#Increased efficiency
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Discover Self-Supervised Learning for LLMs

Artificial intelligence is transforming the world at an unprecedented pace, and at the heart of this revolution lies a powerful learning technique: self-supervised learning. Unlike traditional methods that demand painstaking human effort to label data, self-supervised learning flips the script, allowing AI models to teach themselves from the vast oceans of unlabeled data that exist today. This method has rapidly emerged as the cornerstone for training Large Language Models (LLMs), powering applications from virtual assistants to creative content generation. It drives a fundamental shift in our thinking about AI's societal role.
Self-supervised learning propels LLMs to new heights by enabling them to learn directly from the data—no external guidance is needed. It's a simple yet profoundly effective concept: train a model to predict missing parts of the data, like guessing the next word in a sentence. But beneath this simplicity lies immense potential. This process enables AI to capture the depth and complexity of human language, grasp the context, understand the meaning, and even accumulate world knowledge. Today, this capability underpins everything from chatbots that respond in real time to personalized learning tools that adapt to users' needs.
This approach's advantages go far beyond just efficiency. By tapping into a virtually limitless supply of data, self-supervised learning allows LLMs to scale massively, processing billions of parameters and honing their ability to understand and generate human-like text. It democratizes access to AI, making it cheaper and more flexible and pushing the boundaries of what these models can achieve. And with the advent of even more sophisticated strategies like autonomous learning, where models continually refine their understanding without external input, the potential applications are limitless. We will try to understand how self-supervised learning works, its benefits for LLMs, and the profound impact it is already having on AI applications today. From boosting language comprehension to cutting costs and making AI more accessible, the advantages are clear and they're just the beginning. As we stand on the brink of further advancements, self-supervised learning is set to redefine the landscape of artificial intelligence, making it more capable, adaptive, and intelligent than ever before.
Understanding Self-Supervised Learning
Self-supervised learning is a groundbreaking approach that has redefined how large language models (LLMs) are trained, going beyond the boundaries of AI. We are trying to understand what self-supervised learning entails, how it differs from other learning methods, and why it has become the preferred choice for training LLMs.
Definition and Differentiation
At its core, self-supervised learning is a machine learning paradigm where models learn from raw, unlabeled data by generating their labels. Unlike supervised learning, which relies on human-labeled data, or unsupervised learning, which searches for hidden patterns in data without guidance, self-supervised learning creates supervisory signals from the data.
For example, a self-supervised learning model might take a sentence like "The cat sat on the mat" and mask out the word "mat." The model's task is to predict the missing word based on the context provided by the rest of the sentence. This way, we can get the model to learn the rules of grammar, syntax, and context without requiring explicit annotations from humans.
Core Mechanism: Next-Token Prediction
A fundamental aspect of self-supervised learning for LLMs is next-token prediction, a task in which the model anticipates the next word based on the preceding words. While this may sound simple, it is remarkably effective in teaching a model about the complexities of human language.
Here's why next-token prediction is so powerful:
Grammar and Syntax
To predict the next word accurately, the model must learn the rules that govern sentence structure. For example, after seeing different types of sentences, the model understands that "The cat" is likely to be followed by a verb like "sat" or "ran."
Semantics
The model is trained to understand the meanings of words and their relationships with each other. For example, if you want to say, "The cat chased the mouse," the model might predict "mouse" because it understands the words "cat" and "chased" are often used with "mouse."
Context
Effective prediction requires understanding the broader context. In a sentence like "In the winter, the cat sat on the," the model might predict "rug" or "sofa" instead of "grass" or "beach," recognizing that "winter" suggests an indoor setting.
World Knowledge
Over time, as the model processes vast amounts of text, it accumulates knowledge about the world, making more informed predictions based on real-world facts and relationships. This simple yet powerful task forms the basis of most modern LLMs, such as GPT-3 and GPT-4, allowing them to generate human-like text, understand context, and perform various language-related tasks with high proficiency .
The Transformer Architecture
Self-supervised learning for LLMs relies heavily on theTransformer architecture, a neural network design introduced in 2017 that has since become the foundation for most state-of-the-art language models. The Transformer Architecture is great for processing sequential data, like text, because it employs a mechanism known as attention. Here's how it works:
Attention Mechanism
Instead of processing text sequentially, like traditional recurrent neural networks (RNNs), Transformers use an attention mechanism to weigh the importance of each word in a sentence relative to every other word. The model can focus on the most relevant aspects of the text, even if they are far apart. For example, in the sentence "The cat that chased the mouse is on the mat," the model can pay attention to both "cat" and "chased" while predicting the next word.
Parallel Processing
Unlike RNNs, which process words one at a time, Transformers can analyze entire sentences in parallel. This makes them much faster and more efficient, especially when dealing large datasets. This efficiency is critical when training on datasets containing billions of words.
Scalability
The Transformer's ability to handle vast amounts of data and scale to billions of parameters makes it ideal for training LLMs. As models get larger and more complex, the attention mechanism ensures they can still capture intricate patterns and relationships in the data.
By leveraging the Transformer architecture, LLMs trained with self-supervised learning can learn from context-rich datasets with unparalleled efficiency, making them highly effective at understanding and generating language.
Why Self-Supervised Learning?
The appeal of self-supervised learning lies in its ability to harness vast amounts of unlabeled text data. Here are some reasons why this method is particularly effective for LLMs:
Utilization of Unlabeled Data
Self-supervised learning uses massive amounts of freely available text data, such as web pages, books, articles, and social media posts. This approach eliminates costly and time-consuming human annotation, allowing for more scalable and cost-effective model training.
Learning from Context
Because the model learns by predicting masked parts of the data, it naturally develops an understanding of context, which is crucial for generating coherent and relevant text. This makes LLMs trained with self-supervised learning well-suited for tasks like translation, summarization, and content generation.
Self-supervised learning enables models to continuously improve as they process more data, refining their understanding and capabilities. This dynamic adaptability is a significant advantage over traditional models, which often require retraining from scratch to handle new tasks or data.
In summary, self-supervised learning has become a game-changing approach for training LLMs, offering a powerful way to develop sophisticated models that understand and generate human language. By leveraging the Transformer architecture and utilizing vast amounts of unlabeled data, this method equips LLMs that can perform a lot of tasks with remarkable proficiency, setting the stage for future even more advanced AI applications.
Key Benefits of Self-Supervised Learning for LLMs
Self-supervised learning has fundamentally reshaped the landscape of AI, particularly in training large language models (LLMs). Concretely, what are the primary benefits of this approach, which is to enhance LLMs' capabilities and performance?
Leverage of Massive Unlabeled Data
One of the most transformative aspects of self-supervised learning is its ability to utilize vast amounts of unlabeled data. Traditional machine learning methods rely on manually labeled datasets, which are expensive and time-consuming. In contrast, self-supervised learning enables LLMs to learn from the enormous quantities of online text—web pages, books, articles, social media, and more.
By tapping into these diverse sources, LLMs can learn language structures, grammar, and context on an unprecedented scale. This capability is particularly beneficial because: Self-supervised learning draws from varied textual sources, encompassing multiple languages, dialects, topics, and styles. This diversity allows LLMs to develop a richer, more nuanced understanding of language and context, which would be impossible with smaller, hand-labeled datasets. The self-supervised learning paradigm scales effortlessly to massive datasets containing billions or even trillions of words. This scale allows LLMs to build a comprehensive knowledge base, learning everything from common phrases to rare idioms, technical jargon, and even emerging slang without manual annotation.
Improved Language Understanding
Self-supervised learning significantly enhances an LLM's ability to understand and generate human-like text. LLMs trained with self-supervised learning can develop a deep understanding of language structures, semantics, and context by predicting the next word or token in a sequence.
Deeper Grasp of Grammar and Syntax
LLMs implicitly learn grammar rules and syntactic structures through repetitive exposure to language patterns. This capability allows them to construct sentences that are not only grammatically correct but also contextually appropriate.
Contextual Awareness
Self-supervised learning teaches LLMs to consider the broader context of a passage. When predicting a word in a sentence, the model doesnt just look at the immediately preceding words but considers th'e entire sentence or even the paragraph. This context awareness is crucial for generating coherent and contextually relevant text.
Learning World Knowledge
LLMs process massive datasets and accumulate factual knowledge about the world. This helps them make informed predictions, generate accurate content, and even engage in reasoning tasks, making them more reliable for applications like customer support, content creation, and more.
Scalability and Cost-Effectiveness
The cost-effectiveness of self-supervised learning is another major benefit. Traditional supervised learning requires vast amounts of labeled data, which can be expensive. In contrast, self-supervised learning bypasses the need for labeled data by using naturally occurring structures within the data itself.
Self-supervised learning dramatically cuts costs by eliminating the reliance on human-annotated datasets, making it feasible to train very large models. This approach democratizes access to AI by lowering the barriers to entry for researchers, developers, and companies. Because self-supervised learning scales efficiently across large datasets, LLMs trained with this method can handle billions or trillions of parameters. This capability makes them suitable for various applications, from simple language tasks to complex decision-making processes.
Autonomous Learning and Continuous Improvement
Recent advancements in self-supervised learning have introduced the concept of Autonomous Learning, where LLMs learn in a loop, similar to how humans continuously learn and refine their understanding.
In autonomous learning, LLMs first go through an "open-book" learning phase, absorbing information from vast datasets. Next, they engage in "closed-book" learning, recalling and reinforcing their understanding without referring to external sources. This iterative process helps the model optimize its understanding, improve performance, and adapt to new tasks over time. Autonomous learning allows LLMs to identify gaps in their knowledge and focus on filling them without human intervention. This self-directed learning makes them more accurate, efficient, and versatile.
Better Generalization and Adaptation
One of the standout benefits of self-supervised learning is the ability of LLMs to generalize across different domains and tasks. LLMs trained with self-supervised learning draw on a wide range of data. They are better equipped to handle various tasks, from generating creative content to providing customer support or technical guidance. They can quickly adapt to new domains or tasks with minimal retraining. This generalization ability makes LLMs more robust and flexible, allowing them to function effectively even when faced with new, unseen data. This adaptability is crucial for applications in fast-evolving fields like healthcare, finance, and technology, where the ability to handle new information quickly can be a significant advantage.
Support for Multimodal Learning
Self-supervised learning principles can extend beyond text to include other data types, such as images and audio. Multimodal learning enables LLMs to handle different forms of data simultaneously, enhancing their ability to generate more comprehensive and accurate content. For example, an LLM could analyze an image, generate a descriptive caption, and provide an audio summary simultaneously. This multimodal capability opens up new opportunities for AI applications in areas like autonomous vehicles, smart homes, and multimedia content creation, where diverse data types must be processed and understood together.
Enhanced Creativity and Problem-Solving
Self-supervised learning empowers LLMs to engage in creative and complex tasks.
Creative Content Generation
LLMs can produce stories, poems, scripts, and other forms of creative content by understanding context, tone, and stylistic nuances. This makes them valuable tools for creative professionals and content marketers.
Advanced Problem-Solving
LLMs trained on diverse datasets can provide novel solutions to complex problems, assisting in medical research, legal analysis, and financial forecasting.
Reduction of Bias and Improved Fairness
Self-supervised learning helps mitigate some biases inherent in smaller, human-annotated datasets. By training on a broad array of data sources, LLMs can learn from various perspectives and experiences, reducing the likelihood of bias resulting from limited data sources. Although self-supervised learning doesn't eliminate bias, the continuous influx of diverse data allows for ongoing adjustments and refinements, promoting fairness and inclusivity in AI applications.
Improved Efficiency in Resource Usage
Self-supervised learning optimizes the use of computational resources. It can directly use raw data instead of extensive preprocessing and manual data cleaning, reducing the time and resources needed to prepare data for training. As learning efficiency improves, these models can be deployed on less powerful hardware, making advanced AI technologies more accessible to a broader audience.
Accelerated Innovation in AI Applications
The benefits of self-supervised learning collectively accelerate innovation across various sectors. LLMs trained with self-supervised learning can analyze medical texts, support diagnosis, and provide insights from vast amounts of unstructured data, aiding healthcare professionals. In the financial sector, LLMs can assist in analyzing market trends, generating reports, automating routine tasks, and enhancing efficiency and decision-making. LLMs can act as personalized tutors, generating tailored content and quizzes that enhance students' learning experiences.
Practical Applications of Self-Supervised Learning in LLMs
Self-supervised learning has enabled LLMs to excel in various practical applications, demonstrating their versatility and power across multiple domains
Virtual Assistants and Chatbots
Virtual assistants and chatbots represent one of the most prominent applications of LLMs trained with self-supervised learning. These models can do the following:
Provide Human-Like Responses
By understanding and predicting language patterns, LLMs deliver natural, context-aware responses in real-time, making them highly effective for customer service, technical support, and personal assistance.
Handle Complex Queries
They can handle complex, multi-turn conversations, understand nuances, detect user intent, and manage diverse topics accurately.
Content Generation and Summarization
LLMs have revolutionized content creation, enabling automated generation of high-quality text for various purposes.
Creative Writing
LLMs can generate engaging content that aligns with specific tone and style requirements, from blogs to marketing copies. This capability reduces the time and effort needed for content production while maintaining quality and consistency. Writers can use LLMs to brainstorm ideas, draft content, and even polish their work by generating multiple variations.
Text Summarization
LLMs can distill lengthy articles, reports, or documents into concise summaries, making information more accessible and easier to consume. This is particularly useful in fields like journalism, education, and law, where large volumes of text need to be synthesized quickly. Summarization algorithms powered by LLMs help professionals keep up with information overload by providing key takeaways and essential insights from long documents.
Domain-Specific Applications
LLMs trained with self-supervised learning have proven their worth in domain-specific applications where understanding complex and specialized content is crucial. LLMs assist in interpreting medical literature, supporting diagnoses, and offering treatment recommendations. Analyzing a wide range of medical texts can provide healthcare professionals with rapid insights into potential drug interactions and treatment protocols based on the latest research. This helps doctors stay current with the vast and ever-expanding medical knowledge.
LLMs analyze market trends in finance, automate routine tasks like report generation, and enhance decision-making processes by providing data-driven insights. They can help with risk assessment, compliance monitoring, and fraud detection by processing massive datasets in real time. This capability reduces the time needed to make informed decisions, ultimately enhancing productivity and accuracy. LLMs can assist with tasks such as contract analysis, legal research, and document review in the legal domain. By understanding legal terminology and context, they can quickly identify relevant clauses, flag potential risks, and provide summaries of lengthy legal documents, significantly reducing the workload for lawyers and paralegals.
How to Implement Self-Supervised Learning for LLMs
Implementing self-supervised learning for LLMs involves several critical steps, from data preparation to model training and fine-tuning. Here's a step-by-step guide to setting up and executing self-supervised learning for training LLMs:
Data Collection and Preparation
Data Collection
Web Scraping
Collect text from websites, forums, blogs, and online articles.
Open Datasets
For medical texts, use publicly available datasets such as Common Crawl, Wikipedia, Project Gutenberg, or specialized corpora like PubMed.
Proprietary Data
Include proprietary or domain-specific data to tailor the model to specific industries or applications, such as legal documents or company-specific communications.
Pre-processing
Tokenization
Convert the text into smaller units called tokens. Tokens may be words, subwords, or characters, depending on the model's architecture.
Normalization
Clean the text by removing special characters, URLs, excessive whitespace, and irrelevant content. If case sensitivity is not essential, standardize the text by converting it to lowercase.
Data Augmentation
Introduce variations in the text, such as paraphrasing or back-translation, to improve the model's robustness and generalization capabilities.
Shuffling and Splitting
Randomly shuffle the data to ensure diversity and divide it into training, validation, and test sets.
Define the Learning Objective
Self-supervised learning requires setting specific learning objectives for the model:
Next-Token Prediction
Set up the primary task of predicting the next word or token in a sequence. Implement "masked language modeling" (MLM), where a certain percentage of input tokens are replaced with a mask token, and the model is trained to predict the original token. This helps the model learn the structure and flow of natural language.
Contrastive Learning (Optional)
Use contrastive learning techniques where the model learns to differentiate between similar and dissimilar examples. For instance, when given a sentence, slightly altered versions are generated, and the model is trained to distinguish the original from the altered versions, enhancing its contextual understanding.
Model Training and Optimization
After preparing the data and defining the learning objectives, proceed to train the model:
Initialize the Model
Start with a suitable architecture, such as a Transformer-based model (e.g., GPT, BERT). Use pre-trained weights to leverage existing knowledge and reduce the required training time if available.
Configure the Learning Process
Set hyperparameters such as learning rate, batch size, and sequence length. Use gradient-based optimization techniques like Adam or Adagrad to minimize the loss function during training.
Use Computational Resources Effectively
Training LLM systems demands a lot of computational resources, including GPUs or TPUs. The training process can be distributed across multiple devices, or cloud-based solutions can handle high processing demands.
Hyperparameter Tuning
Adjust hyperparameters regularly to find the optimal configuration. Experiment with different learning rates, batch sizes, and regularization methods to improve the model's performance.
Evaluation and Fine-Tuning
Once the model is trained, its performance is evaluated and fine-tuned for specific applications. Here is how it works:
Model Evaluation
Use perplexity, accuracy, and loss metrics to evaluate the model's performance. Test the model on a separate validation set to measure its generalization ability to new data.
Fine-Tuning
Refine the model for specific domains or tasks using labeled data or additional unsupervised techniques. Fine-tune a general-purpose LLM on domain-specific datasets to make it more accurate for specialized applications.
Deploy and Monitor
After fine-tuning, deploy the model in a production environment. Continuously monitor its performance and collect feedback to identify areas for further improvement.
Advanced Techniques: Autonomous Learning
To enhance the model further, consider implementing autonomous learning techniques:
Open-Book and Closed-Book Learning
Train the model to first absorb information from datasets ("open-book" learning) and then recall and reinforce this knowledge without referring back to the original data ("closed-book" learning). This process mimics human learning patterns, allowing the model to optimize its understanding continuously.
Self-optimization and Feedback Loops
Incorporate feedback loops where the model evaluates its outputs, identifies errors or gaps, and adjusts its internal parameters accordingly. This self-reinforcing process leads to ongoing performance improvements without requiring additional labeled data.
Ethical Considerations and Bias Mitigation
Implementing self-supervised learning also involves addressing ethical considerations:
Bias Detection and Mitigation
Audit the training data regularly for biases. Use techniques such as counterfactual data augmentation or fairness constraints during training to minimize bias.
Transparency and Accountability
Ensure the model's decision-making processes are transparent. Develop methods to explain the model's outputs and provide users with tools to understand how decisions are made.
Concluding Thoughts
Implementing self-supervised learning for LLMs offers significant benefits, including leveraging massive unlabeled data, enhancing language understanding, improving scalability, and reducing costs. This approach's practical applications span multiple domains, from virtual assistants and chatbots to specialized healthcare, finance, and law uses. By following a systematic approach to data collection, training, optimization, and evaluation, organizations can harness the power of self-supervised learning to build advanced LLMs that are versatile, efficient, and capable of continuous improvement. As this technology continues to evolve, it promises to push the boundaries of what AI can achieve, paving the way for more intelligent, adaptable, and creative systems to better understand and interact with the world around us.
Ready to explore the full potential of LLM?
Our AI-savvy team tackles the latest advancements in self-supervised learning to build smarter, more adaptable AI systems tailored to your needs. Whether you're looking to enhance customer experiences, automate content generation, or revolutionize your industry with innovative AI applications, we've got you covered. Keep your business from falling behind in the digital age. Connect with our team of experts today to discover how our AI-driven strategies can transform your operations and drive sustainable growth. Let's shape the future together — get in touch with Coditude now and take the first step toward a smarter tomorrow!
#AI#artificial intelligence#LLM#transformer architecture#self supervised learning#NLP#Machine Learning#scalability#cost effectiveness#unlabelled data#chatbot#virtual assistants#increased efficiency#data quality
0 notes
Text
Let’s face it: target practice is expensive. Between range fees and the cost per round, a trip to hone your skills can dent your wallet. At Aegis Precision Kinetics, we understand the importance of getting the most out of your training without breaking the bank. That’s where bulk ammunition comes in!
0 notes
Text
Open 24/7 Customer Support with ChatGPT ChatBot API Integration on Your Website.
In today's digital world, businesses need to engage visitors and provide quick, efficient customer support. One powerful tool to achieve this is integrating the ChatGPT ChatBot API into your website. Here's why and how to get started.
What is ChatGPT ChatBot API?
ChatGPT ChatBot API leverages advanced AI technology to create a conversational interface on your website. It helps in automating responses to customer inquiries, offering support, and providing a personalized user experience.
Benefits of Integrating ChatGPT ChatBot API
24/7 Customer Support: Your website can provide round-the-clock assistance to visitors, answering common questions and resolving issues instantly.
Enhanced User Experience: Chatbots engage users with personalized interactions, making their experience on your site more enjoyable and efficient.
Increased Efficiency: Automating responses saves time for your support team, allowing them to focus on more complex issues.
Boosted Engagement: Interactive chatbots keep visitors engaged, increasing the likelihood of conversions and sales.
How to Integrate ChatGPT ChatBot API
Integrating ChatGPT ChatBot API into your website is straightforward:
-Sign Up for API Access: Start by signing up for the ChatGPT ChatBot API on the provider's website.
-Generate API Key: Once you have access, generate your unique API key. This key will be used to authenticate your chatbot.
-Install the API: Add the API to your website's code. This typically involves copying a few lines of code into your site's backend.
Customize the Chatbot: Customize the chatbot's responses to suit your business needs. You can set predefined responses for common queries and customize the chatbot’s appearance.
Test and Launch: Before going live, thoroughly test the chatbot to ensure it functions correctly. Once satisfied, launch it on your site.
Conclusion Integrating ChatGPT ChatBot API into your website can transform how you interact with your customers, providing seamless support and enhancing user engagement. Start today and watch your business thrive with the power of AI-driven conversations.
#ChatGPT ChatBot API#Website integration#Customer support automation#AI chatbot#Enhanced user experience#Increased efficiency#Boosted engagement#Conclusion#ChatGPT#ChatBot#AIChatBot#WebsiteIntegration#CustomerSupport#24x7Support#UserExperience#Automation#DigitalEngagement#BusinessGrowth
0 notes
Text
The Synergy of Robots and Press Brakes: Transforming Manufacturing Precision
In the ever-evolving landscape of manufacturing, the integration of robotics has become a game-changer, significantly impacting efficiency, precision, and overall productivity. One notable area where this synergy is making waves is in the realm of press brakes–essential tools used in metal forming processes.
Press brakes have been a part of metalworking for generations, offering the ability to bend and shape metal sheets with precision. Traditional press brakes operated manually, requiring skilled operators to adjust settings and oversee the process. While effective, this method often posed limitations in terms of speed, consistency, and the ability to handle complex tasks.
The arrival of robotics prompted a paradigm shift in manufacturing. Robots, equipped with advanced sensors, vision systems, and programmable precision, emerged as a partner to traditional machinery. In the context of press brakes, robots have become integral for automating repetitive tasks, enhancing precision, and enabling the seamless handling of intricate sheet metal designs.
Advantages of Robot-Enhanced Press Brakes
Precision and Consistency: Robots excel in executing tasks with unparalleled precision, eliminating variations that can arise from human intervention. This precision is particularly crucial in metal forming processes where accuracy is paramount for achieving desired shapes and dimensions consistently.
Increased Efficiency: By automating the loading, unloading, and bending processes, the integration of robots with press brakes significantly improves overall efficiency. Robots operate tirelessly, reducing cycle times and increasing the throughput of the manufacturing process.
Complex Forming Capabilities: The combination of robots and press brakes enables the handling of complex forming tasks that might be challenging for traditional methods. This includes intricate designs, multiple bends, and the production of components with high geometric complexity.
Safety: Robots—particularly cobots—are evolving into helpmates that can work in proximity to humans safely. By taking over repetitive and potentially hazardous tasks, they contribute to a safer working environment. This not only minimizes the risk of accidents but also allows human operators to focus on more strategic and complex aspects of production. They do the dull, dirty, and dangerous work.
Challenges and Considerations
While the integration of robots with press brakes brings numerous advantages, it is not without its challenges. Initial setup costs, programming complexities, and the need for skilled technicians to operate and maintain these systems are common hurdles. Additionally, there is a learning curve for manufacturers transitioning from traditional methods to automated systems.
As technology continues to advance, the collaboration between robots and press brakes is likely to evolve further. The integration of artificial intelligence (AI) and machine learning into robotic systems holds the promise of adaptive and self-optimizing manufacturing processes. This can lead to even greater efficiency, reduced waste, and improved overall production outcomes.
The fusion of robots with press brakes offers new levels of precision, efficiency, and versatility. While challenges exist, the long-term benefits far outweigh them, paving the way for a future where the integration of robotics becomes synonymous with enhanced manufacturing precision and productivity.
#Synergy of Robots#Press Brakes#Transforming#impacting efficiency#precision#brakes–essential tools#metal forming processes speed#consistency#advanced sensors#traditional machinery#Precision and Consistency#Increased Efficiency#Complex Forming Capabilities#Safety#intricate designs#multiple bends
0 notes
Text
Material handling solutions are an essential tool that businesses operating in manufacturing can benefit from. This service involves using semi-automated or automated processes to move bulk cargo, raw goods, and similar objects between different locations. Material handling also includes protecting, storing, and controlling materials throughout manufacturing, distribution, and warehousing.
0 notes
Text

Something for @fizzyboy wasteland au
Big HC that since astro only recently discovered the extent of his magic, he ends up pouring waaayyy too much power into fairly simple spells and that helps drain his stamina stupid fast
He can't exactly improve his stamina while he's constantly in danger
Poppy, on the other hand, has used her full magic her whole life, so it's probably a lot easier for her to distribute energy into each spell more resourcefully.
#having the power of god doesnt stop making u mortal#amd in astro's case TIRED AF#dandys world#poppy dandys world#astro dandys world#dandys wasteland#bit more drawing context for fun#one way to increase magical stamina is holding a spell#realize how much magic the spell needs at minimum and hold it there for as long as possible#keeping a constant concentration on magic useage is super efficient for building stamina
182 notes
·
View notes
Text
My "hot-take":
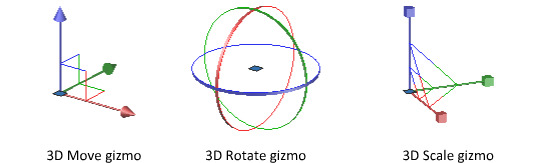
FUCK. THESE. THINGS.
I have never encountered a gizmo nor gimbal that I enjoyed interfacing with, not even once. They are the most cumbersome way to interact with anything in 3D space; I would rather chop off my limbs than have to laggardly click, hold, and drag these teeny tiny little tools (for often subtle and precise transformations!).
It is incredibly common to be at an angle where an entire axis is unavailable or unreasonably difficult for you to manipulate. When you're composing a scene of 3D objects, it's not unusual to want to do it in a way that is informed by the current position of your camera. I could rotate the viewport to reach whatever axis is being obscured, but fuck you! I don't want to! Most programs with gizmos have a way to enlarge the axes for this reason—which is great, if you're a fan of having vast portions of the model you're working on obscured by STUPID COLORFUL ARROWS.
So, if not gizmos, then what? I argue that Blender has the best alternative, but Unreal has a pretty compelling one as well. (There are probably other inventive ways of forgoing gizmos in 3D, but these are the two I'm most familiar with. If you know of any other unique control methods for 3D software, I would love to hear about them.)
For Blender, you simply have to press the X, Y, or Z key to constrain the transformation to the corresponding axis; the following manipulation is controlled entirely by the movement of your mouse. You don't have to hold down anything! It is precise, agile, and ergonomic. These controls might be less immediately intuitive than having a literal, visual representation of the axes, but it SIGNIFICANTLY reduces strain on the hands, and with practice, allows you to model so much faster than any gizmo could ever let you.
Unreal, while not a modelling tool, has a similar method of manipulation available. You hold Ctrl, then press a mouse button and drag—left click controls X, right click controls Y, and both simultaneously control Z. It feels very sexy and sleek, like operating a jet. For me, it isn't perfectly ideal (it still involves holding buttons for extended periods of time, and it occupies both hands), but it is infinitely more enjoyable than dealing with gizmos.
I do feel guilty about the sheer extent of my hatred for these poor things. They're so colorful and visually appealing, and certainly the most intuitive way to represent transformations in 3D space. But they suck. They just suck. And they hurt me.
#I definitely do recognize that the intuitiveness of gizmos is their greatest appeal; I taught a friend Blender basics not that long ago‚#and completely forgot to tell him that gizmos were an option until we were done.#And doing so probably would've alleviated like 75% of the navigation struggle. Oops.#Listen you just have to trust me. Learn this weird control scheme to increase your efficiency in the long term.#And to make you passionately hate any 3D software that doesn't let you use it. This will only benefit you
57 notes
·
View notes
Text
playing cultist simulator to escape the Looming Dread in real life to only have to avoid the Dread That Kills You in-game by going to the club and grinding out that sweet, sweet contentment so you don't fall into despair and kill yourself.
#it's a card game about gothic horrors set in 1920's london but also the learning curve is balls to the walls crazy. i have 10 hours into it#and i still don't know how to increase my lore efficiently.#also connie lee fucked me up by arresting me which was a game over but also ??????#MAN i thought i could cheese the early game but maybe not i guess#cultist simulator
63 notes
·
View notes
Text
just heard somebody mention how everything being so rapid pace and overly efficient is like taking the fun menial tasks out of cozy games.
most of my ideas come from the in-between bits of living where i find some cool insight from a ritualized task like taking care of my bunny. why are we trying to take the silly side quests out of life, those are my favourite parts of the game
waste time, read books, get into super niche things that nobody else finds value in because you can and you should
38 notes
·
View notes
Text


pov you’re supposed to be resting after your head injury but you thought you could sneak in some tinkering at 2 am
#macgyver 2016#angus macgyver#jack dalton#macgyver#fanart#macgyver fanart#messy sketch#caught red handed#go to bed mac#jack is not messing around when it comes to mac’s health#he was trying to supercharge the toaster in case anyone was wondering#(to increase Toast efficiency)
48 notes
·
View notes
Text
This card always makes me want to sit in his lap...

I won't be needing a chair to work at the Ada, I'll just sit in his lap instead. Don't worry, we can share the desk space, and I'll throw pens at Dazai.
#sitting on Kunikida's lap would increase my efficiency by 200%#the void speaks#bsd#bungo stray dogs#bsd mayoi#bungou stray dogs#bungo stray dogs kunikida#bsd kunikida#kunikida bsd#kunikida doppo
61 notes
·
View notes
Text

Melotober - Day 3 - Potion
The ingredients matter, or it won't heal at all. But the magic and intent of the crafter can make them better. (aka I wish you could take lessons from villagers in later games in place of the dang skill bread)
#Melotober#I really just wanted to draw Lara for this even if another idea was aesthetically stronger#Rune Factory#RF#Rune Factory 1#RF1#Margot's RF Art#Rune Factory Raguna#RF Raguna#Rune Factory Lara#RF Lara#My other idea was that I have a HC where potions can be drank OR thrown- in case of emergency literally break the glass#but maybe aerosol usage isn't as efficient so drinking or a healing spell is still better#BUT a good emergency use#but again I wanted Lara so I drew calmer idea with Lara instead#also seriously. Let us increase skills via some lesson or event with a villager- maybe 10 or 15 at a rare time.#Let us get recipes from that too#NOT DANG BREAD#Luckily Raguna didn't have to ever deal with that nonsense#also hello the world interrupted my sleep SO bad on the 2nd so I am already off balance#queue time set from 2pm to 4pm because I will be low on sleep until next Tuesday. RIP me
36 notes
·
View notes
Text
Hey y'all! Another weird question for you: How long do you have to fast for a blood sugar reading to count as a fasting blood sugar measurement? Also, does drinking soda (like, full sugar soda) slowly over the time before the blood test count as not-fasting? Asking because I keep testing* in the fasting blood sugar range when I am pretty sure I am not supposed to. Like, two hours after eating a meal when I've been slowly drinking soda the whole intervening time, or half an hour after drinking a whole full-sugar gatorade *with the home blood sugar test thing, not like doctor's office tests. though I test in the fasting range there too? I do know the word for the tester thing but I am brain fogged at the moment
#the person behind the yarn#blood mention#food mention#like. obliquely? but sort of there so I tag it just in case#I have a new personal record for lowest blood sugar when testing at home now! 91#I ate lunch two hours ago had some goldfish crackers after that and have been slowly sipping on a dr pepper#(as well as water I have two drinks going at all times)#and my blood sugar is STILL low#so I am eating some candy and then I will eat more goldfish and make sure I get extra protein with dinner#but seriously what the heck#this is not how blood sugar works for other people right????#it's not just always low but technically not hypoglycemic?????#I do not have diabetes I have been checked for that. a lot. it's probably the second or third most common thing they test me for#but nope whatever my problem is it's not that my body just yearns to yeet nutrients as efficiently as possible without retaining them#salt and sugar both apparently. also vitamin D but that one could just be that I don't go outside much#I take supplements for that it's fine#but there's not really salt and sugar supplements?#okay there are. I take the salt pills. but sugar is iffier. like there are sugar pills but I suspect#that's probably not the best way to increase my blood sugar
33 notes
·
View notes
Text



It's not your fault.
@sae-mian's M'alik tia
#PUTTING HIM IN THE BONE WIGGLER PAID OFF#I have learned. I have grown. I have increased my gposing efficiency by 4000%.#anyway if m'khemi doesn't want him as her brother I am adopting him#this man needs hugs and forgiveness#m'alik tia#vera grace#gpose#ffxiv gpose#ffxiv
7 notes
·
View notes
Text
hyperfixation so bad that i'm playing Satisfactory rn and i caught myself thinking 'Dorn and Perty would love this'
#i'm having to gut and restructure my assembly line to increase fuel use efficiency#wish some sort of primarch husband could do this for me#dear god i need so many damn cables#perturabo#rogal dorn#but like not really#delete l8r
11 notes
·
View notes
Text
It’s funny that a bunch of my coworkers older than me don’t know how to do basic stuff on computers and I also know my future coworkers younger than me (hell, even half my classmates in college) who were raised on phone apps won’t know how to do basic stuff on computers. So somehow me having the understanding of file trees, where our cloud saves are located, basic functions of Microsoft office programs, how to change settings, basic troubleshooting, and the ability to look things up if I don’t know how to do them apparently puts me above most people in my workplace when it comes to technology. And by “funny” I meant very frustrating
#we talk about how the working world has become too efficient and that’s in some ways true#but good lord the increase in efficiency if everyone in the office knew the very basic things I do would be astronomical#these people are so content to use these programs without ever trying to understand how they work and how to make it more efficient#and that’s alien to me
41 notes
·
View notes