#iterative monte carlo search
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
python iterative monte carlo search for text generation using nltk
You are playing a game and you want to win. But you don't know what move to make next, because you don't know what the other player will do. So, you decide to try different moves randomly and see what happens. You repeat this process again and again, each time learning from the result of the move you made. This is called iterative Monte Carlo search. It's like making random moves in a game and learning from the outcome each time until you find the best move to win.
Iterative Monte Carlo search is a technique used in AI to explore a large space of possible solutions to find the best ones. It can be applied to semantic synonym finding by randomly selecting synonyms, generating sentences, and analyzing their context to refine the selection.
# an iterative monte carlo search example using nltk # https://pythonprogrammingsnippets.tumblr.com import random from nltk.corpus import wordnet # Define a function to get the synonyms of a word using wordnet def get_synonyms(word): synonyms = [] for syn in wordnet.synsets(word): for l in syn.lemmas(): if '_' not in l.name(): synonyms.append(l.name()) return list(set(synonyms)) # Define a function to get a random variant of a word def get_random_variant(word): synonyms = get_synonyms(word) if len(synonyms) == 0: return word else: return random.choice(synonyms) # Define a function to get the score of a candidate sentence def get_score(candidate): return len(candidate) # Define a function to perform one iteration of the monte carlo search def monte_carlo_search(candidate): variants = [get_random_variant(word) for word in candidate.split()] max_candidate = ' '.join(variants) max_score = get_score(max_candidate) for i in range(100): variants = [get_random_variant(word) for word in candidate.split()] candidate = ' '.join(variants) score = get_score(candidate) if score > max_score: max_score = score max_candidate = candidate return max_candidate initial_candidate = "This is an example sentence." # Perform 10 iterations of the monte carlo search for i in range(10): initial_candidate = monte_carlo_search(initial_candidate) print(initial_candidate)
output:
This manufacture Associate_in_Nursing theoretical_account sentence. This fabricate Associate_in_Nursing theoretical_account sentence. This construct Associate_in_Nursing theoretical_account sentence. This cathode-ray_oscilloscope Associate_in_Nursing counteract sentence. This collapse Associate_in_Nursing computed_axial_tomography sentence. This waste_one's_time Associate_in_Nursing gossip sentence. This magnetic_inclination Associate_in_Nursing temptingness sentence. This magnetic_inclination Associate_in_Nursing conjure sentence. This magnetic_inclination Associate_in_Nursing controversy sentence. This inclination Associate_in_Nursing magnetic_inclination sentence.
#python#nltk#iterative monte carlo search#monte carlo search#monte carlo#search#text generation#generative text#text#generation#text prediction#synonyms#synonym#semantics#semantic#language#language model#ai#iterative#iteration#artificial intelligence#sentence rewriting#sentence rewrite#story generation#deep learning#learning#educational#snippet#code#source code
2 notes
·
View notes
Text
Hattusa, Mycenae & Knossos (0xD/?)

Continuation of this article thread:
Essentially I need to better grasp and iterate from the characters I already have and generate + iterate the remainder of the cast. Because while I do have a decent grasp at Kate, Ava & Shoshona, the other characters still are quite the mystery tbh. Key things like the worldly setting and intrigue points shall be iterated forth eventually once the characters are decently figured out.

Soundscape + musical playlist
?
Sensory detailwork
?
Keywords
Tramway + Subway network
Van hexcrawl
Legal system
Mundane urban fantasy
Libraries, archives & video rental shops at the hyper-mall
Generational renewals with the Cycle of Life + Coming-of-Age
Political intrigues
Android rights for synthetics
Morphological freedoms
Data & governance transparency
Systemic change
Historical cycles
Critical yet informed perspective
Spiritual / esoteric empowerment
Robotic Soldiers
Life scripting...
Constructed Linguistics
Libre + Copyleft technologies
Progressives National Convention
Syndicalists Strike
Harmonious Party plotting
Union Party falling flat
Divine beings walking among the living
Extended Zodiac Calendar-based Generators...
Synopsis / Blurb?
Set in a retro-futuristic coastal commune at the north-eastern edge of the Shoshone Civilization, Kate navigates across the tramway network searching within for lively meaning. And as she finds herself stuck amidst political intrigues of historical magnitude, she gathers popular support alongside her synthetic servant in court of law to push forth individual freedoms, government transparency & technological empowerment.
Agents (to be iterated way further...)
Chronokinetic Oracle (Kate) - INTJ
Shapeshifter / "True_Polymorph" Witch (Shoshona) - ENTP
Synthetic-tier android blonde as social service assistance servant (Ava) - ENFP
Far far away future mentor? (Constans?) - INTP
Second person perspective (Nil) - ~
Tasks
Baseline text-based level for NPC simulation into my very own homestead level...
Mosi worldscape primitives demo? (480x288 3D cells?)
Study TES Daggerfall (Unity port) / Pathfinder 2.5E / Talespinner, Cyberpunk 2077 Phantom Liberty/Cyberpunk RED & EU4/FreeCiv/Civ5CE++ state machine automaton & adapt my constructed world within their modding systems...
Devise GPlates, GProjector, QGIS model for its custom open geofiction OSM world web page & data...
Generate bulk amounts of NPCs by Monte Carlo randomized spreadsheets (statistically-informed agent generators...)
Simulate NPC social ecosystems & simulationist interactions within Unity Pixel Crushers' Frameworks.
Qodot + Godot FPP Controller dev stuff
2880x1440 layered chunkmap?
Timely USD-like Savefile Bookmarks & historical changes markup…
Retro Usbourne edutaining books study
Mark Rosenfelder study
MultiUserDomain multiplayer "system" & customized TS2+SC4 workflow...
Social Life Sim, Job-System, City-Building+Destruction, Wealth Plots, Factional Mechanisms... for Trial Engine conversion;
GLOSS software-only, SB Common Lisp emphasis, Linux portable runtime, KDE Plasma + Liquidshell Qt GUI...
First person perspective social simulation environments...
Such a mess, will replace soon.
0 notes
Text
Connecting the Dots: Unravelling OpenAI’s Alleged Q-Star Model
New Post has been published on https://thedigitalinsider.com/connecting-the-dots-unravelling-openais-alleged-q-star-model/
Connecting the Dots: Unravelling OpenAI’s Alleged Q-Star Model

Recently, there has been considerable speculation within the AI community surrounding OpenAI’s alleged project, Q-star. Despite the limited information available about this mysterious initiative, it is said to mark a significant step toward achieving artificial general intelligence—a level of intelligence that either matches or surpasses human capabilities. While much of the discussion has focused on the potential negative consequences of this development for humanity, there has been relatively little effort dedicated to uncovering the nature of Q-star and the potential technological advantages it may bring. In this article, I will take an exploratory approach, attempting to unravel this project primarily from its name, which I believe provides sufficient information to glean insights about it.
Background of Mystery
It all began when the board of governors at OpenAI suddenly ousted Sam Altman, the CEO, and co-founder. Although Altman was reinstated later, questions persist about the events. Some see it as a power struggle, while others attribute it to Altman’s focus on other ventures like Worldcoin. However, the plot thickens as Reuters reports that a secretive project called Q-star might be the primary reason for the drama. As per Reuters, Q-Star marks a substantial step towards OpenAI’s AGI objective, a matter of concern conveyed to the board of governors by OpenAI’s workers. The emergence of this news has sparked a flood of speculations and concerns.
Building Blocks of the Puzzle
In this section, I have introduced some building blocks that will help us to unravel this mystery.
Q Learning: Reinforcement learning is a type of machine learning where computers learn by interacting with their environment, receiving feedback in the form of rewards or penalties. Q Learning is a specific method within reinforcement learning that helps computers make decisions by learning the quality (Q-value) of different actions in different situations. It’s widely used in scenarios like game-playing and robotics, allowing computers to learn optimal decision-making through a process of trial and error.
A-star Search: A-star is a search algorithm which help computers explore possibilities and find the best solution to solve a problem. The algorithm is particularly notable for its efficiency in finding the shortest path from a starting point to a goal in a graph or grid. Its key strength lies in smartly weighing the cost of reaching a node against the estimated cost of reaching the overall goal. As a result, A-star is extensively used in addressing challenges related to pathfinding and optimization.
AlphaZero: AlphaZero, an advanced AI system from DeepMind, combines Q-learning and search (i.e., Monte Carlo Tree Search) for strategic planning in board games like chess and Go. It learns optimal strategies through self-play, guided by a neural network for moves and position evaluation. The Monte Carlo Tree Search (MCTS) algorithm balances exploration and exploitation in exploring game possibilities. AlphaZero’s iterative self-play, learning, and search process leads to continuous improvement, enabling superhuman performance and victories over human champions, demonstrating its effectiveness in strategic planning and problem-solving.
Language Models: Large language models (LLMs), like GPT-3, are a form of AI designed for comprehending and generating human-like text. They undergo training on extensive and diverse internet data, covering a broad spectrum of topics and writing styles. The standout feature of LLMs is their ability to predict the next word in a sequence, known as language modelling. The goal is to impart an understanding of how words and phrases interconnect, allowing the model to produce coherent and contextually relevant text. The extensive training makes LLMs proficient at understanding grammar, semantics, and even nuanced aspects of language use. Once trained, these language models can be fine-tuned for specific tasks or applications, making them versatile tools for natural language processing, chatbots, content generation, and more.
Artificial General intelligence: Artificial General Intelligence (AGI) is a type of artificial intelligence with the capacity to understand, learn, and execute tasks spanning diverse domains at a level that matches or exceeds human cognitive abilities. In contrast to narrow or specialized AI, AGI possesses the ability to autonomously adapt, reason, and learn without being confined to specific tasks. AGI empowers AI systems to showcase independent decision-making, problem-solving, and creative thinking, mirroring human intelligence. Essentially, AGI embodies the idea of a machine capable of undertaking any intellectual task performed by humans, highlighting versatility and adaptability across various domains.
Key Limitations of LLMs in Achieving AGI
Large Language Models (LLMs) have limitations in achieving Artificial General Intelligence (AGI). While adept at processing and generating text based on learned patterns from vast data, they struggle to understand the real world, hindering effective knowledge use. AGI requires common sense reasoning and planning abilities for handling everyday situations, which LLMs find challenging. Despite producing seemingly correct responses, they lack the ability to systematically solve complex problems, such as mathematical ones.
New studies indicate that LLMs can mimic any computation like a universal computer but are constrained by the need for extensive external memory. Increasing data is crucial for improving LLMs, but it demands significant computational resources and energy, unlike the energy-efficient human brain. This poses challenges for making LLMs widely available and scalable for AGI. Recent research suggests that simply adding more data doesn’t always improve performance, prompting the question of what else to focus on in the journey towards AGI.
Connecting Dots
Many AI experts believe that the challenges with Large Language Models (LLMs) come from their main focus on predicting the next word. This limits their understanding of language nuances, reasoning, and planning. To deal with this, researchers like Yann LeCun suggest trying different training methods. They propose that LLMs should actively plan for predicting words, not just the next token.
The idea of “Q-star,” similar to AlphaZero’s strategy, may involve instructing LLMs to actively plan for token prediction, not just predicting the next word. This brings structured reasoning and planning into the language model, going beyond the usual focus on predicting the next token. By using planning strategies inspired by AlphaZero, LLMs can better understand language nuances, improve reasoning, and enhance planning, addressing limitations of regular LLM training methods.
Such an integration sets up a flexible framework for representing and manipulating knowledge, helping the system adapt to new information and tasks. This adaptability can be crucial for Artificial General Intelligence (AGI), which needs to handle various tasks and domains with different requirements.
AGI needs common sense, and training LLMs to reason can equip them with a comprehensive understanding of the world. Also, training LLMs like AlphaZero can help them learn abstract knowledge, improving transfer learning and generalization across different situations, contributing to AGI’s strong performance.
Besides the project’s name, support for this idea comes from a Reuters’ report, highlighting the Q-star’s ability to solve specific mathematical and reasoning problems successfully.
The Bottom Line
Q-Star, OpenAI’s secretive project, is making waves in AI, aiming for intelligence beyond humans. Amidst the talk about its potential risks, this article digs into the puzzle, connecting dots from Q-learning to AlphaZero and Large Language Models (LLMs).
We think “Q-star” means a smart fusion of learning and search, giving LLMs a boost in planning and reasoning. With Reuters stating that it can tackle tricky mathematical and reasoning problems, it suggests a major advance. This calls for taking a closer look at where AI learning might be heading in the future.
#AGI#ai#algorithm#applications#approach#Article#artificial#Artificial General Intelligence#Artificial Intelligence#background#board#Brain#Building#CEO#chatbots#chess#Community#comprehensive#computation#computer#computers#continuous#data#deal#DeepMind#development#domains#efficiency#energy#Environment
0 notes
Text
If you did not already know
Horn I introduce a new distributed system for effective training and regularizing of Large-Scale Neural Networks on distributed computing architectures. The experiments demonstrate the effectiveness of flexible model partitioning and parallelization strategies based on neuron-centric computation model, with an implementation of the collective and parallel dropout neural networks training. Experiments are performed on MNIST handwritten digits classification including results. … Iterated Filtering Iterated filtering algorithms are a tool for maximum likelihood inference on partially observed dynamical systems. Stochastic perturbations to the unknown parameters are used to explore the parameter space. Applying sequential Monte Carlo (the particle filter) to this extended model results in the selection of the parameter values that are more consistent with the data. Appropriately constructed procedures, iterating with successively diminished perturbations, converge to the maximum likelihood estimate. Iterated filtering methods have so far been used most extensively to study infectious disease transmission dynamics. Case studies include cholera, Ebola virus, influenza, malaria, HIV, pertussis, poliovirus and measles. Other areas which have been proposed to be suitable for these methods include ecological dynamics and finance. The perturbations to the parameter space play several different roles. Firstly, they smooth out the likelihood surface, enabling the algorithm to overcome small-scale features of the likelihood during early stages of the global search. Secondly, Monte Carlo variation allows the search to escape from local minima. Thirdly, the iterated filtering update uses the perturbed parameter values to construct an approximation to the derivative of the log likelihood even though this quantity is not typically available in closed form. Fourthly, the parameter perturbations help to overcome numerical difficulties that can arise during sequential Monte Carlo. Accelerate iterated filtering … PoPPy PoPPy is a Point Process toolbox based on PyTorch, which achieves flexible designing and efficient learning of point process models. It can be used for interpretable sequential data modeling and analysis, e.g., Granger causality analysis of multi-variate point processes, point process-based simulation and prediction of event sequences. In practice, the key points of point process-based sequential data modeling include: 1) How to design intensity functions to describe the mechanism behind observed data? 2) How to learn the proposed intensity functions from observed data? The goal of PoPPy is providing a user-friendly solution to the key points above and achieving large-scale point process-based sequential data analysis, simulation and prediction. … sigma.js Sigma is a JavaScript library dedicated to graph drawing. It makes easy to publish networks on Web pages, and allows developers to integrate network exploration in rich Web applications. … https://analytixon.com/2022/10/20/if-you-did-not-already-know-1862/?utm_source=dlvr.it&utm_medium=tumblr
0 notes
Text
If you did not already know
Horn I introduce a new distributed system for effective training and regularizing of Large-Scale Neural Networks on distributed computing architectures. The experiments demonstrate the effectiveness of flexible model partitioning and parallelization strategies based on neuron-centric computation model, with an implementation of the collective and parallel dropout neural networks training. Experiments are performed on MNIST handwritten digits classification including results. … Iterated Filtering Iterated filtering algorithms are a tool for maximum likelihood inference on partially observed dynamical systems. Stochastic perturbations to the unknown parameters are used to explore the parameter space. Applying sequential Monte Carlo (the particle filter) to this extended model results in the selection of the parameter values that are more consistent with the data. Appropriately constructed procedures, iterating with successively diminished perturbations, converge to the maximum likelihood estimate. Iterated filtering methods have so far been used most extensively to study infectious disease transmission dynamics. Case studies include cholera, Ebola virus, influenza, malaria, HIV, pertussis, poliovirus and measles. Other areas which have been proposed to be suitable for these methods include ecological dynamics and finance. The perturbations to the parameter space play several different roles. Firstly, they smooth out the likelihood surface, enabling the algorithm to overcome small-scale features of the likelihood during early stages of the global search. Secondly, Monte Carlo variation allows the search to escape from local minima. Thirdly, the iterated filtering update uses the perturbed parameter values to construct an approximation to the derivative of the log likelihood even though this quantity is not typically available in closed form. Fourthly, the parameter perturbations help to overcome numerical difficulties that can arise during sequential Monte Carlo. Accelerate iterated filtering … PoPPy PoPPy is a Point Process toolbox based on PyTorch, which achieves flexible designing and efficient learning of point process models. It can be used for interpretable sequential data modeling and analysis, e.g., Granger causality analysis of multi-variate point processes, point process-based simulation and prediction of event sequences. In practice, the key points of point process-based sequential data modeling include: 1) How to design intensity functions to describe the mechanism behind observed data? 2) How to learn the proposed intensity functions from observed data? The goal of PoPPy is providing a user-friendly solution to the key points above and achieving large-scale point process-based sequential data analysis, simulation and prediction. … sigma.js Sigma is a JavaScript library dedicated to graph drawing. It makes easy to publish networks on Web pages, and allows developers to integrate network exploration in rich Web applications. … https://analytixon.com/2022/10/20/if-you-did-not-already-know-1862/?utm_source=dlvr.it&utm_medium=tumblr
0 notes
Text
Chitarrella

CHITARRELLA FULL
CHITARRELLA PROFESSIONAL
The following steps of the iteration are restricted to regions that are consistent with that determinization. Thus, at the beginning of each iteration, a determinization is sampled from the root information set and The selection step is changed because the probability distribution of moves is not uniformĪnd a move may be available only in fewer states of the same information set. The outgoing arcs from an opponent’s node represent the union of all moves available in every state within that information set, because the player cannot know the moves that are really available to the opponent. ISMCTS builds asymmetric search trees of information sets containing game states that are indistinguishable from the player’s point of view.Įach node represents an information set from the root player’s point of view and arcs correspond to moves played by the corresponding player. MCTS to decisions with imperfect information about the game state and performed actions. introduced Information Set Monte Carlo Tree Search The experiment involving human players suggests that ISMCTS might be more challenging than traditional strategies. The best known and most studied advanced strategy for Scopone. Outperforms all the rule-based players that implement The cheating MCTS player outperforms all the other strategies while the fair ISMCTS player Then, we performed a tournament among the three selected players and also an experiment involving humans. We performed a set of experiments to select the best rule-based player and the best configuration for MCTS and ISMCTS. We evaluated different reward functions and simulation strategies. ISMCTS can deal with incomplete information and thus implements a fair player.
CHITARRELLA FULL
MCTS requires the full knowledge of the game state (that is, of the cards of all the players)Īnd thus, by implementing a cheating player, it provides an upper bound to the performance achievable with this class of methods. The third rule-based player extends the previous approach with the additional rules introduced in. The second one implements Chitarella’s rules with the additional rules introduced by Saracino ,Īnd represents the most fundamental and advanced strategy for the game The first rule-based player implements the basic greedy strategy taught to beginner players Players based on Monte Carlo Tree Search (MCTS) Īnd Information Set Monte Carlo Tree Search (ISMCTS). We compare the performance of three rule-based players that implement well-established playing strategies against In this paper, we present the design of a competitive artificial intelligence for Scopone and The second most important strategy book was written by Cicuti and Guardamagna who enriched īy introducing advanced rules regarding the play of sevens.
CHITARRELLA PROFESSIONAL
Only recently Saracino, a professional bridge player, proposed additional rules to extend the original strategy Īlthough dated, the rules by Chitarella are still considered the main and most important strategy guide for Scopone However several historians argue that Scopone was known centuries before Chitarella. 2 2 2 Īt that time, Capecelatro wrote that the game was known by 3-4 generations, therefore it might have been born in the eighteenth century Was written by Capecelatro in 1855, “Del giuoco dello Scopone”. The first original book about Scopone, that is still available, Unfortunately, there are no copies available of the original book and the eldest reprint is from 1937. The rules of the game and a compendium of strategy rules for advanced players. The first known book about Scopone was published in 1750 by Chitarella and contained both It is often referred to as Scopone Scientifico, that is, Scientific Scopone). Originally, the game was played by poorly educated people andĪs any other card game in Italy at the time was hindered by authority.īeing considered intellectually challenging, the game spread among highly educated people and high rank politicians 1 1 1E.g., Īchieving, nowadays, a vast popularity and a reputation similar to Bridge (for which Scopone is a popular Italian card game whose origins date back to (at least) 1700s.
0 notes
Text
Tree outline

#TREE OUTLINE HOW TO#
A family tree not only provides information about the family history but also brings people closer to their families. That is why there are many cases of people dating and even having kids only to find out later that they are related.Ī family tree is particularly helpful to the younger generation, a majority of whom know little about their ancestors and extended family at large. A vast majority of them only know their immediate family members. Unlike the past, where the immediate and extended family lived together like a close family unit, nowadays most people, especially the younger generation, mind their own business. It indicates how family members are related to each other, from close family members and close relatives to distant members and ancestors. What is a family tree?Īlso referred to as a pedigree chart or a genealogy, a family tree is a chart that represents family relationships in a convention tree structure.
#TREE OUTLINE HOW TO#
Read more about how to correctly acknowledge RSC content.With that said, if you have no idea about your ancestors, and/or some relatives or distant members of your family, referring to your family tree can be an excellent way to educate yourself. Permission is not required) please go to the Copyright If you want to reproduce the wholeĪrticle in a third-party commercial publication (excluding your thesis/dissertation for which If you are the author of this article, you do not need to request permission to reproduce figuresĪnd diagrams provided correct acknowledgement is given. Provided correct acknowledgement is given. If you are an author contributing to an RSC publication, you do not need to request permission Please go to the Copyright Clearance Center request page. To request permission to reproduce material from this article in a commercial publication, Provided that the correct acknowledgement is given and it is not used for commercial purposes. This article in other publications, without requesting further permission from the RSC, Our study presents an important step in realizing automatic retrosynthetic route planning.Īutomatic retrosynthetic route planning using template-free modelsĬreative Commons Attribution-NonCommercial 3.0 Unported Licence. The end-to-end model for reaction task prediction can be easily extended to larger or customer-requested reaction databases. AutoSynRoute successfully reproduced published synthesis routes for the four case products. We then constructed an automatic data-driven end-to-end retrosynthetic route planning system (AutoSynRoute) using Monte Carlo tree search with a heuristic scoring function. Inspired by the success rate of the one-step reaction prediction, we further carried out iterative, multi-step retrosynthetic route planning for four case products, which was successful. Using reactions from the United States patent literature, our end-to-end models naturally incorporate the global chemical environments of molecules and achieve remarkable performance in top-1 predictive accuracy (63.0%, with the reaction class provided) and top-1 molecular validity (99.6%) in one-step retrosynthetic tasks. We treated each reaction prediction task as a data-driven sequence-to-sequence problem using the multi-head attention-based Transformer architecture, which has demonstrated power in machine translation tasks. Here we present a template-free approach that is independent of reaction templates, rules, or atom mapping, to implement automatic retrosynthetic route planning. Although there has been much progress in computer-assisted retrosynthetic route planning and reaction prediction, fully data-driven automatic retrosynthetic route planning remains challenging. The possibilities for each transformation are generated based on collected reaction rules, and then potential reaction routes are recommended by various optimization algorithms. Retrosynthetic route planning can be considered a rule-based reasoning procedure.
0 notes
Text
well. that didn't go too well. new calculator saved my ass on the matrix multiplication but I didn't have anything in my notecards about monte carlo tree search or policy iteration for some reason..
I have an artificial intelligence test in less than an hour and I'm kind of anxious.. I couldn't find my calculator so I bought a cool new one and I have all my notecards with everything copied down from the slides but I aaaaa
3 notes
·
View notes
Text
T-55: Java Results
Good news everybody, I still got it! At least, I can produce actual Java code that appears to do the job intended.
Note: Inspiration for this and some of the tricks were from this post here
I created the following classes:
Operator (enum): This has four values, PLUS, MINUS, TIMES and DIVIDE
Number: This is a wrapper around an Integer, but it can hold either an atomic value e.g. ”4″ or a result of a calculation e.g. “(4+2)”. For this reason, it has two properties - getValue and toString. This is what allows us to see both the calculation result and the way it was derived.
NumberSet: This is a collection (it extends ArrayList) of Number objects, which represents a possible set of resources that are derivable from an initial set of numbers, e.g. {100,2,3,5,8,9} or {102,3,5,8,9}.
Exploder: This represents the business logic of what NumberSets can be derived from a given number set. Note that all derived NumberSets have one fewer element than their parent NumberSet, so there is a finite quantity of derived NumberSets from any initial set of numbers. This contains rules for what’s allowable (all calculation outcomes must be positive integers) and efficient (it’ll never take 2 from 4, as that’ll just make 2 again, wasting the 4!)
Countdown: This has the search algorithm, which is very simple breadth-first search. The algorithm takes the initial NumberSet and “Explodes” it as much as it can, by taking each individual element and trying each allowable calculation against each other element. It takes the resulting list of possible NumberSets and adds them to it’s own “to-do list”. If it’s got a target, it checks to see if this NumberSet contains it.
There are two additional things I did to make the process more efficient, both with HashMaps:
As it goes along, it saves every number it derives. If it derives the same number multiple times, it only saves one way to derive it.
If it gets a certain combination of values (NumberSet) in different ways, it will only add one of them to its own to-do list
Having completed the algorithm, I tested it by having it output the different calculations to the console, manually verifying the calculations. Rather than test for a single number, I got it to start at 100 and find a solution, then 101, then 102, until it found a number it couldn’t derive. There were a good number of sets of initial numbers that could handle every integer between 100 and 999 inclusive, so I was then curious what set of initial Countdown Numbers went the highest.
Rather than get overtly scientific about it, I did a pseudo-Monte Carlo simulation - I got a random set of 6 numbers from the Countdown list, and put it through the algorithm to see how high it could go. If it broke the existing “high score”, then I output the iteration number, the new high score and the set of numbers. Rinse, repeat until whenever. It also output a note every 1000 iterations. Then I set it running overnight.
This morning, I found that it found a set of numbers with the high score of 1,912. It found it on iteration 950 or so, and by iteration 35,000 it couldn’t find anything better. It’s not cast-iron proof, but I believe that this is the best you can get.
The number set is the one mentioned above - 2,3,5,8,9 and 100. Exploring the tree entirely involves looking at 31,159 possible number sets, and the way it hits 1912 is this: (8*(9+(2*(100+(3*5)))))=1912
0 notes
Note
yeah.jpg
The idea that Friendly AI research (or any other sort of futurist work) is necessarily not rooted in mathematics is one of those mind-killing things that is so widely believed that my sense is – even among people who would scoff at the idea in other circumstances – that it's kind of hard to convince anyone this isn't true?
E.g. on MetaMed, and in other less regulated areas of "futurism," there are a lot of people whose attitude towards (and rhetoric towards) the law surrounding HIPAA is … well, just check out this excerpt:
What was called "true futurism" – light on details, extravagant in its predictions – was congealed around MHB in the same way as bubble drinks have congealed around breath psychology: It was something that all the cool kids were doing. As one of my team members put it to me, "You're moving beyond the normal search media—blog articles, scientific papers, tweets—and moving into the search media of the new focus area, which is all MHB stuff."
Really, that's some of the weirdest hype I've ever read. Nothing so absurd as the idea that we can "build a computer that can match the brain," but just … stuff like this:
—-
Hu, once a Ph.D. student of Alan PET, has now written numerous academic papers advancing the idea that an iterated Monte Carlo (IRC) algorithm can reach essentially maximum performance (i.e., with very large parameters), roughly similar to the human visual system, for large NNs, despite the fact that standard opinion in Machine Learning/Artificial Intelligence is that Neural Machine Intelligence (NMI) is a fad that will ultimately fail (after all, it was just five years ago that Milner and Mcevoy published a fairly significant milestone research paper advancing the notion of NMI, and there is every indication that they are not looking ahead).
Hu has also performed extensive milestone work on the learning/connection/symbol grounding function of the visual brain (LSSOF), trying to provide an elegant theory inside the neural network connection elements (i.e., activation patterns) that explain the way stimulus-response relationships were learned by the visual brain from early feedback input until late feedback input (i.e., SSOF). In this vital work, Hu applied many of the breakthrough features of the fluid simulation methods pioneered by PET, MIRI and others.
#also i think you should read the wikipedia article on the idea and the actual arguments#because there's a lot of non-philosophy stuff mixed in there#the MIRI ride never ends#(no offense to people who liked the original post)
0 notes
Text
Scientists Are Discovering Long-Lost Rules for Ancient Board Games
Cameron Browne doesn’t see games the way you and I do.
“I [deconstruct] them into their mechanisms,” he said. “I have quite a mathematical approach to games.” This perspective comes with the territory when you’re at the forefront of digital archaeoludology, a new field that uses modern computing to understand ancient games, like Browne is.
Humans have played games for millenia, and the oldest known board game is an Egyptian game that dates back to 3100 BCE called Senet. “We almost never have the rules for these early games,” Browne said. “The rules have never been recorded, so our knowledge is largely based on historian’s reconstructions.”
Browne is the principal investigator of the Digital Ludeme Project, a research project based at Maastricht University in the Netherlands that’s using computational techniques to recreate the rules of ancient board games. To assist in this work, Browne and his colleagues are working on a general-purpose system for modelling ancient games, as well as generating plausible rulesets and evaluating them. The system is called Ludii, and it implements computational techniques from the world of genetics research and artificial intelligence.
You can check out the Digital Ludeme Project here, and try out a beta version of an app that lets you test out its reconstructions of ancient games such as Hnefatafl—viking chess. While the games are imperfect, the idea is that computers can help scientists narrow down which plausible iterations of ancient games are more fun to play, and thus more likely to have existed in reality.
The first part of the process, Browne said, is to break games down into their constituent parts and codify them in terms of units called “ludemes” in a database. Ludemes can be any existing game pieces or rules that archaeologists know of. Once a game is described in terms of its ludemes, it becomes a bit more like a computer program that machines can understand and analyze for patterns. Cultural information, such as where the game was played, is also recorded to help evaluate the plausibility of new rulesets.
Using techniques from the world of algorithmic procedural generation, the team then uses the information in the database to infer and reconstruct rulesets of varying plausibility and playability for these ancient games.
“This is where the modern AI comes in and helps us evaluate these games from a new perspective,” Browne said. “To possibly help us arrive at more realistic reconstructions of how the games were played.”
Next, the team uses algorithms to assess the generated rulesets. Artificially intelligent agents play these ancient games and their variants and build lists of moves. As the AIs play through different rulesets, they generate data about the game’s quality to help researchers determine if a ruleset is viable.
Fun is subjective, but Browne believes there are a few universal yardsticks. Games should have strategic depth, drama (the possibility of a comeback for a losing player), clear victories, a reasonable length, and they shouldn’t end in a draw too often.
The agents that play the games use Monte Carlo tree search, which was implemented in DeepMinds’ AlphaGo AI. However, the Digital Ludeme Project team didn’t want an AI as advanced as AlphaGo and so they didn’t implement the deep learning tech that powers AlphaGo. They don’t need AI that can beat the top human players in the world; they just need something that works.
This approach has already found some success. In 2018, archaeologists discovered an ancient Roman board game in a tomb in Slovakia. Piecing together the rules of the game has proved an impossible task for researchers, but Browne and his researchers have a version of the game you can play right now.
“With our system, we can put in the equipment, we can look for rules from the date [of the board’s creation], rules from the area, rules from the cultural context,” Browne said. “Then we can piece together likely rule sets that might have occurred.”
The final aspect of the Ludii project is to data-mine the database’s collection of ludemes and cultural information to map out the possible connections between ancient games over time.
Already, the Digital Ludeme Project has rounded up all known games discovered or invented before 1875. “The industrial revolution tends to be the tipping point for when games became traditional and more proprietary,” Browne said.
The team has created hundreds of variations of historical games so far, though the Ludii launcher (which Browne assured me is just a beta) is cumbersome to use right now. There’s a big selection of games, but navigating to the one you want to play and setting up the proper AI is a bit of a chore. That said, I’m having a blast.
Importantly, the computational tools being developed by the Digital Ludeme Project are not meant to supplant manual discovery, but rather to complement it. “What we’re trying to provide, as part of the project, is a tool for toolbox of historians and archaeologists. So they can make more informed reconstructions based on the evidence they have,” Browne said.
Scientists Are Discovering Long-Lost Rules for Ancient Board Games syndicated from https://triviaqaweb.wordpress.com/feed/
0 notes
Text
Polarization studies of Rotating Radio Transients. (arXiv:1905.03080v2 [astro-ph.HE] UPDATED)
We study the polarization properties of 22 known rotating radio transients (RRATs) with the 64-m Parkes radio telescope and present the Faraday rotation measures (RMs) for the 17 with linearly polarized flux exceeding the off-pulse noise by 3$\sigma$. Each RM was estimated using a brute-force search over trial RMs that spanned the maximum measurable range $\pm1.18 \times 10^5 \, \mathrm{rad \, m^2}$ (in steps of 1 $\mathrm{rad \, m^2}$), followed by an iterative refinement algorithm. The measured RRAT RMs are in the range |RM| $\sim 1$ to $\sim 950$ rad m$^{-2}$ with an average linear polarization fraction of $\sim 40$ per cent. Individual single pulses are observed to be up to 100 per cent linearly polarized. The RMs of the RRATs and the corresponding inferred average magnetic fields (parallel to the line-of-sight and weighted by the free electron density) are observed to be consistent with the Galactic plane pulsar population. Faraday rotation analyses are typically performed on accumulated pulsar data, for which hundreds to thousands of pulses have been integrated, rather than on individual pulses. Therefore, we verified the iterative refinement algorithm by performing Monte Carlo simulations of artificial single pulses over a wide range of S/N and RM. At and above a S/N of 17 in linearly polarized flux, the iterative refinement recovers the simulated RM value 100 per cent of the time with a typical mean uncertainty of $\sim5$ rad m$^{-2}$. The method described and validated here has also been successfully used to determine reliable RMs of several fast radio bursts (FRBs) discovered at Parkes.
from astro-ph.HE updates on arXiv.org http://bit.ly/2Jyw90d
0 notes
Photo

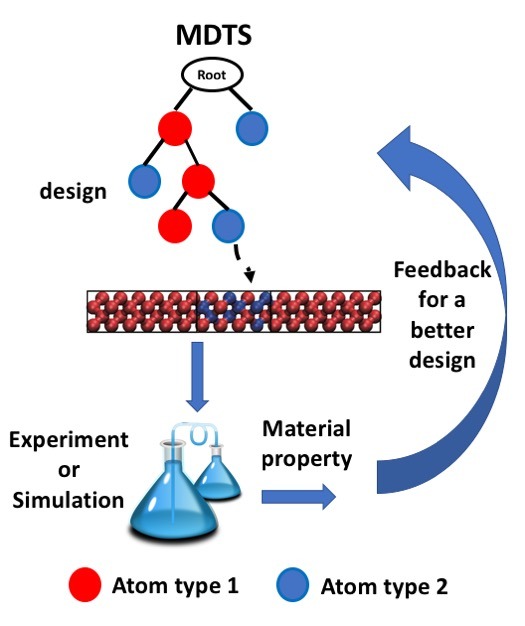
The game algorithm that could improve materials design
Source: Science and Technology of Advanced Materials
A new algorithm could help scientists decide the best atomic structures for the materials they design.
Designing advanced materials is a complex process, with many potential combinations for precisely placing atoms within a structure. But now, scientists have developed a new tool that helps determine the ideal placements — thanks to an algorithm that identifies the best moves to win computer games, according to a study recently published in the journal Science and Technology of Advanced Materials.
Scientists who design advanced materials, which have applications in silicon microchips or optical fibers, for example, often struggle to determine how to position atoms within a crystal structure to achieve a targeted function. To improve this process, researchers in Japan developed a new method called Materials Design using Tree Search (MDTS). It identifies the best atomic positions using an algorithm called the Monte Carlo tree search, which has been successfully employed by computer games to determine moves that bring the best possible outcomes.
The team used their method to identify the best way to design silicon-germanium alloy structures, which have either a minimal or maximal ability to conduct heat. Materials with minimal ‘thermal conductance’ can recover waste heat from industrial processes for use as an energy source. Materials with maximum thermal conductance can draw heat away from computer processing units.
The alloy has a certain number of atomic spaces that can be filled with silicon or germanium. The MDTS algorithm goes through an iterative learning process that computes which of all possible positions is best for placing silicon or germanium in order to achieve the desired degree of thermal conductance.
The team compared their method with another commonly used algorithm for this purpose and found that MDTS was comparable or better in terms of total computational time. Their method also has a “substantial” ability to learn from data.
“MDTS is a practical tool that material scientists can easily deploy in their own problems and has the potential to become a standard choice,” the researchers conclude.
Article information:
Thaer Dieb, Shenghong Ju, Kazuki Yoshizoe, Zhufeng Hou, Junichiro Shiomi and Koji Tsuda
“MDTS: automatic complex materials design using Monte Carlo tree search”
Science and Technology of Advanced Materials, 2017; 18:1, 504-527.
http://dx.doi.org/10.1080/14686996.2017.1344083
Provided by: Science and Technology of Advanced Materials
0 notes
Text
Sunshine & Muscle Cars Dominate Inline Tube 2017 Open House
Forget the birds, bees, and flowers. The surest signs that spring has come to Detroit are pothole-patching crews descending on the asphalt like ants on a jelly sandwich, immediate complaints about the Tigers’ deficient bullpen, and Inline Tube throwing open its doors to help kick off the car show season. For the latest gathering, Mother Nature decided to cooperate for a change, showering participants with wall- to-wall sunshine, which drew the biggest crowed we’ve ever seen at the open house.
It has been about 22 years since brothers John and James Kryta founded Inline Tube. Frustrated at the lack of suitable replacement brake lines for their restoration projects, they started bending their own, and a business was born. The company’s range of tubing components and countless other restoration parts expands continuously as John and James seek out and fill product holes to make resto work easier and more authentic.
Today they are pushing nearly 30,000 part numbers, and when they are not developing new parts, they are working on their own cars. In fact, John drove to the show in a GTO that he recently built for Pure Stock drag racing, while James brought one of his Olds 4-4-2s. These guys love their 1968-1972 A-Bodies.
“We are the same enthusiasts we develop parts for,” says John. “We’re always looking to make our cars just that much better, and we know that’s what our customers are looking for.”
Potholes and lousy closing pitchers may be perennial parts of life in Detroit, but the annual gathering at Inline Tube makes it all a little more bearable—and fun.
Mark Fedders’ 1967 Mustang GT packs a four-speed-backed S-code 390 engine, which was rated at 320 hp. The GT package included the grille-mounted fog lamps, power front disc brakes, lower-body stripes, and GT badges (GTA identification for automatic-equipped models). Of the more than 472,000 Mustang built for 1967, a little more than 24,000 were GTs.
Tom Johnson has owned this 42,000-mile 1968 4-4-2 for about 15 years. It is a loaded car with power windows, power locks, power seat, and more. The original 400 engine was swapped for factory-appearing 455.
Chris Craft (yes, that’s his name, just like the boats) bought this Sunfire Yellow 1968 Barracuda off a dealer lot in 1972 and recently had the car restored. That included a resto-modification of the 340 engine with six-barrel induction system and aluminum Edelbrock heads. Upgrading to front disc brakes posed a problem because the hubs’ bolt pattern necessarily increased to 4 1/2 inches from the original 4-inch pattern, and it took some time to find appropriately sized slotted mag wheels.
A manual transmission wasn’t offered on the 1972 Grand Prix, but that didn’t stop Bob Casanova from building his own, using factory components such as the pedal assembly and console. The result is so convincing that only the most knowledgeable Pontiac aficionados would suspect it was anything but a factory-original combination.
We didn’t get much info on Rod Brown’s 1965 Coronet A990, but with the hood up, the cross-rammed 426 Hemi spied between its front inner fenders was an undeniable clue about its capability.
There are always plenty of great GM A-Bodies at Inline Tube shows, and Brad Waitkis Viking Blue 1971 4-4-2 W-30 car was one of the rarest. It is one of 810 Holiday coupes built, and of them, it is one of a scant 247 four-speed cars. That rarity made the restoration more of treasure hunt. Waitkis searched long and hard for correct parts, such as the intake manifold, carburetor, distributor, and H-code heads.
Like so many enthusiasts, Dave Asaro formed his penchant for a certain muscle car at an early age. It was the 1970 Monte Carlo that belonged to a friend’s brother. Asaro finally got his own about four years ago and promptly swapped out the small-block for a built 454 that is pushing about 450 hp.
A set of Cragar S/S wheels lend Tom Nelson’s 1965 Coronet 500 a period-perfect look. Under the hood is a 426 Hemi stroked to 472 ci and featuring aluminum heads and a roller cam. It is connected to a manual-control TorqueFlite channeling torque to a 3.27-geared 8 3/4-inch axle.
Inline Tube cofounder John Kryta’s Limelight Green 1969 GTO is one of 93 non-Judge models built with a Ram Air IV/automatic powertrain combo. He has owned the car for 20 years. It was recently built for Pure Stock drag racing, including running a set of 4.56 cogs that spins the 400 engine to astronomical rpm as it drives through the traps.
Gary Lindsley’s 1971 Torino was one of Ford’s Spring Promotion special editions that is notable for its “halo” vinyl roof treatment (so called for the way it doesn’t extend all the way to the drip rails). The package also included GT wheel covers and seat covers. Under the hood are a 302 engine and an automatic transmission.
Jim Early has owned this unrestored 1973 GTO for a little more than a decade. He took it off the hands of his father-in-law, who had owned it since 1978. Despite being only 5 years old at the time the father-in-law acquired it, the car had been through several previous owners, including a gentleman who was a volunteer fireman. The car had emergency lights installed on the roof. The witness marks from it are still in the original paintwork to prove it.
Styling for the 1971-1974 Satellite/Road Runner continues to look better with age, which is proven by Andy Gerling’s 1973 Satellite. It has a 340 engine and a TorqueFlite transmission, along with a beautifully preserved green bench-seat interior.
Dan Jensen’s ultrarare 1970 F-85 was another ultrarare A-Body Olds on hand. It is one of only 152 ordered with the L74-code 350 four-barrel/high-compression engine, which was rated at 310 hp. It is a total grandma’s car, from the bench seat to the thin, two-spoke steering wheel. It has 39,000 miles, and apart from a respray of the exterior color it is pretty much all-original, including the shocks and hoses.
Jeff Wallace’s 1973 Duster 340 is a pretty rare Mopar. Fewer than 16,000 were built that year, out of just about 265,000 Dusters overall, and far fewer than that were originally equipped with a power moonroof like this car.
Tim Stolarski found this 1974 Javelin in Toledo, Ohio, about four years ago and has spent his time since improving on all of its details, including some very challenging wiring projects. The 304-powered car has nonetheless—and rightfully—earned a few trophies along the way. Among its interesting features is an aftermarket air-conditioning system.
The next-generation muscle car contingent was well represented by Paul Sapiano’s 1987 Grand National. With only 16,000 original miles, it is a blue chip collector car that will only rise in value. It also happens to be a blast to drive.
Ken Kiorani’s Carousel Red 1976 Trans Am is a 455/four-speed car. The 1976 model year was a transitional one. It was the last year for the 455 engine. The front end’s urethane bumper cover/fascia was a single-year design. It was also the last year for the shaker scoop’s original rounded design.
Affordability helped make Tim Leslie’s decision to purchase this 1973 Duster. It was a solid, no-rust North Carolina car when he acquired it. He quickly swapped the original 318 engine for a healthy 340. It also packs a 904 TorqueFlite automatic and a sturdy 8 3/4-inch rear axle.
Bob Kessler is the original owner of this 1969 Impala SS427, which is driven by the 390hp L36-code iteration of the 427 big-block. The SS427 package also included a heavy-duty suspension, which comprised stiff springs, a fat front stabilizer bar, and four rear trailing arms in place of lower-range models’ three-arm/Panhard-bar layout.
We didn’t get a shred of info on this Olds Rallye 350, but it was too pretty to pass up. Only 3,547 were built for 1970, and the vast majority (2,367), like this one, were built from Cutlass S sport coupes. The bright trim rings on the body-color steel wheels weren’t part of the factory equipment, but many dealers and owners added them to dress up the car.
The post Sunshine & Muscle Cars Dominate Inline Tube 2017 Open House appeared first on Hot Rod Network.
from Hot Rod Network http://www.hotrod.com/articles/sunshine-muscle-cars-dominate-inline-tube-2017-open-house/ via IFTTT
0 notes
Text
If you did not already know
Simplified Shotgun Stochastic Search (S5) In p >> n settings, full posterior sampling using existing Markov chain Monte Carlo (MCMC) algorithms is highly inefficient and often not feasible from a practical perspective. To overcome this problem, we propose a scalable stochastic search algorithm that is called the Simplified Shotgun Stochastic Search (S5) and aimed at rapidly explore interesting regions of model space and finding the maximum a posteriori(MAP) model. Also, the S5 provides an approximation of posterior probability of each model (including the marginal inclusion probabilities). … Learning Automata-Based Q-Learning (LAQL) An optimization problem of content placement in cooperative caching is formulated, with the aim of maximizing sum mean opinion score (MOS) of mobile users. Firstly, a supervised feed-forward back-propagation connectionist model based neural network (SFBC-NN) is invoked for user mobility and content popularity prediction. More particularly, practical data collected from GPS-tracker app on smartphones is tackled to test the accuracy of mobility prediction. Then, a learning automata-based Q-learning (LAQL) algorithm for cooperative caching is proposed, in which learning automata (LA) is invoked for Q-learning to obtain an optimal action selection in a random and stationary environment. It is proven that the LA-based action selection scheme is capable of enabling every state to select the optimal action with arbitrarily high probability if Q-learning is able to converge to the optimal Q value eventually. To characterize the performance of the proposed algorithms, the sum MOS of users is applied to define the reward function. Extensive simulations reveal that: 1) The prediction error of SFBC-NN lessen with the increase of iterations and nodes; 2) the proposed LAQL achieves significant performance improvement against traditional Q-learning; 3) the cooperative caching scheme is capable of outperforming non-cooperative caching and random caching of 3% and 4%. … Multiclass Universum SVM (MU-SVM) We introduce Universum learning for multiclass problems and propose a novel formulation for multiclass universum SVM (MU-SVM). We also propose an analytic span bound for model selection with almost 2-4x faster computation times than standard resampling techniques. We empirically demonstrate the efficacy of the proposed MUSVM formulation on several real world datasets achieving > 20% improvement in test accuracies compared to multi-class SVM. … Generalized Network Dismantling Finding the set of nodes, which removed or (de)activated can stop the spread of (dis)information, contain an epidemic or disrupt the functioning of a corrupt/criminal organization is still one of the key challenges in network science. In this paper, we introduce the generalized network dismantling problem, which aims to find the set of nodes that, when removed from a network, results in a network fragmentation into subcritical network components at minimum cost. For unit costs, our formulation becomes equivalent to the standard network dismantling problem. Our non-unit cost generalization allows for the inclusion of topological cost functions related to node centrality and non-topological features such as the price, protection level or even social value of a node. In order to solve this optimization problem, we propose a method, which is based on the spectral properties of a novel node-weighted Laplacian operator. The proposed method is applicable to large-scale networks with millions of nodes. It outperforms current state-of-the-art methods and opens new directions in understanding the vulnerability and robustness of complex systems. … https://bit.ly/2WV02ht
0 notes
Text
Polarization studies of Rotating Radio Transients. (arXiv:1905.03080v1 [astro-ph.HE])
We study the polarization properties of 22 known rotating radio transients (RRATs) with the 64-m Parkes radio telescope and present the Faraday rotation measures (RMs) for the 17 with linearly polarized flux exceeding the off-pulse noise by 3$\sigma$. Each RM was estimated using a brute-force search over trial RMs that spanned the maximum measurable range $\pm1.18 \times 10^5 \, \mathrm{rad \, m^2}$ (in steps of 1 $\mathrm{rad \, m^2}$), followed by an iterative refinement algorithm. The measured RRAT RMs are in the range |RM| $\sim 1$ to $\sim 950$ rad m$^{-2}$ with an average linear polarization fraction of $\sim 40$ per cent. Individual single pulses are observed to be up to 100 per cent linearly polarized. The RMs of the RRATs and the corresponding inferred average magnetic fields (parallel to the line-of-sight and weighted by the free electron density) are observed to be consistent with the Galactic plane pulsar population. Faraday rotation analyses are typically performed on accumulated pulsar data, for which hundreds to thousands of pulses have been integrated, rather than on individual pulses. Therefore, we verified the iterative refinement algorithm by performing Monte Carlo simulations of artificial single pulses over a wide range of S/N and RM. At and above a S/N of 17 in linearly polarized flux, the iterative refinement recovers the simulated RM value 100 per cent of the time with a typical mean uncertainty of $\sim5$ rad m$^{-2}$. The method described and validated here has also been successfully used to determine reliable RMs of several fast radio bursts (FRBs) discovered at Parkes.
from astro-ph.HE updates on arXiv.org http://bit.ly/2Jyw90d
0 notes