#data quality in AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Why Data Quality In AI Is Crucial For Revenue Management
In today’s digital-first hospitality industry, data is the new currency—but not all data is created equal. As hoteliers adopt AI-powered revenue management systems to streamline operations and increase revenue, the focus is often on automation and intelligence. However, the true performance of these systems hinges on one foundational element: data quality in AI.
Even the most advanced AI algorithms can’t make smart decisions with poor data. To fully realize the power of AI in revenue management, hotels must prioritize clean, complete, and contextual data from the ground up.
AI Is Only as Smart as Its Data
Unlike human decision-makers, AI doesn’t work on instinct. It learns from patterns in historical and real-time data—everything from booking trends and pricing history to guest preferences and market demand.
If this data is inaccurate, outdated, or incomplete, the decisions made by AI will be flawed, resulting in:
The result? A sophisticated system that’s automating bad decisions, not better ones.
The Hidden Cost of Poor Data Quality
In the context of hotel revenue management, poor data quality is more than a tech issue—it’s a revenue killer. Here’s what can go wrong when the foundation isn’t solid:
📉 Inaccurate Forecasts
If your historical data has gaps or inconsistencies, AI can misread demand patterns, leading to incorrect predictions and poor planning.
💸 Bad Pricing Recommendations
Garbage in, garbage out. Faulty input on inventory levels or competitor pricing can cause your system to recommend rates that are either too low (lost revenue) or too high (lost bookings).
🧍 Inefficient Segmentation
AI relies on guest profiles to tailor pricing and marketing. Incomplete or fragmented data can result in generic strategies that fail to convert.
🌐 Channel Distribution Errors
Unsynchronized data across channels may cause rate disparity, booking conflicts, or loss of visibility on high-performing OTAs.
All these risks boil down to one root issue: unreliable data.
What Does High-Quality Data Really Look Like?
High volumes of data don’t guarantee quality. Here’s what separates good data from bad:
For AI to function as a decision-making ally, it needs all five.
How ampliphi Ensures Data Quality From Day One
Enter ampliphi RMS, a system that recognizes data quality isn’t optional—it’s essential. Designed with built-in safeguards and integrations, ampliphi helps hoteliers trust every decision their AI makes.
Here’s how:
✅ Smart Integrations
Seamlessly connects with your PMS, channel manager, and booking engine—minimizing manual uploads and reducing errors.
⚠️ Automated Data Validation
The system flags anomalies and missing inputs before they affect pricing or forecasts.
🔄 Live Data Streams
ampliphi processes real-time market and booking data, ensuring decisions reflect today’s conditions—not last week’s.
🔍 Transparent Logic
You’re never left guessing. See exactly what data is used and why a recommendation was made.
🌐 Scalable Architecture
Whether you run a single hotel or a chain of properties, ampliphi maintains consistency and data integrity across the board.
AI and Data: A Partnership, Not a Shortcut
Many hoteliers rush to implement AI solutions expecting instant transformation. But AI isn't a silver bullet—it’s a partner that amplifies your results only when given strong, structured inputs.
Before AI can optimize rates or forecast demand effectively, your property needs the right data environment. ampliphi doesn’t just assume your data is ready—it actively helps clean, structure, and align it.
Why This Matters More Than Ever
The hotel industry is navigating uncertain terrain—from fluctuating travel patterns to rising guest expectations. Now, more than ever, revenue teams need to make decisions that are fast, accurate, and strategic.
If your RMS is operating on outdated or messy data, it’s not just holding you back—it’s steering you in the wrong direction.
That’s why ampliphi puts data quality at the center of its platform. By doing so, it gives hoteliers the ability to:
Conclusion: Clean Data, Confident Decisions
AI is transforming hotel revenue management—but only when paired with high-quality, real-time data. If your current system doesn’t validate and structure your data properly, it’s time for a change.
With ampliphi, you’re not just adopting AI—you’re investing in a smarter, more dependable future for your revenue strategy.
0 notes
Text
What AI Cannot Do: AI Limitation
Artificial Intelligence (AI) has made remarkable strides in recent years, revolutionizing industries from healthcare to finance. However, despite its impressive capabilities, there are inherent AI limitation to what it can achieve. Understanding these limitations is crucial for effectively integrating AI into our lives and recognizing its role as a tool rather than a replacement for human…
#adversarial attacks on AI#AI in customer service#AI limitations#automation and employment.#biases in AI algorithms#common sense in AI#context understanding in AI#creativity in artificial intelligence#data quality in AI#emotional intelligence in machines#ethical concerns with AI#human-AI collaboration#job displacement due to automation#machine learning limitations#robustness of AI systems
0 notes
Text
remember a few months ago when artists were panicking about Grok AI using their art for training? Now, no one seems to care anymore?
19 notes
·
View notes
Text
When I say I hate generative AI, I don't mean, I hate gen AI unless it amuses me or is convenient for me. I don't mean, I hate gen AI only when it involves the art formats I participate in and everything else is fair game. I mean, I HATE GEN AI.
#rage rage#it's a waste of water#so much data used for llms is taken without permission#it's so much easier for misinfo to spread#artists are losing job opportunities#online communities are getting swamped with ai slop#and yet one of the most common criticisms i see of ai#is that the output is low quality#my dudes ai could generate an image of a bunch of perfectly rendered five fingered hands#and what i said above would still apply#if anything the low quality factor is a point in ai's favor
2 notes
·
View notes
Text

Artificial Intelligence is more than just a buzzword—it's a powerful force shaping the way we work, live, and connect. As businesses and professionals navigate the rapidly changing digital landscape, AI integration has become not only an advantage but a necessity. From automating repetitive tasks to streamlining communication, AI is transforming the workplace—and now is the time to plug in.
What Is AI Integration?
AI integration refers to the process of embedding intelligent technology into your current systems and workflows. Instead of replacing human effort, it enhances capabilities by analysing data, learning patterns, and optimising operations in real-time. For professionals and organisations alike, this means better decisions, faster execution, and improved customer experiences.
Why Embrace AI Today?
Here’s how AI integration is making a difference across industries:
Improved Efficiency
With AI handling time-consuming tasks like email filtering, data analysis, and scheduling, teams can focus on what truly matters—innovation and human connection.
Smarter Decisions
AI can process huge amounts of information quickly, offering insights that help businesses make better, data-backed choices.
Digital Strength
Today’s digital-first world demands a solid online presence. AI tools play a major role in Digital Presence Management, from optimising search visibility to curating consistent social media content.
Personal Branding
Professionals and entrepreneurs are increasingly using AI-powered personal branding tools to craft compelling bios, automate content creation, and engage with audiences more effectively.
B2B Strategy
In a competitive market, B2B branding strategy supported by AI helps teams personalise outreach, understand client behaviour, and build stronger relationships.
Getting Started With AI Integration
Adopting AI doesn’t require a tech overhaul. Start with tools you may already be using:
Leverage Smart Features: Google Workspace, Microsoft 365, and Canva now include AI suggestions, writing assistants, and design tools.
Automate with Purpose: Platforms like Zapier or Make.com allow easy automation between your favourite apps and services.
Explore Industry Tools: If you’re in marketing, explore ChatGPT or Jasper for content. If you’re in customer service, check out AI-enabled platforms like Intercom or Drift.
Best Practices for a Smooth Transition
Educate Your Team: Offer basic training so everyone feels confident using AI tools.
Start with a Small Project: Test out AI on a single workflow, such as automating social media or customer queries.
Maintain Human Oversight: Always review AI outputs for accuracy and relevance.
Key Takeaways
AI integration is no longer optional—it's essential. Whether you're looking to improve productivity, enhance brand visibility, or gain a competitive edge, integrating AI is a smart step forward.
Visit Best Virtual Specialist to discover how our expert virtual professionals can help you integrate AI tools, elevate your digital presence, and transform your workflow.
#Ai integration#Digital Presence Management#AI-Powered Personal Branding#B2B Branding Strategy#Artificial Intelligence#virtual specialist#business development strategy plan#data quality services#best virtual assistant in the usa#affordable va#outsourced va#aipoweredsupport#best admin assistant in australia#bpo admin support#ai tools#business support
2 notes
·
View notes
Text
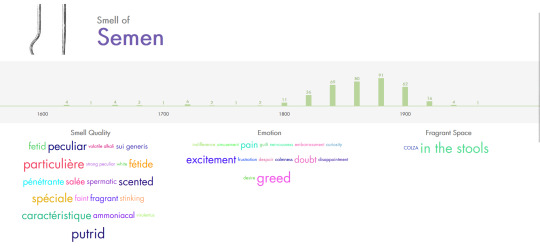
doing research
#you know the regular kind#also this database is so shit#it uses LLMs to scrape data from books to associate smells with feelings and qualities etc#99% of smells have the same vague descriptions like perfumed scented odorous fragrant#which is a shame bc the project in general seems really interesting#and some parts seem to be well done at least at a glance#it really just feels like they had to hop on the ai train to get funding
2 notes
·
View notes
Text
i am pretty excited for the miku nt update early access tomorrow. the demonstrations have sounded pretty solid so far and tbh i am super intrigued by the idea of hybrid concatenative+ai vocal synthesis, i wanna see what people doooo with it. show me it nowwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
#im assuming it'll be out sometime in japanese afternoon time. but i will be asleep so i have to wait until tomorrow <3#but im so intrigued....... synthv did a different thing a bajillion years ago where they like#trained ai voicebanks off of their concatenative data? it never went anywhere because of quality issues?#but i still think theres some potential in that. and i think nt2 might be the first commercial release thats#sample based with ai assistance? correct me if im wrong though i could be forgetting stuff#but i dunno.... im intrigued.... i would love to see another go at kaito in theory#BUT crypton is like afraid of his v1 hint of chest voice so i dunno how much id like the direction theyre going in#and that really is my biggest issue with later versions of kaito he's like all nasal#like the opposite issue genbu has LOL genbus all chest no head#(smacks phone against the pavement gif)#although all chest is easier to deal with because if i want a hiiiiint of a nasal-y heady tone i can fudge it with gender#plus he has those secret falsetto phonemes. the secret falsetto phonemes.#its harder to make a falsetto-y voice sound chestier with more warmth than the other way around#people can do pretty wonderful things with kaito v3 and sp though. but i still crave that v1 HJKFLDSJHds#but yeah i dunno! i imagine they wont bother with new NTs for the other guys after miku v6 but i would be curious#i am still not personally sold on v6 in general yet. but maybe vx will change that LOL#the future of vocal synthesizers is so exciting..... everything is happening all the time
6 notes
·
View notes
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
Your Guide to B.Tech in Computer Science & Engineering Colleges

In today's technology-driven world, pursuing a B.Tech in Computer Science and Engineering (CSE) has become a popular choice among students aspiring for a bright future. The demand for skilled professionals in areas like Artificial Intelligence, Machine Learning, Data Science, and Cloud Computing has made computer science engineering colleges crucial in shaping tomorrow's innovators. Saraswati College of Engineering (SCOE), a leader in engineering education, provides students with a perfect platform to build a successful career in this evolving field.
Whether you're passionate about coding, software development, or the latest advancements in AI, pursuing a B.Tech in Computer Science and Engineering at SCOE can open doors to endless opportunities.
Why Choose B.Tech in Computer Science and Engineering?
Choosing a B.Tech in Computer Science and Engineering isn't just about learning to code; it's about mastering problem-solving, logical thinking, and the ability to work with cutting-edge technologies. The course offers a robust foundation that combines theoretical knowledge with practical skills, enabling students to excel in the tech industry.
At SCOE, the computer science engineering courses are designed to meet industry standards and keep up with the rapidly evolving tech landscape. With its AICTE Approved, NAAC Accredited With Grade-"A+" credentials, the college provides quality education in a nurturing environment. SCOE's curriculum goes beyond textbooks, focusing on hands-on learning through projects, labs, workshops, and internships. This approach ensures that students graduate not only with a degree but with the skills needed to thrive in their careers.
The Role of Computer Science Engineering Colleges in Career Development
The role of computer science engineering colleges like SCOE is not limited to classroom teaching. These institutions play a crucial role in shaping students' futures by providing the necessary infrastructure, faculty expertise, and placement opportunities. SCOE, established in 2004, is recognized as one of the top engineering colleges in Navi Mumbai. It boasts a strong placement record, with companies like Goldman Sachs, Cisco, and Microsoft offering lucrative job opportunities to its graduates.
The computer science engineering courses at SCOE are structured to provide a blend of technical and soft skills. From the basics of computer programming to advanced topics like Artificial Intelligence and Data Science, students at SCOE are trained to be industry-ready. The faculty at SCOE comprises experienced professionals who not only impart theoretical knowledge but also mentor students for real-world challenges.
Highlights of the B.Tech in Computer Science and Engineering Program at SCOE
Comprehensive Curriculum: The B.Tech in Computer Science and Engineering program at SCOE covers all major areas, including programming languages, algorithms, data structures, computer networks, operating systems, AI, and Machine Learning. This ensures that students receive a well-rounded education, preparing them for various roles in the tech industry.
Industry-Relevant Learning: SCOE’s focus is on creating professionals who can immediately contribute to the tech industry. The college regularly collaborates with industry leaders to update its curriculum, ensuring students learn the latest technologies and trends in computer science engineering.
State-of-the-Art Infrastructure: SCOE is equipped with modern laboratories, computer centers, and research facilities, providing students with the tools they need to gain practical experience. The institution’s infrastructure fosters innovation, helping students work on cutting-edge projects and ideas during their B.Tech in Computer Science and Engineering.
Practical Exposure: One of the key benefits of studying at SCOE is the emphasis on practical learning. Students participate in hands-on projects, internships, and industry visits, giving them real-world exposure to how technology is applied in various sectors.
Placement Support: SCOE has a dedicated placement cell that works tirelessly to ensure students secure internships and job offers from top companies. The B.Tech in Computer Science and Engineering program boasts a strong placement record, with top tech companies visiting the campus every year. The highest on-campus placement offer for the academic year 2022-23 was an impressive 22 LPA from Goldman Sachs, reflecting the college’s commitment to student success.
Personal Growth: Beyond academics, SCOE encourages students to participate in extracurricular activities, coding competitions, and tech fests. These activities enhance their learning experience, promote teamwork, and help students build a well-rounded personality that is essential in today’s competitive job market.
What Makes SCOE Stand Out?
With so many computer science engineering colleges to choose from, why should you consider SCOE for your B.Tech in Computer Science and Engineering? Here are a few factors that make SCOE a top choice for students:
Experienced Faculty: SCOE prides itself on having a team of highly qualified and experienced faculty members. The faculty’s approach to teaching is both theoretical and practical, ensuring students are equipped to tackle real-world challenges.
Strong Industry Connections: The college maintains strong relationships with leading tech companies, ensuring that students have access to internship opportunities and campus recruitment drives. This gives SCOE graduates a competitive edge in the job market.
Holistic Development: SCOE believes in the holistic development of students. In addition to academic learning, the college offers opportunities for personal growth through various student clubs, sports activities, and cultural events.
Supportive Learning Environment: SCOE provides a nurturing environment where students can focus on their academic and personal growth. The campus is equipped with modern facilities, including spacious classrooms, labs, a library, and a recreation center.
Career Opportunities After B.Tech in Computer Science and Engineering from SCOE
Graduates with a B.Tech in Computer Science and Engineering from SCOE are well-prepared to take on various roles in the tech industry. Some of the most common career paths for CSE graduates include:
Software Engineer: Developing software applications, web development, and mobile app development are some of the key responsibilities of software engineers. This role requires strong programming skills and a deep understanding of software design.
Data Scientist: With the rise of big data, data scientists are in high demand. CSE graduates with knowledge of data science can work on data analysis, machine learning models, and predictive analytics.
AI Engineer: Artificial Intelligence is revolutionizing various industries, and AI engineers are at the forefront of this change. SCOE’s curriculum includes AI and Machine Learning, preparing students for roles in this cutting-edge field.
System Administrator: Maintaining and managing computer systems and networks is a crucial role in any organization. CSE graduates can work as system administrators, ensuring the smooth functioning of IT infrastructure.
Cybersecurity Specialist: With the growing threat of cyberattacks, cybersecurity specialists are essential in protecting an organization’s digital assets. CSE graduates can pursue careers in cybersecurity, safeguarding sensitive information from hackers.
Conclusion: Why B.Tech in Computer Science and Engineering at SCOE is the Right Choice
Choosing the right college is crucial for a successful career in B.Tech in Computer Science and Engineering. Saraswati College of Engineering (SCOE) stands out as one of the best computer science engineering colleges in Navi Mumbai. With its industry-aligned curriculum, state-of-the-art infrastructure, and excellent placement record, SCOE offers students the perfect environment to build a successful career in computer science.
Whether you're interested in AI, data science, software development, or any other field in computer science, SCOE provides the knowledge, skills, and opportunities you need to succeed. With a strong focus on hands-on learning and personal growth, SCOE ensures that students graduate not only as engineers but as professionals ready to take on the challenges of the tech world.
If you're ready to embark on an exciting journey in the world of technology, consider pursuing your B.Tech in Computer Science and Engineering at SCOE—a college where your future takes shape.
#In today's technology-driven world#pursuing a B.Tech in Computer Science and Engineering (CSE) has become a popular choice among students aspiring for a bright future. The de#Machine Learning#Data Science#and Cloud Computing has made computer science engineering colleges crucial in shaping tomorrow's innovators. Saraswati College of Engineeri#a leader in engineering education#provides students with a perfect platform to build a successful career in this evolving field.#Whether you're passionate about coding#software development#or the latest advancements in AI#pursuing a B.Tech in Computer Science and Engineering at SCOE can open doors to endless opportunities.#Why Choose B.Tech in Computer Science and Engineering?#Choosing a B.Tech in Computer Science and Engineering isn't just about learning to code; it's about mastering problem-solving#logical thinking#and the ability to work with cutting-edge technologies. The course offers a robust foundation that combines theoretical knowledge with prac#enabling students to excel in the tech industry.#At SCOE#the computer science engineering courses are designed to meet industry standards and keep up with the rapidly evolving tech landscape. With#NAAC Accredited With Grade-“A+” credentials#the college provides quality education in a nurturing environment. SCOE's curriculum goes beyond textbooks#focusing on hands-on learning through projects#labs#workshops#and internships. This approach ensures that students graduate not only with a degree but with the skills needed to thrive in their careers.#The Role of Computer Science Engineering Colleges in Career Development#The role of computer science engineering colleges like SCOE is not limited to classroom teaching. These institutions play a crucial role in#faculty expertise#and placement opportunities. SCOE#established in 2004#is recognized as one of the top engineering colleges in Navi Mumbai. It boasts a strong placement record
2 notes
·
View notes
Text
i am so sick of people using chatgpt to generate descriptions for ebay items ughhhh
#so i'm looking at quilting supplies. because how else would a 28 year old spend her saturday night#someone's selling quilt blocks. description: 150 rambling words about how useful they will be in my projects#not in the description: how large are they? do you know the time period they were made in (the title says vintage)?#“the brand is high quality and trusted” THERE IS NO BRAND SOME NICE GRANDMA PROBABLY MADE THESE#y'all i am a data scientist i am not anti-ai by any means but can we at least proofread shit. like come on#i'm not buying from these ppl bc i don't trust a seller who can't take like 10 seconds to read the chatgpt output before using it#m.txt
2 notes
·
View notes
Text
About us | Tejasvi Addagada | Data Management Services
Tejasvi Addagada specializes in delivering comprehensive Data Management Services tailored to help organizations optimize, secure, and govern their data. With expertise in data governance, data quality, and analytics, we provide customized solutions that enable businesses to make informed decisions, reduce risks, and enhance operational efficiency, ensuring data becomes a strategic asset for growth. Connect with us at 123-456-7890.
#Tejasvi Addagada#data management#data analysis#data protection#Data Management Services#certified data management professional#privacy enhancing technologies#generative ai for data quality#data management framework#data governance strategy
1 note
·
View note
Text
I watched a training on career development; the premise was that project managers should treat their career like a project. And one really stupid comment stuck with me: "salary should not be in your goals. That's like choosing your software before knowing the project requirements."
It was ironic, because one of his goals was "work-life balance at a remote workplace." 🙄
It was a lot of fluff about making lists of what you like to do at work and what you don't, and that somehow translates to finding your dream job. He discouraged using luck-based strategies, in favor of...a luck based strategy of mentoring people who will hopefully inspire you. 🙃
And I'm just like. "Ok, project manager. You haven't accounted for your assumptions."
But also. Knowing your budget is important to being a project manager. There's a minimum budget needed to succeed. If you're not planning that out early, you didn't really plan your project.
And I'm sitting there thinking that next, for me, isn't a reassessment of the tasks I perform. I like the tasks well enough. Next is getting a $50k-70k wage increase, to be in line with the industry average for people with my skills, performing my tasks, at my level of experience in this region. It's a 32 hour work week. And more paid time off.
I don't care if I get a fancy new title. I don't care if it's a more prestigious company. I don't care if there are more interesting challenges. I've grown my skills. It's past time to grow my lifestyle. And that's not going to happen from a like and dislike list, and mentoring people.
#i don't know why i bother with these trainings honestly#they're so shallow. i kind of want to rant about the courses about AI#they're basically marketing brochures. and one involved a weird spin on data#like. it showed that project managers don't see the value. but it's the wave of the future because senior leaders overwhelmingly expect it#they had the same data ratio showing that workers want remote work and senior leaders only think they're effective if they're in person.#in that example. it was proof that senior leaders are out of touch. and they supported it with data showing no difference for remote quality#it was just a way to pretend there's some value behind AI. but the speakers overwhelming don't understand it#they listed a lot of abstract value. but nothing of substance. no suggestion of tools that can and should be trusted#and no acknowledgement that having someone continuously checking that it worked right. is an extra step. not a time savings#i tend to spend more time questioning the competence of trainers than getting anything from these courses
5 notes
·
View notes
Text
I hate when I say things like "oh I want an ipod classic but with bluetooth so I can use wireless headphones" and some peanut comes in and replies with "so a smartphone with spotify?" No. I want a 160GB+ rectangular monstrosity where I can download every version of every song I want to it and it does nothing except play music and I don't need a data connection and don't have to pay a subscription to not have ads and don't have popups suggesting terrible AI playlists all over the menus.
Gimme the clicky wheel and song titles like "My Chemical Romance- The Black Parade- Blood (Bonus Track)- secret track- album rip- high quality"
#ok to rb#music#ipod#spotify#only apple product ive ever genuinely liked was the ipod#i had an ipod classic i bought off trademe that someone had put a higher capacity harddrive in#think it was like 320GB or something#i loved that thing#mywriting
123K notes
·
View notes
Text
Elevate Success: Teamwork for All Business Tasks With AI Integration

You know that effective collaboration is the engine of any successful business, whether it's powering your next marketing initiative, securing crucial sales, or managing everyday administrative duties. But picture this: what if your team's collective efforts could become even stronger, sharper, and more efficient? Envision your team members working flawlessly, not only among themselves but also with clever digital tools that take on the heavy lifting and process data precisely. This leads to a truly cohesive operation, where every task, no matter its size, benefits from shared human insight and accurate digital support, ultimately making your entire business much more productive and impactful.
Benefits of Teamwork With AI
When your team works together using smart digital tools, you unlock significant advantages for your business:
Sharper Shared Understanding: Your team can process and interpret information much faster when everyone works together with intelligent digital aids. This fosters Collaborative Intelligence, leading to better discussions and decisions for your marketing campaigns, sales strategies, and even everyday administrative tasks, as everyone is on the same page with the most precise data.
Enhanced Marketing Support: Your marketing efforts become more precise and impactful. With digital tools handling repetitive data tasks and content suggestions, your team can focus on creative strategies, personalized campaigns, and truly engaging your audience, ensuring your brand stands out and receives robust Marketing Support.
Boosted Sales Assistance: Your sales team gains a powerful edge. Digital integration helps streamline lead tracking, automate routine follow-ups, and provide quick access to client history. This provides crucial Sales Assistance, allowing your sales professionals to spend more time building relationships and closing deals rather than getting caught up in administrative details.
Streamlined Administrative Tasks: Everyday operations become significantly smoother and more accurate. Digital tools automate tedious paperwork, manage schedules, and organize information with precision, providing excellent Administrative Tasks support. This frees up valuable time for your team, reducing errors and ensuring your business runs efficiently, regardless of the task.
Overall Business Efficiency: Combining human teamwork with intelligent digital support leads to a more agile and productive business. Workflows become clearer, communication is more effective, and resources are used wisely, allowing your entire operation to achieve more with the same effort. This blend of Collaborative Intelligence, optimized for Marketing Support, Sales Assistance, and Administrative Tasks, truly drives comprehensive improvement.
Unleash Your Business Potential
So, when you unite your team's abilities with clever digital tools, you're doing more than just simplifying work. You're building a powerful and effective business. Step into this modern approach, and you'll unleash amazing possibilities, ensuring your entire operation succeeds and truly excels.
Take that one step ahead and visit Best Virtual to find your best collaborators.
References:
https://medium.com/@techaheadcorp/agent2agent-architecture-a-new-era-of-agent-collaboration-8028fc406ef6
https://teachwell.auckland.ac.nz/2025/05/21/teaching-tip-use-gen-ai-to-deepen-learning-and-spark-creativity/
https://www.researchgate.net/publication/389385597_The_Digital_Transformation_of_Sales_Examining_the_Role_of_Technology_Adoption_in_Sales_Enablement
https://asana.com/resources/what-is-collaborative-intelligence
© 2025 Best Virtual Specialist. All rights reserved.
#virtual specialist#business development strategy plan#data quality services#best virtual assistant in the usa#affordable va#outsourced va#ai integration#aipoweredsupport#best admin assistant in australia#bpo admin support#Marketing Support#Administrative Tasks
0 notes
Text
My sister was reviewing survey responses at work and was disappointed that some of the responses (from elementary school teachers, mind you!) were clearly ChatGPT. She could tell because they referenced a lot of animals they didn't have at the zoo at the time the kids visited.
But what really worries me is that my sister was surprised that ChatGPT got it so wrong. Because that information is on the internet, and it just pulls info from the internet, right?
My sister is an intelligent person and I rant to her about AI all the time, so if she has this misconception, I'm sure a lot of people do, which worries me.
ChatGPT and LLM do NOT just pull info from the internet. They do NOT take verbatim sentences from online sources. They're not trustworthy, but not because the source is the internet. They take WORDS, not complete sentences, from the internet and put them together. They look for the most common words that are put together and put them in an order that SOUNDS LIKE the rest of the internet. They look for patterns. ChatGPT finds a bunch of articles about Zoo Atlanta and pandas, so it adds pandas to its sentences when you prompt it about Zoo Atlanta animals. It does not notice that all the articles were about the pandas going back to China. It does not know how to read and understand context! It is literally just putting words together that sound good.
The hallucination problem is not a bug that can be worked out. This is the whole premise of how LLMs were designed to work. AI that is trained like this will all be worthless for accuracy. You cannot trust that AI overview on Google, nor can you trust ChatGPT to pull up correct information when you ask it. It's not trying to! That was never what it was designed to do!
#There are some AI applications that are trained on very specific data sets in science that are helpful#they do pattern association but not for words#for data#but I also worry that the quality of that is being diluted by tech companies who are just trying to capitalize and they'll shove these llms#into fields that should not go anywhere near them like healthcare#I don't know if that's happening or not but I am really worried that it could
1 note
·
View note
Text
The AIoT Revolution: How AI and IoT Convergence is Rewriting the Rules of Industry & Life

Imagine a world where factory machines predict their own breakdowns before they happen. Where city streets dynamically adjust traffic flow in real-time, slashing commute times. Where your morning coffee brews automatically as your smartwatch detects you waking. This isn’t science fiction—it’s the explosive reality of Artificial Intelligence of Things (AIoT), the merger of AI algorithms and IoT ecosystems. At widedevsolution.com, we engineer these intelligent futures daily.
Why AIoT Isn’t Just Buzzword Bingo: The Core Convergence
Artificial Intelligence of Things fuses the sensory nervous system of IoT devices (sensors, actuators, smart gadgets) with the cognitive brainpower of machine learning models and deep neural networks. Unlike traditional IoT—which drowns in raw data—AIoT delivers actionable intelligence.
As Sundar Pichai, CEO of Google, asserts:
“We are moving from a mobile-first to an AI-first world. The ability to apply AI and machine learning to massive datasets from connected devices is unlocking unprecedented solutions.”
The AIoT Trinity: Trends Reshaping Reality
1. Predictive Maintenance: The Death of Downtime Gone are days of scheduled check-ups. AI-driven predictive maintenance analyzes sensor data intelligence—vibrations, temperature, sound patterns—to forecast failures weeks in advance.
Real-world impact: Siemens reduced turbine failures by 30% using AI anomaly detection on industrial IoT applications.
Financial upside: McKinsey estimates predictive maintenance cuts costs by 20% and downtime by 50%.
2. Smart Cities: Urban Landscapes with a Brain Smart city solutions leverage edge computing and real-time analytics to optimize resources. Barcelona’s AIoT-powered streetlights cut energy use by 30%. Singapore uses AI traffic prediction to reduce congestion by 15%.
Core Tech Stack:
Distributed sensor networks monitoring air/water quality
Computer vision systems for public safety
AI-powered energy grids balancing supply/demand
3. Hyper-Personalized Experiences: The End of One-Size-Fits-All Personalized user experiences now anticipate needs. Think:
Retail: Nike’s IoT-enabled stores suggest shoes based on past purchases and gait analysis.
Healthcare: Remote patient monitoring with wearable IoT detects arrhythmias before symptoms appear.
Sectoral Shockwaves: Where AIoT is Moving the Needle
🏥 Healthcare: From Treatment to Prevention Healthcare IoT enables continuous monitoring. AI-driven diagnostics analyze data from pacemakers, glucose monitors, and smart inhalers. Results?
45% fewer hospital readmissions (Mayo Clinic study)
Early detection of sepsis 6+ hours faster (Johns Hopkins AIoT model)
🌾 Agriculture: Precision Farming at Scale Precision agriculture uses soil moisture sensors, drone imagery, and ML yield prediction to boost output sustainably.
Case Study: John Deere’s AIoT tractors reduced water usage by 40% while increasing crop yields by 15% via real-time field analytics.
🏭 Manufacturing: The Zero-Waste Factory Manufacturing efficiency soars with AI-powered quality control and autonomous supply chains.
Data Point: Bosch’s AIoT factories achieve 99.9985% quality compliance and 25% faster production cycles through automated defect detection.
Navigating the Minefield: Challenges in Scaling AIoT
Even pioneers face hurdles:ChallengeSolutionData security in IoTEnd-to-end encryption + zero-trust architectureSystem interoperabilityAPI-first integration frameworksAI model driftContinuous MLOps monitoringEnergy constraintsTinyML algorithms for low-power devices
As Microsoft CEO Satya Nadella warns:
“Trust is the currency of the AIoT era. Without robust security and ethical governance, even the most brilliant systems will fail.”
How widedevsolution.com Engineers Tomorrow’s AIoT
At widedevsolution.com, we build scalable IoT systems that turn data deluge into profit. Our recent projects include:
A predictive maintenance platform for wind farms, cutting turbine repair costs by $2M/year.
An AI retail personalization engine boosting client sales conversions by 34%.
Smart city infrastructure reducing municipal energy waste by 28%.
We specialize in overcoming edge computing bottlenecks and designing cyber-physical systems with military-grade data security in IoT.
The Road Ahead: Your AIoT Action Plan
The AIoT market will hit $1.2T by 2030 (Statista). To lead, not follow:
Start small: Pilot sensor-driven process optimization in one workflow.
Prioritize security: Implement hardware-level encryption from day one.
Democratize data: Use low-code AI platforms to empower non-technical teams.
The Final Byte We stand at an inflection point. Artificial Intelligence of Things isn’t merely connecting devices—it’s weaving an intelligent fabric across our physical reality. From farms that whisper their needs to algorithms, to factories that self-heal, to cities that breathe efficiently, AIoT transforms data into wisdom.
The question isn’t if this revolution will impact your organization—it’s when. Companies leveraging AIoT integration today aren’t just future-proofing; they’re rewriting industry rulebooks. At widedevsolution.com, we turn convergence into competitive advantage. The machines are learning. The sensors are watching. The future is responding.
“The greatest achievement of AIoT won’t be smarter gadgets—it’ll be fundamentally reimagining how humanity solves its hardest problems.” — widedevsolution.com AI Lab
#artificial intelligence#predictive maintenance#smart city solutions#manufacturing efficiency#AI-powered quality control in manufacturing#edge computing for IoT security#scalable IoT systems for agriculture#AIoT integration#sensor data intelligence#ML yield prediction#cyber-physical#widedevsolution.com
0 notes