#PRIVACY POLICY
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Anyone who follows me on here with a Twitter/X account:
In case you haven't heard, the Twitter Privacy Policy is changing on September 29th. The new policy states that any public content uploaded there will be used to train AI models. This, in addition to the overarching content policy which gives Twitter the right to "use, copy, reproduce, process, adapt, modify, publish and display" any content published on the platform without permission or creator compensation, means that any original content on there could potentially be used to generate AI content for use on the platform, without the original creator's consent.
If you publish original content on Twitter (especially art) and you don't like or agree with the policy update, now may be the time to review the changes for yourself and if necessary take things down before the policy update is published.
Edit: I wanna offer a brief apology for the original post, my wording was a bit unclear and may have drawn people to the wrong assumptions! I have changed the original post a bit now to hopefully be a more accurate reflection of the situation.
Let me just clarify some things since I certainly don't wanna fearmonger and also I feel like some people may take this more seriously than it actually is!:
The part of the privacy policy I mentioned regarding "use, copy, reproduce, process, adapt, modify, publish and display" is included in the policies of every social media site nowadays. That part on its own is not scary, as they have to include that in order to show your content to other users and have it published outside of the site (ie. embedding on other sites, news articles).
The scenario I mentioned is pretty unlikely to happen, I highly doubt the site will suddenly start stealing art or other consent and use it to pump stuff out all over the web without consent or compensation. I simply mentioned it because the fact that the data is being used to train AI models means that stuff on there may end up being used as references for it at some point, and that could then lead to the scenario I mentioned where peoples content becomes the food for new AI content. I don't know myself how likely that is for definite, but I know many people still don't trust the training of AI, which is why I feel it is important to mention.
I cannot offer professional or foolproof advice to people on the platform who have posted content before, I'm just some guy! I don't wanna make people freak out or anything. If you have content already on the site, chances are its probably already floating around somewhere you wouldn't want it. That's, unfortunately, the reality of the internet. You don't have to take down everything you've ever posted or delete your accounts, however I wouldn't recommend posting new content on the site if you are uncomfortable with the changes.
THIS POST WAS MADE FOR AWARENESS ONLY!! I AM NOT SUGGESTING WHAT YOU SHOULD AND SHOULD NOT DO, I AM NOT RESPONSIBLE!! /lh
TL;DR: I worded the original post slightly poorly, for clarification the policy being changed to allow for AI training doesn't automatically mean that all your creations will be stolen and be recreated with AI or anything, it just means that those creations will be used to teach the AI to make things of it's own. If you don't like the sound of that, consider looking into this matter yourself for a more detailed insight.
308 notes
·
View notes
Text
fuck microsoft
24 notes
·
View notes
Text

8 notes
·
View notes
Text
I just deleted my X account. I’ve been going to do it since the election because I choose not to support Elon Musk. I did it today, 11/15/24 because the privacy policy has changed today. X can now use your account in creating AI. Think about what that means.
2 notes
·
View notes
Link
TikTok kept tabs on users who watched clips that were tagged under topics such as “LGBT,” short for lesbian, gay, bisexual and transgender, and monitored them for at least a year.
…
Social media companies are known to maintain user profiles in order to offer them personalized ads. However, social media platforms are advised not to collect sensitive data like sexual orientation as it has the potential to make users into targets.
lists… tiktok and every other corporation
#queer safety#queer privacy#privacy#privacy policy#social media#tiktok#surveillance#gay#lesbian#bi#trans#queer#online safety#lgbt#lgbtq#lgbqti#data safety#marketing#exploitation#fascism
28 notes
·
View notes
Text
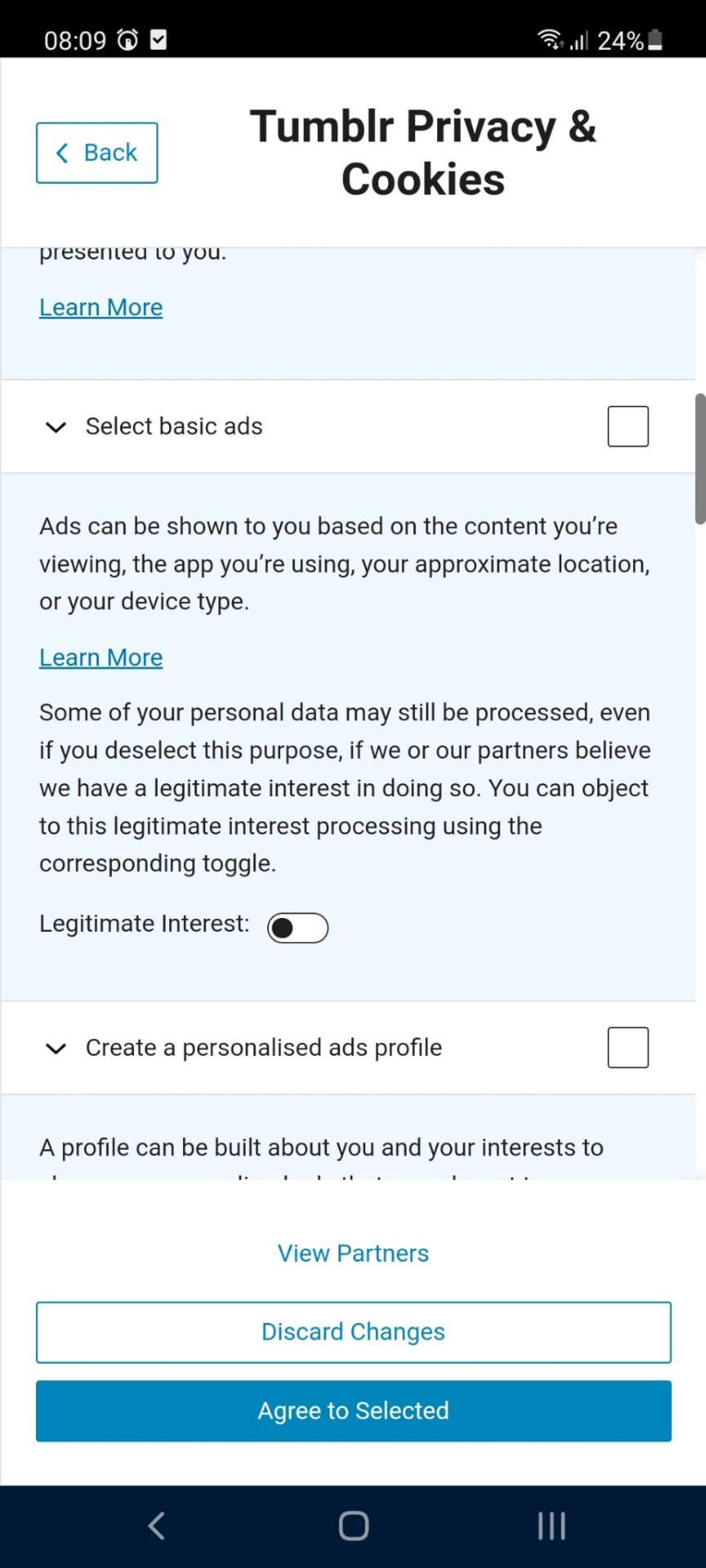
Warning! Tumblr has a new cookie policy thing!
They mamaged to hide the "legitimate interest" toggle very sneakily, so be sure to expand the details for every part to toggle "legitimate intetest" (THERE'S NOTHING LEGITIMATE ABOUT YOUR "INTEREST" YOU GREEDY PIECES OF SHIT) off
Also, make sure to disable the cookies off all the 9999 "partners" (other disgusting greedy corporations that waste space on your phone) or else they'll have your cookie data
Fuck corporations and fuck cookies, remember, don't give them an inch! (thank you EU GDPR, hopefully you will be expanded soon! (note, technically this form is NOT GDPR complacant btw, because it hides options behind an unclear clickthrough, which is technically illegal!))
9 notes
·
View notes
Text

I don't remember having to do this more than once. And I thought my agreement going forward was implied the first time I agreed to use this service?
Also, if these updates are so important, then why not just list the summary in the pop-up so I don't have to go web-surfing for answers?

... oh! Because the "summary" page is absolutely rubbish. I see.
Man, to think I used to trust this company. "Skype-killer", indeed.
#screen captures#Discord#Terms of Service#Paid Services Terms#Privacy Policy#Community Guidelines#updates#what is this?#I already said yes once#leave me alone
3 notes
·
View notes
Text
Privacy is a fundamental human right
Privacy is widely considered a fundamental human right. It is recognized and protected by various international and regional human rights treaties and declarations, such as the Universal Declaration of Human Rights and the International Covenant on Civil and Political Rights. Privacy is essential for individuals to exercise their autonomy, maintain personal dignity, and freely express themselves without fear of surveillance or intrusion.
Privacy encompasses the right to control one's personal information, the right to be free from unwarranted surveillance, and the right to privacy in one's home, communications, and personal activities. It also includes the right to protect sensitive personal data from unauthorized access, use, or disclosure.
In an increasingly digital world, privacy concerns have become more prominent due to technological advancements and the vast amount of personal information being collected, stored, and shared. Protecting privacy in the digital age is crucial to safeguarding individuals' rights and preventing abuses of power.
Governments, organizations, and individuals have a responsibility to respect and uphold privacy rights. However, striking a balance between privacy and other societal interests, such as public safety or national security, can be a complex challenge that requires careful consideration and legal frameworks to ensure that privacy rights are not unjustifiably infringed upon.
#PrivacyRights#HumanRights#DataProtection#DigitalPrivacy#PersonalAutonomy#Surveillance#InformationSecurity#today on tumblr#deep thoughts#Privacy Laws#Right to Privacy#Privacy Policy#Data Privacy#Online Privacy#Privacy Advocacy#Privacy Awareness#Privacy Breach#Privacy Concerns#Privacy Legislation#Privacy Practices#Privacy Protection#Privacy Rights Activism#Privacy Safeguards#Privacy Violations#Privacy Ethics#Privacy and Technology#Privacy Best Practices#Privacy Education#Privacy Transparency
12 notes
·
View notes
Text
Anson is Detective Barry in the 2007 short film Privacy Policy 🥰

3 notes
·
View notes
Text
Guys, more shit is happening over at "X"
The privacy policy and terms of service will be changing and the details are sickening. I'm finally deleting my accounts because enough is enough.

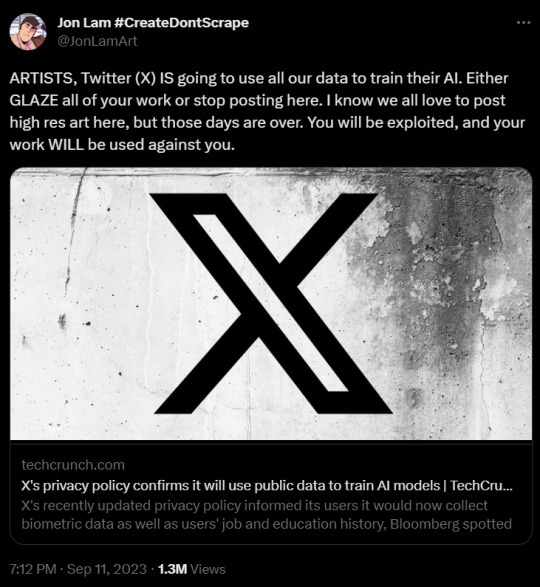
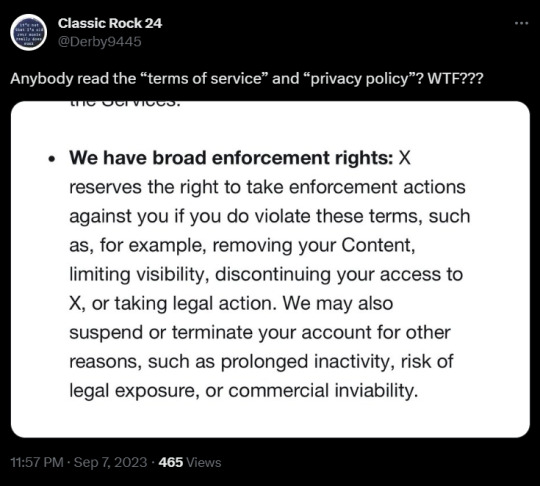
first tweet source | second tweet source | third tweet source
#x#twitter#elon musk#AI#privacy policy#terms of service#ToS#personal information#biometric data#psa#warning
5 notes
·
View notes
Text


" i agree", dima yarovinsky, 2018
4 notes
·
View notes
Text
Heads up for artists - Twitter has updated their privacy policy to enable any and all tweets to be used to train AI models.
If you have your art on there you may want to take it down before it comes into effect on September 29th
14K notes
·
View notes
Text
Sleek Sterling: Privacy Policy for Secure Shopping
At Sleek Sterling, your privacy and security are our top priorities. Our privacy policy outlines how we collect, use, and protect your personal information when you shop with us. We collect data such as your name, email address, and payment details to process your orders and enhance your shopping experience. We do not share your personal information with third parties, except as necessary for processing payments or fulfilling orders. We use advanced security measures to ensure your data is protected. By shopping with us, you agree to our privacy policy, ensuring a safe and trusted experience.
0 notes
Text
Privacy Policy | Encox Services – Your Data Protection Matters
Read Encox Services' Privacy Policy to understand how we collect, use, and protect your personal data. Your privacy and security are important to us.
0 notes
Text
Privacy Policy - Greystack Solutions
Understand how Greystack Solutions protects your privacy and handles your information. Read the detailed privacy policy outlining data collection, usage, and security practices. Visit now to learn how your privacy is safeguarded while using our services.
0 notes
Photo

U.S. Marshalls Spied on Abortion Protesters Using DATAMINR >
Twitter’s “official partner” monitored the precise time and location of post-Roe demonstrations, internal emails show.
DATAMINR, AN “OFFICIAL PARTNER” of Twitter, alerted a federal law enforcement agency to pro-abortion protests and rallies in the wake of the reversal of Roe v. Wade, according to documents obtained by The Intercept through a Freedom of Information Act request.
Internal emails show that the U.S. Marshals Service received regular alerts from Dataminr, a company that persistently monitors social media for corporate and government clients, about the precise time and location of both ongoing and planned abortion rights demonstrations. The emails show that Dataminr flagged the social media posts of protest organizers, participants, and bystanders, and leveraged Dataminr’s privileged access to the so-called firehose of unrestricted Twitter data to monitor constitutionally protected speech.
[Sam Biddle, The Intercept, May 15 2023]
#twitter#elon musk#musk#social media#abortion#roe v wade#roe vs wade#abortion rights#pro-abortion#abortion access#healthcare#body autonomy#supreme court#politics#us politics#us government#privacy policy#privacy#datamining#data for sale#government privatization#policing#surveillance#free speech#right of assembly#corporate spying#protest#demonstration#activism#activists
20 notes
·
View notes