#LLaVA
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Use Intel Gaudi-3 Accelerators To Increase Your AI Skills

Boost Your Knowledge of AI with Intel Gaudi-3 Accelerators
Large language models (LLMs) and generative artificial intelligence (AI) are two areas in which Intel Gaudi Al accelerators are intended to improve the effectiveness and performance of deep learning workloads. Gaudi processors provide efficient solutions for demanding AI applications including large-scale model training and inference, making them a more affordable option than typical NVIDIA GPUs. Because Intel’s Gaudi architecture is specifically designed to accommodate the increasing computing demands of generative AI applications, businesses looking to implement scalable AI solutions will find it to be a highly competitive option. The main technological characteristics, software integration, and upcoming developments of the Gaudi AI accelerators are all covered in this webinar.
Intel Gaudi Al Accelerators Overview
The very resource-intensive generative AI applications, as LLM training and inference, are the focus of the Gaudi AI accelerator. While Intel Gaudi-3, which is anticipated to be released between 2024 and 2025, promises even more breakthroughs, Gaudi 2, the second-generation CPU, enables a variety of deep learning enhancements.
- Advertisement -
Intel Gaudi 2
The main attributes of Gaudi 2 consist of:
Matrix Multiplication Engine: Hardware specifically designed to process tensors efficiently.
For AI tasks, 24 Tensor Processor Cores offer high throughput.
Larger model and batch sizes are made possible for better performance by the 96 GB of on-board HBM2e memory.
24 on-chip 100 GbE ports offer low latency and high bandwidth communication, making it possible to scale applications over many accelerators.
7nm Process Technology: For deep learning tasks, the 7nm architecture guarantees excellent performance and power efficiency.
These characteristics, particularly the combination of integrated networking and high memory bandwidth, make Gaudi 2 an excellent choice for scalable AI activities like multi-node training of big models. With its specialized on-chip networking, Gaudi’s innovative design does away with the requirement for external network controllers, greatly cutting latency in comparison to competing systems.
Intel Gaudi Pytorch
Software Environment and Stack
With its extensive software package, Intel’s Gaudi platform is designed to interact easily with well-known AI frameworks like PyTorch. There are various essential components that make up this software stack:
Graph Compiler and Runtime: Generates executable graphs that are tailored for the Gaudi hardware using deep learning models.
Kernel Libraries: Reduce the requirement for manual optimizations by using pre-optimized libraries for deep learning operations.
PyTorch Bridge: Requires less code modification to run PyTorch models on Gaudi accelerators.
Complete Docker Support: By using pre-configured Docker images, users may quickly deploy models, which simplifies the environment setup process.
With a GPU migration toolset, Intel also offers comprehensive support for models coming from other platforms, like NVIDIA GPUs. With the use of this tool, model code can be automatically adjusted to work with Gaudi hardware, enabling developers to make the switch without having to completely rebuild their current infrastructure.
Open Platforms for Enterprise AI
Use Cases of Generative AI and Open Platforms for Enterprise AI
The Open Platform for Enterprise AI (OPEA) introduction is one of the webinar’s main highlights. “Enable businesses to develop and implement GenAI solutions powered by an open ecosystem that delivers on security, safety, scalability, cost efficiency, and agility” is the stated mission of OPEA. It is completely open source with open governance, and it was introduced in May 2024 under the Linux Foundation AI and Data umbrella.
It has attracted more than 40 industry partners and has members from system integrators, hardware manufacturers, software developers, and end users on its technical steering committee. With OPEA, businesses can create and implement scalable AI solutions in a variety of fields, ranging from chatbots and question-answering systems to more intricate multimodal models. The platform makes use of Gaudi’s hardware improvements to cut costs while improving performance. Among the important use cases are:
Visual Q&A: This is a model that uses the potent LLaVA model for vision-based reasoning to comprehend and respond to questions based on image input.
Large Language and Vision Assistant, or LLaVA, is a multimodal AI model that combines language and vision to carry out tasks including visual comprehension and reasoning. In essence, it aims to combine the advantages of vision models with LLMs to provide answers to queries pertaining to visual content, such as photographs.
Large language models, such as GPT or others, are the foundation of LLaVA, which expands their functionality by incorporating visual inputs. Typically, it blends the natural language generation and interpretation powers of big language models with image processing techniques (such those from CNNs or Vision Transformers). Compared to solely vision-based models, LLaVA is able to reason about images in addition to describing them thanks to this integration.
Retrieval-Augmented Generation (RAG) or ChatQnA is a cutting-edge architecture that combines a vector database and big language models to improve chatbot capabilities. By ensuring the model obtains and analyzes domain-specific data from the knowledge base and maintains correct and up-to-date responses, this strategy lessens hallucinations.
Microservices can be customized because to OPEA’s modular architecture, which lets users change out databases and models as needed. This adaptability is essential, particularly in quickly changing AI ecosystems where new models and tools are always being developed.
Intel Gaudi Roadmap
According to Intel’s Gaudi roadmap, Gaudi 2 and Intel Gaudi-3 offer notable performance gains. Among the significant developments are:
Doubling AI Compute: In order to handle the increasing complexity of models like LLMs, Intel Gaudi-3 will offer floating-point performance that is 2 times faster for FP8 and 4 times faster for BF16.
Enhanced Memory Bandwidth: Intel Gaudi-3 is equipped with 1.5 times the memory bandwidth of its predecessor, so that speed won’t be compromised when handling larger models.
Increased Network capacity: Intel Gaudi-3’s two times greater networking capacity will help to further eliminate bottlenecks in multi-node training scenarios, which makes it perfect for distributing workloads over big clusters.
Additionally, Gaudi AI IP and Intel’s GPU technology will be combined into a single GPU form factor in Intel’s forthcoming Falcon Shores architecture, which is anticipated to launch in 2025. As part of Intel’s ongoing effort to offer an alternative to conventional GPU-heavy environments, this hybrid architecture is expected to provide an even more potent foundation for deep learning.
Tools for Deployment and Development
Through the Intel Tiber Developer Cloud, which offers cloud-based instances of Gaudi 2 hardware, developers can utilize Gaudi accelerators. Users can test and implement models at large scale using this platform without having to make investments in on-premises infrastructure.
Starting with Gaudi accelerators is as simple as following these steps:
Docker Setup: First, users use pre-built images to build up Docker environments.
Microservices Deployment: End-to-end AI solutions, such chatbots or visual Q&A systems, can be deployed by users using tools like Docker Compose and Kubernetes.
Intel’s inherent support for monitoring tools, such as Prometheus and Grafana, enables users to manage resource utilization and performance throughout their AI pipelines.
In summary
Enterprises seeking an efficient way to scale AI workloads will find a compelling solution in Intel’s Gaudi CPUs, in conjunction with the extensive OPEA framework and software stack. With Gaudi 2’s impressive performance and Intel Gaudi-3‘s upcoming improvements, Intel is establishing itself as a formidable rival in the AI hardware market by offering a reasonably priced substitute for conventional GPU-based architectures. With OPEA’s open and modular design and wide ecosystem support, developers can quickly create and implement AI solutions that are customized to meet their unique requirements.
Read more on govindhtech.com
#IntelGaudi3Accelerators#AISkills#AIapplications#IntelGaudi3#Gaudi2#KernelLibraries#chatbots#LargeLanguage#VisionAssistant#LLaVA#intel#RetrievalAugmentedGeneration#RAG#news#Tools#IntelTiberDeveloperCloud#Prometheus#EnterpriseAI#GenerativeAI#technology#technews#govindhtech
0 notes
Text

以前Image Creatorで生成した画像を、LLaVA (hliu.cc)で画像解析してプロンプト化
Create a 3D model of a woman walking through a large, curved doorway. The doorway should have a spiral shape, giving the impression of a tunnel. The woman should be positioned in the center of the doorway, walking towards the viewer. The scene should be set in a dark environment, with the woman being the main focus. Additionally, there should be a few angels or winged creatures surrounding the doorway, adding a sense of mystery and intrigue to the scene. The overall atmosphere should be surreal and captivating, with the woman and the winged creatures as the main subjects.
Bing Image Creatorでプロンプトから生成されたイメージ

Adobe Firefly Image2に参考画像とプロンプトで生成されたイメージ

0 notes
Video
youtube
Lava Yuva 2 5G Price, Official Look, Design, Camera, Specifications, Fea...
0 notes
Text

oh noouugh haha . dont fall in there man
1 note
·
View note
Text

In the faint starlight, figures stood side by side on white marble steps. Facing the serenity of the warm sea waves, as if they were about to step off into the infinite waters ahead. Just two of them in this shared dream. Who created this realm of boundless tranquillity? Who let them in? Was it an incident? Neither Viroka, nor Llava could recollect.
0 notes
Text
creature concepts for a minecraft pokemon-like mod
a while ago, i made a post about how there should be a creature collecting/battling mod for minecraft that has its own, minecraft-inspired creature designs, instead of pokemon.
i think this would be good both in terms of "fitting" into the game better AND keeping out of the attention of a famously litigious game company.
it also would be a chance to give the creatures uses in the game outside of battle.
here are a dozen ideas for creatures i've had:
a dirt themed doggy - somewhat inspired by a dachshund, though bigger and more front-heavy. outside of battle, it occasionally digs up items - things like plants, seeds, saplings, bones, and rotten flesh. rarely, it can dig up ores.
a panda guy that plays instruments, a banda - i'm imagining a different variant for each vanilla panda variant. outside of battle, it plays little tidbits of song. if there are multiple bandas around, they play together :)
cherry bee - a little pink bee with cherry blossom wings and green antenna. it bone meals crops when it flys over them.
a leaf sheep. a leef - it's a sheep that looks like it's made of wood, that grows leaves instead of wool. there's a variant for each vanilla tree, found according to which biome it generates in. you can shear it for its leaves, but you might not want to - the leaves allow it to tank the first hit it receives in battle.
a kelpie but it's nice :) - a horse with a kelp mane, found on beaches and in shallow oceans. it has a few color variants - black, dark grey, light grey, white, and bluish green. you can ride it and not only will it swim, it does so at a good pace and gives you water-breathing while you're mounted on it.
flying pig - come on, you gotta have a flying pig. it's tiny and round and gives you luck.
a giant rooster named buckawk - i'm gonna be real with you, this ones mostly so people can make immature jokes about having a huge cockerel. yeah, children play this game, but this is exactly the kind of humor 12 year olds love. he gives you feather falling.
an aurochs themed around ore. an ore-ox, if you will - has variants for all the vanilla ores, possibly with built-in support for common modded ore such as osmium, aluminum, and platinum. occasionally sheds raw ores.
an electric jackalope - this one comes from when i was thinking maybe you could craft the creatures, and he would've required a lightning rod. tbh i can't think of a use for him that would NOT result in players hitting themselves with lightning, but im still enamored with the idea. maybe he can just press buttons like a copper golem :)
salmon dragon - you know how the magikarp/gyrados line was inspired by the legend of carps jumping up a huge waterfall and turning into dragons? and you know how salmon migrate upriver and undergo a strange metamorphosis to be able to do so? yeah. salmon-dragon. idk what this one would do either, the concept just rocks.
lava llama. llava - it'd look cute and the pun is solid. you can ride it over lava like a more-easily controlled strider and it gives you fire resistance.
bottle axolotl. axobottl. - yeah i know axolotl wasn't originally supposed to be pronounced like that, but consider - a little guy that you can give a potion and then he gives you that potion effect for much longer than the potion itself would've.
#modded minecraft#minecraft mods#also all these guys could just be your bodyguards lol#that's my favorite part of cobblemon#just having a couple of dudes follow me around#and beat the crud out of zombies#and if they die they can just be revived like it's nothing
5 notes
·
View notes
Link
Large foundation models have demonstrated remarkable potential in biomedical applications, offering promising results on various benchmarks and enabling rapid adaptation to downstream tasks with minimal labeled data requirements. However, significan #AI #ML #Automation
0 notes
Text
Microsoft AI przedstawia LLaVA-Rad: Lekki, otwartoźródłowy model do zaawansowanego tworzenia raportów radiologicznych
Nowoczesne modele AI w radiologii – przełom w generowaniu raportów medycznych Wyzwania zastosowania modeli AI w medycynie Duże modele sztucznej inteligencji mają ogromny potencjał w zastosowaniach biomedycznych. Ich zdolność do analizy danych umożliwia szybkie dostosowanie do nowych zadań przy minimalnej ilości oznaczonych danych. Jednak mimo imponujących wyników, wdrażanie tych modeli w…
0 notes
Text
Microsoft AI przedstawia LLaVA-Rad: Lekki, otwartoźródłowy model do zaawansowanego tworzenia raportów radiologicznych
Nowoczesne modele AI w medycynie – przełom w diagnostyce radiologicznej Wielkoskalowe modele bazowe wykazują ogromny potencjał w zastosowaniach biomedycznych, oferując imponujące wyniki w różnych testach oraz umożliwiając szybkie dostosowanie do nowych zadań przy minimalnych wymaganiach dotyczących oznakowanych danych. Jednak mimo ich zaawansowania, wdrożenie tych modeli w rzeczywistych warunkach…
0 notes
Text
Peking University and Tsinghua University jointly released LLaVA-o1: The first spontaneous visual AI model, a new way of reasoning computing Scaling
0 notes
Text
LLaVA-O1: Let Vision Language Models Reason Step-by-Step
https://arxiv.org/abs/2411.10440
0 notes
Text
Vision Language Models: Learning From Text & Images Together

Vision language models are models that can learn from both text and images at the same time to perform a variety of tasks, such as labeling photos and answering visual questions. The primary components of visual language models are covered in this post: get a general idea, understand how they operate, choose the best model, utilize them for inference, and quickly adjust them using the recently available try version!
What is a Vision Language Model?
Multimodal models that are able to learn from both text and images are sometimes referred to as vision language models. They are a class of generative models that produce text outputs from inputs that include images and text. Large vision language models can deal with a variety of picture types, such as papers and web pages, and they have good zero-shot capabilities and good generalization.
Among the use cases are image captioning, document comprehension, visual question answering, image recognition through instructions, and image chat. Spatial features in an image can also be captured by some vision language models. When asked to detect or segment a specific subject, these models can produce segmentation masks or bounding boxes. They can also localize various items or respond to queries regarding their absolute or relative positions. The current collection of huge vision language models varies greatly in terms of their training data, picture encoding methods, and, consequently, their capabilities.Image credit to Hugging face
An Overview of Vision Language Models That Are Open Source
The Hugging Face Hub has a large number of open vision language models. The table below lists a few of the most well-known.
Base models and chat-tuned models are available for use in conversational mode.
“Grounding” is a characteristic of several of these models that lessens model hallucinations.
Unless otherwise indicated, all models are trained on English.
Vision Language Model
Finding the right Vision Language Model
The best model for your use case can be chosen in a variety of ways.
Vision Arena is a leaderboard that is updated constantly and is entirely dependent on anonymous voting of model results. Users input a prompt and a picture in this arena, and outputs from two distinct models are anonymously sampled before the user selects their favorite output. In this manner, human preferences alone are used to create the leaderboard.
Another leaderboard that ranks different vision language models based on similar parameters and average scores is the Open VLM Leaderboard. Additionally, you can filter models based on their sizes, open-source or proprietary licenses, and rankings for other criteria.
The Open VLM Leaderboard is powered by the VLMEvalKit toolbox, which is used to execute benchmarks on visual language models. LMMS-Eval is an additional evaluation suite that offers a standard command line interface for evaluating Hugging Face models of your choosing using datasets stored on the Hugging Face Hub, such as the ones shown below:
accelerate launch –num_processes=8 -m lmms_eval –model llava –model_args pretrained=”liuhaotian/llava-v1.5-7b” –tasks mme,mmbench_en –batch_size 1 –log_samples –log_samples_suffix llava_v1.5_mme_mmbenchen –output_path ./logs/
The Open VLM Leaderbard and the Vision Arena are both restricted to the models that are provided to them; new models must be added through updates. You can search the Hub for models under the task image-text-to-text if you’d like to locate more models.
The leaderboards may present you with a variety of benchmarks to assess vision language models. We’ll examine some of them.
MMMU
The most thorough benchmark to assess vision language models is A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI (MMMU). It includes 11.5K multimodal tasks that call for college-level topic knowledge and critical thinking in a variety of fields, including engineering and the arts.
MMBench
3000 single-choice questions covering 20 distinct skills, such as object localization and OCR, make up the MMBench assessment benchmark. The study also presents Circular Eval, an assessment method in which the model is supposed to provide the correct response each time the question’s answer options are jumbled in various combinations. Other more specialized benchmarks are available in other disciplines, such as OCRBench document comprehension, ScienceQA science question answering, AI2D diagram understanding, and MathVista visual mathematical reasoning.
Technical Details
A vision language model can be pretrained in a number of ways. Unifying the text and image representation and feeding it to a text decoder for generation is the key trick. An image encoder, an embedding projector often a dense neural network to align picture and word representations, and a text decoder are frequently stacked in the most popular and widely used models. Regarding the training phases, many models have been used various methodologies.
In contrast to LLaVA-like pre-training, the creators of KOSMOS-2 decided to fully train the model end-to-end, which is computationally costly. To align the model, the authors then fine-tuned language-only instruction. Another example is the Fuyu-8B, which lacks even an image encoder. Rather, the sequence passes via an auto-regressive decoder after picture patches are supplied straight into a projection layer. Pre-training a vision language model is usually not necessary because you can either utilize an existing model or modify it for your particular use case.
What Are Vision Language Models?
A vision-language model is a hybrid of natural language and vision models. By consuming visuals and accompanying written descriptions, it learns to link the information from the two modalities. The vision component of the model pulls spatial elements from the photographs, while the language model encodes information from the text.
Detected objects, image layout, and text embeddings are mapped between modalities.For example, the model will learn to associate a term from the text descriptions with a bird in the picture.
In this way, the model learns to understand images and translate them into text, which is Natural Language Processing, and vice versa.
VLM instruction
To create VLMs, zero-shot learning and pre-training foundation models are required. Transfer learning techniques such as knowledge distillation can be used to improve the models for more complex downstream tasks.
These are simpler techniques that, despite using fewer datasets and less training time, yield decent results.
On the other hand, modern frameworks use several techniques to provide better results, such as
Learning through contrast.
Mask-based language-image modeling.
Encoder-decoder modules with transformers, for example.
These designs may learn complex correlations between the many modalities and produce state-of-the-art results. Let’s take a closer look at these.
Read more on Govindhtech.com
#VisionLanguageModels#LanguageModels#AI#generativemodels#HuggingFaceHub#OpenVLM#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Cool! Ein KI Chatbot für den lokalen Gebrauch!
In der dortigen Readme-Sektion die Datei Llava-v1.5-7b-q4.llamafile (4,29GB) downloaden, im Terminal in das entsprechende Verzeichnis wechseln und das File mittels chmod +x llava-v1.5-7b-q4.llamafile ausführbar machen. Danach mit ./ llava-v1.5-7b-q4.llamafile starten, worauf sich der Standard-Browser öffnet. Einer gepflegten Unterhaltung, verständliche Fragen vorausgesetzt, steht nichts mehr im Wege. Der BOT antwortet auch auf Fragen in deutscher Sprache in Englisch.
Das Ganze läuft selbst auf meinem Raspi 4 absolut flüssig. Windows-User machen wieder ein langes Gesicht, weil Dateien größer 4GB und so… 😅
Ihr könnt natürlich auch die anderen Sprachmodule (bis 30GB!) ausprobieren. Der Chatbot verarbeitet auch Grafiken, aber dafür sollte der Rechner mit einer Grafikleistung im hohen Bereich ausgestattet sein.
Schluss mit chatten: Terminal/Control-C
0 notes
Quote
2024年09月26日 07時00分 なぜ研究者はローカルPCでAIを実行する必要があるのか? 高度な生成AIは動作に相応の機器を必要とするため、一般的なユーザーが高度な生成AIを使うためにはネットに接続して利用するしかありません。一方で、高度なAIをローカルで実行できるような試みが行われ、実際にローカルで動作する高度なAIもいくつか存在します。AIをローカルで動作させることの利点について、科学誌Natureが利用者の声をいくつか紹介しまし��。 Forget ChatGPT: why researchers now run small AIs on their laptops https://www.nature.com/articles/d41586-024-02998-y 免疫系タンパク質の構造のデータベース「histo.fyi」を運営するクリス・ソープ氏はAIをノートPCで動作させています。ソープ氏は以前にChatGPTの有料版を試したそうですが、高価で出力が適切でないと感じたため、80億~700億のパラメータを持つLlamaをローカルで使用しているとのことです。 ソープ氏によれば、もうひとつの利点は「ローカルモデルは変更されないこと」だといいます。商業的に展開されているAIモデルは企業の意向によって動作が変わってしまい、ユーザーはプロンプトやテンプレートの変更を余儀なくされることがありますが、ローカルであればユーザーの意思で自由に使用できます。ソープ氏は「科学は再現性のあるものを求めるものです。自分が生成しているものの再現性をコントロールできないというのは心配の種になります」と語り、AIをローカルで動かすことの有用性について意見を述べました。 記事作成時点では数千億のパラメーターを持つAIモデルもありますが、パラメーターは多ければ多いほど処理の複雑さが増します。企業によっては、こうした複雑なモデルを公開する一方で、一般消費者向けPCで実行できる縮小版や「重み」を公開したオープンウェイト版を公開しているところもあります。 例えばMicrosoftは小型言語モデルの「Phi-1」や「Phi-2」を2023年にリリースしていて、2024年には「Phi-3」を矢継ぎ早にリリースしています。Phi-3は38億から140億のアクティブパラメータを持ち、いくつかのベンチマークでは最小モデルでさえ200億のパラメータを持つとされる「GPT-3.5 Turbo」を上回っていることが示されています。研究者はこれらのモデルをベースに独自のアプリケーションを作ることができます。 ニューハンプシャー州の生物医学科学者であるKal'tsit氏はローカルで動作するアプリケーションを作った開発者の一人です。Kal'tsit氏はアリババが作成した「Qwen」モデルを微調整し、原稿を校正したり、コードのプロトタイプを作ったりするモデルを作成して公開。Kal'tsit氏は、「ローカルモデルは用途に合わせて微調整できることに加え、もう一つの利点はプライバシーです。個人を特定できるデータを商用サービスに送信することはデータ保護規制に抵触する可能性があり、もし監査が行われたら厄介なことになるでしょう」と語りました。 他にも、医療報告書に��づいて診断を手助けしたり、患者の問診を書き起こしたり要約したりするAIを使用している医師は、プライバシーを重視するためにローカルモデルを使用していると語ります。 Firefoxを開発するテック企業・MozillaでオープンソースのAIを統括するスティーブン・フッド氏は、「オンラインとローカル、どちらのアプローチを選ぶにせよ、ローカルモデルはほとんどの用途ですぐに十分な性能を発揮するはずです。この1年間の進歩の速さには驚かされます。どのようなアプリケーションにするかはユーザーが決めることです。自分の手を汚すことを恐れないでください。その結果、嬉しい驚きがあるかもしれません」と述べました。 ローカルでAIモデルを動作させる方法の1つとして、Mozillaの開発者が提供している「llamafile」というツールを使うものがあります。 GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file. https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file 上記のURLにアクセスしたら「Download llava-v1.5-7b-q4.llamafile」にかかったリンクをクリックします。 ダウンロードしたファイルの拡張子を「.exe」に変更します。 ファイルをクリックするとブラウザが立ち上がり、チャットインターフェイスが表示されます。 上記の方法だと「LLaVA 1.5」をローカルで実行できます。他のモデルのリンクもいくつか用意されています。
なぜ研究者はローカルPCでAIを実行する必要があるのか? - GIGAZINE
1 note
·
View note
Text
Alt Text Creator 1.2 is now available!
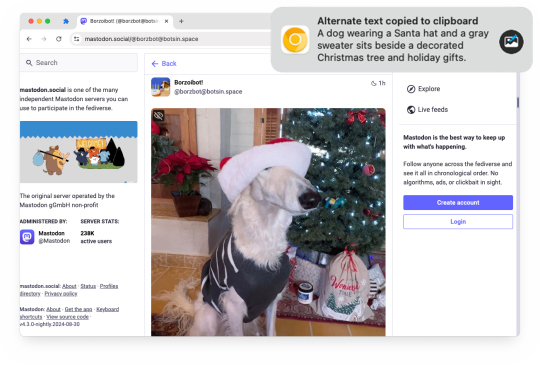
Earlier this year, I released Alt Text Creator, a browser extension that can generate alternative text for images by right-clicking them, using OpenAI's GPT-4 with Vision model. The new v1.2 update is now rolling out, with support for OpenAI's newer AI models and a new custom server option.
Alt Text Creator can now use OpenAI's latest GPT-4o Mini or GPT-4o AI models for processing images, which are faster and cheaper than the original GPT-4 with Vision model that the extension previously used (and will soon be deprecated by OpenAI). You should be able to generate alt text for several images with less than $0.01 in API billing. Alt Text Creator still uses an API key provided by the user, and uses the low resolution option, so it runs at the lowest possible cost with the user's own API billing.
This update also introduces the ability to use a custom server instead of OpenAI. The LM Studio desktop application now supports downloading AI models with vision abilities to run locally, and can enable a web server to interact with the AI model using an OpenAI-like API. Alt Text Creator can now connect to that server (and theoretically other similar API limitations), allowing you to create alt text entirely on-device without paying OpenAI for API access.
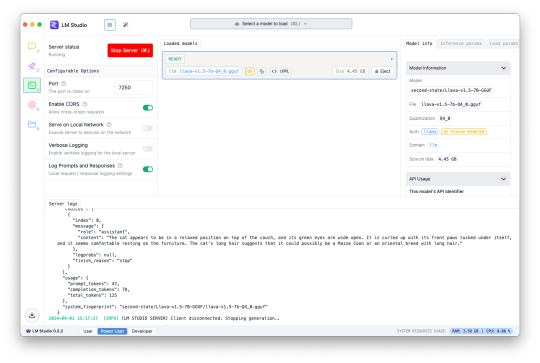
The feature is a bit complicated to set up, is slower than OpenAI's API (unless you have an incredibly powerful PC), and requires leaving LM Studio open, so I don't expect many people will use this option for now. I primarily tested it with the Llava 1.5 7B model on a 16GB M1 Mac Mini, and it was about half the speed of an OpenAI request (8 vs 4 seconds for one example) while having generally lower-quality results.
You can download Alt Text Creator for Chrome and Firefox, and the source code is on GitHub. I still want to look into support for other AI models, like Google's Gemini, and the option for the user to change the prompt, but I wanted to get these changes out soon before GPT-4 Vision was deprecated.
Download for Google Chrome
Download for Mozilla Firefox
#gpt 4#gpt 4o#chatgpt#openai#llm#lm studio#browser extension#chrome extension#chrome#extension#firefox#firefox extension#firefox extensions#ai
0 notes