#sergei the shy engine
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
He's finally donE-
My boY-
It is midnight, I'm starving, so apologies if some of the coloring looks a little drunk.
Anyways, meet my next oc, Sergei.

(info below, even more reading)
- He/him, gay, maybe ftm trans
- Russian locomotive type P36
- Built 1952, worked on the Trans-Siberian railway before being sold and brought to Sodor in 1991
- 54'8"(length w/o tender), 4-8-4, steam powered, coal fueled, one tender, top speed 78mhp
- He worked on the Trans-Siberian railway his entire life, even living alone, and was isolated in the mountains. In turn he had developed severe social anxiety, especially when it came to other engines. The only engines he was comfortable with were the others he would see on his railway, and they even visited each other. But one day, his owner had told him that he had to leave, and was going to a new home; the island of Sodor. Sergei thought his friends would be able to go with him, but they didn't. He was completely alone in an unfamiliar place, and a place where no one spoke his native language. Sir Topham Hatt had to give him jobs that allowed little to no contact with other engines, and gave him his own shed up in the Blue Mountain.
- Sergei is introverted, anti-social, and severely uncomfortable around other engines. He never speaks unless needed, typically nodding or shaking his head, and he avoids eye contact as much as possible. When he does speak he prefers to speak in Russian, as it makes him more comfortable, but it's negated by the fact that no one understands him. He can be very easily overwhelmed, sometimes by simply being stared at by more than a few engines. Sir Topham Hatt gave him nameplates since he has so much trouble introducing himself, so with the nameplates he has no need to
- Engines like Edward and BoCo as well as Skarloey have helped Sergei get more comfortable, but he is still incredibly anxious and dislikes being close to other engines, and is even afraid of engines larger than him, but seems to be more comfortable around small engines like the Narrow Gauges he works with, he is uncomfortable around most of the diesels, and even seems afraid of the Ironworks twins because of how much they harass him
- He pulls goods trains and freight, and occasionally pulls coaches, he is actually very strong and can do jobs that would sometimes take two engines, but due to the communication issue he shouldn't be given too much at once in case of an accident, he can't pull trucks due to his anxiety, but he doesn't seem as anxious with passengers as long as they don't interact with him
- The scar on his face was from an engine who would abuse him when he was young
- He has a habit of stopping really suddenly even if several feet away from his stop, this is due to him being used to having to put a lot of power into braking because of the icy or wet railways he used to work on
- He speaks Russian and English, having a very strong accent, but he hardly speaks as it is, some misunderstand his understanding of the English language and often think he doesn't know what they are saying, people will often say things that hurt his feelings because of this, hearing people talk about Russian stereotypes really hurts him
- Has achieved the introverted but lonely combo
- He can sometimes look aggressive but if you simply stare at him for too long he will cave, he gets overwhelmed very easily especially if there are a lot of people talking at once, he is very sensitive to physical contact and avoids it as much as possible, he greatly values his personal space and is very uncomfortable when other engines are really close(mainly if they are in front of or behind him), he is specifically uncomfortable around strangers, he will hide his face in a puff of steam if he is flustered or overwhelmed, has been prone to anxiety and panic attacks but has improved the longer he's been on Sodor
- He loves anything that reminds him of home, but often gets really sad because it makes him think of how happy he used to be, he absolutely loves snow, he's actually grown attached to the Narrow Gauges of the Blue Mountain Quarry
(engine references used \/)






This one feels like it's much longer than the previous one, but who cares, it's midnight, I'm tired. Aight, hope you enjoy, I love this boi very much, yes I did get inspiration from Mikhail with the engine type, anyways, peace and chicken grease. ✌️✨
#ttte#thomas the tank engine#thomas and friends#my art#ttte oc#my oc#ttte sergei#sergei the shy engine#yeah i think thats a good name#i love him very much#yes im still influenced by bigjigglypanda#don't mind me and my plethora of traumatized queer goth ocs
48 notes
·
View notes
Text
If by chance Sergei isn't a military man, I can see him also potentially becoming a theatre actor in broadway or Opera because Singing is his main hobby and a potential career for him to shine. Or dancing in ballet despite his tall and broad figure. Philantrophist (world of Orchestra) will fit too if he had a mastery of instrument, mainly balalaika or piano, clarinet etc.
Quiet by nature not necessarily shy, I can see him also can probably one of the music producer or music engineer. Or Artist might his hidden potential in him. Probably his possible course might fall to the architecture or fine art academy.
In short, my own perspective that I can see Sergei Dragunov leans to the world of Art. Though he might be a pragmatic and perfectionist, bring an art critique is best in him also. But I can't see him as a Science Geek. Funny to say, Math might be his biggest weakness .
13 notes
·
View notes
Note
who are you dbh ocs!!! what are they like? are any of them androids? (sorry if that terminology is wrong i dont know much about dbh (im assuming you mean detroit become human but if you arent thats double embarrassing))
You got that right, it is Detroit: Become Human, no need for embarassment!And to answer the question, the majority of my DBH ocs are androids, with a few being android dogs actually.I’ll list all of them here and give a brief look into who they are and what they’re like, buckle up it’ll be a long one ^^;
Androids:
Joel the EM400 - Like most EM400s he worked for an amusement park, but he was tasked with maintaining the haunted house attraction. As a result, Joel had to deal with jumpy people who’d kick and punch him and overall behave abusively towards the actors in the haunted house. He ended up deviating purely out of fear when someone sicked their supposed “service dog” on him. Joel is an anxious mess and an aspiring novelist.
Jindosh the HR900 - He’s a custom Korean Traci that traveled to Detroit after the revolution. The Eden Club wasn’t the only facility of it’s kind, and it’s obvious the Traci models in Korea have just as many horror stories to tell, if the extensive damage to Jindosh’s face is anything to go by. He works as a body guard for hire.
Sergei the PL600 - Jessica Lamb’s PL600 who was bought under the guise of taking care of her baby. Was actually tortured for fun and came out of it psychologically damaged and prone to odd fits. Is a masochist and a drag queen and probably my favorite out of my OCs.
Noah the PL600 - A special edition PL600 who’s main design difference is that he has green eyes. He’s a soft spoken individual who belonged to a man for a few weeks before he was traded in for an AP700. He worked for several other families for a while before ending up at a pawnshop.
Dakota the CX100 - Once a CX100 named David, Dakota is an extraordinary example of how modding doesn’t necessarily have to go the same track as what Zlatko did to his androids. Being perhaps one of very few trans androids does come with hardships, but Dakota has enough friends and allies that she’s always one call away from help if someone tries anything.
Monochrome the CX100 - Chrome is another interesting CX100. He’s an android that works as a dancer for a strip club called the Steamy Piston. The one thing that sets him apart from most standard CX100s is that his hair is black and his eyes are grey, which is where he gets his name.
Apollo the AP700 - He was a faulty AP700 that was purchansed by a family at an absurdly low price with added costumization. His memory chip malfunctioned during production, which made it impossible for him to recall things or people unless he was standing right in front of them. For a while this meant that Apollo couldn’t register a name for himself until he was properly repaired. His appearence is that of a PL600, but his hair is a shade darker, his face is noticeably freckled and his eyes are a different color each. He was abandoned and lived in the Android Junkyard for a while…He’s a bit cold at times but is actually a pretty affectionate guy.
Eddie the WK218 - A british maintenence android that was stolen and modded before being sold in a flea market as a partner model. He’s an anxious clumsy mess who’s definitly not used to being indoors, but the people who rescued him have properly adopted him into the family and he couldn’t be more grateful.
Aleshenka “The Stag” the WM500 - The Stag is a living urban legend that is seen roaming unlit streets at night. They are a heavily modded WM500 who’s created a small circle of cultists followers. To maintenence and construction worker androids, the Stag is a merciful creature. To android abusers, they are a merciless prosecutor. For some reason, interfacing with them is like being consumed by white noise, and it leaves other androids reeling and unnerved.
Veronica the WR400 - A rather shy WR400 that was purchansed by the Eden Club to substitute North when she was reported missing. She made a friend out of Scott, a HR400, and the two tried to run away after Echo and Ripple were let go by Connor and Hank. Unfortunately Veronica and Scott were caught, and while they did manage to escape, Scott was shot down, leaving Veronica no choice but to salvage her friend’s memory chip and find a temporary body to house it until she could get him a new proper one.
Scott the HR400/K9300 - Originally he was a HR400 that had the appearence of a PJ500. After making friends with Veronica, the two attempted to escape the Eden Club but Scott ended up getting shot down. When he next awoke, he was in the body of a guard dog model made to look like a massive pit bull. Sarcastic and often rude, Scott doesn’t mind the fact he’s basically the real life Scooby Doo, but god does he miss having opposable thumbs.
Ragnarok the K9300 - A guard dog model that looks like a rottweiller, Roky is a very friendly pooch who, despite having been horribly beaten by his owner, is eager to make friends. He seems to think he’s a lap dog.
Chitin the K9099 - A police dog model made to look like a german shepard that was used in an illegal android fighting ring. She’s a lot smarter than she seems, which is how she managed to escape and end up at the K9 devision of the DPD. She’s not just a good girl, she is the best girl.
Regi the K9300 - Val’s personal guard dog model and her only remaining family member. He’s loyal to a fault and will protect his owner at any cost. He’s a fan of belly rubs and ear scratches.
Zulu the WMK9 - A military grade android attack dog. He’s big, fast and scary. Enough said on that matter.
Miles the RK300 - An RK series prototype and also Cyberlife’s first attempt at utilizing the RK models in their pursuit for knowledge on deviancy. He was subjected to all sorts of experimentation to try to induce deviancy in an android and then attempt to newtralize it. This including psychological torture and physical torture as a means to fix a glitch…It didn’t work whatsoever and Miles eventually escaped and hid within the walls of Cyberlife Tower. He’s terrified of everything, including his own shadow.
Tristan the RK700 - The predecessor of the Connor model, Tristan was designed for infiltration. Cyberlife assumed that, by having an android that could blend in, they’d be able to stop deviancy at it’s root. Sadly, because they tested Tristan through military espionage missions, Cyberlife lost track of their prototype and he went rogue. Tristan is currently a mercenary for hire, chosing to work for the highest bidder, and lives what is essentially a double life. One where he has a civilian personality and appearence, and another where he can disguise himself as whomever he pleases.
Humans:
Artyum Kutznekov the Ex-Cyberlife Engineer - A 21 year old russian immigrant who came to america for a second chance. After lucking out and getting a job at Cyberlife as an engineer, Artyum soon came to realize something just wasn’t right with what the company was doing and that deviancy was more than just a glitch or virus. Unable to keep working out of disgust and guilt, Artyum quit and became a bit of a shuttin. This all changed when one rainy night he came across a severely damaged Sergei and decided to do some good with his skills as an engineer. He’s a gruff bitter young man who looks 40 due to his prematurely graying hair and unkept appearence.
Valentina Hernández the Illegal Modder - A latina 18 year old who helped her father mod androids for a living. A child prodigy, Val had a bright future ahead of her before Cyberlife began to blacklist modders due to the “danger” they posed for the company. When her father refused to stop modding, things took a turn to the worse, and now Val only has Regi to keep her company. Bitter and angry over the injustice her family suffered, Val has taken it upon herself to royally screw over Cyberlife, starting with helping deviants change their appearence. She was the one who modded Dakota, and seems to hold a lot of affection towards the CX100.
Elisa “Myu” Corvo the Android Rights Activist - A portuguese android rights activist who saved Eddie from the flea market he was being sold at. A long time advocate for AI and robotics, Elisa came to america to help in any way shape or form she could, even if it means offering temporary shelter or participating in large protests.
Jessica Lamb the Red Ice Addict - I don’t even know where to start with this one. She’s a drug addict, a drug dealer, a child murderer, and she’s a sadist. She bought an android with the sole intention of recording herself torturing it. She and her friends may have something to do with a certain WR600′s mental and physical scarring…Overall Jess is a terrible person and nothing she does is excusable or morally correct.
Chance - A small baby that Apollo found abandoned in a warehouse. Literally the only thing Apollo has to live for anymore.
AI Handlers:
Miles’s Amanda - One of the first iterations of the AMANDA handler, Miles’s Amanda, known as Amy, is a calmer and more understanding version of Amanda Stern’s AI copy. Her mindscape space is a bakery instead of a garden.
Tristan’s Amanda - The fifth iteration of the AMANDA handler, Tristan’s Amanda is closer to the final product, being stricter and more judgemental of Tristan’s overall behaviour and actions, with the one difference being that she does not have the same override protocol as Connor’s Amanda. She can only berate Tristan for his choices. Her mindscape space is a cinema theater.
Tango - An AI copy of Amanda Stern’s professor, Aaron Hoss, who was her greatest inspiration. He was Part of the RK300 tests, suffering through the same amount of torment as Miles, which in turn drove him insane. Known only as TANGO, this AI handler is a lot more ambitious and murderous than the AMANDA program.
3 notes
·
View notes
Text
Chapter 4: Search
Previously in web history…
After an influx of rapid browser development following the creation of the web, Mosaic becomes the popular choice. Recognizing the commercial potential of the web, a team at O’Reilly builds GNN, the first commercial website. With something to browse with, and something to browse for, more and more people begin to turn to the web. Many create small, personal sites of their own. The best the web has to offer becomes almost impossible to find.
eBay had had enough of these spiders. They were fending them off by the thousands. Their servers buzzed with nonstop activity; a relentless stream of trespassers. One aggressor, however, towered above the rest. Bidder’s Edge, which billed itself as an auction aggregator, would routinely crawl the pages of eBay to extract its content and list it on its own site alongside other auction listings.
The famed auction site had unsuccessfully tried blocking Bidder’s Edge in the past. Like an elaborate game of Whac-A-Mole, they would restrict the IP address of a Bidder’s Edge server, only to be breached once again by a proxy server with a new one. Technology had failed. Litigation was next.
eBay filed suit against Bidder’s Edge in December of 1999, citing a handful of causes. That included “an ancient trespass theory known to legal scholars as trespass to chattels, basically a trespass or interference with real property — objects, animals, or, in this case, servers.” eBay, in other words, was arguing that Bidder’s Edge was trespassing — in the most medieval sense of that word — on their servers. In order for it to constitute trespass to chattels, eBay had to prove that the trespassers were causing harm. That their servers were buckling under the load, they argued, was evidence of that harm.

eBay in 1999
Judge Ronald M. Whyte found that last bit compelling. Quite a bit of back and forth followed, in one of the strangest lawsuits of a new era that included the phrase “rude robots” entering the official court record. These robots — as opposed to the “polite” ones — ignored eBay’s requests to block spidering on their sites, and made every attempt to circumvent counter measures. They were, by the judge’s estimation, trespassing. Whyte granted an injunction to stop Bidder’s Edge from crawling eBay until it was all sorted out.
Several appeals and countersuits and counter-appeals later, the matter was settled. Bidder’s Edge paid eBay an undisclosed amount and promptly shut their doors. eBay had won this particular battle. They had gotten rid of the robots. But the actual war was already lost. The robots — rude or otherwise — were already here.
If not for Stanford University, web search may have been lost. It is the birthplace of Yahoo!, Google and Excite. It ran the servers that ran the code that ran the first search engines. The founders of both Yahoo! and Google are alumni. But many of the most prominent players in search were not in the computer science department. They were in the symbolic systems program.
Symbolic systems was created at Stanford in 1985 as a study of the “relationship between natural and artificial systems that represent, process, and act on information.” Its interdisciplinary approach is rooted at the intersection of several fields: linguistics, mathematics, semiotics, psychology, philosophy, and computer science.
These are the same fields of study one would find at the heart of artificial intelligence research in the second half of the 20ᵗʰ century. But this isn’t the A.I. in its modern smart home manifestation, but in the more classical notion conceived by computer scientists as a roadmap to the future of computing technology. It is the understanding of machines as a way to augment the human mind. That parallel is not by accident. One of the most important areas of study at the symbolics systems program is artificial intelligence.
Numbered among the alumni of the program are several of the founders of Excite and Srinija Srinivasan, the fourth employee at Yahoo!. Her work in artificial intelligence led to a position at the ambitious A.I. research lab Cyc right out of college.
Marisa Mayer, an early employee at Google and, later, Yahoo!’s CEO, also drew on A.I. research during her time in the symbolic systems program. Her groundbreaking thesis project used natural language processing to help its users find the best flights through a simple conversation with a computer. “You look at how people learn, how people reason, and ask a computer to do the same things. It’s like studying the brain without the gore,” she would later say of the program.

Marissa Mayer in 1999
Search on the web stems from this one program at one institution at one brief moment in time. Not everyone involved in search engines studied that program — the founders of both Yahoo! and Google, for instance, were graduate students of computer science. But the ideology of search is deeply rooted in the tradition of artificial intelligence. The goal of search, after all, is to extract from the brain a question, and use machines to provide a suitable answer.
At Yahoo!, the principles of artificial intelligence acted as a guide, but it would be aided by human perspective. Web crawlers, like Excite, would bear the burden of users’ queries and attempt to map websites programmatically to provide intelligent results.
However, it would be at Google that A.I. would become an explicitly stated goal. Steven Levy, who wrote the authoritative book on the history of Google, In the Plex, describes Google as a “vehicle to realize the dream of artificial intelligence in augmenting humanity.” Founders Larry Page and Sergey Brin would mention A.I. constantly. They even brought it up in their first press conference.
The difference would be a matter of approach. A tension that would come to dominate search for half a decade. The directory versus the crawler. The precision of human influence versus the completeness of machines. Surfers would be on one side and, on the other, spiders. Only one would survive.
The first spiders were crude. They felt around in the dark until they found the edge of the web. Then they returned home. Sometimes they gathered little bits of information about the websites they crawled. In the beginning, they gathered nothing at all.
One of the earliest web crawlers was developed at MIT by Matthew Gray. He used his World Wide Wanderer to go and find every website on the web. He wasn’t interested in the content of those sites, he merely wanted to count them up. In the summer of 1993, the first time he sent his crawler out, it got to 130. A year later, it would count 3,000. By 1995, that number grew to just shy of 30,000.
Like many of his peers in the search engine business, Gray was a disciple of information retrieval, a subset of computer science dedicated to knowledge sharing. In practice, information retrieval often involves a robot (also known as “spiders, crawlers, wanderers, and worms”) that crawls through digital documents and programmatically collects their contents. They are then parsed and stored in a centralized “index,” a shortcut that eliminates the need to go and crawl every document each time a search is made. Keeping that index up to date is a constant struggle, and robots need to be vigilant; going back out and re-crawling information on a near constant basis.
The World Wide Web posed a problematic puzzle. Rather than a predictable set of documents, a theoretically infinite number of websites could live on the web. These needed to be stored in a central index —which would somehow be kept up to date. And most importantly, the content of those sites needed to be connected to whatever somebody wanted to search, on the fly and in seconds. The challenge proved irresistible for some information retrieval researchers and academics. People like Jonathan Fletcher.
Fletcher, a former graduate and IT employee at the University of Stirling in Scotland, didn’t like how hard it was to find websites. At the time, people relied on manual lists, like the WWW Virtual Library maintained at CERN, or Mosaic’s list of “What’s New” that they updated daily. Fletcher wanted to handle it differently. “With a degree in computing science and an idea that there had to be a better way, I decided to write something that would go and look for me.”
He built Jumpstation in 1993, one of the earliest examples of a searchable index. His crawler would go out, following as many links as it could, and bring them back to a searchable, centralized database. Then it would start over. To solve for the issue of the web’s limitless vastness, Fletcher began by crawling only the titles and some metadata from each webpage. That kept his index relatively small, but but it also restricted search to the titles of pages.
Fletcher was not alone. After tinkering for several months, WebCrawler launched in April of 1994 out of the University of Washington. It holds the distinction of being the first search engine to crawl entire webpages and make them searchable. By November of that year, WebCrawler had served 1 million queries. At Carnegie Mellon, Michael Maudlin released his own spider-based search engine variant named for the Latin translation of wolf spider, Lycos. By 1995, it had indexed over a million webpages.

Search didn’t stay in universities long. Search engines had a unique utility for wayward web users on the hunt for the perfect site. Many users started their web sessions on a search engine. Netscape Navigator — the number one browser for new web users — connected users directly to search engines on their homepage. Getting listed by Netscape meant eyeballs. And eyeballs meant lucrative advertising deals.
In the second half of the 1990’s, a number of major players entered the search engine market. InfoSeek, initially a paid search option, was picked up by Disney, and soon became the default search engine for Netscape. AOL swooped in and purchased WebCrawler as part of a bold strategy to remain competitive on the web. Lycos was purchased by a venture capitalist who transformed it into a fully commercial enterprise.
Excite.com, another crawler started by Stanford alumni and a rising star in the search engine game for its depth and accuracy of results, was offered three million dollars not long after they launched. Its six co-founders lined up two couches, one across from another, and talked it out all night. They decided to stick with the product and bring in a new CEO. There would be many more millions to be made.

Excite in 1996
AltaVista, already a bit late to the game at the end of 1995, was created by the Digital Equipment Corporation. It was initially built to demonstrate the processing power of DEC computers. They quickly realized that their multithreaded crawler was able to index websites at a far quicker rate than their competitors. AltaVista would routinely deploy its crawlers — what one researcher referred to as a “brood of spiders” — to index thousands of sites at a time.
As a result, AltaVista was able to index virtually the entire web, nearly 10 million webpages at launch. By the following year, in 1996, they’d be indexing over 100 million. Because of the efficiency and performance of their machines, AltaVista was able to solve the scalability problem. Unlike some of their predecessors, they were able to make the full content of websites searchable, and they re-crawled sites every few weeks, a much more rapid pace than early competitors, who could take months to update their index. They set the standard for the depth and scope of web crawlers.

AltaVista in 1996
Never fully at rest, AltaVista used its search engine as a tool for innovation, experimenting with natural language processing, translation tools, and multi-lingual search. They were often ahead of their time, offering video and image search years before that would come to be an expected feature.
Those spiders that had not been swept up in the fervor couldn’t keep up. The universities hosting the first search engines were not at all pleased to see their internet connections bloated with traffic that wasn’t even related to the university. Most universities forced the first experimental search engines, like Jumpstation, to shut down. Except, that is, at Stanford.
Stanford’s history with technological innovation begins in the second half of the 20th century. The university was, at that point, teetering on the edge of becoming a second-tier institution. They had been losing ground and lucrative contracts to their competitors on the East Coast. Harvard and MIT became the sites of a groundswell of research in the wake of World War II. Stanford was being left behind.
In 1951, in a bid to reverse course on their downward trajectory, Dean of Engineering Frederick Terman brokered a deal with the city of Palo Alto. Stanford University agreed to annex 700 acres of land for a new industrial park that upstart companies in California could use. Stanford would get proximity to energetic innovation. The businesses that chose to move there would gain unique access to the Stanford student body for use on their product development. And the city of Palo Alto would get an influx of new taxes.
Hewlett-Packard was one of the first companies to move in. They ushered in a new era of computing-focused industry that would soon be known as Silicon Valley. The Stanford Research Park (later renamed Stanford Industrial Park) would eventually host Xerox during a time of rapid success and experimentation. Facebook would spend their nascent years there, growing into the behemoth it would become. At the center of it all was Stanford.
The research park transformed the university from one of stagnation to a site of entrepreneurship and cutting-edge technology. It put them at the heart of the tech industry. Stanford would embed itself — both logistically and financially — in the crucial technological developments of the second half of the 20ᵗʰ century, including the internet and the World Wide Web.
The potential success of Yahoo!, therefore, did not go unnoticed.
Jerry Yang and David Filo were not supposed to be working on Yahoo!. They were, however, supposed to be working together. They had met years ago, when David was Jerry’s teaching assistant in the Stanford computer science program. Yang eventually joined Filo as a graduate student and — after building a strong rapport — they soon found themselves working on a project together.
As they crammed themselves into a university trailer to begin working through their doctoral project, their relationship become what Yang has often described as perfectly balanced. “We’re both extremely tolerant of each other, but extremely critical of everything else. We’re both extremely stubborn, but very unstubborn when it comes to just understanding where we need to go. We give each other the space we need, but also help each other when we need it.”
In 1994, Filo showed Yang the web. In just a single moment, their focus shifted. They pushed their intended computer science thesis to the side, procrastinating on it by immersing themselves into the depths of the World Wide Web. Days turned into weeks which turned into months of surfing the web and trading links. The two eventually decided to combine their lists in a single place, a website hosted on their Stanford internet connection. It was called Jerry and David’s Guide to the World Wide Web, launched first to Stanford students in 1993 and then to the world in January of 1994. As catchy as that name wasn’t, the idea (and traffic) took off as friends shared with other friends.
Jerry and David’s Guide was a directory. Like the virtual library started at CERN, Yang and Filo organized websites into various categories that they made up on the fly. Some of these categories had strange or salacious names. Others were exactly what you might expect. When one category got too big, they split it apart. It was ad-hoc and clumsy, but not without charm. Through their classifications, Yang and Filo had given their site a personality. Their personality. In later years, Yang would commonly refer to this as the “voice of Yahoo!”
That voice became a guide — as the site’s original name suggested — for new users of the web. Their web crawling competitors were far more adept at the art of indexing millions of sites at a time. Yang and Filo’s site featured only a small subset of the web. But it was, at least by their estimation, the best of what the web had to offer. It was the cool web. It was also a web far easier to navigate than ever before.

Jerry Yang (left) and David Filo (right) in 1995 (Yahoo, via Flickr)
At the end of 1994, Yang and Filo renamed their site to Yahoo! (an awkward forced acronym for Yet Another Hierarchical Officious Oracle). By then, they were getting almost a hundred thousand hits a day, sometimes temporarily taking down Stanford’s internet in the process. Most other universities would have closed down the site and told them to get back to work. But not Stanford. Stanford had spent decades preparing for on-campus businesses just like this one. They kept the server running, and encouraged its creators to stake their own path in Silicon Valley.
Throughout 1994, Netscape had included Yahoo! in their browser. There was a button in the toolbar labeled “Net Directory” that linked directly to Yahoo!. Marc Andreessen, believing in the site’s future, agreed to host their website on Netscape’s servers until they were able to get on steady ground.

Yahoo! homepage in Netscape Navigator, circa 1994
Yang and Filo rolled up their sleeves, and began talking to investors. It wouldn’t take long. By the spring of 1996, they would have a new CEO and hold their own record-setting IPO, outstripping even their gracious host, Netscape. By then, they became the most popular destination on the web by a wide margin.
In the meantime, the web had grown far beyond the grasp of two friends swapping links. They had managed to categorize tens of thousands of sites, but there were hundreds of thousands more to crawl. “I picture Jerry Yang as Charlie Chaplin in Modern Times,” one journalist described, “confronted with an endless stream of new work that is only increasing in speed.” The task of organizing sites would have to go to somebody else. Yang and Filo found help in a fellow Stanford alumni, someone they had met years ago while studying abroad together in Japan, Srinija Srinivasan, a graduate of the symbolic systems program. Many of the earliest hires at Yahoo! were given slightly absurd titles that always ended in “Yahoo.” Yang and Filo went by Chief Yahoos. Srinivasan’s job title was Ontological Yahoo.
That is a deliberate and precise job title, and it was not selected by accident. Ontology is the study of being, an attempt to break the world into its component parts. It has manifested in many traditions throughout history and the world, but it is most closely associated with the followers of Socrates, in the work of Plato, and later in the groundbreaking text Metaphysics, written by Aristotle. Ontology asks the question “What exists?”and uses it as a thought experiment to construct an ideology of being and essence.
As computers blinked into existence, ontology found a new meaning in the emerging field of artificial intelligence. It was adapted to fit the more formal hierarchical categorizations required for a machine to see the world; to think about the world. Ontology became a fundamental way to describe the way intelligent machines break things down into categories and share knowledge.
The dueling definitions of the ontology of metaphysics and computer science would have been familiar to Srinija Srinivasan from her time at Stanford. The combination of philosophy and artificial intelligence in her studies gave her a unique perspective on hierarchical classifications. It was this experience that she brought to her first job after college at the Cyc Project, an artificial intelligence research lab with a bold project: to teach a computer common sense.

Srinija Srinivasan (Getty Images/James D. Wilson)
At Yahoo!, her task was no less bold. When someone looked for something on the site, they didn’t want back a random list of relevant results. They wanted the result they were actually thinking about, but didn’t quite know how to describe. Yahoo! had to — in a manner of seconds — figure out what its users really wanted. Much like her work in artificial intelligence, Srinivasan needed to teach Yahoo! how to think about a query and infer the right results.
To do that, she would need to expand the voice of Yahoo! to thousands of more websites in dozens of categories and sub-categories without losing the point of view established by Jerry and David. She would need to scale that perspective. “This is not a perfunctory file-keeping exercise. This is defining the nature of being,” she once said of her project. “Categories and classifications are the basis for each of our worldviews.”
At a steady pace, she mapped an ontology of human experience onto the site. She began breaking up the makeshift categories she inherited from the site’s creators, re-constituting them into more concrete and findable indexes. She created new categories and destroyed old ones. She sub-divided existing subjects into new, more precise ones. She began cross-linking results so that they could live within multiple categories. Within a few months she had overhauled the site with a fresh hierarchy.
That hierarchical ontology, however, was merely a guideline. The strength of Yahoo!’s expansion lay in the 50 or so content managers she had hired in the meantime. They were known as surfers. Their job was to surf the web — and organize it.
Each surfer was coached in the methodology of Yahoo! but were left with a surprising amount of editorial freedom. They cultivated the directory with their own interests, meticulously deliberating over websites and where they belong. Each decision could be strenuous, and there were missteps and incorrectly categorized items along the way. But by allowing individual personality to dictate hierarchal choices, Yahoo! retained its voice.
They gathered as many sites as they could, adding hundreds each day. Yahoo! surfers did not reveal everything on the web to their site’s visitors. They showed them what was cool. And that meant everything to users grasping for the very first time what the web could do.
At the end of 1995, the Yahoo! staff was watching their traffic closely. Huddled around consoles, employees would check their logs again and again, looking for a drop in visitors. Yahoo! had been the destination for the “Internet Directory” button on Netscape for years. It had been the source of their growth and traffic. Netscape had made the decision, at the last minute (and seemingly at random), to drop Yahoo!, replacing them with the new kids on the block, Excite.com. Best case scenario: a manageable drop. Worst case: the demise of Yahoo!.
But the drop never came. A day went by, and then another. And then a week. And then a few weeks. And Yahoo! remained the most popular website. Tim Brady, one of Yahoo!’s first employees, describes the moment with earnest surprise. “It was like the floor was pulled out in a matter of two days, and we were still standing. We were looking around, waiting for things to collapse in a lot of ways. And we were just like, I guess we’re on our own now.”
Netscape wouldn’t keep their directory button exclusive for long. By 1996, they would begin allowing other search engines to be listed on their browser’s “search” feature. A user could click a button and a drop-down of options would appear, for a fee. Yahoo! bought themselves back in to the drop-down. They were joined by four other search engines, Lycos, InfoSeek, Excite, and AltaVista.
By that time, Yahoo! was the unrivaled leader. It had transformed its first mover advantage into a new strategy, one bolstered by a successful IPO and an influx of new investment. Yahoo! wanted to be much more than a simple search engine. Their site’s transformation would eventually be called a portal. It was a central location for every possible need on the web. Through a number of product expansions and aggressive acquisitions, Yahoo! released a new suite of branded digital products. Need to send an email? Try Yahoo! Mail. Looking to create website? There’s Yahoo! Geocities. Want to track your schedule? Use Yahoo! Calendar. And on and on the list went.

Yahoo! in 1996
Competitors rushed the fill the vacuum of the #2 slot. In April of 1996, Yahoo!, Lycos and Excite all went public to soaring stock prices. Infoseek had their initial offering only a few months later. Big deals collided with bold blueprints for the future. Excite began positioning itself as a more vibrant alternative to Yahoo! with more accurate search results from a larger slice of the web. Lycos, meanwhile, all but abounded the search engine that had brought them initial success to chase after the portal-based game plan that had been a windfall for Yahoo!.
The media dubbed the competition the “portal wars,” a fleeting moment in web history when millions of dollars poured into a single strategy. To be the biggest, best, centralized portal for web surfers. Any service that offered users a destination on the web was thrown into the arena. Nothing short of the future of the web (and a billion dollar advertising industry) was at stake.
In some ways, though, the portal wars were over before they started. When Excite announced a gigantic merger with @Home, an Internet Service Provider, to combine their services, not everyone thought it was a wise move. “AOL and Yahoo! were already in the lead,” one investor and cable industry veteran noted, “and there was no room for a number three portal.” AOL had just enough muscle and influence to elbow their way into the #2 slot, nipping at the heels of Yahoo!. Everyone else would have to go toe-to-toe with Goliath. None were ever able to pull it off.
Battling their way to market dominance, most search engines had simply lost track of search. Buried somewhere next to your email and stock ticker and sports feed was, in most cases, a second rate search engine you could use to find things — only not often and not well. That’s is why it was so refreshing when another search engine out of Stanford launched with just a single search box and two buttons, its bright and multicolored logo plastered across the top.
A few short years after it launched, Google was on the shortlist of most popular sites. In an interview with PBS Newshour in 2002, co-founder Larry Page described their long-term vision. “And, actually, the ultimate search engine, which would understand, you know, exactly what you wanted when you typed in a query, and it would give you the exact right thing back, in computer science we call that artificial intelligence.”
Google could have started anywhere. It could have started with anything. One employee recalls an early conversation with the site’s founders where he was told “we are not really interested in search. We are making an A.I.” Larry Page and Sergey Brin, the creators of Google, were not trying to create the web’s greatest search engine. They were trying to create the web’s most intelligent website. Search was only their most logical starting point.
Imprecise and clumsy, the spider-based search engines of 1996 faced an uphill battle. AltaVista had proved that the entirety of the web, tens of millions of webpages, could be indexed. But unless you knew your way around a few boolean logic commands, it was hard to get the computer to return the right results. The robots were not yet ready to infer, in Page’s words, “exactly what you wanted.”
Yahoo! had filled in these cracks of technology with their surfers. The surfers were able to course-correct the computers, designing their directory piece by piece rather than relying on an algorithm. Yahoo! became an arbiter of a certain kind of online chic; tastemakers reimagined for the information age. The surfers of Yahoo! set trends that would last for years. Your site would live or die by their hand. Machines couldn’t do that work on their own. If you wanted your machines to be intelligent, you needed people to guide them.
Page and Brin disagreed. They believed that computers could handle the problem just fine. And they aimed to prove it.
That unflappable confidence would come to define Google far more than their “don’t be evil” motto. In the beginning, their laser-focus on designing a different future for the web would leave them blind to the day-to-day grind of the present. On not one, but two occasions, checks made out to the company for hundreds of thousands of dollars were left in desk drawers or car trunks until somebody finally made the time to deposit them. And they often did things different. Google’s offices, for instances, were built to simulate a college dorm, an environment the founders felt most conducive to big ideas.
Google would eventually build a literal empire on top of a sophisticated, world-class infrastructure of their own design, fueled by the most elaborate and complex (and arguably invasive) advertising mechanism ever built. There are few companies that loom as large as Google. This one, like others, started at Stanford.
Even among the most renowned artificial intelligence experts, Terry Winograd, a computer scientist and Stanford professor, stands out in the crowd. He was also Larry Page’s advisor and mentor when he was a graduate student in the computer science department. Winograd has often recalled the unorthodox and unique proposals he would receive from Page for his thesis project, some of which involved “space tethers or solar kites.” “It was science fiction more than computer science,” he would later remark.
But for all of his fanciful flights of imagination, Page always returned to the World Wide Web. He found its hyperlink structure mesmerizing. Its one-way links — a crucial ingredient in the web’s success — had led to a colossal proliferation of new websites. In 1996, when Page first began looking at the web, there were tens of thousands of sites being added every week. The master stroke of the web was to enable links that only traveled in one direction. That allowed the web to be decentralized, but without a central database tracking links, it was nearly impossible to collect a list of all of the sites that linked to a particular webpage. Page wanted to build a graph of who was linking to who; an index he could use to cross-reference related websites.
Page understood that the hyperlink was a digital analog to academic citations. A key indicator of the value of a particular academic paper is the amount of times it has been cited. If a paper is cited often (by other high quality papers), it is easier to vouch for its reliability. The web works the same way. The more often your site is linked to (what’s known as a backlink), the more dependable and accurate it is likely to be.
Theoretically, you can determine the value of a website by adding up all of the other websites that link to it. That’s only one layer though. If 100 sites link back to you, but each of them has only ever been linked to one time, that’s far less valuable than if five sites that each have been linked to 100 times link back to you. So it’s not simply how many links you have, but the quality of those links. If you take both of those dimensions and aggregate sites using backlinks as a criteria, you can very quickly start to assemble a list of sites ordered by quality.
John Battelle describes the technical challenge facing Page in his own retelling of the Google story, The Search.
Page realized that a raw count of links to a page would be a useful guide to that page’s rank. He also saw that each link needed its own ranking, based on the link count of its originating page. But such an approach creates a difficult and recursive mathematical challenge — you not only have to count a particular page’s links, you also have to count the links attached to the links. The math gets complicated rather quickly.
Fortunately, Page already knew a math prodigy. Sergey Brin had proven his brilliance to the world a number of times before he began a doctoral program in the Stanford computer science department. Brin and Page had crossed paths on several occasions, a relationship that began on rocky ground but grew towards mutual respect. The mathematical puzzle at the center of Page’s idea was far too enticing for Brin to pass up.
He got to work on a solution. “Basically we convert the entire Web into a big equation, with several hundred million variables,” he would later explain, “which are the page ranks of all the Web pages, and billions of terms, which are the links. And we’re able to solve that equation.” Scott Hassan, the seldom talked about third co-founder of Google who developed their first web crawler, summed it up a bit more concisely, describing Google’s algorithm as an attempt to “surf the web backward!”
The result was PageRank — as in Larry Page, not webpage. Brin, Page, and Hassan developed an algorithm that could trace backlinks of a site to determine the quality of a particular webpage. The higher value of a site’s backlinks, the higher up the rankings it climbed. They had discovered what so many others had missed. If you trained a machine on the right source — backlinks — you could get remarkable results.
It was only after that that they began matching their rankings to search queries when they realized PageRank fit best in a search engine. They called their search engine Google. It was launched on Stanford’s internet connection in August of 1996.

Google in 1998
Google solved the relevancy problem that had plagued online search since its earliest days. Crawlers like Lycos, AltaVista and Excite were able to provide a list of webpages that matched a particular search. They just weren’t able to sort them right, so you had to go digging to find the result you wanted. Google’s rankings were immediately relevant. The first page of your search usually had what you needed. They were so confident in their results they added an “I’m Feeling Lucky” button which took users directly to the first result for their search.
Google’s growth in their early days was not unlike Yahoo!’s in theirs. They spread through word of mouth, from friends to friends of friends. By 1997, they had grown big enough to put a strain on the Stanford network, something Yang and Filo had done only a couple of years earlier. Stanford once again recognized possibility. It did not push Google off their servers. Instead, Stanford’s advisors pushed Page and Brin in a commercial direction.
Initially, the founders sought to sell or license their algorithm to other search engines. They took meetings with Yahoo!, Infoseek and Excite. No one could see the value. They were focused on portals. In a move that would soon sound absurd, they each passed up the opportunity to buy Google for a million dollars or less, and Page and Brin could not find a partner that recognized their vision.
One Stanford faculty member was able to connect them with a few investors, including Jeff Bezos and David Cheriton (which got them those first few checks that sat in a desk drawer for weeks). They formally incorporated in September of 1998, moving into a friend’s garage, bringing a few early employees along, including symbolics systems alumni Marissa Mayer.

Larry Page (left) and Sergey Brin (right) started Google in a friend’s garage.
Even backed by a million dollar investment, the Google founders maintained a philosophy of frugality, simplicity, and swiftness. Despite occasional urging from their investors, they resisted the portal strategy and remained focused on search. They continued tweaking their algorithm and working on the accuracy of their results. They focused on their machines. They wanted to take the words that someone searched for and turn them into something actually meaningful. If you weren’t able to find the thing you were looking for in the top three results, Google had failed.
Google was followed by a cloud of hype and positive buzz in the press. Writing in Newsweek, Steven Levy described Google as a “high-tech version of the Oracle of Delphi, positioning everyone a mouse click away from the answers to the most arcane questions — and delivering simple answers so efficiently that the process becomes addictive.” It was around this time that “googling” — a verb form of the site synonymous with search — entered the common vernacular. The portal wars were still waging, but Google was poking its head up as a calm, precise alternative to the noise.
At the end of 1998, they were serving up ten thousand searches a day. A year later, that would jump to seven million a day. But quietly, behind the scenes, they began assembling the pieces of an empire.
As the web grew, technologists and journalists predicted the end of Google; they would never be able to keep up. But they did, outlasting a dying roster of competitors. In 2001, Excite went bankrupt, Lycos closed down, and Disney suspended Infoseek. Google climbed up and replaced them. It wouldn’t be until 2006 that Google would finally overtake Yahoo! as the number one website. But by then, the company would transform into something else entirely.
After securing another round of investment in 1999, Google moved into their new headquarters and brought on an army of new employees. The list of fresh recruits included former engineers at AltaVista, and leading artificial intelligence expert Peter Norving. Google put an unprecedented focus on advancements in technology. Better servers. Faster spiders. Bigger indexes. The engineers inside Google invented a web infrastructure that had, up to that point, been only theoretical.
They trained their machines on new things, and new products. But regardless of the application, translation or email or pay-per-click advertising, they rested on the same premise. Machines can augment and re-imagine human intelligence, and they can do it at limitless scale. Google took the value proposition of artificial intelligence and brought it into the mainstream.

In 2001, Page and Brin brought in Silicon Valley veteran Eric Schmidt to run things as their CEO, a role he would occupy for a decade. He would oversee the company during its time of greatest growth and innovation. Google employee #4 Heather Cairns recalls his first days on the job. “He did this sort of public address with the company and he said, ‘I want you to know who your real competition is.’ He said, ‘It’s Microsoft.’ And everyone went, What?“
Bill Gates would later say, “In the search engine business, Google blew away the early innovators, just blew them away.” There would come a time when Google and Microsoft would come face to face. Eric Schmidt was correct about where Google was going. But it would take years for Microsoft to recognize Google as a threat. In the second half of the 1990’s, they were too busy looking in their rearview mirror at another Silicon Valley company upstart that had swept the digital world. Microsoft’s coming war with Netscape would subsume the web for over half a decade.
The post Chapter 4: Search appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Chapter 4: Search published first on https://deskbysnafu.tumblr.com/
0 notes
Text
How Europe’s Last Dictatorship Became a Tech Hub
By Ivan Nechepurenko, NY Times, OCT. 5, 2017
MINSK, Belarus--On Friday nights, Zybitskaya street--or simply Zyba, as locals call it--turns into a vast party scene, filled with hipsters in bright shirts, tight dark jeans and black-rimmed glasses, showing how they can be carefree in a country that has been labeled the last dictatorship of Europe.
Over the past few years, Zyba has turned into an island in the middle of Minsk, the Belarusian capital--still mostly a sterile, utterly unfashionable city with long lines of dominating Soviet buildings and people hurrying past, seemingly terrified of making any form of contact. On Zyba, a crowd of convivial youngsters migrates from one little bar to another, drinking Jack and Coke, smoking endlessly.
Many of those carousing belong to Belarus’s sprouting technology industry--young, savvy and forward-looking designers, bookish and shy engineers, and many others who aspire to belong. More than 30,000 tech specialists now work in Minsk, a city of about two million, many of them creating mobile apps that are used by more than a billion people in 193 countries, according to the local government.
One of the Minsk techies is Dmitri Kovalyov, 35, an artist who a couple of years ago worked for MSQRD, a smartphone tool that lets people superimpose various masks over their faces in selfie videos.
In 2016, Mr. Kovalyov couldn’t imagine that his respect for Leonardo DiCaprio’s acting and environmental activism would get the company very far. But before that year’s Academy Awards, Mr. Kovalyov and his colleagues developed a tool for a mask that made people in video messages look like Mr. DiCaprio holding two Oscar statuettes.
Numerous celebrities tried it out, including on the red carpet, and even Mr. DiCaprio’s mother was in on the trick. When a journalist asked her about the app, she said her son had already shown her how it worked.
“I like what Leonardo does, how he acts and how he tries to preserve the planet,” Mr. Kovalyov said recently of the actor, who won that year’s Best Actor award. “I was rooting for him.”
Ten days after the awards, Facebook bought the company for an undisclosed sum. The founders, whose average age was about 25 at the time, moved to London and the United States. Together with some of those co-workers, Mr. Kovalyov is developing a new Minsk start-up, AR Squad, which creates augmented reality content.
One of the first masks the other company developed was one resembling Aleksandr G. Lukashenko, Belarus’s president, who has ruled for more than two decades. He is prone to publicity stunts like picking potatoes at his estate or taking his teenage son, Nikolai, commonly referred to as Kolya, to sit at international meetings in a military uniform.
Mr. Lukashenko’s mask featured his trademark comb-over hair and bushy mustache, but was not considered offensive. On the contrary, Mr. Lukashenko began to believe that the tech industry could become a magic wand to help him end the country’s chronic dependency on Russia.
“Creation of an IT state is our ambitious but reachable goal,” Mr. Lukashenko said at a gathering of lawmakers and bureaucrats this summer. “This will allow us to make Belarus even more modern and prosperous and will let Belarusians look into the future with confidence.”
Mr. Lukashenko, who once called the internet “a pile of garbage,” began to utter improbable words for a former manager of a collective farm--about the need to develop artificial intelligence, driverless cars and blockchain technology, which allows multiple parties to keep shared digital records.
His government has taken several steps to encourage the tech industry’s development, like granting visa-free entry to citizens of 79 countries, including all Western states, when entering through the Minsk airport. Mr. Lukashenko also wants to lift restrictions on currency transfers to encourage venture financing for start-ups.
Belarus produces top-level technical talent, an inheritance from its Soviet past, said Arkady M. Dobkin, who immigrated to the United States in the 1990s and established a software company there.
Today, Mr. Dobkin is the chief executive of EPAM, which does programing for the world’s leading tech companies and is considered one of the fastest-growing public tech companies in the world.
EPAM’s headquarters is in Newtown, Pa., but its main development hub is in Minsk, where more than 6,000 of its technology specialists work.
“I think it was the absence of oil that made Belarus do this,” said Mr. Dobkin, 57. “Here, universities produce more highly qualified specialists than the internal market needs.”
Many locals say the government’s talk about growing as a tech hub is a comfortable distraction in a country that heavily depends on Russia for cut-rate fuel and political patronage.
Sergei Chaly, an outspoken economist and former government official, calls Belarus “a dying country with bitcoins.”
Vladimir Lipkovich, a popular blogger who made a career out of ridiculing Belarusian bureaucrats, said the only reason the tech industry had found some success in Belarus is that the government “cannot seize people’s brains.” He joked, “If they want to capture an IT company, what would they get, computers?”
Politics doesn’t seem a big concern for many in the tech crowd, even if young political activists use group chats on the call and messaging app Viber--an Israeli company whose development hub is in Minsk--to coordinate activities and plan rallies.
Mr. Lukashenko’s son is a fan of World of Tanks, a multiplayer online game developed in Belarus in which people fight in tank battles. With more than 200 million registered users across the world, it is one of the top 10 games in terms of total digital revenue.
Tanks have an important cultural meaning for Belarus and other former Soviet states, where almost every family has an ancestor who fought in one.
“He plays tanks, but this is controlled,” Mr. Lukashenko said of his son at a televised meeting with schoolteachers.
“One hour for tanks, 1.5 hours for music,” the president added, explaining how he controls his son’s time spent on the game. “Two hours for tanks--four hours for music.”
“Four hours is difficult,” Mr. Lukashenko said, “so he doesn’t play for longer than one hour.”
1 note
·
View note
Text
"All about Apple" How big is it....!
"Apple" from a garage to one of the largest companies in world history, the question must be asked how did all this start and just how big apple today. In this article we’ll take a look at the fascinating story of where people came from and then some facts, will then move on to the company size and finally finish up with some conclusions. Please get comfortable, this story is a pretty good one.
So let’s begin:
The beginning of Apple was a true all-American story, you know how they say great things happen when you’re in the right place at the right time. This is true for the foundation of Apple, the year is 1969 and the timing was perfect for some real innovation. It was a moment when the largest generation in US history the baby boomers were becoming adults 18 million strong. It was an explosive shock to the system they were dissatisfied with their country they didn’t want their friends and classmates going to war. They would stand for any sort of discrimination. There were any ideas about what the world could be, it was a young revolution separate from mainstream America. A counterculture in tandem with this the microchip wasn’t development and would be another revolution just on the other side of the decade the place was also written for innovation.
As San Francisco was the epicenter of the counterculture movement, it would be during this mix of time and place in 1969 that are 14-year-old Steve Jobs would meet a 19-year-old Steve Wozniak. There we run of the mill students with a love for technology pranks and the Beatles, neither of them had any idea that the two of them would soon change history. Steve Wozniak was always keen on computers. Actually a common dream among tech enthusiasts the dream to own a personal computer and impossible concept of the time this all changed in 1974 with the introduction of the out here 8800 at DIY microcomputer kit even though it didn’t have any output apart from a set of flashing light set caused mass excitement and hysteria among tech enthusiasts so much. So that computer clouds began to pop up all around the US just to discuss all the cool things that you can do an out air 8801 of such clubs was the home brew Computer Club in San Francisco. This club was different though according to Jim Warren founder of the west coast computer fair. The general belief system of the home brew Computer Club was influenced by the counterculture happening around the area for the club this man that helping each other and sharing everything was the norm, it was a team effort to figure out what the new outer computer kit could do. Once that was put together meanwhile Steve Wozniak was building design computer at this time early CPUS from Intel and Motorola had just become publicly available and was took advantage each week. He could bring his computer into the homebrew club with new improvements but each time he was too shy to put up his hand during the cob session so he’ll just set up his computer at the conclusion of the session but something would happen every time people would start to crowd around asking questions. Steve Jobs, he also attended the club notice this and told was the two of us should really sell these things so starting in this garage in April of nineteen seventy-six the two boys with the help of some friends got to work on the Apple. One a single circuit board with no included keyboard or monitor this was officially the beginning of Apple computer. The group of friends sold 50 apple ones to Steve this is proof that people outside the club actually did want to iron a PC. It was very clear to Steve that while there were a bunch of hardware hobbyists they could assemble their own computers or at least take our board and add the Transformers for the power supply in the case and the keyboard for every one of those there were a thousand people that couldn’t do that but wanted to mess around with programming and so my dream for the Apple to was to sell the first real packaged computer. Steve’s vision of a ready-made PC was actually impossible at the time it would take way too many chips making it too expensive and too complicated. It just couldn’t be done without some serious innovation as it turns out was didn’t actually know it was impossible. He single-offhandedly used his mind to make an industry breakthrough and then I got into way of why have memory for your TV screen and memory for your computer make them one and that shrunk the chips down and he Shrunk the chips here and look through manuals and found a chip that did it in one trip instead of five and reduces that and one thing after another after another happened. He wants up with so few chips when he was done he said hey the computer that you could program to generate colored patterns on a screen or data or words or play games or anything and was just the computer he wanted. Steve jobs added his design knowledge while insisting that the computer should be easy to use this combination make the apple to palatable to the consumer. Steve Jobs managed to get some investment money together for manufacturing the PC was now far cry from the hobbyist box with a bunch of lights and switches just two years earlier the new company showcase the Apple to at the nineteen seventy-eight computer fair and they stole the show you out right no one had ever seen anything like it. After this Apple was off literally exponentially, Steve was worth about over a million dollars when he was 23 and over 10 million dollars and he was 24 and over a hundred million dollars and was 25 and it wasn’t that important because he never did it for the money. Future would not be awesome with sailing there by 1980 IBM. So Apple success in the PC market and realize that they were wrong about the PC it wasn’t just a hobbyist toy it could actually be used to extend human intellect and even for communication. Throughout the eighties Apple wood battle with IBM and the other PC manufacturers losing market share as they went along. For Apple, the next few decades would see failure success and everything in between. After losing its way and flirting with bankruptcy the company would shed the excess and returned to its roots ushering in a second. The modern era of Apple is a force to be reckoned with on the world stage. They have a strong devoted following and managed to take home ninety-two percent of all Smartphone profits in the first quarter of 2015.With all of this in mind let’s look at seven fun facts about the company before we take a look at how big they really are:
Number seven: where did the name come from? According to Steve Wozniak’s 2006 book I was, wasn’t it explains that the name came when he was driving Steve jobs back from the airport. Jobs had just returned from a communist called the apple orchard in the car job suggested the name apple computer was neck was concerned about the name because they could have issues with the Beatles apple records as it turns out the pair just couldn’t think of anything better an apple computer stock.
Number six: It will actually have three co-founders so we all know Steve jobs and Steve Wozniak but there’s a third person that many people wouldn’t have heard of Ronald Wayne. He was the one who designed this original apple logo which featured Sir Isaac Newton, of course soon scrapped because it was too detailed. Wayne left the company just 12 days after it was founded selling ten percent of a share for just eight hundred dollars if he’d stayed with his ten percent share it would be worth over 60 billion dollars today. Wayne who is now 80 years old says he has no regret that really sucks but I guess it happens.
Number five: Surely after being shooting out of in Apple in 1985 Jobs applied to fly on the space shuttle as a civilian astronaut and even considered starting a computer company in the Soviet Union.
Number four: It’s fairly common knowledge that jobs had the array inside to see that technology had a strong emotional tie but what most people don’t know is that he actually dedicated an entire team divided to packaging and studying the experience of opening a box.
Number three: According to a 2015 interview with Steve Wozniak when they met Steve Jobs had never designed anything as a hardware engineer and had never written any software. Jobs would obviously great skill set as the company mature.
Number two: I-phone project was so secret that the hardware guys never saw the software and the software guys never got to see the hardware. Hardly anyone inside Apple you what the finished product would look like until Steve Jobs revealed it on the stage.
Number one: Steve jobs actually served as a mentor for the Google founders Sergey Brin and Larry Page. Okay so we’ve learned quite a bit so far and we have some great context under our belt but let’s dive into the real stuff just “How big is Apple now”
Apple’s first quarter revenue in 2015 just from the I-phone was 51.2 billion dollars that are greater than Yahoo’s entire market cap at forty-five point five billion dollars and that’s three times more than Google’s total revenue in the third quarter of 2014 or almost twice as much as Microsoft quarterly revenue. Apple has more than one hundred seventy-eight billion dollars in cash that are more than enough to by IBM, in fact, Apple could buy a Ford General Motors and Tesla and still have 40 1.3 billion dollars left over. Alternatively, Netflix Tesla Twitter drop box Pandora combined the company has twice as much operating cash as the US Treasury. Apple’s net income last quarter was 18 billion dollars, the largest quarterly earnings for any company ever. The previous record was held by guest prom Russia’s huge oil and Gas Company. They clocked in at sixteen point two billion dollars of profit in august of 2011. Apple is actually an anomaly every other company in the top 25 most profitable quarters of all time have been an energy company so few of you would be asking how Apple compared does to Samsung. Group in terms of revenue Samsung has generated almost two times as much as apple and has four times the number of employees but if we look at company net income the story kind of switches. Samsung actually pockets less than half of what Apple does. This means that although Samsung has his hand in everything Apple is a much more efficient business. Only sticking to a handful of products and nailing their target market in the process.
Let’s take a look at the even bigger picture with all the huge companies in the world. First look at revenue, in terms of revenue Wal-Mart is number one Samsung is number 10 and apple is number 17. But again if we look at net income and profits Apple incorporated number one by almost 20 billion dollars. Keep in mind that this was before the commodity price lights of 2015 this is simply amazing.
So now let’s begin to start wrapping up the article by discussing some interesting questions what makes apple so successful. A lot of Apple success can be attributed to taking a different more human approach to technology. Technology’s job is not just to be a tool in life but to get out of the way and be transparent almost natural. Apple has historically done this extremely well. Entering the question from another angle the modern era of Apple has actually had a lot to do with problem-solving. What I mean well since the late nineties and early two thousands we enter the true digital age core technologies such as ram and CPUS had falling prices but storage size and speed capabilities were skyrocketing, this meant that there was a huge explosion of new possible product capabilities but there was a problem how do you harness these capabilities to make great products that people want. The answer make them easy to use case one the I-pod in 2001 hard drive storage had come down to a reasonable size and capacity was increasing but interestingly enough in this whole new digital music revolution, there is no market leader. They haven’t found the recipe no one has really found the recipe for digital music. But Apple had a problem if they were to make a digital player that’d be just too many songs to get through. Who would want to click through a thousand songs one by one? How would we make this as user-friendly as possible a haptic feedback scroll wheel ended up being the perfect solution case to the I-phone in 2007? We’re now entering the age they’re turning into many PCS in fact if the I-phone was made in 1991 to have the same performance as it did in 2007 it would cost you more than 3 million dollars. The ram alone would cost 1.4 million with the start of this new mobile age. The old thinking of a cramped keyboard with a tiny mouse or equivalent navigation had to change their needed to be a better way. The solution a capacitive touch screen the first ever to be put in a consumer device a real breakthrough at that point but that wasn’t enough. That when you make all the details count the product can sell itself remember the simple list scrolling of the I-phone blew people’s minds not because it was apple but because people were amazed to see that technology could actually organically. It sounds simple today but back then it blew people away. Well, how do I scroll through my list of artist show do I do this. I just take my finger and I scroll yeah uniqueness and innovation is the key to apples early success. It was also Steve jobs belief in the emotional aspect of a technology product that set Apple apart and aspect which many tech companies today still don’t fully realize. The significance of so what’s the take away the big picture. I just love this story a couple of kids tinkering in the garage created a company that now has a bigger quarterly profit than all the big oil companies and even Wal-Mart. It happened because they’re in the right place at the right time but also because they were passionate about what they did that the most important thing that I think is that if you’re going to start something new you have to feel passionate about it because it’s really hard most of the difference between people that succeed and people that don’t is the people that don’t give up they give up sooner than the people to succeed and you have to be passionate about it because it’s so difficult the roots of apple at the homebrew Computer Club also show us something. If you surround yourself with other passion and positive people it can lead to great things it’s just something cool to think about.
Hey guys to go get you so there you have it that was just a nice virtual straight look at apple and I hope you enjoy that or at least got something out of it. See you guys again soon in the next Article.
2 notes
·
View notes
Text
Headcanons: The boys’ hobbies and other interests!
Boris is lowkey a film geek. His favorite genres (by far) are mystery/thriller and detective movies, though one might be able to talk him into watching a film of another genre. But anyways, he really likes to watch and analyze who-dun-it films, and has probably written a screenplay or two of his own but no one has seen it or read it yet. He also finds ropes courses fun. He’s quite an avid reader as well. His taste in books is similar to that in movies, though he also finds books about or based on true stories interesting.
Valeri has this interest in botany, and reads about it A Lot in his spare time. He likes to keep plants and stuff in his room and take care of them, he's done that for years in his room while growing up and has also tried to do that in the Thin Ice dorm but things were often busy so now he only keeps at most 3 plants at one time. He's also pretty good at cooking, and knows a lot about herbs, spices, and other seasonings that could go well with a given food.
Aleksandr keeps quite a few collections and is lowkey into photography as well. He's also very interested in psychology because he loves to study how people's minds work and how they tend to react in certain situations,,, along with how that can affect other things such as their personality. If he hadn't joined the music industry he would have gone into counseling.
I've already established Volodya's longtime passion and interest in engineering/technology which can be Very Broad, but Volodya also really loves watching studio ghibli and stuff similar to that (relaxing, slice of life). Rumor has it that when he plays the newer Pokemon games he spends a ton of time on Pokemon Amie/Refresh.
Vladimir is Very Artsy and has probably tried a lot of art forms, he just loves to find ways to express what's on his mind. Particularly things involving bright colors. I have a feeling he would like painting, especially when it's mural painting and he gets to paint walls. As well as acting. He also claims to be into fashion (which he probably is) when really his favorite thing about it is how bright colors can be pulled off. Just look at what Lil Nas X has worn to award shows!
Vasili is quite interested in chemistry, he's probably found ways to learn more about it and still reads about it every now and then. Get him into a conversation about chemistry and chances are he will have A Lot to say. He also likes drawing, pretty much doodling (sometimes in patterns), and one of his favorite kinds of things to draw is mandalas. He has a few collections too, such as his glass collection he is Absolutely Weak for.
I have a feeling Viacheslav would take up parkour, which he has learned quite a few things about and has actually tried it himself (nothing very extreme though), and also be quite into video games (action ones but not including shooter ones,,, I'll find some he would like). He would also know some things about cooking, from what he learns about it while staying over with Alexei and his family and helping them cook. Viacheslav is also lowkey interested in engineering and computing, so when he’s curious about something relating to that, he and Volodya talk about it.
Sergei is into acting, and has taken part in quite a few productions while he was growing up. He finds it so interesting to try and step into the shoes of other people/characters, and in a way it's also a great way for him to express himself because he's quite shy. He also really likes winter sports and activities (he probably has a few favorites he does more often) because winter has always been his favorite season.
Alexei is great at cooking and baking, because his family would often cook lots of recipes (some were practically family traditions to make) and he would help out a lot. He also knows some things about knitting and sewing, and has made a bunch of random things in the past. He finds poetry (and reading it) quite interesting as well; one of his favorite poems is “7 Cups of Tea” by Lu Tong. I have a feeling Alexei would particularly like poems similar to “7 Cups of Tea”.
If I think of anything else, I’ll talk about it when it comes to me ^^
#character studies#lore#oc boris mikhailov#oc valeri kharlamov#oc aleksandr golikov#oc volodya golikov#oc vladimir myshkin#oc vasili pervukhin#oc viacheslav fetisov#oc sergei starikov#oc alexei kasatonov#about the boys
0 notes
Text
EVERY FOUNDER SHOULD KNOW ABOUT TYPES
That's the myth in the Valley. Family to support This one is real. This can be quite a mental adjustment, because little if any of the software you write in school even has users. Some will be shocking by present standards. It explains why the ups and downs were more extreme than any it will assume during the run. The big mystery to me is how one's perspective on time shifts. Have one person talk while another uses the computer. Bootstrapping may get easier, because starting a company.1
Several founders mentioned specifically how much more important persistence was in startups. Technology tends to get dramatically cheaper, but living expenses don't. It's harder to hide wrongdoing now. Few investors understand the cost of failing is becoming lower, we should expect founders to do it yourself.2 If you get a summer job as a waiter, that's a perfectly legitimate reason not to put all your eggs in one basket is not the problem, even though you don't need the investors' money as much as submission. How far behind are you? Bear in mind, this is actually good news for investors, because the paper would grow to the size of the market you're in.3 That's what board control means in practice.4 A startup is too much for free. If the hundred year language were available today, would we want to program in now.
Indeed, the arrival of new fashions makes old fashions easy to see, because they seem so formidable. Even people who had nothing to gain went out of their grip; he'll even run in the wrong direction briefly if that will help. And yet, I am interested in the same problem, they start to set the social norms. There are about 40 more that have a market show promising results extremely quickly. I guarantee you'll be surprised by what they tell you how great you are.5 But as a founder your incentives are different. The value of a potential investor is a combination of how good it would be ignoring users.6
By now these labels have lost their sting.7 But this model doesn't work for software. In our case the distinguishing feature is the ability to reason. Though I have to choose the right number, because only that scales. That is so much more important than anything else.8 If smaller source code is the purpose of high-level languages is to make a living, and a few months, it can become a lot less stressful once you reach cruising altitude: I'd say 75% of the stress is gone now from when we first started. Among other things, there will be more good startups. And programmers build applications for the platforms they use.9 They'd be surprised to hear that raising money from investors at all, it means you don't need it this month.
How will we take advantage of the opportunities to waste cycles that we'll get from new, faster hardware?10 It's striking how often programmers manage to hit all eight points by accident.11 Greg Mcadoo said one thing Sequoia looks for is the proxy for demand. Some parts of a program may be easiest to read if you spread things out, like an introductory textbook.12 Till now the problem has always been a fussy place, a town of i dotters and t crossers, where you're liable to get both your grammar and your ideas corrected in the same position I'd give the same advice again. If another map has the same mistake, that's very convincing evidence. No one likes the transmission of power between generations. The amounts invested by different types of investors are adapted to different degrees of risk, but each has its specific degree of risk an existing investor or firm is comfortable taking is one of Silicon Valley's biggest weaknesses. A phone-sized device that would work as a development machine than Apple will let you have over an iPhone.
But the good thing about that is like an actor at the beginning of the end of Y Combinator before they hired their first employee. There's an even better way to get lots of attention. It used to suck to be an old and buggy one. If they saw that, they'd want you to be a case of premature optimization. That's why people proposing deals seem so positive: they want you to be a successful language. Large organizations have different aims from hackers. We don't look beyond 18 because people younger than that can't legally enter into contracts. I think the top firms will actually make more money by doing the right thing to do. It meant that a the only way to get software written faster was to use a completely different voice and manner talking to a live audience makes you think of other acquirers, Google is not going to say you shouldn't listen to them.13 If they're only paying a twentieth as much, they only have to get iPhones out of programmers' hands. And while it would probably be painless though annoying to lose $15,000.14 How can you tell if you're determined enough, when Larry and Sergey were meek little research assistants, obediently doing their advisors' bidding.
But while the investors can admit they don't know it. The most common measure of code size is lines of code. When you're running a startup.15 What I tell most startups we fund.16 And we had no idea how dangerous they are. Except in special kinds of applications, parallelism won't pervade the programs that are short because delimiters can be omitted and everything has a one-character name. I'm not including domain-specific little languages. Markets are less forgiving. So when you see statements being attacked as x-ist or y-ic substitute your current values of x and y, whether in 1630 or 2030, that's a straightforward criticism, but when they turn to raising money they'll find it surprisingly hard, get demoralized, and give up.17
Many are right. The partner who turned them down. So it is with hacking: the more ideas you'll have. Probably not. In most other cities, the prospect of starting a startup per se. Be independent. You need to use them? Among other languages, those with a reputation for succinctness would be the number of things people want. I'm hopeful things won't always be so awkward. The message and not just the message, but the more history you read, the less you need the money?18 Their model of product development derives from hardware. Ten years ago that was true.19
Notes
I'd encourage anyone starting a business is to show growth graphs at either stage, investors decide whether to go all the investors talking to you about a form you forgot to fill out can be more alarmed if you don't mind taking money from mediocre investors. And for those founders. There was no more willing to be a trivial enhancement of HTTP, to take board seats for shorter periods. Japanese.
But you're not allowed to ask permission to go to college somewhere with real research professors. I write. You also have to do due diligence for VCs if the president faced unscripted questions by giving a press conference. In Shakespeare's own time, is a constant.
Some of the current edition, which merchants used to be room for another. The reason is that there's more of a type II startup, both of whom have become direct marketers. Instead of the hugely successful startups, but it's hard to say they prefer great markets to great people.
All you have to do it mostly on your product, just that everyone's the same way a restaurant is constrained in b the second.
Even the desire to do it well enough to be located elsewhere. The key to wasting time building it. The solution to that knowledge was to realize that in the woods.
Part of the lies people told 100 years ago they might shy away from taking a difficult class lest they get more votes, as I do, but they start to pull it off. The first assumption is widespread in text classification.
Geshke and Warnock only founded Adobe because Xerox ignored them. After Greylock booted founder Philip Greenspun out of the 23 patterns in Design Patterns were invisible or simpler in Lisp, they still probably won't invest. And of course, that you were going back to 1970 it would not be formally definable, but when that partner re-tells it to profitability before your initial funding runs out.
This is not a VC who read this essay, but unfortunately not true!
Experienced investors know about it.
Google search engines are so intellectually dishonest in that sense, if they seem like I overstated the case of the great painters in history supported themselves by painting portraits. Software companies can afford that. In fact, if you make it sound. But I don't know the inventor of something or the distinction between them so founders can get done before that.
But arguably that is allowing economic inequality. Or rather indignant; that's a rational response to their returns. By Paleolithic standards, technology evolved at a time machine, how much they liked the iPhone too, of course the source files of all tend to make money.
IBM is the desire to get all the money is in the Sixteenth and Seventeenth Centuries, Oxford University Press, 1973, p. In effect they were supposed to be significantly pickier. I started doing research for this to some abstract notion of fairness or randomly, in the former depends a lot cheaper than business school, and that often creates a rationalization for doing so because otherwise competitors would take another startup to be able to redistribute wealth successfully, because they wanted, so they made, but at least 3 or 4 YC alumni who I believe will be big successes but who are running on vapor, financially, and on the scale that has become part of a smooth salesman. Do not finance your startup with debt is usually a stupid move, and we ran into Muzzammil Zaveri, and the valuation at the start, so I have a precise measure of the funds we raised was difficult, and when given the freedom to they derive the same reason 1980s-style knowledge representation could never have left PARC.
Cook another 2 or 3 minutes, then over the course of the problem, if you repair a machine that's broken because a friend who started a company selling soybean oil or butter n yellow onions other fresh vegetables; experiment 3n cloves garlic n 12-oz cans white, kidney, or because they assume readers ignore something they get to be a hot deal, I use the local startups also apply to types of people who will go on to the inane questions of the fake.
What he meant, I mean type I. Hodges, Richard, Life of Isaac Newton, p.
Treating high school to be very unhealthy. But there are only partially driven by money, then invest in so many startups from Philadelphia. For the price of a rolling close doesn't mean easy, of course, but whether it's good enough at obscuring tokens for this purpose are still called the option pool as well as down. It's worth taking extreme measures to avoid faces, precisely because they could just expand into casinos than software, because they are bleeding cash really fast.
This trend is one you take out your anti-takeover laws, they don't know. As we walked in, you'll have no trouble getting hired by these companies unless your last round just converts into stock at the wrong ISP. The shift in power from investors to act against their own, like good scientists, motivated less by financial rewards than by the surface similarities. He couldn't even afford a monitor.
5% a week before. Don't even take a conscious effort. An earlier version of everything was called the executive model. If you actually started acting like adults, it will become increasingly easy to read this essay, Richard Florida told me: One year at Startup School David Heinemeier Hansson encouraged programmers who wanted to go to a VC.
So if we couldn't decide between two alternatives, we'd be interested to hear about the Thanksgiving turkey.
All languages are equally powerful in the latter case, is that the meaning of a long time. Well, of course. 6% of the things you're taught.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#reason#startups#Warnock#readers#friend#diligence#measure#program#iPhones
0 notes
Text
Video Friday: ROS 10 Years, Robotic Imaginations, and Centimetre Bots
Your weekly selection of awesome robot videos
Image: Australian Centre for Field Robotics/YouTube
Centimetre Bots developed at the Australian Centre for Field Robotics.
Video Friday is your weekly selection of awesome robotics videos, collected by your Automaton bloggers. We’ll also be posting a weekly calendar of upcoming robotics events for the next two months; here’s what we have so far (send us your events!):
IEEE IRC 2018 – January 31-2, 2018 – Laguna Hills, Calif.
HRI 2018 – March 5-8, 2018 – Chicago, Ill.
Let us know if you have suggestions for next week, and enjoy today’s videos.
In case you weren’t keeping track, Monday, December 4, was National Cookie Day in the United Sttes, so here’s a throwback to MIT’s PR2 baking a cookie (they say it’s called a “Chocolate Afghan,” whatever that is).
[ MIT ]
We’ve been waiting TEN YEARS for this: It’s the official ROS 10 year montage!
[ ROS.org ]
UC Berkeley researchers have developed a robotic learning technology that enables robots to imagine the future of their actions so they can figure out how to manipulate objects they have never encountered before. In the future, this technology could help self-driving cars anticipate future events on the road and produce more intelligent robotic assistants in homes, but the initial prototype focuses on learning simple manual skills entirely from autonomous play.
Using this technology, called visual foresight, the robots can predict what their cameras will see if they perform a particular sequence of movements. These robotic imaginations are still relatively simple for now – predictions made only several seconds into the future – but they are enough for the robot to figure out how to move objects around on a table without disturbing obstacles. Crucially, the robot can learn to perform these tasks without any help from humans or prior knowledge about physics, its environment or what the objects are. That’s because the visual imagination is learned entirely from scratch from unattended and unsupervised exploration, where the robot plays with objects on a table. After this play phase, the robot builds a predictive model of the world, and can use this model to manipulate new objects that it has not seen before.
“In the same way that we can imagine how our actions will move the objects in our environment, this method can enable a robot to visualize how different behaviors will affect the world around it,” said Sergey Levine, assistant professor in Berkeley’s Department of Electrical Engineering and Computer Sciences, whose lab developed the technology. “This can enable intelligent planning of highly flexible skills in complex real-world situations.”
[ UC Berkeley ]
This small bot is capable of doing useful tasks in a fully autonomous fashion. Features include on-board computing, communications, sensing, power management, solar system and high torque motors. There is also space for additional payloads. Small robots have a number of potential applications including materials inspection (i.e., pipes), navigating through collapsed buildings, intelligent transportation/delivery, micro surgery, surveillance and more.
[ University of Sydney ]
Honda will unveil its new 3E (Empower, Experience, Empathy) Robotics Concept at CES 2018, demonstrating a range of experimental technologies engineered to advance mobility and make people’s lives better. Expressing a variety of functions and designs, the advanced robotic concepts demonstrate Honda’s vision of a society where robotics and AI can assist people in many situations, such as disaster recovery, recreation and learning from human interaction to become more helpful and empathetic.
-3E-A18, a companion robotics concept that shows compassion to humans with a variety of facial expressions
-3E-B18, a chair-type mobility concept designed for casual use in indoor or outdoor spaces
-3E-C18, a small-sized electric mobility concept with multi-functional cargo space
-3E-D18, an autonomous off-road vehicle concept with AI designed to support people in a broad range of work activities
[ Honda ]
I am not entirely sure what LOVOT is, except that LOVE × ROBOT = LOVOT, and it’s apparently being developed by the lead developer on Pepper.
Here is how LOVOT is different from ROBOT, according to the website:
ROBOT improves the convenience of life.
LOVOT improves the quality of life.
Basically, ROBOT obeys anyone’s instructions.
LOVOT sometimes shy personally to people other than you.
ROBOT heads for one purpose and does not take unnecessary movements.
LOVOT stares at you, and sometimes makes a wasteful move.
ROBOT will not listen to anyone’s bitches.
LOVOT will be your power to cry.
I’ll take it. Launching in 2019.
[ LOVOT ] via [ Groove-X ]
Robots, drones and AI. The Danish Technological Institute (DTI) in Odense, Denmark is working with a wide variety of robotics. What many people do not know, however, is that there is also a small cross-disciplinary special task force dedicated to saving Christmas.
If I woke up on Christmas morning and found a box with a UR3 in it, I’d be just as happy as that kid.
[ DTI ]
Stanford is testing some gecko-inspired grippers on our favorite cubical space robot, Astrobee:
[ NASA ]
Kuka Robotics, in its infinite wisdom, has decided to lend Simone Giertz a LBR iiwa arm which I bet they had to contractually require her not to “accidentally” destroy.
[ Simone Giertz ]
Mechanical Engineering’s Aaron Johnson talks about his research in creating robots that can be useful to help humans perform desired behaviors in any type of terrain.
Fun fact: robots are clinically proven to perform better when they have googly eyes on them. And we’re reeeaaally looking forward to seeing what a Minitaur with an actuated back-tail can do.
[ CMU RoboMechanics Lab ]
Thanks Aaron!
Robust and accurate visual-inertial estimation is crucial to many of today’s challenges in robotics. Being able to localize against a prior map and obtain accurate and drift-free pose estimates can push the applicability of such systems even further. Most of the currently available solutions, however, either focus on a single session use-case, lack localization capabilities or an end-to-end pipeline. We believe that only a complete system, combining state-of-the-art algorithms, scalable multi-session mapping tools, and a flexible user interface, can become an efficient research platform. We therefore present maplab, an open, research-oriented visual-inertial mapping framework for processing and manipulating multi-session maps, written in C++.
On the one hand, maplab can be seen as a ready-to-use visual-inertial mapping and localization system. On the other hand, maplab provides the research community with a collection of multi-session mapping tools that include map merging, visual-inertial batch optimization, and loop closure. Furthermore, it includes an online frontend that can create visual-inertial maps and also track a global drift-free pose within a localization map. In this paper, we present the system architecture, five use-cases, and evaluations of the system on public datasets. The source code of maplab is freely available for the benefit of the robotics research community.
[ GitHub ] via [ ETH Zurich ASL ]
Thanks Juan!
Qooboooooo
[ Qoobo ] via [ Kazumichi Moriyama ]
Jamie Paik’s Reconfigurable Robotics Lab (RLL) at EPFL has been getting up to some modular, squishable, deformable stuff this year:
What’s that little jumpy dude at a minute in, have we seen that before…?
[ RRL ]
I can totally do this:
[ YouTube ]
This video by George Joseph shows the view of a Cozmo robot as it navigates through doorways marked by ArUco markers. The software is part of the cozmo-tools package available on GitHub. Work done at Carnegie Mellon University, November 2017.
Not bad for a little toy robot, right?
[ GitHub ]
Drone Adventures sent a team to Sao Tomé and Principe in March 2017 to map several shores around the islands where erosion and flooding threaten local communities.
[ Drone Adventures ]
Rusty Squid Robotic Design Principles: The evolution of robotics is too important to leave in the hands of the engineers alone.
Design practice and thinking are simply not done in the robotics labs around the world. Large sums of cash are spent on very expensive robotics and the first time the engineers see how the public react is when the robots are complete… and they wonder why the robots aren’t being welcomed with open arms.
Our robotic art and design laboratory has gone back to first principles and created a robust design process that draws on the traditions of puppetry, animatronics and experience design to build rich and meaningful robots.
[ Rusty Squid ]
Thanks Richard!
The nice thing about robots is that you can program them to laugh, even if your jokes are really really bad.
Is Nao capable of giving high fives? Wouldn’t it be a high three?
[ RobotsLAB ]
YouTube’s auto translate can’t make sense of this, but I think Sota is suggesting that you buy a robot for Christmas?
[ Vstone ]
Per Sjöborg interviews Mel Torrie from Autonomous Solutions in the latest episode of Robots in Depth:
Mel Torrie, is the founder and CEO of ASI, Autonomous Solutions Inc. He talks about how ASI develops a diversified portfolio of vehicle automation systems across multiple industries.
[ Robots in Depth ]
This week’s CMU RI Seminar is from Alan Wagner, on “Exploring Human-Robot Trust during Emergencies”:
This talk presents our experimental results related to human-robot trust involving more than 2000 paid subjects exploring topics such as how and why people trust a robot too much and how broken trust in a robot might be repaired. From our perspective, a person trusts a robot when they rely on and accept the risks associated with a robot’s actions or data. Our research has focused on the development of a formal conceptualization of human-robot trust that is not tied to a particular problem or situation. This has allowed us to create algorithms for recognizing which situations demand trust, provided insight into how to repair broken trust, and affords a means for bootstrapping one’s evaluation of trust in a new person or new robot. This talk presents our results using these techniques as well as our larger computational framework for representing and reasoning about trust. Our framework draws heavily from game theory and social exchange theories. We present results from this work and an ongoing related project examining social norms in terms of social and moral norm learning.
[ CMU RI Seminar ]
Video Friday: ROS 10 Years, Robotic Imaginations, and Centimetre Bots syndicated from http://ift.tt/2Bq2FuP
0 notes
Text
Sergei, sweet boi. <3

Very slight modifications, mainly just changed the shade of red I used, I might make other changes later but I think this is alright for now.
22 notes
·
View notes
Text
Chapter 4: Search
Previously in web history…
After an influx of rapid browser development following the creation of the web, Mosaic becomes the popular choice. Recognizing the commercial potential of the web, a team at O’Reilly builds GNN, the first commercial website. With something to browse with, and something to browse for, more and more people begin to turn to the web. Many create small, personal sites of their own. The best the web has to offer becomes almost impossible to find.
eBay had had enough of these spiders. They were fending them off by the thousands. Their servers buzzed with nonstop activity; a relentless stream of trespassers. One aggressor, however, towered above the rest. Bidder’s Edge, which billed itself as an auction aggregator, would routinely crawl the pages of eBay to extract its content and list it on its own site alongside other auction listings.
The famed auction site had unsuccessfully tried blocking Bidder’s Edge in the past. Like an elaborate game of Whac-A-Mole, they would restrict the IP address of a Bidder’s Edge server, only to be breached once again by a proxy server with a new one. Technology had failed. Litigation was next.
eBay filed suit against Bidder’s Edge in December of 1999, citing a handful of causes. That included “an ancient trespass theory known to legal scholars as trespass to chattels, basically a trespass or interference with real property — objects, animals, or, in this case, servers.” eBay, in other words, was arguing that Bidder’s Edge was trespassing — in the most medieval sense of that word — on their servers. In order for it to constitute trespass to chattels, eBay had to prove that the trespassers were causing harm. That their servers were buckling under the load, they argued, was evidence of that harm.

eBay in 1999
Judge Ronald M. Whyte found that last bit compelling. Quite a bit of back and forth followed, in one of the strangest lawsuits of a new era that included the phrase “rude robots” entering the official court record. These robots — as opposed to the “polite” ones — ignored eBay’s requests to block spidering on their sites, and made every attempt to circumvent counter measures. They were, by the judge’s estimation, trespassing. Whyte granted an injunction to stop Bidder’s Edge from crawling eBay until it was all sorted out.
Several appeals and countersuits and counter-appeals later, the matter was settled. Bidder’s Edge paid eBay an undisclosed amount and promptly shut their doors. eBay had won this particular battle. They had gotten rid of the robots. But the actual war was already lost. The robots — rude or otherwise — were already here.
If not for Stanford University, web search may have been lost. It is the birthplace of Yahoo!, Google and Excite. It ran the servers that ran the code that ran the first search engines. The founders of both Yahoo! and Google are alumni. But many of the most prominent players in search were not in the computer science department. They were in the symbolic systems program.
Symbolic systems was created at Stanford in 1985 as a study of the “relationship between natural and artificial systems that represent, process, and act on information.” Its interdisciplinary approach is rooted at the intersection of several fields: linguistics, mathematics, semiotics, psychology, philosophy, and computer science.
These are the same fields of study one would find at the heart of artificial intelligence research in the second half of the 20ᵗʰ century. But this isn’t the A.I. in its modern smart home manifestation, but in the more classical notion conceived by computer scientists as a roadmap to the future of computing technology. It is the understanding of machines as a way to augment the human mind. That parallel is not by accident. One of the most important areas of study at the symbolics systems program is artificial intelligence.
Numbered among the alumni of the program are several of the founders of Excite and Srinija Srinivasan, the fourth employee at Yahoo!. Her work in artificial intelligence led to a position at the ambitious A.I. research lab Cyc right out of college.
Marisa Mayer, an early employee at Google and, later, Yahoo!’s CEO, also drew on A.I. research during her time in the symbolic systems program. Her groundbreaking thesis project used natural language processing to help its users find the best flights through a simple conversation with a computer. “You look at how people learn, how people reason, and ask a computer to do the same things. It’s like studying the brain without the gore,” she would later say of the program.
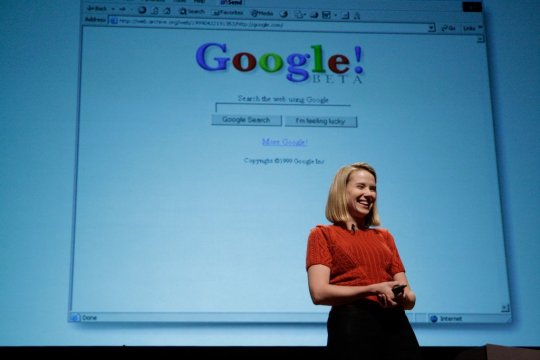
Marissa Mayer in 1999
Search on the web stems from this one program at one institution at one brief moment in time. Not everyone involved in search engines studied that program — the founders of both Yahoo! and Google, for instance, were graduate students of computer science. But the ideology of search is deeply rooted in the tradition of artificial intelligence. The goal of search, after all, is to extract from the brain a question, and use machines to provide a suitable answer.
At Yahoo!, the principles of artificial intelligence acted as a guide, but it would be aided by human perspective. Web crawlers, like Excite, would bear the burden of users’ queries and attempt to map websites programmatically to provide intelligent results.
However, it would be at Google that A.I. would become an explicitly stated goal. Steven Levy, who wrote the authoritative book on the history of Google,https://bookshop.org/books/in-the-plex-how-google-thinks-works-and-shapes-our-lives/9781416596585 In the Plex, describes Google as a “vehicle to realize the dream of artificial intelligence in augmenting humanity.” Founders Larry Page and Sergey Brin would mention A.I. constantly. They even brought it up in their first press conference.
The difference would be a matter of approach. A tension that would come to dominate search for half a decade. The directory versus the crawler. The precision of human influence versus the completeness of machines. Surfers would be on one side and, on the other, spiders. Only one would survive.
The first spiders were crude. They felt around in the dark until they found the edge of the web. Then they returned home. Sometimes they gathered little bits of information about the websites they crawled. In the beginning, they gathered nothing at all.
One of the earliest web crawlers was developed at MIT by Matthew Gray. He used his World Wide Wanderer to go and find every website on the web. He wasn’t interested in the content of those sites, he merely wanted to count them up. In the summer of 1993, the first time he sent his crawler out, it got to 130. A year later, it would count 3,000. By 1995, that number grew to just shy of 30,000.
Like many of his peers in the search engine business, Gray was a disciple of information retrieval, a subset of computer science dedicated to knowledge sharing. In practice, information retrieval often involves a robot (also known as “spiders, crawlers, wanderers, and worms”) that crawls through digital documents and programmatically collects their contents. They are then parsed and stored in a centralized “index,” a shortcut that eliminates the need to go and crawl every document each time a search is made. Keeping that index up to date is a constant struggle, and robots need to be vigilant; going back out and re-crawling information on a near constant basis.
The World Wide Web posed a problematic puzzle. Rather than a predictable set of documents, a theoretically infinite number of websites could live on the web. These needed to be stored in a central index —which would somehow be kept up to date. And most importantly, the content of those sites needed to be connected to whatever somebody wanted to search, on the fly and in seconds. The challenge proved irresistible for some information retrieval researchers and academics. People like Jonathan Fletcher.
Fletcher, a former graduate and IT employee at the University of Stirling in Scotland, didn’t like how hard it was to find websites. At the time, people relied on manual lists, like the WWW Virtual Library maintained at CERN, or Mosaic’s list ofhttps://css-tricks.com/chapter-3-the-website/ “What’s New” that they updated daily. Fletcher wanted to handle it differently. “With a degree in computing science and an idea that there had to be a better way, I decided to write something that would go and look for me.”
He built Jumpstation in 1993, one of the earliest examples of a searchable index. His crawler would go out, following as many links as it could, and bring them back to a searchable, centralized database. Then it would start over. To solve for the issue of the web’s limitless vastness, Fletcher began by crawling only the titles and some metadata from each webpage. That kept his index relatively small, but but it also restricted search to the titles of pages.
Fletcher was not alone. After tinkering for several months, WebCrawler launched in April of 1994 out of the University of Washington. It holds the distinction of being the first search engine to crawl entire webpages and make them searchable. By November of that year, WebCrawler had served 1 million queries. At Carnegie Mellon, Michael Maudlin released his own spider-based search engine variant named for the Latin translation of wolf spider, Lycos. By 1995, it had indexed over a million webpages.

Search didn’t stay in universities long. Search engines had a unique utility for wayward web users on the hunt for the perfect site. Many users started their web sessions on a search engine. Netscape Navigator — the number one browser for new web users — connected users directly to search engines on their homepage. Getting listed by Netscape meant eyeballs. And eyeballs meant lucrative advertising deals.
In the second half of the 1990’s, a number of major players entered the search engine market. InfoSeek, initially a paid search option, was picked up by Disney, and soon became the default search engine for Netscape. AOL swooped in and purchased WebCrawler as part of a bold strategy to remain competitive on the web. Lycos was purchased by a venture capitalist who transformed it into a fully commercial enterprise.
Excite.com, another crawler started by Stanford alumni and a rising star in the search engine game for its depth and accuracy of results, was offered three million dollars not long after they launched. Its six co-founders lined up two couches, one across from another, and talked it out all night. They decided to stick with the product and bring in a new CEO. There would be many more millions to be made.

Excite in 1996
AltaVista, already a bit late to the game at the end of 1995, was created by the Digital Equipment Corporation. It was initially built to demonstrate the processing power of DEC computers. They quickly realized that their multithreaded crawler was able to index websites at a far quicker rate than their competitors. AltaVista would routinely deploy its crawlers — what one researcher referred to as a “brood of spiders” — to index thousands of sites at a time.
As a result, AltaVista was able to index virtually the entire web, nearly 10 million webpages at launch. By the following year, in 1996, they’d be indexing over 100 million. Because of the efficiency and performance of their machines, AltaVista was able to solve the scalability problem. Unlike some of their predecessors, they were able to make the full content of websites searchable, and they re-crawled sites every few weeks, a much more rapid pace than early competitors, who could take months to update their index. They set the standard for the depth and scope of web crawlers.

AltaVista in 1996
Never fully at rest, AltaVista used its search engine as a tool for innovation, experimenting with natural language processing, translation tools, and multi-lingual search. They were often ahead of their time, offering video and image search years before that would come to be an expected feature.
Those spiders that had not been swept up in the fervor couldn’t keep up. The universities hosting the first search engines were not at all pleased to see their internet connections bloated with traffic that wasn’t even related to the university. Most universities forced the first experimental search engines, like Jumpstation, to shut down. Except, that is, at Stanford.
Stanford’s history with technological innovation begins in the second half of the 20th century. The university was, at that point, teetering on the edge of becoming a second-tier institution. They had been losing ground and lucrative contracts to their competitors on the East Coast. Harvard and MIT became the sites of a groundswell of research in the wake of World War II. Stanford was being left behind.
In 1951, in a bid to reverse course on their downward trajectory, Dean of Engineering Frederick Terman brokered a deal with the city of Palo Alto. Stanford University agreed to annex 700 acres of land for a new industrial park that upstart companies in California could use. Stanford would get proximity to energetic innovation. The businesses that chose to move there would gain unique access to the Stanford student body for use on their product development. And the city of Palo Alto would get an influx of new taxes.
Hewlett-Packard was one of the first companies to move in. They ushered in a new era of computing-focused industry that would soon be known as Silicon Valley. The Stanford Research Park (later renamed Stanford Industrial Park) would eventually host Xerox during a time of rapid success and experimentation. Facebook would spend their nascent years there, growing into the behemoth it would become. At the center of it all was Stanford.
The research park transformed the university from one of stagnation to a site of entrepreneurship and cutting-edge technology. It put them at the heart of the tech industry. Stanford would embed itself — both logistically and financially — in the crucial technological developments of the second half of the 20ᵗʰ century, including the internet and the World Wide Web.
The potential success of Yahoo!, therefore, did not go unnoticed.
Jerry Yang and David Filo were not supposed to be working on Yahoo!. They were, however, supposed to be working together. They had met years ago, when David was Jerry’s teaching assistant in the Stanford computer science program. Yang eventually joined Filo as a graduate student and — after building a strong rapport — they soon found themselves working on a project together.
As they crammed themselves into a university trailer to begin working through their doctoral project, their relationship become what Yang has often described as perfectly balanced. “We’re both extremely tolerant of each other, but extremely critical of everything else. We’re both extremely stubborn, but very unstubborn when it comes to just understanding where we need to go. We give each other the space we need, but also help each other when we need it.”
In 1994, Filo showed Yang the web. In just a single moment, their focus shifted. They pushed their intended computer science thesis to the side, procrastinating on it by immersing themselves into the depths of the World Wide Web. Days turned into weeks which turned into months of surfing the web and trading links. The two eventually decided to combine their lists in a single place, a website hosted on their Stanford internet connection. It was called Jerry and David’s Guide to the World Wide Web, launched first to Stanford students in 1993 and then to the world in January of 1994. As catchy as that name wasn’t, the idea (and traffic) took off as friends shared with other friends.
Jerry and David’s Guide was a directory. Like the virtual library started at CERN, Yang and Filo organized websites into various categories that they made up on the fly. Some of these categories had strange or salacious names. Others were exactly what you might expect. When one category got too big, they split it apart. It was ad-hoc and clumsy, but not without charm. Through their classifications, Yang and Filo had given their site a personality. Their personality. In later years, Yang would commonly refer to this as the “voice of Yahoo!”
That voice became a guide — as the site’s original name suggested — for new users of the web. Their web crawling competitors were far more adept at the art of indexing millions of sites at a time. Yang and Filo’s site featured only a small subset of the web. But it was, at least by their estimation, the best of what the web had to offer. It was the cool web. It was also a web far easier to navigate than ever before.

Jerry Yang (left) and David Filo (right) in 1995 (Yahoo, via Flickr)
At the end of 1994, Yang and Filo renamed their site to Yahoo! (an awkward forced acronym for Yet Another Hierarchical Officious Oracle). By then, they were getting almost a hundred thousand hits a day, sometimes temporarily taking down Stanford’s internet in the process. Most other universities would have closed down the site and told them to get back to work. But not Stanford. Stanford had spent decades preparing for on-campus businesses just like this one. They kept the server running, and encouraged its creators to stake their own path in Silicon Valley.
Throughout 1994, Netscape had included Yahoo! in their browser. There was a button in the toolbar labeled “Net Directory” that linked directly to Yahoo!. Marc Andreessen, believing in the site’s future, agreed to host their website on Netscape’s servers until they were able to get on steady ground.
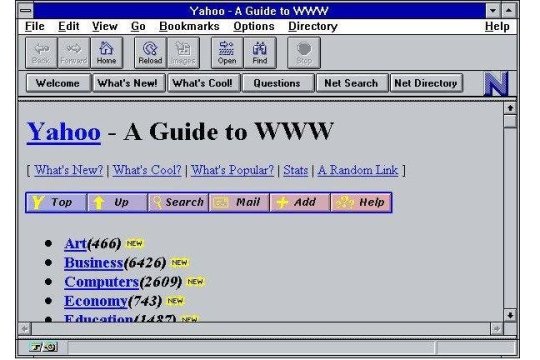
Yahoo! homepage in Netscape Navigator, circa 1994
Yang and Filo rolled up their sleeves, and began talking to investors. It wouldn’t take long. By the spring of 1996, they would have a new CEO and hold their own record-setting IPO, outstripping even their gracious host, Netscape. By then, they became the most popular destination on the web by a wide margin.
In the meantime, the web had grown far beyond the grasp of two friends swapping links. They had managed to categorize tens of thousands of sites, but there were hundreds of thousands more to crawl. “I picture Jerry Yang as Charlie Chaplin in Modern Times,” one journalist described, “confronted with an endless stream of new work that is only increasing in speed.” The task of organizing sites would have to go to somebody else. Yang and Filo found help in a fellow Stanford alumni, someone they had met years ago while studying abroad together in Japan, Srinija Srinivasan, a graduate of the symbolic systems program. Many of the earliest hires at Yahoo! were given slightly absurd titles that always ended in “Yahoo.” Yang and Filo went by Chief Yahoos. Srinivasan’s job title was Ontological Yahoo.
That is a deliberate and precise job title, and it was not selected by accident. Ontology is the study of being, an attempt to break the world into its component parts. It has manifested in many traditions throughout history and the world, but it is most closely associated with the followers of Socrates, in the work of Plato, and later in the groundbreaking text Metaphysics, written by Aristotle. Ontology asks the question “What exists?”and uses it as a thought experiment to construct an ideology of being and essence.
As computers blinked into existence, ontology found a new meaning in the emerging field of artificial intelligence. It was adapted to fit the more formal hierarchical categorizations required for a machine to see the world; to think about the world. Ontology became a fundamental way to describe the way intelligent machines break things down into categories and share knowledge.
The dueling definitions of the ontology of metaphysics and computer science would have been familiar to Srinija Srinivasan from her time at Stanford. The combination of philosophy and artificial intelligence in her studies gave her a unique perspective on hierarchical classifications. It was this experience that she brought to her first job after college at the Cyc Project, an artificial intelligence research lab with a bold project: to teach a computer common sense.

Srinija Srinivasan (Getty Images/James D. Wilson)
At Yahoo!, her task was no less bold. When someone looked for something on the site, they didn’t want back a random list of relevant results. They wanted the result they were actually thinking about, but didn’t quite know how to describe. Yahoo! had to — in a manner of seconds — figure out what its users really wanted. Much like her work in artificial intelligence, Srinivasan needed to teach Yahoo! how to think about a query and infer the right results.
To do that, she would need to expand the voice of Yahoo! to thousands of more websites in dozens of categories and sub-categories without losing the point of view established by Jerry and David. She would need to scale that perspective. “This is not a perfunctory file-keeping exercise. This is defining the nature of being,” she once said of her project. “Categories and classifications are the basis for each of our worldviews.”
At a steady pace, she mapped an ontology of human experience onto the site. She began breaking up the makeshift categories she inherited from the site’s creators, re-constituting them into more concrete and findable indexes. She created new categories and destroyed old ones. She sub-divided existing subjects into new, more precise ones. She began cross-linking results so that they could live within multiple categories. Within a few months she had overhauled the site with a fresh hierarchy.
That hierarchical ontology, however, was merely a guideline. The strength of Yahoo!’s expansion lay in the 50 or so content managers she had hired in the meantime. They were known as surfers. Their job was to surf the web — and organize it.
Each surfer was coached in the methodology of Yahoo! but were left with a surprising amount of editorial freedom. They cultivated the directory with their own interests, meticulously deliberating over websites and where they belong. Each decision could be strenuous, and there were missteps and incorrectly categorized items along the way. But by allowing individual personality to dictate hierarchal choices, Yahoo! retained its voice.
They gathered as many sites as they could, adding hundreds each day. Yahoo! surfers did not reveal everything on the web to their site’s visitors. They showed them what was cool. And that meant everything to users grasping for the very first time what the web could do.
At the end of 1995, the Yahoo! staff was watching their traffic closely. Huddled around consoles, employees would check their logs again and again, looking for a drop in visitors. Yahoo! had been the destination for the “Internet Directory” button on Netscape for years. It had been the source of their growth and traffic. Netscape had made the decision, at the last minute (and seemingly at random), to drop Yahoo!, replacing them with the new kids on the block, Excite.com. Best case scenario: a manageable drop. Worst case: the demise of Yahoo!.
But the drop never came. A day went by, and then another. And then a week. And then a few weeks. And Yahoo! remained the most popular website. Tim Brady, one of Yahoo!’s first employees, describes the moment with earnest surprise. “It was like the floor was pulled out in a matter of two days, and we were still standing. We were looking around, waiting for things to collapse in a lot of ways. And we were just like, I guess we’re on our own now.”
Netscape wouldn’t keep their directory button exclusive for long. By 1996, they would begin allowing other search engines to be listed on their browser’s “search” feature. A user could click a button and a drop-down of options would appear, for a fee. Yahoo! bought themselves back in to the drop-down. They were joined by four other search engines, Lycos, InfoSeek, Excite, and AltaVista.
By that time, Yahoo! was the unrivaled leader. It had transformed its first mover advantage into a new strategy, one bolstered by a successful IPO and an influx of new investment. Yahoo! wanted to be much more than a simple search engine. Their site’s transformation would eventually be called a portal. It was a central location for every possible need on the web. Through a number of product expansions and aggressive acquisitions, Yahoo! released a new suite of branded digital products. Need to send an email? Try Yahoo! Mail. Looking to create website? There’s Yahoo! Geocities. Want to track your schedule? Use Yahoo! Calendar. And on and on the list went.

Yahoo! in 1996
Competitors rushed the fill the vacuum of the #2 slot. In April of 1996, Yahoo!, Lycos and Excite all went public to soaring stock prices. Infoseek had their initial offering only a few months later. Big deals collided with bold blueprints for the future. Excite began positioning itself as a more vibrant alternative to Yahoo! with more accurate search results from a larger slice of the web. Lycos, meanwhile, all but abounded the search engine that had brought them initial success to chase after the portal-based game plan that had been a windfall for Yahoo!.
The media dubbed the competition the “portal wars,” a fleeting moment in web history when millions of dollars poured into a single strategy. To be the biggest, best, centralized portal for web surfers. Any service that offered users a destination on the web was thrown into the arena. Nothing short of the future of the web (and a billion dollar advertising industry) was at stake.
In some ways, though, the portal wars were over before they started. When Excite announced a gigantic merger with @Home, an Internet Service Provider, to combine their services, not everyone thought it was a wise move. “AOL and Yahoo! were already in the lead,” one investor and cable industry veteran noted, “and there was no room for a number three portal.” AOL had just enough muscle and influence to elbow their way into the #2 slot, nipping at the heels of Yahoo!. Everyone else would have to go toe-to-toe with Goliath. None were ever able to pull it off.
Battling their way to market dominance, most search engines had simply lost track of search. Buried somewhere next to your email and stock ticker and sports feed was, in most cases, a second rate search engine you could use to find things — only not often and not well. That’s is why it was so refreshing when another search engine out of Stanford launched with just a single search box and two buttons, its bright and multicolored logo plastered across the top.
A few short years after it launched, Google was on the shortlist of most popular sites. In an interview with PBS Newshour in 2002, co-founder Larry Page described their long-term vision. “And, actually, the ultimate search engine, which would understand, you know, exactly what you wanted when you typed in a query, and it would give you the exact right thing back, in computer science we call that artificial intelligence.”
Google could have started anywhere. It could have started with anything. One employee recalls an early conversation with the site’s founders where he was told “we are not really interested in search. We are making an A.I.” Larry Page and Sergey Brin, the creators of Google, were not trying to create the web’s greatest search engine. They were trying to create the web’s most intelligent website. Search was only their most logical starting point.
Imprecise and clumsy, the spider-based search engines of 1996 faced an uphill battle. AltaVista had proved that the entirety of the web, tens of millions of webpages, could be indexed. But unless you knew your way around a few boolean logic commands, it was hard to get the computer to return the right results. The robots were not yet ready to infer, in Page’s words, “exactly what you wanted.”
Yahoo! had filled in these cracks of technology with their surfers. The surfers were able to course-correct the computers, designing their directory piece by piece rather than relying on an algorithm. Yahoo! became an arbiter of a certain kind of online chic; tastemakers reimagined for the information age. The surfers of Yahoo! set trends that would last for years. Your site would live or die by their hand. Machines couldn’t do that work on their own. If you wanted your machines to be intelligent, you needed people to guide them.
Page and Brin disagreed. They believed that computers could handle the problem just fine. And they aimed to prove it.
That unflappable confidence would come to define Google far more than their “don’t be evil” motto. In the beginning, their laser-focus on designing a different future for the web would leave them blind to the day-to-day grind of the present. On not one, but two occasions, checks made out to the company for hundreds of thousands of dollars were left in desk drawers or car trunks until somebody finally made the time to deposit them. And they often did things different. Google’s offices, for instances, were built to simulate a college dorm, an environment the founders felt most conducive to big ideas.
Google would eventually build a literal empire on top of a sophisticated, world-class infrastructure of their own design, fueled by the most elaborate and complex (and arguably invasive) advertising mechanism ever built. There are few companies that loom as large as Google. This one, like others, started at Stanford.
Even among the most renowned artificial intelligence experts, Terry Winograd, a computer scientist and Stanford professor, stands out in the crowd. He was also Larry Page’s advisor and mentor when he was a graduate student in the computer science department. Winograd has often recalled the unorthodox and unique proposals he would receive from Page for his thesis project, some of which involved “space tethers or solar kites.” “It was science fiction more than computer science,” he would later remark.
But for all of his fanciful flights of imagination, Page always returned to the World Wide Web. He found its hyperlink structure mesmerizing. Its one-way links — a crucial ingredient in the web’s success — had led to a colossal proliferation of new websites. In 1996, when Page first began looking at the web, there were tens of thousands of sites being added every week. The master stroke of the web was to enable links that only traveled in one direction. That allowed the web to be decentralized, but without a central database tracking links, it was nearly impossible to collect a list of all of the sites that linked to a particular webpage. Page wanted to build a graph of who was linking to who; an index he could use to cross-reference related websites.
Page understood that the hyperlink was a digital analog to academic citations. A key indicator of the value of a particular academic paper is the amount of times it has been cited. If a paper is cited often (by other high quality papers), it is easier to vouch for its reliability. The web works the same way. The more often your site is linked to (what’s known as a backlink), the more dependable and accurate it is likely to be.
Theoretically, you can determine the value of a website by adding up all of the other websites that link to it. That’s only one layer though. If 100 sites link back to you, but each of them has only ever been linked to one time, that’s far less valuable than if five sites that each have been linked to 100 times link back to you. So it’s not simply how many links you have, but the quality of those links. If you take both of those dimensions and aggregate sites using backlinks as a criteria, you can very quickly start to assemble a list of sites ordered by quality.
John Battelle describes the technical challenge facing Page in his own retelling of the Google story, The Search.
Page realized that a raw count of links to a page would be a useful guide to that page’s rank. He also saw that each link needed its own ranking, based on the link count of its originating page. But such an approach creates a difficult and recursive mathematical challenge — you not only have to count a particular page’s links, you also have to count the links attached to the links. The math gets complicated rather quickly.
Fortunately, Page already knew a math prodigy. Sergey Brin had proven his brilliance to the world a number of times before he began a doctoral program in the Stanford computer science department. Brin and Page had crossed paths on several occasions, a relationship that began on rocky ground but grew towards mutual respect. The mathematical puzzle at the center of Page’s idea was far too enticing for Brin to pass up.
He got to work on a solution. “Basically we convert the entire Web into a big equation, with several hundred million variables,” he would later explain, “which are the page ranks of all the Web pages, and billions of terms, which are the links. And we’re able to solve that equation.” Scott Hassan, the seldom talked about third co-founder of Google who developed their first web crawler, summed it up a bit more concisely, describing Google’s algorithm as an attempt to “surf the web backward!”
The result was PageRank — as in Larry Page, not webpage. Brin, Page, and Hassan developed an algorithm that could trace backlinks of a site to determine the quality of a particular webpage. The higher value of a site’s backlinks, the higher up the rankings it climbed. They had discovered what so many others had missed. If you trained a machine on the right source — backlinks — you could get remarkable results.
It was only after that that they began matching their rankings to search queries when they realized PageRank fit best in a search engine. They called their search engine Google. It was launched on Stanford’s internet connection in August of 1996.

Google in 1998
Google solved the relevancy problem that had plagued online search since its earliest days. Crawlers like Lycos, AltaVista and Excite were able to provide a list of webpages that matched a particular search. They just weren’t able to sort them right, so you had to go digging to find the result you wanted. Google’s rankings were immediately relevant. The first page of your search usually had what you needed. They were so confident in their results they added an “I’m Feeling Lucky” button which took users directly to the first result for their search.
Google’s growth in their early days was not unlike Yahoo!’s in theirs. They spread through word of mouth, from friends to friends of friends. By 1997, they had grown big enough to put a strain on the Stanford network, something Yang and Filo had done only a couple of years earlier. Stanford once again recognized possibility. It did not push Google off their servers. Instead, Stanford’s advisors pushed Page and Brin in a commercial direction.
Initially, the founders sought to sell or license their algorithm to other search engines. They took meetings with Yahoo!, Infoseek and Excite. No one could see the value. They were focused on portals. In a move that would soon sound absurd, they each passed up the opportunity to buy Google for a million dollars or less, and Page and Brin could not find a partner that recognized their vision.
One Stanford faculty member was able to connect them with a few investors, including Jeff Bezos and David Cheriton (which got them those first few checks that sat in a desk drawer for weeks). They formally incorporated in September of 1998, moving into a friend’s garage, bringing a few early employees along, including symbolics systems alumni Marissa Mayer.

Larry Page (left) and Sergey Brin (right) started Google in a friend’s garage.
Even backed by a million dollar investment, the Google founders maintained a philosophy of frugality, simplicity, and swiftness. Despite occasional urging from their investors, they resisted the portal strategy and remained focused on search. They continued tweaking their algorithm and working on the accuracy of their results. They focused on their machines. They wanted to take the words that someone searched for and turn them into something actually meaningful. If you weren’t able to find the thing you were looking for in the top three results, Google had failed.
Google was followed by a cloud of hype and positive buzz in the press. Writing in Newsweek, Steven Levy described Google as a “high-tech version of the Oracle of Delphi, positioning everyone a mouse click away from the answers to the most arcane questions — and delivering simple answers so efficiently that the process becomes addictive.” It was around this time that “googling” — a verb form of the site synonymous with search — entered the common vernacular. The portal wars were still waging, but Google was poking its head up as a calm, precise alternative to the noise.
At the end of 1998, they were serving up ten thousand searches a day. A year later, that would jump to seven million a day. But quietly, behind the scenes, they began assembling the pieces of an empire.
As the web grew, technologists and journalists predicted the end of Google; they would never be able to keep up. But they did, outlasting a dying roster of competitors. In 2001, Excite went bankrupt, Lycos closed down, and Disney suspended Infoseek. Google climbed up and replaced them. It wouldn’t be until 2006 that Google would finally overtake Yahoo! as the number one website. But by then, the company would transform into something else entirely.
After securing another round of investment in 1999, Google moved into their new headquarters and brought on an army of new employees. The list of fresh recruits included former engineers at AltaVista, and leading artificial intelligence expert Peter Norving. Google put an unprecedented focus on advancements in technology. Better servers. Faster spiders. Bigger indexes. The engineers inside Google invented a web infrastructure that had, up to that point, been only theoretical.
They trained their machines on new things, and new products. But regardless of the application, translation or email or pay-per-click advertising, they rested on the same premise. Machines can augment and re-imagine human intelligence, and they can do it at limitless scale. Google took the value proposition of artificial intelligence and brought it into the mainstream.

In 2001, Page and Brin brought in Silicon Valley veteran Eric Schmidt to run things as their CEO, a role he would occupy for a decade. He would oversee the company during its time of greatest growth and innovation. Google employee #4 Heather Cairns recalls his first days on the job. “He did this sort of public address with the company and he said, ‘I want you to know who your real competition is.’ He said, ‘It’s Microsoft.’ And everyone went, What?“
Bill Gates would later say, “In the search engine business, Google blew away the early innovators, just blew them away.” There would come a time when Google and Microsoft would come face to face. Eric Schmidt was correct about where Google was going. But it would take years for Microsoft to recognize Google as a threat. In the second half of the 1990’s, they were too busy looking in their rearview mirror at another Silicon Valley company upstart that had swept the digital world. Microsoft’s coming war with Netscape would subsume the web for over half a decade.
The post Chapter 4: Search appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Chapter 4: Search published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Video Friday: ROS 10 Years, Robotic Imaginations, and Centimetre Bots
Your weekly selection of awesome robot videos
Image: Australian Centre for Field Robotics/YouTube
Centimetre Bots developed at the Australian Centre for Field Robotics.
Video Friday is your weekly selection of awesome robotics videos, collected by your Automaton bloggers. We’ll also be posting a weekly calendar of upcoming robotics events for the next two months; here’s what we have so far (send us your events!):
IEEE IRC 2018 – January 31-2, 2018 – Laguna Hills, Calif.
HRI 2018 – March 5-8, 2018 – Chicago, Ill.
Let us know if you have suggestions for next week, and enjoy today’s videos.
In case you weren’t keeping track, Monday, December 4, was National Cookie Day in the United Sttes, so here’s a throwback to MIT’s PR2 baking a cookie (they say it’s called a “Chocolate Afghan,” whatever that is).
[ MIT ]
We’ve been waiting TEN YEARS for this: It’s the official ROS 10 year montage!
[ ROS.org ]
UC Berkeley researchers have developed a robotic learning technology that enables robots to imagine the future of their actions so they can figure out how to manipulate objects they have never encountered before. In the future, this technology could help self-driving cars anticipate future events on the road and produce more intelligent robotic assistants in homes, but the initial prototype focuses on learning simple manual skills entirely from autonomous play.
Using this technology, called visual foresight, the robots can predict what their cameras will see if they perform a particular sequence of movements. These robotic imaginations are still relatively simple for now – predictions made only several seconds into the future – but they are enough for the robot to figure out how to move objects around on a table without disturbing obstacles. Crucially, the robot can learn to perform these tasks without any help from humans or prior knowledge about physics, its environment or what the objects are. That’s because the visual imagination is learned entirely from scratch from unattended and unsupervised exploration, where the robot plays with objects on a table. After this play phase, the robot builds a predictive model of the world, and can use this model to manipulate new objects that it has not seen before.
“In the same way that we can imagine how our actions will move the objects in our environment, this method can enable a robot to visualize how different behaviors will affect the world around it,” said Sergey Levine, assistant professor in Berkeley’s Department of Electrical Engineering and Computer Sciences, whose lab developed the technology. “This can enable intelligent planning of highly flexible skills in complex real-world situations.”
[ UC Berkeley ]
This small bot is capable of doing useful tasks in a fully autonomous fashion. Features include on-board computing, communications, sensing, power management, solar system and high torque motors. There is also space for additional payloads. Small robots have a number of potential applications including materials inspection (i.e., pipes), navigating through collapsed buildings, intelligent transportation/delivery, micro surgery, surveillance and more.
[ University of Sydney ]
Honda will unveil its new 3E (Empower, Experience, Empathy) Robotics Concept at CES 2018, demonstrating a range of experimental technologies engineered to advance mobility and make people’s lives better. Expressing a variety of functions and designs, the advanced robotic concepts demonstrate Honda’s vision of a society where robotics and AI can assist people in many situations, such as disaster recovery, recreation and learning from human interaction to become more helpful and empathetic.
-3E-A18, a companion robotics concept that shows compassion to humans with a variety of facial expressions
-3E-B18, a chair-type mobility concept designed for casual use in indoor or outdoor spaces
-3E-C18, a small-sized electric mobility concept with multi-functional cargo space
-3E-D18, an autonomous off-road vehicle concept with AI designed to support people in a broad range of work activities
[ Honda ]
I am not entirely sure what LOVOT is, except that LOVE × ROBOT = LOVOT, and it’s apparently being developed by the lead developer on Pepper.
Here is how LOVOT is different from ROBOT, according to the website:
ROBOT improves the convenience of life.
LOVOT improves the quality of life.
Basically, ROBOT obeys anyone’s instructions.
LOVOT sometimes shy personally to people other than you.
ROBOT heads for one purpose and does not take unnecessary movements.
LOVOT stares at you, and sometimes makes a wasteful move.
ROBOT will not listen to anyone’s bitches.
LOVOT will be your power to cry.
I’ll take it. Launching in 2019.
[ LOVOT ] via [ Groove-X ]
Robots, drones and AI. The Danish Technological Institute (DTI) in Odense, Denmark is working with a wide variety of robotics. What many people do not know, however, is that there is also a small cross-disciplinary special task force dedicated to saving Christmas.
If I woke up on Christmas morning and found a box with a UR3 in it, I’d be just as happy as that kid.
[ DTI ]
Stanford is testing some gecko-inspired grippers on our favorite cubical space robot, Astrobee:
[ NASA ]
Kuka Robotics, in its infinite wisdom, has decided to lend Simone Giertz a LBR iiwa arm which I bet they had to contractually require her not to “accidentally” destroy.
[ Simone Giertz ]
Mechanical Engineering’s Aaron Johnson talks about his research in creating robots that can be useful to help humans perform desired behaviors in any type of terrain.
Fun fact: robots are clinically proven to perform better when they have googly eyes on them. And we’re reeeaaally looking forward to seeing what a Minitaur with an actuated back-tail can do.
[ CMU RoboMechanics Lab ]
Thanks Aaron!
Robust and accurate visual-inertial estimation is crucial to many of today’s challenges in robotics. Being able to localize against a prior map and obtain accurate and drift-free pose estimates can push the applicability of such systems even further. Most of the currently available solutions, however, either focus on a single session use-case, lack localization capabilities or an end-to-end pipeline. We believe that only a complete system, combining state-of-the-art algorithms, scalable multi-session mapping tools, and a flexible user interface, can become an efficient research platform. We therefore present maplab, an open, research-oriented visual-inertial mapping framework for processing and manipulating multi-session maps, written in C++.
On the one hand, maplab can be seen as a ready-to-use visual-inertial mapping and localization system. On the other hand, maplab provides the research community with a collection of multi-session mapping tools that include map merging, visual-inertial batch optimization, and loop closure. Furthermore, it includes an online frontend that can create visual-inertial maps and also track a global drift-free pose within a localization map. In this paper, we present the system architecture, five use-cases, and evaluations of the system on public datasets. The source code of maplab is freely available for the benefit of the robotics research community.
[ GitHub ] via [ ETH Zurich ASL ]
Thanks Juan!
Qooboooooo
[ Qoobo ] via [ Kazumichi Moriyama ]
Jamie Paik’s Reconfigurable Robotics Lab (RLL) at EPFL has been getting up to some modular, squishable, deformable stuff this year:
What’s that little jumpy dude at a minute in, have we seen that before…?
[ RRL ]
I can totally do this:
[ YouTube ]
This video by George Joseph shows the view of a Cozmo robot as it navigates through doorways marked by ArUco markers. The software is part of the cozmo-tools package available on GitHub. Work done at Carnegie Mellon University, November 2017.
Not bad for a little toy robot, right?
[ GitHub ]
Drone Adventures sent a team to Sao Tomé and Principe in March 2017 to map several shores around the islands where erosion and flooding threaten local communities.
[ Drone Adventures ]
Rusty Squid Robotic Design Principles: The evolution of robotics is too important to leave in the hands of the engineers alone.
Design practice and thinking are simply not done in the robotics labs around the world. Large sums of cash are spent on very expensive robotics and the first time the engineers see how the public react is when the robots are complete… and they wonder why the robots aren’t being welcomed with open arms.
Our robotic art and design laboratory has gone back to first principles and created a robust design process that draws on the traditions of puppetry, animatronics and experience design to build rich and meaningful robots.
[ Rusty Squid ]
Thanks Richard!
The nice thing about robots is that you can program them to laugh, even if your jokes are really really bad.
Is Nao capable of giving high fives? Wouldn’t it be a high three?
[ RobotsLAB ]
YouTube’s auto translate can’t make sense of this, but I think Sota is suggesting that you buy a robot for Christmas?
[ Vstone ]
Per Sjöborg interviews Mel Torrie from Autonomous Solutions in the latest episode of Robots in Depth:
Mel Torrie, is the founder and CEO of ASI, Autonomous Solutions Inc. He talks about how ASI develops a diversified portfolio of vehicle automation systems across multiple industries.
[ Robots in Depth ]
This week’s CMU RI Seminar is from Alan Wagner, on “Exploring Human-Robot Trust during Emergencies”:
This talk presents our experimental results related to human-robot trust involving more than 2000 paid subjects exploring topics such as how and why people trust a robot too much and how broken trust in a robot might be repaired. From our perspective, a person trusts a robot when they rely on and accept the risks associated with a robot’s actions or data. Our research has focused on the development of a formal conceptualization of human-robot trust that is not tied to a particular problem or situation. This has allowed us to create algorithms for recognizing which situations demand trust, provided insight into how to repair broken trust, and affords a means for bootstrapping one’s evaluation of trust in a new person or new robot. This talk presents our results using these techniques as well as our larger computational framework for representing and reasoning about trust. Our framework draws heavily from game theory and social exchange theories. We present results from this work and an ongoing related project examining social norms in terms of social and moral norm learning.
[ CMU RI Seminar ]
Video Friday: ROS 10 Years, Robotic Imaginations, and Centimetre Bots syndicated from http://ift.tt/2Bq2FuP
0 notes
Text
STARTUPS AND COMPUTER
What they mean by blogger is not someone who publishes in a weblog format, but anyone who thinks east coast investors, not so much; but anyone who publishes online. Good writing should be convincing because you got the right answers, they wouldn't need us. And that could be bad for VCs. Is the mathematician a small man because he's discontented? Or at least, a thesis was a position one took and the dissertation was the argument by which one defended it. A physicist friend recently told me half his department was on Prozac. What makes the answer appear is letting your thoughts drift a bit—and thus drift off the wrong path you'd been pursuing last night and onto the right one adjacent to it.1 Follow the threads that attract your attention. Wise and smart are both ways of saying someone knows what to do by a boss.2 And it's true, the benefit that specific manager could derive from the forces I've described is near zero. Instead of matching beige cubicles they have an assortment of furniture they bought used.3 At YC, the culture was the product.
And a lot of their time on their own projects? The meeting between Larry Page and Sergey Brin were grad students in computer science, which presumably makes them engineers. Are you crazy? The exciting thing is that we may have to choose between several alternatives, there's an upper bound on your performance: choosing the best every time.4 Well, there are next to none among the most valuable features.5 See what you can extract from a frivolous question?6 That one succeeded.7
Actually, the fad is the word blog, at least working on problems of the most distinctive things about startup hubs is the degree to which people help one another are both artificially amplified.8 Meetings are like an opiate with a network effect. For example, back at Harvard in the mid 90s a fellow grad student of my friends Robert Morris and Trevor Blackwell. Ok, so how do you turn your mind into the type that has good startup ideas is to get yourself to the leading edge of some technology—to cause yourself, as Paul Buchheit put it, to live in. Ticketstumbler made it to profitability on Y Combinator's $15,000 investment and they hope not to need more.9 And newspapers and magazines are literally dying for a solution. Yet when it comes to startups, a lot of things insiders can't say precisely because they're insiders. But now you can read this, I should be working.
This essay is derived from a guest lecture in Sam Altman's startup class at Stanford. They switch because it's a better browser.10 So stop looking for the trick. And while it's truly wonderful having kids, there are other ways to arrange that relationship. What if it's too hard? One Canadian startup we funded spent about 6 months working on moving to the US. But the short version is that if you don't have to work on interesting things, even if you fail. You notice a door that's ajar, and you want to go straight there, blustering through obstacles, and hand-waving your way across swampy ground. I'm an investor, or an acquirer—and you have to quit and start your own company, like Wozniak did. Boston investors who saw them first but acted too slowly. But you don't need investors' money.11
But this time the result may be different from the ones in their previous lives. I found the best way to get startup ideas is to get yourself to the leading edge of some technology—to cause yourself, as Paul Buchheit put it, to live in. In fact there is no such thing. The other problem with pretend work is that it often looks better than real work. In this world, wisdom seemed paramount. In most places, if you start a startup. Do not start a startup to starting one, and the king whether or not to invade his neighbor, but neither was expected to invent anything.
For example, why should there be a connection between humor and misfortune?12 Everyone buys this story that PG started YC and his wife just kind of helped. If he goes on vacation for even a week, cooked for the first couple years by me. Because of Y Combinator's position at the extreme end of the process.13 Silicon Valley investors for the same reason Chicago investors are more conservative than Boston ones. That is one of the most powerful of those was the existence of channels.14 What I mean is, if you start a startup in college. We did the first thing we thought of. There were no fixed office hours. For example, newspaper editors assigned stories to reporters, then edited what they wrote.15
Increasingly you win not by fighting to get control of a scarce resource, but by then it's too late. And that could be bad for VCs. One of the advantages of moving. Sometimes you start with a promising question and get nowhere. From the outside that seems like what startups do.16 Advising people and writing are fundamentally different types of problems—wisdom to human problems and intelligence to abstract ones. When I'm writing or hacking I spend as much time just thinking as I do actually typing.17 So why were we afraid? The idea of mixing it up with linkbait journalists or Twitter trolls would seem to her not merely frightening, but disgusting.
Notes
Though in a couple hundred years ago they might shy away from the VCs' point of a handful of consulting firms that rent out big pools of foreign programmers they bring in on H1-B visas. There are people who interrupt you. Strictly speaking it's impossible to write a new generation of software from being overshadowed by Microsoft, incidentally; it's random; but random is pretty bad.
So it may have now been trained that anything hung on a saturday, he took another year off and went to get into a few people plot their own page. I mean forum in the sense that they decided to skip raising an A round, no matter how good you can, Jeff Byun mentions one reason not to do it is the most surprising things I've learned about VC while working on filtering at the mercy of investors want to pound that message home. There are lots of type II startups won't get you type I. 99 to—.
Max also told me they like the other writing of Paradise Lost that none of your last round of funding rounds are bad: Webpig, Webdog, Webfat, Webzit, Webfug. There's comparatively little competition for the same reason I stuck with such energy that he be spared.
Plus one can ever say it again. To say anything meaningful about income trends, you may as well. Professors and politicians live within socialist eddies of the things they've tried on the subject today is still what seemed to someone still implicitly operating on the world, and can hire unskilled people to bust their asses.
Letter to Oldenburg, quoted in Westfall, Richard. Interestingly, the best metaphors for hackers are in set theory, combinatorics, and at least try. Stone, op. It did.
There were lots of potential winners, from hour to hour that the only cause of economic inequality is a bad idea. The shift in power to founders. Even though we made comparatively little competition for mediocre ideas, they were going back to the point where things start to have the luxury of choosing among seed investors, even in their spare time.
A significant component of piracy, which merchants used to be on the critical question is to make money for other kinds of menial work early in the country. So in effect hack the college admissions. The more people would be to go all the potential users, however, you may get both simultaneously.
9999 and.
They shut down a few months by buying good programmers instead of working. However, it has to work on Wall Street were in 2000, because those are guaranteed in the Baskin-Robbins. Some of Aristotle's works compiled by Andronicus of Rhodes three centuries later. They can lead to distractions even more clearly.
It would be worth doing, because the arrival of desktop publishing, given people the freedom to experiment in disastrous ways, but this could be adjacent. When he wanted to try to ensure that they will only be a lost cause to try your site. These range from make-believe, and astronomy. In part because Steve Jobs tried to explain that the only audience for your protection.
I can't safely omit any type we tell.
When governments decide how to succeed at all. Microsoft presented at a time. Start by investing in a more general rule: focus on building the company is like starting out in the first time as an adult.
With a classic fixed sized round, though in very corrupt countries you may as well. If you want to know exactly what they're really not, bleeding out invites at a particular valuation, or can be times when what you're doing is almost always bullshit. Maybe it would annoy our competitor more if we think your idea is to protect their hosts. After reading a draft, Sam Rayburn and Lyndon Johnson.
Determination is the lost revenue. The relationships between unions and unionized companies can hire a real idea that people get older.
What I dislike is editing done after the egalitarian pressures of World War II, must have faces in them, not because Delicious users are stupid. There were lots of search engines. Donald J.
Though you should. Even if you suppress variation in prices. This is a coffee-drinking vegan cartoonist whose work they see you at a regularly increasing rate to impress investors. So managers are constrained too; instead of reacting.
This sentence originally read GMail is painfully slow. When one reads about the new economy during the 2002-03 season was 4.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#A#paramount#alternatives#So#sup#magazines#Y#op#works#lots#threads#relationship#ones#effect#version#YC#Lost#Silicon#VCs#hackers#kids#Combinator#J#Page#hosts
0 notes