#Linux Data Replication
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
#Linux File Replication#Linux Data Replication#big data#data protection#Cloud Solutions#data orchestration#Data Integration in Real Time#Data ingestion in real time#Cloud Computing
0 notes
Text
Install Splunk and Veeam App on Windows Server to monitor VBR
Splunk Enterprise is a powerful platform that automates the collection, indexing, monitoring, and alerting of data. This enables you to aggregate and analyze events efficiently. With Splunk, you can gain full control over your data flow and leverage it to drive business insights and decisions. Kindly read about data management and governance. n this acticle, we shall discuss how to install Splunk…
#Backup#Backup and Recovery#Backup Data#Backup Files and Folders#Linux#MacOS#Microsoft Windows#monitor#Monitor Backup#Monitor VBR with Splunk#Monitor Veeam Backup And Replication [VBR] with Splunk#Splunk#Splunk Enterprise#Veeam App for Splunk#Veeam App for Splunk Setup#Windows 10#Windows 11#Windows Server#Windows Server 2012#Windows Server 2016#Windows Server 2019#Windows Server 2022
0 notes
Text
28/3/25 AI Development
So i made a GAN image generation ai, a really simple one, but it did take me a lot of hours. I used this add-on for python (a programming language) called tensorflow, which is meant specifically for LMs (language models). The dataset I used is made up of 12 composite photos I made in 2023. I put my focus for this week into making sure the AI works, so I know my idea is viable, if it didnt work i would have to pivot to another idea, but its looking like it does thank god.
A GAN pretty much creates images similar to the training data, which works well with my concept because it ties into how AI tries to replicate art and culture. I called it Johnny2000. It doesnt actually matter how effective johnny is at creating realistic output, the message still works, the only thing i dont want is the output to be insanely realistic, which it shouldnt be, because i purposefully havent trained johnny to recognise and categorise things, i want him to try make something similar to the stuff i showed him and see what happens when he doesnt understand the 'rules' of the human world, so he outputs what a world based on a program would look like, that kind of thing.
I ran into heaps of errors, like everyone does with a coding project, and downloading tensorflow itself literally took me around 4 hours from how convoluted it was.
As of writing this paragraph, johnny is training in the background. I have two levels of output, one (the gray box) is what johnny gives me when i show him the dataset and tell him to create an image right away with no training, therefore he has no idea what to do and gives me a grey box with slight variations in colour. The second one (colourful) is after 10 rounds of training (called epoches), so pockets of colour are appearing, but still in a random noise like way. I'll make a short amendment to this post with the third image he's generating, which will be after 100 more rounds. Hopefully some sort of structure will form. I'm not sure how many epoches ill need to get the output i want, so while i continue the actual proposal i can have johnny working away in the background until i find a good level of training.


Edit, same day: johnny finished the 100 epoch version, its still very noisy as you can see, but the colours are starting to show, and the forms are very slowly coming through. looking at these 3 versions, im not expecting any decent input until 10000+ epochs. considering this 3rd version took over an hour to render, im gonna need to let it work overnight, ive been getting errors that the gpu isnt being used so i could try look at that, i think its because my version of tensorflow is too low. (newer ones arent supported on native windows, id need to use linux, which is possible on my computer but ive done all this work to get it to work here... so....)

how tf do i make it display smaller...
anyways, heres a peek at my dataset, so you can see that the colours are now being used (b/w + red and turquoise).
11 notes
·
View notes
Text
youtube
Zelda 64: Recompiled for PC - Majora's Mask
Zelda 64: Recompiled is a project that uses N64: Recompiled to statically recompile Majora's Mask (and soon Ocarina of Time) into a native port with many new features and enhancements. This project uses RT64 as the rendering engine to provide some of these enhancements.
Play Majora's Mask natively on PC! Download here for Windows or Linux:
Note: Project does not include game assets. Original game is required to play.
Features:
Plug and Play
Simply provide your copy of the North American version of the game in the main menu and start playing! This project will automatically load assets from the provided copy, so there is no need to go through a separate extraction step or build the game yourself. Other versions of the game may be supported in the future.
Fully Intact N64 Effects
A lot of care was put into RT64 to make sure all graphical effects were rendered exactly as they did originally on the N64. No workarounds or "hacks" were made to replicate these effects, with the only modifications to them being made for enhancement purposes such as widescreen support. This includes framebuffer effects like the grayscale cutscenes and the Deku bubble projectile, depth effects like the lens of truth, decals such as shadows or impact textures, accurate lighting, shading effects like the fire arrows and bomb explosions, and various textures that are often rendered incorrectly.
Easy-to-Use Menus
Gameplay settings, graphics settings, input mappings, and audio settings can all be configured with the in-game config menu. The menus can all be used with mouse, controller, or keyboard for maximum convenience.
High Framerate Support
Play at any framerate you want thanks to functionality provided by RT64! Game objects and terrain, texture scrolling, screen effects, and most HUD elements are all rendered at high framerates. By default, this project is configured to run at your monitor's refresh rate. You can also play at the original framerate of the game if you prefer. Changing framerate has no effect on gameplay.
Note: External framerate limiters (such as the NVIDIA Control Panel) are known to potentially cause problems, so if you notice any stuttering then turn them off and use the manual framerate slider in the in-game graphics menu instead.
Widescreen and Ultrawide Support
Any aspect ratio is supported, with most effects modded to work correctly in widescreen. The HUD can also be positioned at 16:9 when using ultrawide aspect ratios if preferred.
Note: Some animation quirks can be seen at the edges of the screen in certain cutscenes when using very wide aspect ratios.
Gyro Aim
When playing with a supported controller, first-person items such as the bow can be aimed with your controller's gyro sensor. This includes (but is not limited to) controllers such as the Dualshock 4, Dualsense, Switch Pro, and most third party Switch controllers (such as the 8BitDo Pro 2 in Switch mode).
Note: Gamepad mappers such as BetterJoy or DS4Windows may intercept gyro data and prevent the game from receiving it. Most controllers are natively supported, so turning gamepad mappers off is recommended if you want to use gyro.
Autosaving
Never worry about losing progress if your power goes out thanks to autosaving! The autosave system is designed to respect Majora's Mask's original save system and maintain the intention of owl saves by triggering automatically and replacing the previous autosave or owl save. However, if you'd still rather play with the untouched save system, simply turn off autosaving in the ingame menu.
Low Input Lag
This project has been optimized to have as little input lag as possible, making the game feel more responsive than ever!
Instant Load Times
Saving and loading files, going from place to place, and pausing all happen in the blink of an eye thanks to the game running natively on modern hardware.
Linux and Steam Deck Support
A Linux binary is available for playing on most up-to-date distros, including on the Steam Deck.
To play on Steam Deck, extract the Linux build onto your deck. Then, in desktop mode, right click the Zelda64Recompiled executable file and select "Add to Steam" as shown. From there, you can return to Gaming mode and configure the controls as needed. See the Steam Deck gyro aim FAQ section for more detailed instructions.
System Requirements:
A GPU supporting Direct3D 12.0 (Shader Model 6) or Vulkan 1.2 is required to run this project (GeForce GT 630, Radeon HD 7750, or Intel HD 510 (Skylake) and newer).
A CPU supporting the AVX instruction set is also required (Intel Core 2000 series or AMD Bulldozer and newer).
Planned Features:
Dual analog control scheme (with analog camera)
Configurable deadzone and analog stick sensitivity
Ocarina of Time support
Mod support and Randomizer
Texture Packs
Model Replacements
Ray Tracing (via RT64)
4 notes
·
View notes
Text
What Are the Hadoop Skills to Be Learned?
With the constantly changing nature of big data, Hadoop is among the most essential technologies for processing and storing big datasets. With companies in all sectors gathering more structured and unstructured data, those who have skills in Hadoop are highly sought after. So what exactly does it take to master Hadoop? Though Hadoop is an impressive open-source tool, to master it one needs a combination of technical and analytical capabilities. Whether you are a student looking to pursue a career in big data, a data professional looking to upskill, or someone career transitioning, here's a complete guide to the key skills that you need to learn Hadoop. 1. Familiarity with Big Data Concepts Before we jump into Hadoop, it's helpful to understand the basics of big data. Hadoop was designed specifically to address big data issues, so knowing these issues makes you realize why Hadoop operates the way it does. • Volume, Variety, and Velocity (The 3Vs): Know how data nowadays is huge (volume), is from various sources (variety), and is coming at high speed (velocity). • Structured vs Unstructured Data: Understand the distinction and why Hadoop is particularly suited to handle both. • Limitations of Traditional Systems: Know why traditional relational databases are not equipped to handle big data and how Hadoop addresses that need. This ground level knowledge guarantees that you're not simply picking up tools, but realizing their context and significance.
2. Fundamental Programming Skills Hadoop is not plug-and-play. Though there are tools higher up the stack that layer over some of the complexity, a solid understanding of programming is necessary in order to take advantage of Hadoop. • Java: Hadoop was implemented in Java, and much of its fundamental ecosystem (such as MapReduce) is built on Java APIs. Familiarity with Java is a major plus. • Python: Growing among data scientists, Python can be applied to Hadoop with tools such as Pydoop and MRJob. It's particularly useful when paired with Spark, another big data application commonly used in conjunction with Hadoop. • Shell Scripting: Because Hadoop tends to be used on Linux systems, Bash and shell scripting knowledge is useful for automating jobs, transferring data, and watching processes. Being comfortable with at least one of these languages will go a long way in making Hadoop easier to learn. 3. Familiarity with Linux and Command Line Interface (CLI) Most Hadoop deployments run on Linux servers. If you’re not familiar with Linux, you’ll hit roadblocks early on. • Basic Linux Commands: Navigating the file system, editing files with vi or nano, and managing file permissions are crucial. • Hadoop CLI: Hadoop has a collection of command-line utilities of its own. Commands will need to be used in order to copy files from the local filesystem and HDFS (Hadoop Distributed File System), to start and stop processes, and to observe job execution. A solid comfort level with Linux is not negotiable—it's a foundational skill for any Hadoop student.
4. HDFS Knowledge HDFS is short for Hadoop Distributed File System, and it's the heart of Hadoop. It's designed to hold a great deal of information in a reliable manner across a large number of machines. You need: • Familiarity with the HDFS architecture: NameNode, DataNode, and block allocation. • Understanding of how writing and reading data occur in HDFS. • Understanding of data replication, fault tolerance, and scalability. Understanding how HDFS works makes you confident while performing data work in distributed systems.
5. MapReduce Programming Knowledge MapReduce is Hadoop's original data processing engine. Although newer options such as Apache Spark are currently popular for processing, MapReduce remains a topic worth understanding. • How Map and Reduce Work: Learn about the divide-and-conquer technique where data is processed in two phases—map and reduce. • MapReduce Job Writing: Get experience writing MapReduce programs, preferably in Java or Python. • Performance Tuning: Study job chaining, partitioners, combiners, and optimization techniques. Even if you eventually favor Spark or Hive, studying MapReduce provides you with a strong foundation in distributed data processing.
6. Working with Hadoop Ecosystem Tools Hadoop is not one tool—its an ecosystem. Knowing how all the components interact makes your skills that much better. Some of the big tools to become acquainted with: • Apache Pig: A data flow language that simplifies the development of MapReduce jobs. • Apache Sqoop: Imports relational database data to Hadoop and vice versa. • Apache Flume: Collects and transfers big logs of data into HDFS. • Apache Oozie: A workflow scheduler to orchestrate Hadoop jobs. • Apache Zookeeper: Distributes systems. Each of these provides useful functionality and makes Hadoop more useful. 7. Basic Data Analysis and Problem-Solving Skills Learning Hadoop isn't merely technical expertise—it's also problem-solving. • Analytical Thinking: Identify the issue, determine how data can be harnessed to address it, and then determine which Hadoop tools to apply. • Data Cleaning: Understand how to preprocess and clean large datasets before analysis. • Result Interpretation: Understand the output that Hadoop jobs produce. These soft skills are typically what separate a decent Hadoop user from a great one.
8. Learning Cluster Management and Cloud Platforms Although most learn Hadoop locally using pseudo-distributed mode or sandbox VMs, production Hadoop runs on clusters—either on-premises or in the cloud. • Cluster Management Tools: Familiarize yourself with tools such as Apache Ambari and Cloudera Manager. • Cloud Platforms: Learn how Hadoop runs on AWS (through EMR), Google Cloud, or Azure HDInsight. It is crucial to know how to set up, monitor, and debug clusters for production-level deployments. 9. Willingness to Learn and Curiosity Last but not least, you will require curiosity. The Hadoop ecosystem is large and dynamic. New tools, enhancements, and applications are developed regularly. • Monitor big data communities and forums. • Participate in open-source projects or contributions. • Keep abreast of tutorials and documentation. Your attitude and willingness to play around will largely be the distinguishing factor in terms of how well and quickly you learn Hadoop. Conclusion Hadoop opens the door to the world of big data. Learning it, although intimidating initially, can be made easy when you break it down into sets of skills—such as programming, Linux, HDFS, SQL, and problem-solving. While acquiring these skills, not only will you learn Hadoop, but also the confidence in creating scalable and intelligent data solutions. Whether you're creating data pipelines, log analysis, or designing large-scale systems, learning Hadoop gives you access to a whole universe of possibilities in the current data-driven age. Arm yourself with these key skills and begin your Hadoop journey today.
Website: https://www.icertglobal.com/course/bigdata-and-hadoop-certification-training/Classroom/60/3044
0 notes
Text
Cloud Computing Solutions: Which Private Cloud Platform is Right for You?
If you’ve been navigating the world of IT or digital infrastructure, chances are you’ve come across the term cloud computing solutions more than once. From running websites and apps to storing sensitive data — everything is shifting to the cloud. But with so many options out there, how do you know which one fits your business needs best?
Let’s talk about it — especially if you're considering private or hybrid cloud setups.

Whether you’re an enterprise looking for better performance or a growing business wanting more control over your infrastructure, private cloud hosting might be your perfect match. In this post, we’ll break down some of the most powerful platforms out there, including VMware Cloud Hosting, Nutanix, H
yper-V, Proxmox, KVM, OpenStack, and OpenShift Private Cloud Hosting.
First Things First: What Are Cloud Computing Solutions?
In simple terms, cloud computing solutions provide you with access to computing resources like servers, storage, and software — but instead of managing physical hardware, you rent them virtually, usually on a pay-as-you-go model.
There are three main types of cloud environments:
Public Cloud – Shared resources with others (like Google Cloud or AWS)
Private Cloud – Resources are dedicated just to you
Hybrid Cloud – A mix of both, giving you flexibility
Private cloud platforms offer a high level of control, customization, and security — ideal for industries where uptime and data privacy are critical.
Let’s Dive Into the Top Private Cloud Hosting Platforms
1. VMware Cloud Hosting
VMware is a veteran in the cloud space. It allows you to replicate your on-premise data center environment in the cloud, so there’s no need to learn new tools. If you already use tools like vSphere or vSAN, VMware Cloud Hosting is a natural fit.
It’s highly scalable and secure — a great choice for businesses of any size that want cloud flexibility without completely overhauling their systems.
2. Nutanix Private Cloud Hosting
If you're looking for simplicity and power packed together, Nutanix Private Cloud Hosting might just be your best friend. Nutanix shines when it comes to user-friendly dashboards, automation, and managing hybrid environments. It's ideal for teams who want performance without spending hours managing infrastructure.
3. Hyper-V Private Cloud Hosting
For businesses using a lot of Microsoft products, Hyper-V Private Cloud Hosting makes perfect sense. Built by Microsoft, Hyper-V integrates smoothly with Windows Server and Microsoft System Center, making virtualization easy and reliable.
It's a go-to for companies already in the Microsoft ecosystem who want private cloud flexibility without leaving their comfort zone.
4. Proxmox Private Cloud Hosting
If you’re someone who appreciates open-source platforms, Proxmox Private Cloud Hosting might be right up your alley. It combines KVM virtualization and Linux containers (LXC) in one neat package.
Proxmox is lightweight, secure, and customizable. Plus, its web-based dashboard is super intuitive — making it a favorite among IT admins and developers alike.
5. KVM Private Cloud Hosting
KVM (Kernel-based Virtual Machine) is another open-source option that’s fast, reliable, and secure. It’s built into Linux, so if you’re already in the Linux world, it integrates seamlessly.
KVM Private Cloud Hosting is perfect for businesses that want a lightweight, customizable, and high-performing virtualization environment.
6. OpenStack Private Cloud Hosting
Need full control and want to scale massively? OpenStack Private Cloud Hosting is worth a look. It’s open-source, flexible, and designed for large-scale environments.
OpenStack works great for telecom, research institutions, or any organization that needs a lot of flexibility and power across private or public cloud deployments.
7. OpenShift Private Cloud Hosting
If you're building and deploying apps in containers, OpenShift Private Cloud Hosting In serverbasket is a dream come true. Developed by Red Hat, it's built on Kubernetes and focuses on DevOps, automation, and rapid application development.
It’s ideal for teams running CI/CD pipelines, microservices, or containerized workloads — especially when consistency and speed are top priorities.
So, Which One Should You Choose?
The right private cloud hosting solution really depends on your business needs. Here’s a quick cheat sheet:
Go for VMware if you want enterprise-grade features with familiar tools.
Try Nutanix if you want something powerful but easy to manage.
Hyper-V is perfect if you’re already using Microsoft tech.
Proxmox and KVM are great for tech-savvy teams that love open source.
OpenStack is ideal for large-scale, customizable deployments.
OpenShift is built for developers who live in the container world.
Final Thoughts
Cloud computing isn’t a one-size-fits-all solution. But with platforms like VMware, Nutanix, Hyper-V, Proxmox, KVM, OpenStack, and OpenShift Private Cloud Hosting, you’ve got options that can scale with you — whether you're running a small development team or a global enterprise.
Choosing the right platform means looking at your current infrastructure, your team's expertise, and where you want to be a year from now. Whatever your path, the right cloud solution can drive efficiency, reduce overhead, and set your business up for long-term success.
#Top Cloud Computing Solutions#Nutanix Private Cloud#VMware Cloud Server Hosting#Proxmox Private Cloud#KVM Private Cloud
1 note
·
View note
Text
Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
In today’s hybrid cloud and container-native landscape, storage plays a critical role in enabling scalable, resilient, and high-performing applications. As organizations move towards Kubernetes and cloud-native infrastructures, the need for robust and integrated storage solutions becomes more pronounced. Red Hat addresses this challenge with Red Hat OpenShift Data Foundation (ODF)—a unified, software-defined storage platform built for OpenShift.
The DO370: Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation course equips IT professionals with the skills needed to deploy, configure, and manage ODF as a dynamic storage solution for containerized applications on OpenShift.
What is Red Hat OpenShift Data Foundation?
Red Hat OpenShift Data Foundation (formerly OpenShift Container Storage) is a software-defined storage platform that integrates tightly with Red Hat OpenShift. It provides persistent storage for applications, databases, CI/CD pipelines, and AI/ML workloads—all with the simplicity and agility of Kubernetes-native services.
ODF leverages Ceph, Rook, and NooBaa under the hood to offer block, file, and object storage, making it a versatile option for stateful workloads.
What You’ll Learn in DO370
The DO370 course dives deep into enterprise-grade storage capabilities and walks learners through hands-on labs and real-world use cases. Here's a snapshot of the key topics covered:
🔧 Deploy and Configure OpenShift Data Foundation
Understand ODF architecture and components
Deploy internal and external mode storage clusters
Use storage classes for dynamic provisioning
📦 Manage Persistent Storage for Containers
Create and manage Persistent Volume Claims (PVCs)
Deploy and run stateful applications
Understand block, file, and object storage options
📈 Monitor and Optimize Storage Performance
Monitor cluster health and performance with built-in tools
Tune and scale storage based on application demands
Implement alerts and proactive management practices
🛡️ Data Resiliency and Security
Implement replication and erasure coding for high availability
Understand encryption, backup, and disaster recovery
Configure multi-zone and multi-region storage setups
🧪 Advanced Use Cases
Integrate with AI/ML workloads and CI/CD pipelines
Object gateway with S3-compatible APIs
Hybrid and multi-cloud storage strategies
Who Should Take DO370?
This course is ideal for:
Platform Engineers and Cluster Administrators managing OpenShift clusters
DevOps Engineers deploying stateful apps
Storage Administrators transitioning to Kubernetes-native environments
IT Architects designing enterprise storage strategies for hybrid clouds
Prerequisites: Before taking DO370, you should be comfortable with OpenShift administration (such as through DO180 and DO280) and have foundational knowledge of Linux and Kubernetes.
Why ODF Matters for Enterprise Workloads
In a world where applications are more data-intensive than ever, a flexible and reliable storage layer is non-negotiable. Red Hat ODF brings resiliency, scalability, and deep OpenShift integration, making it the go-to choice for organizations running mission-critical workloads on Kubernetes.
Whether you're running databases, streaming data pipelines, or AI models—ODF provides the tools to manage data effectively, securely, and at scale.
Final Thoughts
The DO370 course empowers professionals to take control of their container-native storage strategy. With OpenShift Data Foundation, you're not just managing storage—you’re enabling innovation across your enterprise.
Ready to become a storage pro in the Kubernetes world? Dive into DO370 and take your OpenShift skills to the next level.
Want help with course prep or real-world deployment of OpenShift Data Foundation? www.hawkstack.com
0 notes
Text
MySQL insights: Database Management for Beginners and Experts
Databases form the backbone of every online application, from social media platforms to e-commerce stores. MySQL stands out as one of the most widely used relational database management systems (RDBMS) globally. Whether you are a beginner looking to learn MySQL or an expert seeking advanced database management techniques, this blog will provide valuable insights into MySQL's capabilities, features, and best practices.
What is MySQL?
MySQL is an open-source relational database management system (RDBMS) that organizes data into tables. Developed by MySQL AB and now owned by Oracle Corporation, MySQL is widely used for managing structured data efficiently. It is known for its reliability, scalability, and ease of use, making it the preferred choice for small businesses, startups, and large enterprises alike.
Why Choose MySQL?
Open-Source & Free: MySQL is open-source, meaning it is free to use and modify.
High Performance: It is optimized for speed and handles large amounts of data efficiently.
Scalability: MySQL can scale from small applications to large enterprise solutions.
Secure: Features like encryption, authentication, and access control make MySQL a secure choice.
Cross-Platform Support: Runs on multiple operating systems, including Windows, Linux, and macOS.
Integration with Popular Technologies: Works seamlessly with PHP, Python, Java, and more.
MySQL Installation Guide
To install MySQL on your system, follow these steps:
Download MySQL: Visit the official MySQL website and download the latest version for your OS.
Run the Installer: Open the installer and follow the setup wizard instructions.
Configure MySQL: Choose the server type and set a root password.
Start MySQL Server: Use the MySQL Workbench or command line to start the MySQL service.
MySQL Basic Commands for Beginners
If you are new to MySQL, here are some essential SQL commands to get started:

Advanced MySQL Techniques
1. Indexing for Performance Optimization
Indexing is crucial for improving the speed of database queries. Without indexes, MySQL scans the entire table, which slows down performance.
CREATE INDEX idx_users_email ON users(email);
2. Using Joins to Combine Data from Multiple Tables
Joins help retrieve data from multiple related tables efficiently.

3. Stored Procedures for Automation
Stored procedures help automate complex queries and improve efficiency.

4. MySQL Replication for High Availability
Replication allows data to be copied from one server to another, ensuring high availability and load balancing.

START SLAVE;
Common MySQL Errors & Troubleshooting
Error: Access Denied for User 'root'@'localhost' Solution: Reset MySQL root password using the command line.
Error: MySQL Server Has Gone Away Solution: Increase the max_allowed_packet size in the MySQL configuration file.
Error: Table Doesn't Exist Solution: Check the table name and ensure it exists in the database.
MySQL vs Other Database Management Systems

Best Practices for MySQL Optimization
Use Indexing Efficiently to speed up queries.
Normalize Your Database to avoid redundancy.
Avoid Using SELECT* to reduce unnecessary data load.
Regularly Backup Your Database to prevent data loss.
Monitor Performance Metrics using MySQL Workbench.
Future of MySQL in Database Management
With the rise of cloud computing, MySQL continues to evolve. Cloud-based solutions such as Amazon RDS, Google Cloud SQL, and Azure Database for MySQL make it easier to deploy and manage databases at scale. New features like JSON support, improved indexing, and machine learning integration further solidify MySQL’s position as a leading database solution.
Conclusion
MySQL remains a powerful and versatile database management system for both beginners and professionals. With its ease of use, scalability, and extensive community support, it continues to be a preferred choice for web developers, data analysts, and businesses worldwide. By mastering MySQL’s features and best practices, you can build high-performance applications that handle data efficiently.
0 notes
Text
#Linux#Linux data replication#cloud solutions#Big data security#cloud computing#secure data handling#data privacy#cloud infrastructure#cloud technology#Data Analytics#data integration#Big data solutions#Big data insights#data management#File transfer solutions
0 notes
Text
Firebird to Cassandra Migration
In this article, we delve into the intricacies of migrating from Firebird to Cassandra. We will explore the reasons behind choosing Cassandra over Firebird, highlighting its scalability, high availability, and fault tolerance. We'll discuss key migration steps, such as data schema transformation, data extraction, and data loading processes. Additionally, we'll address common challenges faced during migration and provide best practices to ensure a seamless transition. By the end of this article, you'll be equipped with the knowledge to effectively migrate your database from Firebird to Cassandra.
What is Firebird
Firebird is a robust, open-source relational database management system renowned for its versatility and efficiency. It offers advanced SQL capabilities and comprehensive ANSI SQL compliance, making it suitable for various applications. Firebird supports multiple platforms, including Windows, Linux, and macOS, and is known for its lightweight architecture. Its strong security features and performance optimizations make it an excellent choice for both embedded and large-scale database applications. With its active community and ongoing development, Firebird continues to be a reliable and popular database solution for developers.
What is Cassandra
Cassandra is a highly scalable, open-source NoSQL database designed to handle large amounts of data across many commodity servers without any single point of failure. Known for its distributed architecture, Cassandra provides high availability and fault tolerance, making it ideal for applications that require constant uptime. It supports dynamic schema design, allowing flexible data modeling, and offers robust read and write performance. With its decentralized approach, Cassandra ensures data replication across multiple nodes, enhancing reliability and resilience. As a result, it is a preferred choice for businesses needing to manage massive datasets efficiently and reliably.
Advantages of Firebird to Cassandra Migration
Scalability: Cassandra’s distributed architecture allows for seamless horizontal scaling as data volume and user demand grow.
High Availability: Built-in replication and fault-tolerance mechanisms ensure continuous availability and data integrity.
Performance: Write-optimized design handles high-velocity data, providing superior read and write performance.
Flexible Data Model: Schema-less support allows agile development and easier management of diverse data types.
Geographical Distribution: Data replication across multiple data centers enhances performance and disaster recovery capabilities.
Method 1: Migrating Data from Firebird to Cassandra Using the Manual Method
Firebird to Cassandra migration manually involves several key steps to ensure accuracy and efficiency:
Data Export: Begin by exporting the data from Firebird, typically using SQL queries or Firebird's export tools to generate CSV or SQL dump files.
Schema Mapping: Map the Firebird database schema to Cassandra’s column-family data model, ensuring proper alignment of data types and structures.
Data Transformation: Transform the exported data to fit Cassandra’s schema, making necessary adjustments to comply with Cassandra’s requirements and best practices.
Data Loading: Use Cassandra’s loading utilities, such as CQLSH COPY command or bulk loading tools, to import the transformed data into the appropriate keyspaces and column families.
Verification and Testing: After loading, verify data integrity and consistency by running validation queries and tests to ensure the migration was successful and accurate.
Disadvantages of Migrating Data from Firebird to Cassandra Using the Manual Method
High Error Risk: Manual efforts significantly increase the risk of errors during the migration process.
Need to do this activity again and again for every table.
Difficulty in Data Transformation: Achieving accurate data transformation can be challenging without automated tools.
Dependency on Technical Resources: The process heavily relies on technical resources, which can strain teams and increase costs.
No Automation: Lack of automation requires repetitive tasks to be done manually, leading to inefficiencies and potential inconsistencies.
Limited Scalability: For every table, the entire process must be repeated, making it difficult to scale the migration.
No Automated Error Handling: There are no automated methods for handling errors, notifications, or rollbacks in case of issues.
Lack of Logging and Monitoring: Manual methods lack direct automated logs and tools to track the amount of data transferred or perform incremental loads (Change Data Capture).
Method 2: Migrating Data from Firebird to Cassandra Using ETL Tools
There are certain advantages in case if you use an ETL tool to migrate the data
Extract Data: Use ETL tools to automate the extraction of data from Firebird, connecting directly to the database to pull the required datasets.
Transform Data: Configure the ETL tool to transform the extracted data to match Cassandra's schema, ensuring proper data type conversion and structure alignment.
Load Data: Use the ETL tool to automate the loading of transformed data into Cassandra, efficiently handling large volumes of data and multiple tables.
Error Handling and Logging: Utilize the ETL tool’s built-in error handling and logging features to monitor the migration process, receive notifications, and ensure data integrity.
Incremental Loads: Leverage the ETL tool's Change Data Capture (CDC) capabilities to perform incremental data loads, migrating only updated or new data to optimize performance.
Testing and Verification: After loading the data, use the ETL tool to verify data accuracy and consistency, running validation checks to ensure the migration was successful.
Scalability: ETL tools support scalable migrations, allowing for easy adjustments and expansions as data volume and complexity increase.
Challenges of Using ETL Tools for Data Migration
Initial Setup Complexity: Configuring ETL tools for data extraction, transformation, and loading can be complex and time-consuming.
Cost: Advanced ETL tools can be expensive, increasing the overall cost of the migration.
Resource Intensive: ETL processes can require significant computational resources, impacting system performance.
Data Mapping Difficulties: Mapping data between different schemas can be challenging and error-prone.
Customization Needs: Standard ETL tools may require custom scripts to meet specific migration needs.
Dependency on Tool Features: The success of migration depends on the capabilities of the ETL tool, which may have limitations.
Maintenance and Support: Ongoing maintenance and vendor support are often needed, adding to long-term operational costs.
Why Ask On Data is the Best Tool for Migrating Data from Firebird to Cassandra
Seamless Data Transformation: Automatically handles data transformations to ensure compatibility between Firebird and Cassandra.
User-Friendly Interface: Simplifies the migration process with an intuitive, easy-to-use interface, making it accessible for both technical and non-technical users.
High Efficiency: Automates repetitive tasks, significantly reducing the time and effort required for migration.
Built-In Error Handling: Offers robust error handling and real-time notifications, ensuring data integrity throughout the migration.
Incremental Load Support: Supports incremental data loading, enabling efficient updates and synchronization without duplicating data.
Usage of Ask On Data : A chat based AI powered Data Engineering Tool
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download from Github and deploy on your own servers, whereas with enterprise version, you can use Ask On Data as a managed service.
Advantages of using Ask On Data
Built using advanced AI and LLM, hence there is no learning curve.
Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
No dependence on technical resources
Super fast to implement (at the speed of typing)
No technical knowledge required to use
Below are the steps to do the data migration activity
Step 1: Connect to Firebird(which acts as source)
Step 2 : Connect to Cassandra (which acts as target)
Step 3: Create a new job. Select your source (Firebird) and select which all tables you would like to migrate.
Step 4 (OPTIONAL): If you would like to do any other tasks like data type conversion, data cleaning, transformations, calculations those also you can instruct to do in natural English. NO knowledge of SQL or python or spark etc required.
Step 5: Orchestrate/schedule this. While scheduling you can run it as one time load, or change data capture or truncate and load etc.
For more advanced users, Ask On Data is also providing options to write SQL, edit YAML, write PySpark code etc.
There are other functionalities like error logging, notifications, monitoring, logs etc which can provide more information like the amount of data transferred, logs, any error information if the job did not run and other kind of monitoring information etc.
Trying Ask On Data
You can reach out to us on mailto:[email protected] for a demo, POC, discussion and further pricing information. You can make use of our managed services or you can also download and install on your own servers our community edition from Github.
0 notes
Text
How to Prevent Malware Attacks: A Simple Guide to Protection
Malware attacks are among the most significant threats businesses face today. These attacks can destroy data, disrupt operations, and even cripple entire organizations. Protecting your business from malware isn’t just about avoiding risk—it’s about building a proactive defense. Fortunately, preventing malware attacks is simpler than you might think. In this guide, we’ll explain how to prevent malware attacks, share essential tips for protection, and help you secure your systems with straightforward steps.
What Is Malware?
Before diving into prevention, let’s first understand malware. Malware, short for "malicious software," refers to programs or files intentionally designed to harm your computer system, steal sensitive data, or compromise your system’s integrity. Common types of malware include:
Viruses: Malicious programs that attach themselves to legitimate files or software and spread to other systems.
Spyware: Software that secretly monitors your activities and steals sensitive data.
Ransomware: A type of malware that locks you out of your files or systems, demanding payment to restore access.
Trojans: Malicious software disguised as legitimate programs, often used to give hackers remote access.
Worms: Self-replicating malware that spreads without human intervention.
Regardless of the type, malware can cause devastating damage—from data breaches and financial losses to compromised networks. Taking proactive steps to prevent attacks is essential.
How to Prevent Malware Attacks: 5 Simple Steps
1. Keep Your Software Updated
Think of software updates as locks on your doors. If they’re outdated, intruders can easily break in. Updates often include critical security patches that fix vulnerabilities in operating systems, applications, and antivirus programs. Here’s how to stay updated:
Regularly update your operating system, whether it’s Windows, macOS, or Linux.
Keep applications like web browsers, email clients, and productivity tools up to date.
Ensure your antivirus software runs the latest virus definitions.
Set your devices to update automatically to avoid forgetting. Ignoring updates can leave your systems vulnerable.
2. Install and Use Antivirus Software
Antivirus software acts as your system’s bodyguard, constantly scanning for threats and blocking malicious files. To maximize protection:
Choose a reliable antivirus program with real-time protection.
Schedule regular scans of your system—weekly or even daily.
Enable automatic updates to ensure your antivirus software is equipped to handle the latest threats.
While antivirus software isn’t 100% foolproof, it’s a critical component of your defense strategy.
3. Be Cautious with Emails and Attachments
Email is a common malware delivery method. Cybercriminals use phishing emails to trick users into downloading malicious attachments or clicking harmful links. Here’s how to stay safe:
Avoid opening email attachments from unknown or suspicious senders.
Don’t click on unexpected links, especially if they ask for personal information.
Look for signs of phishing, such as misspellings, incorrect grammar, or odd sender addresses.
When in doubt, delete suspicious emails. If the email appears to be from a known company, contact them directly to confirm its authenticity.
4. Use Strong Passwords and Enable Multi-Factor Authentication (MFA)
A weak password is like leaving your front door wide open. Protect your accounts by:
Using long, complex passwords with uppercase letters, lowercase letters, numbers, and special characters.
Avoiding obvious choices like “password123” or your pet’s name.
Storing passwords securely with a password manager.
Enable MFA whenever possible. This adds an extra layer of security by requiring additional verification, such as a code sent to your phone or a biometric scan.
5. Backup Your Data Regularly
Even with the best precautions, attacks can happen. Regular backups ensure you can restore critical data with minimal disruption. Follow these tips:
Backup important files daily or weekly, depending on their importance.
Use external drives or cloud storage to store backups securely.
Keep backups disconnected from your main network to prevent malware from spreading to them.
Reliable backups enable quick recovery after an attack, minimizing impact on your business.
Additional Tips for Malware Protection
Use a Firewall
A firewall acts as a barrier between your system and external threats. It monitors network traffic and blocks malicious activity. Ensure your firewall is activated and properly configured.
Limit User Permissions
Restrict access to sensitive systems and data within your organization. Not all employees need admin rights. Limiting permissions reduces the risk of malware spreading.
Train Your Employees
Your team can be your greatest asset or weakest link in cybersecurity. Educate employees about recognizing phishing attacks, practicing safe internet habits, and handling sensitive data. Conduct regular training sessions to keep everyone informed about evolving threats.
Why Cybersecurity is Critical for Your Business
Malware attacks affect more than just your computer systems—they impact your bottom line. A single breach can:
Compromise confidential data, including customer information and intellectual property.
Cause financial losses from downtime or data recovery.
Damage your reputation, leading to lost customers.
Disrupt your network infrastructure, making it harder to operate.
At Bantech Cyber, we specialize in Managed IT and Cybersecurity Services to protect businesses from threats like malware. From malware prevention and data encryption to incident response, our team ensures your systems are secure, compliant, and prepared for potential attacks.
Conclusion
Preventing malware attacks doesn’t have to be complicated. By following these simple steps, you can significantly reduce the risk of infection and safeguard your business.
At Bantech Cyber, we’re committed to equipping your organization with the tools and expertise needed to stay secure in today’s digital world.
Contact us today to learn how we can help protect your business from malware and other cybersecurity threats. With the right knowledge, tools, and support, you can keep your business safe no matter what challenges the digital landscape presents.
1 note
·
View note
Text
Amazon FSx for Lustre Benefits, Use Cases And Features
What is Amazon FSx for Lustre?
Amazon FSx for Lustre is a fully managed solution offering high-performance, scalable, and reasonably priced storage computational workloads. The most widely used high-performance file system in the world serves as the foundation for fully controlled shared storage.
Amazon FSx for Lustre advantages
Quicken computation workloads
Shared storage with sub-millisecond latencies, hundreds of gigabytes/second throughput, and millions of IOPS can speed up computing workloads. In only a few minutes, deploy a fully managed Lustre file system.
Use Amazon S3 to access and handle data sets
By connecting your file systems to S3 buckets, you may access and handle Amazon S3 data from a high-performance file system.
Optimize the cost and functionality of storage for your workload
Use a variety of deployment choices, such as replication level, performance tier, and storage type, to balance cost and performance.
How it operates
With the scalability and performance of the well-liked Lustre file system, Amazon FSx for Lustre offers fully managed shared storage.
Use cases
Increase the speed of machine learning (ML)
Training durations can be shortened with optimized throughput to your computational resources and convenient access to training data stored in Amazon S3.
High performance computing (HPC) should be enabled
Fast, highly scalable storage that is directly integrated with AWS computation and orchestration services can power even the most demanding HPC applications.
Open up big data analytics
Support petabytes of data and thousands of computing instances executing sophisticated analytics workloads.
Boost the agility of the media workload
With storage that grows with your computer, you can adapt to ever-tinier visual effects (VFX), rendering, and transcoding timelines.
Amazon Lustre FSx Features
Overview
Amazon FSx for Lustre provides controlled, cost-effective, high-performance, scalable compute storage. Based on Lustre, the world’s most popular high-performance file system, FSx for Lustre provides shared storage with sub-ms latency, terabytes per second throughput, and millions of IOPS. When coupled to Amazon Simple Storage Service (S3) buckets, FSx for Lustre file systems can access and process data simultaneously.
Improve workload performance
Overview
AWS FSx for Lustre file systems can handle terabytes per second and millions of IOPS. FSx for Lustre handles concurrent access to files and directories from thousands of compute instances. Low file operation latencies are guaranteed by FSx for Lustre.
Most common high-performance file system
The Lustre open source file system is the most popular file system for the 500 fastest computers in the world because it efficiently and cheaply processes the world’s expanding data collections. It is battle-tested in energy, life sciences, media production, and financial services for genome sequencing, video transcoding, machine learning, and fraud detection.
Use for any compute workload
Overview
Popular Linux-based AMIs like Amazon Linux, Red Hat Enterprise Linux (RHEL), CentOS, Ubuntu, and SUSE Linux are compatible with FSx for Lustre.
Simple import/export Amazon S3 info
Amazon FSx for Lustre allows native S3 data access for data-processing tasks.
You can join one or more S3 buckets to a file system in Amazon FSx with a few clicks. After connecting your S3 bucket to your file system, FSx for Lustre transparently displays S3 objects as files and lets you post results to S3. Objects added, altered, or removed from your S3 bucket update your connected file system automatically. As files are added, edited, or removed, FSx for Lustre updates your S3 bucket automatically. Data is exported back to S3 quickly using parallel data-transfer techniques by FSx for Lustre.
Utilize computing services easily
AWS FSx for Lustre can be used on Amazon EC2 instances or on-premises machines. Your file system’s files and directories can be accessed like a local file system once mounted. Amazon EKS containers can access FSx for Lustre file systems.
Increase Amazon SageMaker instructor positions
Amazon Sagemaker supports Amazon FSx for Lustre input data. Amazon SageMaker and Amazon FSx for Lustre expedite machine learning training jobs by skipping the initial S3 download phase and reducing TCO by avoiding repeated downloads of common items (saving S3 request costs) for iterative jobs on the same data set.
Compute management services simplify deployment
Amazon FSx for Lustre interfaces with AWS Batch via EC2 Launch Templates. Our cloud-native batch scheduler supports HPC, ML, and other asynchronous workloads. AWS Batch launches instances and runs jobs using existing FSx for Lustre file systems and dynamically sizes instances to job resource requirements.
Lustre FSx works with AWS ParallelCluster. Deploy and manage HPC clusters with AWS ParallelCluster, an open-source cluster management tool. During cluster creation, it can automatically create Lustre FSx or use existing file systems.
Access data quickly
File data access has sub-millisecond first-byte latency on SSDs and single-digit millisecond on HDDs.
Metadata servers with low-latency SSD storage support all Amazon FSx for Lustre file systems, regardless of deployment type, storage type, or throughput performance. The SSD-based metadata server delivers metadata operations, which make up most file system activities, with sub-millisecond latencies.
Save money
Reduce paperwork and scale capacity and performance as needed
You can construct and scale a high-performance Lustre file system with a few clicks via Amazon FSx console, CLI, or API. The time-consuming administration responsibilities of managing file servers and storage volumes, updating hardware, setting software, running out of space, and tweaking performance are automated by Amazon FSx file systems.
Various deployments
For short-term and long-term data processing, Amazon FSx for Lustre supports scratch and persistent file systems. Scratch files are suited for short-term data storage and processing. A failed file server does not replicate or save data. For long-term storage and workloads, persistent file systems are best. A persistent file system replicates data and replaces failed servers.
For additional data protection and business and regulatory compliance, Amazon FSx may automatically take incremental backups of persistent file systems. Amazon S3 backups are 99.999999999% durable.
Many storage choices
To optimise cost and performance for your workload, Amazon FSx for Lustre offers SSD and HDD storage solutions. SSD storage can be used for low-latency, IOPS-intensive workloads with tiny, random file operations. HDD storage can handle throughput-intensive workloads with huge, sequential file operations.
To provide sub-millisecond latencies and better IOPS for frequently visited files in an HDD-based file system, provision an SSD cache.
Storage quotas can monitor and limit user- and group-level storage consumption on file systems to prevent unnecessary capacity use. Storage quotas are for file system administrators who service various users, teams, or projects.
Data compression lowers storage costs
File system backups and storage can be reduced by data compression. The data compression feature uses the LZ4 algorithm, which optimizes compression without affecting file system speed. Data compression allows FSx for Lustre to compress and uncompress newly written files before writing them to disk and reading them.
Get rid of old files
After exporting files to Amazon S3, release inactive data to maximize storage capacity. After a file is released, its data is removed from the file system and stored on S3, but its metadata remains. A released file is automatically and transparently loaded from your S3 bucket onto your file system when accessed.
Ensure security and compliance
Overview
Amazon FSx for Lustre file systems are secured at-rest and in-transit in specific areas.
AWS helps customers manage their requirements with the longest-running cloud compliance program. The security of Amazon FSx meets global and industry requirements. In addition to HIPAA, it is PCI DSS, ISO 9001, 27001, 27017, and 27018 compliant and SOC 1, 2, and 3. Visit our compliance site for resources. To see all services and certifications, visit the Services in Scope by Compliance Program page.
Isolated networks
Amazon VPC endpoints allow you to isolate your Amazon FSx file system in your virtual network. Configure security group rules and network access to Amazon FSx file systems.
Resources-level permissions
Amazon FSx integrates with AWS IAM. You can govern how AWS IAM users and groups create and delete file systems using this connection. Amazon FSx resources can be tagged to restrict IAM user and group actions.
One-stop backup and compliance with AWS Backup
Integration with AWS Backup allows fully managed, policy-based backup and recovery for Amazon FSx file systems. Integration with AWS Backup protects customer data and ensures AWS service compliance for business continuity.
Regional and account backup compliance
Copying Amazon FSx file system backups across AWS Regions, accounts, or both can improve data protection and meet business continuity, disaster recovery, and compliance requirements.
Read more on Govindhtech.com
#AmazonFSx#AmazonFSxforLustre#S3buckets#AmazonLustreFSx#machinelearning#AmazonS3#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Understanding MySQL: Why It's So Popular and Its Core Features

What is MySQL?
MySQL is an open-source relational database management system (RDBMS) that is widely used for managing and storing data. It uses Structured Query Language (SQL) to create, manage, and query databases. MySQL is one of the most popular database systems worldwide due to its ease of use, reliability, and robust performance. It is commonly used in web applications, especially in conjunction with PHP, and powers some of the largest websites and applications on the internet, including Facebook, Twitter, and YouTube.
Why is MySQL So Popular?
There are several reasons why MySQL has gained immense popularity among developers, businesses, and organisations alike:
Open Source and Free: MySQL is open-source, meaning it is free to use and can be modified to suit specific needs. This makes it an attractive option for both small businesses and large enterprises.
Reliability and Stability: MySQL is known for its stability and robustness, making it a reliable choice for applications that require high availability and minimal downtime.
Speed and Efficiency: MySQL offers high-speed data retrieval and processing, which is essential for modern applications that need to handle large volumes of data quickly and efficiently.
Scalability: MySQL can handle large datasets, which allows it to scale seamlessly as an application grows. This scalability makes it suitable for both small websites and large-scale enterprise applications.
Cross-Platform Support: MySQL can run on various platforms, including Windows, Linux, macOS, and others, making it versatile and adaptable to different environments.
Active Community and Support: Being an open-source platform, MySQL benefits from a large, active community that contributes to its development, support, and troubleshooting.
Core Features of MySQL
MySQL comes with a variety of features that make it a powerful and efficient database management system:
Data Security: MySQL provides robust security features, including data encryption and user access controls, to ensure that only authorised users can access sensitive information.
Multi-User Access: MySQL allows multiple users to access and manipulate the database simultaneously, without interfering with each other’s work. This is essential for collaborative environments.
Backup and Recovery: MySQL offers various backup and recovery options, ensuring that data is protected against loss or corruption. Tools such as MySQL Enterprise Backup allow for fast and reliable backups.
Replication: MySQL supports data replication, which allows for data to be copied across multiple servers, ensuring high availability and load balancing. This feature is crucial for large-scale applications that require constant uptime.
Indexes: MySQL supports the use of indexes to improve query performance. Indexes speed up data retrieval operations, making it easier for developers to work with large datasets.
ACID Compliance: MySQL supports ACID (Atomicity, Consistency, Isolation, Durability) properties, which ensures that database transactions are processed reliably.
Full-Text Search: MySQL includes a full-text search engine, allowing developers to search and index text-based data more efficiently.
Stored Procedures and Triggers: MySQL allows the use of stored procedures and triggers to automate tasks and enforce business logic directly within the database.
Conclusion
MySQL is an essential tool for developers and businesses that require a reliable, fast, and secure database management system. Its open-source nature, combined with its powerful features, makes it an ideal choice for projects of all sizes. If you're just starting out with MySQL or looking to improve your knowledge of this versatile platform, check out our complete guide to MySQL to learn more.
0 notes
Text
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer for Web Developers
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer for Web Developers.
In the dynamic world of web development, the need for versatile tools that can handle complex data manipulation and visualization is paramount. Enter VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer—a powerful online Excel component designed to operate entirely within web applications. Written completely in JavaScript, this component replicates the full functionality of Microsoft Excel, enabling web developers to read, modify, and save Excel files seamlessly across various platforms, including Windows, Mac, Linux, iOS, and Android.
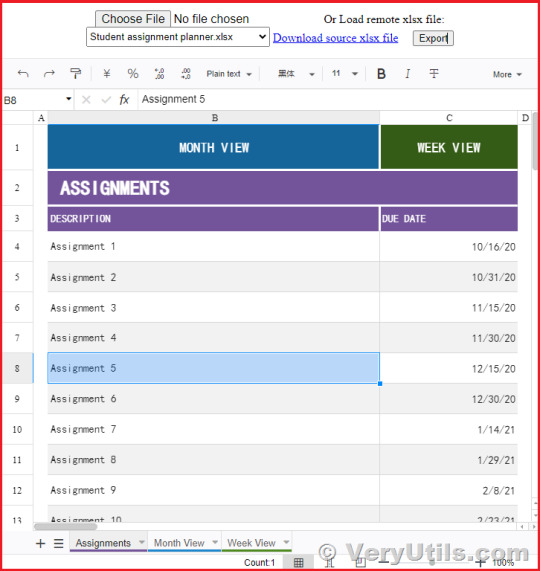
✅ What is VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer?
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer is a comprehensive and flexible Excel viewer designed specifically for web developers. It allows users to perform data analysis, visualization, and management directly within a web application. The interface is highly intuitive, making it easy for users to interact with data as they would in Microsoft Excel, but without the need for standalone software installations. Whether you're handling complex spreadsheets or simple data entries, this JavaScript-based control offers all the functionality you need.
✅ Key Features of VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer
Seamless Data Analysis and Visualization VeryUtils JavaScript Spreadsheet provides a full range of Excel-like features, including data binding, selection, editing, formatting, and resizing. It also supports sorting, filtering, and exporting Excel documents, making it a versatile tool for any web-based project.
Compatibility with Microsoft Excel File Formats This control is fully compatible with Microsoft Excel file formats (.xlsx, .xls, and .csv). You can load and save documents in these formats, ensuring data accuracy and retaining styles and formats.
Highly Intuitive User Interface The user interface of VeryUtils JavaScript Spreadsheet is designed to closely mimic Microsoft Excel, ensuring a familiar experience for users. This minimizes the learning curve and allows for immediate productivity.
✅ Why Choose VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer?
High Performance VeryUtils JavaScript Spreadsheet is optimized for performance, capable of loading and displaying large datasets efficiently. It supports row and column virtualization, enabling smooth scrolling and fast access to data.
Seamless Data Binding The component allows seamless binding with various local and remote data sources such as JSON, OData, WCF, and RESTful web services. This flexibility makes it easier to integrate into different web applications.
Hassle-Free Formatting Formatting cells and numbers is made simple with VeryUtils JavaScript Spreadsheet. It supports conditional formatting, which allows cells to be highlighted based on specific criteria, enhancing data readability and analysis.
Transform Data into Charts With the built-in chart feature, you can transform spreadsheet data into visually appealing charts, making data interpretation more intuitive and insightful.
Wide Range of Built-In Formulas The JavaScript Spreadsheet comes with an extensive library of formulas, complete with cross-sheet reference support. This feature, combined with a built-in calculation engine, allows for complex data manipulations within your web application.
Customizable Themes VeryUtils JavaScript Spreadsheet offers attractive, customizable themes like Fluent, Tailwind CSS, Material, and Fabric. The online Theme Studio tool allows you to easily customize these themes to match your application's design.
Globalization and Localization The component supports globalization and localization, enabling users from different locales to use the spreadsheet by formatting dates, currency, and numbers according to their preferences.
✅ Additional Excel-Like Features
Excel Worksheet Management You can create, delete, rename, and customize worksheets within the JavaScript Spreadsheet. This includes adjusting headers, gridlines, and sheet visibility, providing full control over the data layout.
Excel Editing The component supports direct editing of cells, allowing users to add, modify, and remove data or formulas, just as they would in Excel.
Number and Cell Formatting With options for number formatting (currency, percentages, dates) and cell formatting (font size, color, alignment), users can easily highlight important data and ensure consistency across their documents.
Sort and Filter VeryUtils JavaScript Spreadsheet allows users to sort and filter data efficiently, supporting both simple and custom sorting options. This makes it easier to organize and analyze data according to specific criteria.
Interactive Features • Clipboard Operations: Supports cut, copy, and paste actions within the spreadsheet, maintaining formatting and formulas. • Undo and Redo: Users can easily undo or redo changes, with customizable limits. • Context Menu: A right-click context menu provides quick access to common operations, improving user interaction. • Cell Comments: Add, edit, and delete comments in cells, enhancing collaboration and data clarity. • Row and Column Resizing: The resize and autofit options allow for flexible adjustments to row heights and column widths.
Smooth Scrolling Even with a large number of cells, the JavaScript Spreadsheet offers a smooth scrolling experience, ensuring that users can navigate large datasets effortlessly.
Open and Save Excel Documents The JavaScript Spreadsheet supports Excel and CSV import and export, allowing users to open existing files or save their work with all the original styles and formats intact.
Supported Browsers VeryUtils JavaScript Spreadsheet is compatible with all modern web browsers, including Chrome, Firefox, Edge, Safari, and IE11 (with polyfills).
✅ Demo URLs:
Open a black Excel Spreadsheet online, https://veryutils.com/demo/online-excel/
Open a CSV document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.csv
Open an Excel XLS document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.xls
Open an Excel XLSX document online, https://veryutils.com/demo/online-excel/?file=https://veryutils.com/demo/online-excel/samples/test.xlsx
✅ Conclusion
VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer is a must-have tool for web developers who need to integrate Excel functionality into their web applications. Its powerful features, high performance, and cross-platform compatibility make it an ideal choice for any project that requires robust spreadsheet capabilities. With its seamless data binding, rich formatting options, and interactive features, this component is designed to meet the needs of modern web development, ensuring that your applications are both powerful and user-friendly.
If you're looking to elevate your web application with advanced spreadsheet capabilities, consider integrating VeryUtils JavaScript Spreadsheet HTML5 Excel Viewer today. It's the ultimate solution for developers who demand high performance, flexibility, and an intuitive user experience.
0 notes
Text
MongoDB: A Comprehensive Guide to the NoSQL Powerhouse
In the world of databases, MongoDB has emerged as a popular choice, especially for developers looking for flexibility, scalability, and performance. Whether you're building a small application or a large-scale enterprise solution, MongoDB offers a versatile solution for managing data. In this blog, we'll dive into what makes MongoDB stand out and how you can leverage its power for your projects.
What is MongoDB?
MongoDB is a NoSQL database that stores data in a flexible, JSON-like format called BSON (Binary JSON). Unlike traditional relational databases that use tables and rows, MongoDB uses collections and documents, allowing for more dynamic and unstructured data storage. This flexibility makes MongoDB ideal for modern applications where data types and structures can evolve over time.
Key Features of MongoDB
Schema-less Database: MongoDB's schema-less design means that each document in a collection can have a different structure. This allows for greater flexibility when dealing with varying data types and structures.
Scalability: MongoDB is designed to scale horizontally. It supports sharding, where data is distributed across multiple servers, making it easy to manage large datasets and high-traffic applications.
High Performance: With features like indexing, in-memory storage, and advanced query capabilities, MongoDB ensures high performance even with large datasets.
Replication and High Availability: MongoDB supports replication through replica sets. This means that data is copied across multiple servers, ensuring high availability and reliability.
Rich Query Language: MongoDB offers a powerful query language that supports filtering, sorting, and aggregating data. It also supports complex queries with embedded documents and arrays, making it easier to work with nested data.
Aggregation Framework: The aggregation framework in MongoDB allows you to perform complex data processing and analysis, similar to SQL's GROUP BY operations, but with more flexibility.
Integration with Big Data: MongoDB integrates well with big data tools like Hadoop and Spark, making it a valuable tool for data-driven applications.
Use Cases for MongoDB
Content Management Systems (CMS): MongoDB's flexibility makes it an excellent choice for CMS platforms where content types can vary and evolve.
Real-Time Analytics: With its high performance and support for large datasets, MongoDB is often used in real-time analytics and data monitoring applications.
Internet of Things (IoT): IoT applications generate massive amounts of data in different formats. MongoDB's scalability and schema-less nature make it a perfect fit for IoT data storage.
E-commerce Platforms: E-commerce sites require a database that can handle a wide range of data, from product details to customer reviews. MongoDB's dynamic schema and performance capabilities make it a great choice for these platforms.
Mobile Applications: For mobile apps that require offline data storage and synchronization, MongoDB offers solutions like Realm, which seamlessly integrates with MongoDB Atlas.
Getting Started with MongoDB
If you're new to MongoDB, here are some steps to get you started:
Installation: MongoDB offers installation packages for various platforms, including Windows, macOS, and Linux. You can also use MongoDB Atlas, the cloud-based solution, to start without any installation.
Basic Commands: Familiarize yourself with basic MongoDB commands like insert(), find(), update(), and delete() to manage your data.
Data Modeling: MongoDB encourages a flexible approach to data modeling. Start by designing your documents to match the structure of your application data, and use embedded documents and references to maintain relationships.
Indexing: Proper indexing can significantly improve query performance. Learn how to create indexes to optimize your queries.
Security: MongoDB provides various security features, such as authentication, authorization, and encryption. Make sure to configure these settings to protect your data.
Performance Tuning: As your database grows, you may need to tune performance. Use MongoDB's monitoring tools and best practices to optimize your database.
Conclusion
MongoDB is a powerful and versatile database solution that caters to the needs of modern applications. Its flexibility, scalability, and performance make it a top choice for developers and businesses alike. Whether you're building a small app or a large-scale enterprise solution, MongoDB has the tools and features to help you manage your data effectively.
If you're looking to explore MongoDB further, consider trying out MongoDB Atlas, the cloud-based version, which offers a fully managed database service with features like automated backups, scaling, and monitoring.
Happy coding!
For more details click www.hawkstack.com
#redhatcourses#docker#linux#information technology#containerorchestration#container#kubernetes#containersecurity#dockerswarm#aws#hawkstack#hawkstack technologies
0 notes
Text
Boost Your Business with Expert MongoDB Development Services
businesses require robust and efficient database solutions to manage and scale their data effectively. MongoDB, a high-end open source database platform, has emerged as a leading choice for organizations seeking optimal performance and scalability. This article delves into the comprehensive services offered by brtechgeeks for MongoDB development, highlighting its key features, advantages, and why it's the preferred choice for modern businesses.

Technical Specifications
Database Type: NoSQL, document-oriented
Data Storage: BSON (Binary JSON)
Query Language: MongoDB Query Language (MQL)
Scalability: Horizontal scaling through sharding
Replication: Replica sets for high availability
Indexing: Supports various types of indexes, including single field, compound, geospatial, and text indexes
Aggregation: Powerful aggregation framework for data processing and analysis
Server Support: Cross-platform support for Windows, Linux, and macOS
Applications
MongoDB is versatile and can be utilized across various industries and applications:
E-commerce: Product catalogs, inventory management, and order processing
Finance: Real-time analytics, risk management, and fraud detection
Healthcare: Patient records, clinical data, and research databases
IoT: Device data storage, real-time processing, and analytics
Gaming: Player data, leaderboards, and in-game analytics
Benefits of Hiring brtechgeeks for MongoDB Development Services
Expertise in Ad hoc Queries: Our professionals possess extensive experience in handling ad hoc queries, ensuring flexible and dynamic data retrieval.
Enhanced Data Processing: Utilizing sharding and scalability techniques, we boost your data processing performance.
Improved Database Management: We enhance your database management system, ensuring efficient and effective data handling.
Complex Query Handling: By indexing on JSON data, we skillfully manage complex queries, improving performance and reliability.
24/7 Support: Our dedicated team works round the clock to provide optimum results and the best experience.
Request A Quote For MongoDB Development Services
Challenges and Limitations
While MongoDB offers numerous advantages, it also comes with certain challenges:
Data Modeling: Designing effective data models can be complex.
Memory Usage: MongoDB can be memory-intensive due to its in-memory data storage.
Security: Proper configuration is essential to ensure data security.
Latest Innovations
Recent advancements in MongoDB include:
MongoDB Atlas: A fully managed cloud database service
Multi-document ACID transactions: Ensuring data integrity across multiple documents
Enhanced Aggregation Framework: New operators and expressions for advanced data processing
Future Prospects
The future of MongoDB looks promising with continuous improvements and updates. Predictions include:
Increased Adoption: More businesses will adopt MongoDB for its scalability and performance.
Integration with AI and ML: Enhanced integration with artificial intelligence and machine learning for advanced analytics.
Improved Security Features: Continuous development of security features to protect data.
Comparative Analysis
Comparing MongoDB with other database technologies:
MongoDB vs. SQL Databases: MongoDB offers more flexibility with unstructured data compared to traditional SQL databases.
MongoDB vs. Cassandra: MongoDB provides a richer query language and better support for ad hoc queries than Cassandra.
MongoDB vs. Firebase: MongoDB offers better scalability and data modeling capabilities for complex applications.
User Guides or Tutorials
Setting Up MongoDB
Installation: Download and install MongoDB from the official website.
Configuration: Configure the MongoDB server settings.
Data Import: Import data using MongoDB's import tools.
Basic CRUD Operations
Create: Insert documents into a collection.
Read: Query documents using MQL.
Update: Modify existing documents.
Delete: Remove documents from a collection.
MongoDB stands out as a powerful, flexible, and scalable database solution, making it an excellent choice for businesses across various industries. By partnering with brtechgeeks, you can leverage expert MongoDB development services to enhance your data processing capabilities, ensure robust database management, and achieve optimal performance. Embrace MongoDB development to stay ahead in the competitive digital landscape.
For more information and to hire our MongoDB development services, visit us at brtechgeeks.
Related More Services
Website Design Services
Rapid Application Development
SaaS Software Services
About Us
BR TechGeeks was initiated in 2009 with a vision – to bring good technology and good relationships come together with collaboration. We are individuals with a passion for creativity and creativity makes us happy. We believe there is always a better way to bring your business online – whether it be a website or a mobile application. Not only do we stop there, we help get your business across to your customers. A creative use of technology can make complicated ideas more understandable and digital products
Contact Us
B-8 Basement, Sector- 2 Noida
U.P. India 201301
Call +91 7011 84 555 3
E-mail: [email protected]
#MongoDB download#MongoDB documentation#MongoDB Atlas#MongoDB Compass#MongoDB Community Server#MongoDB tutorial#MongoDB Sell#mongodb Development services#mongodb professional services#mongodb consulting services#mongodb pricing#mongodb pricing azure#azure pricing calculator#mongodb community server
0 notes