skill set.

For instance, tools like SQL allowed me to delve into database management and querying, while Scala opened doors to big data analytics. Each tool found its place in my toolkit, serving as a valuable asset in different scenarios.
V. The Learning Curve: Challenges and Rewards
The path I took wasn't without its share of difficulties. Learning Python, R, and specialized tools presented a steep learning curve. Debugging code, grasping complex algorithms, and troubleshooting errors were all part of the process.
However, these challenges brought about incredible rewards. With persistence and dedication, I overcame obstacles, gained a profound understanding of data science, and felt a growing sense of achievement and empowerment.
VI. Leveraging Python and R Together
One of the most exciting revelations in my journey was discovering the synergy between Python and R. These two languages, once considered competitors, complemented each other beautifully.

I began integrating Python and R seamlessly into my data science workflow. Python's data manipulation capabilities combined with R's statistical prowess proved to be a winning combination. Together, they enabled me to tackle diverse data science tasks effectively.
VII. Tips for Beginners
For fellow data science enthusiasts beginning their own journeys, I offer some valuable tips:
Embrace curiosity and stay open to learning.
Work on practical projects while engaging in frequent coding practice.
Explore data science courses and resources to enhance your skills.
Seek guidance from mentors and engage with the data science community.
Remember that the journey is continuous—there's always more to learn and discover.
My adventures with Python, R, and various data science tools have been transformative. I've learned that choosing the right tool for the job is crucial, but versatility and adaptability are equally important traits for a data scientist.
As I summarize my expedition, I emphasize the significance of selecting tools that align with your project requirements and objectives. Each tool has a unique role to play, and mastering them unlocks endless possibilities in the world of data science.
I encourage you to embark on your own tool exploration journey in data science. Embrace the challenges, relish the rewards, and remember that the adventure is ongoing. May your path in data science be as exhilarating and fulfilling as mine has been.
Happy data exploring!
22 notes
·
View notes