#data drift
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Fluent Bit and AI: Unlocking Machine Learning Potential
These days, everywhere you look, there are references to Generative AI, to the point that what have Fluent Bit and GenAI got to do with each other? GenAI has the potential to help with observability, but it also needs observation to measure its performance, whether it is being abused, etc. You may recall a few years back that Microsoft was trailing new AI features for Bing, and after only having…
View On WordPress
#AI#Cloud#Data Drift#development#Fluent Bit#GenAI#Machine Learning#ML#observability#Security#Tensor Lite#TensorFlow
0 notes
Text
Data Drift: How Does it Affect Your Machine Learning Model?
Across the globe, organizations are tapping into the potential of data to drive informed decision-making, streamline operations, and gain a competitive edge through artificial intelligence and machine-learning. However, amidst this data-driven revolution, a formidable challenge known as “Data Drift” looms, capable of exerting a profound impact on the performance of machine learning models. In…

View On WordPress
0 notes
Text
Okay I'm curious: I've seen a lot of Christians use/refer to the phrase "hosanna in the highest!" which is used in the New Testament and I've frequently heard it pronounced "hoh-ZAHN-ah". However, it's a much older liturgical phrase in Hebrew and definitely not pronounced like that. I want to know: (1) were you taught the actual meaning of this word by your community/do you know what it actually means without googling it, (2) what variety of Christian are you, and (3) if, after googling it, were you correct?
Sorry fellow yidden and other non-Christians; this poll is specific to people who identify as Christian and/or who were raised as such. (Edit: gerim who were raised Christian can vote, but you have to base it off of what you were taught as a Christian, not what you know now.)
Christians who answer: if you googled this after voting yes and were taught wrong about it, please let me know in the notes.
(If you're wondering if you "count" as Christian or having been raised as such, for these purposes I would say interpret it broadly to include anyone who views Jesus as the messiah and grew up reading the New Testament as part of your bible.)
#christian#non-Christians please boost but don't vote#I have... a theory about this but am curious to have at least informal data about this first#yes I realize linguistic drift from other languages is probably how ''hozanna'' happened#but the Hebrew is different#this post brought to you by: Sukkot#every hour is theology hour around here apparently
727 notes
·
View notes
Text
...
#hm. im in limbo. but at least i can draw again at last. ive never spent so long not wanting to draw. it was terrible#my job search lasted 4 days before i secured a position at target but i dont start until the 26th so im drifting until then#it feels so weird. like i dunno. i keep thinking abt jobs in a weird way now bc i just sorta drifted into what i do#weird academic stuff but i think most jobs arent like being a grad student and that never really occured to me#i dunno why. i could have done so many things but here i am. an ecologist mostly. i dunno. well see what the summer brings#maybe ill grow some social skills. its sorta weird but like the medication has made my head less terrible with intrusive thoughts. like i#can actually drive my car without hyperventilating which is fucking wild. so Maybe ill grow some confidence abt interacting with the world#going back in the fall still seems impossible rn but so does starting a job somewhere else. but i dunno#not where i expected to be in my life. im just lucky i dont have to worry much abt money#especially bc i got an ultrasound done so they cold make sure something wasnt wrong with my uterus#and its fine. guess it just hates me but that means i spent like 350 dollars for a 10min scan that showed nothing#ay. the us medical system#anyway. i guess ill continue drifting until the 26th#probably i should find something to do. or work on my old unpublished data#unrelated
15 notes
·
View notes
Text





The man on the radio keeps playing Enya ... not my cup of tea, but then I have coffee. Today's quiz was all about The Boss. The answer was very obvious, even to me, but I never text in. The traffic lady talked about traffic, before going on to say two friends had stayed over and were extreme fans of the man on the radio and would he give a shout out to them. The chef on the radio is in and as it's Friday it's all about fish, prawns and breadcrumbs.
The three minute misery came and went with reports that the data centre people need more of everything to build even more data centres. They need more land ... and electricity ... and funding ... and ... and ... and ... so could the Emeraldians please get off the Emerald Isle. I don't think the chef on the radio has a recipe for that.
The peony has finally flowered. The plant has quite some age on it. I've been here 10 years and it was here before I came. Have been given a Tayberry plant and a blueberry plant. The Tayberry is a cross between a raspberry and a blackberry. I already don't get any blackberries or raspberries from the garden ... so I'm pretty sure if these fruits appear the birds will be the only ones holding up taste and texture score cards.
Pineapple, raspberries and blueberries are on the cake menu today, plus flapjacks, plus the coffee pot. Friday, Friday, Friday and the man on the radio is playing The Drifters 'Up On The Roof' ...
#man on the radio#traffic lady#chef on the radio#friday#berries#raspberry#blueberry#tayberry#peony#fish#friday is fish day#bloody data centres#flowercore#naturecore#treecore#sycamore#writers of tumblr#wry humour#humour#original writing#writers on tumblr#good morning#photographers on tumblr#original photography on tumblr#naturephotography#three minutes#three minute misery#ivycore#drifting
11 notes
·
View notes
Text

Oddly enough, I haven't encountered any Purple Mountain legs in Gen 5 yet despite them being a good chunk of the leg genes from Gen 4. I'm guessing that the first 5-8 norns in Gen 4 just got real busy with each other, making the percent chance of inheriting PMN legs pretty low. That should change once we get deeper into Gen 5, although I'm guessing that Forest legs are going to start dominating the population. Just a guess though. Genetic drift is one hell of a thing...
#data#family tree#creatures 1#genetic drift#oh also i'm missing MOST of the lineage for these guys#however i can trace some of the norns with horse genes#if they have a horse head or body then they HAVE to be related to one norn#same with arms#it will also tell me who's related to Conifer (4-7)???#it makes no sense#i love it#i eat this nonsense UP
2 notes
·
View notes
Text
Data could pilot a Jaeger by himself but he and Geordi are drift compatible so he would NEVER.
#that is all#daforge#star trek tng#data and geordi#data tng#geordi la forge#drift compatible#pacific rim#commander data
24 notes
·
View notes
Text
what if i backed up my pc chao garden and started it over and played it like a normal person and not like a dog breeder. as a treat
#soda offers you a can#imagine if there had been a 3ds chao garden game so i could have it portably and enjoy all the features#a ds chao garden even im not picky i just want it portably on two screens#“switch is portable tho” switches are massive in comparison and have joycon drift#and i'd much rather shove a ds/3ds into a bag than a goddamn 500€+ home console thank you very much#anyway time to investigate save data locations
3 notes
·
View notes
Text

A messy animation of the hand break hero
#I drew everything and scanned it so it could be warped and animated in Procreate#which unfortunately means there’s too much data for tumble to handle so it’ll have to settle with the potato web ready version#my drawing#artists on tumblr#my sketchbook#artist alley#my painting#drawing#animation#2d animation#animated gif#2d animated video#animated#oil pastels#fiat#fiat 500#hand break turn#hand break hero#tokyo drift#drift#skid
5 notes
·
View notes
Text
Inteligencia Artificial en Marketing y Publicidad: Herramientas Clave que Definen el Futuro
¿Qué es la Inteligencia Artificial (IA) en Marketing y Publicidad y Para Qué Sirve? La Inteligencia Artificial (IA) en Marketing y Publicidad se refiere a la aplicación de tecnologías y algoritmos de IA (como el aprendizaje automático, el procesamiento del lenguaje natural y el análisis predictivo) para optimizar y automatizar diversas tareas y estrategias de marketing. No se trata de robots…
#Adext AI#Adobe Sensei#AdTech#Albert AI#Amplify.ai#análisis predictivo#Aprendizaje Automático#Automatización de Marketing#Big Data Marketing#Brandwatch#chatbots#Conversica#Cortex#Crimson Hexagon#Drift#Experiencia del Cliente#Generación de Contenido AI#HubSpot Marketing Hub#IA en Marketing#inteligencia artificial#Marketing Conversacional#marketing digital#Marketo Engage#MarTech#Optimización de Campañas#Optimove#Persado#personalización#Phrasee#Publicidad Online
0 notes
Photo
9:50 AM EST December 28, 2024:
The Mercury Program - "Slightly Drifting" From the album A Data Learn the Language (September 10, 2002)
Last song scrobbled from iTunes at Last.fm
0 notes
Text
oh. i understand the hype about next gen now.
Data,
#like it is the whole crew obv him himself would be good but not the same thing#but its like how when i get people into (my beloved) tos#i can see the change when they're like. oh. i get it. Spock#like its the whole crew! BUT#u find the- the--#yeah#i get it now!#Data#or ds9- Dax#i wonder if this is part of what contributes to voyager's status#because it's captain janeway (o captain my captain) who is that#but since she's the captain it's not as expected so if you don't go in knowing that it's totally hard to get your head around?#but also-- and this isn't a detriment-- Spock is so strong with that in TOS and i wonder if that drifts and changes th/o#like how much presence that is as a unit#hm. hm hm hm hm. much to think about#hm. you know that recent power rangers movie?#im not 18 it was more than two years ago but--#one of things important/ i respect about it was that they cast a black character as the spock#now did they do a good job? eh#but they set it up like that and that's a good thing#and i may be misinterpreting but i feel like power rangers is for the billys of the world yk?#as a billy myself
0 notes
Text
It’s time for the long awaited
✨Generation 5 Overview✨
It’s a looooong post, so if you care to read, it’s under this handy dandy read more.
The generation was made up of 47 norns and lasted approximately 58 hours, including a period of time where I left the game on overnight. The average lifespan was 6:32, with the highest natural lifespan being 9:11 and the lowest being 5:35.
Phenotypes
There were 188 body-type genes total.
45.21% were Purple Mountain, 39.89% were Forest, 6.38% were Horse, 6.38% were Ron, and 2.13% were Banana (For funsies at the end of the run. There were no males to breed with.) I did not see any body-type genes disappear.
I’m now seeing Horse genes and Ron genes intersect in the gene pool timeline, but no norn had both Horse and Ron phenotypes.
The female:male ratio was 2.13:1. Lucky guys.
Genotypes
Two norns had extra pigment genes.
One norn had an extra chemical emitter gene.
One norn produced alcohol in some amount in all stages of life. The stumbling was the giveaway. It’s possible that norns are producing odd chemicals right under my nose, but I haven’t caught them because the effects aren’t obvious.
One norn seemed unable to give birth (Gonadotrophin maxes out but progesterone stays at a low level). I used the Advanced Breeder’s Kit to help her out a few times. Sometimes I can’t bear to see them suffer. Plus she still needed to eat like a pregnant norn and was taking a lot of time to care for.
No norns inherited the 100% life force gene, sadly.
Deaths
37/47 were exported due to old age (Only 78.7%, yikes)
5/47 died from Antigen 1 (10.6%)
3/47 died upon being imported (6.4%)
2/47 died from “Failure to thrive”, which includes Child of the Mind syndrome and the lack of interest in eating (4.3%)
Poor norns kind of had a rough time in this generation.
Important Discoveries
The game tries to “correct” your gender ratio when hatching eggs, leading to long stretches of males or females. This is why the next generation is going to be mostly males, sometimes in stretches of 12-13. I am fixing this in the next generation by occasionally exporting all but one female (To “cancel out” my grendel) to hatch eggs when I have nowhere to put them in order to get a ratio closer to 1:1 for Gen 7.
I now have a Disease tab in my Excel doc keeping track of what diseases do what and here is what I’ve found:
Antigen 1 is killer. High frequency of sneezes/coughs, leading to difficulty feeding norns to keep their life force up, and slow antibody response time. Absolutely deadly if your norn is not a reliable eater.
Antigen 3 is easy to get over. I had one note about it in my journal (From before I had my Diseases tab) saying that antibody production is so fast that it almost kills the antigen before it hits “critical mass” in the Biochemistry tab of the Science Kit.
Antigen 5 isn’t horrible. The antibody response time is very good, although life force declines rapidly. I had two norns on opposite sides of the world contract it very close together, so I can’t really say anything about infectiousness, but I’d guess it was a coincidence.
New Tools
The community patch, which does a lot of things. (May provide link to list eventually)
The Grendel Friendly COB, since now I can keep an eye on my little dude.
The Advanced Breeder’s Kit, which should help any norns experiencing pregnancy issues, although I am not yet sure if that’s a good idea. You will definitely hear about it in the next report if it was a bad idea
I also found the Genetics Kit and got it working, which should solve any issues if I accidentally leave the game on. That seems to happen at least once a generation, but now I close the game if I’m going to step away from my computer. That should stop the problem before it even starts.
—
Whew! That was a longer summary than I meant to put together, but it’s good for me to get it all down and in one place, even if nobody but me finds it interesting.
On to Generation 6! 😁
#summary#overview#genetic data#genetic drift#statistics#this taught me how to make ratios to 1 btw#i must have learned that in high school at some point but that was 11-15 years ago#god this was so much longer than i originally intended#and it took an hour to put together#also you can tell that i’m Super Serious bc i put a period at the end of the ending sentence in a paragraph#just a small quirk of mine
1 note
·
View note
Text

SBD engine, 2l, built in great britain, around 350hp to the rear wheels with a weight of 480kg, this westfield is the perfect machine for race days, a perfect image of the classic Lotus Eleven
#driftnoob3 obsesion quicks in#car spotting#drift carspotting#I had to ask the owner for the data of the car#cool guy#I love car guys :]
0 notes
Text
Top unisex names of the 1990s: where are they now?

The below two plots show the top 20 unisex/gender-neutral names of the 1990s, based on total usages from 1990-9. You can see the gender trend (F% share) post-1999, split into two plots for better visibility.
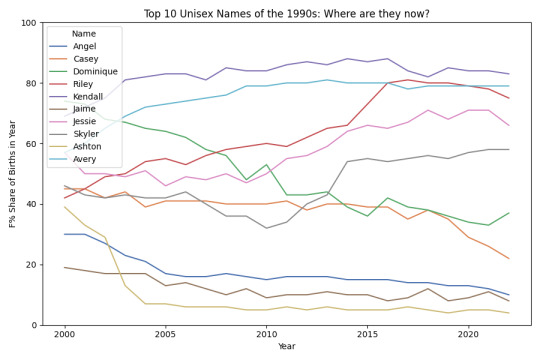
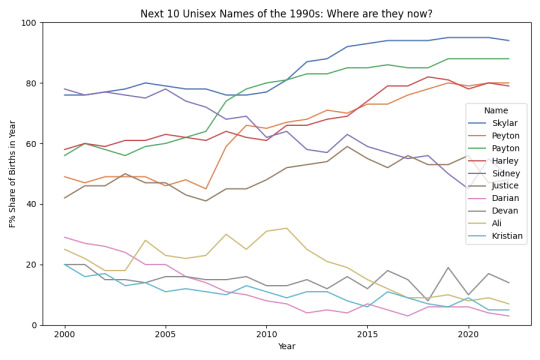
#gender-neutral#unisex#drift of unisex names#unisex names#gender-neutral names#neutral names#social security administration#social security administration name data#social security administration data#ssa name data#ssa data#name data#names data#naming data#names#naming#naming trends#name trends
0 notes
Text
The Lake House
Part 1: All of Us Strangers
Sana x Miyeon x Male Reader
word count 22K

You pull up to the lake house in your beat-up SUV, tires crunching on the gravel driveway, and the second you step out, you’re hit with it—this place is way more stunning than the pics online. The air smells like pine and damp earth, and the lake stretches out in front of you, its surface flat and gray under a thick blanket of clouds. The house itself is this cozy, modern thing—wood and glass, with a big deck overlooking the lake. It’s got this vibe, like it’s begging you to chill out and forget the world for a while. You’re already thinking, Shit, if this week goes as good as it looks, maybe I’ll buy this place. Peace, quiet, and nature all around—perfect for your photography, which is the whole damn reason you’re here. And you’d bet your camera nobody’s around for miles—pure solitude, just how you like it—until you catch a faint wisp of smoke curling up from the chimney of that dark house across the lake, and now your solo trip’s got some unexpected company popping off.
You pop the trunk and grab your gear—camera bag slung over your shoulder, a duffel with clothes, and a cooler stuffed with groceries you snagged earlier. Your day job’s nothing special, just some remote gig doing data entry for a logistics company. It’s boring as hell—punching numbers into spreadsheets, tracking shipments, answering emails from people who can’t figure out their own schedules. Pays the bills, though, and it’s flexible enough to let you fuck off to places like this whenever you want. Photography’s where your heart’s at. You’ve been at it for years, lugging your Canon everywhere, chasing the perfect shot. Landscapes mostly—sunsets, forests, water, anything that moves you. You’re no pro, but you’re good, and you’ve got a decent following on Insta for it. This trip? It’s all about that—getting out, breathing, and nailing some killer shots.
The lake house sits on this little peninsula, surrounded by trees so thick you can barely see the dirt road you came in on. It’s isolated, yeah, but not too far out. There’s a small city—more like a big town, really—about twenty minutes back. You stopped there on the way in, hit up a grocery store for the basics: beer, burgers, some frozen pizzas, and a bag of apples ‘cause you’re trying to be healthy or whatever. They’ve got a coffee shop and a gas station too, so you’re not totally cut off. Still, out here, it’s just you, the water, and the woods. No traffic, no neighbors blasting music—pure silence, except for the occasional bird or ripple on the lake.
You haul your stuff inside, drop it on the hardwood floor, and take a sec to check the place out. Big windows everywhere, letting in that soft, cloudy light. The living room’s got a plush couch and a stone fireplace you’re already itching to use. Kitchen’s sleek, all stainless steel and granite, and the bedroom upstairs has a view that makes you wanna cry—straight across the lake. Speaking of which, you step out onto the deck, hands in your pockets, and squint through the gloom. On the far shore, maybe half a mile away, there's that other house. Two stories, painted some dark color—navy or black, hard to tell with the weather. It’s got these big windows too, glowing faintly, and there’s a car parked out front. A white sedan, nothing fancy. There's definitely someone there, you think, and it weirds you out a little. You weren’t expecting company out here, not this close. The mystery of it nags at you—who the hell are they? Vacationers? Locals? You shake it off for now, but your eyes keep drifting back to that house as you unpack.
The clouds hang low, heavy with the promise of rain, and the air’s got that cool, damp bite to it. You grab your camera—couldn’t resist—and step back outside, adjusting the lens. The lake’s like a mirror, reflecting the sky, and the trees are all moody greens and browns. You snap a few shots, playing with the exposure, already imagining how they’ll look edited. This spot’s a goldmine; you can feel it. But that house across the water—it’s still there in the corner of your frame, pulling your focus. You zoom in, just curious, but it’s too far to make out much. Still, you’ve got this itch now, this tiny spark of intrigue. Whoever’s over there, they’ve got no idea you’re watching.
You’re fiddling with your camera, trying to frame up a shot of some birds skimming the lake, when movement catches your eye. Two figures step out of that dark house across the water. Girls, both of them, and even from this distance, they stand out. One’s got silky brown hair that catches the dull light, flowing down her back like she just stepped out of a shampoo ad. The other’s got jet-black hair, shorter, framing her face. They’re dressed casual—leggings and hoodies, nothing fancy, just comfy vibes. The black-haired one’s got a phone pressed to her ear, pacing a little, while the brown-haired one hovers close, hands in her pockets. You freeze for a sec, then casually swing your camera away, pretending to focus on the lake, the trees, anything but them. Don’t be that guy, you tell yourself, heart picking up a bit. Last thing you need is them thinking some random dude’s creeping on them with a lens.
But your curiosity’s a bitch. After a minute, you sneak the camera back their way, zooming in just enough to see them better. And then—shit—they’re looking right at you. Like, right at you. Your stomach drops, and you yank the camera down, turning your head so fast you almost tweak your neck. Fuck, fuck, fuck. You can already hear the headlines: “Outsider Caught Stalking Innocent Girls With Telephoto Lens.” You’re not that guy, but try explaining that across a lake. Hoping they didn’t get a good look, you ditch the deck and hustle to your car, popping the trunk like you’ve got urgent business. You grab the cooler and a bag of groceries, hauling them inside, your pulse still thudding in your ears.
You’re not out there five minutes before you’ve gotta go back for the rest. Stepping onto the deck again, you freeze—they’re coming your way. Like, actually walking around the lake toward your side. Your brain scrambles. Bolting inside might look shady as hell, but standing here like a deer in headlights? Not much better. You opt to stay, fiddling with something in the trunk—your spare tire, maybe?—pretending you’re too busy to notice them closing in. Your palms are sweaty, and you’re half-braced for them to start yelling or waving a phone with 911 already dialed.
“Hey!” a voice calls out, bright and chill, not pissed. You glance up, and the black-haired girl’s waving at you, a little grin on her face. You wave back, tentative, still expecting the vibe to shift. “Didn’t know anyone was over here,” she says as they get closer, her tone all friendly-like. “This place was a total dump last year—falling apart, windows smashed, the works. Looks dope now, though. They fix it up?”
You nod, relaxing a bit. “Yeah, rented it for the week. Guess it got a glow-up since then.” Up close, she’s got this energy—outgoing, loud in a good way. She sticks out her hand. “I’m Miyeon. This is Sana.” She jerks her thumb at the brown-haired girl, who gives you a small smile and a nod, quieter, maybe shyer.
“Sana, hey,” you say your name as you shake Miyeon's hand, then glancing at Sana. “Yeah, I’m just crashing here for a bit. You guys local?”
“Nah,” Miyeon says, leaning against your car like she owns it. “This house over there? My parents’. Been coming here forever, usually with a crew of friends. It’s our spot.” She gestures across the lake, where that dark two-story looms.
“Friends?” you ask, glancing between them. “Where’s the rest of the squad?”
Miyeon’s face falls a little, and Sana looks down at her shoes. “Yeah, that’s the shitty part,” Miyeon says, voice dipping. “They just called me—like, right before we came over. There’s a fuckin’ landslide or something on the main road in. Rain’s been nuts, and it’s blocked off. They were driving up from a couple hours away, so they just turned back. Not worth the hassle.”
“Damn,” you say, genuinely feeling for them. “That sucks. So what’s the plan now?”
Miyeon shrugs, kicking a pebble. “Hang out, I guess. Wait for the road to clear, then head home. Not much else to do.”
Sana pipes up then, her voice softer but curious. “That camera,” she says, nodding at it slung over your shoulder. “You a photographer or something?”
“Nah, just a hobby,” you say, brushing it off. “I work some boring-ass data job—spreadsheets and shit. This is what keeps me sane. Love shooting nature, landscapes, whatever catches my eye.”
Miyeon perks up. “You got an Insta for it? Let’s see.” You hesitate, then rattle off your handle. She pulls out her phone, taps away, and Sana leans over her shoulder as they scroll. “Yo, these are good,” Miyeon says, legit impressed. “Like, really good. You’re underselling yourself, dude.”
“Yeah,” Sana adds, her shy edge melting a bit. “The lighting in this one? Wow.” She points at her screen, and you feel a dumb little rush of pride.
“Thanks,” you say, scratching the back of your neck. “I’m here to chill and snap some shots of the lake, the woods, you know. Recharge.”
“Smart move,” Miyeon says. “We were gonna swim out there—” she nods at the pier stretching into the lake—“but it’s freezing. Usually it’s warm enough this time of year, but not today.”
“Global warming’s fucking with everything,” you toss out, and they both nod like, yep, that tracks.
Then Miyeon tilts her head, grinning. “Hey, since you’re Mr. Camera Guy, how about you take a pic of us out on the pier? Something to remember this weird-ass trip by?”
You blink, caught off guard, but they’re both looking at you expectantly. “Uh, yeah, sure,” you say, slinging the camera off your shoulder. “Let’s do it.”
They lead the way to the pier, Miyeon strutting ahead like she’s on a mission, Sana trailing a step behind, sneaking little glances at you. You’re still buzzing from the fact they’re cool with you—more than cool, actually friendly. You follow the girls down to the pier, boots thudding against the weathered wooden planks. The lake stretches out around you, still as glass under the heavy, gray sky, and the air’s got that sharp, pre-rain chill. Miyeon’s practically bouncing as she strides to the end, her black hair swinging, while Sana trails a little slower, her silky brown locks catching the faint breeze. They stop at the edge, the water lapping gently below, and turn to face you. “Alright, camera guy,” Miyeon says with a grin, planting her hands on her hips. “Work your magic.”
You lift the Canon, squinting through the viewfinder, and—damn—they’re gorgeous. Like, unfairly photogenic. Miyeon’s all confidence, popping a playful pose, one leg bent, head tilted, flashing a smirk that’s equal parts goofy and charming. Sana’s quieter about it, crossing her arms and giving a shy smile, but there’s something striking in the way she stands, the way her hair frames her face. You snap a few shots—wide angles with the lake behind them, then some tighter ones, playing with the depth of field so the cloudy horizon blurs out. Miyeon keeps it lively, throwing out dumb poses—peace signs, a fake pout—while Sana giggles and follows her lead, loosening up bit by bit.
“Yo, let’s see!” Miyeon calls after a dozen clicks, jogging over with Sana in tow. You flip the camera around, scrolling through the shots on the screen, and their faces light up. “Holy shit, these are fire,” Miyeon says, leaning in so close her shoulder brushes yours. “You sure you’re not a pro?”
“They’re so good,” Sana adds, her voice softer but just as impressed. “Like, we actually look cool.” The pics are sharp, the girls popping against the moody backdrop, their colors—black hoodie, brown hair—standing out in the gloom. You nailed the focus, the composition, everything.
“Yeah, well, you guys make it easy,” you say, shrugging, though you’re secretly stoked they like them. “Wish the weather wasn’t so shitty, though. This light’s all flat and gray—makes it look like you’re in some creepy thriller flick or something.”
Miyeon’s grin falters for a sec, and she nudges you with her elbow. “Dude, don’t even joke about that. We’re already kinda freaked out being alone over there.”
You laugh, raising an eyebrow. “What, you think some axe murderer’s hiding in the woods? Any crimes around here I should know about?”
She shakes her head, smirking but with a little edge. “Not that I’ve heard of, thank God. Just… it’s quiet, you know? Too quiet sometimes.”
“Fair,” you say, glancing out at the lake, the stillness of it almost eerie now that she’s put the thought in your head. “Well, if you guys need anything—someone to fend off the boogeyman or whatever—just hit me up. I’m right across the water.”
Miyeon’s eyes spark up, and she pulls out her phone. “Bet. What’s your Insta again? I’ll follow you, and you can DM me those pics.” You give her the handle, and she taps it in, tossing you hers in return—@miyeonnotmignon, which makes you snort ‘cause it’s so her. “Send ‘em whenever,” she says. “I need these for the grid.”
Sana glances at the sky, tugging her hoodie tighter. “We should head back. Looks like rain’s coming soon.”
“Yeah, true,” Miyeon agrees, squinting up at the clouds, which are starting to clump thicker, darker. “Don’t wanna get stuck out here when it dumps.” She turns to you, flashing that big, easy grin. “Enjoy the place, dude. Don’t let the thriller vibes get to you.”
You smirk. “I’ll try. You guys stay safe over there. Don’t go summoning ghosts or anything.”
Sana giggles at that, and Miyeon just rolls her eyes, waving as they start back down the pier. “See ya, camera guy!” she calls over her shoulder. You wave back, watching them go—Miyeon’s loud laugh echoing faintly, Sana’s quieter figure beside her—until they hit the shore and start the trek around the lake. You linger a minute, camera still in hand, the pier creaking under your weight. The air’s heavier now, the first hint of rain prickling your skin. You glance at their house across the water, its dark shape fuzzing out in the haze, and that little spark of mystery flares up again. They’re cool, way cooler than you expected. And something about them—maybe Miyeon’s loud charm, maybe Sana’s shy warmth—sticks with you as you head back to your own place, the promise of rain rumbling in the distance.
—
It’s been a few hours since you got back from the pier, and the world outside’s turned into a damn monsoon. Rain’s hammering the windows like it’s pissed off, streaking down the glass in relentless sheets, and the wind’s howling through the trees, making the whole lake house groan. Inside, though, it’s cozy—borderline toasty, thanks to the heater humming away in the corner and the fireplace lit downstairs. You’re sprawled on the bed upstairs, legs kicked out, a half-empty beer sweating on the nightstand from dinner—frozen pizza and some chips, nothing fancy. The generator’s chugging along out back, but you’re keeping an eye on the lights, half-worried it’s gonna crap out from all the juice the heater’s pulling. Last thing you need is to freeze your ass off out here.
You’ve got your laptop propped on your thighs, scrolling through the shots you took earlier—the pier pics of Miyeon and Sana, plus some moody lake stuff before the sky opened up. The girls’ photos are gold, even with the flat light. Miyeon’s got this wild, carefree energy in every frame, while Sana’s softer, her shy smile sneaking through. You tweak a couple in Lightroom, bumping the contrast, and damn, they’re Instagram-worthy for sure.
Eventually, you shut the laptop and roll off the bed, stretching. You can’t help it—your eyes drift to the window. It’s pitch-black out there, the rain turning everything into a blurry void. You press your forehead to the cold glass, squinting across the lake. Their house is just a smudge in the dark, but the lights are on—warm little squares glowing through the storm. You wonder what they’re up to. Probably curled up on a couch, watching some cheesy rom-com or maybe a horror flick, given Miyeon’s half-joking about being spooked. Popcorn, blankets, the whole vibe. You picture it for a sec—Miyeon yapping over the movie, Sana giggling at her—and it’s kinda cute.
Then—blink—the lights across the lake go out. All of them, at once. You blink too, like maybe your eyes are screwing with you, but nope, it’s dark over there now. Weird as hell. Your first thought is they hit the sack, but it’s too sudden, too synchronized. No way they flipped every switch at the exact same second. A power outage? Maybe the storm fried something. You stare into the blackness, chewing your lip. Okay, maybe you’re overthinking it. You’ve been out here alone too long, and those two are the only blips of life in this wilderness. It’s not like you’re obsessed or anything—they’re just… there. Still, it bugs you. You shake it off, muttering “whatever” to yourself, and decide to crash. Bed’s calling, and the rain’s drumming hard enough to knock you out.
You’re halfway to brushing your teeth when—thump thump—a sound cuts through the storm. You freeze, toothbrush dangling, listening. Imagination, right? This place creaks all the time. But then it comes again, louder—THUMP THUMP THUMP—straight from the front door downstairs. Your heart kicks up, and you spit into the sink, wiping your mouth with the back of your hand. Could be a branch or some shit blowing around in the wind, but it sounded too deliberate. You grab your phone, thumb hovering over the flashlight app, and creep to the stairs, ears straining. The rain’s deafening, but there’s something else—a muffled voice maybe?
You pad down to the first floor, barefoot on the cold wood, nerves buzzing. The knocking’s real, no doubt now, and it’s insistent. “Who the fuck—” you mutter, snagging a jacket from the couch and shrugging it on. You’re half-expecting a drenched hiker or some rando stranded in the storm, but part of you—okay, a big part—wonders if it’s them. You flip on the porch light, yank the door open, and—bam—a flashlight beam hits you square in the face, blinding you for a sec.
“Shit, sorry!” a familiar voice says, and the light drops. It’s Miyeon, soaked to the bone, her black hair plastered to her face, hoodie clinging like a second skin. Sana’s right behind her, brown hair dripping, looking like a drowned kitten in her oversized sweater. They’re both shivering, rain streaming off them, pooling on your doorstep.
“Jesus, you guys okay?” you say, stepping back to let them in. “What the hell happened?”
Miyeon’s teeth are chattering, but she’s still got that spark. “Our generator fucking died, dude. No lights, no heat, nothing. We’ve got no clue what’s wrong, and it’s creepy as shit over there. Can you—please—come take a look?”
“Yeah, of course,” you say, already zipping up your jacket. You grab your boots from the mat, shoving them on while they hover by the door, dripping and miserable. “You sure you don’t wanna dry off first? You’re gonna catch pneumonia or something.”
Sana shakes her head, hugging herself. “We just wanna get it fixed. It’s freezing, and I swear I heard something moving in the dark.”
“Probably just the wind,” Miyeon says, but she doesn’t sound convinced. “Still, let’s go. I’m not sleeping in a blackout.”
You snag a flashlight from the kitchen drawer—bigger than theirs, one of those heavy-duty ones—and flick it on. “Alright, lead the way. Let’s see if we can save your night.”
They nod, grateful, and you step out into the storm with them. The rain hits like needles, cold and relentless, soaking through your jeans in seconds. Miyeon’s ahead, power-walking around the lake, while Sana sticks closer, her flashlight beam jittering across the muddy path. You’re all hunched against the wind, shouting over the roar of the downpour—Miyeon bitching about how her parents need to upgrade their shit, Sana muttering about hating storms. It’s a slog, wet and miserable, but you can’t help feeling a little badass, trekking out here to play hero. The house looms ahead, a dark silhouette against the storm, and the second you step inside, the vibe hits you—cold, damp, and way too quiet without the hum of electronics. Miyeon flicks her flashlight around, leading the way through the living room—furniture shadowy lumps in the gloom—down a narrow hall to a back door. “Generator’s out here,” she says, shoving it open. The wind blasts in, spraying rain across your face, and you grimace as you follow them into a little shed attached to the house.
The generator sits there like a grumpy old beast, silent and useless. Sana holds her flashlight steady, the beam jittering a little from her shaky hands, while Miyeon aims hers at the control panel. “It just… stopped,” she says, kicking the base lightly. “No warning, no nothing.” You crouch down, popping the side panel open with a grunt, and peer inside. The smell of wet metal and fuel hits you, and you sweep your flashlight over the guts—wires, gauges, a fuel tank that’s still half-full. You’re no expert, but you’ve fucked around with enough random shit to spot trouble. And there it is: a busted fuel line, cracked clean through, leaking diesel into the housing. Probably shook loose from the storm’s vibration or just shitty luck. Either way, it’s toast—no quick fix tonight, not without a replacement part and better light to work in.
“Bad news,” you say, straightening up and wiping your wet hands on your jeans. “Fuel line’s fucked. It’s leaking everywhere, and I can’t patch it with what’s here. You’re outta power ‘til we get a new one.”
Miyeon’s face drops, and she lets out a loud, “Are you kidding me?!” She paces a little, flashlight beam swinging wildly. “This is some horror movie bullshit. What the hell are we supposed to do now?”
Sana’s quieter, but you can tell she’s freaked too—her arms are wrapped tight around herself, and her voice comes out small. “It’s so cold already. And dark. I don’t like this. I swear I keep hearing noises.”
You glance around the shed, the rain drumming on the tin roof like it’s trying to break in. The house beyond it looks like a black hole, swallowing every bit of light. “Yeah, no kidding,” you say, scratching your jaw. “Look, I’m not gonna leave you guys stranded out here. My place has power, heat, and light. Unfortunately there is only one room with a mattress because, well, I wasn't expecting guests. But you can crash there tonight if you don't mind sharing a bed. No point in freezing your asses off in this.”
They both freeze, turning to look at each other. Sana’s the first to speak, hesitant. “Are you sure? We don’t wanna, like, invade your space or anything.”
“Nah, it’s cool,” you say, waving it off. “I’ve got a nice couch. Beats sitting here waiting for the boogeyman to show up, right?”
Miyeon snorts, but there’s relief in it. “Okay, yeah, that sounds way better than this shitshow. Give us a sec to grab some stuff.” They dart back inside, flashlights bobbing, and you wait by the door, leaning against the frame, listening to the storm rage. You hear them rummaging around—drawers slamming, muffled chatter—before they reappear, each with a small duffel bag slung over their shoulder. Miyeon’s got a hoodie pulled tight over her head, and Sana’s clutching a blanket like it’s a lifeline, her wet hair still dripping.
“Ready,” Miyeon says, zipping her bag. “Let’s get the fuck outta here before something else breaks.”
The trek back is brutal—rain in your face, wind shoving you sideways, the girls huddled close like you’re some kinda human shield. By the time you stumble through your front door, you’re all drenched again, leaving a trail of puddles across the hardwood. You kick off your boots, shaking water out of your hair, and point down the hall. “Bathroom’s that way. Go change or whatever—I’ll grab some towels.”
“Thanks, dude,” Miyeon says, already peeling off her soaked hoodie right there in the living room, revealing a damp tee underneath. Sana scurries off, blanket dragging, and you head to the linen closet, snagging a couple of big fluffy towels. When you come back, Miyeon’s in dry sweatpants and a loose tank top, toweling her hair, while Sana emerges in an oversized hoodie and leggings, looking less like a drowned rat now.
“God, you’re a lifesaver,” Miyeon says, flopping onto your couch like she owns it. Sana nods, settling next to her, tucking her legs under. “Seriously, thank you. I was about to lose it over there.”
“No worries,” you say, tossing them the towels. “You guys warm enough? I can put more wood in the fireplace if you want.”
“It’s good,” Sana says, pulling the blanket over her lap. “This is already a million times better.”
You nod, feeling weirdly proud of your little rescue mission, and head to the kitchen. “I’ll make some tea or something. You guys just chill.” The kettle’s already half-full from earlier, so you flick it on, rummaging for some random herbal shit you bought ages ago—chamomile, maybe? Close enough. While it heats, you lean against the counter, listening to them talk on the couch. Miyeon’s voice carries, loud and animated—“I swear, if my parents don’t fix that generator, I’m never coming back”—while Sana’s softer, giggling at her rant.
When the kettle whistles, you pour three mugs, balancing them as you shuffle back. “Here,” you say, handing them over. Miyeon takes hers with a grin, Sana with a quiet “thanks,” and you plop into the armchair across from them, cradling your own. The steam curls up, warm against your face, and for a minute, it’s just the sound of rain on the roof and the three of you sipping.
Miyeon stretches out, kicking her feet up on the coffee table. “So, what’s your deal, camera guy? Are you planning to buy this house or something?”
You laugh. “Nah, just a rental for the week. Needed a break from my boring-ass data job. From the city too. Figured I’d mess around with my camera, get some shots of the lake and stay close to nature.”
“Well, you’re stuck with us now,” she says, smirking. “Hope you don’t mind the company.”
Sana glances at you, a little smile tugging at her lips. “Yeah, you’re kinda our hero tonight.”
You shrug, playing it off, but your chest puffs up a bit anyway. “Hey, beats being alone in this storm. You guys can crash as long as you need.” They nod, settling deeper into the couch, and the vibe shifts—warm, easy, like you’ve known them longer than a day. The rain keeps pounding, but in here, it’s just you, them, and the crackling of the fireplace making everything feel alright.
“So, what’s your story?” you ask, blowing on your tea to cool it. “You guys come up here a lot, huh?”
Miyeon smirks, setting her mug on the coffee table with a little clink. “Yeah, like I said, it’s my parents’ place. Been dragging people up here since I was a kid. Used to be all family trips, but now it’s more for me and my crew to fuck around—swim, drink, whatever. This time it was supposed to be a big thing, but, well, landslide screwed that.”
“That sucks,” you say, leaning back. “You two stuck it out, though. Pretty badass.”
Sana giggles, peeking over her mug. “Barely. We were freaking out before you showed up. I’m not good with storms—or, like, anything going wrong.”
“She’s a spoiled city girl,” Miyeon teases, nudging Sana with her foot. “Needs her Wi-Fi and hot showers or she starts crying.”
“Shut up,” Sana fires back, but she’s laughing, swatting Miyeon’s leg. “You’re the one who screamed when the power went out.”
Miyeon shrugs, unbothered. “Yeah, ‘cause it was creepy as fuck. Point is, we’re here now, thanks to Mr. Hero over there.” She jerks her chin at you, grinning.
You snort. “Just doing my part. So, what’s the deal with you two? You’ve known each other forever or what?” You figure they’re tight—besties or something, the way they bounce off each other.
They exchange a look, quick but loaded, and Miyeon’s grin turns a little sly. “Not forever,” she says, stretching her arms over her head, tank top riding up a bit. “We’ve been together, what, two years now?”
“Two and a half,” Sana corrects, softer, her eyes flicking to Miyeon like she’s double-checking.
“Together?” you echo, tilting your head. “Like… roommates?”
Miyeon laughs, loud and sharp, while Sana hides a smile behind her mug. “Nah, dude,” Miyeon says, sitting up a little. “Like, together together. Girlfriends. Dating. You know?”
“Oh,” you say, blinking, then catch yourself quick. “Oh, shit, that’s cool. I just assumed—uh, never mind. Awesome.”
Sana’s cheeks go pink, but she’s giggling at your stumble. “It’s fine. People assume we’re just friends all the time. We’re used to it.”
“Yeah, we don’t exactly scream ‘couple,’” Miyeon adds, smirking. “I’m too loud, she’s too sweet. Throws people off.”
You laugh, easing up. “Nah, I get it now. You balance each other out. That’s dope.” You mean it—they’ve got this vibe, like they click without even trying. Miyeon’s all fire and Sana’s the calm, but together it works.
“What about you?” Sana asks, shifting the spotlight. “You got anyone back home?”
“Me? Nah,” you say, shaking your head. “Solo mission right now. Work’s too boring to drag someone else into it, and I spend most of my free time with my camera anyway. Not exactly boyfriend material.”
“Bullshit,” Miyeon says, pointing at you with her mug. “You’re chill, you’ve got a cool hobby, and you’re not a total asshole. You’d do fine.”
“High praise,” you deadpan, grinning. “I’ll put that on my dating profile: ‘Not a total asshole, says random lake girl.’”
They both crack up, and the room feels lighter, like the storm’s just background noise now. You keep chatting—little stuff at first. You tell them about your data gig, how it’s mind-numbing but pays the bills, and how you’ve been shooting photos since you were a teenager, chasing sunsets and storms like this one. Miyeon spills about her graphic design side hustle, how she’s always doodling on her iPad, while Sana admits she’s a barista at some trendy coffee shop, secretly loving the chaos of the morning rush.
“Hold up,” you say, setting your empty mug down. “You’re telling me you’re out here pulling espresso shots all day, and you’re still this chill? Respect.”
Sana shrugs, blushing a little. “It’s not that hard. I just smile and people tip me.”
“She’s lying,” Miyeon cuts in. “She’s a pro. Makes latte art and everything. I can barely pour cereal without fucking it up.”
“Stop it,” Sana mumbles, shoving her playfully, and you can’t help but laugh at how easy they are together. It’s cute—real, not forced.
The convo drifts, and you’re all a little looser, the tea warming you up from the inside. Miyeon yawns, stretching so hard her tank top rides up again, showing a sliver of stomach. “Man, this storm’s not letting up. What’s the plan tomorrow if it’s still like this?”
You glance out the window—still a wall of rain and dark. “Dunno. If it clears, I was gonna hike around, take some shots. If not, I’ve got a deck of cards and some beer. We could kill time.”
“Beer?” Miyeon perks up, eyes glinting. “Why didn’t you say that earlier? Let’s do drinks tomorrow night, storm or not. We’ll make it a thing.”
“Deal,” you say, nodding. “I’ve got some whiskey too, if we’re feeling fancy. You guys in?”
Sana hesitates, then smiles. “Yeah, okay. Sounds fun.”
“Sweet,” Miyeon says, clapping her hands once, like it’s settled. “Something to look forward to after this shitty day.”
You all sit there a minute longer, the mugs empty now, the fire crackling mixing with the rain. Sana yawns next, covering her mouth with the blanket edge. “I’m so tired,” she mumbles. “This whole thing wiped me out.”
“Yeah, same,” Miyeon agrees, rubbing her eyes. “We should crash. You really good with us stealing your bedroom?”
“Take it,” you say, standing up to stretch. “Bed’s made, pillows and shit are in the closet if you need extra. I’ll grab the couch.”
“Are you sure we're not—” Sana starts, but you wave her off.
“Nah, it’s fine. Couch is comfy enough. You guys get the room, no biggie.” You grab the mugs, stacking them to carry to the sink, and they shuffle off the couch, gathering their bags.
“Thanks again, dude,” Miyeon says, dragging her duffel over her shoulder. “You’re, like, our storm savior.”
“Anytime,” you say, smirking. “Night, you two.”
“Night,” Sana echoes, giving you a little wave as they head down the hall. You hear the spare room door click shut, some muffled giggles and whispers filtering through before it quiets down. You rinse the mugs in the kitchen, flick off the lights, and flop onto the couch, dragging a throw blanket over yourself. The rain’s still going hard outside, but inside it’s warm and peaceful. Tomorrow’s got drinks on deck, and with Miyeon and Sana around, it’s shaping up to be a hell of a night. You close your eyes, the storm lulling you off, and crash out with a dumb little smile tugging at your lips.
—
You blink awake on the couch, the blanket tangled around your legs, sunlight sneaking through the blinds in thin, golden stripes. The house is quiet—no rain, no wind, just the soft hum of the heater ticking down, the fireplace already out. You sit up, rubbing your face, and that’s when you smell it: coffee, faint but fresh, and something sweet lingering in the air. Stumbling to your feet, you shuffle to the kitchen and spot a little spread on the counter—toast stacked on a plate, a jar of jam open next to it, and a couple strips of bacon still warm under a paper towel. There’s a note scribbled in messy handwriting: “Thanks for last night! Enjoy – M & S.” You smirk, figuring it’s the girls’ doing. They’re not around, though—place feels empty without their chatter.
You scarf down the breakfast—crisp toast slathered with strawberry jam, bacon salty and perfect—then hit the shower, letting the hot water blast away the last of the sleep haze. By the time you’re dressed—jeans, a hoodie, sneakers—it’s pushing 9 a.m. You grab your camera bag, sling it over your shoulder, and step outside. Holy shit, it’s a different world. After yesterday’s apocalyptic downpour, the sun’s out, blazing in a sky so blue it looks photoshopped. The lake sparkles, all glassy and calm, and the air’s crisp but not freezing, a perfect late-morning vibe. You’re still marveling at it when a loud whoop cuts through the silence, followed by a splash.
Your head snaps toward the pier, and there’s Miyeon, mid-air, cannonballing into the water with a scream that’s half-laugh, half-battle cry. She’s in a red swimsuit, bright against the lake, and as she surfaces, shaking wet hair out of her face, you spot Sana on the pier, waving at you in a pink bikini that hugs her curves just right. They’re both stupidly gorgeous, and for a second, you’re just standing there, camera dangling, brain short-circuiting. Miyeon’s got a little more thickness to her—medium, perky breasts filling out that swimsuit top, a round ass that’s damn near hypnotizing as she climbs back onto the pier. Sana’s slimmer, all sleek lines and subtle curves, the bikini showing off her tiny waist and long legs. You snap out of it when they call you over, Miyeon’s voice carrying: “Yo, camera guy! Get your ass down here!”
You jog over, grinning as you hit the pier’s edge. “Morning, ladies,” you say, shielding your eyes from the sun. “You two look way too chipper after last night.”
“Slept like babies,” Miyeon says, wringing water out of her hair, droplets splattering the wood. “Your place is cozy as hell. How’d you hold up on that couch?”
“Good enough,” you say, shrugging. “Woke up to breakfast, though—that was clutch. Thanks for that.”
Sana beams, sitting cross-legged on the pier, her pink bikini practically glowing in the sunlight. “I made it. Miyeon can’t cook for shit, so I took over.”
“Facts,” Miyeon says, not even arguing. “She’s a wizard in the kitchen. That bacon? Her doing. I’d burn the house down trying.”
“Shit, well, it was awesome,” you say, nodding at Sana. “Seriously, thank you. Didn’t expect the VIP treatment.”
Sana blushes a little, tucking a strand of hair behind her ear. “No biggie. Least we could do.”
Miyeon flops onto her back, stretching out like a cat in the sun. “Weather’s fuckin’ perfect today. Checked the forecast—sunny all day, but there’s another cold front rolling in tomorrow. Gotta soak this up while we can.” She props up on her elbows, eyeing you. “Come swim with us, dude. Water’s not even that cold.”
“Yeah, join us!” Sana chimes in, standing up and tugging at your arm. They’re both at it now, pulling you toward the edge, their wet hands slippery on your hoodie. Miyeon’s got that mischievous grin, and Sana’s giggling like she’s in on the plot.
You laugh, but it’s nervous, your feet planted. “Nah, I’ve got plans—gonna hike around, shoot some nature stuff. You know, trees, birds, all that shit.”
Miyeon sits up, crossing her arms under her chest, which—fuck, that swimsuit’s doing work. “Bro, we’re nature. Take pics of us instead. Way prettier than some random-ass tree.”
You smirk, caught off guard but not mad about it. “Can’t argue that. Alright, fine—photo shoot it is.”
Sana claps, bouncing a little. “Yes! These swimsuits are new, too. Gotta show ‘em off. Right, Miyeon?”
“Hell yeah,” Miyeon says, hopping to her feet. “Red’s my color, and pink’s hers. Perfect combo.”
You sling your camera out, adjusting the settings quick—bright sun, sharp focus. They start posing, and it’s like they were born for this. Miyeon’s all bold energy, leaning forward with a flirty smirk, then turning to show off that ass, one hand on her hip. Sana’s softer, tilting her head, letting her hair spill over her shoulder, giving you these quiet, sultry looks that hit harder than they should. Then they get together—arms around each other, laughing, pressing close like the girlfriends they are. Miyeon pulls Sana in for a playful kiss on the cheek, and Sana squeals, shoving her off, but they’re both cracking up. You’re snapping away, the shutter clicking like crazy, and every shot’s a banger—sunlight glinting off their skin, the lake shimmering behind them.
“Check these out,” you say, flipping the camera around. They crowd in, still dripping, Miyeon’s arm brushing yours as they ooh and ahh over the screen. “Holy shit, we look hot,” Miyeon says, zooming in on one where she’s tossing her hair back mid-laugh. Sana nods, pointing at another. “That one’s my favorite. The light’s perfect.”
“Glad you like ‘em,” you say, pocketing the camera. “I’ll send ‘em later with yesterday's photos.”
“Sweet,” Miyeon says, then glances at the lake. “You sure you won’t swim? Last chance before it’s all cold and shitty again.”
“Nah, I’m good,” you say, stepping back. “Gonna roam around, get some shots of the woods. Plus, I’ll swing by the city later—grab that fuel line part for your generator and fix it up.”
Sana’s eyes widen. “Wait, for real? You don’t have to do that.”
“It’s nothing,” you say, waving it off. “Hardware store’s not far, and I’ve got the tools. Beats you guys sitting in the dark again.”
Miyeon grins, big and genuine. “Dude, you’re too nice. Like, suspiciously nice. What’s your angle?”
You laugh. “No angle. Just don’t wanna see you stuck. Plus, I’m bored out here—gives me something to do.”
“Well, we owe you big time,” Sana says, hugging herself as a breeze kicks up. “Oh—can we charge our phones at your place? They’re basically dead, and we’ve got no juice over there.”
“Yeah, no problem,” you say, nodding toward your house. “Plenty of outlets. Leave ‘em as long as you need.”
“Sweet, thanks,” Miyeon says, already heading back to the pier’s edge. “We’ll catch you later then—drinks tonight, right?”
“Bet,” you say, giving them a mock salute. “Enjoy the sun, ladies.”
They wave as you head off, Miyeon shouting, “Don’t get lost in the woods, camera guy!” before cannonballing back into the water with another splash. You shake your head, smirking, and start down the path toward the trees, camera in hand. The day’s wide open, the girls are vibing, and you’ve got a solid plan—photos now, hero shit later, drinks to cap it off.
Not a bad way to spend a Saturday.
—
The sun’s dipping low now, painting the sky in lazy streaks of orange and pink as you roll back up to the lake house in your SUV. The gravel crunches under the tires, and you kill the engine, grabbing the plastic bag from the passenger seat—inside’s the new fuel line you snagged from the hardware store in town, plus a couple bags of chips, some salsa, and a pack of those sour gummy worms Miyeon seemed like she’d vibe with. You step out, the air cooler now that the afternoon’s winding down, and spot the girls on your porch, sprawled out like they’ve claimed the place.
Miyeon’s lounging in one of the wooden chairs, legs kicked up on the railing, scrolling her phone with one hand while the other toys with a strand of her damp hair—she’s still in that red swimsuit, a towel draped over her lap. Sana’s cross-legged on the floor next to her, phone plugged into an extension cord snaking through the open window, her pink bikini swapped for a loose tee and shorts. They look up as you approach, Miyeon tossing you a lazy wave while Sana gives a little smile, like they’ve been waiting for you to roll in.
“Yo, I’m back,” you say, holding up the bag. “Got the fuel line. And some snacks for later—figured we’d need something to munch on with the drinks.”
Miyeon drops her feet from the railing, sitting up with a grin. “You’re a fucking legend, dude. I’ll Venmo you later for the part—how much was it?”
“Like, twenty bucks,” you say, shrugging. “No rush.”
Sana tilts her head, brushing her hair behind her ear. “You sure you don’t need help with the generator? I’m useless with that stuff, but I can, like, hold a flashlight or something.”
“Nah, I got it,” you say, slinging your camera bag off your shoulder and setting it by the door. “Watched a couple YouTube vids earlier—think I can handle it solo. You guys just chill here.”
Miyeon laughs, leaning back in her chair. “Yeah, good call. We’d probably just fuck it up worse. I don’t even know what a fuel line is.”
“Same,” Sana adds, giggling. “You’re on your own, hero.”
“Cool,” you say, grabbing the bag with the part and heading off. “I’ll trek over there and sort it out. Be back in a bit.”
You make the short walk around the lake, the last of the sunlight glinting off the water, your boots sinking slightly into the still-damp ground. Their house looks less ominous now, just a quiet two-story sitting there in the evening glow. You head to the shed out back, popping it open with a creak, and there’s the generator—same sad, silent hunk of metal from last night. You drop to your knees, fishing the new fuel line out of the bag, and get to work.
The YouTube tutorials you skimmed earlier play back in your head—some dude with a thick accent walking through the steps like it’s no big deal. First, you kill the fuel switch, making sure no gas is leaking out, then unhook the old line—cracked and crusty, just like you thought. A little diesel dribbles onto your hands, stinking like hell, but you wipe it on your jeans and keep going. The new line’s a perfect fit, sliding into place with a satisfying click. You tighten the clamps with a screwdriver from their toolbox, double-checking everything’s snug. Then it’s just a matter of priming the fuel pump—couple quick pumps like the guy said—and flipping the switch. The generator sputters once, twice, then roars to life, a steady hum kicking in. You stand back, grinning like an idiot. Fixed. Lights flicker on in the house behind you, and you give yourself a mental high-five—DIY king shit.
You trudge back to your place, wiping your greasy hands on a rag you snagged from their shed. The girls spot you coming and perk up—Miyeon’s on her feet, Miyeon swapped her swimsuit for shorts and a tank top. Sana’s leaning forward, both of them looking hopeful. “Well?” Miyeon calls out, arms crossed.
“Done,” you say, tossing the rag onto the porch steps. “Generator’s purring like a kitten. You’ve got power again.”
Sana lets out this big, relieved sigh, clutching her phone to her chest. “Oh my God, thank you. I was legit stressed about that.”
Miyeon whoops, bounding over and throwing her arms around you in a quick, tight hug. “Dude, you’re the best! I owe you more than twenty bucks for this.”
You laugh, patting her back before she pulls away. “Nah, just keep the drinks flowing tonight, and we’re square.”
“Deal,” Sana says, standing up now, her whole vibe brighter. “Speaking of, let’s crack those beers. I’m way happier now that we’re not, like, pioneer women anymore.”
“Bet,” you say, heading inside to drop the snacks on the kitchen counter. The girls follow, Miyeon raiding your fridge for the beers while Sana digs into the chip bag already. You grab a deck of cards from a drawer, flipping it in your hand. “You guys play cards?”
Miyeon pops a beer open, foam hissing as she takes a sip. “I do. Poker, blackjack, whatever. I’m decent.”
Sana shrugs, munching a chip. “I’ve never played. Like, ever. I don’t even know the rules.”
“No shit?” you say, pulling out a chair at the table and motioning them over. “Alright, I’ll teach you. Easy stuff—let’s start with blackjack. You’ll pick it up quick.”
They settle in, Miyeon plopping down across from you with her beer, Sana sliding into the seat next to her, still clutching the chip bag like it’s a security blanket. You shuffle the deck, the cards snapping under your fingers, and deal out the first hand—two cards each. “Goal’s simple,” you say, tossing yourself a jack and a five. “Get as close to twenty-one as you can without going over. Face cards are ten, aces are one or eleven, whatever you need. You want another card, you say ‘hit.’ You’re good, you ‘stay.’ Bust, you lose.”
Sana stares at her cards—a seven and a three—furrowing her brow like it’s a math test. “Okay… hit?”
You flick her a nine, and she gasps. “Shit, that’s nineteen! I stay, right?”
“Yeah, smart call,” you say, grinning. “Miyeon?”
She’s got a queen and a four, smirking like she’s already won. “Hit.” You deal her a six—twenty. “Stay,” she says, leaning back with a cocky tilt to her head.
You flip your second card—a nine. “Dealer’s got nineteen,” you say, checking the deck. “Sana, you’re good. Miyeon wins, though—twenty’s closer.”
“Fuck yeah,” Miyeon says, fist-pumping. “Told you I’m good.”
Sana pouts, but she’s laughing. “Beginner’s luck doesn’t count, right?”
“Nope,” you say, gathering the cards. “Let’s go again. You’ll get the hang of it.”
The hours slip by like nothing, the table a mess of empty beer cans, crumpled chip bags, and a half-eaten pile of gummy worms stuck to the salsa lid. The cards are long forgotten, scattered across the table from your last sloppy round of blackjack—Sana kept busting and blaming the “stupid rules,” while Miyeon was raking in wins like she’d been hustling casinos her whole life. The drinks keep flowing, whiskey now in the mix, poured into mismatched mugs because you ran out of clean glasses. The room’s warm, a little hazy, the heater still chugging along as the night deepens outside, but there are no more stars in the sky, and you already know what's coming.
You’re slouched in your chair, one leg kicked up on the empty seat next to you, feeling the buzz settle into your bones. Across the table, Sana’s climbed into Miyeon’s lap at some point—nobody batted an eye, least of all you. They’re comfy like that, Sana’s head tucked against Miyeon’s shoulder, her fingers tracing lazy patterns on Miyeon’s arm while Miyeon’s got one hand draped around Sana’s waist, the other nursing her whiskey mug. They’re drunk, giggling messes, and you’re not far behind, the room spinning just enough to make everything funnier than it should be.
“Alright, camera guy,” Miyeon says, her voice a little slurred but still sharp, cutting through the haze. “Spill it. When’s the last time you had a girlfriend? You’re too chill to be single forever.”
You laugh, rubbing the back of your neck, the whiskey loosening your tongue. “Uh, shit, like two years ago? She was cool, but it didn’t stick. Been flying solo since then—works better that way, you know? Just me and my camera, no drama.”
Sana tilts her head, her lips curling into a teasing little smile. “Two years? Damn, you’re basically a monk.”
“Monk with a lens,” Miyeon adds, smirking. “Bet you’ve got girls tripping over you and you just don’t notice.”
“Nah,” you say, waving it off, though the compliment lands nice. “I’m good on my own. Relationships are… a lot.”
They exchange a look then—quick, sneaky, like they’re in on some secret. Sana whispers something in Miyeon’s ear, her breath tickling Miyeon’s neck, and Miyeon snickers, her eyes flicking to you. They both start giggling, sloppy and loud, and you lean forward, squinting. “What? What’s so funny?”
Miyeon shakes her head, still laughing. “Nothing, nothing. Just—we’ve got this friend, Shuhua. She’s super chill, loves hiking, nature vibes, all that shit you’re into. You’d hit it off.”
“Oh, yeah,” Sana pipes up, sitting up a little straighter on Miyeon’s lap, her cheeks flushed from the booze. “And Tzuyu too! She’s, like, gorgeous and artsy. Total your type.”
Miyeon nods like it’s settled. “Yeah, Tzuyu’s got that quiet, mysterious thing going. You’d be obsessed.”
You snort, taking a sip of your whiskey, the burn sliding down easy. “What, you two playing matchmaker now? I said I’m good.”
Miyeon’s grin turns mischievous, her eyes glinting under the dim kitchen light. “Okay, fine, but let’s be real for a sec. Between me and Sana—” she tightens her grip on Sana’s waist, making her squirm and giggle—“who’d you pick? Like, if you had to. Be honest.”
Sana’s head snaps up, her face going red. “Miyeon! Don’t ask that, oh my God!” She swats at Miyeon’s hand, but she’s laughing too, hiding her face in Miyeon’s shoulder for a sec before peeking out at you, all shy and curious.
You freeze, the mug halfway to your lips, caught off guard. “Uh… what?” Your voice comes out higher than you mean it to, and you clear your throat, trying to play it cool. “I don’t—I mean, I can’t just… pick. I don’t know.”
Miyeon’s eyebrows shoot up, and she leans forward, dragging Sana with her. “Oh, come on! You’re dodging. You totally know, you’re just too chicken to say it.”
“Am not,” you shoot back, but your face is heating up, and the whiskey’s not helping. You glance between them—Miyeon’s got that bold, flirty edge, all confidence and heat, her lips quirked like she’s daring you to say something stupid. Sana’s softer, her blush spreading, but there’s this spark in her eyes now, playful and warm, like she’s testing you too. They’re both ridiculous, and it’s doing shit to your head.
“So what I’m hearing,” Miyeon says, dragging the words out, “is you’d take both of us. Greedy bastard.”
“What—no!” you sputter, nearly choking on your drink. “That’s not what I said! You’re twisting it!”
Sana bursts out laughing, her whole body shaking against Miyeon. “Oh my God, you’re so greedy! Wanting us both, huh?”
“Fuck off, I didn’t say that,” you protest, but you’re laughing too, the absurdity of it hitting you all at once. “You two are wasted. I’m not even dignifying this.”
Miyeon grins wider, leaning closer across the table, her voice dropping low and teasing. “Oh, please. You couldn’t handle us anyway. We’re a lot, you know. High maintenance.”
Sana nods, mock-serious. “So much work. You’d be crying in a week.”
“Yeah, right,” you fire back, the whiskey buzzing through you now, making you bold. “I’d keep up. You’d be the ones begging for a break.”
Miyeon’s eyes widen, and she lets out a loud, “Ooooh!” Sana gasps, covering her mouth, but she’s smiling like crazy behind her hand. “He’s got some fight in him,” Miyeon says, leaning back and fanning herself dramatically. “Sana, you hear that? He thinks he’s tough enough for us.”
“I’m just saying,” you mutter, sinking into your chair, “you’re the ones who’d tap out first.”
Sana giggles, sliding off Miyeon’s lap to grab another beer from the fridge, her shorts riding up as she bends over. She spins back around, popping the cap with a lighter she snagged off the table. “You’re funny,” she says, pointing at you. “And shy as hell right now. Look at you.”
“Shut up,” you say, but you’re grinning, your face burning under their stares. “You’re both too drunk. This convo’s going off the rails—I’m scared of where it’s headed.”
Miyeon laughs, loud and unfiltered, tipping her mug back for the last of her whiskey. “Scared? Good. You should be. We’re trouble, camera guy. Double trouble.”
“Triple, with the drinks,” Sana adds, sliding back onto Miyeon’s lap, beer in hand. She takes a sip, then offers it to Miyeon, who leans in close, their lips brushing for a second as she drinks. It’s casual, natural for them, but it hits you like a punch—subtle, hot, and gone too fast to process.
You shake your head, trying to clear the fog. “Yeah, I’m calling it. You two are a menace. I’m having way too much fun, though.”
“Same,” Sana says, her voice softer now, her head resting on Miyeon’s shoulder again. “You’re cool, you know that?”
“Very cool,” Miyeon agrees, her hand sliding up Sana’s back, casual but possessive. “We’ll let you off the hook for now. But don’t think we’re done messing with you.”
You laugh, raising your mug in a mock toast. “Wouldn’t dream of it. Night’s still young, right?”
They clink their drinks against yours, the three of you grinning like idiots, the flirtation simmering under the surface—light, playful, but with an edge that keeps you on your toes. You take a sip of your whiskey, the burn familiar now, and figure it’s your turn to flip the script. “Alright,” you say, setting the mug down with a little thud to get their attention. “You’ve been grilling me about my love life—or lack of it. What about you two? How’d you even end up together?”
Miyeon’s head tilts back as she laughs, her black hair spilling over her shoulders. “Oh, dude, it’s a story. We met at some shitty college party—like, the kind with warm beer and a playlist that’s just Top 40 on repeat. I was trashed, trying to shotgun a can, and Sana was there, all cute and quiet, holding a red cup she wasn’t even drinking from.”
Sana nods, her cheeks already pink from the booze. “She spilled beer all over me trying to show off. I was pissed, but then she started apologizing like a maniac, and… I don’t know, she was funny about it. We just clicked.”
“Clicked, huh?” you say, smirking. “That’s cute. So, what’s the secret? Two and a half years is solid—most people can’t keep a houseplant alive that long.”
Miyeon shrugs, her hand sliding idly up Sana’s back, fingers tracing the hem of her tee. “Dunno. We just vibe. She keeps me from doing dumb shit—like, most of the time—and I make sure she doesn’t stay in her shell forever. Balance, you know?”
“Yeah,” Sana adds, leaning into Miyeon’s touch, her voice soft. “She’s loud and I’m not. Works out.”
You nod, letting the moment settle, then push a little further, keeping it chill. “Ever have any big fights? Like, the kind where you’re slamming doors or sleeping on the couch?”
Sana giggles, shaking her head. “Not really. We argue sometimes—stupid stuff, like who forgot to buy milk—but Miyeon’s too lazy to storm out, and I hate sleeping alone.”
“Facts,” Miyeon says, grinning. “I’d rather just bitch for five minutes and then make out. Way easier.”
You laugh, the image of them bickering-then-kissing too good to not picture. “Smart move. Alright, let’s level up—any exes still lurking around? Old flames trying to slide back in?”
Miyeon’s eyes narrow playfully, like she’s onto your game, but she answers anyway. “Couple of mine tried. Dudes mostly—had a few boyfriends before Sana. They’d hit me up like, ‘Oh, you’re with a girl now? That’s hot.’ Blocked them so fast. Sana’s exes are too scared of me to try anything.”
Sana snorts, nudging Miyeon’s shoulder. “You’re not that scary. They’re just… I don’t know, they’re all girls anyway. Nobody’s dumb enough to mess with us now.”
“Fair,” you say, leaning forward, resting your elbows on the table. The whiskey’s got your tongue loose, and the vibe’s right, so you nudge the questions up a notch—still smooth, but with a little heat. “So, Miyeon, you’ve dated guys before, right? Sana—you ever been with one? Like, ever?”
They glance at each other quick, a flicker of something passing between them—Sana’s blush deepens, and Miyeon’s grin turns sly. “Me? Yeah,” Miyeon says, casual as hell. “I’m bi—guys, girls, whatever. If they’re hot and fun, I’m down. Dated a couple dudes before I figured out I liked girls just as much. No big deal.”
Sana shifts on Miyeon’s lap, her fingers tightening around her beer bottle. “I… no. Never been with a guy. Always just girls for me.” Her voice is quieter, a little shy, but she doesn’t look away.
Miyeon tilts her head, resting her chin on Sana’s shoulder, her eyes locked on you now. “She’s curious, though,” she says, dropping it like a bomb, her tone teasing but deliberate. “Always has been. Right, babe?”
Sana’s face flares red, and she swats at Miyeon’s arm, flustered. “Miyeon! Shut up, oh my God!” She buries her face in her hands for a sec, then peeks out, still giggling despite herself. “I mean… yeah, okay, I’ve thought about it. Like, wondered what it’d be like. But that’s it. Closest I’ve gotten is—” She stops, biting her lip, and Miyeon finishes for her.
“The strap,” Miyeon says, smirking like she’s proud of it. “I’ve got this one that’s, uh, pretty realistic. She loves it, but it’s still not the real deal, you know?”
Sana groans, dropping her forehead onto Miyeon’s shoulder. “You’re the worst. Why do you say shit like that?”
You laugh, holding up your hands. “Hey, no judgment here. We’re all adults—shit gets spicy sometimes. Sounds like you’ve got it figured out anyway.”
Miyeon’s still watching you, her smirk softening into something sharper, more curious. Sana lifts her head, her embarrassment fading into a playful little pout as she takes a swig of her beer. “Okay, but why’re you asking?” she says, her tone turning provocative, her eyes narrowing just a bit. “You digging for details, huh? What’s your deal?”
You freeze for a sec, caught off guard, the whiskey making your brain a little slow to catch up. “What? Nah, I’m just—curious, I guess. Making conversation. That’s all.”
Miyeon’s not buying it, her head tilting like she’s sizing you up. “Bullshit. You’re interested. I can see it. All these questions—you’re fishing for something, aren’t you?”
“Fishing?” you say, leaning back, trying to play it cool but feeling the heat creeping up your neck. “Come on, I’m just chilling. Anyone stuck out here with you two would be asking the same shit. You’re the only entertainment I’ve got.”
Sana giggles, her pout turning into a grin as she leans forward, elbows on the table now, her chin in her hands. “Oh, so we’re entertainment? That’s your excuse?”
“Yeah, exactly,” you say, grinning back, the tension easing but still simmering under the surface. “Two hot girls, drunk and spilling secrets? Who wouldn’t be into that?”
Miyeon laughs, loud and bright, tipping her head back. “Fair. You’ve got a point. We are hot.” She nudges Sana, who’s still blushing but clearly loving the vibe. “He’s not wrong, babe.”
“Still,” Sana says, her voice softer but with a teasing edge, “you’re digging pretty deep. What’s next, you gonna ask our favorite positions or something?”
You choke on your whiskey, coughing into your fist as Miyeon cackles. “Jesus, no,” you manage, wiping your mouth. “I’m not that drunk. Yet.”
“Yet,” Miyeon echoes, her eyes glinting with mischief. “Give it an hour. We’ll get you there.”
The room’s buzzing now, the flirtation weaving through the air like a quiet current—nothing overt, but it’s there, subtle and growing. You take another sip, letting it burn, and lean back in your chair, meeting Miyeon’s gaze for a second longer than you should. Sana’s watching too, her smile small but knowing, like she’s in on the game.
The conversation’s still humming along, the whiskey keeping the edges soft and the laughter loud. You’re mid-sentence, riffing on some dumb story about a camping trip gone wrong years ago, when a faint patter hits the deck outside. At first, you think it’s just the wind kicking up, but then it gets louder, steadier—rain, drumming hard against the wood. The temperature drops fast, a chill sneaking through the open window, cutting through the cozy haze of the kitchen. Miyeon shivers, rubbing her bare arms, and Sana pulls her tee tighter around herself, her beer bottle clinking against the table as she sets it down.
“Shit, there it goes again,” you say, standing up to slide the window shut. The cold’s biting now, the kind that makes your breath fog indoors if you’re not careful. “The couch is calling us.”
They nod, grabbing their drinks and stumbling after you, a little wobbly from the booze. You flick on the living room lamp, its warm glow spilling over the plush couch and the throw blankets piled on the armrest. The fireplace is out, but the heater’s still doing its thing, and the room feels like a bubble against the storm outside. You flop into the corner of the couch, one leg tucked under you, the whiskey mug warm in your hands. Miyeon and Sana collapse together on the other end, a tangle of limbs and giggles—Sana’s half-draped over Miyeon, her head lolling against Miyeon’s chest as Miyeon wraps an arm around her.
“Fuck, your place is so warm,” Miyeon sighs, kicking off her flip-flops and pulling her feet up onto the cushions. “Ours would be an icebox right now with that busted generator.”
“Perks of not slacking on maintenance,” you say, smirking as you take a sip. “You’re welcome to crash anytime it shits the bed.”
Sana hums, her eyes half-closed, nestled into Miyeon like she’s ready to doze off. “Good to know. You’re spoiling us.”
The rain’s pounding now, a steady roar against the roof, and for a while, you all just sit there, letting the sound fill the silence. It’s not awkward—more like a breather, the kind where everyone’s too buzzed and content to force more chatter. But then you catch it: the way they’re looking at you. Miyeon’s got this lazy, lidded gaze, her lips parted just enough to show a hint of teeth, and Sana’s peeking up from Miyeon’s chest, her eyes brighter than they should be for how drunk she is. They’re giggling to themselves, quiet little bursts, like they’re sharing some inside joke you’re not in on yet.
You lean back, resting your head against the couch, and glance out at the deck, rain streaking the glass doors. “Getting late,” you say, casual, testing the vibe. “This storm’s not letting up anytime soon.”
Sana stretches, her tee riding up to flash a sliver of stomach, and sits up a little. “Tonight was so fun, though. Way more than we thought it’d be, stuck out here alone.”
“Yeah,” Miyeon agrees, her hand lingering on Sana’s thigh, fingers tracing absent circles. “Didn’t expect to end up with a generator-fixing, blackjack-teaching hero. You’re full of surprises.”
You laugh, shrugging it off, but the compliment sticks. “Glad I could keep you entertained. We can run it back tomorrow—more drinks, more cards, whatever. Weather’s supposed to clear up.”
“Sweet,” Sana says, her voice soft but perky. Then Miyeon shifts, her eyes locking onto yours, and there’s something different in them now—sharper, bolder.
“Fun doesn’t have to end now, though,” she says, slow and deliberate, like she’s dropping a hint she knows you’ll catch.
You tilt your head, playing dumb but feeling the shift. “What’s that mean?”
She smirks, leaning forward just enough to close some distance, her arm sliding behind Sana on the couch. “What’re you doing later? After we’re done sitting here?”
“Uh, sleeping?” you say, half-laughing, though your pulse kicks up a notch. “That’s the plan, anyway.”
Miyeon’s grin widens, and she glances at Sana, who’s biting her lip like she’s holding back a laugh. “Yeah, well, me and Sana—we’re probably gonna fuck,” Miyeon says, blunt as hell, her tone light but her eyes steady on you. “We were supposed to last night, but, you know, generator drama killed the mood. So now we’re kinda pent up. Horny as shit, honestly.”
You choke on your whiskey, coughing into your sleeve as the words hit you like a freight train. “Jesus, warn a guy,” you mutter, wiping your mouth, your face hot. Sana’s giggling now, hiding half her face in Miyeon’s shoulder, but she’s not denying it.
“What?” Miyeon says, all fake innocence, leaning back and pulling Sana closer. “Just being real. You asked.”
“I literally didn't ask anything,” you say, but you’re laughing, the shock mixing with the buzz and turning into something else—something that’s got your stomach tightening.
Sana whispers something into Miyeon’s ear, her voice too low to catch, and Miyeon’s smirk softens into something… hungrier. She looks back at you. “It’s pouring out there,” she says, nodding toward the glass doors, where the rain’s still hammering down in sheets. “We’d get soaked going back. Mind if we crash here tonight?”
“Yeah, of course,” you say, automatic, trying to keep your cool. “The bed is yours, I'm getting used to the couch.”
Sana’s the one who pipes up now, her voice quiet but cutting through the tension. “Sleeping alone in this cold sucks, though. Don’t you think?”
You blink, caught off guard again, your brain scrambling. “Uh… yeah, I guess?”
Miyeon’s watching you close now, her hand sliding up Sana’s back again, possessive but gentle. “What if…” she starts, pausing just long enough to let it sink in, “you joined us? Like, all three of us. Together.”
Your mouth goes dry, the words landing heavy. “Wait, what—like, serious? Or are you just drunk and fucking with me?”
Miyeon doesn’t flinch. She leans forward instead, setting her mug on the table with a soft clink, then turns to Sana. Without breaking eye contact with you, she cups Sana’s face and kisses her—slow, deep, not some quick peck but a real, sensual thing. Lips parted, tongues meeting, the kind of kiss that’s got heat behind it. Sana melts into it, her hands clutching Miyeon’s tank top, and when they pull apart, breathless, they both turn to you. Sana’s flushed, her eyes glassy, and Miyeon’s got this smug, daring look.
“Does that look like we’re fucking with you?” Miyeon says, wiping the corner of her mouth with her thumb.
Sana’s quieter, her voice a little shaky but steady enough. “You’re cool. And… kinda hot, honestly. We’ve been talking about it all night.”
“Yeah,” Miyeon adds, leaning into it now, her confidence dialed up. “I wanna see you fuck Sana. Like, I’d be there too—watching, helping, whatever. She’s curious, and I think you’d be perfect for her first time with a guy.”
Your head’s spinning, the room suddenly way too small, the air thick with something you can’t shake. Your dick twitches at the thought—Sana’s soft curves under you, Miyeon’s eyes on you, directing it all. It’s a lot, fast, and your heart’s pounding against your ribs. “Fuck,” you breathe, running a hand through your hair. “You’re not kidding.”
“Nope,” Miyeon says, popping the ‘p’ again, her smirk lethal. “So? What do you say?”
Sana’s staring at you now, bottom lip caught between her teeth, nervous but wanting, and Miyeon’s got that predatory edge, like she’s already decided how this is gonna go. The tension’s a live wire, humming between you, and you’re stuck, half-panicked, half-turned on, trying to process what the hell’s happening as the rain keeps drumming outside.
“Fuck it, I’m up for it.”
Miyeon’s grin stretches wide, victorious, and she slides off the couch, her bare feet hitting the hardwood with a soft thud. “Good answer,” she says, her voice low and sultry, like she’s been waiting for this all night. “Come closer, then.” She beckons you with a curl of her finger, her eyes locked on yours, daring you to hesitate.
You don’t. You push off the couch, the whiskey buzz making your steps feel loose, and cross the small gap to where she’s standing. Up close, she’s all heat and confidence—her tank top clings to her frame, her dark hair messy from the day, and she smells faintly of sunscreen and beer. She steps in, closing the distance, and grabs the front of your hoodie, pulling you down just enough to crash her lips into yours.
It’s sudden, rough, and you’re caught off guard—your hands hover for a split second, unsure where to land, before instinct kicks in. You kiss her back, tentative at first, lips brushing hers, tasting the sharp edge of whiskey and the faintest hint of her chapstick. Then she presses closer, her tongue flicking against your bottom lip, and you’re done holding back. You dive in, deepening the kiss, your hands finding her waist, sliding up the curve of her sides under her tank. Her skin’s warm, smooth, and she lets out this little hum against your mouth that sends a jolt straight down your spine.
Sana’s still on the couch, watching, her breath hitching audibly. You can feel her eyes on you, a quiet intensity in the way she’s perched there—legs tucked under her, hands gripping the blanket like it’s an anchor. Miyeon breaks the kiss for a second, her lips hovering an inch from yours, her breath hot against your skin. She glances over her shoulder at Sana, smirking. “Your turn, babe,” she says, her voice thick with promise.
Sana hesitates, her wide eyes darting between you and Miyeon, but there’s no mistaking the want there, the curiosity flickering behind her nerves. She slides off the couch slow, her bare feet padding across the floor, and stops just in front of you. Up close, she’s smaller than Miyeon—slimmer, softer, her oversized tee swallowing her frame, her shorts barely peeking out. Her lips glisten with gloss, and when she looks up at you, all shy and flushed, makes you breathless.
You don’t wait for her to make the first move. You step in, gentle but sure, cupping her face with one hand, your thumb brushing her cheek. “You good?” you murmur, giving her an out, but she just nods, quick and eager, her breath catching. Then you lean in, and her lips meet yours—soft, plush, addictive as hell. She tastes like gloss and the faint tang of beer, sweet and heady, and it’s different from Miyeon’s fire—slower, more tentative, but just as hungry. You kiss her deeper, letting her melt into it, your free hand settling on her hip, pulling her closer. She sighs into your mouth, a tiny, needy sound that lights you up.
Miyeon’s not sitting this out. She steps in behind Sana, her hands sliding over Sana’s shoulders, then down to her waist, guiding her closer to you. She’s watching, her lips parted, eyes dark with heat. Sana’s still kissing you, lost in it, when Miyeon takes her hand—small, trembling—and moves it, pressing it against the front of your jeans. You’re already hard, straining against the denim, and the second Sana’s fingers brush over you, your breath hitches.
“Fuck,” you mutter against Sana’s lips, and Miyeon laughs, low and throaty.
“Hot, right?” Miyeon says, her voice dripping with satisfaction. She’s pressed up against Sana’s back now, her chin resting on Sana’s shoulder, watching you both like she’s directing this whole show. Sana’s hand trembles, but she doesn’t pull away—she squeezes, hesitant but curious, her warm palm cupping you through the fabric. It’s clumsy, unsure, but that only makes it hotter, the newness of it driving you wild.
“Jesus, this is insane,” you say, pulling back just enough to look at them—Sana’s blushing hard, her eyes wide and dazed, Miyeon’s grinning, all smug and turned on. Sana’s hand stays where it is, her fingers flexing slightly, like she’s testing how you feel, and it’s taking every ounce of self-control not to lose it right there.
Miyeon’s eyes flick down to where Sana’s touching you, then back up to your face. “She’s doing good, huh?” she teases, her hand sliding up Sana’s arm, encouraging her. “But fuck, I’m already soaked just watching this. Let’s take it to your room, yeah? This couch isn’t big enough for what I’ve got in mind.”
Sana finally pulls her hand back, her face half-hidden in Miyeon’s neck, embarrassed but buzzing with excitement. You nod, still half-dazed, the reality of it sinking in. “Yeah… yeah, let’s go,” you say, voice rough, your heart hammering as you lead the way.
The hallway’s a blur, your footsteps heavy, their bare feet padding behind you. You push open your bedroom door—messy bed, clothes tossed on the chair, the faint glow of a lamp in the corner—and step inside, the air cooler here but still thick with tension. You turn to face them, Miyeon moves first, her fingers hooking under the hem of her tank top. She peels it off slow, deliberate, letting it slide up her torso, exposing the smooth plane of her stomach, then the curve of her ribs, before tugging it over her head and tossing it aside. Her black bra clings to her, lacy and thin, her medium, perky breasts straining against it—she’s all confidence, hips cocked, watching your reaction.
Sana’s shyer, her hands trembling just a little as she grabs the bottom of her oversized tee. She lifts it up, inch by inch, revealing her slim waist, the faint dip of her navel, then higher until the pink bra comes into view—simple but cute, hugging her slighter, curvier frame. She hesitates for a second before pulling the shirt all the way off, her brown hair tumbling back over her shoulders, and when she drops it to the floor, she’s blushing hard but smiling, caught up in the moment.
They kick off their shorts next—Miyeon’s denim cutoffs hit the ground with a soft thud, leaving her in matching black panties that sit low on her hips, showing off the roundness of her ass. Sana’s shorts slide down her legs slower, pooling at her ankles, and she steps out, her pink panties a soft contrast to Miyeon’s darker set, clinging to her narrower hips. Standing there in just bras and panties, they’re a fucking vision—Miyeon’s thicker, all curves and bold energy, Sana’s slimmer but still lush, her skin glowing in the low light. It’s almost too much, the way they move together, like they’re perfectly in sync even now.
Miyeon steps forward, her bare feet silent on the hardwood, and nods at Sana. “You take the hoodie,” she says, her voice low and husky, thick with intent. “I’ve got the pants.”
Sana moves in, her hands tentative but eager, reaching for the hem of your hoodie. Her fingers brush your stomach as she lifts it, her touch light, almost ticklish, and you raise your arms to help her. She pulls it up and over, her breath catching as she gets a good look at your chest, her eyes flicking up to yours—nervous, excited, a little overwhelmed. The hoodie drops to the floor, and she steps back, biting her lip, like she’s sizing you up.
Miyeon’s not wasting time. She’s already at your waist, her hands deft and sure as she pops the button on your jeans. The zipper comes down with a quick, sharp sound, and she tugs them down, past your hips, letting them pool at your ankles. Her fingers hook into the waistband of your boxers next, and with one smooth pull, those are gone too, sliding down your legs until you’re bare in front of them. She’s kneeling now, right between your thighs as you sit back on the edge of the bed, her movements all purpose and hunger, no hesitation.
Sana joins her, dropping to her knees beside Miyeon, her eyes wide and fixed on your cock—hard, thick, standing up proud. It’s the first one she’s seen up close, and you can tell it’s hitting her all at once. “Holy shit,” she whispers, almost to herself, her hand hovering like she’s not sure what to do with it yet.
Miyeon’s already on it, her fingers wrapping around the base, stroking slow and light, her thumb brushing the underside. “Go on,” she says, glancing at Sana with a smirk. “Touch it.”
Sana reaches out, her small hand trembling just a bit as she lays it over Miyeon’s, following her lead. Her fingers slide up, tentative, tracing the shaft, feeling the weight of it—the heat. She runs her thumb over the tip, where a bead of precum’s already leaking out, and her breath hitches again. “It’s… big,” she says, her voice soft, awed. “And, like… really hot.”
You groan low in your throat, the sound slipping out as their hands work together—Sana’s delicate, curious grip mixing with Miyeon’s firmer, more practiced strokes. Your cock’s throbbing now, pulsing under their touch, and it’s driving you fucking insane. Sana’s fingers wander lower, brushing over the veins, then down to your balls, cupping them gently, rolling them in her palm like she’s figuring it all out. “This is wild,” she mutters, half-laughing, her eyes flicking up to yours for a second before darting back down.
“What do you think?” Miyeon asks her, her voice teasing but edged with her own arousal. She’s watching Sana explore, her own hand still moving, keeping the rhythm steady.
Sana bites her lip, her cheeks flushed deep red. “It’s… I don’t know, it’s kinda crazy how much I like it,” she admits, her fingers tightening slightly, testing the give. “Feels alive or something.”
“Fuck, you’re killing me,” you say, your voice rough, your head tipping back for a second as the sensation hits hard. Miyeon chuckles, low and dirty, and leans closer.
“Taste it,” she says, her eyes locked on Sana’s, pushing her just a little. “Go for it.”
Sana freezes, her hand stilling, but the curiosity’s there—bright and burning in her gaze. She leans in slow, hesitant, her breath warm against your skin as she presses a tiny kiss to the tip, barely grazing it. Then another, softer, her lips parting just enough to taste the salt of you. She pulls back, blinking like she’s surprised herself, then goes again—small licks this time, her tongue darting out, testing the waters. It’s clumsy, unsure, but the heat of her mouth, the wet flick of her tongue—it’s fucking electric.
Miyeon’s watching, her own breath ragged now, her hand slipping away to let Sana take over. “Good, right?” she murmurs, her voice thick. “Keep going.”
Sana gains confidence, her lips closing around the head, sucking gently—experimental, like she’s figuring out how it feels. Her tongue swirls once, twice, and you groan again, louder, your hands gripping the sheets to keep from grabbing her head and guiding her yourself. She pulls back, a thin string of spit connecting her lips to you, and looks up, dazed but grinning. “Okay, yeah,” she says, wiping her mouth with the back of her hand. “That’s… a lot.”
Miyeon laughs, shifting to kneel closer, her shoulder brushing Sana’s. “Told you it’s hot. You’re doing good, babe.” She glances at you, her eyes dark. “He’s loving this shit.”
You nod, breathless, the sight of them there—half-naked, on their knees, Sana’s shy exploration and Miyeon’s hungry stare—burning into your brain.
Miyeon’s got your cock in her hand, her grip firm but teasing, her fingers curling around the base as she angles it toward Sana. “Go on, babe,” she says, her voice a low purr, her eyes flicking up to meet yours—dark, horny, locked in. “He’s all yours.”
Sana’s determination’s kicking in, the shy edge melting away as she leans forward. Her lips part, soft and wet, and she takes you in again—slower this time, more deliberate. The taste’s sinking into her now, the salt and heat, and you can see it in her eyes—she’s getting hooked. Her tongue flattens against the underside, sliding up, then curling around the tip, and you groan, low and rough, your head tipping back for a split second before you snap it forward again to watch. Miyeon’s staring too, her lips parted, her breath coming faster—she’s as turned on as you are, her thighs pressing together like she’s already feeling it.
Sana pushes further, her lips stretching around you, trying to take more. She slides down, her throat tightening, and then—she gags, a little choke that jerks her back. Her eyes water, and she pulls off, coughing into her hand, a flush creeping up her neck.
“Easy, babe,” Miyeon says, her tone soft but firm, one hand rubbing Sana’s back while the other still holds you steady. “Don’t rush it. Breathe.” She brushes Sana’s hair out of her face, gentle but with that edge of control—she’s done this before, knows the game.
Sana nods, wiping her mouth with the back of her wrist, catching her breath. “Okay,” she rasps, her voice shaky but eager. “I’m good.”
Miyeon smirks, then shifts her gaze to you. “My turn,” she says, and there’s no hesitation—she’s all in, sliding down to take Sana’s place. Her mouth’s on you in a heartbeat, hot and wet, her tongue moving like she’s mapped you out already. She’s not shy, not slow—she takes you deep right off the bat, her lips sealing tight as she sucks, hard and deliberate. Her hand works what her mouth can’t reach, stroking in sync, slick and fast. You groan louder, your hips twitching, and she hums around you, the vibration hitting you like a fucking freight train.
Sana’s watching, wide-eyed, her embarrassment replaced by something else—amazement, maybe a little envy. She’s seeing a side of Miyeon she didn’t know existed, this confident, dirty edge that’s got her girlfriend deep-throating you like it’s nothing. Miyeon’s eyes flick up to yours, locked in as she bobs her head, her cheeks hollowing out, spit slicking her lips. She pulls off slow, dragging her tongue along the underside one last time, leaving you dripping—your cock’s a mess now, glistening with her spit, throbbing hard.
“Wet enough for you, babe,” Miyeon says, wiping her chin with a smirk, her voice thick with pride. She glances at Sana, who’s still staring, her breath uneven. “Ready?”
They both stand, peeling off the last of their clothes with a slow, teasing grace that’s almost cruel. Miyeon unhooks her bra first, letting it fall to the floor—her breasts bounce free, full and perky, nipples already hard in the cool air. She shimmies out of her black panties next, kicking them aside, and she’s stark naked now, all smooth skin and curves, thick in the right places. Sana follows, quieter, her fingers fumbling with her bra clasp until it snaps open—her breasts are smaller, softer, but perfect, her nipples a faint pink that matches her blush. She slides her panties down her legs, stepping out delicately, and when they’re both bare in front of you, it’s like every dirty dream you’ve ever had coming to life.
Miyeon twirls once, playful but deliberate, her ass jiggling just enough to make your mouth dry. “What do you think?” she asks, hands on her hips, her voice dripping with that cocky flirtation she’s mastered. Sana spins too, a little clumsier, her hair swinging as she laughs through her nerves.
“Fuck,” you say, the word slipping out before you can stop it. “You’re the hottest girls I’ve ever seen. No contest.”
They grin—Miyeon smug, Sana shy—and climb onto the bed. The mattress dips under their weight, the sheets rustling as Sana lies back, stretching out on her back, her head resting on the pillows. Her legs part slightly, not blatant but enough to draw your eye, her body a soft, inviting curve against the dark fabric. Miyeon slides in beside her, propping herself up on one elbow, her naked body pressed close to Sana’s—her hand rests on Sana’s stomach, casual but possessive, her fingers splaying out like she’s staking a claim.
The rain’s still hammering outside, a dull roar that only amps up the tension in here. You’re sitting at the foot of the bed, cock still hard and slick from their mouths, and the way they’re looking at you—Sana’s nervous excitement, Miyeon’s hungry confidence—it’s like they’re pulling you in without even moving.
You’re kneeling between Sana’s legs now, her thighs soft and trembling under your hands, her skin flushed pink from the booze and the buildup. She’s sprawled out beneath you, her chest rising and falling fast, her eyes locked on yours—wide, nervous, but burning with want.
You pause, reality cutting through the haze for a second, and clear your throat. “Uh, shit—girls, I don’t have a condom,” you say, voice rough, a little sheepish. “Wasn’t exactly planning on… this when I booked the lake house.”
Miyeon smirks, unfazed, her fingers tracing lazy circles on Sana’s skin. “It’s fine,” she says, her tone smooth, deliberate. “She needs to feel you—like, really feel you. No rubber bullshit. Right, babe?” She glances at Sana, squeezing her breast gently, her thumb brushing over a nipple that’s already pebbled and sensitive.
Sana bites her lip, her breath hitching, but she nods—small at first, then firmer. “Yeah… I want that,” she whispers, her voice shaky but sure, her eyes flicking down to where your cock’s resting against her thigh, hard and leaking. “I’ve never… you know. I wanna know what it’s like.”
You swallow hard, the weight of it hitting you—Sana’s first time with a guy, and it’s you, bare, with Miyeon watching, guiding. It’s a fucking rush, equal parts thrilling and insane. “Alright,” you say, voice low, steadying yourself. “I’ll go slow. Promise.”
Miyeon leans in, her lips brushing Sana’s in a kiss that’s soft but deep, all tongue and tenderness, her hand kneading Sana’s breast harder now, rolling the nipple between her fingers. Sana moans into it, her body arching slightly, and you take that as your cue. You shift, lining yourself up, the tip of your cock brushing her entrance—she’s soaked, slick from everything before, her folds glistening in the dim light. You press forward just enough to part her, the head nudging inside, and Sana gasps, her mouth breaking away from Miyeon’s, her hands clutching the sheets.
“Fuck,” she breathes, her eyes squeezing shut for a second, then fluttering open to look at you. It’s tight—hot, wet and tight as hell—and you freeze, letting her adjust, feeling her walls clench around you like they’re figuring you out.
“Slow,” Miyeon murmurs, her voice a soft command, her eyes flicking to yours. “Don’t hurt her, okay? She’s my girl.” There’s that edge of possession in her tone, but it’s laced with something romantic, something deep—she’s sharing Sana with you, but it’s all love, all care, and it’s fucking hot how she balances both.
“I got her,” you say, your hands sliding to Sana’s hips, gripping her gently, keeping her steady. “You good?” you ask, checking in, your voice tight with how bad you want to move.
Sana nods, her lips parting. “Yeah… keep going.”
You ease in, slow as fuck, inch by inch, watching her face—her brows furrow a little, her mouth opens wider, and then she sighs, a long, shaky sound that’s pure relief mixed with want. She’s so tight it’s unreal, her heat wrapping you, pulling you in, and you’re halfway there when she tenses, her thighs squeezing your hips. You stop, breathing hard, your fingers digging into her skin just enough to hold her still.
“Tell me when,” you say, your control hanging by a thread, the way Miyeon’s watching you both—eyes dark, lips wet—only making it worse.
Sana exhales, nodding again. “Now… more.”
You push deeper, careful but steady, until you’re all the way in, buried to the hilt, her walls fluttering around you like a fucking heartbeat. She’s full of you now, and you can feel it—every twitch, every pulse—and it’s driving you nuts. Sana’s head tips back, a low moan slipping out, and Miyeon’s right there, kissing her neck, whispering something soft you can’t catch, her hand still working Sana’s breast like she’s coaxing her through it.
“Goddamn,” you mutter, your voice breaking, because this—Miyeon giving her girl to you, Sana taking you raw, the love and the lust all twisted up—is some next-level shit. “You feel… fuck, unreal.”
Miyeon smirks at you, her hand sliding down Sana’s stomach now, teasing just above where you’re connected. “She’s perfect, right?” she says, then leans into Sana’s ear. “You like him inside you, babe?”
Sana whimpers, nodding fast. “Yeah… so much,” she breathes, her hips shifting like she’s testing the feel of you, and that’s all it takes—you start moving, slow pulls back, gentle thrusts in, letting her get used to it. Her moans are quiet at first, little gasps and sighs, but they build fast, her body responding, her legs spreading wider.
Miyeon’s eyes are on you now, hot and approving. “Faster,” she says, her voice cutting through the haze. “She can take it. Give it to her harder.”
You hesitate for a second, checking Sana’s face—she’s nodding, her hands reaching for your arms, pulling you closer—so you pick up the pace, thrusting deeper, the bed creaking under you. Sana’s moans turn sharp, her nails digging into your forearms, and Miyeon’s right there, kissing her through it, her hand slipping between Sana’s legs, fingers brushing her clit to push her higher.
“Fuck, yes,” Sana gasps, her voice trembling, her walls clenching tighter around you with every stroke. “Don’t stop.”
You don’t—can’t—your hips snapping harder now, the wet sound of skin on skin mixing with the rain outside, filthy and raw. Miyeon’s watching you like you’re putting on a show just for her, her lips parted, her breathing ragged, and it’s that—her gaze, Sana’s tight heat, the whole damn scene—that’s got you teetering on the edge already, every thrust pulling you deeper into the madness of it.
You’re buried deep in Sana, your hips driving into her with a steady, hard rhythm that’s got the headboard tapping the wall like a metronome. Her moans are loud now—sharp, desperate little cries that fill the room, her thin frame trembling beneath you. She’s so tight it’s unreal, her walls gripping you like a vise, slick and hot, pulling you in deeper with every thrust. You’ve got her legs spread wide, one hand hooked under her knee, holding her open, the other braced on the mattress as you lean into her.
Miyeon’s right there beside her, naked and sprawled out, her hand slipping between her own thighs. She’s touching herself, slow at first, her fingers circling her clit as she watches you fuck her girlfriend. Her eyes are half-lidded, lips parted, her breathing ragged—she’s so turned on it’s obscene, and she doesn’t hold back with the dirty talk. “Fuck, babe,” she says, her voice husky, glancing at Sana. “Is his cock better than my strap? Tell me.”
Sana’s head jerks back, a loud moan ripping from her throat as you hit a deep spot. “Yes—fuck, yes,” she gasps, her nails clawing at your arms, leaving little crescent marks. “So much better… it’s so fucking good.”
That’s like rocket fuel to you. You grin, sweat beading down your forehead, and double down, your thrusts picking up speed, the wet slap of skin on skin echoing in the room. Miyeon’s fingers move faster too, her other hand gripping the sheets as she watches, her pride flaring up. “Hear that?” she says, locking eyes with you, her voice dripping with heat. “You loving this? Fucking my girl senseless?”
“Shit, yeah,” you groan, your breath ragged, your cock throbbing inside Sana’s tight heat. “She’s so fucking tight, Miyeon. Like—Jesus, I can barely think straight.”
Miyeon smirks, smug and horny all at once, her fingers plunging into herself now, matching your pace. “Proud of her,” she purrs, her gaze flicking between your face and where you’re disappearing into Sana. “Bet you’d kill to feel that pussy all the time, huh? So hot, so tight, those sweet little moans—she’s a goddamn dream, right?”
You can’t even form words, just a low, needy moan that’s half-agreement, half-losing-your-shit. Sana’s whimpering now, her body rocking with every thrust, her skinny frame so delicate you can see the faint bulge of your cock stretching her out, pressing against her flat stomach. Miyeon’s mesmerized by it, her eyes glued to the sight, her own moans mixing with Sana’s as she fucks herself harder.
“Ruin her,” Miyeon says suddenly, her voice sharp, commanding, her fingers slick and fast. “Fucking pound that tight little pussy. She can take it.”
You go all out, pounding into Sana now, her skinny frame jolting beneath you with every thrust, her legs splayed wide—knees hooked over your arms, her pussy open and vulnerable, taking you deep. She’s a mess, her brown hair plastered to her forehead with sweat, her cheeks flushed a wild, desperate pink. Her moans are loud, unrestrained, spilling out in sharp bursts that cut through the steady slap of your hips against hers. You’ve got her pinned, driving hard, her tight little pussy gripping you like it’s trying to strangle your cock—hot, wet, and pulsing with every slam, and her walls are clenching tighter now, her breath hitching, and you can feel it—she’s teetering right on the edge, her body trembling like a live wire about to snap.
“Fuck—fuck, your cock,” Sana gasps, her voice breaking into a raw, filthy moan, her hands clawing at the sheets, ripping at them like she’s losing her goddamn mind. “It’s so fucking good—shit, I love it, I love your cock so much!” Her hips buck up to meet you, sloppy and wild, chasing the friction, her pussy soaking you, dripping down your thighs. She’s unhinged, her words tumbling out fast and dirty, no filter, just pure need. “Harder—fuck me harder, don’t stop, I need it, I fucking need it!”
You growl, the sound ripping from your chest, and give her what she wants—slamming into her with everything you’ve got, your cock stretching her out, hitting that deep, sweet spot that makes her scream. Her whole body locks up, her skinny frame arching off the bed, her tits bouncing with every brutal thrust. “Like that?” you snarl, gripping her hips so hard your fingers leave red marks, pulling her back onto you. “Fucking take it—cum all over this dick, Sana.”
Miyeon’s moaning now, her fingers plunging into her own pussy, her other hand tweaking her nipple as she watches, her voice a low, horny rasp. “Goddamn, babe—look at you,” she says, her eyes glued to where your cock’s disappearing into Sana’s dripping cunt. “You’re losing it—fucking love that cock, don’t you? So hot, so fucking slutty like this.” She’s panting, her thighs trembling as she fucks herself faster, turned on beyond reason by Sana’s unraveling. “Cum for him—fucking soak that dick, I wanna see it.”
Sana’s eyes roll back, her mouth open in a silent scream that turns into a loud, broken wail as the orgasm hits her like a goddamn freight train. “Fuck—oh fuck, I’m cumming!” she cries, her voice shattering, her pussy clamping down so hard around you it’s almost painful—spasming wildly, gushing wet heat that slicks your cock, her thighs, the sheets. She’s thrashing now, completely out of control, her skinny body jerking like she’s possessed, her hands flying to your arms, nails digging in deep enough to draw blood. “Your cock—shit, I love it, it’s so big, so fucking deep—don’t stop, don’t fucking stop!”
You don’t—can’t—your hips slamming into her harder, faster, riding her through it as her pussy milks you, her cum dripping down your balls, pooling under her ass. She’s screaming, incoherent now—just raw, animal sounds, her head thrashing side to side, her hair sticking to her face. “Yes—fuck yes, keep fucking me—love it, love your cock—fuck!” Her voice is a mess, slurring into sobs, her body shaking uncontrollably, her orgasm stretching out, relentless, like it’s tearing her apart.
Miyeon’s losing her mind watching it, her hand a blur between her legs, her moans turning sharp and desperate. “Holy shit—look at her,” she gasps, her voice thick with lust, her pussy dripping onto the sheets as she rubs herself raw. “She’s cumming so fucking hard—so goddamn sexy, babe, you’re a fucking mess on that dick.” She’s panting, her eyes flicking between Sana’s wrecked face and the bulge of your cock stretching her girlfriend’s flat stomach with every thrust. “Keep going—fuck her stupid, she loves it, look at her fucking cum!”
Sana’s still going, her pussy pulsing like a heartbeat, her moans turning into whimpers as the pleasure overloads her—sensitive, raw, but she’s still pushing back against you, greedy for more. “Please—shit, please, keep fucking me,” she begs, her voice hoarse, trembling, her hands reaching for you like she’s drowning. “Your cock’s so good—so fucking good—I can’t stop cumming!”
You growl again, leaning over her, your chest heaving as you keep up the pace, your cock throbbing inside her, the wet, filthy sound of her pussy taking you over and over driving you wild. “You’re a fucking addict,” you mutter, your voice rough, dripping with heat. “Love this dick so much—cum again, Sana, let me feel that tight little pussy lose it.”
Miyeon’s moaning louder now, her fingers plunging deep, her hips bucking against her own hand. “She’s so fucking hot,” she says, her voice cracking, her eyes wide and wild. “Look at her—cumming like a slut on your cock. Fuck, I’m gonna cum just watching this—keep fucking her, make her scream!”
Sana’s beyond words now—just gasps and cries, her body convulsing, her pussy still spasming around you as the orgasm drags on, relentless, her cum soaking everything—your cock, your hips, the bed. She’s shaking so hard her thighs are quivering, her breath coming in short, ragged bursts, her eyes squeezed shut as she rides the last waves. “Fuck—fuck, I love it,” she whimpers, her voice barely audible, wrecked and raw. “Your cock—shit, it’s everything.”
You slow down, just enough to let her breathe, but you’re still buried deep, her pussy twitching around you, sensitive as hell. Miyeon’s panting, her hand slowing as she watches Sana come down, her own chest heaving. “Jesus Christ,” she mutters, licking her lips, her fingers still slick with her own arousal. “That was fucking insane—she’s never cum like that. You’re a goddamn beast.”
Sana’s eyes flutter open, glassy and dazed, a weak smile tugging at her lips as she looks up at you. “Fuck… that was…” She can’t finish, just shakes her head, her breath still shaky, her body limp beneath you. You pull out slow, your cock slick with her, and she whimpers at the loss, her pussy glistening, fucked-out and dripping with her cum. Miyeon’s still staring, horny and proud, her girlfriend a beautiful, shattered mess—and it’s all because of you.
Then, before you can react, Miyeon’s on you in a heartbeat, her hand wrapping around your shaft, stroking it as she leans in close. “Messy boy,” she teases, then lowers her mouth, licking you clean—long, slow swipes of her tongue that taste Sana all over you. She sucks the tip for a second, pulling a groan from your throat, before pulling back with a wet pop, her lips shiny.
You reach over, giving Miyeon’s ass a firm squeeze—round, perfect, begging for attention. “Your turn now,” you say, voice rough, still riding the high of fucking Sana senseless.
Miyeon grins, wicked and eager, and pushes you back onto the bed with a shove to your chest. You hit the mattress flat on your back, the sheets cool against your skin, your cock standing up hard and ready. “Lie down for me,” she says, climbing over you, her knees straddling your hips. She’s all curves and heat, her pussy already glistening as she hovers above you. Then she turns to Sana, who’s still catching her breath, propped up on her elbows. “Sit on his face, babe,” Miyeon says, her tone playful but firm. “He needs to taste you too—it’s fucking addictive.”
Sana hesitates for a second, still dazed, but the idea lights something in her eyes. She crawls up the bed, her slim frame moving slow, deliberate, until she’s kneeling over your head. You look up, and it’s a goddamn sight—her pussy right there, pink and wet from her orgasm, her thighs trembling just slightly as she lowers herself. “You sure?” she murmurs, glancing down at you, her voice soft but thick with want.
“Fuck yes,” you say, grabbing her hips and pulling her down. Her scent hits you first—sweet, musky, heady as hell—and then she’s on you, her folds slick against your lips. You groan into her, your tongue flicking out, tasting her—salty and tangy and so fucking good. She gasps, her hands bracing against the headboard, her body rocking slightly as you lick into her, slow and deep, savoring every inch.
Miyeon’s not waiting around. She lines herself up over your cock, her hands on your chest for balance, and sinks down—slow at first, just the tip, her pussy hot and tight around you. “Oh, fuck,” she moans, her head tipping back, her hair spilling over her shoulders as she takes you deeper, inch by inch. She’s thicker than Sana, her walls plush and soaking, and when she’s fully seated, her ass flush against your thighs, you’re gone—lost in the dual sensation of Miyeon riding you and Sana on your face.
“God, you’re big,” Miyeon says, her voice breathy, her hips rolling once, testing the stretch. “Feels so fucking good.”
Sana’s whimpering above you, her thighs clenching around your head as you suck on her clit, your tongue circling, then plunging inside her again. “Don’t stop,” she breathes, her voice trembling. “Please, don’t fucking stop.”
Miyeon starts moving, her hips lifting and dropping, slow at first, then faster, her hands digging into your chest. “Look at her,” she pants, glancing up at Sana. “She’s losing her mind up there. You like his tongue, babe?”
“Fuck—yes,” Sana chokes out, her hips grinding down now, smearing her wetness across your face. “So good… didn’t know it’d be this good.”
You groan into Sana, the vibration making her buck, and Miyeon laughs, low and dirty. “I knew,” she says, picking up the pace, her pussy slamming down on you harder now, wet and messy. “He’s a fucking natural.”
The room’s a mix of filth—Sana’s moans, Miyeon’s gasps, the slick sounds of skin and sex, all layered over the rain’s dull roar. You’re drowning in it—Sana’s taste flooding your mouth, Miyeon’s tight heat swallowing your cock, the insane push-pull of giving and taking. Your hands grip Sana’s hips harder, guiding her as you eat her out, your tongue relentless, and Miyeon’s riding you like she owns you, her nails leaving red trails on your skin.
“Fuck—don’t stop,” she gasps, then she shifts her gaze, looking up at Miyeon, and her voice turns filthy, wilder than you’ve heard all night. “God, babe, you look so fucking hot riding his cock like that. Bouncing on him—shit, it’s driving me crazy.”
Miyeon groans, her pace faltering for a second as Sana’s words hit her like a spark. She glances down, her dark hair swinging over her face, her lips curling into a horny smirk. “Yeah? You’re so fucking sexy like this, Sana—spread out, moaning on his face. Never seen you this slutty before.” Her hands slide up her own body, squeezing her tits through the motion, her nipples hard and poking against her palms.
Sana whimpers, her hips bucking against your mouth, and fires back, “You’re one to talk—look at you, fucking him like a pro. So hot, babe. Love watching you take that dick.”
The dirty talk’s like gasoline on a fire—Miyeon’s pussy clenches tighter around you, her thrusts turning sharper, more desperate, and you groan into Sana, the vibration making her jolt. “Keep sucking her,” Miyeon says, her voice rough, commanding, her eyes locked on yours through the haze. “Make her cum again. I wanna see her lose it.”
Sana’s already sensitive as hell—her last orgasm left her shaky, her clit throbbing under your tongue—but you don’t let up. You flatten your tongue against her, dragging it up slow, then circling fast, sucking hard enough to make her cry out. “Fuck—too much,” she whines, but her hips keep grinding, chasing it anyway, her body begging for more. You’re so caught up in it—Sana’s wet heat on your face, Miyeon’s tight grip riding you—that your own control’s slipping, your cock pulsing hard inside her with every filthy word they trade.
“Goddamn, you’re gonna make me cum just talking like that,” Miyeon moans, her hands gripping your thighs now, slamming down harder, her ass jiggling with every impact, her pussy’s dripping, soaking your hips. “Keep going, babe,” she tells Sana, her voice dripping with lust. “Tell me how much you love this.”
Sana’s panting, her words slurring into gasps as you push her closer. “Love it—fuck, love watching you ride him. So good… so fucking good,” she manages, her voice breaking as you suck her clit between your lips, flicking your tongue over it fast and relentless. Her thighs clamp around your head, her moans turning into sharp little screams, and you can feel it—she’s right there.
“Cum on his face,” Miyeon growls, her hips snapping down harder, her own breath hitching as she watches Sana unravel. “Fucking soak him.”
Sana loses it—her second orgasm crashes through her, her body seizing up as she cries out, high and raw. You keep your mouth on her, licking her through it, and then she’s shaking, her pussy pulsing hard against your tongue. She shifts, desperate now, and rubs herself over your face, her hand flying between her legs to work her clit faster. Then—holy shit—she squirts, little bursts of wet heat splashing across your chest, your neck, dripping down your jaw. It’s messy, wild, and you lap up what you can, groaning into her as she collapses forward, gasping for air.
“Holy fuck,” Miyeon says, slowing her ride for a second to watch, her eyes wide, her pussy clenching around you like she’s about to blow too. “That was insane. Now I need a taste.” She slides off you, your cock springing free, slick and throbbing, and you’re still catching your breath as she takes charge.
“69,” Miyeon says, decisive, pointing at the bed. “Sana, lie down—head at the edge. Let’s switch this up.”
Sana’s still dazed, her legs wobbly, but she does it—crawling onto the bed, stretching out on her back, her head hanging just off the mattress’ edge, her brown hair spilling down like a curtain. She’s panting, her skin glistening with sweat, her pussy still twitching from her release. Miyeon climbs over her, positioning herself on all fours—her knees bracketing Sana’s head, her ass sticking out toward you, round and perfect, her own pussy glistening and begging for attention.
You’re off the bed now, standing at the edge, your cock hard and slick with both of them, the room spinning with how fucking intense this is. Miyeon looks back at you over her shoulder, her eyes dark and commanding. “Fuck me,” she says, simple and raw, wiggling her ass just enough to make it clear what she wants. “And Sana’s gonna eat me out while you do it.”
Sana’s hands reach up, grabbing Miyeon’s thighs, pulling her down closer to her mouth, and you can hear the soft, wet sound of her tongue already working—Miyeon moans instantly, her body arching. You step up, gripping Miyeon’s hips, your cock brushing against her entrance, and the scene in front of you—Sana’s face buried between Miyeon’s legs, Miyeon’s ass up and waiting—is so filthy, so perfect, you can barely process it. The rain’s a distant hum, the world narrowed down to this bed, these girls, this moment.
And before you know it, you're already inside her
Your hands grab Miyeon’s cheeks, spreading them wide as you watch your cock slide in and out of her—glistening, thick, stretching her tight little hole with every thrust. Her pussy’s hypnotic, a vise of heat and wet that sucks you in deeper each time, her walls pulsing like they’re trying to milk you dry. She’s on all fours over Sana, her knees sinking into the mattress, her ass high and perfect, swaying with every pounding you give her.
Below, Sana’s lying flat, her head tilted off the edge, her slim throat exposed as she devours Miyeon’s pussy. Her tongue’s working hard, flicking over Miyeon’s clit, dipping into her folds, and you can hear the sloppy, wet noises—Sana’s eager, relentless, her mouth making these little sucking sounds that drive Miyeon wild. Miyeon’s trying to keep up, her face buried between Sana’s thighs, licking and sucking in return, but it’s a mess—she’s too fucked-out to focus, her moans vibrating against Sana’s skin every time you slam into her. Her dark hair’s plastered to her back with sweat, strands sticking to her neck, and her body’s trembling, caught between the dual assault of your cock and Sana’s tongue.
“Fuck, you’re so tight,” you groan, your voice rough, hands digging into Miyeon’s flesh as you pull her back onto you, watching the way her pussy swallows your dick whole. “This shit’s unreal—look at you, taking it like a champ.”
Miyeon lifts her head just enough to gasp, her voice cracking with pleasure. “Goddamn—don’t stop, don’t you fucking dare. It’s too much—shit, I’m so close.” Her words slur together, half-muffled as she dives back into Sana’s pussy, but you can tell she’s struggling to keep it together—her tongue’s sloppy now, her focus shredded by the way you’re railing her.
Sana’s moaning too, her hips twitching up against Miyeon’s mouth, her hands clawing at Miyeon’s thighs to pull her closer. “Fuck, sweetie—your pussy’s so wet,” she whimpers, her voice high and needy, muffled against Miyeon’s clit. “He’s fucking you so good—I can taste it, babe, it’s dripping all over me.”
That sends a jolt through Miyeon—she groans into Sana, her hips bucking back against you harder, like she’s begging for more. “You like that, huh?” you say, smirking, spreading her wider, thrusting deeper until you’re hitting that spot that makes her whole body jolt. “Love hearing your girl talk dirty while I’m balls-deep in you?”
“Fuck—yes,” Miyeon chokes out, her ass jiggling with every slam, her voice shaking as Sana’s tongue flicks faster. “She’s—shit—she’s driving me insane down there. And you… you’re gonna make me fucking cum.”
“Do it,” you growl, your grip tightening, your cock throbbing inside her as the tension builds. “Cum for me, Miyeon. Let me feel that pussy lose it.”
Sana pulls back just enough to gasp, her lips shiny with Miyeon’s juices, her eyes wide and wild. “Please, babe—cum all over his dick. I wanna taste it after, wanna lick it clean.” Her words are pure filth, her voice trembling with how horny she is, and it’s like a switch flips in Miyeon.
“Fuck—okay, I’m—fuck!” Miyeon’s voice cuts off, her body locking up, and you feel it—her pussy clamping down hard around you, spasming wildly as she hits her peak. She’s loud, screaming into Sana’s thighs, her whole frame shaking as the orgasm rips through her. You keep thrusting, riding it out with her, but it’s intense—her walls fluttering, squeezing you so tight it’s almost too much.
You pull out slow, your cock slick and dripping with her, and Miyeon’s still trembling, her ass quivering like she’s not done yet. “Sana—lube him up,” you say, voice hoarse, stepping closer to where Sana’s head hangs off the bed. Sana’s quick—she cranes her neck, her mouth open and eager, and takes you in deep. Her lips wrap around you, soft and warm, her tongue swirling as she sucks you clean, tasting Miyeon all over you. She moans around your cock, her eyes fluttering shut like it’s the best thing she’s ever had, her small hands gripping your thighs to pull you closer.
“Fuck, Sana,” you mutter, your hand tangling in her hair, guiding her as she bobs her head, sloppy and wet. “You’re so good at this—you're loving the taste of her on my cock, huh?”
She pulls off with a gasp, spit trailing from her lips to your tip, nodding fast. “Yeah—fuck, she’s so sweet. I could eat her all day, but this… this is hot as hell.” Her tongue darts out, licking you one more time, and you’re rock-hard, pulsing with need.
“Back in,” Miyeon pants, her voice raw, still on her knees over Sana. “Fuck me again—harder this time. I want it.”
You don’t hesitate. You step back behind her, grabbing her hips, spreading her ass again as you line up and thrust in—one smooth, deep push that has her screaming, her voice echoing off the walls. “Fuck—yes!” she cries, her hands fisting the sheets, her pussy still sensitive but greedy, sucking you in like it can’t get enough. You go hard, pounding into her with a force that makes her whole body shake, her ass bouncing with every brutal thrust.
“Take it—fucking take it,” you growl, slapping her ass sharp, the crack of skin on skin cutting through the room. The sting makes her yelp, her pussy clenching tighter, and you feel the heat building in your gut, the pressure coiling fast. “Cum again, Miyeon—cum for us.”
Sana’s still under her, her tongue working Miyeon’s clit in frantic little circles, and she’s begging now, her voice high and desperate. “Please, babe—cum again. I need it—need to feel you lose it on him. Cum all over that fat dick.”
Miyeon’s a wreck, her head thrashing, her moans turning into sobs as the pleasure overloads her. “Fuck—Sana—you’re—shit, I can’t—” She breaks, her pussy spasming hard around you again, wet and wild, her second orgasm hitting like a storm. She screams, her ass pushing back against you, and it’s too fucking much—her tightness, Sana’s filthy pleas, the whole damn scene.
“Gonna cum,” you moan, your voice breaking, your thrusts turning erratic as the pleasure blinds you. “Fuck—Miyeon, you’re too good—gonna blow.”
Sana’s quick, her head twisting up from under Miyeon. “I want it,” she says, breathless, her eyes glinting with something feral. “Wanna taste your cum—first time, fuck, give it to me.”
Miyeon’s slutty side flares—she’s still shaking, still clenching you, but she grins through it. “Yeah—give it to her,” she pants, her voice thick with lust. “She’s begging so nice, huh? Fucking coat her with it.”
That does it. You’re at the edge, your cock throbbing, and you pull out fast, one hand stroking yourself hard, the other gripping Miyeon’s ass for balance. “Fuck—here it comes,” you groan, aiming the tip at Miyeon’s pussy—still wet, warm, pulsing from her orgasm. You rub it against her entrance, slick, red and swollen from the pounding you gave her, and then you’re there—cumming, thick and hot, spilling over Miyeon’s entrance in heavy ropes—white streaks painting her folds, dripping down her slit, pooling in the creases where her pussy meets her thighs. It’s a fucking load, more than you expected, a messy testament to how long it’s been, and it smears across her skin, glossy and obscene in the dim light.
“Sana, now,” you rasp, voice hoarse, your chest heaving as the last of it drips from your tip. “Taste it.”
Miyeon’s still in position, her ass up, her pussy hovering over Sana’s face—she shifts her hips down closer, eager, her breath hitching with a horny little whimper. “Fuck, babe, go for it,” she urges, her voice thick with lust, her fingers digging into Sana’s thighs to hold her steady. “Lick it up—his cum’s all over me. Tell me how it feels.”
Sana’s beneath her, her slim frame pinned to the bed, her head tilted back off the edge—her brown hair a wild spill, her lips parted and trembling. She’s never done this before, never tasted a guy’s cum, and you can see it in her eyes—nervous excitement, a raw curiosity burning behind the flush on her cheeks. Her tongue darts out first, tentative, a soft little flick against Miyeon’s inner thigh where a bead of your cum’s trickled down. She pauses, tasting it—salty, bitter, warm on her tongue—and her breath catches, a tiny gasp slipping out.
“More,” Miyeon coaxes, lowering herself further, her pussy brushing Sana’s lips now, your cum streaking across her mouth. “Get it all, babe. I want you to feel him.”
Sana dives in, bolder now, her tongue sweeping up Miyeon’s slit in a slow, deliberate stroke—dragging through the sticky mess of your cum, thick and creamy, mixed with Miyeon’s own slickness. She moans, low and shaky, the sound vibrating against Miyeon’s pussy, and it’s like she’s tasting something forbidden—something filthy and new that’s lighting her up inside. Her lips close around Miyeon’s folds, sucking gently, pulling your cum into her mouth, and her eyes flutter shut, lost in it. It’s raw, messy—her chin’s wet with it now, smears of white clinging to her skin, and she’s licking harder, deeper, chasing every drop.
“Fuck, yes,” Miyeon groans, her hips rocking down, grinding herself against Sana’s tongue. She’s horny as hell, her voice dripping with it—proud and turned on, watching her girlfriend taste you off her wrecked cunt. “How is it, babe? How’s his cum taste? Tell me.”
Sana pulls back just enough to speak, her voice muffled, lips glossy and dripping—a mix of your cum and Miyeon’s juices shining on her like some lewd, natural gloss. “It’s—fuck, it’s intense,” she says, her words slurring with arousal, her tongue flicking out again to lap at a thick streak sliding down Miyeon’s slit. “Salty… hot… kinda bitter, but—shit, I love it.” She dives back in, her tongue plunging deeper, scooping up more, her moans louder now, needy and unrestrained. She’s sucking Miyeon clean, her lips smacking softly, wet and sloppy, and it’s the hottest fucking thing you’ve ever seen—Sana’s first taste of cum, and she’s devouring it like it’s her new favorite drug.
Miyeon’s trembling above her, her thighs quaking, her fingers tightening on Sana’s legs as Sana’s tongue works her over. “Goddamn, babe—you’re so fucking dirty,” she pants, her eyes rolling back for a second before snapping to you, wild and gleaming. “Look at her—she’s eating your cum like she’s starving. So fucking hot.” She shifts, pressing her pussy harder against Sana’s mouth, smearing more of the mess across her lips, and Sana takes it—greedy, unashamed, her tongue swirling through it all, swallowing every bit she can get.
Sana’s hands slide up, gripping Miyeon’s ass now, pulling her down tighter, her nails digging into the soft flesh. She’s moaning into Miyeon’s pussy, the sound raw and desperate, muffled by the wet heat she’s buried in. “More,” she mumbles, barely audible, her tongue lashing across Miyeon’s clit where a last streak of your cum lingers—thick and clinging. She sucks it off, slow and deliberate, her lips closing around the sensitive bud, and Miyeon jolts, a sharp cry tearing from her throat.
“Fuck—Sana,” Miyeon gasps, her voice breaking, her body shuddering as Sana’s mouth pushes her toward overstimulation. She’s still horny, still buzzing, but this moment—it’s intimate, just them now, sharing something primal. So she moves, leaving the 69 position to sit facing Sana, because she needs to see her girlfriend's delicate and lovely face covered in pure lust, in pure pleasure, her fingers tangling in Sana’s hair, gentle but firm, holding her there. “How’s it feel? First time tasting him—tell me everything.”
Sana pulls back again, just enough to breathe, her face a wreck—chin dripping, lips swollen and shiny, your cum streaked across her mouth like war paint. She licks her lips slow, deliberate, tasting the last of you, and looks up at Miyeon with this dazed, lust-drunk grin. “It’s—so fucking good,” she whispers, her voice trembling with how much she means it. “Like… I didn’t know it’d be this thick, this warm. It’s—fuck, it’s everywhere, and I can’t stop wanting it.” She leans in, pressing a soft, open-mouthed kiss to Miyeon’s pussy, her tongue darting out one last time to swipe through the mess—your cum, her spit, Miyeon’s slick—all blending together in a filthy, perfect mix.
Miyeon moans, soft and low, her body relaxing into it now, her horny edge softening into something tender. “You’re so fucking cute,” she murmurs, her hand stroking Sana’s hair, her thumb brushing her cheek where a smear of cum still clings. “My dirty girl—loving it, huh?”
Sana nods, her eyes bright, a little shy now but glowing with satisfaction. She crawls up slow, sliding off the bed to sit up, her lips still wet and glistening—your cum and Miyeon’s juices a slick sheen across her mouth and chin. Miyeon follows, shifting to kneel in front of her, their bodies close, intimate. She cups Sana’s face, her thumbs tracing the edges of her lips, smearing the mess a little more, and leans in—kissing her deep, slow, tasting you on her tongue. It’s raw, possessive, but soft too—their mouths moving together, sharing the aftermath, a quiet hum of pleasure passing between them.
You’re slumped beside them, chest still heaving, your cock twitching with the last echoes of your orgasm as you watch—mesmerized, spent, but still buzzing from the sight. Miyeon pulls back from the kiss, a thin string of spit and cum connecting their lips for a second before it snaps, and she licks it away, grinning. “Good, right?” she whispers, her eyes flicking to Sana’s.
“So good,” Sana breathes, her smile small but real, her first taste of you lingering on her tongue—intense, erotic, a memory she’s already savoring. They lean into each other again, foreheads touching, giggling softly in the afterglow.
“Glad you liked it,” you say, voice rough, still catching your breath. “Shit, that was intense.”
Miyeon turns to you, her hand resting on your thigh, casual but warm. “You liked it too, huh? We can do this again—anytime you’re up for it. You’re, like… officially our guy now.”
Sana giggles, leaning in to kiss your cheek, her lips soft and sticky. “Yeah, you’re stuck with us. Such a good friend—taking care of me like that.”
Miyeon follows, pressing a kiss to your other cheek, her touch lingering. “Thanks, dude. For real—for being so cool with Sana. Means a lot.”
You laugh, the sound tired but content, your hand running through your hair. “Anytime. Fucking honor, honestly.”
Miyeon stretches out, her body glistening with sweat, and yawns. “Okay, post-sex vibe check—we’re done fucking, right? Let’s crash here, all of us. Naked, cozy, whatever.”
“Works for me,” you say, settling back against the pillows, the mattress dipping as Sana curls up on one side, Miyeon on the other. Their skin’s warm against yours, their breaths slowing, and the rain outside lulls the room into a quiet, sated haze. You’re all wrecked, tangled, and happy as hell—ready to sleep it off, together.
—
The morning sun filters through the blinds, casting soft, golden stripes across the tangled mess of sheets and limbs on the bed. You wake up slow, your body heavy and warm, sandwiched between two soft, naked forms—Miyeon on your left, her arm draped lazily over your chest, her breath warm against your neck; Sana on your right, her legs tangled with yours, her head nestled into your shoulder. It’s a surreal fucking moment, the kind that makes you blink and wonder if last night was a dream. But the ache in your muscles, the faint sting of scratch marks on your arms, and the raw, vivid memory of their moans tell you it was real—insanely, mind-blowingly real. You shift slightly, trying to stretch without waking them, but your morning wood’s already making itself known, tenting the sheet that’s barely clinging to your hips. Damn, even after all that, your body’s still ready to go.
Miyeon stirs first, her eyes fluttering open, still heavy with sleep, a lazy smile tugging at her lips as she spots your hard-on. “Well, good morning to you too,” she mumbles, her voice low and raspy, thick with that post-sleep huskiness that’s sexy as hell. Her hand slides down your chest, slow and teasing, fingers brushing over your stomach before wrapping around your cock. She strokes you lightly, still half-asleep, her grip loose but deliberate, like she’s just playing with you for now. “Guess you’re not tapped out yet, huh?”
You groan softly, the touch sending a jolt through you, and turn your head to see Sana blinking awake too, her brown hair a messy halo around her face. She yawns, stretching her arms above her head, her small tits peeking out from under the sheet, then glances down at Miyeon’s hand on you. A sleepy grin spreads across her face. “Seriously? Already?” she says, her voice soft but amused, scooting closer to join in. Her hand slides under the sheet too, her fingers brushing against Miyeon’s as they both stroke you now—Sana’s touch gentler, curious, Miyeon’s firmer, knowing exactly what she’s doing. “You’re insatiable, you know that?”
“Blame you two,” you mutter, your voice rough, still waking up, your hips twitching involuntarily as their hands work you over. “Fucking waking up like this—who wouldn’t be hard?”
Sana giggles, her fingers tightening slightly, her thumb brushing over the tip where you’re already leaking a little. “Fair point,” she says, then sits up, the sheet falling away completely, leaving her bare and glowing in the morning light. “Come on—let’s take care of that in the shower. You, me, and Miyeon. Sound good?”
Miyeon’s already rolling out of bed, her round ass bouncing as she stands, stretching with a groan that’s half-tired, half-horny. “Hell yeah,” she says, tossing her hair back, her eyes flicking to you with a smirk. “Let’s clean up—and get dirty again.”
You don’t need convincing. The three of you stumble to the bathroom, naked and laughing, the hardwood cold under your feet. The shower’s big enough for all of you—glass walls, a rainfall head that pours hot water the second you turn it on. Steam starts fogging up the space as you step in, Miyeon right behind you, Sana trailing with a shy grin. The water hits your skin, hot and perfect, and Miyeon’s already pressing herself against your back, her tits soft and slick against you, her hands sliding around to your cock again. “Turn around,” she murmurs, her lips brushing your ear, and you do, pinning her against the tiles, the water streaming down her face as you kiss her hard, all tongue and heat.
Sana’s watching, her fingers trailing down her own stomach as she steps closer, the water soaking her hair, making it stick to her shoulders. “Fuck her first,” she says, her voice low, a little daring, her eyes locked on where Miyeon’s hand is guiding you between her legs. You don’t hesitate—lifting Miyeon’s thigh, hooking it over your hip, and sliding into her in one smooth thrust. She’s still tight, still wet from last night, and she moans loud, her head tipping back against the glass, the sound echoing in the steam.
“Goddamn, you feel so good,” you groan, thrusting slow at first, watching the way her pussy takes you, the water making everything slicker, louder. Miyeon’s hands grip your shoulders, her nails biting in, and she’s grinning through the pleasure, loving it.
Sana steps in closer, her fingers brushing Miyeon’s clit as you fuck her, making Miyeon gasp sharper. “Your turn next,” you say, glancing at Sana, and she nods, biting her lip, her hand slipping lower to touch herself as she waits. You pull out of Miyeon after a few more thrusts, spinning Sana around, bending her over so her hands brace against the wall, her ass up and perfect. You slide into her from behind, her pussy tight and dripping, and she whimpers, the sound soft but needy as you start pounding into her, the water splashing around you both.
“Fuck—yes,” Sana moans, her voice shaking, her skinny frame rocking with every thrust, her head bowing as the pleasure hits. Miyeon’s right there, kissing her neck, her hands roaming over Sana’s wet skin, squeezing her tits, making it a messy, horny tangle of bodies under the spray. You fuck Sana hard, then switch back to Miyeon, trading off until you’re all panting, the shower a blur of steam, moans, and slick, wet skin. You finish fast—pulling out, stroking yourself as they kneel under the water, mouths open, catching every drop as you cum, their tongues flicking out to taste you, giggling through it like it’s a game.
After, you’re all dripping and laughing, toweling off in a haze of post-sex glow, the bathroom mirror fogged to hell. Sana’s the first out, wrapping a towel around herself and heading to the kitchen. “I’ll make breakfast,” she calls over her shoulder, her voice chipper despite the wild morning. You and Miyeon follow slower, still naked, flopping onto the couch to catch your breath, her head lolling against your shoulder.
The smell of coffee and bacon fills the house soon, and when Sana calls you over, you find her in full domestic mode—hair tied back, still in just a towel, flipping pancakes like she’s auditioning for a cooking show. She’s good, too—golden, fluffy stacks piling up on a plate, bacon sizzling crisp on the side, scrambled eggs fluffy and perfect. You all sit around the small kitchen table, naked under loosely draped towels, digging in like it’s the most normal thing in the world. The pancakes are sweet, dripping with syrup, the bacon’s salty crunch a perfect balance, and the coffee’s strong, cutting through the morning fog. It’s quiet for a bit, just the clink of forks and the occasional hum of satisfaction, everyone still waking up, still processing the insanity of last night and this morning.
Miyeon’s the one to break the silence, grabbing her phone from the counter mid-bite, syrup glistening on her lips. “Oh, shit,” she says, scrolling quick, her eyes lighting up. “Road’s fixed—traffic’s moving again. Guess the landslide’s cleared.”
You take a sip of coffee, the mug warm in your hands, and nod, glancing between them. “Guess that’s my cue, huh? It was a pleasure meeting you girls. Really.”
They both freeze, forks halfway to their mouths, then look at each other—Sana’s brows shoot up, Miyeon’s lips twitch—and they burst out laughing, loud and sudden, like you’ve just said the dumbest thing imaginable. “What?” you say, caught off guard, setting the mug down. “What’s so funny?”
Miyeon leans forward, still chuckling, wiping a tear from her eye. “Dude, no way. After last night? And this morning? We’re not going anywhere.”
Sana nods, her grin wide and bright, pushing a piece of bacon around her plate. “Yeah, like—we had so much fun. Leaving now would be stupid. We wanna stay the week with you.”
You blink, stunned, the words sinking in slow. “Wait—for real? The whole week?”
“Uh-huh,” Miyeon says, leaning back in her chair, stretching so the towel slips a little, showing off the curve of her chest. “This place just got a million times better with you here. You’re a fucking gem, dude—we’re not letting that go.”
Sana’s still smiling, softer now, her eyes warm as she looks at you. “It’s already special, you know? Memorable as hell. And it’s only been, what, a day? Imagine the rest of the week.”
You laugh, shaking your head, still processing. “Shit, I mean—I’d love that. Didn’t expect you’d wanna stick around, but hell yeah, I’m in.”
“Good,” Miyeon says, pointing her fork at you, a smirk tugging at her lips. “You’re a great find—fun, chill, and you fuck like a goddamn champ. We like having you as a friend.”
Sana nods, popping a piece of pancake in her mouth, chewing thoughtfully. “Yeah, you’re open-minded—know how to roll with it, enjoy shit without being a dick about it. And you’re respectful, which is huge. I mean, last night was wild, and you never made it weird.”
You grin, leaning back, the warmth of the coffee and their words settling in your chest. “You two are fucking unreal—the coolest couple I’ve ever met, hands down. I’m stoked you crashed into my trip like this.”
Miyeon laughs, finishing her bacon with a satisfied crunch. “Settled then—no one’s leaving. This lake house just became our little sex-and-breakfast paradise, and you’re stuck with us.”
“Couldn’t ask for better company,” you say, raising your mug in a mock toast, and they clink their coffee cups against it, laughing through the syrup-sticky mess. The road’s open, sure, but fuck going anywhere—this week’s already gold, and it’s only just started.
#Sana smut#sana twice#sana x reader#Sana x male reader#twice smut#kpop smut#male reader#twice sana#Miyeon#miyeon smut#miyeon x reader#gidle miyeon#gidle smut#g idle smut#kpop male reader#kpop gg smut#sana minatozaki
2K notes
·
View notes