#dataloader
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
IBM Research Data Loader Helps Open-source AI Model Training

IBM Research data loader improves open-source community’s access to AI models for training.
Training AI models More quickly than ever
IBM showcased new advances in high-throughput AI model training at PyTorch 2024, along with a state-of-the-art data loader, all geared toward empowering the open-source AI community.
IBM Research experts are contributing to the open-source model training framework at this year’s PyTorch Conference. These contributions include major advances in large language model training throughput as well as a data loader that can handle enormous amounts of data with ease.
It must constantly enhance the effectiveness and resilience of the cloud infrastructure supporting LLMs’ training, tuning, and inference to supply their ever-increasing capabilities at a reasonable cost. The open-source PyTorch framework and ecosystem have greatly aided the AI revolution that is about to change its lives. IBM joined the PyTorch Foundation last year and is still bringing new tools and techniques to the AI community because it recognizes that it cannot happen alone.
In addition to IBM’s earlier contributions, these new tools are strengthening PyTorch’s capacity to satisfy the community’s ever-expanding demands, be they related to more cost-effective checkpointing, faster data loading, or more effective use of GPUs.
An exceptional data loader for foundation model training and tuning
Using a high-throughput data loader, PyTorch users can now easily distribute LLM training workloads among computers and even adjust their allocations in-between jobs. In order to prevent work duplication during model training, it also enables developers to save checkpoints more effectively. And all of it is attributable to a group of researchers who were only creating the instruments they required to complete a task.
When you wish to rerun your training run with a new blend of sub-datasets to alter model weights, or when you have all of your raw text data and want to use a different tokenizer or maximum sequence length, the resulting tool is well-suited for LLM training in research contexts. With the help of the data loader, you can tell your dataset what you want to do on the fly rather than having to reconstruct it each time you want to make modifications of this kind.
You can adjust the job even halfway through, for example, by increasing or decreasing the number of GPUs in response to changes in your resource quota. The data loader makes sure that data that has already been viewed won’t be viewed again.
Increasing the throughput of training
Bottlenecks occur because everything goes at the speed of the slowest item when it comes to model training at scale. The efficiency with which the GPU is being used is frequently the bottleneck in AI tasks.
Fully sharded data parallel (FSDP), which uniformly distributes big training datasets across numerous processors to prevent any one machine from becoming overburdened, is one component of this method. It has been demonstrated that this distribution greatly increases the speed and efficiency of model training and tuning while enabling faster AI training with fewer GPUs.
This development progresses concurrently with the data loader since the team discovered ways to use GPUs more effectively while they worked with FSDP and torch.compile to optimize GPU utilization. Consequently, data loaders rather than GPUs became the bottleneck.
Next up
Although FP8 isn’t yet generally accessible for developers to use, Ganti notes that the team is working on projects that will highlight its capabilities. In related work, they’re optimizing model tweaking and training on IBM’s artificial intelligence unit (AIU) with torch.compile.
Triton, Nvidia’s open-source platform for deploying and executing AI, will also be a topic of discussion for Ganti, Wertheimer, and other colleagues. Triton allows programmers to write Python code that is then translated into the native programming language of the hardware Intel or Nvidia, for example, to accelerate computation. Although Triton is currently ten to fifteen percent slower than CUDA, the standard software framework for using Nvidia GPUs, the researchers have just completed the first end-to-end CUDA-free inferencing with Triton. They believe Triton will close this gap and significantly optimize training when this initiative picks up steam.
The starting point of the study
IBM Research’s Davis Wertheimer outlines a few difficulties that may arise during extensive training: It’s possible to use an 80/20 rule to large-scale training. In the published research, algorithmic tradeoffs between GPU memory and compute and communication make up 80% of the work. However, because the pipeline moves at the pace of the narrowest bottleneck, you may expect a very long tail of all these other practical concerns when you really try to build something 80 percent of the time.
The IBM team was running into problems when they constructed their training platform. Wertheimer notes, “As we become more adept at using our GPUs, the data loader is increasingly often the bottleneck.”
Important characteristics of the data loader
Stateful and checkpointable: If your data loader state is saved whenever you save a model, and both the model state and data loader states need to be recovered at the same time whenever you recover from a checkpoint.”
Checkpoint auto-rescaling: During prolonged training sessions, the data loader automatically adapts to workload variations. There are a lot of reasons why you might have to rescale your workload in the middle. Training could easily take weeks or months.”
Effective data streaming: There is no build overhead for shuffling data because the system supports data streaming.
Asynchronous distributed operation: The data loader is non-blocking. The data loader states to be saved and then distributed in a way that requires no communication at all.”
Dynamic data mixing: This feature is helpful for changing training requirements since it allows the data loader to adjust to various data mixing ratios.
Effective global shuffling: As data accumulates, shuffling remains effective since the tool handles memory bottlenecks when working with huge datasets.
Native, modular, and feature-rich PyTorch: The data loader is built to be flexible and scalable, making it ready for future expansion. “What if we have to deal with thirty trillion, fifty trillion, or one hundred trillion tokens next year?” “it needs to build the data loader so it can survive not only today but also tomorrow because the world is changing quickly.”
Actual results
The IBM Research team ran hundreds of small and big workloads over several months to rigorously test their data loader. They saw code numbers that were steady and fluid. Furthermore, the data loader as a whole runs non-blocking and asynchronously.
Read more on govindhtech.com
#IBMResearch#DataLoaderHelp#OpensourceAI#ModelTraining#AImodel#IBM#dataloader#Triton#IBMartificialintelligence#startingpoint#ibm#technology#technews#news#govindhtech
0 notes
Text
Due to recent experiences, I am feeling an urge to make an anti-drug-style PSA except it's warning impressionable machine-learning-curious teens to never, ever try a thing called "Huggingface transformers Trainer"
Not. Even. Once.
#and don't even get me started on “unsloth”#this week i learned what “unsloth” actually does when you import it and... man.#i thought i'd seen the worst of “hacky brittle 'it-just-works' (by doing the most cursed shit imaginable) ML python code” but no.#no. unsloth was Worse#and huggingface Trainer is bad enough by itself#did you know it has 131 (one hundred and thirty one!) config arguments and yet it cannot log *more than one loss number at once*#(for like multitask training or whatever)#i don't just mean it's hard to do - i mean its logging mechanism is built from the ground up on the assumption you would never do this.#you'd have to rewrite a bunch of internals to get it working - i.e. basically write a new nontrivial feature on HF's behalf#and just writing your own damn training loop is easier than that lol#it's not that hard kids. take it from me. dataset + dataloader + model(*args) + loss.backward() + opt.step() + opt.zero_grad(). that's it#it'll take you 30 minutes and save you a billion hours down the road#i do not understand computers#(is a category tag)
79 notes
·
View notes
Text

At the core of our engineering services lies our commitment to ETL (Extract, Transform, Load) excellence. This involves seamlessly extracting data from diverse sources, including databases, cloud storage, and streaming platforms, APIs, and IoT devices. Once extracted, we meticulously transform the data into actionable insights by cleaning, formatting, and enriching it to ensure accuracy and relevance. This transformation process also involves advanced techniques such as data aggregation and normalization to enhance the quality of the dataset. Finally, we efficiently load the transformed data into the systems or databases, selecting the appropriate storage infrastructure and optimizing the loading process for speed and reliability. Our ETL excellence approach ensures that the data is handled with precision and care, resulting in valuable insights that drive informed decision-making and business success.
Learn more about services at https://rtctek.com/data-engineering-services/ Contact us at https://rtctek.com/contact-us/
#etl#extract#transform#load#dataintegration#dataengineering#dataloading#dataextraction#datatransformation#datawarehousing#dataanalytics#bigdata#dataquality#dataarchitecture#datamigration
0 notes
Text
#Greetings from Ashra Technologies#we are hiring#ashra#ashratechnologies#jobs#hiring#jobalert#jobsearch#jobhunt#recruiting#recruitingpost#maximo#ibm#java#automation#dataloading#datamapping#dataextraction#upgrade#patching#installation#integrity#chennai#bangalore#pune#mumbai#linkedin#linkedinprofessionals#linkedinlearning#linkedinads
0 notes
Text
Has anyone found a way to use both GraphQL Shield and dataloaders at the same time while using Apollo Server and NestJS?
I recently found that because I have asynchronous calls being made in some of my shield rules, it's causing my dataloader batch functions to be called multiple times, when they should only be called once, which leaves me with the N+1 problem across my entire app.
I believe this is due to how dataloader requires that all of the batch function calls occur during the same event loop "tick", and the async calls in my shield rules are preventing this.
Here's where I asked the question on reddit
27 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
GAI Project 3 PEFT on GLUE benchmarks
• Topic: PEFT on GLUE Scoring Criteria GLUE website: httmligluebenchmark.com/tasks thttmagluebenchmark.comitasks) 1. Data (Task1, 20 pts) • You can choose any perferring dataset in GLUE benchmark to fine-tuning. 1. Load the train and validation split of data (10 pts). You can use pandas, Dataset and Dataloader. 2. Select two datasets on GLUE benchmarks (10 pts). Tokenize the text. You can design…
0 notes
Text
Introduction to GraphQL for Full Stack Applications
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries by leveraging a type system defined for the data. Developed by Facebook in 2012 and open-sourced in 2015, GraphQL provides a flexible and efficient alternative to REST APIs by allowing clients to request exactly the data they need — nothing more, nothing less.
Why Use GraphQL for Full Stack Applications?
Traditional REST APIs often come with challenges such as over-fetching, under-fetching, and versioning complexities. GraphQL solves these issues by offering:
Flexible Queries: Clients can specify exactly what data they need.
Single Endpoint: Unlike REST, which may require multiple endpoints, GraphQL exposes a single endpoint for all queries.
Strongly Typed Schema: Ensures clear data structure and validation.
Efficient Data Fetching: Reduces network overhead by retrieving only necessary fields.
Easier API Evolution: No need for versioning — new fields can be added without breaking existing queries.
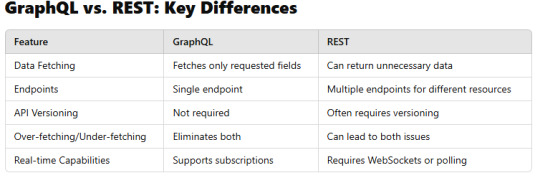
GraphQL vs. REST: Key Differences
Core Concepts of GraphQL
1. Schema & Types
GraphQL APIs are built on schemas that define the data structure.
Example schema:graphqltype User { id: ID! name: String! email: String! }type Query { getUser(id: ID!): User }
2. Queries
Clients use queries to request specific data.graphqlquery { getUser(id: "123") { name email } }
3. Mutations
Used to modify data (Create, Update, Delete).graphqlmutation { createUser(name: "John Doe", email: "[email protected]") { id name } }
4. Subscriptions
Enable real-time updates using Web Sockets.graphqlsubscription { newUser { id name } }
Setting Up GraphQL in a Full Stack Application
Backend: Implementing GraphQL with Node.js and Express
GraphQL servers can be built using Apollo Server, Express-GraphQL, or other libraries.
Example setup with Apollo Server:javascriptimport { ApolloServer, gql } from "apollo-server"; const typeDefs = gql` type Query { hello: String } `;const resolvers = { Query: { hello: () => "Hello, GraphQL!", }, };const server = new ApolloServer({ typeDefs, resolvers });server.listen().then(({ url }) => { console.log(`Server running at ${url}`); });
Frontend: Querying GraphQL with React and Apollo Client
Example React component using Apollo Client:javascriptimport { useQuery, gql } from "@apollo/client";const GET_USER = gql` query { getUser(id: "123") { name email } } `;function User() { const { loading, error, data } = useQuery(GET_USER); if (loading) return <p>Loading...</p>; if (error) return <p>Error: {error.message}</p>; return <div>{data.getUser.name} - {data.getUser.email}</div>; }
GraphQL Best Practices for Full Stack Development
Use Batching and Caching: Tools like Apollo Client optimize performance.
Secure the API: Implement authentication and authorization.
Optimize Resolvers: Use DataLoader to prevent N+1 query problems.
Enable Rate Limiting: Prevent abuse and excessive API calls.
Conclusion
GraphQL provides a powerful and efficient way to manage data fetching in full-stack applications. By using GraphQL, developers can optimize API performance, reduce unnecessary data transfer, and create a more flexible architecture.
Whether you’re working with React, Angular, Vue, or any backend framework, GraphQL offers a modern alternative to traditional REST APIs.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
BME646 and ECE60146: Homework 2
1 Introduction The goal of this homework is to introduce you to the pieces needed to implement an image dataloader for training or testing your deep neural networks. To that end, this homework will help you familiarize yourself with the image representations as provided by PIL, Numpy, and PyTorch libraries. It will also make you more familiar with the idea of data augmentation. Upon completing…
0 notes
Text
Optimizing Neural Network Training on Cloud Platforms: Anton R Gordon’s Tips for TensorFlow and PyTorch
In today’s AI-driven landscape, training neural networks effectively and efficiently is key to producing cutting-edge models. Anton R Gordon, a seasoned AI architect, emphasizes the importance of optimizing training processes on cloud platforms to harness full computational power and cost-effectiveness. Leveraging TensorFlow and PyTorch, two of the most popular deep learning frameworks, Gordon provides valuable insights into making the training process faster, scalable, and less resource-intensive.
Choosing the Right Cloud Platform and Instance Type
According to Anton R Gordon, selecting the appropriate cloud platform and instance type is essential. Platforms like AWS, Google Cloud Platform (GCP), and Azure offer a range of instance types optimized for different needs. For high-performance tasks like neural network training, instances with GPU or TPU (Tensor Processing Unit) support are crucial. GCP’s TPU instances are particularly optimized for TensorFlow workloads, whereas PyTorch performs well with Nvidia GPUs on AWS and Azure. Choosing these optimized instances can lead to faster training and significant cost savings.
Distributed Training for Large-Scale Models
For large datasets and complex models, Gordon recommends utilizing distributed training across multiple nodes to shorten the training time. Both TensorFlow and PyTorch support distributed training, which splits data and computation across various nodes, allowing simultaneous processing. Gordon highlights using TensorFlow's MirroredStrategy or PyTorch’s Distributed Data-Parallel (DDP) to coordinate and synchronize models across GPUs. This approach helps maintain model accuracy while reducing training time significantly, a key benefit in a cloud environment where time equals cost.
Using Data Pipelines and Preprocessing Efficiently
Efficient data preprocessing and loading are often overlooked but are crucial in cloud-based training. Gordon advises setting up data pipelines that preprocess data on the fly, reducing memory bottlenecks. Both TensorFlow and PyTorch offer data loading and transformation utilities. In TensorFlow, the tf.data API allows for efficient dataset handling, while PyTorch’s DataLoader helps in loading and batching data seamlessly. By optimizing these pipelines, cloud resources are used more efficiently, preventing idle GPUs and ensuring a continuous flow of data.
Implementing Model Checkpoints and Early Stopping
Model checkpoints and early stopping are critical for preventing overfitting and managing costs. Gordon emphasizes setting checkpoints to save the model state periodically, ensuring that progress isn’t lost if there’s an interruption in the training process. Additionally, using early stopping techniques can halt training once performance ceases to improve, saving both time and money. TensorFlow’s tf.keras.callbacks.EarlyStopping and PyTorch’s early stopping implementation are highly effective in cloud-based environments.
Monitoring and Optimizing Resource Usage
Cloud platforms provide real-time monitoring tools that track resource consumption and utilization. Gordon suggests using these insights to make real-time adjustments to the training process, optimizing for both speed and cost-efficiency. AWS CloudWatch, GCP’s Monitoring, and Azure Monitor are valuable for keeping an eye on GPU, TPU, CPU, and memory usage, ensuring that allocated resources match the training requirements effectively.
Final Thoughts
By adopting these strategies, Anton R Gordon showcases how developers can optimize neural network training on cloud platforms. With the right choice of instances, effective data handling, distributed training, and vigilant resource management, training complex models become a streamlined, cost-effective process that unlocks the potential of AI for real-world applications.
0 notes
Text
Direct Preference Optimization: A Complete Guide
New Post has been published on https://thedigitalinsider.com/direct-preference-optimization-a-complete-guide/
Direct Preference Optimization: A Complete Guide
import torch import torch.nn.functional as F class DPOTrainer: def __init__(self, model, ref_model, beta=0.1, lr=1e-5): self.model = model self.ref_model = ref_model self.beta = beta self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr) def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): """ pi_logps: policy logprobs, shape (B,) ref_logps: reference model logprobs, shape (B,) yw_idxs: preferred completion indices in [0, B-1], shape (T,) yl_idxs: dispreferred completion indices in [0, B-1], shape (T,) beta: temperature controlling strength of KL penalty Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair. """ # Extract log probabilities for the preferred and dispreferred completions pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs] # Calculate log-ratios pi_logratios = pi_yw_logps - pi_yl_logps ref_logratios = ref_yw_logps - ref_yl_logps # Compute DPO loss losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios)) rewards = self.beta * (pi_logps - ref_logps).detach() return losses.mean(), rewards def train_step(self, batch): x, yw_idxs, yl_idxs = batch self.optimizer.zero_grad() # Compute log probabilities for the model and the reference model pi_logps = self.model(x).log_softmax(-1) ref_logps = self.ref_model(x).log_softmax(-1) # Compute the loss loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs) loss.backward() self.optimizer.step() return loss.item() # Usage model = YourLanguageModel() # Initialize your model ref_model = YourLanguageModel() # Load pre-trained reference model trainer = DPOTrainer(model, ref_model) for batch in dataloader: loss = trainer.train_step(batch) print(f"Loss: loss")
Challenges and Future Directions
While DPO offers significant advantages over traditional RLHF approaches, there are still challenges and areas for further research:
a) Scalability to Larger Models:
As language models continue to grow in size, efficiently applying DPO to models with hundreds of billions of parameters remains an open challenge. Researchers are exploring techniques like:
Efficient fine-tuning methods (e.g., LoRA, prefix tuning)
Distributed training optimizations
Gradient checkpointing and mixed-precision training
Example of using LoRA with DPO:
from peft import LoraConfig, get_peft_model class DPOTrainerWithLoRA(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8): lora_config = LoraConfig( r=lora_rank, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) self.model = get_peft_model(model, lora_config) self.ref_model = ref_model self.beta = beta self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr) # Usage base_model = YourLargeLanguageModel() dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Multi-Task and Few-Shot Adaptation:
Developing DPO techniques that can efficiently adapt to new tasks or domains with limited preference data is an active area of research. Approaches being explored include:
Meta-learning frameworks for rapid adaptation
Prompt-based fine-tuning for DPO
Transfer learning from general preference models to specific domains
c) Handling Ambiguous or Conflicting Preferences:
Real-world preference data often contains ambiguities or conflicts. Improving DPO’s robustness to such data is crucial. Potential solutions include:
Probabilistic preference modeling
Active learning to resolve ambiguities
Multi-agent preference aggregation
Example of probabilistic preference modeling:
class ProbabilisticDPOTrainer(DPOTrainer): def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob): # Compute log ratios pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs] log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1) loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) + (1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff)) return loss.mean() # Usage trainer = ProbabilisticDPOTrainer(model, ref_model) loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combining DPO with Other Alignment Techniques:
Integrating DPO with other alignment approaches could lead to more robust and capable systems:
Constitutional AI principles for explicit constraint satisfaction
Debate and recursive reward modeling for complex preference elicitation
Inverse reinforcement learning for inferring underlying reward functions
Example of combining DPO with constitutional AI:
class ConstitutionalDPOTrainer(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None): super().__init__(model, ref_model, beta, lr) self.constraints = constraints or [] def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs) constraint_loss = 0 for constraint in self.constraints: constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs) return base_loss + constraint_loss # Usage def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs): # Implement safety checking logic unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps) return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5 constraints = [safety_constraint] trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Practical Considerations and Best Practices
When implementing DPO for real-world applications, consider the following tips:
a) Data Quality: The quality of your preference data is crucial. Ensure that your dataset:
Covers a diverse range of inputs and desired behaviors
Has consistent and reliable preference annotations
Balances different types of preferences (e.g., factuality, safety, style)
b) Hyperparameter Tuning: While DPO has fewer hyperparameters than RLHF, tuning is still important:
β (beta): Controls the trade-off between preference satisfaction and divergence from the reference model. Start with values around 0.1-0.5.
Learning rate: Use a lower learning rate than standard fine-tuning, typically in the range of 1e-6 to 1e-5.
Batch size: Larger batch sizes (32-128) often work well for preference learning.
c) Iterative Refinement: DPO can be applied iteratively:
Train an initial model using DPO
Generate new responses using the trained model
Collect new preference data on these responses
Retrain using the expanded dataset
Direct Preference Optimization Performance
This image delves into the performance of LLMs like GPT-4 in comparison to human judgments across various training techniques, including Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT), and Proximal Policy Optimization (PPO). The table reveals that GPT-4’s outputs are increasingly aligned with human preferences, especially in summarization tasks. The level of agreement between GPT-4 and human reviewers demonstrates the model’s ability to generate content that resonates with human evaluators, almost as closely as human-generated content does.
Case Studies and Applications
To illustrate the effectiveness of DPO, let’s look at some real-world applications and some of its variants:
Iterative DPO: Developed by Snorkel (2023), this variant combines rejection sampling with DPO, enabling a more refined selection process for training data. By iterating over multiple rounds of preference sampling, the model is better able to generalize and avoid overfitting to noisy or biased preferences.
IPO (Iterative Preference Optimization): Introduced by Azar et al. (2023), IPO adds a regularization term to prevent overfitting, which is a common issue in preference-based optimization. This extension allows models to maintain a balance between adhering to preferences and preserving generalization capabilities.
KTO (Knowledge Transfer Optimization): A more recent variant from Ethayarajh et al. (2023), KTO dispenses with binary preferences altogether. Instead, it focuses on transferring knowledge from a reference model to the policy model, optimizing for a smoother and more consistent alignment with human values.
Multi-Modal DPO for Cross-Domain Learning by Xu et al. (2024): An approach where DPO is applied across different modalities—text, image, and audio—demonstrating its versatility in aligning models with human preferences across diverse data types. This research highlights the potential of DPO in creating more comprehensive AI systems capable of handling complex, multi-modal tasks.
_*]:min-w-0″ readability=”16″>
Conclusion
Direct Preference Optimization represents a significant advancement in aligning language models with human preferences. Its simplicity, efficiency, and effectiveness make it a powerful tool for researchers and practitioners alike.
By leveraging the power of Direct Preference Optimization and keeping these principles in mind, you can create language models that not only exhibit impressive capabilities but also align closely with human values and intentions.
#2023#2024#agent#agreement#ai#AI optimization techniques#AI preference alignment#AI systems#applications#approach#Artificial Intelligence#audio#Bias#binary#challenge#comparison#comprehensive#content#data#data quality#direct preference#direct preference optimization#domains#DPO#efficiency#extension#Future#GPT#GPT-4#human
0 notes
Text
GraphQL WhereInputs
When you resolve properties in GraphQL types, especially resolving relational types, you usually take a single ID & expand it into an object.
Frustratingly, GraphQL doesn’t support the same resolver behaviour for input types. Typically you’d have to send up the ID as a standalone property - which you need to know/lookup beforehand. And what about bulk queries, where you (atomically) can’t fetch all IDs at once to perform updates?

To address this issue I tend to build a series of "WhereInput" types into the GraphQL project, which are small reusable inputs throughout the schema, to create a uniform way to filter entries or select a relational entry when creating/updating entries:

An example usage of these might include:

Implementing WhereInputs into your GraphQL project has plenty of benefits & side effects, the top three include:
Unify how you specify relational entities in your GraphQL schema. Rather than using a quick entryID input property (e.g. author: $userID) you can use a uniform object (e.g. author: { id: $userID } or author: { email: $email }). And, depending on how you structure your Input functions, you could perform additional validation on the relational entry you want to use) e.g. { id: $userID, status: ACTIVE }).
When you want to filter entries by a new property, e.g. a user’s favourite colour, you add a few lines of code in one function & now anywhere you already filter users can now filter by email!
A good WhereInput implementation can also give your application logic a unified way of searching for entries by your WhereInput query, simplifying your application logic further.
Remarks
By habit, I tend to append "Input"/"Enum" to the end of these types so when used throughout the codebase, it's always clear that what type I'm using.
It would be nice to have a type/input class that works for both reading & writing though!
If you’re building a GraphQL API in Node.JS without dataloader or graphql-resolve-batch be sure to check them out - both libraries make bulk-loading data ruthlessly efficient!
You can combine your Inputs with a Dataloader instance to create a uniform way of fetching entry IDs from a schema-defined object internally. This is incredibly useful within your resolvers but throughout the rest of your application too!

0 notes