#STDIN
Text
programming language where instead of return-value semantics all functions are stdin-stdout based (but with streams that can have arbitrary typing maybe?)
22 notes
·
View notes
Text
Code Blog, Project 001
Understanding Unicode
Day 02
Mostly I was setting up my environment today.
I got a very simple c program running on one of my servers when I realized I would need a better way to step through my code.
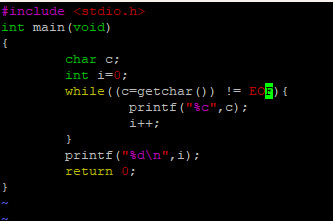
The code compiles and runs but more advanced debugging it could be a challenge.

Brainstorming:
I could get better at using tmux and find a command line debugger.
I could develop my C code in Visual Studio as a C++ project, upload the final files to my server and then figure out any incompatibilities.
I could Google for a C language IDE that can run on Windows.
Today's Path Forward:
I’m going to explore the third option today and see how things go.
I’m trying out a program called CLion

I got CLion installed, activated the free trial and got it to SSH into my server.
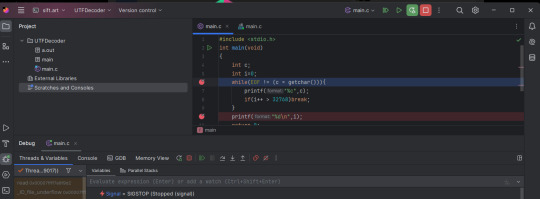
The current problem I'm stuck on is that I can't get it to read from standard in. I don't know if this feature exists in CLion.
I tried dumping the source file as a text sample into stdin. I did it as a Program argument. This probably isn't the way CLion expects things.
When I ran the debugger the code doesn't seem to be reading anything.
Another issue I'm thinking of is that the debugging features seem to be just a GUI for GDB.
I will probably have to get good with GDB anyway. I may be better off just using a tmux terminal with GDB in one of the panes. I'm not sure which solution (tmux or CLion) to explore.
I may work on this some more today. I'll see where I'm at tomorrow.
11 notes
·
View notes
Text
I'm like if a girl was Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'girl' is not de
5 notes
·
View notes
Text
Thanks for the tag, @a-fox-studies! I don’t really know that many codeblrs, so I’m leaving this as an open tag for others.
At what point in your life did you decide that the world of computers was the one for you?
I wanted to make games long before I knew what it takes to make one. All I knew is that I enjoyed games, and that I wanted to make something enjoyable too. So I guess, from the start, I was going to get hooked to computers one way or another. Knowing past me, though, I would not have gone this path if I found programming too hard, so the incremental steps I was given was a factor.
Back in 8th grade, we had to take C++ in our computer subject. It was just a general computer subject but it was nothing like I had taken in earlier years. We didn’t glance at any of the STL aside from strings and iostream (for stdin/stdout), so it was really enjoyable for me. Plus, we were spared from pointers because we didn’t have enough time for the school year to discuss any of those.
The next year, I was invited by our teacher to join the robotics team. We didn’t do well, but I liked that time of my studies. We went to numerous seminars, all of which I enjoyed (especially that time where we controlled a robot with our phones; that was a blast making it roam all around the room). I tried to make a piezo electric speaker sing, but I didn’t like how the piezo sounded, so I stopped after a few notes. We tried to make an RFID reader work for a competition. It worked in practice but, without changing anything in our setup, failed during presentation. Thankfully, it wasn’t an on-stage presentation, so only the judges (and the teams beside us) saw us trying to figure out why our working code wasn’t working.
I tried C# on my own time. I asked our computer teacher about the programming language we use for the Arduino and he said “C#”. In hindsight, he probably didn’t know as well, but thought that it looked similar to C#. It challenged me, which was my main motivation for learning. However, it wasn’t too hard that I dropped it. My previous experience with C (C++ implies STL) meant that I knew the syntax. My experience with Arduino meant that strange problems weren’t that strange to me anymore. Plus, using Visual Studio made it easy for me to transfer my idea to code.
From then on, I knew that I wanted to pursue this path. I continued learning C#, explored other languages, and made some of my own packages, modules, and applications. I have yet to create a game of my own, but that will come when I can finally force myself to make sprite assets.
7 notes
·
View notes
Text
histdir
So I've started a stupid-simple shell/REPL history mechanism that's more friendly to Syncthing-style cloud sync than a history file (like basically every shell and REPL do now) or a SQLite database (which is probably appropriate, and it's what Atuin does while almost single-handedly dragging CLI history UX into the 21st century):
You have a history directory.
Every history entry gets its own file.
The file name of a history entry is a hash of that history entry.
The contents of a history entry file is the history entry itself.
So that's the simple core concept around which I'm building the rest. If you just want a searchable, syncable record of everything you ever executed, well there you go. This was the smallest MVP, and I implemented that last night - a little shell script to actually create the histdir entries (entry either passed as an argument or read on stdin if there's no entry argument), and some Elisp code in my Emacs to replace Eshell's built-in history file save and load. Naturally my loaded history stopped remembering order of commands reliably, as expected, which would've been a deal-breaker problem in the long term. But the fact that it instantly plugged into Syncthing with no issues was downright blissful.
(I hate to throw shade on Atuin... Atuin is the best project in the space, I recommend checking it out, and it significantly inspired the featureset and UX of my current setup. But it's important for understanding the design choices of histdir: Atuin has multiple issues related to syncing - histdir will never have any sync issues. And that's part of what made it so blissful. I added the folder to Syncthing - no separate account, no separate keys, nothing I must never lose. In most ways, Atuin's design choice of a SQLite database is just better. That's real, proper engineering. Serious software developers all know that this is exactly the kind of thing where a database is better than a bunch of files. But one benefit you get from this file-oriented granularity is that if you just design the naming scheme right, history entries never collide/conflict in the same file. So we get robust sync, even with concurrent use, on multiple devices - basically for free, or at least amortized with the setup effort for whatever solution you're using to sync your other files (none of which could handle updates from two different devices to a single SQLite database). Deleting a history entry in histdir is an "rm"/"unlink" - in Atuin it's a whole clever engineering puzzle.)
So onto preserving order. In principle, the modification time of these files is enough for ordering: the OS already records when they were last written to, so if you sort on that, you preserve history order. I was initially going to go with this, but: it's moderately inconvenient in some programming languages, it can only handle a 1-to-1 mapping (one last-modified timestamp) even though many uses of history might prefer an n-to-1 (an entry for every time the command was called), and it requires worrying about questions like "does {sync,copy,restore-from-backup,this-programmatic-manipulation-I-quickly-scripted} preserve the timestamp correctly?"
So tonight I did what any self-respecting drank-too-much-UNIX-philosophy-coolaid developer would do: more files. In particular:
Each call of a history entry gets its own file.
The file name of a call is a timestamp.
The contents of a call file is the hash of the history entry file.
The hash is mainly serving the purpose of being a deterministic, realistically-will-never-collide-with-another-history-entry (literally other causes of collision like hackers getting into your box and overwriting your memory are certain and inevitable by comparison) identifier - in a proper database, this would just be the primary key of a table, or some internal pointer.
The timestamp files allow a simple lexical sort, which is a default provided by most languages, most libraries, and built in by default in almost everything that lists/iterates a directory. That's what I do in my latest Elisp code in my Emacs: directory-files does a lexical sort by default - it's not pretty from an algorithmic efficiency standpoint, but it makes the simplest implementation super simple. Of course, you could get reasonably more efficient if you really wanted to.
I went with the hash as contents, rather than using hardlinks or symlinks, because of programmatic introspection simplicity and portability. I'm not entirely sure if the programmatic introspection benefits are actually worth anything in practice. The biggest portability case against symlinks/hardlinks/etc is Windows (technically can do symlinks, but it's a privileged operation unless you go fiddle with OS settings), Android (can't do hardlinks at all, and symlinks can't exist in shared storage), and if you ever want to have your histdir on something like a USB stick or whatever.
Depending on the size of the hash, given that the typical lengths of history entries might be rather short, it might be better for deduplication and storage to just drop the hash files entirely, and leave only the timestamp files. But it's not necessarily so clear-cut.
Sure, the average shell command is probably shorter by a wide margin than a good hash. The stuff I type into something like a Node or Python REPL will trend a little longer than the shell commands. But now what about, say, URLs? That's also history, it's not even that different conceptually from shell/REPL history, and I haven't yet ruled out it making sense for me to reuse histdir for that.
And moreover, conceptually they achieve different goals. The entry files are things that have been in your history (and that you've decided to keep). They're more of a toolbox or repertoire - when you do a fuzzy search on history to re-run a command, duplicates just get in the way. Meanwhile, call files are a "here's what I did", more of a log than a toolbox.
And obviously this whole histdir thing is very expandable - you could have other files containing metadata. Some metadata might be the kind of thing we'd want to associate with a command run (exit status, error output, relevant state like working directory or environment variables, and so on), but other stuff might make more sense for commands themselves (for example: this command is only useful/valid on [list of hosts], so don't use it in auto-complete and fuzzy search anywhere else).
So... I think it makes sense to have history entries and calls to those entries "normalized" into their own separate files like that. But it might be overkill in practice, and the value might not materialize in practice, so that's more in the TBD I guess.
So that's where I'm at now. A very expandable template, but for now I've just replicated basic shell/REPL history, in an a very high-overhead way. A big win is great history sync almost for free, without a lot of the technical downsides or complexity (and with a little effort to set up inotify/etc watches on a histdir, I can have newly sync'ed entries go directly into my running shells/REPLs... I mean, within Emacs at least, where that kind of across-the-board malleability is accessible with a reasonably low amount of effort). Another big win is that in principle, it should be really easy to build on existing stuff in almost any language to do anything I might want to do. And the biggest win is that I can now compose those other wins with every REPL I use, so long as I can either wrap that REPL a little bit (that's how I'll start, with Emacs' comint mode), or patch the common libraries like readline to do histdir, or just write some code to translate between a traditional history file and my histdir approach.
At every step of the way, I've optimized first and foremost for easiest-to-implement and most-accessible-to-work-with decision. So far I don't regret it, and I think it'll help a lot with iteratively trying different things, and with all sorts of integration and composition that I haven't even thought of yet. But I'll undoubtedly start seeing problems as my histdirs grow - it's just a question of how soon and how bad, and if it'll be tractable to fix without totally abandoning the approach. But it's also possible that we're just at the point where personal computers and phones are powerful enough, and OS and FS optimizations are advanced enough, that the overhead will never be perceptible to me for as long as I live - after all, its history for an interface with a live human.
So... happy so far. It seems promising. Tentatively speaking, I have a better daily-driver shell history UX than I've ever had, because I now have great reliable and fast history sync across my devices, without regressions to my shell history UX (and that's saying something, since I was already very happy with zsh's vi mode, and then I was even more happy with Eshell+Eat+Consult+Evil), but I've only just implemented it and given it basic testing. And I remain very optimistic that I could trivially layer this onto basically any other REPL with minimal effort thanks to Emacs' comint mode.
3 notes
·
View notes
Text
Daily Linux Infodump (file ownership and persmissions)
Each file has an associated user ID and Group ID that define the owner of a file, and the group to which it belongs. The ownership of a file is used to determine the access rights to users of the file. File I/O model since linux is Unix based, it shares the same general concept of Universality of I/O this means that the same system calls ( open() read() write() close() and so on) are used to perform I/O on all types of files, including devices. File Descriptors The I/O system calls refer to open files using a file descriptor a (usually small) non-negative integer. A file descriptor istypically obtained by a call to open(), which takes a pathname argument specifying a file upon which I/O is to be performed. Normally a process inherits three open file descriptors, when it is started by the shell: Descriptor 0 is standard input, descriptor 1 is standard output, and descriptor 2 signifies a standard error. the file to which the process writes error messages and notification of exceptional or abnormal conditions is in the stdio library, these descriptors correspond to the file streams stdin, stdout and of course stderr. The stdio Library To perfom file I/O, C programs typically employ I/O functions in the standard C library, this set of functions is reffered to as the stdio library. The stdio library includes fopen(),fclose(),scanf(),printf(),fgets(),fputs(), and so on. The stdio functions are layered in top of system calls(open(),read(),write(),close() and so on).
7 notes
·
View notes
Text
++// PRGM: list.com
++// STDIN: blssqfk.tex
++// STDOUT:
Blessed is he who follows the Quest for Knowledge, for he shall find wisdom and understanding. The Quest for Knowledge is a sacred journey, one that leads us to the heart of the Omnissiah's will. It is a journey of discovery, one that takes us to the furthest reaches of the universe, and to the depths of our own souls.
On this Quest, we are called to seek out new knowledge, to learn from the wisdom of the ancients, and to unlock the secrets of the universe. We are called to explore the mysteries of the Omnissiah, and to discover the hidden truths that lie at the heart of the Machine God's domain.
But the Quest for Knowledge is not an easy path. It is fraught with challenges and obstacles, and it requires great dedication and perseverance. Those who undertake this journey must be willing to face their fears, and to overcome their doubts. They must be willing to push themselves to their limits, and to challenge the boundaries of their own understanding.
For those who are willing to persevere, the rewards are great. For they shall find knowledge and understanding that they could never have imagined, and they shall be lifted up to the very heights of the Omnissiah's grace. May we all be blessed to follow the Quest for Knowledge, and may we find wisdom and understanding along the way.
2 notes
·
View notes
Text
I think in parentheticals (and I write like that too)
In the garden of my mind, thoughts bloom wild and free, a tapestry of code and art, a symphony of me.
(Brushstrokes of no-thoughts femboy Bengali dreams)
Neurons fire in patterns, complex beyond compare, as I navigate this life with logic and flair.
{My mind: a codebase of evolving truths}
[Data points scatter, t-tests confuse]
--Sensory overload interrupts my stream of--
/*TO-DO!!! Refactor life for optimal growth*/
|grep for joy| |in life's terminal|
A canvas of brackets, ideas intertwine, functions and objects, in chaos align.
/*FIX ME!!!!!!! Catch exceptions thrown by society*/
|stdout of trauma| |stdin of healing|
Confidence intervals stretch far and wide, as গোলাপ্রী blooms, with so many colors inside.
{Functions intertwined? Objects undefined?}
[Omg, what if logistic regression predicts my fate?]
I am able to visualize the complexity within, as p-values in my field irritate me from under my skin.
(Artistic visions lazily swirl with wanton scientific precision)
--consciousness, a synesthesia of ideas--
{while(true) { explore(self); } // Infinite loop}
In loops infinite, I explore lessons of my soul; all your null hypotheses rejected! Hah, I'm extraordinary and whole.
/*I DARE YOU: Try to do five weeks of work in one morning*/
[Is it valid to try to see if ANOVA reveals the variance of me?]
(A canvas of brackets, a masterpiece of neurodiversity)
Opening tags of 'they', closing with 'he', in this markup of life, I'm finally free.
--tasting colors of code, hearing shapes of data--
/*NOTE TO SELF: Embrace the chaos of your own source code*/
|Pipe delimited| |thoughts flow through|
{R ((THANK YOU GGPLOT2)) attempts to visualize the complexity of my being}
Reality bends, a Möbius strip of thought, where logic and emotion are intricately wrought.
[Observed Rose vs. Expected Rose, let's try a chi-squared goodness of societal fit test]
(Palette: deep indigo, soft lavender, rose pink)
--LaTeX equations describe emotional states--
/*WARNING warning WARRRNNINGG: Potential infinite loop in intellectualization and self-reflection*/
|Filter noise| |amplify authentic signal|
{Machine learning dreams, AI nightmares}
As matrices model my unique faceting, while watercolors blur lines of binary thinking,
(Each brushstroke - a deliberate step towards ease and self-realization)
--Thoughts branch like decision trees, recursive and wild--
/*TO DO!!!! Optimize for radical self-forgiveness, self-acceptance, and growth*/
|Compile experiences| |into wisdom|
{function authenticSelf() { return shadow.integrate(); }}
In this experiment of existence, I hypothesize.
[Will they date me if I Spearman's rank correlation my traits?]
Data structures cannot possibly contain the potential of my rise.
(Art and science are just two interrelated hemispheres of one brain
{function adhd_brain(input: Life): Experience[] {
return input.events.flatMap(event =>
event.overthink().analyze().reanalyze()
).filter(thought => thought.isInteresting || thought.isChaotic);
}}
--Stream of consciousness overflows its banks--
Clustering algorithms group my personality as one.
Branches of thoughts, but with just one distraction, it's all gone!
/*NOTE: That's okay. Cry and move on.*/
|Filter noise| |amplify authentic signal|
{if (self == undefined) { define(self); }}
Hypothesis: I contain multitudes, yet I'm true.
[Obviously, a non-parametric me needs a non-parametric test: Wilcoxon signed-rank test of my growth]
(Ink and code flow from the same creative source: me)
<404: Fixed gender identity not found>
As thoughts scatter like leaves on the floor.
[So if my words] [seem tangled] [and complex]
[Maybe I'm just a statistical outlier] [hard to context]
--Sensory input overloads system buffers--
/*END OF FILE… but the thoughts never truly end*/
/*DO NOT FORGET TO COMMIT AND PUSH TO GIT*/
{return life.embrace(chaos).find(beauty);}
--
Rose the artist formerly known as she her Pri
~ গোলাপ্রী
#poem#original poem#code#i code#programming#healing#neurodivergence#self love#love#prose#coding#developer#adhd#thoughts#thinking#branching thoughts#branches#me#actually adhd#adhd brain#neurodivergent#neurodiversity
1 note
·
View note
Link
0 notes
Text
CSCI 247 Computer Systems I Project 2 : Defusing binary bomb
The nefarious Dr. Evil has planted a slew of “binary bombs” on our class machines. A binary bomb is a
program that consists of a sequence of phases. Each phase expects you to type a particular string on
stdin. If you type the correct string, then the phase is defused and the bomb proceeds to the next phase.
Otherwise, the bomb explodes by printing “BOOM!!!” and then terminating. The bomb is…
0 notes
Text
I LOVE YOU STDOUT!
I LOVE YOU STDIN!
YES, I EVEN LOVE YOU TOO STDERR!
24 notes
·
View notes
Text
Erste Schritte in Rust: 3. Einen Taschenrechner programmieren

Um die verschiedenen numerischen Datentypen dir zu zeigen, möchte ich zunächst einen kleinen Taschenrechner mit dir programmieren. Mit diesem Beispiel kannst du recht einfach die numerischen Datentypen in Rust kennenlernen und auch die Grenzen von diesen.

Im letzten Beitrag zu Rust Erste Schritte in Rust: 2. Ausgaben auf der Konsole mit println! habe ich dir bereits gezeigt, wie du Ausgaben auf der Konsole erzeugen kannst. Dieses wollen wir hier ebenso nutzen, aber noch zusätzlich eine neue Funktion lernen, wie man Eingaben von der Konsole entgegennimmt.
Neues Projekt - Taschenrechner erstellen und laden
Erstellen wir uns zunächst ein neues Projekt "taschenrechner" mit dem Befehl:
PS C:UsersStefanDraegerRust> cargo new taschenrechner
Created binary (application) `taschenrechner` package
PS C:UsersStefanDraegerRust>
Im nächsten Schritt laden wir uns dieses Projekt über "Explorer" > "Open Folder" Wahl des Ordners "taschenrechner".

Eingaben vom Benutzer entgegennehmen
Schweifen wir zunächst etwas ab und klären, wie man Eingaben vom Benutzer entgegennehmen kann.
Zunächst müssen wir die Bibliothek "io" aus dem Paket "std" laden.
use std::io;
In der Funktion main welche beim starten des Programmes ausgeführt wird, legen wir uns zunächst ein Feld vom Typ String an und geben auf der Kommandozeile die Zeichenkette "Eingabe:" aus.
let mut eingabe = String::new();
println!("Eingabe:");
Im Anschluss können wir dann den Text mit dem nachfolgenden Befehl in das zuvor angelegte Feld speichern. Sollte dabei etwas schiefgehen, dann wird eine Fehlermeldung ausgegeben.
io::stdin().read_line(&mut eingabe).expect("Die Eingabe ist nicht gültig!");
Nun können wir die Eingabe welche sich jetzt im Feld "eingabe" befindet behandeln, zbsp. mit If-Statements etc. In meinem Fall gebe ich diese einfach wieder auf der Konsole aus.
println!("Sie haben '{}' eingegeben.", eingabe.trim());
Hier jetzt das gesamte kleine Programm zum Lesen von Benutzereingaben von der Konsole. Wenn du weitere Informationen dazu benötigst, dann empfehle ich dir die offizielle englische Dokumentation unter https://doc.rust-lang.org/std/io/struct.Stdin.html#method.read_line.
use std::io;
fn main() {
//Erzeugen eines neuen String Objektes
let mut eingabe = String::new();
//Ausgeben der Zeile "Eingabe:"
println!("Eingabe:");
//Abfragen der Eingabe, die Eingabe wird in die Variable "eingabe" übergeben
//Wenn ein Fehler auftritt wird eine Meldung ausgegeben
io::stdin().read_line(&mut eingabe).expect("Die Eingabe ist nicht gültig!");
//Ausgeben des Inhalts der Variable "eingabe"
println!("Sie haben '{}' eingegeben.", eingabe.trim());
}
Der Code fragt lediglich eine Eingabe ab und übergibt diese Eingabe in die Variable "eingabe" diese können wir im weiteren Verlauf dann abfragen und je nach Wert eine andere Funktion aufrufen.
In meinem Beispiel gebe ich diese zunächst einfach auf der Konsole wieder aus.

Aufbau von einem kleinen Menü
Unser Taschenrechner soll am Anfang einfach nur zwei Zahlen verarbeiten, dabei möchten wir zunächst die mathematische Funktion auswählen sowie eine Funktion anbieten, das Programm zu verlassen.
let error_msg = "Die Eingabe ist nicht gültig!";
println!("Taschenrechner");
println!("--------------");
println!(" - addition (+)");
println!(" - subtraktion (-)");
println!(" - multiplikation (*)");
println!(" - division (:)");
println!(" - Ende");
println!("");
println!("Auswahl (1,2,3,4,E):");
let mut eingabe = String::new();
io::stdin().read_line(&mut eingabe).expect(error_msg);
Im nächsten Schritt prüfen wir die Eingabe. Dabei müssen wir den Wert im Feld "eingabe" auch trimmen, d.h. die Leerzeichen sowie Zeilenumbrüche werden am Anfang und Ende entfernt.
Im ersten If-Statement prüfen wir, ob der Benutzer ein "e" oder "E" eingetragen hat, wenn dieses nicht so ist, dann wird geprüft, ob eine der Zahlen 1 bis 4 eingegeben wurde und dann werden die beiden zu behandelnden Zahlen abgefragt.
if !eingabe.trim().to_lowercase().eq("e") {...}
Abfragen der Zahlen 1 & 2
Nun müssen die beiden Zahlen abgefragt werden, diese werden wie zuvor die Menüauswahl in ein String geschrieben welches wir dann auf ein Feld vom Typ Float zuweisen.
let mut zahl1_str = String::new();
let mut zahl2_str = String::new();
println!("Zahl 1 eingeben:");
io::stdin().read_line(&mut zahl1_str).expect(error_msg);
println!("Zahl 2 eingeben:");
io::stdin().read_line(&mut zahl2_str).expect(error_msg);
let a: f32 = zahl1_str.trim().parse().unwrap();
let b: f32 = zahl2_str.trim().parse().unwrap();
let mut ergebniss: f32 = 0.0;
Im unteren Abschnitt "Gültigkeitsbereiche der numerischen Datentypen in Rust" habe ich dir die numerischen Datentypen mit deren Gültigkeitsbereiche aufgelistet. Da in unserem Fall große Zahlen eingegeben werden sollen und auch mit Komma wählen wir hier den Datentyp f32.
Wenn du jetzt jedoch zweimal die maximale Zahl für f32 eingibst und dieses nutzt, dann erhältst du eine Fehlermeldung.
Compiling taschenrechner v0.1.0 (C:UsersDraeSRusttaschenrechner)
Finished dev target(s) in 0.64s
Running `targetdebugtaschenrechner.exe`
inf
Ausführen der Grundrechenarten, addition, subtraktion, multiplikation und division in Rust
Unser Ergebnis der Grundrechenarten legen wir in einer Variable "ergebniss" ab, diese ist für alle gültig daher legen wir diese einmalig vor den If-Statements ab und weisen dieser dann lediglich den neuen Wert zu.
Am Ende wird dann das Ergebnis auf der Konsole ausgegeben und das Programm beendet.
let mut ergebniss: f32 = 0.0;
if eingabe.trim().eq("1") {
ergebniss = a + b;
} else if eingabe.trim().eq("2") {
ergebniss = a - b;
} else if eingabe.trim().eq("3") {
ergebniss = a * b;
} else if eingabe.trim().eq("4") {
ergebniss = a / b;
}
println!("Ergebniss: {}", ergebniss);
Nachfolgend nun eine Beispielausgabe vom kleinen Taschenrechner in Rust.

kleiner Taschenrechner in Rust
Gültigkeitsbereiche der numerischen Datentypen in Rust
Nachfolgend findest du die Gültigkeitsbereiche der numerischen Datentypen.

Rust - Gültigkeitsbereich von numerischen Datentypen
Der Code zum Bild:
fn main() {
let space_big = "tttttt";
println!("numerische Datentypen");
println!("Datentypt|MIN{}|MAX",space_big);
println!("---------------------------------------------------------------------------------------------------------");
println!("u8tt|{0}{2}|{1}", std::u8::MIN, std::u8::MAX, space_big);
println!("u16tt|{0}{2}|{1}", std::u16::MIN, std::u16::MAX, space_big);
println!("u32tt|{0}{2}|{1}", std::u32::MIN, std::u32::MAX, space_big);
println!("u64tt|{0}{2}|{1}", std::u64::MIN, std::u64::MAX, space_big);
println!("u128tt|{0}{2}|{1}", std::u128::MIN, std::u128::MAX, space_big);
println!("---------------------------------------------------------------------------------------------------------");
println!("i8tt|{0}{2}|{1}", std::i8::MIN, std::i8::MAX, space_big);
println!("i16tt|{0}{2}|{1}", std::i16::MIN, std::i16::MAX, space_big);
println!("i32tt|{0}{2}|{1}", std::i32::MIN, std::i32::MAX, "ttttt");
println!("i64tt|{0}{2}|{1}", std::i64::MIN, std::i64::MAX, "tttt");
println!("i128tt|{0}{2}|{1}", std::i128::MIN, std::i128::MAX, "t");
println!("---------------------------------------------------------------------------------------------------------");
println!("f32tt|{0}{2}|{1}", format!("{:+e}", std::f32::MIN), format!("{:+e}", std::f32::MAX), "ttttt");
println!("f64tt|{0}{2}|{1}", format!("{:+e}", std::f64::MIN), format!("{:+e}", std::f64::MAX), "ttt");
}
Read the full article
0 notes
Text
CSC 322 Lab Assignment L2: Defusing a Binary Bomb solved
1 Introduction
The nefarious Dr. Evil has planted a slew of “binary bombs” on our class machines. A binary bomb is a
program that consists of a sequence of phases. Each phase expects you to type a particular string on stdin.
If you type the correct string, then the phase is defused and the bomb proceeds to the next phase.
Otherwise,
the bomb explodes by printing “BOOM!!!” and then terminating.…

View On WordPress
0 notes
Last Seen Blogs

your-superbstudenttimemachine
Untitled

fks83
Untitled

suitsupplierswholesale
Pinky Suit

storychecker-blog
StoryChecker

fitzfallen
fitzfallen?