#adenine pairs with thymine in dna
Text
In honour of exams, have an incredibly niche biology meme for the style and stendy girlies

#south park#sp stan#stan marsh#sp kyle#kyle broflovski#style#Stan is adenine#Wendy is thymine#Kyle is uracil#adenine pairs with thymine in dna#but adenine pairs with uracil in rna#basically#Stan has bitches
31 notes
·
View notes
Text
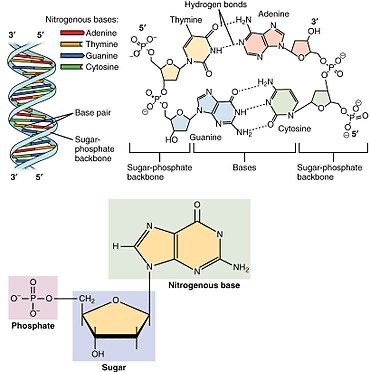
According to scale models, the dimensions of an adenine-thymine base pair are almost identical to the dimensions of a guanine-cytosine base pair, and length of each pair is consistent with the core thickness of a DNA strand (figure 25.9).

"Chemistry" 2e - Blackman, A., Bottle, S., Schmid, S., Mocerino, M., Wille, U.
#book quotes#chemistry#nonfiction#textbook#base pairs#dna#deoxyribonucleic acid#thymine#adenine#cytosine#guanine
0 notes
Text
Exploring the Marvels of Biological Macromolecules: The Molecular Machinery of Life (Part 3)
Nucleotide Structure: The Building Blocks
Nucleotides, the monomers of nucleic acids, consist of three fundamental components:
1. Phosphate Group (PO4): Provides a negatively charged backbone for the nucleic acid strand.
2. Pentose Sugar: In DNA, it's deoxyribose; in RNA, it's ribose. The sugar moiety forms the framework of the nucleotide.
3. Nitrogenous Base: Adenine (A), Guanine (G), Cytosine (C), Thymine (T) in DNA, and Uracil (U) in RNA. These bases are responsible for the genetic code.
DNA (Deoxyribonucleic Acid): The Repository of Genes
DNA is a double-stranded helical molecule, with each strand composed of a linear sequence of nucleotides. It encodes the genetic information necessary for an organism's development, growth, and functioning. The Watson-Crick base pairing rules—A with T and C with G
DNA (Deoxyribonucleic Acid): The Repository of Genes
DNA is a double-stranded helical molecule, with each strand composed of a linear sequence of nucleotides. It encodes the genetic information necessary for an organism's development, growth, and functioning. The Watson-Crick base pairing rules—A with T and G with C—ensure DNA's complementary and faithful replication.
RNA (Ribonucleic Acid): From DNA's Blueprint to Protein Synthesis
RNA plays diverse roles in the cell, including serving as a messenger (mRNA) for protein synthesis, a structural component of ribosomes (rRNA), and an adapter molecule (tRNA) that brings amino acids to the ribosome during translation. Unlike DNA, RNA is often single-stranded and contains uracil (U) instead of thymine (T).
Genome Organization and Chromosomes
Genomic DNA is organized into chromosomes within the cell nucleus. These structures enable efficient storage, replication, and transmission of genetic information during cell division and reproduction.
Replication and Transcription
DNA replication ensures the faithful duplication of genetic material during cell division, while transcription converts DNA into RNA, providing a template for protein synthesis.
Translation
The cellular machinery, composed of ribosomes and tRNA, reads the mRNA code and assembles amino acids into polypeptides during translation, ultimately forming functional proteins.
Genetic Code
The genetic code, a triplet code of nucleotide sequences (codons), dictates a protein's sequence of amino acids. It is nearly universal, with only minor variations across species.
Epigenetics
Epigenetic modifications, such as DNA methylation and histone modifications, regulate gene expression without altering the underlying DNA sequence, pivotal in development and cell differentiation.
Macromolecular interactions are the essence of cellular life. Within the complex microcosm of a cell, countless molecules engage in precise and choreographed dances, forming intricate networks that govern every facet of biology. These interactions, governed by the principles of biochemistry, are the foundation upon which life's processes are built.
Amino Acids: The Building Blocks
Proteins are composed of amino acids organic molecules that contain an amino group (-NH2), a carboxyl group (-COOH), a hydrogen atom, and a distinctive side chain (R group). There are 20 different amino acids, each with a unique side chain that confers specific properties to the amino acid.
Primary Structure: Amino Acid Sequence
The primary structure of a protein refers to the linear sequence of amino acids in the polypeptide chain. The genetic information in DNA encodes the precise arrangement of amino acids.
Secondary Structure: Folding Patterns
Proteins don't remain linear; they fold into specific three-dimensional shapes. Secondary structures, such as α-helices and β-sheets, result from hydrogen bonding between nearby amino acids along the polypeptide chain.
Tertiary Structure: Spatial Arrangement
The tertiary structure is the overall three-dimensional shape of a protein, determined by interactions between amino acid side chains. These interactions include hydrogen bonds, disulfide bridges, ionic bonds, and hydrophobic interactions.
Quaternary Structure: Multiple Polypeptide Chains
Some proteins, known as quaternary structures, comprise multiple polypeptide chains. These subunits come together to form a functional protein complex. Hemoglobin, with its four subunits, is an example.
Protein Functions: Diverse and Essential
Proteins are involved in an astounding array of functions:
1. Enzymes: Proteins catalyze chemical reactions, increasing the speed at which reactions occur.
2. Structural Proteins: Proteins like collagen provide structural support to tissues and cells.
3. Transport Proteins: Hemoglobin transports oxygen in red blood cells, and membrane transport proteins move molecules across cell membranes.
4. Hormones: Hormonal proteins, such as insulin, regulate various physiological processes.
5. Immune Function: Antibodies are proteins that play a crucial role in the immune system's defense against pathogens.
6. Signaling: Proteins are critical in cell signaling pathways, transmitting information within cells.
Protein Denaturation and Folding
Protein Diversity: The vast diversity of proteins arises from the combinatorial possibilities of amino acid sequences, secondary structure arrangements, and three-dimensional conformations.
Nucleic acids, the remarkable macromolecules that govern all living organisms' genetic information, are life's quintessential molecules. These complex polymers of nucleotides play an unparalleled role in the storage, replication, and expression of genetic information, shaping the development, characteristics, and functions of every living entity on Earth. Let's embark on an exploration of the intricate world of nucleic acids.
Nucleotide Structure: The Building Blocks
Nucleotides, the monomers of nucleic acids, consist of three fundamental components:
1. Phosphate Group (PO4): Provides a negatively charged backbone for the nucleic acid strand.
2. Pentose Sugar: In DNA, it's deoxyribose; in RNA, it's ribose. The sugar moiety forms the framework of the nucleotide.
3. Nitrogenous Base: Adenine (A), Guanine (G), Cytosine (C), Thymine (T) in DNA, and Uracil (U) in RNA. These bases are responsible for the genetic code.
DNA (Deoxyribonucleic Acid): The Repository of Genes
DNA is a double-stranded helical molecule, with each strand composed of a linear sequence of nucleotides. It encodes the genetic information necessary for an organism's development, growth, and functioning. The Watson-Crick base pairing rules—A with T and G with C—ensure DNA's complementary and faithful replication.
RNA (Ribonucleic Acid): From DNA's Blueprint to Protein Synthesis
RNA plays diverse roles in the cell, including serving as a messenger (mRNA) for protein synthesis, a structural component of ribosomes (rRNA), and an adapter molecule (tRNA) that brings amino acids to the ribosome during translation. Unlike DNA, RNA is often single-stranded and contains uracil (U) instead of thymine (T).
Genome Organization and Chromosomes:
Replication and Transcription: DNA replication ensures the faithful duplication of genetic material during cell division, while transcription converts DNA into RNA, providing a template for protein synthesis.
Translation: The cellular machinery, composed of ribosomes and tRNA, reads the mRNA code and assembles amino acids into polypeptides during translation, ultimately forming functional proteins.
Genetic Code: The genetic code, a triplet code of nucleotide sequences (codons), dictates the sequence of amino acids in a protein. It is nearly universal, with only minor variations across species.
Epigenetics: Epigenetic modifications, such as DNA methylation and histone modifications, regulate gene expression without altering the underlying DNA sequence, pivotal in development and cell differentiation.
Macromolecular interactions are the essence of cellular life. Within the complex microcosm of a cell, countless molecules engage in precise and choreographed dances, forming intricate networks that govern every facet of biology. These interactions, governed by the principles of biochemistry, are the foundation upon which life's processes are built.
#science#biology#college#education#school#student#medicine#doctors#health#healthcare#genetics#genetic engineering#science nerds#dna activation#new dna
24 notes
·
View notes
Note
Hiiii Dona:]🪐 💜Aka pretty boy
It's moonie again🌙🤍
I missed heeerrrrrreeeeee🍀 ༎ຶ‿༎ຶ 🫂
and also ....may I request a Comprehensive infodump about DNA encodings by any chance
(─ ~ ─||) ??
Of course, you don't have to 🤍💫
wishing you the very best please be happy <3💜🧚🫂
Oh, Moonie, again with your words of sheer admiration ~ pretty boy???? Ksksksksksks
🧬 DNA-Encoding 🧬
YESSSS
How is information stored in DNA?
DNA stores biological information in sequences of four bases of nucleic acid that are strung along ribbons of sugar-phosphate molecules in a shape of a double helix:
Adenine (A)
Thymine (T)
Cytosine (C)
Guanine (G)
Each base will only form hydrogen bonds across the helix with its opposing base (A with T, C with G), an unzipped DNA molecule creates two templates for exact copies.
The sequence of these four bases can provide all the instructions needed to build any living organism.
Think about the English language, which can represent a huge amount of information using just 26 letters.
Even more profound is the binary code used to write computer programs. This code contains only ones and zeros - hello computers!!
The DNA alphabet can encode very complex instructions using just four letters, though the messages end up being really long.
The human genome (all the DNA of an organism) consists of around three billion nucleotides divided up between 23 paired DNA molecules, or chromosomes.
The information stored in the order of bases is organized into genes: each gene contains information for making a functional product.
And NOW I could dive into HOW information becomes... for example me ;)
But this is already so long & I messed up posting soooo.
Here's very interesting study I've found while researching:
DNA encoding could be the solution to our words data storage problem.
About 10 trillion gigabytes of digital data already exist today & EVERY days there are another 2.5 million gigabytes of data added to that massive pile.
Much of this data is stored in enormous facilities known as exabyte data centers (an exabyte is 1 billion gigabytes), which can be the size of several football fields and cost around $1 billion to build and maintain.
Many scientists believe there might be an alternative solution of all of this costly maintaing of data, which is at the moment not really great for the environment either.
DNA evolved to store massive quantities of information at very high density.
A coffee mug full of DNA could theoretically store all of the world’s data. Just think about it!
You probably know that digital storage systems encode any kind of information as a series of 0s & 1s.
This same information can be encoded in DNA using the four nucleotides that make up the genetic code. For example, G & C could be used to represent 0 while A & T represent 1.
DNA has several other features that make it desirable as a storage medium:
It is extremely stable
Fairly easy (but expensive) to synthesize & sequence
It's high density — each nucleotide, equivalent to up to two bits, is about 1 cubic nanometer — an exabyte of data stored as DNA could fit in the palm of your hand!
Edit: have I posted this ON ACCIDENT without finishing? Yes. Yes I have.

#donnie speaks#donnie answers#donatello infodumps#donnies exceptional mind#rottmnt#turtle net#rise of the teenage mutant ninja turtles#rottmnt donnie#rottmnt donatello#dna#dna encoding
16 notes
·
View notes
Text
So far, whenever I see fanon chumhandles for the dancestors, it's always the same letters as their descendants, maybe flipped around. Kankri gets the same CG initials as Karkat, etc.
This is a huge missed opportunity to use the nucleotide base pairings in the names. In DNA, the nucleotide bases Adenine pairs with Thymine and Cytosine pairs with Guanine.
Or, more simply, A to T, C to G.
The dancestors should use corresponding nucleotide matching names! I added some example names following the idea.
Meenah: GG (gemstoneGlaucus)
Cronus: GT (gnomonicTerran)
Kurloz: AG (agonizingGrace)
Horuss: GA (godivaAcquiesced)
Aranea: TC (tarantulaCalligrapher)
Latula: CG (cavalierGamegirl)
Porrim: CT (celestialTorchbearer)
Meulin: TG (tigressGallavant)
Mituna: AT (apocalypseTermination)
Rufioh: TA (talewrightAnimation)
Damara: TT (terrorsThaumaturge)
Kankri: GC (grievousConviction)
#Homestuck#Dancestors#Let me know if I made mistakes or if you have better ideas for names#opal says words#fanon chumhandles
39 notes
·
View notes
Text
This evening, I will adopt an academic perspective to deconstruct the misleading notion that human differences are primarily attributed to skin color or variations in pigmentation. It is fundamentally misguided to consider blood as a determinant of racial purity, especially when scientific understanding reveals that humans can be categorized into a mere four blood types, which can expand to eight when considering the Rh factor.
1. The 20 amino acids discussed are all L-isomer, α-amino acids. Chromosomes, which are threadlike structures composed of proteins and a single DNA molecule, function to transmit genomic information between cells. In both plants and animals, including humans, chromosomes are located within the cell nucleus. Humans possess 22 pairs of autosomes and one pair of sex chromosomes (XX or XY), totaling 46 chromosomes.
2. Each of the four nucleotides—adenine (A), thymine (T), guanine (G), and cytosine (C)—is formed by attaching a phosphate group and a nucleobase to a sugar molecule. The sugar present in all four nucleotides is deoxyribose, characterized by its cyclic structure, which consists of one oxygen atom and four carbon atoms arranged in a ring. Additionally, a fifth carbon atom is linked to the fourth carbon in the ring, and a hydroxyl group (-OH) is bonded to the third carbon.
3. This underscores the undeniable reality that all humans share a commonality, challenging the notion that individuals with red or yellow skin differ fundamentally, or that the concept of whiteness supersedes all human classifications; in truth, no human can reproduce the full spectrum of skin color variations except for those identified as Black.
2 notes
·
View notes
Text
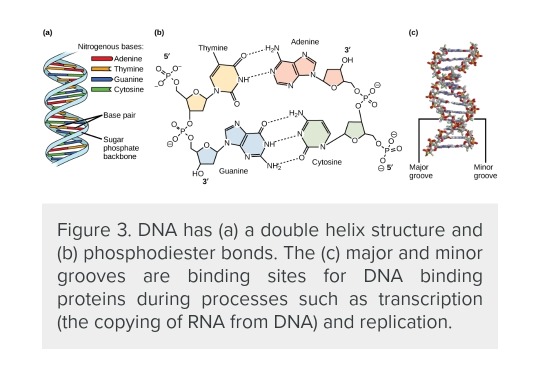
Genetic code is the basis on which the genetic variety of life is founded. The codes determine and manage the function and creation of new cells by reading the genetic code from deoxyribonucleic acid – better known as DNA – the library where genetic information is stored. DNA is housed in chromosomes, which themselves are found in every cell. In humans, a set of 23 chromosomes to each cell, though the number may differ depending on the species. As DNA must be stored in every cell, it must also be replicated, a process that could lead to a loss of information. DNA manages to avoid most losses by ensuring every nitrogen base is always linked to its complimentary base, Adenine with Thymine, and Guanine with Cytosine. During replication, the DNA strand splits in two, with a new half forming along the lines of the paired bases.
is any of this true at all
4 notes
·
View notes
Text

DNA is a molecule that carries the genetic information for all living things. It is made of smaller units called nucleotides, which have three parts: a sugar, a phosphate, and a nitrogen base. There are four types of nitrogen bases: adenine (A), thymine (T), cytosine (C), and guanine (G). The nucleotides are linked together in a chain, forming a strand of DNA. Two strands of DNA pair up with each other, forming a double helix. The pairing is based on the rule that A always binds with T and C always binds with G. This way, the two strands are complementary to each other and can store the same information.
DNA is found inside the cells of all organisms. Most of it is located in the nucleus, where it is organized into structures called chromosomes. Each chromosome contains a long piece of DNA that has many genes. Genes are segments of DNA that code for proteins, which are the building blocks and regulators of life. Some DNA is also found in the mitochondria, which are the energy factories of the cell.
DNA is very long compared to its width. A single strand of human DNA is about 5 feet or 1.5 meters long, but it is only 2 nanometers wide. To fit inside the cell, DNA has to be compacted and coiled. It wraps around proteins called histones, forming beads called nucleosomes. The nucleosomes are further coiled into fibers called chromatin, which can condense into chromosomes during cell division.
If we could stretch out all the DNA in one human cell, it would be about 3 km or 6.6 feet long. If we could stretch out all the DNA in all the cells in our body, it would be about twice the diameter of the solar system. That means that our body contains an enormous amount of information encoded in our DNA. This information determines our traits, such as our eye color and height, as well as our risk of diseases and our response to drugs. It also makes us unique from other individuals, except for identical twins who share the same DNA.
DNA is not static; it can change over time due to mutations, which are errors or changes in the sequence of nucleotides. Some mutations are harmless or beneficial, while others are harmful or cause diseases. Mutations can also create variation among individuals and populations, which is the basis of evolution and natural selection.
DNA is a fascinating molecule that reveals a lot about ourselves and our ancestors. By studying DNA, we can learn more about our health, our history, and our future.
3 notes
·
View notes
Text
Going on pre-med was biggest mistake ever.
Cuz like, when we have deoxyribonucleic acid, y'know, that polynucleotide chains thing that coil around each other, probablly dating, and they form DNA.
There also are C- cytosine, A- adenine, G- guanine, and T- thymine.
And they always pairing cytosine with guanine and adenine with thymine.
The thing I want to say is, that when we have Garmadon and Clouse-
#my brain isn't working anymore#i hate school#lego#lego ninjago#ninjago#garmadon#garmaclouse#ninjago clouse#clouse#garmadon x clouse#clouse ninjago#garmadon ninjago
19 notes
·
View notes
Text
The reason there are only four nucleotides (Adenine [A], Thymine [T], Cytosine [C], and Guanine [G])
In summary, the four-nucleotide system (A, T, C, G) is the result of both chemical efficiency and evolutionary optimization. It provides a robust and stable framework for genetic encoding, replication, and expression, which has been preserved across all known life forms.
c:
The reason there are only four nucleotides (Adenine [A], Thymine [T], Cytosine [C], and Guanine [G]) in DNA is due to the fundamental chemical and biological properties of nucleic acids and the evolutionary history of life on Earth. Here’s a detailed explanation:
Chemical Basis
Structure of Nucleotides:
Adenine (A) and Guanine (G) are purines, which are larger, double-ringed structures.
Thymine (T) and Cytosine (C) are pyrimidines, which are smaller, single-ringed structures.
The complementary base pairing between purines and pyrimidines (A with T, and C with G) stabilizes the DNA double helix structure.
Chemical Stability and Bonding:
The four nucleotides have stable chemical structures that form hydrogen bonds with each other in a specific pairing pattern (A with T, and C with G).
This stability and specificity are crucial for the accurate replication and transcription of genetic material.
Evolutionary Reasons
Efficiency:
Four nucleotides are sufficient to encode the vast amount of genetic information required for all living organisms. The combination of four nucleotides in sequences of three (codons) provides 64 possible combinations, which is more than enough to code for the 20 standard amino acids used in proteins.
The simplicity and efficiency of using four nucleotides allow for a stable and effective encoding system without unnecessary complexity.
Historical Consistency:
Life on Earth evolved with this four-nucleotide system, and it has been preserved across all known organisms. This uniformity suggests that this system is optimal for encoding genetic information and maintaining genetic stability.
Any significant deviation from this system would require fundamental changes in the biochemistry of life, which would have profound implications for the structure and function of nucleic acids and proteins.
Genetic Encoding
Redundancy and Error Correction:
The genetic code has built-in redundancy, meaning multiple codons can encode the same amino acid. This redundancy helps in minimizing the effects of mutations and errors in genetic transcription and translation.
Universality:
The four-nucleotide system is universal among all known forms of life, from bacteria to humans. This universality supports the idea that this system is highly effective and well-adapted for the storage and transfer of genetic information.
Potential for Variation
Synthetic Biology:
While the natural genetic code is based on four nucleotides, researchers in synthetic biology have explored the possibility of using alternative nucleotides or expanded genetic codes to create synthetic life forms or enhance biological functions. However, such systems are still in the experimental stages and do not replace the fundamental four-nucleotide system found in nature.
In summary, the four-nucleotide system (A, T, C, G) is the result of both chemical efficiency and evolutionary optimization. It provides a robust and stable framework for genetic encoding, replication, and expression, which has been preserved across all known life forms.
0 notes
Text
DNA Data Storage: Preserving the Digital World in Genetic Code

DNA data storage is an innovative approach that leverages the genetic material of life—deoxyribonucleic acid (DNA)—to store vast amounts of digital information. As the world continues to generate unprecedented volumes of data, traditional storage technologies are being pushed to their limits. Hard drives, magnetic tapes, and optical discs are rapidly becoming obsolete due to their limited lifespan and storage capacity. This is where DNA data storage steps in as a promising alternative, offering extraordinary potential for both data longevity and density.
At its core, DNA data storage involves encoding binary data—composed of 0s and 1s—into the four chemical bases of DNA: adenine (A), cytosine (C), guanine (G), and thymine (T). These bases pair up to form the rungs of the DNA double helix, creating sequences that can be used to represent digital information. By synthesizing custom DNA strands according to specific sequences, data can be written and stored in a molecular form.
One of the key advantages of DNA as a storage medium is its incredible density. A single gram of DNA can theoretically store up to 215 petabytes (215 million gigabytes) of data. This level of density is unmatched by any existing technology, making DNA data storage an attractive solution for archiving the ever-growing volumes of digital content.
Moreover, DNA is remarkably stable over long periods, capable of preserving information for thousands of years under the right conditions. Unlike traditional storage media, which degrade over time and require frequent migration to new formats, DNA can remain intact and readable over millennia. This makes it an ideal medium for preserving important historical records, scientific data, and cultural artifacts that need to be safeguarded for future generations.
However, there are challenges to be addressed before DNA data storage can be widely adopted. The processes of encoding data into DNA and subsequently retrieving it are currently slow and expensive. Advances in DNA synthesis and sequencing technologies are needed to reduce costs and increase efficiency. Furthermore, data retrieval from DNA involves complex processes, such as polymerase chain reaction (PCR) amplification, which also require refinement.
Despite these challenges, the potential of DNA data storage is undeniable. Researchers are actively exploring ways to optimize the technology, and significant progress has been made in recent years. As these developments continue, DNA data storage could revolutionize the way we think about data preservation, offering a sustainable, efficient, and nearly limitless solution to the data storage crisis of the future.
0 notes
Text
auhgh. yknow how chumhandles are only words that start with GCAT. Because those are the 4 nucleotide monomers in dna. It’s a refrance. Guanine, cytosine, adenine, and thymine. The base pairs are guanine and cytosine (GC) and adenine and thymine (AT). Those are the ONLY hydrogen bonds that dna helixes can have. (So, you could never have AC, adenine bonding with cytosine, ect) and like. It physically pains me to write chumhandles with anything else than GC and AT. BECAUSE GRRR. THOSE NUCLEOTIDE MONOMERS WOULD NEVER BOND IRL. AUHGH. But it’s extremely limiting so I must make fucked up combinations … :(
#trying to draw Abel’s ref but . Mr covenantTransfiguration (CT) over here had to have a not accurate hydrogen bond. grah!!!!#however!!! I reallt appreciate the cherubs also having u (uracil) for their handles :)#URACIL DOES NOT BOND WIRH URACIL IS BONDS WIRH ADENINE. but whatever#it’s a really nice touch since when dna is transcripted into mrna the uracil takes the thymine’s place basically#god my head hurts so fucking bad it’s like 3am I hope I said the correct things#we will see tomorrow when I re resd this post#hollowspeak
1 note
·
View note
Text
Unveiling the Power of Data: Global DNA Sequencing Services Market
The global DNA sequencing services market is anticipated to rise sharply and amount to USD 2,080.2 million by 2033. This significant increase from its USD 945.6 million base in 2023 is the outcome of an 8.2% compound annual growth rate (CAGR).
Because they enable the analysis of genetic material and the discovery of variants, mutations, and biomarkers associated with a range of disorders, including cancer, DNA sequencing services are crucial to the field of genomics. These services encompass a broad spectrum of sequencing methodologies and procedures, offering physicians, researchers, and pharmaceutical companies enlightening details on the genetic origins of illnesses and personalized therapeutic strategies.
Empower Strategies With Your Report Sample:
https://www.futuremarketinsights.com/reports/sample/rep-gb-6453
The primary driver of the expected growth of the global market for DNA sequencing services is the rising incidence of cancer across the globe. The need for precision medical techniques and state-of-the-art genetic technologies to enhance diagnosis, prognosis, and treatment results is growing along with the global cancer patient population. The use of DNA sequencing services in oncology is being driven by researchers’ and doctors’ ability to define tumors, discover promising therapeutic targets, and create individualized therapy regimens based on individual genetic profiles.
DNA Sequencing: Unlocking the Secrets Within
The order of the four building units of DNA—adenine (A), thymine (T), guanine (G), and cytosine (C)—can be determined via DNA sequencing, a potent technology. Interestingly, A and C always pair with T and G, respectively. Deciphering the base pair sequence is essential to obtaining an individual’s genetic code. This information holds immense potential for various applications, including:
Identifying regulatory instructions within DNA
Pinpointing the location of genes
Understanding the genetic underpinnings of diseases
Top Highlights from the FMI’s Analysis of the DNA Sequencing Services Market:
•The North American region is expected to account for the leading market share of more than 40.6% in 2023, followed by Europe, which is projected to account for 32.4% in the same year.
•The United Kingdom is forecast to expand at a CAGR of 12.9% over the estimated period, suggesting significant business avenues that the country is expected to present.
•India is anticipated to record a CAGR of 8.5% over the forecast period, whereas China is forecast to propel at a CAGR of 7.8%. DNA sequencing services are expected to increase in the region to meet the increasing medical demands of the population.
•Japan is forecast to account for a market share of 2.7%, comparatively lower than the other competitive markets. However, the market is expected to offer diverse growth opportunities to businesses.
•Based on solutions and services, the data analysis and sequencing services segment is forecast to account for 41.8% of the global market.
•Under the end-user category, the academic institutes and research centers segment is anticipated to record more than 37.7% over the forecast period.
Market Competition:
Illumina Inc., Thermo Fischer Scientific Inc., Oxford Nanopore Technologies Plc, Agilent Technologies, Inc., QIAGEN, Eurofins Scientific, F. Hoffmann-La Roche Ltd., Takara Bio Inc., GENEWIZ, Inc., Hamilton Company, Macrogen Inc., Zymo Research Corporation, and Tecan Trading AG are a few of the major players in the global DNA sequencing services market.
Owing to the involvement of multiple prominent players, the industry exhibits intense competition. International firms like Oxford Nanopore Technologies plc, Thermo Fischer Scientific Inc., and Illumina Inc. In addition to making up a sizeable portion of the market, a number of regional players are active in important growing areas, mainly in North America.
Recent Developments
In December 2020, Eurofins Genomics released SARS-CoV-2 NGS services that are both cost-effective and optimized, allowing for entire viral genome sequencing.
In May 2020, Roche introduced the KAPA Target Enrichmentportfolio and the KAPA HyperExome whole-exome research panel for target enrichment during sequencing.
Illumina recently received Emergency Use Authorization (EUA) from the FDA for its COVIDSeq Test, which is used to sequence the entire genome of the novel SARS-CoV-2 virus.
Face2Gene LABS was launched in June 2019 by PerkinElmer, Inc. and FDNA, an artificial intelligence company, to provide genomic services in conjunction with Next-Generation Phenotyping (NGP) technologies for more accurate and efficient diagnoses.
Key Segments Profiled in The DNA Sequencing Services Industry Survey:
By Product Type:
Maxam–Gilbert DNA Sequencing
Chain-Termination Methods
Dye-Terminator Sequencing
Automation and Sample Preparation
Large-scale DNA Sequencing
New DNA Sequencing Methods
High Throughput DNA Sequencing
Parallel Signature Sequencing (MPSS)
Polony Sequencing
Pyrosequencing
Illumina (Solexa) Sequencing
SOLiD Sequencing
Others
By End Use:
Automotive Industry
Chemical Industry
Agriculture
Oil and Gas
Research and Development
Other End Uses
By Application:
Hospitals
Diagnostic Centers
Biotechnology and Pharmaceutical Industry
Academic Research Institutes
Other Application Areas
By Region:
North America
Latin America
Europe
Asia Pacific
The Middle East & Africa
0 notes
Text
DNA=ATGC 8th biology
1. Adenine. Purine
Plays a vital role in protein synthesis and energy metabolism.
2. Guanine (G):
Also belongs to the Purine group.
Always pairs with cytosine (C) in DNA through hydrogen bonding.
Plays a crucial role in cell division and protein synthesis.
3. Cytosine (C):
Belongs to a group of molecules called pyrimidines. Pyrimidines have a single-ring structure.
Always pairs with guanine (G) in DNA through hydrogen bonding.
Plays a role in cell division and DNA methylation, which regulates gene expression.
4. Thymine (T): ONLY in DNA
Belongs to the pyrimidine group.
0 notes
Text
Enzymes Can’t Tell Artificial DNA From the Real Thing - Technology Org
New Post has been published on https://thedigitalinsider.com/enzymes-cant-tell-artificial-dna-from-the-real-thing-technology-org/
Enzymes Can’t Tell Artificial DNA From the Real Thing - Technology Org
UC San Diego researchers are exploring how to add letters to the genetic alphabet to make never-before-seen proteins.
The genetic alphabet contains just four letters, referring to the four nucleotides, the biochemical building blocks that comprise all DNA. Scientists have long wondered whether adding more letters to this alphabet is possible by creating brand-new nucleotides in the lab.
Still, this innovation’s utility depends on whether cells can recognize and use artificial nucleotides to make proteins.
Like adding new letters to an existing language’s alphabet to expand its vocabulary, adding new synthetic nucleotides to the genetic alphabet could expand the possibilities of synthetic biology. This image shows a rendering of RNA polymerase (center) and a synthetic nucleotide (lower right). Image credit: UC San Diego Health Sciences
Now, researchers at Skaggs School of Pharmacy and Pharmaceutical Sciences at the University of California San Diego have come one step closer to unlocking the potential of artificial DNA. The researchers found that RNA polymerase, one of the most important enzymes involved in protein synthesis, was able to recognize and transcribe an artificial base pair in exactly the same manner as it does with natural base pairs.
The findings, published December 12, 2023 in Nature Communications, could help scientists create new medicines by designing custom proteins.
“Considering how diverse life on Earth is with just four nucleotides, the possibilities of what could happen if we can add more are enticing,” said senior author Dong Wang, PhD, a professor at Skaggs School of Pharmacy and Pharmaceutical Sciences at UC San Diego. “Expanding the genetic code could greatly diversify the range of molecules we can synthesize in the lab and revolutionize how we approach designer proteins as therapeutics.”
Wang co-led the study with Steven A. Benner, PhD, at the Foundation for Applied Molecular Evolution, and Dmitry Lyumkis, PhD, at Salk Institute for Biological Studies.
The four nucleotides that comprise DNA are called adenine (A), thymine (T), guanine (G) and cytosine (C). In a molecule of DNA, nucleotides form base pairs with a unique molecular geometry called Watson and Crick geometry, named for the scientists who discovered the double-helix structure of DNA in 1953.
These Watson and Crick pairs always form in the same configurations: A-T and C-G. The double-helix structure of DNA is formed when many Watson and Crick base pairs come together.
“This is a remarkably effective system for encoding biological information, which is why serious mistakes in transcription and translation are relatively rare,” said Wang. “As we’ve also learned, we may be able to exploit this system by using synthetic base pairs that exhibit the same geometry.”
The study uses a new version of the standard genetic alphabet, called the Artificially Expanded Genetic Information System (AEGIS), that incorporates two new base pairs. Originally developed by Benner, AEGIS began as a NASA-supported initiative to try to understand how extraterrestrial life could have developed.
By isolating RNA polymerase enzymes from bacteria and testing their interactions with synthetic base pairs, they found that the synthetic base pairs from AEGIS form a geometric structure that resembles the Watson and Crick geometry of natural base pairs. The result: the enzymes that transcribe DNA can’t tell the difference between these synthetic base pairs and those found in nature.
“In biology, structure determines function,” said Wang. “By conforming to a similar structure as standard base pairs, our synthetic base pairs can slip in under the radar and be incorporated in the usual transcription process.”
In addition to expanding the possibilities for synthetic biology, the findings also support a hypothesis that dates back to Watson and Crick’s original discovery. This hypothesis, called the tautomer hypothesis, says the standard four nucleotides can form mismatched pairs due to tautomerization, or the tendency of nucleotides to oscillate between several structural variants with the same composition. This phenomenon is thought to be one source of point mutations, or genetic mutations that only impact one base pair in a DNA sequence.
“Tautomerization allows nucleotides to come together in pairs when they aren’t usually supposed to,” said Wang. “Tautomerization of mispairs has been observed in replication and translation processes, but here we provide the first direct structural evidence that tautomerization also happens during transcription.”
The researchers are next interested in testing whether the effect they observed here is consistent in other combinations of synthetic base pairs and cellular enzymes.
“We are excited to assemble a multidisciplinary collaborative team with Steve and Dmitry that allow us to tackle the molecular basis of transcription on expanded alphabet,” said Wang. “There could be many other possibilities for new letters besides what we’ve tested here, but we need to do more work to figure out how far we can take it.”
Source: UCSD
You can offer your link to a page which is relevant to the topic of this post.
#2023#approach#artificial#artificial DNA#Bacteria#Biology#Biotechnology news#Building#Cells#code#collaborative#communications#Composition#dates#december#Difference Between#DNA#double#earth#enzymes#Evolution#extraterrestrial#extraterrestrial life#Featured life sciences news#form#Foundation#genetic#Genetic engineering news#Geometric#geometry
0 notes
Note
Okay you gotta explain the gamzee vriska swap I'm curious
okay here is the explanation...... because of the system™ i used to switch it around.
basically since in actually dna, adenine and thymine pair and guanine pairs with cytosine i thought that if i switched the chumhandles around it would be interesting. so vriska (ag) becomes (tc) which is gamzee!
1 note
·
View note
Last Seen Blogs

bloo-dybasement-blog
they call it art

lapetiteballejaune
Tumblr de

stefanyascritor
stefan yacov

jen4everfangirl
Untitled

oublimonetoile
Beauty and the beast