#Search
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Photo

Late night searches. A fear submitted by Jackie to Deep Dark Fears - thanks!
You can find original art in my shop!
#comics#Deep Dark Fears#DeepDarkFears#scary movies#fear#scary#sketch#sketchbook#art#illustration#watercolor#nightmares#nightmare#phone#search#mania
9K notes
·
View notes
Text
Even if you think AI search could be good, it won’t be good

TONIGHT (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

The big news in search this week is that Google is continuing its transition to "AI search" – instead of typing in search terms and getting links to websites, you'll ask Google a question and an AI will compose an answer based on things it finds on the web:
https://blog.google/products/search/generative-ai-google-search-may-2024/
Google bills this as "let Google do the googling for you." Rather than searching the web yourself, you'll delegate this task to Google. Hidden in this pitch is a tacit admission that Google is no longer a convenient or reliable way to retrieve information, drowning as it is in AI-generated spam, poorly labeled ads, and SEO garbage:
https://pluralistic.net/2024/05/03/keyword-swarming/#site-reputation-abuse
Googling used to be easy: type in a query, get back a screen of highly relevant results. Today, clicking the top links will take you to sites that paid for placement at the top of the screen (rather than the sites that best match your query). Clicking further down will get you scams, AI slop, or bulk-produced SEO nonsense.
AI-powered search promises to fix this, not by making Google search results better, but by having a bot sort through the search results and discard the nonsense that Google will continue to serve up, and summarize the high quality results.
Now, there are plenty of obvious objections to this plan. For starters, why wouldn't Google just make its search results better? Rather than building a LLM for the sole purpose of sorting through the garbage Google is either paid or tricked into serving up, why not just stop serving up garbage? We know that's possible, because other search engines serve really good results by paying for access to Google's back-end and then filtering the results:
https://pluralistic.net/2024/04/04/teach-me-how-to-shruggie/#kagi
Another obvious objection: why would anyone write the web if the only purpose for doing so is to feed a bot that will summarize what you've written without sending anyone to your webpage? Whether you're a commercial publisher hoping to make money from advertising or subscriptions, or – like me – an open access publisher hoping to change people's minds, why would you invite Google to summarize your work without ever showing it to internet users? Nevermind how unfair that is, think about how implausible it is: if this is the way Google will work in the future, why wouldn't every publisher just block Google's crawler?
A third obvious objection: AI is bad. Not morally bad (though maybe morally bad, too!), but technically bad. It "hallucinates" nonsense answers, including dangerous nonsense. It's a supremely confident liar that can get you killed:
https://www.theguardian.com/technology/2023/sep/01/mushroom-pickers-urged-to-avoid-foraging-books-on-amazon-that-appear-to-be-written-by-ai
The promises of AI are grossly oversold, including the promises Google makes, like its claim that its AI had discovered millions of useful new materials. In reality, the number of useful new materials Deepmind had discovered was zero:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
This is true of all of AI's most impressive demos. Often, "AI" turns out to be low-waged human workers in a distant call-center pretending to be robots:
https://pluralistic.net/2024/01/31/neural-interface-beta-tester/#tailfins
Sometimes, the AI robot dancing on stage turns out to literally be just a person in a robot suit pretending to be a robot:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
The AI video demos that represent "an existential threat to Hollywood filmmaking" turn out to be so cumbersome as to be practically useless (and vastly inferior to existing production techniques):
https://www.wheresyoured.at/expectations-versus-reality/
But let's take Google at its word. Let's stipulate that:
a) It can't fix search, only add a slop-filtering AI layer on top of it; and
b) The rest of the world will continue to let Google index its pages even if they derive no benefit from doing so; and
c) Google will shortly fix its AI, and all the lies about AI capabilities will be revealed to be premature truths that are finally realized.
AI search is still a bad idea. Because beyond all the obvious reasons that AI search is a terrible idea, there's a subtle – and incurable �� defect in this plan: AI search – even excellent AI search – makes it far too easy for Google to cheat us, and Google can't stop cheating us.
Remember: enshittification isn't the result of worse people running tech companies today than in the years when tech services were good and useful. Rather, enshittification is rooted in the collapse of constraints that used to prevent those same people from making their services worse in service to increasing their profit margins:
https://pluralistic.net/2024/03/26/glitchbread/#electronic-shelf-tags
These companies always had the capacity to siphon value away from business customers (like publishers) and end-users (like searchers). That comes with the territory: digital businesses can alter their "business logic" from instant to instant, and for each user, allowing them to change payouts, prices and ranking. I call this "twiddling": turning the knobs on the system's back-end to make sure the house always wins:
https://pluralistic.net/2023/02/19/twiddler/
What changed wasn't the character of the leaders of these businesses, nor their capacity to cheat us. What changed was the consequences for cheating. When the tech companies merged to monopoly, they ceased to fear losing your business to a competitor.
Google's 90% search market share was attained by bribing everyone who operates a service or platform where you might encounter a search box to connect that box to Google. Spending tens of billions of dollars every year to make sure no one ever encounters a non-Google search is a cheaper way to retain your business than making sure Google is the very best search engine:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
Competition was once a threat to Google; for years, its mantra was "competition is a click away." Today, competition is all but nonexistent.
Then the surveillance business consolidated into a small number of firms. Two companies dominate the commercial surveillance industry: Google and Meta, and they collude to rig the market:
https://en.wikipedia.org/wiki/Jedi_Blue
That consolidation inevitably leads to regulatory capture: shorn of competitive pressure, the companies that dominate the sector can converge on a single message to policymakers and use their monopoly profits to turn that message into policy:
https://pluralistic.net/2022/06/05/regulatory-capture/
This is why Google doesn't have to worry about privacy laws. They've successfully prevented the passage of a US federal consumer privacy law. The last time the US passed a federal consumer privacy law was in 1988. It's a law that bans video store clerks from telling the newspapers which VHS cassettes you rented:
https://en.wikipedia.org/wiki/Video_Privacy_Protection_Act
In Europe, Google's vast profits lets it fly an Irish flag of convenience, thus taking advantage of Ireland's tolerance for tax evasion and violations of European privacy law:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
Google doesn't fear competition, it doesn't fear regulation, and it also doesn't fear rival technologies. Google and its fellow Big Tech cartel members have expanded IP law to allow it to prevent third parties from reverse-engineer, hacking, or scraping its services. Google doesn't have to worry about ad-blocking, tracker blocking, or scrapers that filter out Google's lucrative, low-quality results:
https://locusmag.com/2020/09/cory-doctorow-ip/
Google doesn't fear competition, it doesn't fear regulation, it doesn't fear rival technology and it doesn't fear its workers. Google's workforce once enjoyed enormous sway over the company's direction, thanks to their scarcity and market power. But Google has outgrown its dependence on its workers, and lays them off in vast numbers, even as it increases its profits and pisses away tens of billions on stock buybacks:
https://pluralistic.net/2023/11/25/moral-injury/#enshittification
Google is fearless. It doesn't fear losing your business, or being punished by regulators, or being mired in guerrilla warfare with rival engineers. It certainly doesn't fear its workers.
Making search worse is good for Google. Reducing search quality increases the number of queries, and thus ads, that each user must make to find their answers:
https://pluralistic.net/2024/04/24/naming-names/#prabhakar-raghavan
If Google can make things worse for searchers without losing their business, it can make more money for itself. Without the discipline of markets, regulators, tech or workers, it has no impediment to transferring value from searchers and publishers to itself.
Which brings me back to AI search. When Google substitutes its own summaries for links to pages, it creates innumerable opportunities to charge publishers for preferential placement in those summaries.
This is true of any algorithmic feed: while such feeds are important – even vital – for making sense of huge amounts of information, they can also be used to play a high-speed shell-game that makes suckers out of the rest of us:
https://pluralistic.net/2024/05/11/for-you/#the-algorithm-tm
When you trust someone to summarize the truth for you, you become terribly vulnerable to their self-serving lies. In an ideal world, these intermediaries would be "fiduciaries," with a solemn (and legally binding) duty to put your interests ahead of their own:
https://pluralistic.net/2024/05/07/treacherous-computing/#rewilding-the-internet
But Google is clear that its first duty is to its shareholders: not to publishers, not to searchers, not to "partners" or employees.
AI search makes cheating so easy, and Google cheats so much. Indeed, the defects in AI give Google a readymade excuse for any apparent self-dealing: "we didn't tell you a lie because someone paid us to (for example, to recommend a product, or a hotel room, or a political point of view). Sure, they did pay us, but that was just an AI 'hallucination.'"
The existence of well-known AI hallucinations creates a zone of plausible deniability for even more enshittification of Google search. As Madeleine Clare Elish writes, AI serves as a "moral crumple zone":
https://estsjournal.org/index.php/ests/article/view/260
That's why, even if you're willing to believe that Google could make a great AI-based search, we can nevertheless be certain that they won't.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/15/they-trust-me-dumb-fucks/#ai-search
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
djhughman https://commons.wikimedia.org/wiki/File:Modular_synthesizer_-_%22Control_Voltage%22_electronic_music_shop_in_Portland_OR_-_School_Photos_PCC_%282015-05-23_12.43.01_by_djhughman%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#twiddling#ai#ai search#enshittification#discipline#google#search#monopolies#moral crumple zones#plausible deniability#algorithmic feeds
1K notes
·
View notes
Note
I recently encountered yet another tumblr user who didn't realize that the Blog Settings option to hide your blog from search engines also includes tumblr's own search. It's surprisingly common in my experience, where people for years complain that search is broken for their blog, or that their posts don't show up in the public tags/search, but have no idea it was their own choice that put them in that situation. I know that the explainer text for the "discourage searching of [blog]" option is definitely more detailed than it used be, but if you haven't checked your settings since then, well...
Anyway, is it possible that the option could be separated into "hide from external search engines" and "hide from tumblr's search"? For people who would prefer not to be googleable (and assumed that's the only thing the option was doing) but are ok with their posts showing up in tumblr's own search.
Or possibly the options could be "hide from external search engines" and "turn off tumblr search for my blog"? Or at the very least, could there be further explainer text that hiding your from tumblr's search means that your blog's own searchbar won't ever find anything?
Answer: Hello, @nobodysuspectsthebutterfly!
Well, what do you know. We were looking at this same issue just recently and could not agree more: this setting really should be separated. Ideally, it would look a little something like this:
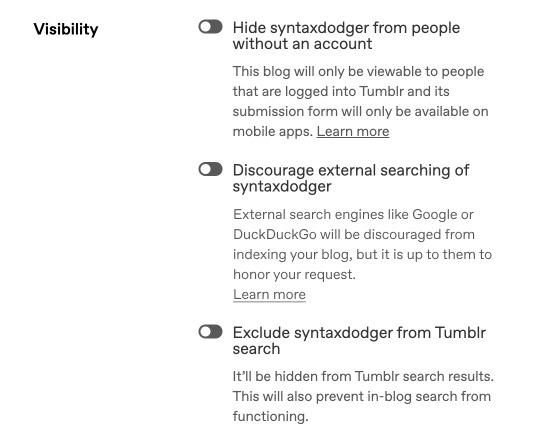
We need to take another look at this, as splitting search settings into Tumblrs vs. others makes a whole lot of sense. What is less clear is when a member of the team will have the capacity to work on it.
But rest assured we will be adding this to our agenda, and will be in touch with you with updates as and when we have them. And we hope you do not have to wait too long for news on this. We’ll keep you posted!
2K notes
·
View notes
Text
Remus, watching James do push-ups: Woah, he's been going at that for a while now. I wonder where he gets all that motivation.
James, to himself: I'm gonna be so good at hugging my friends. I'm gonna be so good at hugging my friends. I'm gonna be—
#marauders#james potter#remus lupin#the marauders fandom#james potter headcanon#incorrect marauders#incorrect quotes#search#remus and james#james and remus#james potter incorrect quotes#potter#harry potter#hp#hogwarts#quidditch#marauders fanfiction#ao3#ao3 writer#ao3 fanfic
578 notes
·
View notes
Note
Hi Jstor! Bless what you do, but I have to know: is there a way you can filter out reviews of articles? I keep trying to find specific articles for some searches and all I get is reviews by other people OF the specific article.
If it does not exist yet, maybe that's a function to look into eventually? It'd sure make my life easier, I bet others agree. If that's not feasible, I understand.
Thanks!
Hi there, yes you can! Here's a video tutorial we put together a while ago.
172 notes
·
View notes
Text


🎀Things you should know about me🎀
I post myself on here and I repost a lot of posts I relate to
I love men older than I am..who would love and care for me🎀i haven’t seen any yet tho it could be you..my Dm is open anytime🤍
I’m a super sweet girl..you’d love me
We could hook up if you’d like that..
I’m Sophie…I’m 24,I’m a student,University of California and I wanna sell my content on here cos I obviously need all the support I can get for school
I’m also in search of a relationship or a (daddy) I volunteer to be your sb😗
Or you could simply support me without my nudes if you don’t like that..I’d really appreciate pookie🤍
Feel free to send your photos or dick pics and nudes..I don’t mind but just know mine is not for free..it would cost a little…
I’m here to help you reach your fantasies and cum all you need😍to ease all your stress..we could make it a regular thing..I don’t charge much Incase you wanna change your mind
I’m ready to be your little slut,you could use me anytime and any day pookie💋
My dm is open if interested
Be nice🤍
#oldermen#real#bigtiddy#buymycontent#content#pretty#foryou foryoupage#search#older is better#college life#older man younger woman#i sell content#content buyers#contentboost#foryou
108 notes
·
View notes
Text
Tumblr Search Function Basics 🔎
Are you also tired of scrolling past unrelated self insert fanfictions when searching for posts about a fandom/show?
Or are you trying to find posts about a weekly show but you're several episodes behind and don't want spoilers?
Look no further because I am here to bestow upon you the knowledge of how you can make the most of the tumblr search function!!
Search just the Tags
If you keep seeing unrelated posts to the fandom you're trying to search for, try searching just for tags by ending you search with:
match:tags
Your search input doesn't need to match the tags precisely but if you do want to search for specific tags just use quotation marks like
"ice cream" "quality content" match:tags
An alternative to match:tags is using # as
#ice cream #quality content
These search operators for searching just the tags are particularly useful because the reason you get unrelated posts like fanfiction in your search is because those posts contain a LOT of words and as such are very likely to contain your search words, but this way the wall of text isn't factored into your search!
Using the search function instead of the Tags search means you can also specify which types of posts you're looking for and what period of time you want to search by using the built-in "Filter by".

If you want to be even more specific about which time period you're searching, I've got just the tip for you!
Searching in time
I often use these when I'm watching an TV show but I'm behind the airing schedule so I don't want to see posts about newer episodes that I have yet to watch.
By defining which period of time you want to search within you can make sure to not see any posts posted after the date you choose.
This could for example be the date before the most recent episode you haven't seen of the show you're currently watching.
Search for posts within a time period by adding the dates you want to search between as
since:YYYY-MM-DD before:YYYY-MM-DD
@rythyme made a great post on how to get the "watch along" experience this way!
Specifically the dates seem to be according to your timezone and the search is including the "since" date but excluding the "before" date. Also you don't have to include both dates if you just want to search since a specific date and until now or before a certain date and as far back as possible.
You can also just search for a specific date or year by writing
date:YYYY-MM-DD or year:YYYY
Misc
And finally you can also specify which blog's posts you want to search for by adding this to your search
from:blog or from:@blog
Additionally to match:tags you can also use match:text instead to only search the text body of posts.
All these search operators should also work on people's blogs.
112 notes
·
View notes
Text

A Canadian Military Policeman searches a captured German soldier - France, date unknown. CREDIT : Canadian National Archives
#world war two#ww2#worldwar2photos#history#1940s#ww2 history#wwii#world war 2#ww2history#wwii era#military police#France#canadian#pow#mp#search
63 notes
·
View notes
Text

Bas Jan Ader, In search of the miraculous, 1973.
#Bas Jan Ader#ander#performance#miracolous#search#los angeles#walk#walking#contemporary art#landscape
140 notes
·
View notes
Text
Do you have any recommendations for free writing programs? Because of the rise of ai i don't trust Microsoft Word or Google Docs anymore, but i want to get back to writing. I prefer when i can reach my files online/mobile like docs.
EDIT: I've already got my pick so no need for other recomendations but i want to leave this post so others could look in the comments as a little resource collection
MANY people sugested Ellipsus, i would add Reedsy as interesting alternative too, tho if you still have something else to recommend, feel free to do so :>
#writers#writeblr#writer things#tumblr writers#fanfiction#creative writing#writing#wattpad#google docs#search#docs#ms word#word#microsoft word#writing software
108 notes
·
View notes

Text
Skinnamarinkstump Linkdump

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me TODAY (Feb 15) for a virtual event with YANIS VAROUFAKIS, and on MONDAY (Feb 17) for an event at KEPLER'S in MENLO PARK with CHARLIE JANE ANDERS. More tour dates here.

It's Saturday and I'm on a book tour, and the world is in chaos, and there are more links to write about than I could fit in to this week's newsletter, so time for a cubic linkdump, the 27th such:
https://pluralistic.net/tag/linkdump/
Let's start with the best thing I saw all week: a 3D-printed, spring-loaded, clockwork chess pawn that uses a magnet to sense when it has reached the end of the board and SPROING! turns into a queen:
https://www.youtube.com/watch?v=CSOnnle3zbA
The whole video is a fascinating account of the design process, from idea to prototype to finished item, but if you're impatient and want to skip right to the eyeball kick, it's at 12:27-12:35. And if you want to print your own, the files are $12 (cheap!):
https://www.patreon.com/WorksByDesign/shop/queen-pawn-3d-printing-files-614491?source=storefront
Regrettably, not every tech project is a good one. This week, Google abandoned its AI ethics pledge. Unlike most AI ethics pledge, which are full of nonsense about not accidentally creating a vengeful god that turns the human race into paperclips, Google's AI pledge was actually very important, in that the company promised not to make AI that violates human rights, international law, or privacy. There comes a point where harping on Google's abandoned "don't be evil" motto can feel a little hacky, but in this case, I'll make an exception. My EFF colleague Matthew Guariglia tears Google a much-deserved new AIhole over this latest heel turn:
https://www.eff.org/deeplinks/2025/02/google-wrong-side-history
Not all bad technology is evil. Some of it is merely very, very stupid. How stupid? Check out Thom Dunn's Wirecutter review of The Heatbit Trio, a space-heater that uses Bitcoin-mining GPUs to generate some of its heat, very slightly offsetting the cost of warming your room – but at a rate that would take decades to recoup the $700 price-tag. Thom got some spicy quotes from Molly White for this one – possibly the first time she's been cited in a home appliance review:
https://www.nytimes.com/wirecutter/reviews/heatbit-space-heater-review/
Staying with crypto freaks for a moment here, Adam Levitin dissects the cryptocurrency "industry"'s latest chorus of aggrieved whining over "debanking":
https://www.creditslips.org/creditslips/2025/02/debanked-by-the-market.html
As Levitin writes, banks aren't kicking cryptocurrency "companies" off their books because the government wants to punish them. Banks have a very good reason to want to avoid doing business with high-dollar scams that have highly correlated implosions, which is to say, times when everyone wants their money back from the cryptocurrency "company" the bank is handling charges for. For a longer explanation that gets into the nitty gritty of bank supervision, check out Patio11's excellent, detailed explainer:
https://www.bitsaboutmoney.com/archive/debanking-and-debunking/
As all the real heads know, "crypto means cryptography," and cryptographers continue to contrive privacy marvels. This week, Kagi – the best search engine, a million times better than Google – released a Privacy Pass authentication plugin, which lets you login to Kagi and run searches without Kagi being able to connect any of the searches you make with your account:
https://blog.kagi.com/kagi-privacy-pass
As an sf/crime writer who sometimes (often) searches for information on committing ghastly crimes and 'orrible murders, the fact that my favorite search engine will be technically incapable of tying those searches to my identity is quite a relief. Read my review of Kagi here:
https://pluralistic.net/2024/04/04/teach-me-how-to-shruggie/#kagi
If you're one of those marvel-contriving hackers, cryptographers, security researchers or tinkerers, you should really consider attending this summer's Hackers on Planet Earth (HOPE), 2600 Magazine's (now) annual (formerly biennial) hacker con. They've just posted their CFP – get those submission in!
https://www.hope.net/cfp-talks.html
Well, I have to post this and get ready for this morning's virtual book tour event with Yanis Varoufakis:
https://www.youtube.com/watch?v=xkIDep7Z4LM
But before I go, one more link: Kevin Steele's 2005 essay on Hypercard, "When Multimedia Was Black & White," an absolute classic, and a beautiful meditation on the art and promise of early hypertext:
https://web.archive.org/web/20240213190609/http://www.kevinsteele.com/smackerel/black_white_00.html
I've known Kevin for most of my life, long before he helped found Mackerel, the pioneering Toronto multimedia company. Long after Mackerel, Kevin went on making wonderful things. In 2023, he published a monumental act of portraiture – a "sequential art" time-series of panoramas of Toronto's hip, ever-changing Queen Street West strip:
https://pluralistic.net/2023/09/13/spadina-to-bathurst/#dukes-cycle
Comparing Kevin's more recent work with that lovely old essay reveals deep correspondences and the progress of a unique and creative soul.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/02/15/intermixture/#debunking-debanking
#pluralistic#bitcoin#kevin steele#mulitmedia#patio11#adam levitin#thom dunn#eff#wirecutter#linkdump#linkdumps#google#ai#dont be evil#hope#hackers on planet earth#hackercons#privacy pass#kagi#search#debanking#chess#3d printing#clockworks
152 notes
·
View notes
Note
Will it ever be possible to filter search results or a tag by date posted? Right now you can select for stuff posted in the last (day/week/month/year etc) but I often find myself trying to look at only stuff from, say, 5 years ago and before or something like that. Would love to be able to put in a custom range!
Answer: Hi, @luxpenumbra!
Good news. This is actually already possible! It was announced in this blog post from @changes.
Use the date and year operators to get posts posted on a particular date or particular year respectively. For a more custom time range, use the since: and before: operators.
Examples:
halloween since:2019-10-08 for posts containing the term halloween posted since 2019-10-08.
#halloween before:2019-10-08 for posts with the tag halloween posted before 2019-10-08.
halloween since:2019-10-08 before:2020-07-01 for posts containing the term halloween posted since 2019-10-08 but before 2020-07-01.
We should add that the operators only work for posts from 2017 onwards. You can find more information at the Tumblr Help Center.
Thanks for getting in touch here, and we hope this helps. Keep the questions coming!
236 notes
·
View notes

Text
This entomologist does not exist.

I decided to find out if any progress had been made on the science behind why some ants are attracted to electrical fields. After filtering out exterminators (it's so demoralizing to search for information on creatures you love and find nothing but people who know nothing about them boasting about how they will kill them all) I found what looked like a blog. But, who the heck is "James Brown"? Never heard of the dude. Maybe he could be my new friend if he likes ants enough to blog about them!
As far as I can tell, these people are phantoms. That's cruel on multiple levels. If I was not familiar with this SEO (Search Engine Optimization) trick I'd spend time looking for them both (to politely tell them about the errors in their blog... which I would assume they would care about since they love insects.)
But, I know what this is now. It's probably the exterminators behind all of this. To get their page ranks up they need "legitimate" pages such as personal blogs to link to them. So they make fake versions of the blogs.
They are pretending to be *ME*

We are expected to take this kind of BS as "harmless gaming of the system." but I find it incredibly distrustful and hurtful. It's making it harder for people to find each other by putting all these fake people in the way. It's LIES the pages are full of half-true nonsense. It's making people know less and filling their heads with false facts.
And this kind of page is what you find FIRST in nearly all search engines. You won't find Alex Wild or the formiculture forum.
You find these mendacious SEO ghosts.
These fake pages ought to be blacklisted to oblivion. But, I don't see any search engines taking this seriously at all.
Not really in their interest to do that, is it? We need to make more noise about just how terrible these pages are. Fake experts? Fake people? Fake images? Fake facts?
Information pollution & fragmentation of natural networks of human learning. A rot on the body of human knowledge: any search engine that puts such pages at the top should be ashamed.
We had a very lively conversation about this on the fediverse (join us if you've been looking for a better kind of social media.)
#ants#antposting#bugblr#ant#invertebrates#myrmecology#antblr#bugs#people#lies#internet#search#google#yahoo#misinformation
123 notes
·
View notes