#ai art is art
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Inspired by Yuri on Ice (I miss it sm... 😭😭😭):




Bonus:


#yuri on ice#viktor nikiforov#yuuri katsuki#yuri katsuki#yuri plisetsky#otabek altin#viktuuri#freepik#freepik pikaso#pikaso#ai art#ai art IS art#ai artwork#ai#ai artist
36 notes
·
View notes
Text
AI Haters, Please Read to the End
I see people celebrating every time something bad happens in the AI art world, and that makes me very sad. Because I am partially colorblind, and have ADHD, clinical depression, and other health issues that I'm less comfortable talking about. Because I can't work, and rely on family for housing and government assistance to afford essentials. For someone like me, the barrier to entry on art is high. I'm never going to own a drawing tablet, I can't get professional lessons, my focus sucks to the point where it's hard to follow tutorials no matter how much I want to, and even if all of that could be sorted, my own eyes are against me.
But I still have ideas. I still have pictures in my head that want to get out. Characters that want faces, scenes that want to be expressed, and the like. I'm still creative. I just can't properly express that creativity. Nor can I pay someone else to express it for me. However, I can tell an AI what I'm trying to depict. I can tweak the settings, make small changes, spend hours on end generating and re-generating, tweaking and re-tweaking, and making small edits that are within my power to do, until I have a picture that satisfies my need to bring the thing in my head to life. That's not "stealing". It's not pushing a button and letting the computer do the work for me. That's me having my own ideas, and trying to use the tools at my disposal to turn them into something that other people can see.
Plus, there's one other thing I can do. This is a picture I generated with AI that I'm actually quite proud of.

And do you know why? Because it started as this.

I fed my terrible MSPaint rough as hell doodle into an AI, and told it what the picture was supposed to be. And I tried again, and again, and again, until I was able to refine the result into something that I was happy with - which took a whole lot more than just pressing the button again, let me tell you.
This is my idea, from start to finish, and my shitty art became something that actually looks halfway decent. Yeah, I'm aware of the wonkiness and AI jank. I know the jawline's weird, his eyes don't match, and there's something up with his ear. It's not perfect, but it's a whole lot better than what I could do on my own.
Look, when it comes to stopping the commercialization of AI art, I'm right there with you guys. Fuck corporations that want to replace their whole art department. Fuck people who want to impersonate other artists, or take commissions to turn someone's description of what they want into a prompt. Hell, fuck the people who take the first result they're given without trying to refine it at all!
However, I don't want AI to die. AI is an accessibility option. AI is a tool that lets me go from saying for years, "I wish I could have art of my first D&D character, I have so many fond memories of him." to having that one picture. It lets me stop stealing every time I want a character portrait for a new TTRPG that I'm starting up. Because you know what? I don't have the ability to be a "real artist", and I never will. There's too many barriers for entry.
...and my situation is mild compared to what some people have to deal with. Sure, there are people who find ways to make traditional art despite disabilities, but that's an exception. It could be the rule. Why shouldn't it be?
As far as "theft" goes, I have yet to hear one explanation of why it's okay to use references, but not AI, that didn't boil down to "it's different when we do it". And what about collage? Is a collage art, or is it "theft?" What about sculptural works that use reclaimed objects? They didn't create that. They just decided how it would be arranged. Hell, what about pieces like "The Fountain" for that matter? That's a big problem I have with all this hate. If you applied the same standards to other things as to AI, then there's a lot of things that currently are art we'd have to say aren't any more.
If you have a problem with AI, why not work to make it better, instead of trying to deprive people who rely on it for self-expression of a creative outlet?
#ai#ai art#ai artwork#art#creativity#creative expression#self expression#accessibility#ai is an accessibility tool#ai art is art#all art is art#art is subjective#everyone deserves to be creative#self expression should not be gatekept#i know i'm opening myself up to receive hate#this is a touchy subject#a lot of emotions involved#but i wanted to share my perspective#i won't be replying to responses
9 notes
·
View notes
Text
Thoughts on “AI Art”
I’ve seen a lot of controversy over “AI Art” recently, with “AI Art” referring to images generated by text-to-image generators. Speaking as someone who has studied Computational Creativity as a graduate student (including reading the DALL-E 2 paper before the model had public access), I can confirm that these images are not considered to be AI art by experts in the field since the generator is not designed to act creatively - which is an entirely different discussion from whether any AI can truly be creative. I personally wouldn’t even consider these generators AI at all, creative or otherwise, since they are just matching patterns, not making rational decisions to solve problems, so “AI Art” is an inaccurate description of these images. That does not mean these images are not art though. Simply put, computational creativity is not the proper paradigm to analyze these works, and I suggest they instead be analyzed as digital art where the prompter is a digital artist using the generator as a tool to create their digital art.
While my profession is as a computer scientist, I identify first and foremost as a digital artist. I have thought long and hard about what it this means. My output is diverse, featuring images, text, audio, and things that integrate on all three like video games. Focusing on just the images, I’ve created them through a wide variety of means, including scanned sketches, digital painting, photography, editing existing images, and coding up my own programs that generate images (all images embedded are works of mine). What unites all these things are the process by which they were created and the resulting artifact: I provide information to some digital tool which transforms that information into the artifact, which is information that encodes the work. A computer is required to display this artifact in a way that a human can appreciation. This can be contrasted with something like sculpture, where the artifact is a physical object that is produced, and may be produced directly through the artist’s actions on the material being sculpted. In some cases though a physical artifact is then converted into a digital artifact using some tool that captures some information from the physical artifact using sensors and transforms it into the final encoding, so as long as the final artifact being distributed is digital (which is necessary for anything distributed digitally) then the artist is producing digital art.

It is easy to see how this process includes art that was produced at least in part using a text-to-image generator. The generator is one tool in the process, transforming text information into information encoding an image, but it’s not the only tool being used. For example, some hardware device such as a keyboard or microphone is used to transform physical actions from the artist into the textual information that encode the prompt. A subtle but more important part of the pipeline is the decision of what generator to use, which will be communicated to the computer the artist is using in one way or another. Any time an artist makes a decision which impacts the final artifact, they create information which will be passed through the pipeline. As such, the information used to generate the piece is more than just the information present in the prompt. This is especially true if the prompt went through several iterations with feedback from the generator, making the information in the prompt more specific to the intentions of the artist. Whether it comes from conscious control or subconscious distortions, it is this specificity of information that makes art art, putting something of the creator into the work.
There is a reason though that I did not list text-to-image generators among the tools that I use to make digital art. Simply put, while they can be used as a tool for making digital art, I find them to be a very poor tool for the task - I’ve played around with them like everyone has, but they are really more toys than tools at this point. The fundamental issue is not that don’t produce good looking results, but that they process fairly little specific information and so they simply aren’t very useful. It’s like the adage “an image is worth a million words” - if an image is essentially summed up in four words, then what value does the image have over the original prompt? The problem with text-to-image generators that attempt to mimic human perception is that we can apply the same sort of information transformation the generator applies using our own imagination, so merely converting the prompt to an image adds nothing. As a toy, the value comes from the fact you can’t predict exactly how the generator is going to interpret the prompt, but as an artist that is undesirable since the unexpected information is coming from the tool, not the artist. So while someone can certainly be an artist by coming up with creative idea for a prompt, using the generator instead of just writing the prompt doesn’t necessarily make them any more artistic.
There are times though were the use of the generator does add something to prompt beyond an arbitrary visualization, and thus we shouldn’t be automatically dismissive of “AI Art” even if most of what we see doesn’t use the generator artistically. I guess there are seven ways one could truly be artistic by utilizing text-to-image generators. That may sound like a lot, but all the ways are either limited or deviate from the idea of “AI Art”, and in the grand scheme of things seven ways to be artistic isn’t very many. I’ll go through them roughly in the order of increasing artistic control and deviating from the idea of AI art. The first is the most controversial, which is to simply generate many images and exploit serendipity by keeping only those that match the artist’s vision. While this may initially appear as cheating since the artist is apparently functioning as a critic rather than an artist, the artist is specifying information by choosing what to accept or reject, so it’s a valid approach to artistic expression. The thing that needs to be understood is that ANY work of digital could be potentially created through the combination of a random generator and a filter that selects a randomly generated piece that matches some artistic vision, but this method is extremely inefficient. As this relates to “AI Art”, the combination of the use of targeted prompts and the generator’s knowledge about the distribution of art greatly increases the efficiency of a search over randomly generated images.
In general, this sort of approach is typical to people working creatively in a new medium, where early actions are essentially random, but they become more purposeful as people discover what works to achieve the desired result. In this particular medium, this leads to the next way of using text-to-image generators, where prompts are not longer intuitively understood by the reader, but are intuitively understood by the prompter, allowing them to use prompts to an effect beyond what the reader gets out of reading them. This also includes things like Midjourney’s variation tag where the artist iteratively refines the work by iteratively refining the prompt as a search strategy. The prompts made in this way appear cryptic when taken out of context, but the process by which they were created was well understood. At this point the artist has significantly more control over what they produce, and it’s where you start to see serious artists attempting to master the medium rather than just people fooling around with a toy and accidentally creating something interesting. Still, it’s a MUCH less precise tool than pretty much any other tool for creating digital, with even some paper doll makers and filter apps (even while ignoring the information from choosing an image to apply the filters to) being able to process more information than most text-to-image generators while still being much easier for the artists to anticipate the effect of their actions. Sure, this is a tool that can be mastered to create art, by why bother when there are much better tools out there?
For the use of this medium to be truly meaningful, there needs to be an actual reason to work with it as opposed to using another tool. The more the more general reason to do this, and thus the decision that adds less specific information and artistic control, is to have the generative process be part of the concept in a conceptual work. In general, conceptual art is similar to “AI Art” in that the most essential information can be adequately represented with a textual description. The key thing though is the fact someone actually went through with the process of creating the art that was described creates meaning, some of which may be encoded in the final artifact produced in the form of unexpected, emergent information. There is no reason a text-to-image generator couldn’t be part of the process of producing the final artifact, and the fact AI as philosophical idea is of great interest means “AI Art” is a popular subject for concept artists. Aleatoric art where the artist chooses to sacrifice control to use the generator to add some noise their art as part of their artistic vision also fits in this category, but it’s not as fashionable right now because aleatoric art is old and AI is new. As it is this appears to perspective towards “AI Art” that the world of fine art (eg. the Museum of Modern Art) has taken, both because they value conceptual art more than the general population does, and because they aren’t AI experts so they think these “AI”s are much deeper than they actually are. With that being said, the fact “AI Art” has gotten me to write as much as I have means it certainly has potential as a discussion starter, so even if it’s not actually made by AI it’s still valuable conceptual art. Conversely, while I wouldn’t consider it to be AI, in most cases it is machine learning, which implies another use as conceptual art. The fact the models were trained on human data means the generated images are a form of visualization of that data. As such, “AI Art” can be used a means of reflecting our culture back at us, and if that isn’t art I don’t know what is.
The other reason to use a text-to-image generator is because one wants to evoke the specific aesthetics of art produced by a particular generator. Let’s get this out of the way first, “AI Art” tends to have an extremely detailed aesthetic and I don’t think there is anything wrong with using a generator to save time to achieve that aesthetic if it’s really what the artist wants. However, it’s also a watered-down version of the lowest common denominator variant of that aesthetic that gives the artist no control over said details, which is most the fun in drawing in that sort of style anyway. It’s aspiring to mediocrity instead of developing one’s own voice. As such, I don’t think that aesthetic is actually anyone’s artistic vision, most people going for it just want superficially impressive visuals without any further depth, creating the most banal of retinal art without actually being artists since they did nothing creative. More interesting is deliberately introducing the medium’s distinct aberrations - things like extra fingers and the like. This often has a conceptual basis in things like eldritch horror, giving it a specific artistic vision, and the subtler side effects of generation can’t be added by other means so more is being done than just saving time. There are things these generators can do that more conventional tools cannot that are more conventionally pleasing to the eye as well. The main thing I can think of is these generators have a very particular way of blending different images together. In general I’ve found the best artwork produced just by converting text to images is based around combining subjects that unexpectedly work well together.
To go any more control, the artist needs to provide more information than just a textual prompt. The most basic way to do this is for the generator to take in additional information beyond just a prompt. A good example would be a generator that takes in an image as a seed which it attempts to approximate while also satisfying the prompt. Since an arbitrary image can be taken as input, enough information can be given to specify any arbitrary image. Conversely though the generator would act more like a filter than a text-to-image generator if it too greatly resembled the input image. The amount of influence from the image or prompt can be mixed to varying degrees, with more influence from the image corresponding with greater control by the artist, but the generator acting more like image filter as well. For this I’ll focus when it lacks less like an image filter. In that case you can still get much more information from an image than from just a prompt, and it can be useful for specifying something like style information, which cannot be encapsulated entirely within a text description unless said style was already coded into the generator.
A prompter can get more control while still remaining a prompter by building their own text-to-image generator. All the generators people use in practice are machine learning models, so I’ll talk only about those. There are two ways to change a machine learning model. Either one can change the algorithm (and any of its hyper parameters) that is used to train the model, or they can change the dataset that the model learns from. Which of these to change depends on what the one is trying to accomplish. If one wants to embrace the alien aesthetic of AI, it would be best to alter the algorithm to induce desired artifacts. Altering the dataset meanwhile is used for controlling what images are being blended together. Note these modifications functionally enable doing anything additional input can do without actually adding the optional for addition input since any specific addition input can be added as part of the custom program. Really having input text at all is superfluous at this point, and there are much more interesting things that can be done with using machine learning to create images that converting text to images. I’m personally not a fan of machine learning as I find it much more finicky than other programming methods with less opportunities to be creative in algorithmic design, but I did make one work using machine learning. It’s not my favorite work by any means and the main reason I did it was just for a class project (I believe Nick Walton of AI Dungeon fame was in the same class), but it is my most favorited deviation on DeviantArt so I guess people liked it. I worry though that people liked it for the wrong reasons - while it’s nothing compared to the generators people use these days, at time it was made people found the technology impressive. I fear people liked the image purely for the technological potential and not for its actual artistic merit. We’re at the point now where AI Art is no longer novel, so it should be held to higher standards than as a novelty. There is still lots of potential for creative coding of new generators on practical, aesthetic, and conceptual levels that has not been realized. I just don’t think that potential is best exploited in the form of text-to-image generators, especially when half the draw of adding natural language interpretation in the first place was making generators accessible to people other than programmers since actual code gives so much more control than vague prompts.

Lastly, one can use the generator as one one step in a larger artistic pipeline. As the use with most control, it’s also the most readily accepted use in the online art community. The use I’ve seen with the most support is using the generator to create a reference, or for coming up with conceptual arrangements to then draw. I see some purpose in the prior when google results are limited, though I wouldn’t trust it’s abilities to fabricate a spatially accurate scene, and I just don’t get the appeal of using a generated arrangement rather than one I came up with myself, but people can use whatever they find works for them. I find it more interesting when the generated images are themselves edited as it allows an artist to take advantage both of the AIs unique style which cannot be created by hand while still adding in the richness of control that hand-drawn art has. Technically this would include when people edit out anomalies like extra hands out of piece, a process I see most often advocated by proponents of “AI Art” as proving some artistic skill is needed to make “artistically legitimate” “AI Art”, but I think that’s lame as you took out what made the process special in the first place. It’s suitable for saving time satisfying the most uninspiring sort of commissions, but not desirable for creating actual art. Instead, a method of editing “AI Art” I approve of is using it as a background. In particular I know one artist who draws characters into generated scenes in a way so they feel like they are part of the scene rather than just drawn on top of them, as seen here. I’d even go on to say that is the most interesting use of “AI Art” I’ve seen so far...which isn’t really saying much as for all the hype it really is just a bad tool for making art. There is one variation on this way for utilizing generators, which is where the generated image is an explicit component of a larger whole so the actual art is the content surrounding the image, and the only reason the image was used instead of the prompt that generated it is because the nature of the medium inherently requires images instead of text - think of stuff like comics and games. I personally wouldn’t be caught dead publishing something like that out using generated images, but it is an effective tool for developing prototypes which can be shared for early feedback. This is also one of the applications where artists feel the most threatened since they fear they are being used instead of commissions, but no one in their right mind would commission artwork at this stage of development because doing so would be prohibitively expensive when the images aren’t even going to included in the final product - the AI is just replacing bad sketches that the person would have made themselves as placeholders, or images they would have found online. Maybe some other people might use generated images in a final product, but they are probably people who couldn’t afford to commission artists anyway. So while text to image generators aren’t a great tool for art, they are still helping some people create art who otherwise wouldn’t be able the art they wanted to, even if the “AI Art” isn’t the actual art they made.
The key thing to note though is that while text-to-image generators are poor tools for creating artwork, they are not the only tool that uses the same sort of underlying “AI” technology (specifically deep learning) to create artwork, and thus the images they produce are not the only things being branded as “AI Art”. While there is at least some “AI Art” that is definitely art where the generative process was a meaningful contribution to the artistic process, my biggest issue with people dismissing “AI Art” is that it doesn’t just act as an attack against text-to-image generators, but a much wider range of art. As it is, there are already AI tools for art that are much more desirable. My favorite is NVIDIA Canvas, which allows the generation of photorealistic landscapes from an abstract version of the landscape the artist drew consisting of colored regions corresponding with landscape features. More importantly though we need to consider the technology not yet made. As it is, most AI generation tools were simply not created to be artistic tools, they are just tech demos to get people interested in the technology. Unsavory businesses have been quick to capitalize on the hype and attempt to capitalize on their own commercialized clones of these tech demos, but other people have actually been trying to create artistic tools, and are taking feedback from artists in the process of creating these tools. One professor I know is working on a co-creative AI (note the lack of quotes, I actually consider this to be AI instead of just being automatically classified as AI due to the use of deep learning, but that’s that's due to the computational creativity framework this AI is embedded in rather than any specific features of the algorithm) called Reframer where instead of the generative process being framed as the AI creating the art, there is continuous interaction between the artist and AI in generating novel images. Ultimately control is given to the artist, but they are free to let the AI tweak elements of the image to introduce news ideas in the image that the artist is free to accept or reject. What I ultimately see down the line is aspects of these different tools being integrated into a single tool such as the next generation of Photoshop, and they will be viewed with no more scrutiny than the current version of the magic lasso which already uses the same technology to segment the subject from the background. Stuff like NVIDIA Canvas could be added as type of paint bucket, co-creative AI could function like a sort of blurring tool, and text-to-image generators could be used in a manner akin to clip art. No one is going to view the art created in these programs as “AI Art”, it will just be viewed as digital art, even though it will be created at least in part using the same algorithms. The difference is not in how the art is created as even now people are using text-to-image generators as only one part in the larger image but still publishing the results as “AI Art”, but in the framing, and we should not be fooled by the framing of this art as “AI Art” in order to both dismiss it’s artistic merit, or exceptionalize the technology as a particularly insidious threat.
The tools I discussed previously would make creating certain works of art more efficient, even to the point where it may be infeasible for someone to create the results without the tools, but they are not theoretically impossible to create without them. It is possible for them to be applied in a way though that goes beyond a mere increase in efficiency. What I envision as being the greatest use of this technology for expanding artistic potential is in the use of video games. The key thing is these generators fill a niche that is simply impossible to fill without generation technology as without them a game cannot generate novel images on a fly. AI Dungeon has already started doing this, but the technology has much greater potential than just illustrating textual scenes. It could potentially be used to create new worlds. Games are one of the media where there is a practical difference in portraying information visually instead of textually, so generators will fill in the role bridging between the textual code specifying a world and the visual world the player interacts with. AI has had a long history in games, ranging from the traditional AI controlling opponents in most games to more interpretative AI like that in Façade, and the addition of images generators would be a natural addition to the procedural generation that many games depend on. Of course, it would be impractical for a game to wrap around a client like Midjourney, but all that is needed is the actual algorithm that does the generation, so something like Stable Diffusion could easily be used to implement this functionality. In practice a good game would probably need something a bit more sophisticated than Stable Diffusion since the goal would be to create sprites or models and not just images, but the technology isn’t going to get there without a starting point, and Stable Diffusion is an important development.
In conclusion, it should be obvious at this point that “AI Art” can be art. More importantly, the technology is still being developed, and has a lot of potential that has not yet been realized, including potential that cannot be reached through any other means. In order to realize this potential, we need to be tolerant to “AI Art”. Yes, a lot of “AI Art” is bad, but the does mean the medium itself should be condemned before it has the chance to be properly developed. We can also recognize the limitations of the current technology without being dismissive to those trying to make the most of it. After all, there is certainly a craft in making the most of the limits of a medium. So lets abandon the “AI Art is Not Art” mindset, and instead think “AI is a tool, it can be used for good or bad like any tool”, and encourage people who use the tool well while advocating for the development of tools that are actually would be useful for most artists.
With the question of whether or not “AI Art” is art out of the way, lets go over some of the ethical concerns about the medium. Please note that while I may occasionally refer to the law, this is a philosophical discussion of ethics, not a legal one. First and foremost is the question or whether or not “AI Art” is “art theft”. In short, it’s not, though it’s still exploitive in practice, and not necessarily original. The first thing that needs to be clarified is what even is art theft. The simplest definition as it applies to how the digital art community uses the phrase is that art theft is intentionally claiming someone’s work is one’s own. This differs from the actual definition of the phrase, which refers to the stealing of physical artifacts, but that doesn’t apply to digital art due to the ease of replicating digital files, and so we’ll use the phrase the way digital artists use it. It is worth noting that there are AI tools that aid in doing this, such as those which scrub out watermarks by attempting to infer what would be underneath them. However, “AI Art” does not do that, at all. It even ends up creating it’s own watermarks. When people create “AI Art”, they are intending to create their own art, not steal someone else’s, and thus it is not art theft by this definition.
The thing to note though is that “intentionally” is doing significant work here. The issue comes from the fact the generators people use are trained on the artwork of others, often without their consent. This issue may or may not actually be a problem as far as originality is concerned, but determining such requires picking apart what is actually going on here. What the models behind these generators do is learn distributions, which is just a function giving the probability that any image would be described with any description, which can be written as P(d|i). This distribution is then used to calculate the probability P(i|d) - when given any description, what is the probability that it is used to describe a particular image - and that probability is used as the probability that the generator will generator any particular image. The key thing to note about these distributions though is that they aren’t the distributions of images that actually were labeled with specific descriptions, but the distributions of images that could potentially be labeled as such. For example, if I were to show you a picture of a dog labeled “picture of a dog”, you could evaluate that is a likely description of the picture, regardless of whether or not you’ve seen that exact image with any particular labels before, as you intuitively understand the distribution of images of dogs. Conversely, if that same picture of a dog was instead labeled “picture of a cat”, you would likely evaluate it as being a less likely description of the image. The goal for these AI is for them to have the same intuitive understanding of what makes a “picture of dog” as we do.

While the ideal distribution covers all possible images, learning the distribution requires pairs of existing images and labels. These act as points the machine learning algorithm interpolates between, producing a function that ideally matches the distribution people use. In practice, that distribution is going to be affected by what pairs it was given, but in theory with an unbiased sample of enough pairs the distribution it learns will become indistinguishable in practice from the actual distribution. This has some important implications. First and foremost, the more images the model is trained on, the less it it is shaped by any particular image it was trained on. If there are enough images images describing a phenomenon to the point it has learned the actual distribution of the phenomenon, then it will cease to contain any distinct information describing any of the sources of images about the phenomena. To see how this works, lets consider the example of an artist being commissioned to drawn image of a dog without further instruction. The resulting image will be an image of a dog done by the artist, containing both general information about dogs as well as specific information the artist put in. Ideally the model will learns what images of dogs look like, in which case case all the specific information the artist put in that particular image of a dog will no longer be associated with dogs. As result when prompted to draw an image of a dog the AI would just draw an image of a dog, not an image of a dog inspired by any of the artists who happened to draw images of dogs.
While that’s the ideal, it’s not something that happens in practice as the samples are neither unbiased nor large enough to precisely learn the distribution. Of particular concern is the problem of overfitting, where a cruder approximation of the distribution was actually closer to the real distribution then the one that was ultimately used because the one that used was draws too much from it’s training data and fails to generalize in its interpolation. The most extreme cause of overfitting would be memorization, where the model reproduces specific images it was trained on. In practice, exact memorization has not been seen, but that doesn’t mean it’s impossible. As someone who has studies these generators, one issue I’ve always had with them is they have no rigorous proof that they will create original images, and at best they have empirical evidence only that they usually create images that aren’t exact copies of anything in their dataset and at least appear to be original with a surface level examination. This sort of empirical evidence only applies to image generators that don’t take strings as input though. The problem is that every individual prompt would need to be evaluated to see if it produces original images or not because while they dataset as a whole is extremely large and diverse, the set of images that relate to a particular prompt maybe extremely sparse or biased, and as a result overfitting will occur in that case even if the distribution models other prompts well. An example where this occurred in practice was with the prompt “Sharbat Gula“, where while each generated image was technically unique in terms of pixel values, anyone looking at it could tell it’s just recreation of the photo “Afghan Girl”. While this is not the only photo of Sharbat Gula, it is by far the most frequently referenced photo of her, resulting in the data set scraped over the internet becoming so biased towards that one image that it became as if the other images simply didn’t exist. This same phenomenon could potentially happen for any image.
Fortunately, it is easy to verify if a produced image is actually original. If the image was memorized exactly a reverse image search could easily find the original, and many reverse image searches can also identify if an image is essentially identical, like those produced of Sharbat Gula. More important though is identifying if the content of the image is original, which can also be verified in some cases. The fact that the model was trained on tagged images means the same tags can be used for verification of the content of the image. If someone can identify phenomena in the image which should be tagged and was present in the prompt, confirm that images with those tags separately exist in the data set, but no images with the combinations of tags can be found, then the image was confirmed to contain original content. The fact that such images exist shows the real power of these models, which is that they can visually capture complex semantic relationships. For this reason, the sort of artwork that I previously stated most effectively uses these tools by blending images together are also those whose originality can be most easily verified as being original. Ultimately whether or not “AI Art” is original needs to be handled on a case to case basis, but using good practices goes a long way to ensuring ordinality.
Lastly, lets discuss how “AI Art” is exploitive in practice. In order for these models to be trained, they require vast amounts of images, and those images had to come from somewhere. Many of those images came from artists without consent or compensation, and thus their labor was exploited to create the generators and any images generated by images. This is an issue of practice though, not theory. One common misconception is that “AI Art” requires existing artwork as the generators could not be trained otherwise. While they do require images, those images do not need to be art - the majority of the images most the generators are trained on are non-artistic photography. A model could be trained entirely on non-artistic photography and still be used to create artwork as that is sufficient to learn concepts that can be artistically composed. The problem with this approach though is that such a model would be extremely biased, as much of art depicts images that do not naturally occur, especially in terms of style. I would say such a model would be limited to only create artwork in a photorealistic style, but it would also include stylistic elements from the generation process, so I think “AI realism” may be a better description for the resulting style than photorealism. Regardless, it is a very specific style, and it’s extremely limiting for an artist to be contained to it when these generators are capable of producing so many other different styles.
The easiest way to get diverse artistic styles is to include artwork in diverse styles, but this isn’t strictly necessary either. The other potential source of images other than photos and artwork would be algorithmically generated or altered images. As far as computer generated images go, pre-training neural networks on fractals has proven to be an effective technique for getting them to learn to identify real objects as fractal patterns are often found in nature, but there is plenty of potential to use training on fractals for artistic effect as well, especially since generated fractals are definitely not photorealistic. There are also hard-coded methods for altering images in order to produce a particular style. A famous example would be the “oil paint” style, which is just a variation on a median filter. Pixel art styles are also easy to generate through down-sampling and rescaling. Potentially filters could be automatically applied to a data set of photos to produce additional images, which would then have style tags added based on the filter used to produce an augmented data set, and a model can be trained on the augmented data set. This approach would still be limited to styles that coders have figured out how to induce algorithmically, but it gives a much wider range of styles then could be produced using photos alone.

Its also possible to include only artwork that was consensually given for training. It won’t cover everything, but I’m sure enough people would consent to cover the breadth of what is out there. The reason this wasn’t done was simply efficiency - scraping is much faster than getting data from volunteers, and previous court cases have established that permission is not needed to scrape data for many applications. It’s also worth noting that in many cases people actually did consent for the images they uploaded to be used for training these models, they just didn’t realize they did because they failed to read or understand the terms of service for the sites they were using. Conversely, it’s difficult to verify if the artist behind a work of art actually consented to their art being used because the uploader may not have been the artist - just look at the mess with NFTs - but manually verifying each work in a collection large enough to train these models is not feasible, and people who run sites used to create such collections have certain legal protections against the illegal activities of users due to inability to moderate all user activity. Legality aside, its of course preferable to get people’s express permission if possible, and if nothing else respect people’s wishes to not be included, which is the case for many people.
It’s worth noting though that withholding one’s artwork from generation could potentially backfire. In order to get something to specifically not generate something, you must provide the same information that would be used to generate it. In the short term this could manifest in something like a black list - a good way to learn swear words is to figure out what words are being censored. In the long term, things that are forbidden to generate would leave a hole the distribution. Just like a figure can be made from a hole in a mold, this hole could potentially be used to recreate the missing images, and thus something being conspicuously absent from a data set could make it be easier to generate than if if the dataset matched the true distribution. I don’t think this would ever happen in practice in art since it’s just so vast, but it has happened in other contexts where it’s a security concern. In theory though there is a point where before which some people would want their art to be included in the set to increase the spread of the information encoding it, and after which people would their art to be included to *decrease* the spread of information encoding it. I don’t think that point would ever actually be reached though except in very specific contexts (liking trying to exhaust a particular style of minimalist art), so we can focus on before that point.
I for one would not only gladly allow my art to be used to train generative models, but would go out of my way to ensure its included in their datasets. This is because I’m generally of the copyleft mentality rather than the copyright mentality. Not only do I enjoy helping others by giving them access to my work to sample, but it benefits me as well since it ensures *my* work is spread, broadening it’s impact. To be frank, I’ve never really understood the obsession over art theft, and I think I’d be flattered if someone considered my art to be worth stealing, but maybe that’s just because it hasn’t happened, and as a hobbyist my incentives differ from that of professional who may be more concerned with making money than making an impact. Regardless, “AI Art” is not art theft, but distinct phenomenon. The dataset for Stable Diffusion is public and includes the source for all images in it, so the credit is given in addition to the impact. Aside from being taken without permission the only thing not being given is compensation, but there is no reason a future generator trained only on voluntarily given images couldn’t pay artists to use their images. Since some of these generators charge people to generate it even opens up the possibility for paying royalties on generation, though figuring out how much to give to each artist for each image is an unresolved technical problem that goes beyond the scope of this discussion.

While artists can be compensated, that is largely not happening in practice. The reason for this is the same for why the images are used for training without express permission - scraping existing images is much more efficient than curating a novel collection with all the desired properties. As it stands, there is clear precedence for the legality of scraping (though how the scraped data is used or stored may be illegal - I’m not lawyer so take my discussion of legality with a grain of salt), and it serves an essential function, though being legal is not the same thing as being ethical. The way scraping is used is definitely exploitative because the labor of artists is being used to benefit those who create and use these generators without compensating the artists for their labor.
It’s important to note though that just because “AI Art” is exploitive doesn’t mean said exploitation is necessarily unethical. There are different ethical frameworks, but a good one to analyze the accepting of this exploitation is meeting the standards of nonmaleficence (do not harm) and beneficence (do good), which are the main guiding principals in human subject research (there is also a third principal of respecting autonomy, but we’ve already covered that). This is particularly relevant because the development of the tools for “AI Art” has been driven by research for the purported public good, whether it’s OpenAI’s DALL-E or Stable Diffusion from Ludwig Maximilian University of Munich. In terms of beneficence the obvious benefit is the creation of new means of production which have the potential previously described, but its also important to consider the broader context of this research that goes beyond the application of image generators for tools of art. I’ve seen people complain about the fact art is being automated rather than processes people don’t enjoy like say cleaning, but what people who aren’t experts in this field don’t realize is that this research is a step in doing the latter. The key thing is image synthesis and image recognition are two sides of the same coin - as previously stated, the same distribution provides the information both to label and generate images. In order to build a cleaning robot more sophisticated than a washing machine, sensors are needed, and image processing is needed to use visual data from those sensors. The reason why image synthesis is valuable is because it allows us to visualize the distributions that are needed for image recognition tasks - if a generator produces output that make sense, then it means it has a good understand of the underlying concepts that the distribution is designed to emulate. This is the express purpose of the earliest image synthesis research, such as that which lead to the development of Google DeepDream. Art generation has never been the primary concern of research in this field, it’s just a gimmick to develop public interest, which it’s been incredibly successful in doing. When you consider the applications of image recognition, it’s clear there is immense potential for public benefit in domains ranging from accessibility to robotics to medicine, so the criteria of beneficence is clearly reached.
Now lets cover the issue of non-maleficence. First lets get this out of the way, I see people passing around lists of “victims” of “AI Art”, but training AI on someone’s artwork does not automatically victimize them. In particular, I see an example being passed around of models being trained on a recently deceased artist’s work. While this is in poor taste and clearly exploitative as it does nothing to benefit the dead, it’s also clearly harmless as the dead can’t be harmed either. It makes no difference if an artist has been dead for days or centuries, in both cases it’s equally exploitive and harmless, it’s just in worse taste in the prior case. While merely using an artist’s art to train a model does not harm them, there are plenty of ways a trained model can be used to to harm the artist whose art it was trained on. For example, it could be used to produce forgeries which can in then be used to damage an artists reputation. I’m not going to go into all the potential ways the technology could be used to harm people as they are limited only by imagination, I just think it suffices to say there are legitimate ethical concerns with the development and use of this technology. I think the potential for good far outweighs the potential for harm, but it’s important for researchers to follow best practices in order to minimize the amount of harm done.
Lastly I’ll address a specific form of potential harm, which is the issue of if the AI are stealing jobs rather than art. The answer to that is maybe, but banning AI in response is a terrible idea that I in no way support. Actually proving AI is replacing artists is extremely hard to do. People using “AI Art” in applications where they potentially could have commissioned an artist does not prove damages because there is no guarantee they would have commissioned an artist if AI wasn’t an option. People frequently point to Christopher Paolini’s book Fractal Noise, but what they fail to realize is that “fractal noise” is a technique used in computer generated imagery to produce realistic looking images, so it’s likely his intent was always to use a computer generated image for the cover of the book. Merely having someone train their model on an artist’s work and sell what their generator produces is not enough to prove damages because there is no guarantee someone would have bought from the original artist instead of the “pirate”. Even an aggregate reduction in sales isn’t enough to prove damages because it only proves that the reduction is correlated with the rise of “AI Art”. Establishing a causal relationship is especially fraught because the rise of “AI Art” coincided with the COVID-19 Pandemic, which caused a massive reduction in most people’s disposable income and thus can be provided as an alternative explanation for reduced sales. Even without proof though it’s certainly possible that “AI Art” may hurt artists financially by outcompeting them through increased efficiency. While there may be short-term negative effect for artists, improving efficiency has a long-term positive effect for everyone, and so I’m a priori against impeding technological progress.

The common response to this is that efficiency isn’t everything, and a lot is lost in the process of increasing efficiency. This is true if one chooses to use the technology, as discussed in all the ways that these generators are bad tools for art, but in an ideal would all technological advancing does is give people more options - if someone doesn’t like using these tools they can continue to use what they have been using. This is not the case in reality due to competitive market forces that may valuing efficiency over all else by favoring quantity over quality, but that reveals the real problem is an economic one, not a technological one. As such the solution to the problem should be fixing the economy, not fighting technological process.
From a purely economic standpoint, the proper solution in a capitalist system with social welfare would be to pay structurally unemployed people so they may be retrained and cease to be structurally unemployed, and continue to pay those who cannot be retrained - not only because it’s humane, but to act as security for other positions which people fear may be replaced in the future to ensure people still develop those skills while they are needed. Since its good for the economy this does happen to some extent, but it doesn’t happen more because someone needs to decide who is structurally unemployed, and people are reluctant to spend public funds to help others unless they get something themselves. The other issue is that it implies people may no longer be artists for a living unless they adopt these tools they do not want to use, which is not desirable because people like doing art, and they like doing it well. While this frankly sucks, its not a particularly great evil as far as class struggle is concerned, and people who have the time are going to continue making art regardless.
A popular misconception here about professional artists is that they are poor because they are working class. Professional artists are actually overwhelmingly middle class, which makes sense because time is needed to develop artistic talent and said time is a privilege afforded by wealth which then becomes a form of personal capital. Aside from the difference in upbringing, a key reason artists do not belong to the working class is that they are not paid wages - generally they are paid salary if they are contracted to a single employer, paid for gigs in the form of commissions, or earn money as entrepreneurs selling their own creations, all traits of professionals in the middle class. The reason artists don’t make as much money as many professionals is because collectively they choose to pursue something they enjoy doing over something that makes more money, which in turn drives the price of art down by increasing supply without increasing demand. In a capitalist society, it is an immense privilege to be able to afford to do work one enjoys. It is true some people turn to art because as a result of disability they are unable to thrive in more typical work environment and I’d hardly call such people privileged, but price is determined collectively, not individually. It would be great if everyone was so privileged, but with the previously proposed solution the worst case is most artists lose their privilege and join the working class, while those who are disabled will continue to receive payment due to being unable to be retrained.
One thing that is overlooked in the discussion about “AI Art” though is the main victims of the use of the technology aren’t artists, but stock photographers. Not only are the majority of the images used to train these models photographs and not art, but the use case is quite different due to it being a poor tool for art and the fact art’s value increases with originality. Meanwhile, the use case of text-image generators is very similar to that of stock photography - type a phrase to find matching images to some ideal without regard to originality, then taking what is available and editing them as needed. The difference is stock photography is limited to only things stock photographers have bothered to take pictures of and label, while generators can create novel combinations on the fly. Ultimately I think making stock photography become obsolete is a good thing, but it is important that this is not due to the exploitation of stock photographers, and that when such obsolescence occurs that the people who used to be stock photographers are properly cared for. Currently there is lawsuit by Getty against Stability.AI, which from what I’ve seen lawyers seem to agree is a much more substantial suite than the one artists made against the same company, both with being more technically accurate with regards to how the technology functions, and to what rights were violated and what potential harms occurred, and from reading the suits myself I agree with the consensus. However, while it is standard practice in suits to overshoot, their demands are frankly ridiculous, and I think their request to have Stable Diffusion destroyed is particularly problematic as it would be futile, dangerous, or both due to it being an open-source model. Regardless, they deserve compensation for the use of their images in training this model. Ultimately though stock images are not needed to train these models, they just accelerate the process, and unless major attempts are made to curb technological progress in general this specific aspect of technological progress with continue and the stock image industry as we know it will likely die.
Unfortunately, there are in fact people demanding a stop to AI research, and I’m not talking about the letter for a pause with models larger while safe AI research is funded, but fully stopping it in a much more generally sense. This is a terrible idea, not just because it prevents all the benefits of AI that go far beyond art tools, but because it would induce the same problems such a halt is attempting to solve. Demands to stop AI research would put AI specialists such as myself out of work, as well as working class people who make their living adding labels to data. The latter has become a major industry in recent years, and in particular has vastly improved employment of autistic people - the latter being something I discovered while working on my Master’s thesis, which centered on the problem of increasing gainful employment for autistic adults. While its not as fun as making art, its much more accessible as a career for many people, and has been a life changer for many in the same way.
What we should get out of this is that the economic conditions suck for everyone involved. The real tragedy is not that people lose their jobs as artists, but that art was even commodified in the first place. Ideally everyone should be able to make the art they want, free from commercial pressure, and still receive a living wage. Achieving such may require radical economic upheaval, but in the meantime I think it the best option is for people in arts and people in tech to work together to pursue their common interests instead of manufacturing conflict between “techbros” and “drawslaves”. One of the great things about software in comparison to other means of production is that it is easily to duplicate, and thus easier to work for equitable improvement of society instead of further empowering capitalists. As it is there are many attempts to monetize text-to-image generation, which is understandable since creating the necessary models is expensive, but it gives those who are already wealthier an advantage. Conversely, there is also a large open-source community developing these tools for free use. If so, artists would be as free to use these tools as profiteers and could make the same output as them at the same rate, but since they are also more skilled they can produce higher quality art at a faster pace as well and thus have the competitive advantage so they can drive the profiteers out of the market and defend their livelihood.
To achieve this, artists should support the open source community in it’s development of ethical tools for art creation. Both communities have something the other wants - the open source community wants art so they can train their models, while artists need affordable tools so they can retain their competitive advantage in the face of proprietary software benefiting wealthy outsiders. An explicit alliance can work to ensure training data is ethically sourced so the autonomy of artists is respected and they are properly compensated, and ensure the tools developed are useful for artists, including fixing many of the existing problems that are prevalent with “AI art”.
Frankly, most the problems with “AI art” discussed could be solved with people just being honest about how they create their art. For example, if people value art which required great skill to create, which many do, then they can choose to buy art that was not generated with text, and thus skilled artists are secure in their position. Lying is generally unethical so this is not a problem with the technology itself and has been a problem in the art world long before AI was a thing, but the technology may actually help solve this problem. For one, machine learning can be used to detect generated images by recognizing the aberrations characteristic of the technology, allowing cheaters to be flagged. Tools can also be designed so they keep track of what images they generate, making it trivial to detect anyone who cheated using that particular tool. DeviantArt has already started working on both approaches, so we can see how effective it ends up being, but for their efforts I think DeviantArt deserves more respect than they’ve been getting after their last couple missteps. Outside of DeviantArt there are plenty of other developers worth allying with.
Ultimately I think the greatest contribution of “AI” to art will not be as an artistic tool, but be liberating artists from non-art labor so they can spend more time creating actual art. In the same way that photography liberated painters from realism by decreasing the demand for portrait paintings without decreasing the demand for art, “AI” can cause a second artistic revolution. Lets face it, the greatest demand these generators are replacing that would have gone to artists is porn commissions, and those are not art. This is not to say erotic art is not art because of course it is, but if someone who was commissioned to draw “Disney’s Pocahontas with big tits” can be effectively replaced by an text-to-image generator handling the same prompt then they clearly weren’t really drawing anything of artistic value in the first place. After being able to get generate their own porn people are going to have the same money they would have spent on commissioning porn left over, and some are going to continue to use it to commission artists. Hopefully they will commission actual art, or better yet act as patrons, giving their favorite artists more freedom as to what to create while financially supporting them.
So yeah, while most “AI Art” produced right now has little artistic value and is causing plenty of problems, I do think its long term potential is for the better of the art community, and is just yet to realized. It’s important to realize the problem is not the technology, but the economy. The villains here are not AI researchers, but those who use the technology unethically, and are driven to do so by financial incentives. The economy emerges from people’s actions though, so we can change things for the better, and in particular the same technology that is being blamed now can help the current issues. Realizing this potential is dependent on supporting the ethical development and use of the technology. Instead of trying to fight a losing battle and making untold enemies, it is better to make friends and art will be for the better for it.
TL;DR: AI Artists are the real artists, while drawslaves are mere pretentious artisans.
#ai art#drawslaves#ai art is not art#ai art is art#ai art debate#ai art discussion#ai artists#ai art can be art#ai is a tool#ai art is not art art theft#art theft#dalle2#stable difusion#gans#image synthesis#ai research#ethical ai#conceptual art#retinal art#art#remix culture#human subjects research#ganondox#deep dream#fractal noise#dalle 2#digital art#stock photos#deviantart#technology
8 notes
·
View notes
Text
AI art is art because I consider it art
3 notes
·
View notes
Text

Ok if you've seen this moral panic post going around about this film's backgrounds done "in Al" I just want to say fuck it and fuck everyone complaining about "oh no robots are stealing Actual Real Human Jobs don't watch it !!!". Here's some info :
A lot of your favorite anime shows have backgrounds TRACED STRAIGHT FROM PHOTOS, sometimes even just photos processed to look like they're drawn. Also you may not know this if you've never set foot in the actual animation industry but your favorite modern digital animated shows and films all use automation in some way to the point where programs like TV Paint have built-in auto coloring and stabilizing the frames, After Effects has interpolation and movement/timing/deformation keys, because it makes things way easier and faster. That's the thing about film and art, there isn't just "one proper way" to make something. If you think it's unethicaI of this film's crew to not hire background artists, why don't you start insulting digital animation films and shows for not hiring inkers and cell painters ? It's too bad the GAN users aren't properly named in this film's credits, but let's get real, that's no reason to morph into the "techonology is bad fire is scary Edison was a witch" guy (and if they were credited you fuckers would send them death threats to no end like you already do with artists that work with Al).
And if you think a good film has to have everything and every frame drawn and animated by hand, if you think using anything other than fully hand drawn backgrounds (say, actual photos or random paint splatter for backgrounds) would be cheating, you are not only against some of the big studio films you love, but also reactionary and very much against experimental digital media.
Not to mention the appeal to emotions with that "3D and Al and automation is stealing Real Artists' jobs, we must protect background artists" shit and a fucking reaction pic of Miyazaki is laughable when you know the horrible "you have to work harder and overtime and cheaper because that's what Real Artists do" workplace environment many GhibIi artists and animators faced. The man's studios broke labor laws, he thinks 3D is the end of animation because it's not the kind of animation he's been making for decades, and you fuckers applaud him as the ~icon of cottagecore anti-technology true artisan workers that makes his employees do RealArtTM which takes 10000 hours~.
No, drawing isn't over because photography exists, hand drawn animation isn't over because 3D exists, and hand drawn backgrounds won't be over if some anime studios use GANs to generate some instead of taking photos and running them through Photoshop like they used to.
14 notes
·
View notes
Text










13 notes
·
View notes
Text

Powerful, beautiful, proud.
#ai art#ai art gallery#ai art generation#ai art generator#ai artwork#ai assisted art#aiartcommunity#aiartdaily#aiartist#aiartlovers#ai generated#my ai art#powerful black woman#black femininity#black queen#ai art is art#beautiful women#african beauty#representation matters
2 notes
·
View notes
Text
Normalize this response

150K notes
·
View notes
Text
No. they don't look real at all. There are many glaring issues besides the wonky hand, but most of all people should at least be able to discern the fact that the lighting and the compositions are much too "perfect" for them to be real. These look very very staged and composed. They are images of stereotypical white "men" and very pretty white women. They're blatantly obvious in their fakeness. So the problem isn't AI art. The problem is that people are not using a critical eye and their brains before just hitting a button and sharing. It's absolutely disingenuous to blame this on AI art.
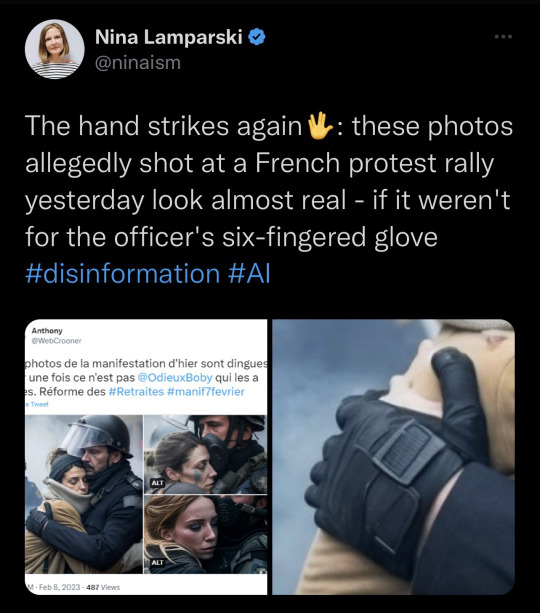
Once the bugs get ironed out, AI Image Generation will forever change propaganda and how easy it is to make and distribute.
93K notes
·
View notes
Text
AI disturbance overlays for those who don't have Ibis paint premium. found them on tiktok






#ibispaintx#fuck ai art#fuck ai everything#fuck ai all my homies hate ai#fuck ai bros#fuck ai writing
111K notes
·
View notes
Text
As gen-AI becomes more normalized (Chappell Roan encouraging it, grifters on the rise, young artists using it), I wanna express how I will never turn to it because it fundamentally bores me to my core. There is no reason for me to want to use gen-AI because I will never want to give up my autonomy in creating art. I never want to become reliant on an inhuman object for expression, least of all if that object is created and controlled by tech companies. I draw not because I want a drawing but because I love the process of drawing. So even in a future where everyone’s accepted it, I’m never gonna sway on this.
#personal#im still fighting it but im also a realist so I’ve accepted that this will be our future#rant#gen ai is fucking boring#I hope this doesn’t make me sound like a ‘going against the crowd. not like the rest of society’ type (it would be depressing if it did)#but yeah even in a world where it’s considered totally fine to use ai to make art I’ll still be using my bare hands#because I like it and nobody can take that from me#if you’re a young artist interested in or already using ai. just know that the thing you rely on to make art can be taken away at any point#all of it. and there’s nothing you can do about it if they decide to. it doesn’t belong to you
40K notes
·
View notes


Text
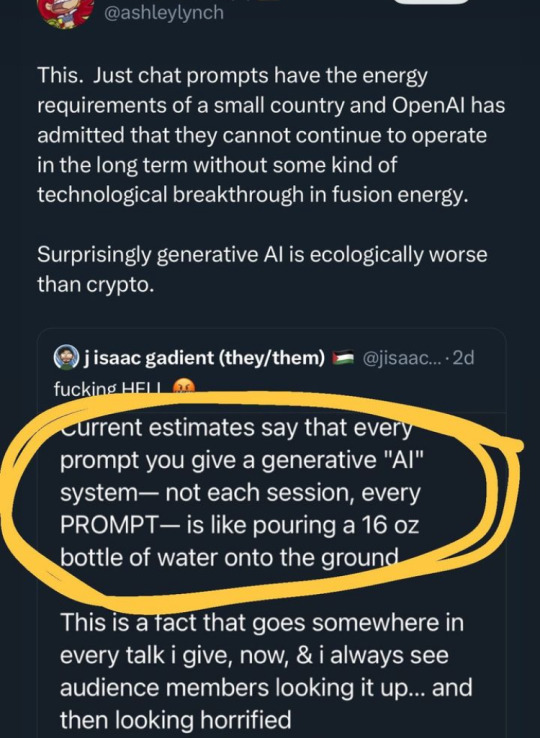
#ai#ai art#climate change#ecology#ecocide#water rights#land back#respect water treaties with First Nations#wasteland#waste#waste fraud and abuse#desertification
63K notes
·
View notes
Text
This machine kills AI
81K notes
·
View notes
