#Multitenant
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Video
youtube
🚨🚀 ¡Próximamente! Curso donde Dominarás Multi Tenant con Django 5 y Docker 🐍🐳 🔜 👉 https://youtu.be/8oyRDZ05gQk 👈
#multitenant#docker#youtube#django#python#django5#nginx#signals#udemy online courses#udemy#gunicorn#postgresql#javascript#jquery#Api#endpoint#udemyCourse
0 notes
Text
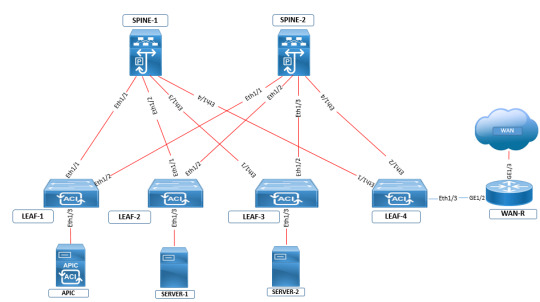
Elevate your data center expertise with #CCIEDC certification. Tackle intricate challenges, from storage to automation, and design resilient architectures. Lead with confidence in the evolving tech landscape. https://www.dclessons.com/category/courses/aci
#ACI#CiscoACI#DataCenterNetworking#SDN#DCCOR#350-601#DCACIA#300-620#ApplicationCentricInfrastructure#DataCenterFabric#Multitenant#Multipod#NetworkingTraining#ITTraining#CloudNetworking
0 notes
Text
🌈CSP Assets MasterList🌈
I use Clip Studio Paint a lot… and i am always checking the assets store
This is a big list of assets i find interesting/useful that are ✨free✨
🖌️Brushes
Belt Buckle
Scattering Papers
Bullet Band
Simple Rope
Wisteria Flowers
Rubble/Debris
Vertical Rocks
Pointy Rocks
Chains
Simple Chains
Floor Pattern
Wizard Bookshelf
Cartoon Leaf Brush
Large Foliage
Bushes
🛋️3d Furniture:
Modern Bookshelf
Antique Books
Chesterfield Antique Chair
Bookcase
Simple Computer Chair
2 seats Sofa
Armrest Chair
Office Chair
Fancy Chair
Celestial Globe Set
Simple Queen Bed
Bird Cage Chair
Toilet Set
Bunk Bed
Hospital Bed
⚙️3d Misc:
Angel Wings
Cogs
Helm
Wires
Cowboy Hat
Camera
Dog Muzzle
Valves
🏠3d Buildings / Structures / etc
Back Alley Wall
Cartoonish Back Alley
Mobile/Ice Cream Stand
Outside Asian Insp. Lantern
Tall Upscale building with 4 entrances
Medieval Market Stand
Fantasy city street
Mansion
Wooden School Hall
Boxing Ring
Multitenant Building
Sci-fi Door
City
Medieval Ruins
Throne Room
Big House
Iron Gate
Torii Gate
Japanese Style Room
Cliff Covered With Concrete Blocks
Medieval Shop Stand
Bus Seats
Boxing Hall
Simple Building Apartments
Sci-fi Medical Pod
Basic Ruins
Tiny Cafe Table Set
Tall Shopping Street Building
Shopping Street Building
Inside Castle Throne Room
Inside Castle Hall
Inside Castle Corridor
Skyscraper
Fantasy Castle/Church
🚲3d Vehicles
Racing Bike
Bicycle
⚔️3d Weapons
Nodachi Sword
Medieval Sword
Dart Gun
Pistol Parts
Automatic rifle
Futuristic Weapon Set
🎸3d Instruments:
Drum Set
Guitar
Electric Guitar
Electric Guitar (Mustang Type)
🌈Hope it helps? idk... bye bye🌈

#clip studio paint#Assets#Masterlist#csp#csp assets#if any of the links are wrong..or dont work just let me know ill fix it ;_;
27 notes
·
View notes
Text
How To Setup Elasticsearch 6.4 On RHEL/CentOS 6/7?

What is Elasticsearch? Elasticsearch is a search engine based on Lucene. It is useful in a distributed environment and helps in a multitenant-capable full-text search engine. While you query something from Elasticsearch it will provide you with an HTTP web interface and schema-free JSON documents. it provides the ability for full-text search. Elasticsearch is developed in Java and is released as open-source under the terms of the Apache 2 license. Scenario: 1. Server IP: 192.168.56.101 2. Elasticsearch: Version 6.4 3. OS: CentOS 7.5 4. RAM: 4 GB Note: If you are a SUDO user then prefix every command with sudo, like #sudo ifconfig With the help of this guide, you will be able to set up Elasticsearch single-node clusters on CentOS, Red Hat, and Fedora systems. Step 1: Install and Verify Java Java is the primary requirement for installing Elasticsearch. So, make sure you have Java installed on your system. # java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode) If you don’t have Java installed on your system, then run the below command # yum install java-1.8.0-openjdk Step 2: Setup Elasticsearch For this guide, I am downloading the latest Elasticsearch tar from its official website so follow the below step # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.tar.gz # tar -xzf elasticsearch-6.4.2.tar.gz # tar -xzf elasticsearch-6.4.2.tar.gz # mv elasticsearch-6.4.2 /usr/local/elasticsearch Step 5: Permission and User We need a user for running elasticsearch (root is not recommended). # useradd elasticsearch # chown -R elasticsearch.elasticsearch /usr/local/elasticsearch/ Step 6: Setup Ulimits Now to get a Running system we need to make some changes of ulimits else we will get an error like “max number of threads for user is too low, increase to at least ” so to overcome this issue make below changes you should run. # ulimit -n 65536 # ulimit -u 2048 Or you may edit the file to make changes permanent # vim /etc/security/limits.conf elasticsearch - nofile 65536 elasticsearch soft nofile 64000 elasticsearch hard nofile 64000 elasticsearch hard nproc 4096 elasticsearch soft nproc 4096 Save files using :wq Step 7: Configure Elasticsearch Now make some configuration changes like cluster name or node name to make our single node cluster live. # cd /usr/local/elasticsearch/ Now, look for the below keywords in the file and change according to you need # vim conf/elasticsearch.yml cluster.name: kapendra-cluster-1 node.name: kapendra-node-1 http.port: 9200 to set this value to your IP or make it 0.0.0.0 ID needs to be accessible from anywhere from the network. Else put your IP of localhost network.host: 0.0.0.0 There is one more thing if you have any dedicated mount pint for data then change the value for #path.data: /path/to/data to your mount point.
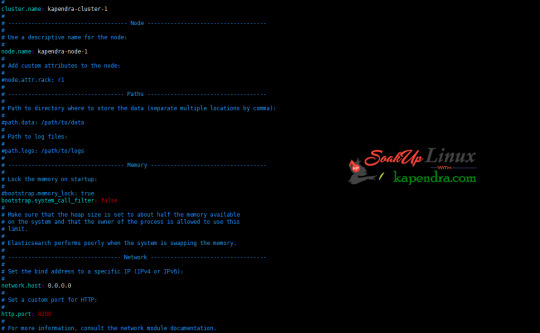
Your configuration should look like the above. Step 8: Starting Elasticsearch Cluster As the Elasticsearch setup is completed. Let the start Elasticsearch cluster with elastic search user so first switch to elastic search user and then run the cluster # su - elasticsearch $ /usr/local/elasticsearch/bin/elasticsearch 22278 Step 9: Verify Setup You have all done it, just need to verify the setup. Elasticsearch works on port default port 9200, open your browser to point your server on port 9200, You will find something like the below output http://localhost:9200 or http://192.168.56.101:9200 at the end of this article, you have successfully set up Elasticsearch single node cluster. In the next few articles, we will try to cover a few commands and their setup in the docker container for development environments on local machines. Read the full article
2 notes
·
View notes
Text
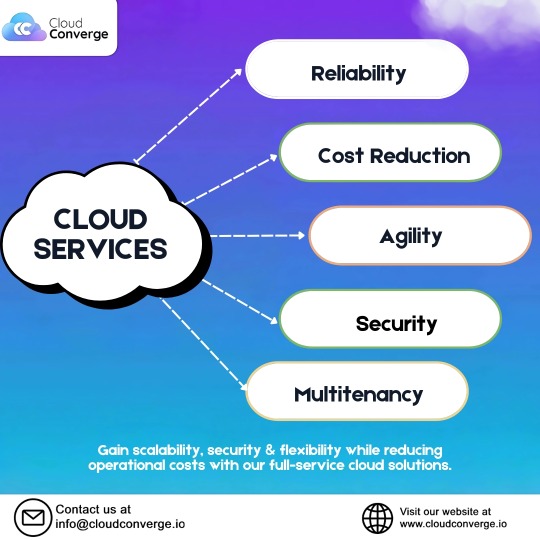
Unlock the full potential of the cloud with seamless scalability, top-tier security, and cost-efficient solutions. Our cloud services ensure reliability, agility, and multitenancy—empowering your business for the future.
Visit us at 🌐cloudconverge.io 📩 For inquiries: [email protected]
#CloudComputing#CloudSolutions#DigitalTransformation#Scalability#Security#DataProtection#BusinessGrowth#CloudTechnology#ITInfrastructure#CloudInnovation#CostEfficiency#TechSolutions#EnterpriseCloud#AgileBusiness#SmartIT
0 notes
Text
Charles Xie, Founder & CEO of Zilliz – Interview Series
New Post has been published on https://thedigitalinsider.com/charles-xie-founder-ceo-of-zilliz-interview-series/
Charles Xie, Founder & CEO of Zilliz – Interview Series

Charles Xie is the founder and CEO of Zilliz, focusing on building next-generation databases and search technologies for AI and LLMs applications. At Zilliz, he also invented Milvus, the world’s most popular open-source vector database for production-ready AI. He is currently a board member of LF AI & Data Foundation and served as the board’s chairperson in 2020 and 2021. Charles previously worked at Oracle as a founding engineer of the Oracle 12c cloud database project. Charles holds a master’s degree in computer science from the University of Wisconsin-Madison.
Zilliz is the team behind LF AI Milvus®, a widely used open-source vector database. The company focuses on simplifying data infrastructure management, aiming to make AI more accessible to corporations, organizations, and individuals alike.
Can you share the story behind founding Zilliz and what inspired you to develop Milvus and focus on vector databases?
My journey in the database field spans over 15 years, including six years as a software engineer at Oracle, where I was a founding member of the Oracle 12c Multitenant Database team. During this time, I noticed a key limitation: while structured data was well-managed, unstructured data—representing 90% of all data—remained largely untapped, with only 1% analyzed meaningfully.
In 2017, the growing ability of AI to process unstructured data marked a turning point. Advances in NLP showed how unstructured data could be transformed into vector embeddings, unlocking its semantic meaning. This inspired me to found Zilliz, with a vision to manage “zillions of data.” Vector embeddings became the cornerstone for bridging the gap between unstructured data and actionable insights. We developed Milvus as a purpose-built vector database to bring this vision to life.
Over the past two years, the industry has validated this approach, recognizing vector databases as foundational for managing unstructured data. For us, it’s about more than technology—it’s about empowering humanity to harness the potential of unstructured data in the AI era.
How has the journey of Zilliz evolved since its inception six years ago, and what key challenges did you face while pioneering the vector database space?
The journey has been transformative. When we started Zilliz seven years ago, the real challenge wasn’t fundraising or hiring—it was building a product in completely uncharted territory. With no existing roadmaps, best practices, or established user expectations, we had to chart our own course.
Our breakthrough came with the open-sourcing of Milvus. By lowering barriers to adoption and fostering community engagement, we gained invaluable user feedback to iterate and improve the product. When Milvus launched in 2019, we had around 30 users by year-end. This grew to over 200 by 2020 and nearly 1,000 soon after.
Today, vector databases have shifted from a novel concept to essential infrastructure in the AI era, validating the vision we started with.
As a vector database company, what unique technical capabilities does Zilliz offer to support multimodal vector search in modern AI applications?
Zilliz has developed advanced technical capabilities to support multimodal vector search:
Hybrid Search: We enable simultaneous searches across different modalities, such as combining an image’s visual features with its text description.
Optimized Algorithms: Proprietary quantization techniques balance recall accuracy and memory efficiency for cross-modal searches.
Real-Time and Offline Processing: Our dual-track system supports low-latency real-time writes and high-throughput offline imports, ensuring data freshness.
Cost Efficiency: Our Extended Capacity instances leverage intelligent Tiered Storage to reduce storage costs significantly while maintaining high performance.
Embedded AI Models: By integrating multimodal embedding and ranking models, we’ve lowered the barrier to implementing complex search applications.
These capabilities allow developers to efficiently handle diverse data types, making modern AI applications more robust and versatile.
How do you see Multimodal RAG advancing AI’s ability to handle complex real-world data like images, audio, and videos alongside text?
Multimodal RAG (Retrieval-Augmented Generation) represents a pivotal evolution in AI. While text-based RAG has been prominent, most enterprise data spans images, videos, and audio. The ability to integrate these diverse formats into AI workflows is critical.
This shift is timely, as the AI community debates the limits of available internet text data for training. While text data is finite, multimodal data remains vastly underutilized—ranging from corporate videos to Hollywood films and audio recordings.
Multimodal RAG unlocks this untapped reservoir, enabling AI systems to process and leverage these rich data types. It’s not just about addressing data scarcity; it’s about expanding the boundaries of AI’s capabilities to better understand and interact with the real world.
How does Zilliz differentiate itself from competitors in the rapidly growing vector database market?
Zilliz stands out through several unique aspects:
Dual Identity: We are both an AI company and a database company, pushing the boundaries of data management and AI integration.
Cloud-Native Design: Milvus 2.0 was the first distributed vector database to adopt a disaggregated storage and compute architecture, enabling scalability and cost-efficiency for over 100 billion vectors.
Proprietary Enhancements: Our Cardinal engine achieves 3x the performance of open-source Milvus and 10x over competitors. We also offer disk-based indexing and intelligent Tier Storage for cost-effective scaling.
Continuous Innovation: From hybrid search capabilities to migration tools like VTS, we’re constantly advancing vector database technology.
Our commitment to open source ensures flexibility, while our managed service, Zilliz Cloud, delivers enterprise-grade performance with minimal operational complexity.
Can you elaborate on the significance of Zilliz Cloud and its role in democratizing AI and making vector search services accessible to small developers and enterprises alike?
Vector search has been used by tech giants since 2015, but proprietary implementations limited its broader adoption. At Zilliz, we’re democratizing this technology through two complementary approaches:
Open Source: Milvus allows developers to build and own their vector search infrastructure, lowering technical barriers.
Managed Service: Zilliz Cloud eliminates operational overhead, offering a simple, cost-effective solution for businesses to adopt vector search without requiring specialized engineers.
This dual approach makes vector search accessible to both developers and enterprises, enabling them to focus on building innovative AI applications.
With advancements in LLMs and foundation models, what do you believe will be the next big shift in AI data infrastructure?
The next big shift will be the wholesale transformation of AI data infrastructure to handle unstructured data, which makes up 90% of the world’s data. Existing systems, designed for structured data, are ill-equipped for this shift.
This transformation will impact every layer of the data stack, from foundational databases to security protocols and observability systems. It’s not about incremental upgrades—it’s about creating new paradigms tailored to the complexities of unstructured data.
This transformation will touch every aspect of the data stack:
Foundational database systems
Data pipelines and ETL processes
Data cleaning and transformation mechanisms
Security and encryption protocols
Compliance and governance frameworks
Data observability systems
We’re not just talking about upgrading existing systems – we’re looking at building entirely new paradigms. It’s like moving from a world optimized for organizing books in a library to one that needs to manage, understand, and process the entire internet. This shift represents a total new world, where every component of data infrastructure might need to be reimagined from the ground up.
This revolution will redefine how we store, manage, and process data, unlocking vast opportunities for AI innovation.
How has the integration of NVIDIA GPUs influenced the performance and scalability of your vector search?
The integration of NVIDIA GPUs has significantly enhanced our vector search performance in two key areas.
First, in index building, which is one of the most compute-intensive operations in vector databases. Compared to traditional database indexing, vector index construction requires several orders of magnitude more computational power. By leveraging GPU acceleration, we’ve dramatically reduced index-building time, enabling faster data ingestion and improved data visibility.
Second, GPUs have been crucial for high-throughput query use cases. In applications like e-commerce, where systems need to handle thousands or even tens of thousands of queries per second (QPS), GPU’s parallel processing capabilities have proven invaluable. By utilizing GPU acceleration, we can efficiently process these high-volume vector similarity searches while maintaining low latency.
Since 2021, we’ve been collaborating with NVIDIA to optimize our algorithms for GPU architecture, while also developing our system to support heterogeneous computing across different processor architectures. This gives our customers the flexibility to choose the most suitable hardware infrastructure for their specific needs.
As vector databases play a critical role in AI, do you see their application extending beyond traditional use cases like recommendation systems and search to industries like healthcare?
Vector databases are rapidly expanding beyond traditional applications like recommendation systems and search, penetrating industries we never imagined before. Let me share some examples.
In healthcare and pharmaceutical research, vector databases are revolutionizing drug discovery. Molecules can be vectorized based on their functional properties, and using advanced features like range search, researchers can discover all potential drug candidates that might treat specific diseases or symptoms. Unlike traditional top-k searches, range search identifies all molecules within a certain distance of the target, providing a comprehensive view of potential candidates.
In autonomous driving, vector databases are enhancing vehicle safety and performance. One interesting application is in handling edge cases – when unusual scenarios are encountered, the system can quickly search through massive databases of similar situations to find relevant training data for fine-tuning the autonomous driving models.
We’re also seeing innovative applications in financial services for fraud detection, cybersecurity for threat detection, and targeted advertising for improved customer engagement. For instance, in banking, transactions can be vectorized and compared against historical patterns to identify potential fraudulent activities.
The power of vector databases lies in their ability to understand and process similarity in any domain – whether it’s molecular structures, driving scenarios, financial patterns, or security threats. As AI continues to evolve, we’re just scratching the surface of what’s possible. The ability to efficiently process and find patterns in vast amounts of unstructured data opens up possibilities we’re only beginning to explore.
How can developers and enterprises best engage with Zilliz and Milvus to leverage vector database technology in their AI projects?
There are two main paths to leverage vector database technology with Zilliz and Milvus, each suited for different needs and priorities. If you value flexibility and customization, Milvus, our open-source solution, is your best choice. With Milvus, you can:
Experiment freely and learn the technology at your own pace
Customize the solution to your specific requirements
Contribute to development and modify the codebase
Maintain complete control over your infrastructure
However, if you want to focus on building your application without managing infrastructure, Zilliz Cloud is the optimal choice. It offers:
An out-of-the-box solution with one-click deployment
Enterprise-grade security and compliance
High availability and stability
Optimized performance without operational overhead
Think of it this way: if you enjoy ‘tinkering’ and want maximum flexibility, go with Milvus. If you want to minimize operational complexity and get straight to building your application, choose Zilliz Cloud.
Both paths will get you to your destination – it’s just a matter of how much of the journey you want to control versus how quickly you need to arrive
Thank you for the great interview, readers who wish to learn more should visit Zilliz or Milvus.
#000#adoption#advertising#ai#AI innovation#AI integration#AI models#AI systems#Algorithms#amp#applications#approach#architecture#audio#autonomous#autonomous driving#banking#barrier#billion#board#Books#box#Building#CEO#challenge#chart#Cloud#Cloud-Native#Commerce#Community
0 notes
Text
Oracle Apps and Core DBA
: Strong knowledge of installation, upgrade, patching and cloning of EBS R12.1 and R12.2.x application from single node to multinode… with experience in handling multitenant databases and Disaster Recovery setup for single node as well as Oracle RAC. DMZ setup… Apply Now
0 notes
Text
Building a Multitenant Application with Node.js and Express for SaaS
Introduction Building a Multitenant Application with Node.js and Express for SaaS (Software as a Service) is a complex task that requires a deep understanding of software architecture, security, and scalability. In this tutorial, we will guide you through the process of creating a multitenant application using Node.js and Express, covering the technical background, implementation guide, code…
0 notes
Text
🔴🚀 ¡Próximamente! Curso de Multi Tenant con Django 5 y Docker 🏢✨
youtube
Estoy emocionado de anunciar que estoy preparando un nuevo curso sobre Multi Tenant con Django 5. En este curso, aprenderás a crear aplicaciones multi-tenant robustas y escalables utilizando Django 5 y todas las herramientas en sus últimas versiones.
🔍 ¿Qué aprenderás?
❏ Configuración de entornos multi-tenant con entornos aislados y entornos compartidos (sucursales) ❏ Uso de Docker para la contenedorización y despliegue. ❏ Gestión de bases de datos y esquemas. ❏ Implementación de seguridad y autenticación. ❏ Optimización y escalabilidad. ❏ Y mucho más…
Este curso está diseñado para desarrolladores de todos los niveles que quieran llevar sus habilidades de Django al siguiente nivel. ¡No te lo pierdas!
🔔 Suscríbete y activa las notificaciones para no perderte ninguna actualización.
¡Nos vemos en el curso! 🚀
👉 Haz clic aquí para acceder a los cursos con descuento o inscribirte 👈 https://bit.ly/cursos-mejor-precio-daniel-bojorge
#django#python#web#tenant#multi tenant#multitenant#saas#saas technology#teaching#code#developers & startups#education#programming#postgresql#software#Docker#Youtube
0 notes
Text
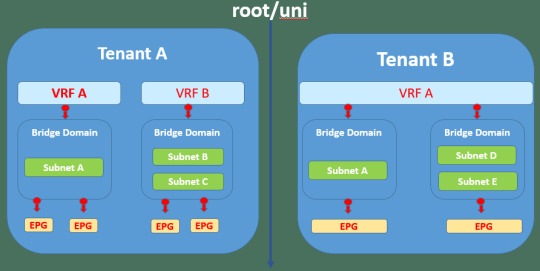
Are you ready to demystify the terminology of Cisco's Application Centric Infrastructure (ACI)? DC Lessons offers a fantastic course that's perfect for IT professionals, network engineers, and anyone eager to navigate the world of ACI with confidence. https://www.dclessons.com/aci-terminology
#ACI#DataCenter#NetworkInfrastructure#SDN#Cisco#NetworkAutomation#CloudInfrastructure#NetworkSecurity#ITTerminology#TechGlossary#NetworkManagement#Virtualization#NetworkArchitecture#Multitenancy#NetworkOrchestration
0 notes
Text
PEGACPLSA23V1 PEGA Lead System Architect Practice Exam For Final Success
The journey to becoming a Certified Pega Lead System Architect (LSA) is demanding but rewarding. To help you prepare effectively, the latest PEGACPLSA23V1 PEGA Lead System Architect Practice Exam from Cert007 is an invaluable resource. This practice exam is designed to align with the latest exam syllabus, offering targeted questions and explanations to ensure you're well-prepared for the real test. By practicing with Cert007's resources, you can build confidence and identify areas for improvement before exam day.
Overview of the Certified Pega Lead System Architect Certification
The Certified Pega Lead System Architect (CPLSA) certification is the pinnacle of Pega architecture certifications. This program is tailored for Certified Pega Senior System Architects with a minimum of 36 months of field experience. It equips professionals with the expertise required to design and architect advanced Pega applications.
The PEGACPLSA23V1 exam is a critical step in this certification journey. It emphasizes the design and architecture of Pega applications, ensuring candidates are well-versed in Pega’s latest features and best practices. As every Pega project presents unique challenges, it is crucial for candidates to be familiar with Pega Infinity and its extensive capabilities.
Key Exam Details
Exam Code: PEGACPLSA23V1
Number of Questions: 60
Duration: 120 Minutes
Passing Score: 65%
Language: English
Prerequisites: Lead System Architect Certification
The exam includes a mix of scenario-based questions, multiple-choice questions, and drag-and-drop items to assess your knowledge and problem-solving skills.
PEGACPLSA23V1 Exam Topics
1. Pega Platform Design (15%)
Center-out business architecture and its impact on enterprise applications.
Deployment options and their influence on design decisions.
Application monitoring, performance, and distributed case interactions.
Features like Pega Process Fabric, Pega Mobile, and Pega Intelligent Virtual Assistant.
Knowledge of multitenancy, high availability, containerization, and cloud deployment architecture.
Agile tools: Agile Workbench and Agile Studio.
2. Pega Platform Design Extended (10%)
Use of App Studio, Prediction Studio, and Admin Studio.
UX design principles, DX API, and Constellation.
Reusing assets and relevant records for streamlined application development.
3. Application Design (15%)
Microjourney analysis for Pega applications.
Design approach for application structure, case hierarchy, and case specialization.
Best practices from Pega Express.
4. Application Design Extended (15%)
Work assignment best practices and routing methods.
Advanced techniques for background processing and asynchronous integration.
Usage of Job Schedules, Queue Processors, and Stream Services.
5. Data Model Design (10%)
Data relationship fundamentals, data virtualization, and dynamic class referencing.
Greenfield data modeling and extending industry foundation models.
6. Reporting Design (10%)
Strategic reporting for business needs, SQL optimization, and troubleshooting performance issues.
Designing high-performing, complex reports using associations and sub-reports.
7. Security Design (15%)
Authentication and authorization strategies for securing Pega applications.
Identifying and mitigating security risks, using security event logging, and following security best practices.
8. Deployment and Testing Design (10%)
Production deployment, release pipelines, and continuous integration strategies.
Automating and monitoring testing strategies for quality assurance.
Preparation Tips for PEGACPLSA23V1 Exam
Understand the Exam Blueprint: Familiarize yourself with the detailed exam topics and allocate study time to each area based on your strengths and weaknesses.
Leverage Cert007 Practice Exam: Use the practice tests to simulate real exam conditions and identify areas that need further study.
Hands-on Experience: Work on Pega projects to gain practical experience with features like case hierarchy, data flows, and security configurations.
Utilize Pega Learning Resources: Explore the Senior System Architect mission on Pega Academy to stay updated with the latest features and best practices.
Join the Pega Community: Engage with other Pega professionals to share insights and solutions to challenging problems.
Final Thoughts
The PEGACPLSA23V1 exam is a robust test of your knowledge and expertise in Pega application design and architecture. By combining practical experience with targeted resources like the Cert007 Practice Exam, you can approach the exam with confidence. Prepare thoroughly, stay focused, and soon you’ll join the elite group of Certified Pega Lead System Architects, ready to tackle complex enterprise challenges with precision and efficiency.
Good luck with your certification journey!
0 notes
Text
Amazon QuickSight: Hyperscale Unified Business Intelligence

Amazon QuickSight, Business Analytics Service: Hyperscale unified business intelligence
What is Amazon Quicksight?
You may utilize Amazon QuickSight, a cloud-scale business intelligence (BI) tool, to provide your colleagues with clear insights no matter where they are. Data from several sources is combined via Amazon QuickSight, which links to your data in the cloud. QuickSight can combine data from AWS, third parties, spreadsheets, SaaS, B2B, and other sources into a single data dashboard. As a fully managed cloud-based solution, Amazon QuickSight offers built-in redundancy, worldwide availability, and enterprise-grade security. You can scale from 10 users to 10,000 with its user-management features, and you won’t need to deploy or manage any infrastructure.
QuickSight provides a visual environment that allows decision makers to examine and analyze information. Any device on your network, including mobile devices, can safely access dashboards.
Amazon QuickSight BI
Created with all end users in mind
Answers with pertinent visuals can be provided to end users in organizations who ask queries in natural language.
Analysts for business
Business analysts don’t need client software or server infrastructure to generate and distribute pixel-perfect dashboards and visualizations in a matter of minutes.
With strong AWS APIs, developers can scale and implement integrated analytics for apps with hundreds or thousands of users.
Managers
QuickSight adapts to the demand automatically, allowing administrators to deliver constant performance. Because of its pay-per-session model, QuickSight is affordable for both small and large-scale implementations.
What Makes QuickSight Unique?
Individuals inside your company make decisions that impact your company on a daily basis. They can take the decisions that will steer your business in the right path if they have the proper information at the right time.
For analytics, data visualization, and reporting, Amazon QuickSight offers the following advantages:
Pay just for the things you use.
Add tens of thousands of users.
It’s simple to incorporate statistics to make your apps stand out.
All users can enable BI with QuickSight Q
The response time of the SPICE in-memory engine is lightning fast.
The total cost of ownership (TCO) is inexpensive and there are no license fees up front.
Analytics for collaboration without requiring the installation of an application.
Consolidate several data sources into a single study.
Share your analysis as a dashboard by publishing it.
Activate the dashboard’s functions.
You can avoid managing fine-grained database permissions because dashboard visitors can only see the content you share.
More capabilities are available for more experienced users with QuickSight Enterprise edition
Includes the following additional enterprise security features:
Single sign-on (IAM Identity Center), federated users, and groups using AWS Directory Service for Microsoft Active Directory, SAML, OpenID Connect, or Identity and Access Management (IAM) Federation.
Specific authorization to access AWS data.
Row-level protection.
At-rest, extremely safe data encryption.
Access to Amazon Virtual Private Cloud data as well as on-premises data
For users assigned to the “reader” security role dashboard subscribers who view reports but do not generate them it provides pay-per-session pricing.
Enables you to integrate QuickSight with your own apps and websites by implementing dashboard sessions and console analytics incorporated.
Enables value-added resellers (VARs) of analytical services to use our business’s multitenancy features.
Allows you to write dashboard templates programmatically so they may be shared across different AWS accounts.
Organizes and manages access more easily with shared and private folders for analytical resources.
More frequent scheduled data refreshes and higher data import quotas for SPICE data intake are made possible.
Watch the video below for a two-minute overview of Amazon QuickSight and to find out more. All the pertinent information is in the audio.
Amazon Q in QuickSight
With the help of your generative AI helper, gain insights more quickly and make smarter decisions.
For everyone, generative business intelligence
Make decisions more quickly and increase company efficiency with QuickSight’s Generative BI features, which are powered by Amazon Q. With dashboard-authoring capabilities, business analysts can quickly create, discover, and disseminate insightful information through natural language prompts. Make data easier for business users to grasp with configurable data stories, executive summaries, and a context-aware Q&A experience that uses insights to guide and influence choices.
Visual dashboards that are dynamic and created by you
It’s simple to create impressive dashboards by using natural language to express your goals. You can use natural language prompts to create, find, hone, and share valuable insights in a matter of minutes.
Use your data to create intriguing narratives
Produce eye-catching documents and presentations that make your data come to life. Highlight important discoveries, clearly communicate complicated concepts, and provide doable next steps to advance your company.
Your Q&A experience was transformed
Investigate your data with confidence outside of the constraints of pre-made dashboards. Suggested inquiries, data previews, and support for ambiguous searches make it simple to find important insights in your data.
More methods QuickSight’s Amazon Q provides faster insights.
Quickly create intricate computations
It’s no longer necessary to commit syntax to memory or look up computation references. Amazon Q makes it easy and uncomplicated to build computations using natural language.
Produce executive summaries in real time
Create executive summaries, period-over-period changes, and important insights quickly from anywhere on your dashboard with Amazon Q.
Amazon Q in QuickSight benefits
Get more done with AI
Business users can quickly create, find, and share actionable insights with Amazon Q’s Generative BI features in QuickSight. When new queries arise, users don’t have to wait for BI teams to update dashboards. Self-serve querying, automated executive summaries, and interactive data storytelling with natural language prompts are all made feasible by generative BI. By rapidly creating and improving computations and graphics, business analysts can increase productivity with Generative BI.
Ensure privacy and security
With security and privacy in mind, Amazon Q was created. It can comprehend and honor your current governance identities, roles, and permissions to tailor its interactions. Amazon Q is made to satisfy the most exacting business needs in QuickSight. Users cannot access data within Amazon Q if they are not allowed to do so without it. No one other than you can utilize your data or Amazon Q inputs and outputs to enhance models of Amazon Q.
Utilize AI analytics to empower everyone
Amazon Q in QuickSight makes it easy and clear for anyone to confidently understand data. AI-driven analytics enable data-driven decision-making for everyone with easily accessible and actionable insights, regardless of experience level. Even ambiguous questions in natural language are addressed with thorough, contextual responses that provide detailed explanations of data together with images and anecdotes to ensure that everyone can examine the information and comprehend it more thoroughly.
Amazon QuickSight pricing
Amazon QuickSight on the Free TierPRODUCTDESCRIPTION FREE TIER OFFER DETAILS PRODUCT PRICINGAmazon QuickSightFast, easy-to-use, cloud-powered business analytics service at 1/10th the cost of traditional BI solutions.30 Days Free10 GB of SPICE capacity for the first 30 days for free for a total of 4 usersAmazon QuickSight Pricing
Read more on Govindhtech.com
#AmazonQuickSight#businessintelligence#SaaS#generativeAI#AmazonQ#News#Technews#Technology#Technologynwes#Technologytrends#govindhtech
0 notes
Text
This Week in Rust 571
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on X (formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
Project/Tooling Updates
An update on Apple M1/M2 GPU drivers
Announcing Toasty, an async ORM for Rust
gitoxide - October 2024
Glues v0.4 - MongoDB support and Vim editing features
Meilisearch 1.11 - AI-powered search & federated search improvements
Observations/Thoughts
Toward safe transmutation in Rust
The performance of the Rust compiler
A new approach to validating test suites
Why You Shouldn't Arc a HashMap in Rust
Implementing the Tower Service Trait
Best Practices for Derive Macro Attributes in Rust
Trimming down a rust binary in half
A deep look into our new massive multitenant architecture
Unsafe Rust Is Harder Than C
Generators with UnpinCell
Which LLM model is best for generating Rust code?
Learnings from Contributing to the Rust Project
Dyn Box Vs. Generics: What is the best approach for achieving conditional generics in Rust?
Rust Walkthroughs
Basic Integer Compression
Miscellaneous
Rust Prism
[audio] Rust vs. C++ with Steve Klabnik and Herb Sutter
[audio] What's New in Rust 1.76, 1.77, and 1.78
[video] Talk on Chrome's new Rust font stack, fontations
[video] Architecting a Rust Game Engine (with Alice Cecile)
[video] Gitoxide: What it is, and isn't - Sebastian Thiel
Crate of the Week
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
RFCs
No calls for testing were issued this week.
Rust
No calls for testing were issued this week.
Rustup
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
wtx - [HTTP/2] Investigate requests latency
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (formerly Twitter) or Mastodon!
Updates from the Rust Project
Rust Compiler Performance Triage
This week saw a lot of activity both on the regressions and improvements side. There was one large regression, which was immediately reverted. Overall, the week ended up being positive, thanks to a rollup PR that caused a tiny improvement to almost all benchmarks.
Triage done by @kobzol. Revision range: 3e33bda0..c8a8c820
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 0.7% [0.2%, 2.7%] 15 Regressions ❌ (secondary) 0.8% [0.1%, 1.6%] 22 Improvements ✅ (primary) -0.6% [-1.5%, -0.2%] 153 Improvements ✅ (secondary) -0.7% [-1.9%, -0.1%] 80 All ❌✅ (primary) -0.5% [-1.5%, 2.7%] 168
6 Regressions, 6 Improvements, 4 Mixed; 6 of them in rollups 58 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
Rust
[disposition: merge] Decide whether blocks inside asm goto should default to safe
[disposition: merge] #[inline(never)] does not work for async functions
[disposition: not specified] Add LowerExp and UpperExp implementations to NonZero
Cargo
No Cargo Tracking Issues or PRs entered Final Comment Period this week.
Language Team
No Language Team Proposals entered Final Comment Period this week.
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline Tracking Issues or PRs entered Final Comment Period this week.
New and Updated RFCs
[new] RFC: Labeled match
[new] RFC: Never patterns
[new] [RFC] Allow packed types to transitively contain aligned types
[new] [RFC] Target Modifiers
Upcoming Events
Rusty Events between 2024-10-30 - 2024-11-27 🦀
Virtual
2024-10-31 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-10-31 | Virtual (Nürnberg, DE) | Rust Nurnberg DE
Rust Nürnberg online
2024-11-01 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-11-02 | Virtual( Kampala, UG) | Rust Circle Kampala
Rust Circle Meetup
2024-11-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-11-08 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-11-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-11-14 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-11-14 | Virtual and In-Person (Lehi, UT, US) | Utah Rust
Green Thumb: Building a Bluetooth-Enabled Plant Waterer with Rust and Microbit
2024-11-14 | Virtual and In-Person (Seattle, WA, US) | Seattle Rust User Group
November Meetup
2024-11-15 | Virtual (Jersey City, NJ, US) | Jersey City Classy and Curious Coders Club Cooperative
Rust Coding / Game Dev Fridays Open Mob Session!
2024-11-19 | Virtual (Los Angeles, CA, US) | DevTalk LA
Discussion - Topic: Rust for UI
2024-11-19 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2024-11-20 | Virtual and In-Person (Vancouver, BC, CA) | Vancouver Rust
Embedded Rust Workshop
2024-11-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Trustworthy IoT with Rust--and passwords!
2024-11-21 | Virtual (Rotterdam, NL) | Bevy Game Development
Bevy Meetup #7
2024-11-26 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
Europe
2024-10-30 | Hamburg, DE | Rust Meetup Hamburg
Rust Hack & Learn October 2024
2024-10-31 | Berlin, DE | OpenTechSchool Berlin + Rust Berlin
Rust and Tell - Title
2024-10-31 | Copenhagen, DK | Copenhagen Rust Community
Rust meetup #52 sponsored by Trifork and OpenZeppelin
2024-11-05 | Copenhagen, DK | Copenhagen Rust Community
Rust Hack Night #10: Rust <3 Nix
2024-11-06 | Oxford, UK | Oxford Rust Meetup Group
Oxford Rust and C++ social
2024-11-06 | Paris, FR | Paris Rustaceans
Rust Meetup in Paris
2024-11-12 | Zurich, CH | Rust Zurich
Encrypted/distributed filesystems, wasm-bindgen
2024-11-13 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup
2024-11-14 | Stockholm, SE | Stockholm Rust
Rust Meetup @UXStream
2024-11-19 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
Daten sichern mit ZFS (und Rust)
2024-11-21 | Edinburgh, UK | Rust and Friends
Rust and Friends (pub)
2024-11-21 | Oslo, NO | Rust Oslo
Rust Hack'n'Learn at Kampen Bistro
2024-11-23 | Basel, CH | Rust Basel
Rust + HTMX - Workshop #3
North America
2024-10-30 | Chicago, IL, US | Deep Dish Rust
Rust Workshop: deploying your code
2024-10-31 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-11-04 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Nov 4
2024-11-07 | Montréal, QC, CA | Rust Montréal
November Monthly Social
2024-11-07 | St. Louis, MO, US | STL Rust
Game development with Rust and the Bevy engine
2024-11-12 | Ann Arbor, MI, US | Detroit Rust
Rust Community Meetup - Ann Arbor
2024-11-14 | Mountain View, CA, US | Hacker Dojo
Rust Meetup at Hacker Dojo
2024-11-15 | Mexico City, DF, MX | Rust MX
Multi threading y Async en Rust parte 2 - Smart Pointes y Closures
2024-11-15 | Somerville, MA, US | Boston Rust Meetup
Ball Square Rust Lunch, Nov 15
2024-11-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-11-23 | Boston, MA, US | Boston Rust Meetup
Boston Common Rust Lunch, Nov 23
2024-11-25 | Ferndale, MI, US | Detroit Rust
Rust Community Meetup - Ferndale
2024-11-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-10-31 | Auckland, NZ | Rust AKL
Rust AKL: Rust on AWS: Sustainability + Peace: Zero Stress Automation
2024-11-12 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
1 note
·
View note