#anaphoric ambiguity
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text





[collective image description: a brief exchange on "house".
kutner: "i asked what the odds were that he would've put down food or drink where the dog could reach. he said he put a glass of juice on the floor while he was fixing the television."
house: "the dog was fixing the television?"
kutner: "yes".
\end image description]
0 notes
Note
does sanskrit have some sort of. grammatical emphasis on anaphora. in the translated sanskrit ive read theyre always clarifiying what "that" or "this" refers to in the text, like its frequently unclear what pronouns refer to, presumably it was more naturally clear in the sanskrit...?
If there's something subtle and pragmatic going on then I'm not nearly competent enough in Sanskrit to know what it is, but it might just be that Sanskrit nouns (and pronouns) have case and gender, so certain anaphoric relationships will naturally be differentiated that way which are ambiguous in English translation (presumably a natural English translation would disambiguate paraphrastically, but maybe a translation that's going for a greater level of literalism might keep the anaphora?). I might be able to say something more substantive than this if I saw some examples.
21 notes
·
View notes
Note
Aleut has a really odd system of verbal agreement. Quoting from Wikipedia:
Verbs are inflected for mood and, if finite, for person and number. Person/number endings agree with the subject of the verb if all nominal participants of a sentence are overt: Piitra-x̂ Peter-SG.ABS tayaĝu-x̂ man-SG.ABS kidu-ku-x̂. help-PRES-3SG 'Peter is helping the man.' If a 3rd person complement or subordinate part of it is omitted, as known from context, there is an anaphoric suffixal reference to it in the final verb and the nominal subject is in the relative case: Piitra-m Peter-SG.REL kidu-ku-u. help-PRES-3SG.ANA 'Peter is helping him.' When more than one piece of information is omitted, the verb agrees with the element whose grammatical number is greatest. This can lead to ambiguity: kidu-ku-ngis help-PRES-PL.ANA 'He/she helped them.' / 'They helped him/her/them.'
When looking at natural languages, have you ever found a feature that really surprised you?
All the time—and in every language! There is no language—even the big ones that are so widely spoken that they're thought of as "normal"—that can be described as basic or boring—no, not even languages like English or Spanish or German. Every language has something exciting—multiple somethings.
For the latest, here's something weird. In Finnish, numbers trigger singular agreement on the verb. Observe:
Hiiri juoksee. "The mouse is running."
Hiiret juoksevat. "The mice are running."
Viisi hiirtä juoksee. "Five mice are running."
Okay, this make sense so far? Hiiri is "mouse", hiiret is "mice", and we have the agreement on the verb as either juoksee for singular ("is running") or juoksevat for plural ("are running"). The number five is viisi and it causes the following noun to be in the partitive singular, which is hiirtä (think of it like "five of mouse"). "Partitive singular?" you say. "Why, that's why the verb is singular!" Okay. Sure. A fine hypothesis.
Now let's look at relative clauses.
How about "The mouse who is running is small"? Sure. Here it is in singular and plural:
Hiiri, joka juoksee, on pieni.
Hiiret, jotka juoksevat, ovat pienet.
There we are. I am 99% sure that is correct (where I'm unsure is the predicative adjectival agreement and I won't speak to how common this type of relative clause structure is).
Now, knowing what we do about the five mice above, you might expect you'd get singular, but...
Viisi hiirtä, jotka juoksevat, on pieni.
Okay, going out on a limb on this one, but I am fairly certain this is correct. That is you get singular agreement with the matrix verb but plural agreement with the relative clause. You have to get a plural verb because it's agreeing with jotka, but why do you get jotka instead of joka?! It's plural enough for a relative pronoun but not for a matrix verb?! How weird is that?!
So yeah. Unbelievable stuff happening in every language every single day. Somewhere right this very moment some language is doing something no language could EVER possibly do—and yet there it is, happening all the same! What a wonderful world we live in. :)
496 notes
·
View notes
Text
Workshop Monday, April 10th: Florian Schwarz, ‘Exploring the contrast between weak and strong definite articles experimentally’
Our speaker on Monday, April 10th will be Florian Schwarz, who is Associate Professor of Linguistics at UPenn. Florian will give a talk called ‘Exploring the contrast between weak and strong definite articles experimentally’:
Schwarz (2009) proposed a distinction between weak and strong definite articles, reflected in Standard German in the presence or absence of contraction of the article with certain prepositions (e.g., vom vs. von dem). Semantically, the analysis took the former to be a situationally restricted uniqueness article, and the latter an anaphoric article bearing an index, just like a pronoun. In subsequent work, numerous authors, have applied this distinction to analyze contrasts between definite forms in a wide range of languages. While this cross-linguistic evidence supports the availability of the ingredients of the distinction in natural language in general (with some analytical variations and adjustments, and quite possibly further aspects in play in certain languages), the basic semantic contrast remains subtle and has generally not been captured systematically in experimental investigations. I present data from a simple picture selection task paradigm where the contrast in anaphoricity is pitched against another factor, that of typicality, which do provide quantitative support of the posited contrast. Next, I turn to a question vexingly left open in this literature, namely whether articles in languages that do not seem to make such a contrast and only use one form for definites throughout, like English, are ambiguous or map onto either weak or strong articles. Extending the experimental paradigm to English seems to provide an answer to this question. However, the relevant cross-linguistic comparisons, and assumptions feeding into them, are not as straightforward on second look. I close by considering data from some further extensions of the overall approach, as well as an outlook on possible future directions to further narrow down the interpretation of the empirical picture and to explore a wider range of relevant languages by extending the experimental paradigm.
The workshop will take place on Monday, April 10th from 6:00 until 8:00 (Eastern Time) in room 202 of NYU's Philosophy Building (5 Washington Place).
RSVP: If you don't have an NYU ID, and if you haven't RSVPed for a workshop yet during this academic year, please RSVP no later than 10am on the day of the talk by emailing your name, email address, and phone number to Jack Mikuszewski at [email protected]. This is required by NYU in order to access the building. When you arrive, please be prepared to show proof of vaccination and boosters at the request of the security guard.
0 notes
Text
DJSS: Due to their reclusive nature, scientists are unsure how long a pangolin lives in the wild.
Yinu: Maybe they should leave their labs and go find one in the wild then.
Tatiana: This may be my new favorite example of anaphoric referent ambiguity.
#incorrect quotes#incorrect no straight roads quotes#dj subatomic supernova#yinu#tatiana qwartz#NSR#source: tumblr
108 notes
·
View notes
Text
Fennorian: Due to their reclusive nature, scientists are unsure how long a pangolin lives in the wild.
Cassian: Maybe they should leave their labs and go find one in the wild then.
Melina: This may be my new favorite example of anaphoric referent ambiguity.
#incorrect quotes#elder scrolls#elder scrolls online#eso#fennorian#the vestige#vestige oc#vestige cassian lupus#melina cassel#house ravenwatch#source: tumblr
17 notes
·
View notes
Text
Janelle: Due to their reclusive nature, scientists are unsure how long a pangolin lives in the wild.
Adam: Maybe they should leave their labs and go find one in the wild then.
Chase: This may be my new favorite example of anaphoric referent ambiguity.
18 notes
·
View notes
Text
Commentary on “Written by Himself” by Gregory Pardlo
Poem:
“Written by Himself” from Digest by Gregory Pardlo
I was born in minutes in a roadside kitchen a skillet whispering my name. I was born to rainwater and lye; I was born across the river where I was borrowed with clothespins, a harrow tooth, broadsides sewn in my shoes. I returned, though it please you, through no fault of my own, pockets filled with coffee grounds and eggshells. I was born still and superstitious; I bore an unexpected burden. I gave birth, I gave blessing, I gave rise to suspicion. I was born abandoned outdoors in the heat-shaped air, air drifting like spirits and old windows. I was born a fraction and a cipher and a ledger entry; I was an index of first lines when I was born. I was born waist-deep stubborn in the water crying ain't I a woman and a brother I was born to this hall of mirrors, this horror story I was born with a prologue of references, pursued by mosquitoes and thieves, I was born passing off the problem of the twentieth century: I was born. I read minds before I could read fishes and loaves; I walked a piece of the way alone before I was born.
Commentary:
The very title of "Written by Himself" by Gregory Pardlo indicates that it will be an investigation into the nature of the self; it is not written by the speaker as "me" or by a name given in the third person, but by "Himself", an agent with a relationship to the self that is almost identity, but not quite. The investigates the many forces that condition the self, which are by definition beyond the self's choice or desire. The poem uses the device called anaphora, or repetition, repeating the phrase "I was born" to enumerate these forces. The birth of the self indicated by this phrase is not a chronological point in time but the point at which it comes into being from amongst the conditioning forces; in particular, the entity who is speaking is not referring to infancy per se. In addition to the exact anaphoric repetitions, there are also similar phrases, such as "I gave" and "I bore" which develop in other directions, which indicate the tangents and developments of the conditioning forces.
In the first line, the speaker says that he was born "in minutes in a roadside kitchen a skillet/whispering my name." The primary factor around any person's birth is their nuclear family and its circumstances. A family just giving birth to a child has much going on; their attention may be on the immediacies and exigencies of life, meaning that the situation of birth may be simultaneously casual and urgent as in a "roadside kitchen". Even the child's name might be suggested by the whisper of a hot pan, something that is seems to lack the requisite formality and attention but utterly fits the broader situation. The "rainwater and lye" on line 2 suggests the difficult situations that the family may be facing.
The element of identity beyond the nuclear family enters on line 3 where the speaker states that he was "born across the river". Pardlo is an African-American man, and while it doesn't say explicitly that the speaker is, it's not a far leap to suppose that being born on the other side of the river, and coming back with such downscale circumstances as being "borrowed with clothespins" and carrying "coffee grounds and eggshells" could allude to the second class status that African-Americans still face due to racism and inequality. The speaker also comes with "broadsides sewn in my shoes", which could indicate on one hand the gift for song and art that African-Americans have displayed; but another meaning of "broadsides", indicating the cannons on one side of a ship, could also indicate the aggression that someone who has been wronged might have towards the initial aggressor. But there are hints of resolution in the split between the races, since the speaker comes back "though/it please you, through no fault of my own"; also the speaker's pockets are filled with two food waste items, one dark, coffee grounds, and one light, eggshells.
After dealing with the familial and societal levels of conditioning, on line 8 the poem focuses in on the level of the individual. The individual may have such idiosyncratic psychological qualities as being "still and superstitious"; bearing an "unexpected burden" is something that happens to all of us, and must be faced alone. But the individual in dealing with his troubles and burdens is only a step away from the deification of the individual; line 9 deals with the mythological, as the speaker "gave birth", perhaps in the manner of the Virgin Mary, "gave blessing" as Jesus did, and "gave rise to suspicion", as both Jesus and an African-American venturing into the wrong neighborhood might, unfairly. The religious prophet as well as the second-class citizen might face being born "abandoned outdoors in the heat-shaped air" (10), left to the elements, without the protective forces of society fully on their side.
At a climactic juncture in the poem, the speaker juxtaposes two diametrically opposed views of the self. On one hand, it is a "fraction and a cipher and a ledger entry" as in line 12, a cog in the machinery of society or the state; and on the other hand as in line 13 it is an "index of first lines", the fount of all possibilities of beauty and self expression. In the next 6 lines the poem addresses the conditions of the world that the self is born into which invariably shape the self. The lack of periods further intensifies the portrait. It is a world where civil rights issues still occur and one must declare "ain't I a woman and a brother" (15); a world of confusions as in a "hall of mirrors" and even evils as in a "horror story" (16); a world where the condition of the self can only come by understanding the "prologue of references" that is history (17). There are problems big and small, both "mosquitoes and thieves", as well as the great existential quandaries of the "problem of the twentieth century". Line 19 ends with the simple statement "I was born", which can be said without further elaboration now that the poem has catalogued everything that must be said to fully understand that statement.
There is a final turn on line 20, where the speaker switches modes from explanation to a more intimate psychological disclosure. He says that he could "read minds before I could read fishes and loaves", meaning that the intellectual understanding of these forces came before the understanding of the problems of life and how to deal with them, the so called "bread-and-butter" issues, or here bread-and-fish issues. Once again there is an allusion to the religious figure Jesus, who famously fed a crowd with nothing more than a few fish and loaves of bread. Here, the ambiguity as to whether this speaker is a normal human or a religious figure is as clear as ever; but perhaps it doesn't matter, as the great religions insist that every man has both earthly and divine potentials within himself. In either case, whether relating to the reader as a prophet or as an everyman, the final line 21 acknowledges that there is a share of difficulty that all must surmount in order to fashion a self; one must walk "piece of the way alone" before being born as a fully realized self.
0 notes
Text
Nouvelles acquisitions (Octobre 2018) Rattrapage
Vendredi 05.10.18 Café-librairie Michèle Firk, 9 Rue François Debergue, 93100 Montreuil Fernand Combet - SchrummSchrumm ou l'excursion dominicale aux sables mouvants

Livre singulier, très original, un peu décevant aussi. J'ai découvert ce livre grâce à la lecture qu'en fit Denis Lavant ici : https://bit.ly/3eC1jAW Lavant raconte sa rencontre avec ce livre, c'est Éric Dussert, dénicheur infatigable de chefs d'œuvres méconnues, qui l'arrête un jour dans la rue et qui, dans la conversation, lui vente les mérites de ce livre. Contre toute attente, Lavant l'ouvre rapidement et se trouve pris dans les filets du mystérieux Fernand Combet. J'ai entendu un entretien de Jean-Paul Cisife (Comédien et adaptateur) datant de 1971. C'est Jean-Claude Grumberg (l'auteur de théâtre) qui, le premier, trouve le livre de Combet sur le quais. Il le prête à Sisyphe qui, bien qu’un peu déprimé par certains passages, l'adapte pour la radio.
Combet est l'auteur de trois livres. SchrummSchrumm ou l'excursion dominicale aux sables mouvants, 1966 ; Factice ou les hommes-oiseaux, 1968 ; Mort et passion de Félix C. Scribator, 1971. Tous trois parus chez Pauvert. Plus tard, l'éditeur affirmera que SchrummSchrumm est un des meilleurs livres qu'il ait édité. Un chef d'œuvre alors ? Oui et non. D’abord, ça parle de quoi ? SchrummSchrumm est un excursionniste de première classe. (On ne sait jamais à quoi correspond exactement cette profession, « une vocation » précise SchrummSchrumm, on n'en saura pas plus.) Un jour, un car vient le chercher en bas de chez lui pour l'emmener en excursion… aux sables mouvants. Pourtant, SchrummSchrumm ne se souvient pas d'en avoir fait la demande. Peu importe. On l'emmène, presque de force. Dans le car, les voyageurs sont attachés, les yeux bandés. On les moleste, on leur parle mal. Ce n'est que le début d'un récit absurde, ritualisé et angoissant, dans lequel SchrummSchrumm attendra longtemps les réponses à ses questions. Stagnant dans une citadelle étrange appelée Malentendu, cernée de miradors, aux portes des sables mouvant, il sera confronté à des personnages aberrants, ambigus, cauchemardesques, qui ne semblent mis sur son chemin que pour mieux le perdre. Il en vient à souhaiter le plus vite possible, et nous aussi, le départ pour les sables mouvants, qui tarde à venir. Qui est le Saint directeur de Malentendu ? Que fait-il là, lui, SchrummSchrumm ? Qu’est-ce qui l’attend une fois passée l’épreuve des sables mouvants ? Sera-t-il plus malin, plus habile que ses prédécesseurs à en déjouer les pièges ?
Malgré l'originalité de ce roman, qui reste, il faut le dire, longtemps en tête, quelques bémols… Dès le départ, on sent quand même venir la fin, et on n'a, hélas, pas de surprise de ce côté-là. Le récit, vers le milieu, tourne un peu en rond et il faut à ce moment se forcer pour continuer la lecture. L'histoire prend alors une direction inattendue et finit somme tout assez vite, de façon abrupte. Ceci dit, le monde décrit par Combet, irrationnel au possible quoique crédible, est assez marquant et des scènes vous restent durablement en tête, comme la mort des petits obèses nus, qui se dégonflent en lâchant un : « aaah, nous avons bien aimé la vie ! » On est forcé en lisant Combet de penser à Kafka. Jean-Paul Cisife, lui, y voit surtout une influence de Michaud, ce qui n’est pas faux. Combet, de son côté, parlait d'un roman d'adolescence. Il est vrai que malgré une originalité et une folie évidentes, ce roman vous laisse sur un sentiment mitigé. Il faut pourtant le lire, si on aime les récits absurdes et les univers décalés, on n’en trouve pas des dizaines qui ont le pouvoir de vous rester en tête. Malgré son côté glauque et déprimant, c'est un livre qu'on a envie de refiler ; sous le manteau, certes, mais j'allais dire comme une sorte d'ivresse, pas désagréable, car elle tourne un peu la tête, mais dont on n’est pas mécontent de se débarrasser et de voir quel effet elle aura chez les autres. Comme le firent, pour des raisons diverses, Grumberg avec Cisife et Dussert avec Lavant... Cisife et Lavant ont fait leur travail de passeurs. Je m’y colle, car c’est le genre de livre qui ne peut laisser indifférent.
Samedi 06.10.18 Gilda, 36 rue Bourdonnais Michel Onfray - Le deuil de la mélancolie

Je l'avais pourtant écouté raconter ici ou là le récit de son second AVC, égrener les erreurs de diagnostiques qu'il a rencontré... Cela aurait pu me suffire. Il y a pourtant une plus-value à la lecture de ce livre. C'est la même à chaque fois, d'ailleurs : la force de l'écriture. S'il sort de cette épreuve diminué, champ de vision altéré, problèmes de spacialisation... son écriture demeure intacte.
Il y a en outre un passage bouleversant au coeur du livre : l'oraison funèbre écrite à la mort de sa compagne, et qu'il n'a pas eu la force lire sur le moment. Lecteur de longue date d'Onfray (1990, avec Cynismes) j'avais entendu parler de Marie-Claude, ici où là, depuis Fééries Anatomiques. Elle n'était souvent qu'une silhouette, qu'un prénom. On découvre soudain toute une vie, et on est pris à la gorge à la description des choses qu'elle aimait et qui lui survivent, comme dit Onfray, sous la forme d'une belle anaphore. Les chats, les chevaux, les arbres, les jardins, ses élèves, certains endroits de sa ville. Avec des phrases d'une simplicité brute comme : « seuls les morts n'ont plus à mourir et sont fait d'une étoffe de mémoire. » Ou encore, comme un écho au très beau Requiem Athée : « Je te survivrai un temps, mais l'éternité du néant nous réunira. »
On sort aussi du livre avec l'envie de lire, ou de relire Marc Aurèle (qui sans doute apparaîtra tout entier dans Sagesse ?), auteur que pour ma part j'avais survolé lors de ma lecture de Cioran vers 1992. Pour des phrases de ce genre :
« Que la force me soit donnée de supporter ce qui ne peut être changé et le courage de changer ce qui peut l'être, mais aussi la sagesse de distinguer l'un et l'autre. »
Ce livre rappelle à tous les pédants qui dénient à Onfray le titre de philosophe, 1) que la philosophie est au centre de tout ce qu'il écrit et 2) que la philosophie doit être avant tout utile, sinon elle ne vaut rien. Pour certains, les mêmes pédants, un auteur qui nous transmet cela n'est pas un philosophe. Il l'est pour moi. Il est même plus, il est important.
Jean-Pierre Martinet - La grande vie

Encore un texte qui a été lu (sur scène) par Denis Lavant et édité par Éric Dussert à l’Arbre vengeur. La grande vie est un court récit, euh... dérangeant. Un personnage un peu falot, fossoyeur de son état, qui habite, évidemment, en face d'un cimetierre, vit une histoire d'amour sordide avec sa concierge, personnage ideux et déluré. Pour les amateurs de noiceur et de vies tragiques sans issue, ce livre est pour vous !
« Je pensais souvent à ce cinéaste japonais, Ozu, qui avait fait graver ces simples mots sur sa tombe « Néant ». Moi aussi je me promenais avec une telle épitaphe, mais de mon vivant. »
Tout est dit, ou presque. Texte sombre voire sordide, certes, mais intense. Et drôle. L'humour, comme on s'en doute, est aussi noir que le reste.
« A vrai dire, je ne désirais pas grand-chose. Ma règle de conduite était simple : vivre le moins possible pour souffrir le moins possible. »
Martinet est l'auteur d’un roman culte, Jérôme, autre livre que je ne m'interdirai pas de lire à l'avenir.
Gibert Jeune - Nouvelle Braderie, place St Michel Umberto Eco - Comment voyager avec un saumon James Thurber - Ma chienne de vie
Boulinier HISTORIA SPECIAL N°477 - La commune de Paris - 1871, Les 72 jours de l'insurrection Gaston Leroux - Hardigras ou le fils de 3 pères
Dimanche 07.10.18 Boulinier Jean-Pierre Andrevon - Les revenants de l'ombre HISTORIA N°471 - Mars 1986 - Hetzel éditeur, Le trésor de Charette, Tuer Heydrich, L'année 1936 Henri Michaux - Plume, précédé de Lointain intérieur Jean-Pierre Martin - L'autre vie d'Orwell Shirley Jackson - La loterie Huysmans - En rade, Un dilemme, Croquis parisiens
Samedi 13.10.18 Gilda, 36 rue Bourdonnais Michel Onfray - La Cavalière de Pégase - Dernière leçon de Démocrite

Lu et apprécié ce nouveau recueil de haïkus, inattendus de la part de l'auteur. Je garde une petite préférence pour le recueil Un Requiem athée.
Boulinier Jacques Pessis - Pierre Dac, mon maître soixante-trois, théâtre Graham Greene - Un américain bien tranquille - Notre agent à la Havane - Le facteur humain (Coll. Bouquins) John Steinbeck - La grande vallée, nouvelles
Gibert Jeune - Nouvelle Braderie, place St Michel Europe n°853 - Mai 2000 - Ramuz, Iossif Brodski, Ecrivains d'Acadie Albert Camus - Caligula, suivi de Le Malentendu
Sur les quais Henri Pichette - Les Epiphanies (Coll. Poésie Gallimard) Jean Follain - Exister, suivi de Territoires (Coll. Poésie Gallimard)
Samedi 20.10.18 Librairie Le Dilettante (7, place de l'Odéon) Luke Rhinehart - Invasion Raymond Cousse - Le bâton de la maréchale, roman militaire et pornographique Henry Miller - Peindre c'est aimer à nouveau, suivi de Le sourire au pied de l'échelle Isaac Bashevis Singer - Yentl et autres nouvelles
Librairie Rieffel (15, rue l’Odéon, Paris) Michel Onfray - La cour des miracles, carnets de campagne 2
Boulinier José Corti - Souvenirs désordonnés
Vendredi 26.10.18 Via internets Isaac Bashevis Singer - Une sorte d'autobiographie spirituelle - T1. Un jeune homme à la recherche de l'amour
Samedi 27.10.18 Boulinier Ivan Bounine - Elle Remy de Gourmont - Histoires magiques et autres récits
Gibert Jeune - Nouvelle Braderie, place St Michel Neeli Cherkovski - La vie de Charles Bukowski Serge Valletti - Pourquoi j'ai jeté ma grand-mère dans le Vieux-Port Saul Bellow - L'hiver du doyen Christopher Isherwood - Le mémorial, portrait d'une famille René Depestre - Eros dans un train chinois Juan Carlos Onetti - Les bas-fonds du rêve
Mercredi 31.10.18 Via internet Gérard Guégan - Ascendant Sagittaire - Une histoire subjective des années soixante-dix

J'ai commencé par piocher dans ce livre en ciblant les auteurs qui m'intéressaient : Charles Bukowski, Ken Kesey, Jean-Jacques Abrahams (L’auteur de L'homme au magnétophone, qui mis à mal la psychanalyse, avant le Livre Noir et avant celui d’Onfray), Jean-Pierre Martinet, dont je parle plus haut et sur qui on apprend quelques éléments biographiques. Guégan, viré de Champ Libre, qui relança les éditions Sagitaire (grand éditeur surréaliste), de 1975 à 1979, date de disparition de la maison, est un personnage souvent arrogant, aux postures très post soixante-huitarde, toujours un peu dans l’excès, la provoc’. Et sa proximité avec Raphaël Sorin, que je trouve tout aussi antipathique, malgré son admiration pour Louise Brooks, fait que j’ai souvent reposé le livre avec un soupir agacé. Mais j'aime les livres qui parlent de livres, alors parfois j’y replonge. Tenir l'homme à distance ne sous-entend pas qu'il n'ait pas un avis sûr en matière de livres, qu'on puisse partager.
Anecdote encourageante pour les traducteurs en herbe : Quand Guégan a commencé à traduire son premier Bukowski, les poèmes de L’amour est chien de l’enfer, il n'avait que de faibles bases en anglais et un mini dictionnaire bilingue de la collection Poucet. Il a fait des progrès ensuite, vu le nombre de ses traductions. Ceci dit, dans Bukowski, je préfère quand même celles de Philippe Garnier.
0 notes
Text
A deep dive into BERT: How BERT launched a rocket into natural language understanding
by Dawn Anderson Editor’s Note: This deep dive companion to our high-level FAQ piece is a 30-minute read so get comfortable! You’ll learn the backstory and nuances of BERT’s evolution, how the algorithm works to improve human language understanding for machines and what it means for SEO and the work we do every day.

If you have been keeping an eye on Twitter SEO over the past week you’ll have likely noticed an uptick in the number of gifs and images featuring the character Bert (and sometimes Ernie) from Sesame Street. This is because, last week Google announced an imminent algorithmic update would be rolling out, impacting 10% of queries in search results, and also affect featured snippet results in countries where they were present; which is not trivial. The update is named Google BERT (Hence the Sesame Street connection – and the gifs). Google describes BERT as the largest change to its search system since the company introduced RankBrain, almost five years ago, and probably one of the largest changes in search ever. The news of BERT’s arrival and its impending impact has caused a stir in the SEO community, along with some confusion as to what BERT does, and what it means for the industry overall. With this in mind, let’s take a look at what BERT is, BERT’s background, the need for BERT and the challenges it aims to resolve, the current situation (i.e. what it means for SEO), and where things might be headed.
Quick links to subsections within this guide The BERT backstory | How search engines learn language | Problems with language learning methods | How BERT improves search engine language understanding | What does BERT mean for SEO?
What is BERT?
BERT is a technologically ground-breaking natural language processing model/framework which has taken the machine learning world by storm since its release as an academic research paper. The research paper is entitled BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018). Following paper publication Google AI Research team announced BERT as an open source contribution. A year later, Google announced a Google BERT algorithmic update rolling out in production search. Google linked the BERT algorithmic update to the BERT research paper, emphasizing BERT’s importance for contextual language understanding in content and queries, and therefore intent, particularly for conversational search.
So, just what is BERT really?
BERT is described as a pre-trained deep learning natural language framework that has given state-of-the-art results on a wide variety of natural language processing tasks. Whilst in the research stages, and prior to being added to production search systems, BERT achieved state-of-the-art results on 11 different natural language processing tasks. These natural language processing tasks include, amongst others, sentiment analysis, named entity determination, textual entailment (aka next sentence prediction), semantic role labeling, text classification and coreference resolution. BERT also helps with the disambiguation of words with multiple meanings known as polysemous words, in context. BERT is referred to as a model in many articles, however, it is more of a framework, since it provides the basis for machine learning practitioners to build their own fine-tuned BERT-like versions to meet a wealth of different tasks, and this is likely how Google is implementing it too. BERT was originally pre-trained on the whole of the English Wikipedia and Brown Corpus and is fine-tuned on downstream natural language processing tasks like question and answering sentence pairs. So, it is not so much a one-time algorithmic change, but rather a fundamental layer which seeks to help with understanding and disambiguating the linguistic nuances in sentences and phrases, continually fine-tuning itself and adjusting to improve.
The BERT backstory
To begin to realize the value BERT brings we need to take a look at prior developments.
The natural language challenge
Understanding the way words fit together with structure and meaning is a field of study connected to linguistics. Natural language understanding (NLU), or NLP, as it is otherwise known, dates back over 60 years, to the original Turing Test paper and definitions of what constitutes AI, and possibly earlier. This compelling field faces unsolved problems, many relating to the ambiguous nature of language (lexical ambiguity). Almost every other word in the English language has multiple meanings. These challenges naturally extend to a web of ever-increasing content as search engines try to interpret intent to meet informational needs expressed by users in written and spoken queries.
Lexical ambiguity
In linguistics, ambiguity is at the sentence rather than word level. Words with multiple meanings combine to make ambiguous sentences and phrases become increasingly difficult to understand. According to Stephen Clark, formerly of Cambridge University, and now a full-time research scientist at Deepmind:
“Ambiguity is the greatest bottleneck to computational knowledge acquisition, the killer problem of all natural language processing.”
In the example below, taken from WordNet (a lexical database which groups English words into synsets (sets of synonyms)), we see the word “bass” has multiple meanings, with several relating to music and tone, and some relating to fish. Furthermore, the word “bass” in a musical context can be both a noun part-of-speech or an adjective part-of-speech, confusing matters further. Noun
S: (n) bass (the lowest part of the musical range)
S: (n) bass, bass part (the lowest part in polyphonic music)
S: (n) bass, basso (an adult male singer with the lowest voice)
S: (n) sea bass, bass (the lean flesh of a saltwater fish of the family Serranidae)
S: (n) freshwater bass, bass (any of various North American freshwater fish with lean flesh (especially of the genus Micropterus))
S: (n) bass, bass voice, basso (the lowest adult male singing voice)
S: (n) bass (the member with the lowest range of a family of musical instruments)
S: (n) bass (nontechnical name for any of numerous edible marine and freshwater spiny-finned fishes)
Adjective
S: (adj) bass, deep (having or denoting a low vocal or instrumental range) “a deep voice”; “a bass voice is lower than a baritone voice”; “a bass clarinet”
Polysemy and homonymy
Words with multiple meanings are considered polysemous or homonymous.
Polysemy
Polysemous words are words with two or more meanings, with roots in the same origin, and are extremely subtle and nuanced. The verb ‘get’, a polysemous word, for example, could mean ‘to procure’,’ to acquire’, or ‘to understand’. Another verb, ‘run’ is polysemous and is the largest entry in the Oxford English Dictionary with 606 different meanings.
Homonymy
Homonyms are the other main type of word with multiple meanings, but homonyms are less nuanced than polysemous words since their meanings are often very different. For example, “rose,” which is a homonym, could mean to “rise up” or it could be a flower. These two-word meanings are not related at all.
Homographs and homophones
Types of homonyms can be even more granular too. ‘Rose’ and ‘Bass’ (from the earlier example), are considered homographs because they are spelled the same and have different meanings, whereas homophones are spelled differently, but sound the same. The English language is particularly problematic for homophones. You can find a list over over 400 English homophone examples here, but just a few examples of homophones include:
Draft, draught
Dual, duel
Made, maid
For, fore, four
To, too, two
There, their
Where, wear, were
At a spoken phrase-level word when combined can suddenly become ambiguous phrases even when the words themselves are not homophones. For example, the phrases “four candles” and “fork handles” when splitting into separate words have no confusing qualities and are not homophones, but when combined they sound almost identical. Suddenly these spoken words could be confused as having the same meaning as each other whilst having entirely different meanings. Even humans can confuse the meaning of phrases like these since humans are not perfect after all. Hence, the many comedy shows feature “play on words” and linguistic nuances. These spoken nuances have the potential to be particularly problematic for conversational search.
Synonymy is different
To clarify, synonyms are different from polysemy and homonymy, since synonymous words mean the same as each other (or very similar), but are different words. An example of synonymous words would be the adjectives “tiny,” “little” and “mini” as synonyms of “small.”
Coreference resolution
Pronouns like “they,” “he,” “it,” “them,” “she” can be a troublesome challenge too in natural language understanding, and even more so, third-person pronouns, since it is easy to lose track of who is being referred to in sentences and paragraphs. The language challenge presented by pronouns is referred to as coreference resolution, with particular nuances of coreference resolution being an anaphoric or cataphoric resolution. You can consider this simply “being able to keep track” of what, or who, is being talked about, or written about, but here the challenge is explained further.
Anaphora and cataphora resolution
Anaphora resolution is the problem of trying to tie mentions of items as pronouns or noun phrases from earlier in a piece of text (such as people, places, things). Cataphora resolution, which is less common than anaphora resolution, is the challenge of understanding what is being referred to as a pronoun or noun phrase before the “thing” (person, place, thing) is mentioned later in a sentence or phrase. Here is an example of anaphoric resolution:
“John helped Mary. He was kind.”
Where “he” is the pronoun (anaphora) to resolve back to “John.” And another:
The car is falling apart, but it still works.
Here is an example of cataphora, which also contains anaphora too:
“She was at NYU when Mary realized she had lost her keys.”
The first “she” in the example above is cataphora because it relates to Mary who has not yet been mentioned in the sentence. The second “she” is an anaphora since that “she” relates also to Mary, who has been mentioned previously in the sentence.
Multi-sentential resolution
As phrases and sentences combine referring to people, places and things (entities) as pronouns, these references become increasingly complicated to separate. This is particularly so if multiple entities resolve to begin to be added to the text, as well as the growing number of sentences. Here is an example from this Cornell explanation of coreference resolution and anaphora:
a) John took two trips around France. b) They were both wonderful.
Humans and ambiguity
Although imperfect, humans are mostly unconcerned by these lexical challenges of coreference resolution and polysemy since we have a notion of common-sense understanding. We understand what “she” or “they” refer to when reading multiple sentences and paragraphs or hearing back and forth conversation since we can keep track of who is the subject focus of attention. We automatically realize, for example, when a sentence contains other related words, like “deposit,” or “cheque / check” and “cash,” since this all relates to “bank” as a financial institute, rather than a river “bank.” In order words, we are aware of the context within which the words and sentences are uttered or written; and it makes sense to us. We are therefore able to deal with ambiguity and nuance relatively easily.
Machines and ambiguity
Machines do not automatically understand the contextual word connections needed to disambiguate “bank” (river) and “bank” (financial institute). Even less so, polysemous words with nuanced multiple meanings, like “get” and “run.” Machines lose track of who is being spoken about in sentences easily as well, so coreference resolution is a major challenge too. When the spoken word such as conversational search (and homophones), enters the mix, all of these become even more difficult, particularly when you start to add sentences and phrases together.
How search engines learn language
So just how have linguists and search engine researchers enabling machines to understand the disambiguated meaning of words, sentences and phrases in natural language? “Wouldn’t it be nice if Google understood the meaning of your phrase, rather than just the words that are in the phrase?” said Google’s Eric Schmidt back in March 2009, just before the company announced rolling out their first semantic offerings. This signaled one of the first moves away from “strings to things,” and is perhaps the advent of entity-oriented search implementation by Google. One of the products mentioned in Eric Schmidt’s post was ‘related things’ displayed in search results pages. An example of “angular momentum,” “special relativity,” “big bang” and “quantum mechanic” as related items, was provided. These items could be considered co-occurring items that live near each other in natural language through ‘relatedness’. The connections are relatively loose but you might expect to find them co-existing in web page content together. So how do search engines map these “related things” together?
Co-occurrence and distributional similarity
In computational linguistics, co-occurrence holds true the idea that words with similar meanings or related words tend to live very near each other in natural language. In other words, they tend to be in close proximity in sentences and paragraphs or bodies of text overall (sometimes referred to as corpora). This field of studying word relationships and co-occurrence is called Firthian Linguistics, and its roots are usually connected with 1950s linguist John Firth, who famously said:
“You shall know a word by the company it keeps.” (Firth, J.R. 1957)
Similarity and relatedness
In Firthian linguistics, words and concepts living together in nearby spaces in text are either similar or related. Words which are similar “types of things” are thought to have semantic similarity. This is based upon measures of distance between “isA” concepts which are concepts that are types of a “thing.” For example, a car and a bus have semantic similarity because they are both types of vehicles. Both car and bus could fill the gap in a sentence such as: “A ____ is a vehicle,” since both cars and buses are vehicles. Relatedness is different from semantic similarity. Relatedness is considered ‘distributional similarity’ since words related to isA entities can provide clear cues as to what the entity is. For example, a car is similar to a bus since they are both vehicles, but a car is related to concepts of “road” and “driving.” You might expect to find a car mentioned in amongst a page about road and driving, or in a page sitting nearby (linked or in the section – category or subcategory) a page about a car. This is a very good video on the notions of similarity and relatedness as scaffolding for natural language. Humans naturally understand this co-occurrence as part of common sense understanding, and it was used in the example mentioned earlier around “bank” (river) and “bank” (financial institute). Content around a bank topic as a financial institute will likely contain words about the topic of finance, rather than the topic of rivers, or fishing, or be linked to a page about finance. Therefore, “bank’s” company are “finance,” “cash,” “cheque” and so forth.
Knowledge graphs and repositories
Whenever semantic search and entities are mentioned we probably think immediately of search engine knowledge graphs and structured data, but natural language understanding is not structured data. However, structured data makes natural language understanding easier for search engines through disambiguation via distributional similarity since the ‘company’ of a word gives an indication as to topics in the content. Connections between entities and their relations mapped to a knowledge graph and tied to unique concept ids are strong (e.g. schema and structured data). Furthermore, some parts of entity understanding are made possible as a result of natural language processing, in the form of entity determination (deciding in a body of text which of two or more entities of the same name are being referred to), since entity recognition is not automatically unambiguous. Mention of the word “Mozart” in a piece of text might well mean “Mozart,” the composer, “Mozart” cafe, “Mozart” street, and there are umpteen people and places with the same name as each other. The majority of the web is not structured at all. When considering the whole web, even semi-structured data such as semantic headings, bullet and numbered lists and tabular data make up only a very small part of it. There are lots of gaps of loose ambiguous text in sentences, phrases and paragraphs. Natural language processing is about understanding the loose unstructured text in sentences, phrases and paragraphs between all of those “things” which are “known of” (the entities). A form of “gap filling” in the hot mess between entities. Similarity and relatedness, and distributional similarity) help with this.
Relatedness can be weak or strong
Whilst data connections between the nodes and edges of entities and their relations are strong, the similarity is arguably weaker, and relatedness weaker still. Relatedness may even be considered vague. The similarity connection between apples and pears as “isA” things is stronger than a relatedness connection of “peel,” “eat,” “core” to apple, since this could easily be another fruit which is peeled and with a core. An apple is not really identified as being a clear “thing” here simply by seeing the words “peel,” “eat” and “core.” However, relatedness does provide hints to narrow down the types of “things” nearby in content.
Computational linguistics
Much “gap filling” natural language research could be considered computational linguistics; a field that combines maths, physics and language, particularly linear algebra and vectors and power laws. Natural language and distributional frequencies overall have a number of unexplained phenomena (for example, the Zipf Mystery), and there are several papers about the “strangeness” of words and use of language. On the whole, however, much of language can be resolved by mathematical computations around where words live together (the company they keep), and this forms a large part of how search engines are beginning to resolve natural language challenges (including the BERT update).
Word embeddings and co-occurrence vectors
Simply put, word embeddings are a mathematical way to identify and cluster in a mathematical space, words which “live” nearby each other in a real-world collection of text, otherwise known as a text corpus. For example, the book “War and Peace” is an example of a large text corpus, as is Wikipedia. Word embeddings are merely mathematical representations of words that typically live near each other whenever they are found in a body of text, mapped to vectors (mathematical spaces) using real numbers. These word embeddings take the notions of co-occurrence, relatedness and distributional similarity, with words simply mapped to their company and stored in co-occurrence vector spaces. The vector ‘numbers’ are then used by computational linguists across a wide range of natural language understanding tasks to try to teach machines how humans use language based on the words that live near each other.
WordSim353 Dataset examples
We know that approaches around similarity and relatedness with these co-occurrence vectors and word embeddings have been part of research by members of Google’s conversational search research team to learn word’s meaning. For example, “A study on similarity and relatedness using distributional and WordNet-based approaches,” which utilizes the Wordsim353 Dataset to understand distributional similarity. This type of similarity and relatedness in datasets is used to build out “word embeddings” mapped to mathematical spaces (vectors) in bodies of text. Here is a very small example of words that commonly occur together in content from the Wordsim353 Dataset, which is downloadable as a Zip format for further exploration too. Provided by human graders, the score in the right-hand column is based on how similar the two words in the left-hand and middle columns are.
money cash 9.15 coast shore 9.1 money cash 9.08 money currency 9.04 football soccer 9.03 magician wizard 9.02
Word2Vec
Semi-supervised and unsupervised machine learning approaches are now part of this natural language learning process too, which has turbo-charged computational linguistics. Neural nets are trained to understand the words that live near each other to gain similarity and relatedness measures and build word embeddings. These are then used in more specific natural language understanding tasks to teach machines how humans understand language. A popular tool to create these mathematical co-occurrence vector spaces using text as input and vectors as output is Google’s Word2Vec. The output of Word2Vec can create a vector file that can be utilized on many different types of natural language processing tasks. The two main Word2Vec machine learning methods are Skip-gram and Continuous Bag of Words. The Skip-gram model predicts the words (context) around the target word (target), whereas the Continuous Bag of Words model predicts the target word from the words around the target (context). These unsupervised learning models are fed word pairs through a moving “context window” with a number of words around a target word. The target word does not have to be in the center of the “context window” which is made up of a given number of surrounding words but can be to the left or right side of the context window. An important point to note is moving context windows are uni-directional. I.e. the window moves over the words in only one direction, from either left to right or right to left.
Part-of-speech tagging
Another important part of computational linguistics designed to teach neural nets human language concerns mapping words in training documents to different parts-of-speech. These parts of speech include the likes of nouns, adjectives, verbs and pronouns. Linguists have extended the many parts-of-speech to be increasingly fine-grained too, going well beyond common parts of speech we all know of, such as nouns, verbs and adjectives, These extended parts of speech include the likes of VBP (Verb, non-3rd person singular present), VBZ (Verb, 3rd person singular present) and PRP$ (Possessive pronoun). Word’s meaning in part-of-speech form can be tagged up as parts of speech using a number of taggers with a varying granularity of word’s meaning, for example, The Penn Treebank Tagger has 36 different parts of speech tags and the CLAWS7 part of speech tagger has a whopping 146 different parts of speech tags. Google Pygmalion, for example, which is Google’s team of linguists, who work on conversational search and assistant, used part of speech tagging as part of training neural nets for answer generation in featured snippets and sentence compression. Understanding parts-of-speech in a given sentence allows machines to begin to gain an understanding of how human language works, particularly for the purposes of conversational search, and conversational context. To illustrate, we can see from the example “Part of Speech” tagger below, the sentence:
“Search Engine Land is an online search industry news publication.”
This is tagged as “Noun / noun / noun / verb / determiner / adjective / noun / noun / noun / noun” when highlighted as different parts of speech.

Problems with language learning methods
Despite all of the progress search engines and computational linguists had made, unsupervised and semi-supervised approaches like Word2Vec and Google Pygmalion have a number of shortcomings preventing scaled human language understanding. It is easy to see how these were certainly holding back progress in conversational search.
Pygmalion is unscalable for internationalization
Labeling training datasets with parts-of-speech tagged annotations can be both time-consuming and expensive for any organization. Furthermore, humans are not perfect and there is room for error and disagreement. The part of speech a particular word belongs to in a given context can keep linguists debating amongst themselves for hours. Google’s team of linguists (Google Pygmalion) working on Google Assistant, for example, in 2016 was made up of around 100 Ph.D. linguists. In an interview with Wired Magazine, Google Product Manager, David Orr explained how the company still needed its team of Ph.D. linguists who label parts of speech (referring to this as the ‘gold’ data), in ways that help neural nets understand how human language works. Orr said of Pygmalion:
“The team spans between 20 and 30 languages. But the hope is that companies like Google can eventually move to a more automated form of AI called ‘unsupervised learning.'”
By 2019, the Pygmalion team was an army of 200 linguists around the globe made up of a mixture of both permanent and agency staff, but was not without its challenges due to the laborious and disheartening nature of manual tagging work, and the long hours involved. In the same Wired article, Chris Nicholson, who is the founder of a deep learning company called Skymind commented about the un-scaleable nature of projects like Google Pygmalion, particularly from an internationalisation perspective, since part of speech tagging would need to be carried out by linguists across all the languages of the world to be truly multilingual.
Internationalization of conversational search
The manual tagging involved in Pygmalion does not appear to take into consideration any transferable natural phenomenons of computational linguistics. For example, Zipfs Law, a distributional frequency power law, dictates that in any given language the distributional frequency of a word is proportional to one over its rank, and this holds true even for languages not yet translated.
Uni-directional nature of ‘context windows’ in RNNs (Recurrent Neural Networks)
Training models in the likes of Skip-gram and Continuous Bag of Words are Uni-Directional in that the context-window containing the target word and the context words around it to the left and to the right only go in one direction. The words after the target word are not yet seen so the whole context of the sentence is incomplete until the very last word, which carries the risk of some contextual patterns being missed. A good example is provided of the challenge of uni-directional moving context-windows by Jacob Uszkoreit on the Google AI blog when talking about the transformer architecture. Deciding on the most likely meaning and appropriate representation of the word “bank” in the sentence: “I arrived at the bank after crossing the…” requires knowing if the sentence ends in “… road.” or “… river.”

Text cohesion missing
The uni-directional training approaches prevent the presence of text cohesion. Like Ludwig Wittgenstein, a philosopher famously said in 1953:
“The meaning of a word is its use in the language.” (Wittgenstein, 1953)
Often the tiny words and the way words are held together are the ‘glue’ which bring common sense in language. This ‘glue’ overall is called ‘text cohesion’. It’s the combination of entities and the different parts-of-speech around them formulated together in a particular order which makes a sentence have structure and meaning. The order in which a word sits in a sentence or phrase too also adds to this context. Without this contextual glue of these surrounding words in the right order, the word itself simply has no meaning. The meaning of the same word can change too as a sentence or phrase develops due to dependencies on co-existing sentence or phrase members, changing context with it. Furthermore, linguists may disagree over which particular part-of-speech in a given context a word belongs to in the first place. Let us take the example word “bucket.” As humans we can automatically visualize a bucket that can be filled with water as a “thing,” but there are nuances everywhere. What if the word bucket word were in the sentence “He kicked the bucket,” or “I have yet to cross that off my bucket list?” Suddenly the word takes on a whole new meaning. Without the text-cohesion of the accompanying and often tiny words around “bucket” we cannot know whether bucket refers to a water-carrying implement or a list of life goals.
Word embeddings are context-free
The word embedding model provided by the likes of Word2Vec knows the words somehow live together but does not understand in what context they should be used. True context is only possible when all of the words in a sentence are taken into consideration. For example, Word2Vec does not know when river (bank) is the right context, or bank (deposit). Whilst later models such as ELMo trained on both the left side and right side of a target word, these were carried out separately rather than looking at all of the words (to the left and the right) simultaneously, and still did not provide true context.
Polysemy and homonymy handled incorrectly
Word embeddings like Word2Vec do not handle polysemy and homonyms correctly. As a single word with multiple meanings is mapped to just one single vector. Therefore there is a need to disambiguate further. We know there are many words with the same meaning (for example, ‘run’ with 606 different meanings), so this was a shortcoming. As illustrated earlier polysemy is particularly problematic since polysemous words have the same root origins and are extremely nuanced.
Coreference resolution still problematic
Search engines were still struggling with the challenging problem of anaphora and cataphora resolution, which was particularly problematic for conversational search and assistant which may have back and forth multi-turn questions and answers. Being able to track which entities are being referred to is critical for these types of spoken queries.
Shortage of training data
Modern deep learning-based NLP models learn best when they are trained on huge amounts of annotated training examples, and a lack of training data was a common problem holding back the research field overall.
So, how does BERT help improve search engine language understanding?
With these short-comings above in mind, how has BERT helped search engines (and other researchers) to understand language?
What makes BERT so special?
There are several elements that make BERT so special for search and beyond (the World – yes, it is that big as a research foundation for natural language processing). Several of the special features can be found in BERT’s paper title – BERT: Bi-directional Encoder Representations from Transformers. B – Bi-Directional E – Encoder R – Representations T – Transformers But there are other exciting developments BERT brings to the field of natural language understanding too. These include:
Pre-training from unlabelled text
Bi-directional contextual models
The use of a transformer architecture
Masked language modeling
Focused attention
Textual entailment (next sentence prediction)
Disambiguation through context open-sourced
Pre-training from unlabeled text
The ‘magic’ of BERT is its implementation of bi-directional training on an unlabelled corpus of text since for many years in the field of natural language understanding, text collections had been manually tagged up by teams of linguists assigning various parts of speech to each word. BERT was the first natural language framework/architecture to be pre-trained using unsupervised learning on pure plain text (2.5 billion words+ from English Wikipedia) rather than labeled corpora. Prior models had required manual labeling and the building of distributed representations of words (word embeddings and word vectors), or needed part of speech taggers to identify the different types of words present in a body of text. These past approaches are similar to the tagging we mentioned earlier by Google Pygmalion. BERT learns language from understanding text cohesion from this large body of content in plain text and is then educated further by fine-tuning on smaller, more specific natural language tasks. BERT also self-learns over time too.
Bi-directional contextual models
BERT is the first deeply bi-directional natural language model, but what does this mean?
Bi-directional and uni-directional modeling
True contextual understanding comes from being able to see all the words in a sentence at the same time and understand how all of the words impact the context of the other words in the sentence too. The part of speech a particular word belongs to can literally change as the sentence develops. For example, although unlikely to be a query, if we take a spoken sentence which might well appear in natural conversation (albeit rarely):
“I like how you like that he likes that.”
as the sentence develops the part of speech which the word “like” relates to as the context builds around each mention of the word changes so that the word “like,” although textually is the same word, contextually is different parts of speech dependent upon its place in the sentence or phrase. Past natural language training models were trained in a uni-directional manner. Word’s meaning in a context window moved along from either left to right or right to left with a given number of words around the target word (the word’s context or “it’s company”). This meant words not yet seen in context cannot be taken into consideration in a sentence and they might actually change the meaning of other words in natural language. Uni-directional moving context windows, therefore, have the potential to miss some important changing contexts. For example, in the sentence:
“Dawn, how are you?”
The word “are” might be the target word and the left context of “are” is “Dawn, how.” The right context of the word is “you.” BERT is able to look at both sides of a target word and the whole sentence simultaneously in the way that humans look at the whole context of a sentence rather than looking at only a part of it. The whole sentence, both left and right of a target word can be considered in the context simultaneously.
Transformers / Transformer architecture
Most tasks in natural language understanding are built on probability predictions. What is the likelihood that this sentence relates to the next sentence, or what is the likelihood that this word is part of that sentence? BERT’s architecture and masked language modeling prediction systems are partly designed to identify ambiguous words that change the meanings of sentences and phrases and identify the correct one. Learnings are carried forward increasingly by BERT’s systems. The Transformer uses fixation on words in the context of all of the other words in sentences or phrases without which the sentence could be ambiguous. This fixated attention comes from a paper called ‘Attention is all you need’ (Vaswani et al, 2017), published a year earlier than the BERT research paper, with the transformer application then built into the BERT research. Essentially, BERT is able to look at all the context in text-cohesion by focusing attention on a given word in a sentence whilst also identifying all of the context of the other words in relation to the word. This is achieved simultaneously using transformers combined with bi-directional pre-training. This helps with a number of long-standing linguistic challenges for natural language understanding, including coreference resolution. This is because entities can be focused on in a sentence as a target word and their pronouns or the noun-phrases referencing them resolved back to the entity or entities in the sentence or phrase. In this way the concepts and context of who, or what, a particular sentence is relating to specifically, is not lost along the way. Furthermore, the focused attention also helps with the disambiguation of polysemous words and homonyms by utilizing a probability prediction / weight based on the whole context of the word in context with all of the other words in the sentence. The other words are given a weighted attention score to indicate how much each adds to the context of the target word as a representation of “meaning.” Words in a sentence about the “bank” which add strong disambiguating context such as “deposit” would be given more weight in a sentence about the “bank” (financial institute) to resolve the representational context to that of a financial institute. The encoder representations part of the BERT name is part of the transformer architecture. The encoder is the sentence input translated to representations of words meaning and the decoder is the processed text output in a contextualized form. In the image below we can see that ‘it’ is strongly being connected with “the” and “animal” to resolve back the reference to “the animal” as “it” as a resolution of anaphora.

This fixation also helps with the changing “part of speech” a word’s order in a sentence could have since we know that the same word can be different parts of speech depending upon its context. The example provided by Google below illustrates the importance of different parts of speech and word category disambiguation. Whilst a tiny word, the word ‘to’ here changes the meaning of the query altogether once it is taken into consideration in the full context of the phrase or sentence.

Masked Language Modelling (MLM Training)
Also known as “the Cloze Procedure,” which has been around for a very long time. The BERT architecture analyzes sentences with some words randomly masked out and attempts to correctly predict what the “hidden” word is. The purpose of this is to prevent target words in the training process passing through the BERT transformer architecture from inadvertently seeing themselves during bi-directional training when all of the words are looked at together for combined context. Ie. it avoids a type of erroneous infinite loop in natural language machine learning, which would skew word’s meaning.
Textual entailment (next sentence prediction)
One of the major innovations of BERT is that it is supposed to be able to predict what you’re going to say next, or as the New York Times phrased it in Oct 2018, “Finally, a machine that can finish your sentences.” BERT is trained to predict from pairs of sentences whether the second sentence provided is the right fit from a corpus of text. NB: It seems this feature during the past year was deemed as unreliable in the original BERT model and other open-source offerings have been built to resolve this weakness. Google’s ALBERT resolves this issue. Textual entailment is a type of “what comes next?” in a body of text. In addition to textual entailment, the concept is also known as ‘next sentence prediction’. Textual entailment is a natural language processing task involving pairs of sentences. The first sentence is analyzed and then a level of confidence determined to predict whether a given second hypothesized sentence in the pair “fits” logically as the suitable next sentence, or not, with either a positive, negative, or neutral prediction, from a text collection under scrutiny. Three examples from Wikipedia of each type of textual entailment prediction (neutral / positive / negative) are below. Textual Entailment Examples (Source: Wikipedia) An example of a positive TE (text entails hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has good consequences.
An example of a negative TE (text contradicts hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has no consequences.
An example of a non-TE (text does not entail nor contradict) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man will make you a better person.
Disambiguation breakthroughs from open-sourced contributions
BERT has not just appeared from thin air, and BERT is no ordinary algorithmic update either since BERT is also an open-source natural language understanding framework as well. Ground-breaking “disambiguation from context empowered by open-sourced contributions,” could be used to summarise BERT’s main value add to natural language understanding. In addition to being the biggest change to Google’s search system in five years (or ever), BERT also represents probably the biggest leap forward in growing contextual understanding of natural language by computers of all time. Whilst Google BERT may be new to the SEO world it is well known in the NLU world generally and has caused much excitement over the past 12 months. BERT has provided a hockey stick improvement across many types of natural language understanding tasks not just for Google, but a myriad of both industrial and academic researchers seeking to utilize language understanding in their work, and even commercial applications. After the publication of the BERT research paper, Google announced they would be open-sourcing vanilla BERT. In the 12 months since publication alone, the original BERT paper has been cited in further research 1,997 times at the date of writing. There are many different types of BERT models now in existence, going well beyond the confines of Google Search. A search for Google BERT in Google Scholar returns hundreds of 2019 published research paper entries extending on BERT in a myriad of ways, with BERT now being used in all manner of research into natural language. Research papers traverse an eclectic mix of language tasks, domain verticals (for example clinical fields), media types (video, images) and across multiple languages. BERT’s use cases are far-reaching, from identifying offensive tweets using BERT and SVMs to using BERT and CNNs for Russian Troll Detection on Reddit, to categorizing via prediction movies according to sentiment analysis from IMDB, or predicting the next sentence in a question and answer pair as part of a dataset. Through this open-source approach, BERT goes a long way toward solving some long-standing linguistic problems in research, by simply providing a strong foundation to fine-tune from for anyone with a mind to do so. The codebase is downloadable from the Google Research Team’s Github page. By providing Vanilla BERT as a great ‘starter for ten’ springboard for machine learning enthusiasts to build upon, Google has helped to push the boundaries of State of the art (SOTA) natural language understanding tasks. Vanilla BERT can be likened to a CMS plugins, theme, or module which provides a strong foundation for a particular functionality but can then be developed further. Another simpler similarity might be likening the pre-training and fine-tuning parts of BERT for machine learning engineers to buying an off-the-peg suit from a high street store then visiting a tailor to turn up the hems so it is fit for purpose at a more unique needs level. As Vanilla BERT comes pre-trained (on Wikipedia and Brown corpus), researchers need only fine-tune their own models and additional parameters on top of the already trained model in just a few epochs (loops / iterations through the training model with the new fine-tuned elements included). At the time of BERT’s October 2018, paper publication BERT beat state of the art (SOTA) benchmarks across 11 different types of natural language understanding tasks, including question and answering, sentiment analysis, named entity determination, sentiment classification and analysis, sentence pair-matching and natural language inference. Furthermore, BERT may have started as the state-of-the-art natural language framework but very quickly other researchers, including some from other huge AI-focused companies such as Microsoft, IBM and Facebook, have taken BERT and extended upon it to produce their own record-beating open-source contributions. Subsequently, models other than BERT have become state of the art since BERT’s release. Facebook’s Liu et al entered the BERTathon with their own version extending upon BERT – RoBERTa. claiming the original BERT was significantly undertrained and professing to have improved upon, and beaten, any other model versions of BERT up to that point. Microsoft also beat the original BERT with MT-DNN, extending upon a model they proposed in 2015 but adding on the bi-directional pre-training architecture of BERT to improve further.

There are many other BERT-based models too, including Google’s own XLNet and ALBERT (Toyota and Google), IBM’s BERT-mtl, and even now Google T5 emerging.

The field is fiercely competitive and NLU machine learning engineer teams compete with both each other and non-expert human understanding benchmarks on public leaderboards, adding an element of gamification to the field. Amongst the most popular leaderboards are the very competitive SQuAD, and GLUE. SQuAD stands for The Stanford Question and Answering Dataset which is built from questions based on Wikipedia articles with answers provided by crowdworkers. The current SQuAD 2.0 version of the dataset is the second iteration created because SQuAD 1.1 was all but beaten by natural language researchers. The second-generation dataset, SQuAD 2.0 represented a harder dataset of questions, and also contained an intentional number of adversarial questions in the dataset (questions for which there was no answer). The logic behind this adversarial question inclusion is intentional and designed to train models to learn to know what they do not know (i.e an unanswerable question). GLUE is the General Language Understanding Evaluation dataset and leaderboard. SuperGLUE is the second generation of GLUE created because GLUE again became too easy for machine learning models to beat.

Most of the public leaderboards across the machine learning field double up as academic papers accompanied by rich question and answer datasets for competitors to fine-tune their models on. MS MARCO, for example, is an academic paper, dataset and accompanying leaderboard published by Microsoft; AKA Microsoft MAchine Reaching COmprehension Dataset. The MSMARCO dataset is made up of over a million real Bing user queries and over 180,000 natural language answers. Any researchers can utilize this dataset to fine-tune models.

Efficiency and computational expense
Late 2018 through 2019 can be remembered as a year of furious public leaderboard leap-frogging to create the current state of the art natural language machine learning model. As the race to reach the top of the various state of the art leaderboards heated up, so too did the size of the model’s machine learning engineers built and the number of parameters added based on the belief that more data increases the likelihood for more accuracy. However as model sizes grew so did the size of resources needed for fine-tuning and further training, which was clearly an unsustainable open-source path. Victor Sanh, of Hugging Face (an organization seeking to promote the continuing democracy of AI) writes, on the subject of the drastically increasing sizes of new models:
“The latest model from Nvidia has 8.3 billion parameters: 24 times larger than BERT-large, 5 times larger than GPT-2, while RoBERTa, the latest work from Facebook AI, was trained on 160GB of text 😵”
To illustrate the original BERT sizes – BERT-Base and BERT-Large, with 3 times the number of parameters of BERT-Base. BERT–Base, Cased : 12-layer, 768-hidden, 12-heads , 110M parameters. BERT–Large, Cased : 24-layer, 1024-hidden, 16-heads, 340M parameters. Escalating costs and data sizes meant some more efficient, less computationally and financially expensive models needed to be built.
Welcome Google ALBERT, Hugging Face DistilBERT and FastBERT
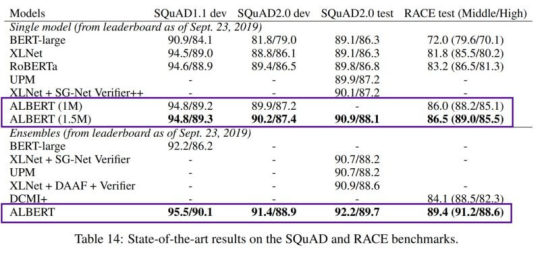
Google’s ALBERT, was released in September 2019 and is a joint work between Google AI and Toyota’s research team. ALBERT is considered BERT’s natural successor since it also achieves state of the art scores across a number of natural language processing tasks but is able to achieve these in a much more efficient and less computationally expensive manner. Large ALBERT has 18 times fewer parameters than BERT-Large. One of the main standout innovations with ALBERT over BERT is also a fix of a next-sentence prediction task which proved to be unreliable as BERT came under scrutiny in the open-source space throughout the course of the year. We can see here at the time of writing, on SQuAD 2.0 that ALBERT is the current SOTA model leading the way. ALBERT is faster and leaner than the original BERT and also achieves State of the Art (SOTA) on a number of natural language processing tasks.
Other efficiency and budget focused, scaled-down BERT type models recently introduced are DistilBERT, purporting to be smaller, lighter, cheaper and faster, and FastBERT.
So, what does BERT mean for SEO?
BERT may be known among SEOs as an algorithmic update, but in reality, it is more “the application” of a multi-layer system that understands polysemous nuance and is better able to resolve co-references about “things” in natural language continually fine-tuning through self-learning. The whole purpose of BERT is to improve human language understanding for machines. In a search perspective this could be in written or spoken queries issued by search engine users, and in the content search engines gather and index. BERT in search is mostly about resolving linguistic ambiguity in natural language. BERT provides text-cohesion which comes from often the small details in a sentence that provides structure and meaning. BERT is not an algorithmic update like Penguin or Panda since BERT does not judge web pages either negatively or positively, but more improves the understanding of human language for Google search. As a result, Google understands much more about the meaning of content on pages it comes across and also the queries users issue taking word’s full context into consideration.

BERT is about sentences and phrases
Ambiguity is not at a word level, but at a sentence level, since it is about the combination of words with multiple meanings which cause ambiguity.

BERT helps with polysemic resolution
Google BERT helps Google search to understand “text-cohesion” and disambiguate in phrases and sentences, particularly where polysemic nuances could change the contextual meaning of words. In particular, the nuance of polysemous words and homonyms with multiple meanings, such as ‘to’, ‘two’, ‘to’, and ‘stand’ and ‘stand’, as provided in the Google examples, illustrate the nuance which had previously been missed, or misinterpreted, in search.
Ambiguous and nuanced queries impacted
The 10% of search queries which BERT will impact may be very nuanced ones impacted by the improved contextual glue of text cohesion and disambiguation. Furthermore, this might well impact understanding even more of the 15% of new queries which Google sees every day, many of which relate to real-world events and burstiness / temporal queries rather than simply long-tailed queries.
Recall and precision impacted (impressions?)
Precision in ambiguous query meeting will likely be greatly improved which may mean query expansion and relaxation to include more results (recall) may be reduced. Precision is a measure of result quality, whereas recall simply relates to return any pages which may be relevant to a query. We may see this reduction in recall reflected in the number of impressions we see in Google Search Console, particularly for pages with long-form content which might currently be in recall for queries they are not particularly relevant for.
BERT will help with coreference resolution
BERT(the research paper and language model)’s capabilities with coreference resolution means the Google algorithm likely helps Google Search to keep track of entities when pronouns and noun-phrases refer to them. BERT’s attention mechanism is able to focus on the entity under focus and resolve all references in sentences and phrases back to that using a probability determination / score. Pronouns of “he,” “she,” “they,” “it” and so forth will be much easier for Google to map back in both content and queries, spoken and in written text. This may be particularly important for longer paragraphs with multiple entities referenced in text for featured snippet generation and voice search answer extraction / conversational search.
BERT serves a multitude of purposes
Google BERT is probably what could be considered a Swiss army knife type of tool for Google Search. BERT provides a solid linguistic foundation for Google search to continually tweak and adjust weights and parameters since there are many different types of natural language understanding tasks that could be undertaken. Tasks may include:
Coreference resolution (keeping track of who, or what, a sentence or phrase refers to in context or an extensive conversational query)
Polysemy resolution (dealing with ambiguous nuance)
Homonym resolution (dealing with understanding words which sound the same, but mean different things
Named entity determination (understanding which, from a number of named entities, text relates to since named entity recognition is not named entity determination or disambiguation), or one of many other tasks.
Textual entailment (next sentence prediction)
BERT will be huge for conversational search and assistant
Expect a quantum leap forward in terms of relevance matching to conversational search as Google’s in-practice model continues to teach itself with more queries and sentence pairs. It’s likely these quantum leaps will not just be in the English language, but very soon, in international languages too since there is a feed-forward learning element within BERT that seems to transfer to other languages.
BERT will likely help Google to scale conversational search
Expect over the short to medium term a quantum leap forward in application to voice search however since the heavy lifting of building out the language understanding held back by Pygmalion’s manual process could be no more. The earlier referenced 2016 Wired article concluded with a definition of AI automated, unsupervised learning which might replace Google Pygmalion and create a scalable approach to train neural nets:
“This is when machines learn from unlabeled data – massive amounts of digital information culled from the internet and other sources.” (Wired, 2016)
This sounds like Google BERT. We also know featured snippets were being created by Pygmalion too. While it is unclear whether BERT will have an impact on Pygmalion’s presence and workload, nor if featured snippets will be generated in the same way as previously, Google has announced BERT will be used for featured snippets and is pre-trained on purely a large text corpus. Furthermore, the self-learning nature of a BERT type foundation continually fed queries and retrieving responses and featured snippets will naturally pass the learnings forward and become even more fine-tuned. BERT, therefore, could provide a potentially, hugely scalable alternative to the laborious work of Pygmalion.
International SEO may benefit dramatically too
One of the major impacts of BERT could be in the area of international search since the learnings BERT picks up in one language seem to have some transferable value to other languages and domains too. Out of the box, BERT appears to have some multi-lingual properties somehow derived from a monolingual (single language understanding) corpora and then extended to 104 languages, in the form of M-BERT (Multilingual BERT). A paper by Pires, Schlinger & Garrette tested the multilingual capabilities of Multilingual BERT and found that it “surprisingly good at zero-shot cross-lingual model transfer.” (Pires, Schlinger & Garrette, 2019). This is almost akin to being able to understand a language you have never seen before since zero-shot learning aims to help machines categorize objects that they have never seen before.
Questions and answers
Question and answering directly in SERPs will likely continue to get more accurate which could lead to a further reduction in click through to sites. In the same way MSMARCO is used for fine-tuning and is a real dataset of human questions and answers from Bing users, Google will likely continue to fine-tune its model in real-life search over time through real user human queries and answers feeding forward learnings. As language continues to be understood paraphrase understanding improved by Google BERT might also impact related queries in “People Also Ask.”
Textual entailment (next sentence prediction)
The back and forth of conversational search, and multi-turn question and answering for assistant will also likely benefit considerably from BERT’s ‘textual entailment’ (next sentence prediction) feature, particularly the ability to predict “what comes next” in a query exchange scenario. However, this might not seem apparent as quickly as some of the initial BERT impacts. Furthermore, since BERT can understand different meanings for the same things in sentences, aligning queries formulated in one way and resolving them to answers which amount to the same thing will be much easier. I asked Dr. Mohammad Aliannejadi about the value BERT provides for conversational search research. Dr. Aliannejadi is an information retrieval researcher who recently defended his Ph.D. research work on conversational search, supervised by Professor Fabio Crestani, one of the authors of “Mobile information retrieval.” Part of Dr. Aliannejadi’s research work explored the effects of asking clarifying questions for conversational assistants, and utilized BERT within its methodology. Dr. Aliannejadi spoke of BERT’s value:
“BERT represents the whole sentence, and so it is representing the context of the sentence and can model the semantic relationship between two sentences. The other powerful feature is the ability to fine-tune it in just a few epochs. So, you have a general tool and then make it specific to your problem.”
Named entity determination
One of the natural language processing tasks undertaken by the likes of a fine-tuned BERT model could be entity determination. Entity determination is deciding the probability that a particular named entity is being referred to from more than one choice of named entity with the same name. Named entity recognition is not named entity disambiguation nor named entity determination. In an AMA on Reddit Google’s Gary Illyes confirmed that unlinked mentions of brand names can be used for this named entity determination purpose currently.

BERT will assist with understanding when a named entity is recognized but could be one of a number of named entities with the same name as each other. An example of multiple named entities with the same name is in the example below. Whilst these entities may be recognized by their name they need to be disambiguated one from the other. Potentially an area BERT can help with. We can see from a search in Wikipedia below the word “Harris” returns many named entities called “Harris.”

BERT could be BERT by name, but not by nature
It is not clear whether the Google BERT update uses the original BERT or the much leaner and inexpensive ALBERT, or another hybrid variant of the many models now available, but since ALBERT can be fine-tuned with far fewer parameters than BERT this might make sense. This could well mean the algorithm BERT in practice may not look very much at all like the original BERT in the first published paper, but a more recent improved version which looks much more like the (also open-sourced) engineering efforts of others aiming to build the latest SOTA models. BERT may be a completely re-engineered large scale production version, or a more computationally inexpensive and improved version of BERT, such as the joint work of Toyota and Google, ALBERT. Furthermore, BERT may continue to evolve into other models since Google T5 Team also now has a model on the public SuperGLUE leaderboards called simply T5. BERT may be BERT in name, but not in nature.
Can you optimize your SEO for BERT?
Probably not. The inner workings of BERT are complex and multi-layered. So much so, there is now even a field of study called “Bertology” which has been created by the team at Hugging Face. It is highly unlikely any search engineer questioned could explain the reasons why something like BERT would make the decisions it does with regards to rankings (or anything). Furthermore, since BERT can be fine-tuned across parameters and multiple weights then self-learns in an unsupervised feed-forward fashion, in a continual loop, it is considered a black-box algorithm. A form of unexplainable AI. BERT is thought to not always know why it makes decisions itself. How are SEOs then expected to try to “optimize” for it? BERT is designed to understand natural language so keep it natural. We should continue to create compelling, engaging, informative and well-structured content and website architectures in the same way you would write, and build sites, for humans. The improvements are on the search engine side of things and are a positive rather than a negative. Google simply got better at understanding the contextual glue provided by text cohesion in sentences and phrases combined and will become increasingly better at understanding the nuances as BERT self-learns.
Search engines still have a long way to go
Search engines still have a long way to go and BERT is only a part of that improvement along the way, particularly since a word’s context is not the same as search engine user’s context, or sequential informational needs which are infinitely more challenging problems. SEOs still have a lot of work to do to help search engine users find their way and help to meet the right informational need at the right time.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author

Dawn Anderson is a SEO & Search Digital Marketing Strategist focusing on technical, architectural and database-driven SEO. Dawn is the director of Move It Marketing.
https://www.businesscreatorplus.com/a-deep-dive-into-bert-how-bert-launched-a-rocket-into-natural-language-understanding/
0 notes
Text
null relativization
a thing i really like is when languages use syntax or morphology instead of particles to indicate relativization.
english is the most obvious example of this, but it’s kind of a cheat. (also i hate doing grammatical analyses of my native language because that’s extremely bad behavior as a linguist and it’s also just fucking boring, but since it’s the elephant in the room here i can’t really avoid it.)
(1) the drugs Clarice bought
(2) Clarice bought drugs from an undercover cop who entrapped her.
(3) the drugs that Clarice bought
(4) the drugs that were in Clarice’s van
(5) they didn’t find the drugs that were in Clarice’s van.
*(6) Clarice bought from an undercover cop entrapped her.
(7) the drugs were in Clarice’s van.
(8) they didn’t find the drugs were in Clarice’s van.
(9) Clarice shot up under a tree that fell on her.
*(10) Clarice shot up under a tree fell on her.
(11) They didn’t find that the drugs were in Clarice’s van.
in (1), we see the basic strategy: place the modified NP before a verb phrase that describes it. while this singular example would indicate English is a null-relativizing language, (3) shows the presence of a relativizing particle (”that”), which can be used in any situation where null-relativization could also be used. therefore, even if we ignore diachronic analysis (which is usually a good policy imo) and considerations of register, we can reasonably conclude that null-relativization in English is nothing more than an optional elision of an implied relativizing particle.
where it gets interesting, though, is when we try to elide that relativizer naively. (2) is grammatical in standard English and uses the relativizer “who” (which performs the same function as “that” but can only be used to relativize persons, as opposed to “that” or “which,” which preferentially relativize things but can be used in colloquial speech to relativize persons, at the risk of dehumanizing them). (6), however, the same sentence with the relativizer removed is not grammatical. how does this differ from the contrast between (3) and (1)?
the licensing criteria become clear when we break the sentences down by grammatical role. in (1) “Clarice” is the subject of the verb “bought,” where the relativized phrase “the drugs” is the indicated object. (n.b. some languages use different particles or morphology to indicate whether a noun phrase is being relativized as the subject or object of the subordinate clause; apart from imposing these extra syntactic constraints, English relies entirely on word order for this purpose.)
in (2) however, the pig is the subject of the subordinate clause. the pig entrapped her, not the other way around (so Clarice better lawyer the fuck up because that is totally not legit.) as seen in (6), dropping the complementizer becomes ungrammatical.
at this point, we can reasonably conclude that when nouns are relativized in the object role, the relativizer may be grammatically elided. however, in the subject role, the relativizer must be present.
“but wait!” you might exclaim, “hang on, the examples you’ve cited don’t prove anything. those are completely different relativizers. it could be a property of the person/nonperson distinction, and have nothing to do with subject/object role!”
and you would be correct! that’s why it’s perilous to try to do grammatical analyses of your own language: you already know all the finicky little details (or at least think you do), so examining the grammar requires working backwards from the conclusion to show your work.
in this case, however, we also have examples (9) and (10) to prove the relativizer “that” obeys the same constraint, and also that Clarice just can’t get a break, the poor girl.
let’s look at some more examples of what removing the relativizer does in subject-relativized noun phrases. in (4) and (5), “the drugs” are the relativized as subjects of the verb “were.” but when we delete the relativizer, the sentence (or clause) doesn’t become ungrammatical - it just radically changes the meaning!
in (7) and (8) we see the outcome of that transformation. deleting the relativizer transforms (4), a fragment, into a full sentence simply stating the location of Clarice’s stash. something even more remarkable happens in (8), where the phrase is likewise flattened into a plain sentence — but is then complementized as the argument the verb “find,” with the sense of “discover the fact that,” as expanded in (11). this happens English also allows elision of complementizers, which contributes to the wonderful phenomenon of garden-path sentences - the grammatical structure of the utterance remains ambiguous until it is completed, and overly-eager parsing can lead to parse errors. just like in C++.
can you see why we anglophones have such a hard time grasping these concepts in other languages?
things get more interesting in arabic, where null relativizers aren’t just an innovation by lazy speakers, but a core part of the grammar.
(12) أقرأ كتابا. “‹a›qr‹a›ʔ-u k‹i›t‹ā›b-a-n.” — read‹1SG.NPST›-IND book‹SG›-ACC-SG.INDEF — “i read a book.”
(13) يأكل رشيد كتابا قرأته . “‹ya›ʔk‹u›l‹u› Rašīd-an k‹i›t‹ā›b-an q‹a›r‹a›ʔ‹tu›-hu” — eat‹3SG.M.NPST› Rashīd-3SG.NOM book‹SG›-ACC.SG read‹1SG.PST›-3SG.M.ACC — “Rashīd eats a book that i read.”
(14) يأكل رشيد الكتاب الذي قرأته. “‹ya›ʔk‹u›l‹u› Rašīd-an al-k‹i›t‹ā›b-a allaðī q‹a›r‹a›ʔ‹tu›-hu” — eat‹3SG.M.NPST› Rashīd-3SG.NOM DEF-book‹SG›-ACC PART read‹1SG.PST›-3SG.M.ACC — “Rashīd eats the book that i read.”
(15) قرأت الكتاب الذي أكل رشيدا. “q‹a›r‹a›ʔ‹tu› al-k‹i›t‹ā›b-a allaðī ‹ʔa›’k‹a›l‹a› Rašīd-an” — read‹1SG.PST› DEF-book‹SG›-ACC PART read‹3SG.M.PST› Rashīd-3SG.NOM — “I read the book that ate Rashid.”
okay, so, that notation may be a little overwhelming to people who haven’t done work on Semitic languages. the first field is the original arabic, the second is a romanization with separated morphomes, the third is a morpheme-by-morpheme gloss, and the fourth is a translation. the ‹ › brackets denote the vowel templates Semitic languages use to inflect triliteral roots like [QRʔ] “read.” yeah, it’s a mess.
in (12) we have a plain sentence, “i read a book.” the object كتاب follows the verb and takes the marker ـا “an,” indicating that it is in the singular masculine accusative case. (note that, while the feminine singular accusative takes the same marker, it is not indicated in writing, which the masculine is.)
in (13) we have a relativized sentence with an indefinite relativized NP (كتابا “a book”). the relativization is encoded simply by placing a descriptive sentence after the relativized NP, in this case قرأته “i read it.” here arabic demonstrates wildly different syntax from english: rather than marking the explicit role of the NP in the subordinate clause, the NP takes on a topical role and is referenced anaphorically in the subordinate clause, in this case by the 3rd-person masculine singular accusative pronoun ـه “-hu”.
this structure is much more flexible than English and can encode complex meanings that the standard English equivalent cannot. a closer approximation of Arabic relativizers in English might perhaps be the phrase “such that,” rendering (13) in English as “Rashīd eats a book such that I read it.”
in (14) we see the use of the masculine singular relativizer particle الذي, which is required in order to relativize definite nouns such as الكتاب “the book”, and cannot be used with indefinite nouns like كتاب “a book”. other than that, the syntax and semantics are indentical.
finally, in (15) we see how arabic encodes subject-relativization. while in (14) the accusative pronoun ـه “-hu” was used to reference the topic, in (15) the topic is referenced by the person for which the verb أكل is conjugated - as the person encoded by أكل matches the topic in gender, number, and animacy, the topic takes on a subject role in the subordinate clause.
if you haven’t studied arabic yourself, it probably seems like a complicated bureaucratic nightmare of a language to you now. so i’d like the reassure you that what you’ve witnessed here was only the tip of the iceberg that is the fractal intricacy of Arabic morphosyntax.
at last we come to japanese, the most interesting of the three (and the one i’m currently learning, so if i make any errors, あたしに叫んで下さい!). like arabic, japanese relativizes NPs into a topic role — but unlike arabic or english, japanese provides no way to explicitly specify the subsequent grammatical role of the topic, which should surprise nobody since japanese is a topic-comment language.
(16) 本です。”hon desu.” — book COP.POLITE — “(It) is (a) book.”
(17) 本の中で麻薬を隠した。”hon no naka de mayaku wo kaku-shita.” — book GEN inside LOC drugs OBJ hide-PST — “(I) hid drugs inside (a) book.”
(18) 雪さんが麻薬を中で隠した本 “yuki-san ga mayaku wo naka de kaku-shita hon” — Yuki PART SUBJ drugs OBJ inside LOC hide-PST book — “the book Yuki hid her drugs in”
(19) 事が大好きだ。”koto ga daisuki da.” — thing SUBJ loved COP.FAMILIAR — “I love the thing.” / “This shit’s great, man.” / “Good stuff!”
(19) 雪ちゃん はいつも麻薬がある事が大好きだね? “yuki-chan wa itsumo mayaku ga aru koto ga daisuki da ne?” — Yuki PART TOP always drugs SUBJ exist thing SUBJ loved COP.FAMILIAR PART — “Man, isn’t it great how little Yuki’s always got drugs?”, “Gotta love how my girl Yuki’s always got drugs, huh?” or even “Yuki, it’s great how you’ve always got drugs.” Japanese is crazy context-dependent.
(20) 死んだ景観だけいい景観です。”shi-nda keikan dake ii keikan desu.” — die-PST cop only good cop COP — “The only good cop is a dead cop.” / “Only dead cops are good cops.”
being an aggressively left-branching language, it should be no surprise that the subordinate clause precedes the noun it modifies, unlike English or Arabic. Japanese relativization is accomplished purely through word order. (16) and (17) show the structure of basic sentences, and that Yuki is way sneakier than Clarice. (18) shows the term「本」 “book” relativized with the subordinate clause「雪さんが麻薬を中で隠した」which is in fact a complete and valid sentence on its own, meaning “Yuki hid the drugs inside.”
modifying「本」with this clause leads to a fairly straightforward reading of “the book Yuki hid her drugs in,” but since「本」is taking a topic role rather than a defined syntactic role, it could mean anything from that to “the book that suggested Yuki hide her drugs inside things” to even “the book Yuki avoided hiding her drugs in” (although that last one’s a stretch). it all depends on context.
the extreme flexibility of Japanese relative constructions has led to a fascinating phenomenon where complementization and relativization are unified. since any noun can be modified by a verb phrase, any noun can be a complementizer, as we see in (19) where「事」”thing” is modified by the clause「雪ちゃはいつも麻薬がある」”as for little miss Yuki, there’s always drugs” or more idiomatically “Yuki’s always got drugs.” appending「事」enables the clause to be discussed in the abstract.
(the particle「の」is also used as a complementizer in some circumstances, but it’s a little less common than「事」and carries more specific connotations.「と」also functions as a subjunctive~quotative complementizer tho im not totally sure how to use it yet)
finite verb forms also are responsible in Japanese for what past participles or adjectives are used for in english, as seen in (20) where「死んだ」”died” and「いい」”be good” directly modify nouns. verbs ending in 〜い are often described as adjectives in Japanese teaching materials, but they are not syntactically distinguishable from verbs.
anyway English is boring, Arabic is beautiful but excruciating, and Japanese is the Ideal Language imo.
5 notes
·
View notes
Text
The Prophet of 'No' and the Priest of 'Yes': the Ambiguous Transcendentalism of True Detective and Hannibal's Neo-Pagan Priesthood
(What follows is an examination of the intertextuality of Hannibal and True Detective along with apposite philosophical thought. So, if you haven't watched Season 2 of Hannibal and Season 1 of True Detective (but intend to) be aware that this post has a couple of spoilers.)
NBC's Hannibal and HBO's True Detective were, for me, the most captivating shows on television this spring, and by a wide margin. Their acting, writing, direction, cinematography, sound, and overall artistry were magnificent, but it's the way these supported the development of vital characters who embodied complex philosophies that set them apart functionally from franchises of similar stature (Deadwood, Madmen, et al.).
Both series center on a string of haunting ritual murders and the liminal hunters that circle our flock and pick us off one by one like wolves in the night. Critically, however, where Hannibal is named for its villain and takes us on a season-long tour through his thoughts, behavior, and relationships, True Detective doesn't reveal what it calls the "monster at the end of the dream" until its final episode, and only at the very climax of the finale do we hear what we're essentially told are the ravings of this quasi-religious lunatic, barely audible as they echo through stone corridors of his strange labyrinth. His creed and code are thus presented as mere appetitive grunts of a minotaur whose body may be human but whose head (and mind) are bestial and inexplicable.
True Detective's namesake and focus is rather the killer's antagonist, Rustin "Rust" Cohle, who is somehow portrayed masterfully by the real-life version of Michelangelo from Teenage Mutant Ninja Turtles, Matthew McConaughey. Rust is an over-read skeptic who peers out on a universe of death and decay and rejects its basic premise, grimly resigned to the unavailability of transcendence beyond time's "flat circle" (as the show's villain, the Yellow King, glosses Nietzsche's notion of the "eternal recurrence of the same") and the inescapability of brutality, despair, pain, and death - the absurd birthright of consciousness, which is little more than Fate's miserable bastard. What makes Rust loveable despite the fog of gloom that seethes from his mouth and envelops his every scene like Pig-Pen's filth-cloud, is his unwavering desperation for this transcendence he is certain is impossible, the integrity of his universal depression that doesn't soothe itself in the sardonic humor and supercilious irony of so many hipster cynics. Rust is an abstemious monk who waits without pleasure or distraction for a dawn he knows will never come, an inconsolable bereaved father who curses his own glaring flaws in endless self-flagellation and tries to set the world to rights as best he can.
Juxtapose the slippery-smooth marble edifice of Hannibal, who yields no foothold to our emotional attachment. He isn't Showtime's eponymous Dexter, who keeps his knife-work within the lines to avoid criminal consequences and cut the image of some sort of "dark avenger" who operates on behalf of society and its hackneyed "eye for an eye" juridical sensibilities. Hannibal is a skein of contradictions. He is an ascetic aestheticist, a diligent bon vivant devoted zealously to the curation of exquisite, epicurean delights, the most refined of which are the sumptuous feasts he derives out of the most brutal and repulsive acts we can fathom. A disciplined decadence, and a reverential, ritual hedonism link him as much to ancient mystery cults as the maenadic intensities of the High Romantic poet-priests, and reveal him to be Nietzsche's ideal man as a hale and rational animal, his desires and action fully integrated with each other. Hannibal's every act, none more than his stalking and butchery of human game, is fully sacrament, fully indulgence, and fully art, as much the demesne of Apollo as Dionysus, whom Nietzsche once told us simply cannot coexist.
Let us consider now the prodigy of Hannibal, what his appearance in our night sky means to us and toward us, rather than what his internal life, personal intentions and impressions might be.
Hannibal is of the Wagnerian-Aeschylean, Olympian god-aristocracy ruling by, enforcing, and embodying a draconian, but not arbitrary, ethics. We use "ethics" here in the Greekest sense of the word, as a matter of habit, character, nature, inertial reference, or even of basic construction, an inflexible order, Lucretius' "way things are." Ethics is thus a trope of limitation, the girdle of grim necessity or the serpent goddess "ananke" coiled around us. Birth and death, hunter and hunted, the cycle of the seasons, the anaphorized aphorisms of the Ecclesiast, are all of the edifice of the natural Order revered by Hannibal as one of Wagner's ideal and cyclically-recurrent and thus timeless aristocrats, simply because it is and must be so.
On a Freudian grid, Hannibal is not a product of the ego, nor even of the id, but rather the id's ubiquitous "death drive" sublimated into an orderly and code-heeding superego of polite murder. He is the personification of nature's sublime will, which is antithetical and inimical to our own, the "will" of all that which lies beyond our Wordsworthian or Wittgensteinian solipsistic shell of self, all that is Kant's noumena, or Emerson's "not-me," doled out to us mortals by Fate. He embodies everything that is alien to our own control.
Hannibal is thus become death, one with the natural order any of whose characteristic operations or "ethic" is of course the definitional opposite of "hubris" (a word whose Greek roots denote violence and outrage, and which indicates any presumption beyond the stipulations of that very natural Order).
In his cannibalism, he communes of us, and yes, of death, which he thus becomes in a trope of perfect Christology. But we too commune of him as our anti-Christ not in sanctioning his ethics but in becoming thralls to his estate of necessity and irresistible change through our deaths, not only into his stews and soufflés but wherever they occur and in whatever synecdochal skirmish along the full gamut of our powerlessness: from succumbing to murder, to losing coins in the couch cushions.
We invoked Wagner and his prized divine aristocracy as the template of Hannibal-as-Necessity. For Wagner, in accordance with contemporary historical fact, capitalism, the target for so much modern hatred over exploitation, was perfectly opposed to this feudalistic genealogical meritocracy, and this aristocracy defends its traditions and apotheosized aesthetics from the crude reductions of capital and commodity. The notion then of Hannibal as aristocrat is not one of acquisitiveness or egotism, nor of exploitation, but of a dread and sublime order, as the hunter who honors his prey and sees both as parts of a sacred world.
Nietzsche's "amor fati" ("love of fate"), and the High Romantic sublimation of death into beauty, is the moral regiment of Hannibal, the gauntlet tossed before us requiring answer in a universe which, for most of us, is devoid of other gods. Decidedly it is not the code of Faust or Paracelsus, or the Hermetic neo-Platonics, or even Descartes, who all seek freedom from the bonds of nature. They seek to overthrow the aristocracy in a Promethean revolution, whether of egalitarian or egotistical essence, the same sort of upheaval enacted by Christ, and (as we'll see) the Christ-figure of Rust Cohle.
Where Hannibal prepares us as the Eucharistic banquet of "This Present Age," converting his life and operations into our death, Christ gives himself as the banquet of "The Coming Kingdom," converting his death into our life and sustenance through the real presence of an apocalypse, as it foreshadows future and coming transcendence. This rejection of the way things are, the voluntary acceptance of the death of this world in the hopes of a better to come, is what unites all the foregoing codes as essentially transcendental.
Nietzsche and his son Hannibal revere the world rather as it is. They affirm the sacred dignity of their One True God, Fate. In a world without a personal divinity, however, Fate's essence is at risk. Without direction from a Lawgiver, events are surely chaotic, universal history a "tale told by an idiot." In such a world, into which the infinity of unbounded time and space threatens to hurtle us, Necessity itself is hardly necessary, and there is no Fate without Necessity, and without Fate, no objective and external meaning in the absence of God. Hence Nietzsche's "eternal recurrence of the same" (glossed by True Detective's villains with "time is a flat circle") asserting that each and every occurrence, however minuscule, is a vital part of a spatiotemporal tapestry of events the course of which repeats and repeats, rather than meandering at random, through the infinite voids of time and space.
Fate's fatality is saved by eternal recurrence, and each moment takes on the nature of a liturgical act, a ritual repetition intended (not by God, but by the god that is the cosmos itself in its necessary operation) and attended by the "amen, amen, amen" of its priests, Nietzsche and Hannibal, with difficult amor fati. The annual revisitation of the voluntary castration of Attis, the departure and return of Persephone from Dis, the rhythm of the seasons, death and sacrifice, life and rebirth that vivified the world of the ancient fertility cults takes root again antithetically in the essentially northern-latitude, huntsman religion of Hannibal. His monotheistic huntsman's God is Fate, and his polytheistic agrarian fertility-goddess is Death, on whom Change is begotten by Fate.
That bleak and twilight noon that so defines the visual aesthetic of Hannibal, whose star (Mads Mikkelsen) is himself a Dane, is truly the boreal, severe sky of Kierkegaard and not of Gaughin's or Bizet's complex but blithe equatorial fertility. It is a sky carried on the backs of nomadic hunter religions and the monotheistic austerities of the High Protestants and their Arian precursors. Wodin's apocalyptic clairvoyance, psychopompic transportation upon Valkyries beyond the here and now, and the transcendent undercurrent of epochal overthrow in the fated and looming Ragnarök echo through its thin golden filaments. Such strains of north and south are as mutually antithetical as Apollo and Dionysus, but are wed just as well in the person of Hannibal by the artists who render him on screen.
These musings on ancient religion bear deeply on our modern spirituality. If one disavows literal transcendence, the final trampling down of death, as any atheist surely must, then, as Wallace Stevens puts it, the only positive credo must be "death is the mother of beauty," a cognate of amor fati. For to reject the motive force behind all change and the ephemeration which defines a purely terrestrial and atheistic notion of life - that is, to reject the substantiation of Necessity in Death - while simultaneously denying any hidden and supernatural transcendence, is to reject life itself and all beauty in equivalent extent, and to posit in their stead utter void as the meet nourishment of the human spirit. It is to cry out for the truth of the Gospel or Upanishads while steadfastly denying them. It is to posit a world in which the human is not even tragic, lacking sufficient nobility for tragedy, not even pathetic, lacking sufficient emotional credibility for pathos, but at best merely absurd.
And so with deep irony it becomes clear that the moralistic censor or restrainer of Hannibal (all of us who are appalled by his bloody career through the mid-Atlantic), who nonetheless shares his atheism (or perhaps, more precisely, his anti-transcendentalism), becomes himself the ego-directed, presumptuous, arbitrary, and nihilistic destroyer of our humanity, the hubris-spurred violator outraging the way things are meant to be and blotting out the last lusters of beauty that linger in the twilight of the idols. From our vantage, Hannibal is not wanton but rule-bound, a sober agent and exact representation of Fate: grim and horrifically beautiful in his deathly operations. Restraining him according to standards not his own is a reduction of the natural world which is, by the presumption of modern man, the only world. The grace, beauty, urbanity and sophistication this murderer cherishes in all realms of his life are not antithetical to his predation of his fellow man but in fact aspects and synecdoches of the same grand design of glittering death that Fate has etched between molecules and constellations.
Incidentally, this implicit tension in Romanticism is where Showtime's Penny Dreadful is picking up as well, taking the alternate tack toward a terrestrial resurrection, prizing Mary Shelley's vision of the half-transcendent Faustian power of that proto-transhumanist Dr. Frankenstein, rather than the proto-Nietzschean death-sublime and amor fati affirmation of her husband Percy's Adonaïs, who is the dark precursor of Hannibal. Where Hannibal confronts us with a vivid tableau of the only positive philosophical alternative to transcendental religion (positive in the logical sense), and bids us choose between "Heart of Darkness at the MOMA" or a morass of nihilistic abnegation at best verging on Frankenstein's futile fight against nature in the face of life's inescapable term limits, True Detective makes of its villain a transcendentalist, and forces its protagonist, Rust, to abandon his perfect nihilism and accept the very worldview of the ghastly Yellow King, albeit while rejecting the means he uses to pursue transcendental ends.
Unlike True Detective, Hannibal ends spiritually right where it begins, with an "amen" to amor fati, forcing Hannibal to chose life, in its fullness of pleasure and pain, over its restriction, adulteration, and curtailment. To escape death or the confines of prison, which would of course spell death for Hannibal as Hannibal and as synecdoche of the stern and sacred beauty-terrors of the sublime world of fate, Hannibal must (at least attempt to) murder his best and really only friend, Will Graham. This stands in stark contrast to the slow spiritual transformation of True Detective, which inaugurates itself in Rust's nihilism and its opposition to the transcendental yearnings of the Yellow King, and ends with Rust's victory being found in his essential adoption of his enemy's transcendentalism after dispatching him to the (now plausible) afterlife.
In establishing its villain's transcendental cult on rites of child sacrifice (and also of course by linking the bizarre bayou syncretism to local churchmen), True Detective identifies the horrors of "Carcosa" with Christianity (likewise founded of course on the sacrifice of an innocent). This isn't a stretch through the world-weary gaze of Rust, who cannot reconcile himself to a natural order that would require the death of the unblemished lamb that was his daughter, blameless as Christ, and the inexplicable cultic rites of even, e.g., the Catholic Church, that eventuated so recently in the molestation of innocent children and that banish the unbaptized to limbo.
Cohle cries out desperately for transcendence while steadfastly declaring it to be impossible. He thus castrates the act of consciousness by rendering it willfully impotent, ultimately declaring it a cosmic mistake and thus nullifying any chance of his essentially nihilistic worldview's success by failing to posit even the possibility of value. He is the prophet of "no" to Hannibal's priest of "yes," the proponent of death where Hannibal holds forth life. That is, until he changes his tune at the very finale of the finale, seeing in the twilight what he reads ambiguously to be a new dawn.
The season ends with Rust (who is named after a physical trope of Fate: of ceaseless, inevitable decay) emerging from a brief (say, three-day?) sojourn through and conquest over quasi-death after slaying the Evil One to pronounce a guarded redemption over a universe of disintegration at its very midnight: a Rust no longer rust, and death trampled down by death. He limps with the fertile, life-giving, essentially self-inflicted wound not of Attis (who you might expect given his aforementioned self-castration), Attis who regenerated for the ancient vegetation cults a bloody world of constant death (the "flat-circle" world Rust rejected of Nietzsche's "eternal recurrence"); but rather, to be more anatomically as well as thematically accurate, it is the wound of Christ, whose salvific blood poured not from his loins like Attis, but from his heart.
It may be that the light is waxing, as the season finale of True Detective suggests through a beautiful Manichean juxtaposition of light and dark in the midnight heavens, fashioning onto Eliot's "vacant interstellar spaces" where ranges Stevens' "secretive hunter" (surely an apt epithet of Hannibal!) among the "straight" lines "between the stars." These lines are "much too dark and much too sharp," are "swift and fall without diverging," that is, without indulging in the swerve of freedom or chance, following cold, invariable Necessity. They fall "for their pleasure, their pleasure that is all bright-edged and cold" chants the Nietzschean Stevens in his early "Stars at Tallapoosa," in which he regards the severe, frigid, brilliant beauty of the deathly and inhuman heavens carving Fate's command into the tortured sentience of mankind. But when the background blackness is hobbled on the expectation of its mitigation in the warming light of a new dawn, those ancient stars lose luster, merge, blend, and decline, and the violent contrasts of pure midnight muddle into the drab dusk Rust fled in the first place, the merely half life of Frankenstein's monster and humanity's lie to itself that putting off death is meaning enough.
For to restrict life in its essence without offering anything new is to perform the limitation of fate upon fate itself, abbreviating the curriculum of the boundless universe, the snake ouroboros thus swallowing its tail and not regenerating worlds endlessly anew as the myths proclaim, but rather disappearing little by little. It is to see the sublime evanesce only to leave behind the base in residue. When we trample death by death but do not then return with "the Kingdom," we merely reduce death, "the mother of beauty," and hence the beauty of our world. The proof for this reduction is the utter lack of sublimity in the course of True Detective, where Hannibal bodies forth a full-blooded Aeschylean sublime with its grim circular seasonal arc.
Cohle (who, as a Christ-figure also draws on Mithras, the god whose energies of life sprang out of a "generating stone" like say, coal) realizes that the coal-black void is warm and filled with children's laughter and the sure embrace of all he once lost, like Odysseus waking up on the shore in Ithaca and diving tear-eyed into his possessions miraculously salvaged from the sea. Like Christ triumphant pulling Adam and Eve out of Hades, Rust returns from the blackness with his daughter and his father if not in hand then in heart, half-saved from oblivion. Hannibal as the hand of Fate guts the will (literally gutting Will (Graham) his best friend and the show's chief protagonist) just as the Yellow King guts Rust, but Hannibal escapes, while, in contrast, the bestialized mind of the Yellow King is blown to pieces by Rust's partner Marty's revolver. Rust thus scores a victory over Fate and time's "flat circle" that completes itself in his aforementioned return from the (near) dead, the season ending with Marty carrying Rust like Aeneas bearing Anchises out of the ashes of Troy and into the new Troy, which was destroyed only to be re-established as Rome in a better place and time.
True Detective thus eschews the Greek-pagan tragic mode of an "ethical" (read: rigidly defined by a natural order) world that is essential flux, that bends only so far to our aims and snaps right back into place. Instead, it posits a linear, dualistic, and more Roman-Christian saga, the "Life->Death->Life Redeemed" trajectory of the Aeneid or the Harrowing of Hell over the "Nature->Hubris->Fall->Nature" course of Aeschylus or Sophocles. At the end of this nightmare, we all wake after "the monster at the end" (as Rust puts it) is slain to find our Christ, Rust Cohle, establishing a new Rome after demolishing the old: a new post-Christianity hopeful of transcendence, a renewed preoccupation with the guilt and innocence battle between the forces of light and dark, and an essential embrace of the eschatological dreams of the Yellow King to conquer death and Fate.
Where Rust is Christ or Aeneas, sojourning in Hades, tearing down life by death only to raise it up again redeemed, Hannibal threatens to sack this Rome with irresistible, elephantine force - much like the Carthaginian general who is his namesake. He is thus not only a trope of Necessity and Fate, but the destruction of the Roman order as anti-Christ. But his name of course also offers us "cannibal" unavoidably, man feasting on man not only as a dark anti-Eucharist but an ouroboros: man devouring man and thus himself, ending and then regenerating itself as a cosmic order of Death and Necessity begetting more death and necessity - death indeed the mother of this "beauty". It is the serpent, ananke, sustaining itself upon itself. Hannibal thus embodies this endless cycle, akin to Nietzsche's "eternal recurrence" and the Yellow King's "flat circle" of time, which though infinite is yet reconciled to a finite and definite nature that preserves the necessity of necessity, the fatality of fate, and thus the integrity and sacredness of the natural order, as we discussed earlier. This is the perpetual generative agony that the image of a self-swallowing serpent so vividly represents.
Where Rust's true daughter is quasi-redeemed from death, Will's quasi-daughter, Abigail, is truly redeemed from death, appearing before him at the very climax of Season 2. Showing Will one he loved deeply and had believed dead, Hannibal stunningly declares "time did reverse." Had the flow of fate inverted? Christ gave his body for food rather than taking food for his body and died for the life of the world instead of living by the unabated process of the world's death. This transcendent sacrifice reversed the very flow of time, the ouroboros serpent ananke no longer swallowing its tail but regurgitating it as the Buddha's endless appetitive cycle of "action and suffering" is overturned by an endless kenotic cycle of self-giving. The great snake that slithered through Eden is finally trampled underfoot.
Could the brotherly love of Hannibal and Will, selfless acts of mutual sacrifice in Hannibal's return of a prodigal daughter presumed dead and Will's protection against the police and the violent judgment of law like Christ intervening at the stoning of the prostitute, truly reverse time? Not in the neo-pagan sublime of Hannibal. Life is not redeemed and improved after death in Aeschylus as it is in Virgil: death is the beginning and end, brilliant in its middle with the singeing wings of Icarus tumbling through the sky. And so the fatal, necessitarian indulgence of jealousy, the severing of communion and termination of brotherly love renewed so incessantly since Cain and Abel simply reinaugurated the eternal recurrence and returned time and fate to their normal course. "I wanted to surprise you," Hannibal explains of this gift of transcendent resurrection which the presence of Abigail so vitally promises; "and you wanted to surprise me" he concludes, disclosing to Will that he has discovered what he thinks is his treachery in bringing the authorities in to capture Hannibal. The surprise, the unexpected, impossible escape from fate which the disciples of Christ encountered at the empty tomb, its source in the unadulterated purity of brotherly love even unto death, the hubris of somehow interrupting fate: this is the unthinkable sin that tragically snaps the natural Order right back into place. Hannibal slits Abigail's throat, and with no external, personal God to intervene like Yahweh staying Abraham's knife as it fell toward Isaac, Will (the will) is powerless to do anything but watch death lavish itself in the artful operation of its implements.
In stark contrast, the ambiguity of Rust's transcendence, and True Detective's subsequent philosophical devolution into a simpering half-Christianity, weakens what still manages to end beautifully and poignantly, though certainly "not with a bang but a whimper." If in fact the light's slow victory Rust proclaims is not transcendental, but merely the process of humanity slowly "getting its act together" interpersonally or enjoying "better living through chemistry," we are left in the grotesque Faustian tableau of Penny Dreadful or Frankenstein, and find ourselves betrayers of the sublime and addicts to biology, staggering only half-human with cadaverous pallor through a world only half-transcendent.
Where there is no division of the sacred and profane, all must be sacred, or all must be profane. Hannibal worships at the altar of "all there is" and challenges us to show it something greater; it's unclear whether True Detective is able to answer the bell.
#hannibal#true detective#philosophy#nietzsche#literature#eternal recurrence#amor fati#ancient religion#transhumanism#wagner#wallace stevens#frankenstein#religion#penny dreadful#attis#nihilism#ananke#ouroboros#transcendentalism#romanticism#apollo#dionysus#mythology
4 notes
·
View notes
Text
Jobs: Research Assistant, Queen Mary University of London
3 years Postdoctoral Position on the (Computational) Linguistics of Anaphora/Coreference and Anaphoric Ambiguity Applications are invited from outstanding computational linguists / NLP researchers combining an excellent background in theoretical linguistics (in particular semantics) with demonstrated exciting research skills in the use of machine learning methods for NLP/CL , for a three-year Postdoctoral Research Assistant position in DALI, a project funded by the European Research Council http://dlvr.it/QXjg0v
0 notes
Note
Looking for papers on Sanskrit anaphora, I mostly came across comp ling work on anaphora resolution algorithms. I can't vouch for the quality of any of this stuff but these guys say in their abstract:
The method we adopt here for resolving the anaphors is by exploiting the morphological richness of the language.
Which suggests that, yeah, the main thing making this less ambiguous in Sanskrit is case, number, and gender.
does sanskrit have some sort of. grammatical emphasis on anaphora. in the translated sanskrit ive read theyre always clarifiying what "that" or "this" refers to in the text, like its frequently unclear what pronouns refer to, presumably it was more naturally clear in the sanskrit...?
If there's something subtle and pragmatic going on then I'm not nearly competent enough in Sanskrit to know what it is, but it might just be that Sanskrit nouns (and pronouns) have case and gender, so certain anaphoric relationships will naturally be differentiated that way which are ambiguous in English translation (presumably a natural English translation would disambiguate paraphrastically, but maybe a translation that's going for a greater level of literalism might keep the anaphora?). I might be able to say something more substantive than this if I saw some examples.
21 notes
·
View notes