#Azure Jujuy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Azure Synapse Analytics - Distribución de componentes
Azure Synapse Analytics es una tecnología que suena cada día más como una opción estable de arquitectura robusta para construir una solución de medio y alto nivel de analítica o datos. Sin embargo, mucho más conocidos son los recursos individuales que provee azure como servicio y puede resultar confuso usarlo.
Este artículo nos ayudará a mapear y entender la orientación de los servicios de Synapse mapeados con algo semejante en servicios individuales de Azure y como se organizan para encontrar todos los elementos bajo los cuales se trabaja diariamente.
Luego de crear nuestro Azure Synapse, tal como vimos en el post anterior, nos dirigimos al recurso y abrimos su interfaz para encontrarnos con lo siguiente:

Puede que la primera vez nos pida sincronizar un repositorio para trabajarlo. En dicho caso podemos proceder a sincronizar con un repo de Azure DevOps o GitHub. No mostraremos eso en este post, sino que nos centraremos en el menú.
El menú cuenta con dos secciones, la primera en 3 ítems para construir y la segunda para configurar y monitorear. Analicemos lo que encontraremos aquí:
Menú Data
Data es el espacio donde podemos revisar el contenido de nuestro Storage. Todo lo que llevemos a nuestro Data Lake será visible desde este apartado. Ahora bien, existen distintas secciones en el almacenamiento. Las veremos en las siguientes imágenes como Workspace y Linked. Estas pestañas nos ayudarán a separar la visión de datos en distintos modos.
Linked
Comúnmente contiene dos tipos de elementos que pueden resultarnos familiares a otros productos de data en Azure. Por un lado, tenemos Integration Datasets que será algo similar a los Linked Services de Data Factory. Orígenes de datos con credenciales que luego podemos utilizar para copiar datos de un lugar a otro. Por otro lado, está literalmente los containers del Lake. Si expandemos esta opción y clickeamos nos encontraremos con algo semejante al Azure Storage Explorer.

Workspace
Contiene lo que me gustaría llamar el apartado “estructurado”. En esta sección contamos con dos tipos de componentes. Por un lado, el famoso LakeHouse y por otro, los Dedicated SQL Pools antes conocidos como Warehouse. Cuando trabajamos/operamos con archivos al Lake podemos crear Bases de datos y tablas para orientar nuestros archivos en un esquema más estructurado. Estas bases internas al lake tambien se las conoce como LakeHouse. El otro tipo de componente lo podemos hacer aparecer creando el recurso de SQL Dedicated Pool en el portal de azure dentro del recurso de Azure. Al hacerlo aparecerá la sección de Base de datos SQL. El funcionamiento del Pool o la base es la clásica tecnología de Warehouse que existió por mucho tiempo en Azure. Aquella con orientación a almacenamiento columnar y gran velocidad de respuesta a consultas analíticas.

Menú Develop
En este apartado aparece la magia analítica. Contiene tres elementos de los cuales dos nos ayudarán a consultar y/o construir las transformaciones y limpiezas complejas de datos.

SQL Scripts
Para generar SQL Scripts podemos simplemente explorar los archivos del lake y cuando veamos uno que nos gustaría consultar darle click derecho como muestra la imagen:

Esto nos genera el formato de código que SQL Serverless para consultar el Data Lake (Algo semejante a Athena de otro vendor). Nos encontraremos con un SQL Standard que nos permite realizar consultas sintiéndonos como si estuviéramos tratando con una base de datos tradicional con la diferencia que hay cierto código que aclarar contra los archivos. Les indique ese método para fácilmente revisarlo y familiarizarse. Creando uno en blanco tal vez no sabríamos llegar allí.
Todo lo que escribamos aquí puede ser guardado como un procedimiento o script que podemos llamar desde un pipeline.
Notebooks
Ya muchos estamos familiarizados con este apartado. Sobre todo, los data engineers gracias a la tecnología de Jupyter y DataBricks. Aquí nos encontraremos con exactamente eso. Tendremos notebooks disponibles para utilizar los lenguajes más comunes con librería Spark. Se puede crear o utilizar por celda PySpark, Scala, .NET Spark, Spark SQL y SparkR.
Al igual que DataBricks los notebooks necesitarán un motor para funcionar. En esa tecnología llamados Cluster y en Synapse llamados Apache Spark Pools.
Power Bi
De momento la opción más limitada. Nos permite sincronizar a un Power Bi Workspace V2. A partir de ese momento podemos explorar conjuntos de datos publicados en esa Área, visualizar los informes desde esa y editarlos. Estimo que más adelante darán más valor a esta sección que por ahora parece muy poco útil.
Menú Integrate
El último apartado es quien contiene los Pipelines de datos. Fanáticos de Azure Data Factory van a sentirse cómodos en esté menú puesto que podemos crear pipelines con sus elementos varios como el proceso estrella “Copy Data”. Está claro que no será idéntico a ADF. Tiene algunas semejanzas y unas pocas diferencias.
Menú Restante
Al final dispondremos de un aparatado de Monitoreo que nos permite visualizar todos los procesos antes mencionados que corren en Synapse. Manage será el dueño de las configuraciones. Aqui podemos visualizar delimitaciones de paquetes, repositorios, pools, etc.
Así concluimos nuestro paseo por Azure Synapse para sentirnos más familiarizados cuando comencemos a utilizarlo luego de crearlo. Ya verán que a medida que más lo probamos se siente bastante cómodo tener todo a mano en una misma interfaz. Espero que esto los ayude.
#Azure Synapse#Azure#Azure Synapse Analytics#Azure Data Platform#Azure notebooks#Azure Tips#Azure Tutorial#Azure Training#Azure data#synapse#Azure Argentina#Azure Jujuy#Azure cordoba
0 notes
Text
Azure Synapse Analytics - Definiciones y creación
Hace tiempo que una herramienta de nivel Enterprise está introduciéndose al mercado de Data Platform. Una que busca integrar muchos servicios en una sola área de trabajo. Intenta resolver múltiples problemáticas de múltiples roles en un solo entorno para mantener el ambiente familiar en las distintas tareas que un equipo de datos debe manejar.
Seguramente ya escucharon nombrar a Azure Synapse Analytics. Este artículo nos ayudará a dar el salto e iniciarnos en la herramienta mostrándonos como crear uno. Así podremos estar preparados para posteriormente estudiar lo que nos provee en las distintas perspectivas de datos como los pipelines o tal vez notebooks. Quien sabe hasta capas que hablamos más detalladamente de Dedicated SQL Pool (antiguamente llamado warehouse)
¿Qué es Azure Synapse Analytics?
Microsoft lo define como un servicio de análisis empresarial que acelera el tiempo necesario para obtener información de los sistemas de almacenamientos de datos y de macrodatos. Azure Synapse reúne lo mejor de las tecnologías SQL que se usan en el almacenamiento de datos empresariales, las tecnologías de Spark que se utilizan para macrodatos, Data Explorer para análisis de serie temporal y de registro, Pipelines para la integración de datos y ETL/ELT, y la integración profunda con otros servicios de Azure, como Power BI, CosmosDB y AzureML.

Este servicio permitiría a los distintos roles de equipo de data trabajar en una misma plataforma. Podemos hacer ingesta, transformación y carga de datos. Tenemos notebooks y machine learning. Disponemos de sql serverless o dedicated sql pool (warehouse tradicional). Inclusive una exploración de datos basada en power bi.
NOTA: al crear el recurso el único costo que contiene es el de un storage account. A medida que demos uso posterior de los servicios de la plataforma (ejemplo correr pipelines) aparecen otros.
Para iniciarnos en este mundo maravilloso de un entorno de trabajo de synapse y analítica avanzada, vamos a buscar el recurso Azure Synapse Analytics. Al momento de crearlo definimos la subscripción y grupo de recursos.
A modo de buena práctica podemos revisar las nomenclaturas sugeridas en este enlace:
El mismo cuenta que, para un Synapse Workspace, podemos usar el prefijo synw.

Toda área de trabajo de Synapse necesita un motor de almacenamiento. En este caso este espacio será controlado por una Storage Account también conocida como Data Lake Gen2. Antes de seguir vamos a crear un Lake. Este recurso tiene una particular opción que debemos prestar atención. El mismo synapse nos advierte de ella cuando nos posicionamos en el icono de información:

Mientras creamos el recurso podemos ponerle nombre, elegir la misma región y determinar la redundancia y plan. En este caso veamos el ejemplo con los menores costos.

Con los datos principales nos vamos a la prestaña advanced para activar el nombrado jerárquico que nos solicita synapse para que nuestro lago sea el file system en formato requerido.

Luego de crearlo necesitamos definir un file system dentro del lake. Esto podemos hacerlo desde el recurso que acabamos de crear o desde la interfaz que teníamos mientras creamos el área de trabajo.

Nombramos el área de trabajo y seguimos con la pestaña de seguridad para determinar el usuario y contraseña de acceso a los servicios de SQL Server que nos brinda la herramienta.

Finalmente podremos ir a nuestro recurso y abrir el espacio de trabajo para comenzar nuestros desarrollos. A partir de ese momento dispondremos las herramientas de Synapse Analytics para disfrutarlo.

Sería una buena práctica integrar nuestra área a un repositorio de DevOps o GitHub para persistir nuestros desarrollos, pero tengan cuidado en solo hacerlo si conocen o entienden de tecnología GIT puesto que si más de una persona desarrolla sobre synapse podrían aparecer conflictos en el repo.
Espero que esto los ayude a dar el primer salto para comenzar a usar Synapse Analytics. No te pierdas los próximos posts hablando de sus herramientas.
#azure#azuresynapse#azure synapse#azure synapse analytics#azure cordoba#azure jujuy#azure argentina#azure synapse tutorial
0 notes
Text
[Fabric] Protegé credenciales en Notebooks con Azure KeyVault
Ciertamente, cuando usamos notebooks, no todo es transformación y limpieza del contenido de nuestro lakehouse. En distintas oportunidades se nos presenta la opción de utilizarlos para integrar datos. Los Notebooks nos pueden ayudar a conectarnos a APIs en nube u otros entornos cloud directamente usando código.
Para que esta opción sea viable, necesitamos evitar exponer las credenciales o claves del origen de datos usadas en el código. Sino imaginen que cualquier persona con acceso al código (ya sea en Fabric o en el repositorio), podría obtener una key de acceso a una API. Para evitar esto, vamos a utilizar un servicio de Azure que ya existe hace tiempo, Azure KeyVaults.
¿Qué es el servicio de Azure Key Vaults?
En palabras Microsoft "Azure Key Vault es un servicio en la nube para el almacenamiento de los secretos y el acceso a estos de forma segura. Un secreto es todo aquello cuyo acceso desea controlar de forma estricta, como las claves API, las contraseñas, los certificados o las claves criptográficas."
Si bien el servicio varias operaciones, nosotros nos quedaremos con la idea que nos permite ingresar una clave o contraseña a encapsular. Solo usuarios con permiso de lectura de claves al servicio podrá utilizar el encapsulado. De ese modo garantizamos que únicamente usuarios aprobados para usarlo, lo usen.
Veamos como crear este secreto antes de usarlo en un Fabric Notebook.
La creación del servicio es bastante simple, basta seleccionar suscripción + grupo de recursos, nombre, region y plan:
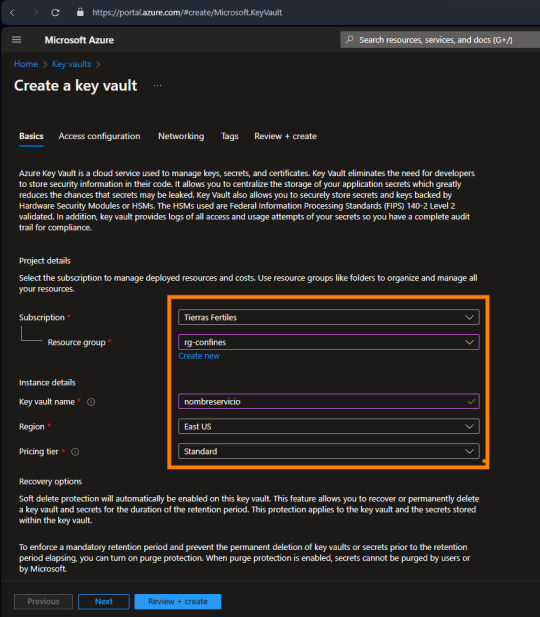
Como mencioné antes, el servicio cuenta con muchas más cosas de las que usaremos nosotros. Ahora nos vamos a concentrar en "Secretos" que es lo que nos interesa.
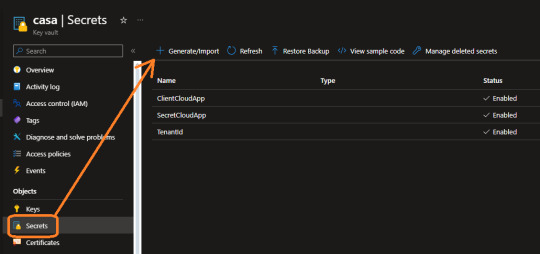
Aqui por ejemplo ya contamos con tres secretos que usaremos para conectar a la PowerBi Rest API. Guardamos secreto para el tenantid, appid y secretvalue de nuestra app registrada en Azure.
Veamos como generar uno nuevo. Es tan simple como darle un nombre y delimitar lo que queremos encapsular. También podemos delimitarlo como algo temporal:
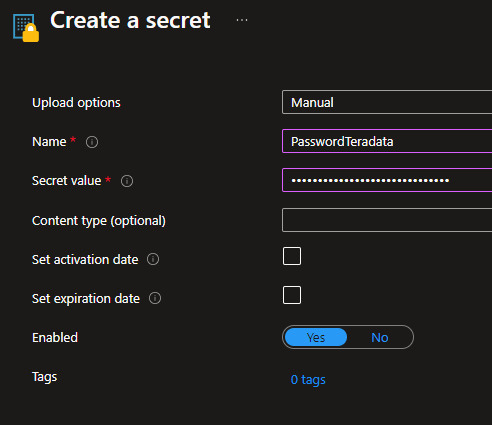
De ese modo podemos crear un nuevo secreto para nuestro almacén de claves. ¿Qué sigue? permitir la lectura a quien vaya a utilizarlo.
Los recursos de azure se manejan con permisos RBAC (role-based access control). Éstos los encontramos en el "Access Control (IAM)". Podemos abrir nuestro menú de permisos y agregar el que lleva el nombre de "Key Vault Secrets User". La cuenta de EntraID con ese permiso, podrá llamar por código a nuestro secreto almacenado aquí.
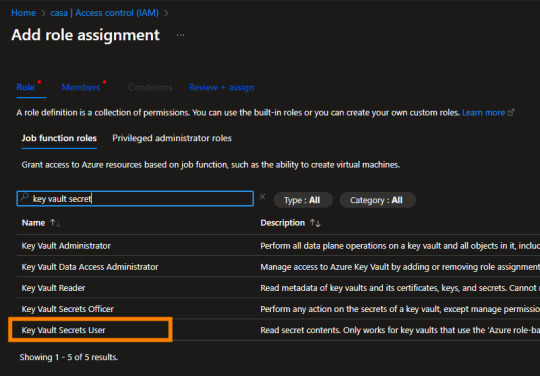
Este proceso es muy importante. Imaginen que con esto podríamos dar permisos a un desarrollador para construir un proceso sin saber nunca las credenciales de origen.
¿Cómo llamarlo desde Fabric?
Para utilizar este servicio desde Fabric Notebook usando python, vamos a nutrirnos de la librería de Microsoft que tiene muchas facilidades de interacción. Pueden leer más detalles aqui: https://learn.microsoft.com/en-us/fabric/data-engineering/microsoft-spark-utilities
Dentro de nuestro notebook vamos a comenzar importando SimplePBI para conectarme a la Power Bi Rest API. Luego importaremos las librerías necesarias. El foco está en nuestra tercera celda. Aqui podremos apreciar como llamar el secreto almacenado recientemente:
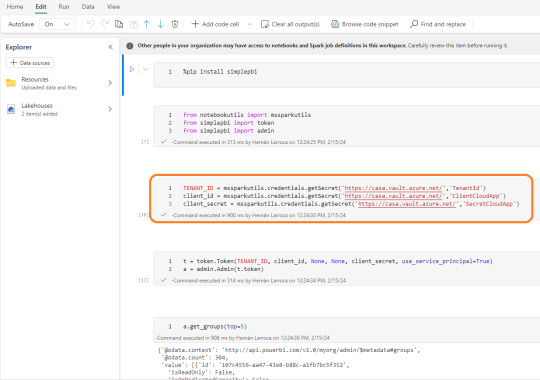
Utilizamos el método getSecret que necesita dos parámetros. El primero es "Vault URI" que podemos encontrarlo en el Overview de nuestro recurso en el portal de Azure. El segundo es el nombre que le dimos a nuestro secreto.
mssparkutils.credentials.getSecret('https://casa.vault.azure.net/','TenantId')
De ese modo almacenamos en variables nuestro resultado y podemos continuar la autenticación de la API en las siguientes filas que crea un token y pide ver el top 5 de workspaces. Recordemos que aquí buscamos seguridad, no solo de exposición de contraseña en código sino de visualización del contenido del secreto. Si el desarrollador intenta leer la variable se encontrará con una limitante:
NOTA: ésta tercera celda pidiendo el secreto solo puede ser ejecutada por una cuenta logueada en Fabric con permisos "Key Vault Secrets User" en nuestro Key Vault. Sino fallará por prohibición de acceso al secreto.
Espero que esto les sea de utilidad para poner automatizar flujos de manera más segura usando Fabric Notebooks.
#Azure#Azure keyvaults#Fabric#Microsoft fabric#Fabric argentina#fabric cordoba#Fabric jujuy#Fabric tutorial#fabric training#Fabric tips#SimplePBI#Fabric python#Fabric notebooks
0 notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
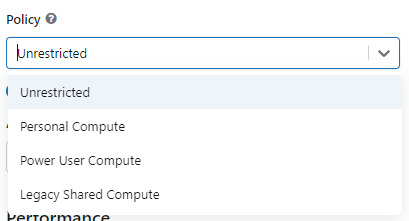
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
Utilizar un policy "unrestricted" o "power user compute"
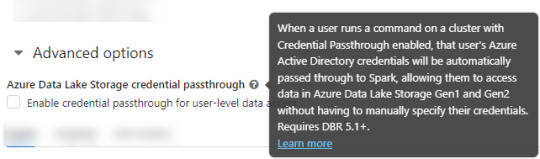
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
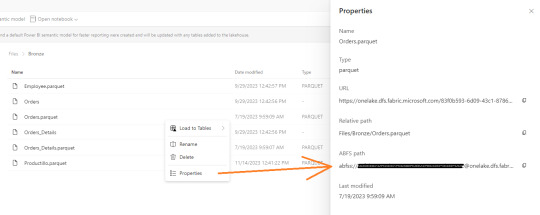
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
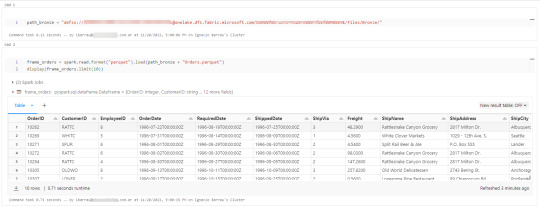
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
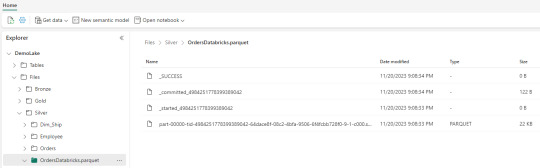
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
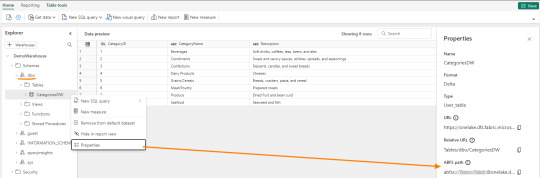
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
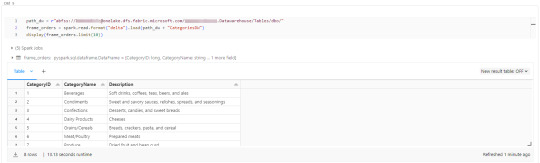
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text
Origen web para evitar gateway PowerBi y Azure Functions
Existen diversos escenarios donde PowerBi nos va a exigir un gateway para actualizar nuestra información. A veces es muy necesario y tiene sentido, pero otras veces no y resulta hasta molesto.
Puede que haya muchos escenarios más que los que voy a mencionar pero normalmente al escrapear un sitio web (funcion Web.Pages de power query) se exige un gateway. Tal vez tenes alguna operación tan compleja que se te ocurre usar Python para resolverla porque esta dentro de Power Bi, pero con eso también te exige Gateway.
Este artículo mostrará como podemos usar Azure Functions para realizar una operación simple con Python para luego leerlo desde PowerBi como un simple Get Request de API.
Primero que nada un poco de teoría. Existen escenarios web los cuales requeiren de Gateway para su tratamiento. Aun si estamos en power query online (dataflows) necesitaremos uno. Hay tres funciones cláscias que son de interés y funcionan distinto. WebContent, WebPages y WebContentBrowser. Si quieren conocer la diferencia y entender cual pide gateway y cual no, pueden leer la siguiente doc: https://learn.microsoft.com/en-us/power-query/connectors/web/web-troubleshoot
Me gustaría comenzar aclarando que no voy a hacer una introducción a Azure Functions. No voy a explicar que es, cómo funciona y cómo setear el entorno. Para eso ya hay excelentes videos en internet o podemos leer más en la siguiente doc de microsoft:
https://learn.microsoft.com/es-es/azure/azure-functions/create-first-function-vs-code-python?pivots=python-mode-configuration
Para este post necesitamos conocimientos previos en Python básico y Visual Studio Code. Asumiendo que ya tenemos el entorno seteado con las extensiones de Visual Studio code, vamos a comenzar con un ejemplo sencillo conectando a una API. Ya logueados en el apartado de Azure y con visibilidad a nuestra suscripción, vamos a crear una Function App. Podemos pensarlo como el servidor de procesamiento de muchas Azure Functions. En ese espacio podemos tener muchas functions, pensemos a cada una como un request.
Al momento de crearla tenemos 4 pasos
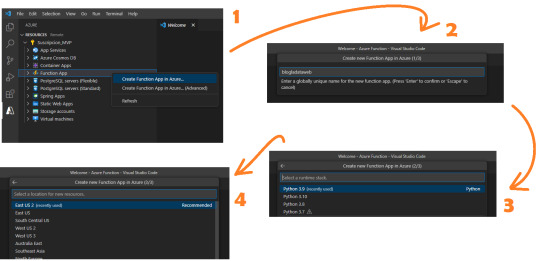
Ese nombre será participe de la URL de la API que estamos generando.
Ahora podremos crear la función. Se almacenará en la carpeta que tengamos apuntando el Visual Studio Code. Clickeamos el rayito para crear una función dentro de la Function App

La aplicación creada se verá así:
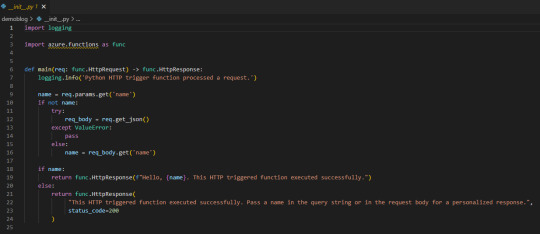
Lo que necesitamos saber es que tenemos una función main donde se ejecutará el código principal. Luego depende si llamamos a la función con get o post si podemos capturar items de parametros de url o body. Eso nos ayudaría a incrementar la seguridad puesto que sin los parametros correctos o autenticación no podríamos obtener la respuesta. A modo de ejemplo vamos a hacer una simple lógica para que la url retorne el resultado cada vez que sea llamada sin necesidad de nada más puesto que considero que no es sensible la data del nombre de los workspaces en mi tenant de demo.
Veamos que simple es escribir código dentro de main devolviendo un dict o json en el return bajo el status_code deseado. Podemos aprovecharnos de los mensajes para ser claros en fallas para recibirlas en Power Bi.
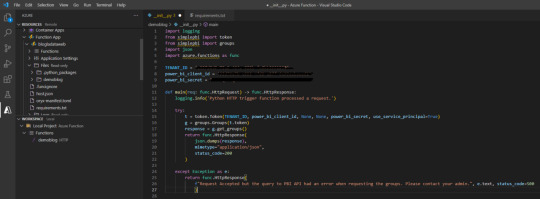
Código de la imagen en mi Github.
Usando SimplePBI para obtener grupos, pueden ver que simplemente generamos token, creamos objeto de grupo (workspaces) y llamamos a los workspaces que nuestro Service Principal puede ver.
Luego agregue al return una aclaración adicional para cuando lo que queremos devolver no es un “texto” literal sino un dict o json que es el “mimetype”.
NOTA: Si no sabes que es SimplePBI podes pasar por aqui.
IMPORTANTE: aclaro que tenemos un secret expuesto en este código, lo mejor para una azure function así sería usar un Azure KeyVault a nuestras contraseñas y secretos para que no queden expuestos.
Si vamos a usar una librería importada tendremos que buscar el archivo requirements.txt en el panel de recursos y agregarla. Yo lo hice para SimplePBI.
Si necesitamos utilizar pandas para tomar datos de un origen estructurado, podemos utilizar “ DataFrame.to_dict(orient="records") ” en el json.dumps del return para convertir nuestro frame al formato de mimetype json.
Get data
Mucho sobre python y funciones, vamos a PowerBi Desktop a conectarnos. Usaremos el conector web para traer la información con credenciales anónimas.
Dependiendo como orientamos nuestro json devuelto en la API que nos generamos en Azure Functions vamos a tener que efectuar transformaciones en power query. En este caso la devuelta por SimplePBI es muy uniforme y el motor practicamente lo resuelve solo.
Veamos como queda:
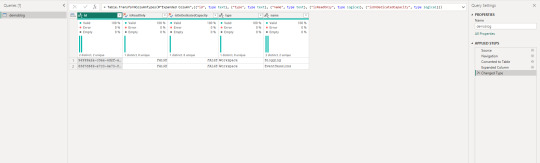
Ahora tenemos nuestra data cargada en Power Bi usando python sin necesidad de un gateway personal. Ya podemos publicar nuestro informe al servicio de power bi y configurar las credenciales como anónimas.
ACLARACIÓN: las Azure Functions tiene un límte de uso (timeout) en 5 minutos. Nuestra ejecución no puede durar más de eso o fallaría y nuestro propósito quedaría perdido.
Conclusión
Esta metodología puede ayudarnos a dar más velocidad a pequeños desarrollos, scrappings u origenes cloud complicados que PowerBi no tenga connector sin driver (ejemplo: oracle o mysql). Con una Azure Function construir rápido y fácilmente una API que responda. Para aumentar la seguridad es necesario utilizar Azure KeyVaults en nuestro código y en caso de necesitar disponibilizar data más sensible, lo mejor sería pedir un parámetro o body con alguna clase de key (que puede ser inventada por nosotros) para que no todo quede sobre una URL pública. Espero que este ejemplo les despierte nuevas ideas.
#powerbi#power bi#power bi desktop#power bi python#python power bi#azure functions#Azure functions python#power bi tips#power bi argentina#power bi jujuy#power bi cordoba#power bi tutorial#power bi training#azure functions power bi#ladataweb
0 notes
Text
[Fabric] ¿Por donde comienzo? OneLake intro
Microsoft viene causando gran revuelo desde sus lanzamientos en el evento MSBuild 2023. Las demos, videos, artículos y pruebas de concepto estan volando para conocer más y más en profundidad la plataforma.
Cada contenido que vamos encontrando nos cuenta sobre algun servicio o alguna feature, pero muchos me preguntaron "¿Por donde empiezo?" hay tantos nombres de servicios y tecnologías grandiosas que aturden un poco.
En este artículo vamos a introducirnos en el primer concepto para poder iniciar el camino para comprender a Fabric. Nos vamos a introducir en OneLake.
Si aún no conoces nada de Fabric te invito a pasar por mi post introductorio así te empapas un poco antes de comenzar.
Introducción
Para introducirnos en este nuevo mundo me gustaría comenzar aclarando que es necesaria una capacidad dedicada para usar Fabric. Hoy esto no es un problema para pruebas puesto que Microsoft liberó Fabric Trials que podemos activar en la configuración de inquilinos (tenant settings) de nuestro portal de administración.
Fabric se organiza separando contenido que podemos crear según servicios nombrados como focos de disciplinas o herramientas como PowerBi, Data Factory, Data Science, Data Engineering, etc. Estos son formas de organizar el contenido para visualizar lo que nos pertine en la diaria. Sin embargo, al final del día el proyecto que trabajamos esta en un workspace que tiene contenidos varios como: informes, conjuntos de datos, lakehouse, sql endpoints, notebooks, pipelines, etc.
Para poder comenzar a trabajar necesitaremos entender LakeHouse y OneLake.
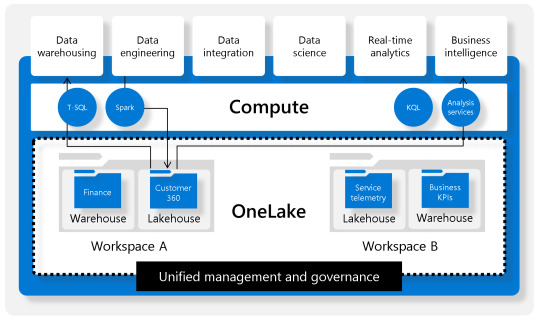
Podemos pensar en OneLake como un storage único por organización. Esta única fuente de datos puede tener proyectos organizados por Workspaces. Los proyectos permiten crear sub lagos del único llamado LakeHouse. El contenido LakeHouse no es más que una porción de gran OneLake. Los LakeHouses combinan las funcionalidades analíticas basadas en SQL de un almacenamiento de datos relacional y la flexibilidad y escalabilidad de un Data Lake. La herramienta permite almacenar todos los formatos de archivos de datos conocidos y provee herramientas analíticas para leerlos. Veamos una imagen como referencia estructural:
Beneficios
Usan motores Spark y SQL para procesar datos a gran escala y admitir el aprendizaje automático o el análisis de modelado predictivo.
Los datos se organizan en schema-on-read format, lo que significa que se define el esquema según sea necesario en lugar de tener un esquema predefinido.
Admiten transacciones ACID (Atomicidad, Coherencia, Aislamiento, Durabilidad) a través de tablas con formato de Delta Lake para conseguir coherencia e integridad en los datos.
Crear un LakeHouse
Lo primero a utilizar para aprovechar Fabric es su OneLake. Sus ventajas y capacidades será aprovechadas si alojamos datos en LakeHouses. Al crear el componente nos encontramos con que tres componentes fueron creados en lugar de uno:
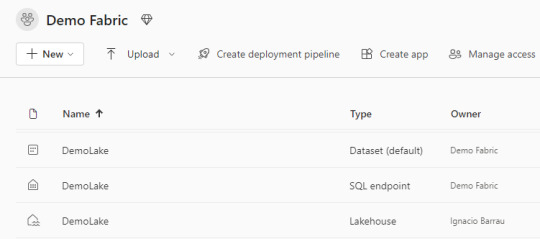
Lakehouse contiene los metadatos y la porción el almacenamiento storage del OneLake. Ahi encontraremos un esquema de archivos carpetas y datos de tabla para pre visualizar.
Dataset (default) es un modelo de datos que crea automáticamente y apunta a todas las tablas del LakeHouse. Se pueden crear informes de PowerBi a partir de este conjunto. La conexión establecida es DirectLake. Click aqui para conocer más de direct lake.
SQL Endpoint como su nombre lo indica es un punto para conectarnos con SQL. Podemos entrar por plataforma web o copiar sus datos para conectarnos con una herramienta externa. Corre Transact-SQL y las consultas a ejecutar son únicamente de lectura.
Lakehouse
Dentro de este contenido creado, vamos a visualizar dos separaciones principales.
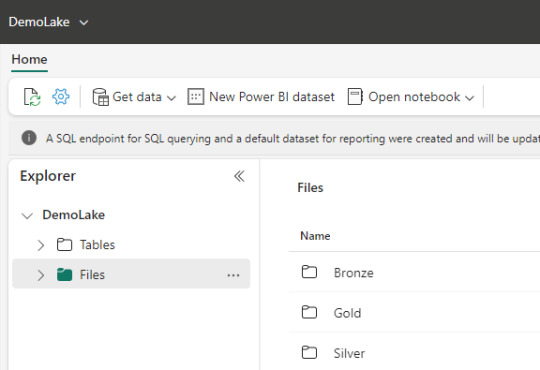
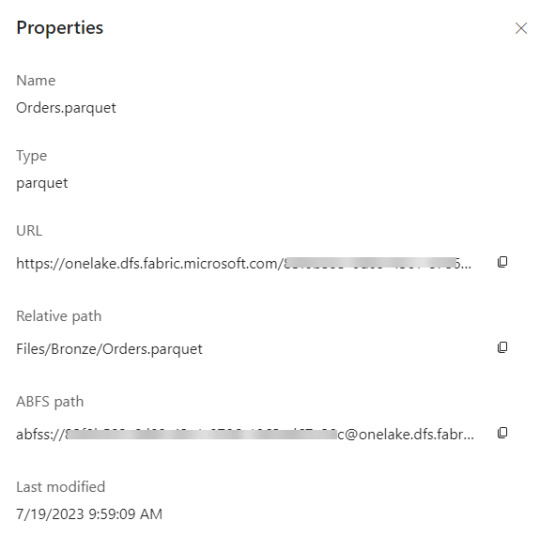
Archivos: esta carpeta es lo más parecido a un Data Lake tradicional. Podemos crear subcarpetas y almacenar cualquier tipo de archivos. Podemos pensarlo como un filesystem para organizar todo tipo de archivos que querramos analizar. Aquellos archivos que sean de formato datos como parquet o csv, podrán ser visualizados con un simple click para ver una vista previa del contenido. Como muestra la imagen, aquí mismo podemos trabajar una arquitectura tradicional de medallón (Bronze, Silver, Gold). Aquí podemos validar que existe un único lakehouse analizando las propiedades de un archivo, si las abrimos nos encontraremos con un ABFS path como en otra tecnología Data Lake.
Tablas: este espacio vendría a representar un Spark Catalog, es decir un metastore de objetos de data relacionales como son las tablas o vistas de un motor de base de datos. Esta basado en formato de tablas DeltaLake que es open source. Delta nos permite definir un schema de tablas en nuestro lakehouse que podrá ser consultado con SQL. Aquí no hay subcarpetas. Aqui solo hay un Meta store tipo base de datos. De momento, es uno solo por LakeHouse.
Ahora que conocemos más sobre OneLake podemos iniciar nuestra expedición por Fabric. El siguiente paso sería la ingesta de datos. Podes continuar leyendo por varios lugares o esperar nuestro próximo post sobre eso :)
#onelake#fabric#microsoft fabric#fabric onelake#fabric tutorial#fabric training#fabric tips#azure data platform#ladataweb#powerbi#power bi#fabric argentina#fabric jujuy#fabric cordoba#power bi service
0 notes
Text
[PowerBi] Integración con AzureDevOps Git Repos
El lanzamiento de Power Bi Developer Mode durante el evento Microsoft Build está causando gran revuelo no solo por su posibilidad resguardar un proyecto de PowerBi sino también porque por primera vez tendríamos la posibilidad de que dos o más usuarios trabajen en un mismo proyecto. Esto no es trabajo concurrente instantáneo como Word Online sino más bien cada quien modificando los mismos archivos de un repositorio y logrando integrarlos al final del día.
La deuda de versionado y trabajo en equipo finalmente estaría cumplida. Según uno de los personajes más importantes del equipo, Rui Romano, aún hay mucho por hacer. Veamos que nos depara esta característica por el momento.
Vamos a iniciar asumiendo que el lector tiene un conocimiento básico de repositorios. Entienden que en un repositorio se almacenan versiones de archivos. Se pueden crear ramas/branches por persona que permita modificar archivos y luego se puedan integrar/merge para dejar una versión completa y definitiva.
Todo esto es posible gracias a la nueva característica de Power Bi Desktop que nos permite guardar como proyecto. Esto dividirá nuestro pbix en dos carpetas y un archivo:
Carpeta de <nombre del archivo>.Dataset: Una colección de archivos y carpetas que representan un conjunto de datos de Power BI. Contiene algunos de los archivos más importantes en los que es probable que trabajes, como model.bim.
Carpeta de <nombre del archivo>.Report: Una colección de archivos y carpetas que representan un informe de Power BI. El archivo más importante es "report.json", aunque durante la vista previa no se admiten modificaciones externas en este archivo.
Archivo <nombre del archivo>.pbip: El archivo PBIP contiene un enlace a una carpeta de informe. Al abrir un archivo PBIP, se abre el informe en Power Bi Desktop y el modelo correspondiente.
Entorno
Lo primero es configurar y determinar nuestro entorno para poder vincular las herramientas. Necesitamos una cuenta en Azure DevOps y un workspace con capacidad en Power Bi Service. Para que la integración sea permitida necesitamos asegurarnos que nuestra capacidad y la de la Organización de Azure DevOps estén en la misma región.
La región de una organización de Azure DevOps puede ser elegida al crearla, al igual que podemos elegir la región de una capacidad cuando creamos una premium, embedded o fabric.
En caso de utilizar capacidad PowerBi Premium Per User o Fabric Trial, no podríamos elegir la región. Sin embargo, podríamos revisar la región de nuestro PowerBi para elegir la misma en Azure DevOps
En ese caso creamos la organización de DevOps igual que nuestro PowerBi porque haremos el ejemplo con un workspace PPU.
Seteo
Dentro de Power Bi Service y el Área de trabajo con capacidad que queremos versionar iremos a la configuración. Con la misma cuenta de ambos entornos completaremos los valores de organización, proyecto, repositorio, rama y carpeta (opcional).
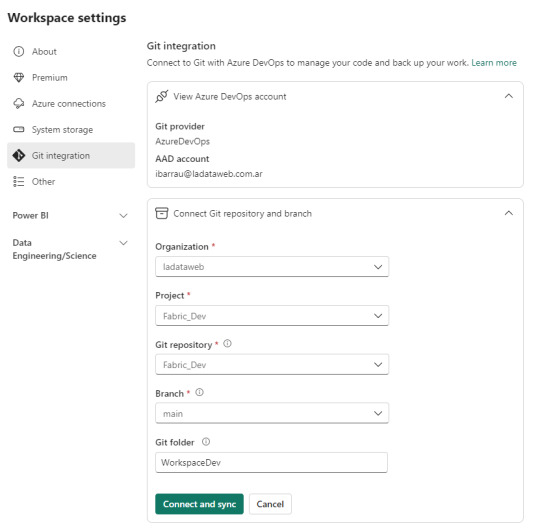
Como nuestro repositorio esta vacío, lo primero que sucederá cuando conectemos será una sincronización de todos los items del área de trabajo en el repositorio. Ahora bien, si teníamos reportes en el repositorio y en el area, tendremos un paso más para coordinar la operación deseada si pisar o integrar.
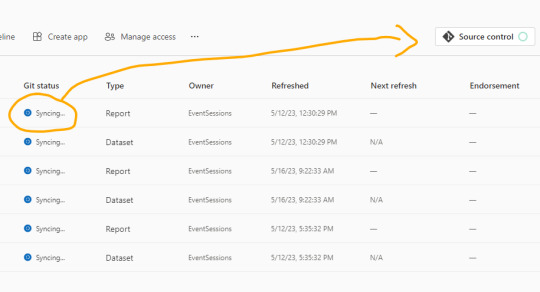
Una vez que todo tenga tilde verde y esté sincronizado, podremos ver como queda el repositorio.
En caso que ya tuvieramos informes cuando inicio el proceso, se crearán carpetas pero no el archivo .pbip que nos permitiría abrirlo con Power Bi Desktop.
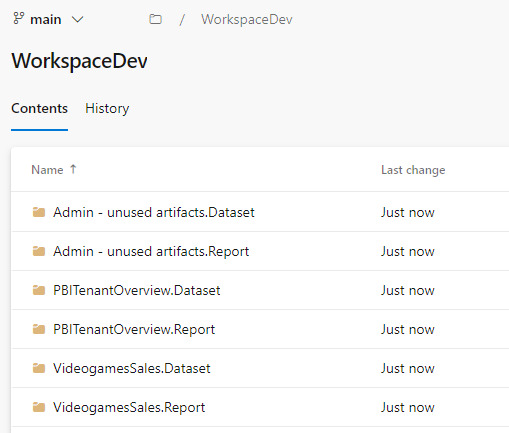
Si crearamos el informe con Power Bi Desktop y eligieramos “Guardar como proyecto” si se crearía. Entonces podríamos hacer un commit al repositorio y automáticamente se publicaría en nuestra área de trabajo.
El archivo pbip es un archivo de texto. Podemos abrirlo con un bloc de notas para conocer como se constituye para generarlo en caso que necesitemos abrir con Desktop uno de los informes que sincronizamos antes. Ejemplo del archivo:
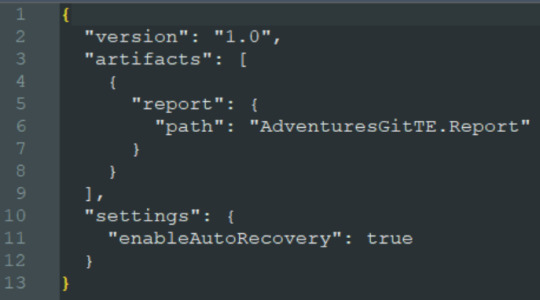
Al tener sincronizado el repositorio con el workspace podemos usar un entorno local. Si está en el repositorio en la rama principal, entonces estará publicado en el área de trabajo. Veamos como sería el proceso.

Esta sincronización también nos favorece en el proceso de Integración y Deploy continuo puesto que varios desarrolladores podrían tener una rama modificada y al integrarlo con la principal delimitada en el área de trabajo tendríamos automáticamente todo deployado.
Si algo no se encuentra en su última versión o hacemos modificaciones en línea, podemos acceder al menú de source control que nos ayudaría a mantener ordenadas las versiones.
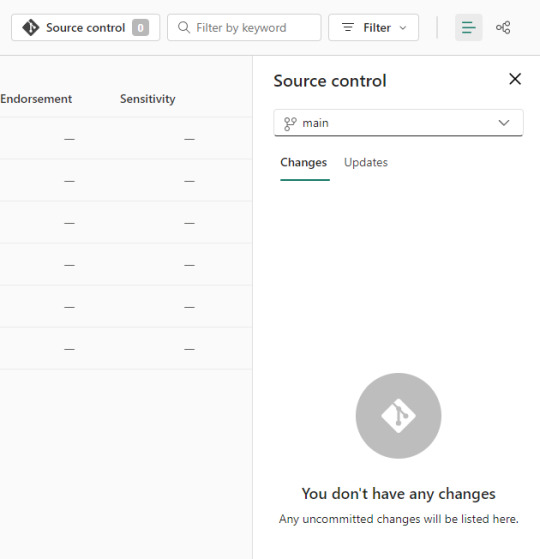
Alternativa Pro
Con las nuevas actualizaciones de Fabric en agosto 2023, podremos por primera vez, trabajar en equipo en PowerBi sin licencia por capacidad o premium. Guardar como proyecto es una característica de PowerBi Desktop. Por lo tanto, podemos usarla contra un repositorio Git en cualquier tecnología. Al termino del desarrollo, una persona encargada debería abrir el PBIP y publicarlo al área pertinente. Ahora podemos publicar desde Desktop los informes guardados como proyectos. Esto nos permite que los casos de puras licencias pro puedan aprovechar las características de histórico y control de versiones. Quedará pendiente la automatización para deploy e integración que aún no podría resolverse solo con PRO.
Conclusión
Esta nueva característica nos trae una práctica indispensable para el desarrollo. Algo que era necesario hace tiempo. Sería muy prudente usarlo aún en proyectos que no modifiquen un informe al mismo tiempo puesto que ganamos una gran capacidad en lo que refiere a control de versiones.
Si no tenemos capacidad dedicada, deberíamos trabajar como vimos en post anteriores sobre metodología de integración continua de repositorio https://blog.ladataweb.com.ar/post/717491367944781824/simplepbicd-auto-deploy-informes-de-powerbi
Esperemos que pronto tengamos una opción para importar por API estos proyectos al PowerBi Service para poder idear nuestros propios procesos sin usar las integraciones por defecto sino una personalizada a nuestro gusto.
#powerbi#power bi#power bi desktop#power bi git#azure devops#azure repos#power bi tutorial#power bi tips#power bi training#power bi argentina#power bi jujuy#power bi cordoba#ladataweb#power bi developer mode
0 notes
Text
[DAX] Descripciones en medidas con Azure Open AI
Hace un tiempo lanzamos un post sobre documentar descripciones de medidas automaticamente usando la external tool Tabular Editor y la API de ChatGPT. Lo cierto es que la API ahora tiene un límite trial de tres meses o una cantidad determinada de requests.
Al momento de decidir si pagar o no, yo consideraría que el servicio que presta Open AI dentro de Azure tiene una diferencia interesante. Microsoft garantiza que tus datos son tus datos. Qué lo que uses con la AI será solo para vos. Para mi eso es suficiente para elegir pagar ChatGPT por Open AI o por Azure.
Este artículo nos mostrará como hacer lo que ya vimos antes pero deployando un ChatGPT 3.5 y cambiando el script de C# para utilizar ese servicio en Azure.
Para poder realizar esta práctica necesitamos contar con un recurso de Azure Open AI. Este recurso se encuentra limitado al público y solo podremos acceder llenando una encuesta. Fijense al momento de crear el recurso debajo de donde seleccionaríamos el precio.

La respuesta de Microsoft para permitirnos usar el recurso puede demorar unos días. Una vez liberado nos permitirá usar un Tier S0. Este recurso es un espacio que nos permite explorar, desarrollar, deployar modelos. En nuestro caso queremos deployar uno ya existente. Al crear el recurso veremos lo siguiente y antes de ingresar a Deploy, copiaremos valores de interes.
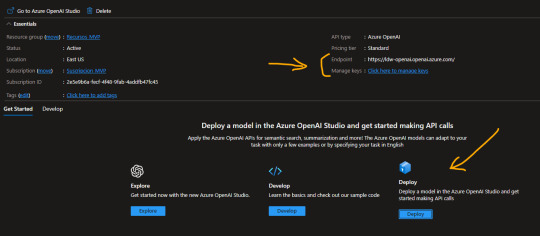
Para nuestro script vamos a necesitar el “Endpoint” y una de las “Keys” generadas. Luego podemos dar click en “Deploy”.
Al abrir Azure AI Studio vamos a “Deployments” para generar uno nuevo y seguimos esta configuración:
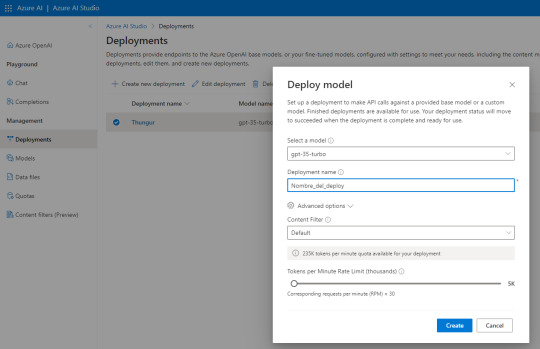
El nombre del deploy es importante puesto que será parte de la URL que usamos como request. Seleccionen esa versión de modelo que se usa para Chat especificamente de manera que repliquemos el comportamiento deseado de ChatGPT.
Atención a las opciones avanzadas puesto que nos permiten definir la cuota de tokens por minuto y el rate limiting de requests por minuto. Para mantenerlo similar a la API gratuita de Open AI lo puse en 30. Son 10 más que la anterior.
NOTA: ¿Por qué lo hice? si ya intentaron usar la API Trial de GPT verán que les permite ver sus gastos y consumos. Creo que manteniendo ese rate limiting tuve un costo bastante razonable que me ayudó a que no se extienda demasiado puesto que no solo lo uso para descripciones DAX. Uds pueden cambiar el valor
Con esto sería suficiente para tener nuestro propio deploy del modelo. Si quieren probarlo pueden ir a “Chat” y escribirle. Nos permite ver requests, json y modificarle parámetros:

Con esto ya creado y lo valores antes copiados podemos proceder a lo que ya conocemos. Abrimos PowerBi Desktop del modelo a documentar. Luego abrimos Tabular Editor y usaremos el siguiente Script para agregar descripciones a todas las medidas que no tengan descripción previa. Tiene un pausador al llegar a 30 porque es el rate limiting que yo definí en mi modelo. Eso pueden cambiarlo
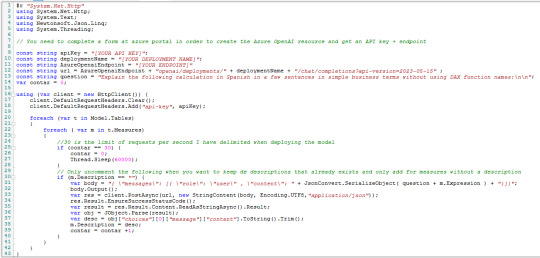
Las primeras variables son los valores que copiamos y el nombre del deployment. Completando esos tres el resto debería funcionar. El script lo pueden copiar de mi Github.
Con esto obtendrán las descripciones de las medidas automaticamente en sus modelos utilizando el servicio de Azure Open AI, espero que les sirva.
#powerbi#power bi#power bi desktop#azure openai service#azure ai#power bi argentina#power bi jujuy#power bi cordoba#power bi tips#power bi training#power bi tutorial#ladataweb#fabric
0 notes
Text
Intro a Microsoft Fabric la solución Data Platform todo en uno
Recientemente Microsoft ha realizado fantásticos anuncios durante la conferencia MS Build 2023. Si bien la misma suele tener un foco en desarrollo de software, el apartado de la industria de data ha tenido un revuelco enorme con sus anuncios.
En este artículo vamos a introducir características y funcionalidades de la nueva herramienta de Microsoft que va a intentar tomar todos los roles de data trabajando en un mismo espacio.
¿Qué es Microsoft Fabric?
Durante el lanzamiento de la nueva herramienta que contemplaría un end to end de proyectos de data se lanzó mucha documentación. Microsoft define a su herramienta de la siguiente manera: Microsoft Fabric es una solución de análisis todo en uno para empresas que abarca todo, desde el movimiento de datos a la ciencia de datos, Real-Time Analytics y la inteligencia empresarial. Ofrece un conjunto completo de servicios, como data lake, ingeniería de datos e integración de datos, todo en un solo lugar. La definición nos permite ver que quieren unir los mundos de BI o Data Analysis con Data Engineering, Data Science y hasta Governance bajo un mismo software como servicio (SaaS) buscando la simplicidad. Fabric es un producto que tiene su propio dominio y esta dentro de Azure.
¿Qué servicios tiene?
Fabric llegó buscando simpleza y conceptos familiares de la herramienta que más venía sonando en el mercado, PowerBi. A partir de PowerBi tomó su entorno y conceptos para crear Fabric. Su interfaz y experiencia de usuario es sumamente similar. PowerBi quedará como parte de una de las secciones de servicio de Fabric. La pantalla principal se ve casi identico a Power Bi Service. El menú si cambió con nuevos conceptos y abajo a la izquierda veremos la un botón para cambiar las posibilidades (lo que marca la diferencia con el power bi de todos los dias). Veamos sus secciones.

Como pueden ver hay muchos productos centrado en los mayores éxitos de data en los servicios de Azure. Data Factory es un orquestador y herramienta de integración por pipeles predilecta asi como Power Bi lo es para reporting y respuesta en modelos tabulares. Se incorpora de synapse lo referido a Notebooks y modelos en ciencia de datos y Lakehouse para data enginierring. Existen dos apartados que pienso no serían tan frecuentes como el caso de Aarehouse y Real Time Analytics. Sabemos que real time no es algo para desarrollar en todos los escenarios sino en puntuales en que es necesario para el proceso de negocio que el dato esté y no porque un cliente quiere estar al día con todo todo el tiempo, por eso digo no tan frecuente. Warehouse me parecía interesante pero creo que no sería tan elegido luego de ver que su motor será literalmente un lakehouse pero visiblemente tendrá todo una capa para trabajar con esquemas de bases de datos para sentirnos en un pool deciado con scripts SQL.
Lo más interesante y diferente me pareció el concepto de Lake. Fabric con tiene un único Lake que será como dicen “el OneDrive for Data”. Un único espacio que puede tener varios lakehouses con punteros a otros lakehouse de tecnología delta. Con esto me refiero a que si un departamento como Recursos Humanos tiene cargado en su LakeHouse una tabla de Dimension de Empleados que necesitan usar otras áreas. Las otras áreas pueden nutrirse de ella creando un punturo a ese origen siempre y cuando seal del tipo Delta. Lo más fascinante es que no solo podemos crear punturos dentro del mismo OneLake, sino también contra otros origenes del estilo como un Azure Data Lake Gen2 y hasta un AWS S3. En demos a futuro hasta mostraron Delta de DataBricks corriendo en cualquier nube. Esto puede estar sonando confuso asique veamos un poco de orden.
¿Cómo se organiza?
Nutriendose de la organización de PowerBi, los espacios de trabajo de todos los componentes serán organizados por Areas de Trabajo (workspaces). Éstos contienen distintos componentes según la sección seleccionada, por ejemplo, el Workspace LaDataWebTest en la sección Power Bi puede tener informes, datasets, dashboards y apps, mientras que el mismo Workspace en la sección Data Engineering contiene pipelines, lakehouses, notebooks o dataflows gen2.
Una vez prendido Fabric los datos transcurren en un único transfondo de lake llamado OneLake. Si bien cada workspace puede tener su lakehouse, el almacenamiento es el mismo pero organizado en distintos workspaces.

De este modo cada profesional de datos bajo un mismo proyecto estaría trabajando en un mismo workspace. Seguramente se vería así:

Repleto de componentes varios. Aqui podemos ver un Lakehouse y Warehouse llenados con un Dataflow Gen2 y dieron lugar a datasets. Asi mismo hay un SQL Endpoint para hacer consultas SQL al Lakehouse. Tal vez más adelante tenga notebooks de un data scientist trabajando en algun modelo.
Roles de data
Los Data Engineers pienso que estarán contentos de seguir trabajando con Data Factory y notebooks tal como lo hacían en Azure. Solo les cambiará la interfaz de la plataforma. Del mismo modo los Data Scientist deberán acostumbrarse a sus nuevos accesos pero mantienen las esencias de trabajo que tenían antes con diferencia en la puesta en marcha de modelos. El rol más empoderado pienso que es el Bi o Data Analyst. Incorporaría en la plataforma, que ya manejaba a la perfección, los servicios de otros roles al mejor estilo PowerBi. Por si fuera poco ahora DataFlow Gen2 como evolución de Power Bi DataFlows se convirtió en una herramienta total de ETL. ¿Por qué digo eso? porque nuestro Power Query Online tiene el poder de sus connectores como siempre con una supuesta optimización de performance y sobre todo porque permite elegir el destino del procesamiento. Dataflows permitirá seleccionar el destino del procesamiento de datos. Podremos depositar nuestro desarrollo como DeltaTables en un Lakehouse o directos a un Warehouse. De ese modo se empodera el rol puesto conocería un modo de hacer Integración de Datos que comunmente lo trabajan los Data engineers. Cabe aclarar que no estoy afirmando que sea la mejor práctica ni que los Engineers quedarían sin trabajo, para nada, solo menciono que se empodera el rol del Analista.
Versionado de solución
Algo increible que incorporaron es integración con Git. Seguro suenda burdo para los perfiles de datos que trabajan con la diaria en Azure, pero los que venimos usando hace tiempo Power Bi además de Azure, sabemos que es una cuenta pendiente. El Workspace COMPLETO se vincularía a un repositorio Git en Azure DevOps. Esta integración tiene un camino brutal en próximos releases puesto que Power Bi Desktop permitiría guardar como “proyecto” que desmantelaría los .pbix en carpetas de código que permitan versionado y trabajo en conjunto. Por si eso fuera poco mostraron que al terminar un push de los datos automáticamente estaría actualizado el informe en el Área de Trabajo gracias a la integración.

Administración
Por si todo lo anterior fuera poco, incorporaron un workspace de administración que contiene un pequeño, pero mucho mejor que lo que existía antes, informe del uso de la plataforma. Además hay otro informe para entender mejor el flujo de datos que se ajustaría y acompañaría con Purview para governanza.

Quiero comenzar ¿que hago?
Para dar inicio a todo esto necesitamos ser viejos Administradores de Power Bi o como ahora lo llaman Administradores de Fabric. En el portal de administración que se manejan Tenant Settings veremos dos opciones claves

Por otro lado

Con esas opciones listas podremos actival el Fabric Trial y comenzar a probarlo. Si quieren conocer más detalles sobre licencias:
SKU: https://learn.microsoft.com/en-us/fabric/enterprise/buy-subscription
Fabric Capacity: https://learn.microsoft.com/en-us/fabric/enterprise/licenses
Direct Lake
Existe un nuevo método de lectura de datos de PowerBi. Conocíamos live connection, direct query y el más popular, import mode. Ahora se creó uno nuevo para lo que es conectividad de un dataset contra un lakehouse de Fabric. Esta conexión es directa y veloz. Dicen que no es como Direct Query sino algo superior. La premisa para justificar es bastante interesante. Considerando que al importar datos creamos un Modelo Tabular en vertipaq engine. Ese motor es un almacenamiento columnar en memoria. Ahora Lakehouse guardaría tablas delta, que son un almacenamiento columnar. Esta conexión dice que tendría la misma performance puesto que de ambas formas (import mode y direct lake) Power Bi emitía una una consulta contra un motor de almacenamiento columnar. Hay mucho por testear aún puesto que no se si las delta tables estarían en memoria como vertipaq, pero hay mucho esfuerzo detrás que motiva a un buen resultado.

Lo más importante antes de trabajar con esto, sería conocer sus limitaciones: https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview#known-issues-and-limitations
IA
No me va a alcanzar escribir todo lo que está incluido en Fabric y no quería dejar de mencionar que es la suite de data que integraría muchisimo de IA. Cada servicio a su modo y la totalidad tendría integración con Copilot (la IA de Microsoft entrenada con Chat GPT de los servicios de Open AI). Esto fortalecería todo luegar donde necesitemos escribir código como los notebooks y hasta incluso para realizar gráficos o escribir DAX en Power Bi.
Dominios
Mientras vamos esas opciones veremos que existe una nueva llama “Dominios”. Si bien aún no esta claro como funcionarían en todos esto, los dominios se los nombraron para ayudar a catalogar conjuntos de workspaces dentro de un mismo departamento en una empresa. Por ejemplo Marketing con dos workspaces como muestra la siguiente imagen.

Todo parece apuntar a algo de grandes compañias de nivel Enterprise que tengan maduro los desarrollos de data para contemplar una organización en muchos desarrollos.
¿Qué hay de synapse?
Escribiendo basado en opiniones personales creo que al no haber contemplado todo el end to end de proyectos de datos la herramienta no tuvo tanto impacto. Sus servicios más fuertes fueron los de almacenamiento y transformación LakeGen2, SQL Serverless, Notebooks o Warehouses. Dejaron afuera la explotación de presentación del dato, Power Bi. La nueva solución buscó contemplar todo con la simpleza de Power Bi Service. Seguramente sus servicios seguirán existiendo en Azure, pero dudo que su uso para integración de datos y semejante sea elegido.
Conclusiones
Este nuevo camino de integración de todo en uno de Microsoft tiene un fuerte impacto a la integración de roles y plataformas. No tengo dudas que la participación activa de una inteligencia artificial que asista será un muy fuerte impacto al momento de elegir tecnología para un proyecto de datos. La tecnología promete mucho y tienen mucho que mejorar, no dejaremos de aclarar que Fabric esta en “preview”, lo que significa que siguen trabajando en ella para mejorarla todos los días. Pienso que si hoy usan Power Bi y no tienen tanta madurez en Lake o warehouse, sería un momento hermoso para probar esto. Incluso si se inicia un proyecto nuevo aún teniendo otra arquitectura madura para probar y contrastar. Lo que si no iría corriendo a migrar una arquitectura madura y funcional de Azure a Fabric de golpe. Los servicios seguirán activos y será cuestión de ir probando y viendo la evolución de la herramienta para introducirse poco a poco.
#MicrosoftFabric#Fabric#Micorosft Fabric#powerbi#power bi#power bi service#Microsoft Fabric Argentina#Microsoft Fabric jujuy#Microsoft Fabric Cordoba#azure data platform#datalake#notebooks#data science#data engineering#data analyst#bi
0 notes
Text
[SimplePBI][CD] Auto Deploy informes de PowerBi con Azure Devops Pipelines
CI/CD, DataOps, Devops y muchos otros nombres han recorrido las redes para referirse al proceso más continuo y automático de deploy. Hoy luego de tanto tiempo de dos herramientas como Azure Devops y PowerBi existen muchos posts y artículos que nos hablan de esto.
¿Qué diferencia este artículo de otro? que haremos el deploy continuo con SimplePBI (librería de python para usar la PowerBi Rest API) dentro de Azure Devops. Solo prácticas de CD. Luego compartiré pensamientos sobre CI. Para esto nos acompañaremos de un repositorio Git en Azure Devops.
No se si llamarle algo “Ops” o simplemente CD PowerBi. Asique sin más charla que dar seguí leyendo si te interesa este mix de temas.
Si hay algo de lo que estoy seguro sobre todo esto de Ops, CI o CD es que tiene un origen y base en software que consiste en facilitar la experiencia del desarrollador. Con ese objetivo vamos a mantener la metodología de un post anterior. El desarrollador no necesita saber más nada. Todo lo siguiente lo configuraría un admin o persona que se dedique a “Ops”.
NOTA: Antes de iniciar aclaro que para que funcione la metodología anterior vamos a quitar el “tracking” del archivo y mantener unicamente el lock. Debemos quitarlo puesto que modifica la metadata guardada en gitattributes y le impide a la API de PowerBi importar el informe. Código: git lfs untrack "Folder/File_name.pbix"
Proceso
Intentando simular metodologías de desarrollo de software es que vamos a plantear este artículo. Cabe aclarar que funcionaría en tradicionales esquemas que siguen el hilo de “Origenes -> Power Bi Desktop -> Power Bi Service”. Nuestro enfoque aquí esta centrado en que los desarrolladores no tengan contacto con Power Bi Service. Su herramienta de desarrollo Desktop y Git serían la diaria. De este modo solo deben preocuparse por tomar la última versión desarrollada, efectuar modificaciones bloqueando el archivo y devolverlo al repositorio modificado y desbloqueado.
La responsabilidad del profesional Ops será la de asegurar que esos desarrollos publicados se disponibilicen en el servicio de PowerBi con flujos automáticos. Con este propósito, y aprovechando nuestro repositorio, vamos a utilizar la herramienta de Azure Devops Pipelines. Para tener acceso a los procesamientos paralelos que nos permiten ejecutar el pipeline, será necesario llenar una encuesta especificada en la documentación de Microsoft como nueva política. Forms y doc para más info en el siguiente link: https://learn.microsoft.com/en-us/azure/devops/pipelines/licensing/concurrent-jobs?view=azure-devops&tabs=ms-hosted
Si bien existen muchas formas y procesos de generar deploys automáticos, la que vamos a generar es la siguiente:
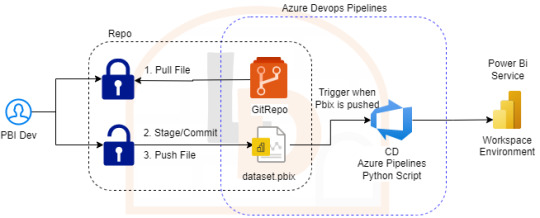
Nos vamos a concentar en importar archivos de PowerBi Desktop ni bien hayan sido pusheados al repositorio. Nuestro enfoque consiste en tener un Pipeline por Área de Trabajo, lo que llevaría a un archivo .yml por area de trabajo. Para mejorar la consistencia de nuestros desarrollos les recomiendo ordenar las carpetas para que coincidan con las areas de trabajo, datasets/reportes o ambientes. Por ejemplo:
De ese modo podríamos controlar ambientes, shared datasets o simplemente informes con el dataset. Cada quien conoce sus desarrollos para aplicar la complejidad deseada. Vamos a ver el ejemplo con un solo ambiente que tiene informes en areas de trabajo sin separación de shared datasets.
Configuración
Para iniciarnos en este camino abrimos dev.azure.com y creamos un proyecto. El proyecto trae muchos componentes. De momento a nosotros nos interesan dos. Repos y Pipelines. Asumiendo que saben de lo que hablo y ya tienen un repositorio en esta tecnología o Github, procedemos a crear el pipeline eligiendo el repo:
Luego nos preguntará si tenemos una acción concreta de creación incial para nuestro archivo yaml (archivos de configuración de pipelines que orientan el proceso). Podemos elegir iniciar en blanco e ir completando o descarguen el código que veremos en el artículo, ponganlo en el repositorio y creen el pipeline a partir de un archivo existente
Ahora si tendremos nuestro archivo yml en el repositorio listo para modificarlo. Veamos como hacemos la configuración.
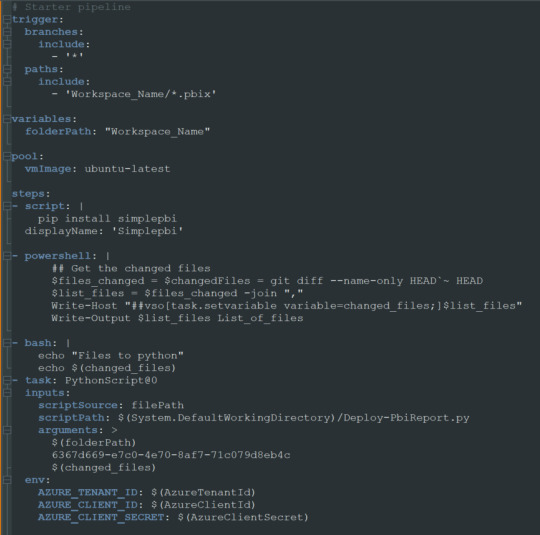
Enlace de github del archivo.
Nuestro pequeño pipeline cuenta con una serie de pasos.
Trigger
Variables
Pool
Steps
NOTA: Estos son un mínimo viable para correr una automatización. Si desean leer más y conocer mayor profundidad puede adentrarse en la documentación de microsoft: https://learn.microsoft.com/es-es/azure/devops/pipelines/yaml-schema/?view=azure-pipelines
Trigger nos mencionará en que parte del repositorio y sobre que branch tiene que prestar atención. En nuestro caso dijimos cualquier branch del path con carpeta “Workspace_Name” y al modificar cualquier archivo PBIX de dicha carpeta. Eso significa que al realizar un commit y push de un archivo de Power Bi Desktop dentro de esa carpeta, se ejecutará el pipeline.
Variables nos permite definir un texto que podremos reutilizar más adelante. En este caso el path de la carpeta. Si bien es una sola carpeta, la práctica de la variable puede ser útil si queremos usar paths más largos. IMPORTANTE: los nombres de carpetas en la variable path no pueden contener espacios dado que la captura de python posterior los reconoce como argumentos separados. Recomiendo usar “_” en lugar de espacios.
Pool viene por defecto y es el trasfondo que correrá el pipeline. Recomiendo dejarlo en ubuntu-latest.
Steps aquí estan los pasos ejecutables de nuestro pipeline. La plataforma nos permite ayudarnos a escribir esta parte cuando elegimos basarnos de la ayuda del wizard. En este caso podemos basarnos en lo que proveemos en ladataweb. Hablemos más de estos pasos.
Detalle de Steps
Primero haremos la instalación de la librería de Python que nos permite utilizar la Power Bi Rest API de manera sencilla en el paso Script.
El paso powershell puesto que nos permite jugar con una consola directa sobre el repositorio. Aqui aprovecharemos para ejecutar un comando git que nos informe cuales fueron los últimos archivos afectados entre el commit anteriores y el actual. Tengamos en cuenta que para poder realizar esta comparación necesitamos cambiar el shallow fetch de nuestro repositorio. Esto significa la memoria de cambio reciente que normalmente viene resguardando 1 commit “más reciente”. Para realizar este cambio necesitamos guardar el pipeline. Luego lo editamos nuevamente y nos dirigimos a triggers:

Una vez allí en la pestaña Yaml podremos encontrar la siguiente opción que igualaremos a 3 como el mínimo necesario para la comparativa.
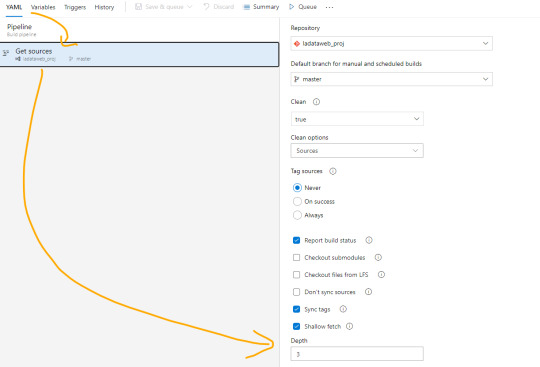
Esta operación también se puede realizar con un Bach de Git local, pero este modo me parece más simple y visual. Para más información pueden leer aqui: https://learn.microsoft.com/es-es/azure/devops/pipelines/repos/azure-repos-git?view=azure-devops&tabs=yaml#shallow-fetch
El paso bash es simplemente para mostrarnos en la consola los archivos que reconoció el script y estan listos para pasar entre pasos.
El paso crítico es Task que llamará a un python script. Para ser más ordenado vamos a llamar a un archivo en el repositorio que nos permita leer un código que cambie con unos parámetros que envía el pipeline para no estar reescribiendolo en cada pipeline de cada workspace/carpeta. Aqui completamos que en script source del file path definido podemos encontrar el script path hasta el archivo puntual que usuará los siguientes tres argumentos. La lista de argumentos refiere al path de los archivos pbix, el id del workspace en donde publicaremos y los archivos que se modificaron según el último commit. Cierra definiendo unas variables de entorno para garantizar la seguridad del script evitando la exposición de la autenticación de la API. En el menú superior derecho veremos la posibilidad de agregar variables:

Sugiero mantener oculto el secret del cliente y visible el id del cliente. Visible este segundo para reconocer con que App Registrada de Azure AD nos estamos conectado a usar la Power Bi Rest API.
Ya definido nuestro Pipeline creemos el script de python que hará la operación de publicar el archivo. En nuestro script lo dejé en la Raíz del repositorio $(System.DefaultWorkingDirectory)/Deploy-PbiReport.py para reutilizarlo en los pipelines de las carpetas/workspaces. Veamos el script

Enlace de github del archivo.
Primero importaremos simplepbi y otras dos librerías. OS para reconocer las variables del entorno y SYS para recibir argumentos.
Iniciarmos recibiendo los argumentos de pipeline con sys.argv en el orden correspondiente. Como la recepción de python lee los argumentos separados por espacios como distintos, vamos a asumir que el parámetro 3 o más se unan separados por espacios (puesto que llegaron como argumentos separados. Luego tomamos la lista de archivos en cadena de texto para construir una lista de python que nos permita recorrerla. En este proceso aprovecharemos para quitar archivos modificados en el commit que no pertenezcan a la carpeta/workspace deseada y sean de extensión “.pbix”. Leemos las variables de entorno para loguear nuestro Power Bi Rest API y todo lo siguiente es mágia de SimplePBI. Pedimos el token para nuestra operaciones, hacemos un for de archivos a importar y realizamos la importación con cuidados de capturas de excepciones y condiciones. Todos los prints nos ayudarán a ver los mensajes al termino de la ejecución para reconocer alguna eventualidad. Esto apunta a no cortar si uno de los archivos falla en publicar no corte al resto. Sino que seguirá y al finalizar podremos lanzar la excepción para que falle el pipeline general a pesar que tal vez corrieran 4/5. Por supuesto que esta decisión podría cambiarse a que si uno falla ninguno continue, o que siga pero al final lanzar una excepción
NOTA: Claro que si es la primera vez que colocamos el archivo.pbix en el repositorio no bastará solo con la importación automática. Será necesario ir a ingresar las credenciales para las actualizaciones manualmente. De momento eso no es posible hacerlo automáticamente.
Para ejecutar la prueba solo bastaría con modificar un archivo .pbix dentro de la carpeta del repo, commit y push. Ese debería ejecutar la acción y publicar el archivo.
De ese modo el desarrollador solo se enfoca en desarrollar con Power Bi Desktop de manera apropiada contra un repositorio y nada más. Un profesional Ops y Administrador serían quienes tendrían licencias PRO que administren el entorno de Áreas de trabajo, apps y distribución de audiencias y permisos.
Demo final commiteando con visual studio code:
Conclusión
Estas posibilidades llevan no solo a buenas prácticas en desarrollo sino también a mantener una linea de desarrolladores que no necesitarían licencias pro a menos que querramos que tengan más responsabilidades en el servicio.
Todo este ejemplo puede expandirse mucho más. Podríamos desarrollar los informes con Parametros para apuntar a distintas bases de datos y tener ambientes de desarrollo. Los desarrolladores no cambiarían más que agregar parametros y tal vez tener otro branch o repositorio. Los profesionales Ops podrían incorporar en el script de importación el cambio del parámetro en service. Incluso podrían efectuarse prácticas de CI moviendo automáticamente versiones estables de un repo a otro. Hablar de CI no me gusta porque no podemos hacer build ni correr tests, pero dejen volar su imaginación. Cada día las prácticas de desarrollo son más posibles y cercanas en proyectos de datos.
En ese archivo python podríamos usar todo el poder de SimplePBI para ajustar nuestro escenario a la práctica Ops deseada.
#powerbi#power bi#power bi devops#power bi cicd#azure devops#azure devops pipelines#power bi tips#power bi tutorial#power bi training#power bi versioning#simplepbi#ladataweb#power bi jujuy#power bi argentina#power bi cordoba#power bi rest api
0 notes
Text
[Azure DataLake] Métodos para dar acceso
Hay muchos artículos que hablan sobre la creación de una plataforma unificada de datos, donde equipos de Analítica (bajo diferentes nombres) arman un data lake con ETLs y procesos de ingesta tomando datos de múltiples fuentes de información, almacenando y organizando datos para alimentar modelos de Business Intelligence, Data Science, Machine Learning, y otras ramas relacionadas de la analítica.
En este proceso de crecimiento, tanto en volumen como en fuentes de datos a considerar, siempre llega el momento en el que hay que compartir datos que tenemos en nuestro data lake con personas/equipos que desean usarlos y accederlos, externos al equipo que desarrollo la ingesta y transformación de datos. Este es un punto que muchos saben que eventualmente habrá que hacer, pero como no es vital al comienzo de un proyecto entonces se saltea (la conocida “deuda técnica”) y luego cuando aparece la necesidad, ¡estamos en un apuro por resolverlo! En este articulo voy a mostrar algunas de las opciones que tenemos para dar este tipo de permisos sin que esto sea un peligro para todo el trabajo que venimos realizando.
1- Azure Data Share
La primera opción que vamos a ver es Azure Data Share. Este recurso (distinto al data lake), nos va a permitir compartir snapshots de determinadas carpetas dentro de nuestro data lake. Esta opción es práctica pero tiene varias desventajas, la principal es que estamos replicando datos fuera de nuestro data lake (quien recibe el Data Share, debe mapear el snapshot a su propio data lake), esto da pie a que haya diferentes “versiones” de los datos y quien desee consultarlos no estará usando los datos actualizados, además de estar pagando por almacenamiento que no debería con otras opciones.
2- SFTP
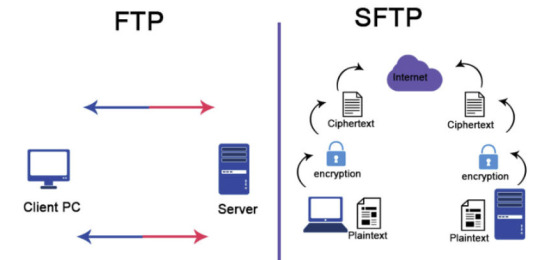
¡La segunda opción que veremos es más directa que la anterior! El único requisito es que nuestro data lake debe tener activada la jerarquía de carpetas (Hierarchical Namespace en un Data lake Storage Gen2). Si tenemos eso deberíamos ver la opción en el portal para activar SFTP (preview por ahora). Esta opción nos permitirá levantar un servidor SFTP (ssh file transfer protocol) que leerá directamente desde nuestro data lake. La configuración es bastante sencilla, simplemente se crea un usuario (local al FTP, no será parte del Active Directory), se selecciona el contenedor que queremos compartir y los permisos (el mínimo sería READ y LIST). ¿Desventajas de este método? El permiso elegido en el FTP será independiente de la configuración de permisos RBAC, ABAC o ACLs que tengamos dispuesto en nuestro data lake, y los permisos rigen para todo el contenedor, no solo una carpeta. Otras desventajas son: esta opción no permite que el usuario lea directamente el data lake como otras opciones, y este servidor SFTP no es accesible por Data Factory (por ahora, ojalá cambie esto en un futuro).
Muchos clientes son capaces de conectarse a un servidor SFTP como si se tratase de una “carpeta remota” para descargar o subir archivos, de modo que es una opción practica para compartir datos con usuarios de todo tipo (negocio o técnicos). Los clientes clásicos para windows son WinSCP o FileZilla, pero ¡hay muchos más! (ni hablar para linux)
3- SAS
El tercer método que veremos para conectarnos es mediante un SAS (Shared Access Signature) y este sí que nos permitirá conectarnos y leer directamente el data lake desde cualquier software que pueda hacerlo (por ejemplo, código Python, desde Databricks, u otros servicios de Azure como Data Factory). Un SAS es básicamente una cadena de conexión, generada a partir de las Access Keys del lake, que permite que nos conectemos al data lake con determinados permisos que son elegidos al momento de crear esta SAS. Crear un SAS es muy sencillo, vamos a la opción homónima en el portal de Azure, elegimos que servicio deseamos habilitar (por lo general Blob), completamos las siguientes opciones según nuestras necesidades y finalmente damos click en Generar. La desventaja de este método es que los permisos que definamos valen para TODO el data lake, no solo para un contenedor o una carpeta, por lo que es fácil caer en dar demasiados permisos con este método. Arreglarlo es sencillo, ya que como los SAS son creados a partir de las Access Keys, renovando estas últimas todos los SAS que la utilizaron quedaran sin efecto.
Desde el explorer del lake, podemos generar SAS para una carpeta o archivo especifico, con lo que ganaremos mucho en seguridad sobre el método de creación de SAS anterior. Les dejo una imagen, no es para nada complicado, simplemente navegamos hasta la carpeta que queremos y damos click con el botón derecho:
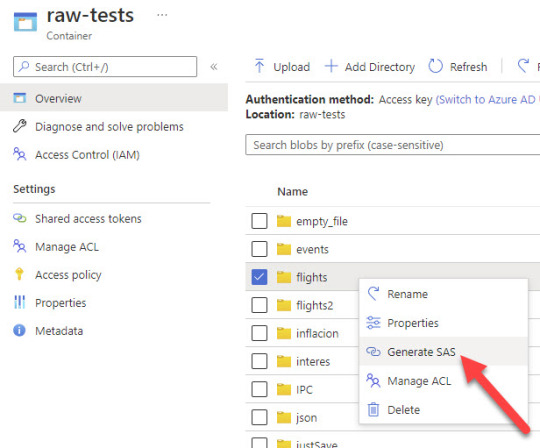
Recordemos que los permisos mínimos para poder conectarnos y ver que archivos hay dentro de la carpeta son READ (obvio) y LIST. Este último es fácil de olvidar, pero si no lo agregamos el SAS podrá leer los archivos solo si le indicamos el nombre y la ruta exactos del archivo que queremos leer.
4- Service principal
El cuarto método que veremos para conectarnos es mediante un Service Principal. Esto es crear un usuario de servicio (App Registration) y luego asignarle los permisos necesarios para conectarse y leer el data lake. Este método es el recomendado por ser el más seguro de todos, ya que podemos definir los permisos de este usuario como lo haríamos con cualquier otro, mediante RBAC, ACL o el nuevo ABAC.
SPOILER: Si no sabes que significan estas siglas, atentos porque habrá un artículo sobre esto próximamente.
Básicamente, este método es el único mediante el cual tendremos un control más granular sobre los permisos que estamos dando dentro de nuestro data lake.
5- Autorizar usuario AD - ¡NO recomendada!
Este método es prácticamente igual al anterior, solo que en lugar de autorizar un Service Principal, lo haremos con un usuario de AD. La razón por la que no es recomendado hacer esto es porque no ofrece ninguna ventaja sobre hacerlo con un Service Principal y compartir sus credenciales (secret key o certificado). Además, como regla general y buena práctica, ningún proceso automatizado debería estar autenticándose con un usuario de AD.
Con esto concluye el artículo, por supuesto que ¡estas opciones no son todas las disponibles! Siempre hay muchas formas de lograr el mismo resultado, y decidí dejar afuera los requisitos específicos de algunos recursos como Synapse por ejemplo, que requiere que asignemos permisos RBAC al MSI del workspace, pero eso puede ser tema para otro post 😊
¡Espero que les sea de ayuda! Nos vemos en la próxima.
Escrito por Martin Zurita
#datalake#azure data lake#azure storage account#Azure datalake#service principal#azure#azure cordoba#azure argentina#azure jujuy#azure data platform
0 notes
Text
[AzureDataFactory] Invocar procesamiento externo
En este artículo vamos a ver las formas más comunes de llamar a servicios de procesamiento externos.
Muchas veces se confunde a Data Factory con una herramienta ETL, cuando en realidad es un servicio de integración de datos y orquestación de procesos. La actividad estrella en Data Factory es el “Copy Activity” que permite tomar datos de una fuente de datos origen, y los deposita en algún almacenamiento destino, y ¡es muy buena haciéndolo! Soporta multitud de orígenes y destinos, permite conectar con datos on premise (incluso ODBC), consultar APIs, etc. Todo el resto de las actividades de Data Factory están hechas alrededor de Copy Activity y dan soporte a esta, ya sea consultando marcas de agua, haciendo validaciones o consultando metadata, entre otras. Lo que no hace Data Factory por sí solo (dejando afuera el nuevo Data Flow que prácticamente es otra herramienta), es realizar tareas típicas de ETL tales como filtrar filas, crear columnas derivadas de otras, controlar la limpieza de los datos, existencia de datos, agregaciones, etc, y para llevar a cabo estas tareas podemos utilizar servicios de procesamiento fuera de lo que es Data Factory. A continuación, vamos a ver algunos de los más comunes, y sus ventajas:
Azure Functions/Azure Automation:
Empezamos por los servicios más baratos de todos. Estos servicios nos permiten ejecutar código (de diferentes lenguajes) haciéndoles un llamado. Ambos permiten generar una URL que al recibir un request, empezara a ejecutar el código. Este código deberá ser capaz de autenticarse en Azure y ejecutar determinadas acciones. Normalmente, se utilizan para operaciones menores ya que están limitados en su poder de procesamiento y duración máxima de la ejecución.
¿Cómo los uso?
En el caso de Azure Functions, hay que crear una función HttpTrigger (viene como ejemplo en cualquier lenguaje), hacer el deploy desde VS Code (crea automáticamente los recursos en Azure) y esto nos generará la URL a la cual deberemos hacer el request. Para llamarlo desde Data Factory hay 2 opciones: podemos usar el activity dedicado a esto (Azure Function Activity) o usar el Web activity (recomiendo usar el activity porque ofrece mejor seguridad y control de errores). En Azure Automation es muy similar solo que funciona sin una función en particular (ejecuta todo lo que haya dentro) y no lleva deploy porque se edita directamente desde el portal. Acá debemos crear un Runbook con el código y luego dentro de ese mismo runbook, crear un Webhook. ¡Es importante aclarar que un runbook puede tener más de un webhook! Para llamarlo desde ADF tenemos la opción de usar un Web activity o usar Webhook activity. La diferencia es que webhook activity quedara esperando a que el runbook envíe una confirmación de que la ejecución se realizó con éxito. Un ejemplo de este tipo de llamada lo encontramos aquí: https://docs.microsoft.com/en-us/azure/analysis-services/analysis-services-refresh-azure-automation

Azure Databricks:
Databricks es un servicio que nos ofrece la posibilidad de crear clusters donde se va a ejecutar el código que necesitemos. Es decir, este servicio ya no es serverless como los anteriormente mencionados, sino que en este deberemos elegir el hardware y dispondremos del mismo de forma dedicada (o sea sin compartir con otros usuarios que estén utilizando Databricks).
La desventaja de ser dedicado es que tendremos una demora de unos pocos minutos al hacer el llamado ya que el clúster deberá encenderse antes de poder correr nuestro código. Compensa muy bien la desventaja con que ofrece el uso de spark, R, python y hasta SQL (SparkSQL) para hacer nuestras transformaciones, con todas las ventajas que trae ese lenguaje (paralelismo, manejo de grandes datasets que sean más grandes que la RAM disponible, la librería delta lake, optimizaciones, etc).
Usarlo es bastante simple, Data Factory tiene una categoría de actividades llamada Databricks, desde donde podremos llamar una notebook, un .jar (Java) o un Python script. También tenemos la posibilidad de hacer un llamado con Web Activity a databricks utilizando el API, pero teniendo opciones más simples de configurar es difícil que valga la pena el esfuerzo.

Stored Procedures:
Los procedimientos almacenados en bases de datos son buenas formas (aunque a veces un poco limitadas) de realizar todo tipo de operaciones sobre los datos. Las principales ventajas de este metodo es que casi todo el mundo que haya trabajado con datos sabe o conoce SQL, y que no tendremos un costo extra, ya que se ejecutara sobre el mismo hardware donde está la base. Las desventajas son:
Los datos necesitan estar en una tabla de la base antes de que sea posible tomarlos para realizarles operaciones (con excepción de Polybase)
Puede que este método no escale muy bien si los datos a procesar son cada vez más grandes, lo que congestionara la base y la dejara menos rápida para responder consultas mientras este procesando. Esta desventaja puede ser mitigada usando alguna tecnologia de procesamiento paralelo como la que ofrece SQL Pool de Synapse por ejemplo.
Para llamar a un procedimiento almacenado desde Data Factory podemos usar el activity llamado “Stored procedure” para la mayoría de las bases de datos. Otro método más “rustico” para hacer el llamado es utilizando un Lookup activity, configurando en Settings Query y pasando el comando de base de datos para ejecutar un procedimiento almacenado (en Sql Server por ejemplo, seria “exec [NombreSP]”), esta opción nos permite llamar a procedimientos almacenados en bases de datos que no estén soportadas por el Store Procedure Activity (Oracle, IBM, etc).

Data Factory Data Flows:
Previamente mencione que es prácticamente otra herramienta, pero no por eso es menos valida que las otras opciones que hemos visto en este artículo. Tiene la facilidad de ser muy visual, muy “estilo Microsoft”. Está integrada a Data Factory por lo que podremos usarla desde la misma interfaz y es simple hacer llamados a los procesos que definamos en este servicio.
Este servicio utiliza la configuración que hayamos puesto en nuestro Azure Integration Runtime para levantar un clúster de spark (muy similar a Databricks) donde se ejecutaran las operaciones que definamos en el Flow. El costo también es parecido a Databricks, solo que en este nos ahorraremos los DBU, que es como la “licencia” por usar databricks. Otra ventaja fuerte que tiene es que nos permite ir paso a paso viendo como quedaran los datos para asegurarnos que estamos haciendo las operaciones correctas, y que permite el uso del formato Delta Lake (de nuevo, igual que databricks).
La desventaja que tienen es que solo permite hacer operaciones a nivel visual, o sea no admite código. Esto lo hace deseable para operaciones pequeñas, pero no para procesos complejos, ya que la falta de comentarios en el código y lo diverso de las interfaces de cada operación pueden hacer difícil el seguimiento de procesos largos. Además, tiene un delay de unos minutos hasta disponibilizar el clúster.
Para usarlo, hay que crear un Data Flow en Data Factory y llamarlo desde algún pipeline con la actividad homónima.

Power Query:
Otra de las opciones que tenemos es Power Query (previamente llamados Wrangling Dataflow en Data Factory), el querido lenguaje M que se usa en Power Bi al ingresar en su editor de consultas. Es una muy buena opción para cuando tenemos que migrar un pbix grande hacia Azure para hacerlo escalar, y también es buena opción si nos sentimos cómodos usando el lenguaje ya que es más versátil de lo que parece inicialmente.
Su uso es similar a Data Flow, ya que tiene una interfaz integrada al portal de Data Factory. Y se lo llama de manera similar también, usando Power Query activity. Lamentablemente al día de hoy, esta opción no está disponible en Synapse Pipelines (la versión de Data Factory integrada con Synapse)

Integration Services:
El viejo y confiable SSIS (Sql Server Integration Services) tambien puede ser ejecutado y orquestado por Data Factory. Si bien es un poco incomoda la forma de desarrollar procesos en este servicio, la realidad es que es super comodo si ya tenemos procesos muy grandes y que no podemos migrar por cualquier motivo (no hay tiempo, son procesos legacy, no se van a modificar, etc). Para modificar el proceso tendremos que tener una version de Visual Studio tradicional (no VS code), con el modulo de SSIS instalado, ademas del proyecto de SSIS. Si cumplimos con tener eso, es una herramienta bastante simple que cumple con lo que buscamos: conectamos a diversas fuentes de datos, hacemos transformaciones y guarda el resultado.
Para usar este metodo, hay que crear un Integration Runtime particular llamado "Azure-SSIS IR", el cual debera correr sobre una base de datos SQL Server Standard o Enterprise que deberemos crear para este fin. Una vez creada esta base de datos, deberemos abrir el proyecto de SSIS y hacer el deploy del proyecto sobre la misma. El ultimo paso para ejecutar el paquete de SSIS dentro de Data Factory, sera llamarlo desde un pipeline con el activity "Execute SSIS Package".
Las desventajas de este metodo son los costos, ya que al tener que usar una licencia de Sql Server, los costos seran altos de entrada. La dificultad para modificar y documentar proyectos existentes es otra contra, al ser una herramienta un poco vieja no esta adaptada al desarrollo en nube, y es mas incomoda que otras opciones.

Azure Batch:
El último servicio que veremos aquí es Azure Batch, que es el más “viejo” de todos, se usaba en los inicios de Data Factory v2 para ejecutar el “Custom Activity”. Este servicio básicamente nos permite disponibilizar una máquina virtual donde se ejecutará un script con las operaciones que necesitemos. Es bastante más complicado de configurar que el resto de los servicios, y en mi opinión ofrece poco para compensar. Aquí seremos responsables de crear la máquina virtual, instalar el lenguaje necesario, sus librerías, almacenar certificados con credenciales de acceso, además de codear el script que realice las operaciones. Solo consideraría esta opción si la empresa donde estamos trabajando ya dispone de pools de VMs listas para usar en Batch (ya que se puede usar este servicio con muchos fines distintos a solo procesamiento de datos).
Por supuesto que esta no es una lista exhaustiva de las opciones que tenemos, pero seguro que son las más populares que consideraremos al momento de tener que hacer operaciones con datos desde Data Factory.
Ojalá les haya sido de ayuda este repaso, o les despierte la curiosidad por estudiar un poco más en profundidad alguno de estos servicios, ¡hasta la próxima!
Escrito por Martin Zurita
#Azure data factory#data factory#azure functions#databricks#Azure batch#azure stored procedures#azure power query#power query#data factory data flows#azure data flows#azure databricks#azure argentina#azure jujuy#azure cordoba#azure synapse
0 notes
Text
[AzureDataFactory] Actualizar PowerBi con ServicePrincipal
¡Hola! Soy Josefina Depetris, soy Economista y cuando estudiaba siempre mis materias favoritas fueron aquellas relacionadas a los datos y al manejo de los mismos. En ese momento trabajaba en BI y de a poquito me fui metiendo en el mundo de Data Engineering. Me desvié bastante de mi carrera y encontré algo muy interesante. Ahora hace ya casi un año que trabajo en Pi Data Strategy & Consulting como Data Engineer donde utilizo principalmente los servicios de Azure y trabajo diariamente con Azure Data Factory.
Siempre me han servido mucho los videos y los posts que encuentro en los distintos blogs, y es por eso que en este momento quiero compartirles algo que a mí me viene sirviendo, como refrescar un dataset de Power BI desde Azure Data Factory a través de Service Principal.
En 2019 Martín Zurita junto con Ignacio Barrau escribieron un post en LaDataWeb sobre “Usar Power Bi API sin permiso del administrador” y hoy quiero completarlo añadiendo la opción de usar Service Princial en vez de usuario y ya que estamos, como hacerlo desde Data Factory.
En general, los usuarios siempre estarán interesados en mostrar siempre el último dato o actualización disponible. Podríamos programar una actualización del DataSet de Power BI en determinado horario o cada cierta cantidad de horas, pero si hacemos la carga y transformación de los datos desde un pipeline... ¿Por qué no hacer la actualización apenas finaliza? La respuesta es “deberíamos”, puesto que es mejor para tener todo el flujo orquestado por una sola herramienta. Para esto, agregaremos a nuestro pipeline de Data Factory la actualización del DataSet y estaremos siempre al día.
Seguiremos con la premisa de Martin e Ignacio, conectarnos sin que el administrador le otorgue los permisos a la app que leerá la API y realizaremos los primeros pasos de manera similar.
Configuración en Azure
Primero vamos a registrar la app o Service Principal en Azure Active Directory y agregar URI de redirección https://localhost:13526/Redirect

Una vez que tenemos la app, vamos a asignarle los permisos adecuados:
Permisos de API – conceder permisos de Read and Write All en Power BI Service - DataSet

Y en este momento es cuando separamos el camino del post anterior, una vez que hemos agregado los permisos de la API y la URI de redirección, no necesitaremos agregar más permisos a la app dentro de Active Directory. Ahora necesitamos obtener la clave de esta app.

¡IMPORTANTE! Debemos asegurarnos de copiar el secreto porque aparecerá visible una única vez. Para almacenarlo en un lugar seguro y luego poder utilizarlo. Lo guardaremos en el Azure Key Vault. Más información de Azure Key Vault
Ya que estamos en el Key Vault, nos adelantaremos un poco y le daremos permisos al Data Factory para que pueda acceder a los Secretos. Esto lo hacemos para luego utilizar la API de Power BI y no tener que escribir el Secreto en la llamada de la API – estamos agregando una capa de seguridad a nuestro proceso.

Ahora del lado de Power BI…
Primero debemos asegurarnos qué se les permita a los Service Principals usar la API de Power BI. Para este paso necesitaremos los permisos de administrador o pedirle al administrador de Power BI que nos dé una mano y lo habilite por nosotros.
En el Admin Portal de Power BI, en la pestaña de “Tenant Settings” se debe habilitar (Enable) la opción “Allow service principals to use Power BI APIs”. Acá hay dos opciones, se puede habilitar para toda la organización o para un grupo de seguridad en particular (en ese caso generar Grupo de Seguridad en Azure Active Directory y agregar al Service Principal como miembro de este).
Por último, debemos darle acceso al Service Principal al Workspace o al DataSet de Power BI (debemos buscar el nombre del Service Principal donde pide el Email).

¡Ya tenemos todo configurado y listo para usar las APIs de Power BI!
Podemos utilizar las APIs desde cualquier plataforma, en este caso lo haremos desde Azure Data Factory. Si quisiéramos usar Python, podemos seguir los pasos del post anterior.
El pipeline está completamente parametrizado, y podrán encontrar el código JSON en el repositorio con el cual podrán copiar el mismo y completar con sus valores los parámetros necesarios.
Azure Data Factory - Configuración general del pipeline

PASOS:

1- Service Principal Secret desde AKV
En este paso vamos a obtener el secreto que habíamos guardado en el Key Vault.
Direccion URL: https://@{pipeline().parameters.key_vault_name}.vault.azure.net/secrets/@{pipeline().parameters.secret_name}?api-version=7.0 Método: GET Autenticacion: MSI (para esto es que le dimos permisos al Data Factory en el Key Vault) Recurso: https://vault.azure.net
En la pestaña General seleccionar Salida segura para que no quede expuesto el secreto.

2- Obtener Bearer Token
En este paso obtendremos el Bearer Token para autentificarnos en la API de Power BI
Direccion URL: https://login.microsoftonline.com/@{pipeline().parameters.tenant_id}/oauth2/token Método: POST Encabezados: Content-Type application/x-www-form-urlencoded Cuerpo: grant_type=client_credentials&client_id=@{pipeline().parameters.service_principal_client_id}&client_secret=@{activity('Service Principal Secret desde AKV').output.value}&resource=https://analysis.windows.net/powerbi/api
En la pestaña General seleccionar Entrada segura para que no quede expuesto el secreto.

3- Refrescar DataSet
En este paso obtendremos haremos finalmente el refresh del DataSet a través de la API de Power BI
Direccion URL: https://api.powerbi.com/v1.0/myorg/groups/@{pipeline().parameters.group_id}/datasets/@{pipeline().parameters.dataset_id}/refreshes Método: POST Encabezados: · Content-Type application/json · Authorization Bearer @{activity('Obtener Bearer Token').output.access_token} Cuerpo: {"parametro":"no borrar"}
En la pestaña General seleccionar Entrada segura para que no quede expuesto el secreto.

Ahora ya hemos realizado el refresh en el DataSet, pero no sabemos si ha terminado exitosamente, agregaremos unos cuantos pasos más al pipeline para asegurarnos que así sea.
4- Hasta refresh completo
El paso 4 consiste en hacer otra llamada a una API de Power BI solicitando esta información. Utilizaremos una Actividad de “Hasta” en la que ejecutaremos una API que solicita información sobre los refresh del DataSet hasta que la respuesta no nos devuelva el estado “Unkown” que es aquel estado que devuelve la API mientras el refresh está en progreso.
Le estableceremos “Tiempo de espera agotado” de 1 hora ya que este es el tiempo que tiene validez el Bearer Token.
Expresión: @not(equals('Unknown',variables('Status'))) Esperar: Tiempo de espera en segundos: @int(pipeline().parameters.wait_seconds) Refresh Status: Dirección URL: https://api.powerbi.com/v1.0/myorg/groups/@{pipeline().parameters.group_id}/datasets/@{pipeline().parameters.dataset_id}/refreshes?$top=1 Método: GET Encabezados: Authorization Bearer @{activity('Obtener Bearer Token').output.access_token} Status: Valor: @activity('Refresh Status').output.value[0].status

Así concluimos nuestra configuración para llamar un refresh de un dataset en Power Bi desde Azure Data Factory.
Espero que les haya sido de utilidad. ¡Gracias por leer! Nos vemos la próxima 😊
Escrito por Josefina Depetris
#azure#azure data factory#powerbi#power bi#adf#power bi service#azure service principal#azure tips#azure training#azure tutorial#data engineer#data engineering#ladataweb#azure argentina#azure jujuy#azure cordoba
0 notes
Text
[AzureScript][T1:E4] ¡Enmascarando contraseñas!
¡Hola! Ésta será la última parte de esta serie, por si no recordas bien o queres repasar las anteriores, acá están los links:
T1:E1 - Introducción
T1:E2 - Usos Básicos
T1:E3 - Login Automático
Haciendo un breve repaso de la serie, básicamente hemos visto las librerías básicas para interactuar con Azure utilizando PowerShell. Vimos ejemplos de éstas interacciones y la forma de automatizar 100% nuestros scripts para que no requieran interacción alguna con el usuario.
En esta última parte de la serie, vamos a abordar un tema que quedó pendiente en la anterior: no exponer nuestras credenciales a simple vista en el Script. Imagínense lo poco seguro que sería tener la contraseña a simple vista en nuestro script, algo como $password = "martin123" probablemente nos llevaría (con suerte) a un reto en una inspección de auditoria. Incluso si somos cuidadosos con el script, nos restringe la posibilidad de compartirlo para mostrar la lógica, o subirlo a un repositorio público de github para compartir conocimiento. Por esta razón, el broche de oro de esta serie tendrá foco en formas comunes de evitar exponer nuestras credenciales. Para esto veremos 2 formas, cada una con sus ventajas y desventajas.
Una particularidad de esta entrada en el blog, es que finalmente me mude definitivamente a Linux. Por lo que verán que las rutas a los archivos no comienzan con C:/ como en windows, pero a los fines prácticos es lo mismo. También mencionaré que para esta oportunidad estaré usando el módulo Az para comunicarme con Azure, en lugar de AzureRM como venia haciéndolo en entregas anteriores (ya expliqué sus diferencias, y como llevar los comandos de uno a otro de forma simple).
Primera forma
Ésta es la mas obvia quizás, la primera que se nos ocurriría: guardar la contraseña en un archivo separado y encriptado. Por suerte, esto es sencillo de hacer con PowerShell. Primero deberíamos abrir una nueva consola y crear este archivo, para luego llamarlo desde nuestro script. Abrimos PowerShell y tipeamos:
$mypass = "martin123" | ConvertTo-SecureString -AsPlainText -Force $mypass = Read-Host -AsSecureString $mypass | ConvertFrom-SecureString | Set-Content "/home/martin/python/Investigacion/Powershell/creds.txt"
¿Que hemos hecho acá? En la primera linea simplemente creamos un objeto de powershell conocido como SecureString, que básicamente almacena una variable tipo string encriptada y no puede ser leída fácilmente. En la segunda linea simplemente almacenamos el contenido de esta variable en el archivo creds.txt. Esto lo haríamos por única vez, y no estaría incluido en el script final. Es, simplemente, para generar el archivo. Si abrimos este archivo de texto, no veremos la contraseña sino una cadena de caracteres encriptados que no nos permitirán saber la contraseña original, en mi caso decía algo así:
6d0061007200740069006e00310032003300.
Luego, para tomar el contenido del archivo simplemente ejecutamos. Esto SI estaría en nuestro script final:
$mypass = Get-Content "/home/martin/python/Investigacion/Powershell/creds.txt" | ConvertTo-SecureString
De este modo, habremos tomado el contenido encriptado del archivo, y lo almacenamos en una variable de powershell en un objeto tipo SecureString que podemos utilizar como nuestra contraseña al crear el objeto PSCredential (explicado en la parte 3 de esta serie).
Podríamos llevar esto un paso mas avanzado en la seguridad, teniendo una clave propia para desencriptar la password en otro archivo separado, con la desventaja de que esto nos lleva a tener 2 archivos ademas del script, pero con la ventaja de que nosotros manejamos la clave de encriptacion con SHA-256. Veamos como hacerlo.
El primer paso sera crear el archivo con la llave de encriptacion (recuerden cambiar la ruta de archivo):
$Key = New-Object Byte[] 32 [Security.Cryptography.RNGCryptoServiceProvider]::Create().GetBytes($Key) $Key | out-file /home/martin/python/Investigacion/Powershell/key.key
De este modo habremos creado un archivo con la clave de encriptacion que usaremos para encriptar nuestra password en el archivo creds.txt. Ahora, volvamos a generar creds.txt:
$mypass = Read-Host -AsSecureString $mypass | ConvertFrom-SecureString -Key (Get-Content /home/martin/python/Investigacion/Powershell/key.key) | Set-Content "/home/martin/python/Investigacion/Powershell/creds.txt"
Así, creamos un archivo que tendrá nuestra password encriptada según la clave que creamos previamente. Para recuperar esta contraseña, usamos:
$password = Get-Content "/home/martin/python/Investigacion/Powershell/creds.txt" | ConvertTo-SecureString -Key (Get-Content "/home/martin/python/Investigacion/Powershell/key.key")
¡Listo! De este modo, no alcanza solo con tener el archivo con la contraseña encriptada, sino que también tendremos que utilizar el archivo .key para poder desencriptar el primer archivo, y crear satisfactoriamente el objeto SecureString (el cual tampoco nos mostrara la contraseña en texto plano).
Segunda forma
Otra manera de no exponer nuestras contraseñas, seria mediante el uso de un servicio de Azure llamado KeyVault. En este servicio podemos almacenar claves, y recuperarlas de un modo seguro, pudiendo acceder a ellas solo quienes estén autorizados en Azure para hacerlo. Para esto, primero logueamos en Azure y creamos un recurso KeyVault (cambia el nombre del grupo de recursos según lo que tengas creado en tu suscripción):
Login-AzAccount New-AzKeyVault -Name 'LaDataKeys' -ResourceGroupName 'Wasteland' -Location 'East US'
Después, generamos el objeto SecureString y lo agregamos como un secreto:
$mypass = Read-Host -AsSecureString Set-AzKeyVaultSecret -VaultName 'LaDataKeys' -Name 'TutorialPassword' -SecretValue $mypass
Para recuperar el objeto SecureString, usamos:
$password = (Get-AzKeyVaultSecret -vaultName "LaDataKeys" -name "TutorialPassword").SecretValue
¡Listo! Mucho más fácil ¿verdad? Es que ese es el objetivo y uno de los principales beneficios de los servicios cloud. Simplificarnos la vida. En este caso mediante la protección de nuestras claves en un llavero.
Por supuesto que necesitaremos darle permisos a nuestro Service Principal sobre el KeyVault que acabamos de crear, de otro modo ¡no podrá acceder al secreto! Para cualquier trabajo que tenga que quedar productivo, recomiendo mezclar ambos métodos y nunca mostrar en texto plano el SecretId, menos ahora que sabemos encriptarlo con SHA-256 ;)
Con esto cierro este ciclo de PowerShell con Azure, espero les haya sido de utilidad, ¡sigan leyendo y aprendiendo contenido en LaDataWeb!
Escrito por Martin Zurita
#Azure#Powershell#AzureArgentina#azureautomation#AzureKeyVault#KeyVault#AzurePowershell#AzureCLI#Encryption#azure cordoba#azure jujuy#azure argentina#azure tutorial#azure training#powershell tutorial#powershell training
0 notes
Text
[Azure] Montar Data Lake como disco entorno local
Montando mi data lake como un disco externo!!
¡Hola a todos! En esta ocasión quiero escribir sobre algo que me pareció super útil para tener en cuenta al momento de trabajar con (casi) cualquier storage en la nube. Con este procedimiento podemos montar nuestro storage como si fuera un disco más dentro de nuestra pc, lo cual facilita muchísimo no solo explorarlo sino también interactuar con el tanto para subir archivos como para leer archivos.
La Magia
Para lograrlo vamos a servirnos de un hermoso proyecto Open Source llamado Rclone, él es quien en realidad hará la magia mediante unos pocos comandos. Antes de empezar quiero aclarar que explicare el procedimiento para hacerlo en Windows, porque para Linux es incluso más fácil!
Requerimientos previos
En Windows tenemos un requerimiento en particular que es instalar WinFsp, yo elegí instalarlo con Chocolatey, por lo que si no lo tienen van a tener que instalarlo también. No se preocupen, es muy fácil solo abran una consola de PowerShell con permisos de admin y escriban:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))
Esta línea la saque de la web oficial de Chocolatey https://chocolatey.org/install
Una vez instalado Chocolatey, instalamos WinFsp con la siguiente línea:
choco install winfsp --pre
Link al paquete de choco: https://chocolatey.org/packages/winfsp
¡Bien! Ya con esto instalado tenemos casi todo lo necesario para empezar, solo falta descargar Rclone, desde acá https://rclone.org/downloads/. Descargamos la versión para la versión de Windows que tengamos y descomprimimos en alguna carpeta.
Configurando nuestro acceso
Ahora sí, después de tanto programa nuevo vamos con lo que nos interesa! Como primer paso abrimos una ventana nueva de PowerShell (en este caso sin permisos de admin) y navegamos hasta la carpeta donde hayamos dejado los archivos de Rclone.
Entonces empecemos a configurar el acceso a nuestro blob storage ejecutando
.\rclone.exe config
Esto nos abrirá la configuración inicial de Rclone y nos mostrará los storage que ya tenemos configurados (al ser nuestra primera ejecución no tendremos ninguno, claro). Acá presionamos n para configurar un nuevo acceso remoto, y a continuación nos pedirá un nombre, para este ejemplo voy a usar DataLake1 asique ingreso ese nombre.
Hecho esto último, nos muestra un listado de los cloud storage que soporta la herramienta. En mi caso el blob storage de Azure es el número 22, pero esto puede variar para futuras versiones, en todo caso asegúrense de elegir el que diga Microsoft Azure Blob Storage.
Después nos va a pedir el nombre del data lake en Azure, y su account key. Dejo una foto para que sea más fácil localizar los en el portal de Azure.
Después de insertar esos valores, nos ofrece la posibilidad de usar un sas_url, que sin duda es una muy buena opción ya que nos permite acceder a data lakes a los cuales podemos no tener acceso al account key, pero no es lo que utilizaremos en este ejemplo asique solo damos enter dejando en blanco. Haremos lo mismo con el paso siguiente en el cual nos dejara indicarle si estamos usando un emulador de data lake local.
Luego n para no entrar a la configuración avanzada, y q para salir del modo configuración.
Probando la conexión al lake
Para testear si todo quedo bien configurado, podemos ejecutar un simple comando ls que como en Linux, nos listara los archivos que encuentre en un directorio determinado. Para eso reemplazamos a continuación (nombre container) por el nombre del contenedor al que se quiera acceder y ejecutar:
.\rclone.exe ls DataLake1:(nombre container)
En mi caso tengo 2 contenedores para este data lake
Elegí usar el primero asique mi comando queda así:
.\rclone.exe ls DataLake1:adventure-works
Si a continuación nos lista las carpetas y archivos que forman el data lake, estamos listos para seguir!
Montando nuestro lake como un disco externo
Al fin llegamos a la parte donde ocurre la magia! Estamos a solo un comando de lograrlo. En esta parte considero importante aclarar el porque de ejecutar el siguiente comando desde una ventana de PowerShell SIN permisos de admin, y esto es porque vamos a "crear" un disco externo, si hacemos esto con privilegios de admin no podremos verlo con nuestro usuario de Windows (aunque este también sea admin).
Ahora sí, sin más vueltas ejecutamos el siguiente comando:
.\rclone.exe mount DataLake1:adventure-works X:
Esto creara un disco X: que será el acceso a nuestro data lake! El disco existirá mientras no cerremos esta ventana que lo creo.
Si abrimos el explorador de archivos podremos verlo como si fuera un disco más!! La integración está muy bien hecha y en la mayoría de los casos es transparente al usuario. En este paso, una imagen vale más que mil palabras:
¡La prueba de fuego!
Bueno, todo esto es muy lindo pero que utilidad práctica tiene? Lo interesante de esto es que podemos usarlo realmente como un disco más y de forma transparente descargará o subirá archivos al mismo con los mismos procedimientos que usamos para nuestros discos locales!! En mi caso hice la prueba de leer un archivo CSV con Python desde este disco externo.
Como pueden ver, lo accedí de la misma forma que usaría si el archivo estuviera en mi computadora local! Esto es super útil, mucho más sencillo que subir archivos con la librería oficial de Microsoft (perdón, alguien tenía que decirlo) y ya se imaginaran los miles de casos de uso que puede tener esta genial herramienta.
Espero que les haya gustado, tengo en mente algunos posts más sobre los data lake asique estén atentos como siempre a LaDataWeb!!
Escrito por Martin Zurita
#azure#azure data lake#azure tips#data engineer#data engineering#azure cordoba#azure jujuy#azure argentina#data lake
0 notes
Text
Data Factory ¿Que es? ¿Que NO es?
Hola a todos! En esta oportunidad quiero hablarles de mi servicio favorito (y probablemente de muchos otros Ingenieros de Datos) en Azure, que es Azure Data Factory. A modo de introducción, para hacer algo distinto se me ocurrió escribir sobre que es y que NO es Data Factory, ya que el servicio muchas veces es evaluado
Es un servicio que casi todo proyecto relacionado con analítica en Azure debería utilizar, salvando algunas muy raras excepciones. Provee muchísimas ventajas y simplifica un montón de aspectos clave para estos proyectos, como calendarización, orquestación, modularidad para procesos, entre otros. Pero también tiene (como todo servicio) sus limitaciones, que si bien son salvables de uno u otro modo, pueden llegar a dejar una mala impresión cuando recién nos iniciamos con la tecnología. El objetivo de este post es aclarar que ES Data Factory y que NO es, o que no hace por defecto (y posiblemente algún work-around para esas limitaciones).
¿Que es?
Empecemos por mencionar que es Data Factory, y porque es una herramienta casi imprescindible:
Pipelines!! Es simple agregar actividades (y dependencias entre ellas) como llevar datos de un storage a otro, buscar datos en bases de datos, condicionales, y todo tipo de estructuras de control.
Interfaz gráfica simple de entender, cualquiera que le dedique 10 minutos a ver la interfaz podrá entender y hacer algún pipeline básico para orquestar algún proceso.
Múltiples opciones de calendarización de pipelines gracias a los Triggers (disparadores), en función a eventos, ventanas de tiempo, según día, hora, numero de día. Por ej: el primer día de cada mes, todos los Miércoles, etc.
Parámetros: igual que en cualquier lenguaje de programación, podemos usar parámetros para alterar el funcionamiento de algunos componentes como Pipelines, Actividades, Datasets, etc. Pueden usarse básicamente en cualquier lugar donde haya un string, para evitar errores lo mejor es encapsular el llamado a parámetros en @{nombreParametro}. Nos permiten recorrer bases de datos enteras con 1 o 2 actividades.
Variables: podemos almacenar valores en variables para utilizarlos después, se asignan con la actividad de asignar variables y se llaman del mismo modo que los parámetros.
Modularidad en diseño: podemos "encapsular" ciertos procesos que vamos a repetir frecuentemente en un pipeline y después llamarlo desde otro pipe, mediante la actividad "Ejecutar pipeline", esto brinda mucha flexibilidad a la herramienta si agregamos el uso de parámetros y variables.
Serverless!! Nunca sabemos (ni nos importa) donde están los servidores que ejecutan los trabajos. Solo darle play al pipeline y Azure se encargara de manejar por nosotros la memoria, ancho de banda, procesador, etc. Hay algunas excepciones, como en el caso del Integration Runtime (que sera instalado en una pc/vm on premise) o los Mapping Dataflow (en los cuales elegimos el tamaño del cluster que sera provisto).
Alertas configurables para enterarnos inmediatamente cuando algo anda mal, con la opción de ser informados mediante Email, SMS, Push (notificación en el celular), o con un mensaje de voz. Esto se logra gracias a la integración con Azure Monitor.
Soporte para utilizar Polybase al mover datos entre un Data Lake o Blob Storage y Synapse, aprovechando la mejora en performance de esta tecnología.
Conexión con muchos servicios!! Mas de 80 conectores, literalmente se conecta a todo lo que este dentro de Azure, pero ademas puede interactuar con varios servicios de otras nubes como AWS (S3, Redshift, etc), recursos que se encuentren en redes on premise (requiere la instalación de un Integration Runtime) e incluso soporta Rest apis o conexiones ODBC, así que si un servicio no esta en el listado pero soporta esas formas de conexión, también sera posible conectarnos.
Múltiples tipos de archivos soportados: Json, Csv, Excel, ORC, Parquet, Avro, Binario (cualquier archivo, no sera interpretado el contenido).
Soporte para trabajar de forma cooperativa gracias a la integración con Git, se pueden usar repositorios en GitHub o Azure DevOps. Como todo su código son definiciones en Json, podemos enviar ese código a un repositorio y trabajarlo con una metodología similar a la de desarrollo convencional. Por ej: creamos nuestro propio branch, desarrollamos una feature, y una vez que esta todo testeado y funcionando, creamos un pull request a master.
Soporte para deploys automáticos, de modo que podemos tener entornos separados y asegurarnos que solo llegan a producción aquellas versiones de código que sabemos que funcionan bien.
Esas features mencionadas son excelentes! Ya podemos ver porque no imagino un proyecto de analítica ejecutado en Azure sin usar Data Factory.
¿Que NO es?
A pesar de todas las bondades del servicio, es notorio que cuando arrancamos a utilizarlo muchas personas esperan mas de el, y creo que es porque por todos lados lo muestran o publicitan como una "herramienta ETL", siendo que no lo es en un 100% (al menos en su versión básica). Por eso, para evitar malos entendidos y tener opciones para evaluar, acá va un listado de las cosas que NO es Data Factory (con sugerencias de solución):
NO es una herramienta de transformación de datos! Su principal objetivo es ser un orquestador, mantener servicios y procesos trabajando, moviendo los datos de un modo coordinado, con todas las ventajas nombradas anteriormente. Recientemente se añadió la posibilidad de hacer algunas transformaciones de datos gracias a sus dataflows (Wrangling y Mapping), pero aun así es una opción con mucho tiempo de startup, bastante costosa y mi recomendación es siempre utilizar algún servicio externo para hacer las transformaciones (puede ser Databricks, T-SQL en una base de datos o en Synapse, para algo sencillo Azure Functions o Automation).
NO maneja de forma automática las cargas incrementales! Esta es una consulta habitual que tengo entre los clientes. No es complicado de hacer, pero tampoco es tan straight-forward como muchos esperan (sobretodo si tienen experiencia previa con alguna herramienta ETL como StreamSets, Pentaho, Talend, NiFi, etc).
Por si solo NO prende o apaga servicios tales como Synapse, o Analysis Services. Para esto sera necesario escribir un pequeño script en PowerShell para ejecutar en Azure Automation o en uno de los múltiples lenguajes que soporta Azure Functions. Por supuesto que Data Factory si tiene capacidades para llamar a esos servicios y ejecutar el encendido o apagado de estos servicios. Cuando nos conectamos a Databricks, si tiene la capacidad de encender un job cluster, ejecutar un código y apagarlo.
Lo mismo sucede con el refresh de modelos en Azure Analysis Services, para estos sera necesario un script en alguno de los servicios mencionados previamente. Otra opción es disparar el refresco mediante la REST api del servicio.
Data Factory NO almacena datos (solo metadatos), de modo que si creamos un dataset para una tabla en una base de datos que tiene 1 millón de registros, ese dataset solo tendrá la forma de acceder a la base de datos (mediante su linked service), el nombre de la tabla, tipo de dato de cada columna, pero bajo ningún escenario contendrá todos los registros en Data Factory.
Entre actividades SOLO podemos intercambiar Metadata! Con la excepción de Lookup activity, que nos devolverá el resultado de una consulta como output de la actividad, que podremos consultar desde otras actividades o asignarlas a variables.
Seguro estoy olvidando algunas limitaciones o beneficios, pero a modo introductorio creo que estos son los puntos principales a tener en cuenta al momento de crearnos expectativas respecto a las capacidades del servicio.
Espero que les haya gustado, seguramente vendrán algunos artículos mas sobre el tema.
#azure#azure data factory#data factory#data engineering#azure argentina#azure cordoba#azure jujuy#azure tips
0 notes