#WordPress site removal
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
#free_tech_simu#freetech#simu#simu akter#freelancer simu#Remove WordPress installation#Uninstall WordPress#Delete WordPress website#Remove WordPress completely#Delete WordPress#Clear WordPress data#Erase WordPress site#WordPress site removal#Remove WordPre
0 notes
Text
I knew the dudes runnin the place were transphobic but I didn't know it extended to literally following women to other websites to stalk and harass them 😭??? And now slavery and racism???
If you're continuing to use this site, remember these great tips:
Never pay for a website's premium features
Use an adblocker. You may have to use element zappers for some things.
Xkit. Also comes with adblockers and anti-premium/promotion features in both new xkit and xkit rewritten.
#i hope wordpress buying tumblr was yet another huge income loss like all the past purchases when tossing this site around#anyway if i get removed for these posts i am out there on other sites. just look for signs of t0pj0y
18 notes
·
View notes
Text
#malware removal#malware#hacked wordpress#virus removal#remove malware#fix wordpress#wordpress help#wordpress update#wordpress security#blacklist removal#this site may be hacked#google blacklist#google red warning
0 notes
Text
How to Easily Remove a Page Title in WordPress

Removing a page title in WordPress can enhance the look and feel of your pages, especially for custom layouts or landing pages. If you're interested in learning more, be sure to read our detailed guide on How to Remove Page or Post Title in WordPress for additional strategies.
Below, we explore several ways to remove page titles in WordPress—via the editor, CSS, and plugins.
Why Would You Want to Remove Page Titles?
Page titles can sometimes disrupt the flow of a page’s design, particularly when you’re using a custom layout or page builder. Removing the title allows for a cleaner presentation, especially on pages where the title isn’t necessary.
Method 1: Remove Titles in the WordPress Editor
If you prefer a quick fix:
Go to the page you want to edit.
Delete the title from the editor, effectively removing it from the page.
Method 2: CSS for Removing Titles
For those looking for more precision:
Identify the page ID by checking the URL while editing the page.
Apply this CSS in the customizer:
Replace [ID] with the correct page ID.
Method 3: Plugin for Title Removal
You can also use a plugin for a code-free solution:
Install and activate a plugin like "Hide Page and Post Title."
Hide the title from the page settings.
Conclusion
Removing page titles in WordPress is a simple task that can dramatically improve the look of your site. For more in-depth instructions, refer to our related post, How to Remove Page or Post Title in WordPress.
0 notes
Text
How To Remove Malware From WordPress Site: A Step-by-Step Guide By Reliqus Consulting

In the digital age, websites are the storefronts of the online world, and just like physical stores, they can fall prey to vandalism—in this case, malware.
Malware can severely damage your WordPress website, leading to data breaches, loss of customer trust, and even penalties from search engines.
If you suspect that your WordPress site has been compromised, it's essential to act quickly and methodically to remove the malware and safeguard your site from future attacks.
Identifying the Infection
The first step in dealing with malware is to confirm its presence. Several signs can indicate a malware infection:
Performance Issues: A sudden slowdown in website performance is a common symptom of malware.
Unexpected Ads or Pop-Ups: Malware can inject unwanted ads or pop-ups into your site.
Redirection: If your site redirects to unfamiliar websites, it's a clear sign of malware.
Search Engine Warnings: Google may display warnings about your site being insecure or compromised.
To accurately identify malware, use security plugins like Wordfence, Sucuri Security, or MalCare. These plugins are designed to scan your website for known threats and vulnerabilities. Installing one and conducting a thorough scan can pinpoint the specific issues affecting your site.
However, it's important to note that while effective, these plugins can be expensive and may require a certain level of technical knowledge to use effectively for malware removal. Given these challenges, it might be more efficient and cost-effective to opt for a professional malware removal service.
One standout option is the WordPress malware removal service offered by Reliqus Consulting. Priced at just $79, this service not only provides an affordable alternative to the often costly plugins but also eliminates the need for technical expertise on your part.
Backing Up Your Site
Before taking any steps to remove the malware, ensure you have a complete backup of your website. This includes all files, the WordPress database, plugins, and themes.
Although backing up a compromised site might seem counterintuitive, it ensures that you have a fallback option should anything go wrong during the cleanup process. Use a trusted plugin or your hosting provider’s backup solution to secure your data.
Removing the Malware
With a backup in place, you can begin the process of removing the malware from your WordPress site.
1. Update Everything: Malware often exploits vulnerabilities in outdated WordPress core files, themes, and plugins. Update all components to their latest versions to close these security gaps.
2. Manually Remove Malware: If the malware is not removed by updates, you may need to manually clean your site.
Access your site files via FTP or your hosting provider's file manager.
Look for recently modified files or any files that don’t belong. Malware can often be found in the wp-content folder or in the core WordPress files.
Compare suspicious files with the original files from the official WordPress repository. If discrepancies are found, delete the malicious files or replace corrupted files with clean versions.
3. Clean the Database: Malware can also infect your WordPress database.
Access your database via tools like phpMyAdmin.
Inspect the wp_options table for suspicious links or scripts, as well as the wp_posts table for any malicious content within your posts.
Carefully remove any identified malware.
4. Use a Malware Removal Service: If manual removal is daunting or if the malware persists, consider hiring a professional service like from Reliqus Consulting. These services specialize in deep cleaning and can often expedite the recovery process.
Strengthening Your Site's Security
After removing the malware, it's crucial to take steps to enhance your site’s security and prevent future infections.
1. Change All Passwords: Immediately change your WordPress admin, hosting account, FTP, and database passwords to strong, unique alternatives.
2. Implement Security Measures: Install a reputable WordPress security plugin and configure its settings to protect your site. Implementing a firewall, limiting login attempts, and enabling two-factor authentication can significantly enhance your site's security.
3. Regular Updates and Backups: Keep all site components updated and conduct regular backups. Store backups in a secure, off-site location.
Monitoring Your Site
Vigilance is key in maintaining the security of your WordPress site. Regularly monitor your site’s health through services like Google Search Console, which can alert you to security issues, and keep an eye on site performance and traffic for anomalies.
Conclusion
Addressing malware on your WordPress site can be daunting but is manageable with a structured approach. For those seeking to thoroughly understand and implement each step of this process, read our full blog. This comprehensive resource provides the in-depth knowledge needed to not only remove existing malware but also to fortify your site against future threats, ensuring your digital storefront remains secure and thriving.
0 notes
Text

#WordPress site deletion#Delete WordPress website#Removing WordPress site#Uninstall WordPress from cPanel#Backup WordPress website#WordPress database deletion#Website platform migration#WordPress site management#cPanel tutorial#WordPress site backup#WordPress website security#Data backup and recovery#Website content management#WordPress maintenance#WordPress database management#Website data protection#Deleting WordPress files#Secure data storage#WordPress site removal process#WordPress website best practices
0 notes
Text
WordPress Malware Removal
When our Website Got Hacked Or Infected With Malware/Code injection your site Redirects To Others Spam Sites
Don't Worry, You Have Come To The Right Place, I Will Definitely Help You To Recover your site
Malware Removal
Remove Malware From Any Website
Redirecting To Another Site
Website That Redirects From Google Search
Showing Hacked site
Hosting Provider Suspension
Remove Blacklist
WP Admin Not Working
Security For WP Admin Login
Hide WordPress Default Login Url
Protect From brute-force attack
To Factor Authentication
#wordpress#malware#hacked#remove malware#virus#malware warning#wordpress malware#wordpress security#wordpress website#malware issue#Clean Malware#google blacklist#google redirect#security#wordpress malware removal#japanese keyword hack#red warning#deceptive site ahead
1 note
·
View note
Text
Another Matt update

11.10: Automattic taunts WP Engine with loss tracker website, which likely uses data mined from .org
A new website (childishly) named WordPress Engine Tracker claims to track the sites that have migrated away from WP Engine and to other hosts. It’s an official Automattic project, and the public GitHub repo is by an Automattic employee.
It’s a dick move. But it’s also a baffling move, if your legal defense is “I didn’t do this to try and bust-out my biggest rival and take their money.” Because wow, it sure seems like making your biggest rival fail is a thing you’re really excited about and watching closely, as you all but take credit for it.
As usual this is per Josh Collinsworth’s ongoing coverage of Matt’s meltdown
79 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
242 notes
·
View notes
Text
Full text of article as follows:
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either. Instead of answering direct questions about these deals and the compiling of user data, Automattic sent a statement, which it posted publicly after this story was published, titled "Protecting User Choice." In it, Automattic promises that it's blocked AI crawlers from scraping its sites. The statement says, "We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control. Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training."
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believepartners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live postsays, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
Updated 4:05 p.m. EST with a statement from Automattic.
#It’s amazing how dishonest the staff post was#Original post#Posted for the convenience of users who are not currently subscribed to 404 media#But you absolutely should they’re great#10/10 highly recommended
162 notes
·
View notes
Text
tuesday again 10/1/2024
come getcher BOY in HOUSTON TX limited time DEAL he will be going to the shelter where they hopefully have more resources to place FIV+ cats on FRIDAY!!! he has gotten so sleek and healthy looking after only a month of unlimited kibble he will be SUCH a nice silly companion for someone but unfortunately that someone is not me



^worried about the air purifier turning on
listening
OWW. feat BUBBLE by Halo Boy is fun bc it’s fun to yell “gimme love bites like OWW!” brain empty just songs that are fun to blast in the car. not quite a candidate for the “SOMEBODY COME FUCK THIS (GAY)” playlist but certainly worthy of inclusion on the “SOMEBODY COME FUCK THIS (NOT GAY)” playlist
-
reading

i have a lot of uncomplimentary thoughts about frank lloyd wright. part of them revolve around the fact that buildings are really not meant to last forever, especially experimental buildings made with experimental materials. i am furious, however, that a cryptocurrency grifter couple bought his only skyscraper for $10 to "save it from bankruptcy" from a tiny nonprofit, seem to be hacking it up to sell the furnishings in pieces, and have put the building up for commercial sale on a site mostly used for fast food franchises and strip malls. the building, like many frank lloyd wright buildings, is in pretty rough shape. i've seen some walkthroughs and video tours and there's a ton of water damage and then extra water damage from oklahoma winter ice. i do not know if the building as a whole is reasonably salvageable without tens of millions put into it and a new foundation put in place to take care of it.
Liz Waytkus, the executive director of Docomomo US, an organization that works to preserve modern architecture, said it strongly opposes any sale of the Wright materials. “They’re trafficked goods,” Waytkus said. “The same that you would say of pottery or vases from Egypt or Mesopotamia that were obtained through illegal ways, these pieces from Frank Lloyd Wright should be thought of in the same exact way.”
i think the above quote is a little dramatic. what the crypto couple are doing is more in bad taste than anything, bc they do own the building. in my heart of hearts, i do think pieces and fixtures designed specifically for a site should stay with the site as long as reasonably possible. they're not going to look or function quite the same anywhere else. this is the unfortunate reality of getting a superstar architect to design The Whole Site and not just the building, you're kind of (in good taste and not legally) obligated to continue to preserve The Whole Site and not just the building.
another in the "not technically illegal but in bad taste" file, for both sides imo but i do think the misbehavior is greater on one side. idk if matt is like Unwell, or if he has tech founder brain and it's simply been more visible lately. oh my god i looked up how old he was (40) and he is local to me. ive probably seen him patio dining somewhere or walked past him at the rodeo and simply haven't noticed
But in a dispute that’s meant to clarify what is and isn’t WordPress, Mullenweg risks blurring the lines even more. WordPress.org and WordPress.com both have a point — but it looks an awful lot like they’re working together to make it.
-
watching
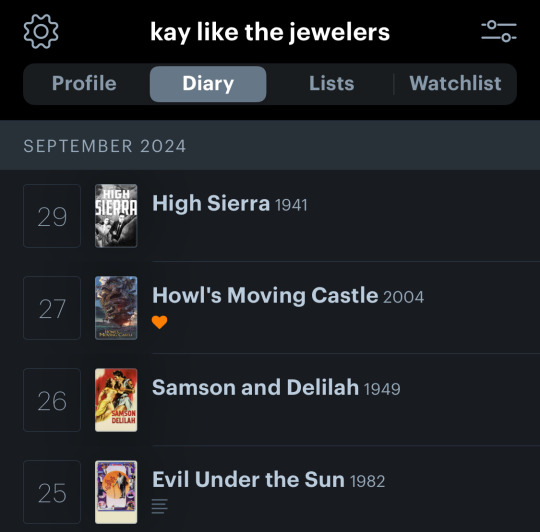
kind of a light week? i don’t have anything particularly interesting to say about any of these.
i did not plan this bc i was kidnapped last minute by my bestie to see Howl’s Moving Castle in theaters, which was a very fun movie to see on the big screen. i have not seen a movie in theaters since Birds of Prey in early 2020, kind of scary to be inside a theater again! wish covid had not so thoroughly broken my health and confidence and i also wish covid was Over over instead of a constantly rolling crisis!!

-
playing
i am going to preface this section with two facts: 1) i have been playing genshin impact since version 1.0, before the second major region in the game came out and 2) i have been unemployed since january and have spent more hours per day playing this game than really anyone should in the past couple months.
ive set a bunch of very silly goals for myself bc genshin impact is largely a game about making your own fun within the grindy gacha framework and i have hit two and a half of them. you can "ascend" a character six different times to up stats by a decent percentage, and i have now ascended all 64 characters the maximum 6 times. the last one was heizou bc 1) fuck a cop and 2) fuck the machine boss in the chasm for his mats. why did THREE characters need these mats. wretched.
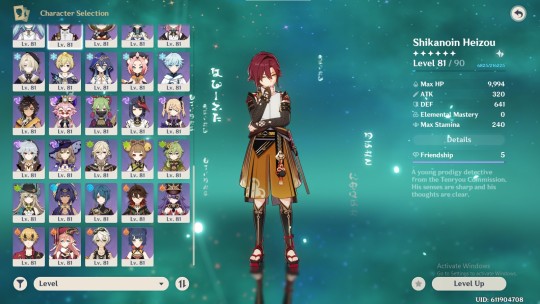
my next goal is to get all my characters to friendship level 10. you can increase this mostly by spending the in-game renewable resource "resin". getting your characters to friendship level 10 has no in-game benefits but does give you a fun little namecard for ur profile. i have been prioritizing my five-star characters and then going through the nations' characters in order. ive been done with the mondstadt kids for a while, i just maxed out my last five-star (dehya) today. as u can see by this list sorted by friendship level, i have five liyue characters and two inazuma characters left and just buckets and oodles of sumeru and fontaine characters.
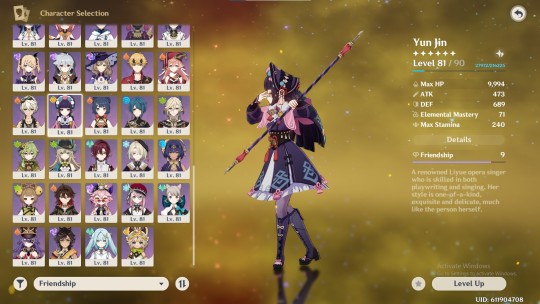
i haven't really done much with the newest natlan character, kachina, bc i do not enjoy playing as the small children characters. there are so many tall hot ladies in this game. speaking of, the next character i will be pulling for is this tall drink of water
i have also caught one of every catachable animal! this one was very irritating bc u can only buy five nets a week. finding this one specific lizard was also very irritating. none of the point in the desert the official game map assured me were spawn points were actually spawning for some reason. had to go to several underwater caves and cross my fingers

-
making
fallow week
29 notes
·
View notes
Text
Automattic, the company that owns WordPress.com, is required to remove a controversial login checkbox from WordPress.org and let WP Engine back into its ecosystem after a judge granted WP Engine a preliminary injunction in its ongoing lawsuit. In addition to removing the checkbox—which requires users to denounce WP Engine before proceeding—the preliminary injunction orders that Automattic is enjoined from “blocking, disabling, or interfering with WP Engine’s and/or its employees’, users’, customers’, or partners’ access to wordpress.org” or “interfering with WP Engine’s control over, or access to, plugins or extensions (and their respective directory listings) hosted on wordpress.org that were developed, published, or maintained by WP Engine,” the order states. In the immediate aftermath of the decision, Automattic founder and CEO Matt Mullenweg asked for his account to be deleted from the Post Status Slack, which is a popular community for businesses and people who work on WordPress’s open-source tools.
“It's hard to imagine wanting to continue to working on WordPress after this,” he wrote in that Slack, according to a screenshot viewed by 404 Media. “I'm sick and disgusted to be legally compelled to provide free labor to an organization as parasitic and exploitive as WP Engine. I hope you all get what you and WP Engine wanted.” His username on that Slack has been changed to “gone 💀” Mullenweg began to publicly denounce WP Engine in September, calling the web hosting platform a “cancer” to the larger Wordpress open-source project and accusing it of improperly using the WordPress brand. He’s “at war” with WP Engine, in his own words. In October, Mullenweg added a required checkbox at login for WordPres.org, forcing users to agree that they are not affiliated with WP Engine. The checkbox asked users to confirm, “I am not affiliated with WP Engine in any way, financially or otherwise.” The checkbox was still present and required on the WordPress.org login page as of Wednesday morning. Automattic and Mullenweg have 72 hours from the order to take it down, according to the judge’s order. WP Engine sent a cease and desist demanding that he “stop making and retract false, harmful and disparaging statements against WP Engine,” the platform posted on X. Automattic sent back its own cease and desist, saying, “Your unauthorized use of our Client’s intellectual property has enabled WP Engine to compete with our Client unfairly, and has led to unjust enrichment and undue profits.” WP Engine filed a lawsuit against Automattic and Mullenweg, accusing them of extortion and abuse of power. In October, Mullenweg announced that he’d given Automattic employees a buyout package, and 159 employees, or roughly 8.4 percent of staff, took the offer. “I feel much lighter,” he wrote. But shortly after, he reportedly complained that the company was now “very short staffed.” All of this has created an environment of chaos and fear within Automattic and in the wider WordPress open-source community. Within 72 hours of the order, Automattic and Mullenweg are also required to remove the “purported” list of WP Engine customers contained in the ‘domains.csv’ file linked to Automattic’s website wordpressenginetracker.com, which Automattic launched in November and tracks sites that have left WP Engine. It’s also required to restore WP Engine’s access to WordPress.org, including reactivating and restoring all WP Engine employee login credentials to wordpress.org resources and “disable any technological blocking of WPEngine’s and Related Entities’ access to wordpress.org that occurred on or around September 25, 2024, including IP address blocking or other blocking mechanisms.” The judge also ordered Mullenweg to restore WP Engine’s access to its Advanced Custom Fields (“ACF”) plugin directory, which its team said was “unilaterally and forcibly taken away from its creator without consent” and called it a “new precedent” in betrayal of community access. “We are grateful that the court has granted our motion for a preliminary injunction,” a spokesperson for WP Engine told 404 Media. “The order will bring back much-needed stability to the WordPress ecosystem. WP Engine is focused on serving our partners and customers and working with the community to find ways to ensure a vigorous, and thriving WordPress community.” A spokesperson for Automattic told 404 Media: “Today’s ruling is a preliminary order designed to maintain the status quo. It was made without the benefit of discovery, our motion to dismiss, or the counterclaims we will be filing against WP Engine shortly. We look forward to prevailing at trial as we continue to protect the open source ecosystem during full-fact discovery and a full review of the merits.”
16 notes
·
View notes
Text
status update ~
thought i'd write a summary of what I've been up to, and what's next art-wise! honestly, I'm finding that I work well mentally consolidating projects to quarters of the year; it gives me hard deadlines while allowing nuttiness to blow up two weeks (or more) of my life at a time and still not be stressed.
year recap first!



(Q1) collaborated with @/lululeighsworld to give gunter the fabulous possessed gacha entrance he deserves!! leigh's writing here to this day feels uncannily and perfectly in-character, no small feat with the mind games this devious possessed old man likes to play ~



(Q1) also finished the 140k your ruin, my ruin gunter/corrin revelation fic! the reception from y'all has been absolutely exceptional and while I don't think I'll ever write another fanfic of that length (lol) being able to point to it re: my fire emblem fates: revelation feelings is so ... satisfying. the ossan smut holds up pretty damn well too.
(Q1) NaZine (I) anthology printed and completely sold out, but the digital version is eternally available on the shop if you're still interested. I'll admit that anthologies are not normally my thing for being too prim and milquetoast, but this is anything but. if you've been dying for more sleazy uniform fetish, we got it there!



(Q2) Comics-wise, both Dead is Calling and YRMR:[Epilouge] were finished and ready to be collected in my planned gunter/corrin doujinshi called ashes and ghost; there's one more (eye-blistering smut) strip planned there with a few internal pages.
(Q3) Website-wise, IRON CROWN moved to rarebit from wordpress, and the main landing page was revamped entirely to better pave a road for preparations to self-host the website.
that's not even counting the smaller flash artwork like the fe: alphabet challenge, and hellsing exchange work also done in between everything else.
what's next?


(Q4) you might have seen me show wip's from a FE:Heroes (gacha) comic; while it's tonally softer than my usual work, It's 14-ish pages of some very, very guilty pleasure topics. raw feelings but in a different way? idk, you'll see.
(Q4) I have a personal deadline to get the website updates done by November, namely moving my art/update logs off of wordpress, and also likewise either moving to a different host or self-hosting the entire site (on a rasbpi lol) and removing the middle-man entirely.
(Q4/2025) finishing ashes and ghost (the gunter/corrin doujinshi)! I've been taking a needed break from it (something learned back in the webcomics days) but I can't wait to get back in some hentai level smut that's frankly, going to push me in so many ways. :D;;
(2025) NaZine II will likely be printed in the upcoming year with the same team heading it up. There's delicious stories already planned including multiple shotas and Daddies, oh my - needless to say, it's the kind of sleaze and sauce i dig.
that's all for now!
30 notes
·
View notes
Text
Are Game Blogs Uniquely Lost?
All this started with my looking for the old devlog of Storyteller. I know at some point it was linked from the blogroll on the Braid devlog. Then I tried to look at on old devlog of another game that is still available. The domain for Storyteller is still active. The devblog is gone.
I tried an old bookmark from an old PC (5 PCs ago, I think). It was a web site linked to pixel art and programming tutorials. Instead of linking to the pages directly, some links link led to a twitter threads by authors that collected their work posted on different sites. Some twitter threads are gone because the users were were suspended, or had deleted their accounts voluntarily. Others had deleted old tweets. There was no archive. I have often seen links accompanied by "Here's a thread where $AUTHOR lists all his writing on $TOPIC". I wonder if the sites are still there, and only the tweets are gone.
A lot of "games studies" around 2010 happened on blogs, not in journals. Games studies was online-first, HTML-first, with trackbacks, tags, RSS and comment sections. The work that was published in PDF form in journals and conference proceedings is still there. The blogs are gone. The comment sections are gone. Kill screen daily is gone.
I followed a link from critical-distance.com to a blog post. That blog is gone. The domain is for sale. In the Wayback Machine, I found the link. It pointed to the comment section of another blog. The other blog has removed its comment sections and excluded itself from the Wayback Machine.
I wonder if games stuff is uniquely lost. Many links to game reviews at big sites lead to "page not found", but when I search the game's name, I can find the review from back in 2004. The content is still there, the content management systems have been changed multiple times.
At least my favourite tumblr about game design has been saved in the Wayback Machine: Game Design Tips.
To make my point I could list more sites, more links, 404 but archived, or completely lost, but when I look at small sites, personal sites, blogs, or even forums, I wonder if this is just confirmation bias. There must be all this other content, all these other blogs and personal sites. I don't know about tutorials for knitting, travel blogs, stamp collecting, or recipe blogs. I usually save a print version of recipes to my Download folder.
Another big community is fan fiction. They are like modding, but for books, I think. I don't know if a lot of fan fiction is lost to bit rot and link rot either. What is on AO3 will probably endure, but a lot might have gone missing when communities fandom moved from livejournal to tumblr to twitter, or when blogs moved from Wordpress to Medium to Substack.
I have identified some risk factors:
Personal home pages made from static HTML can stay up for while if the owner meticulously catalogues and links to all their writing on other sites, and if the site covers a variety of interests and topics.
Personal blogs or content management systems are likely to lose content in a software upgrade or migration to a different host.
Writing is more likely to me lost when it's for-pay writing for a smaller for-profit outlet.
A cause for sudden "mass extinction" of content is the move between social networks, or the death of a whole platform. Links to MySpace, Google+, Diaspora, and LiveJournal give me mostly or entirely 404 pages.
In the gaming space, career changes or business closures often mean old content gets deleted. If an indie game is wildly successful, the intellectual property might ge acquired. If it flops, the domain will lapse. When development is finished, maybe the devlog is deleted. When somebody reviews games at first on Steam, then on a blog, and then for a big gaming mag, the Steam reviews might stay up, but the personal site is much more likely to get cleaned up. The same goes for blogging in general, and academia. The most stable kind of content is after hours hobbyist writing by somebody who has a stable and high-paying job outside of media, academia, or journalism.
The biggest risk factor for targeted deletion is controversy. Controversial, highly-discussed and disseminated posts are more likely to be deleted than purely informative ones, and their deletion is more likely to be noticed. If somebody starts a discussion, and then later there are hundreds of links all pointing back to the start, the deletion will hurt more and be more noticeable. The most at-risk posts are those that are supposed to be controversial within a small group, but go viral outside it, or the posts that are controversial within a small group, but then the author says something about politics that draws the attention of the Internet at large to their other writings.
The second biggest risk factor for deletion is probably usefulness combined with hosting costs. This could also be the streetlight effect at work, like in the paragraph above, but the more traffic something gets, the higher the hosting costs. Certain types of content are either hard to monetise, and cost a lot of money, or they can be monetised, so the free version is deliberately deleted.
The more tech-savvy users are, the more likely they are to link between different sites, abandon a blogging platform or social network for the next thing, try to consolidate their writings by deleting their old stuff and setting up their own site, only to let the domain lapse. The more tech-savvy users are, the more likely they are to mess with the HTML of their templates or try out different blogging software.
If content is spread between multiple sites, or if links link to social network posts that link to blog post with a comment that links to a reddit comment that links to a geocities page, any link could break. If content is consolidated in a forum, maybe Archive team could save all of it with some advance notice.
All this could mean that indie games/game design theory/pixel art resources are uniquely lost, and games studies/theory of games criticism/literary criticism applied to games are especially affected by link rot. The semi-professional, semi-hobbyist indie dev, the writer straddling the line between academic and reviewer, they seem the most affected. Artists who start out just doodling and posting their work, who then get hired to work on a game, their posts are deleted. GameFAQs stay online, Steam reviews stay online, but dev logs, forums and blog comment sections are lost.
Or maybe it's only confirmation bias. If I was into restoring old cars, or knitting, or collecting stamps, or any other thing I'd think that particular community is uniquely affected by link rot, and I'd have the bookmarks to prove it.
Figuring this out is important if we want to make predictions about the future of the small web, and about the viability of different efforts to get more people to contribute. We can't figure it out now, because we can't measure the ground truth of web sites that are already gone. Right now, the small web is mostly about the small web, not about stamp collecting or knitting. If we really manage to revitalise the small web, will it be like the small web of today except bigger, the web-1.0 of old, or will certain topics and communities be lost again?
60 notes
·
View notes
Text
Learn to secure your WordPress site! This video guide walks you through identifying and removing malware step-by-step. Discover tools and techniques to clean your website, ensuring it's safe for visitors. Gain essential skills to protect your online presence from threats. Perfect for beginners seeking practical, effective solutions. Join us and fortify your website now! reliqus.com/how-to-remove-malware-from-your-wordpress-site/
0 notes
Text
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
45 notes
·
View notes