#datasourcing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Data Sourcing: The Key to Informed Decision-Making

Introduction
Data sourcing in the contemporary business environment, has been known to result in gaining a competitive advantage in business. Data sourcing is a process of gathering data, processing, and managing it coming from different sources so that business people can make the right decisions. A sound data sourcing strategy will yield many benefits, including growth, increased efficiency, and customer engagement.
Data sourcing is the process of finding and assembling data from a variety of sources, including surveys, publicly available records, or third-party data sources. It's important in attaining the right amount of data that will lead strategic business decisions. Proper data sourcing can allow companies to assemble quality datasets that may provide strategic insights into market trends and consumer behavior patterns.
Types of Data Sourcing
Understanding the various forms of data sourcing will allow firms to identify the suitable type to apply for their needs:
Primary data sourcing: In this method, data sources are obtained from the primary and original source. Among the techniques are surveys, interviews, and focus groups. The benefit of using primary data is that it is unique and specifically offers a solution that meets the requirements of the business and may provide insights that are one-of-a-kind.
Secondary data sourcing: Here, data that already exists and has been collected, published, or distributed is utilized; such sources may encompass academic journals, the industry's reports, and the use of public records. Though secondary data may often be less precise, it usually goes easier to access and cheaper.
Automated Data Sourcing: Technology and tools are used when sourcing data. Sourcing can be completed faster with reduced human input errors. Businesses can utilize APIs, feeds, and web scraping to source real-time data.
Importance of Data Sourcing
Data sourcing enhances actual informed decision-making with quality data. Organizations do not assume things will become the case in the future as an assumption; they will use evidence-based decision-making. In addition, risk exposure is minimized and opportunities are exploited.
Cost Efficiencies: Effective data sourcing will always help to save money through the identification of what data is needed and utilized in analysis. This helps in optimizing resource allocation.
Market Insights: With a variety of data sourcing services, a business can gain a better understanding of its audience and thus change marketing campaigns to match that audience, which is always one aspect that will increase customer engagement and, therefore, drive sales.
Competitive Advantage: This ability can differentiate a business as it gains the advantage to access and analyze data faster than its competition in a world of data dominance. Companies that may expend more resources on robust data sourcing capabilities will have better abilities to find trends sooner and adjust accordingly.
Get more info about our data sourcing services & data building services and begin transforming your data into actionable insights Contact us now.
Data Sourcing Services
Data sourcing services could really smooth out your process of collecting data. The data sourcing providers are capable of offering you fresh, accurate, and relevant data that defines a cut above the rest in the market. Benefits of data sourcing outsourcing include:
Professional competencies: Data sourcing providers possess all the skills and tools necessary for gathering data efficiently and in good quality.
Time Saving: Outsourced management allows the organizations to focus on their core business by leaving the data collection to the experts.
Scalability: As the size of the business grows, so do its data needs. Outsourced data sourcing services can change with the evolved needs of the business.
Data Building Services
In addition to these services, data-building services help develop a specialized database for companies. This way, companies can be assured that the analytics and reporting done for them will be of high caliber because quality data comes from different sources when combined. The benefits associated with data-building services include:
Customization: They are ordered according to the needs of your company to ensure the data collected is relevant and useful.
Quality Assurance: Some data building services include quality checks so that any information gathered is the latest and accurate.
Integration: Most data building services are integrated into existing systems, thereby giving a seamless flow of data as well as its availability.
Data Sourcing Challenges
Even though data sourcing is highly vital, the process has challenges below:
Data Privacy: Firms should respect the general regulations regarding the protection of individual's data. For example, informing consumers on how firms collect as well as use their data.
Data Quality: All the data collected is not of good quality. Proper control quality measures should be installed so as not to base decisions on wrong information.
Cost: While benefits occur in outsourcing the data source, it may also incur a cost in finance. Businesses have to weigh their probable edge against the investment cost.
Conclusion
As a matter of fact, no business would function without proper data sourcing because that is what makes it competitive. True strategic growth indeed calls for the involvement of companies in overall data sourcing, which creates operational value and sets an organization up for success long-term. In the data-centric world of today, investing in quality data strategies is unavoidable if you want your business to be ahead of the curve.
Get started with our data sourcing services today and make your data building process lighter as well as a more effective decision-making. Contact us now.
Also Read:
What is Database Building?
Database Refresh: A Must for Data-Driven Success
Integration & Compatibility: Fundamentals in Database Building
Data analysis and insights: Explained
0 notes
Text

🏆🌟 Unlock your dream team with our cost-effective RPO services! 🚀 Optimize hiring and secure top talent for business success. Join us today! #rpo #TalentAcquisition #BusinessSuccess 💼✨ https://rposervices.com/ #rposervices #recruitment #job #service #process #hr #companies #employee #it #hiring #recruiting #management #USA #india
#career#employment#job#bestrposervicesinindia#resumes#cvsourcing#datasourcing#offshorerecruitingservices#recruitingprocessoutsourcing
0 notes
Text
How to Configure ColdFusion Datasource for MySQL, SQL Server, and PostgreSQL?
0 notes

Text
Integrate Google Sheets as a Data Source in AIV for Real-Time Data Analytics
In today’s data-driven world, seamless integration between tools can make or break your analytics workflow. For those using AIV or One AIV for data analytics, integrating Google Sheets as a data source allows real-time access to spreadsheet data, bringing powerful insights into your analysis. This guide will walk you through how to connect Google Sheets to AIV, giving you a direct pipeline for real-time analytics with AIV or One AIV. Follow this step-by-step Google Sheets data analysis guide to get started with AIV.
0 notes
Text
Utilize Dell Data Lakehouse To Revolutionize Data Management

Introducing the Most Recent Upgrades to the Dell Data Lakehouse. With the help of automatic schema discovery, Apache Spark, and other tools, your team can transition from regular data administration to creativity.
Dell Data Lakehouse
Businesses’ data management plans are becoming more and more important as they investigate the possibilities of generative artificial intelligence (GenAI). Data quality, timeliness, governance, and security were found to be the main obstacles to successfully implementing and expanding AI in a recent MIT Technology Review Insights survey. It’s evident that having the appropriate platform to arrange and use data is just as important as having data itself.
As part of the AI-ready Data Platform and infrastructure capabilities with the Dell AI Factory, to present the most recent improvements to the Dell Data Lakehouse in collaboration with Starburst. These improvements are intended to empower IT administrators and data engineers alike.
Dell Data Lakehouse Sparks Big Data with Apache Spark
An approach to a single platform that can streamline big data processing and speed up insights is Dell Data Lakehouse + Apache Spark.
Earlier this year, it unveiled the Dell Data Lakehouse to assist address these issues. You can now get rid of data silos, unleash performance at scale, and democratize insights with a turnkey data platform that combines Dell’s AI-optimized hardware with a full-stack software suite and is driven by Starburst and its improved Trino-based query engine.
Through the Dell AI Factory strategy, this are working with Starburst to continue pushing the boundaries with cutting-edge solutions to help you succeed with AI. In addition to those advancements, its are expanding the Dell Data Lakehouse by introducing a fully managed, deeply integrated Apache Spark engine that completely reimagines data preparation and analytics.
Spark’s industry-leading data processing capabilities are now fully integrated into the platform, marking a significant improvement. The Dell Data Lakehouse provides unmatched support for a variety of analytics and AI-driven workloads with to Spark and Trino’s collaboration. It brings speed, scale, and innovation together under one roof, allowing you to deploy the appropriate engine for the right workload and manage everything with ease from the same management console.
Best-in-Class Connectivity to Data Sources
In addition to supporting bespoke Trino connections for special and proprietary data sources, its platform now interacts with more than 50 connectors with ease. The Dell Data Lakehouse reduces data transfer by enabling ad-hoc and interactive analysis across dispersed data silos with a single point of entry to various sources. Users may now extend their access into their distributed data silos from databases like Cassandra, MariaDB, and Redis to additional sources like Google Sheets, local files, or even a bespoke application within your environment.
External Engine Access to Metadata
It have always supported Iceberg as part of its commitment to an open ecology. By allowing other engines like Spark and Flink to safely access information in the Dell Data Lakehouse, it are further furthering to commitment. With optional security features like Transport Layer Security (TLS) and Kerberos, this functionality enables better data discovery, processing, and governance.
Improved Support Experience
Administrators may now produce and download a pre-compiled bundle of full-stack system logs with ease with to it improved support capabilities. By offering a thorough evaluation of system condition, this enhances the support experience by empowering Dell support personnel to promptly identify and address problems.
Automated Schema Discovery
The most recent upgrade simplifies schema discovery, enabling you to find and add data schemas automatically with little assistance from a human. This automation lowers the possibility of human mistake in data integration while increasing efficiency. Schema discovery, for instance, finds the newly added files so that users in the Dell Data Lakehouse may query them when a logging process generates a new log file every hour, rolling over from the log file from the previous hour.
Consulting Services
Use it Professional Services to optimize your Dell Data Lakehouse for better AI results and strategic insights. The professionals will assist with catalog metadata, onboarding data sources, implementing your Data Lakehouse, and streamlining operations by optimizing data pipelines.
Start Exploring
The Dell Demo Center to discover the Dell Data Lakehouse with carefully chosen laboratories in a virtual environment. Get in touch with your Dell account executive to schedule a visit to the Customer Solution Centers in Round Rock, Texas, and Cork, Ireland, for a hands-on experience. You may work with professionals here for a technical in-depth and design session.
Looking Forward
It will be integrating with Apache Spark in early 2025. Large volumes of structured, semi-structured, and unstructured data may be processed for AI use cases in a single environment with to this integration. To encourage you to keep investigating how the Dell Data Lakehouse might satisfy your unique requirements and enable you to get the most out of your investment.
Read more on govindhtech.com
#UtilizeDell#DataLakehouse#apacheSpark#Flink#RevolutionizeDataManagement#DellAIFactory#generativeartificialintelligence#GenAI#Cassandra#SchemaDiscovery#Metadata#DataSources#dell#technology#technews#news#govindhtech
0 notes
Text
Types of Sources
Normally Data Source is a point of Origin from where we can expect data .it might be from any Point. Inside System Outside System. Entity-Backed: if the Data For this Record Comes Directly from a Database Table or View i.e. a database entity. Normally view is seen by Appian as just another database table i.e. tables and views are both classed as entities. You can create an Appian record (or…
View On WordPress
0 notes
Text
Data preparation tools enable organizations to identify, clean, and convert raw datasets from various data sources to assist data professionals in performing data analysis and gaining valuable insights using machine learning (ML) algorithms and analytics tools.
#DataPreparation#RawData#DataSources#DataCleaning#DataConversion#DataAnalysis#MachineLearning#AnalyticsTools#BusinessAnalysis#DataCleansing#DataValidation#DataTransformation#Automation#DataInsights
0 notes
Text
Accessing Component Policies in AEM via ResourceType-Based Servlet
Problem Statement: How can I leverage component policies chosen at the template level to manage the dropdown-based selection? Introduction: AEM has integrated component policies as a pivotal element of the editable template feature. This functionality empowers both authors and developers to provide options for configuring the comprehensive behavior of fully-featured components, including…
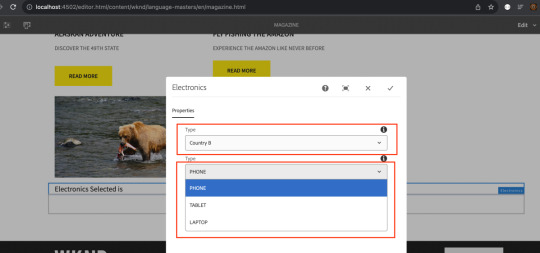
View On WordPress
#AEM#component behavior#component policies#datasource#datasource servlet#dialog-level listener#dropdown selection#dynamic adjustment#electronic devices#frontend developers#ResourceType-Based Servlet#Servlet#template level#user experience
0 notes
Photo

Are you struggling to manage your added data sources in your Data Studio account? Don't worry, we've got you covered! In this step-by-step guide, we'll show you exactly how to effectively manage your added data sources in a hassle-free manner: Step 1: Log in to your Data Studio account and click on the "Data Sources" tab on the left-hand side of the screen. Step 2: Once you're on the "Data Sources" page, you'll be able to see all the data sources that you've added to your account. Select the data source that you want to manage. Step 3: You'll now be taken to the data source details page where you can see all the fields that are available for this particular data source. From here, you can make any necessary edits to the data source. Step 4: If you want to remove a data source from your account, simply click on the "Remove" button at the bottom of the page. You'll be prompted to confirm your decision before the data source is permanently deleted from your account. Step 5: Congratulations, you've successfully managed your added data sources in your Data Studio account! Don't forget to check back periodically to keep your data up-to-date and accurate. If you're looking for a tool to make managing your data sources even easier, check out https://bitly.is/46zIp8t https://bit.ly/3JGvKXH, you can streamline your data management process and make informed decisions based on real-time data insights. So, what are you waiting for? Start effectively managing your added data sources today and see the impact it can have on your business!
#DataStudio#DataSources#DataManagement#RealTimeDataInsights#StreamlineYourProcess#MakeInformedDecisions#DataAnalytics#Marketing#Education
0 notes
Text
youtube
0 notes
Text

Are you ready for a new and exciting career opportunity? Look no further, because we are actively seeking talented individuals like you to join our team!
https://rposervices.com/
#career#employment#job#bestrposervicesinindia#resumes#datasourcing#cvsourcing#offshorerecruitingservices
0 notes
Text
Dell CyberSense Integrated with PowerProtect Cyber Recovery
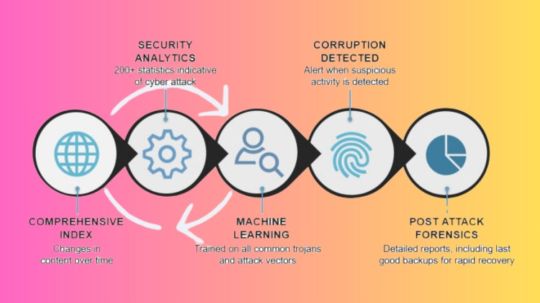
Cybersense compatibility
A smart approach to cyber resilience is represented by Dell CyberSense, which is integrated with the Dell PowerProtect Cyber Recovery platform. In order to continuously verify data integrity and offer thorough insights across the threat lifecycle, it leverages cutting-edge machine learning and AI-powered analysis, drawing on decades of software development experience. This significantly lessens the impact of an attack minimizing data loss, expensive downtime, and lost productivity and enables organisations to quickly recover from serious cyberthreats, like ransomware.
Over 7,000 complex ransomware variations have been used to thoroughly train CyberSense’s AI engine, guaranteeing accuracy over time. Up to 99.99% accuracy in corruption detection is achieved by combining more than 200 full-content-based analytics and machine learning algorithms. A sophisticated and reliable solution for contemporary cyber resilience requirements, Dell CyberSense boasts more than 1,400 commercial deployments and benefits its customers from the combined knowledge and experience acquired from real-world experiences with malware.
By keeping its defence mechanisms current and efficient, this continual learning process improves its capacity to identify and address new threats. In order for you to recover from a cyberattack as soon as possible, Dell CyberSense also uses data forensics to assist you in finding a clean backup copy to restore from.
Dell PowerProtect Cyber Recovery
The financial effects of Dell PowerProtect Cyber Recovery and Dell CyberSense for enterprises were investigated in a Forrester TEI study that Dell commissioned. According to research by Forrester, companies using Dell CyberSense and PowerProtect Cyber Recovery can restore and bring back data into production 75% faster and with 80% less time spent searching for the data.
When it comes to cybersecurity, Dell CyberSense stands out due to its extensive experience and track record, unlike the overhyped claims made by storage vendors and backup firms who have hurriedly rebranded themselves as an all-in-one solution with AI-powered cyber detection and response capabilities. The ability of more recent market entrants, which are frequently speculative and shallow, is in sharp contrast to CyberSense’s maturity and expertise.
Businesses may be sure they are selecting a solution based on decades of rigorous development and practical implementation when they invest in PowerProtect Cyber Recovery with Dell CyberSense, as opposed to marketing gimmicks.
Before Selecting AI Cyber Protection, Consider These Three Questions
Similar to the spike in vendors promoting themselves as Zero Trust firms that Dell saw a year ago, the IT industry has seen a surge in vendors positioning themselves as AI-driven powerhouses in the last twelve months. These vendors appear to market above their capabilities, even though it’s not like they lack AI or Zero Trust capabilities. The implication of these marketing methods is that these solutions come with sophisticated AI-based threat detection and response capabilities that greatly reduce the likelihood of cyberattacks.
But these marketing claims are frequently not supported by the facts. As it stands, the efficacy of artificial intelligence (AI) and generative artificial intelligence (GenAI) malware solutions depends on the quality of the data used for training, the precision with which threats are identified, and the speed with which cyberattacks may be recovered from.
IT decision-makers have to assess closely how providers of storage and data protection have created the intelligence underlying their GenAI inference models and AI analytics solutions. It is imperative to comprehend the training process of these tools and the data sources that have shaped their algorithms. If the wrong training data is used, you might be purchasing a solution that falls short of offering you the complete defence against every kind of cyberthreat that could be present in your surroundings.
Dell covered the three most important inquiries to put to your providers on their AI and GenAI tools in a recent Power Protect podcast episode:
Which methods were used to train your AI tools?
Extensive effort, experience, and fieldwork are needed to develop an AI engine that can detect cyber risks with high accuracy. In order to create reliable models that can recognise all kinds of threats, this procedure takes years to gather, process, and analyse enormous volumes of data. Cybercriminals that employ encryption algorithms that do not modify compression rates, such as the variation of the ransomware known as “XORIST,” these sophisticated threats may have behavioural patterns that are difficult for traditional cyber threat detection systems to detect since they rely on signs like changes in metadata and compression rates. Machine learning systems must therefore be trained to identify complex risks.
Your algorithms are based on which data sources?
Knowing the training process of these tools and the data sources that have influenced their algorithms is essential. AI-powered systems cannot generate the intelligence required for efficient threat identification in the absence of a broad and varied dataset. To stay up with the ever-changing strategies used by highly skilled adversaries, these solutions also need to be updated and modified on a regular basis.
How can a threat be accurately identified and a quick recovery be guaranteed?
Accurate and secure recovery depends on having forensic-level knowledge about the impacted systems. Companies run the danger of reinstalling malware during the recovery process if this level of information is lacking. For instance, two weeks after CDK Global’s customers were rendered unable to access their auto dealership due to a devastating ransomware assault, the company received media attention. They suffered another ransomware attack while they were trying to recover. Unconfirmed, but plausible, is the theory that the ransomware was reintroduced from backup copies because their backup data lacked forensic inspection tools.
Read more on govindhtech.com
#DellCyberSense#Integrated#CyberRecovery#DellPowerProtect#AIengine#AIpowered#AI#ZeroTrust#artificialintelligence#cyberattacks#Machinelearning#ransomware#datasources#aitools#aicyber#technology#technews#news#govindhtech
0 notes
Text
State Parks make Huge Economic Impact in Tennessee
Tennessee State Parks have an economic impact of $1.9 billion in the state and support employment of 13,587 people, according to an analysis by a leading economic consulting firm. Based on figures from fiscal year 2024, the report by Impact DataSource says the parks created $550 million in annual household income for Tennessee families. Because of the strong performance, state parks generated…
#Bledsoe County News#Chattanooga News#Dunlap News#Grundy County News#Haletown#Jasper News#Kimball News#Marion County News#Monteagle#New Hope#Pikeville#Sequatchie County News#Sequatchie Valley News#South Pittsburg News#Tennessee#Tennessee State Parks#Whitwell News
0 notes
Text
How Does Spring Boot Ensure Smooth Integration with Other Technologies?

Software development success depends heavily on the ability to integrate smoothly with other technologies within the ever-evolving world. Spring Boot functions as a preferred framework that developers use to build applications which deliver robustness alongside scalability and maintainability because it operates within the Spring ecosystem. Spring Boot has become a developer and business favorite because it provides effortless integration capabilities across multiple technologies. This blog examines Spring Boot's ability to achieve seamless integration through its features and explains why modern applications require it while recommending the hiring of Spring Boot developers for upcoming projects.
The Need for Integration in Modern Applications
Applications in today's digital world operate independently from other systems. Applications require connectivity to databases and messaging systems and cloud services and third-party APIs and additional components. The efficient connection of these technologies remains vital for both user experience excellence and market leadership.
Statista predicts that the global enterprise software market will grow to $1.2 trillion by 2027 because of rising adoption of cloud-based solutions and microservices architecture and API-driven development. The expansion of enterprise software markets demonstrates why Spring Boot frameworks matter because they simplify integration processes so developers can build innovative features instead of struggling with compatibility issues.
Struggling to build scalable and efficient Java applications? Hire Spring Boot developer to build high-performing Java applications!
What is Spring Boot?
The open-source development stack Spring Boot functions as a Java-based framework which enables developers to build production-ready standalone Spring applications without complexity. The framework uses conventions to eliminate unnecessary configuration requirements thus developers can begin their work without extensive boilerplate code. Spring Boot functions as an extension of the Spring framework which remains a fundamental component of the Java programming world since its launch twenty years ago.
The main advantage of Spring Boot emerges from its effortless integration with multiple technologies. Through its built-in support Spring Boot makes it easy to integrate with databases, messaging systems, cloud platforms and third-party APIs.
How Spring Boot Ensures Smooth Integration with Other Technologies
1. Auto-Configuration: Simplifying Setup and Integration
The main strength of Spring Boot exists in its automated configuration features. The dependencies you add to your project trigger Spring to automatically configure your Spring application. Your application receives automatic configuration from Spring Boot whenever you add dependencies for specific technologies such as databases or messaging systems.
Your project will receive automatic configuration through the dependency addition of "spring-boot-starter-data-jpa" to your codebase. When Spring Boot detects this dependency it creates a DataSource bean while incorporating Hibernate as the default JPA provider. The automatic configuration feature removes the requirement of manual setup while minimizing potential human mistakes.
Auto-configuration delivers exceptional value when dealing with multiple technologies because it enables seamless component integration without needing complex configuration setups.
2. Starter Dependencies: Streamlining Dependency Management
Spring Boot simplifies dependency management through its extensive collection of "starter" dependencies which help developers easily integrate project dependencies. The starter dependencies include pre-packaged dependency collections for common technology integrations which simplify integration processes.
Through 'spring-boot-starter-web' you gain embedded Tomcat together with Spring MVC and Jackson to process JSON which enables web application development. Anglers who use the 'spring-boot-starter-data-mongodb' dependency gain access to libraries which enable MongoDB integration.
Starter dependencies simplify dependency management by automating the process of dependency addition thus reducing version conflicts while ensuring smooth integration with target technologies.
3. Embedded Servers: Simplifying Deployment
Spring Boot provides native support for running applications through embedded servers including Tomcat, Jetty and Undertow. The framework enables you to create a single JAR file which contains all necessary components to execute your application with its built-in web server. The deployment process becomes simpler because embedded servers integrate all necessary components into a single JAR file which eliminates the requirement to handle external server configuration.
Embedded servers help application integration by creating a uniform runtime environment that simplifies the deployment of other technologies. Each microservice in your architecture can exist as a standalone JAR file that embeds its own server which simplifies service management and scalability.
4. Spring Data: Simplifying Database Integration
Through its integration with Spring Data Spring Boot enables developers to work effortlessly with diverse database systems including relational databases (MySQL and PostgreSQL) and NoSQL databases (MongoDB and Cassandra). Spring Data delivers a standardized programming interface for data access which operates across all database platforms.
The Spring Data JPA enables users to work with relational databases through simple interfaces when defining their data models and repositories. Spring Boot generates database queries automatically while it manages all connection operations to the database.
Spring Data MongoDB enables the same simple interface-based programming model for developers who work with MongoDB NoSQL databases. Through Spring Boot the required MongoDB connections will be set up automatically while the data access processes are handled by the framework.
5. Spring Cloud: Simplifying Cloud Integration
Through its Spring Cloud integration Spring Boot enables developers to create cloud-native applications which connect to AWS Azure and Google Cloud platforms. Spring Cloud delivers a complete suite of tools and libraries that help developers construct distributed systems through service discovery and configuration management and load balancing capabilities.
When developing microservices architecture you can leverage Spring Cloud Netflix to enable service discovery with Eureka and load balancing with Ribbon and circuit breaking with Hystrix. Spring Boot takes care of component configuration and enables their smooth operation.
Spring Cloud enables developers to integrate cloud-native databases alongside messaging systems and other services which simplifies the deployment of cloud-native applications.
6. RESTful Web Services: Simplifying API Integration
Spring Boot provides straightforward tools for developing and utilizing RESTful web services because these services represent a standard method to interface with external APIs. Through its Spring MVC integration Spring Boot delivers a standardized approach to create RESTful web services.
Through annotations like `@RestController` Spring Boot quickens web service processing automatically. Through the RestTemplate class users can consume RESTful web services to make integrating with external APIs easier.
Spring Boot enables developers to build SOAP web services and consume them through its versatile framework which supports a broad spectrum of API and service integration.
7. Messaging Systems: Simplifying Event-Driven Integration
Through its messaging system, integrations with Apache Kafka RabbitMQ and JMS Spring Boot enables developers to create event-driven applications that connect with other systems without complexity. Spring Boot delivers a standard programming interface which enables developers to work with messages across all messaging solutions.
When using Apache Kafka with Spring Boot you can utilize the `@KafkaListener` annotation to create message listeners which Spring Boot automatically handles Kafka connections and message processing. Spring Boot manages the message listener code through its built-in automatic connection creation and handling process when using either the RabbitListener annotation or the @RabbitListener annotation.
The system allows developers to create event-driven applications which seamlessly connect to microservices and cloud platforms and third-party APIs.
8. Security: Simplifying Secure Integration
Through its Spring Security integration Spring Boot provides straightforward methods to secure your application and establish secure system connections. The Spring Security framework includes complete libraries and tools to build authentication and authorization systems along with other security features.
Spring Security enables OAuth2 authentication as a standard method to protect RESTful web services while enabling integration with third-party APIs. Spring Boot handles all required security component configuration automatically while maintaining a smooth integration between them.
Spring Security enables secure application integration through its support for LDAP as well as SAML and multiple security protocols which makes it a flexible solution for protecting your application and its secure systems.
9. Testing: Simplifying Integration Testing
Spring Boot achieves effortless integration testing through its support for testing frameworks JUnit and Spring Test alongside Mockito. Spring Boot delivers a unified programming structure for creating integration tests which operates independently from the selected underlying framework.
Through the `@SpringBootTest` annotation you can create integration tests which Spring Boot will automatically set up and verify component connectivity. Testing application integration with other technologies becomes straightforward because of this feature.
10. Monitoring and Management: Simplifying Operational Integration
Spring Boot integrates with monitoring and management tools such as Spring Boot Actuator, Micrometer and Prometheus which enables easy production-level application monitoring and management. Spring Boot Actuator delivers endpoints that enable application monitoring and management through health checks and metrics and environment information retrieval.
Using Spring Boot Actuator you can deploy health check endpoints that assist both load balancers and monitoring tools to assess your application's operational state. Micrometer enables metric collection that Prometheus monitoring tools use to track your application performance.
The framework provides tools to help applications integrate smoothly with operational tools so they run effectively during production operations.
Why Hire a Spring Boot Developer?
Modern applications require skilled Spring Boot developers to achieve project success because of their complexity and requirement for seamless integration. Spring Boot developers use their framework expertise to connect your application with multiple technologies while building robust systems that scale and remain maintainable.
LinkedIn reports that Java stands among the most sought-after programming languages because 40% of available positions need Java expertise. The Java ecosystem's popular framework Spring Boot maintains high demand because numerous companies search for Spring Boot developers to construct and sustain their applications.
By hiring a Spring Boot developer you obtain a skilled professional who understands the framework's complexities to create top-quality applications that work effortlessly with other technologies. A Spring Boot developer supports the development of microservices architectures and cloud-native applications and traditional web applications to help you reach your targets through efficient and effective methods.
Conclusion: The Future of Integration with Spring Boot
The future success of Spring Boot depends on its ability to provide seamless integration with other technologies because demand grows for integrated applications that scale and maintain themselves. Through its auto-configuration features along with starter dependencies and Spring Cloud capabilities Spring Boot streamlines integration processes so developers can concentrate on developing innovative features.
The investment in hiring a Spring Boot developer brings benefits to businesses building new applications and enterprises needing to modernize their existing systems. Spring Boot developers combine their technical skills with the framework to create applications which smoothly connect with other systems and deliver exceptional user experiences that propel business expansion.
The framework Spring Boot provides simple application development capabilities for building future-ready applications in an integrated world. Your next project will benefit from hiring a Spring Boot developer while utilizing Spring Boot's powerful capabilities.
0 notes
Text
[Fabric] Fast Copy con Dataflows gen2
Cuando pensamos en integración de datos con Fabric está claro que se nos vienen dos herramientas a la mente al instante. Por un lado pipelines y por otro dataflows. Mientras existía Azure Data Factory y PowerBi Dataflows la diferencia era muy clara en audiencia y licencias para elegir una u otra. Ahora que tenemos ambas en Fabric la delimitación de una u otra pasaba por otra parte.
Por buen tiempo, el mercado separó las herramientas como dataflows la simple para transformaciones y pipelines la veloz para mover datos. Este artículo nos cuenta de una nueva característica en Dataflows que podría cambiar esta tendencia.
La distinción principal que separa estas herramientas estaba basado en la experiencia del usuario. Por un lado, expertos en ingeniería de datos preferían utilizar pipelines con actividades de transformaciones robustas d datos puesto que, para movimiento de datos y ejecución de código personalizado, es más veloz. Por otro lado, usuarios varios pueden sentir mucha mayor comodidad con Dataflows puesto que la experiencia de conectarse a datos y transformarlos es muy sencilla y cómoda. Así mismo, Power Query, lenguaje detrás de dataflows, ha probado tener la mayor variedad de conexiones a datos que el mercado ha visto.
Cierto es que cuando el proyecto de datos es complejo o hay cierto volumen de datos involucrado. La tendencia es usar data pipelines. La velocidad es crucial con los datos y los dataflows con sus transformaciones podían ser simples de usar, pero mucho más lentos. Esto hacía simple la decisión de evitarlos. ¿Y si esto cambiara? Si dataflows fuera veloz... ¿la elección sería la misma?
Veamos el contexto de definición de Microsoft:
Con la Fast Copy, puede ingerir terabytes de datos con la experiencia sencilla de flujos de datos (dataflows), pero con el back-end escalable de un copy activity que utiliza pipelines.
Como leemos de su documentación la nueva característica de dataflow podría fortalecer el movimiento de datos que antes frenaba la decisión de utilizarlos. Todo parece muy hermoso aun que siempre hay frenos o limitaciones. Veamos algunas consideraciones.
Origenes de datos permitidos
Fast Copy soporta los siguientes conectores
ADLS Gen2
Blob storage
Azure SQL DB
On-Premises SQL Server
Oracle
Fabric Lakehouse
Fabric Warehouse
PostgreSQL
Snowflake
Requisitos previos
Comencemos con lo que debemos tener para poder utilizar la característica
Debe tener una capacidad de Fabric.
En el caso de los datos de archivos, los archivos están en formato .csv o parquet de al menos 100 MB y se almacenan en una cuenta de Azure Data Lake Storage (ADLS) Gen2 o de Blob Storage.
En el caso de las bases de datos, incluida la de Azure SQL y PostgreSQL, 5 millones de filas de datos o más en el origen de datos.
En configuración de destino, actualmente, solo se admite lakehouse. Si desea usar otro destino de salida, podemos almacenar provisionalmente la consulta (staging) y hacer referencia a ella más adelante. Más info.
Prueba
Bajo estas consideraciones construimos la siguiente prueba. Para cumplir con las condiciones antes mencionadas, disponemos de un Azure Data Lake Storage Gen2 con una tabla con información de vuelos que pesa 1,8Gb y esta constituida por 10 archivos parquet. Creamos una capacidad de Fabric F2 y la asignaciones a un área de trabajo. Creamos un Lakehouse. Para corroborar el funcionamiento creamos dos Dataflows Gen2.
Un dataflow convencional sin FastCopy se vería así:

Podemos reconocer en dos modos la falta de fast copy. Primero porque en el menú de tabla no tenemos la posibilidad de requerir fast copy (debajo de Entable staging) y segundo porque vemos en rojo los "Applied steps" como cuando no tenemos query folding andando. Allí nos avisaría si estamos en presencia de fast copy o intenta hacer query folding:
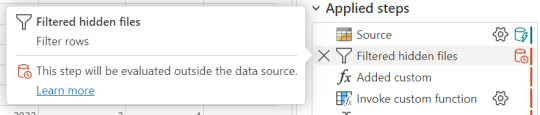
Cuando hace query folding menciona "... evaluated by the datasource."
Activar fast copy
Para activarlo, podemos presenciar el apartado de opciones dentro de la pestaña "Home".
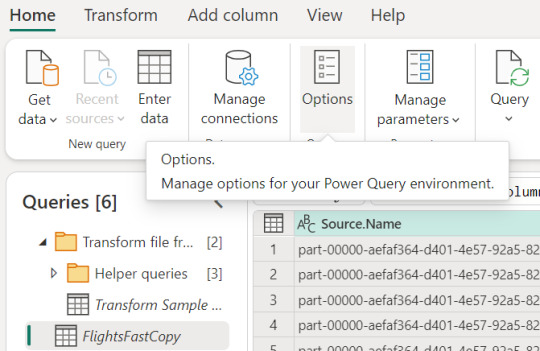
Allí podemos encontrarlo en la opción de escalar o scale:
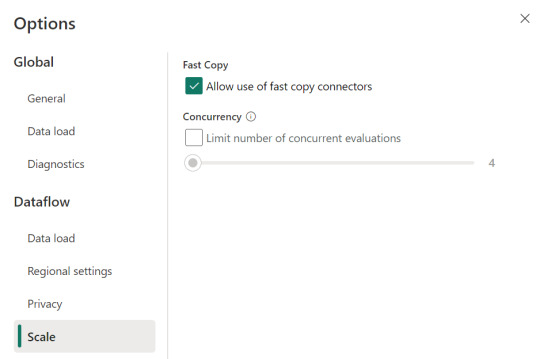
Mientras esa opción esté encendida. El motor intentará utilizar fast copy siempre y cuando la tabla cumpla con las condiciones antes mencionadas. En caso que no las cumpla, por ejemplo la tabla pese menos de 100mb, el fast copy no será efectivo y funcionaría igual que un dataflow convencional.
Aquí tenemos un problema, puesto que la diferencia de tiempos entre una tabla que usa fast copy y una que no puede ser muy grande. Por esta razón, algunos preferiríamos que el dataflow falle si no puede utilizar fast copy en lugar que cambie automaticamente a no usarlo y demorar muchos minutos más. Para exigirle a la tabla que debe usarlo, veremos una opción en click derecho:

Si forzamos requerir fast copy, entonces la tabla devolverá un error en caso que no pueda utilizarlo porque rompa con las condiciones antes mencionadas a temprana etapa de la actualización.
En el apartado derecho de la imagen tambien podemos comprobar que ya no está rojo. Si arceramos el mouse nos aclarará que esta aceptado el fast copy. "Si bien tengo otro detalle que resolver ahi, nos concentremos en el mensaje aclarando que esta correcto. Normalmente reflejaría algo como "...step supports fast copy."
Resultados
Hemos seleccionado exactamente los mismos archivos y ejecutado las mismas exactas transformaciones con dataflows. Veamos resultados.
Ejecución de dataflow sin fast copy:

Ejecución de dataflow con fast copy:

Para validar que tablas de nuestra ejecución usan fast copy. Podemos ingresar a la corrida

En el primer menú podremos ver que en lugar de "Tablas" aparece "Actividades". Ahi el primer síntoma. El segundo es al seleccionar una actividad buscamos en motor y encontramos "CopyActivity". Así validamos que funcionó la característica sobre la tabla.
Como pueden apreciar en este ejemplo, la respuesta de fast copy fue 4 veces más rápida. El incremento de velocidad es notable y la forma de comprobar que se ejecute la característica nos revela que utiliza una actividad de pipeline como el servicio propiamente dicho.
Conclusión
Seguramente esta característica tiene mucho para dar e ir mejorando. No solamente con respecto a los orígenes sino tambien a sus modos. No podemos descargar que también lo probamos contra pipelines y aqui esta la respuesta:
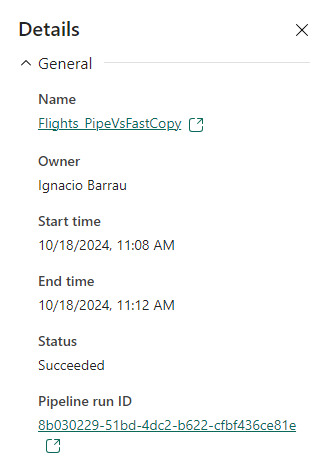
En este ejemplo los Data Pipelines siguen siendo superiores en velocidad puesto que demoró 4 minutos en correr la primera vez y menos la segunda. Aún tiene mucho para darnos y podemos decir que ya está lista para ser productiva con los origenes de datos antes mencionados en las condiciones apropiadas. Antes de terminar existen unas limitaciones a tener en cuenta:
Limitaciones
Se necesita una versión 3000.214.2 o más reciente de un gateway de datos local para soportar Fast Copy.
El gateway VNet no está soportado.
No se admite escribir datos en una tabla existente en Lakehouse.
No se admite un fixed schema.
#fabric#microsoft fabric#fabric training#fabric tips#fabric tutorial#data engineering#dataflows#fabric dataflows#fabric data factory#ladataweb
0 notes