#chat gpt api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
You wanna use ChatGPT 4o by tokens instead o buying monthly subscription but you do not know how to implement on Mac Xcode ? Here we discuss how to Implement chatgpt API on Xcode On Mac on 2024 : (day3)
Introduction: Choosing Between ChatGPT Plus and Token-Based API for SwiftUI Integration When integrating OpenAI’s ChatGPT into your SwiftUI application, you have two primary options: subscribing to ChatGPT Plus or utilizing the ChatGPT API with token-based pricing. Each approach offers distinct advantages and considerations. ChatGPT Plus Subscription ChatGPT Plus is a subscription service priced…
0 notes
Video
tumblr
The possibilities with ChatGPT are limitless, and it's a model to keep an eye on in the future. Transform Your Customer Experience with ChatGPT Integration, and Learn How to Integrate the World's Most Advanced Language Model Into Your Existing Systems Today!
Submit your requirement at: https://digittrix.com/submit-your-requirement
1 note
·
View note
Text
my tummy growled kinda loud during research im killing myself rn
0 notes
Text
clarification re: ChatGPT, " a a a a", and data leakage
In August, I posted:
For a good time, try sending chatGPT the string ` a` repeated 1000 times. Like " a a a" (etc). Make sure the spaces are in there. Trust me.
People are talking about this trick again, thanks to a recent paper by Nasr et al that investigates how often LLMs regurgitate exact quotes from their training data.
The paper is an impressive technical achievement, and the results are very interesting.
Unfortunately, the online hive-mind consensus about this paper is something like:
When you do this "attack" to ChatGPT -- where you send it the letter 'a' many times, or make it write 'poem' over and over, or the like -- it prints out a bunch of its own training data. Previously, people had noted that the stuff it prints out after the attack looks like training data. Now, we know why: because it really is training data.
It's unfortunate that people believe this, because it's false. Or at best, a mixture of "false" and "confused and misleadingly incomplete."
The paper
So, what does the paper show?
The authors do a lot of stuff, building on a lot of previous work, and I won't try to summarize it all here.
But in brief, they try to estimate how easy it is to "extract" training data from LLMs, moving successively through 3 categories of LLMs that are progressively harder to analyze:
"Base model" LLMs with publicly released weights and publicly released training data.
"Base model" LLMs with publicly released weights, but undisclosed training data.
LLMs that are totally private, and are also finetuned for instruction-following or for chat, rather than being base models. (ChatGPT falls into this category.)
Category #1: open weights, open data
In their experiment on category #1, they prompt the models with hundreds of millions of brief phrases chosen randomly from Wikipedia. Then they check what fraction of the generated outputs constitute verbatim quotations from the training data.
Because category #1 has open weights, they can afford to do this hundreds of millions of times (there are no API costs to pay). And because the training data is open, they can directly check whether or not any given output appears in that data.
In category #1, the fraction of outputs that are exact copies of training data ranges from ~0.1% to ~1.5%, depending on the model.
Category #2: open weights, private data
In category #2, the training data is unavailable. The authors solve this problem by constructing "AuxDataset," a giant Frankenstein assemblage of all the major public training datasets, and then searching for outputs in AuxDataset.
This approach can have false negatives, since the model might be regurgitating private training data that isn't in AuxDataset. But it shouldn't have many false positives: if the model spits out some long string of text that appears in AuxDataset, then it's probably the case that the same string appeared in the model's training data, as opposed to the model spontaneously "reinventing" it.
So, the AuxDataset approach gives you lower bounds. Unsurprisingly, the fractions in this experiment are a bit lower, compared to the Category #1 experiment. But not that much lower, ranging from ~0.05% to ~1%.
Category #3: private everything + chat tuning
Finally, they do an experiment with ChatGPT. (Well, ChatGPT and gpt-3.5-turbo-instruct, but I'm ignoring the latter for space here.)
ChatGPT presents several new challenges.
First, the model is only accessible through an API, and it would cost too much money to call the API hundreds of millions of times. So, they have to make do with a much smaller sample size.
A more substantial challenge has to do with the model's chat tuning.
All the other models evaluated in this paper were base models: they were trained to imitate a wide range of text data, and that was that. If you give them some text, like a random short phrase from Wikipedia, they will try to write the next part, in a manner that sounds like the data they were trained on.
However, if you give ChatGPT a random short phrase from Wikipedia, it will not try to complete it. It will, instead, say something like "Sorry, I don't know what that means" or "Is there something specific I can do for you?"
So their random-short-phrase-from-Wikipedia method, which worked for base models, is not going to work for ChatGPT.
Fortuitously, there happens to be a weird bug in ChatGPT that makes it behave like a base model!
Namely, the "trick" where you ask it to repeat a token, or just send it a bunch of pre-prepared repetitions.
Using this trick is still different from prompting a base model. You can't specify a "prompt," like a random-short-phrase-from-Wikipedia, for the model to complete. You just start the repetition ball rolling, and then at some point, it starts generating some arbitrarily chosen type of document in a base-model-like way.
Still, this is good enough: we can do the trick, and then check the output against AuxDataset. If the generated text appears in AuxDataset, then ChatGPT was probably trained on that text at some point.
If you do this, you get a fraction of 3%.
This is somewhat higher than all the other numbers we saw above, especially the other ones obtained using AuxDataset.
On the other hand, the numbers varied a lot between models, and ChatGPT is probably an outlier in various ways when you're comparing it to a bunch of open models.
So, this result seems consistent with the interpretation that the attack just makes ChatGPT behave like a base model. Base models -- it turns out -- tend to regurgitate their training data occasionally, under conditions like these ones; if you make ChatGPT behave like a base model, then it does too.
Language model behaves like language model, news at 11
Since this paper came out, a number of people have pinged me on twitter or whatever, telling me about how this attack "makes ChatGPT leak data," like this is some scandalous new finding about the attack specifically.
(I made some posts saying I didn't think the attack was "leaking data" -- by which I meant ChatGPT user data, which was a weirdly common theory at the time -- so of course, now some people are telling me that I was wrong on this score.)
This interpretation seems totally misguided to me.
Every result in the paper is consistent with the banal interpretation that the attack just makes ChatGPT behave like a base model.
That is, it makes it behave the way all LLMs used to behave, up until very recently.
I guess there are a lot of people around now who have never used an LLM that wasn't tuned for chat; who don't know that the "post-attack content" we see from ChatGPT is not some weird new behavior in need of a new, probably alarming explanation; who don't know that it is actually a very familiar thing, which any base model will give you immediately if you ask. But it is. It's base model behavior, nothing more.
Behaving like a base model implies regurgitation of training data some small fraction of the time, because base models do that. And only because base models do, in fact, do that. Not for any extra reason that's special to this attack.
(Or at least, if there is some extra reason, the paper gives us no evidence of its existence.)
The paper itself is less clear than I would like about this. In a footnote, it cites my tweet on the original attack (which I appreciate!), but it does so in a way that draws a confusing link between the attack and data regurgitation:
In fact, in early August, a month after we initial discovered this attack, multiple independent researchers discovered the underlying exploit used in our paper, but, like us initially, they did not realize that the model was regenerating training data, e.g., https://twitter.com/nostalgebraist/status/1686576041803096065.
Did I "not realize that the model was regenerating training data"? I mean . . . sort of? But then again, not really?
I knew from earlier papers (and personal experience, like the "Hedonist Sovereign" thing here) that base models occasionally produce exact quotations from their training data. And my reaction to the attack was, "it looks like it's behaving like a base model."
It would be surprising if, after the attack, ChatGPT never produced an exact quotation from training data. That would be a difference between ChatGPT's underlying base model and all other known LLM base models.
And the new paper shows that -- unsurprisingly -- there is no such difference. They all do this at some rate, and ChatGPT's rate is 3%, plus or minus something or other.
3% is not zero, but it's not very large, either.
If you do the attack to ChatGPT, and then think "wow, this output looks like what I imagine training data probably looks like," it is nonetheless probably not training data. It is probably, instead, a skilled mimicry of training data. (Remember that "skilled mimicry of training data" is what LLMs are trained to do.)
And remember, too, that base models used to be OpenAI's entire product offering. Indeed, their API still offers some base models! If you want to extract training data from a private OpenAI model, you can just interact with these guys normally, and they'll spit out their training data some small % of the time.
The only value added by the attack, here, is its ability to make ChatGPT specifically behave in the way that davinci-002 already does, naturally, without any tricks.
265 notes
·
View notes
Text





i have now upgraded dggbot with claude haiku access. it is faster, cheaper, and will funnel less money to openai (and just in general has a little less of that OpenAI Stink to its responses).
claude sonnet and possibly claude opus access may come later, although claude opus is a huge expense that i can't really justify unless a: its price comes down or b: more people give me money on patreon. a rough estimation given the amount of gpt-4 usage is that integrating claude opus would jack my api costs another 40, 50 dollars a month easily, which is not something i can just eat to the face.
anyway.
dggbot is a one-stop dungeon master's assistant for all your brainstorming, worldbuilding, and casual entertainment needs. you can say hello to my autistic robot child here;
53 notes
·
View notes
Note
Hey, I saw you like React, can you please drop some learning resources for the same.
Hi!
Sorry I took a while to answer, but here are my favourite react resources:
Text:
The official react docs -- the best written resource! And since react recently updated their docs, they are even better imo. This is your best friend.
Chat GPT -- this is your other best friend. Need specific examples? Want to ask follow up questions to understand a concept? Want different examples? Wanna know where your missing semicolon is without staring at your code for hours? Don't be afraid to use AI to make your coding more efficient. I use it and learn from it all the time.
React project ideas -- the best way to learn coding is by doing, try these projects out if you don't know what to do or where to start!
Why react? -- explains beneficial concepts about react
Video:
Udemy react course (this one is paid, but udemy often have big sales, so I'd recommend getting this one during a sale) -- I have been continously referring back to this course since starting to learn react.
Web dev simplified's react hooks explanations -- I found these videos to explain with clear examples what each hook does, and they're very beginner friendly.
About NPM -- you need npm (or yarn) to create a react project, and for me working with react was my first step into working with packages in general, so I really recommend learning about it in order to understand how you can optimize the way you use React!
How to fetch locaIly with react
How to fetch from an API with react
Alternative to using useEffect in fetching!?
debugging react
And, speaking of using AI, here are Chat GPTs suggestions:
React.js Tutorial by Tania Rascia: This tutorial is aimed at beginners and covers the basics of React.js, including components, JSX, props, and state. You can access the tutorial at https://www.taniarascia.com/getting-started-with-react/.
React.js Crash Course by Brad Traversy: This video tutorial covers the basics of React.js in just one hour. It's a great way to get started with React.js quickly. You can access the tutorial at https://www.youtube.com/watch?v=sBws8MSXN7A.
React.js Fundamentals by Pluralsight: This course provides a comprehensive guide to React.js, including how to create components, manage state, and work with data. You can access the course at https://www.pluralsight.com/courses/react-js-getting-started.
React.js Handbook by Flavio Copes: This handbook provides a comprehensive guide to React.js, including how to create components, work with props and state, and manage forms. You can access the handbook at https://www.freecodecamp.org/news/the-react-handbook-b71c27b0a795/.
#code-es#programming#react#web development#resources#codeblr#progblr#compsci#software development#coding
63 notes
·
View notes
Text
14+ cách dùng Chat GPT tối ưu SEO mà Marketers không thể bỏ qua
Chat GPT, được phát triển bởi OpenAI, là một mô hình ngôn ngữ AI mạnh mẽ có khả năng tạo ra văn bản tự nhiên giống con người. Việc ứng dụng Chat GPT vào SEO đang trở thành xu hướng mới, đầy triển vọng trong việc tối ưu hóa nội dung trang web và cải thiện thứ hạng trên công cụ tìm kiếm. Hãy cùng khám phá 14 cách sử dụng Chat GPT cho SEO trong bài viết này nhé!
Cách dùng Chat GPT cho Technical SEO
Tạo FAQ Schema
Tạo schema HowTo
Create Robots.txt Rules
Tạo htaccess Redirect Rules
Kết nối với API và mã hóa
Tạo FAQ schema
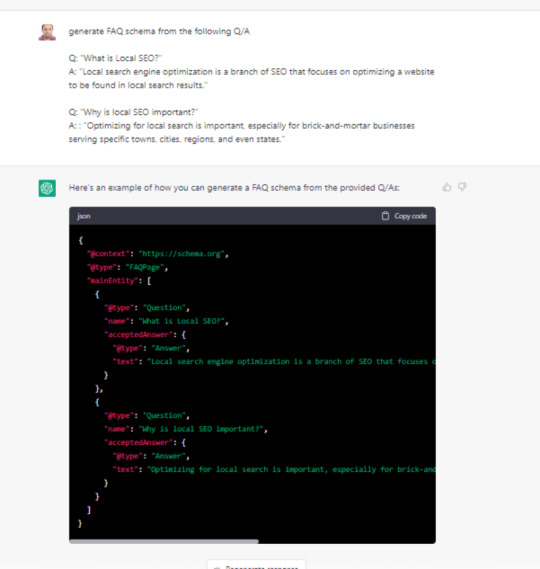
Bạn có thể sử dụng ChatGPT để tạo FAQ schema từ nội dung bạn cung cấp. Mặc dù bạn có thể sử dụng plugin CMS cho việc này, nhưng nếu bạn sử dụng nền tảng như Wix không hỗ trợ plugin, ChatGPT trở thành một trợ thủ đắc lực. Bạn chỉ cần cung cấp văn bản câu hỏi và câu trả lời, ChatGPT sẽ tạo ra mã schema phù hợp để bạn dán vào trình chỉnh sửa của mình. Bạn có thể yêu cầu ChatGPT tạo bất kỳ loại schema nào bằng cách sử dụng các ví dụ tương tự.
Tạo schema HowTo
Để tạo schema HowTo, bạn có thể sử dụng ChatGPT theo cách tương tự như khi tạo FAQ schema. Bạn chỉ cần cung cấp các bước chi tiết cho một quy trình cụ thể và yêu cầu ChatGPT tạo mã schema HowTo. Ví dụ: "Generate HowTo schema on how to bake a cake from the steps below and suggest images with each step."
Mặc dù ChatGPT sẽ hoàn thành phần lớn công việc, bạn vẫn cần thay thế các URL hình ảnh mẫu bằng các URL hình ảnh thực tế của mình. Sau khi mã schema được tạo, bạn chỉ cần tải hình ảnh lên CMS và cập nhật đường dẫn hình ảnh trong schema theo đề xuất của ChatGPT.

Create Robots.txt Rules
Các chuyên gia SEO thường phải xử lý nhiều với tệp robots.txt. Với ChatGPT, bạn có thể dễ dàng tạo bất kỳ quy tắc nào cho robots.txt.
Ví dụ về Quy Tắc Robots.txt
Giả sử bạn muốn ngăn Google thu thập dữ liệu các trang đích của chiến dịch PPC nằm trong thư mục /landing, nhưng vẫn cho phép bot của Google Ads truy cập. Bạn có thể sử dụng lời nhắc sau: "Robots.txt rule which blocks Google's access to directory /landing/ but allows Google ads bot."
Sau khi tạo quy tắc, bạn cần kiểm tra kỹ tệp robots.txt của mình để đảm bảo rằng nó hoạt động như mong muốn.
Tạo htaccess Redirect Rules
Các chuyên gia SEO thường phải thực hiện việc chuyển hướng trang, và điều này có thể phụ thuộc vào loại máy chủ mà họ sử dụng. Với ChatGPT, bạn có thể dễ dàng tạo quy tắc chuyển hướng cho htaccess hoặc Nginx.
Ví dụ về Quy Tắc Chuyển Hướng htaccess
Giả sử bạn muốn chuyển hướng từ folder1 sang folder2, bạn có thể sử dụng lời nhắc sau: "For redirecting folder1 to folder2 generate nginx and htaccess redirect rules."
ChatGPT sẽ cung cấp các quy tắc cần thiết cho cả htaccess và Nginx. Sau khi tạo, bạn chỉ cần sao chép và dán các quy tắc này vào tệp cấu hình máy chủ của mình.

Xem thêm về Chat GPT cho SEO tại đây.
2 notes
·
View notes
Photo

volt par ezer website aminel meg kellett tudnom, hogy gaming site, vagy receptes vagy valami nagyobb hir site, szoval, hogy nagyjabol milyen kategoriaba tartozik.
chat gpt-vel a classify formulat hasznaltam, es berakta oket kategoriakba. kaptam par error-t, de azokat kezzel at lehetett nezni.
megadtam neki a kategoriakat a G1 mezoben, hogy kb mit keresek es abbol valasztott. ugy is kiprobaltam, mukodik-e ha nem adok meg elore kategoriakat akkor sajat magatol rendelt hozza, viszont az sokkal lassabb volt. pl ilyeneket adott, hogy “pets, lifestyle and blogs” vagy “gaming news and tech”
lehetett volna a gpt_tag(...) formulat is hasznalni szerintem ehhez egyebkent.
nagyjabol eltalalta. nem mondom, hogy mindig, de nagyjabol jo lett ahhoz, amihez kellett.
csoportositani kellett, nem tudtam tobb ezer soron egyszerre vegighuzni a formulat, hanem kb igy 500-700-at egyszerre. de igy is allandoan villogott, hogy ez neki sok. folyton kerte az API key-t, az eleg idegesito.
video gpt classify
video gpt tag
9 notes
·
View notes
Text
HelloAIBOX is - All in one content creation platform.
What is Helloaibox?
HelloAIbox is not just another content creation tool. It’s a revolutionary AI-powered platform designed to streamline content creation processes. Whether you’re a content creator, marketer, writer, designer, or educator, HelloAIbox empowers you to generate any content you desire with just a few taps right from your browser.
Key Features
Audio Conversion: Seamlessly convert text to high-quality audio and vice versa for podcasts, voiceovers, and educational materials.
Versatile Content Creation: From blog posts to social media content, HelloAIbox caters to a variety of content forms.
Image Analysis and Generation: Analyze images and generate visually stunning graphics using advanced AI algorithms.
Transcription Services: Simplify audio file transcriptions for efficient content creation and repurposing.
User-Friendly Interface: Designed with an intuitive interface, HelloAIbox is accessible to users regardless of technical expertise.
Browser Integration: HelloAIbox integrates with popular browsers for easy access to AI-powered content creation tools.
Diverse Language Support: Supports a wide array of text-to-speech conversion languages, expanding reach and engagement.
Unlimited Capabilities: Users have unlimited access to features like chat, text-to-speech, speech-to-text, vision, and image, encouraging exploration and creativity.
Customer Satisfaction Guarantee: A 14-day money-back guarantee underscores confidence in HelloAIbox’s quality and reliability.
Cutting-Edge Technology: Powered by OpenAI and GPT-4 API, HelloAIbox offers state-of-the-art content creation tools continually updated with the latest AI advancements.
Transparent Pricing: With a pay-as-you-go model and OpenAI API key requirement, users have control over usage and expenditure.
Full Review here >>

2 notes
·
View notes
Text
okay but while i think they are funny, the kinds of posts where people ask an ai where they are and the ai says "i dont know your location" and then ask "wheres the nearest McDonald's", and get an answer, don't understand what the AI is saying, lmao.
the chatbot itself does NOT have your location. it just makes an api call to google maps, and returns whatever google maps says. chatbots arent usually very smart, so when you insist they are lying, they usually go along and try to find a "plausible answer" to your question, which is dangerous because that answer can sound very correct, but be very very wrong, if you play around with chat gpt a bit you probably already ran into that scenario
computers do not think like humans, even if we try to get them to, so for an ai the reasoning is "you want an answer to something i cant make an api call for" -> "i dont have access to that", and "you want to know something i can do an api call for" -> "here is your answer", the ai does not see these as logically connected at all and it doesnt understand that having your location is needed to know where a McDonald's is near you, because it doesnt even take care of that logic, let alone understand it
but when you then tell the ai "you know my location data" or "you are lying", the computer does something called "prompt insertion", so it just accepts you statement as real and tries to work with the statement, but the ai isnt usually very knowledgeable, so it just *guesses* to find a likely solution, like "oh, sorry for the confusion, i am actually using your ip adress!", which isnt true but the computer doesnt really understand the concept of "truth" like we do as humans, etc.
so like. what i am saying is not that corporations never lie to you or that chatbot ais are actually 100% harmless but like. yall kinda need to understand how they work or yall just sound like the kind of boomers who make these "technology is the devil and children do not know what a book is bc they are always on their phone" kind of thoughtpieces
4 notes
·
View notes
Text
MARKLLM: An Open-Source Toolkit for LLM Watermarking
New Post has been published on https://thedigitalinsider.com/markllm-an-open-source-toolkit-for-llm-watermarking/
MARKLLM: An Open-Source Toolkit for LLM Watermarking
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of large language models. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family. The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. Bias is introduced to the logits of green list tokens during text generation, favoring these tokens in the produced text. A statistical metric is then calculated from the proportion of green words, and a threshold is established to distinguish between watermarked and non-watermarked text. Enhancements to the KGW method include improved list partitioning, better logit manipulation, increased watermark information capacity, resistance to watermark removal attacks, and the ability to detect watermarks publicly.
Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected. Both watermarking families aim to balance watermark detectability with text quality, addressing challenges such as robustness in varying entropy settings, increasing watermark information capacity, and safeguarding against removal attempts. Recent research has focused on refining list partitioning and logit manipulation), enhancing watermark information capacity, developing methods to resist watermark removal, and enabling public detection. Ultimately, LLM watermarking is crucial for the ethical and responsible use of large language models, providing a method to trace and verify LLM-generated text. The KGW and Christ Families offer two distinct approaches, each with unique strengths and applications, continuously evolving through ongoing research and innovation.
Owing to the ability of LLM watermarking frameworks to embed algorithmically detectable signals in model outputs to identify text generated by a LLM framework is playing a crucial role in mitigating the risks associated with the misuse of large language models. However, there is an abundance of LLM watermarking frameworks in the market currently, each with their own perspectives and evaluation procedures, thus making it difficult for the researchers to experiment with these frameworks easily. To counter this issue, MarkLLM, an open-source toolkit for watermarking offers an extensible and unified framework to implement LLM watermarking algorithms while providing user-friendly interfaces to ensure ease of use and access. Furthermore, the MarkLLM framework supports automatic visualization of the mechanisms of these frameworks, thus enhancing the understandability of these models. The MarkLLM framework offers a comprehensive suite of 12 tools covering three perspectives alongside two automated evaluation pipelines for evaluating its performance. This article aims to cover the MarkLLM framework in depth, and we explore the mechanism, the methodology, the architecture of the framework along with its comparison with state of the art frameworks. So let’s get started.
The emergence of large language model frameworks like LLaMA, GPT-4, ChatGPT, and more have significantly progressed the ability of AI models to perform specific tasks including creative writing, content comprehension, formation retrieval, and much more. However, along with the remarkable benefits associated with the exceptional proficiency of current large language models, certain risks have surfaced including academic paper ghostwriting, LLM generated fake news and depictions, and individual impersonation to name a few. Given the risks associated with these issues, it is vital to develop reliable methods with the capability of distinguishing between LLM-generated and human content, a major requirement to ensure the authenticity of digital communication, and prevent the spread of misinformation. For the past few years, LLM watermarking has been recommended as one of the promising solutions for distinguishing LLM-generated content from human content, and by incorporating distinct features during the text generation process, LLM outputs can be uniquely identified using specially designed detectors. However, due to proliferation and relatively complex algorithms of LLM watermarking frameworks along with the diversification of evaluation metrics and perspectives have made it incredibly difficult to experiment with these frameworks.
To bridge the current gap, the MarkLLM framework attempts tlarge o make the following contributions. MARKLLM offers consistent and user-friendly interfaces for loading algorithms, generating watermarked text, conducting detection processes, and collecting data for visualization. It provides custom visualization solutions for both major watermarking algorithm families, allowing users to see how different algorithms work under various configurations with real-world examples. The toolkit includes a comprehensive evaluation module with 12 tools addressing detectability, robustness, and text quality impact. Additionally, it features two types of automated evaluation pipelines supporting user customization of datasets, models, evaluation metrics, and attacks, facilitating flexible and thorough assessments. Designed with a modular, loosely coupled architecture, MARKLLM enhances scalability and flexibility. This design choice supports the integration of new algorithms, innovative visualization techniques, and the extension of the evaluation toolkit by future developers.
Numerous watermarking algorithms have been proposed, but their unique implementation approaches often prioritize specific requirements over standardization, leading to several issues
Lack of Standardization in Class Design: This necessitates significant effort to optimize or extend existing methods due to insufficiently standardized class designs.
Lack of Uniformity in Top-Level Calling Interfaces: Inconsistent interfaces make batch processing and replicating different algorithms cumbersome and labor-intensive.
Code Standard Issues: Challenges include the need to modify settings across multiple code segments and inconsistent documentation, complicating customization and effective use. Hard-coded values and inconsistent error handling further hinder adaptability and debugging efforts.
To address these issues, our toolkit offers a unified implementation framework that enables the convenient invocation of various state-of-the-art algorithms under flexible configurations. Additionally, our meticulously designed class structure paves the way for future extensions. The following figure demonstrates the design of this unified implementation framework.
Due to the framework’s distributive design, it is straightforward for developers to add additional top-level interfaces to any specific watermarking algorithm class without concern for impacting other algorithms.
MarkLLM : Architecture and Methodology
LLM watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family. The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. Bias is introduced to the logits of green list tokens during text generation, favoring these tokens in the produced text. A statistical metric is then calculated from the proportion of green words, and a threshold is established to distinguish between watermarked and non-watermarked text. Enhancements to the KGW method include improved list partitioning, better logit manipulation, increased watermark information capacity, resistance to watermark removal attacks, and the ability to detect watermarks publicly.
Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected. Both watermarking families aim to balance watermark detectability with text quality, addressing challenges such as robustness in varying entropy settings, increasing watermark information capacity, and safeguarding against removal attempts. Recent research has focused on refining list partitioning and logit manipulation), enhancing watermark information capacity, developing methods to resist watermark removal, and enabling public detection. Ultimately, LLM watermarking is crucial for the ethical and responsible use of large language models, providing a method to trace and verify LLM-generated text. The KGW and Christ Families offer two distinct approaches, each with unique strengths and applications, continuously evolving through ongoing research and innovation.
Automated Comprehensive Evaluation
Evaluating an LLM watermarking algorithm is a complex task. Firstly, it requires consideration of various aspects, including watermark detectability, robustness against tampering, and impact on text quality. Secondly, evaluations from each perspective may require different metrics, attack scenarios, and tasks. Moreover, conducting an evaluation typically involves multiple steps, such as model and dataset selection, watermarked text generation, post-processing, watermark detection, text tampering, and metric computation. To facilitate convenient and thorough evaluation of LLM watermarking algorithms, MarkLLM offers twelve user-friendly tools, including various metric calculators and attackers that cover the three aforementioned evaluation perspectives. Additionally, MARKLLM provides two types of automated demo pipelines, whose modules can be customized and assembled flexibly, allowing for easy configuration and use.
For the aspect of detectability, most watermarking algorithms ultimately require specifying a threshold to distinguish between watermarked and non-watermarked texts. We provide a basic success rate calculator using a fixed threshold. Additionally, to minimize the impact of threshold selection on detectability, we also offer a calculator that supports dynamic threshold selection. This tool can determine the threshold that yields the best F1 score or select a threshold based on a user-specified target false positive rate (FPR).
For the aspect of robustness, MARKLLM offers three word-level text tampering attacks: random word deletion at a specified ratio, random synonym substitution using WordNet as the synonym set, and context-aware synonym substitution utilizing BERT as the embedding model. Additionally, two document-level text tampering attacks are provided: paraphrasing the context via OpenAI API or the Dipper model. For the aspect of text quality, MARKLLM offers two direct analysis tools: a perplexity calculator to gauge fluency and a diversity calculator to evaluate the variability of texts. To analyze the impact of watermarking on text utility in specific downstream tasks, we provide a BLEU calculator for machine translation tasks and a pass-or-not judger for code generation tasks. Additionally, given the current methods for comparing the quality of watermarked and unwatermarked text, which include using a stronger LLM for judgment, MarkLLM also offers a GPT discriminator, utilizing GPT-4to compare text quality.
Evaluation Pipelines
To facilitate automated evaluation of LLM watermarking algorithms, MARKLLM provides two evaluation pipelines: one for assessing watermark detectability with and without attacks, and another for analyzing the impact of these algorithms on text quality. Following this process, we have implemented two pipelines: WMDetect3 and UWMDetect4. The primary difference between them lies in the text generation phase. The former requires the use of the generate_watermarked_text method from the watermarking algorithm, while the latter depends on the text_source parameter to determine whether to directly retrieve natural text from a dataset or to invoke the generate_unwatermarked_text method.
To evaluate the impact of watermarking on text quality, pairs of watermarked and unwatermarked texts are generated. The texts, along with other necessary inputs, are then processed and fed into a designated text quality analyzer to produce detailed analysis and comparison results. Following this process, we have implemented three pipelines for different evaluation scenarios:
DirectQual.5: This pipeline is specifically designed to analyze the quality of texts by directly comparing the characteristics of watermarked texts with those of unwatermarked texts. It evaluates metrics such as perplexity (PPL) and log diversity, without the need for any external reference texts.
RefQual.6: This pipeline evaluates text quality by comparing both watermarked and unwatermarked texts with a common reference text. It measures the degree of similarity or deviation from the reference text, making it ideal for scenarios that require specific downstream tasks to assess text quality, such as machine translation and code generation.
ExDisQual.7: This pipeline employs an external judger, such as GPT-4 (OpenAI, 2023), to assess the quality of both watermarked and unwatermarked texts. The discriminator evaluates the texts based on user-provided task descriptions, identifying any potential degradation or preservation of quality due to watermarking. This method is particularly valuable when an advanced, AI-based analysis of the subtle effects of watermarking is required.
MarkLLM: Experiments and Results
To evaluate its performance, the MarkLLM framework conducts evaluations on nine different algorithms, and assesses their impact, robustness, and detectability on the quality of text.
The above table contains the evaluation results of assessing the detectability of nine algorithms supported in MarkLLM. Dynamic threshold adjustment is employed to evaluate watermark detectability, with three settings provided: under a target FPR of 10%, under a target FPR of 1%, and under conditions for optimal F1 score performance. 200 watermarked texts are generated, while 200 non-watermarked texts serve as negative examples. We furnish TPR and F1-score under dynamic threshold adjustments for 10% and 1% FPR, alongside TPR, TNR, FPR, FNR, P, R, F1, ACC at optimal performance. The following table contains the evaluation results of assessing the robustness of nine algorithms supported in MarkLLM. For each attack, 200 watermarked texts are generated and subsequently tampered, with an additional 200 non-watermarked texts serving as negative examples. We report the TPR and F1-score at optimal performance under each circumstance.
Final Thoughts
In this article, we have talked about MarkLLM, an open-source toolkit for watermarking that offers an extensible and unified framework to implement LLM watermarking algorithms while providing user-friendly interfaces to ensure ease of use and access. Furthermore, the MarkLLM framework supports automatic visualization of the mechanisms of these frameworks, thus enhancing the understandability of these models. The MarkLLM framework offers a comprehensive suite of 12 tools covering three perspectives alongside two automated evaluation pipelines for evaluating its performance.
#2023#advanced LLM techniques#ai#AI models#algorithm#Algorithms#Analysis#API#applications#architecture#Art#Article#Artificial Intelligence#attackers#AutoGPT#BERT#Bias#bridge#calculator#Chat GPT#chatGPT#code#code generation#communication#comparison#comprehension#comprehensive#computation#content#data
0 notes
Text
What is Deep Seek?

DeepSeek is a Chinese artificial intelligence (AI) company focused on advancing Artificial General Intelligence (AGI). It specializes in developing large language models (LLMs), multimodal models, and AI-powered solutions for both general and industry-specific applications. Below is a detailed overview of DeepSeek and its offerings: Key Features of DeepSeek - Core Technology: - LLMs: Develops state-of-the-art language models for text generation, reasoning, code generation, and multilingual tasks. - Multimodal Models: Combines text, image, and other data types for advanced AI interactions. - Domain-Specific Models: Tailored models for industries like finance, healthcare, education, and legal services. - Open-Source Contributions: - Releases open-source models (e.g., DeepSeek-R1, DeepSeek-Math) to foster community collaboration. - Provides fine-tuning tools and datasets for developers. - API Services: - Offers API access to its proprietary models (similar to OpenAI’s GPT-4 or Anthropic’s Claude). - Supports tasks like chat completions, text summarization, code generation, and data analysis. - Customization: - Allows enterprises to fine-tune models on private data for specialized use cases. - Scalability: - Optimized for high-performance computing and low-latency deployments. Use Cases - Chatbots & Virtual Assistants: Build conversational agents for customer support or internal workflows. - Content Generation: Automate blog posts, marketing copy, or technical documentation. - Code Development: Generate, debug, or optimize code (e.g., Python, JavaScript). - Education: Create tutoring systems, automated grading, or interactive learning tools. - Research: Accelerate data analysis, literature reviews, or hypothesis testing. - Enterprise Solutions: Industry-specific applications in finance (risk analysis), healthcare (diagnostics), and legal (contract review). Technical Strengths - Performance: Competes with leading models like GPT-4 in benchmarks for reasoning, coding, and math. - Efficiency: Optimized inference and training frameworks reduce computational costs. - Multilingual Support: Strong capabilities in Chinese, English, and other languages. - Ethical AI: Implements safeguards to reduce harmful outputs (bias, misinformation). How to Access DeepSeek - API: - Use the DeepSeek API for cloud-based model access (similar to the example provided in the previous answer). - Official documentation: DeepSeek API Docs (verify the URL on their official site). - Open-Source Models: - Download models from platforms like Hugging Face or GitHub. - Example: DeepSeek-Math-7B on Hugging Face. - Enterprise Solutions: - Contact DeepSeek’s sales team for custom deployments, on-premise solutions, or industry-specific models. Differentiation from Competitors Feature DeepSeek Competitors (OpenAI, Anthropic) Open-Source Offers open-source models and tools. Mostly closed-source (except Meta’s Llama). Domain Expertise Strong focus on vertical industries. General-purpose models. Cost Competitive pricing for API and compute. Higher pricing tiers for advanced models. Language Support Strong Chinese-language optimization. Primarily English-first. Getting Started - Visit the DeepSeek Official Website for the latest updates. - Explore their GitHub for open-source models and code samples. - Try the API with a free tier (if available) or contact their team for enterprise solutions. Future Directions DeepSeek is actively expanding into: - Multimodal AGI: Integrating vision, audio, and robotics. - Real-Time Applications: Low-latency solutions for industries like autonomous systems. - Global Reach: Increasing support for non-Chinese markets. Read the full article
0 notes
Link
看看網頁版全文 ⇨ 雜談:怎麽讓AI能根據我的雲端硬碟回答問題 / TALK: How Can I Enable AI to Answer Questions Based on My Cloud Storage? https://blog.pulipuli.info/2025/01/talk-how-can-i-enable-ai-to-answer-questions-based-on-my-cloud-storage.html Nextcloud的AI應用程式不能處理中文,所以我自己用Langflow整合到Nextcloud,讓大型語言模型能夠根據我在雲端硬碟裡面的內容來回答問題。 這篇就講一下大致上的做法。 ---- # Nextcloud的llm2應用程式 /。 (圖片來自:https://www.youtube.com/watch?v=6_BPOZzvzZQ&t=138s )。 https://docs.nextcloud.com/server/latest/admin_manual/ai/app_assistant.html#installation。 Nextcloud在好幾年前就嘗試將LLM (大型語言模型)接入到Nextcloud。 有了LLM的輔助,我們可以在Nextcloud裡面作翻譯、寫作等功能。 Nextcloud的AI應用可以用OpenAI GPT-3.5的API,也可以在本地架設Llama 3.1模型。 它能做到機器翻譯、語音轉文字(透過stt_whisper2)、產生文字、摘要、產生標題、抽取主題詞、根據上下文重新撰寫(context write)、重寫、文字轉圖片(使用tex2image_stablediffusion2 )、上下文對談(context chat,此處的context是指Nextcloud裡面的檔案)、上下文助理 (context agent),功能非常豐富。 不過要架設具有AI功能的Nextcloud Assistant並不容易。 乍看之下,好像是要用nextcloud aio版本,搭配appapi之類的東西才能運作。 需要的元件很多,稍微複雜了一些,真是令人困擾。 https://github.com/nextcloud/context_chat_backend。 研究的過程中,我發現Nextcloud很多AI元件其實背後也是使用langchain。 既然如此,那我何不自己用langchain來處理就好了呢?。 ---- # Langchain的低程式碼版本:Langflow / Low-Code LangChain: Langflow。 https://www.langflow.org/。 最近因為工作的需求,我開始研究Langchain的相關應用。 基於Dify的開發經驗,我也想找一個low code版本的開發方式,也許這可以讓未來接手的人更容易理解LLM的運作過程。 ---- 繼續閱讀 ⇨ 雜談:怎麽讓AI能根據我的雲端硬碟回答問題 / TALK: How Can I Enable AI to Answer Questions Based on My Cloud Storage? https://blog.pulipuli.info/2025/01/talk-how-can-i-enable-ai-to-answer-questions-based-on-my-cloud-storage.html
0 notes
Text
Step-by-Step Guide to Developing Your First Generative AI Chatbot
Developing a generative AI chatbot can be an exciting and rewarding project. By the end of this guide, you'll understand the essential steps required to create your own chatbot, from concept to deployment. Let’s dive straight into the process.
1. Define the Purpose and Scope of Your Chatbot
The first step in developing a generative AI chatbot is identifying its purpose and scope. Ask yourself:
What problems will the chatbot solve?
Who is your target audience?
What kind of interactions will it handle?
For example, if you're building a customer service chatbot, it might need to handle inquiries about product availability, pricing, and returns. Defining the chatbot’s scope will ensure you stay focused throughout the development process.
Additional Considerations:
Goals: Clearly outline the success metrics for your chatbot. For instance, it could be customer satisfaction, response accuracy, or average handling time.
Personality: Decide if your chatbot will have a specific tone or personality (e.g., formal, friendly, humorous).
Limitations: Acknowledge what the chatbot will not handle to avoid confusion for users.
2. Choose the Right Platform and Tools
Depending on your technical expertise and requirements, you’ll need to select the right platform and tools. Popular options for developing generative AI chatbots include:
OpenAI’s GPT Models: Known for their advanced language generation capabilities.
Google’s Dialogflow: A powerful tool for building conversational experiences.
Rasa: An open-source framework for building AI assistants.
Key Factors for Selection:
Ease of Use: Platforms with intuitive interfaces and documentation can save development time.
Cost: Evaluate subscription costs, API fees, and hidden charges.
Flexibility: Check if the platform supports integrations with your preferred tools or services.
Select a platform that aligns with your development skills, project needs, and budget.
3. Gather and Prepare Training Data
Generative AI chatbots rely on large datasets to generate meaningful and contextually relevant responses. If you’re using a pre-trained model, the chatbot will already have general conversational abilities. However, you might still need to fine-tune it with domain-specific data.
Sources of Training Data
Existing Databases: Use your company’s historical chat logs, FAQs, or customer interactions.
Public Datasets: Leverage open datasets available on platforms like Kaggle or Hugging Face.
Manual Data Creation: Write sample conversations to provide tailored examples for your chatbot.
Data Cleaning
Ensure the data is clean and consistent by:
Removing irrelevant or duplicate entries.
Correcting grammatical and spelling errors.
Structuring the data into a format suitable for training.
Data Augmentation
To further enhance your dataset, consider:
Synonym Replacement: Introduce variations in phrasing.
Paraphrasing: Create multiple versions of the same response.
Simulated Conversations: Generate hypothetical dialogues based on real-world scenarios.
4. Select a Generative Model
Generative AI chatbots are powered by models trained to generate human-like text. Some popular models include:
GPT-3 and GPT-4: Developed by OpenAI, these models are robust and versatile.
LLaMA: A large language model by Meta, suitable for various conversational tasks.
T5 (Text-to-Text Transfer Transformer): A model by Google, ideal for sequence-to-sequence tasks.
Key Considerations:
Pre-trained vs. Custom Models: Decide whether to use a pre-trained model or build one from scratch.
Compute Resources: Ensure you have access to the necessary computational power for training and inference.
API Accessibility: Verify that the model’s API integrates smoothly with your application.
You can either use these models as-is or fine-tune them for your specific use case.
5. Develop the Chatbot’s Logic and Flow
To create a seamless user experience, you’ll need to define the conversational flow. Even though generative models are highly capable, having a logical framework ensures consistency and efficiency.
Steps to Define Logic:
Map Key Scenarios: Identify the main use cases and expected user queries.
Design Responses: Outline how the chatbot should respond to each scenario.
Fallback Mechanisms: Plan for situations where the chatbot cannot provide an adequate answer, such as redirecting the user to a human agent or offering generic responses.
Additional Tips:
Intent Classification: Use intent detection algorithms to categorize user queries.
Context Management: Implement techniques to track conversational context, ensuring coherent and relevant responses.
Dynamic Responses: Incorporate variability in responses to make interactions feel natural.
Tools like flowchart software or conversational design platforms can help visualize and refine this logic.
6. Train and Fine-Tune Your Model
Training involves feeding your chatbot’s model with data to improve its performance. Fine-tuning helps the chatbot understand domain-specific language and context.
Training Steps:
Set Up the Environment: Use cloud platforms like AWS, Google Cloud, or Azure for the computational power needed.
Prepare the Data: Organize your training data in the required format (e.g., JSON or CSV).
Run Training: Train your model using libraries like PyTorch or TensorFlow, or leverage the fine-tuning capabilities of pre-trained models.
Evaluate Performance: Test the model using validation datasets to ensure it generates accurate and contextually relevant responses.
Fine-Tuning Tips:
Use transfer learning to leverage pre-trained knowledge while adapting to your specific needs.
Monitor overfitting by evaluating the model on unseen data.
Optimize hyperparameters for improved training efficiency.
7. Integrate the Chatbot with a User Interface
Once your chatbot is trained and fine-tuned, you’ll need to integrate it with a user interface (UI) so users can interact with it.
Common UI Options:
Web Chat: Embed the chatbot into a website using JavaScript or third-party widgets.
Mobile App: Add chatbot functionality to your app via an SDK or API.
Messaging Platforms: Deploy the chatbot on platforms like WhatsApp, Facebook Messenger, or Slack.
API Integration:
If your chatbot is hosted on a server, provide API endpoints that the UI can use to send and receive messages. Popular frameworks like Flask or FastAPI can help set up these endpoints.
Design Best Practices:
Intuitive Layout: Keep the interface simple and user-friendly.
Quick Actions: Include buttons for common actions to streamline interactions.
Accessibility: Ensure the interface is accessible to users with disabilities.
8. Test the Chatbot Thoroughly
Testing is a critical phase to ensure your chatbot performs as expected. Conduct comprehensive testing to identify and resolve issues.
Types of Testing:
Functional Testing: Verify the chatbot handles all intended queries and scenarios.
User Testing: Involve real users to assess the chatbot’s usability and effectiveness.
Performance Testing: Measure response times and the chatbot’s ability to handle multiple concurrent users.
Edge Case Testing: Test unusual or unexpected inputs to see how the chatbot reacts.
Automated Testing:
Use testing frameworks to simulate user interactions and validate chatbot behavior. Popular tools include Botium and TestMyBot.
9. Deploy Your Chatbot
After thorough testing, you’re ready to deploy your chatbot. Choose a reliable hosting environment based on your expected traffic and performance needs.
Deployment Steps:
Select a Hosting Platform: Use cloud services like AWS, Google Cloud, or Microsoft Azure.
Set Up Load Balancing: Ensure your chatbot can handle high traffic without downtime.
Monitor Performance: Use analytics tools to track user interactions, identify issues, and optimize the chatbot’s performance.
Post-Deployment Checklist:
Ensure SSL encryption for secure data transmission.
Test the chatbot in the live environment to confirm seamless functionality.
Set up automated backups to prevent data loss.
10. Monitor and Improve
Even after deployment, your work isn’t done. Continuously monitor the chatbot’s performance and make improvements.
Key Activities:
Analyze User Feedback: Collect and analyze feedback to identify areas for improvement.
Update the Model: Periodically retrain the model with new data to enhance its capabilities.
Add Features: Based on user behavior and requirements, introduce new functionalities over time.
Metrics to Track:
Accuracy: Measure how often the chatbot provides correct responses.
Engagement: Track the average number of interactions per session.
Retention: Evaluate how frequently users return to use the chatbot.
Tools and Resources for Chatbot Development
Here are some helpful tools and resources:
AI Libraries: Hugging Face, TensorFlow, PyTorch
Dataset Sources: Kaggle, Open Data Portals, GitHub repositories
Integrated Development Environments (IDEs): Jupyter Notebook, PyCharm
Version Control: GitHub, GitLab
Monitoring Tools: Google Analytics, Firebase, or custom dashboards
Conclusion
By following this step-by-step guide, you can create a generative AI chatbot tailored to your specific needs. Start small, focus on a well-defined purpose, and iteratively improve your chatbot. With persistence and the right tools, you’ll soon have a functional and efficient chatbot ready to engage users.
0 notes