#i've heard mentions of it
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Note
have you perchance watched arcane? if so what are your thoughts :3
I haven't, sorry!
10 notes
·
View notes
Text
makes me a little sad when star trek ignores IDIC. like. vulcans are logical. that is true. But 'logical', for vulcans, does not amount to 'without compassion,' and it definitely doesn't amount to 'racial superiority.' Belief in 'infinite diversity in infinite combinations' should NOT result in the weird racist/speciest stuff we're getting in some of the newer treks. It does make sense that some vulcans are discriminatory. They're still flawed. But that should not be common or expected, like it seems to be in SNW. If it is, then it's a race of hypocrites, which. doesn't seem very true to Star Trek's message.
I think TOS Spock does a pretty good job of embodying this. Not always, it was the 60s, after all, but mostly. He was often trying to find non-violent routes, and get by without killing - even if they were in danger or had already been attacked. (See: the mugato, and the horta (until Kirk was the one in danger, lmao. t'hy'la > IDIC), the Gorn ship). Kirk, in his eulogy, calls him the most human soul he's ever known, and I've always read that as Kirk calling out Spock's overwhelming compassion.
It's just so much more interesting when Vulcans get to be radically compassionate. I want them to believe that everything and everyone has value. I want them to respect all ways of being. I want them to find ways for even very non-humanoid aliens to exist unfettered in society. I want them to see hybrids and think that it's amazing. Also, like, disability rep. I want Vulcans to have The Most Accessible Planet and available resources because they want everyone to feel accepted and valued. It makes for better characters and more interesting stories.
#tbh feels like some weird racist/misogynistic enlightenment-era philosophy coming through when they do that. y'know?#like 'oooh if you're fully logical you're BETTER than those who have EMOTIONS like WOMEN do'.#and the paramount execs are eating it up like 'yesss logic means being an ASS to people LESS LOGICAL than you!'.#like really guys. c'mon#like it makes sense in TAS that spock would get bullied by some kids. kids bully. that's common. makes sense that even vulcan kids bully#but if ADULTS are OFTEN doubting spock because he's half-human? that just kinda sucks. if i may it's even illogical#IDIC for me but not for thee type thing.#i think that being discriminatory should be a source of shame on a vulcan's house.#i think vulcans should adore learning about other cultures#star trek#vulcan#star trek vulcan#vulcans#vulcan culture#spock#star trek tos#tos#star trek the original series#sorry for my lack of mention of other major vulcan characters. I am so so behind in my star trek watching.#from what i've heard tuvok is also a good example. i know next to nothing about t'pol so couldn't say for her.
2K notes
·
View notes
Text
Imp and Skizz pod, ep 95: Etho!

Wanted to doodle real quick while listening :3c
#imp and skizz#ethoslab#might clean up??? i dunno#it was so fun listening to the silly guys#i don't think I've ever heard where Etho's name came from! that troll !! /Affectionate#i love that the kiddo outted him to his dad and then Etho had to explained to the dad. i can't remember where he mentioned this story before
2K notes
·
View notes
Text
Collection Of My Disco Elysium Screenshots That I Like A Lot





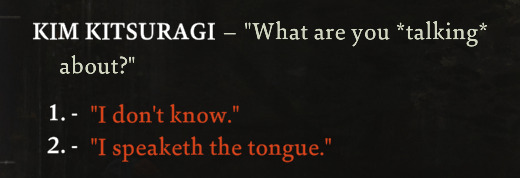








#disco elysium#harry du bois#harrier du bois#somehow my harry went all off-putting and strange and apocalyptic on me#started as a sorry cop; became a cop of the apocalypse#I hear about all the other cop types a lot but I've never heard anyone mention being the cop of the apocalypse#are the majority of people not going the whole 'warning the world about the end times' route?
2K notes
·
View notes
Text

watched over the garden wall today for the first time! I love u horror fantasy mystery genre
#over the garden wall#otgw#a friend and I were looking for a show similar to gravity falls to watch and I mentioned that I had heard of this one#I didn't realize it was so short! But I love it#I love you succinct shows I love you planned out endings#fan art#wirt and greg#otgw beatrice#the frog#can't remember his name#art#this is the first time in so long that I've felt good about art I've made :o#stayed up all night doing this#wouldn't have taken that long but photoshop crashed right when i was getting close to being done and I lost soooo much progress#it was devastating but I decided to start over and I am glad I did#anyway hope someone enjoys this!
579 notes
·
View notes
Text








Making Incorrect H:SR Quotes Until I Run Out of (hopefully) Original Ideas - Pt. 4 - Nuthin' but Boothill Edition
[Pt. 1] [Pt. 2] [Pt. 3] [Pt. 5] [Pt. 6]
#boothill#honkai star rail#hsr#hsr incorrect quotes#hsr memes#honkai star rail memes#hsr meme#honkai star rail meme#hsr textpost#hsr boothill#boothill hsr#hsr spoilers#hsr 2.2 spoilers#hmmm... don't think it's worth tagging the others in the 9th image. this ain't about them#still unsure abt how to do the alt text for these kinda posts properly but hopefully i'm improving#anyways. don't think i've ever seen heard and typed "cowboy' so many times in one day as i have while making this good lord#i did a bit of digging around and haven't Seen any of these done yet so. here's hoping that's the case!#i'm only ~3/4 of the way through the 2.2 main quest but the need to make these compelled me to put these out Now#i can already tell u that there Will be more of these for Boothill tho bc i'm crazy abt him. probably enough to make another dedicated post#but i'm gonna wait until i'm fully caught up on the plot (and will probably spoil myself for more of his character lore after that as well)#speaking of. i'm gonna go eat mac n' cheese and stay up too late playing through the rest of the main quest#i'm loving it so far. many thoughts head full abt it all but in a good way. hoping for more Boothill moments as we approach the end#he's def not the main character here but he is to Me okay. he is to me. i'm scarfing down every crumb he drops#i'm also suffering from Aventurine withdrawals out here. Argenti mentioning him was Interesting but i need More. Where Is He.#also. was Argenti intentionally not voiced or was it a game issue?? the hell was that. threw me off so hard when i couldn't hear him speak#anyways i'm getting off topic and wasting precious gaming time so i'll be takin' my leave now
623 notes
·
View notes
Text



GROWN-UP-TALK
Sam and Mary poem Sam and Mary poem Sam and Mary poem.
#I have heard reports that they don't really have a real conversation after she returns from the grave and that sounds wild to me.#maybe this is not true and I've just never seen it lol#sam winchester#mary campbell#mary winchester#cawis creates#poetry#post partum mention#pregnancy mention
439 notes
·
View notes
Text


Genuinely trying to figure out if Daniel's conversation with Justin Kirk is taking place outside the penthouse (meaning Daniel is, at some point, able to escape without getting vamp'ed) -- or if this is in the penthouse and Justin Kirk is someone Louis/Armand would allow to visit.
It might be the former (it looks like there's two other people in the background, who don't look like Armand/Louis) -- but him saying "I want to get out alive" feels odd if he's already made it out. If it's the latter, that raises the question of who, exactly, would be allowed in to talk to Daniel, because I have THEORIES.
#interview with the vampire#iwtv#daniel molloy#louis de pointe du lac#armand de romanus#justin kirk#i've heard rumors online that justin kirk is playing a Specific Book Character who was briefly mentioned in Season 1#which might explain his attitude towards Armand and Louis if it's true
182 notes
·
View notes
Text
information flow in transformers
In machine learning, the transformer architecture is a very commonly used type of neural network model. Many of the well-known neural nets introduced in the last few years use this architecture, including GPT-2, GPT-3, and GPT-4.
This post is about the way that computation is structured inside of a transformer.
Internally, these models pass information around in a constrained way that feels strange and limited at first glance.
Specifically, inside the "program" implemented by a transformer, each segment of "code" can only access a subset of the program's "state." If the program computes a value, and writes it into the state, that doesn't make value available to any block of code that might run after the write; instead, only some operations can access the value, while others are prohibited from seeing it.
This sounds vaguely like the kind of constraint that human programmers often put on themselves: "separation of concerns," "no global variables," "your function should only take the inputs it needs," that sort of thing.
However, the apparent analogy is misleading. The transformer constraints don't look much like anything that a human programmer would write, at least under normal circumstances. And the rationale behind them is very different from "modularity" or "separation of concerns."
(Domain experts know all about this already -- this is a pedagogical post for everyone else.)
1. setting the stage
For concreteness, let's think about a transformer that is a causal language model.
So, something like GPT-3, or the model that wrote text for @nostalgebraist-autoresponder.
Roughly speaking, this model's input is a sequence of words, like ["Fido", "is", "a", "dog"].
Since the model needs to know the order the words come in, we'll include an integer offset alongside each word, specifying the position of this element in the sequence. So, in full, our example input is
[ ("Fido", 0), ("is", 1), ("a", 2), ("dog", 3), ]
The model itself -- the neural network -- can be viewed as a single long function, which operates on a single element of the sequence. Its task is to output the next element.
Let's call the function f. If f does its job perfectly, then when applied to our example sequence, we will have
f("Fido", 0) = "is" f("is", 1) = "a" f("a", 2) = "dog"
(Note: I've omitted the index from the output type, since it's always obvious what the next index is. Also, in reality the output type is a probability distribution over words, not just a word; the goal is to put high probability on the next word. I'm ignoring this to simplify exposition.)
You may have noticed something: as written, this seems impossible!
Like, how is the function supposed to know that after ("a", 2), the next word is "dog"!? The word "a" could be followed by all sorts of things.
What makes "dog" likely, in this case, is the fact that we're talking about someone named "Fido."
That information isn't contained in ("a", 2). To do the right thing here, you need info from the whole sequence thus far -- from "Fido is a", as opposed to just "a".
How can f get this information, if its input is just a single word and an index?
This is possible because f isn't a pure function. The program has an internal state, which f can access and modify.
But f doesn't just have arbitrary read/write access to the state. Its access is constrained, in a very specific sort of way.
2. transformer-style programming
Let's get more specific about the program state.
The state consists of a series of distinct "memory regions" or "blocks," which have an order assigned to them.
Let's use the notation memory_i for these. The first block is memory_0, the second is memory_1, and so on.
In practice, a small transformer might have around 10 of these blocks, while a very large one might have 100 or more.
Each block contains a separate data-storage "cell" for each offset in the sequence.
For example, memory_0 contains a cell for position 0 ("Fido" in our example text), and a cell for position 1 ("is"), and so on. Meanwhile, memory_1 contains its own, distinct cells for each of these positions. And so does memory_2, etc.
So the overall layout looks like:
memory_0: [cell 0, cell 1, ...] memory_1: [cell 0, cell 1, ...] [...]
Our function f can interact with this program state. But it must do so in a way that conforms to a set of rules.
Here are the rules:
The function can only interact with the blocks by using a specific instruction.
This instruction is an "atomic write+read". It writes data to a block, then reads data from that block for f to use.
When the instruction writes data, it goes in the cell specified in the function offset argument. That is, the "i" in f(..., i).
When the instruction reads data, the data comes from all cells up to and including the offset argument.
The function must call the instruction exactly once for each block.
These calls must happen in order. For example, you can't do the call for memory_1 until you've done the one for memory_0.
Here's some pseudo-code, showing a generic computation of this kind:
f(x, i) { calculate some things using x and i; // next 2 lines are a single instruction write to memory_0 at position i; z0 = read from memory_0 at positions 0...i; calculate some things using x, i, and z0; // next 2 lines are a single instruction write to memory_1 at position i; z1 = read from memory_1 at positions 0...i; calculate some things using x, i, z0, and z1; [etc.] }
The rules impose a tradeoff between the amount of processing required to produce a value, and how early the value can be accessed within the function body.
Consider the moment when data is written to memory_0. This happens before anything is read (even from memory_0 itself).
So the data in memory_0 has been computed only on the basis of individual inputs like ("a," 2). It can't leverage any information about multiple words and how they relate to one another.
But just after the write to memory_0, there's a read from memory_0. This read pulls in data computed by f when it ran on all the earlier words in the sequence.
If we're processing ("a", 2) in our example, then this is the point where our code is first able to access facts like "the word 'Fido' appeared earlier in the text."
However, we still know less than we might prefer.
Recall that memory_0 gets written before anything gets read. The data living there only reflects what f knows before it can see all the other words, while it still only has access to the one word that appeared in its input.
The data we've just read does not contain a holistic, "fully processed" representation of the whole sequence so far ("Fido is a"). Instead, it contains:
a representation of ("Fido", 0) alone, computed in ignorance of the rest of the text
a representation of ("is", 1) alone, computed in ignorance of the rest of the text
a representation of ("a", 2) alone, computed in ignorance of the rest of the text
Now, once we get to memory_1, we will no longer face this problem. Stuff in memory_1 gets computed with the benefit of whatever was in memory_0. The step that computes it can "see all the words at once."
Nonetheless, the whole function is affected by a generalized version of the same quirk.
All else being equal, data stored in later blocks ought to be more useful. Suppose for instance that
memory_4 gets read/written 20% of the way through the function body, and
memory_16 gets read/written 80% of the way through the function body
Here, strictly more computation can be leveraged to produce the data in memory_16. Calculations which are simple enough to fit in the program, but too complex to fit in just 20% of the program, can be stored in memory_16 but not in memory_4.
All else being equal, then, we'd prefer to read from memory_16 rather than memory_4 if possible.
But in fact, we can only read from memory_16 once -- at a point 80% of the way through the code, when the read/write happens for that block.
The general picture looks like:
The early parts of the function can see and leverage what got computed earlier in the sequence -- by the same early parts of the function. This data is relatively "weak," since not much computation went into it. But, by the same token, we have plenty of time to further process it.
The late parts of the function can see and leverage what got computed earlier in the sequence -- by the same late parts of the function. This data is relatively "strong," since lots of computation went into it. But, by the same token, we don't have much time left to further process it.
3. why?
There are multiple ways you can "run" the program specified by f.
Here's one way, which is used when generating text, and which matches popular intuitions about how language models work:
First, we run f("Fido", 0) from start to end. The function returns "is." As a side effect, it populates cell 0 of every memory block.
Next, we run f("is", 1) from start to end. The function returns "a." As a side effect, it populates cell 1 of every memory block.
Etc.
If we're running the code like this, the constraints described earlier feel weird and pointlessly restrictive.
By the time we're running f("is", 1), we've already populated some data into every memory block, all the way up to memory_16 or whatever.
This data is already there, and contains lots of useful insights.
And yet, during the function call f("is", 1), we "forget about" this data -- only to progressively remember it again, block by block. The early parts of this call have only memory_0 to play with, and then memory_1, etc. Only at the end do we allow access to the juicy, extensively processed results that occupy the final blocks.
Why? Why not just let this call read memory_16 immediately, on the first line of code? The data is sitting there, ready to be used!
Why? Because the constraint enables a second way of running this program.
The second way is equivalent to the first, in the sense of producing the same outputs. But instead of processing one word at a time, it processes a whole sequence of words, in parallel.
Here's how it works:
In parallel, run f("Fido", 0) and f("is", 1) and f("a", 2), up until the first write+read instruction. You can do this because the functions are causally independent of one another, up to this point. We now have 3 copies of f, each at the same "line of code": the first write+read instruction.
Perform the write part of the instruction for all the copies, in parallel. This populates cells 0, 1 and 2 of memory_0.
Perform the read part of the instruction for all the copies, in parallel. Each copy of f receives some of the data just written to memory_0, covering offsets up to its own. For instance, f("is", 1) gets data from cells 0 and 1.
In parallel, continue running the 3 copies of f, covering the code between the first write+read instruction and the second.
Perform the second write. This populates cells 0, 1 and 2 of memory_1.
Perform the second read.
Repeat like this until done.
Observe that mode of operation only works if you have a complete input sequence ready before you run anything.
(You can't parallelize over later positions in the sequence if you don't know, yet, what words they contain.)
So, this won't work when the model is generating text, word by word.
But it will work if you have a bunch of texts, and you want to process those texts with the model, for the sake of updating the model so it does a better job of predicting them.
This is called "training," and it's how neural nets get made in the first place. In our programming analogy, it's how the code inside the function body gets written.
The fact that we can train in parallel over the sequence is a huge deal, and probably accounts for most (or even all) of the benefit that transformers have over earlier architectures like RNNs.
Accelerators like GPUs are really good at doing the kinds of calculations that happen inside neural nets, in parallel.
So if you can make your training process more parallel, you can effectively multiply the computing power available to it, for free. (I'm omitting many caveats here -- see this great post for details.)
Transformer training isn't maximally parallel. It's still sequential in one "dimension," namely the layers, which correspond to our write+read steps here. You can't parallelize those.
But it is, at least, parallel along some dimension, namely the sequence dimension.
The older RNN architecture, by contrast, was inherently sequential along both these dimensions. Training an RNN is, effectively, a nested for loop. But training a transformer is just a regular, single for loop.
4. tying it together
The "magical" thing about this setup is that both ways of running the model do the same thing. You are, literally, doing the same exact computation. The function can't tell whether it is being run one way or the other.
This is crucial, because we want the training process -- which uses the parallel mode -- to teach the model how to perform generation, which uses the sequential mode. Since both modes look the same from the model's perspective, this works.
This constraint -- that the code can run in parallel over the sequence, and that this must do the same thing as running it sequentially -- is the reason for everything else we noted above.
Earlier, we asked: why can't we allow later (in the sequence) invocations of f to read earlier data out of blocks like memory_16 immediately, on "the first line of code"?
And the answer is: because that would break parallelism. You'd have to run f("Fido", 0) all the way through before even starting to run f("is", 1).
By structuring the computation in this specific way, we provide the model with the benefits of recurrence -- writing things down at earlier positions, accessing them at later positions, and writing further things down which can be accessed even later -- while breaking the sequential dependencies that would ordinarily prevent a recurrent calculation from being executed in parallel.
In other words, we've found a way to create an iterative function that takes its own outputs as input -- and does so repeatedly, producing longer and longer outputs to be read off by its next invocation -- with the property that this iteration can be run in parallel.
We can run the first 10% of every iteration -- of f() and f(f()) and f(f(f())) and so on -- at the same time, before we know what will happen in the later stages of any iteration.
The call f(f()) uses all the information handed to it by f() -- eventually. But it cannot make any requests for information that would leave itself idling, waiting for f() to fully complete.
Whenever f(f()) needs a value computed by f(), it is always the value that f() -- running alongside f(f()), simultaneously -- has just written down, a mere moment ago.
No dead time, no idling, no waiting-for-the-other-guy-to-finish.
p.s.
The "memory blocks" here correspond to what are called "keys and values" in usual transformer lingo.
If you've heard the term "KV cache," it refers to the contents of the memory blocks during generation, when we're running in "sequential mode."
Usually, during generation, one keeps this state in memory and appends a new cell to each block whenever a new token is generated (and, as a result, the sequence gets longer by 1).
This is called "caching" to contrast it with the worse approach of throwing away the block contents after each generated token, and then re-generating them by running f on the whole sequence so far (not just the latest token). And then having to do that over and over, once per generated token.
#ai tag#is there some standard CS name for the thing i'm talking about here?#i feel like there should be#but i never heard people mention it#(or at least i've never heard people mention it in a way that made the connection with transformers clear)
303 notes
·
View notes
Text

New MH weapon idea: SKATEBOARD
Lightweight, agile blunt weapon. You can use items while unsheathed like the SnS. Rail grind down the monster's spine like dual blades to dish out some powerful elemental/status damage! Cheeky little guard points hidden in some of its attacks >:)
bonus zack under the cut for my ffvii followers~

#capcom hire me.#i've heard a lot of players mention they want a light blunt weapon. usually fists/boxing gloves. or the coveted Shield & Shield#but i think i've figured it out.#other cool weapon ideas i think: whip; ball and chain; literal roller blades; giant shuriken like yuffie#or maybe just bring back the magnet spikes ffs!!!!!!#monster hunter#monhun#mh#my art <3
127 notes
·
View notes
Note
Adding onto the Vasco nightmares thing: it's not uncommon with real losses for the mourner(s) to struggle with dreams where they have to reach an end goal (ex. traveling across the country as fast as they can to reach them) in order to "save" the one they lost, or to be completely taken out of a dream because the lost appears in them (knowing that something isn't real because the mourner KNOWS that this person is dead and can't be alive like they are in the dream).
It could be compelling to explore that side of Vasco's grief more
.
#oh right I think I've heard of that#I only get the ones where people that are actually alive die in a dream#it's much nicer to wake up from those and realize it was only a nightmare#than other way around#Vasco developing some level of ptsd is very likely outcome and something I had thought about way back in summer#for a period of time after it he gets intrusive thougts and involuntary flashbacks both awake and asleep#answered#anonymous#death mention#cw death mention
136 notes
·
View notes
Text

#just looking at the dates/travel distances for Danhausen's toy signing tour makes me feel tired#I have no idea how he does it because he never seems to stop working even when he's injured#but I've heard literally nothing but good things about people's experiences with him#not just from fans either!#he was one of the first names mentioned as being above and beyond nice when I was chatting with someone who works wrestling events in the US#plus if RJ is saying something genuine about danhausen it must be true. RJ would never risk journalistic integrity by lying like that#anyway love that danhausen#AEW#RJ City#Danhausen
303 notes
·
View notes
Text




"Well, here's another secret -- I've never been on an amusement ride. There used to be one in Couron, a small one when I was a kid..." He stares right ahead, as if picturing the rickety wheel in a local marketplace, surrounded by kids.
"I was always too small to be allowed on board. The harness didn't work. And by the time I was finally tall enough, the wheel had fallen apart." He laughs and shakes his head. "But anyway..."
magdalenaolechny.com
#disco elysium#kim kitsuragi#harry du bois#harrier du bois#digital art#artists on tumblr#I don't want to mention how much time I've spent on this#But I'm so proud T^T#Love the game#love the characters#When I heard how little Kim had wanted to ride a Ferris wheel#I needed to paint it#so here we are#First fanart since ages#And first fanart from Disco Elysium ever#my art
396 notes
·
View notes
Text
God I love that Johnny cononically has a fear of deep water and practically begs V not to go diving with Judy during pyramid song. Gives me hc ideas for the sewers in PL. I imagine that so far along in the relic's process, V would pick up a lot more of Johnny's feelings and might feel a foreign panic about it
#cyberpunk 2077#johnny silverhand#hes just like me fr#that's a lie#hes only like me in this aspect#but still#it's a really nice small detail for his character#and not one I've ever heard talked about either#judy mentions diving in the lake and Johnny barely waits for her to finish speaking before going#'No. No way. Bad idea. Tell her to find some other yes-man.'#i just love it#me too Johnny me too
85 notes
·
View notes
Text

Assen 1995/Motegi 2011 (left)


Qatar 2004 (left)

Assen 2006 (right)

Laguna Seca 2007 (left)

Valencia 2007 (right)

Motegi 2011 (left)

Brno 2014 (left)

Motegi 2016 (left)
Valentino Rossi + little finger injuries
#feel like with a lot of riders you have this moment where you're going. I swear I've heard about this body part a lot#and then almost every single mention is attached to a line going 'yeah he's riding anyway'#brr brr#//#comp tag#clown tag
54 notes
·
View notes
Note
Hi, you seem really knowledgable about Jane Austen theories, so I wonder if you know where this whacky theory I heard in 2021 comes from. I forgot who said it and I can't find it again.
The theory basically goes that every Jane Austen book is secretly about extramarital pregnancies. For example, the one in Emma would be that the Weston's baby is actually Jane Fairfax's, and that the only reason Jane came to town was to hide that fact.
Oh I think you stumbled across He Who Must Not Be Named Lest He Appear And Ruin Our Day (Arnie, for an indirect link, here he is on the First Impressions podcast). He's a Jane Austen tinfoil hat conspiracy theorist and his theories are fully bonkers.
Also, he seems to have trouble counting months because his timeline (as I remember it) would have Jane pregnant for far over nine months. If I recall correctly, his idea was that John Knightley (I know) got Jane pregnant, so she seduced Frank Churchill at Weymouth to pass the baby off as his, (this would occur in September) but then doesn't have the baby until July the next year, which is um... too many months! Especially if you consider she has to know she was pregnant, which before tests would take at least 2 months. (Mrs. Weston got pregnant in November, according to the calendar)
I don't usually dismiss people and their ideas out of hand, but just listen to that podcast if you don't believe me. The hosts are eating it right up but that man is fully off the deep end.
So yeah, you can feel free to throw that idea, and that Edward cutting up a scissor sheath is code for sexual assault, right out the window.
#tw: sa mention#question response#jane austen#stay away from this guy and his weirdness#and it's not just benign crazy I guess he is quite mean in public#I've heard bad things#anyway don't believe it#like John Knightley? My John Knightley who loves his wife to death?#Not even in 1 million years
48 notes
·
View notes