#2/Data scraping
Text

#✍I will be your Virtual assistant#data entry#Copy paste#Typing#web research for your company#❤My Service Quality:❤#1/Data Entry (MS Word#Excel#)#2/Data scraping#3/Data mining#4/Virtual assistant#5/Admin support#6/Conversation PDF#DataEntry#Datamining#Datascraping
1 note
·
View note
Text


Aziraphale || Good Omens
#digital art#my artworks#art#portrait#realism#fan art#good omens 2#good omens#aziraphale#If it looks odd it's because I'm using Glaze now#a way to hopefully protect art from being scraped for AI data sets#You can find it without the effect on my ko-fi
243 notes
·
View notes
Text
wip wednesday!!
ty @elysabeththequeene for tagging me <333 !!
have a snippet from my satine post-canon fic:
“Are you sure you’re alright?” he asked. His hand cupped her cheek. “You seem a bit pale.” He had commented the other night, only the cool moon coming in through the window to light her bare face, that she finally had color back in her cheeks again. It had been a quiet murmur, like saying it too confidently, anything just loud enough for God to hear, could jinx it.
“I just need some rest and I’ll be fine,” she said.
Christian kissed her other cheek and rounded the chair to stand behind her. His fingertips brushed her shoulder blades as he rested his hands on the back of her chair. “Do you want me to get your corset?”
tagging: @the-sparkling-diamond-satine @aaronstveit @bumblingest-bee and @dandelion-writes and anyone else who wants to :D <3
#half of this has been posted already but 1. i am sooo scaredgirl about data scraping and#2. i feel like i've posted over half of this fic already lmao#c writes#moulin rouge#tag game#wip wednesday
4 notes
·
View notes
Text
Cakelin Fable over at TikTok scraped the information from Project N95 a few months ago after Project N95 announcing shutting down December 18, 2023 (archived copy of New York Times article) then compiled the data into an Excel spreadsheet [.XLSX, 18.2 MB] with Patrick from PatricktheBioSTEAMist.
You can access the back up files above.
The webpage is archived to Wayback Machine.
The code for the web-scraping project can be found over at GitHub.
Cakelin's social media details:
Website
Beacons
TikTok
Notion
Medium
Substack
X/Twitter
Bluesky
Instagram
Pinterest
GitHub
Redbubble
Cash App
Patrick's social media details:
Linktree
YouTube
TikTok
Notion
Venmo
#Project N95#We Keep Us Safe#COVID-19#SARS-CoV-2#Mask Up#COVID is not over#pandemic is not over#COVID resources#COVID-19 resources#data preservation#web archival#web scraping#SARS-CoV-2 resources#Wear A Mask
2 notes
·
View notes
Text
"We need a new discord!"
"We need a new tumblr!"
"We need a new-"
WHAT DO YOU THINK IS GOING TO HAPPEN WITH THE NEW APP/WEBSITE/WHATEVER

#ITS JUST GOING TO COLLAPSE IN ON ITSELF AGAIN THATS THE STAGE OF INTERNET WE'RE AT#theyre going to start censoring theyre going to start data scraping and selling theyre going to start#cola posting#like im not trying to be all 'oh woe all hope is lost the internet is doomed forever' but changes are going to be slow#and for every bad idea (crypto/ai/etc) that dies something new and worse will rise from the ashes#i think this is going 2 be a Long Fight#AGAIN NOT IN A PESSIMISTIC NO HOPE WAY BUT ITS GOING TO BE A FIGHT
3 notes
·
View notes
Text
I would welcome more thought-out opinions below.
#The application is 1) scraping data and parsing it and 2) server for display that data#the scraping/parsing bit i dont know how to do in typescript as well. does node make string manip any less painful than base js?#because dear god. i am constantly missing [:] syntax.
6 notes
·
View notes
Text
I put my characters through a fair bit of injury for someone who flinches from surgical photos.
#I mean I can look at them with a little prep and mental fortitude#I watched videos of 2 surgeries in high school bio#but man the mental fortitude needs to be scraped together#I wish there were more hand-holdy resources for wimps doing medical research#like images you have to click to unblur with detailed description of what you will see#as well as specific data on healing with timeline#I speak as a writer but also before undergoing surgery myself I might appreciate that kind of thing#I want to know what'll happen to me but not uh what that part of my body looks like inside-out#without warning at least
1 note
·
View note
Text
i havent written all week FUCK MY JOB

#**** **** I HOPE YOU DIE#SO ANGRY I CONVINCED SOMEONE TO JOIN OUR UNION. GRRRRAH!!!!!!!!!!!!#2 40-hour weeks in a row because of a ‘data backlog’ but SURPRISE!!!!! THERES NO FUCKING WORK FOR US TO DO NOW BECAUSE YOU PRESSURED US TO#WORK FT AND GET IT ALL DONE QUICKER SO NOW THERES NOTHING#EASY 32+HRS AT MY COMPUTER. BARELY SCRAPED TOGETHER 20 BILLABLES HRS#i complain about working actively but at least i can switch tabs or look at my phone or WRITE but when im stuck refreshing for 12 hours#to get 6.5hrs paid. i cant do anything else. im so mad im so mad im so mad i hate this stupid dogshit company so fucking MUCH!!!!!!!!!
1 note
·
View note
Text
#loki#loki season 2#tom hiddleston#health#Healthy Restaurant#healthy living#healthy lifestyle#healthy eating#healthy food#healthy diet#healthylifestyle#restaurant point of sale#restaurant pos system#restaurant management software#restaurant data scraping#restaurant design
0 notes
Text
found a guy who built a cagematch scraper for not only python but also, my beloved, r.
so ill finally make myself a scraper to make it easier on me to excel sheet matches
#ill make one for full scrapes and one for specific matches im so hyyyype#as in all punk matches and like. rec'd match of guy 1 & guy 2 in show xyz#sorry i like data and i can not lie and rvest is gonna work or so fuck help me#plappermaul#[[ill github the code if/when i succeed and ppl are interested]]
1 note
·
View note
Text
FYI artists and writers: some info regarding tumblr's new "third-party sharing" (aka selling your content to OpenAI and Midjourney)
You may have already seen the post by @staff regarding third-party sharing and how to opt out. You may have also already seen various news articles discussing the matter.
But here's a little further clarity re some questions I had, and you may too. Caveat: Not all of this is on official tumblr pages, so it's possible things may change.
(1) "I heard they already have access to my data and it doesn't really matter if I opt out"
From the 404 article:
A new FAQ section we reviewed is titled “What happens when you opt out?” states “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
So please, go click that opt-out button.
(2) Some future user: "I've been away from tumblr for months, and I just heard about all this. I didn't opt out before, so does it make a difference anymore?"
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.”
It should make a difference! Go click that button.
(3) "I opted out, but my art posts have been reblogged by so many people, and I don't know if they all opted out. What does that mean for my stuff?"
This answer is actually on the support page for the toggle:
This option will prevent your blog's content, even when reblogged, from being shared with our licensed network of content and research partners, including those that train AI models.
And some further clarification by the COO and a product manager:
zingring: A couple people from work have reached out to let me know that yes, it applies to reblogs of "don't scrape" content. If you opt out, your content is opted out, even in reblog form.
cyle: yep, for reblogs, we're taking it so far as "if anybody in the reblog trail has opted out, all of the content in that reblog will be opted out", when a reblog could be scraped/shared.
So not only your reblogged posts, but anyone who contributed in a reblog (such as posts where someone has been inspired to draw fanart of the OP) will presumably be protected by your opt-out. (A good reason to opt out even if you yourself are not a creator.)
Furthermore, if you the OP were offline and didn't know about the opt-out, if someone contributed to a reblog and they are opted out, then your original work is also protected. (Which makes it very tempting to contribute "scrapeable content" now whenever I reblog from an abandoned/disused blog...)
(4) "What about deleted blogs? They can't opt out!"
I was told by someone (not official) that he read "deleted blogs are all opted-out by default". However, he didn't recall the source, and I can't find it, so I can't guarantee that info. If I get more details - like if/when tumblr puts up that FAQ as reported in the 404 article - I will add it here as soon as I can.
Edit, tumblr has updated their help page for the option to opt-out of third-party sharing! It now states:
The content which will not be shared with our licensed network of content and research partners, including those that train AI models, includes:
• Posts and reblogs of posts from blogs who have enabled the "Prevent third-party sharing" option.
• Posts and reblogs of posts from deleted blogs.
• Posts and reblogs of posts from password-protected blogs.
• Posts and reblogs of posts from explicit blogs.
• Posts and reblogs of posts from suspended/deactivated blogs.
• Private posts.
• Drafts.
• Messages.
• Asks and submissions which have not been publicly posted.
• Post+ subscriber-only posts.
• Explicit posts.
So no need to worry about your old deleted blogs that still have reblogs floating around. *\o/*
But for your existing blogs, please use the opt out option. And a reminder of how to opt out, under the cut:
The opt-out toggle is in Blog Settings, and please note you need to do it for each one of your blogs / sideblogs.
On dashboard, the toggle is at https://www.tumblr.com/settings/blog/blogname [replace "blogname" as applicable] down by Visibility:

For mobile, you need the most recent update of the app. (Android version 33.4.1.100, iOs version 33.4.) Then go to your blog tab (the little person icon), and then the gear icon for Settings, then click Visibility.
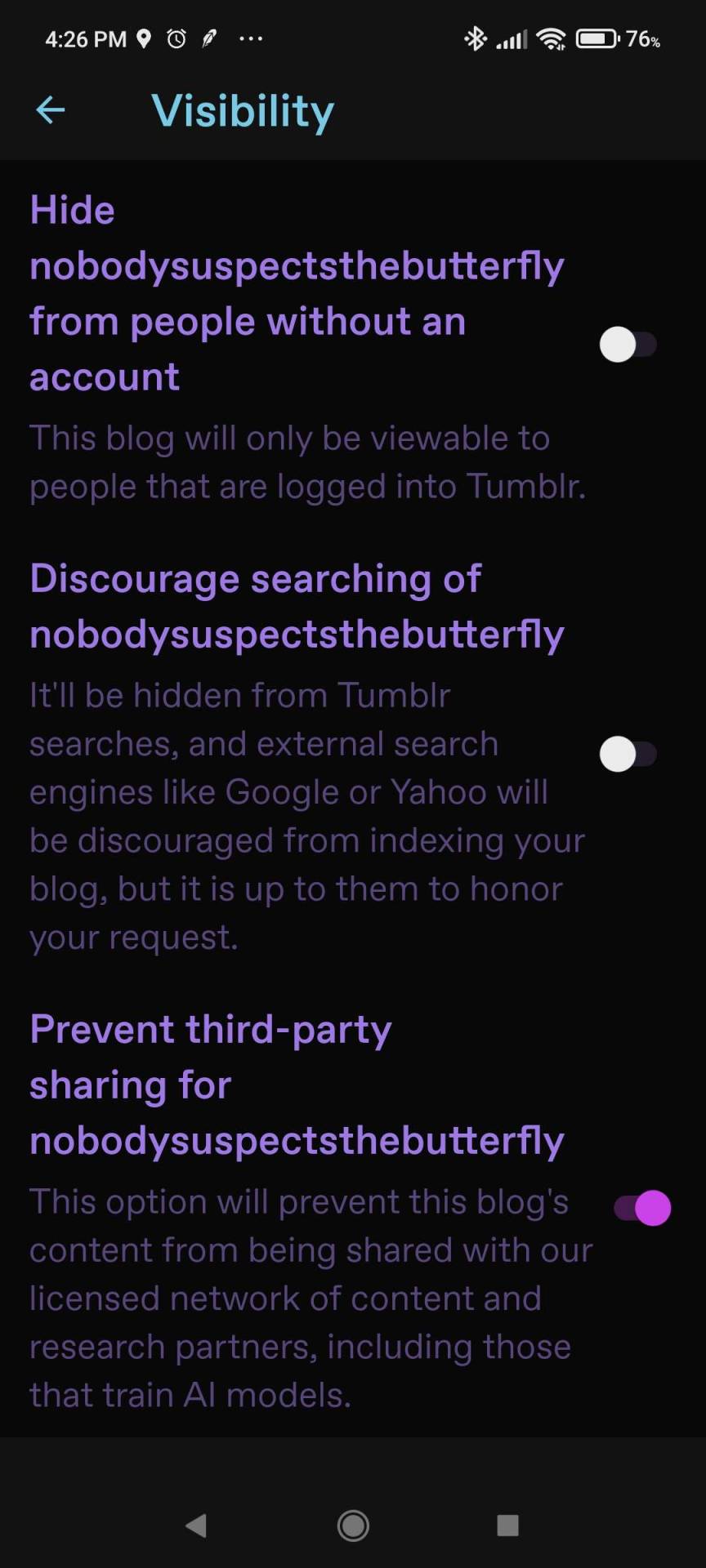
Again, if you have a sideblog, go back to the blog tab, switch to it, and go to settings again. Repeat as necessary.
If you do not have access to the newest version of the app for whatever reason, you can also log into tumblr in your mobile browser. Same URL as per desktop above, same location.
Note you do not need to change settings in both desktop and the app, just one is fine.
I hope this helps!
#tumblr#[tumblr]#third party sharing#openai#midjourney#chatgpt#ai art#ai#fyi#psa#anti-FUD#artists on tumblr#writers on tumblr#illustrators on tumblr#tumblr update#oh tumblr#hellsite (derogatory)#“opt out” no longer looks like a word#but still#opt out my friends#please#also if you want to leave tumblr i don't blame you but please remember to hit that opt-out button before you go
4K notes
·
View notes
Text
how c.ai works and why it's unethical
Okay, since the AI discourse is happening again, I want to make this very clear, because a few weeks ago I had to explain to a (well meaning) person in the community how AI works. I'm going to be addressing people who are maybe younger or aren't familiar with the latest type of "AI", not people who purposely devalue the work of creatives and/or are shills.
The name "Artificial Intelligence" is a bit misleading when it comes to things like AI chatbots. When you think of AI, you think of a robot, and you might think that by making a chatbot you're simply programming a robot to talk about something you want them to talk about, and it's similar to an rp partner. But with current technology, that's not how AI works. For a breakdown on how AI is programmed, CGP grey made a great video about this several years ago (he updated the title and thumbnail recently)
youtube
I HIGHLY HIGHLY recommend you watch this because CGP Grey is good at explaining, but the tl;dr for this post is this: bots are made with a metric shit-ton of data. In C.AI's case, the data is writing. Stolen writing, usually scraped fanfiction.
How do we know chatbots are stealing from fanfiction writers? It knows what omegaverse is [SOURCE] (it's a Wired article, put it in incognito mode if it won't let you read it), and when a Reddit user asked a chatbot to write a story about "Steve", it automatically wrote about characters named "Bucky" and "Tony" [SOURCE].
I also said this in the tags of a previous reblog, but when you're talking to C.AI bots, it's also taking your writing and using it in its algorithm: which seems fine until you realize 1. They're using your work uncredited 2. It's not staying private, they're using your work to make their service better, a service they're trying to make money off of.
"But Bucca," you might say. "Human writers work like that too. We read books and other fanfictions and that's how we come up with material for roleplay or fanfiction."
Well, what's the difference between plagiarism and original writing? The answer is that plagiarism is taking what someone else has made and simply editing it or mixing it up to look original. You didn't do any thinking yourself. C.AI doesn't "think" because it's not a brain, it takes all the fanfiction it was taught on, mixes it up with whatever topic you've given it, and generates a response like in old-timey mysteries where somebody cuts a bunch of letters out of magazines and pastes them together to write a letter.
(And might I remind you, people can't monetize their fanfiction the way C.AI is trying to monetize itself. Authors are very lax about fanfiction nowadays: we've come a long way since the Anne Rice days of terror. But this issue is cropping back up again with BookTok complaining that they can't pay someone else for bound copies of fanfiction. Don't do that either.)
Bottom line, here are the problems with using things like C.AI:
It is using material it doesn't have permission to use and doesn't credit anybody. Not only is it ethically wrong, but AI is already beginning to contend with copyright issues.
C.AI sucks at its job anyway. It's not good at basic story structure like building tension, and can't even remember things you've told it. I've also seen many instances of bots saying triggering or disgusting things that deeply upset the user. You don't get that with properly trigger tagged fanworks.
Your work and your time put into the app can be taken away from you at any moment and used to make money for someone else. I can't tell you how many times I've seen people who use AI panic about accidentally deleting a bot that they spent hours conversing with. Your time and effort is so much more stable and well-preserved if you wrote a fanfiction or roleplayed with someone and saved the chatlogs. The company that owns and runs C.AI can not only use whatever you've written as they see fit, they can take your shit away on a whim, either on purpose or by accident due to the nature of the Internet.
DON'T USE C.AI, OR AT THE VERY BARE MINIMUM DO NOT DO THE AI'S WORK FOR IT BY STEALING OTHER PEOPLES' WORK TO PUT INTO IT. Writing fanfiction is a communal labor of love. We share it with each other for free for the love of the original work and ideas we share. Not only can AI not replicate this, but it shouldn't.
(also, this goes without saying, but this entire post also applies to ai art)
#anti ai#cod fanfiction#c.ai#character ai#c.ai bot#c.ai chats#fanfiction#fanfiction writing#writing#writing fanfiction#on writing#fuck ai#ai is theft#call of duty#cod#long post#I'm not putting any of this under a readmore#Youtube
5K notes
·
View notes
Text
all the frothing-at-the-mouth posts about how "don't you dare put a fic writer's work into chatGPT or an artist's work into stable diffusion" are. frustrating
that isn't how big models are made. it takes an absurd amount of compute power and coordination between many GPUs to re-train a model with billions of parameters. they are not dynamically crunching up anything you put into a web interface.
chances are, if you have something published on a fanfic site, or your art is on deviantart or any publicly available repository, it's already in the enormous datasets that they are using to train. and if it isn't in now, it will be in future: the increases in performance from GPT 2 to 3 to 4 were not gained through novel machine-learning architectures or anything but by ramping up the amount of data they used to train by orders of magnitude. if it can be scraped, just assume it will be. you can prevent your stuff from being used with Glaze, if you're an artist, but for the written word there's nothing you can do.
not to be cynical but the genie is already far more out of the bottle than most anti-AI people realize, i think. there is nothing you can do to stop these models from being made and getting more powerful. only the organizing power of labor has a shot at mitigating some of the effects we're all worried about
10K notes
·
View notes
Text
Update on "No Fandom" tags
AO3 Tag Wranglers recently began testing processes for updating canonical tags (tags that appear in the auto-complete and the filters) that don’t belong to any particular fandom (commonly known as No Fandom tags). We have already begun implementing some of the decisions made during the earliest discussions.
By the time this post is published, you may have already noticed some changes we have made. Several canonical tags are slated to be created or renamed, and we will also be adjusting the subtag and metatag relationships between some tags to better aid Archive users in filtering. Please keep in mind that many of these changes are large and require a lot of work to identify and attach relevant tags, so it will likely take some time to complete. We ask that you please be patient with us while we work!
While we will not be detailing every change we make under the new process, we will be making periodic posts with updates on those changes we believe are most likely to prove helpful for users looking to tag or filter works with the new or revised tags and to avoid confusion as to why changes are being made.
New Canonicals!
1. Edging
For a long while, there has been some confusion caused by the fact that we have a canonical for Edgeplay, but not for Edging which has led to some unintentional mistagging and other challenges. Consequently, we will be creating a canonical tag for Edging with the format Orgasm Edging and this new canonical tag will be subtagged to Orgasm Control.
Relatedly, we will be reorganizing the Orgasm Control tag tree to allow for easier and more straightforward filtering and renaming Edgeplay to add clarity. You’ll find more details regarding these changes in the Renamed and Reorganized canonicals section below.
2. Generative AI
We have canonized three tags related to Generative AI.
Created Using Generative AI
AI-Generated Text
AI-Generated Images
All tags which make mention of specific Generative AI tools will be made a synonym of the most relevant AI-Generated canonical. Additionally, please note that AI-Generated Text and AI-Generated Images will be subtagged to Created Using Generative AI.
How to Use These To Filter For/Filter Out Works Tagged as Using Generative AI:
❌ Filtering Out:
To filter out all works that use tags about being created with AI, add Created Using Generative AI to the “other tags to exclude” field in the works filter. This will also exclude works making use of the subtags AI-Generated Text and AI-Generated Images. If you wish to exclude either the Images or Text tags only, you can do so by excluding either AI-Generated Text or AI-Generated Images.
☑️ Filtering For:
Add Created Using Generative AI to the “other tags to include” field in the works filter. This will also automatically include the works making use of the subtags AI-Generated Text and AI-Generated Images. If you wish to filter for Images or Text only, you can do so by including either AI-Generated Text or AI-Generated Images only .
As a reminder, the use of these tools in the creation of works is not against AO3's ToS. These new tags exist purely to help folks curate their own experience on the Archive. If you would like to see more information about AO3’s policies in regards to AI generated works, please see our News post from May 2023 on AI and Data Scraping on the Archive.
Renamed and Reevaluated Canonicals!
3. EdgeplayAs mentioned above, we will be renaming Edgeplay to clarify the tag's meaning, given that it is often confused for Edging. This tag will be decanonized and made a synonym of Edgeplay | High Risk BDSM Practices. It will be removed as a subtag of Sensation Play and be subtagged instead directly to BDSM. Please note if you have made use of the Edgeplay tag on your works or wish to continue to use it in the future, you are still welcome to do so.
The tag Edgeplay will be made a synonym of the new canonical, so all works tagged with Edgeplay now or in the future will fall under the new tag so that they’re still easy for users to find. If you have made it a favorite tag, it will be transferred automatically when we make this change.
4. Orgasm Delay/Denial
The tag Orgasm Delay/Denial will be decanonized and made a synonym of Orgasm Control to help limit confusion with the more specific Orgasm Delay and Orgasm Denial canonicals. Tags that are currently synonyms of Orgasm Delay/Denial are being analyzed and moved to either Orgasm Control or Orgasm Delay or Orgasm Denial or Orgasm Edging.
The revised tree structure for this tree will feature Orgasm Control as the top-level metatag with subtags Orgasm Edging, Orgasm Delay, and Orgasm Denial. So, if you wish to filter for all these tags at once, you can do so just by filtering for Orgasm Control.
5. Female Ejaculation
Female Ejaculation will be decanonized and made a synonym of Squirting and Vaginal Ejaculation. We hope this new phrasing will be more inclusive, clear, and make the tag easier to find whether users are searching for Squirting or the previous canonical. All current synonyms of Female Ejaculation will also be made a synonym of Squirting and Vaginal Ejaculation, including Squirting. You may continue to tag your works as suits your preferences, and we will make sure these tags are made synonyms of the new canonical so that your work can be found in the filters for it.
These are just some of the changes being implemented. While we won’t be announcing every change, you can expect similar updates in the future as we continue to work toward improving the Archive experience. So if you have an interest in the changes we’ll be making, you can follow us on Twitter @ao3_wranglers or keep an eye on this Tumblr for future announcements.
Thank you for your patience and understanding as we continue our work!
(From time to time, ao3org posts announcements of recent or upcoming wrangling changes on behalf of the Tag Wrangling Committee.)
3K notes
·
View notes
Text
AO3 Ship Stats: Year In Bad Data
You may have seen this AO3 Year In Review.

It hasn’t crossed my tumblr dash but it sure is circulating on twitter with 3.5M views, 10K likes, 17K retweets and counting. Normally this would be great! I love data and charts and comparisons!
Except this data is GARBAGE and belongs in the TRASH.
I first noticed something fishy when I realized that Steve/Bucky – the 5th largest ship on AO3 by total fic count – wasn’t on this Top 100 list anywhere. I know Marvel’s popularity has fallen in recent years, but not that much. Especially considering some of the other ships that made it on the list. You mean to tell me a femslash HP ship (Mary MacDonald/Lily Potter) in which one half of the pairing was so minor I had to look up her name because she was only mentioned once in a single flashback scene beat fandom juggernaut Stucky? I call bullshit.
Now obviously jumping to conclusions based on gut instinct alone is horrible practice... but it is a good place to start. So let’s look at the actual numbers and discover why this entire dataset sits on a throne of lies.
Here are the results of filtering the Steve/Bucky tag for all works created between Jan 1, 2023 and Dec 31, 2023:
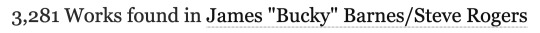
Not only would that place Steve/Bucky at #23 on this list, if the other counts are correct (hint: they're not), it’s also well above the 1520-new-work cutoff of the #100 spot. So how the fuck is it not on the list? Let’s check out the author’s FAQ to see if there’s some important factor we’re missing.
The first thing you’ll probably notice in the FAQ is that the data is being scraped from publicly available works. That means anything privated and only accessible to logged-in users isn’t counted. This is Sin #1. Already the data is inaccurate because we’re not actually counting all of the published fics, but the bots needed to do data collection on this scale can't easily scrape privated fics so I kinda get it. We’ll roll with this for now and see if it at least makes the numbers make more sense:
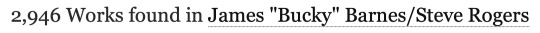
Nope. Logging out only reduced the total by a couple hundred. Even if one were to choose the most restrictive possible definition of "new works" and filter out all crossovers and incomplete fics, Steve/Bucky would still have a yearly total of 2,305. Yet the list claims their total is somewhere below 1,500? What the fuck is going on here?
Let’s look at another ship for comparison. This time one that’s very recent and popular enough to make it on the list so we have an actual reference value for comparison: Nick/Charlie (Heartstopper). According to the list, this ship sits at #34 this year with a total of 2630 new works. But what’s AO3 say?
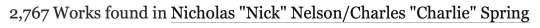
Off by a hundred or so but the values are much closer at least!
If we dig further into the FAQ though we discover Sin #2 (and the most egregious): the counting method. The yearly fic counts are NOT determined by filtering for a certain time period, they’re determined by simply taking a snapshot of the total number of fics in a ship tag at the end of the year and subtracting the previous end-of-year total. For example, if you check a ship tag on Jan 1, 2023 and it has 10,000 fics and check it again on Jan 1, 2024 and it now has 12,000 fics, the difference (2,000) would be the number of "new works" on this chart.
At first glance this subtraction method might seem like a perfectly valid way to count fics, and it’s certainly the easiest way, but it can and did have major consequences to the point of making the entire dataset functionally meaningless. Why? If any older works are deleted or privated, every single one of those will be subtracted from the current year fic count. And to make the problem even worse, beginning at the end of last year there was a big scare about AI scraping fics from AO3, which caused hundreds, if not thousands, of users to lock down their fics or delete them.
The magnitude of this fuck up may not be immediately obvious so let’s look at an example to see how this works in practice.
Say we have two ships. Ship A is more than a decade old with a large fanbase. Ship B is only a couple years old but gaining traction. On Jan 1, 2023, Ship A had a catalog of 50,000 fics and ship B had 5,000. Both ships have 3,000 new works published in 2023. However, 4% of the older works in each fandom were either privated or deleted during that same time (this percentage is was just chosen to make the math easy but it’s close to reality).
Ship A: 50,000 x 4% = 2,000 removed works
Ship B: 5,000 x 4% = 200 removed works
Ship A: 3,000 - 2,000 = 1,000 "new" works
Ship B: 3,000 - 200 = 2,800 "new" works
This gives Ship A a net gain of 1,000 and Ship B a net gain of 2,800 despite both fandoms producing the exact same number of new works that year. And neither one of these reported counts are the actual new works count (3,000). THIS explains the drastic difference in ranking between a ship like Steve/Bucky and Nick/Charlie.
How is this a useful measure of anything? You can't draw any conclusions about the current size and popularity of a fandom based on this data.
With this system, not only is the reported "new works" count incorrect, the older, larger fandom will always be punished and it’s count disproportionately reduced simply for the sin of being an older, larger fandom. This example doesn’t even take into account that people are going to be way more likely to delete an old fic they're no longer proud of in a fandom they no longer care about than a fic that was just written, so the deletion percentage for the older fandom should theoretically be even larger in comparison.
And if that wasn't bad enough, the author of this "study" KNEW the data was tainted and chose to present it as meaningful anyway. You will only find this if you click through to the FAQ and read about the author’s methodology, something 99.99% of people will NOT do (and even those who do may not understand the true significance of this problem):


The author may try to argue their post states that the tags "which had the greatest gain in total public fanworks” are shown on the chart, which makes it not a lie, but a error on the viewer’s part in not interpreting their data correctly. This is bullshit. Their chart CLEARLY titles the fic count column “New Works” which it explicitly is NOT, by their own admission! It should be titled “Net Gain in Works” or something similar.
Even if it were correctly titled though, the general public would not understand the difference, would interpret the numbers as new works anyway (because net gain is functionally meaningless as we've just discovered), and would base conclusions on their incorrect assumptions. There’s no getting around that… other than doing the counts correctly in the first place. This would be a much larger task but I strongly believe you shouldn’t take on a project like this if you can’t do it right.
To sum up, just because someone put a lot of work into gathering data and making a nice color-coded chart, doesn’t mean the data is GOOD or VALUABLE.
#ao3#ao3 stats#psa#my words#fandom#I doubt anyone is even going to read this but I needed to get it out of my system and at least try to stop this from spreading#if you know me#you know I get Big Mad about misinformation#don't take anything at face value#do your own research
2K notes
·
View notes
Text


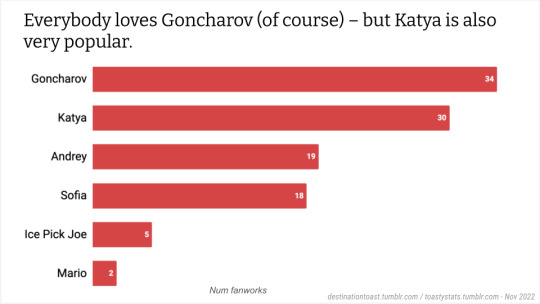

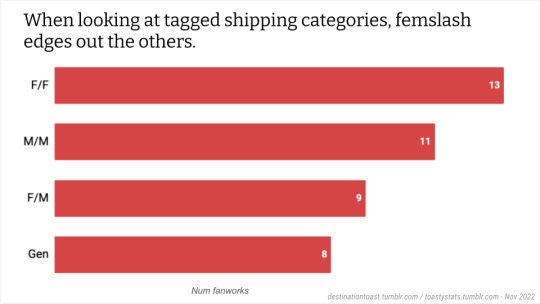
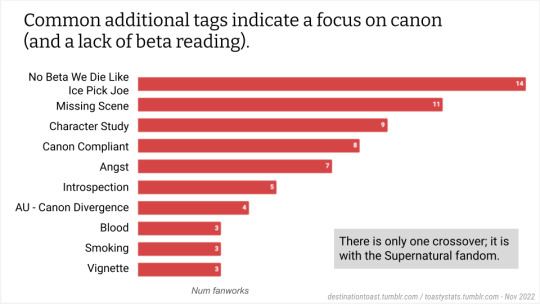
Toastystats: Goncharov on AO3
The fandom for this 1973 film has seen a surprising resurgence as we near the movie's 50th anniversary. While the Tumblr fandom is especially active, I thought I'd take a quick peek at activity over on AO3. Keep in mind, of course, that because this was an older film, many more fanworks may have been posted shared in zines, or in early internet websites or mailing lists. I don't know how many of those have migrated over to AO3.
(Note: I grabbed this data just over 2 hours ago, and in the meantime, 18 new fanworks have been posted! These stats are based only on the first 40 works.)
Also viewable as Google Slides. Data is here; thanks to Flamebyrd's AO3 Work Stats bookmarklet for the fast data scrape.
(P.S. If you're confused by this, see here, or here -- where I made my original threat (in the tags) to do fandom stats.)
#goncharov#fandom stats#toastystats#ao3#unreality#i am a goof#but really#fandom is collectively a goof#50#100#500#1K#btw the fic and stats are real!#only tagged unreality for the movie#5K
10K notes
·
View notes
Last Seen Blogs

nicproducoesof
Untitled

mattetorri-blog
Così opposti io e te.

thehellinsideyourhead
A Wonderful World of Nothing

sistinay02acero-blog
Untitled

azrakon
Azra k.