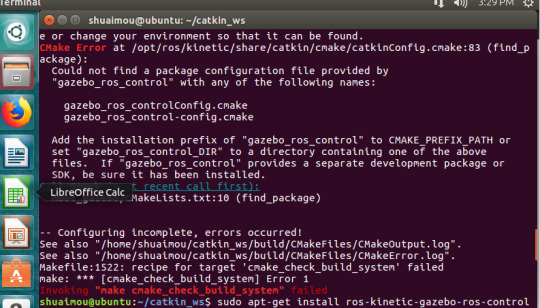
#LD_LIBRARY_PATH
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
How to install the native gog(and maybe steam? I dont own it to check) linux version of Star of Providence (monolith: relics of the past)! a very niche tutorial for maybe 6 people in the world.
This also might slightly help as a base guide in learning how to troubleshoot programs and games on linux.
This guide assumes you have Steam installed and can be trusted to find certain library files if you do not already have them installed. On my personal system I am running openSUSE tumbleweed and will be using Lutris to launch the game, but equivalent steps for launching through Steam will be provided when needed.
Firstly, turn off hidden files.
the base game is 32-bit only and requires files from /.steam/bin/steam-runtime/lib/1386-linux-gnu Base game+DLC is 64-bit only and requires files from /.steam/bin/steam-runtime/lib/x86-64-linux-gnu
if you're using Lutris. inside your monolith game directory place a new folder named "lib" place "libcrypto.so.1.0.0" and "libssl.so.1.0.0" from your respective steam-runtime/lib folders into the monolith lib directory in lutris, right click and confiure on monolith, select toggle "advanced" on the top right of the window under game options "add directory to LD_LIBRARY_PATH" add your lib directory in the monolith folder
on Steam.
into your game properties tab paste either
for base game
LD_PRELOAD="~/.steam/bin/steam-runtime/lib/1386-linux-gnu/libssl.so.1.0.0 ~/.steam/bin/steam-runtime/lib/1386-linux-gnu/libcrypto.so.1.0.0" %command%
OR
for base + DLC
LD_PRELOAD="~/.steam/bin/steam-runtime/lib/x86_64-linux-gnu/libssl.so.1.0.0 ~/.steam/bin/steam-runtime/lib/x86_64-linux-gnu/libcrypto.so.1.0.0" %command%
for the base game we should be done and the game is playable however, with the DLC at this point we're still missing (on opensuse tumbleweed, your system might be different, check your games logs while trying to launch)one library file to make the game launch, it wants to look for libcurl-gnutls.so.4 which is unavailable in the repos of non ubuntu/debian based distros, however this file (seems to be) completely cross compatible with libcurl.so.4 so we're going to be making a symbolic link, so when the game searches for libcurl-gnutls.so.4 it will find libcurl.so.4
open a terminal in your system's /lib64/ folder, with Dolphin this can be done by right clicking an empty space and under actions select "open terminal here", alternatively just move to the directory inside of your terminal paste | sudo ln -s libcurl.so.4 libcurl-gnutls.so.4
(now, this might have negative consequences however, I do not know what they would be and someone who actually codes might be able to pitch in here. if so, just add it to the lib directory for the game for lutris or add a new folder under LD_PRELOAD on the steam properties) the game should now be playable
Alternatively to all of this, just use proton. on Steam just change the compatibility mode to the latest version and in Lutris install the base games windows version and run it using proton or wine-ge, to get the dlc to work select "Run EXE inside Wine prefix, this can be found to the right of the play button at the bottom of the list to the right of the wine button. Now launch the DLC installer. Congrats! You got the game to work in hopefully a quarter of the time it took me to both figure this out and document all of this!
3 notes
·
View notes
Link
0 notes
Text
30.6. CUDA 업데이트
CUDA 업데이트와 관련된 각 단계를 더 구체적으로 살펴보겠습니다. 1. CUDA 업데이트 개요 1.1. CUDA란 무엇인가? CUDA는 NVIDIA가 개발한 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델입니다. 이를 통해 개발자는 GPU를 사용하여 컴퓨팅 작업을 병렬로 수행할 수 있습니다. 이는 특히 과학 계산, 인공지능, 머신러닝, 데이터 분석, 게임 그래픽 등의 분야에서 매우 유용합니다. 2. CUDA 업데이트 절차 2.1. CUDA Toolkit 다운로드 (1) NVIDIA 공식 웹사이트 방문: - (https://developer.nvidia.com/cuda-downloads) 페이지로 이동합니다. (2) 운영체제 및 아키텍처 선택: - Windows, Linux, MacOS 중 사용 중인 운영체제를 선택합니다. - CPU 아키텍처 (예: x86_64, arm64 등)를 선택합니다. (3) CUDA Toolkit 버전 선택: - 사용하려는 CUDA Toolkit 버전을 선택합니다. 최신 버전이 권장되지만, 호환성 문제로 특정 버전을 선택할 수도 있습니다. (4) 설치 파일 다운로드: - 선택한 설정에 맞는 설치 파일을 다운로드합니다. 이 파일은 설치 마법사 또는 패키지 매니저를 통해 설치를 진행할 수 있습니다. 2.2. 설치 (1) 설치 파일 실행: - 다운로드한 설치 파일을 실행합니다. 설치 마법사가 시작되며, 안내에 따라 설치를 진행합니다. (2) CUDA Toolkit 구성 요소 선택: - 기본 설정대로 설치하거나, 설치할 구성 요소 (예: 드라이버, 샘플 코드, 라이브러리 등)를 선택합니다. (3) 드라이버 설치: - 최신 NVIDIA 드라이버가 필요합니다. 설치 과정에서 필요한 드라이버가 포함되어 있지 않은 경우, NVIDIA 드라이버 페이지에서 최신 드라이버를 다운로드하여 설치해야 합니다. 2.3. 환경 변수 설정 (1) 환경 변수 추가 (Linux/MacOS): - CUDA Toolkit의 bin 디렉토리를 PATH 환경 변수에 추가합니다. 예를 들어, `~/.bashrc` 파일에 다음 줄을 추가합니다: export PATH=/usr/local/cuda/bin:$PATH - 라이브러리 경로를 추가합니다: export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH (2) 환경 변수 추가 (Windows): - 시스템 속성 -> 고급 시스템 설정 -> 환경 변수 -> 시스템 변수에서 `Path`를 선택하고 편집합니다. - 새 항목으로 CUDA bin 디렉토리 (예: `C:Program FilesNVIDIA GPU Computing ToolkitCUDAvX.Xbin`)를 추가합니다. 3. 주요 업데이트 내용 3.1. 새로운 기능 (1) Tensor Cores 지원: - AI 및 딥러닝 작업을 가속화하기 위한 Tensor Cores가 추가됩니다. 이는 행렬 연산을 매우 빠르게 수행할 수 있도록 도와줍니다. (2) CUDA Graphs: - 복잡한 작업 흐름을 최적화하여 성능을 향상시키기 위한 CUDA Graphs 기능이 추가됩니다. 이를 통해 커널 실행 순서 및 동기화를 효율적으로 관리할 수 있습니다. (3) 새로운 라이브러리: - 특정 작업을 최적화하기 위한 새로운 라이브러리가 추가됩니다. 예를 들어, cuSPARSE는 희소 행렬 연산을 가속화하기 위한 라이브러리입니다. 3.2. 성능 향상 (1) 커널 실행 최적화: - 새로운 커널 실행 기술을 통해 GPU 자원을 효율적으로 사용하고, 병렬 실행을 최적화하여 성능을 향상시킵니다. (2) 메모리 관리 개선: - 더 빠른 메모리 할당 및 해제를 통해 메모리 사용의 효율성을 ���이고, 전반적인 성능을 개선합니다. 3.3. 버그 수정 (1) 이전 버전의 버그 수정: - 이전 버전에서 발견된 여러 버그가 수정됩니다. 이는 안정성을 높이고, 예기치 않은 오류를 줄이는 데 도움이 됩니다. (2) 안정성 및 호환성 향상: - 새로운 기능 및 기존 기능의 호환성을 개선하여, 다양한 하드웨어 및 소프트웨어 환경에서 더 나은 성능을 제공합니다. 4. 호환성 및 지원 4.1. 하드웨어 호환성 - 최신 CUDA 버전은 최신 NVIDIA GPU를 지원합니다. 특정 GPU 아키텍처 (예: Volta, Turing, Ampere 등)에 대한 최적화가 포함됩니다. - 일부 구형 GPU는 지원되지 않을 수 있으므로, 업데이트 전에 호환성 목록을 확인해야 합니다. 4.2. 소프트웨어 호환성 - 최신 CUDA Toolkit은 최신 운영 체제 버전과 호환됩니다. 이는 주기적으로 운영 체제를 업데이트해야 함을 의미합니다. - 특정 소프트웨어나 라이브러리와의 호환성 문제를 피하기 위해, 개발 환경을 주기적으로 업데이트해야 합니다. 5. 업데이트 시 고려 사항 5.1 백업: - 중요한 데이터나 코드를 업데이트 전에 백업하십시오. 이는 업데이트 중 발생할 수 있는 문제를 예방하기 위함입니다. 5.2 테스트: - 업데이트 후 기존 코드가 정상적으로 작동하는지 테스트하십시오. 새로운 기능을 사용하기 전에 기존 기능의 정상 작동을 확인하는 것이 중요합니다. 5.3 문서 확인: - 새로 추가된 기능이나 변경된 사항에 대해 문서를 꼼꼼히 확인하십시오. (https://docs.nvidia.com/cuda/)를 참고하여 최신 정보와 사용법을 숙지하십시오. 이와 같은 절차를 통해 CUDA 업데이트를 성공적으로 수행할 수 있습니다. 최신 기술과 최적화를 반영한 업데이트를 통해, GPU를 최대한 활용하여 더 나은 성능을 얻을 수 있습니다. Read the full article
0 notes
Text
current circle of hell: i added `export LD_LIBRARY_PATH=/foo` to this script, an extremely normal thing that should just work,
and now `file /baz` is segfaulting. wtaf
#for the record i am committing crimes and i know it#and the more i explain the more insane i will sound#look. i know what i'm doing. it's just that what i'm doing is deranged#so that's all you're getting#filthy hacker shit
6 notes
·
View notes
Text
ok I just want to take a moment to rant bc the bug fix I’d been chasing down since monday that I finally just resolved was resolved with. get this. A VERSION UPDATE. A LIBRARY VERSION UPDATE. *muffled screaming into the endless void*
so what was happening. was that the jblas library I was using for handling complex matrices in my java program was throwing a fucking hissy fit when I deployed it via openshift in a dockerized container. In some ways, I understand why it would throw a fit because docker containers only come with the barest minimum of software installed and you mostly have to do all the installing of what your program needs by yourself. so ok. no biggie. my program runs locally but doesn’t run in docker: this makes sense. the docker container is probably just missing the libgfortran3 library that was likely preinstalled on my local machine. which means I’ll just update the dockerfile (which tells docker how to build the docker image/container) with instructions on how to install libgfortran3. problem solved. right? WRONG.
lo and behold, the bane of my existence for the past 3 days. this was the error that made me realize I needed to manually install libgfortran3, so I was pretty confident installing the missing library would fix my issue. WELL. turns out. it in fact didn’t. so now I’m chasing down why.
some forums suggested specifying the tmp directory as a jvm option or making sure the libgfortran library is on the LD_LIBRARY_PATH but basically nothing I tried was working so now I’m sitting here thinking: it probably really is just the libgfortran version. I think I legitimately need version 3 and not versions 4 or 5. because that’s what 90% of the solutions I was seeing was suggesting.
BUT! fuck me I guess because the docker image OS is RHEL which means I have to use the yum repo to install software (I mean I guess I could have installed it with the legit no kidding .rpm package but that’s a whole nother saga I didn’t want to have to go down), and the yum repo had already expired libgfortran version 3. :/ It only had versions 4 and 5, and I was like, well that doesn’t help me!
anyways so now I’m talking with IT trying to get their help to find a version of libgfortran3 I can install when. I FIND THIS ELUSIVE LINK. and at the very very bottom is THIS LINK.
Turns out. 1.2.4 is in fact not the latest version of jblas according to the github project page (on the jblas website it claims that 1.2.4 is the current verison ugh). And according to the issue opened at the link above, version 1.2.5 should fix the libgfortran3 issue.
and I think it did?! because when I updated the library version in my project and redeployed it, the app was able to run without crashing on the libgfortran3 error.
sometimes the bug fix is as easy as updating a fucking version number. but it takes you 3 days to realize that’s the fix. or at least a fix. I was mentally preparing myself to go down the .rpm route but boy am I glad I don’t have to now.
anyways tl;dr: WEBSITES ARE STUPID AND LIKELY OUTDATED AND YOU SHOULD ALWAYS CHECK THE SOURCE CODE PAGE FOR THE LATEST MOST UP TO DATE INFORMATION.
#this is a loooooong post lmao#god i'm so mad BUT#at least the fix ended up being really easy#it just took me forever to _find_#ok end rant back to work lmao
4 notes
·
View notes
Text
Cmake Makefile

Description
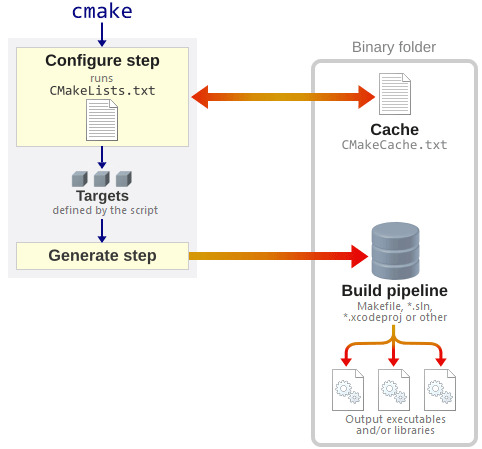
Makefile Syntax. A Makefile consists of a set of rules.A rule generally looks like this: targets: prerequisites command command command. The targets are file names, separated by spaces. Typically, there is only one per rule. The concept of CMake. CMake makes your makefile. Cmake relies on a top level file called CMakeLists.txt; now we can first delete our makefile and out in the previous section. First check our cmake version. 1: cmake -version: You can also use the command cmake to check the usage.
This is a very simple C++ Makefile example and associated template, that can be used to get small to medium sized C++ projects up and running quickly and easily. The Makefile assumes source code for the project is broken up into two groups, headers (*.hpp) and implementation files (*.cpp). The source code and directory layout for the project is comprised of three main directories (include, src and build), under which other directories containing code would reside. The layout used in the example is as follows:
Directory Purpose Project / include Header files (*.hpp, *.h, *.hxx, *.h++)Project / src Implementation files (*.cpp)Project / build / objectsObject files (*.o)Project / build / apps Executables
The Makefile
The Makefile supports building of a single target application called program which once built will be placed in the build/apps directory. All associated objects will be placed in the build/objects directory. The following is a listing of the Makefile in its entirety:
The Makefile and a complete example including source code and directory layout can be downloaded from: HERE
Makefile Commands
The following commands can be used with this Makefile:
make all
make clean
make program
make build
make release
make debug
make info
Example Run
The following is the expected output when the command 'make clean all' is executed:
CMake Version
A CMake based build configuration of the above mentioned project structure can be found HERE
Preface Introduction Under the hood of Visual Studio GNU/Linux Equivalent Visual Studio to Make Utility mapping Example Source Structure Build Run Makefile Details Targets Dependencies Contents NMake Conclusion External Links
If you develop software only on Windows using Visual studio, it’s a luxury. Enjoy it while it lasts. Sooner than later, you will come across Makefiles, maybe exploring some software on Linux or the misfortune of having a build system that uses make with Cygwin on Windows.
Now you figure out that Makefiles are text files and open it in an editor hoping to get some insight into its workings. But, what do you see? Lots of cryptic hard to understand syntax and expressions. So, where do you start? Internet searches for make and Makefiles provide a lot of information but under the assumption that you come from a non-IDE Unix/Linux development environment. Pampered Visual Studio developers are never the target audience.
Here I will try to relate to the Visual Studio build system which will hopefully give an easier understanding of Makefiles. The goal is not to provide yet another tutorial on makefiles (because there are plenty available on the internet) but to instill the concept by comparison.
Visual Studio provides features that are taken for granted until you have to read/create a classic Makefile. For example, Visual Studio auto-magically does the following.
Compiles all the sources in the project file
Create an output directory and puts all the intermediate object files in it
Manages dependencies between the source and object files
Manages dependencies between the object files and binaries
Links the object files and external dependent libraries to create binaries
All of the above have to be explicitly specified in a Makefile. The make utility in some ways is the equivalent of Visual Studio devenv.exe (without the fancy GUI).
Visual Studio is essentially a GUI over the compilation and link process. It utilizes an underlying command line compiler cl.exe and linker link.exe. Additionally, it provides a source code editor, debugger and other development tools.
A simple win32 console application project in Visual Studio is shown below. You have a solution file which contains a project file.
Invoking a build on the solution in Visual Studio calls something like the following under the hood. Yes, it looks ugly! But that is the the project properties translated to compiler/linker flags and options.
It is very similar in GNU/Linux. The equivalent of a compiler and linker is gcc, the GNU project C and C++ compiler. It does the preprocessing, compilation, assembly and linking.
Shown below is a very simple Makefile which can be accessed from GitHub https://github.com/cognitivewaves/Simple-Makefile.
Invoking the make command to build will output the following.
Below is a table relating Visual Studio aspects to Make utility. At a high level, the Project file is equivalent to a Makefile.
Visual Studiomake UtilityCommanddevenv.exemakeSource structure Solution (.sln) has project files (typically in sub-directories)Starting at the root, each Makefile can indicate where other Makefiles (typically in sub-directories) existLibrary build dependencySolution (.sln) has projects and build orderMakefileSource files listProject (.vcproj)MakefileSource to Object dependencyProject (.vcproj)MakefileCompile and Link optionsProject (.vcproj)MakefileCompilercl.exegcc, g++, c++ (or any other compiler, even cl.exe)Linkerlink.exegcc, ld (or any other linker, even link.exe)
Download the example sources from GitHub at https://github.com/cognitivewaves/Makefile-Example. Note that very basic Makefile constructs are used because the focus is on the concept and not the capabilities of make itself.
Source Structure
Build
Visual Studiomake UtilityBuilding in Visual Studio is via a menu item in the IDE or invoking devenv.exe on the .sln file at the command prompt. This will automatically create the necessary directories and build only the files modified after the last build.Initiating a build with makefiles is to invoke the make command at the shell prompt. Creating output directories has to be explicitly done either in the Makefile or externally.
Cmake Command Line
In this example, to keep the makefiles simple, the directories are created at the shell prompt.
The make utility syntax is shown below. See make manual pages for details.
Execute the command make and specify the “root” Makefile. However, it is more common to change to directory where the “root” Makefile exists and call make. This will read the file named Makefile in the current directory and call the target all by default. Notice how make enters sub-directories to build. This is because of nested Makefiles which is explained later in the Makefiles Details section.
Run
Once the code is built, run the executable. This is nothing specific to makefiles but has been elaborated in case you are not familiar with Linux as you will notice that by default is will fail to run with an error message.
This is because the executable app.exe requires the shared object libmath.so which is in a different directory and is not in the system path. Set LD_LIBRARY_PATH to specify the path to it.
Makefile Details
The basis of a Makefile has a very simple structure.
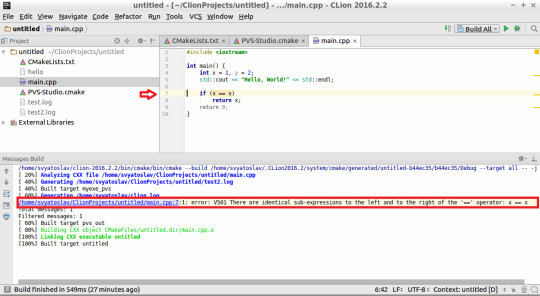
The (tab) separator is very important! Spaces instead of a (tab) is not the same. You will see rather obscure error messages as shown below. Makefile:12: *** missing separator. Stop.

Targets
Here target is a physical file on disk. When the target is more of a label, then it has to be tagged as .PHONY to indicate that the target is not an actual file.
Visual Studiomake UtilityVisual Studio by default provides options to clean and rebuild a project or solution.Clean and rebuild have to be explicitly written in a makefile as targets which can then be invoked.

A typical case would be to clean before rebuilding.
Dependencies
Dependencies can be files on disk or other targets (including phony targets).
Visual Studiomake UtilityVisual Studio by default supports implicit dependencies (source to object files) within a project. Library(project) dependencies have to specified in the solution fileEvery dependency has to be explicitly defined in makefiles
Cmake Makefile Generator
For example, the target all, depends on app.exe which in turn depends on libmath.so. If you remove app.exe, make is capable of recognizing that libmath.so need not be built again.
Contents
Cmake Makefile Link
File: Makefile
File: math/Makefile
Cmake Makefile Difference
File: app/Makefile
NMake is the native Windows alternative to the *nix make utility. The syntax is very similar to *nix makefiles. However, this does not mean that *nix makefiles can be executed seamlessly on Windows. See Makefiles in Windows for a discussion.
Makefiles are very powerful and gives a lot of control and flexibility compared to Visual Studio, but the content is not easily understandable. As an alternative, CMake has adopted similar concepts but the script is much easier and more readable. See CMake and Visual Studio.
1 note
·
View note
Text
Apple M1 para desenvolvedores do zero - Part 1
Eae, essa vai ser uma série ( espero ) de artigos de tudo que fiz assim que recebi o meu Macbook Air com processador M1. Espero que te ajude migrar todo seu ambiente Intel para M1 ( arm64 ).
Infelizmente ainda temos um caminho longo pela frente, boa parte dos softwares já conseguem ser compilados nativamente, porem, outros ainda precisam ser emulados atrav'ées do Rosetta por conta de bibliotecas de sistema com "ffi" que ainda não estao 100% compativels.
Separei em topicos de passos que segui exatamente na ordem que estão, espero que ajude.
Xcode + Rosetta
A instalação é feita através da App Store. Antes de começar toda a configuração da maquina instale a versão mais recente.
Em seguida instalar componentes de desenvolvimento: xcode-select --install
Brew no M1 ( Gerenciador de Pacotes )
As instalação do brew eu segui as instruções dadas a partir do artigo:
https://gist.github.com/nrubin29/bea5aa83e8dfa91370fe83b62dad6dfa
Instalando dependências de sistema
Essas bibliotecas servirão para diversos softwares como Python, Pillow, Node e etc. Elas são necessárias para a compilação e uso dos mesmos.
brew install libtiff libjpeg webp little-cms2 freetype harfbuzz fribidi brew install openblas brew install blis brew install zlib brew install gdal brew install pyenv brew install geoip brew install libgeoip brew install libffi brew install xz
Opcionais:
brew install postgres
Instalando Pyenv no M1
Instalando pyenv para facilitar o isolavento e definição de versões do python no sistema.
Eu tive problemas instalando diretamente no sistema, utilizando o brew. Algumas bibliotecas não eram encontradas e o trabalho para configuração de PATHs me fez migrar para pyenv.
brew install pyenv
Variaveis de ambiente
Para que as futuras compilações e instalações consigam encontrar todas as bibliotecas instaladas através do brew, é necessário configurar variáveis de ambiente para isso.
Adicione as linhas abaixo em seu arquivo de configuração do shell.
Se for bash: .bashrc Se for zsh: .zshrc
Eu fiz um script onde faz cache das chamadas do homebrew. Fique atento as versões das bibliotecas, se por ventura algumas delas não forem encontradas, confira o path das variaveis de ambiente.
Obs.: A melhor forma para obter o path das bibliotecas seria através do comando brew --prefix mas fazer inumeras chamadas pode deixar a inicialização do shell lenta.
Segue o que deve ser inserido em um dos arquivos acima:
if [ -z "$HOMEBREW_PREFIX" ]; then export PATH="/opt/homebrew/bin:$PATH" if command -v brew 1>/dev/null 2>&1; then SHELL_ENV="$(brew shellenv)" echo -n "$SHELL_ENV $(cat ~/.zshrc)" > .zshrc eval $SHELL_ENV fi fi export PATH="$HOMEBREW_PREFIX/opt/[email protected]/bin:$PATH" export LDFLAGS="-L/opt/homebrew/lib -L/opt/homebrew/opt/[email protected]/lib -L/opt/homebrew/opt/sqlite/lib -L/opt/homebrew/opt/[email protected]/lib -L/opt/homebrew/opt/libffi/lib -L/opt/homebrew/opt/openblas/lib -L/opt/homebrew/opt/lapack/lib -L/opt/homebrew/opt/zlib/lib -L/opt/homebrew/Cellar/bzip2/1.0.8/lib -L/opt/homebrew/opt/readline/lib" export CPPFLAGS="-I/opt/homebrew/include -I/opt/homebrew/opt/[email protected]/include -I/opt/homebrew/opt/sqlite/include -I/opt/homebrew/opt/libffi/include -I/opt/homebrew/opt/openblas/include -I/opt/homebrew/opt/lapack/include -I/opt/homebrew/opt/zlib/include -I/opt/homebrew/Cellar/bzip2/1.0.8/include -I/opt/homebrew/opt/readline/include" export PKG_CONFIG_PATH="$HOMEBREW_PREFIX/opt/[email protected]/lib/pkgconfig" export PKG_CONFIG_PATH="$PKG_CONFIG_PATH:$HOMEBREW_PREFIX/opt/[email protected]/lib/pkgconfig:$HOMEBREW_PREFIX/opt/libffi/lib/pkgconfig:$HOMEBREW_PREFIX/opt/openblas/lib/pkgconfig:$HOMEBREW_PREFIX/opt/lapack/lib/pkgconfig:$HOMEBREW_PREFIX/opt/zlib/lib/pkgconfig" export GDAL_LIBRARY_PATH="/opt/homebrew/opt/gdal/lib/libgdal.dylib" export GEOS_LIBRARY_PATH=$GDAL_LIBRARY_PATH export LD_LIBRARY_PATH=$HOMEBREW_PREFIX/lib:$LD_LIBRARY_PATH export DYLD_LIBRARY_PATH=$HOMEBREW_PREFIX/lib:$DYLD_LIBRARY_PATH export OPENBLAS="$(brew --prefix openblas)" if command -v pyenv 1>/dev/null 2>&1; then eval "$(pyenv init -)" fi
Instalando Python 3 no M1
Para instalar o Python através do pipenv no m1 é necessário aplicar um patch para corrigir algumas informações da arquitetura.
O time do Homebrew disponibilizou esses patchs e pode ser localizado em: https://github.com/Homebrew/formula-patches/tree/master/python
Como estou instalando a versão 3.8, segue o comando:
PYTHON_CONFIGURE_OPTS="--with-openssl=$(brew --prefix openssl)" \ pyenv install --patch 3.8.7 <<(curl -sSL "https://raw.githubusercontent.com/Homebrew/formula-patches/master/python/3.8.7.patch")
NVM e Node no M1
mkdir ~/.nvm
Colocar no .zshrc ou .bashrc
export NVM_DIR="$HOME/.nvm" [ -s "/opt/homebrew/opt/nvm/nvm.sh" ] && . "/opt/homebrew/opt/nvm/nvm.sh" # This loads nvm [ -s "/opt/homebrew/opt/nvm/etc/bash_completion.d/nvm" ] && . "/opt/homebrew/opt/nvm/etc/bash_completion.d/nvm" # This loads nvm bash_completion
Fim da primeira parte:
Essa primeira parte mostrei como instalar o gerenciador de pacores, Python e Node. Irei fazer Posts sobre partes especificas como Android Studio, Xcode, Docker e etc.
Espero que me acompanhem e qualquer dúvida pode deixar o comentário.
Até mais
1 note
·
View note
Photo




(第639回 Ubuntuに「トラブル時に」ログインするいろいろな方法:Ubuntu Weekly Recipe|gihyo.jp … 技術評論社から)
ディスクをマウントせずにログインする ストレージは消耗品です。近い将来,必ず壊れます。一番壊れてほしくないタイミングで壊れます。それはUbuntuがインストールされているHDD/SSD/eMMC/microSDであっても例外ではありません。
しかしながら前述のシングルユーザーモードでログインする方法は,必ずルートファイルシステムをマウントする必要があります。たとえストレージが壊れていなかったとしてもマウントできなければ,やはりシステムは起動できません。
そこでストレージ上のルートファイルシステムをマウントせずにシステムにログインする方法を考えてみましょう。
Initramfsに「ログイン」する 第384回でも紹介したように,Ubuntuは最初にブートローダーであるGRUBが,ストレージからカーネルと「Initramfs」を探しだし,そのふたつをメモリー上にロードした上で,システムを起動します。Initramfsにはストレージやネットワークのドライバーが同梱されているため,カーネルはこれらのドライバーをロードしつつ,システムがインストールされているストレージデバイスをマウントします。
Initramfsは「小さなUbuntu」とも言うべき簡易的なシステムです。サイズを小さく保つためにaptコマンドなどは使えませんがそれでも必要最低限のUnixライクな環境として使えます。
なお,Initramfsは一般的にカーネルと一緒に起動ディレクトリに保存されています。UEFI対応マシンならESP(EFI System Partition)と呼ばれるFAT領域となります。よってストレージ��のものが動かない場合は,この方法は使えません。そもそもGRUBも起動しない状態なので注意してください。本項の手順では,あくまでESPは見えている状態(ストレージが完全に壊れているわけではない状態)を想定しています。
Initramfsは大抵の場合,なんらかの理由でルートファイルシステムをマウントできなかったときに表示されます。また,それとは別にGRUBのメニュー画面でカーネルの起動パラメーターを変更すると,InitramfsはルートファイルシステムをマウントすることなくBusyBox環境に「ログイン」します。具体的にはGRUBメニューの一番上のメニュー上で「e」を押します。
図6 起動オプションの編集画面(breakキーワード追加済み)
画像 上記のようにメニューエントリの編集画面になるので,画像のように「linux」で始まる行の最後に「break」を追加してください。基本はカーソルキーで該当する行に移動し,「Ctrl-e」で行末にジャンプ,その後にスペース+「break」と入力すれば良いはずです。
編集できたら,「Ctrl-x」でこのメニューエントリを実行します。なお,この編集結果は保存されませんので安心してください。キャンセルしたい場合は,Ctrl-c」を押します。
図7 Initramfs上のBusyBoxのプロンプト
画像 前述のとおり,このプロンプトはルートファイルシステムをマウントできなかったときにも表示されるため,過去に遭遇した人もいるかもしれません。特にRAIDを組んでいたり,特殊なドライバーが必要なストレージデバイスを使っている人は遭遇しやすいかもしれません。
さて,このBusyBoxは組み込み向けにも使われる一般的なユーティリティコマンド群をひとつのバイナリファイルにまとめたものです。端末ソフトウェアで使うコマンドのうち,一般的に頻度の高いコマンドはひととおり存在するものの,サポートしているオプション等は通常のUbuntu環境における同名のコマンドと大きく異なります。とりあえずコマンド一覧を知りたい場合は「help」と入力してください。
試しにルートファイルシステムをマウントしてみましょう。
図8 Initramfsでルートファイルシステムをマウントする例
画像 上図ではルートファイルシステムのマウントに成功していますが,意図せずInitramfs環境にログインするということは,ルートファイルシステムをマウントできないケースが大半です。実際に手作業でマウントし,出てきたエラーメッセージから原因を推測する流れになるでしょう。もし運が良ければ,fsckするだけで解決する場合もあります。「blkid」や「fdisk -l」でストレージデバイスの名前を推量し,「fsck デバイスファイル名」してみるだけでも良いかもしれません。
ただしfsckコマンドの実行が瀕死のルートファイルシステムにとどめを刺すという可能性も否めません。どうしても重要な情報が含まれるストレージデバイスだということであれば,先にddコマンドなどでディスクイメージ化し,適当な別のストレージにバックアップを取るべきです。
一応udevが動いているので,上記のようなストレージデバイスや,他にもUSBストレージなどを接続してマウントすることも可能です。ただしInitramfsに含まれているカーネルモジュールはルートファイルシステムのそれに比べて少なめになっているので注意してください。可能であれば簡単なファイルシステム経由でコピーすれば,modprobeでロードすることも可能です。
ストレージのバックアップを取る バックアップ用の別のストレージを用意できるなら,次の手順でルートファイルシステムがインストールされたストレージを保存できます。一般的にバックアップ用にはルートファイルシステムと同サイズのストレージを接続するのが理想的ではありますが,必ずしも準備できるとは限りません。そこである程度圧縮すれば収まることを期待して,次のように実行すると良いでしょう。
mount /dev/sdb1 /mnt
dd if=/dev/sda conv=sync,noerror bs=65536 | gzip -c > /mnt/host-sda.img.gz
327600+0 records in 327600+0 records out 21474836480 bytes (21 GB, 20 GiB) copied, 373.366 s 57.5 MB/s
file /mnt/host-sdaimg.gz
/mnt/host-sda.img.gz: gzip compressed data, from Unix, original size module 2^32 0
ls -sh /mnt/host-sda.img.gz
4.4G /mnt/host-sda.img.gz
umount /mnt
まず「/dev/sdb1」は十分に容量があり,きちんと動くストレージデバイスのパーティションのファイル名です。環境によって異なるので注意してください。USBストレージなら接続した直後に「dmesg | tail」すれば,デバイスファイル名がわかるはずです。前述のとおり「blkid」を実行し,ディスクラベルから推定するという方法もあります。
「/dev/sda」がバックアップを取りたいストレージデバイスそのものです。「/dev/sda2」のようにパーティション単位で保存しても良いですし,「/dev/sda」と全体を取ってしまうという方法もあるでしょう。ddコマンドでは「conv=sync,noerror」によりディスクキャッシュを使わずにきちんと保存しつつ,読み込みエラーに遭遇しても継続して読み出すようにしています。
gzipコマンドによってイメージを圧縮しています。ゼロで埋められた空き領域が多いと圧縮率はあがるものの,空き領域にランダムな値が入っているとするとそこまで圧縮されません。結果的に保存先は保存元と同程度の容量のものを選んでおいたほうが安全ではあります。
ライブラリも最低限のものは用意されているので,例えばGo言語のプログラムであればバイナリ一個持ってきて実行することは可能ですし,ルートファイルシステムをマウントできるなら環境変数LD_LIBRARY_PATHにマウントしたディレクトリの共有ライブラリが存在するディレクトリを指定する方法も使えるでしょう。
ネットワークへの接続も,リカバリーモードと異なりひと手間必要です。具体的には「ip link」コマンドを使ってインターフェイスをupし,「dhclient」コマンドを使ってIPアドレスを取得します。
図9 ipコマンドとdhclientを使ってネットワーク接続する方法
画像 wgetコマンドがあるのでネットワーク越しのファイルの取得ぐらいならできるはずです。またNFSマウントするという手もあります。固定IPアドレスを割り当てたいなら,dhclientの代わりに次のコマンドを実行すること��なるでしょう。
ip addr add <IPアドレス> dev <ネットワークインターフェース>
ここでの「<IPアドレス>」はCIDR形式で記述可能です。その他の詳細は「ip -h」を実行してください。残念ながらUbuntu標準のInitramfsでは,WiFiに接続する簡単な方法は用意されていません。どうしても必要ならwpa_supplicantなどをInitramfsに用意する必要があります。
exitコマンドを実行すると,Initramfs環境を抜けて通常の起動を行います。単に電源を切りたいだけならpoweroffコマンドを使ってください。
Initramfs環境は上記で指定した「break」以外にもさまざまなカーネルの起動パラメーターを設定することで挙動を変更できます。詳しいことは「man initramfs-tools」を実行して表示される情報を参照してください。
USBデバイスからブートし,ストレージ領域にログインする 前項とは逆にブート領域(ESPやその上のカーネルなど)のデータがおかしくなり,ルートファイルシステムは無事な状況を考えてみましょう。独自ビルドのカーネルやサードパーティのカーネルモジュールを使用した結果,起動途中にカーネルパニックするケースも該当します。もしくはWindowsとデュアルブートしているときにGRUB領域を書き潰してしまうこともあるかもしれません。他にもUEFIなシステムでインストールしたストレージをそのままレガシーBIOSで起動しようとしたり,その逆だったりすると,同じように起動できません(※5)。
※5 純粋なカーネルの問題であれば,GRUBメニューを表示して古いカーネルを選択したり,悪影響を与えていそうなデバイスを取り外すだけで,とりあえず復旧できる可能性は高いです。原因となるモジュールにあたりがついているなら,GRUBのメニューエントリの編集画面で,linux行の末尾に「modprobe.blacklist=モジュール名」を指定するだけで回避できます。 このような状況においては,UbuntuのライブインストーラーをインストールしたUSBデバイスで起動し,そこからもともとのストレージ領域をマウントし,リカバリーを試みるのが一番簡単です。最近ではデスクトップ版だけでなくサーバー版のインストーラーもライブ環境に対応しています。CLIの操作に慣れているのであれば,サーバー版のインストーラーで起動し,「Ctrl-Alt-Fx」で別の仮想コンソールに切り替えた上で,操作すると良いでしょう。
一般的なリカバリー手順に従えば回復できる場合は,UbuntuのライブインストーラーよりはSystemRescueのようなリカバリーに特化したイメージを使ったほうが楽な場合も多いです。やりたいことがはっきりしている場合はまずはSystemRescueの利用を検討してください。
手元にUbuntuのライブインストーラーがあってそれをそのまま使いたいとか,ストレージの中身を取り出したいだけなら,Ubuntuのライブインストーラーでも良いでしょう。特に後者であれば,ライブインストーラーで起動し,外部ストレージをマウントしたら,あとは前項の「ストレージのバックアップを取る」と手順は一緒です。デスクトップ版のUbuntuを使っているなら,イメージバックアップに対応したGUIツールをインストールして使うという手もあります。本連載を「バックアップ」で検索すればいろいろでてきますので,使い方にあわせて好みのものを選ぶと良いでしょう。
1 note
·
View note
Text
Compiling GDAL with OpenCL on Ubuntu
I needed to apply GDAL operations to very large rasters, so I needed GPU acceleration for these. Our cloud infrastructure has GPUs available, but unfortunately Ubuntu's prebuilt GDAL binaries come without.
I found instructions on the internet how to include it, but they were outdated. The below instructions worked for me on Ubuntu 16.04 compiling GDAL 2.4.2. I strongly suspect the approach works the same on later Ubuntu versions, and only different in flags for later GDAL versions.
I based my method on this and this source.
# Add the nVidia cuda repo curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-ubuntu1604.pin sudo mv cuda-ubuntu1604.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/ /" # Install the necessary Ubuntu packages; I needed cuda-9-0 # Note: opencl is in a separate package, make sure it's the same version as your nvidia driver is (modprobe nvidia; modinfo nvidia) apt update && apt install cuda-9-0 nvidia-libopencl1-455 # Download and unpack GDAL wget http://download.osgeo.org/gdal/2.2.4/gdal-2.4.2.tar.gz tar -xvzf gdal-2.4.2.tar.gz cd gdal-2.4.2 # Set ENV vars to point GDAL to Cuda/OpenCL export LD_LIBRARY_PATH=/usr/local/cuda/lib64 export PATH=/usr/local/cuda/bin:$PATH # Compile with Cuda and OpenCL support # Note that --with-opencl-lib=cuda is necessary ./configure --prefix=/opt/gdal \ --with-threads \ --with-opencl \ --with-opencl-include=/usr/local/cuda/include/ \ --with-opencl-lib="-L/usr/local/cuda/lib64 -lOpenCL" make sudo make install
1 note
·
View note
Text
Bibliotecas Compartilhadas no Linux
Bibliotecas Compartilhadas no Linux
Aprenda como funcionam as biblitoecas compartilhadas (shared libraries) no Linux, e como isso pode interferir no funcionamento dos programas.
Determinar quais as bibliotecas compartilhadas de que um programa executável depende para executar e instalá-las quando necessário faz parte dos objetivos do exame.
Para entendermos a gerência das bibliotecas compartilhadas, precisamos primeiro…
View On WordPress
0 notes
Text
Can anyone help me with a Linux issue?
I hope one of you is a *nix power user, and can help me out.
I was trying to get mixxx to work with shoutcast, and in the process not only did I manage to break mixxx (it says there's no sound device configured, and I can't find a solution anywhere online) but I also managed to break audacity.
So when I try to launch audacity from the menu, it just doesn't start. When I try to launch it from the cli, it fails with an error message: audacity: symbol lookup error: audacity: undefined symbol: PaAlsa_GetStreamInputCard
But if I use this to start it, audacity works normally: LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu/ audacity
So I presume that I messed up my PATH somehow when I was trying to get mixxx to work, and I wonder if anyone who knows how to interpret this information can help me fix it, so I don't have to use that expicitly-defined LIBRARY PATH to start audacity from a terminal?
I'm hopeful that, if I can figure out how to fix this, I will also be able to fix mixxx.
84 notes
·
View notes
Text
OK, the stream from yesterday is up! It's 4 hours, 48 minutes of my 2D creative process from the essential messing-with-the-OS step to the concept, layout, sketch, and base colors. I'll be doing another of these very soon:
youtube
This video was done by hooking my laptop to my Elgato Game Capture HD; I did it this way because I wanted to depict the complete experience of using the Puppy Linux OS and Krita to draw an image.
The operating system is capable of running entirely from RAM; it loads up a save file on startup (up to 4GB in size, at least how I have it configured) and saves to it every 30 minutes or so. It's often used as a stopgap OS to recover files from computers with inoperable OS partitions, or to make old computers useful again for low-impact tasks like word processing or web browsing (since modern OSes are so bloated). And while it's useful for breathing life into older PCs (I have a Toshiba NB505 from 2010 this runs well on), I decided to try to use it to make a portable creativity environment. It works pretty well for this, it turns out! Krita runs great, as depicted in the video; my initial tests in Blender have been promising as well. The resulting stick can be booted into from my desktop, laptop, and netbook without disrupting the contents of the attached computer’s built-in hard drive in any way. Instructions on how I did it are after the break.
THIS IS HOW I DID IT:
REQUIREMENTS: A computer capable of running Windows with 2 empty USB ports, and 2 USB flash drives (one at least 1GB, which we'll be calling the "install drive", the other one however large you want your new OS partition to be. Beware, all files on both flash drives at the start will be lost in the process of doing this.)
Download a .iso file of your desired most recent version of Puppy Linux (I used bionicpup64)
Use a program to flash the install drive with the .iso you just downloaded (I used balenaEtcher)
Reboot, enter the BIOS settings of your PC, and boot from the USB stick you just flashed
You should be in Puppy Linux now; check to make sure the basic stuff works (mouse, keyboard, wifi). In my case, my laptop's wifi and trackpad didn't work; I had to connect a mouse, then run the wifi configuration wizard, then run the Puppy Updates application from the menu, after which everything worked as expected.
Insert the second USB stick, run StickPup from the applications menu, and use it to install the same ISO from earlier onto that. MAKE SURE you select the correct drive here
Shut your PC down, remove the install drive, and start it up again, now booting into the second USB stick
Customize to your heart's content; make sure to shut your PC down whenever you're done using it (instead of pressing the power button)
TIPS & TRICKS:
This is a pared-down version of Linux; while it can be used to test the OS out, and is itself capable of all kinds of tasks, it's not fully representative of what a full install of an OS like Linux Mint (which is installed on my desktop and laptop PCs) can do. Many programs require Puppy-specific versions (distributed via the package manager or through '.pet' files) to run correctly. Firefox was one of those for me; the one from the Ubuntu repository didn't play web audio, the one from the Puppy repository did.
The 4GB size limit can be mostly overcome by keeping your portable applications and personal files on the USB stick outside of the Linux install folder. I say “mostly” because non-portable applications still take up disk space within the save file.
Some .deb application installer files work, some require 32-bit compatibility files. These can be found in the Quickpet program in the application menu; Quickpet acts as a short list of non-essential applications that aren’t included in Puppy distros by default.
If you use the USB stick install and don't want your save file filled up immediately, set your web browser to limit the size of the cache (my personal limit is 50MB; in Firefox I had to manually edit the browser.cache.disk.smart.size.enabled and browser.cache.disk.capacity values in about:config to get it to stick).
Krita is distributed in the .appimage format; some appimages can be run just by double-clicking them, but Krita needs some extra work; it can be run from the terminal through the command LD_LIBRARY_PATH= "./krita-4.1.7-x86_64.appimage" from whichever directory it's placed, or by creating a shell script that runs that command and placing it in Krita's directory.
If you use a Wacom tablet, pressure sensitivity is built into the Linux kernel (this is one of the reasons I switched to Linux a year ago in the first place); some distros have button mapping built into the GUI, but with others (Puppy included) you need to use the xsetwacom terminal command. Comprehensive instructions for how to use this are online; I personally manually run this shell script through a desktop shortcut whenever I connect my tablet and I’m good to go.
My Intel graphics card on my laptop (an Acer Aspire E5-573G) presented screen tearing issues; I stopped them by creating a file in /etc/X11/xorg.conf.d called “20-intel.conf” with this text.
If this looks intimidating (and I don’t blame you if it does) -- I promise you, all the above information was retrieved using standard websearching methods; I’d personally say the only limiting factors for whether someone interested in trying this for themself ‘should’ give this a shot are time and patience, but I also realize those are in short supply for a lot of people. Use your best judgment.
2 notes
·
View notes
Text
30.6. CUDA 업데이트
CUDA 업데이트와 관련된 각 단계를 더 구체적으로 살펴보겠습니다. 1. CUDA 업데이트 개요 1.1. CUDA란 무엇인가? CUDA는 NVIDIA가 개발한 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델입니다. 이를 통해 개발자는 GPU를 사용하여 컴퓨팅 작업을 병렬로 수행할 수 있습니다. 이는 특히 과학 계산, 인공지능, 머신러닝, 데이터 분석, 게임 그래픽 등의 분야에서 매우 유용합니다. 2. CUDA 업데이트 절차 2.1. CUDA Toolkit 다운로드 1. NVIDIA 공식 웹사이트 방문: - (https://developer.nvidia.com/cuda-downloads) 페이지로 이동합니다. 2. 운영체제 및 아키텍처 선택: - Windows, Linux, MacOS 중 사용 중인 운영체제를 선택합니다. - CPU 아키텍처 (예: x86_64, arm64 등)를 선택합니다. 3. CUDA Toolkit 버전 선택: - 사용하려는 CUDA Toolkit 버전을 선택합니다. 최신 버전이 권장되지만, 호환성 문제로 특정 버전을 선택할 수도 있습니다. 4. 설치 파일 다운로드: - 선택한 설정에 맞는 설치 파일을 다운로드합니다. 이 파일은 설치 마법사 또는 패키지 매니저를 통해 설치를 진행할 수 있습니다. 2.2. 설치 1. 설치 파일 실행: - 다운로드한 설치 파일을 실행합니다. 설치 마법사가 시작되며, 안내에 따라 설치를 진행합니다. 2. CUDA Toolkit 구성 요소 선택: - 기본 설정대로 설치하거나, 설치할 구성 요소 (예: 드라이버, 샘플 코드, 라이브러리 등)를 선택합니다. 3. 드라이버 설치: - 최신 NVIDIA 드라이버가 필요합니다. 설치 과정에서 필요한 드라이버가 포함되어 있지 않은 경우, NVIDIA 드라이버 페이지에서 최신 드라이버를 다운로드하여 설치해야 합니다. 2.3. 환경 변수 설정 1. 환경 변수 추가 (Linux/MacOS): - CUDA Toolkit의 bin 디렉토리를 PATH 환경 변수에 추가합니다. 예를 들어, `~/.bashrc` 파일에 다음 줄을 추가합니다: export PATH=/usr/local/cuda/bin:$PATH - 라이브러리 경로를 추가합니다: export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH 2. 환경 변수 추가 (Windows): - 시스템 속성 -> 고급 시스템 설정 -> 환경 변수 -> 시스템 변수에서 `Path`를 선택하고 편집합니다. - 새 항목으로 CUDA bin 디렉토리 (예: `C:Program FilesNVIDIA GPU Computing ToolkitCUDAvX.Xbin`)를 추가합니다. 3. 주요 업데이트 내용 3.1. 새로운 기능 1. Tensor Cores 지원: - AI 및 딥러닝 작업을 가속화하기 위한 Tensor Cores가 추가됩니다. 이는 행렬 연산을 매우 빠르게 수행할 수 있도록 도와줍니다. 2. CUDA Graphs: - 복잡한 작업 흐름을 최적화하여 성능을 향상시키기 위한 CUDA Graphs 기능이 추가됩니다. 이를 통해 커널 실행 순서 및 동기화를 효율적으로 관리할 수 있습니다. 3. 새로운 라이브러리: - 특정 작업을 최적화하기 위한 새로운 라이브러리가 추가됩니다. 예를 들어, cuSPARSE는 희소 행렬 연산을 가속화하기 위한 라이브러리입니다. 3.2. 성능 향상 1. 커널 실행 최적화: - 새로운 커널 실행 기술을 통해 GPU 자원을 효율적으로 사용하고, 병렬 실행을 최적화하여 성능을 향상시킵니다. 2. 메모리 관리 개선: - 더 빠른 메모리 할당 및 해제를 통해 메모리 사용의 효율성을 높이고, 전반적인 성능을 개선합니다. 3.3. 버그 수정 1. 이전 버전의 버그 수정: - 이전 버전에서 발견된 여러 버그가 수정됩니다. 이는 안정성을 높이고, 예기치 않은 오류를 줄이는 데 도움이 됩니다. 2. 안정성 및 호환성 향상: - 새로운 기능 및 기존 기능의 호환성을 개선하여, 다양한 하드웨어 및 소프트웨어 환경에서 더 나은 성능을 제공합니다. 4. 호환성 및 지원 4.1. 하드웨어 호환성 - 최신 CUDA 버전은 최신 NVIDIA GPU를 지원합니다. 특정 GPU 아키텍처 (예: Volta, Turing, Ampere 등)에 대한 최적화가 포함됩니다. - 일부 구형 GPU는 지원되지 않을 수 있으므로, 업데이트 전에 호환성 목록을 확인해야 합니다. 4.2. 소프트웨어 호환성 - 최신 CUDA Toolkit은 최신 운영 체제 버전과 호환됩니다. 이는 주기적으로 운영 체제를 업데이트해야 함을 의미합니다. - 특정 소프트웨어나 라이브러리와의 호환성 문제를 피하기 위해, 개발 환경을 주기적으로 업데이트해야 합니다. 5. 업데이트 시 고려 사항 1. 백업: - 중요한 데이터나 코드를 업데이트 전에 백업하십시오. 이는 업데이트 중 발생할 수 있는 문제를 예방하기 위함입니다. 2. 테스트: - 업데이트 후 기존 코드가 정상적으로 작동하는지 테스트하십시오. 새로운 기능을 사용하기 전에 기존 기능의 정상 작동을 확인하는 것이 중요합니다. 3. 문서 확인: - 새로 추가된 기능이나 변경된 사항에 대해 문서를 꼼꼼히 확인하십시오. (https://docs.nvidia.com/cuda/)를 참고하여 최신 정보와 사용법을 숙지하십시오. 이와 같은 절차를 통해 CUDA 업데이트를 성공적으로 수행할 수 있습니다. 최신 기술과 최적화를 반영한 업데이트를 통해, GPU를 최대한 활용하여 더 나은 성능을 얻을 수 있습니다. Read the full article
0 notes
Text
Oracle DBA Cheet Sheet
Tablespace & Datafile Details ============================= set lines 200 pages 200 col tablespace_name for a35 col file_name for a70 select file_id, tablespace_name, file_name, bytes/1024/1024 MB, status from dba_data_files;
Table Analyze Details ===================== set lines 200 pages 200 col owner for a30 col table_name for a30 col tablespace_name for a35 select owner, table_name, tablespace_name, NUM_ROWS, LAST_ANALYZED from dba_tables where owner='&TableOwner' and table_name='&TableName';
Session Details =============== set lines 200 pages 200 col MACHINE for a25 select inst_id, sid, serial#, username, program, machine, status from gv$session where username not in ('SYS','SYSTEM','DBSNMP') and username is not null order by 1; select inst_id, username, count(*) "No_of_Sessions" from gv$session where username not in ('SYS','SYSTEM','DBSNMP') and username is not null and status='INACTIVE' group by inst_id, username order by 3 desc; select inst_id, username, program, machine, status from gv$session where machine like '%&MachineName%' and username is not null order by 1;
Parameter value =============== set lines 200 pages 200 col name for a35 col value for a70 select inst_id, name, value from gv$parameter where name like '%&Parameter%' order by inst_id;
User Details ============= set lines 200 pages 200 col username for a30 col profile for a30 select username, account_status, lock_date, expiry_date, profile from dba_users where username like '%&username%' order by username;
List and Remove Files and directories ===================================== ls |grep -i cdmp_20110224|xargs rm -r
Tablespace Usage (1) ==================== set pages 999; set lines 132; SELECT * FROM ( SELECT c.tablespace_name, ROUND(a.bytes/1048576,2) MB_Allocated, ROUND(b.bytes/1048576,2) MB_Free, ROUND((a.bytes-b.bytes)/1048576,2) MB_Used, ROUND(b.bytes/a.bytes * 100,2) tot_Pct_Free, ROUND((a.bytes-b.bytes)/a.bytes,2) * 100 tot_Pct_Used FROM ( SELECT tablespace_name, SUM(a.bytes) bytes FROM sys.DBA_DATA_FILES a GROUP BY tablespace_name ) a, ( SELECT a.tablespace_name, NVL(SUM(b.bytes),0) bytes FROM sys.DBA_DATA_FILES a, sys.DBA_FREE_SPACE b WHERE a.tablespace_name = b.tablespace_name (+) AND a.file_id = b.file_id (+) GROUP BY a.tablespace_name ) b, sys.DBA_TABLESPACES c WHERE a.tablespace_name = b.tablespace_name(+) AND a.tablespace_name = c.tablespace_name ) WHERE tot_Pct_Used >=0 ORDER BY tablespace_name;
Tablespace usage (2) ==================== select d.tablespace_name, d.file_name, d.bytes/1024/1024 Alloc_MB, f.bytes/1024/1024 Free_MB from dba_data_files d, dba_free_space f where d.file_id=f.file_id order by 1;
select d.tablespace_name, sum(d.bytes/1024/1024) Alloc_MB, sum(f.bytes/1024/1024) Free_MB from dba_data_files d, dba_free_space f where d.file_id=f.file_id group by d.tablespace_name order by 1;
Datafile added to Tablespace by date ==================================== select v.file#, to_char(v.CREATION_TIME, 'dd-mon-yy hh24:mi:ss') Creation_Date, d.file_name, d.bytes/1024/1024 MB from dba_data_files d, v$datafile v where d.tablespace_name='XXGTM_DAT' and d.file_id = v.file#;
Added in last 72 hours ====================== select v.file#, to_char(v.CREATION_TIME, 'dd-mon-yy hh24:mi:ss') Creation_Date, d.file_name, d.bytes/1024/1024 MB from dba_data_files d, v$datafile v where d.tablespace_name='XXGTM_DAT' and d.file_id = v.file# and v.creation_time > sysdate - 20;
Monitor SQL Execution History (Toad) ==================================== Set lines 200 pages 200 select ss.snap_id, ss.instance_number node, begin_interval_time, sql_id, plan_hash_value, nvl(executions_delta,0) execs, rows_processed_total Total_rows, (elapsed_time_delta/decode(nvl(executions_delta,0),0,1,executions_delta))/1000000 avg_etime, (buffer_gets_delta/decode(nvl(buffer_gets_delta,0),0,1,executions_delta)) avg_lio, (DISK_READS_DELTA/decode(nvl(DISK_READS_DELTA,0),0,1,executions_delta)) avg_pio,SQL_PROFILE from DBA_HIST_SQLSTAT S, DBA_HIST_SNAPSHOT SS where sql_id = '9vv8244bcq529' and ss.snap_id = S.snap_id and ss.instance_number = S.instance_number and executions_delta > 0 order by 1, 2, 3;
Check SQL Plan ============== select * from table(DBMS_XPLAN.DISPLAY_CURSOR('9vv8244bcq529'));
OHS Version ============ export ORACLE_HOME=/apps/envname/product/fmw LD_LIBRARY_PATH=$ORACLE_HOME/ohs/lib:$ORACLE_HOME/oracle_common/lib:$ORACLE_HOME/lib:$LD_LIBRARY_PATH; export LD_LIBRARY_PATH
cd /apps/envname/product/fmw/ohs/bin
/apps/envname/product/fmw/ohs/bin > ./httpd -version
Find duplicate rows in a table. =============================== set lines 1000 col ACTIVATION_ID for a50; col USER_ID for a30; SELECT ACTIVATION_ID, LFORM_ID,USER_ID FROM DBA_BTDEL1.LMS_LFORM_ACTIVATION GROUP BY ACTIVATION_ID, LFORM_ID,USER_ID HAVING count(*) > 1;
Partition Tables in database ============================ set lines 200 pages 200 col owner for a30 col table_name for a30 col partition_name for a30 select t.owner, t.table_name, s.PARTITION_NAME, s.bytes/1024/1024 MB from dba_tables t, dba_segments s where t.partitioned = 'YES' and t.owner not in ('SYS','SYSTEM') and t.table_name=s.segment_name order by 2, 4;
Who is using my system tablespace ================================= select owner, segment_type, sum(bytes/1024/1024) MB, count(*), tablespace_name from dba_segments where tablespace_name in ('SYSTEM','SYSAUX') group by owner, segment_type, tablespace_name order by 1;
What are the largest/biggest tables of my DB. ============================================= col segment_name for a30 Select * from (select owner, segment_name, segment_type, bytes/1024/1024 MB from dba_segments order by bytes/1024/1024 desc) where rownum <=30;
ASM Disk Group Details ====================== cd /oracle/product/grid_home/bin ./kfod disks=all asm_diskstring='ORCL:*' -------------------------------------------------------------------------------- Disk Size Path User Group ================================================================================ 1: 557693 Mb ORCL:DBPRD_AR_544G_01 2: 557693 Mb ORCL:DBPRD_DT01_544G_01 3: 557693 Mb ORCL:DBPRD_FRA_544G_01 4: 16378 Mb ORCL:DBPRD_RC_16G_001 5: 16378 Mb ORCL:DBPRD_RC_16G_002 6: 16378 Mb ORCL:DBPRD_RC_16G_003 7: 16378 Mb ORCL:DBPRD_RC_16G_004 8: 16378 Mb ORCL:DBPRD_RC_16G_005 9: 16378 Mb ORCL:DBPRD_RC_M_16G_001 10: 16378 Mb ORCL:DBPRD_RC_M_16G_002 11: 16378 Mb ORCL:DBPRD_RC_M_16G_003 12: 16378 Mb ORCL:DBPRD_RC_M_16G_004 13: 16378 Mb ORCL:DBPRD_RC_M_16G_005 14: 1019 Mb ORCL:GRID_NPRD_3026_CL_A_1G_1 15: 1019 Mb ORCL:GRID_NPRD_3026_CL_A_1G_2 16: 1019 Mb ORCL:GRID_NPRD_3026_CL_B_1G_1 17: 1019 Mb ORCL:GRID_NPRD_3026_CL_B_1G_2 18: 1019 Mb ORCL:GRID_NPRD_3026_CL_C_1G_1 19: 1019 Mb ORCL:GRID_NPRD_3026_CL_C_1G_2
./kfod disks=all asm_diskstring='/dev/oracleasm/disks/*' -------------------------------------------------------------------------------- Disk Size Path User Group ================================================================================ 1: 557693 Mb /dev/oracleasm/disks/DBPRD_AR_544G_01 oracle dba 2: 557693 Mb /dev/oracleasm/disks/DBPRD_DT01_544G_01 oracle dba 3: 557693 Mb /dev/oracleasm/disks/DBPRD_FRA_544G_01 oracle dba 4: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_16G_001 oracle dba 5: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_16G_002 oracle dba 6: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_16G_003 oracle dba 7: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_16G_004 oracle dba 8: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_16G_005 oracle dba 9: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_M_16G_001 oracle dba 10: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_M_16G_002 oracle dba 11: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_M_16G_003 oracle dba 12: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_M_16G_004 oracle dba 13: 16378 Mb /dev/oracleasm/disks/DBPRD_RC_M_16G_005 oracle dba 14: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_A_1G_1 oracle dba 15: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_A_1G_2 oracle dba 16: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_B_1G_1 oracle dba 17: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_B_1G_2 oracle dba 18: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_C_1G_1 oracle dba 19: 1019 Mb /dev/oracleasm/disks/GRID_NPRD_3026_CL_C_1G_2 oracle dba
Clear SQL Cache =============== SQL> select ADDRESS, HASH_VALUE from V$SQLAREA where SQL_ID like '7yc%';
ADDRESS HASH_VALUE ---------------- ---------- 000000085FD77CF0 808321886
SQL> exec DBMS_SHARED_POOL.PURGE ('000000085FD77CF0, 808321886', 'C');
PL/SQL procedure successfully completed.
SQL> select ADDRESS, HASH_VALUE from V$SQLAREA where SQL_ID like '7yc%';
no rows selected
Thread/dump =========== jstack -l <pid> > <file-path> kill -3 pid
Get the object name with block ID ================================== SET PAUSE ON SET PAUSE 'Press Return to Continue' SET PAGESIZE 60 SET LINESIZE 300
COLUMN segment_name FORMAT A24 COLUMN segment_type FORMAT A24
SELECT segment_name, segment_type, block_id, blocks FROM dba_extents WHERE file_id = &file_no AND ( &block_value BETWEEN block_id AND ( block_id + blocks ) ) /
DB link details ================ col DB_LINK for a30 col OWNER for a30 col USERNAME for a30 col HOST for a30 select * from dba_db_links;
1 note
·
View note
Text
DropboxをCentOS 7で動かす(2019年2月時点の情報)
Dropboxは2018年10月にLinux版のシステム要件を情け容赦なく更新し、これまで動いていた環境を切り捨てた。主には
Ubuntu 14.04 以上、Fedora 21 以上 のオペレーティング システム
Glibc 2.19 以上
Dropbox フォルダは ext4 形式のハード ドライブかパーティションに配置すること
などの要件が新たに科され、対応するディストリビューションについては(本質的問題ではないので)ともかく、xfsやbtrfsなどext4以外のファイルシステム上で使えなくなった。これはもともとext4以外を標準とするディストリビューションや、宗教上の理由でext4以外を使いたいユーザーへの打撃となった。しかしこれに対してはいくつかのworkaroundが考案された(e.g. btrfsでDropboxを使う とか btrfs? Dropboxさん, あなたが見ているのはext4ですよ とか)。ただ私自身は諦めてext4でフォーマットし直したので、これらの有効性は確認していない。 何より致命的な問題はglibcのバージョンで、CentOS 7はglibc 2.17を採用しているから、ファイルシステム問題をクリアしてもCentOS 7では動作させられなくなった。なおこのシステム要件の更新直後は上記ファイルシステムの問題と同様にglibcのバージョンを騙してやるworkaround(e.g. 2018年版、CentOS 7 で Dropbox を使う)があったようだが、その後にDropboxがアップデートされ、少なくともglibc 2.18を呼ぶようになったみたいでこの方法もまた使えなくなった。 当然システムのglibcをアップデートしてしまうのは影響範囲が甚大で危険だから、Dropboxだけが使う新しいglibcを別に入れるのが比較的安全だとは思っていたが、新しいglibc自体のビルドに必要な要件をCentOS 7が満たしていないので、ちょっとてこずった。 同じようなことを試した人も既にいたが、何が違ってうまく行かないのか不明なので、取り敢えず手元でうまく行ったメモ。
Developer Toolset 7を入れる
新しいglibcをビルドするにはGCCなどのバージョンが古いため、Developer Toolsetを入れる。現在��最新版は7であるが、どんどん更新されているようなので新しいバージョンが出ているのかも知れない(現在はたまたま7だが、CentOSのバージョンと一致している、とかいう性格のものではない)。
$ sudo yum install centos-release-scl $ sudo yum install centos-release-scl patchelf $ sudo yum-config-manager --enable rhel-server-rhscl-7-rpms $ sudo yum install devtoolset-7 $ scl enable devtoolset-7 bash
新しいglibcを入れる
現在の最新版はglibc 2.29だが、試行錯誤の過程でglibc 2.27を入れた(別にゆかりんの誕生日だからと思ったわけじゃない)。 Developer Toolset 7であれば問題はないはずなので、本当は最新版を入れた方がよい気がする。(参考にしたサイト:Dropbox - glibc and file systems support)
$ tar xzvf glibc-2.27.tar.gz $ cd glibc-2.27 $ mkdir build $ cd build $ ../configure --prefix=/opt/glibc-2.27 $ make $ sudo make install
patchelf する
処理内容の想像はついているが、理解していない。Dropboxはしょっちゅうバージョンアップするので、最新のパスにする。バージョンアップした後にまたpatchelfする必要がある気がするが、まだそこまで確認していない方法は下の補足を参照。
(2019.02.23追記:Tumblrの仕様でsetの前のハイフン2個をダッシュに自動変換してしまうようなので、コピペの際にはご注意)
$ patchelf --set-interpreter /opt/glibc-2.27/lib/ld-2.27.so ~/.dropbox-dist/dropbox-lnx.x86_64-66.4.84/dropbox $ patchelf --set-rpath /opt/glibc-2.27/lib ~/.dropbox-dist/dropbox-lnx.x86_64-66.4.84/dropbox
シンボリックリンクとかはる
(参考にしたサイト: CentOS7でDropBox glibc2.9以上でないと使えなくなった対応)
同サイトのglibcバージョン表記は誤記(2.7→2.17、2.9→2.19)だと思うが、取り敢えず気にしないことにする。
$ cd ~/.dropbox-dist/dropbox-lnx.x86_64-66.4.84/ $ ln -s /lib64/libgcc_s.so.1 $ ln -s /usr/lib64/libstdc++.so.6 $ ln -s /lib64/libz.so.1 $ ln -s /lib64/libgthread-2.0.so.0 $ ln -s /lib64/libglib-2.0.so.0
Dropboxを起動する
インストールから行う場合は公式サイト参照。
$ export LD_LIBRARY_PATH=~/.dropbox-dist/dropbox-lnx.x86_64-66.4.84:$LD_LIBRARY_PATH $ ~/.dropbox-dist/dropboxd
うまく行くのを確認したら、LD_LIBRARY_PATHを加えて起動するスクリプトでも用意するとよいかも。例えばこんな感じ?
#!/bin/sh export LD_LIBRARY_PATH=~/.dropbox-dist/dropbox-lnx.x86_64-`/usr/bin/cat ~/.dropbox-dist/VERSION`:$LD_LIBRARY_PATH exec ~/bin/dropbox.py "$@"
Dropboxアップデート時の補足(2019.02.23追記)
Dropboxのdaemonは新しいバージョンを自動的��探して自動的にアップデートするが、上記手順からしてこのアップデート機構はうまく動作せず、何らかの工夫が必要となる。放置しておくと、自動アップデートを試みた後、予想通り古いglibcを見に行ってしまう。
ImportError: /lib64/libc.so.6: version `GLIBC_2.18' not found (required by /tmp/.dropbox-dist-new-45n94tcl/.dropbox-dist/dropbox-lnx.x86_64-67.4.83/dbxlog._dbxlog.cpython-36m-x86_64-linux-gnu.so)
取り敢えず手動で回避しておいて、後から自動化する方法を考えることにする(以下の手順はscl enable devtoolset-7していない通常の環境下で差し支えない)。
$ dropbox stop $ dropbox update
アップデートそのものは途中まで成功するが、ここでも(当然)エラーが出るので、手動で処理する。
※上と同じでTumblrの仕様でsetの前のハイフン2個をダッシュに自動変換してしまうようなので、以下コピペの際にはご注意
$ dropbox stop $ cd ~/.dropbox-dist/dropbox-lnx.x86_64-`/usr/bin/cat ~/.dropbox-dist/VERSION` $ patchelf --set-interpreter /opt/glibc-2.27/lib/ld-2.27.so dropbox $ patchelf --set-rpath /opt/glibc-2.27/lib dropbox $ ln -s /lib64/libgcc_s.so.1 $ ln -s /usr/lib64/libstdc++.so.6 $ ln -s /lib64/libz.so.1 $ ln -s /lib64/libgthread-2.0.so.0 $ ln -s /lib64/libglib-2.0.so.0 $ dropbox start
(2019.05.03追記)最終的には自動化したいが、まだ実現してない。ちなみにアップデートを試みている際は
$ dropbox status Dropbox をアップグレード中...
となるため、この返り値をキーにして自動化できるとは思うので、誰か実現したら教えろください。
(2019.09.07追記)アップデート自動化の方法は http://www.haijiso.com/pc-memo/1553154674 に記載した。
2 notes
·
View notes