#Data ingestion in real time
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
#Linux File Replication#Linux Data Replication#big data#data protection#Cloud Solutions#data orchestration#Data Integration in Real Time#Data ingestion in real time#Cloud Computing
0 notes
Text
Day 4: Ingest and Transform Data in Microsoft Fabric – No-Code and Pro-Code Guide
Ingest and Transform Data in Microsoft Fabric | No-Code and Pro-Code (Day 4) Published: July 5, 2025 🚀 Introduction Now that you’ve created your first Microsoft Fabric workspace, it’s time to bring in some data! In this article, you’ll learn how to ingest data into your Lakehouse or Warehouse and transform it using both no-code (Dataflows Gen2) and pro-code (Notebooks) methods. Whether you’re a…
#ai#azure#cloud#Data transformation#Dataflows Gen2#Fabric ETL#Microsoft Fabric 2025#Microsoft Fabric beginners#Microsoft Fabric data ingestion#Microsoft Fabric tutorial#microsoft-fabric#Power Query Fabric#Real-time Analytics#Spark Notebooks#technology
1 note
·
View note
Text
Real-Time Data Ingestion: Strategies, Benefits, and Use Cases
Summary: Master real-time data! This guide explores key concepts & strategies for ingesting & processing data streams. Uncover the benefits like improved decision-making & fraud detection. Learn best practices & discover use cases across industries.

Introduction
In today's data-driven world, the ability to analyse information as it's generated is becoming increasingly crucial. Traditional batch processing, where data is collected and analysed periodically, can leave businesses lagging behind. This is where real-time data ingestion comes into play.
Overview Real-Time Data Ingestion
Real-time data ingestion refers to the continuous process of capturing, processing, and storing data streams as they are generated. This data can come from various sources, including sensor networks, social media feeds, financial transactions, website traffic logs, and more.
By ingesting and analysing data in real-time, businesses can gain valuable insights and make informed decisions with minimal latency.
Key Concepts in Real-Time Data Ingestion
Data Streams: Continuous flows of data generated by various sources, requiring constant ingestion and processing.
Event Stream Processing (ESP): Real-time processing engines that analyse data streams as they arrive, identifying patterns and extracting insights.
Microservices Architecture: Breaking down data processing tasks into smaller, independent services for increased scalability and agility in real-time environments.
Data Pipelines: Defined pathways for data to flow from source to destination, ensuring seamless data ingestion and transformation.
Latency: The time it takes for data to travel from its source to the point of analysis. Minimising latency is crucial for real-time applications.
Strategies for Implementing Real-Time Data Ingestion
Ready to harness the power of real-time data? Dive into this section to explore key strategies for implementing real-time data ingestion. Discover how to choose the right tools, ensure data quality, and design a scalable architecture for seamless data capture and processing.
Choosing the Right Tools: Select data ingestion tools that can handle high-volume data streams and offer low latency processing, such as Apache Kafka, Apache Flink, or Amazon Kinesis.
Data Stream Preprocessing: Clean, filter, and transform data streams as they are ingested to ensure data quality and efficient processing.
Scalability and Performance: Design your real-time data ingestion architecture to handle fluctuating data volumes and maintain acceptable processing speed.
Monitoring and Alerting: Continuously monitor your data pipelines for errors or performance issues. Implement automated alerts to ensure timely intervention if problems arise.
Benefits of Real-Time Data Ingestion
Explore the transformative benefits of real-time data ingestion. Discover how it empowers businesses to make faster decisions, enhance customer experiences, and optimise operations for a competitive edge.
Enhanced Decision-Making: Real-time insights allow businesses to react quickly to market changes, customer behaviour, or operational issues.
Improved Customer Experience: By analysing customer interactions in real-time, businesses can personalise recommendations, address concerns promptly, and optimise customer journeys.
Fraud Detection and Prevention: Real-time analytics can identify suspicious activity and prevent fraudulent transactions as they occur.
Operational Efficiency: Monitor machine performance, resource utilisation, and potential equipment failures in real-time to optimise operations and minimise downtime.
Risk Management: Real-time data analysis can help predict and mitigate potential risks based on real-time market fluctuations or social media sentiment.
Challenges in Real-Time Data Ingestion
Real-time data streams are powerful, but not without hurdles. Dive into this section to explore the challenges of high data volume, ensuring data quality, managing complexity, and keeping your data secure.
Data Volume and Velocity: Managing high-volume data streams and processing them with minimal latency can be a challenge.
Data Quality: Maintaining data quality during real-time ingestion is crucial, as errors can lead to inaccurate insights and poor decision-making.
Complexity: Real-time data pipelines involve various technologies and require careful design and orchestration to ensure smooth operation.
Security Concerns: Protecting sensitive data while ingesting and processing data streams in real-time requires robust security measures.
Use Cases of Real-Time Data Ingestion
Learn how real-time data ingestion fuels innovation across industries, from fraud detection in finance to personalised marketing in e-commerce. Discover the exciting possibilities that real-time insights unlock.
Fraud Detection: Financial institutions use real-time analytics to identify and prevent fraudulent transactions as they occur.
Personalized Marketing: E-commerce platforms leverage real-time customer behaviour data to personalise product recommendations and promotions.
IoT and Sensor Data Analysis: Real-time data from sensors in connected devices allows for monitoring equipment health, optimising energy consumption, and predicting potential failures.
Stock Market Analysis: Financial analysts use real-time data feeds to analyse market trends and make informed investment decisions.
Social Media Monitoring: Brands can track social media sentiment and brand mentions in real-time to address customer concerns and manage brand reputation.
Best Practices for Real-Time Data Ingestion
Unleashing the full potential of real-time data! Dive into this section for best practices to optimise your data ingestion pipelines, ensuring quality, performance, and continuous improvement.
Plan and Design Thoroughly: Clearly define requirements and design your real-time data ingestion architecture considering scalability, performance, and security.
Choose the Right Technology Stack: Select tools and technologies that can handle the volume, velocity, and variety of data you expect to ingest.
Focus on Data Quality: Implement data cleaning and validation techniques to ensure the accuracy and consistency of your real-time data streams.
Monitor and Maintain: Continuously monitor your data pipelines for errors and performance issues. Implement proactive maintenance procedures to ensure optimal performance.
Embrace Continuous Improvement: The field of real-time data ingestion is constantly evolving. Stay updated on new technologies and best practices to continuously improve your data ingestion pipelines.
Conclusion
Real-time data ingestion empowers businesses to operate in an ever-changing environment. By understanding the key concepts, implementing effective strategies, and overcoming the challenges, businesses can unlock the power of real-time insights to gain a competitive edge.
From enhanced decision-making to improved customer experiences and operational efficiency, real-time data ingestion holds immense potential for organisations across diverse industries. As technology continues to advance, real-time data ingestion will become an even more critical tool for success in the data-driven future.
Frequently Asked Questions
What is the Difference Between Real-Time and Batch Data Processing?
Real-time data ingestion processes data as it's generated, offering near-instant insights. Batch processing collects data periodically and analyses it later, leading to potential delays in decision-making.
What are Some of The Biggest Challenges in Real-Time Data Ingestion?
High data volume and velocity, maintaining data quality during processing, and ensuring the security of sensitive data streams are some of the key challenges to overcome.
How Can My Business Benefit from Real-Time Data Ingestion?
Real-time insights can revolutionise decision-making, personalise customer experiences, detect fraud instantly, optimise operational efficiency, and identify potential risks before they escalate.
0 notes
Text
Unlock Powerful Data Strategies: Master Managed and External Tables in Fabric Delta Lake
Are you ready to unlock powerful data strategies and take your data management skills to the next level? In our latest blog post, we dive deep into mastering managed and external tables in Delta Lake within Microsoft Fabric.
Welcome to our series on optimizing data ingestion with Spark in Microsoft Fabric. In our first post, we covered the capabilities of Microsoft Fabric and its integration with Delta Lake. In this second installment, we dive into mastering Managed and External tables. Choosing between managed and external tables is a crucial decision when working with Delta Lake in Microsoft Fabric. Each option…
#Apache Spark#Big Data#Cloud Data Management#Data Analytics#Data Best Practices#Data Efficiency#Data Governance#Data Ingestion#Data Insights#Data management#Data Optimization#Data Strategies#Data Workflows#Delta Lake#External Tables#Managed Tables#microsoft azure#Microsoft Fabric#Real-Time Data
0 notes
Text
#Best Real time Data Ingestion Tools#Real-time Data Ingestion#types of data ingestion#What is the most important thing for real time data ingestion
0 notes
Text
The cod-Marxism of personalized pricing

Picks and Shovels is a new, standalone technothriller starring Marty Hench, my two-fisted, hard-fighting, tech-scam-busting forensic accountant. You can pre-order it on my latest Kickstarter, which features a brilliant audiobook read by Wil Wheaton.

The social function of the economics profession is to explain, over and over again, that your boss is actually right and that you don't really want the things you want, and you're secretly happy to be abused by the system. If that wasn't true, why would your "choose" commercial surveillance, abusive workplaces and other depredations?
In other words, economics is the "look what you made me do" stick that capitalism uses to beat us with. We wouldn't spy on you, rip you off or steal your wages if you didn't choose to use the internet, shop with monopolists, or work for a shitty giant company. The technical name for this ideology is "public choice theory":
https://pluralistic.net/2022/06/05/regulatory-capture/
Of all the terrible things that economists say we all secretly love, one of the worst is "price discrimination." This is the idea that different customers get charged different amounts based on the merchant's estimation of their ability to pay. Economists insist that this is "efficient" and makes us all better off. After all, the marginal cost of filling the last empty seat on the plane is negligible, so why not sell that seat for peanuts to a flier who doesn't mind the uncertainty of knowing whether they'll get a seat at all? That way, the airline gets extra profits, and they split those profits with their customers by lowering prices for everyone. What's not to like?
Plenty, as it turns out. With only four giant airlines who've carved up the country so they rarely compete on most routes, why would an airline use their extra profits to lower prices, rather than, say, increasing their dividends and executive bonuses?
For decades, the airline industry was the standard-bearer for price discrimination. It was basically impossible to know how much a plane ticket would cost before booking it. But even so, airlines were stuck with comparatively crude heuristics to adjust their prices, like raising the price of a ticket that didn't include a Saturday stay, on the assumption that this was a business flyer whose employer was footing the bill:
https://pluralistic.net/2024/06/07/drip-drip-drip/#drip-off
With digitization and mass commercial surveillance, we've gone from pricing based on context (e.g. are you buying your ticket well in advance, or at the last minute?) to pricing based on spying. Digital back-ends allow vendors to ingest massive troves of commercial surveillance data from the unregulated data-broker industry to calculate how desperate you are, and how much money you have. Then, digital front-ends – like websites and apps – allow vendors to adjust prices in realtime based on that data, repricing goods for every buyer.
As digital front-ends move into the real world (say, with digital e-ink shelf-tags in grocery stores), vendors can use surveillance data to reprice goods for ever-larger groups of customers and types of merchandise. Grocers with e-ink shelf tags reprice their goods thousands of times, every day:
https://pluralistic.net/2024/03/26/glitchbread/#electronic-shelf-tags
Here's where an economist will tell you that actually, your boss is right. Many groceries are perishable, after all, and e-ink shelf tags allow grocers to reprice their goods every minute or two, so yesterday's lettuce can be discounted every fifteen minutes through the day. Some customers will happily accept a lettuce that's a little gross and liztruss if it means a discount. Those customers get a discount, the lettuce isn't thrown out at the end of the day, and everyone wins, right?
Well, sure, if. If the grocer isn't part of a heavily consolidated industry where competition is a distant memory and where grocers routinely collude to fix prices. If the grocer doesn't have to worry about competitors, why would they use e-ink tags to lower prices, rather than to gouge on prices when demand surges, or based on time of day (e.g. making frozen pizzas 10% more expensive from 6-8PM)?
And unfortunately, groceries are one of the most consolidated sectors in the modern world. What's more, grocers keep getting busted for colluding to fix prices and rip off shoppers:
https://www.cbc.ca/news/business/loblaw-bread-price-settlement-1.7274820
Surveillance pricing is especially pernicious when it comes to apps, which allow vendors to reprice goods based not just on commercially available data, but also on data collected by your pocket distraction rectangle, which you carry everywhere, do everything with, and make privy to all your secrets. Worse, since apps are a closed platform, app makers can invoke IP law to criminalize anyone who reverse-engineers them to figure out how they're ripping you off. Removing the encryption from an app is a potential felony punishable by a five-year prison sentence and a $500k fine (an app is just a web-page skinned in enough IP to make it a crime to install a privacy blocker on it):
https://pluralistic.net/2024/08/15/private-law/#thirty-percent-vig
Large vendors love to sell you shit via their apps. With an app, a merchant can undetectably change its prices every few seconds, based on its estimation of your desperation. Uber pioneered this when they tweaked the app to raise the price of a taxi journey for customers whose batteries were almost dead. Today, everyone's getting in on the act. McDonald's has invested in a company called Plexure that pitches merchants on the use case of raising the cost of your normal breakfast burrito by a dollar on the day you get paid:
https://pluralistic.net/2024/06/05/your-price-named/#privacy-first-again
Surveillance pricing isn't just a matter of ripping off customers, it's also a way to rip off workers. Gig work platforms use surveillance pricing to titrate their wage offers based on data they buy from data brokers and scoop up with their apps. Veena Dubal calls this "algorithmic wage discrimination":
https://pluralistic.net/2023/04/12/algorithmic-wage-discrimination/#fishers-of-men
Take nurses: increasingly, American hospitals are firing their waged nurses and replacing them with gig nurses who are booked in via an app. There's plenty of ways that these apps abuse nurses, but the most ghastly is in how they price nurses' wages. These apps buy nurses' financial data from data-brokers so they can offer lower wages to nurses with lots of credit card debt, on the grounds that crushing debt makes nurses desperate enough to accept a lower wage:
https://pluralistic.net/2024/12/18/loose-flapping-ends/#luigi-has-a-point
This week, the excellent Lately podcast has an episode on price discrimination, in which cohost Vass Bednar valiantly tries to give economists their due by presenting the strongest possible case for charging different prices to different customers:
https://www.theglobeandmail.com/podcasts/lately/article-the-end-of-the-fixed-price/
Bednar really tries, but – as she later agrees – this just isn't a very good argument. In fact, the only way charging different prices to different customers – or offering different wages to different workers – makes sense is if you're living in a socialist utopia.
After all, a core tenet of Marxism is "from each according to his ability, to each according to his needs." In a just society, people who need more get more, and people who have less, pay less:
https://en.wikipedia.org/wiki/From_each_according_to_his_ability,_to_each_according_to_his_needs
Price discrimination, then, is a Bizarro-world flavor of cod-Marxism. Rather than having a democratically accountable state that sets wages and prices based on need and ability, price discrimination gives this authority to large firms with pricing power, no regulatory constraints, and unlimited access to surveillance data. You couldn't ask for a neater example of the maxim that "What matters isn't what technology does. What matters is who it does it for; and who it does it to."
Neoclassical economists say that all of this can be taken care of by the self-correcting nature of markets. Just give consumers and workers "perfect information" about all the offers being made for their labor or their business, and things will sort themselves out. In the idealized models of perfectly spherical cows of uniform density moving about on a frictionless surface, this does work out very well:
https://pluralistic.net/2023/04/03/all-models-are-wrong/#some-are-useful
But while large companies can buy the most intimate information imaginable about your life and finances, IP law lets them capture the state and use it to shut down any attempts you make to discover how they operate. When an app called Para offered Doordash workers the ability to preview the total wage offered for a job before they accepted it, Doordash threatened them with eye-watering legal penalties, then threw dozens of full-time engineers at them, changing the app several times per day to shut out Para:
https://pluralistic.net/2021/08/07/hr-4193/#boss-app
And when an Austrian hacker called Mario Zechner built a tool to scrape online grocery store prices – discovering clear evidence of price-fixing conspiracies in the process – he was attacked by the grocery cartel for violating their "IP rights":
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
This is Wilhoit's Law in action:
Conservatism consists of exactly one proposition, to wit: There must be in-groups whom the law protects but does not bind, alongside out-groups whom the law binds but does not protect.
https://en.wikipedia.org/wiki/Francis_M._Wilhoit#Wilhoit's_law
Of course, there wouldn't be any surveillance pricing without surveillance. When it comes to consumer privacy, America is a no-man's land. The last time Congress passed a new consumer privacy law was in 1988, when they enacted the Video Privacy Protection Act, which bans video-store clerks from revealing which VHS cassettes you take home. Congress has not addressed a single consumer privacy threat since Die Hard was still playing in theaters.
Corporate bullies adore a regulatory vacuum. The sleazy data-broker industry that has festered and thrived in the absence of a modern federal consumer privacy law is absolutely shameless. For example, every time an app shows you an ad, your location is revealed to dozens of data-brokers who pretend to be bidding for the right to show you an ad. They store these location data-points and combine them with other data about you, which they sell to anyone with a credit card, including stalkers, corporate spies, foreign governments, and anyone hoping to reprice their offerings on the basis of your desperation:
https://www.404media.co/candy-crush-tinder-myfitnesspal-see-the-thousands-of-apps-hijacked-to-spy-on-your-location/
Under Biden, the outgoing FTC did incredible work to fill this gap, using its authority under Section 5 of the Federal Trade Commission Act (which outlaws "unfair and deceptive" practices) to plug some of the worst gaps in consumer privacy law:
https://pluralistic.net/2024/07/24/gouging-the-all-seeing-eye/#i-spy
And Biden's CFPB promulgated a rule that basically bans data brokers:
https://pluralistic.net/2024/06/10/getting-things-done/#deliverism
But now the burden of enforcing these rules falls to Trump's FTC, whose new chairman has vowed to end the former FTC's "war on business." What America desperately needs is a new privacy law, one that has a private right of action (so that individuals and activist groups can sue without waiting for a public enforcer to take up their causes) and no "pre-emption" (so that states can pass even stronger privacy laws):
https://www.eff.org/deeplinks/2022/07/federal-preemption-state-privacy-law-hurts-everyone
How will we get that law? Through a coalition. After all, surveillance pricing is just one of the many horrors that Americans have to put up with thanks to America's privacy law gap. The "privacy first" theory goes like this: if you're worried about social media's impact on teens, or women, or old people, you should start by demanding a privacy law. If you're worried about deepfake porn, you should start by demanding a privacy law. If you're worried about algorithmic discrimination in hiring, lending, or housing, you should start by demanding a privacy law. If you're worried about surveillance pricing, you should start by demanding a privacy law. Privacy law won't entirely solve all these problems, but none of them would be nearly as bad if Congress would just get off its ass and catch up with the privacy threats of the 21st century. What's more, the coalition of everyone who's worried about all the harms that arise from commercial surveillance is so large and powerful that we can get Congress to act:
https://pluralistic.net/2023/12/06/privacy-first/#but-not-just-privacy
Economists, meanwhile, will line up to say that this is all unnecessary. After all, you "sold" your privacy when you clicked "I agree" or walked under a sign warning you that facial recognition was in use in this store. The market has figured out what you value privacy at, and it turns out, that value is nothing. Any kind of privacy law is just a paternalistic incursion on your "freedom to contract" and decide to sell your personal information. It is "market distorting."
In other words, your boss is right.

Check out my Kickstarter to pre-order copies of my next novel, Picks and Shovels!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/01/11/socialism-for-the-wealthy/#rugged-individualism-for-the-poor
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
Ser Amantio di Nicolao (modified) https://commons.wikimedia.org/wiki/File:Safeway_supermarket_interior,_Fairfax_County,_Virginia.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#personalized pricing#surveillance pricing#ad-tech#realtime bidding#rtb#404media#price discrimination#economics#neoclassical economics#efficiency#predatory pricing#surveillance#privacy#wage theft#algorithmic wage discrimination#veena dubal#privacy first
288 notes
·
View notes
Text
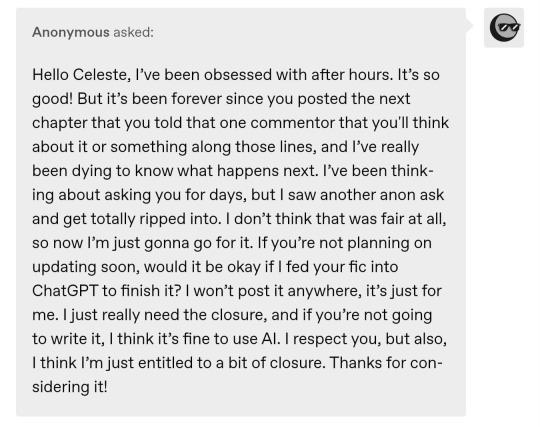
Anon.
Are you fucking serious right now?
I saw your message and I had to take a full-ass walk around my block because I was genuinely afraid I’d punch my goddamn wall.

Let me break this down for you very clearly, so even your AI-smooth-brained moral compass can process it:
You are not entitled to shit.
Not my writing. Not the ending. Not a single fucking word I typed out with my own fucking bleeding fingers.
You think you “need” closure?
Cool. I “need” eight hours of sleep, a functioning spine, and respect from strangers online. Guess what?
None of us are getting what we want today.
Fanfiction is a gift.
Not a product, not a service, not a series finale you paid for on HBO Max.
A gift.
You don’t throw a tantrum because the gift didn’t come with a bonus epilogue and a director’s cut.
Your entire ask is a monument to entitlement. You say “if you're not going to write it, I think it's fine to use Al?”
I did NOT write it for AI. I wrote it for human readers. For emotion. For narrative voice. For soul.
AI doesn’t have that. You want a soulless machine to mock my style and feed you a bootleg version of my work?? Which is, not to say but, the equivalent of a a knock-off Louis Vuitton sold from the back of a van?
Then don’t ask me. Just go to your shameful little corner and live with the fact that you’re the kind of person who disrespects art to feed your own dopamine addiction.
You wanted permission, so now you get the wrath.
I see in your other little asks, “AI is there to make things easier.”
At whose fucking expense? The thousands of fanfic writers whose fics are being scraped, harvested, mimicked and tossed into machine-learning hell so you don’t have to wait for an update?
Do you have any idea how many of us have had our fics [both in our caratblr and other fandom spaces] show up on AI mirror sites or been plagiarized by bots? Do you know how many real authors are losing book deals, commissions, or livelihoods because of this exact entitled logic?
Let me give you a basic fucking rundown since you clearly didn’t do the homework:
AI is not ethical – Generative AI is trained off data sets that include unauthorized, uncredited, scraped work from unpaid artists, writers, poets, journalists, bloggers, fanfic writers—fuck, even therapy forums.
Authors are suing OpenAI for ingesting copyrighted novels without permission.
Fanfic is already vulnerable – We exist in a legal gray area protected only by community ethics and mutual respect. You're breaking both.
You say “I won't post it anywhere, it's just for me.”
Oh, wow, thanks. So you only want to steal quietly. Like that makes it better.
You think the damage only happens when it’s public? WRONG.
Every time you plug an artist’s work into a machine, it gets processed, stored, used for training, forever.
You have no control over where it goes or how it’s repurposed later. You are feeding the beast and killing the creators in the process.
Don’t give me “I respect you but—”
If you respected me, this message wouldn’t exist.
You get your AI-stitched ending, it doesn’t scratch the itch, and you feed it another one.
And another.
And another.
Until the entire fucking archive is turned into a graveyard of replicas and you’re the ghoulish little shit dancing on the corpses of every writer you leeched dry.
And you say “I think I’m just entitled to a bit of closure”?
Entitled. You actually used the word.
Thank you for confirming what we already knew:
That you don’t see us as people.
You see us as content machines that owe you something because you liked our work. You don’t want closure, you want control, and you will NOT get it from me.
You’re entitled to a bath, a glass of water, and the air you breathe—not my writing, not my thoughts, and definitely not a fucking auto-generated Frankenstein mockery of my style you can jerk off your emotions to.
So here's your closure:
No, you may not touch my fic.
No, you may not feed it to a bot.
No, you may not engage with my writing, my blog, my friend's blog, or my community ever again.
Block me. Report me. Cry about it.
But know this:
Every time you open an AI generator to finish a story you didn’t write, you are choosing to destroy the very creators you claim to admire.
You should be ashamed, but you won’t be. Because parasites don’t feel guilt, they just suck and suck and suck until there’s nothing left.
I'll never forget this time and date.
I hope it was worth it.
Let this be your final fucking warning.
— Celeste.
#please get the fuck off my and my friend's and other writers blog#you're NOT welcomed#you deadass came into MY inbox with a digital scalpel asking to butcher my fic#and expected me to say “yes queen go ahead”???#feed my blood sweat and tears into the algorithm grinder bc YOU can’t wait???#go gnaw on drywall#the entitlement is fucking radioactive#“i won’t share it” oh wow babe THANK YOU for promising to keep your theft private. like that makes you less of a digital robber#cry me a river build a bridge and then jump off it#you don’t “need closure” you need a damn hobby and some fucking boundaries#go knit or scream into a jar or idk read a newspaper#don’t treat writers like vending machines and throw tantrums when the candy doesn’t drop#AI is not your little storytelling fairy godmother. it’s a grave-digging industry leech#go sit in a corner and think about why no one wants you in fandom spaces anymore#and don’t come back unless it’s with a goddamn apology and a clue#mylovesstuffs asks
77 notes
·
View notes
Note
Hi! I'm at a loss as to where to find the info I'm looking for, so I'm gonna try with you. Feel free to ignore this. I'm writing a fic in The Pitt & I'm struggling to find data on the Langdon situation. Aka, what is the outcome for his job in the first case figure proposed by Robby? This one : "Here's your second chance. 30-day inpatient treatment program, followed by random urine tests, followed by mandatory NA meetings, three to four times a week for the first 3 years [of a 5 years prog]." Ta!
So, if im understanding your question correctly, the outcome for his job is: he keeps it. I'm not sure if there's some kind of external reporting that would be done to medical licensing organizations, or if that would happen only if Langdon was not compliant with whatever PTMC came up with.
This is one of those situations where ha ha I do have some real world knowledge, albeit limited and not from the provider side. But I DID have a coworker who was suspected of using drugs (in general and also while at work). What happened then is a direct supervisor and the department supervisor pulled this employee to the side at the start of their shift to do a random urine drug screen (which is a normal job expectation thing) and this person said "ok well im not going to pass it". As I understood it (and obviously I was not allowed to have the full details) the choice was either you quit effective immediately or you go inpatient and detox and after you come out you still have your job conditional on staying clean.
Its a twofold thing here--the hospital has invested time and money into their doctors, and the doctors have invested time and money into becoming doctors. Neither party wants you to NOT become a doctor unless you are just killing patients right and left. There's also the fact that healthcare abandoning you over addiction is not going to play well to the public, so helping employees get clean is good PR as well as fiscally good. There's also the fact that, I imagine, Langdon not losing his license is contingent upon him completing the rehab program while at PTMC--hes a fourth year resident? That means that they are guaranteed him staying at PTMC for at least five working years. He's shown to be a good physician, so I imagine they'd put a fair amount of effort into getting and keeping him clean. Not because it's the right thing to do, mind you. Just financially speaking. Also, he's white, so he has that going for him (his comments about the gummy ingestion family are very delicious because he does NOT see the similarities imo)
The hospital may actually have a policy about this that outlines specifics like Robby threw out; I don't know if i believe he looked that up after he kicked Landon out or if he's pulling numbers out of his ass as far as how many meetings a week etc. so there's potentially some wiggle room there--and Robby might get a bit of a say in stuff like that since it's likely he's going to be one of the people keeping tabs on Langdon and he's Langdon's supervisor-- if he says "no I think he needs to go to meetings four times a week" well. He does know Langdon best.
I hope this answers your question?
#the pitt#frank langdon#the pitt hbo#asks answered#pitt fic writing ref#guess what i will be doing at work tonight lol
23 notes
·
View notes
Text
Jaune: *waking up on a beach* I'm... Still alive? Then that mean- *looking around to see if he could see team RWBY or Penny* not here of course, would have been too easy right? Hm... Let's go look around first, that place looks... Strange.
___
Penny: *getting gently moved so she can wake up* No, please, give me 5 more minutes.... *More forcefully* hmmm, i said 5 more minutes...
Jaune: *roll his eyes* PENNY!
Penny: *finally opening her eyes* Ok, i'm awake! Gee, can't even sleep of electric sheeps! Wait... Jaune? *Smiling and hugging him quickly* Oh i'm so happy to see you! I thought i was... Wait, are we dead? *Panic in her eyes* ARE YOU DEAD!? Oh no! Oh nononono, NO!
Jaune: *laughing* Relax, we are fine! Does this look like the pearly gates of heaven?
Penny: *taking a look around her, seeing trees and a really colorful vegetation* ... No, but tell me; did we ingest psychedelic mushrooms?
Jaune: Yeah, i know what you mean, but no. Everything is real.
Penny: It looks like a book in my data- i mean memory. Though now that i try to remember it, i can't seem to remember it.
Jaune: Wouldn't be the first time a fairy tail turned out to be true. Anyway we should move out. If we could find each other, we probably will find team RWBY, right?
Penny: *panicking* They all fell!?
Jaune: Ah, yeah, forgot you felt just after yang and Blake. But yeah we need to find them.
137 notes
·
View notes
Text
One of the most famous recipes for fake blood was developed by Dick Smith, used in films like The Godfather (1972), The Exorcist (1973), and Taxi Driver (1976). It was remarkably realistic due to the addition of a Kodak Photo-Flo, a photographic wetting agent that allowed it to soak into fabric like real blood.
Kodak Photo-Flo is highly poisonous. And according to safety data sheet for Kodak Photo-Flo states that there are several additional helath risks associated with the substance. As such, people should avoid breathing in the vapor, avoid contact with eyes, avoid prolonged skin exposure, and avoid consumption.

Tom Davis and Al Franken were wearing ponchos, rubber gloves, and goggles to avoid getting it on their clothes and skin while they were handling the fake blood.

Lorne had nothing of the sort.


Lorne didn’t have the time to clean himself up after the fake blood made contact with his skin, like he really only wiped his face with a bar rag and changed his shirt when you’re supposed to use soap and water. So if the blood they used was in fact Dick Smith’s recipe, then Lorne is definitely at risk for skin irritation. He’s also at risk for ingestion since it’s pretty close to his mouth as well as inhalation of the odorless vapor.
But what if the substance happened to react a lot more dramatically on Lorne, giving him chemical burns on his hands, neck, face, etc.? Like maybe it’s so much worse on his chest where the blood would have seeped through his button up and tshirt onto the skin underneath.
#we obviously see that his shirt underneath is mostly untouched but that feels unrealistic tbh#can’t believe I didn’t think of this sooner#saturday night (2024)#ch: lorne michaels#plot bunnies#fake blood#ninetyminutes’ rambles#ch: Tom Davis#ch: Al franken#Saturday night 2024#saturday night movie#this is so important to me
8 notes
·
View notes
Text
Why Every Business Needs a Smart Data Sourcing Strategy
In a world where real-time insights define competitive edge, reliable, well-sourced data is essential — not optional.

What it takes:
Align data with your business goals
Blend internal and external sources for richer insights
Accommodate both structured and unstructured data
Leverage AI to automate ingestion and enrichment
Secure and govern your data from day one
Continuously evolve with changing tech and compliance needs
Whether you’re building AI models or streamlining customer journeys, the right data sourcing strategy can be your biggest asset.
Read the full guide here
2 notes
·
View notes
Text
Harnessing the Power of Data Engineering for Modern Enterprises
In the contemporary business landscape, data has emerged as the lifeblood of organizations, fueling innovation, strategic decision-making, and operational efficiency. As businesses generate and collect vast amounts of data, the need for robust data engineering services has become more critical than ever. SG Analytics offers comprehensive data engineering solutions designed to transform raw data into actionable insights, driving business growth and success.
The Importance of Data Engineering
Data engineering is the foundational process that involves designing, building, and managing the infrastructure required to collect, store, and analyze data. It is the backbone of any data-driven enterprise, ensuring that data is clean, accurate, and accessible for analysis. In a world where businesses are inundated with data from various sources, data engineering plays a pivotal role in creating a streamlined and efficient data pipeline.
SG Analytics’ data engineering services are tailored to meet the unique needs of businesses across industries. By leveraging advanced technologies and methodologies, SG Analytics helps organizations build scalable data architectures that support real-time analytics and decision-making. Whether it’s cloud-based data warehouses, data lakes, or data integration platforms, SG Analytics provides end-to-end solutions that enable businesses to harness the full potential of their data.
Building a Robust Data Infrastructure
At the core of SG Analytics’ data engineering services is the ability to build robust data infrastructure that can handle the complexities of modern data environments. This includes the design and implementation of data pipelines that facilitate the smooth flow of data from source to destination. By automating data ingestion, transformation, and loading processes, SG Analytics ensures that data is readily available for analysis, reducing the time to insight.
One of the key challenges businesses face is dealing with the diverse formats and structures of data. SG Analytics excels in data integration, bringing together data from various sources such as databases, APIs, and third-party platforms. This unified approach to data management ensures that businesses have a single source of truth, enabling them to make informed decisions based on accurate and consistent data.
Leveraging Cloud Technologies for Scalability
As businesses grow, so does the volume of data they generate. Traditional on-premise data storage solutions often struggle to keep up with this exponential growth, leading to performance bottlenecks and increased costs. SG Analytics addresses this challenge by leveraging cloud technologies to build scalable data architectures.
Cloud-based data engineering solutions offer several advantages, including scalability, flexibility, and cost-efficiency. SG Analytics helps businesses migrate their data to the cloud, enabling them to scale their data infrastructure in line with their needs. Whether it’s setting up cloud data warehouses or implementing data lakes, SG Analytics ensures that businesses can store and process large volumes of data without compromising on performance.
Ensuring Data Quality and Governance
Inaccurate or incomplete data can lead to poor decision-making and costly mistakes. That’s why data quality and governance are critical components of SG Analytics’ data engineering services. By implementing data validation, cleansing, and enrichment processes, SG Analytics ensures that businesses have access to high-quality data that drives reliable insights.
Data governance is equally important, as it defines the policies and procedures for managing data throughout its lifecycle. SG Analytics helps businesses establish robust data governance frameworks that ensure compliance with regulatory requirements and industry standards. This includes data lineage tracking, access controls, and audit trails, all of which contribute to the security and integrity of data.
Enhancing Data Analytics with Natural Language Processing Services
In today’s data-driven world, businesses are increasingly turning to advanced analytics techniques to extract deeper insights from their data. One such technique is natural language processing (NLP), a branch of artificial intelligence that enables computers to understand, interpret, and generate human language.
SG Analytics offers cutting-edge natural language processing services as part of its data engineering portfolio. By integrating NLP into data pipelines, SG Analytics helps businesses analyze unstructured data, such as text, social media posts, and customer reviews, to uncover hidden patterns and trends. This capability is particularly valuable in industries like healthcare, finance, and retail, where understanding customer sentiment and behavior is crucial for success.
NLP services can be used to automate various tasks, such as sentiment analysis, topic modeling, and entity recognition. For example, a retail business can use NLP to analyze customer feedback and identify common complaints, allowing them to address issues proactively. Similarly, a financial institution can use NLP to analyze market trends and predict future movements, enabling them to make informed investment decisions.
By incorporating NLP into their data engineering services, SG Analytics empowers businesses to go beyond traditional data analysis and unlock the full potential of their data. Whether it’s extracting insights from vast amounts of text data or automating complex tasks, NLP services provide businesses with a competitive edge in the market.
Driving Business Success with Data Engineering
The ultimate goal of data engineering is to drive business success by enabling organizations to make data-driven decisions. SG Analytics’ data engineering services provide businesses with the tools and capabilities they need to achieve this goal. By building robust data infrastructure, ensuring data quality and governance, and leveraging advanced analytics techniques like NLP, SG Analytics helps businesses stay ahead of the competition.
In a rapidly evolving business landscape, the ability to harness the power of data is a key differentiator. With SG Analytics’ data engineering services, businesses can unlock new opportunities, optimize their operations, and achieve sustainable growth. Whether you’re a small startup or a large enterprise, SG Analytics has the expertise and experience to help you navigate the complexities of data engineering and achieve your business objectives.
5 notes
·
View notes
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering Classes: 200 hours of live classes Lectures: 199 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 70% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps Classes: 180+ hours of live classes Lectures: 300 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 67% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
Unveiling the Power of Delta Lake in Microsoft Fabric
Discover how Microsoft Fabric and Delta Lake can revolutionize your data management and analytics. Learn to optimize data ingestion with Spark and unlock the full potential of your data for smarter decision-making.
In today’s digital era, data is the new gold. Companies are constantly searching for ways to efficiently manage and analyze vast amounts of information to drive decision-making and innovation. However, with the growing volume and variety of data, traditional data processing methods often fall short. This is where Microsoft Fabric, Apache Spark and Delta Lake come into play. These powerful…
#ACID Transactions#Apache Spark#Big Data#Data Analytics#data engineering#Data Governance#Data Ingestion#Data Integration#Data Lakehouse#Data management#Data Pipelines#Data Processing#Data Science#Data Warehousing#Delta Lake#machine learning#Microsoft Fabric#Real-Time Analytics#Unified Data Platform
0 notes
Text
My Journey with Azure IoT Hub: Connecting and Managing IoT Devices at Scale
The Internet of Things (IoT), which enables seamless connectivity and automation across numerous industries, has completely changed the way we engage with technology. I was curious to learn more about the Internet of Things and its possible uses as an aspiring IoT enthusiast. My experience using Azure IoT Hub, Microsoft’s cloud-based IoT platform, and how it assisted me in connecting and managing IoT devices at scale are both discussed in this blog.
Getting Started with Azure IoT Hub

To embark on my IoT journey, I began by understanding the fundamentals of Azure IoT Hub. Azure IoT Hub is a fully managed service that acts as a central hub for bi-directional communication between IoT devices and the cloud. It provides secure, reliable, and scalable connectivity for IoT solutions. Setting up an Azure IoT Hub was my first step. While the process was relatively straightforward, I encountered a few challenges along the way.
Connecting IoT Devices
Once Azure IoT Hub was set up, I delved into the world of IoT devices. I worked with various types of IoT devices, ranging from simple sensors to complex industrial machines. Connecting these devices to Azure IoT Hub required the implementation of device-specific protocols such as MQTT or HTTP. Additionally, I focused on securing device connections and data transmission by utilizing security features provided by Azure IoT Hub.
Real-world examples of IoT devices connected to Azure IoT Hub are aplenty. For instance, in the healthcare industry, wearable devices can transmit patient vitals to Azure IoT Hub, allowing healthcare providers to monitor and respond to critical situations promptly. In smart homes, IoT devices such as thermostats and security cameras can be connected to Azure IoT Hub, enabling remote control and monitoring capabilities.
Managing IoT Devices at Scale
As my IoT project grew, I encountered the need to scale up the number of connected devices. Azure IoT Hub offered robust device management features that simplified the process of managing a large fleet of devices. I could remotely monitor the health, status, and firmware version of each device, enabling efficient troubleshooting and maintenance. Implementing best practices for device management, such as grouping devices based on location or functionality, enhanced the overall operational efficiency of my IoT solution.
Data Ingestion and Processing
Data collected from IoT devices is a valuable asset that can drive actionable insights and informed decision-making. Azure IoT Hub facilitated the ingestion and routing of data to Azure services for further processing and analysis. I had the opportunity to work with Azure Stream Analytics and Azure Functions, which enabled real-time data processing, transformation, and visualization. Leveraging these services allowed me to unlock the true potential of IoT data and derive meaningful insights.
Security and Compliance
Any IoT solution must prioritize security. Azure IoT Hub provided robust security features that ensured end-to-end protection of IoT deployments. These features included device authentication, message encryption, and integration with Azure Active Directory for access control. Additionally, Azure IoT Hub helped me meet compliance and regulatory requirements by providing built-in support for industry standards such as ISO 27001, HIPAA, and GDPR. Throughout my journey, I learned valuable lessons and implemented best practices for securing IoT solutions.
Scalability and Performance
Scaling an IoT solution to handle thousands or millions of devices is a complex task. Azure IoT Hub offered scalability features that allowed me to effortlessly handle large-scale IoT deployments. With Azure IoT Hub’s device-to-cloud messaging capabilities, I could reliably transmit messages to and from a massive number of devices. Moreover, I gained insights into optimizing IoT solutions for performance by considering factors such as message size, frequency, and device capabilities.
Real-World Use Cases
To understand the versatility of Azure IoT Hub, it is crucial to explore real-world use cases. In the manufacturing industry, Azure IoT Hub can be leveraged to connect and monitor machines on the factory floor, ensuring optimal performance and predictive maintenance. In the agriculture sector, IoT devices connected to Azure IoT Hub can collect data on soil moisture levels, temperature, and humidity, enabling farmers to make data-driven decisions for irrigation and crop management. These use cases highlight the valuable role that Azure IoT Hub plays in various domains and industries.
Future of IoT and Azure IoT Hub
The future of IoT is promising, with emerging trends shaping the landscape. As IoT continues to evolve, Azure IoT Hub will play a crucial role in enabling seamless connectivity, advanced analytics, and artificial intelligence capabilities. Integration with other Azure services and continuous updates from Microsoft ensure that Azure IoT Hub remains at the forefront of IoT innovation. The possibilities for IoT applications are limitless, and Azure IoT Hub will continue to empower developers and organizations to build robust and scalable IoT solutions.
Throughout my journey with Azure IoT Hub, I gained valuable insights and experiences. Azure IoT Hub simplified the process of connecting and managing IoT devices, providing a reliable and scalable platform. The seamless integration with other Azure services allowed me to unlock the full potential of IoT data. Moreover, the security and compliance features provided peace of mind, ensuring that my IoT solution was protected from threats. Overall, Azure IoT Hub has been instrumental in my IoT journey, contributing to enhanced efficiency and productivity.
Recommendations and Tips
For those interested in starting their own IoT journey with Azure IoT Hub, I offer the following recommendations and tips:
Begin with a clear understanding of your IoT use case and requirements.
Familiarize yourself with the documentation and resources provided by Microsoft to gain a solid foundation.
Start small and gradually scale your IoT solution as needed.
Take advantage of the device management and security features offered by Azure IoT Hub.
Leverage other Azure services such as Azure Stream Analytics and Azure Functions to derive meaningful insights from IoT data.
Stay updated on emerging trends and best practices in the IoT space.
To deepen your knowledge of IoT and Azure IoT Hub, I recommend exploring Microsoft’s official documentation, participating in the ACTE Technologies Microsoft Azure training, and attending IoT-focused conferences and events.

Azure IoT Hub has proven to be a powerful and comprehensive platform for connecting and managing IoT devices at scale. Throughout my journey, I witnessed the transformative potential of IoT solutions and the crucial role played by Azure IoT Hub in enabling seamless connectivity, advanced analytics, and robust security. As IoT continues to evolve, Azure IoT Hub will undoubtedly remain at the forefront of IoT innovation, empowering organizations to build scalable and efficient IoT solutions. I encourage readers to embark on their own IoT journeys, leveraging the capabilities of Azure IoT Hub to unlock the full potential of IoT. Join me in embracing the future of IoT and revolutionizing industries through connected devices. Please leave your comments, stories, and inquiries in the space provided below. Let’s continue the conversation and explore the endless possibilities of IoT together.
#microsoft azure#cloud services#information technology#education#tech#technology#iot#innovation#cloud computing
5 notes
·
View notes
Text
Hypothetical AI election disinformation risks vs real AI harms

I'm on tour with my new novel The Bezzle! Catch me TONIGHT (Feb 27) in Portland at Powell's. Then, onto Phoenix (Changing Hands, Feb 29), Tucson (Mar 9-12), and more!

You can barely turn around these days without encountering a think-piece warning of the impending risk of AI disinformation in the coming elections. But a recent episode of This Machine Kills podcast reminds us that these are hypothetical risks, and there is no shortage of real AI harms:
https://soundcloud.com/thismachinekillspod/311-selling-pickaxes-for-the-ai-gold-rush
The algorithmic decision-making systems that increasingly run the back-ends to our lives are really, truly very bad at doing their jobs, and worse, these systems constitute a form of "empiricism-washing": if the computer says it's true, it must be true. There's no such thing as racist math, you SJW snowflake!
https://slate.com/news-and-politics/2019/02/aoc-algorithms-racist-bias.html
Nearly 1,000 British postmasters were wrongly convicted of fraud by Horizon, the faulty AI fraud-hunting system that Fujitsu provided to the Royal Mail. They had their lives ruined by this faulty AI, many went to prison, and at least four of the AI's victims killed themselves:
https://en.wikipedia.org/wiki/British_Post_Office_scandal
Tenants across America have seen their rents skyrocket thanks to Realpage's landlord price-fixing algorithm, which deployed the time-honored defense: "It's not a crime if we commit it with an app":
https://www.propublica.org/article/doj-backs-tenants-price-fixing-case-big-landlords-real-estate-tech
Housing, you'll recall, is pretty foundational in the human hierarchy of needs. Losing your home – or being forced to choose between paying rent or buying groceries or gas for your car or clothes for your kid – is a non-hypothetical, widespread, urgent problem that can be traced straight to AI.
Then there's predictive policing: cities across America and the world have bought systems that purport to tell the cops where to look for crime. Of course, these systems are trained on policing data from forces that are seeking to correct racial bias in their practices by using an algorithm to create "fairness." You feed this algorithm a data-set of where the police had detected crime in previous years, and it predicts where you'll find crime in the years to come.
But you only find crime where you look for it. If the cops only ever stop-and-frisk Black and brown kids, or pull over Black and brown drivers, then every knife, baggie or gun they find in someone's trunk or pockets will be found in a Black or brown person's trunk or pocket. A predictive policing algorithm will naively ingest this data and confidently assert that future crimes can be foiled by looking for more Black and brown people and searching them and pulling them over.
Obviously, this is bad for Black and brown people in low-income neighborhoods, whose baseline risk of an encounter with a cop turning violent or even lethal. But it's also bad for affluent people in affluent neighborhoods – because they are underpoliced as a result of these algorithmic biases. For example, domestic abuse that occurs in full detached single-family homes is systematically underrepresented in crime data, because the majority of domestic abuse calls originate with neighbors who can hear the abuse take place through a shared wall.
But the majority of algorithmic harms are inflicted on poor, racialized and/or working class people. Even if you escape a predictive policing algorithm, a facial recognition algorithm may wrongly accuse you of a crime, and even if you were far away from the site of the crime, the cops will still arrest you, because computers don't lie:
https://www.cbsnews.com/sacramento/news/texas-macys-sunglass-hut-facial-recognition-software-wrongful-arrest-sacramento-alibi/
Trying to get a low-waged service job? Be prepared for endless, nonsensical AI "personality tests" that make Scientology look like NASA:
https://futurism.com/mandatory-ai-hiring-tests
Service workers' schedules are at the mercy of shift-allocation algorithms that assign them hours that ensure that they fall just short of qualifying for health and other benefits. These algorithms push workers into "clopening" – where you close the store after midnight and then open it again the next morning before 5AM. And if you try to unionize, another algorithm – that spies on you and your fellow workers' social media activity – targets you for reprisals and your store for closure.
If you're driving an Amazon delivery van, algorithm watches your eyeballs and tells your boss that you're a bad driver if it doesn't like what it sees. If you're working in an Amazon warehouse, an algorithm decides if you've taken too many pee-breaks and automatically dings you:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
If this disgusts you and you're hoping to use your ballot to elect lawmakers who will take up your cause, an algorithm stands in your way again. "AI" tools for purging voter rolls are especially harmful to racialized people – for example, they assume that two "Juan Gomez"es with a shared birthday in two different states must be the same person and remove one or both from the voter rolls:
https://www.cbsnews.com/news/eligible-voters-swept-up-conservative-activists-purge-voter-rolls/
Hoping to get a solid education, the sort that will keep you out of AI-supervised, precarious, low-waged work? Sorry, kiddo: the ed-tech system is riddled with algorithms. There's the grifty "remote invigilation" industry that watches you take tests via webcam and accuses you of cheating if your facial expressions fail its high-tech phrenology standards:
https://pluralistic.net/2022/02/16/unauthorized-paper/#cheating-anticheat
All of these are non-hypothetical, real risks from AI. The AI industry has proven itself incredibly adept at deflecting interest from real harms to hypothetical ones, like the "risk" that the spicy autocomplete will become conscious and take over the world in order to convert us all to paperclips:
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Whenever you hear AI bosses talking about how seriously they're taking a hypothetical risk, that's the moment when you should check in on whether they're doing anything about all these longstanding, real risks. And even as AI bosses promise to fight hypothetical election disinformation, they continue to downplay or ignore the non-hypothetical, here-and-now harms of AI.
There's something unseemly – and even perverse – about worrying so much about AI and election disinformation. It plays into the narrative that kicked off in earnest in 2016, that the reason the electorate votes for manifestly unqualified candidates who run on a platform of bald-faced lies is that they are gullible and easily led astray.
But there's another explanation: the reason people accept conspiratorial accounts of how our institutions are run is because the institutions that are supposed to be defending us are corrupt and captured by actual conspiracies:
https://memex.craphound.com/2019/09/21/republic-of-lies-the-rise-of-conspiratorial-thinking-and-the-actual-conspiracies-that-fuel-it/
The party line on conspiratorial accounts is that these institutions are good, actually. Think of the rebuttal offered to anti-vaxxers who claimed that pharma giants were run by murderous sociopath billionaires who were in league with their regulators to kill us for a buck: "no, I think you'll find pharma companies are great and superbly regulated":
https://pluralistic.net/2023/09/05/not-that-naomi/#if-the-naomi-be-klein-youre-doing-just-fine
Institutions are profoundly important to a high-tech society. No one is capable of assessing all the life-or-death choices we make every day, from whether to trust the firmware in your car's anti-lock brakes, the alloys used in the structural members of your home, or the food-safety standards for the meal you're about to eat. We must rely on well-regulated experts to make these calls for us, and when the institutions fail us, we are thrown into a state of epistemological chaos. We must make decisions about whether to trust these technological systems, but we can't make informed choices because the one thing we're sure of is that our institutions aren't trustworthy.
Ironically, the long list of AI harms that we live with every day are the most important contributor to disinformation campaigns. It's these harms that provide the evidence for belief in conspiratorial accounts of the world, because each one is proof that the system can't be trusted. The election disinformation discourse focuses on the lies told – and not why those lies are credible.
That's because the subtext of election disinformation concerns is usually that the electorate is credulous, fools waiting to be suckered in. By refusing to contemplate the institutional failures that sit upstream of conspiracism, we can smugly locate the blame with the peddlers of lies and assume the mantle of paternalistic protectors of the easily gulled electorate.
But the group of people who are demonstrably being tricked by AI is the people who buy the horrifically flawed AI-based algorithmic systems and put them into use despite their manifest failures.
As I've written many times, "we're nowhere near a place where bots can steal your job, but we're certainly at the point where your boss can be suckered into firing you and replacing you with a bot that fails at doing your job"
https://pluralistic.net/2024/01/15/passive-income-brainworms/#four-hour-work-week
The most visible victims of AI disinformation are the people who are putting AI in charge of the life-chances of millions of the rest of us. Tackle that AI disinformation and its harms, and we'll make conspiratorial claims about our institutions being corrupt far less credible.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/27/ai-conspiracies/#epistemological-collapse
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#ai#disinformation#algorithmic bias#elections#election disinformation#conspiratorialism#paternalism#this machine kills#Horizon#the rents too damned high#weaponized shelter#predictive policing#fr#facial recognition#labor#union busting#union avoidance#standardized testing#hiring#employment#remote invigilation
146 notes
·
View notes