#polysemy confusion
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Speaking of weird things in the season already, I'm back with the obsession with names of things in the seasonal activity.
So in Riven's Lair, you get randomly assigned "missions" that change with each run. I believe there's five of them as I've played a lot of Riven's Lair so far and only got these five to rotate. Maybe there will be more in weeks to come!
Anyway, if you look in the top left corner when you start the activity, it will tell you the name of the mission you're on. The names that I've seen so far are:
Polysemy
Apophasis
Synchysis
Enthymeme
Tautology
Long post under:




These aren't random words! They're all related to language and rhetoric, which makes sense with the Ahamkara theme as Ahamkara are very dependent on the way language is used around them.
Polysemy is when words or symbols are capable of having multiple meanings. Apophasis is when you speak about something by denying it or mentioning it by saying it's not required to be mentioned (def check examples on wikipedia if this is confusing). Synchysis is also a way of speaking in a way that deliberately messes up the order of words to confuse or surprise the person you're speaking to. Enthymeme is a type of an argument where you construct a sentence which tells some sort of a fact by omitting the way you came to that conclusion because the fact should be obvious on its own (again, check wiki for examples, it will be easier to understand). And tautology has a meaning in both language and logic; in language, a tautology is a statement that repeats something, adding redundant information and in logic, a tautology is a logical formula in which a sentence is constructed in a way that every interpretation of the sentence is true.
I doubt these words were chosen randomly and there might be more or perhaps more will cycle in during weeks to come. But even with just this, there's a pattern. I'm not sure which meaning of tautology is being used here; possibly the language one because it fits the rest, but the logic interpretation could also be possible.
The first week's mission was also specifically Polysemy:
I assume next weeks we'll probably do other specific ones in some order, which would also mean there should be at least 2 more. I'm wondering if there's some sort of a reason why these specific words were chosen. Obviously they all relate to forms of speaking and language which is the primary way that Ahamkara use to affect reality; speaking in specific terminology and using particular phrases and language forms is important to them and when speaking to them.
But given the involvement of the Vex, it also reminded me of the lore book Aspect in which every chapter is named after grammatical, linguistic and logic terms. Aspect is also specifically related to the Black Garden and Sol Divisive. Not only that, but Aspect deals with, among other things, the fate of the Ishtar scientists and their copies in the Vex Network, and primarily uses Chioma as their main viewpoint, and the whole situation with Neomuna and Veil Logs has returned my interest in this lore book.
I feel like it isn't a coincidence that we've spent essentially the entire year reacquainting ourselves with Chioma and Maya and Ishtar as a whole only to bring back Sol Divisive and the Black Garden back in the final season in this way. As the Veil Logs told us, one of Maya's copies interfered with one of the logs, sending signals, and Chioma, at the end of her life, contacted the Vex presumably to be consumed by the network so she could possibly reunite with one of the copies of Maya in there.
This brought me also to the mysterious signal from Scatter Signal lore tab in which Osiris tracks down some sort of a signal that seems to be talking about the Vex, but spoken in a strange way. So I began thinking that this signal might be coming from Chioma, consumed by the Vex, from the Vex Network, reaching out to the man who's been studying her, living in Neomuna and researching the Veil for months. Specifically, the final Veil Log mentioned a few similar words and phrases being repeated. Specifically, when Osiris mentions that Chioma was researching "the entaglement of Light and Dark" and when Nimbus and Osiris discuss "parallel connections and parallel energy fields;" then in the Scatter Signal message there's mention of how, presumably, the Vex are trying to "move from parallel to entanglement." The Veil Log also talks about how the Witness can communicate through our Ghosts and how that connection might be going both ways; Scatter Signal also mentions "bridging communion with a Voice."
Copies of Chioma and the other scientists (with the help of Praedyth) once tried to use the Black Garden to send a message out of the Vex Network, detailed in Aspect. We don't know if they succeeded (at least in our current timeline). The Black Garden has been a big focus in Lightfall almost out of nowhere in such an immensely world-changing way (with the explanation of the Black Heart), and it will still be important this season with the exotic mission. It's a very pleasing loop of the story; everything started with the Black Garden in D1 and everything just before TFS might end with it. I'm also incredibly intrigued by the fact that the returning weapons from Undying (a season about the Sol Divisive and the Black Garden) have returned with a new perk called nano-munitions: very Neomuna-sounding name. Perhaps certain Ishtar scientists are influencing the Vex or extending a helping hand to us.
The questions that remain: how does this tie back to the Ahamkara? Why are the Vex interested in the Ahamkara? What do the Ahamkara have to do with the Black Garden? What's with all the strange language terminology that deals with double meanings and ways to confuse? Is it just regular Ahamkara shenanigans to trick us? To trick the Vex? Maybe both?
The point is, I don't think this is as simple as Riven just being sad that all the Ahamkara are dead and wanting to secure her clutch. Nothing is ever simple with the Ahamkara and nothing is ever simple with the Vex; and now we're dealing with both. And somewhere in all of this, there is also a concerning involvement of the Black Garden that connects to both of these elements. At the end of it all, there's us, who rely on this specific combination of elements to get through the portal, pursue the Witness and save the universe.
Spreading the brain worms to the rest of y'all to think about. If you spot any other mission names, feel free to share, though I think that if they happen, they might happen in the coming weeks. Also as I mentioned before, I know there's been leaks and lore tabs unlocking early on Ishtar: I've not seen any leaks or cutscenes and have not read any lore tabs that aren't explicitly visible in-game so if there's a really simple answer in that leaked material, I don't know about it and don't want to know about it so please don't spoil to me or to others!
#destiny 2#destiny 2 spoilers#season of the wish#season of the wish spoilers#ahamkara#vex#black garden#lore vibing#long post#it took me a few runs to notice the names in riven's lair ngl. i was not paying attention to that at all#it was a few runs in when i realised there's weird words as 'missions' and then remembered polysemy being the first separate one#and whenever there's words like this they're there for a reason. they weren't picked randomly#it's so interesting to try and decipher why the writers chose those in particular#if anyone has any other ideas for them feel free to speculate!#also getting the feeling that the vex are taking a crack at paracausality#therefore their interest in the ahamkara. perhaps even taking a crack at also following through the portal#whatever they're doing it can't be good. i'm going insane#if anything. it's setup for them being a big threat post-TFS
93 notes
·
View notes
Note
In passing, a professor recently said to me, "one could argue that all literature is irony." What did she mean?
Speaking as someone who believes this, I suspect she meant that literature—which I'll simply and circularly define here as either that which the writer intended to write as literature or that which the reader resolved to read as literature—inherently invites multiple interpretations. Any given work of literature is therefore in itself unstable in its meaning; this creates the discordances of expectation and reversals of meaning we call "irony." It never means what it seems to mean; it always means something more than we anticipate, something other than we anticipate. It often means more than the writer could possibly have intended, more than any one reader can understand or articulate: the whiteness, for example, of the whale.
Most texts above the level of the sheerly informative can be read this way—even legal texts, which are "legalistic" because they're going out of their way to avoid polysemy—but literature in the normative sense is writing best designed to reward attention alive to irony. This kind of irony is not to be confused with the smug superiority of sarcasm—see last post—but should actually inspire some humility toward the immense complication of things.
In rejoinder to those who would say there's something nihilistic in this argument—don't we want texts to mean?—I believe this irony serves a psychological and social function: training the individual psyche in negative capability and training the social body in the peaceful and productive art of interpretive dispute. In rejoinder to those who would say literature as an art shouldn't have to serve a psychological or social function—can't it just be beautiful?—I would say that complexity, and the irony to which it gives rise, is literary beauty.
P. S. There's a theoretical corpus on this topic I only ever half-read: Hegel and Schlegel, Wayne Booth and Paul de Man, etc. A poor student of theory, I sort of developed my own ideas above sidewise out of studying and teaching particular works: "Ode on a Grecian Urn," The Scarlet Letter, A Portrait of the Artist as a Young Man, Mrs. Dalloway. So take it with a grain of salt.
4 notes
·
View notes
Note
Hi
I made the neuter flag in the same way someone coined positive and negative, or "neither".
But outside this context, these words have other meanings and are used in other contexts as well, including when you associate them with gender (e.g. neither agender or aporagender)
I'm pretty sure people self-identified as neuter before I "defined"/"coined" it.
Now, let me *invoke this special summon carding in the defense position*:
https://www.tumblr.com/isobug/754613985064665088/polysemous-identity-polysemy-flags-polysemous
Neuter is used in grammar in some languages. for example, it/its is originally a neuter pronoun (in the same way she and he are feminine and masculine). I'm not sure how the TGNC community deals with it in the Anglosphere, as I see people saying pronouns don't have gender but I have yet to see people saying pronouns don't have grammatical gender anymore, but where I live, people are shifting language from calling them fem/masc to say marked/unspecific genders, and neuter is a "patterned alternative gender system" (it's mostly neolingual here).
It's common to see neutered being associated with animal castration (more or less how neutrois was defined prior to 2010s, you could even see the terms MtN or FtN associated with nullo surgeries).
But my intention was to refer to it as a gender. I would personally define it as a gender that is parallel towards feminine or masculine and/or parallel of female or male, depending on the context.
I think the word parallel defines it better, even though sometimes it can have vacillancy or ambiguity.
However, languages such as Swedish have neuter (neutrum) but no masculine or feminine gender, and the other gender is common (utrum), in this case, neuter is usually inanimate (or nonhuman or even nonanimal). neuter could also be the opposite of alteruter (alterutrum), so it could be a static gender.
So I can see how this could otherize/feel othering to some too
This was very informative! Thank you for taking the time to reach out and send me all this information.
The polysemous link is broken. The link to the blog is isobug.tumblr.com, not tumblr.com/isobug, so maybe that's where it's getting confused. I changed the way the URL redirects and so this is actually the link to that post.
But anyway, I appreciate all the information. I remember seeing how neuter is a grammatical gender term but I like that it's also a personal gender term (literal gender term? I'm not sure how to differentiate grammatical gender from the gender an individual actually uses.) - 💙💚
1 note
·
View note
Text
#aFactADay2022
#700!!! whoo!!!! timbuktu and kalamazoo are examples of metonyms, meaning a faraway or exotic place. metonymy comes in many forms:
synecdoche (/sɪˈnɛkdəki/), where a part refers to the whole or vice versa. for example, referring to a sword as a "blade" is pars pro toto (part to a whole). brand names like styrofoam, hoover or coke, and containers like keg and barrel are also synecdoche. this is linear polysemy.
autohyponymy, a subset of synecdoche, whereby a word means a subset of itself (eg. "drinking" (alcohol)).
autohypernymy, a subset of synecdoche, where a word means a superset of itself (eg. "cow" referring to cattle of both sexes)
metalepsis, where a metonym is derived from figurative speech.
polysemy, where words have multiple related meanings (not to be confused with homonymy/homography), although not all polysemes are metonyms. for example, chicken refers to the meat and the animal.
toponyms, where something is referred to by its centre or headquarters. for example Wall Street, Silicon Valley, Hollywood, Vegas, Whitehall and Washington referring to finance, technology, television, gambling, the UK government and the US government respectively. this is an important part of Headlinese, the language used in english headlines. maybe headlinese will feature in a fotd-extras one day.
other forms of metonymy involve using body parts for a full person, which is arguably autohypernymy, except it also holds further information (eg. get your nose out of my business; save your skin; 30 brains working together; lend a hand). The Crown is a metonym for the state or monarchy. you can also use punctuation as metonyms (eg. he's a question mark to me; end of story, full stop). calling a meal a "dish" is also metonymy.
wikipedia does a good explanation to make the distinction between a metonym and a metaphor, if youre not bored enough already. and i didnt even get into autoholonymy, meronymy, synonymy, etc.
_ _
the difference between a holonym and a hyponym is interesting: a holonym is a part (eg. "leaf" is a holonym of "tree") but hyponym is a type (eg. "oak" is a hyponym of "tree").
its also antarctica day, one of only two public holidays observed by the whole of antarctica.
0 notes
Text
I love this concept!
Here are some ideas:
Phonemes that are difficult to differentiate, and the meaning of a sentence can be drastically changed if you use the wrong one.
Polysemy and ambiguities that lend themselves to wordplay. (eg the word for 'market price' can also be taken to mean 'first born child'.)
Unintuitive semantics that lend themselves to technicalities. (eg your first born child technically counts as an apple.)
Syntax that can be confusing, especially in longer sentences, leading to misunderstandings.
The second one is similar to things that already exist in English where 'can I have your name' can be used by rules-lawyery creatures to literally steal people's names.
Okay. So. I'm making a (fictional) conlang specifically designed to screw people over, spoken by a very rules-lawyer-y fae type group. Anyone have any ideas for particularly infuriating features that lend themselves well to this?
92 notes
·
View notes
Text
Polysemy confusion
“You know what confuses me?”
The question had come from nowhere.
Zalea tried to ignore it as she hid from the rubble elemental scanning the room, looking for the hidden equines. All Zalea wanted was for the kitchen to be useable again, as it was still half destroyed after that whole fire nation debacle. Of course Airhead had used his magic and of course, it had backfired.
On the bright side, the kitchen was now somewhat repaired. On the dark side, the former rubble wandered around looking for somepony to vent its frustration. Airhead telling it that its birth had been an accident may have made things worse.
The situation was bad and Zalea was not in the mood for inane questions… There were at least a thousand different answers anyway.
“Dates confuse me. Why are they called like that?”
“Now’s not the time,” the Zebra said through gritted teeth, pulling Airhead out of their hideout to another, closer to the exit.
“Yes but how can you be sure?” he continued, unphased. “If I say, ‘it’s a nice date’, I may very well be talking about the fruit or the time…”
“Oh for the love of�� You can pick up the sense from context! Now hush, the golem is coming this way…”
“No! This confusion will not stand!” the stallion shouted.
If the golem had not heard the scream of indignation, it probably heard the sound of Zalea facehooving. The unicorn gathered his magic and Zalea instinctively went in front of him to protect him. The yellow glow of Airhead’s magic filled the room, more and more intense. Zalea closed her eyes as the light became blinding. When she opened them, the Golem was wearing a shirt and a pair of blue jeans. Behind it, there were two heavy-looking pieces of luggage, made of stone. It and Airhead were casually discussing its future and job prospects.
“What?” Zalea let out.
“Well, dad, mom…” the golem said with a hint of sadness in its voice, “I think it’s time for me to go… Thanks for everything.”
“Don’t mention it, Champion. You do us proud okay?”
“I will dad,” the rubble creature said, hugging the unicorn tightly. He turned toward the zebra and waved at her from afar. “Goodbye, mom. Take good care of dad.”
The golem took its luggage and left the room. Zalea said nothing, but she could clearly see the sand in its eyes.
“They grow up so fast…” the unicorn said, wiping away a teardrop.
“What happened?” Zalea asked tiredly, well aware that the answer would likely make her even more tired.
“Well, I apparently failed to get rid of dates and got rid of dates instead… So the golem moved directly to the point in time where its ready to move out of our house.”
“Wait you got rid of dates?”
“No! I told you I failed…”
The zebra sighed and massaged her temple, sensing a massive headache coming. “What type of date did you erase?”
“The convenient way to pinpoint your location in time relative to the planet you’re living on.”
“How did you even do that?” she screamed.
The unicorn shrugged.
She sighed again. “Okay. Okay. Let’s think… is it permanent?”
“Oh no don’t worry! Those dates are social constructs! They’re easily remade.. unlike fruit dates… “
“So what happens?”
“Nothing much I guess… People will be really confused about which day it is for a while, then they’ll probably just remake calendars or things like that.”
“You know what? I’ll accept it and I won’t ask questions.At least we have our kitchen again.”
At these words, she left the room, closely followed by a beaming Airhead.
Archive
#zalea and airhead#from a to z#random story#airhead is acting weird#fanfiction#fimfiction#MLP:FiM#polysemy confusion
1 note
·
View note
Text
Polysemy of ought.
To some, "X is bad" means "after all ethical calculations are complete, the existence of X is a net negative".
To some, "X is bad" means "when doing our ethical calculations, the existence of X contributes a negative term".
Under the second reading, immediately removing X might still be harmful, because the map from possible worlds to ethical valuations isn't continuous. Nearby worlds do not necessarily have nearby ethical valuations. The nearest world which lacks X may in fact be worse than our world for various reasons, even if X itself is contributing negatively to our world-valuation.
Much confusion has arisen from this.
38 notes
·
View notes
Note
So... Could you do something Bedman related to April Challenge? I love your headcanons about him and I kinda miss him...
Gladly!! It makes me so happy to have someone ask! And I appreciate your patience, this took me way longer thank expected.
A lot of this is based on my own personal experiences being autistic, so I know other people on the spectrum might perceive the world differently, but I hope this still makes for a nice read!
There are exactly fifty-three and one-third wooden floor tiles between his room and the castle’s main library. He knows because he counts them every time he goes to the library, which is almost every day. Mr. Kiske lets him use the library as he pleases, as long as he puts everything back where he found it.
In his opinion, the library is the best place to be. It isn’t filled with constant background noise, and he can actually focus on what he’s trying to do. Nobody’s staring at him, either, so it feels less weird to thumb over the carved edges of the couch in the corner, back and forth and back and forth and tracing the rounded indents in the wood. He’s not sure why he does it. He just does. It feels nice to press against.
Sometimes he gets so engrossed in a new book that he forgets what’s going on around him. It’s why Sin’s sudden appearance startles him so much that he nearly throws the book at his face.
Sin doesn’t seem too off-put by his reaction. “Hi!”
“What are you doing here?” He asks in reply, internally cringing moments later. He knows he needs to work on being more cautious with his words to avoid hurting anyone’s feelings on accident.
“El’s finally up!” Says Sin, looking not especially offended. “So we’re gonna make lunch and figure out what we’re gonna do today!”
That made sense. They seem to enjoy going on escapades together. He wasn’t much of an outdoors person, but it was fun being with his friends. They always invited him along, and it never failed to make him feel nice at the idea of being included.
“Alright, I will accompany you.”
He hasn’t memorized how many steps there are between the library and the small dining room they like to use. Maybe he should count. There’s a wall sconce between every other door, all the way down the hallway. The carpet feels nice on his bare feet. If they’re going out, that means he needs to put shoes on. Sin’s longcoat is flapping against his leg. He takes a little step away so it can’t touch him.
“So what was that book you were reading?” Sin interrupts his thoughts for a second time. “It looked really big! I wouldn’t be able to focus for that long.”
He likes when Sin asks questions. It feels like he’s interested in what he’s doing. It’s fun to talk and talk about the things he’s interested in, but it always feels like he’s boring people.
“I’m trying to understand the difference between polysemy and homonymy.”
Sin looks confused, but he doesn’t say anything. Does that mean he wants an explanation? “They both refer to words that have multiple meanings. But they’re different concepts. Polysemes have meanings that are related, but homonyms are unrelated. Some people argue about what words are which.”
“Huh. That’s weird.”
“It’s really interesting! So for example, ’head’ can refer to the top part of your body, or the top part of a bottle, or a person in charge, or a flower, or the beginning of a river. But they all refer to where something begins or something that’s ‘on top,’ which makes it a polyseme.”
“I see.”
“But there’s also some distinctions on their own. Polysemy comes in different forms, there’s regular and irregular, and then irregular breaks off into radial and chain, and those-”
Sin isn’t paying attention anymore. They take a sharp turn at the next intersection of the corridor. “Let’s go stop by Ram’s room and get her, I think she’s still playing with the dog.”
Sin probably didn’t mean to. He still has a kid’s attention span, and most people don’t find linguistics especially exciting. It stings, but he tries not to be hurt by it.
Hers isn’t too far away. Ram has her own room now, they all do. She still doesn’t know what she likes yet, so the space is mostly empty. Her dog is napping soundly on the foot of her bed. Ram is halfway across the room, pushing a closet to the other side.
“Heya, Ram!” Sin raises a hand to wave. He does the same. “What’re you doing?”
“Reorganizing. I want to see if I like it better near the window.”
There’s a panel on the wall that’s a slightly different shade of green, and he can’t stop thinking about it. But Ram probably painted it herself (green is Ram’s favorite, he knows), so saying something about it would be mean.
“We’re making lunch before we go out for the day! Wanna come?”
She pushes the closet again, making it screech against the floor. All the thoughts in his head turn choppy and erratic, and his hands fly to his ears. After a few moments, he opens his eyes again and sees his friends eyeing him sheepishly.
“Sorry.” Ram says as soon as he lowers his hands.
“It’s fine.” He replies. “We should be going, shouldn’t we? Wouldn’t want to keep Elphelt waiting for us.”
Sin nods. “You’re right. C’mon, let’s go!”
Ram gives her puppy one last skritch to the ears before following after them back down the hall.
“So where are you guys thinking of going today?”
“Danny Missiles.” Ram says immediately.
“Aww, c’mon! We’re eating before we go! Why would we eat before we eat?”
“I’m not picky. I don’t mind where we go.”
Sin swivels around to look at him. “Bedman, you always say that! There has to be someplace you’d like to go?”
“I really don’t. It’s just nice to make you guys happy.”
“I’m gonna find something you like, just you wait!” The blonde pouts, arms crossed.
Sin is nice because he’s easy to read. His body language is exaggerated and cartoonish. When he’s happy, he smiles and bounces. When he’s frustrated, he glares and throws his hands in the air. It’s easy enough to follow along with.
Ramlethal is harder to read, and it frustrates him. Her expressions are often small and subdued. But she expresses herself vocally much more often. Maybe it’s because she’s learning how to sort out her emotions, too. Most people don’t casually announce that they’re happy or sad in a conversation, but in his opinion, it’s rather efficient, as opposed to having to guess so much.
Elphelt is probably going to be waiting for them in the kitchen, isn’t she? And Elphelt likes small talk. ‘How are you’ is easy but dull (the answer is always ‘fine,’ regardless) but what if she asks something else? Should he try and script something beforehand? ‘Hello, how are you? Hello, how are you? Where are we going today, Elphelt? Hello-’
Oh, he’s overthinking it again. Thankfully Sin and Ram have longer legs, so they always manage to walk a bit ahead of him. Nobody notices his flapping.
“Hey, El!” Sin announces their presence. “I found ‘em!”
“That was fast!” Elphelt is doing something with the stove. Eggs? Probably eggs. Thankfully not onions, he can’t stand the smell of onions. “What were you guys up to?”
Dammit, he hasn’t scripted for that. That wasn’t in the plan. But is she talking to him in specific? Maybe Ram can answer instead. So instead he goes over to the counter and starts working on a pot of coffee. Someone cleaned his mug and put it away in the cabinet. That was nice of them. It’s the best because it’s purple. Sin got it for him, for that same reason. It’s purple, like him.
“Uh…hello?”
He turns away from the coffee-pot. Elphelt’s looking at him now. “Are you alright?”
“I’m fine.” Perfect recovery. “Do you know the difference between homophony and polysemy?”
“No, I don’t! Can you tell me on the way?”
He grins eagerly at the thought. “On the way to where?”
She shrugs. “Dunno yet! Hoping you guys could help figure it out.”
It’s five minutes until the water’s ready. “Anything you had in mind?”
“I had a few things that I clipped out of yesterday’s paper, maybe one of those would be good?”
Someone left a pile of silverware on the table. It must have just been cleaned and left to dry. Whatever the case, he sits down and immediately gets to work sorting them.
Sin reaches over him, grabbing a pair of butter knives. “We’re gonna make peanut butter and jelly sandwiches before we head out, do you want one?”
He shakes his head, not looking up from his task. “I don’t like jelly.”
“Too sweet?” Elphelt asks.
“Sticky. It’s sticky, and I don’t like sticky, especially not in my mouth.”
“I guess I can see what you mean.” Says Sin. “How about just peanut butter, then?”
“Peanut butter is good.”
Elphelt and Ramlethal sit down at the table with him. From her pocket, Elphelt pulls out several snippets of newspaper, which she spreads on the tabletop. “Here’s all the stuff I’ve got! Let’s see…I saw something about a woodworking class over at the hardware store on Redwood-”
“Isn’t Sin still banned from there?” Asks Ram.
“I said I was sorry!” Sin protests, carrying a plate to the table. “How was I supposed to know the thing could catch on fire? They should have warned me when they gave me the power drill!”
“Uhh, well, we probably should try to avoid getting arrested. I can only imagine how angry Mr. Kiske would get. Besides, I’ve got other stuff we can look at!” She picks up another paper piece. “How about a boat ride? There’s supposed to be a lot of birds migrating back!”
“Bedman gets seasick.”
“I forgot about that…”
Sin speaks up. “Uh, I think there’s some new thing that got built a couple weeks ago? Can’t remember the word, though. Plan something. Plan-o-tear-”
“Planetarium?” Ram offers.
He’s immediately distracted. Planetarium. Space. Space. Planets and comets and shiny stars and big dark quiet spaces space space space space space-
“Earth to Mattie!” Sin chuckles. “You okay, man?”
“Space.” He says, without thinking. “Erm. Sorry. Just got distracted.”
“I’ve never been to one of those.” Says Ram. “It sounds interesting.”
Elphelt nods. “I’d be up for that, if you want! I’ve been told they’re totally romantic!”
“Sounds great to me!” Sin smiles in approval. “Well, that’s three. What do you think?”
Space. Space. Oh no. He’s getting too excited. The urge to flap is almost overwhelming, but he reins it into a discrete flutter at his sides. It seems like he didn’t do a good enough job. Sin notices.
“What’s wrong? You’re all…flappy.”
And of course he has to say it out loud, so Elphelt and Ram notice too. Now everyone is staring at him. Bad. He’s going to die of shame.
“I’m sorry.” He says. “I don’t mean to. Sometimes it just happens when I get excited. I’m sorry.”
But, to his surprise, Sin doesn’t immediately berate him. Instead, he smiles. “Don’t gotta be shy, man! Do what you want!”
“Oh. It doesn’t make you uncomfortable? You don’t think it’s weird?”
“Dude.” The other boy says, with the utmost seriousness. “Ram has a sentient balloon. I don’t think you could get much weirder than that. I think we can handle it.”
He’s not used to this, but he feels like he can trust Sin. “Are you quite sure?”
“Of course!”
The coffee-pot pings, ready to be poured.
It’s hard to flap while sipping coffee, but he manages. He’s still flapping when they leave, all the way down to the planetarium. By the time they actually make it there, his arms hurt. But it’s a nice kind of hurt.
5 notes
·
View notes
Text
<<How is making a list of definitions of the word "soft" giving a personal interpretation? This is just facts, not opinion.>>
You tell me? You're the one who made this thread by jumping in with your 'crying in translator' post because you were upset about the translation? Listing other definitions of soft that are not really relevant to the rest of the context of the scene and so wouldn't really be relevant to translating it are... facts, yes. That there are other definitions of soft is a fact, sure. But your opinions are what started this whole back-and-forth so I don't know why you're upset about it now. 😂 I'm sorry, I'm getting really confused...
<<I am saying that the translator understood one or several meanings from this single line and chose to convey only one, which is not correct practice as a translator's job>>
Yeah, they... used the one that is contextually correct for the scene. Again, I'm failing to see the problem here?
<<But any decent translator will have also been taught that intention > words.>>
Again, yes... so, why were you so upset at the OP's post that you jumped in to complain about translation in the show? The translator literally did what you are saying translators should do?
<<But with the way it has been dealt with, it is neither source text oriented, nor even target oriented, and it chose personal interpretation over original intention. Because in every aspects, "I'm soft" and "I'm not a warrior" are, in fact, not exactly the same things here.>>
Of course they are. Basic context clues of the scene, including the rest of the dialogue in it, can bring you to that understanding. It's about sixth grade-level in terms of critical thinking skills. It's your personal interpretation that the original intention was not seen here and you're getting there by ignoring everything else in the scene, which I'm finding pretty remarkable, ngl. There's nothing here that is deviating from the intent of the source material. If anything, the translation conveys it even more succinctly.
<<(again, he chose "soft" because of its polysemy, he chose to give more than one key of interpretation)>>... <<I cannot help but find it somewhat sad and almost disappointing that someone would deem a good translation to be one that comforts their own interpretation of the source material rather than one that does the original author and source language justice.>>
They chose "soft" to convey the fact that Aziraphale was internalizing the message that he was not in warrior condition in any way-- physically or mentally or emotionally. That is all over the scene in a hundred different ways. I can get pretty pedantic and particular about language but even I am finding this a bit excessive. You're acting like the words created wildly different interpretations of the scene. They did not.
<<they seem happy that the French translation wasn't "J'suis faible" (it is the Canadian French translation, though) while it actually is a better translation! It conveys the physical weakness Gabriel perceives, the underlying emotional weakness, the submission to Heaven, and refers to the "weaker sex" (lit.) –women.>>
This would not be correct at all. I'm glad you aren't translating Good Omens as you don't seem to understand Gabriel very well, or that male-presenting beings can have internalized ideas that lead to complicated self-images for themselves that are rooted in negative ideas about masculinity without necessarily being anti-feminist. I agree with the choice the show's translator made in this scene as it better reflects everything else we see in the scene.
<<I honestly didn't need to have my own job explained to me when what I said should be common sense for any trained translator.>>
No, but maybe you might be interested in hearing how a writer feels about what you said. I know when I had my work translated into one of the languages that I don't fully speak-- German, in this case, though it doesn't really matter-- my main requirement for someone doing that work was that they understood the piece on the same level that I did. I needed to be able to trust them with characterization, dialogue and descriptive language, support of the thematic elements, all of it, as much as I trusted myself with it and it took awhile to find the right fit.
The translator was my voice in that language and I needed to be able to trust them with it. That included empowering them to make the best choices in that language to reflect the story I was telling. The translator was my partner in that way and we both had a great experience working together creatively because they thought like an artist and they were more concerned with helping me convey meaning in another language more than they were with linguistic pedantry. They understood my characters enough to make the choices that I would make because they knew that being a good reader was the first step to being a good translator. Some others might feel differently but I'm sure there are plenty like me who are looking for someone who feels confident enough in their own interpretive abilities to be able to discern meaning and find the best words to convey best the story we're telling. Just some food for thought.
A lot of people have trouble with dubbed shows/anime/cartoons… and the changes they do. But I have to say I love the french version of Good Omens. For a lot of reasons, but the one that struck me the most is the translation of "I'm soft" (from Aziraphale) Most people would assume this sentence would be translated as "Je suis mou" or even "Je suis faible", but no. They use "Je ne suis pas un soldat" ("I'm not a soldier")

I love it!!! Even in the original version, fans seems to interpret this sentence in different ways, wether it's about his bodyshape, his persona… but the french version really choose to emphasise as Aziraphale not being a warrior.
Aziraphale is a protector, a guardian, and that's very different. He may not be Gabriel's "lean mean fighting machine", but he will fight for what he deems necessary!

Heaven is very, very fucked...
709 notes
·
View notes
Text
Love when polysemy works in favor of my writing. Yes “femme” means “woman” and “wife”. No I won’t clarify which one I mean in this sentence, because the confusion is the point here.
#writing#french language being like#i will create polysemies with implications that are so interesting
1 note
·
View note
Text
Hi guys! This is a repost of my story “Not So Bad Like I Thought” cuz the original post was deleted with my old blog! For those who haven’t read it yet, it’s a self indulgent fic based off of Polysemy by Froldgapp. The original story is a very good read!
Being trapped in a cramped cell with one of her enemies was not something that Axca had anticipated. Yet, here she was, imprisoned by a race of strange looking aliens with one of the paladins of Voltron. It was the the leader of the bunch, the one who piloted the Black Lion. And Lotor’s assumption that he wasn’t the original Black Paladin was correct it seemed, because the armor he had been wearing was red, not black. Axca looked at the paladin, who was almost squished against her in the small space.
They had both been stripped nude when their captors had cleaned them, which had involved being blasted with icy water, and it seemed like the creatures weren’t planning on giving them their armor back anytime soon. The paladin didn’t seem to be faring well, shivering violently where he sat. Axca sat with her legs crossed and arms over her chest, more concerned about modesty than the cold. Though of course, that was the least of her worries. There didn’t seem to be a way to escape; they had both already tried. She hoped that Lotor and the others would find her soon.
“hih! Htchiu!”
Axca jumped, looking up at the source of the noise. It had come from the paladin. Axca furrowed her brows in confusion as she watched him. He had a peculiar expression on his face. Eyebrows drawn, jaw slack, and a faraway look in his eyes. He gasped once, twice, and then pitched forward, hands covering his face. He made the same noise again, a small squeaky sound.
“Hitchiew!”
The paladin looked up, noticing her looking at him.
“Excuse me,” he mumbled, a small blush spreading across his face. She was confused, but shrugged it off. Right now she cared more about trying to get some sleep. Sleeping seemed like a better option than sitting in this dark, cold cell wondering was going to happen to her. So she leaned her head back against the damp walls and closed her eyes. She was just drifting off into sleep when she was startled awake by the same sound from before.
“Hitshieww! Ihh-chiu!”
She whipped her head up, glaring at the paladin, who was swiping his wrist across the underside of his nose.
“Stop making that noise,” she snapped. The paladin looked at her, shocked at first. Then his expression morphed into one of indignation.
“I can’t help it!” he cried.
“What do you mean? Just be quiet, it should not be so difficult.”
“Are you kidding me!?” Keith said. He couldn’t believe that she was getting on his case just for sneezing. “I can’t control it when I sneeze! Sorry it’s such an inconvenience for you!” he said the last part with biting sarcasm. But Axca’s irritation had disappeared, being replaced with confusion.
“Sneeze? What does that mean?” Keith’s anger faded as well. As soon as she asked him that, he understood where her confusion was coming from.
“Oh...you don’t know what that is. Do Galra really not sneeze?” Axca raised an eyebrow at him instead of answering. Keith took that as a no. He decided that he might as well explain.
“I guess that means no. Well basically, a sneeze is a bodily function. It’s a human thing I guess.” Keith stopped, considering. “Well maybe it’s more of an Earth thing. Because animals do it too.”
Axca would be lying if she said she wasn’t interested at this point.
“What is the purpose of this sneeze?” she asked.
“Well, it gets rid of germs or other particles that enter through the nose.”
“It’s an immune response? Do humans not have a mechanism that kills the virus?”
“We do, but I think that’s only if it gets in your system...I mean, humans have white blood cells that attack foreign bacteria. Even then, it sometimes takes awhile for our immune systems to get rid of something we’ve never had before. I think sneezing is just extra protection, maybe? It happens more when someone is sick.”
Axca considered his words. “So you are getting sick then.” She stated it as more of a fact than a question. That same look of indignation flashed across the paladin’s face, like he was offended at the idea of being sick.
“Of course not! I-I don’t know... it’s probably just the cold. It doesn’t always happen when germs get in the body. Sometimes other things can set it off, like cold air, even sunlight sometimes.”
It was pretty cold, and the creatures that had captured them still hadn’t bothered to give them their clothes back. Axca had thick skin, so the cold was somewhat bearable for her. The paladin however was shivering so hard that his teeth were chattering, and his skin was much paler than usual. It seemed that human skin didn’t provide much protection from the cold.
Really, when she thought about it, humans seemed so frail, at least when compared to the Galra. She wondered how it came to be that five humans became the paladins that would fight against the Galra empire. But wasn’t this paladin Galra as well? Half Galra, like her. Though it seemed that he hadn’t inherited many traits from his Galra side. Axca was brought out of her musings by the sound of the paladins breath hitching, becoming more erratic by the second until he pitched forward, that same sound from before (a sneeze, her mind supplied) bursting from him.
“hhtshiew! aah-tchiu!” he sniffled, his breath immediately hitching again.
“hhih! Hhh! Hii-tchii! Ah-TCHIEW!! Ugh…”
“I guess that this sneezing is not going to be stopping any time soon.” Axca said. Keith immediately became defensive.
“Why? Does it really bother you that much?”
In truth, it did a little bit. But she didn’t really see any point in making a big deal about it, especially since he couldn’t control it. So she sighed and said,
“It is no bother. Just make sure to cover your mouth and nose. I do not want to get sick.” He grumbled something about not being sick and bent forward, resting his head between his knees. After that, they sat in silence, the only sound being the paladins occasional sneezing, only stopping when the paladin finally fell asleep. Axca took this opportunity to get some rest as well and closed her eyes, leaning against the wall. Before falling asleep, she wondered if Lotor was any closer to finding her.
✦✦✦
As it turned out, the paladin was sick. She wasn’t sure how long they had slept, but after awhile the paladin erupted into a harsh coughing fit that woke both of them up, leaving him gasping for breath when it was over. Axca couldn’t bring herself to yell at him for waking her, especially after she took in his appearance. His skin was much paler than usual, except around his cheeks and nose, which glew bright red. She could hear him panting from where she sat, as if he was having trouble breathing, and he was trembling all over. He also felt hotter than usual, feeling the unnatural heat on her thigh where it was touching his leg.
“I guess it’s not just the cold then,” she said, almost smug at the fact that she had been correct about the paladins ailment.
“Shut up,” he said, but there wasn’t any fire behind it, and the glare he was giving her was subdued. Axca wasn't sure if it was because he wasn’t feeling well, or if he knew she was right. She figured it was probably both. At that moment, the paladins breath began to hitch, as if his body wanted to prove that he was sick. He snapped forward, hands cupping his nose and mouth
“ahh! haah! ha-TCHiew! hih-TCHIU!”
Axca felt his entire body shudder with the force of the expulsion. He groaned tiredly afterwards, sniffling miserably.
“Are you alright?” she asked. The paladin looked at her skeptically.
“Why do you care? I figured you would try to take this opportunity to attack me ”
“I am not evil like you seem to think. I would never attack anyone who was sick” Axca said, slightly offended. “As I told you before, we help people,”
“No offense, but enslaving people doesn’t seem like helping them.”
Axca glared at him. “Zarkon enslaves people, we build our empire by gaining followers, not slaves.”
“And what about those who don’t want to join your empire?” he asked bitingly
She didn’t have a chance to answer. At that moment, the slithering creatures returned. They dragged the pair from the cell, pushing them roughly from the prisoners area to the showers. Axca was definitely not looking forward to what was about to happen. She could handle the cool air of the cell, but the icy water was something that she could not tolerate. She knew that she was probably going to be shivering as bad as the paladin for awhile before she adjusted to the cold.
They were pushed into the tiled room, the door closing behind them. Almost immediately, the sprinklers on the ceiling began pelting them with frigid water. Sighing to herself, resigned, she began scrubbing herself with the rag that she had been given, doing her best to ignore the chill. It wasn't until she finished cleaning herself that she noticed the paladin struggling to do the same. He trembled violently, knees knocking together and teeth chattering. His breath came im short wheezes, as if even his lungs were cold. He was currently trying to clean his legs, but it seemed he was having a hard time accomplishing the small task. Suddenly, his chest heaved with two large gasps before a loud, violent sneeze made him lose his balance
“HITCHIEWW!”
The paladin dropped the rag he had been holding. He stumbled from the force of the sneeze, slipping on the tiled floor and falling hard on his bottom.
“Are you alright?” she asked him. There was no skepticism from him this time. He answered tiredly,
“Yeah, I thigk I’b alright.”
His voice had a strange lilt to it, sounding congested. She briefly wondered if this sneezing made congestion worse for humans, before turning her attention back to the paladin. He had said he was fine, but he wasn’t making any attempt to get up from the floor. He seemed to be frozen in place, body rigid and shaking from the intense cold. The flush on his face was also more prominent than it had been before. The paladins nose seemed to turn redder, nostrils quivering. He started gasping again, except they came out weaker than before. He clumsily brought his hands to his face, more sneezes erupting from him.
“hih! hih! hih! Ihh-chiiu! Hishhiew! Ngt’chiew! H’eshiew! T’shiew! Ht”chiew!
When he removed his hands from his face, she saw that his upper lip was coated in mucus. He sniffled wetly, shaking as he attempted to clean himself. Axca walked over to him, kneeling down beside him.
“Here,” she said, grabbing the rag that he had dropped and handing it to him. He grabbed the rag from her and thanked her, gently wiping his nose. Their hands brushed together briefly during the exchange and she winced at the heat she felt. His fever was getting worse, and she was shocked to find that she was actually worried about him. Sure, she wasn’t heartless enough to do anything to him in this condition, but he was still her enemy. It dismayed her that she was worried about him the way that she was.
Axca sighed in relief when the faucets on the ceiling were finally shut off. Before she could do anything else, the creatures came into the tiled room and grabbed them. They dragged the pair harshly to their cell. The paladin fell into another sneezing fit on the way, and one of the creatures mercilessly kicked him to the floor, as if the action had offended them somehow.
When they arrived at their cell, Axca and Keith were thrown into the small room, some of the creatures hissing ‘Galra scum’ before slithering away. The paladin had not stopped shivering the entire time, and his nose was dripping again. Now that she was pressed so close to him, she could feel the intense heat radiating from him. He was practically a natural heater.
“Hey,” Axca said. She nudged the paladin with her foot, trying to get his attention.
“What is the normal body temperature for humans?” She asked. When he finally looked at her, she noticed that his eyes were glassy, unfocused. She wondered if he had even heard her, or understood her. But then he answered her, his voice noticeably weaker.
“Ninety eight degrees. Though, my body temperature was always higher than everyone else's. Usually my normal temperature is a hundred.”
Axca didn’t know what degrees were, or how to translate them into Galra measurements. In any case, he wouldn’t be as weak as he was if he didn’t have a fever. The problem was that she had no idea how severe it was. She just hoped it wasn’t life threatening.
Again, she briefly wondered why she cared so much. At first, Axca wanted to deny it, but after thinking about it she realized that she actually had some respect for the paladin. He was a formidable opponent, that much was clear from their battles. And his behavior so far had shown her that he was honorable and steadfast. Someone like him didn’t deserve to die from sickness, in a small dirty cell.
She looked at the paladin again and saw that he had fallen asleep. Even in his sleep, his breathing was labored, his body shivering every now and then. She decided then that she was not going to let him die, not this way. She was going to make sure that they both got out of this alive.
✦✦✦
The next day wasn’t any better. When the paladin awoke, he didn’t even remember where he was at first and promptly fell into a panic. The heat from his skin almost burned her. He was definitely hotter than he was before falling asleep, and she didn’t know what to do.
He was hyperventilating. When she tried to grab him by the shoulders to bring him back to reality, he freaked out, pushing her away and screaming at her, as much as he could scream with his weakened voice. He seemed to think that she was going to hurt him. She couldn’t blame him, really. If he didn’t remember where he was, he probably didn’t remember their time trapped together. At the moment, he saw her as someone who wanted to hurt him.
The paladin balled his hand into a fist, throwing a punch at her. However, his energy was so low that it was easy for her to stop the punch, grabbing a hold of his hand and not letting go. She took this opportunity to try and reason with him.
“Listen to me, I’m not going to hurt you,” she told him.
“Where am I?” he asked. His voice was hoarse, unable to speak above a whisper. “Why do you have me trapped here?”
“I’m not the one who has you trapped here,” Axca said. “We were both captured by the native species of the planet we landed on. Do you not remember?”
He furrowed his brows, as if remembering was a struggle. Slowly, but surely, the tension began to drain from his body. Finally, he looked up at her.
“I...I remember,” he said at last. His expression morphed into one of embarrassment.
“I’m sorry,” he said.
“Don’t apologize,” Axca said. “It is not your fault.”
“Everything feels...fuzzy. It’s hard to focus.”
That didn't sound good. She was almost positive that his fever was near fatal by now. She wasn’t sure how to get his fever down, and she knew the freezing showers would only shock his system and make things worse.
“Your illness is getting worse,” she told him. “To tell you the truth, I am not sure what to do about it. I am hoping that your immune system will be strong enough to fight off whatever virus you have.”
“So I’m going to die here then,” the paladin said. Axca could hear the bitterness in his weakened voice.
“Not if I can help it,” she said before she could stop herself. For a moment, his gaze cleared a bit, and he looked at her in surprise.
“You would really put effort into making sure I don’t die?” he asked.
“Yes, I would.”
“But why?”
A moment passed before Axca replied.
“Because someone like you does not deserve to die this way.”
This seemed to confuse the paladin.
“Someone like me?” he asked
“Someone honorable, strong,” Axca clarified.
The paladin chuckled. “Never thought you would be the type of person to value those kinds of things.”
Axca poked him with her toe, giving him an annoyed glare. “You thought wrong. I told you that I am not evil.”
“Yeah, I guess so,” he said. “You really aren’t so bad like I thought. To be honest, you’re not the worst person to be trapped with.”
Axca gave a small smile. “You’re not so bad yourself,” she said. They fell into a comfortable silence after that. It wasn’t much longer before the paladin began to drift back into sleep. Meanwhile, Axca tried to think of a way to escape, or a way to ease the paladin’s symptoms, but came up short. They didn’t exactly have any resources in here and there wasn’t any way they could get out of the small cell.
The most she could do at the moment was to make sure that he got some rest. She intended to let him sleep, but unfortunately their captors had other plans. The paladin had only been asleep for maybe half a varga when they came, roughly waking the paladin and dragging them both to the showers. The paladin was disoriented, but this time when his eyes met hers there was no fear or confusion there. However, he began struggling when he realized they were being taken.
“Let go of me,” he said, voice slurred from the fever and exhaustion. His struggling accomplished nothing but an extra harsh push into the tiled room. He stumbled, landing hard on the floor. Axcs was pushed in as well, and the door immediately slammed shut behind them.
Keith was attempting to stand when the showers came on and freezing water rained on them both. He couldn’t help the whimper that escaped him. The water was too cold to feel good on his fevered skin. All it did was give him a headache and worsen his chills, and it wasn’t long before he felt his nose start to hurt from the cold.
Suddenly, he felt hands on his shoulders and felt himself being guided somewhere. He was too weak and cold to protest, so he just went with it. He was guided to a corner where there was less water.
“Stay here,” Axca told him. “Try not to let the cold water touch you too much.”
Keith nodded in response. The water wasn’t hitting him as much as before, but the cold was still unbearable, and his nose was starting to drip. He sniffled, trying to stop it, but the only thing he accomplished was making his nose tickle. He could feel it building into a fit. His breath hitched desperately, the air rattling in his lungs.
He tried to hold them back. He didn’t want to sneeze, it would just make his headache worse and he didn’t want to make a mess. Holding the sneezes back was futile however, and he was overcome with a powerful fit, unable to do anything but try to make as little of a mess as possible
“Heh! Heh! Hh’ESCHIIU! Heh’eTCHHiew! Hh’HITCHII! ATCHIEW!”
Axca winced as she watched the paladin struggle helplessly through the sneezes. When he was done his weakened muscles could no longer support him and he slid down the tiled wall until he was sitting. His nostrils still ticked, the cold water messing with the sensitive nerves in his nose. His breath began to hitch again, coming out in strong, vocal gasps. He pressed his wrist against his nose in an attempt to quell the tickle, but it had no effect.
“HIH! HEHH! HEHHH! NGT’CHIEW!! HEH! HEH’TCHIIEW!! IHH! HIH’CHIIU!! AHHCHIEW!! HEH’SHHIU!! ohhh!”
The paladin groaned in pain. When he removed his wrist from his face, a string of mucus followed. Axca frowned, walking over to him and handing him a rag. He accepted it with a small ‘thank you.’ After he finished cleaning himself, he laid his head between his knees and groaned miserably. Axca wasn’t sure what else to do. She just hoped that they would turn off the water soon.
After what seemed like forever, the water finally stopped. Right on cue, their captors opened the door and pushed them back towards their cell. They practically had to drag the paladin, who could barely walk from how ill he was. When they got to their cell, the creatures pushed them roughly inside and left.
The rest of the time went about the same. They sat in their cell, the paladin shivering with sickness and cold. It seemed like with every passing varga, his fever spiked more and more. Axca had never felt more helpless. There simply wasn’t anything she could do without something cool to help the fever go down. All she could do was sit there and watch him suffer, offering words of comfort. She also tried to keep up a conversation to try to keep the paladin aware. She grew worried when the paladin became confused and unable to follow the conversation anymore. After awhile, he fell asleep. Axca resolved to stay awake and keep an eye on his condition.
His slumber wasn’t peaceful. His eyebrows were furrowed as if he were having a nightmare, and his breathing was labored. The paladin never stayed asleep for long either, waking up every once and awhile in a daze, calling for someone named ‘Shiro.’ Axca couldn’t do much in those moments besides try and comfort him, telling him that whoever he was calling for would be there soon.
There was an awful moment when she thought that he was going to die. His body was sweltering, his breaths coming out in tiny puffs. When she checked his pulse, she found that it was worryingly slow. Axca wasn’t sure how she could help him. She resorted to trying to call out to their captors, demanding that they give the paladin medical attention. Of course, she was ignored. When Axca finally gave up, She plopped down beside the paladin, holding back a scream of frustration. She leaned into his side, wrapping her arms around him and holding him close.
“It’s going to be okay,” she said. She wasn't sure if she was saying it to him, or herself, or both of them. The last thing she was aware of before surrendering to sleep was the feeling of his hand squeezing hers.
✦✦✦
When they awoke again, they found that the paladins fever had broke.
The creatures returned later on and Axca dreaded what would happen next. However, instead of what she expected, the creatures provided them with a basin and rag and told them that they’re on lockdown.
“This must mean that the others are close,” Axca said. The paladin hummed in response. She could see the relief on his face.
“I guess we’re getting out alive after all,” he said. She did not miss the way that he said “we.” She didn’t pull away when he laid his hand on top of hers.
18 notes
·
View notes
Text
U2
13/1--20/1
This week is very important for my new project. I made ppt of all my research and sketch. We have more in-depth research and views on Emma Kay and Mark Leckey's works. In Emma Kay's works, human memory is not the precise expression of experience, but the reconstruction of experience. Experience itself is based on personal point of view. In her works, it is more her own reconstruction of things in memory than the reality itself. It can be said that the decomposition and reconstruction of memory is the essence of human memory, the fusion of new knowledge and existing knowledge. Both construction and creation. In Mark Leckey's works, the audience is brought into the works, just like a movie or a stage. In this space, these works are successively lit in the style of Saint Lumiere. The underpass of the highway with concrete slopes and supports is the place he has visited in various exhibitions in the past few years, and it is also a visual symbol of a dreamy British child. It seems to be a fixed place in Mark Leckey's inner world, an illusion that may be burning in the memory of the work's theme "children"; a film that collages fragments selected from popular culture into a visual biography. Both dream and memory. In addition, I also saw a new movie called The Lighthouse. The movie was full of memory and time confusion, which formed a horrible atmosphere, or a repressive atmosphere. It's not only a psychological horror film, but also a character plot film, maybe even a fable story, a new myth. Beyond its simple narrative line, there are a series of scenes and symbols that are chaotic and polysemy, fuzzy time and lack of explanation. At last, like the two protagonists, we walk into the light of the lighthouse covered with mud in the waves, noisy seabirds and never-ending fog and flute, and we can no longer distinguish between the real and the virtual, just like the lens chamber on the lighthouse head.

0 notes
Note
So I am barely an armchair linguist, much less a conlanger, but I do like language a lot and am trans and have been deeply in queer/gendery circles for well over a decade now. I think OP's answer here is overall pretty great - a couple clarifications there:
First, as someone said in replies, "trans" doesn't actually come from "transition", it's literally a prefix meaning roughly "on the other side of" that is the opposite of cis ("on the same side of"). It's also used in fields like chemistry (trans- and cis-isomers) and astronomy (cislunar is between the earth and the moon, translunar is beyond).
Thus, "trans" is generally used as an umbrella term for anyone whose gender is different from what they were assigned at birth. Depending on how you slice it that covers most genderqueer/nonbinary/etc folks (since "neither man nor woman" is different from "man" or "woman"), and many (but certainly not all) of them would indeed describe themselves as trans.
A short sidenote on "having any doubt": while lots of people have doubts about their gender, genderqueer/nonbinary people are not definitionally uncertain about what their gender is, and many are in fact quite certain. They just are certain that their gender is not described well by either of the two boxes that our society/language provides. Genderfluid folks may shift how well those labels fit them over time, but they're not necessarily uncertain at any given point.
The group you're describing above are people like me, who are trans and do identify with "man" or "woman". Generally I've seen folks use "binary trans people" to make that distinction. And we are indeed generally covered by "man" or "woman" just fine, although as you note, folks vary on how much they consider transness itself as an important part of their gender - given choices of "man/woman/trans man/trans woman", I would choose "trans woman", but many trans folks would choose simply "man" or "woman".
Which is all to say: yes, all the polysemy, no one term is going to encompass the hugely diverse experiences people have with gender, and as far as I'm concerned, the fewer gendered boxes and structures a language has, the better. My gender confuses people enough that I get people using more-lumped terms when referring to me ("can you help...uhh...this person find the cat food?"), so that being the default would be great. The fewer times people have to guess what gender box to put me in, the better, really.
Another example: I'm learning ASL, and it doesn't have gendered pronouns at all - you mainly refer to people (present or not) by simply pointing. There is still gender in ASL still - "mother" and "father" are the same sign just in different places - but when I'm communicating in ASL, I generally don't know what gender people are assigning to me unless they're explicitly referring to me with a gendered role (man/woman, boy/girl, aunt/uncle, etc), and that happens a lot less often than pronouns do in English.
One interesting wrinkle I could see coming up in conlangs is that in a natural language, most people using the language know the rules of the language, either implicitly or explicitly, simply by virtue of being fluent in the language - so ingroups inventing/adopting terms will generally follow those rules. In a conlang - especially one that's expanded on/filled in from a canon source - people aren't fluent in it in the same way, so e.g. your average trans person trying to coin a term is less likely to have a deep understanding of the rules/grammar of the language, and thus you are more likely to end up with coined terms that don't make sense structurally or w/e.
Obviously the ideal is having enough people who are both very familiar with the language and trans (or w/e), but when both of those communities are relatively small, that's harder to come by.
This actually mirrors something that's been happening with gender in ASL as too! Here's where I get to disclaim that I'm a fairly new learner, so I'm happy to have any Deaf and/or more fluent folks chime in. But I am learning from queer Deaf folks, and the queer Deaf community has started to develop signs to create gender-neutral versions of gendered signs, but that development has often lagged behind similar developments in English, I think because there just haven't been that many concentrated communities of people who are both queer and Deaf as there are people who are queer and fluent in English.
So yeah, as a trans person I think this post is great. Terms for a community should come from within the community, but especially for communities where the overlap of e.g. trans people and people fluent in High Valyrian is small, it's very helpful to have a dialog between trans people who are coining terms and people (like you!) who are deeply familiar with the language terms are being coined in to offer advice on coining terms that fit in with the language as a whole.
I am not nearly involved in the conlang scene to actually contribute much on that front, but in general I do really love the idea of playing with roots of "true", I think that's a neat way to differentiate from just copying what e.g. English does, while speaking well to most folks' experience.
"Choose" is as you noted dicier - while I think there's a lot of nuance to be had here (and am not a huge fan of the oversimplification of "born this way"), a whole lot of queer/trans folks would take umbrage at the implication that they "chose" their gender (or orientation etc).
Thanks for digging in and providing such thoughtful answers, and especially for acknowledging the limits of your role here as someone not in the community being described. It sounds to me like there's plenty of room in your languages for these terms, they just have to be created and find usage - just like with natural languages!
I don't think that any of your conlangs are progressive enough to express being trans, but if they were, how would they? What about other gender/sexuality things?
That first clause is quite a thing to say. Languages aren't progressive. Their users may be, but the languages aren't anything. They're just languages. If you mean they're not modern (i.e. a lot of the languages I create are for cultures that are somewhat antiquated compared to our world), this is true, but that doesn't necessarily mean the languages won't have terminology for different gender identities.
There is a major assumption here, though. My understanding (and please do note: I am a cis man; please feel free to correct), cis and trans individuals, as opposed to nonbinary and genderfluid, are similar in that neither have any doubt about what gender they are, identifying with either male or female. So if any language I've created has a word for "man" or "woman", then there's sufficient vocabulary for a trans individual to express their identity that way.
However, there is a terminological difference, and it's both an individual choice and societal preference: Whether to identify as one's chosen gender identity, as trans, or both (e.g. "I am a woman", "I am trans", or "I am a trans woman"—and then preferring to use one of those or all of those, or some other combination of the three). My personal language preference (as a user and language creator) is fewer distinctions are better (why have three third person singular pronouns—or four or twelve—when you can have one?), because it's less to memorize, less work to use, and demands less specificity of the user—and allows the hearer/reader to make fewer assumptions. Unless the situation calls for it (e.g. the gender system hard-coded into Ravkan in Shadow & Bone), I prefer lumping rather than splitting. This is especially useful as I'm often not in charge of the culture I create languages for.
For example, the languages I've created for A Song of Ice and Fire were for cultures created and maintained by George R. R. Martin. Whatever cultural innovations I have made in creating the languages are, at best, pending—that is, true until George R. R. Martin says otherwise, which he is free to do at any time, as it's his world. As a result, I don't feel confident enough to say what life is like for a trans individual in his world, and how that might be reflected in the languages there. There's simply not enough information.
Where I might be in charge of the culture, you do know my preference now (i.e. fewer distinctions), but, as I am not trans, I'd prefer to leave it to the trans community to decide, and then do what I can to support those decisions linguistically (i.e. to make it work within the language). Any term chosen highlights some aspect of the experience while downplaying others. In English, trans, coming from transition, highlights the change from one identity to another. Other ideas for how to come up with a term might be using a root that refers to "true", highlighting the transition to one's true gender expression. Perhaps another root to look for would be "choose", framing it as one's chosen gender expression—IF one wishes to look at it that way.
In many ways, both the term and the experience are highly individual, and it's difficult to come up with a blanket term and say "this is the term". It's especially difficult since this isn't a life experience I share. It feels both disingenuous and a bit icky to come up with a term to describe an experience that is decidedly not my own.
My own preference in this regard is a twofold approach:
Allow trans users of whatever language to figure out what term works for them, and then support them in creating a term that obeys the various language rules (i.e. the phonology is correct, derived words are derived correctly, etc.). Those users, however, will be operating under the same "rules" that I operate under, e.g. the one who's creating the culture has the final say, if they care to weigh in, and so the result may end up not being canon, at which point it's up to the user to decide whether they care or not. (Note: I shouldn't have to explain it here on Tumblr, but, of course, you don't have to care if the creator of the canon says something isn't so, no matter how many billions they have.)
Allow polysemy. There will never be a term that is THE term. It may be an individual's preferred term, but someone else may like another, in which case it should be allowed.
A very important language-specific note (and the same is true of fandom, generally). By agreeing to work within a language, we're essentially agreeing to rules of a game. The rules can always be broken. When rules are broken, the question language users have to answer is if they've been broken so egregiously that they're no longer playing the game, or if it's fine. For example, if you look at fanfic, there's plenty of fanfic with gender-swapped characters, or the same characters in a radically different setting. Some readers may decide they don't want the characters to be gender-swapped. Others may decide that if it's not in the same setting they're not interested. And that's fine! Both the writers and the readers are deciding which rules of the game can be broken while still calling it the same game. This works very, very well so long as no one gets mad at anyone else. If someone says, "I don't enjoy this because it breaks the rules in a way that ruins my enjoyment", that's perfectly fine. If that same person says, "You're not allowed to break the rules in this way", that's not fine.
So hopefully this all makes sense. And, furthermore, when I say I want to support those who wish to create their own terms, I do mean it. If anyone has suggestions or needs help coining a possible word, feel free to message me! But do bear (2) above in mind. I'm not going to say any term is THE term, and have that be the end of it. It'll be one possibility amongst a rainbow of possibilities.
369 notes
·
View notes
Text
A deep dive into BERT: How BERT launched a rocket into natural language understanding
by Dawn Anderson Editor’s Note: This deep dive companion to our high-level FAQ piece is a 30-minute read so get comfortable! You’ll learn the backstory and nuances of BERT’s evolution, how the algorithm works to improve human language understanding for machines and what it means for SEO and the work we do every day.

If you have been keeping an eye on Twitter SEO over the past week you’ll have likely noticed an uptick in the number of gifs and images featuring the character Bert (and sometimes Ernie) from Sesame Street. This is because, last week Google announced an imminent algorithmic update would be rolling out, impacting 10% of queries in search results, and also affect featured snippet results in countries where they were present; which is not trivial. The update is named Google BERT (Hence the Sesame Street connection – and the gifs). Google describes BERT as the largest change to its search system since the company introduced RankBrain, almost five years ago, and probably one of the largest changes in search ever. The news of BERT’s arrival and its impending impact has caused a stir in the SEO community, along with some confusion as to what BERT does, and what it means for the industry overall. With this in mind, let’s take a look at what BERT is, BERT’s background, the need for BERT and the challenges it aims to resolve, the current situation (i.e. what it means for SEO), and where things might be headed.
Quick links to subsections within this guide The BERT backstory | How search engines learn language | Problems with language learning methods | How BERT improves search engine language understanding | What does BERT mean for SEO?
What is BERT?
BERT is a technologically ground-breaking natural language processing model/framework which has taken the machine learning world by storm since its release as an academic research paper. The research paper is entitled BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018). Following paper publication Google AI Research team announced BERT as an open source contribution. A year later, Google announced a Google BERT algorithmic update rolling out in production search. Google linked the BERT algorithmic update to the BERT research paper, emphasizing BERT’s importance for contextual language understanding in content and queries, and therefore intent, particularly for conversational search.
So, just what is BERT really?
BERT is described as a pre-trained deep learning natural language framework that has given state-of-the-art results on a wide variety of natural language processing tasks. Whilst in the research stages, and prior to being added to production search systems, BERT achieved state-of-the-art results on 11 different natural language processing tasks. These natural language processing tasks include, amongst others, sentiment analysis, named entity determination, textual entailment (aka next sentence prediction), semantic role labeling, text classification and coreference resolution. BERT also helps with the disambiguation of words with multiple meanings known as polysemous words, in context. BERT is referred to as a model in many articles, however, it is more of a framework, since it provides the basis for machine learning practitioners to build their own fine-tuned BERT-like versions to meet a wealth of different tasks, and this is likely how Google is implementing it too. BERT was originally pre-trained on the whole of the English Wikipedia and Brown Corpus and is fine-tuned on downstream natural language processing tasks like question and answering sentence pairs. So, it is not so much a one-time algorithmic change, but rather a fundamental layer which seeks to help with understanding and disambiguating the linguistic nuances in sentences and phrases, continually fine-tuning itself and adjusting to improve.
The BERT backstory
To begin to realize the value BERT brings we need to take a look at prior developments.
The natural language challenge
Understanding the way words fit together with structure and meaning is a field of study connected to linguistics. Natural language understanding (NLU), or NLP, as it is otherwise known, dates back over 60 years, to the original Turing Test paper and definitions of what constitutes AI, and possibly earlier. This compelling field faces unsolved problems, many relating to the ambiguous nature of language (lexical ambiguity). Almost every other word in the English language has multiple meanings. These challenges naturally extend to a web of ever-increasing content as search engines try to interpret intent to meet informational needs expressed by users in written and spoken queries.
Lexical ambiguity
In linguistics, ambiguity is at the sentence rather than word level. Words with multiple meanings combine to make ambiguous sentences and phrases become increasingly difficult to understand. According to Stephen Clark, formerly of Cambridge University, and now a full-time research scientist at Deepmind:
“Ambiguity is the greatest bottleneck to computational knowledge acquisition, the killer problem of all natural language processing.”
In the example below, taken from WordNet (a lexical database which groups English words into synsets (sets of synonyms)), we see the word “bass” has multiple meanings, with several relating to music and tone, and some relating to fish. Furthermore, the word “bass” in a musical context can be both a noun part-of-speech or an adjective part-of-speech, confusing matters further. Noun
S: (n) bass (the lowest part of the musical range)
S: (n) bass, bass part (the lowest part in polyphonic music)
S: (n) bass, basso (an adult male singer with the lowest voice)
S: (n) sea bass, bass (the lean flesh of a saltwater fish of the family Serranidae)
S: (n) freshwater bass, bass (any of various North American freshwater fish with lean flesh (especially of the genus Micropterus))
S: (n) bass, bass voice, basso (the lowest adult male singing voice)
S: (n) bass (the member with the lowest range of a family of musical instruments)
S: (n) bass (nontechnical name for any of numerous edible marine and freshwater spiny-finned fishes)
Adjective
S: (adj) bass, deep (having or denoting a low vocal or instrumental range) “a deep voice”; “a bass voice is lower than a baritone voice”; “a bass clarinet”
Polysemy and homonymy
Words with multiple meanings are considered polysemous or homonymous.
Polysemy
Polysemous words are words with two or more meanings, with roots in the same origin, and are extremely subtle and nuanced. The verb ‘get’, a polysemous word, for example, could mean ‘to procure’,’ to acquire’, or ‘to understand’. Another verb, ‘run’ is polysemous and is the largest entry in the Oxford English Dictionary with 606 different meanings.
Homonymy
Homonyms are the other main type of word with multiple meanings, but homonyms are less nuanced than polysemous words since their meanings are often very different. For example, “rose,” which is a homonym, could mean to “rise up” or it could be a flower. These two-word meanings are not related at all.
Homographs and homophones
Types of homonyms can be even more granular too. ‘Rose’ and ‘Bass’ (from the earlier example), are considered homographs because they are spelled the same and have different meanings, whereas homophones are spelled differently, but sound the same. The English language is particularly problematic for homophones. You can find a list over over 400 English homophone examples here, but just a few examples of homophones include:
Draft, draught
Dual, duel
Made, maid
For, fore, four
To, too, two
There, their
Where, wear, were
At a spoken phrase-level word when combined can suddenly become ambiguous phrases even when the words themselves are not homophones. For example, the phrases “four candles” and “fork handles” when splitting into separate words have no confusing qualities and are not homophones, but when combined they sound almost identical. Suddenly these spoken words could be confused as having the same meaning as each other whilst having entirely different meanings. Even humans can confuse the meaning of phrases like these since humans are not perfect after all. Hence, the many comedy shows feature “play on words” and linguistic nuances. These spoken nuances have the potential to be particularly problematic for conversational search.
Synonymy is different
To clarify, synonyms are different from polysemy and homonymy, since synonymous words mean the same as each other (or very similar), but are different words. An example of synonymous words would be the adjectives “tiny,” “little” and “mini” as synonyms of “small.”
Coreference resolution
Pronouns like “they,” “he,” “it,” “them,” “she” can be a troublesome challenge too in natural language understanding, and even more so, third-person pronouns, since it is easy to lose track of who is being referred to in sentences and paragraphs. The language challenge presented by pronouns is referred to as coreference resolution, with particular nuances of coreference resolution being an anaphoric or cataphoric resolution. You can consider this simply “being able to keep track” of what, or who, is being talked about, or written about, but here the challenge is explained further.
Anaphora and cataphora resolution
Anaphora resolution is the problem of trying to tie mentions of items as pronouns or noun phrases from earlier in a piece of text (such as people, places, things). Cataphora resolution, which is less common than anaphora resolution, is the challenge of understanding what is being referred to as a pronoun or noun phrase before the “thing” (person, place, thing) is mentioned later in a sentence or phrase. Here is an example of anaphoric resolution:
“John helped Mary. He was kind.”
Where “he” is the pronoun (anaphora) to resolve back to “John.” And another:
The car is falling apart, but it still works.
Here is an example of cataphora, which also contains anaphora too:
“She was at NYU when Mary realized she had lost her keys.”
The first “she” in the example above is cataphora because it relates to Mary who has not yet been mentioned in the sentence. The second “she” is an anaphora since that “she” relates also to Mary, who has been mentioned previously in the sentence.
Multi-sentential resolution
As phrases and sentences combine referring to people, places and things (entities) as pronouns, these references become increasingly complicated to separate. This is particularly so if multiple entities resolve to begin to be added to the text, as well as the growing number of sentences. Here is an example from this Cornell explanation of coreference resolution and anaphora:
a) John took two trips around France. b) They were both wonderful.
Humans and ambiguity
Although imperfect, humans are mostly unconcerned by these lexical challenges of coreference resolution and polysemy since we have a notion of common-sense understanding. We understand what “she” or “they” refer to when reading multiple sentences and paragraphs or hearing back and forth conversation since we can keep track of who is the subject focus of attention. We automatically realize, for example, when a sentence contains other related words, like “deposit,” or “cheque / check” and “cash,” since this all relates to “bank” as a financial institute, rather than a river “bank.” In order words, we are aware of the context within which the words and sentences are uttered or written; and it makes sense to us. We are therefore able to deal with ambiguity and nuance relatively easily.
Machines and ambiguity
Machines do not automatically understand the contextual word connections needed to disambiguate “bank” (river) and “bank” (financial institute). Even less so, polysemous words with nuanced multiple meanings, like “get” and “run.” Machines lose track of who is being spoken about in sentences easily as well, so coreference resolution is a major challenge too. When the spoken word such as conversational search (and homophones), enters the mix, all of these become even more difficult, particularly when you start to add sentences and phrases together.
How search engines learn language
So just how have linguists and search engine researchers enabling machines to understand the disambiguated meaning of words, sentences and phrases in natural language? “Wouldn’t it be nice if Google understood the meaning of your phrase, rather than just the words that are in the phrase?” said Google’s Eric Schmidt back in March 2009, just before the company announced rolling out their first semantic offerings. This signaled one of the first moves away from “strings to things,” and is perhaps the advent of entity-oriented search implementation by Google. One of the products mentioned in Eric Schmidt’s post was ‘related things’ displayed in search results pages. An example of “angular momentum,” “special relativity,” “big bang” and “quantum mechanic” as related items, was provided. These items could be considered co-occurring items that live near each other in natural language through ‘relatedness’. The connections are relatively loose but you might expect to find them co-existing in web page content together. So how do search engines map these “related things” together?
Co-occurrence and distributional similarity
In computational linguistics, co-occurrence holds true the idea that words with similar meanings or related words tend to live very near each other in natural language. In other words, they tend to be in close proximity in sentences and paragraphs or bodies of text overall (sometimes referred to as corpora). This field of studying word relationships and co-occurrence is called Firthian Linguistics, and its roots are usually connected with 1950s linguist John Firth, who famously said:
“You shall know a word by the company it keeps.” (Firth, J.R. 1957)
Similarity and relatedness
In Firthian linguistics, words and concepts living together in nearby spaces in text are either similar or related. Words which are similar “types of things” are thought to have semantic similarity. This is based upon measures of distance between “isA” concepts which are concepts that are types of a “thing.” For example, a car and a bus have semantic similarity because they are both types of vehicles. Both car and bus could fill the gap in a sentence such as: “A ____ is a vehicle,” since both cars and buses are vehicles. Relatedness is different from semantic similarity. Relatedness is considered ‘distributional similarity’ since words related to isA entities can provide clear cues as to what the entity is. For example, a car is similar to a bus since they are both vehicles, but a car is related to concepts of “road” and “driving.” You might expect to find a car mentioned in amongst a page about road and driving, or in a page sitting nearby (linked or in the section – category or subcategory) a page about a car. This is a very good video on the notions of similarity and relatedness as scaffolding for natural language. Humans naturally understand this co-occurrence as part of common sense understanding, and it was used in the example mentioned earlier around “bank” (river) and “bank” (financial institute). Content around a bank topic as a financial institute will likely contain words about the topic of finance, rather than the topic of rivers, or fishing, or be linked to a page about finance. Therefore, “bank’s” company are “finance,” “cash,” “cheque” and so forth.
Knowledge graphs and repositories
Whenever semantic search and entities are mentioned we probably think immediately of search engine knowledge graphs and structured data, but natural language understanding is not structured data. However, structured data makes natural language understanding easier for search engines through disambiguation via distributional similarity since the ‘company’ of a word gives an indication as to topics in the content. Connections between entities and their relations mapped to a knowledge graph and tied to unique concept ids are strong (e.g. schema and structured data). Furthermore, some parts of entity understanding are made possible as a result of natural language processing, in the form of entity determination (deciding in a body of text which of two or more entities of the same name are being referred to), since entity recognition is not automatically unambiguous. Mention of the word “Mozart” in a piece of text might well mean “Mozart,” the composer, “Mozart” cafe, “Mozart” street, and there are umpteen people and places with the same name as each other. The majority of the web is not structured at all. When considering the whole web, even semi-structured data such as semantic headings, bullet and numbered lists and tabular data make up only a very small part of it. There are lots of gaps of loose ambiguous text in sentences, phrases and paragraphs. Natural language processing is about understanding the loose unstructured text in sentences, phrases and paragraphs between all of those “things” which are “known of” (the entities). A form of “gap filling” in the hot mess between entities. Similarity and relatedness, and distributional similarity) help with this.
Relatedness can be weak or strong
Whilst data connections between the nodes and edges of entities and their relations are strong, the similarity is arguably weaker, and relatedness weaker still. Relatedness may even be considered vague. The similarity connection between apples and pears as “isA” things is stronger than a relatedness connection of “peel,” “eat,” “core” to apple, since this could easily be another fruit which is peeled and with a core. An apple is not really identified as being a clear “thing” here simply by seeing the words “peel,” “eat” and “core.” However, relatedness does provide hints to narrow down the types of “things” nearby in content.
Computational linguistics
Much “gap filling” natural language research could be considered computational linguistics; a field that combines maths, physics and language, particularly linear algebra and vectors and power laws. Natural language and distributional frequencies overall have a number of unexplained phenomena (for example, the Zipf Mystery), and there are several papers about the “strangeness” of words and use of language. On the whole, however, much of language can be resolved by mathematical computations around where words live together (the company they keep), and this forms a large part of how search engines are beginning to resolve natural language challenges (including the BERT update).
Word embeddings and co-occurrence vectors
Simply put, word embeddings are a mathematical way to identify and cluster in a mathematical space, words which “live” nearby each other in a real-world collection of text, otherwise known as a text corpus. For example, the book “War and Peace” is an example of a large text corpus, as is Wikipedia. Word embeddings are merely mathematical representations of words that typically live near each other whenever they are found in a body of text, mapped to vectors (mathematical spaces) using real numbers. These word embeddings take the notions of co-occurrence, relatedness and distributional similarity, with words simply mapped to their company and stored in co-occurrence vector spaces. The vector ‘numbers’ are then used by computational linguists across a wide range of natural language understanding tasks to try to teach machines how humans use language based on the words that live near each other.
WordSim353 Dataset examples
We know that approaches around similarity and relatedness with these co-occurrence vectors and word embeddings have been part of research by members of Google’s conversational search research team to learn word’s meaning. For example, “A study on similarity and relatedness using distributional and WordNet-based approaches,” which utilizes the Wordsim353 Dataset to understand distributional similarity. This type of similarity and relatedness in datasets is used to build out “word embeddings” mapped to mathematical spaces (vectors) in bodies of text. Here is a very small example of words that commonly occur together in content from the Wordsim353 Dataset, which is downloadable as a Zip format for further exploration too. Provided by human graders, the score in the right-hand column is based on how similar the two words in the left-hand and middle columns are.
money cash 9.15 coast shore 9.1 money cash 9.08 money currency 9.04 football soccer 9.03 magician wizard 9.02
Word2Vec
Semi-supervised and unsupervised machine learning approaches are now part of this natural language learning process too, which has turbo-charged computational linguistics. Neural nets are trained to understand the words that live near each other to gain similarity and relatedness measures and build word embeddings. These are then used in more specific natural language understanding tasks to teach machines how humans understand language. A popular tool to create these mathematical co-occurrence vector spaces using text as input and vectors as output is Google’s Word2Vec. The output of Word2Vec can create a vector file that can be utilized on many different types of natural language processing tasks. The two main Word2Vec machine learning methods are Skip-gram and Continuous Bag of Words. The Skip-gram model predicts the words (context) around the target word (target), whereas the Continuous Bag of Words model predicts the target word from the words around the target (context). These unsupervised learning models are fed word pairs through a moving “context window” with a number of words around a target word. The target word does not have to be in the center of the “context window” which is made up of a given number of surrounding words but can be to the left or right side of the context window. An important point to note is moving context windows are uni-directional. I.e. the window moves over the words in only one direction, from either left to right or right to left.
Part-of-speech tagging
Another important part of computational linguistics designed to teach neural nets human language concerns mapping words in training documents to different parts-of-speech. These parts of speech include the likes of nouns, adjectives, verbs and pronouns. Linguists have extended the many parts-of-speech to be increasingly fine-grained too, going well beyond common parts of speech we all know of, such as nouns, verbs and adjectives, These extended parts of speech include the likes of VBP (Verb, non-3rd person singular present), VBZ (Verb, 3rd person singular present) and PRP$ (Possessive pronoun). Word’s meaning in part-of-speech form can be tagged up as parts of speech using a number of taggers with a varying granularity of word’s meaning, for example, The Penn Treebank Tagger has 36 different parts of speech tags and the CLAWS7 part of speech tagger has a whopping 146 different parts of speech tags. Google Pygmalion, for example, which is Google’s team of linguists, who work on conversational search and assistant, used part of speech tagging as part of training neural nets for answer generation in featured snippets and sentence compression. Understanding parts-of-speech in a given sentence allows machines to begin to gain an understanding of how human language works, particularly for the purposes of conversational search, and conversational context. To illustrate, we can see from the example “Part of Speech” tagger below, the sentence:
“Search Engine Land is an online search industry news publication.”
This is tagged as “Noun / noun / noun / verb / determiner / adjective / noun / noun / noun / noun” when highlighted as different parts of speech.

Problems with language learning methods
Despite all of the progress search engines and computational linguists had made, unsupervised and semi-supervised approaches like Word2Vec and Google Pygmalion have a number of shortcomings preventing scaled human language understanding. It is easy to see how these were certainly holding back progress in conversational search.
Pygmalion is unscalable for internationalization
Labeling training datasets with parts-of-speech tagged annotations can be both time-consuming and expensive for any organization. Furthermore, humans are not perfect and there is room for error and disagreement. The part of speech a particular word belongs to in a given context can keep linguists debating amongst themselves for hours. Google’s team of linguists (Google Pygmalion) working on Google Assistant, for example, in 2016 was made up of around 100 Ph.D. linguists. In an interview with Wired Magazine, Google Product Manager, David Orr explained how the company still needed its team of Ph.D. linguists who label parts of speech (referring to this as the ‘gold’ data), in ways that help neural nets understand how human language works. Orr said of Pygmalion:
“The team spans between 20 and 30 languages. But the hope is that companies like Google can eventually move to a more automated form of AI called ‘unsupervised learning.'”
By 2019, the Pygmalion team was an army of 200 linguists around the globe made up of a mixture of both permanent and agency staff, but was not without its challenges due to the laborious and disheartening nature of manual tagging work, and the long hours involved. In the same Wired article, Chris Nicholson, who is the founder of a deep learning company called Skymind commented about the un-scaleable nature of projects like Google Pygmalion, particularly from an internationalisation perspective, since part of speech tagging would need to be carried out by linguists across all the languages of the world to be truly multilingual.
Internationalization of conversational search
The manual tagging involved in Pygmalion does not appear to take into consideration any transferable natural phenomenons of computational linguistics. For example, Zipfs Law, a distributional frequency power law, dictates that in any given language the distributional frequency of a word is proportional to one over its rank, and this holds true even for languages not yet translated.
Uni-directional nature of ‘context windows’ in RNNs (Recurrent Neural Networks)
Training models in the likes of Skip-gram and Continuous Bag of Words are Uni-Directional in that the context-window containing the target word and the context words around it to the left and to the right only go in one direction. The words after the target word are not yet seen so the whole context of the sentence is incomplete until the very last word, which carries the risk of some contextual patterns being missed. A good example is provided of the challenge of uni-directional moving context-windows by Jacob Uszkoreit on the Google AI blog when talking about the transformer architecture. Deciding on the most likely meaning and appropriate representation of the word “bank” in the sentence: “I arrived at the bank after crossing the…” requires knowing if the sentence ends in “… road.” or “… river.”

Text cohesion missing
The uni-directional training approaches prevent the presence of text cohesion. Like Ludwig Wittgenstein, a philosopher famously said in 1953:
“The meaning of a word is its use in the language.” (Wittgenstein, 1953)
Often the tiny words and the way words are held together are the ‘glue’ which bring common sense in language. This ‘glue’ overall is called ‘text cohesion’. It’s the combination of entities and the different parts-of-speech around them formulated together in a particular order which makes a sentence have structure and meaning. The order in which a word sits in a sentence or phrase too also adds to this context. Without this contextual glue of these surrounding words in the right order, the word itself simply has no meaning. The meaning of the same word can change too as a sentence or phrase develops due to dependencies on co-existing sentence or phrase members, changing context with it. Furthermore, linguists may disagree over which particular part-of-speech in a given context a word belongs to in the first place. Let us take the example word “bucket.” As humans we can automatically visualize a bucket that can be filled with water as a “thing,” but there are nuances everywhere. What if the word bucket word were in the sentence “He kicked the bucket,” or “I have yet to cross that off my bucket list?” Suddenly the word takes on a whole new meaning. Without the text-cohesion of the accompanying and often tiny words around “bucket” we cannot know whether bucket refers to a water-carrying implement or a list of life goals.
Word embeddings are context-free
The word embedding model provided by the likes of Word2Vec knows the words somehow live together but does not understand in what context they should be used. True context is only possible when all of the words in a sentence are taken into consideration. For example, Word2Vec does not know when river (bank) is the right context, or bank (deposit). Whilst later models such as ELMo trained on both the left side and right side of a target word, these were carried out separately rather than looking at all of the words (to the left and the right) simultaneously, and still did not provide true context.
Polysemy and homonymy handled incorrectly
Word embeddings like Word2Vec do not handle polysemy and homonyms correctly. As a single word with multiple meanings is mapped to just one single vector. Therefore there is a need to disambiguate further. We know there are many words with the same meaning (for example, ‘run’ with 606 different meanings), so this was a shortcoming. As illustrated earlier polysemy is particularly problematic since polysemous words have the same root origins and are extremely nuanced.
Coreference resolution still problematic
Search engines were still struggling with the challenging problem of anaphora and cataphora resolution, which was particularly problematic for conversational search and assistant which may have back and forth multi-turn questions and answers. Being able to track which entities are being referred to is critical for these types of spoken queries.
Shortage of training data
Modern deep learning-based NLP models learn best when they are trained on huge amounts of annotated training examples, and a lack of training data was a common problem holding back the research field overall.
So, how does BERT help improve search engine language understanding?
With these short-comings above in mind, how has BERT helped search engines (and other researchers) to understand language?
What makes BERT so special?
There are several elements that make BERT so special for search and beyond (the World – yes, it is that big as a research foundation for natural language processing). Several of the special features can be found in BERT’s paper title – BERT: Bi-directional Encoder Representations from Transformers. B – Bi-Directional E – Encoder R – Representations T – Transformers But there are other exciting developments BERT brings to the field of natural language understanding too. These include:
Pre-training from unlabelled text
Bi-directional contextual models
The use of a transformer architecture
Masked language modeling
Focused attention
Textual entailment (next sentence prediction)
Disambiguation through context open-sourced
Pre-training from unlabeled text
The ‘magic’ of BERT is its implementation of bi-directional training on an unlabelled corpus of text since for many years in the field of natural language understanding, text collections had been manually tagged up by teams of linguists assigning various parts of speech to each word. BERT was the first natural language framework/architecture to be pre-trained using unsupervised learning on pure plain text (2.5 billion words+ from English Wikipedia) rather than labeled corpora. Prior models had required manual labeling and the building of distributed representations of words (word embeddings and word vectors), or needed part of speech taggers to identify the different types of words present in a body of text. These past approaches are similar to the tagging we mentioned earlier by Google Pygmalion. BERT learns language from understanding text cohesion from this large body of content in plain text and is then educated further by fine-tuning on smaller, more specific natural language tasks. BERT also self-learns over time too.
Bi-directional contextual models
BERT is the first deeply bi-directional natural language model, but what does this mean?
Bi-directional and uni-directional modeling
True contextual understanding comes from being able to see all the words in a sentence at the same time and understand how all of the words impact the context of the other words in the sentence too. The part of speech a particular word belongs to can literally change as the sentence develops. For example, although unlikely to be a query, if we take a spoken sentence which might well appear in natural conversation (albeit rarely):
“I like how you like that he likes that.”
as the sentence develops the part of speech which the word “like” relates to as the context builds around each mention of the word changes so that the word “like,” although textually is the same word, contextually is different parts of speech dependent upon its place in the sentence or phrase. Past natural language training models were trained in a uni-directional manner. Word’s meaning in a context window moved along from either left to right or right to left with a given number of words around the target word (the word’s context or “it’s company”). This meant words not yet seen in context cannot be taken into consideration in a sentence and they might actually change the meaning of other words in natural language. Uni-directional moving context windows, therefore, have the potential to miss some important changing contexts. For example, in the sentence:
“Dawn, how are you?”
The word “are” might be the target word and the left context of “are” is “Dawn, how.” The right context of the word is “you.” BERT is able to look at both sides of a target word and the whole sentence simultaneously in the way that humans look at the whole context of a sentence rather than looking at only a part of it. The whole sentence, both left and right of a target word can be considered in the context simultaneously.
Transformers / Transformer architecture
Most tasks in natural language understanding are built on probability predictions. What is the likelihood that this sentence relates to the next sentence, or what is the likelihood that this word is part of that sentence? BERT’s architecture and masked language modeling prediction systems are partly designed to identify ambiguous words that change the meanings of sentences and phrases and identify the correct one. Learnings are carried forward increasingly by BERT’s systems. The Transformer uses fixation on words in the context of all of the other words in sentences or phrases without which the sentence could be ambiguous. This fixated attention comes from a paper called ‘Attention is all you need’ (Vaswani et al, 2017), published a year earlier than the BERT research paper, with the transformer application then built into the BERT research. Essentially, BERT is able to look at all the context in text-cohesion by focusing attention on a given word in a sentence whilst also identifying all of the context of the other words in relation to the word. This is achieved simultaneously using transformers combined with bi-directional pre-training. This helps with a number of long-standing linguistic challenges for natural language understanding, including coreference resolution. This is because entities can be focused on in a sentence as a target word and their pronouns or the noun-phrases referencing them resolved back to the entity or entities in the sentence or phrase. In this way the concepts and context of who, or what, a particular sentence is relating to specifically, is not lost along the way. Furthermore, the focused attention also helps with the disambiguation of polysemous words and homonyms by utilizing a probability prediction / weight based on the whole context of the word in context with all of the other words in the sentence. The other words are given a weighted attention score to indicate how much each adds to the context of the target word as a representation of “meaning.” Words in a sentence about the “bank” which add strong disambiguating context such as “deposit” would be given more weight in a sentence about the “bank” (financial institute) to resolve the representational context to that of a financial institute. The encoder representations part of the BERT name is part of the transformer architecture. The encoder is the sentence input translated to representations of words meaning and the decoder is the processed text output in a contextualized form. In the image below we can see that ‘it’ is strongly being connected with “the” and “animal” to resolve back the reference to “the animal” as “it” as a resolution of anaphora.

This fixation also helps with the changing “part of speech” a word’s order in a sentence could have since we know that the same word can be different parts of speech depending upon its context. The example provided by Google below illustrates the importance of different parts of speech and word category disambiguation. Whilst a tiny word, the word ‘to’ here changes the meaning of the query altogether once it is taken into consideration in the full context of the phrase or sentence.

Masked Language Modelling (MLM Training)
Also known as “the Cloze Procedure,” which has been around for a very long time. The BERT architecture analyzes sentences with some words randomly masked out and attempts to correctly predict what the “hidden” word is. The purpose of this is to prevent target words in the training process passing through the BERT transformer architecture from inadvertently seeing themselves during bi-directional training when all of the words are looked at together for combined context. Ie. it avoids a type of erroneous infinite loop in natural language machine learning, which would skew word’s meaning.
Textual entailment (next sentence prediction)
One of the major innovations of BERT is that it is supposed to be able to predict what you’re going to say next, or as the New York Times phrased it in Oct 2018, “Finally, a machine that can finish your sentences.” BERT is trained to predict from pairs of sentences whether the second sentence provided is the right fit from a corpus of text. NB: It seems this feature during the past year was deemed as unreliable in the original BERT model and other open-source offerings have been built to resolve this weakness. Google’s ALBERT resolves this issue. Textual entailment is a type of “what comes next?” in a body of text. In addition to textual entailment, the concept is also known as ‘next sentence prediction’. Textual entailment is a natural language processing task involving pairs of sentences. The first sentence is analyzed and then a level of confidence determined to predict whether a given second hypothesized sentence in the pair “fits” logically as the suitable next sentence, or not, with either a positive, negative, or neutral prediction, from a text collection under scrutiny. Three examples from Wikipedia of each type of textual entailment prediction (neutral / positive / negative) are below. Textual Entailment Examples (Source: Wikipedia) An example of a positive TE (text entails hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has good consequences.
An example of a negative TE (text contradicts hypothesis) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man has no consequences.
An example of a non-TE (text does not entail nor contradict) is:
text: If you help the needy, God will reward you. hypothesis: Giving money to a poor man will make you a better person.
Disambiguation breakthroughs from open-sourced contributions
BERT has not just appeared from thin air, and BERT is no ordinary algorithmic update either since BERT is also an open-source natural language understanding framework as well. Ground-breaking “disambiguation from context empowered by open-sourced contributions,” could be used to summarise BERT’s main value add to natural language understanding. In addition to being the biggest change to Google’s search system in five years (or ever), BERT also represents probably the biggest leap forward in growing contextual understanding of natural language by computers of all time. Whilst Google BERT may be new to the SEO world it is well known in the NLU world generally and has caused much excitement over the past 12 months. BERT has provided a hockey stick improvement across many types of natural language understanding tasks not just for Google, but a myriad of both industrial and academic researchers seeking to utilize language understanding in their work, and even commercial applications. After the publication of the BERT research paper, Google announced they would be open-sourcing vanilla BERT. In the 12 months since publication alone, the original BERT paper has been cited in further research 1,997 times at the date of writing. There are many different types of BERT models now in existence, going well beyond the confines of Google Search. A search for Google BERT in Google Scholar returns hundreds of 2019 published research paper entries extending on BERT in a myriad of ways, with BERT now being used in all manner of research into natural language. Research papers traverse an eclectic mix of language tasks, domain verticals (for example clinical fields), media types (video, images) and across multiple languages. BERT’s use cases are far-reaching, from identifying offensive tweets using BERT and SVMs to using BERT and CNNs for Russian Troll Detection on Reddit, to categorizing via prediction movies according to sentiment analysis from IMDB, or predicting the next sentence in a question and answer pair as part of a dataset. Through this open-source approach, BERT goes a long way toward solving some long-standing linguistic problems in research, by simply providing a strong foundation to fine-tune from for anyone with a mind to do so. The codebase is downloadable from the Google Research Team’s Github page. By providing Vanilla BERT as a great ‘starter for ten’ springboard for machine learning enthusiasts to build upon, Google has helped to push the boundaries of State of the art (SOTA) natural language understanding tasks. Vanilla BERT can be likened to a CMS plugins, theme, or module which provides a strong foundation for a particular functionality but can then be developed further. Another simpler similarity might be likening the pre-training and fine-tuning parts of BERT for machine learning engineers to buying an off-the-peg suit from a high street store then visiting a tailor to turn up the hems so it is fit for purpose at a more unique needs level. As Vanilla BERT comes pre-trained (on Wikipedia and Brown corpus), researchers need only fine-tune their own models and additional parameters on top of the already trained model in just a few epochs (loops / iterations through the training model with the new fine-tuned elements included). At the time of BERT’s October 2018, paper publication BERT beat state of the art (SOTA) benchmarks across 11 different types of natural language understanding tasks, including question and answering, sentiment analysis, named entity determination, sentiment classification and analysis, sentence pair-matching and natural language inference. Furthermore, BERT may have started as the state-of-the-art natural language framework but very quickly other researchers, including some from other huge AI-focused companies such as Microsoft, IBM and Facebook, have taken BERT and extended upon it to produce their own record-beating open-source contributions. Subsequently, models other than BERT have become state of the art since BERT’s release. Facebook’s Liu et al entered the BERTathon with their own version extending upon BERT – RoBERTa. claiming the original BERT was significantly undertrained and professing to have improved upon, and beaten, any other model versions of BERT up to that point. Microsoft also beat the original BERT with MT-DNN, extending upon a model they proposed in 2015 but adding on the bi-directional pre-training architecture of BERT to improve further.

There are many other BERT-based models too, including Google’s own XLNet and ALBERT (Toyota and Google), IBM’s BERT-mtl, and even now Google T5 emerging.

The field is fiercely competitive and NLU machine learning engineer teams compete with both each other and non-expert human understanding benchmarks on public leaderboards, adding an element of gamification to the field. Amongst the most popular leaderboards are the very competitive SQuAD, and GLUE. SQuAD stands for The Stanford Question and Answering Dataset which is built from questions based on Wikipedia articles with answers provided by crowdworkers. The current SQuAD 2.0 version of the dataset is the second iteration created because SQuAD 1.1 was all but beaten by natural language researchers. The second-generation dataset, SQuAD 2.0 represented a harder dataset of questions, and also contained an intentional number of adversarial questions in the dataset (questions for which there was no answer). The logic behind this adversarial question inclusion is intentional and designed to train models to learn to know what they do not know (i.e an unanswerable question). GLUE is the General Language Understanding Evaluation dataset and leaderboard. SuperGLUE is the second generation of GLUE created because GLUE again became too easy for machine learning models to beat.

Most of the public leaderboards across the machine learning field double up as academic papers accompanied by rich question and answer datasets for competitors to fine-tune their models on. MS MARCO, for example, is an academic paper, dataset and accompanying leaderboard published by Microsoft; AKA Microsoft MAchine Reaching COmprehension Dataset. The MSMARCO dataset is made up of over a million real Bing user queries and over 180,000 natural language answers. Any researchers can utilize this dataset to fine-tune models.

Efficiency and computational expense
Late 2018 through 2019 can be remembered as a year of furious public leaderboard leap-frogging to create the current state of the art natural language machine learning model. As the race to reach the top of the various state of the art leaderboards heated up, so too did the size of the model’s machine learning engineers built and the number of parameters added based on the belief that more data increases the likelihood for more accuracy. However as model sizes grew so did the size of resources needed for fine-tuning and further training, which was clearly an unsustainable open-source path. Victor Sanh, of Hugging Face (an organization seeking to promote the continuing democracy of AI) writes, on the subject of the drastically increasing sizes of new models:
“The latest model from Nvidia has 8.3 billion parameters: 24 times larger than BERT-large, 5 times larger than GPT-2, while RoBERTa, the latest work from Facebook AI, was trained on 160GB of text 😵”
To illustrate the original BERT sizes – BERT-Base and BERT-Large, with 3 times the number of parameters of BERT-Base. BERT–Base, Cased : 12-layer, 768-hidden, 12-heads , 110M parameters. BERT–Large, Cased : 24-layer, 1024-hidden, 16-heads, 340M parameters. Escalating costs and data sizes meant some more efficient, less computationally and financially expensive models needed to be built.
Welcome Google ALBERT, Hugging Face DistilBERT and FastBERT
Google’s ALBERT, was released in September 2019 and is a joint work between Google AI and Toyota’s research team. ALBERT is considered BERT’s natural successor since it also achieves state of the art scores across a number of natural language processing tasks but is able to achieve these in a much more efficient and less computationally expensive manner. Large ALBERT has 18 times fewer parameters than BERT-Large. One of the main standout innovations with ALBERT over BERT is also a fix of a next-sentence prediction task which proved to be unreliable as BERT came under scrutiny in the open-source space throughout the course of the year. We can see here at the time of writing, on SQuAD 2.0 that ALBERT is the current SOTA model leading the way. ALBERT is faster and leaner than the original BERT and also achieves State of the Art (SOTA) on a number of natural language processing tasks.
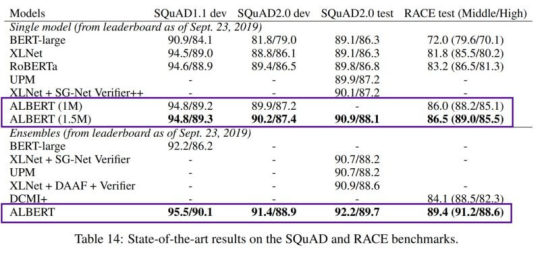
Other efficiency and budget focused, scaled-down BERT type models recently introduced are DistilBERT, purporting to be smaller, lighter, cheaper and faster, and FastBERT.
So, what does BERT mean for SEO?
BERT may be known among SEOs as an algorithmic update, but in reality, it is more “the application” of a multi-layer system that understands polysemous nuance and is better able to resolve co-references about “things” in natural language continually fine-tuning through self-learning. The whole purpose of BERT is to improve human language understanding for machines. In a search perspective this could be in written or spoken queries issued by search engine users, and in the content search engines gather and index. BERT in search is mostly about resolving linguistic ambiguity in natural language. BERT provides text-cohesion which comes from often the small details in a sentence that provides structure and meaning. BERT is not an algorithmic update like Penguin or Panda since BERT does not judge web pages either negatively or positively, but more improves the understanding of human language for Google search. As a result, Google understands much more about the meaning of content on pages it comes across and also the queries users issue taking word’s full context into consideration.

BERT is about sentences and phrases
Ambiguity is not at a word level, but at a sentence level, since it is about the combination of words with multiple meanings which cause ambiguity.

BERT helps with polysemic resolution
Google BERT helps Google search to understand “text-cohesion” and disambiguate in phrases and sentences, particularly where polysemic nuances could change the contextual meaning of words. In particular, the nuance of polysemous words and homonyms with multiple meanings, such as ‘to’, ‘two’, ‘to’, and ‘stand’ and ‘stand’, as provided in the Google examples, illustrate the nuance which had previously been missed, or misinterpreted, in search.
Ambiguous and nuanced queries impacted
The 10% of search queries which BERT will impact may be very nuanced ones impacted by the improved contextual glue of text cohesion and disambiguation. Furthermore, this might well impact understanding even more of the 15% of new queries which Google sees every day, many of which relate to real-world events and burstiness / temporal queries rather than simply long-tailed queries.
Recall and precision impacted (impressions?)
Precision in ambiguous query meeting will likely be greatly improved which may mean query expansion and relaxation to include more results (recall) may be reduced. Precision is a measure of result quality, whereas recall simply relates to return any pages which may be relevant to a query. We may see this reduction in recall reflected in the number of impressions we see in Google Search Console, particularly for pages with long-form content which might currently be in recall for queries they are not particularly relevant for.
BERT will help with coreference resolution
BERT(the research paper and language model)’s capabilities with coreference resolution means the Google algorithm likely helps Google Search to keep track of entities when pronouns and noun-phrases refer to them. BERT’s attention mechanism is able to focus on the entity under focus and resolve all references in sentences and phrases back to that using a probability determination / score. Pronouns of “he,” “she,” “they,” “it” and so forth will be much easier for Google to map back in both content and queries, spoken and in written text. This may be particularly important for longer paragraphs with multiple entities referenced in text for featured snippet generation and voice search answer extraction / conversational search.
BERT serves a multitude of purposes
Google BERT is probably what could be considered a Swiss army knife type of tool for Google Search. BERT provides a solid linguistic foundation for Google search to continually tweak and adjust weights and parameters since there are many different types of natural language understanding tasks that could be undertaken. Tasks may include:
Coreference resolution (keeping track of who, or what, a sentence or phrase refers to in context or an extensive conversational query)
Polysemy resolution (dealing with ambiguous nuance)
Homonym resolution (dealing with understanding words which sound the same, but mean different things
Named entity determination (understanding which, from a number of named entities, text relates to since named entity recognition is not named entity determination or disambiguation), or one of many other tasks.
Textual entailment (next sentence prediction)
BERT will be huge for conversational search and assistant
Expect a quantum leap forward in terms of relevance matching to conversational search as Google’s in-practice model continues to teach itself with more queries and sentence pairs. It’s likely these quantum leaps will not just be in the English language, but very soon, in international languages too since there is a feed-forward learning element within BERT that seems to transfer to other languages.
BERT will likely help Google to scale conversational search
Expect over the short to medium term a quantum leap forward in application to voice search however since the heavy lifting of building out the language understanding held back by Pygmalion’s manual process could be no more. The earlier referenced 2016 Wired article concluded with a definition of AI automated, unsupervised learning which might replace Google Pygmalion and create a scalable approach to train neural nets:
“This is when machines learn from unlabeled data – massive amounts of digital information culled from the internet and other sources.” (Wired, 2016)
This sounds like Google BERT. We also know featured snippets were being created by Pygmalion too. While it is unclear whether BERT will have an impact on Pygmalion’s presence and workload, nor if featured snippets will be generated in the same way as previously, Google has announced BERT will be used for featured snippets and is pre-trained on purely a large text corpus. Furthermore, the self-learning nature of a BERT type foundation continually fed queries and retrieving responses and featured snippets will naturally pass the learnings forward and become even more fine-tuned. BERT, therefore, could provide a potentially, hugely scalable alternative to the laborious work of Pygmalion.
International SEO may benefit dramatically too
One of the major impacts of BERT could be in the area of international search since the learnings BERT picks up in one language seem to have some transferable value to other languages and domains too. Out of the box, BERT appears to have some multi-lingual properties somehow derived from a monolingual (single language understanding) corpora and then extended to 104 languages, in the form of M-BERT (Multilingual BERT). A paper by Pires, Schlinger & Garrette tested the multilingual capabilities of Multilingual BERT and found that it “surprisingly good at zero-shot cross-lingual model transfer.” (Pires, Schlinger & Garrette, 2019). This is almost akin to being able to understand a language you have never seen before since zero-shot learning aims to help machines categorize objects that they have never seen before.
Questions and answers
Question and answering directly in SERPs will likely continue to get more accurate which could lead to a further reduction in click through to sites. In the same way MSMARCO is used for fine-tuning and is a real dataset of human questions and answers from Bing users, Google will likely continue to fine-tune its model in real-life search over time through real user human queries and answers feeding forward learnings. As language continues to be understood paraphrase understanding improved by Google BERT might also impact related queries in “People Also Ask.”
Textual entailment (next sentence prediction)
The back and forth of conversational search, and multi-turn question and answering for assistant will also likely benefit considerably from BERT’s ‘textual entailment’ (next sentence prediction) feature, particularly the ability to predict “what comes next” in a query exchange scenario. However, this might not seem apparent as quickly as some of the initial BERT impacts. Furthermore, since BERT can understand different meanings for the same things in sentences, aligning queries formulated in one way and resolving them to answers which amount to the same thing will be much easier. I asked Dr. Mohammad Aliannejadi about the value BERT provides for conversational search research. Dr. Aliannejadi is an information retrieval researcher who recently defended his Ph.D. research work on conversational search, supervised by Professor Fabio Crestani, one of the authors of “Mobile information retrieval.” Part of Dr. Aliannejadi’s research work explored the effects of asking clarifying questions for conversational assistants, and utilized BERT within its methodology. Dr. Aliannejadi spoke of BERT’s value:
“BERT represents the whole sentence, and so it is representing the context of the sentence and can model the semantic relationship between two sentences. The other powerful feature is the ability to fine-tune it in just a few epochs. So, you have a general tool and then make it specific to your problem.”
Named entity determination
One of the natural language processing tasks undertaken by the likes of a fine-tuned BERT model could be entity determination. Entity determination is deciding the probability that a particular named entity is being referred to from more than one choice of named entity with the same name. Named entity recognition is not named entity disambiguation nor named entity determination. In an AMA on Reddit Google’s Gary Illyes confirmed that unlinked mentions of brand names can be used for this named entity determination purpose currently.

BERT will assist with understanding when a named entity is recognized but could be one of a number of named entities with the same name as each other. An example of multiple named entities with the same name is in the example below. Whilst these entities may be recognized by their name they need to be disambiguated one from the other. Potentially an area BERT can help with. We can see from a search in Wikipedia below the word “Harris” returns many named entities called “Harris.”

BERT could be BERT by name, but not by nature
It is not clear whether the Google BERT update uses the original BERT or the much leaner and inexpensive ALBERT, or another hybrid variant of the many models now available, but since ALBERT can be fine-tuned with far fewer parameters than BERT this might make sense. This could well mean the algorithm BERT in practice may not look very much at all like the original BERT in the first published paper, but a more recent improved version which looks much more like the (also open-sourced) engineering efforts of others aiming to build the latest SOTA models. BERT may be a completely re-engineered large scale production version, or a more computationally inexpensive and improved version of BERT, such as the joint work of Toyota and Google, ALBERT. Furthermore, BERT may continue to evolve into other models since Google T5 Team also now has a model on the public SuperGLUE leaderboards called simply T5. BERT may be BERT in name, but not in nature.
Can you optimize your SEO for BERT?
Probably not. The inner workings of BERT are complex and multi-layered. So much so, there is now even a field of study called “Bertology” which has been created by the team at Hugging Face. It is highly unlikely any search engineer questioned could explain the reasons why something like BERT would make the decisions it does with regards to rankings (or anything). Furthermore, since BERT can be fine-tuned across parameters and multiple weights then self-learns in an unsupervised feed-forward fashion, in a continual loop, it is considered a black-box algorithm. A form of unexplainable AI. BERT is thought to not always know why it makes decisions itself. How are SEOs then expected to try to “optimize” for it? BERT is designed to understand natural language so keep it natural. We should continue to create compelling, engaging, informative and well-structured content and website architectures in the same way you would write, and build sites, for humans. The improvements are on the search engine side of things and are a positive rather than a negative. Google simply got better at understanding the contextual glue provided by text cohesion in sentences and phrases combined and will become increasingly better at understanding the nuances as BERT self-learns.
Search engines still have a long way to go
Search engines still have a long way to go and BERT is only a part of that improvement along the way, particularly since a word’s context is not the same as search engine user’s context, or sequential informational needs which are infinitely more challenging problems. SEOs still have a lot of work to do to help search engine users find their way and help to meet the right informational need at the right time.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author

Dawn Anderson is a SEO & Search Digital Marketing Strategist focusing on technical, architectural and database-driven SEO. Dawn is the director of Move It Marketing.
https://www.businesscreatorplus.com/a-deep-dive-into-bert-how-bert-launched-a-rocket-into-natural-language-understanding/
0 notes
Note
What is "the ass slap that isn't"? From 5.03? I'm confused. Sorry. I hope this isn't a waste of your time.
Oh gosh, this is Lizbob’s thing, actually. But that scene where Dean’s fixing Cas’s tie, telling him why they lie, “because that’s how you become president.”
Lizbob’s headcanon there is that Dean fixes his tie, then there’s a weird little shift to Dean’s shoulders as he says that line, after basically manhandling Cas through that entire scene.
here’s a gif set for your consideration:
https://elizabethrobertajones.tumblr.com/post/127077976002
But, it’s not really an ass slap (most likely), but heck if that isn’t the more hilarious way to interpret it. :P
I asked lizbob to help me find gif evidence, and during our search we thought of two other scenes that could’ve been ass slaps, but weren’t-- when Dean hands Cas some cash, tells him “don’t make me push you” and sends him after Chastity, and then again outside the brothel while Dean’s laughing-- there’s a weird cut from a wide shot to a mid shot while Dean’s raising his arm up to Cas’s shoulders. Like they could’ve cut out the slap (whether ass or just a back slap is up for debate). (I mean the entire thing is up for debate but heck it could’ve been an ass slap. There’s nothing in text to say it wasn’t, you know? Aah, polysemy my old friend.)
Essentially it’s a cracky, fun little headcanon. The sort of headcanon that leads to 2am crack posts about booty shorts and grenade launchers.
22 notes
·
View notes
Photo

Reposted from @rapseminar - Often confused for double entendre, polysemy happens when a phrase has many possible meanings. Y’all get this, right? 😂 Show & prove by telling us what he’s saying, or by naming emcees that you know use polysemy, and as a token of our appreciation we’ll give you a shoutout in our IG story 💎 There’s more @milanothedon analytics on the way, so keep it locked 🔒 🙌🏾 - #regrann https://www.instagram.com/p/ByseEQZgZGP/?igshid=n96056c9z7k8
0 notes