#booking software open source
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
gonna add a take, android is better then ios because ios was created by Apple to maintain a complete monopoly over every single part of the phone so that it is absolutely impossible to get it fixed anywhere but at one of their official stores or licensed repair stores where they can slap you with ridiculously high repair bills for simple fixes. Android isn't a type of phone, it's an operating system. it's the same shit with apple always using a weird ass charging cable when everyone else has been using USB for decades. uniqueness not for improving the quality of the product, but for increasing its price artificially through after purchase repairs upgrades and replacements.
#if you control the OS you control what devices the phone can pair with what speed at whiich the battery drains and the phone runs etc etc#IOS was designed specifically so that Apple could have a complete monopoly over everything related to their devices#accessories software updates and fixes hardware fixes all of it#Louis Rossmann is a great source and he talks at length about this sort of thing as it relates particularly to Mac Books being#overengineered unrepairable garbage#he owns a computer repair store and yeah the mac book air he opens up once and literally realizes it has a fan that is placebo only#it doesnt blow on anything to reduce its temperature#it just makes noise#fuck apple
51K notes
·
View notes
Text
If you haven’t started already, start archiving/downloading everything. Save it to an external hard drive if you’re able. Collecting physical media is also a good idea, if you’re able.
Download your own/your favorite fanfics. Save as much as you can from online sources/digital libraries. Recipes, tutorials, history, LGBTQ media, etc. It has been claimed, though I can’t find the exact source if true, that some materials about the Revolutionary War were deleted from the Library of Congress.
It’s always better to be safe than sorry and save and preserve what you can. Remember that cloud storage also is not always reliable!
Library of Congress - millions of books, films and video, audio recordings, photographs, newspapers, maps, manuscripts.
Internet Archive - millions of free texts, movies, software, music, websites, and more. Has been taken offline multiple times because of cyber attacks last month, it has recently started archiving again.
Anna's Archive - 'largest truly open library in human history.’
Queer Liberation Library - queer literature and resources. Does require applying for a library membership to browse and borrow from their collection.
List of art resources - list of art resources complied on tumblr back in 2019. Not sure if all links are still operational now, but the few I clicked on seemed to work.
Alexis Amber - TikToker who is an archivist who's whole page is about archiving. She has a database extensively recording the events of Hurricane Katrina.
I'll be adding more to this list, if anyone else wants to add anything feel free!
10K notes
·
View notes
Text
all software should be open source wtf. u expect me to run this on my own computer without knowing what its doing???
car manufacturers dont weld the hoods shut to keep ppl from copying their engines. books arent written with a military-grade cipher to avoid plagiarism. and we dont let food have "secret formulas" anymore bc too often one of the "secret ingredients" was fucking lead
when ur distributing a product to the public u forfeit the right to hide whats inside it, u dont get to hand out a black box and expect ppl to just trust u when u totally swear it doesnt have a microphone inside
29K notes
·
View notes
Text
A few years ago I had a phase of being REALLY into digital privacy, using tor, duckduckgo, etc before suffering some burnout because I was trying to be 100% secure. So I'm by no means a expert I'm just relaying experience.
The culture of a lot of left leaning and "fandommy" sites (tumblr, twitter, etc) tends to fear/dislike (or just not know about) a lot of the IT stuff used by people into online privacy because they asscoiate it with "techbros". ESPECIALLY anything even remotely involving cryptocurrency. But if Trump is going to start censoring things and making morning after pills harder to get now might be a VERY good time for Americans to get into online privacy and how to avoid being tracked as well as avoiding censorship. Perhaps even some crypto to buy things discretly (or perhaps if ICE agents start caring about cash?) and because many activists groups also take donations in crypto. Never dealt with crypto myself but from what I know Monero was designed to be more untracable than Bitcoin. Don't know how succesfull that is though. Definetly get into privacy in general though.
I'll leave some useful links to get started. Words of advice:
Don't install a fuckton of privacy extensions on your browser, your unique combination of extensions will give your browser a unique fingerprint. Instead read up on and pick a few commonly used ones.
The BIGGEST annoyance for me was acedemic/proffesional settings because noone wants to switch over to some software they never heard off for one group project. Personally I use some normie software for exclusivly proffesional purposes with NO other information on me and do my actual browsing/leisure computer use more privatly.
https://www.privacytools.io/os: General software/browser/etc recomendations.
https://coveryourtracks.eff.org/: Test how private your browser is.
https://www.torproject.org/: THE gold standard for privacy focused browsers. Also obscures ip. Might not always be practical. Has the disadvantage of being notoriously slow and is blocked by some services/websites to avoid people bypassing ip bans and whatnot. Probably don't use this as your everyday browser but if you ever need to look up anything without censorship use tor.
https://tails.net/: Install a portable mini operating system on a usb stick to browse privately from any computer.
https://www.eff.org/ Electronic frontier foundations website.
https://mastodon.social/explore Don't have experience with it myself. But open source social media that should be much harder to censor.
Tumblr probably won't like me talking too directly about this because of ties to piracy but for people interested in banned books https://en.wikipedia.org/wiki/Shadow_library should be an interesting read...
3K notes
·
View notes
Text
Dirty words are politically potent

On OCTOBER 23 at 7PM, I'll be in DECATUR, presenting my novel THE BEZZLE at EAGLE EYE BOOKS.

Making up words is a perfectly cromulent passtime, and while most of the words we coin disappear as soon as they fall from our lips, every now and again, you find a word that fits so nice and kentucky in the public discourse that it acquires a life of its own:
http://meaningofliff.free.fr/definition.php3?word=Kentucky
I've been trying to increase the salience of digital human rights in the public imagination for a quarter of a century, starting with the campaign to get people to appreciate that the internet matters, and that tech policy isn't just the delusion that the governance of spaces where sad nerds argue about Star Trek is somehow relevant to human thriving:
https://www.newyorker.com/magazine/2010/10/04/small-change-malcolm-gladwell
Now, eventually people figured out that a) the internet mattered and, b) it was going dreadfully wrong. So my job changed again, from "how the internet is governed matters" to "you can't fix the internet with wishful thinking," for example, when people said we could solve its problems by banning general purpose computers:
https://memex.craphound.com/2012/01/10/lockdown-the-coming-war-on-general-purpose-computing/
Or by banning working cryptography:
https://memex.craphound.com/2018/09/04/oh-for-fucks-sake-not-this-fucking-bullshit-again-cryptography-edition/
Or by redesigning web browsers to treat their owners as threats:
https://www.eff.org/deeplinks/2017/09/open-letter-w3c-director-ceo-team-and-membership
Or by using bots to filter every public utterance to ensure that they don't infringe copyright:
https://www.eff.org/deeplinks/2018/09/today-europe-lost-internet-now-we-fight-back
Or by forcing platforms to surveil and police their users' speech (aka "getting rid of Section 230"):
https://www.techdirt.com/2020/06/23/hello-youve-been-referred-here-because-youre-wrong-about-section-230-communications-decency-act/
Along the way, many of us have coined words in a bid to encapsulate the abstract, technical ideas at the core of these arguments. This isn't a vanity project! Creating a common vocabulary is a necessary precondition for having the substantive, vital debates we'll need to tackle the real, thorny issues raised by digital systems. So there's "free software," "open source," "filternet," "chat control," "back doors," and my own contributions, like "adversarial interoperability":
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
Or "Competitive Compatibility" ("comcom"), a less-intimidatingly technical term for the same thing:
https://www.eff.org/deeplinks/2020/12/competitive-compatibility-year-review
These have all found their own niches, but nearly all of them are just that: niche. Some don't even rise to "niche": they're shibboleths, insider terms that confuse and intimidate normies and distract from the real fights with semantic ones, like whether it's "FOSS" or "FLOSS" or something else entirely:
https://opensource.stackexchange.com/questions/262/what-is-the-difference-between-foss-and-floss
But every now and again, you get a word that just kills. That brings me to "enshittification," a word I coined in 2022:
https://pluralistic.net/2022/11/28/enshittification/#relentless-payola
"Enshittification" took root in my hindbrain, rolling around and around, agglomerating lots of different thoughts and critiques I'd been making for years, crystallizing them into a coherent thesis:
https://pluralistic.net/2023/01/21/potemkin-ai/#hey-guys
This kind of spontaneous crystallization is the dividend of doing lots of work in public, trying to take every half-formed thought and pin it down in public writing, something I've been doing for decades:
https://pluralistic.net/2021/05/09/the-memex-method/
After those first couple articles, "enshittification" raced around the internet. There's two reasons for this: first, "enshittification" is a naughty word that's fun to say. Journalists love getting to put "shit" in their copy:
https://www.nytimes.com/2024/01/15/crosswords/linguistics-word-of-the-year.html
Radio journalists love to tweak the FCC with cheekily bleeped syllables in slightly dirty compound words:
https://www.wnycstudios.org/podcasts/otm/projects/enshitification
And nothing enlivens an academic's day like getting to use a word like "enshittification" in a journal article (doubtless this also amuses the editors, peer-reviewers, copyeditors, typesetters, etc):
https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=enshittification&btnG=&oq=ensh
That was where I started, too! The first time I used "enshittification" was in a throwaway bad-tempered rant about the decay of Tripadvisor into utter uselessness, which drew a small chorus of appreciative chuckles about the word:
https://twitter.com/doctorow/status/1550457808222552065
The word rattled around my mind for five months before attaching itself to my detailed theory of platform decay. But it was that detailed critique, coupled with a minor license to swear, that gave "enshittification" a life of its own. How do I know that the theory was as important as the swearing? Because the small wave of amusement that followed my first use of "enshittification" petered out in less than a day. It was only when I added the theory that the word took hold.
Likewise: how do I know that the theory needed to be blended with swearing to break out of the esoteric realm of tech policy debates (which the public had roundly ignored for more than two decades)? Well, because I spent two decades writing about this stuff without making anything like the dents that appeared once I added an Anglo-Saxon monosyllable to that critique.
Adding "enshittification" to the critique got me more column inches, a longer hearing, a more vibrant debate, than anything else I'd tried. First, Wired availed itself of the Creative Commons license on my second long-form article on the subject and reprinted it as a 4,200-word feature. I've been writing for Wired for more than thirty years and this is by far the longest thing I've published with them – a big, roomy, discursive piece that was run verbatim, with every one of my cherished darlings unmurdered.
That gave the word – and the whole critique, with all its spiky corners – a global airing, leading to more pickup and discussion. Eventually, the American Dialect Society named it their "Word of the Year" (and their "Tech Word of the Year"):
https://americandialect.org/2023-word-of-the-year-is-enshittification/
"Enshittification" turns out to be catnip for language nerds:
https://becauselanguage.com/90-enpoopification/#transcript-60
I've been dragged into (good natured) fights over the German, Spanish, French and Italian translations for the term. When I taped an NPR show before a live audience with ASL interpretation, I got to watch a Deaf fan politely inform the interpreter that she didn't need to finger-spell "enshittification," because it had already been given an ASL sign by the US Deaf community:
https://maximumfun.org/episodes/go-fact-yourself/ep-158-aida-rodriguez-cory-doctorow/
I gave a speech about enshittification in Berlin and published the transcript:
https://pluralistic.net/2024/01/30/go-nuts-meine-kerle/#ich-bin-ein-bratapfel
Which prompted the rock-ribbed Financial Times to get in touch with me and publish the speech – again, nearly verbatim – as a whopping 6,400 word feature in their weekend magazine:
https://www.ft.com/content/6fb1602d-a08b-4a8c-bac0-047b7d64aba5
Though they could have had it for free (just as Wired had), they insisted on paying me (very well, as it happens!), as did De Zeit:
https://www.zeit.de/digital/internet/2024-03/plattformen-facebook-google-internet-cory-doctorow
This was the start of the rise of enshittification. The word is spreading farther than ever, in ways that I have nothing to do with, along with the critique I hung on it. In other words, the bit of string that tech policy wonks have been pushing on for a quarter of a century is actually starting to move, and it's actually accelerating.
Despite this (or more likely because of it), there's a growing chorus of "concerned" people who say they like the critique but fret that it is being held back because you can't use it "at church or when talking to K-12 students" (my favorite variant: "I couldn't say this at a NATO conference"). I leave it up to you whether you use the word with your K-12 students, NATO generals, or fellow parishoners (though I assure you that all three groups are conversant with the dirty little word at the root of my coinage). If you don't want to use "enshittification," you can coin your own word – or just use one of the dozens of words that failed to gain public attention over the past 25 years (might I suggest "platform decay?").
What's so funny about all this pearl-clutching is that it comes from people who universally profess to have the intestinal fortitude to hear the word "enshittification" without experiencing psychological trauma, but worry that other people might not be so strong-minded. They continue to say this even as the most conservative officials in the most staid of exalted forums use the word without a hint of embarrassment, much less apology:
https://www.independent.ie/business/technology/chairman-of-irish-social-media-regulator-says-europe-should-not-be-seduced-by-mario-draghis-claims/a526530600.html
I mean, I'm giving a speech on enshittification next month at a conference where I'm opening for the Secretary General of the United Nations:
https://icanewdelhi2024.coop/welcome/pages/Programme
After spending half my life trying to get stuff like this into the discourse, I've developed some hard-won, informed views on how ideas succeed:
First: the minor obscenity is a feature, not a bug. The marriage of something long and serious to something short and funny is a happy one that makes both the word and the ideas better off than they'd be on their own. As Lenny Bruce wrote in his canonical work in the subject, the aptly named How to Talk Dirty and Influence People:
I want to help you if you have a dirty-word problem. There are none, and I'll spell it out logically to you.
Here is a toilet. Specifically-that's all we're concerned with, specifics-if I can tell you a dirty toilet joke, we must have a dirty toilet. That's what we're all talking about, a toilet. If we take this toilet and boil it and it's clean, I can never tell you specifically a dirty toilet joke about this toilet. I can tell you a dirty toilet joke in the Milner Hotel, or something like that, but this toilet is a clean toilet now. Obscenity is a human manifestation. This toilet has no central nervous system, no level of consciousness. It is not aware; it is a dumb toilet; it cannot be obscene; it's impossible. If it could be obscene, it could be cranky, it could be a Communist toilet, a traitorous toilet. It can do none of these things. This is a dirty toilet here.
Nobody can offend you by telling a dirty toilet story. They can offend you because it's trite; you've heard it many, many times.
https://www.dacapopress.com/titles/lenny-bruce/how-to-talk-dirty-and-influence-people/9780306825309/
Second: the fact that a neologism is sometimes decoupled from its theoretical underpinnings and is used colloquially is a feature, not a bug. Many people apply the term "enshittification" very loosely indeed, to mean "something that is bad," without bothering to learn – or apply – the theoretical framework. This is good. This is what it means for a term to enter the lexicon: it takes on a life of its own. If 10,000,000 people use "enshittification" loosely and inspire 10% of their number to look up the longer, more theoretical work I've done on it, that is one million normies who have been sucked into a discourse that used to live exclusively in the world of the most wonkish and obscure practitioners. The only way to maintain a precise, theoretically grounded use of a term is to confine its usage to a small group of largely irrelevant insiders. Policing the use of "enshittification" is worse than a self-limiting move – it would be a self-inflicted wound. As I said in that Berlin speech:
Enshittification names the problem and proposes a solution. It's not just a way to say 'things are getting worse' (though of course, it's fine with me if you want to use it that way. It's an English word. We don't have der Rat für englische Rechtschreibung. English is a free for all. Go nuts, meine Kerle).
Finally: "coinage" is both more – and less – than thinking of the word. After the American Dialect Society gave honors to "enshittification," a few people slid into my mentions with citations to "enshittification" that preceded my usage. I find this completely unsurprising, because English is such a slippery and playful tongue, because English speakers love to swear, and because infixing is such a fun way to swear (e.g. "unfuckingbelievable"). But of course, I hadn't encountered any of those other usages before I came up with the word independently, nor had any of those other usages spread appreciably beyond the speaker (it appears that each of the handful of predecessors to my usage represents an act of independent coinage).
If "coinage" was just a matter of thinking up the word, you could write a small python script that infixed the word "shit" into every syllable of every word in the OED, publish the resulting text file, and declare priority over all subsequent inventive swearers.
On the one hand, coinage takes place when the coiner a) independently invents a word; and b) creates the context for that word that causes it to escape from the coiner's immediate milieu and into the wider world.
But on the other hand – and far more importantly – the fact that a successful coinage requires popular uptake by people unknown to the coiner means that the coiner only ever plays a small role in the coinage. Yes, there would be no popularization without the coinage – but there would also be no coinage without the popularization. Words belong to groups of speakers, not individuals. Language is a cultural phenomenon, not an individual one.
Which is rather the point, isn't it? After a quarter of a century of being part of a community that fought tirelessly to get a serious and widespread consideration of tech policy underway, we're closer than ever, thanks, in part, to "enshittification." If someone else independently used that word before me, if some people use the word loosely, if the word makes some people uncomfortable, that's fine, provided that the word is doing what I want it to do, what I've devoted my life to doing.
The point of coining words isn't the pilkunnussija's obsession with precise usage, nor the petty glory of being known as a coiner, nor ensuring that NATO generals' virgin ears are protected from the word "shit" – a word that, incidentally, is also the root of "science":
https://www.arrantpedantry.com/2019/01/24/science-and-shit/
Isn't language fun?
Tor Books as just published two new, free LITTLE BROTHER stories: VIGILANT, about creepy surveillance in distance education; and SPILL, about oil pipelines and indigenous landback.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/10/14/pearl-clutching/#this-toilet-has-no-central-nervous-system
302 notes
·
View notes
Text
My Open-Source Tolkien Studies Data Sets
One of the best parts of being an independent scholar is that I get to be generous with my research. I am not counting on it for a job, and frankly, between teaching at a small rural school and running the Silmarillion Writers' Guild, I will likely never be able to do all that I want to do with the data that I collect and so love the idea that someone might do something with it.
Because I do love making sets of data. Everything from the mind-numbing copy/paste data entry to learning new spreadsheet formulas is enjoyable to me. I'm an introvert in a very extraverted profession, and after a day of being all on for my students, turning everything into numbers is like a cup of tea under a warm blanket with a Golden Retriever at my feet.
So please use these data sets if they interest you. Play with them. Write about and share what you notice. Expand and build on them. Publish using them. If you use my data or work, credit Dawn Walls-Thumma and link to my website, dawnfelagund.com, if possible. I'd also love if you'd let me know if you share anything using them.
Consolidated Timelines. I made this back in 2013. I was trying to arrange all of Tolkien's timelines side by side. I did some weird things with numbers that I'm not sure I fully understand now, but maybe you can make sense of this or maybe you just want everything Tolkien said about timelines in one handy document. (Make a copy of the Consolidated Timelines.)
Fanfiction Archive Timeline. Made for the 2023 Fan Studies Network North America conference, this timeline-on-a-spreadsheet shows archives in the Tolkien and Harry Potter fandoms, multifandom archives, and social networks and when they came online, were active, became inactive, and went offline, along with data about affiliated communities, software, and rescue efforts. I update this timeline annually with that year's data and will continue to add new archives when I have enough data to do so. (Make a copy of the Fanfiction Archive Timeline spreadsheet.)
References to Sources in the Works of J.R.R. Tolkien. In this document, I record each time a narrator's source is mentioned or alluded to. Ideally, this will one day include The Hobbit and The Lord of the Rings as well! For now, it is just The Silmarillion for the selfish reason that I'm predominantly a Silmarillion researcher. (Make a copy of the References to Sources.)
Silmarillion Characters. A list of all of the characters in The Silmarillion, demographic data about them, the number of times they are mentioned, various aliases, and which "books" of The Silmarillion they appear in. The latter part is a work-in-progress. (Make a copy of Silmarillion Characters.)
Silmarillion Death Scenes (spreadsheet | document). For last year's Tolkien at UVM and Oxonmoot conferences, I collected every death scene in the Quenta Silmarillion and recorded various details about character demographics, cause of death, and grief and mourning rituals. (Make a copy of the spreadsheet. Make a copy of the document.)
The Silmarillion: Who Speaks? This is my newest project, which I hope to complete by the end of the year, documenting which characters get to speak actual words, the number of words they speak, and demographics about the speaking characters. Eventually, I would like to include as well characters who are mentioned as having spoken without being given actual dialogue, but one step at a time. Again, this is a work-in-progress. I have just started working on it. Come back in 2025 and, hopefully, there will be interesting stuff to see.
116 notes
·
View notes
Text
A Comprehensive Guide for Writing Advice
Sometimes, despite enjoying writing so much, something is not working for you. Maybe your well of ideas has run dry. Or your WIP has hit a corner and you can't find your way out to the end of the story. Or you need to go back to your finished draft and see if there are any kinks to clear up.
Fortunately, everyone at Writeblrcafé has experienced such, and to help you out, we have a bunch of links to helpful posts by fellow writers to help you along on your writing journey as well as some helpful links to other websites, resources and software.
General:
WHY IS WRITING IS SO FUCKING HARD? (@writers-hq)
Writer Block First Aid Kit (@isabellestone)
Websites for writers (masterpost @2soulscollide)
Writing advice (masterpost @theliteraryarchitect)
Writing resources (masterpost @stinastar)
One look thesaurus (a reverse dictionary where you can enter words or concepts)
Coming Up with Ideas:
97 Character Motivations (@theplottery)
Character Flaws (@fantasyfillsmysoul)
Character Profile (@mistblossomdesigns)
Characters Unflawed (@emptymanuscript)
Why Theme is More Important than Plot (@theplottery)
Weekly writing prompts on Reedsy
Drafting:
3 of the worst story beginnings (and how to fix them) (@theplottery)
Cheat Sheet for Writing Emotion (@myhoniahaka)
Creative Writing for Writers (@writerscreed)
Describing Physical Things (@wordsnstuff)
How to Craft a Natural Plot (@theplottery)
How to Write a Story? (masterpost @creativepromptsforwriting)
How to write: ethnicity & skin colour (@youneedsomeprompts)
What the F is Show Not Tell (@theplottery)
Writing advice from my uni teachers (@thewritingumbrellas)
First Draft: story outlining template meant to help with planning your next big writing project (@fauxriot)
The wonder/ discovery arc (@evelynmlewis)
How to structure a chapter (@theplottery)
How to pace your storytelling (@charlesoberonn)
How to write and research mental illness (@hayatheauthor)
Seven Blogs You Need To Read As An Author (@hayatheauthor)
Editing/Revising:
Eight steps in making the editing process of your book easier (@joaneunknown)
Kill Your Darlings (@tibodine)
Self editing tips (first pass) (@projecttreehouse)
Publishing:
Chill Subs: biggest database for literary magazines and small presses; track your submissions and get your writing published!
5 steps to get your novel ready to self-publish (by @nanowrimo)
Resources for finishing and publishing your novel (masterpost by @nanowrimo)
For self-publishing: this page gives you the exact pixel count of a book spine based on its page count, and/or a template you can use for the correct width/height ratio.
Software:
Scrivener: one time payment of $60 or 70€ (macOS/windows), $24 (iOS; no Euro listed for iOS); used by professionals, many tools to write and organize your novel
Bibisco: free and "pay what you want" version; multilingual, world building, character profiles, writing goals, story timeline, mind maps, notes and more templates to write a novel.
Manuskript: free open source-tool; outliner, novel assistant, distraction-free mode
Ghostwriter: a free and open alternative which has a decent interface with some interesting features, like Hemingway Mode, which disables one's backspace and delete keys, emulating a typewriter.
NaNoWriMo: an international contest to encourage writers to finish writing their novel with many events, groups for exchange with fellow writers, helpful writing advice and help for self-publishing and publishing traditionally.
Campfire Writing: website, desktop app, and mobile app, with tools built in to help manage characters, magic systems, research, etc. It has a great free option, plus monthly, annual, and lifetime purchase options. It also has built-in NaNoWriMo compatibility and a catalogue of tutorials and writing advice videos (suggestion by @harfblarf)
Websites And Writing Apps Every Author Needs In 2023 (@hayatheauthor)
Let us know in the comments if there are any links we could add to it! Reblog this post to help a fellow writer.
Support our work by buying a cup of coffee on KoFi.
#wc.admin#writing community#writing advice#writing tips#writers on tumblr#creative writing#writing resources#writing software
3K notes
·
View notes
Text
How to read the new Witcher book, Crossroads of Ravens, in English (e-book) [GUIDE]
Thanks to @nohtora for the method, I decided to write up a short post detailing how to use Calibre e-reader to read a side-by-side English translation from the Polish text.
This post is dated 12/02/2024 - as of yet, no English translation has been scheduled, nor even announced. I am writing this because I have seen many fans say they want to read the book and are sad because they can't read Polish and don't want to wait forever for a translation and get to posting memes already. Well, me too.
So, I read it.
Because, if you are an international fan like I, and do not live in Poland, you can still purchase a copy of the new book of Rozdroże kruków ("Crossroads of Ravens") and read it... also in English.
How, you might ask? Well, by buying it and translating it yourself... or rather, not yourself, but with the assistance of... *Percival Schuttenbach voice* modern technology!
Now, when I read it, I did the foolish thing of copying and pasting literally page-by-page into Google Translate. Noels (nohtora) had a much better solution, which I will detail here.
This method is easy, free (well you gotta buy the book, but not the software) and accessible (available on Mac, PC, Linux). If you have access to a computer and are OK with reading from screens, I recommend this.
In total, it took me about 10 to 20 minutes to set up from scratch.
Step 1. Download Calibre, a free and open-source e-reader program. Step 2. Install the translation plugin - also free and open-source. Step 3. Purchase the e-book. Step 4. Open the e-book with the plugin, translate. Step 5. Read!
Step 1: Install your e-book reader.
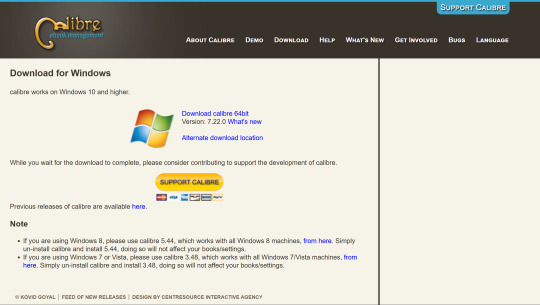
Download Calibre here. It is a free and open-source e-reader program for laptops/computers (although it does not run on mobile devices). You install it like any other program on your computer (Windows, MacOS, or Linux).
Step 2: Download the translation plugin.
youtube
Use this free Calibre plugin to translate e-books.
Watch until 1:00 to install the plugin. The rest of the video you should return to later, during Step 4.
Notes of steps to install plugin: (1) Open Preferences. (2) Get plugins. (3) Get "Ebook Translator" from Author "bookfere.com"
Step 3: Buy the book.
You can purchase Rozdroże kruków online for about $8.
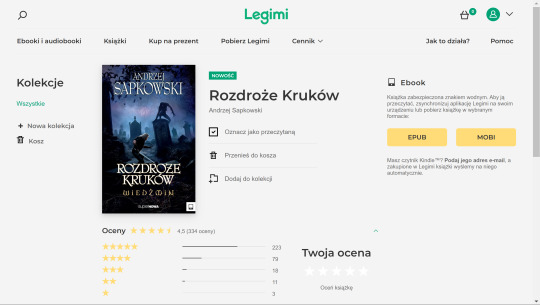
I purchased my copy from Legimi, which I will show you now. I didn't really poke around for other websites, it seems like Legimi had it the quickest. But other sites will have this ebook eventually, so don't feel pressured to get it from Legimi, specifically. I just wanted to include a "how to purchase" step in this guide because (1) it's a direct link to get it (2) in case people felt anxious about navigating a UI they can't read.

This is what the page for Rozdroże kruków looks like. As you can see, it is currently 34.99 zł, or: $8.57 US, $13.21 Aus, £6.77, or €8.15.
For me, it was $8.49 after foreign transaction fees. (I paid through PayPal).
But before you buy anything, you first need to create an account.
From the homepage, click the yellow button, "Zarejestruj się", "Sign up".
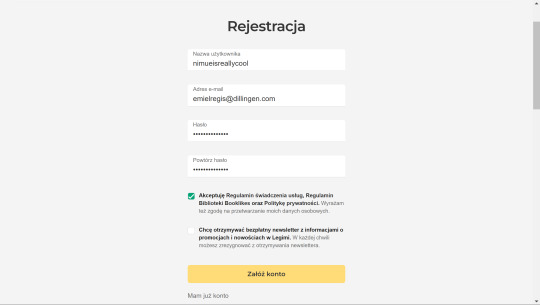
Put your username, email address, password, and confirm password. Check the first box to accept the terms of service. Don't check the second box unless you want their newsletter.
I kind of... already bought the book, so I can't buy it again on this account. I have selected a couple of other books for demonstration purposes. Same process.
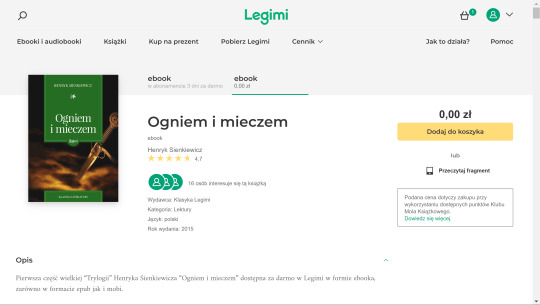
Select the "ebook" tab, the right one on the ribbon (underlined in green), to buy the singular book and not a subscription. Then select the yellow button, "Dodaj do koszyka", or "Add to cart".
After adding to your cart, click the yellow button to go to your cart and checkout.
Check to accept the digital distribution agreement.
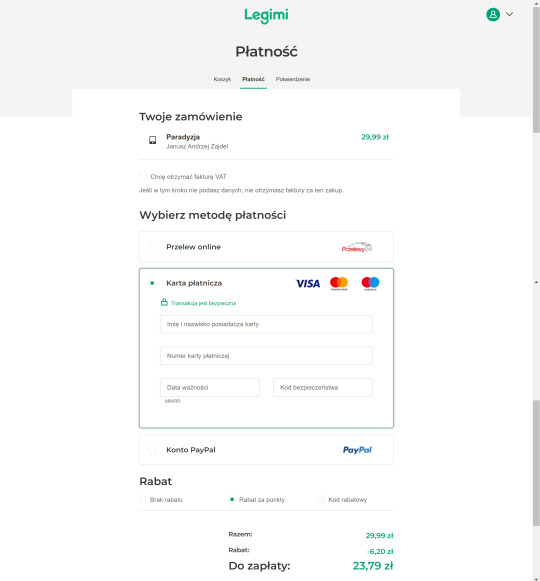
You can then pay with your credit card or PayPal. (From top to bottom, left to right: "First and last name on card" "Credit card number" "Expiration date" "Security code").
Don't worry that it says you will pay in złoty, it will be converted. There may be a foreign transaction fee depending on your bank, but it is typically small (around 3%). If you are only buying an $8 book, that will not be much.
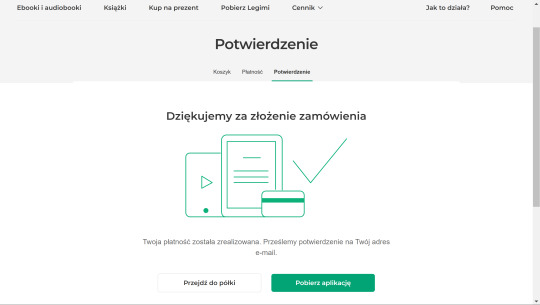
From here, you are going to want to click the WHITE button: "Przejdź do półki", "Go to shelf". (The green button is to download their application, which we're not gonna do for this).
If you skip this on accident, just go to your profile in the top right corner and click "Półka", "Shelf", to see the books on your account.
You will see it in your shelf. Click on it.
Click the yellow button "EPUB" to download it as a .epub format. Save to your Downloads or where-ever is convenient.
Step 4: Open the book in Calibre.
Refer back to the video from Step 2 for this section and watch the part on how to use the plugin. I will add my example here, too.
Open Calibre. Click "Add Book" at the top of the ribbon. Locate rozdroze-krukow.epub from where you saved it. It will be copied to your Calibre library.
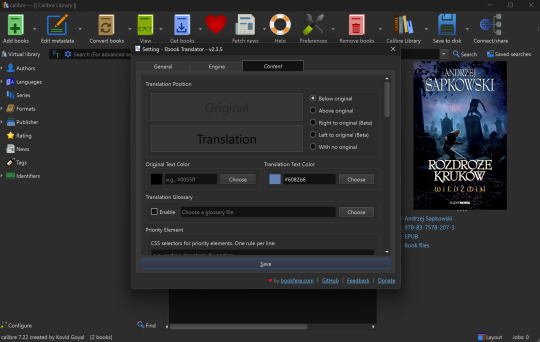
Before starting the translation, make sure to adjust settings in the Translate Book option (sometimes hidden in the ribbon as you can see in my screenshot - just click the kebab menu on the right to bring it up) to export the file the way you would like it to be formatted. I also recommend checking the box in "General" to allow it to merge paragraphs, Google Translate tends to work better when it has more context.
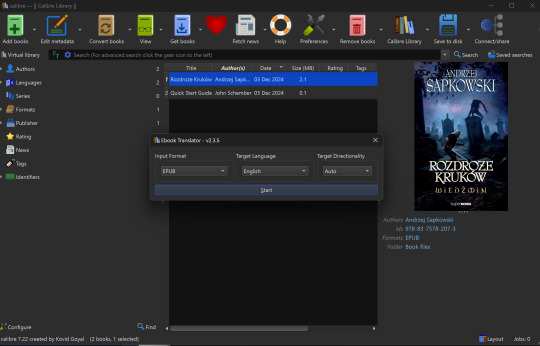
Select Translate Book as shown in the video. Translate into English (or - hey - language of your choice! Sky's the limit). You can also use different translation programs if you'd like, the default is Google.
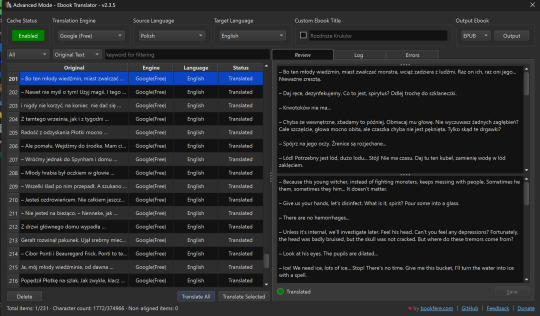
You should select "Output" at the top right after this is complete.

It will create a separate epub in your library, tagged as "Translation."
Step 5: Read it and have fun! It's a fun read!
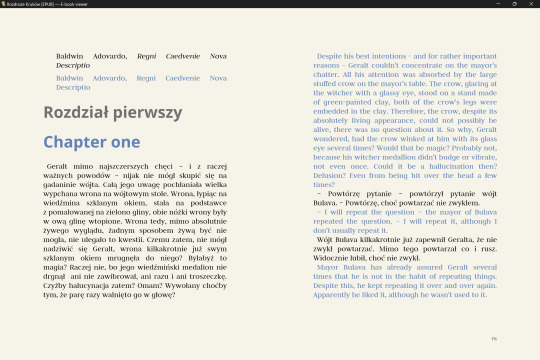
I set up my formatting this way because I want to read a Polish paragraph, then an English paragraph, but you can also set it up to be side-by-side (left page in Polish, right page in English), or even hide the original text if you're not interested and just want the translation.
The days of manually copying-pasting into Google translate are over! Thanks again to Noels for sharing this method in the Discord.
Now, this translation will NOT be 100% perfect - this is a Sapkowski novel after all; humans have difficult translating him, and this is only a machine. I wrote a Reddit post about some caveats to this desperate method of translation, and some silliness I specifically encountered with this book (light spoilers, I mention a couple of characters and settings, but no plot points).
My rule of thumb for when the translation is weird: Pay attention to the context. It is usually not too hard to figure out what the translation meant. If you have real trouble understanding it, or are just curious, Google the Polish phrase that it seems to be hitching on. Make use of Reverso Context, Reddit (r/learnpolish), and Polish learning forums.
Oh, and make sure to watch out for "grasshoppers" ;)
Finally, I recommend you also support the official English translation when it does come out; if not to compare translations, to show Orbit-Gollancz that English readers do want more translations (and ideally we'd like them sooner rather than later).
Good luck on the path ~ Powodzenia na szlaku ~
63 notes
·
View notes
Note
I don't know if this is your royal cup of tea, RTA but there's a long article in the Times of London about Prince Andrew and Fergie's finances as part of an upcoming book late this year on the Duke & Duchess of York. It makes for a interesting read to say the least. Apologies as I do not know how to archive it to your preferences. "Prince Andrew’s finances: my four-year quest to uncover the truth" by Andrew Lownie for The Times.
Thanks. I prefer archive.org links because they're more easily accessible. Web Archive (archive.ph, etc. links get blocked by a lot of security software).
Archived Link
This is but the tip of the iceberg of the York family business activities, because the whole family works together: not just Andrew and Sarah, Duchess of York, his ex-wife, but also their daughters Princess Beatrice, 36, and Princess Eugenie, 34. Both daughters have long been involved in supporting their father’s financial schemes. In November last year, for example, one of Andrew’s business deals in Japan involved a public appearance from Eugenie at a Tokyo event run by Innovate for 1,000 Japanese businessmen. This involvement with their father goes back much further: Andrew often took his daughters on special representative trips and had them join Pitch@Palace events.
and
Until March 2019, Andrew, one of whose courtesy titles is Earl of Inverness, had a 40 per cent stake in a firm based in the British Virgin Islands called Inverness Asset Management, which was ultimately owned by Rowland’s Blackfish Capital Management. His name on the relevant documentation is Andrew Inverness. Andrew has long operated through such names, offshore and nominee accounts (a financial arrangement where a third party holds assets on behalf of the actual owner) and a succession of companies not required to provide full accounts, making it difficult to examine his business activities.
and
The King may be concerned by the optics of a non-working and discredited member of his family continuing to live in such magnificence — he is keen to move Andrew to the smaller Frogmore Cottage — but there is little he can do as long as his younger brother follows the terms of his lease for Royal Lodge. Andrew was granted this lease by the Crown Estates in 2003 after the death of the Queen Mother, who lived in the lodge. This too was controversial, because it was not offered on the open market. The public narrative about Andrew is that the former Falklands hero now spends a lonely life trapped in Royal Lodge, going for horse rides in Windsor Great Park and playing video games and golf. But the reality is rather different. According to one source, he has continued his business activities with recent trips to the Middle East and Switzerland. The King can only hope there are no further scandals to emerge and the press and public soon lose interest in his brother. On present evidence, that is very unlikely.
32 notes
·
View notes
Text
Offline Library
In light of all the Ao3 issues lately I'm gonna throw this up as something people should consider doing. Make your own library of your favorite fics and any you might like to read in the future/are currently reading.
How do you do this? To start: Calibre & ReadEra app
Calibre is a free ebook management software, available on windows, mac, and linux - but also comes in a portable version you can put on a flash drive. Ebooks are very small files, 100s of fics can easily take less than 1GB of space. You can create categories for everything and all the tags on the fics will stay attached to them. You can download directly through ao3, or you can use the browser extension Ficlab which can make the process a little quicker, plus give you a book cover(or you can add your own cover). Epub or Mobi format is best.
ReadEra, is a free reading app with no ads that you can tell to only access a single file where you keep your ebooks. It's open source and the Privacy Statement and Terms & Conditions are very short and easy to read. You can transfer files from Calibre to your phone, but this is also a good option if you don't have a PC to use Calibre. You can make folders to organize all your fics.
Quality of life plugins for Calibre: Preferences > Plugins > Get New Plugins
Look up: EpubMerge, EpubSplit, FanFicFare, Generate Cover (restart calibre once you've added them all) Fun fact, with FanFicFare, you can download new chapters to update fics that are currently in progress directly in Calibre instead of having to open up ao3.
Also, to be clear - back them up for yourself only, don't you fucking dare repost them anywhere.
You can also backup Kindle books (and you should) with Calibre, though that's a bit more complicated; instructions under the read more
Firstly what is DRM? TLDR: digital rights management (DRM) is meant to prevent piracy, however, this also means you never really own your ebooks. If Amazon decides to take down a book you bought? That's it, it's gone and it doesn't matter that you paid for it.
Removing DRM If you're on PC and don't have a kindle device, you'll want kindle version 2.4.0 or it won't work in Calibre.
In Calibre, navigate to Preferences > Plugins > Load Plugin From File - DeDRM - Use the latest Beta or Alpha release, follow instructions on the github page
Preferences > Plugins > Get New Plugins
Look up: KFX Input
You'll have to restart Calibre once you install so just add them all at once before you restart it.
If you need some troubleshooting help setting anything up just ask and I'll try to help!
39 notes
·
View notes
Text

If your library is shutting down, if your downloaded ebooks have vanished from your device, you can get books for free and you can fight back three FREE ways:
Libgen
Calibre
Gutenberg
Libgen allows you to download ebooks for free. The site moves regularly, last time I knew it was libgen.rs but it's here now:
Is that link now dead? Go to your search engine and enter the term LibGen. You'll find where it's moved to. Go there and download books. Save them to a backup. Burn a disk with them on it. Whatever you have to do to keep knowledge accessible to you and others.
In the novel Fahrenheit 451 by Ray Bradbury, books were banned but people assigned themselves a book and memorized it. Then shared the knowledge. We aren't there nor will we be because in Bradbury's time there wasn't the ability to download and save ebooks.
SO DOWNLOAD AND SAVE EBOOKS EXTERNALLY PLEASE.
Libgen helps you do that. So does Calibre, which is a free open-source ebook creator and an ebook reverser. You can take an epub or mobi and turn it into a PDF or a .docx.
Please do this if you fear knowledge will be lost. Or even if you don't. Just…save save save what you can because Amazon and all the other multi-nationals do not care nor will they care if knowledge goes away.
Finally Gutenberg.org is your one stop free source for books out of copyright. Download, download, download. They also have audiobooks.
Happy library building my friends.
(Library image: Wikimedia Commons)
49 notes
·
View notes
Text
I Miss You More Than Anything (Kerry V. Erich)

(a/n: whaddup, this is a two parter. was it supposed to be? no. do i have self-control? also no. my apologies for any mistakes, had to use a new software bc NOTHING WANTS TO WORK. requests still open, enjoy! :))
“They want him to stay a few more days for a few more scans. Dave’s going back tonight but I’ll stay with Kerry.” Kevin explained over the phone late at night. It had been nearly four months since you saw Kerry—minus the broadcasted matches—and you were almost there. Although he should’ve been back nearly two months ago, his father would book any match he could. Now he was in the hospital with Kevin because they were having trouble in between matches.
That knee of his was a common issue, but that issue was only an advantage to his opponents. Not to mention the head injury he received from Ric Flair a couple weeks back, and the lacerations from a cage match. Kevin was possibly looking at a fractured hand due to landing wrong, so he wasn’t as restricted as Kerry.
Kevin called you every night ever since Kerry was admitted. He kept you updated, assured you Kerry was going to be just fine. Every call there was something new, and every call made you worry more than before. Kerry used to call no matter what happened to him, and his voice was enough to put you at ease.
But lately he hadn’t been able to. Kevin, and sometimes David, was your only source to reach him. Without him, it simply wasn’t enough. You wanted to hear him, hold him, be held by him.
“Thank you, Kev,” you held in a sigh. “I know you’ll keep taking care of him.”
It was difficult sleeping that night. The first month was a dream compared to now. All you could do was close your eyes and think endlessly of Kerry. He held you tight the morning he left for the airport. You were half awake and hardly able to see, but you didn’t need to. You could feel him against you, embrace warm and kisses desperate and sweet.
“I’m going to miss you,” he whispered as his large hand cupped your cheek. You opened your eyes then, welcoming the sight of the moonlight casted over him.
“Don’t think of me too much.” You murmur, hand slipping out from under the covers to push come of his hair back. It was slightly damp from showering, no doubt. “I’ll be here when you come back.”
Kerry learned in to press a kiss on your temple. You felt a hint of a smile as he did so, and you tried to picture him as you closed your eyes. He was always affectionate even at the beginning of your relationship. When words got caught in his throat, he always sought out touch.
“I wish you could come with us,” he said quietly. “I know we could make it happen, if—“
“Kerry..” You sighed, “we can’t push it. It’s a miracle I’m even allowed in the locker room when you’re here.”
Kerry could only let out a dry chuckle. He began to litter small kisses over your nose and forehead before surprising you with a deep kiss. Your eyes opened as he moved on top of you.
Pushing back the memory, you opened your eyes to look up at the ceiling. You could almost see him as he was all those months ago. Your skin was on fire then, itching for Kerry to undress you. Yet now it was cold even if you were under covers. It was too quiet, too empty.
You couldn’t do it anymore.
Unable to form a sensible thought, you shoved the comforter down and got out of bed. You slipped on a pair of sneakers and sought out your keys. There was enough gas in the tank to reach Lubbock, then you could head towards out of state. It was taking nearly an entire day to reach their hotel, but you couldn’t seem to care.
The first two hours went by quick. Music carried you through the drive and when you got sleepy, you'd turn up the volume. It didn’t hit you until 3 AM that you were mindlessly traveling out of Texas because you couldn’t sleep. By 4:30 AM you were arguing with yourself, trying to reason with your sudden decision.
Within an hour you were getting gas, and not once did you think about turning back. It was too late, and you had thought over what another day without Kerry would be like.
It wasn’t easy, you understood that from the beginning. Kerry was always going to travel; he was always going to be apart from you for long periods of time. And you were okay with that. You could prepare for those lonely nights and quiet days. But you couldn’t prepare for the constant delays.
“He’s doing it on purpose. I know he is.”
“Well, he can’t keep you away from home forever.”
There was a pause, “..I’m getting tired.”
By sunrise you had fries and a milkshake for breakfast, and a burger for lunch. You skipped dinner in hopes of making it to the hotel before it was completely dark out. While you were completely exhausted, you couldn’t stop. It was almost 10 PM by the time you reached the hotel parking lot, and you prayed you could get ahold of Kevin.
As you unbuckled the seatbelt and gathered what trash you had, you caught a tall figure heading towards the entrance. All it took was the sight of blonde hair to get you scrambling out of your car.
“Kev!” You called out, slamming the door and leaving your purse in your unlocked vehicle. “Kevin—!”
He turned around then, having to double take the sight in front of him. You, twenty hours away from where you were supposed to be, drained and relived. He could hardly form a coherent sentence as you came up to him. All he could muster your name.
“What’re—what’re you..”
“I’m an idiot, I know, but I couldn’t sleep another night. Kev, I—you know how hard it’s been…I need to see him. I need to see with my own eyes that he’s okay. I will never do this again, I promi—“ You were cut by Kevin’s crushing hug. Instinctively, you wrapped your arms around him and closed your eyes. It was an instant mistake. You could hardly hold yourself up, but Kevin was there to keep you steady.
You hadn’t even realized it, but you had begun to cry.
Kevin rubbed your back, still processing how you managed to drive from Denton to Los Angeles within a day. Although it rattled him; something could’ve happened to you, he felt a sense of joy for you and Kerry.
“It’s okay,” he spoke softly. “It’s gonna be okay.”
Kevin took you into the lobby and up to his room. He and Kerry had shared a room while David had been next door, and their dad stayed on the other side. If Fritz knew you were there Kevin and Kerry wouldn’t hear the end of it. Luckily, you snuck in without getting caught.
As soon as the door was closed, Kevin showed you where Kerry slept and where all his things were. He had begun to pack for him, but not everything was put up. You took one of Kerry’s t-shirts and a pair of sweats before heading to go shower.
Sleep came easy that night. Maybe from the lack of, or maybe because home wasn’t so far away.
#iron claw x reader#the iron claw#the iron claw imagine#iron claw fic#jeremy allen white x reader#kerry von erich x reader#jeremy allen white
24 notes
·
View notes
Text
more on art production ~under capitalism~
reading Who Owns This Sentence?, a very engaging and fiercely critical history of the concept of copyright, and it's pretty fire. there's all sorts of fascinating intricacies in the way the notion of IP formed around the world (albeit so far the narrative has mainly focused on Europe, and to a limited extent China), and the different ideologies that justified the types of monopolies that it granted. the last chapter i read skewers the idea that the ability to exploit copyright and patents is what motivates the writing of books and research/invention, and I'll try and pull out the shape of the argument tomorrow. so far I'm only up to the 18th century; I'm looking forward to the rest of their story of how copyright grew from the limited forms of that period into the monster it is today.
it's on libgen if you wanna read it! i feel like the authors would be hypocrites to object :p
it is making me think about the differences between the making of books and other media, from (since this has been rattling around my head lately) an economic angle...
writing books, at least in the case of fiction is usually done on a prospective, spec-work kind of basis (you write your novel with no guarantee it will get published unless you're already an established author under contract). admittedly, a lot of us probably read books by authors who managed to 'make it' as professional authors and write full time - but this is not a lucrative thing to do and to make it work you need truly exceptional luck to get a major hit, or to be extremely prolific in things people want to read.
the films and games of the types most of us play are, by contrast, generally made by teams of salaried people - and thus do rarely get made without the belief it will be profitable. if you went on about your 'monetisation model' when writing a book, people would look at you funny and rightly so, but it's one of the first questions that gets asked when pitching a game.
open source software is a notable comparison here. a lot of it is done for its own sake without any expectation of profit, taking untold hours, but large free software projects tend to sprout foundations, which take donations (typically from companies that use the software) to pay for full time developers. mozilla, notably, gets a huge part of its funding from google paying for their search engine to be the default in Firefox; this in turn drives development of not just Firefox itself but also the Rust programming language (as discussed in this very enlightening talk by Evan Czaplicki). Blender is rightly celebrated as one of the best open source projects for its incredibly fast development, but they do have an office in amsterdam and a number of full time devs.
what money buys in regards to creative works is not motivation, but time - time to work on a project, iterate and polish and all that. in societies where you have to buy food etc. to survive, your options for existence are basically:
work at a job
own capital
rely on someone else (e.g. a parent or partner)
rely on state benefits if you can get them
beg
steal
if you're working at a job, this takes up a lot of your time and energy. you can definitely make art anyway, loads of people do, but you're much more limited in how you can work at it compared to someone who doesn't have to work another job.
so again, what money buys in art is the means of subsistence for someone, freeing them to work fully on realising a project.
where does the money come from that lets people work full time on art? a few places.
one is selling copies of the work itself. what's remarkable is that, when nearly everything can be pirated without a great deal of effort, it is still possible to do this to some degree - though in many ways the ease of digital copying (or at least the fear if it) has forced new models for purely digital creations, which either trade on convenience (streaming services) or in the case of games, find some way to enforce scarcity like requiring connection to a central server and including 'in-app purchases', where you pay to have the software display that you are the nebulous owner of an imaginary thing, and display this to other players. anyway, whichever exact model, the idea is that you turn the IP into capital which you then use to manufacture a product like 'legal copies', 'subscriptions' or 'accounts with a rare skin unlocked'.
the second is using the work to promote some other, more profitable thing - merchandising, an original work, etc. this is the main way that something like anime makes money (for the production committee, if not the studio) - the anime is, economics-wise, effectively an ad for its own source manga, figurines, shirts etc. the reason why there is so much pro media chasing the tastes of otaku is partly because otaku spend a lot on merch. (though it's also because the doujin scene kind of feeds into 'pro' production)
the third is some kind of patronage relationship, notably government grants, but also academic funding bodies, or selling commissions, or subscriptions on a streaming platform/patreon etc.
grants are how most European animated films are funded, and they often open with the logos of a huge list of arts organisations in different countries. the more places you can get involved, the more funds you can pull on. now, instead of working out how to sell your creation to customers who might buy a copy, under this model you need to convince funding bodies that it fits their remit. requesting grants involves its own specialised language.
in general the issue with the audience patronage model is that it only really pays enough to live on if you're working on a pretty huge scale. a minority make a fortune; the vast majority get a pittance at most, and if they do 'make it', it takes years of persistence.
the fourth is, for physical media, to sell an original. this only works if you can accumulate enough prestige, and the idea is to operate on extreme scarcity. the brief fad of NFTs attempted to abstract the idea of 'owning' an original from the legal right to control the physical object to something completely nebulous. in practice this largely ended up just being a speculative bubble - but then again, a lot of the reason fine art is bought and sold for such eye watering sums is pretty much the same, it's an arbitrary holder of an investment.
the fifth is artworks which are kind of intrinsically scarce, like live performances. you can only fit so many people in the house. and in many cases people will pay to see something that can be copied in unique circumstances, like seeing a film at a cinema or festival - though this is a special case of selling copies.
the sixth is to sell advertising: turn your audience into the product, and your artwork into the bait on the hook.
the alternative to all of these options is unpaid volunteer work, like a collab project. the participants are limited to the time and energy they have left after taking care of survival. this can still lead to great things, but it tends to be more unstable by its nature. so many of these projects will lose steam or participants will flake and they'll not get finished - and that's fine! still, huge huge amounts of things already get created on this kind of hobby/indie/doujin basis, generally (tho not always) with no expectation of making enough money to sustain someone.
in every single one of these cases, the economic forces shape the types of artwork that will get made. different media are more or less demanding of labour, and that in turn shapes what types of projects are viable.
books can be written solo, and usually are - collaborations are not the norm there. the same goes for illustrations. on the other hand, if you want to make a hefty CRPG or an action game or a feature length movie, and you're trying to fit that project around your day job... i won't say it's impossible, I can think of some exceptional examples, but it won't be easy, and for many people it just won't be possible.
so, that's a survey of possibilities under the current regime. how vital is copyright really to this whole affair?
one thing that is strange to me is that there aren't a lot of open source games. there are some - i have memories of seeing Tux Racer, but a more recent example would be Barotrauma (which is open source but not free, and does not take contributions from outside the company). could it work? could you pay the salaries of, say, 10 devs on a 'pay what you can' model?
it feels like the only solution to all of this in the long run is some kind of UBI type of thing - that or a very generous art grants regime. if people were free to work on what they wanted and didn't need to be paid, you wouldn't have any reason for copyright. the creations could be publicly archived. but then the question i have is, what types of artwork would thrive in that kind of ecosystem?
I've barely talked about the book that inspired this, but i think it was worth the trouble to get the contours of this kind of analysis down outside my head...
20 notes
·
View notes
Note
Haii, Sosaaa! Okay, so i wanna get into animation BUT I'm really new. Lucky for me I know someone who's awesome at animating (that's you btw) so I need your expertise. What program do you use, and also do you have any tips for a newbie?
Aww Jay, you flatter me~✨but before answering I must put the disclaimer that I'm just a hobbyst animator with no formal training, that during quarintine thought "Oh woah, these Multiple Animation Projects that people do in YT are so cool! I want to join them!" and started learning by herself. Take everything I say with a grain of salt.
First things first: I mainly use TV Paint. However I'm not letting you spent money on paid stuff you don't even know you'll like, so here are some free alternatives that I've used as well:
Krita is mostly a drawing program, but it also has a animation interface. The red and black parts of the Helena AMV were made with this.
Flipaclip is kinda neat phone/tablet app for when you want to animate on the go, but it can also feel more limiting since various features have to be unlocked by watching ads or getting the premuim version (in typical app fashion, I guess...)
Blender, while mainly meant for 3D animation, also has been developing Grease Pencil, that allows 2d animation in both 2D or 3D spaces. And the lines are vectors, so you can edit them after drawing them and such.
You can even use normal drawing programs. I've animated with Paint Tool Sai and Medibang by drawing all the frames, saving each frame as a image in sequence (001, 002, 003...) and putting them together in some editing program or gif maker. It's possible, but it's more work.
There's also OpenToonz, which is an open source version of the software used by Studio Ghibli in some movies?? I haven't used this one, but I'll leave it here in case you want to give it a try.
For editing (In the rare scenarios where I do fancy editing) I use After Effects. I can't personally recommend any free substitute, but as far as I've read, DaVinci Resolve seems like a good replacement.
Now, regarding actual animation advise, I won't explain the principles or terminology because:
It's very overwhelming since it's A LOT of information, specially for a beginner
I work mostly by vibes, so there are concepts I don't undertand well enough to explain to others
Instead I'll foward you this whole book that goes in detail about all that technical stuff.
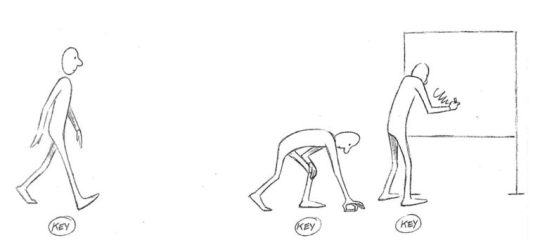
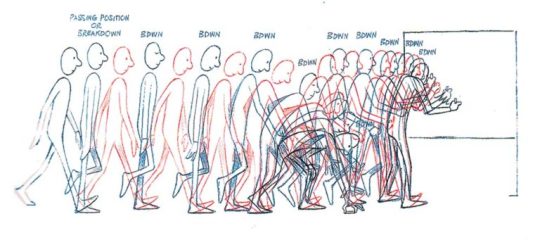
That being said, at the end of the day, hand-drawn animation is drawing main poses (aka key poses) and then drawing a bunch of more drawings in between until the drawings together look like they move.
So yeah, it's a lot of work,
....but it doesn't have to be tedious work~ 👀✨
As a hobbyst I live for the philosophy of vibing during the process instead of chasing perfect results, and I'm assuming that you just want to try for funsies and not that you're trying to become a pro industry animator anyways. Here are my personal tips to make the animation process more bearable:
1- Pick something you love! Seriously, any long task becomes more bearable when it's about a theme or character you enjoy. There's a reason why most of my animations have been about HnK or Signalis,
2- SIMPLIFY THAT DESIGN! Before you even pick the pencil, I want you to really look at the design of whatever you're going to animate and ask yourself "Are all the details in this design really necessary?" Every extra detail really starts to add when you have to draw the same thing multiple times for a single second of animation. You don't need to add all the robotic details on replika bodies, or draw every single stripe a tiger has, to put an example.


3- Keep it simple! At some point you might have a cool idea of an anime style epic battle with looks of cool explosions, camera angles, awesome fighting choreograpies and whatnot; but you first have to start small or else you'll get overwhelmed and not finish anything (been there, done that). Start with something simple like a bouncing ball, or if you're feeling brave, a walk cycle or a character turning their head. In that same sense, remember the book I linked? Don't try to learn all of it at once, go one step at a time.
4-Use references! On google images there are multiples breakdowns of things like run, flight or walk cycles, for example, and you can even use youtube videos! (tip: pause the video and use "," and "." to move back and forth between frames). In case you need help with a very specific pose or movement, you can use yourself or a friend recreating the pose irl (yes, the process is very embarrasing, and yes, the results are worth it)
4- You don't have to animate/redraw everything everytime. We aren't going for Oscar winning levels of animation here anyways. It's ok to copy and paste across different frames, only animate certain parts of the body and leave the rest static, panning the camera to simulate movement... Listen, if actual standars profesionals cut corners, why can't we? We aren't even getting paid for this!
6- It's ok to suck at first. My first animation was this kitty back in 2016,

and here's this Elster from last year doing similar movements.

It's not perfect by any means, but I feel like both art and animation-wise there has been some improvement. And I guess that right now I could remake it and make it even better, but that's because I got more experience and a better eye at finding mistakes and how to solve them, and you get that with practice.
...So yeah, there's that, have fun in your animation endeavors 👍✨
#OH MY GOD THIS IS A TESTAMENT#I'm so sorry Jay for making you read all of this#I know less that you think#but the little I know I try to share to the best of my habilities#animation#ask#the yappening
13 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
253 notes
·
View notes
Text
Important Update Post
Imagine I am sitting staring at a camera with a sigh, no background music before the video cuts to me talking. But Im not caught in a controversy of racism or plagiarism or smth.
Here's the tldr: I will no longer be making AI bots. All current bots will remain up, my bot masterpost will be moved to my masterpost masterpost. I just won't be making new ones. Finished and posted every bot that was in the works here to make this transgression up to yous. I will not be leaving the fandom, I'll still write and clown around.
"Why would you do this you cunt?" I hear you, I am so stinky for this. Before I list my reasons, I want to say first and foremost this is personal and I have less than no judgement for other bot makers. I absolutely love mutuals like Mel that make bots and will continue to support them. Reasons became long and are under the cut.
Reasons I don't wanna continue making ai bots:
I started because it was a low energy way for me to participate in fandoms when I didn't have the spoons to write anymore. It no longer feels like a creative outlet and no longer sparks joy.
I would rather devote myself solely on practicing and improving my writing as a way to contribute my passion to fandoms.
I can't shake the feeling I am plagiarizing. Ai chat models use lots of "work" to train their models, and while I could not find what millions of texts Cai is based on (conveniently not listed on the website), all models like it basically engorge from random sources, books and hell, even this post. Anything goes and currently there are legal battles over this.
It's bad for the environment. Can't find a measurement for Cai specifically, but GPT-3 (same scale) produced 500 tons of carbon dioxide to train that single model, not including its other ones. Please note I'm aware AI can absolutely be used to help fight climate change, as is mentioned in the linked article. Also they use the same amount of water that is required to cool nuclear reactors.
It's always conflicted with my morals. Believe it or not, I'm the person that's usually big into internet privacy, anti ai, piracy is morally good (not indie obvs) etc. Openly creating stuff that supports and funds software that steals peoples works, their information without permission and for profit is not me. So I don't wanna do it.
Again, this is not a judgement or a means to shame people that create ai bots or use them. I've made so many friends because of them. If everyone thats every used my bots stopped, it's not gonna solve capitalism. This is just me, an individual, stepping away from one thingy and feeling the need to be honest and open bc thats my policy and honestly how most of you know me (so now hard feelings if you unfollow).
Love you guys lots and thank you for all the love you've shown me through my bots and for all the times you've made me laugh <3
73 notes
·
View notes